
SEMA-YOLO: Lightweight Small Object Detection in Remote Sensing Image via Shallow-Layer Enhancement and Multi-Scale Adaptation




Abstract
1. Introduction
2. Related Works
2.1. Task-Specific Methods
2.1.1. Multi-Scale Feature
2.1.2. Super-Resolution
2.1.3. Context Based
2.2. Mainstream Frameworks
2.2.1. YOLO Frameworks
2.2.2. Other Object Detection Frameworks
3. Proposed Method
3.1. Overview
3.2. Shallow Layer Enhancement
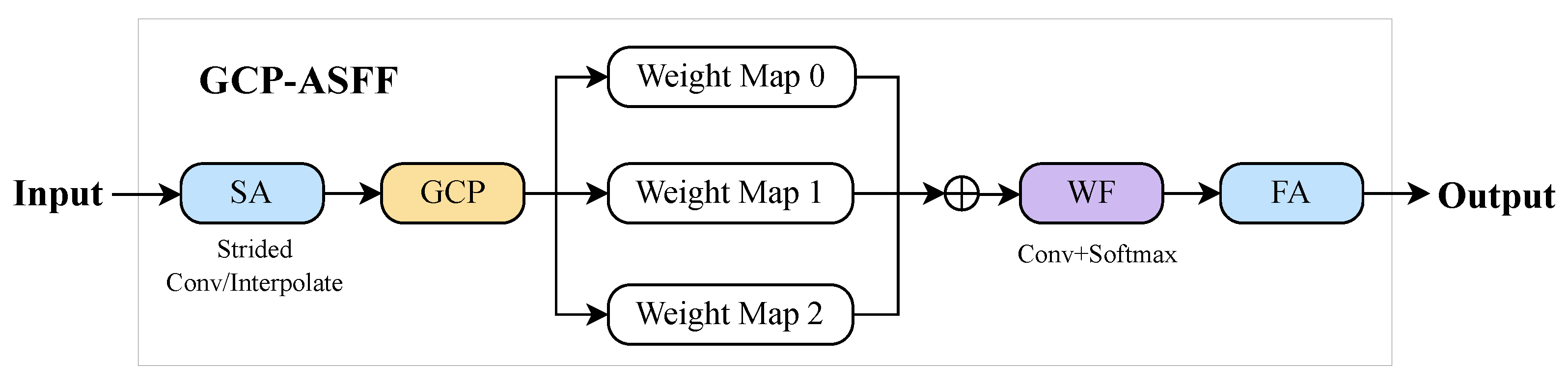
3.3. GCP-ASFF Module
3.4. RFA-C3k2 Module
4. Experimental Results
4.1. Datasets
4.2. Implementation Details
4.3. Evaluation Metrics
4.4. Comparison with State-of-the-Art Methods
4.5. Ablation Experiments
5. Discussion
5.1. Model Potential
5.2. Computational Efficiency
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yu, W.; Cheng, G.; Wang, M.; Yao, Y.; Xie, X.; Yao, X.; Han, J. MAR20: A benchmark for military aircraft recognition in remote sensing images. Natl. Remote Sens. Bull. 2024, 27, 2688–2696. [Google Scholar] [CrossRef]
- Ariza-Sentís, M.; Vélez, S.; Martínez-Peña, R.; Baja, H.; Valente, J. Object detection and tracking in Precision Farming: A systematic review. Comput. Electron. Agric. 2024, 219, 108757. [Google Scholar] [CrossRef]
- Hoalst-Pullen, N.; Patterson, M.W. Applications and Trends of Remote Sensing in Professional Urban Planning: Remote sensing in professional urban planning. Geogr. Compass 2011, 5, 249–261. [Google Scholar] [CrossRef]
- Li, J.; Pei, Y.; Zhao, S.; Xiao, R.; Sang, X.; Zhang, C. A review of remote sensing for environmental monitoring in China. Remote Sens. 2020, 12, 1130. [Google Scholar] [CrossRef]
- Tan, Q.; Ling, J.; Hu, J.; Qin, X.; Hu, J. Vehicle detection in high resolution satellite remote sensing images based on deep learning. IEEE Access 2020, 8, 153394–153402. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the 13th European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar] [CrossRef]
- Wang, X.; Wang, A.; Yi, J.; Song, Y.; Chehri, A. Small object detection based on deep learning for remote sensing: A comprehensive review. Remote Sens. 2023, 15, 3265. [Google Scholar] [CrossRef]
- European Space Agency. WorldView-3 Mission. 2025. Available online: https://earth.esa.int/eogateway/missions/worldview-3 (accessed on 11 March 2025).
- DJI. P4RTK System Specifications. 2019. Available online: https://www.dji.com/cn/support/product/phantom-4-rtk (accessed on 11 March 2025).
- Chinese Academy of Sciences. Gaofen-3 03 Satellite SAR Payload Achieves 1-Meter Resolution with World-Leading Performance. 2022. Available online: http://aircas.ac.cn/dtxw/kydt/202204/t20220407_6420970.html (accessed on 11 March 2025).
- Wikipedia Contributors. TerraSAR-X. 2025. Available online: https://en.wikipedia.org/wiki/TerraSAR-X (accessed on 11 March 2025).
- Wang, C.; Bai, X.; Wang, S.; Zhou, J.; Ren, P. Multiscale visual attention networks for object detection in VHR remote sensing images. IEEE Geosci. Remote Sens. Lett. 2018, 16, 310–314. [Google Scholar] [CrossRef]
- Zhang, Y.; Ye, M.; Zhu, G.; Liu, Y.; Guo, P.; Yan, J. FFCA-YOLO for small object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5611215. [Google Scholar] [CrossRef]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J.; Lei, L.; Zou, H. Multi-scale object detection in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2018, 145, 3–22. [Google Scholar] [CrossRef]
- Wang, J.; Yang, W.; Guo, H.; Zhang, R.; Xia, G.S. Tiny object detection in aerial images. In Proceedings of the 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 3791–3798. [Google Scholar] [CrossRef]
- Liu, S.; Huang, D.; Wang, Y. Learning Spatial Fusion for Single-Shot Object Detection. arXiv 2019, arXiv:1911.09516. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, C.; Yang, D.; Song, T.; Ye, Y.; Li, K.; Song, Y. RFAConv: Innovating Spatial Attention and Standard Convolutional Operation. arXiv 2023, arXiv:2304.03198. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. arXiv 2016, arXiv:1612.03144. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar] [CrossRef]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7029–7038. [Google Scholar] [CrossRef]
- Zhu, L.; Deng, Z.; Hu, X.; Fu, C.W.; Xu, X.; Qin, J.; Heng, P.A. Bidirectional Feature Pyramid Network with Recurrent Attention Residual Modules for Shadow Detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 122–137. [Google Scholar] [CrossRef]
- Qiao, S.; Chen, L.C.; Yuille, A. DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 10213–10224. [Google Scholar] [CrossRef]
- Yang, G.; Lei, J.; Zhu, Z.; Cheng, S.; Feng, Z.; Liang, R. AFPN: Asymptotic Feature Pyramid Network for Object Detection. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics (SMC), Honolulu, HI, USA, 1–4 October 2023; pp. 2184–2189. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Zhang, D.; Zhang, H.; Tang, J.; Wang, M.; Hua, X.; Sun, Q. Feature Pyramid Transformer. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 323–339. [Google Scholar] [CrossRef]
- Liu, H.I.; Tseng, Y.W.; Chang, K.C.; Wang, P.J.; Shuai, H.H.; Cheng, W.H. A DeNoising FPN with Transformer R-CNN for Tiny Object Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4704415. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 73–76. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar] [CrossRef]
- Zhang, J.; Lei, J.; Xie, W.; Fang, Z.; Li, Y.; Du, Q. SuperYOLO: Super Resolution Assisted Object Detection in Multimodal Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5605415. [Google Scholar] [CrossRef]
- Jin, Y.; Zhang, Y.; Cen, Y.; Li, Y.; Mladenovic, V.; Voronin, V. Pedestrian detection with super-resolution reconstruction for low-quality image. Pattern Recognit. 2021, 115, 107846. [Google Scholar] [CrossRef]
- Bashir, S.M.A.; Wang, Y. Small Object Detection in Remote Sensing Images with Residual Feature Aggregation-Based Super-Resolution and Object Detector Network. Remote Sens. 2021, 13, 1854. [Google Scholar] [CrossRef]
- Truong, N.T.; Vo, N.D.; Nguyen, K. The effects of super-resolution on object detection performance in an aerial image. In Proceedings of the 7th NAFOSTED Conference on Information and Computer Science (NICS), Ho Chi Minh City, Vietnam, 26–27 November 2020; pp. 256–260. [Google Scholar] [CrossRef]
- Lim, J.S.; Astrid, M.; Yoon, H.J.; Lee, S.I. Small Object Detection using Context and Attention. In Proceedings of the International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Jeju Island, Republic of Korea, 13–16 April 2021; pp. 181–186. [Google Scholar] [CrossRef]
- Tang, X.; Du, D.K.; He, Z.; Liu, J. PyramidBox: A Context-assisted Single Shot Face Detector. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 797–813. [Google Scholar] [CrossRef]
- Zhao, Z.; Du, J.; Li, C.; Fang, X.; Xiao, Y.; Tang, J. Dense Tiny Object Detection: A Scene Context Guided Approach and a Unified Benchmark. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5606913. [Google Scholar] [CrossRef]
- Liang, X.; Zhang, J.; Zhuo, L.; Li, Y.; Tian, Q. Small Object Detection in Unmanned Aerial Vehicle Images Using Feature Fusion and Scaling-Based Single Shot Detector with Spatial Context Analysis. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 1758–1770. [Google Scholar] [CrossRef]
- Cui, L.; Lv, P.; Jiang, X.; Gao, Z.; Zhou, B.; Zhang, L.; Shao, L.; Xu, M. Context-Aware Block Net for Small Object Detection. IEEE Trans. Cybern. 2022, 52, 2300–2313. [Google Scholar] [CrossRef] [PubMed]
- Tong, K.; Wu, Y. Small object detection using hybrid evaluation metric with context decoupling. Multimed. Syst. 2025, 31, 141. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar] [CrossRef]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; Kwon, Y.; Michael, K.; Xie, T.; Fang, J.; Yifu, Z.; Wong, C.; et al. ultralytics/yolov5: V7.0—YOLOv5 SOTA Realtime Instance Segmentation; Zenodo: Geneve, Switzerland, 2022. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar] [CrossRef]
- Jocher, G.; Qiu, J.; Chaurasia, A. Ultralytics YOLO, Version 8.0.0; Github: San Francisco, CA, USA, 2023; Available online: https://github.com/ultralytics/ultralytics, (accessed on 2 March 2025).
- Wang, C.Y.; Yeh, I.H.; Mark Liao, H.Y. Yolov9: Learning what you want to learn using programmable gradient information. In Proceedings of the European Conference on Computer Vision (ECCV), Milan, Italy, 29 September–4 October 2024; pp. 1–21. [Google Scholar] [CrossRef]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-Time End-to-End Object Detection. arXiv 2024, arXiv:2405.14458. [Google Scholar] [CrossRef]
- Tian, Y.; Ye, Q.; Doermann, D. YOLOv12: Attention-Centric Real-Time Object Detectors. arXiv 2025, arXiv:2502.12524. [Google Scholar] [CrossRef]
- Qiu, M.; Huang, L.; Tang, B.H. ASFF-YOLOv5: Multielement detection method for road traffic in UAV images based on multiscale feature fusion. Remote Sens. 2022, 14, 3498. [Google Scholar] [CrossRef]
- Lin, J.; Zhao, Y.; Wang, S.; Tang, Y. YOLO-DA: An efficient YOLO-based detector for remote sensing object detection. IEEE Geosci. Remote Sens. Lett. 2023, 20, 6008705. [Google Scholar] [CrossRef]
- Li, Z.; Yuan, J.; Li, G.; Wang, H.; Li, X.; Li, D.; Wang, X. RSI-YOLO: Object detection method for remote sensing images based on improved YOLO. Sensors 2023, 23, 6414. [Google Scholar] [CrossRef]
- Xie, S.; Zhou, M.; Wang, C.; Huang, S. CSPPartial-YOLO: A Lightweight YOLO-Based Method for Typical Objects Detection in Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 388–399. [Google Scholar] [CrossRef]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z.X. Scale-Aware Trident Networks for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6053–6062. [Google Scholar] [CrossRef]
- Cao, C.; Wang, B.; Zhang, W.; Zeng, X.; Yan, X.; Feng, Z.; Liu, Y.; Wu, Z. An Improved Faster R-CNN for Small Object Detection. IEEE Access 2019, 7, 106838–106846. [Google Scholar] [CrossRef]
- Ren, Y.; Zhu, C.; Xiao, S. Small object detection in optical remote sensing images via modified faster R-CNN. Appl. Sci. 2018, 8, 813. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. arXiv 2019, arXiv:1904.01355. [Google Scholar] [CrossRef]
- Xu, C.; Wang, J.; Yang, W.; Yu, H.; Yu, L.; Xia, G.S. RFLA: Gaussian receptive field based label assignment for tiny object detection. In Proceedings of the European Conference on Computer Vision(ECCV), Tel Aviv, Israel, 23–27 October 2022; pp. 526–543. [Google Scholar] [CrossRef]
- Kang, S.H.; Park, J.S. Aligned Matching: Improving Small Object Detection in SSD. Sensors 2023, 23, 2589. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar] [CrossRef]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. arXiv 2020, arXiv:2010.04159. [Google Scholar] [CrossRef]
- Li, F.; Zhang, H.; Liu, S.; Guo, J.; Ni, L.M.; Zhang, L. DN-DETR: Accelerate DETR Training by Introducing Query DeNoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 13609–13617. [Google Scholar] [CrossRef]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.Y. DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection. arXiv 2022, arXiv:2203.03605. [Google Scholar] [CrossRef]
- Huang, Y.X.; Liu, H.I.; Shuai, H.H.; Cheng, W.H. DQ-DETR: DETR with Dynamic Query for Tiny Object Detection. In Proceedings of the European Conference on Computer Vision (ECCV), Paris, France, 26–27 March 2025; Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G., Eds.; Springer: Cham, Swizterland, 2025; pp. 290–305. [Google Scholar] [CrossRef]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. DETRs Beat YOLOs on Real-time Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | P↑ | R↑ | F1-Score↑ | mAP50↑ | mAP50:95↑ |
|---|---|---|---|---|---|
| RT-DETR-L | 0.425 | 0.443 | 0.434 | 0.429 | 0.230 |
| RT-DETR-R50 | 0.490 | 0.507 | 0.498 | 0.500 | 0.271 |
| YOLOv8n | 0.732 | 0.630 | 0.677 | 0.671 | 0.416 |
| YOLOv9t | 0.707 | 0.632 | 0.667 | 0.661 | 0.411 |
| YOLOv10n | 0.713 | 0.624 | 0.666 | 0.662 | 0.411 |
| YOLOv11n | 0.708 | 0.643 | 0.674 | 0.672 | 0.412 |
| YOLOv12n | 0.713 | 0.619 | 0.663 | 0.661 | 0.406 |
| SEMA-YOLO | 0.748 | 0.699 | 0.722 | 0.725 | 0.468 |
| Method | SV | LV | SH | AP | OT |
|---|---|---|---|---|---|
| RT-DETR-L | 0.308 | 0.025 | 0.356 | 0.856 | 0.602 |
| RT-DETR-R50 | 0.379 | 0.041 | 0.479 | 0.908 | 0.691 |
| YOLOv8n | 0.600 | 0.136 | 0.744 | 0.983 | 0.894 |
| YOLOv9t | 0.587 | 0.133 | 0.716 | 0.984 | 0.881 |
| YOLOv10n | 0.588 | 0.148 | 0.712 | 0.979 | 0.884 |
| YOLOv11n | 0.600 | 0.141 | 0.746 | 0.984 | 0.887 |
| YOLOv12n | 0.580 | 0.134 | 0.730 | 0.984 | 0.878 |
| SEMA-YOLO | 0.722 | 0.196 | 0.793 | 0.987 | 0.926 |
| Method | P↑ | R↑ | F1-Score↑ | mAP50↑ | mAP50:95↑ |
|---|---|---|---|---|---|
| RT-DETR-L | 0.537 | 0.199 | 0.290 | 0.133 | 0.043 |
| RT-DETR-R50 | 0.394 | 0.308 | 0.346 | 0.242 | 0.080 |
| YOLOv8n | 0.662 | 0.548 | 0.600 | 0.557 | 0.235 |
| YOLOv9t | 0.67 | 0.522 | 0.587 | 0.547 | 0.232 |
| YOLOv10n | 0.619 | 0.514 | 0.562 | 0.532 | 0.229 |
| YOLOv11n | 0.703 | 0.524 | 0.600 | 0.563 | 0.239 |
| YOLOv12n | 0.675 | 0.519 | 0.587 | 0.539 | 0.228 |
| SEMA-YOLO | 0.740 | 0.557 | 0.636 | 0.615 | 0.284 |
| Method | P↑ | R↑ | mAP50↑ | mAP50:95↑ | Para (M)↓ | GFLOPs↓ |
|---|---|---|---|---|---|---|
| Baseline | 0.709 | 0.643 | 0.671 | 0.412 | 2.583 | 6.3 |
| +SLE | 0.752 | 0.681 | 0.717 | 0.464 | 2.075 | 9.7 |
| +SLE+RFA | 0.754 | 0.680 | 0.715 | 0.456 | 2.078 | 9.8 |
| +SLE+ASFF | 0.765 | 0.687 | 0.722 | 0.465 | 3.468 | 12.8 |
| +SLE+ASFF+RFA | 0.749 | 0.698 | 0.721 | 0.466 | 3.471 | 12.9 |
| SEMA-YOLO | 0.746 | 0.700 | 0.725 | 0.468 | 3.645 | 14.2 |
| Method | mAP50↑ | mAP50:95↑ | Para (M)↓ | GFLOPs↓ |
|---|---|---|---|---|
| RT-DETR-R50 | 0.500 | 0.271 | 41.9 | 136 |
| YOLOv11n | 0.671 | 0.412 | 2.6 | 6.3 |
| SEMA-YOLOn | 0.725 | 0.468 | 3.6 | 14.2 |
| SEMA-YOLOs | 0.753 | 0.499 | 13.4 | 43.6 |
| SEMA-YOLOm | 0.768 | 0.521 | 29.7 | 138.1 |
| Method | Para (M)↓ | GFLOPs↓ | Size (MB)↓ | FPS↑ |
|---|---|---|---|---|
| RT-DETR-L | 32.0 | 110 | 63.1 | 182 |
| RT-DETR-R50 | 41.9 | 136 | 84.0 | 156 |
| YOLOv8n | 3.0 | 8.7 | 5.97 | 244 |
| YOLOv9t | 2.0 | 7.7 | 4.44 | 227 |
| YOLOv10n | 2.7 | 6.7 | 5.90 | 277 |
| YOLOv11n | 2.6 | 6.3 | 5.23 | 232 |
| YOLOv12n | 2.6 | 6.3 | 5.29 | 227 |
| SEMA-YOLO | 3.6 | 14.2 | 7.43 | 185 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Z.; Zhen, H.; Zhang, X.; Bai, X.; Li, X. SEMA-YOLO: Lightweight Small Object Detection in Remote Sensing Image via Shallow-Layer Enhancement and Multi-Scale Adaptation. Remote Sens. 2025, 17, 1917. https://doi.org/10.3390/rs17111917
Wu Z, Zhen H, Zhang X, Bai X, Li X. SEMA-YOLO: Lightweight Small Object Detection in Remote Sensing Image via Shallow-Layer Enhancement and Multi-Scale Adaptation. Remote Sensing. 2025; 17(11):1917. https://doi.org/10.3390/rs17111917
Chicago/Turabian StyleWu, Zhenchuan, Hang Zhen, Xiaoxinxi Zhang, Xuechen Bai, and Xinghua Li. 2025. "SEMA-YOLO: Lightweight Small Object Detection in Remote Sensing Image via Shallow-Layer Enhancement and Multi-Scale Adaptation" Remote Sensing 17, no. 11: 1917. https://doi.org/10.3390/rs17111917
APA StyleWu, Z., Zhen, H., Zhang, X., Bai, X., & Li, X. (2025). SEMA-YOLO: Lightweight Small Object Detection in Remote Sensing Image via Shallow-Layer Enhancement and Multi-Scale Adaptation. Remote Sensing, 17(11), 1917. https://doi.org/10.3390/rs17111917