Figure 1.
Overall architecture of the proposed IPACN framework. Key components include the shared Information-Preserving Backbone (IPB), temporal feature interaction, the Frequency-Adaptive Difference Enhancement Module (FADEM), and the decoder head.
Figure 1.
Overall architecture of the proposed IPACN framework. Key components include the shared Information-Preserving Backbone (IPB), temporal feature interaction, the Frequency-Adaptive Difference Enhancement Module (FADEM), and the decoder head.
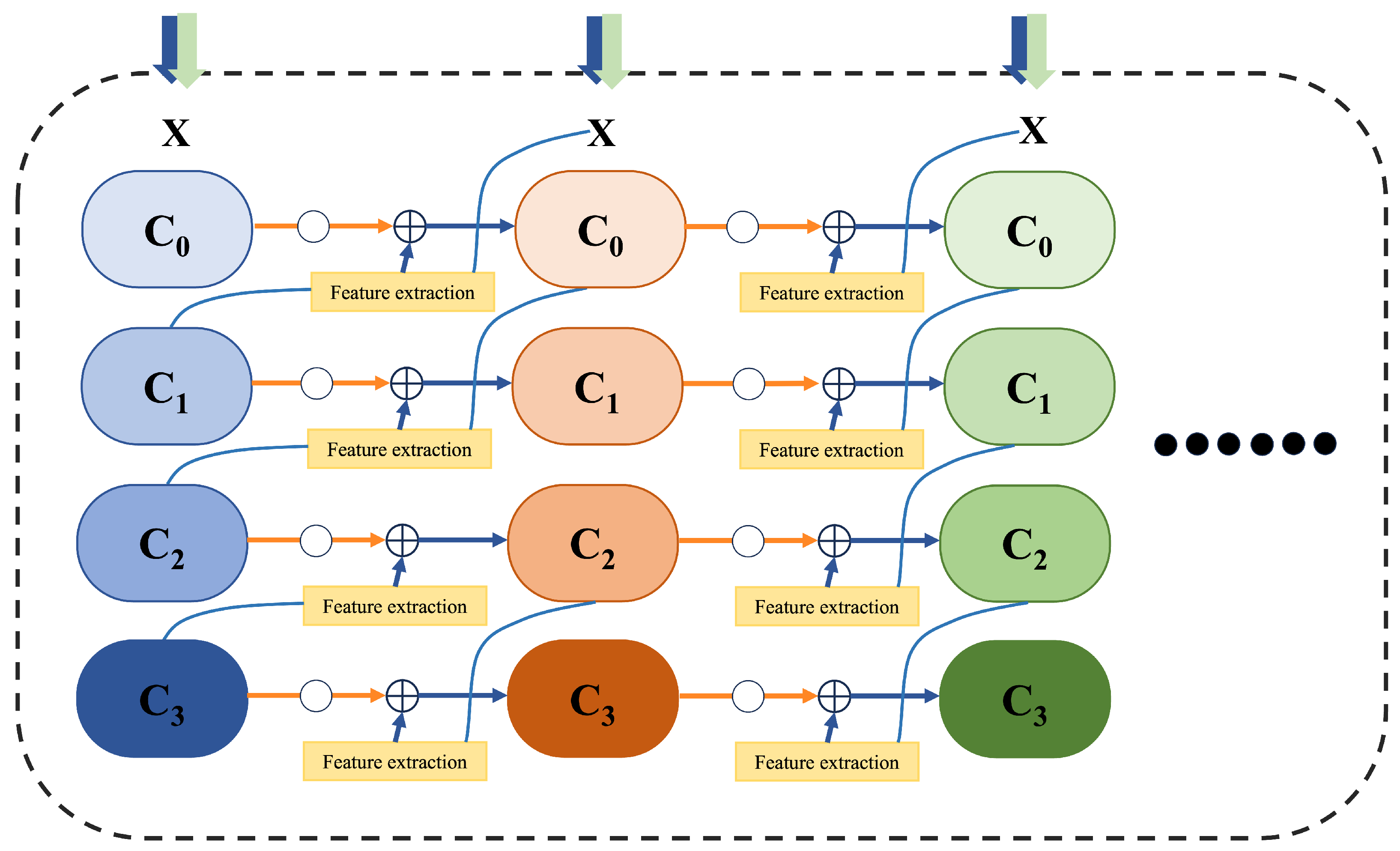
Figure 2.
Detailed conceptual architecture of the Information-Preserving Backbone (IPB). The figure illustrates the multi-column, multi-level structure where features are iteratively refined. At each level, features from the preceding column are combined with newly extracted features from the current column through additive connections (⊕), allowing for progressive information enhancement.
Figure 2.
Detailed conceptual architecture of the Information-Preserving Backbone (IPB). The figure illustrates the multi-column, multi-level structure where features are iteratively refined. At each level, features from the preceding column are combined with newly extracted features from the current column through additive connections (⊕), allowing for progressive information enhancement.
Figure 3.
Conceptual illustration of the Frequency-Adaptive Difference Enhancement Module (FADEM). Input difference features () undergo analysis of local frequency content, which guides the dynamic adaptation of both spatial context aggregation (effective dilation) and filtering frequency response within the adaptive convolution layer, producing enhanced difference features (). Optional frequency-selective pre-processing may precede the adaptive convolution.
Figure 3.
Conceptual illustration of the Frequency-Adaptive Difference Enhancement Module (FADEM). Input difference features () undergo analysis of local frequency content, which guides the dynamic adaptation of both spatial context aggregation (effective dilation) and filtering frequency response within the adaptive convolution layer, producing enhanced difference features (). Optional frequency-selective pre-processing may precede the adaptive convolution.
Figure 4.
Comprehensive visual analysis of the FADEM mechanism on a sample from the LEVIR-CD dataset. The top row displays: the T1 (before change) image, the ground truth mask, the initial Raw Difference Feature Map, and its corresponding frequency spectrum. The bottom row shows: the T2 (after change) image, a Simulated Dilation Map to conceptualize the adaptive process, the resulting Enhanced Difference Feature Map after FADEM processing, and its corresponding cleaned frequency spectrum. This comparison visually confirms FADEM’s ability to suppress high-frequency noise while enhancing true change signals.
Figure 4.
Comprehensive visual analysis of the FADEM mechanism on a sample from the LEVIR-CD dataset. The top row displays: the T1 (before change) image, the ground truth mask, the initial Raw Difference Feature Map, and its corresponding frequency spectrum. The bottom row shows: the T2 (after change) image, a Simulated Dilation Map to conceptualize the adaptive process, the resulting Enhanced Difference Feature Map after FADEM processing, and its corresponding cleaned frequency spectrum. This comparison visually confirms FADEM’s ability to suppress high-frequency noise while enhancing true change signals.
Figure 5.
Example image pairs (T1 images in row (a), T2 images in row (b)) and their corresponding ground truth change masks (row (c)) from four datasets: LEVIR-CD (first column), WHU-CD (second column), CCD (third column), and DSIFN-CD (fourth column).
Figure 5.
Example image pairs (T1 images in row (a), T2 images in row (b)) and their corresponding ground truth change masks (row (c)) from four datasets: LEVIR-CD (first column), WHU-CD (second column), CCD (third column), and DSIFN-CD (fourth column).
Figure 6.
Qualitative comparison results on sample images from the LEVIR-CD test set. Methods shown (left to right after GT): FC-EF, FC-Siam-Di, FC-Siam-Conc, DTCDSCN, STANet, IFNet, SNUNet, BIT, ChangeFormer, IPACN (Full) (ours). Color coding: White = TP, black = TN, blue = FP, red = FN.The rows illustrate diverse building change scenarios: (a) detection of a large newly constructed building; (b) identification of a smaller-scale new structure; and (c) a challenging case with multiple small, densely-packed new buildings.
Figure 6.
Qualitative comparison results on sample images from the LEVIR-CD test set. Methods shown (left to right after GT): FC-EF, FC-Siam-Di, FC-Siam-Conc, DTCDSCN, STANet, IFNet, SNUNet, BIT, ChangeFormer, IPACN (Full) (ours). Color coding: White = TP, black = TN, blue = FP, red = FN.The rows illustrate diverse building change scenarios: (a) detection of a large newly constructed building; (b) identification of a smaller-scale new structure; and (c) a challenging case with multiple small, densely-packed new buildings.
Figure 7.
Qualitative comparison results on sample images from the WHU-CD test set. Methods shown (left to right after GT): FC-EF, FC-Siam-Di, FC-Siam-Conc, DTCDSCN, STANet, IFNet, SNUNet, BIT, ChangeFormer, IPACN (Full) (ours). Color coding: White = TP, black = TN, blue = FP, red = FN.The rows illustrate diverse change scenarios: (a) detection of a large newly constructed building; (b) identification of a smaller new structure; and (c) a challenging scenario involving multiple small, densely-packed new buildings.
Figure 7.
Qualitative comparison results on sample images from the WHU-CD test set. Methods shown (left to right after GT): FC-EF, FC-Siam-Di, FC-Siam-Conc, DTCDSCN, STANet, IFNet, SNUNet, BIT, ChangeFormer, IPACN (Full) (ours). Color coding: White = TP, black = TN, blue = FP, red = FN.The rows illustrate diverse change scenarios: (a) detection of a large newly constructed building; (b) identification of a smaller new structure; and (c) a challenging scenario involving multiple small, densely-packed new buildings.
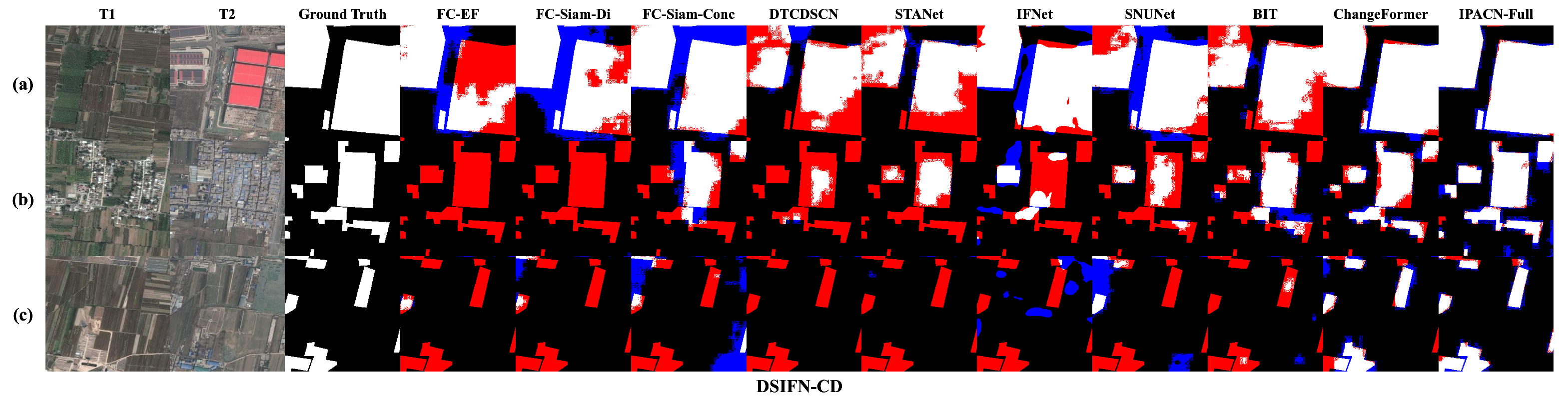
Figure 8.
Qualitative comparison results on sample images from the DSIFN-CD test set. Methods shown (left to right after GT): FC-EF, FC-Siam-Di, FC-Siam-Conc, DTCDSCN, STANet, IFNet, SNUNet, BIT, ChangeFormer, IPACN (Full) (ours). Color coding: White = TP, black = TN, blue = FP, red = FN.The rows display different land cover change types: (a) large-scale conversion of agricultural land; (b) complex changes in a mixed urban scene; and (c) conversion of vegetation into regular rectangular plots.
Figure 8.
Qualitative comparison results on sample images from the DSIFN-CD test set. Methods shown (left to right after GT): FC-EF, FC-Siam-Di, FC-Siam-Conc, DTCDSCN, STANet, IFNet, SNUNet, BIT, ChangeFormer, IPACN (Full) (ours). Color coding: White = TP, black = TN, blue = FP, red = FN.The rows display different land cover change types: (a) large-scale conversion of agricultural land; (b) complex changes in a mixed urban scene; and (c) conversion of vegetation into regular rectangular plots.
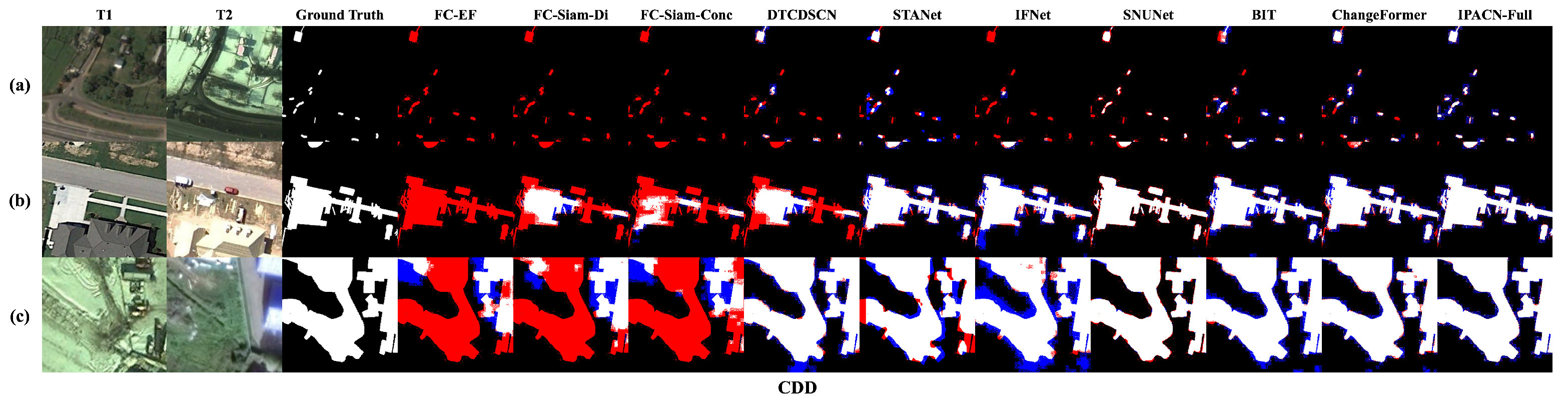
Figure 9.
Qualitative comparison results on sample images from the CDD test set, showcasing robustness to seasonal and illumination variations. Methods shown (left to right after GT): FC-EF, FC-Siam-Di, FC-Siam-Conc, DTCDSCN, STANet, IFNet, SNUNet, BIT, ChangeFormer, IPACN (Full) (ours). Color coding: White = TP, black = TN, blue = FP, red = FN.The rows showcase the model’s robustness against challenging pseudo-changes: (a) a scene with significant seasonal variation; (b) a genuine change under strong illumination and shadow differences; and (c) a complex change object amidst severe background interference.
Figure 9.
Qualitative comparison results on sample images from the CDD test set, showcasing robustness to seasonal and illumination variations. Methods shown (left to right after GT): FC-EF, FC-Siam-Di, FC-Siam-Conc, DTCDSCN, STANet, IFNet, SNUNet, BIT, ChangeFormer, IPACN (Full) (ours). Color coding: White = TP, black = TN, blue = FP, red = FN.The rows showcase the model’s robustness against challenging pseudo-changes: (a) a scene with significant seasonal variation; (b) a genuine change under strong illumination and shadow differences; and (c) a complex change object amidst severe background interference.
Table 1.
Summary of the change detection datasets used in the experiments (after pre-processing into patches).
Table 1.
Summary of the change detection datasets used in the experiments (after pre-processing into patches).
| Dataset | Resolution (m) | Train Pairs | Val Pairs | Test Pairs | Image Size |
|---|
| LEVIR-CD | 0.5 | 7120 | 1024 | 2048 | |
| WHU-CD | 0.075 | 6096 | 762 | 762 | |
| CDD | 0.03–1.0 | 10,000 | 3000 | 3000 | |
| DSIFN-CD | 2.0 | 14,400 | 1360 | 192 | |
Table 2.
Quantitative comparison on the LEVIR-CD test set. Best results in bold.
Table 2.
Quantitative comparison on the LEVIR-CD test set. Best results in bold.
| Method | Pre (%) | Rec (%) | F1 (%) | IoU (%) | OA (%) |
|---|
| FC-EF [14] | 86.91 | 80.17 | 83.40 | 71.53 | 98.39 |
| FC-Siam-Di [14] | 89.53 | 83.31 | 86.31 | 75.92 | 98.67 |
| FC-Siam-Conc [14] | 91.99 | 76.77 | 83.69 | 71.96 | 98.49 |
| DTCDSCN [36] | 88.53 | 86.83 | 87.67 | 78.05 | 98.77 |
| STANet [29] | 83.81 | 91.00 | 87.26 | 77.40 | 98.66 |
| IFNet [34] | 94.02 | 82.93 | 88.13 | 78.77 | 98.87 |
| SNUNet [15] | 89.18 | 87.17 | 88.16 | 78.83 | 98.82 |
| BIT [16] | 89.24 | 89.37 | 89.31 | 80.68 | 98.92 |
| ChangeFormer [17] | 92.05 | 88.80 | 90.40 | 82.48 | 99.04 |
| IPACN-Base (ours) | 91.80 | 90.80 | 91.30 | 83.98 | 99.12 |
| IPACN (Full) (ours) | 93.35 | 91.65 | 92.49 | 85.05 | 99.23 |
Table 3.
Quantitative comparison on the WHU-CD test set. Best results in bold.
Table 3.
Quantitative comparison on the WHU-CD test set. Best results in bold.
| Method | Pre (%) | Rec (%) | F1 (%) | IoU (%) | OA (%) |
|---|
| FC-EF [14] | 71.63 | 67.25 | 69.37 | 53.11 | 97.61 |
| FC-Siam-Di [14] | 47.33 | 77.66 | 58.81 | 41.66 | 96.63 |
| FC-Siam-Conc [14] | 60.88 | 73.58 | 66.63 | 49.95 | 97.04 |
| DTCDSCN [36] | 63.92 | 82.30 | 71.95 | 56.19 | 97.42 |
| STANet [29] | 79.37 | 85.50 | 82.32 | 69.95 | 98.52 |
| IFNet [34] | 96.91 | 73.19 | 83.40 | 71.52 | 98.83 |
| SNUNet [15] | 85.60 | 81.49 | 83.50 | 71.67 | 98.71 |
| BIT [16] | 86.64 | 81.48 | 83.98 | 72.39 | 98.75 |
| ChangeFormer [17] | 92.30 | 86.02 | 89.05 | 80.26 | 99.03 |
| IPACN-Base (ours) | 94.80 | 92.00 | 93.38 | 87.59 | 99.38 |
| IPACN (Full) (ours) | 96.15 | 92.95 | 94.52 | 89.61 | 99.51 |
Table 4.
Quantitative comparison on the DSIFN-CD test set. Best results in bold.
Table 4.
Quantitative comparison on the DSIFN-CD test set. Best results in bold.
| Method | Pre (%) | Rec (%) | F1 (%) | IoU (%) | OA (%) |
|---|
| FC-EF [14] | 72.61 | 52.73 | 61.09 | 43.98 | 88.59 |
| FC-Siam-Di [14] | 59.67 | 65.71 | 62.54 | 45.50 | 86.63 |
| FC-Siam-Conc [14] | 66.45 | 54.21 | 59.71 | 42.56 | 87.57 |
| DTCDSCN [36] | 53.87 | 77.99 | 63.72 | 46.76 | 84.91 |
| STANet [29] | 67.71 | 61.68 | 64.56 | 47.66 | 88.49 |
| IFNet [34] | 67.86 | 53.94 | 60.10 | 42.96 | 87.83 |
| SNUNet [15] | 60.60 | 72.89 | 66.18 | 49.45 | 87.34 |
| BIT [16] | 68.36 | 70.18 | 69.26 | 52.97 | 89.41 |
| ChangeFormer [17] | 88.48 | 84.94 | 86.67 | 76.48 | 95.56 |
| IPACN-Base (ours) | 90.50 | 91.00 | 90.75 | 83.05 | 96.80 |
| IPACN (Full) (ours) | 92.35 | 91.88 | 92.11 | 85.18 | 97.45 |
Table 5.
Quantitative comparison on the CDD test set. Best results in bold.
Table 5.
Quantitative comparison on the CDD test set. Best results in bold.
| Method | Pre (%) | Rec (%) | F1 (%) | IoU (%) | OA (%) |
|---|
| FC-EF [14] | 79.54 | 55.16 | 65.15 | 48.31 | 93.01 |
| FC-Siam-Di [14] | 85.86 | 58.56 | 69.63 | 53.41 | 93.90 |
| FC-Siam-Conc [14] | 84.22 | 66.61 | 74.39 | 59.22 | 94.59 |
| DTCDSCN [36] | 96.08 | 93.91 | 94.98 | 90.44 | 98.82 |
| STANet [29] | 83.80 | 91.60 | 87.50 | 77.80 | 96.90 |
| IFNet [34] | 89.34 | 85.88 | 87.57 | 77.89 | 97.09 |
| SNUNet [15] | 96.85 | 96.68 | 96.77 | 93.73 | 99.24 |
| BIT [16] | 96.12 | 94.94 | 95.52 | 91.43 | 98.94 |
| ChangeFormer [17] | 96.96 | 95.67 | 96.31 | 92.88 | 99.11 |
| IPACN-Base (ours) | 98.80 | 98.50 | 98.65 | 97.35 | 99.68 |
| IPACN (Full) (ours) | 99.25 | 99.30 | 99.27 | 97.56 | 99.84 |
Table 6.
Ablation study performance metrics on the LEVIR-CD test set (units in %). “IPB Rev.” indicates reversible connections. “FADEM” indicates the enhancement module. Best results in bold. Baseline BIT is included for performance context.
Table 6.
Ablation study performance metrics on the LEVIR-CD test set (units in %). “IPB Rev.” indicates reversible connections. “FADEM” indicates the enhancement module. Best results in bold. Baseline BIT is included for performance context.
| Model Configuration | IPB Rev. | FADEM | Pre | Rec | F1 | IoU | OA |
|---|
| BIT [16] (Baseline) | N/A | × | 89.24 | 89.37 | 89.31 | 80.68 | 98.92 |
| IPACN-Base (Non-Rev.) | × | × | 90.00 | 90.00 | 90.00 | 81.80 | 99.00 |
| IPACN-Base | ✓ | × | 91.80 | 90.80 | 91.30 | 83.98 | 99.12 |
| IPACN (Full) | ✓ | ✓ | 93.35 | 91.65 | 92.49 | 85.05 | 99.23 |
Table 7.
Model complexity comparison for IPACN variants in the ablation study.
Table 7.
Model complexity comparison for IPACN variants in the ablation study.
| IPACN Configuration | Params (M) | FLOPs (G) |
|---|
| IPB Non-Rev. | 273 | 39.0 |
| IPB Rev. | 273 | 39.0 |
| Full (IPB Rev. + FADEM) | ∼296 | ∼49.2 |











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}