
SR-DETR: Target Detection in Maritime Rescue from UAV Imagery

Abstract
1. Introduction
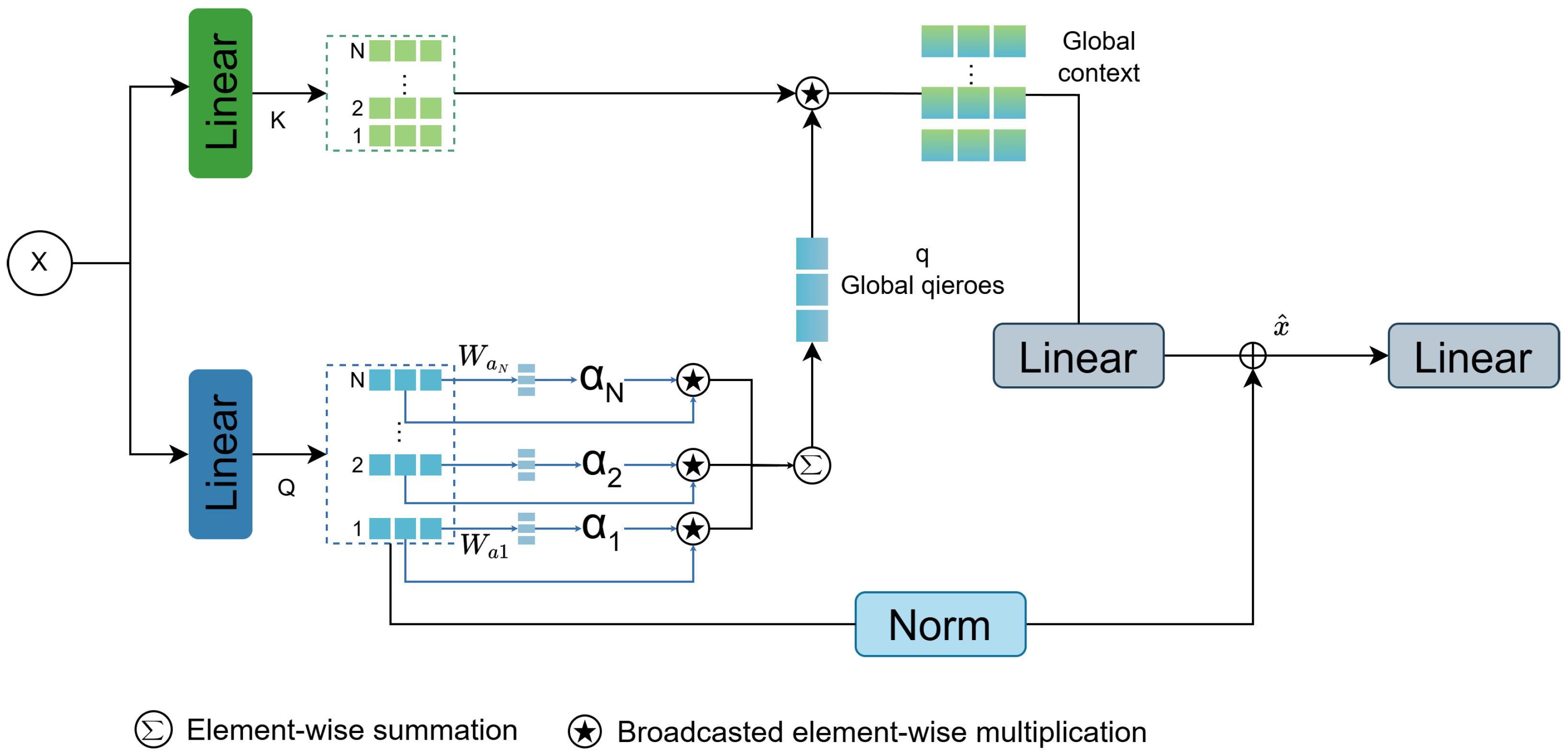
- To enhance feature interaction and improve computational efficiency, we introduce Efficient Additive Attention (EAA), which eliminates redundant interactions and utilizes a linear query–key encoding mechanism. The proposed methodology enhances contextual reasoning capacity while reducing algorithmic overhead, rendering it particularly suitable for latency-sensitive deployments on resource-constrained platforms.
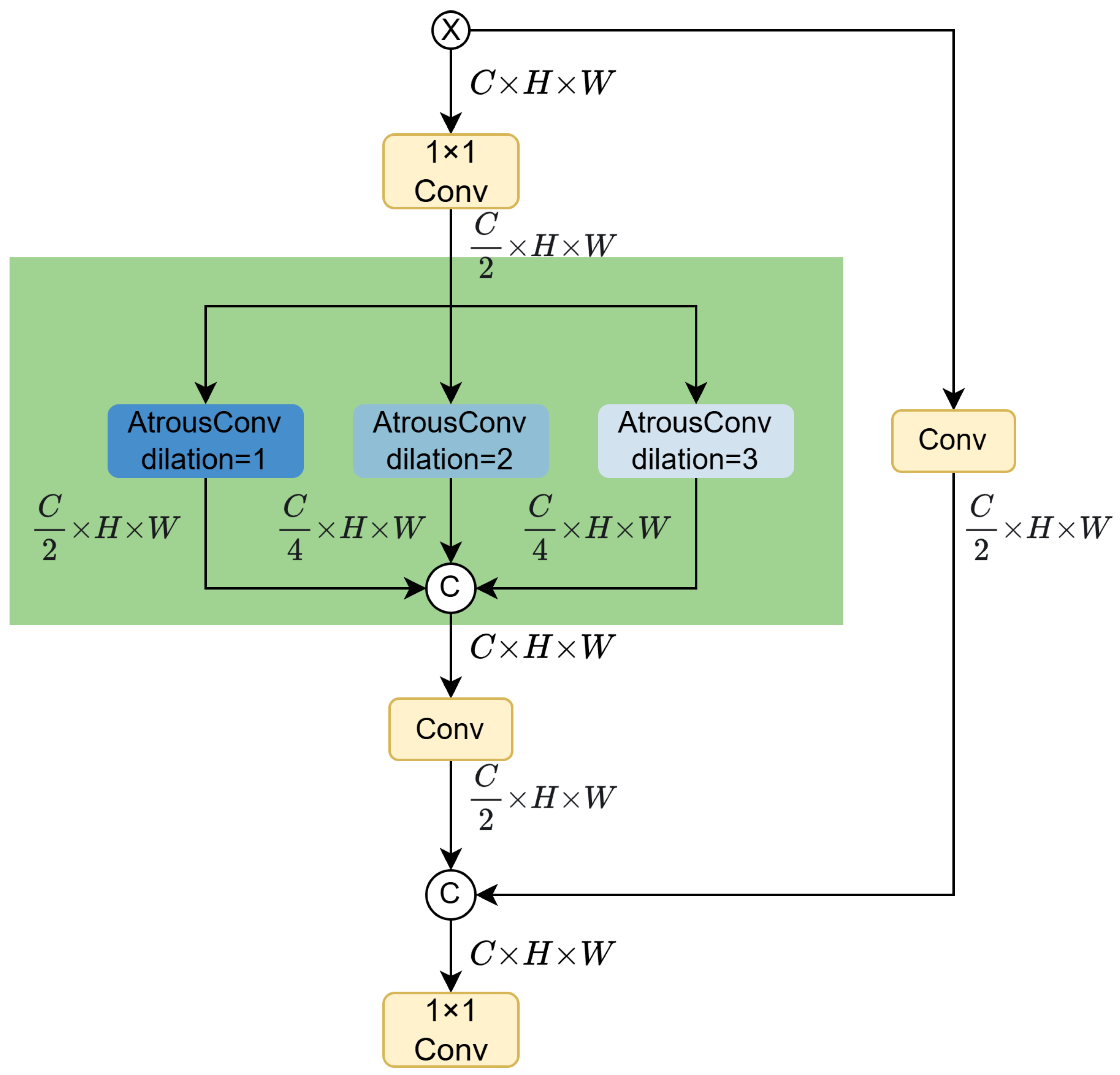
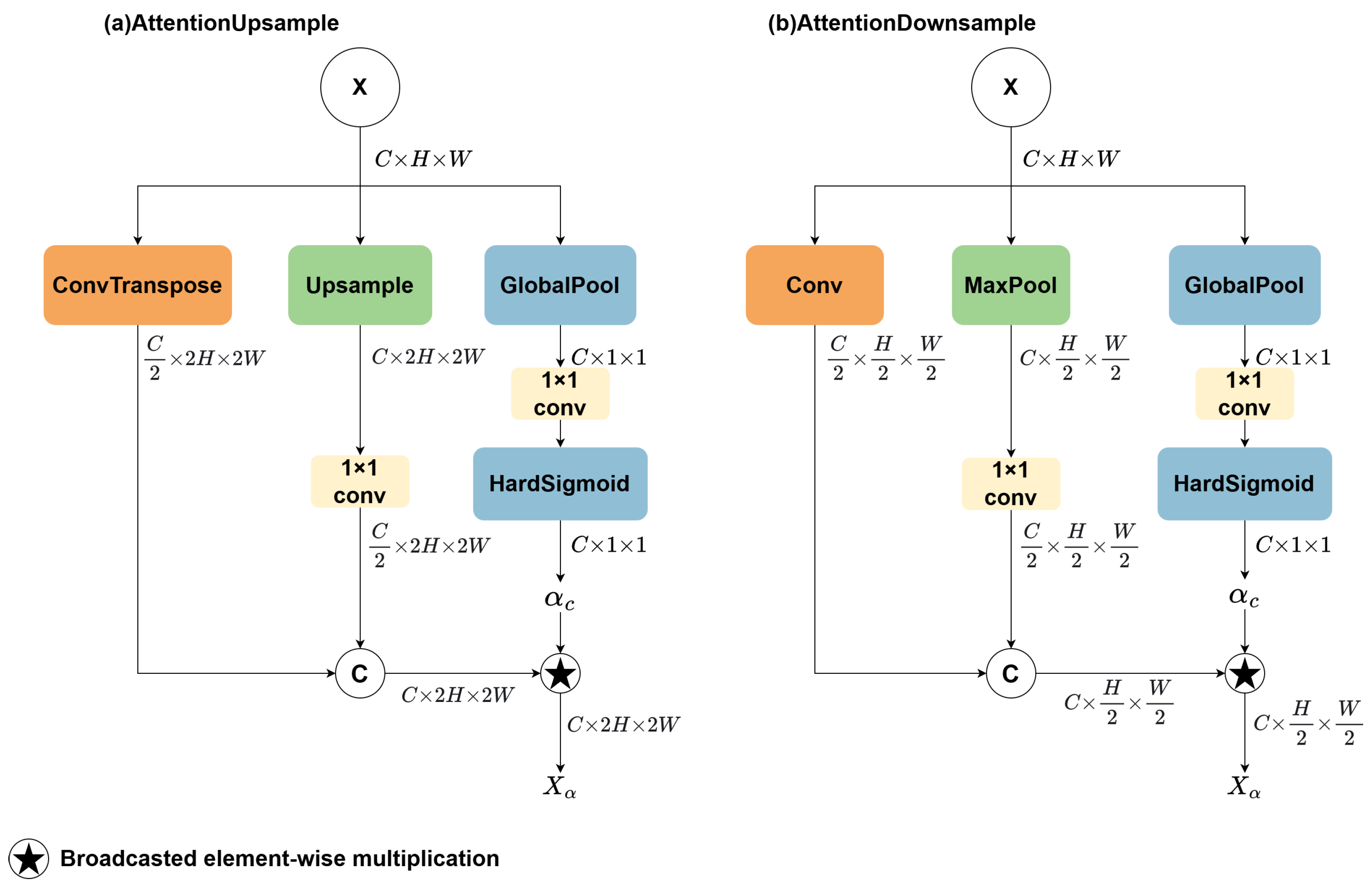
- The Cross-Stage Partial Parallel Atrous Feature Pyramid Network (CPAFPN) is proposed to address multi-scale feature integration challenges and improve small-target recognition performance. By enhancing spatial attention to critical regions and strengthening contextual modeling, CPAFPN improves the model’s capability to detect small objects even under challenging maritime conditions such as sea surface reflections and motion-induced background noise.
- Addressing the dual challenges of few-shot small-object detection and precise localization in marine scenarios, this work introduces an innovative bounding box regression loss formulation. This loss function is crafted to focus on detecting small, challenging objects, thereby boosting localization precision and overall detection effectiveness, especially in environments with numerous small-scale objects.
2. Related Works
2.1. Object Detection
2.2. Target Detection Based on UAV Images
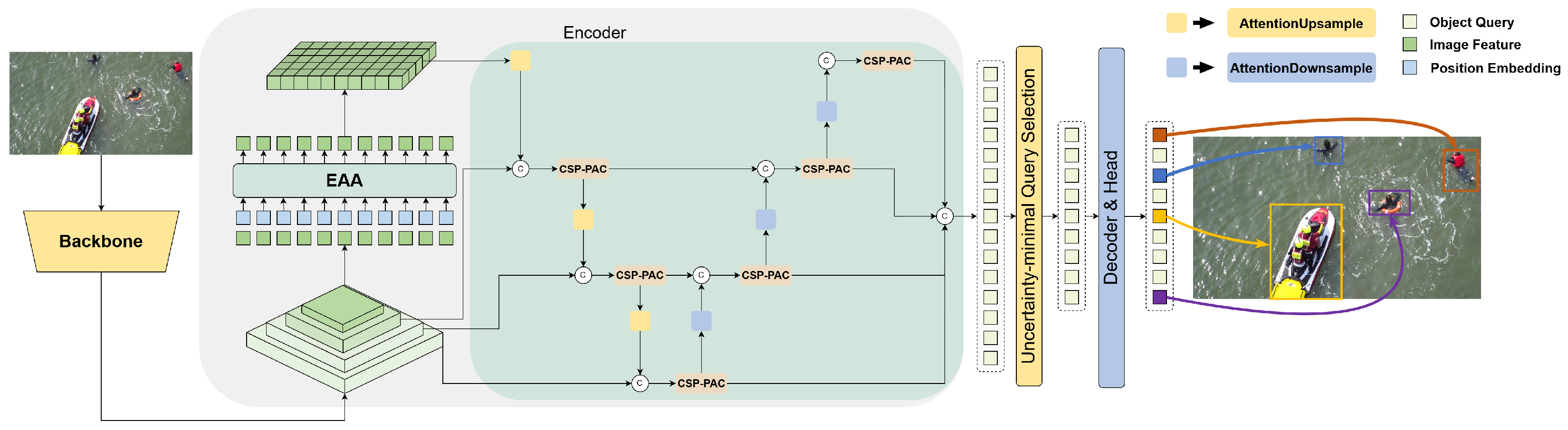
3. Materials and Methods
3.1. Method Review
3.2. Efficient Additive Attention
3.3. Cross-Stage Partial Parallel Atrous Feature Pyramid Network
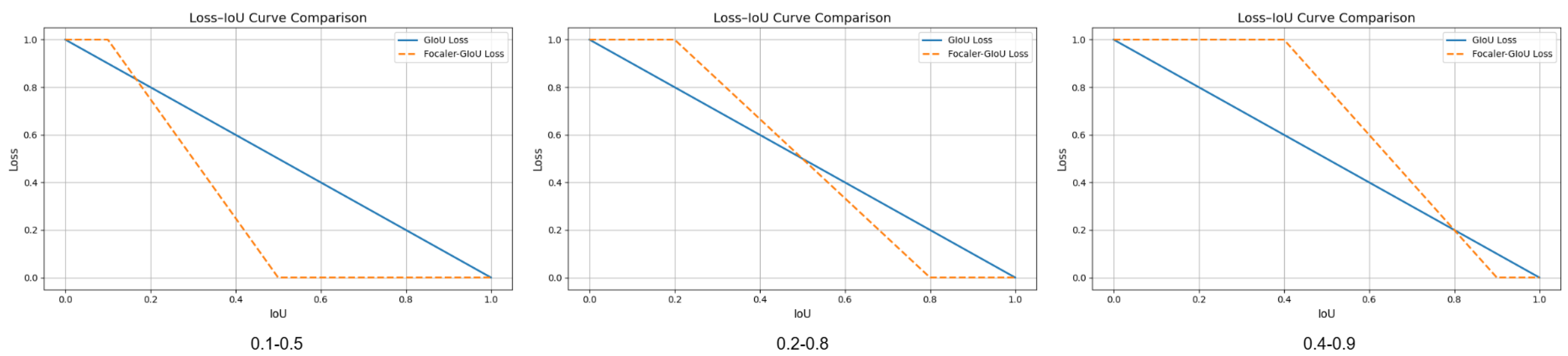
3.4. Focaler-GIoU
4. Experiment
4.1. Dataset
4.2. Experimental Environment
4.3. Evaluation Metrics
4.4. Ablation Experiment
4.5. Comparison Experiment with Other Object Detection Algorithms
4.6. Results
4.7. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mohsan, S.A.H.; Khan, M.A.; Noor, F.; Ullah, I.; Alsharif, M.H. Towards the unmanned aerial vehicles (UAVs): A comprehensive review. Drones 2022, 6, 147. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Sun, Z.; Leng, X.; Zhang, X.; Zhou, Z.; Xiong, B.; Ji, K.; Kuang, G. Arbitrary-direction SAR ship detection method for multi-scale imbalance. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5208921. [Google Scholar] [CrossRef]
- Yang, M.D.; Tseng, H.H. Rule-Based Multi-Task Deep Learning for Highly Efficient Rice Lodging Segmentation. Remote Sens. 2025, 17, 1505. [Google Scholar] [CrossRef]
- Zhou, S.; Zhou, H. Detection based on semantics and a detail infusion feature pyramid network and a coordinate adaptive spatial feature fusion mechanism remote sensing small object detector. Remote Sens. 2024, 16, 2416. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, S.; Sun, Z.; Liu, C.; Sun, Y.; Ji, K.; Kuang, G. Cross-sensor SAR image target detection based on dynamic feature discrimination and center-aware calibration. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5209417. [Google Scholar] [CrossRef]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar]
- Wu, X.; Sahoo, D.; Hoi, S.C. Recent advances in deep learning for object detection. Neurocomputing 2020, 396, 39–64. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1137–1149. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Meng, D.; Chen, X.; Fan, Z.; Zeng, G.; Li, H.; Yuan, Y.; Sun, L.; Wang, J. Conditional detr for fast training convergence. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3651–3660. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.Y. Dino: Detr with improved denoising anchor boxes for end-to-end object detection. arXiv 2022, arXiv:2203.03605. [Google Scholar]
- Liu, Y.; Yang, F.; Hu, P. Small-object detection in UAV-captured images via multi-branch parallel feature pyramid networks. IEEE Access 2020, 8, 145740–145750. [Google Scholar] [CrossRef]
- Tian, G.; Liu, J.; Yang, W. A dual neural network for object detection in UAV images. Neurocomputing 2021, 443, 292–301. [Google Scholar] [CrossRef]
- Chen, C.J.; Huang, Y.Y.; Li, Y.S.; Chen, Y.C.; Chang, C.Y.; Huang, Y.M. Identification of fruit tree pests with deep learning on embedded drone to achieve accurate pesticide spraying. IEEE Access 2021, 9, 21986–21997. [Google Scholar] [CrossRef]
- Prosekov, A.; Vesnina, A.; Atuchin, V.; Kuznetsov, A. Robust algorithms for drone-assisted monitoring of big animals in harsh conditions of Siberian winter forests: Recovery of European elk (Alces alces) in Salair mountains. Animals 2022, 12, 1483. [Google Scholar] [CrossRef]
- Chen, Y.; Zheng, W.; Zhao, Y.; Song, T.H.; Shin, H. Dw-yolo: An efficient object detector for drones and self-driving vehicles. Arab. J. Sci. Eng. 2023, 48, 1427–1436. [Google Scholar] [CrossRef]
- Peng, L.; Zhang, J.; Li, Y.; Du, G. A novel percussion-based approach for pipeline leakage detection with improved MobileNetV2. Eng. Appl. Artif. Intell. 2024, 133, 108537. [Google Scholar] [CrossRef]
- Božić-Štulić, D.; Marušić, Ž.; Gotovac, S. Deep learning approach in aerial imagery for supporting land search and rescue missions. Int. J. Comput. Vis. 2019, 127, 1256–1278. [Google Scholar] [CrossRef]
- Xu, J.; Fan, X.; Jian, H.; Xu, C.; Bei, W.; Ge, Q.; Zhao, T. Yoloow: A spatial scale adaptive real-time object detection neural network for open water search and rescue from uav aerial imagery. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5623115. [Google Scholar] [CrossRef]
- Lu, Y.; Guo, J.; Guo, S.; Fu, Q.; Xu, J. Study on Marine Fishery Law Enforcement Inspection System based on Improved YOLO V5 with UAV. In Proceedings of the 2022 IEEE International Conference on Mechatronics and Automation (ICMA), Guilin, China, 7–10 August 2022; pp. 253–258. [Google Scholar]
- Zhao, J.; Chen, Y.; Zhou, Z.; Zhao, J.; Wang, S.; Chen, X. Multiship speed measurement method based on machine vision and drone images. IEEE Trans. Instrum. Meas. 2023, 72, 2513112. [Google Scholar] [CrossRef]
- Bai, J.; Dai, J.; Wang, Z.; Yang, S. A detection method of the rescue targets in the marine casualty based on improved YOLOv5s. Front. Neurorobot. 2022, 16, 1053124. [Google Scholar] [CrossRef]
- Zhang, Y.; Yin, Y.; Shao, Z. An enhanced target detection algorithm for maritime search and rescue based on aerial images. Remote Sens. 2023, 15, 4818. [Google Scholar] [CrossRef]
- Sun, C.; Zhang, Y.; Ma, S. Dflm-yolo: A lightweight yolo model with multiscale feature fusion capabilities for open water aerial imagery. Drones 2024, 8, 400. [Google Scholar] [CrossRef]
- Liu, K.; Ma, H.; Xu, G.; Li, J. Maritime distress target detection algorithm based on YOLOv5s-EFOE network. IET Image Process. 2024, 18, 2614–2624. [Google Scholar] [CrossRef]
- Shaker, A.; Maaz, M.; Rasheed, H.; Khan, S.; Yang, M.H.; Khan, F.S. Swiftformer: Efficient additive attention for transformer-based real-time mobile vision applications. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 17425–17436. [Google Scholar]
- Zhang, H.; Zhang, S. Focaler-iou: More focused intersection over union loss. arXiv 2024, arXiv:2401.10525. [Google Scholar]
- Varga, L.A.; Kiefer, B.; Messmer, M.; Zell, A. Seadronessee: A maritime benchmark for detecting humans in open water. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 2260–2270. [Google Scholar]
- Du, D.; Zhu, P.; Wen, L.; Bian, X.; Lin, H.; Hu, Q.; Peng, T.; Zheng, J.; Wang, X.; Zhang, Y.; et al. VisDrone-DET2019: The Vision Meets Drone Object Detection in Image Challenge Results. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual explanations from deep networks via gradient-based localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configuration | Name | Type |
|---|---|---|
| Hardware | CPU | Intel(R) Xeon(R) W-2255 |
| GPU | NVIDIA RTX A4000 | |
| Memory | 128 GB | |
| Software | CUDA | 11.8 |
| Python | 3.8.16 | |
| PyTorch | 2.0.1 | |
| Hyperparameters | Image Size | 640 × 640 |
| Batch Size | 4 | |
| Learning Rate | 0.0001 | |
| Maximum Training Epoch | 150 | |
| Other | Same as RT-DETR |
| Model | EAA | CPAFPN | Focaler-GIoU | mAP50(%) | mAP (%) | GFLOPs |
|---|---|---|---|---|---|---|
| A | 83.2 | 50 | 57 | |||
| B | ✓ | 84 | 51 | 57.2 | ||
| C | ✓ | 85.4 | 52.1 | 87.6 | ||
| D | ✓ | ✓ | 86 | 52.1 | 87.9 | |
| E | ✓ | ✓ | ✓ | 86.5 | 52.4 | 87.9 |
| Model | P (%) | R (%) | mAP50(%) | mAP (%) | Params (M) | FPS |
|---|---|---|---|---|---|---|
| YOLOv5m | 81.5 | 61.6 | 68.4 | 41.6 | 25.8 | 97.1 |
| YOlOv5s-EFOE | \ | 75.9 | 79.9 | 44.5 | 13.6 | \ |
| YOLOv8m | 83.9 | 60.4 | 67.4 | 41.2 | 25.0 | 72.1 |
| YOLOv9m | 82.3 | 62.3 | 68.1 | 41.8 | 20.0 | 81.2 |
| YOLOv10m | 79.9 | 61.7 | 67.1 | 41.5 | 16.4 | 59.0 |
| DFLM-YOLO | 85.5 | 71.6 | 78.3 | 43.7 | 3.6 | \ |
| DETR | 75.1 | 72.1 | 73.5 | 38.9 | 41.6 | 10.4 |
| Deformable DETR | 86.7 | 78.9 | 76.6 | 38.9 | 40.1 | 14.8 |
| Dino | 89.3 | 85.7 | 86.4 | 52.0 | 47.6 | 8.3 |
| RT-DETR-R18 | 89.1 | 80.8 | 83.2 | 49.4 | 20.0 | 53.3 |
| SR-DETR | 93.6 | 84.2 | 86.5 | 52.4 | 21.8 | 38.9 |
| Model | P (%) | R (%) | mAP50(%) | mAP (%) | Params (M) | FPS |
|---|---|---|---|---|---|---|
| YOLOv5m | 45.1 | 35.7 | 33.5 | 19.7 | 25.8 | 97.1 |
| YOLOv8m | 48.3 | 35.3 | 33.8 | 19.9 | 25.0 | 72.1 |
| YOLOv9m | 48.4 | 36.6 | 35.4 | 21.0 | 20.0 | 81.2 |
| YOLOv10m | 46.1 | 36.1 | 34.3 | 20.2 | 16.4 | 59.0 |
| DETR | 37.1 | 29.4 | 27.2 | 13.2 | 41.6 | 10.4 |
| Deformable DETR | 47.1 | 37.2 | 36.0 | 20.2 | 40.1 | 14.8 |
| Dino | 53.3 | 45.9 | 45.3 | 21.6 | 47.6 | 8.3 |
| RT-DETR-R18 | 54.8 | 38.7 | 37.3 | 21.6 | 20.0 | 53.3 |
| SR-DETR | 58.3 | 41.2 | 40.7 | 23.8 | 21.8 | 38.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Wei, Y. SR-DETR: Target Detection in Maritime Rescue from UAV Imagery. Remote Sens. 2025, 17, 2026. https://doi.org/10.3390/rs17122026
Liu Y, Wei Y. SR-DETR: Target Detection in Maritime Rescue from UAV Imagery. Remote Sensing. 2025; 17(12):2026. https://doi.org/10.3390/rs17122026
Chicago/Turabian StyleLiu, Yuling, and Yan Wei. 2025. "SR-DETR: Target Detection in Maritime Rescue from UAV Imagery" Remote Sensing 17, no. 12: 2026. https://doi.org/10.3390/rs17122026
APA StyleLiu, Y., & Wei, Y. (2025). SR-DETR: Target Detection in Maritime Rescue from UAV Imagery. Remote Sensing, 17(12), 2026. https://doi.org/10.3390/rs17122026