1. Introduction
In the past few decades, the rapid development of satellite technology has led to a significant increase in the volume of RSIs, with applications spanning disaster monitoring [
1,
2], agriculture [
3], weather forecasting [
4], target detection [
5], and land use classification [
6,
7]. HR images, in particular, offer richer texture information, which is crucial for detailed surface feature extraction and interpretation in downstream tasks, thereby enhancing the accuracy of applications. Although image SR does not increase the physical resolution of the imaging sensor, it can effectively reconstruct high-frequency details from existing image data, enabling more informative representations than traditional enhancement methods. Therefore, SR has emerged as a promising solution for the extraction of richer information from RSIs without increasing hardware costs. Early methods include pan-sharpening [
8] and interpolation [
9], which, while simple and efficient, often suffer from smoothing and blurring issues. Other methods, such as reconstruction-based approaches [
10,
11], sparse representation [
12], and convex projection [
13], offer strong theoretical support but are complex and require substantial a priori knowledge, limiting their widespread application in remote sensing image processing across different sensors.
The rapid advancement of information technology has led to the widespread adoption of deep learning-based methods across various fields, including SR image processing. CNNs [
14] have garnered significant attention in the field of computer vision due to their advantages in automatic feature extraction, parameter sharing, spatial structure preservation, translation invariance, and generalization ability. The seminal work by Dong et al. [
15], which applied CNNs to image SR for the first time, marked a significant milestone, outperforming traditional methods and validating the feasibility of CNNs in this domain. Building upon the success of SRCNN, Dong et al. [
16] proposed FSRCNN, which introduced a novel tail-up sampling training technique, establishing it as a dominant training method for image SR. However, both SRCNN and FSRCNN were limited to only three convolutional layers, which constrained their depth. The advent of residual networks [
17] propelled the development of deep learning models towards greater depths. VDSR [
18], for instance, utilized 20 layers of convolution and achieved element-wise summation of the input image and model output feature maps through residual connections, effectively mitigating the issue of gradient vanishing in deep models. Its performance surpassed that of SRCNN. Subsequently, the performance of CNN-based models progressively advanced to deeper levels [
19,
20,
21], although increasing model depth is not without its limitations. Researchers began to incorporate attention mechanisms into image SR. RCAN [
22] combined the channel attention mechanism with VDSR to construct the first SR network based on attention, demonstrating that attention mechanisms can significantly enhance the performance of SR models. Following this, second-order attention [
23], residual attention [
24], and pixel attention [
25] were employed to further enhance the performance of image SR models. Today, attention mechanisms and residual structures have become standard components in SR models. Moreover, CNNs have been introduced to SR processing of RSIs. RSIs, unlike ordinary optical images, are characterized by complex feature types and significant scale differences [
26]. Leveraging these characteristics, LGCNet [
27] outperformed SRCNN by learning multi-level representations of local details and global environments, becoming the first network specifically designed for the SR of RSIs. Lei et al. [
28] built upon LGCNet and, by incorporating the multi-scale self-similarity of RSIs, proposed HSENet, which has become a classical model for RSISR. To further enhance the effectiveness of RSISR, researchers have continuously improved the network structure and proposed various new attention mechanisms [
29,
30] that significantly improve the quality of generated images. However, the local characteristics of CNNs limit their ability to model the global pixel dependencies in RSIs, which affects their performance in the SR task for RSIs.
Despite the substantial advancements in CNNs for image SR, many of these methods primarily focus on minimizing absolute pixel errors, often resulting in a high peak signal-to-noise ratio (PSNR) but images that appear overly smooth and lack perceptual quality. To overcome these limitations, generative adversarial networks (GANs), as detailed in [
31,
32,
33], have been proposed. GANs consist of two opposing networks: the generator and the discriminator, trained in a zero-sum game. The generator aims to create realistic images to fool the discriminator, while the discriminator’s task is to differentiate between real and generated images. Through this adversarial training, GANs generate images that exhibit superior perceptual quality compared to those produced by traditional CNN-based methods. SRGAN [
31], the pioneering network to apply GANs to image SR, features a generator consisting of multiple stacked residual blocks and a discriminator based on a VGG-style convolutional neural network. SRGAN introduces a novel loss function that utilizes a pre-trained VGG network to extract image features, optimizing the feature distance between generated and real samples to enhance perceptual similarity. However, the use of perceptual loss can sometimes introduce artifacts. To mitigate this issue, ESRGAN [
32] improves upon SRGAN by employing dense residual blocks and removing the batch normalization layer, which reduces artifacts. Despite these improvements, the use of dense residual blocks increases computational resource consumption, potentially affecting ESRGAN’s efficiency. Applying a typical optical image super-resolution GAN model directly to RSIs may lead to feature blurring and texture loss in the generated images. Researchers have made various advancements in GANs for RSISR, including edge sharpening [
34], the introduction of attention mechanisms [
35], gradient referencing [
36], and leveraging the unique characteristics of RSIs [
37]. These improvements often focus on optimizing the generator. As research continues, some scholars have shifted their focus to optimizing the discriminator. For instance, Wei et al. [
38] proposed a multi-scale U-Net discriminator with attention, which captures structural features of images at multiple scales and generates more realistic high-resolution images. Similarly, Wang et al. [
39] introduced a vision Transformer (ViT) discriminator, which also captures structural features at multiple scales and has achieved notable results. Despite these advancements, GAN-based methods still rely on CNN architectures for the construction of the generator and discriminator, and they fall short of fully addressing the inherent localization limitations of CNNs.
The Transformer architecture [
40] was first applied to the field of natural language processing (NLP), and Dosovitskiy et al. [
41] innovatively introduced it into the field of computer vision (CV) by proposing the ViT. ViT has achieved SOTA performance in several CV tasks. ViT directly models the global dependencies of an image through the self-attention mechanism, which outperforms the local convolution operation of CNNs in processing global features, especially in large-scale datasets. However, the computational complexity of the multi-head self-attention (MHSA) mechanism in ViT is quadratic with respect to the length of the input sequence, which consumes significant computational resources when processing large images. To reduce the computational complexity of MHSA, the Swin Transformer [
42] introduces a shift window, limiting the MHSA computation to non-overlapping localized windows. This modification makes the computational complexity linearly related to the image size while still allowing for the interaction of information across the windows, effectively improving computational efficiency. SwinIR [
43] combines the localized feature extraction capability of CNNs with the global modeling capability of Transformers. The model includes a shallow feature extraction module, a deep feature extraction module, and an HR reconstruction module. The deep feature extraction module consists of multiple layers of Swin Transformer with residual connections. This structure has become a mainstream design in Transformer-based SR methods. SRFormer [
44] introduces a replacement attention mechanism in the Transformer, which not only improves the resolution of the image but also effectively reduces the computational burden while retaining details. TransENet [
45] is the first Transformer model applied to the SR of RSIs. However, it upsamples the feature maps before decoding, leading to high computational resource consumption and complexity. To tackle token redundancy and limited multi-scale representation in large-area remote sensing super-resolution, TTST [
46] introduces a Transformer that selectively retains key tokens, enriches multi-scale features, and leverages global context, achieving better performance with reduced computational cost. CSCT [
47] proposes a channel–spatial coherent Transformer that enhances structural detail and edge reconstruction through spatial–channel attention and frequency-aware modeling, aiming to overcome the limitations of CNN- and GAN-based RSISR methods. SWCGAN [
48] integrates CNNs and Swin Transformers in both the generator and discriminator and demonstrates improved perceptual quality compared to earlier CNN-based GANs. However, despite their advantages, these Transformer-based methods still face challenges such as high memory consumption and computational overhead during training, particularly in the deep feature extraction stages. While Swin Transformer improves efficiency using shifted window mechanisms, the limited receptive field within each window may restrict the model’s ability to capture long-range dependencies across wide spatial extents—an essential requirement in remote sensing tasks. In contrast, our proposed NGSTGAN explicitly addresses these limitations by introducing a lightweight and efficient N-Gram-based shifted window self-attention mechanism that enhances the model’s capacity to capture both local structures and global dependencies without significantly increasing computational complexity. Moreover, the ISFE module further strengthens spatial structure preservation by facilitating interaction-based enhancement across features. Compared to TTST, CSCT, and SWCGAN, NGSTGAN strikes a better balance between structural fidelity, perceptual quality, and computational efficiency, which is crucial for scalable deployment in large-area RSISR applications.
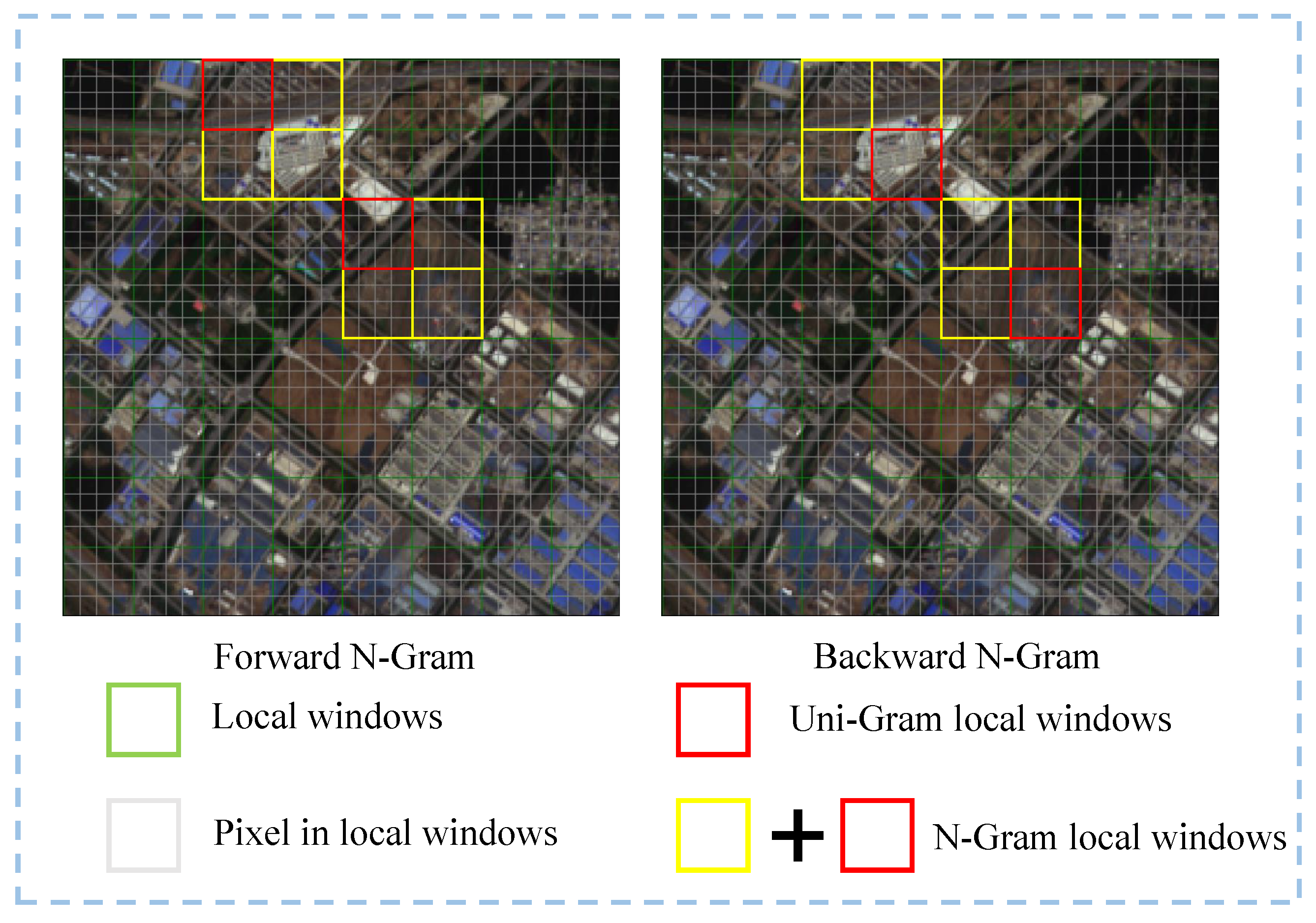
In language modeling (LM), an N-Gram [
49] is a set of consecutive sequences of characters or words, widely used in the field of NLP as a probabilistic, statistics-based language model, where the value of N is usually set to 2 or 3 [
49]. The N-Gram model performed well in early statistical approaches because it could take into account longer context spans in sentences. Even in some deep learning-based LMs, the N-Gram concept is still employed. Sent2Vec [
50] learns N-Gram embeddings using sentence embeddings. To better learn sentence representations, the model proposed in [
51] uses recurrent neural networks (RNNs) to compute the context of word N-Grams and passes the results to the attention layer. Meanwhile, some high-level vision studies have also adopted this concept. For example, pixel N-Grams [
52] apply N-Grams at the pixel level, both horizontally and vertically, and view N-Gram networks [
53] treat successive multi-view images of three-dimensional objects along time steps as N-Grams. Unlike these, this paper builds on previous N-Gram language models. Referring to NGSwin [
54], the concept of N-Grams is introduced into image processing, focusing on bidirectional two-dimensional information at the local window level. This approach offers a new method for processing single RSIs in low-level visual tasks.
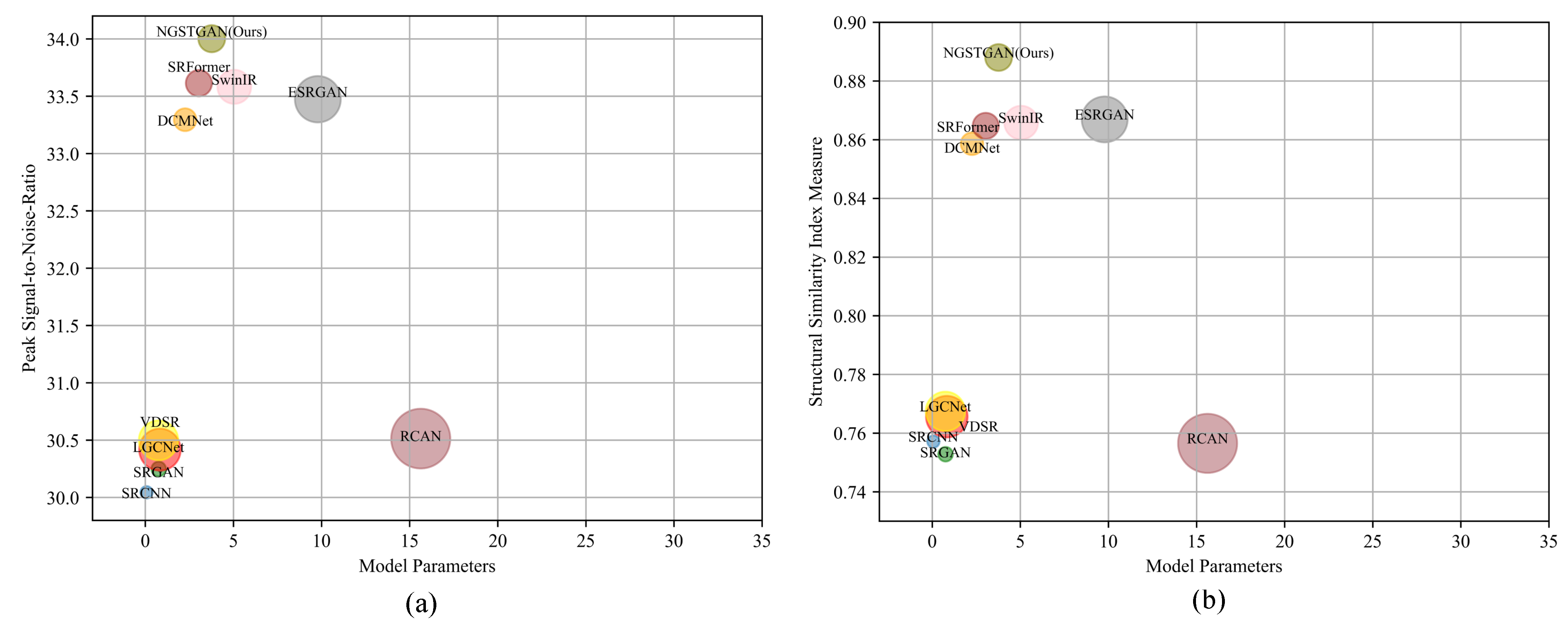
To summarize, current RSISR models face three major limitations. First, RSIs often contain multiple ground objects with strong self-similarity and repeated patterns across different spatial scales. However, most existing methods fail to effectively exploit the inherent multi-scale characteristics of RSIs. Second, the commonly used WSA in Swin Transformer is limited to local windows, making it difficult to leverage texture cues from adjacent regions. The independent and sequential sliding windows further restrict the model’s ability to capture global contextual dependencies. Third, many state-of-the-art RSISR models rely on heavy architectures with high computational cost. It is therefore essential to design lightweight models that not only limit parameters to 1 M∼4 M but also reduce the total number of multiply–accumulate operations during inference [
55,
56].
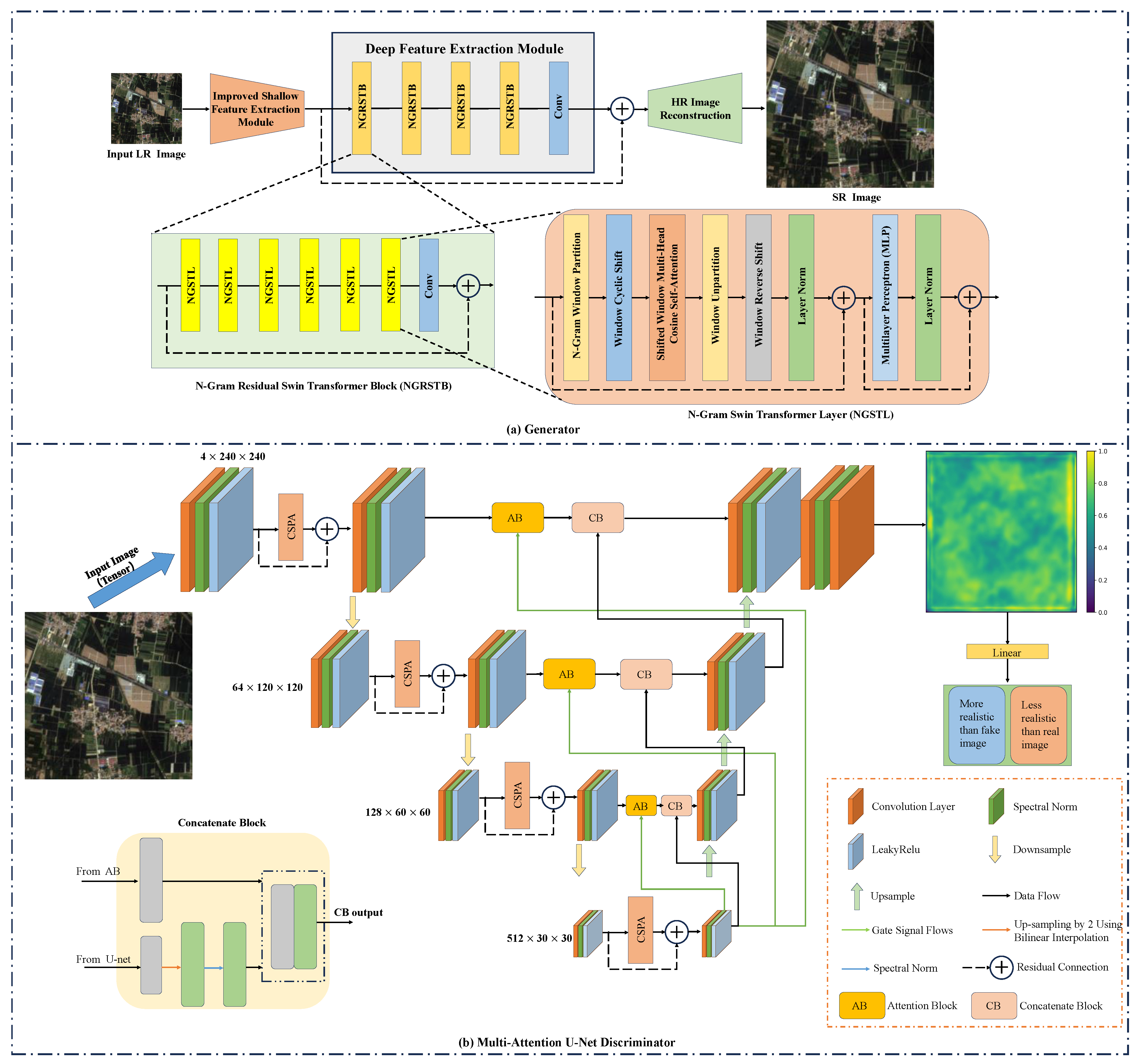
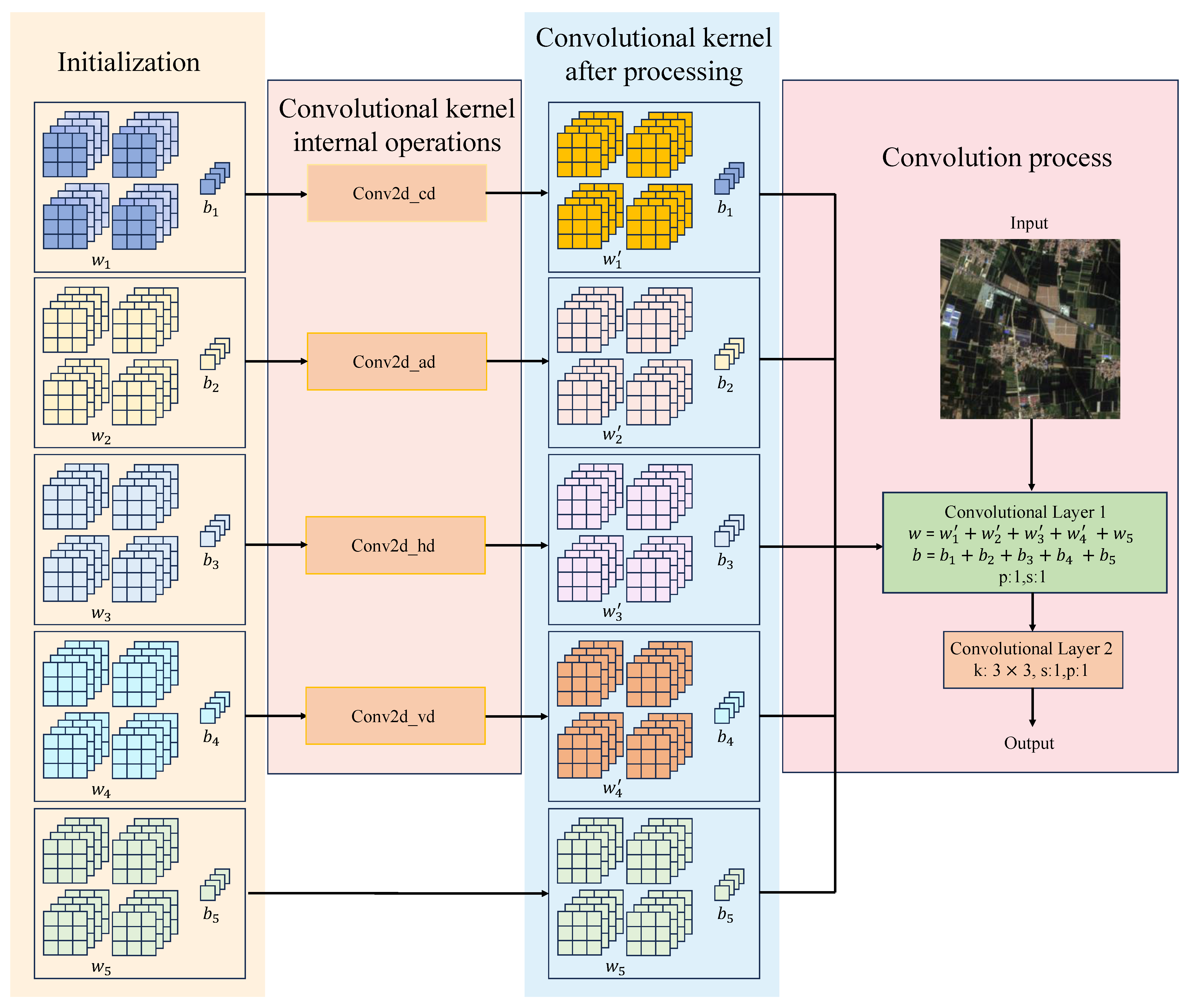
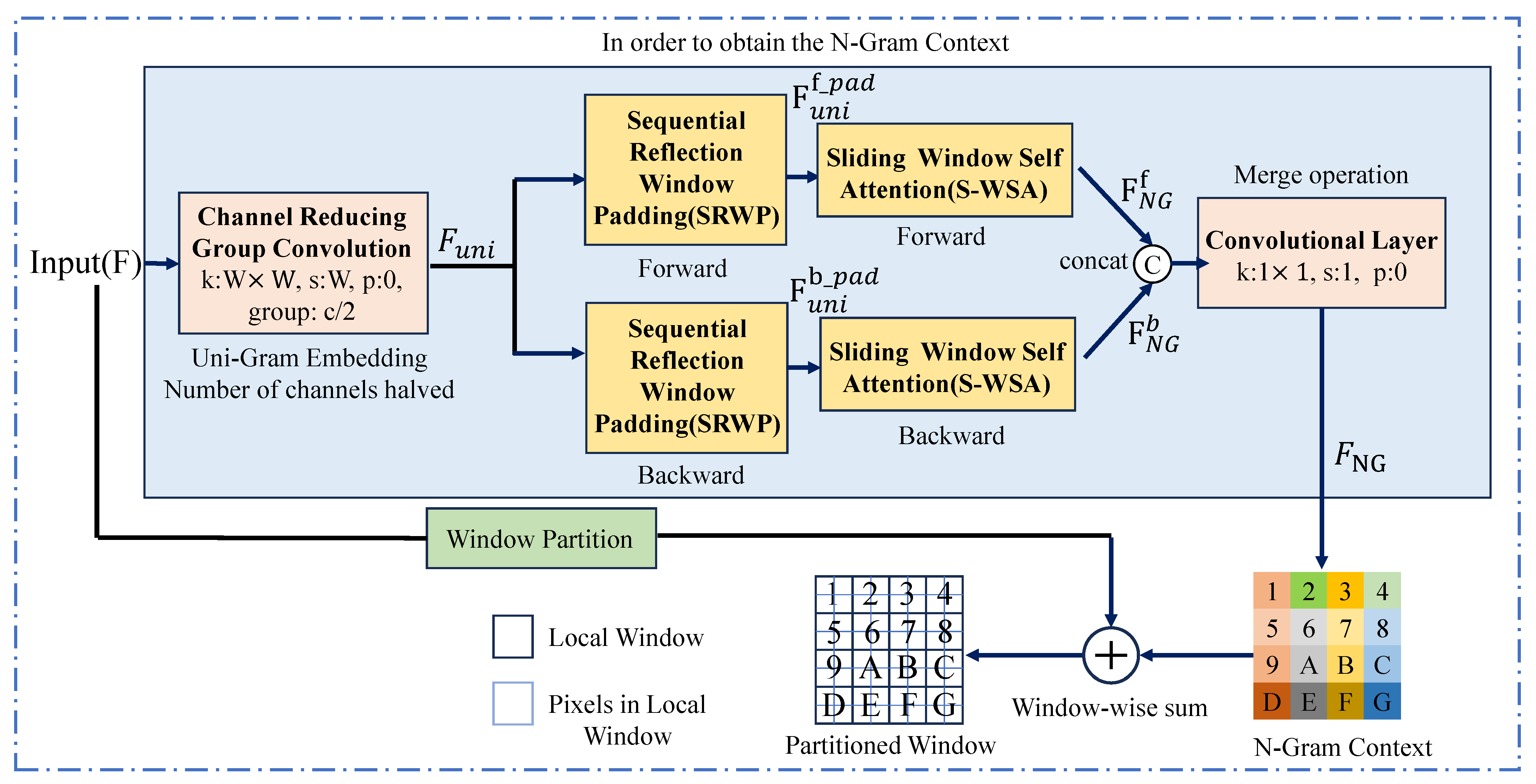
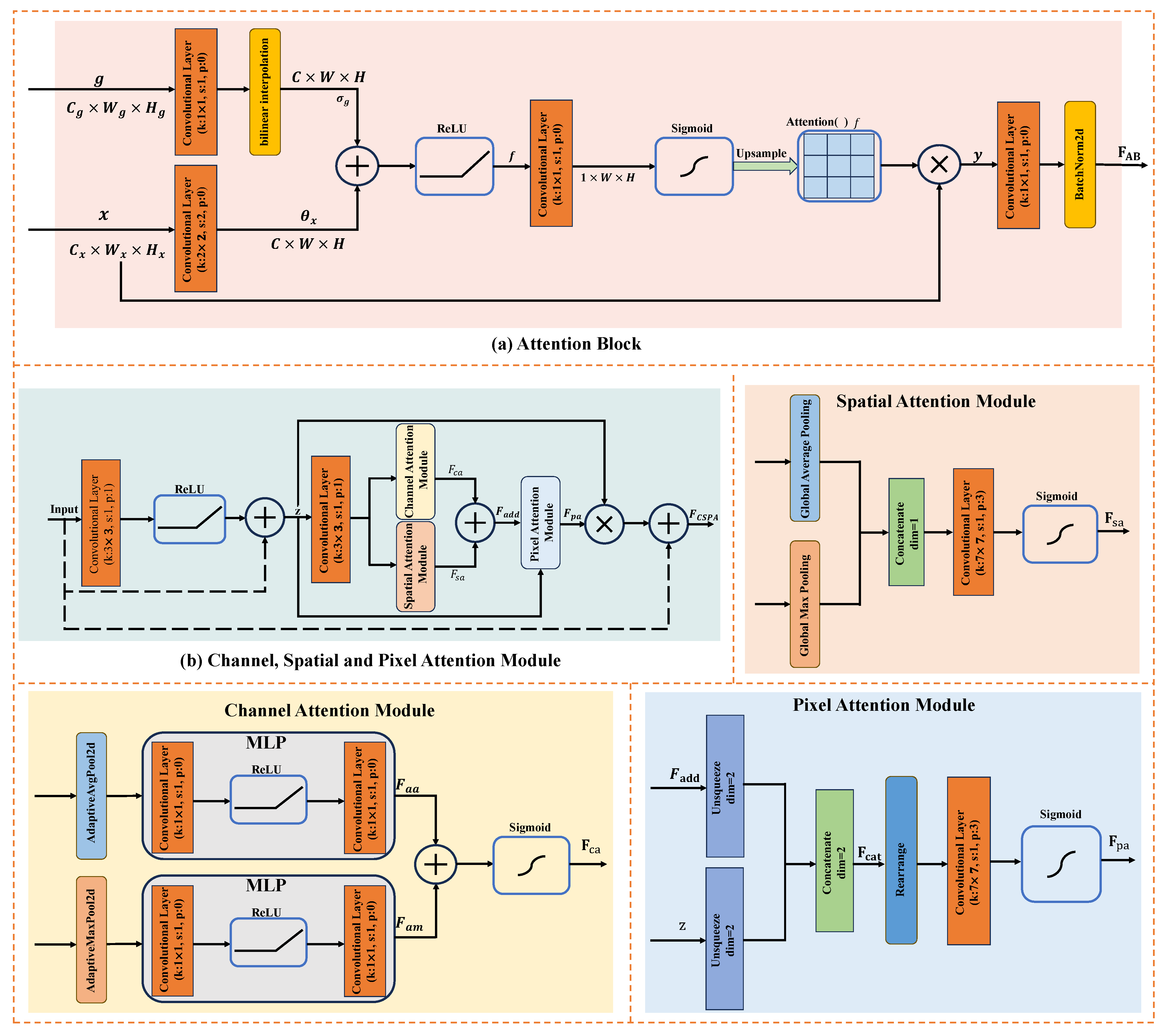
This study aims to enhance the spatial resolution of LR RSIs using deep learning techniques, thereby producing high-quality data for remote sensing applications. To achieve this, this study proposes a new RSISR model, namely NGSTGAN. It integrates the N-Gram Swin Transformer as the generator and combines the multi-attention U-Net as the discriminator. To tackle the multi-scale characteristics of remote sensing imagery, this study proposes a multi-attention U-Net discriminator, which is an extension of the attention U-Net [
38] and incorporates channel, spatial, and pixel attention modules before downsampling. The U-Net structure provides pixel-wise feedback to the generator, facilitating the generation of more detailed features. It also enhances feature extraction capabilities [
57] by integrating information from various scales through multi-level feature extraction and skip connections. The channel attention module enhances the representation of feature maps at each layer, enabling the generator to concentrate on critical channels, which is particularly important for complex remote sensing image features such as texture and color. The spatial attention module efficiently identifies significant regions and improves the spatial detail performance of U-Net in reconstructing high-resolution images, allowing the model to focus on specific feature regions and accurately recover details. Conversely, the pixel attention module offers robust feature representation at the local pixel level, making U-Net more adaptable and flexible in processing fine image information, such as feature edges and small details. Additionally, to extract multi-scale and multi-directional features from the input image, enrich the feature expression, and enhance the model’s ability to capture complex texture and detail information, the ISFE is designed in the generator, achieving promising results. To address the limitation of the Swin Transformer’s limited receptive field, where degraded pixels cannot be recovered by utilizing the information of neighboring windows, we refer to NGSwin [
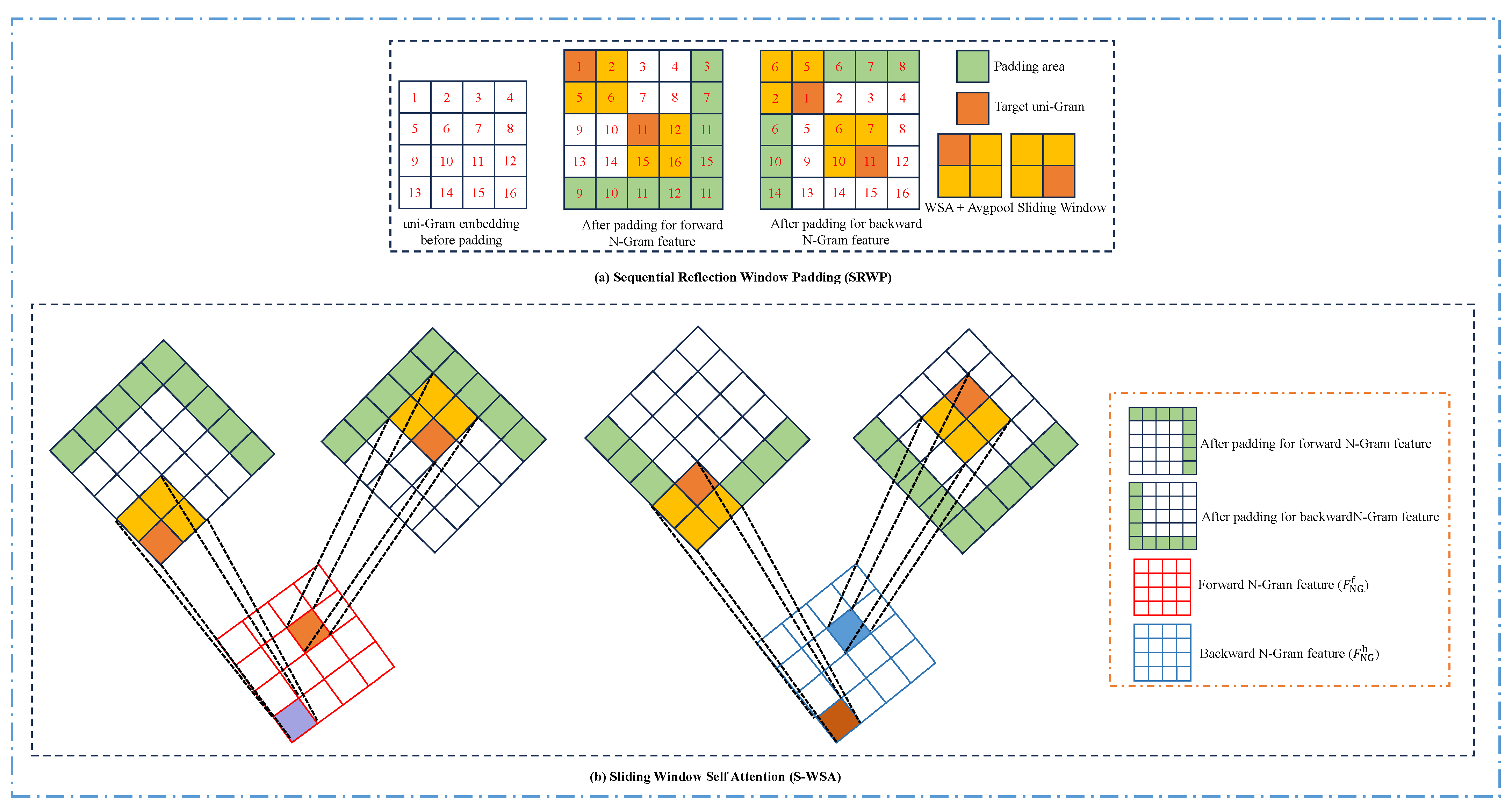
54] and introduce the N-Gram concept into the Swin Transformer. Through the S-WSA method, neighboring uni-Gram embeddings are able to interact with each other, allowing N-Gram contextual features to be generated before window segmentation and enabling the full utilization of neighboring window information to recover degraded pixels. The specifics of the N-Gram implementation are detailed in
Section 2.3.2. To reduce the number of parameters and the complexity of the model, we employ a CRGC method [
54,
58] to simplify the N-Gram interaction process.
Currently, most RSISR studies primarily rely on RGB-band datasets, which are widely used due to their availability and ease of visualization. However, for many real-world applications such as land use classification, crop monitoring, and environmental assessment, multispectral data can provide more comprehensive and accurate information. Recent studies have highlighted the value of multispectral Landsat imagery in various remote sensing tasks beyond RGB, including cloud removal and missing data recovery. For example, spatiotemporal neural networks have been used to effectively remove thick clouds from multi-temporal Landsat images [
59], while tempo-spectral models have demonstrated strong performance in reconstructing missing data across time series of Landsat observations [
60]. These works underscore the growing importance of leveraging multi-band satellite data to enhance the performance of downstream remote sensing tasks. To broaden the application scope of super-resolved imagery, this study introduces a novel SR dataset composed of multi-band remote sensing images derived from publicly available L8 and S2 sources. Unlike most existing RSISR datasets limited to RGB, our dataset includes the NIR band, enabling super-resolution processing on four bands: R, G, B, and NIR. The proposed method is capable of handling this multi-band input, expanding the potential applications of SR-enhanced imagery in multispectral analysis scenarios.
The primary contributions of this paper are summarized as follows:
- (1)
An ISFE is proposed to extract multi-scale and multi-directional features by combining different convolutional kernel parameters, thereby enhancing the model’s ability to capture complex texture and detail information, specifically designed for multispectral RSIs.
- (2)
The N-Gram concept is introduced into Swin Transformer, and the N-Gram window partition is proposed, which significantly reduces the number of parameters and computational complexity.
- (3)
The multi-attention U-Net discriminator is proposed by adding spatial, channel, and pixel attention mechanisms to the attention U-Net discriminator, which improves the accuracy of detail recovery and reduces information loss in SR tasks, ultimately enhancing image quality.
- (4)
A custom multi-band remote sensing image dataset is constructed to further verify the wide applicability and excellent performance of NGSTGAN in the SR task for multispectral images.
This paper is structured as follows.
Section 2 presents the method proposed in this study,
Section 3 describes the datasets and experimental setup,
Section 4 provides both quantitative and qualitative analyses of the experimental results,
Section 5 discusses the findings, and
Section 6 concludes the paper with a summary of the key findings.
5. Discussion
5.1. Advantages of ISFE
To evaluate the effectiveness of the proposed ISFE module, we conducted a series of ablation experiments, as shown in
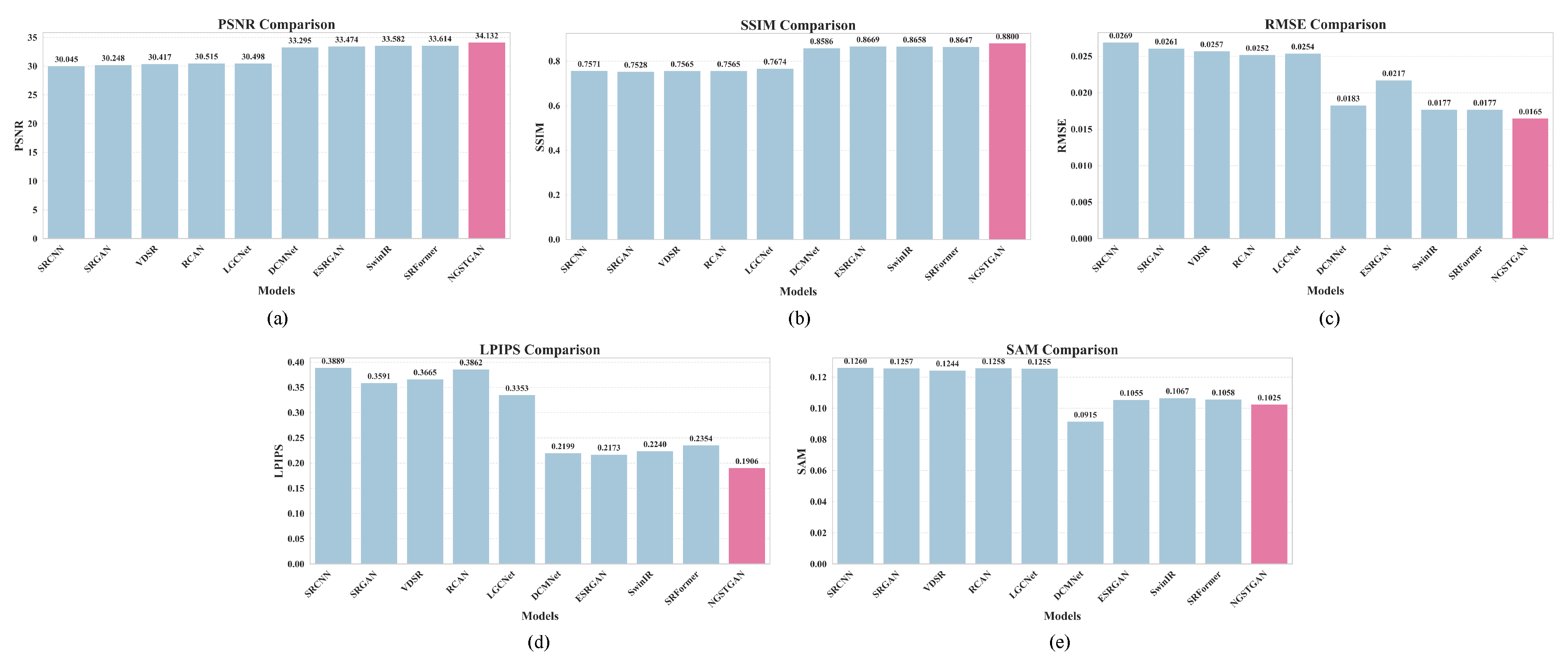
Table 4. These experiments assess the impact of ISFE under different model configurations. First, by comparing the generator with and without the ISFE module, we observe that incorporating ISFE significantly improves performance across all evaluation metrics. Specifically, PSNR increases by 0.3929 dB, SSIM improves by 0.0092, RMSE decreases by 0.0008, LPIPS drops by 0.0226, and SAM is reduced by 0.0029. These improvements indicate that the ISFE module enhances the generator’s ability to reconstruct fine details and maintain spectral consistency.
Furthermore, when comparing GAN-based configurations, the model with both a generator and discriminator (Ours) equipped with the ISFE module achieves the best performance overall. Compared to its counterpart without ISFE, PSNR improves by 0.4106 dB, SSIM increases by 0.0112, RMSE decreases by 0.0009, LPIPS is reduced by 0.0278, and SAM decreases by 0.0031. The consistent improvements across all metrics validate the contribution of the ISFE module, particularly in joint training scenarios where both structural fidelity and perceptual quality are critical.
5.2. Advantages of N-Gram Window Partition
To evaluate the effectiveness of the NGWP module in enhancing model performance and reducing complexity, we conducted a series of comparative and ablation experiments. It is important to emphasize that, in GAN-based architectures, only the generator is active during inference and testing; therefore, all reported parameter counts and MACs refer exclusively to the generator. The detailed results are summarized in
Table 5.
The baseline SwinIR model achieves a PSNR of 33.5820 dB and an SSIM of 0.8658, with corresponding RMSE, LPIPS, and SAM values of 0.0177, 0.2240, and 0.1067, respectively. It contains 5.05 M parameters and requires 32.35 G MACs. After integrating the NGWP module, consistent performance improvements are observed: PSNR increases to 33.6133 dB (+0.0313 dB); SSIM rises to 0.8673; and RMSE and LPIPS decrease to 0.0176 and 0.2224, respectively. These gains are accompanied by notable reductions in model size (3.77 M) and computational cost (20.43 G), underscoring NGWP’s ability to enhance performance while significantly improving efficiency. The inclusion of the ISFE module further boosts performance, raising PSNR to 34.0062 dB and SSIM to 0.8765, with RMSE and LPIPS dropping to 0.0168 and 0.1998, respectively. Crucially, these enhancements are achieved without increasing the parameter count or computational overhead, demonstrating the module’s effectiveness in improving reconstruction quality in a resource-efficient manner. When the discriminator is introduced alongside NGWP and ISFE, the model achieves its best performance: PSNR reaches 34.1317 dB, SSIM improves to 0.8800, RMSE and LPIPS are reduced to 0.0165 and 0.1906, and SAM declines to 0.1025. Compared to the baseline, this corresponds to gains of +0.5497 dB in PSNR and +0.0142 in SSIM and reductions of 0.0012, 0.0334, and 0.0042 in RMSE, LPIPS, and SAM, respectively—highlighting the synergistic effect of the proposed components. In conclusion, the NGWP module substantially improves feature interaction while achieving efficient model compression. When integrated with the ISFE module and the multi-attention discriminator, the overall NGSTGAN framework delivers notable improvements in both reconstruction accuracy and perceptual quality, validating the effectiveness and necessity of these components.
5.3. Advantages of Multi-Attention U-Net Discriminator
In GANs, a proficient discriminator is capable of more accurately distinguishing between generated images and real images, thereby prompting the generator to produce more realistic and high-quality SR images, particularly in the context of remotely sensed imagery, which can enhance detail fidelity and perceptual quality. The multi-attention U-Net discriminator proposed in this paper is adept at capturing the multi-scale features of RSIs, thereby guiding the generator to produce richer and more realistic RSIs. Additionally, the discriminator learns the representation of image edges and enhances its attention to critical details. To validate the effectiveness of the multi-attention u-net discriminator proposed in this paper, a series of experiments were conducted, including comparison and ablation studies. These experiments compared the performance of the proposed discriminator against several other discriminators, including no discriminator, the VGG discriminator [
31], ViT discriminator [
39], U-Net discriminator [
32], and attention U-Net discriminator [
38]. The results are summarized in
Table 6, which illustrates the impact of different discriminators on the model’s performance in the RSISR task and analyzes the performance differences. Without a discriminator, the model achieves baseline performance, with a PSNR of 34.0062 dB and an SSIM of 0.8765. The addition of a VGG discriminator results in decreases in PSNR of 0.4005 dB and SSIM of 0.0098, likely due to its limited feature extraction ability, failing to fully capture the detailed features of the inputs. The ViT discriminator shows a slight improvement in the model, with a decrease in PSNR of only 0.3033 dB compared to the baseline, but its SSIM still declines by 0.0075, and the model fails to outperform the baseline, possibly due to its reliance on the training data. The U-Net discriminator performs similarly to the no-discriminator scenario, with an increase in PSNR of 0.0023 dB and a slight increase in SSIM of 0.0004, indicating its robustness in extracting detailed features. The attention U-Net discriminator further optimizes the performance, with increases in PSNR of 0.0535 dB and SSIM of 0.0535 compared to the no-discriminator scenario. PSNR improves by 0.0589 dB and SSIM by 0.0013 compared to the no-discriminator scenario, thanks to its attention mechanism that can focus on key feature regions more effectively. Our proposed multi-attention U-Net discriminator performs the best, with improvements in PSNR of 0.1255 dB and SSIM of 0.0035 compared to the baseline and reductions in LPIPS and SAM of 0.0092 and 0.0009, respectively. These experimental results demonstrate that the multi-attention mechanism is capable of comprehensively capturing features, significantly improving generation quality and reconstruction accuracy while effectively suppressing reconstruction errors.
Figure 16 illustrates the reconstruction effect of the network under different discriminators, revealing that our proposed multi-attention U-Net discriminator exhibits the best reconstruction quality, capable of reconstructing rich texture and edge information.
5.4. Discussion About Loss Function
The loss function plays a crucial role in guiding the optimization process of the model, directly influencing the quality and characteristics of the generated SR images. A well-chosen loss function not only aims to achieve pixel-level accuracy but also seeks to optimize visual perception, detail retention, and feature consistency. To thoroughly validate the effectiveness of the loss function proposed in this paper, a series of experiments were conducted, and the results are presented in
Table 7. The table illustrates the impact of different loss function combinations on the SR images. In terms of various metrics, when
is used alone, the SR image achieves the best PSNR (34.1011 dB), indicating a higher reconstruction quality, with the lowest RMSE (0.0164) and LPIPS (0.1747) suggesting that the pixel loss effectively recovers image details. However, despite the high PSNR, the optimization in this case lacks in visual quality. As shown in
Figure 17, the image optimized with pixel loss is still rough in details and lacks realism. When
is incorporated, the SSIM and other metrics related to visual quality (e.g., LPIPS and SAM) improve, enhancing the image’s structure and details, albeit with a slight decrease in PSNR (34.0062 dB). The goal of perceptual loss optimization is to reduce the perceived distance of the image, making the generated image closer to the real image in terms of data distribution. Although the PSNR decreases, the visual effect is more natural. The introduction of
further improves PSNR and SSIM (34.2499 dB and 0.8836, respectively), with a slight increase in RMSE but reductions in LPIPS and SAM, indicating that the generated hyper-segmented images are more natural in perception and closer to the real images. Overall, the combination of perceptual loss and adversarial loss effectively enhances the visual quality, even if the PSNR index is slightly lower, making the images closer to the characteristics of real images. To mitigate the artifact issue caused by perceptual loss, the weight of perceptual loss was appropriately reduced in this study.
Figure 17 presents a visual comparison of RSIs reconstructed by the network under different loss function optimizations.
5.5. SR Results in Different Scenarios
RSIs encompass a variety of complex features, and there are significant differences in the reconstruction effects across different scenes. For this reason, we selected several typical scenes and analyzed their reconstruction effects in depth, comparing SwinIR, SRFormer, and the NGSTGAN model proposed in this paper.
Figure 18a illustrates the reconstruction effects of different models in a complex town scene. Compared with other scenes, the features of the town scene are extremely complex and difficult to reconstruct, especially in the high-resolution (HR) image, where the edge features are also difficult to recognize, showing fuzzy highlighted areas. From the figure, we can see that, compared with SwinIR and SRFormer, the NGSTGAN model is more realistic in the reconstruction effect, successfully reconstructing spectral features, and the color performance is closer to the HR image. However, due to the high difficulty of reconstructing the urban construction scene, although the effect of NGSTGAN is improved, the overall reconstruction effect still has a certain gap compared with HR images.
Figure 18b shows the reconstruction effects of different models in a sharp-edge scene, which is a small piece of farmland. Although SwinIR and SRFormer partially recover the clarity of the image during the reconstruction process, there are still the problems of detail loss and blurring of the edges in the sharp areas. In contrast, the NGSTGAN model is outstanding in recovering the details and sharp edges of the image, effectively reducing the blurring phenomenon in the reconstruction and maintaining more original details, especially in the texture and edge parts of the image.
Figure 18c compares the reconstruction effects of several SR reconstruction models in a lake smoothing scene. The SwinIR and SRFormer models improve the image quality to some extent, partially restoring the smooth boundaries of the lake and the surrounding details. However, these two models are still deficient in the natural transition of lake texture and edge clarity. In contrast, the NGSTGAN model performs much better, not only significantly enhancing the smoothness of the lake region but also being able to preserve the details of the edge transition more finely. The color of the reconstruction result is closest to the HR image, and the overall reconstruction effect is closer to the real scene.
5.6. Analysis of Line Distortion in GAN-Based RSISR Results
GAN-based SR methods, including SRGAN and ESRGAN, often produce slight geometric distortions such as warping or bending of originally straight lines in man-made structures like roads and buildings. These distortions affect the geometric fidelity, which is crucial in remote sensing applications. Our proposed NGSTGAN achieves significant improvements in visual quality and detail reconstruction compared to SRGAN and ESRGAN. However, slight line distortions remain a challenge. To reduce this, we use a hybrid loss combining pixel-wise, perceptual, and adversarial losses, along with architectural enhancements like the ISFE module and an N-Gram-based S-WSA mechanism. Despite these advances, preserving strict geometric consistency requires further work. Future research will explore geometry-aware constraints to explicitly address line distortions and improve spatial accuracy in RSISR.
5.7. Complexity and Inference Time Comparison
Table 8 presents a comparative analysis of several representative models based on three key indicators: the number of parameters, MACs, and inference time (IT). These metrics collectively assess model efficiency and deployment cost from multiple perspectives. The number of parameters indicates the memory footprint, MACs reflect the theoretical computational complexity, and inference time measures the actual runtime performance on hardware platforms—serving as a crucial criterion for evaluating model compactness and real-time applicability. As shown in the table, LGCNet achieves the lowest parameter count, at only 0.75 M, reflecting an extremely compact network design. DCMNet excels in both MACs and inference speed, achieving the lowest values of 14.47 G and 0.37 s, respectively, for the processing of 100 images, thereby demonstrating a strong balance between speed and efficiency. SRFormer follows closely in terms of both computational cost and runtime, exhibiting a well-optimized trade-off. In comparison, the proposed NGSTGAN does not outperform all other models in any single metric but shows competitive performance across all three dimensions. It features a moderate parameter count of 3.77 M and 20.43 G MACs while achieving an inference time of 0.47 s for 100 images—comparable to SRFormer and significantly faster than larger models such as SwinIR and ESRGAN. These results indicate that NGSTGAN achieves an effective balance between reconstruction quality and computational efficiency, making it well-suited for real-world deployment. Overall, the comparative results not only validate the rationality of NGSTGAN’s architectural design but also highlight its potential for practical applications and scalable deployment scenarios.
5.8. Potential Applications of NGSTGAN
Although NGSTGAN is primarily designed for multispectral image super-resolution, its architectural components offer promising adaptability to other remote sensing tasks, such as pansharpening and pan-denoising. For pansharpening, methods like GPPNN [
76] utilize gradient priors and deep fusion strategies to integrate spatial details from panchromatic images into multispectral data. NGSTGAN’s generator, built upon hierarchical Swin Transformer blocks enhanced with N-Gram contextual modeling, is well-suited to capture both fine-grained spatial structures and rich spectral information. With appropriate modifications—such as incorporating a high-resolution panchromatic branch and a suitable fusion module—NGSTGAN could be extended to achieve effective pan-guided fusion, preserving spectral integrity while enhancing spatial resolution. In the context of pan-denoising, as addressed by methods like PWRCTV [
77], the objective is to suppress noise in hyperspectral or multispectral images using auxiliary panchromatic guidance. NGSTGAN’s multi-attention design and U-Net-based discriminator naturally facilitate the extraction of salient features while mitigating noise. With the integration of denoising-specific loss functions and training schemes, the model has the potential to be adapted for robust guided denoising tasks. These potential extensions highlight the versatility of the NGSTGAN framework and its relevance beyond its original application, providing a valuable foundation for future research in multimodal remote sensing image enhancement.
5.9. Limitations and Future Perspectives
The primary objective of this study is to investigate the potential of employing remote sensing image SR techniques to generate high-quality, multi-purpose data. Specifically, we aim to enhance the spatial resolution of Landsat-8 satellite imagery from 30 m to 10 m in the R, G, B, and NIR bands. In multispectral image SR tasks, effectively constraining the change of spectral information during the SR process is a critical challenge. However, this study did not incorporate an explicit spectral constraint mechanism; instead, it captured spectral features through implicit adaptive learning with the multiple-attention mechanism of NGSTGAN. Despite this, the results indicate that there is still a certain degree of spectral difference between the generated SR image and the real high-resolution image and a certain degree of color difference between the super-resolved image and the HR image. To further optimize the reconstruction accuracy of spectral information, we plan to introduce a joint spatial–spectral constraint loss function that explicitly corrects the spectral information of the low-resolution images, achieving joint SR in both spatial and spectral dimensions. Additionally, Landsat-8 satellite images cover a wide range of areas and contain a vast amount of data, making it challenging for current hardware resources to meet the demand for large-scale training. In the future, we aim to conduct SR processing for regions of specific research value and construct a high-resolution image dataset. Based on this dataset, we will further explore its potential in various remote sensing applications, such as land use classification, target detection, and crop extraction, to achieve higher precision application results. Furthermore, we plan to select specific areas for comprehensive SR of Landsat series images to construct a HR image dataset with a long time series. This dataset will provide high-quality basic data for further research and applications in the field of remote sensing, laying a solid foundation for the realization of high-precision analysis across multi-temporal and spatial scales.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}