
Extraction of Suaeda salsa from UAV Imagery Assisted by Adaptive Capture of Contextual Information


Abstract

1. Introduction
2. Materials and Methods
2.1. Dataset Construction
2.2. Context-Adaptive Information Model Construction Based on Encoder–Decoder Framework
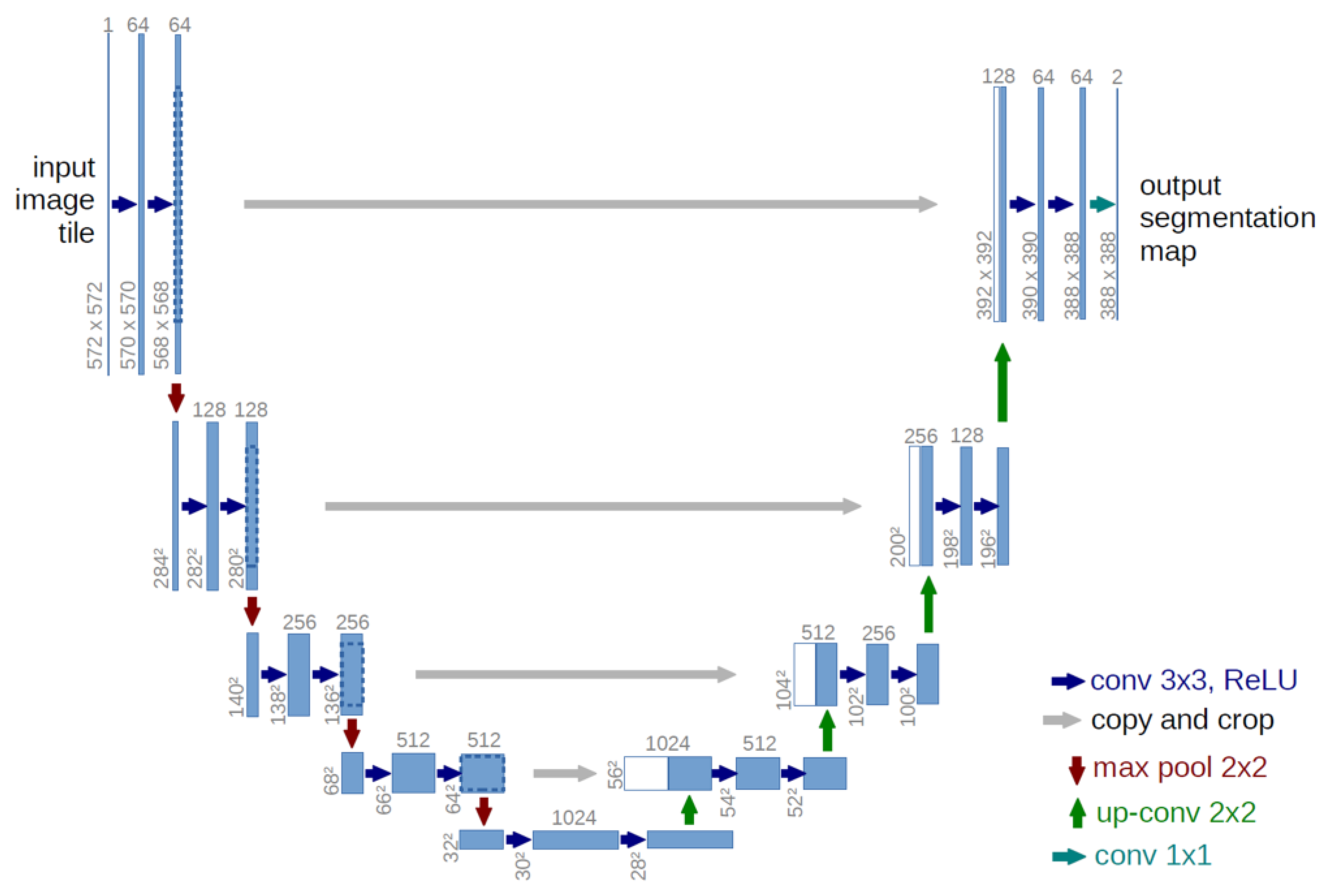
2.2.1. Unet Model
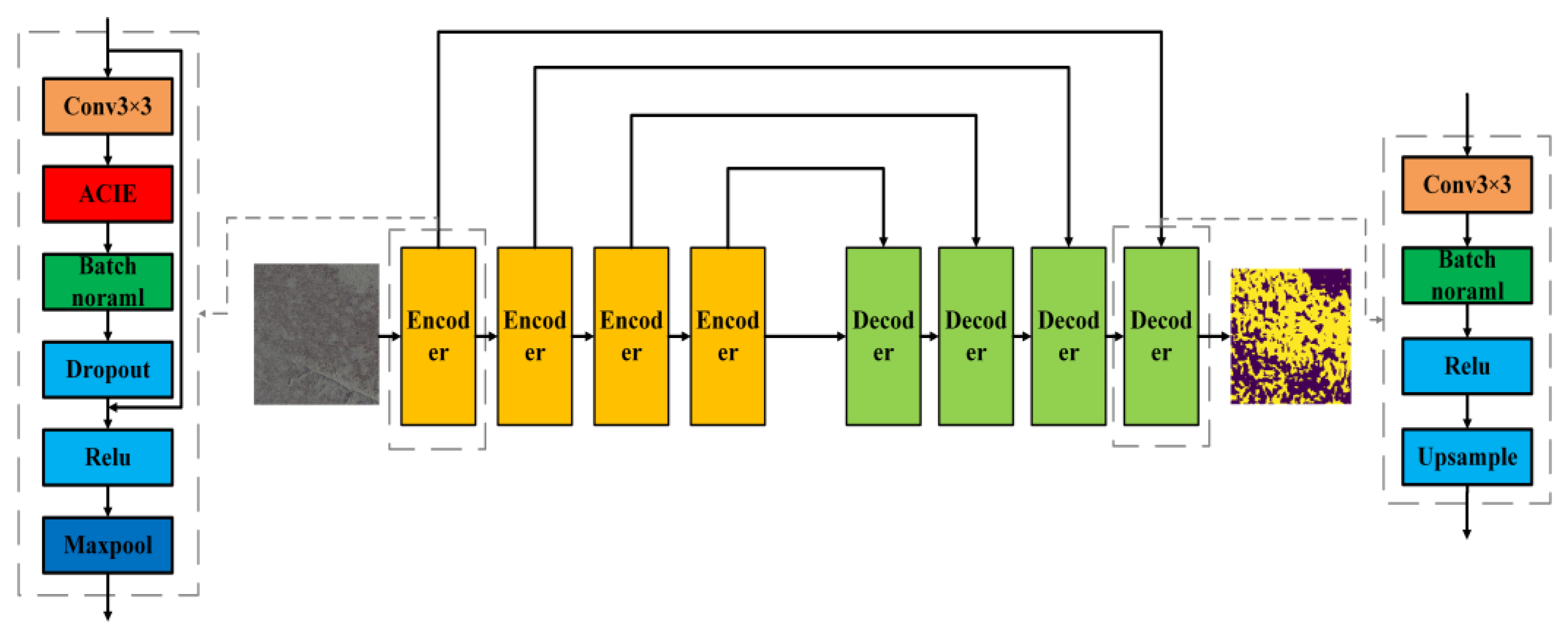
2.2.2. ACIE Module
- (1)
- Large kernel convolutional module
- (2)
- Spatial attention mechanism module
- (3)
- Channel Attention Mechanism Module
2.2.3. The ACI-Unet Model
2.3. Model Evaluation Indicators
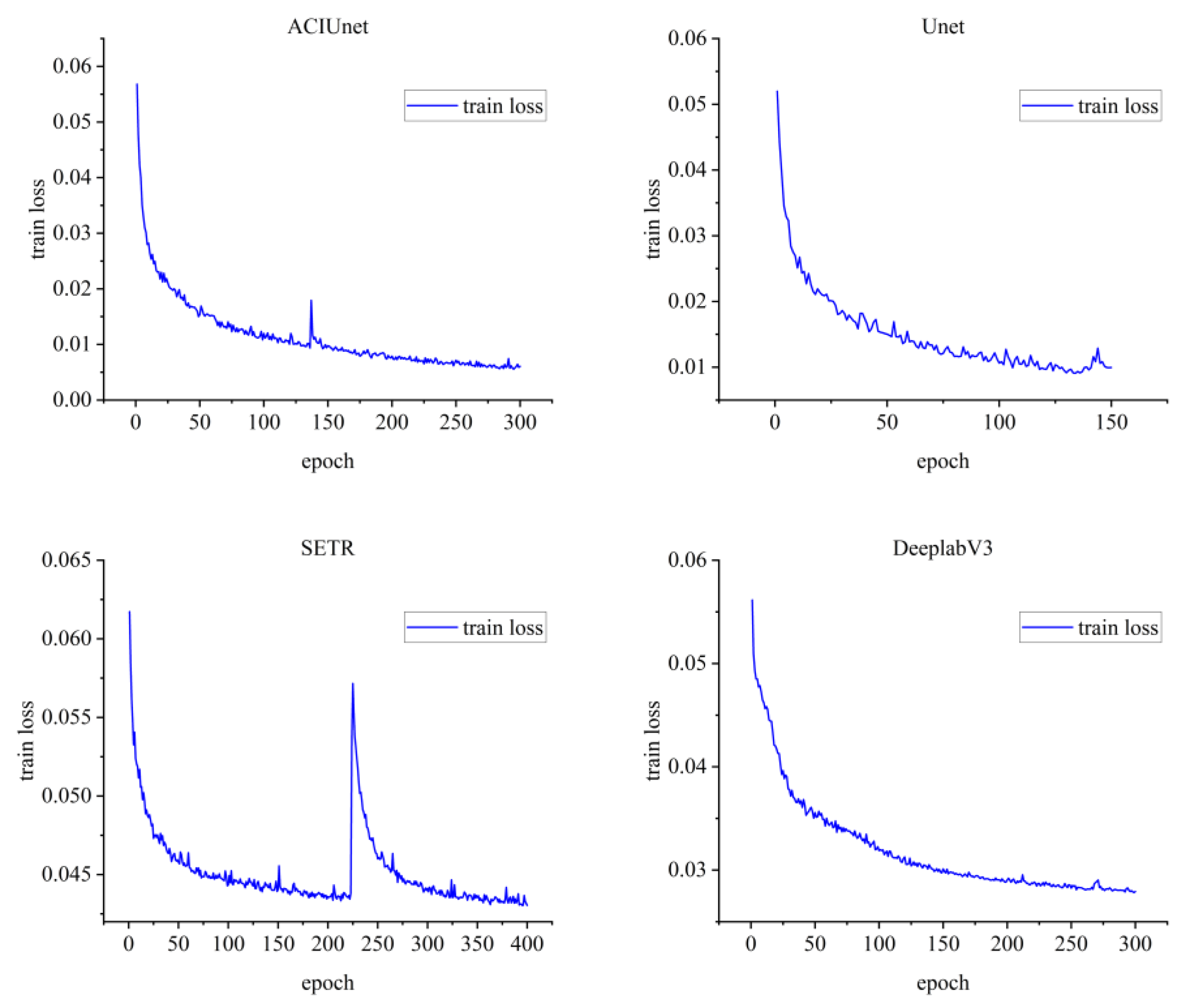
2.4. Experimental Environment and Hyperparameter Setting
3. Results
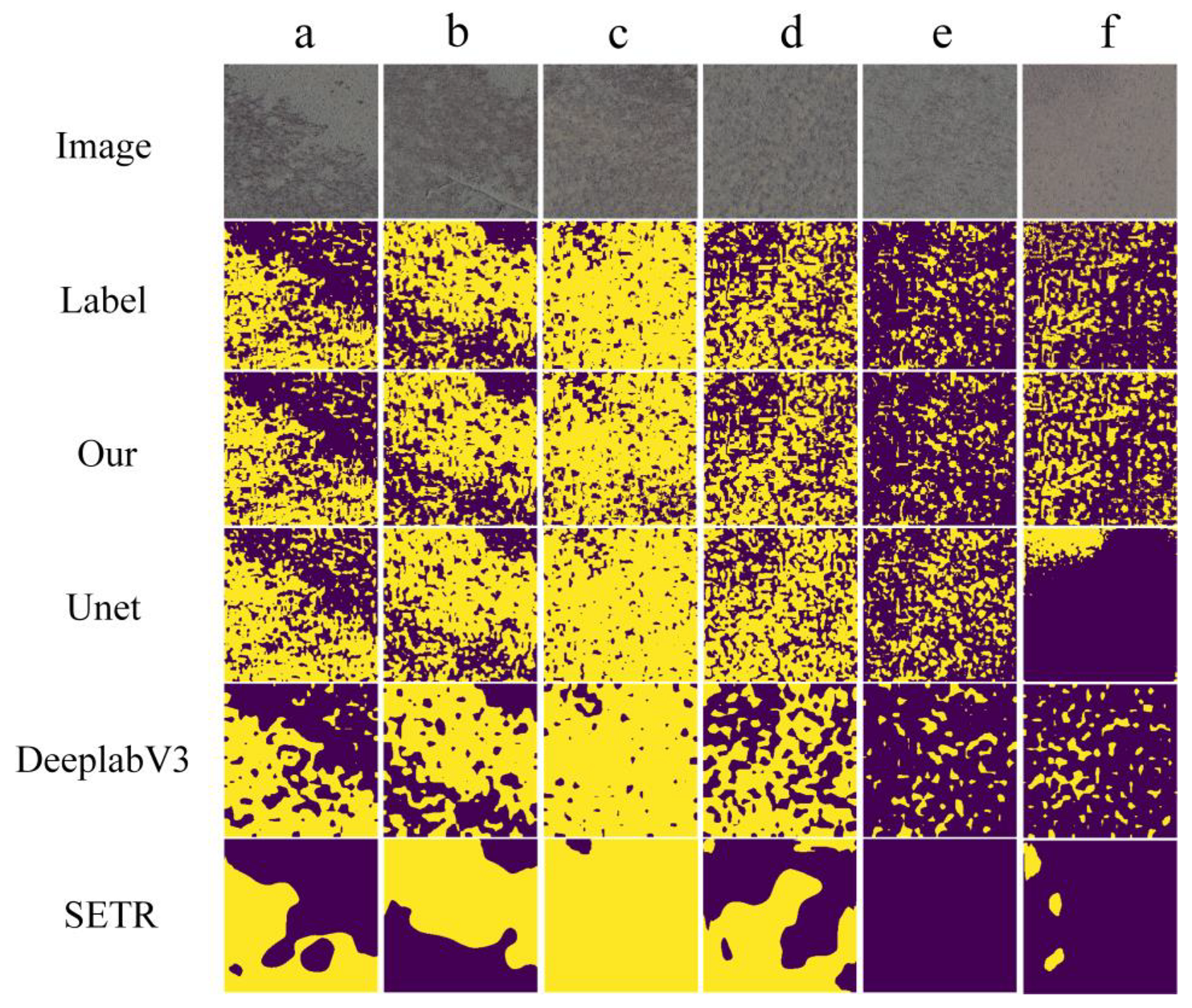
3.1. Identification Results and Analysis of Suaeda salsa
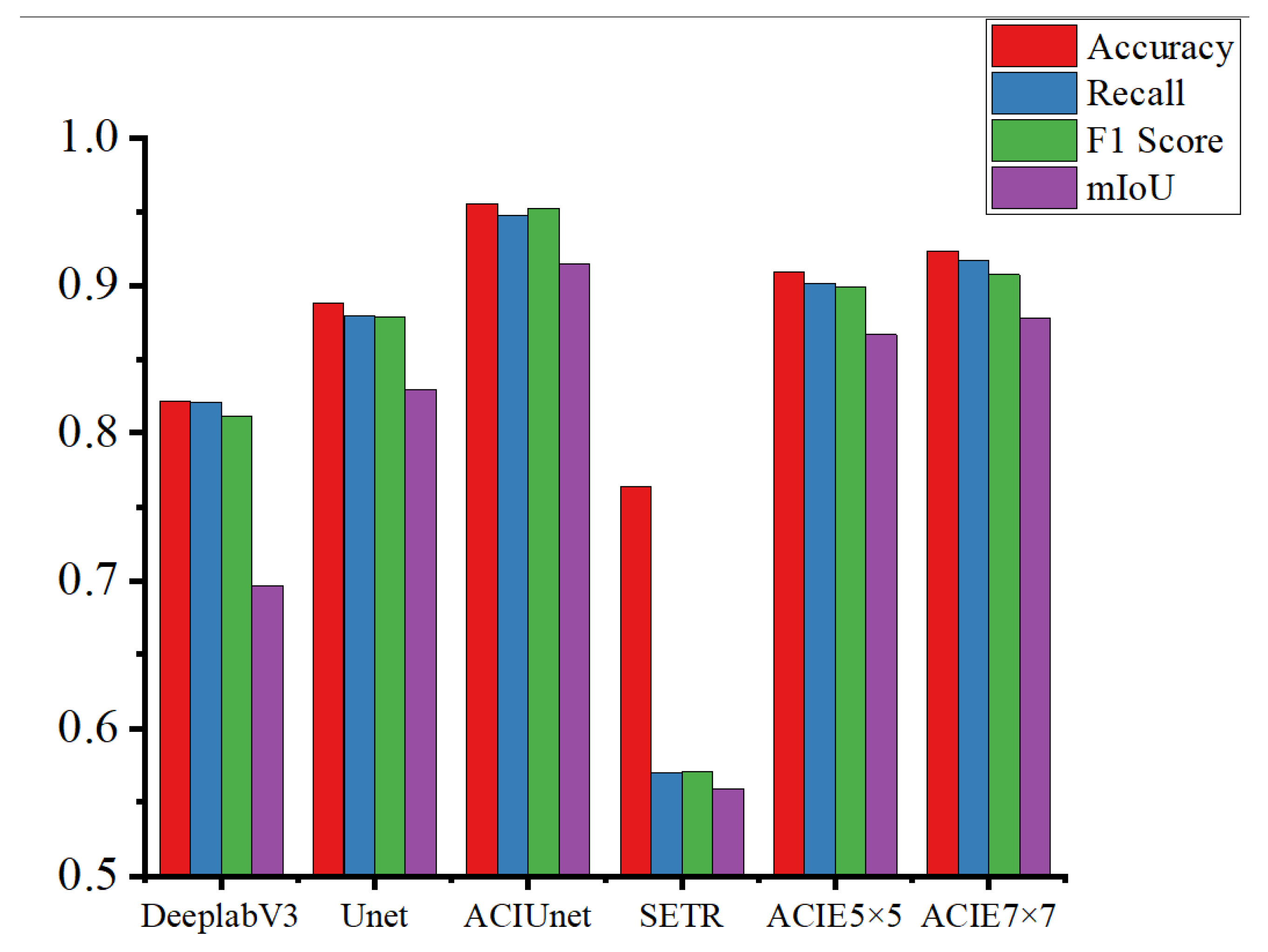
3.2. Comparison and Analysis of Model Results
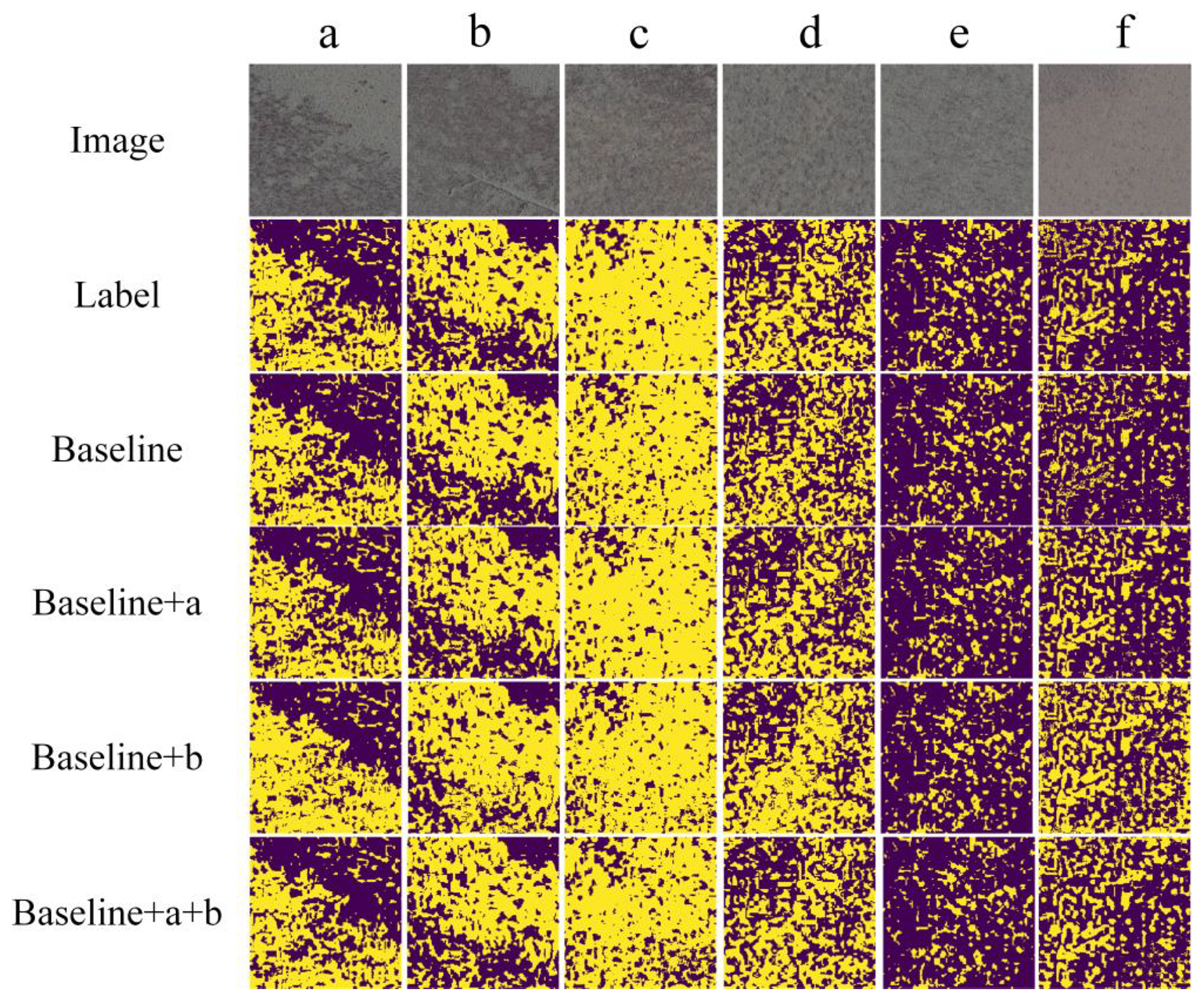
3.3. Result of Ablation Experiments
4. Discussion
4.1. The Evaluation of the ACI-Unet MODEL Based on Ablation Experiments
4.2. The Analysis of the Causes of Different Identification Results
5. Conclusions
- (1)
- An adaptive contextual information extraction module based on a large kernel convolution and attention mechanism is designed, which can be embedded into any kind of network as a multi-scale feature extractor without changing the resolution and can help the model to better extract the contextual adaptive information.
- (2)
- The ACI-Unet model constructed in this paper can realize a high-precision Suaeda salsa recognition for UAV imagery. For Suaeda salsa diversity, our method has a good recognition effect both for Suaeda salsa with a large shape, obvious color, and dense growth area and for Suaeda salsa with a small shape, less obvious color, and sparse growth area. In terms of precision, all four metrics were above 90%.
- (3)
- Our model compares the results of the Suaeda salsa extraction with existing models commonly used for semantic segmentation and finds that they are all improved, especially for the weak Suaeda salsa targets with inconspicuous features, which can accurately segment the spatial distribution details of Suaeda salsa.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gao, F.; Wu, L.; Jia, S.; Sun, Q.; Liu, G. Study on evaluation and impact mechanism of beach lowering restoration effect of Suaeda Heteroptera wetland in Liaohe estuary. Environ. Ecol. 2022, 4, 49–53. [Google Scholar]
- Yang, C.; Wang, L.; Su, F.; Li, H. Characteristics of soil salinity in the distribution area of Suaedaheteroptera in Liaohe estuary wetlands. Sci. Soil Water Conserv. 2019, 17, 117–123. [Google Scholar]
- Li, Y.; Wang, Z.; Zhao, C.; Jia, M.; Ren, C.; Mao, D.; Yu, H. Research on spatial-temporal dynamics of Suaeda salsa in Liaohe estuary and its identification mechanism using remote sensing. Remote Sens. Nat. Resour. 2024, 195–203. [Google Scholar]
- Zhang, N.; Mao, D.; Feng, K.; Zhen, J.; Xiang, H.; Ren, Y. Classification of wetland plant communities in the Yellow River Delta based on GEE and multi-source remote sensing data. Remote Sens. Nat. Resour. 2024, 265–273. [Google Scholar]
- Ke, Y.; Han, Y.; Cui, L.; Sun, P.; Min, Y.; Wang, Z.; Zhuo, Z.; Zhou, Q.; Yin, X.; Zhou, D. Suaeda salsa Spectral Index for Suaeda salsa Mapping and Fractional Cover Estimation in Intertidal Wetlands. ISPRS J. Photogramm. Remote Sens. 2024, 207, 104–121. [Google Scholar] [CrossRef]
- Gao, T. Research on Community Information Extraction of Suaeda salsa Based on UAV Multispectral Data. Master’s Thesis, Dalian Ocean University, Dalian, China, June 2024. [Google Scholar] [CrossRef]
- Ren, G.; Zhang, J.; Wang, W.; Geng, Y.; Chen, Y.; Ma, Y. Reeds and suaeda biomass estimation model based on HJ-1 hyper-spectal image in the Yellow River Estuary. J. Mar. Sci. 2014, 32, 27–34. [Google Scholar]
- Du, Y.; Wang, J.; Liu, Z.; Yu, H.; Li, Z.; Cheng, H. Evaluation on Spaceborne Multispectral Images, Airborne Hyperspectral, and LiDAR Data for Extracting Spatial Distribution and Estimating Aboveground Biomass of Wetland Vegetation Suaeda salsa. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 200–209. [Google Scholar] [CrossRef]
- Zhang, S.; Tian, Q.; Lu, X.; Li, S.; He, S.; Zhang, X.; Liu, K. Enhancing Chlorophyll Content Monitoring in Coastal Wetlands: Sentinel-2 and Soil-Removed Semi-Empirical Models for Phenotypically Diverse Suaeda salsa. Ecol. Indic. 2024, 167, 112686. [Google Scholar] [CrossRef]
- Zhang, S.; Tian, J.; Lu, X.; Tian, Q.; He, S.; Lin, Y.; Li, S.; Zheng, W.; Wen, T.; Mu, X.; et al. Monitoring of Chlorophyll Content in Local Saltwort Species Suaeda salsa under Water and Salt Stress Based on the PROSAIL-D Model in Coastal Wetland. Remote Sens. Environ. 2024, 306, 114117. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional Neural Networks for Large-Scale Remote-Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 645–657. [Google Scholar] [CrossRef]
- Lv, X.; Ming, D.; Chen, Y.; Wang, M. Very High Resolution Remote Sensing Image Classification with SEEDS-CNN and Scale Effect Analysis for Superpixel CNN Classification. Int. J. Remote Sens. 2019, 40, 506–531. [Google Scholar] [CrossRef]
- Zhang, C.; Wei, S.; Ji, S.; Lu, M. Detecting Large-Scale Urban Land Cover Changes from Very High Resolution Remote Sensing Images Using CNN-Based Classification. ISPRS Int. J. Geo-Inf. 2019, 8, 189. [Google Scholar] [CrossRef]
- Li, Z.; Shen, H.; Cheng, Q.; Liu, Y.; You, S.; He, Z. Deep Learning Based Cloud Detection for Medium and High Resolution Remote Sensing Images of Different Sensors. ISPRS J. Photogramm. Remote Sens. 2019, 150, 197–212. [Google Scholar] [CrossRef]
- Hu, K.; Zhang, E.; Xia, M.; Weng, L.; Lin, H. MCANet: A Multi-Branch Network for Cloud/Snow Segmentation in High-Resolution Remote Sensing Images. Remote Sens. 2023, 15, 1055. [Google Scholar] [CrossRef]
- Fu, H.; Fu, B.; Shi, P. An Improved Segmentation Method for Automatic Mapping of Cone Karst from Remote Sensing Data Based on DeepLab V3+ Model. Remote Sens. 2021, 13, 441. [Google Scholar] [CrossRef]
- Kleinschroth, F.; Banda, K.; Zimba, H.; Dondeyne, S.; Nyambe, I.; Spratley, S.; Winton, R.S. Drone Imagery to Create a Common Understanding of Landscapes. Landsc. Urban Plan. 2022, 228, 104571. [Google Scholar] [CrossRef]
- Huang, Y.; Chen, J.; Huang, D. UFPMP-Det:Toward Accurate and Efficient Object Detection on Drone Imagery. Proc. AAAI Conf. Artif. Intell. 2022, 36, 1026–1033. [Google Scholar] [CrossRef]
- Jintasuttisak, T.; Edirisinghe, E.; Elbattay, A. Deep Neural Network Based Date Palm Tree Detection in Drone Imagery. Comput. Electron. Agric. 2022, 192, 106560. [Google Scholar] [CrossRef]
- Du, D.; Zhu, P.; Wen, L.; Bian, X.; Lin, H.; Hu, Q.; Peng, T.; Zheng, J.; Wang, X.; Zhang, Y.; et al. VisDrone-DET2019: The Vision Meets Drone Object Detection in Image Challenge Results. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A Review on Deep Learning Techniques Applied to Semantic Segmentation. arXiv 2017. [Google Scholar] [CrossRef]
- Liu, J.; Wang, Z.; Cheng, K. An Improved Algorithm for Semantic Segmentation of Remote Sensing Images Based on DeepLabv3+. In Proceedings of the 5th International Conference on Communication and Information Processing, Chongqing, China, 15–17 November 2019; ACM: Chongqing China, 2019; pp. 124–128. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.S.; et al. Rethinking Semantic Segmentation From a Sequence-to-Sequence Perspective With Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 6881–6890. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015. [Google Scholar] [CrossRef]
- Minaee, S.; Boykov, Y.Y.; Porikli, F.; Plaza, A.J.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3523–3542. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Huang, Z.; Ye, J.; Tu, C.; Yang, Y.; Du, S.; Deng, Z.; Ma, C.; Niu, J.; He, J. An Evaluation of U-Net in Renal Structure Segmentation. arXiv 2022. [Google Scholar] [CrossRef]
- Zunair, H.; Ben Hamza, A. Sharp U-Net: Depthwise Convolutional Network for Biomedical Image Segmentation. Comput. Biol. Med. 2021, 136, 104699. [Google Scholar] [CrossRef] [PubMed]
- Shamsolmoali, P.; Zareapoor, M.; Wang, R.; Zhou, H.; Yang, J. A Novel Deep Structure U-Net for Sea-Land Segmentation in Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3219–3232. [Google Scholar] [CrossRef]
- Guo, M.-H.; Xu, T.-X.; Liu, J.-J.; Liu, Z.-N.; Jiang, P.-T.; Mu, T.-J.; Zhang, S.-H.; Martin, R.R.; Cheng, M.-M.; Hu, S.-M. Attention Mechanisms in Computer Vision: A Survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 6999–7019. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. arXiv 2016. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. arXiv 2018. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Tian, Z.; He, T.; Shen, C.; Yan, Y. Decoders Matter for Semantic Segmentation: Data-Dependent Decoding Enables Flexible Feature Aggregation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Wang, S.; Hou, X.; Zhao, X. Automatic Building Extraction From High-Resolution Aerial Imagery via Fully Convolutional Encoder-Decoder Network With Non-Local Block. IEEE Access 2020, 8, 7313–7322. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Las Vegas, NV, USA, 2016; pp. 770–778. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; Bach, F., Blei, D., Eds.; PMLR: Lille, France, 2015; Volume 37, pp. 448–456. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; Gordon, G., Dunson, D., Dudík, M., Eds.; PMLR: Fort Lauderdale, FL, USA, 2011; Volume 15, pp. 315–323. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; ISBN 978-0-262-33737-3. [Google Scholar]
- Short, F.T.; Kosten, S.; Morgan, P.A.; Malone, S.; Moore, G.E. Impacts of Climate Change on Submerged and Emergent Wetland Plants. Aquat. Bot. 2016, 135, 3–17. [Google Scholar] [CrossRef]
- Chong, K.Y.; Raphael, M.B.; Carrasco, L.R.; Yee, A.T.K.; Giam, X.; Yap, V.B.; Tan, H.T.W. Reconstructing the Invasion History of a Spreading, Non-Native, Tropical Tree through a Snapshot of Current Distribution, Sizes, and Growth Rates. Plant Ecol. 2017, 218, 673–685. [Google Scholar] [CrossRef]
- Jolly, I.D.; McEwan, K.L.; Holland, K.L. A Review of Groundwater–Surface Water Interactions in Arid/Semi-arid Wetlands and the Consequences of Salinity for Wetland Ecology. Ecohydrology 2008, 1, 43–58. [Google Scholar] [CrossRef]
- Chaurasia, A.; Culurciello, E. LinkNet: Exploiting Encoder Representations for Efficient Semantic Segmentation. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL USA, 10–13 December 2017; IEEE: St. Petersburg, FL, USA, 2017; pp. 1–4. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017. [Google Scholar] [CrossRef]
- Zhang, H.; Dana, K.; Shi, J.; Zhang, Z.; Wang, X.; Tyagi, A.; Agrawal, A. Context Encoding for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A Survey on Vision Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 87–110. [Google Scholar] [CrossRef]
- Bruna, J.; Sprechmann, P.; LeCun, Y. Source Separation with Scattering Non-Negative Matrix Factorization. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, QLD, Australia, 19–24 April 2015; IEEE: South Brisbane, QLD, Australia, 2015; pp. 1876–1880. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Formula | |
|---|---|
| Accuracy | |
| Recall | |
| F1 score | |
| MIou |
| ACI-Unet | Unet | DeepLabV3 | SETR | |
|---|---|---|---|---|
| Batch_size | 8 | 8 | 8 | 10 |
| Lr | 0.01 | 0.01 | 0.016 | 0.01 |
| Dropout | 0.1 | 0 | 0.1 | 0.1 |
| Epochs | 300 | 150 | 300 | 400 |
| Optimizers | SGD | SGD | SGD | Adam |
| Sorters | Sigmod | Sigmod | Sigmod | softmax |
| Accuracy (%) | Recall (%) | F1 Score (%) | MIou (%) | |
|---|---|---|---|---|
| ACI-Unet | 95.55 | 94.73 | 95.21 | 91.44 |
| Unet | 88.79 | 87.93 | 87.84 | 82.95 |
| DeepLabV3 | 82.15 | 82.07 | 81.10 | 69.69 |
| SETR | 76.33 | 56.96 | 57.07 | 55.92 |
| Linknet | 81.96 | 62.36 | 52.93 | 41.30 |
| HRnet | 91.29 | 73.15 | 66.36 | 58.18 |
| Transunet | 92.77 | 71.76 | 72.42 | 67.40 |
| Accuracy (%) | Recall (%) | F1 Score (%) | MIou (%) | |
|---|---|---|---|---|
| Baseline | 93.26 | 89.33 | 89.01 | 87.06 |
| Baseline + a | 94.70 | 90.38 | 90.39 | 88.54 |
| Baseline + b | 94.50 | 90.44 | 90.47 | 87.57 |
| Baseline + a + b | 95.55 | 94.73 | 95.21 | 91.44 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, N.; Du, X.; Yang, M.; Zhao, X.; Gao, E.; Yang, Y. Extraction of Suaeda salsa from UAV Imagery Assisted by Adaptive Capture of Contextual Information. Remote Sens. 2025, 17, 2022. https://doi.org/10.3390/rs17122022
Gao N, Du X, Yang M, Zhao X, Gao E, Yang Y. Extraction of Suaeda salsa from UAV Imagery Assisted by Adaptive Capture of Contextual Information. Remote Sensing. 2025; 17(12):2022. https://doi.org/10.3390/rs17122022
Chicago/Turabian StyleGao, Ning, Xinyuan Du, Min Yang, Xingtao Zhao, Erding Gao, and Yixin Yang. 2025. "Extraction of Suaeda salsa from UAV Imagery Assisted by Adaptive Capture of Contextual Information" Remote Sensing 17, no. 12: 2022. https://doi.org/10.3390/rs17122022
APA StyleGao, N., Du, X., Yang, M., Zhao, X., Gao, E., & Yang, Y. (2025). Extraction of Suaeda salsa from UAV Imagery Assisted by Adaptive Capture of Contextual Information. Remote Sensing, 17(12), 2022. https://doi.org/10.3390/rs17122022