
Assessment of Vegetation Indices Derived from UAV Imagery for Weed Detection in Vineyards

 , and
, and
Abstract

1. Introduction
2. Materials and Methods
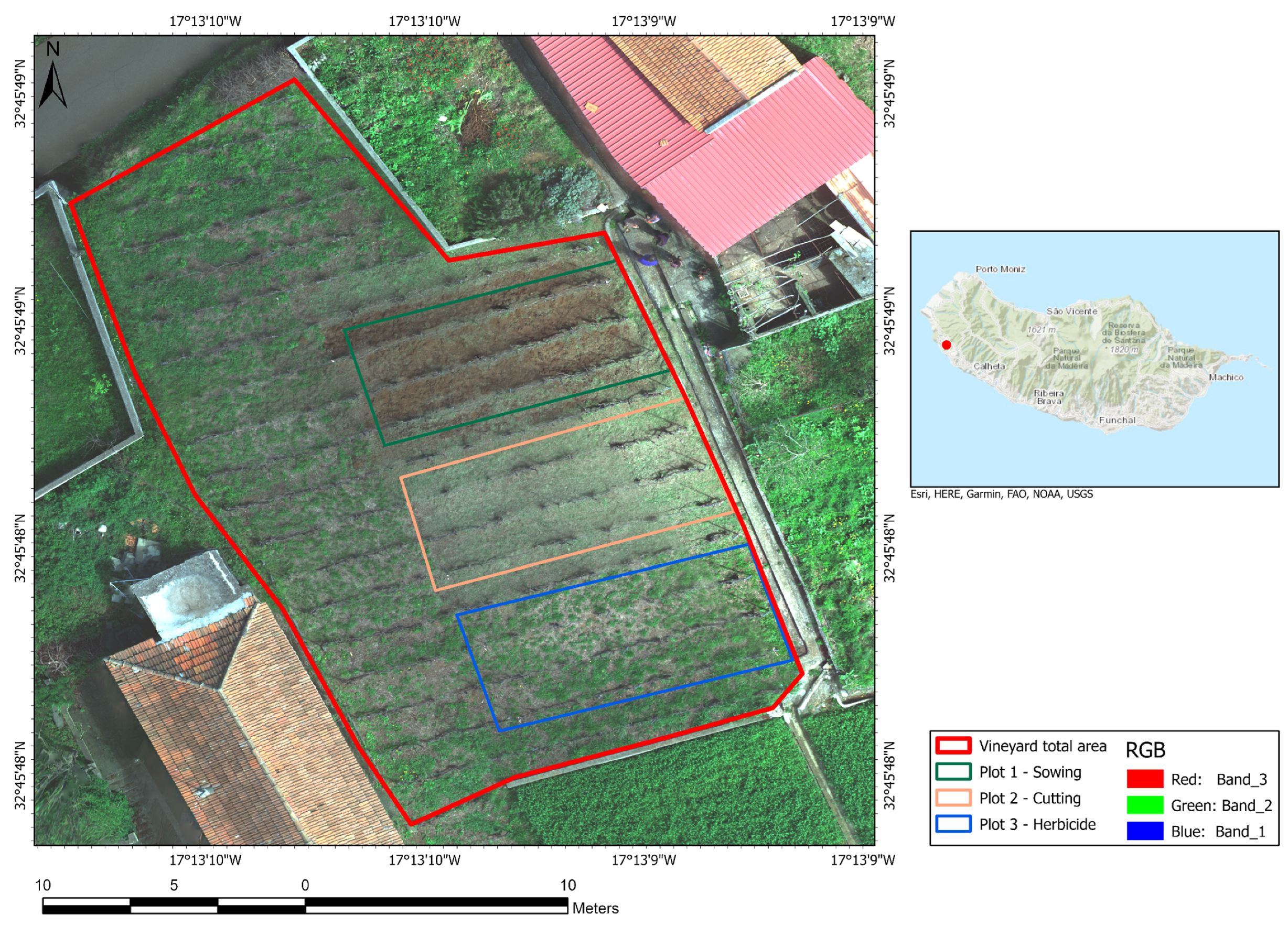
2.1. Study Area
2.2. Experimental Trial
- Cover crops with a mixture of legumes and grasses.
- Mechanical mowing of weeds.
- Conventional herbicide application (glyphosate applied once on 4 September 2024).
2.3. UAV Platform
2.4. Data Acquisition and Processing
2.5. Vegetation Indices
2.6. Classical Classifiers
2.7. Vegetation Index Classification and Class Assignment
- Visual interpretation of the high-resolution RGB drone imagery;
- Prior knowledge of the field layout and typical vegetation distribution;
- Recurring the observation that higher index values were consistently associated with the vine canopy;
- Intermediate values with inter-row vegetation (weeds);
- Lower values for bare soil.
2.8. Accuracy Assessment
3. Results
3.1. Weed Control
3.2. Performance of Vegetation Indices
3.3. Performance of Supervised Classifiers
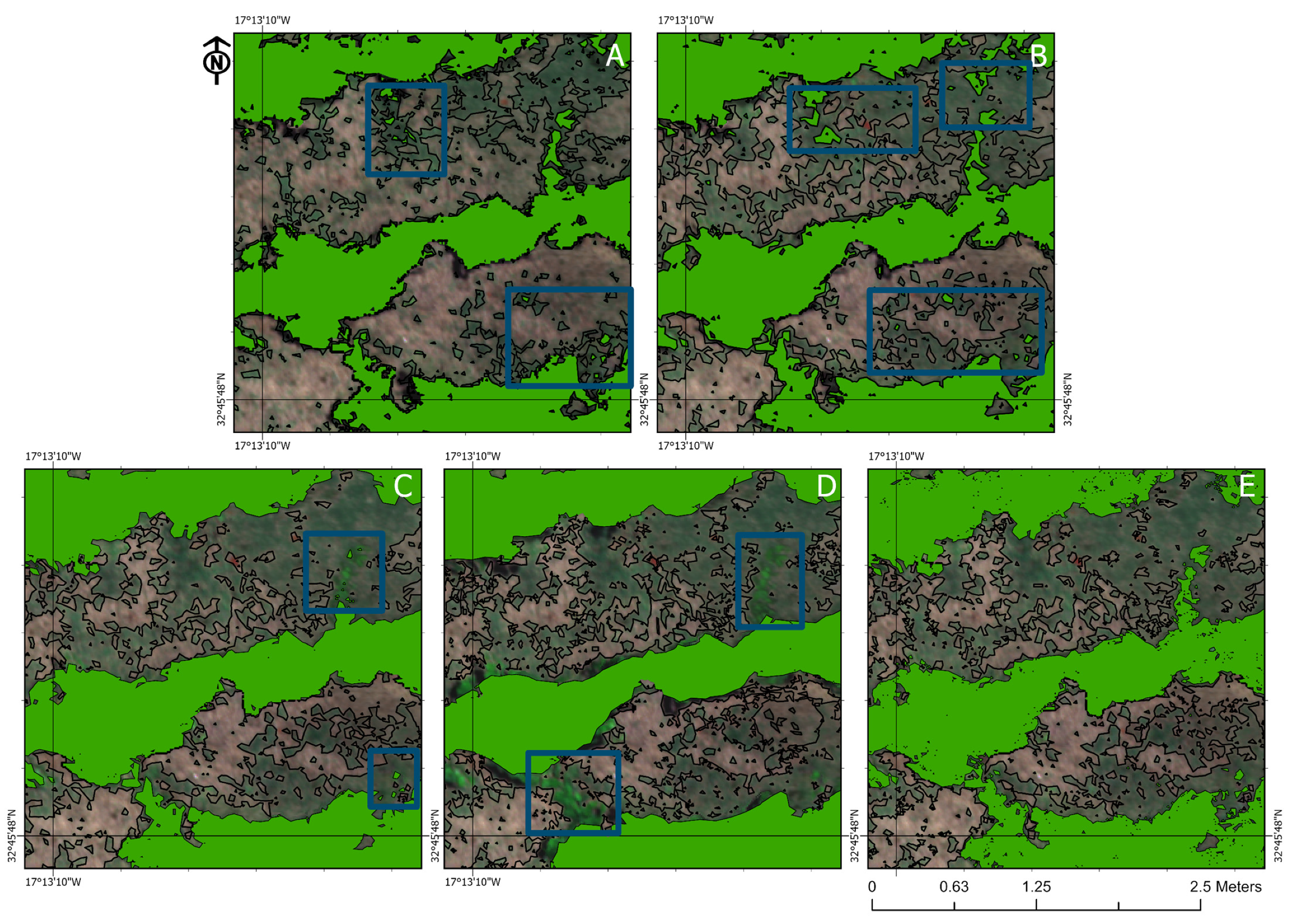
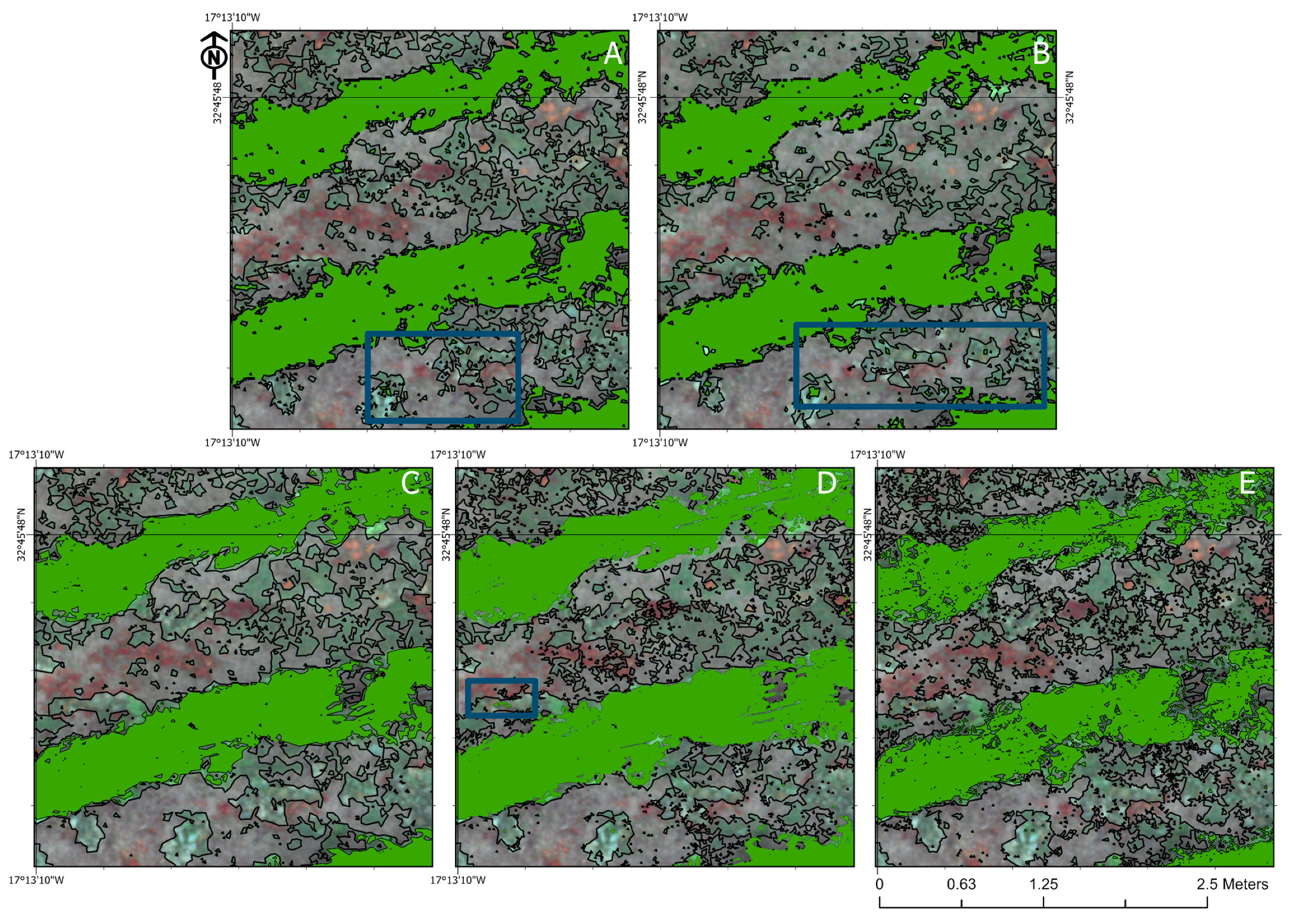
3.4. Visual Analysis of the Classifiers
4. Discussion
4.1. Assessment of Vegetation Index Performance
4.2. Evaluation of Supervised Classifier Performance
4.3. Visual Assessment of the Classification Methods
4.4. Limitations and Future Perspectives
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dmitriev, P.A.; Kozlovsky, B.L.; Kupriushkin, D.P.; Dmitrieva, A.A.; Rajput, V.D.; Chokheli, V.A.; Tarik, E.P.; Kapralova, O.A.; Tokhtar, V.K.; Minkina, T.M.; et al. Assessment of Invasive and Weed Species by Hyperspectral Imagery in Agrocenoses Ecosystem. Remote Sens. 2022, 14, 2442. [Google Scholar] [CrossRef]
- Singh, A.; Ganapathysubramanian, B.; Singh, A.K.; Sarkar, S. Machine Learning for High-Throughput Stress Phenotyping in Plants. Trends Plant Sci. 2016, 21, 110–124. [Google Scholar] [CrossRef]
- Mennan, H.; Jabran, K.; Zandstra, B.H.; Pala, F. Non-chemical weed management in vegetables by using cover crops: A review. Agronomy 2020, 10, 257. [Google Scholar] [CrossRef]
- Izquierdo, J.; Milne, A.E.; Recasens, J.; Royo-Esnal, A.; Torra, J.; Webster, R.; Baraibar, B. Spatial and Temporal Stability of Weed Patches in Cereal Fields under Direct Drilling and Harrow tillage. Agronomy 2020, 10, 452. [Google Scholar] [CrossRef]
- Genze, N.; Ajekwe, R.; Güreli, Z.; Haselbeck, F.; Grieb, M.; Grimm, D.G. Deep learning-based early weed segmentation using motion blurred UAV images of sorghum fields. Comput. Electron. Agric. 2022, 202, 107388. [Google Scholar] [CrossRef]
- Pérez-Ortiz, M.; Peña, J.M.; Gutiérrez, P.A.; Torres-Sánchez, J.; Hervás-Martínez, C.; López-Granados, F. A semi-supervised system for weed mapping in sunflower crops using unmanned aerial vehicles and a crop row detection method. Appl. Soft Comput. 2015, 37, 533–544. [Google Scholar] [CrossRef]
- De Baerdemaeker, J. Future adoption of automation in weed control. In Automation: The Future of Weed Control in Cropping Systems; Springer: Berlin/Heidelberg, Germany, 2014; pp. 221–234. [Google Scholar] [CrossRef]
- FAO and UNEP. Global Assessment of Soil Pollution: Report; FAO and UNEP: Rome, Italy, 2021. [Google Scholar] [CrossRef]
- Brêda-Alves, F.; Militão, F.P.; de Alvarenga, B.F.; Miranda, P.F.; de Oliveira Fernandes, V.; Cordeiro-Araújo, M.K.; Chia, M.A. Clethodim (herbicide) alters the growth and toxins content of Microcystis aeruginosa and Raphidiopsis raciborskii. Chemosphere 2020, 243, 125318. [Google Scholar] [CrossRef]
- Mantle, P. Comparative ergot alkaloid elaboration by selected plecten-chymatic mycelia of Claviceps purpurea through sequential cycles of axenic culture and plant parasitism. Biology 2020, 9, 41. [Google Scholar] [CrossRef]
- Adkins, S.W.; Shabbir, A.; Dhileepan, K. Parthenium Weed: Biology, Ecology and Management; CABI: Wallingford, UK, 2018; Volume 7. [Google Scholar]
- Pérez-Ortiz, M.; Gutiérrez, P.A.; Peña, J.M.; Torres-Sánchez, J.; López-Granados, F.; Hervás-Martínez, C. Machine learning paradigms for weed mapping via unmanned aerial vehicles. In Proceedings of the 2016 IEEE Symposium Series on Computational Intelligence, Athens, Greece, 6–9 December 2016; pp. 1–8. [Google Scholar] [CrossRef]
- López-Granados, F.; Torres-Sánchez, J.; de Castro, A.I.; Serrano-Pérez, A.; Mesas-Carrascosa, F.J.; Peña, J.M. Object-based early monitoring of a grass weed in a grass crop using high resolution UAV imagery. Agron. Sustain. Dev. 2016, 36, 67. [Google Scholar] [CrossRef]
- Su, J.Y.; Yi, D.W.; Coombes, M.; Liu, C.J.; Zhai, X.J.; McDonald-Maier, K.; Chen, W.H. Spectral analysis and mapping of blackgrass weed by leveraging machine learning and UAV multispectral imagery. Comput. Electron. Agric. 2022, 192, 106621. [Google Scholar] [CrossRef]
- Maes, W.H.; Steppe, K. Perspectives for remote sensing with unmanned aerial vehicles in precision agriculture. Trends Plant Sci. 2019, 24, 152–164. [Google Scholar] [CrossRef]
- Bakó, G. Az Özönnövények Feltérképezése a Beavatkozás Megtervezéséhez és Precíziós Kivitelezéséhez. In Practical Experiences in Invasive Alien Plant Control; Csiszár, Á., Korda, M., Eds.; Duna-Ipoly Nemzeti Park Igazgatóság: Budapest, Hungary, 2015; pp. 17–25. [Google Scholar]
- Bolch, E.A.; Santos, M.J.; Ade, C.; Khanna, S.; Basinger, N.T.; Reader, M.O.; Hestir, E.L. Remote Detection of Invasive Alien Species. In Remote Sensing of Plant Biodiversity; Cavender-Bares, J., Gamon, J.A., Townsend, P.A., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; pp. 267–307. [Google Scholar] [CrossRef]
- Cruzan, M.B.; Weinstein, B.G.; Grasty, M.R.; Kohrn, B.F.; Hendrickson, E.C.; Arredondo, T.M.; Thompson, P.G. Small Unmanned Aerial Vehicles (Micro-UAVs, Drones) in plant ecology. Appl. Plant Sci. 2016, 4, 1600041. [Google Scholar] [CrossRef]
- Zisi, T.; Alexandridis, T.K.; Kaplanis, S.; Navrozidis, I.; Tamouridou, A.-A.; Lagopodi, A.; Moshou, D.; Polychronos, V. Incorporating Surface Elevation Information in UAV Multispectral Images for Mapping Weed Patches. J. Imaging 2018, 4, 132. [Google Scholar] [CrossRef]
- Kumar, A.; Desai, S.V.; Balasubramanian, V.N.; Rajalaksmi, P.; Guo, W.; Naik, B.B.; Balram, M.; Desai, U.B. Efficient Maize Tassel-Detection Method using UAV based remote sensing. Remote Sens. Appl. Soc. Environ. 2021, 23, 100549. [Google Scholar] [CrossRef]
- Chang, A.; Yeom, J.; Jung, J.; Landivar, J. Comparison of Canopy Shape and Vegetation Indices of Citrus Trees Derived from UAV Multispectral Images for Characterization of Citrus Greening Disease. Remote Sens. 2020, 12, 4122. [Google Scholar] [CrossRef]
- Dash, J.P.; Pearse, G.D.; Watt, M.S. UAV Multispectral Imagery Can Complement Satellite Data for Monitoring Forest Health. Remote Sens. 2018, 10, 1216. [Google Scholar] [CrossRef]
- Shirzadifar, A.; Bajwa, S.; Nowatzki, J.; Bazrafkan, A. Field identification of weed species and glyphosate-resistant weeds using high resolution imagery in early growing season. Biosyst. Eng. 2020, 200, 200–214. [Google Scholar] [CrossRef]
- Torres-Sánchez, J.; López-Granados, F.; De Castro, A.I.; Peña, J.M. Multi-temporal mapping of the vegetation fraction in early-season wheat fields using images from UAV. Comput. Electron. Agric. 2014, 103, 104–113. [Google Scholar] [CrossRef]
- Malamiri, H.R.G.; Aliabad, F.A.; Shojaei, S.; Morad, M.; Band, S.S. A study on the use of UAV images to improve the separation accuracy of agricultural land areas. Int. J. Remote Sens. 2021, 184, 106079. [Google Scholar] [CrossRef]
- Rodríguez, J.; Lizarazo, I.; Prieto, F.; Angulo-Morales, V. Assessment of potato late blight from UAV-based multispectral imagery. Comput. Electron. Agric. 2021, 184, 106061. [Google Scholar] [CrossRef]
- Cao, Y.; Li, G.L.; Luo, Y.K.; Pan, Q.; Zhang, S.Y. Monitoring of sugar beet growth indicators using wide-dynamic-range vegetation index (WDRVI) derived from UAV multispectral images. Comput. Electron. Agric. 2020, 171, 105331. [Google Scholar] [CrossRef]
- De Castro, A.I.; López-Granados, F.; Jurado-Expósito, M. Broad-scale cruciferous weed patch classification in winter wheat using QuickBird imagery for in-season site-specific control. Precis. Agric. 2013, 14, 392–413. [Google Scholar] [CrossRef]
- Baatz, M.; Schape, A. Multiresolution segmentation: An optimization approach for high quality multiscale image segmentation. In Angewandte Geographische Informations-Verarbeitung XII.; Strobl, J., Blaschke, T., Griesbner, G., Eds.; Wichmann Verlag: Karlsruhe, Germany, 2000; pp. 12–23. [Google Scholar]
- Vélez, S.; Martínez-Peña, R.; Castrillo, D. Beyond Vegetation: A Review Unveiling Additional Insights into Agriculture and Forestry through the Application of Vegetation Indices. J 2023, 6, 421–436. [Google Scholar] [CrossRef]
- Gaitán, J.J.; Bran, D.; Oliva, G.; Ciari, G.; Nakamatsu, V.; Salomone, J.; Ferrante, D.; Buono, G.; Massara, V.; Humano, G.; et al. Evaluating the Performance of Multiple Remote Sensing Indices to Predict the Spatial Variability of Ecosystem Structure and Functioning in Patagonian Steppes. Ecol. Indic. 2013, 34, 181–191. [Google Scholar] [CrossRef]
- Pan, W.; Wang, X.; Sun, Y.; Wang, J.; Li, Y.; Li, S. Karst Vegetation Coverage Detection Using UAV Multispectral Vegetation Indices and Machine Learning Algorithm. Plant Methods 2023, 19, 7. [Google Scholar] [CrossRef]
- Boonrang, A.; Piyatadsananon, P.; Sritarapipat, T. Efficient UAV-Based Automatic Classification of Cassava Fields Using K-Means and Spectral Trend Analysis. AgriEngineering 2024, 6, 4406–4424. [Google Scholar] [CrossRef]
- Turhal, U.C. Vegetation detection using vegetation indices algorithm supported by statistical machine learning. Environ. Monit. Assess. 2022, 194, 826. [Google Scholar] [CrossRef]
- Barrero, O.; Perdomo, S.A. RGB and multispectral UAV image fusion for Gramineae weed detection in rice fields. Precis. Agric. 2018, 19, 809–822. [Google Scholar] [CrossRef]
- Pinheiro de Carvalho, M.Â.A.; Ragonezi, C.; Oliveira, M.C.O.; Reis, F.; Macedo, F.L.; de Freitas, J.G.R.; Nóbrega, H.; Ganança, J.F.T. Anticipating the Climate Change Impacts on Madeira’s Agriculture: The Characterization and Monitoring of a Vine Agrosystem. Agronomy 2022, 12, 2201. [Google Scholar] [CrossRef]
- Macedo, F.L.; Ragonezi, C.; Pinheiro de Carvalho, M.Â.A. Zoneamento Agroclimático da Cultura da Videira para a Ilha da Madeira—Portugal. Caminhos Geogr. 2020, 21, 296–306. [Google Scholar] [CrossRef]
- DREM. Estatísticas da Agricultura e Pesca da Região Autónoma da Madeira 2015; Direção Regional de Estatística da Madeira: Funchal, Portugal, 2015. [Google Scholar]
- Agisoft. Agisoft Metashape Professional, Version 2.1.1; Computer Software; Agisoft: St. Petersburg, Russia, 2024; Available online: https://www.agisoft.com/ (accessed on 19 April 2025).
- Macedo, F.L.; Nóbrega, H.; de Freitas, J.G.R.; Ragonezi, C.; Pinto, L.; Rosa, J.; Pinheiro de Carvalho, M.A.A. Estimation of Productivity and Above-Ground Biomass for Corn (Zea mays) via Vegetation Indices in Madeira Island. Agriculture 2023, 13, 1115. [Google Scholar] [CrossRef]
- Esri. ArcGIS Pro, Version 3.3.2; Computer Software; Environmental Systems Research Institute: Redlands, CA, USA, 2024; Available online: https://www.esri.com/ (accessed on 15 April 2025).
- Louhaichi, M.; Borman, M.M.; Johnson, D.E. Spatially Located Platform and Aerial Photography for Documentation of Grazing Impacts on Wheat. Geocarto Int. 2001, 16, 65–70. [Google Scholar] [CrossRef]
- Gitelson, A.A.; Kaufman, Y.J.; Merzlyak, M.N. Use of a Green Channel in Remote Sensing of Global Vegetation from EOS-MODIS. Remote Sens. Environ. 1996, 58, 289–298. [Google Scholar] [CrossRef]
- Gitelson, A.; Merzlyak, M.N. Spectral Reflectance Changes Associated with Autumn Senescence of Aesculus Hippocastanum L. and Acer Platanoides L. Leaves. Spectral Features and Relation to Chlorophyll Estimation. J. Plant Physiol. 1994, 143, 286–292. [Google Scholar] [CrossRef]
- Rouse, J.W.; Haas, R.H.; Schell, J.A.; Deering, D.W. Monitoring Vegetation Systems in the Great Plains with ERTS. In Third Earth Resources Technology Satellite-1 Symposium: The Proceedings of a Symposium Held by Goddard Space Flight Center; NASA Special Publications: Washington, DC, USA, 1973; pp. 309–318. [Google Scholar]
- Tucker, C.J. Red and Photographic Infrared Linear Combinations for Monitoring Vegetation. Remote Sens. Environ. 1979, 8, 127–150. [Google Scholar] [CrossRef]
- Zhang, X.; Qin, C.; Ma, S.; Liu, J.; Wang, Y.; Liu, H.; An, Z.; Ma, Y. Study on the Extraction of Topsoil-Loss Areas of Cultivated Land Based on Multi-Source Remote Sensing Data. Remote Sens. 2025, 17, 547. [Google Scholar] [CrossRef]
- Chandra, M.A.; Bedi, S.S. Survey on SVM and their application in mage classification. Int. J. Inf. Technol. 2021, 13, 1–11. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Lear. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Nguyen Van, L.; Lee, G. Optimizing Stacked Ensemble Machine Learning Models for Accurate Wildfire Severity Mapping. Remote Sens. 2025, 17, 854. [Google Scholar] [CrossRef]
- Jensen, J.R. Introductory Digital Image Processing: A Remote Sensing Perspective, 4th ed.; Pearson Series in Geographic Information Science; Pearson Education Inc.: Glenview, IL, USA, 2016; ISBN 978-0-13-405816-0. [Google Scholar]
- Islam, N.; Rashid, M.M.; Wibowo, S.; Xu, C.-Y.; Morshed, A.; Wasimi, S.A.; Moore, S.; Rahman, S.M. Early Weed Detection Using Image Processing and Machine Learning Techniques in an Australian Chilli Farm. Agriculture 2021, 11, 387. [Google Scholar] [CrossRef]
- Wan, L.; Li, Y.; Cen, H.; Zhu, J.; Yin, W.; Wu, W.; Zhu, H.; Sun, D.; Zhou, W.; He, Y. Combining UAV-Based Vegetation Indices and Image Classification to Estimate Flower Number in Oilseed Rape. Remote Sens. 2018, 10, 1484. [Google Scholar] [CrossRef]
- Öztürk, M.Y.; Çölkesen, İ. The Impacts of Vegetation Indices from UAV-Based RGB Imagery on Land Cover Classification Using Ensemble Learning. Mersin Photogramm. J. 2021, 3, 41–47. [Google Scholar] [CrossRef]
- Gašparović, M.; Zrinjski, M.; Barković, D.; Radočaj, D. An Automatic Method for Weed Mapping in Oat Fields Based on UAV Imagery. Comput. Electron. Agric. 2020, 173, 105385. [Google Scholar] [CrossRef]
- Pessi, D.D.; José, J.V.; Mioto, C.L.; Silva, N.M. Aeronave Remotamente Pilotada de Baixo Custo no Estudo de Plantas Invasoras em Áreas de Cerrado. Nativa 2020, 8, 65–70. [Google Scholar] [CrossRef]
- Koklu, M.; Unlersen, M.F.; Ozkan, I.A.; Aslan, M.F.; Sabanci, K. A CNN-SVM Study Based on Selected Deep Features for Grapevine Leaves Classification. Measurement 2022, 188, 110425. [Google Scholar] [CrossRef]
- Kaur, P.P.; Singh, S. Classification of Herbal Plant and Comparative Analysis of SVM and KNN Classifier Models on the Leaf Features Using Machine Learning. In Cryptology and Network Security with Machine Learning; Springer: Singapore, 2021; pp. 227–239. [Google Scholar] [CrossRef]
- Rodríguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sánchez, J.P. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Dadashzadeh, M.; Abbaspour-Gilandeh, Y.; Mesri-Gundoshmian, T.; Sabzi, S.; Hernández-Hernández, J.L.; Hernández-Hernández, M.; Arribas, J.I. Weed Classification for Site-Specific Weed Management Using an Automated Stereo Computer-Vision Machine-Learning System in Rice Fields. Plants 2020, 9, 559. [Google Scholar] [CrossRef]
- Feng, C.; Zhang, W.; Deng, H.; Dong, L.; Zhang, H.; Tang, L.; Zheng, Y.; Zhao, Z. A Combination of OBIA and Random Forest Based on Visible UAV Remote Sensing for Accurately Extracted Information about Weeds in Areas with Different Weed Densities in Farmland. Remote Sens. 2023, 15, 4696. [Google Scholar] [CrossRef]
- Kovačević, M.; Bajat, B.; Gajić, B. Soil Type Classification and Estimation of Soil Properties Using Support Vector Machines. Geoderma 2010, 154, 340–347. [Google Scholar] [CrossRef]
- Saponaro, M.; Agapiou, A.; Hadjimitsis, D.G.; Tarantino, E. Influence of Spatial Resolution for Vegetation Indices’ Extraction Using Visible Bands from Unmanned Aerial Vehicles’ Orthomosaics Datasets. Remote Sens. 2021, 13, 3238. [Google Scholar] [CrossRef]
- Pacheco, A.d.P.; Junior, J.A.d.S.; Ruiz-Armenteros, A.M.; Henriques, R.F.F. Assessment of k-Nearest Neighbor and Random Forest Classifiers for Mapping Forest Fire Areas in Central Portugal Using Landsat-8, Sentinel-2, and Terra Imagery. Remote Sens. 2021, 13, 1345. [Google Scholar] [CrossRef]
- Cao, Y.; Dai, J.; Zhang, G.; Xia, M.; Jiang, Z. Combinations of Feature Selection and Machine Learning Models for Object-Oriented “Staple-Crop-Shifting” Monitoring Based on Gaofen-6 Imagery. Agriculture 2024, 14, 500. [Google Scholar] [CrossRef]
- Yang, X.; Guo, X. Quantifying Responses of Spectral Vegetation Indices to Dead Materials in Mixed Grasslands. Remote Sens. 2014, 6, 4289–4304. [Google Scholar] [CrossRef]
- Sun, H.; Wang, Q.; Wang, G.; Lin, H.; Luo, P.; Li, J.; Zeng, S.; Xu, X.; Ren, L. Optimizing kNN for Mapping Vegetation Cover of Arid and Semi-Arid Areas Using Landsat Images. Remote Sens. 2018, 10, 1248. [Google Scholar] [CrossRef]
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Flights | Date | Images Collected | Point Density (pt/cm2) | GSD (mm·pix−1) |
|---|---|---|---|---|
| 1 | 8 May 2024 | 726 | 0.253 | 9.94 |
| 2 | 28 May 2024 | 738 | 0.272 | 9.59 |
| 3 | 25 June 2024 | 726 | 0.277 | 9.51 |
| 4 | 2 August 2024 | 732 | 0.279 | 9.47 |
| Index | Formula | Reference | Equation Number |
| Green Leaf Index | [42] | (1) | |
| Green Normalized Vegetation Index | [43] | (2) | |
| Normalized Difference Red Edge | [44] | (3) | |
| Normalized Difference Vegetation Index | [45] | (4) | |
| Normalized Green Red Difference Index | [46] | (5) |
| NGRDI | GLI | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Vine | Weed | Soil | Precision | Recall | F1-Score | Vine | Weed | Soil | Precision | Recall | F1- Score | |
| Vine | 14.20 | 2.80 | 0 | 0.8353 | 0.7320 | 0.7802 | 14.80 | 7.20 | 0 | 0.6727 | 0.8810 | 0.7629 |
| Weed | 5.20 | 24.20 | 5.20 | 0.6994 | 0.8963 | 0.7857 | 2.00 | 17.80 | 2.80 | 0.7876 | 0.6846 | 0.7325 |
| Soil | 0 | 0 | 48.40 | 1.0000 | 0.9030 | 0.9490 | 0 | 1.00 | 54.40 | 0.9819 | 0.9510 | 0.9663 |
| NDVI | NDRE | |||||||||||
| Vine | 13.77 | 6.590 | 0.40 | 0.665 | 0.7541 | 0.7188 | 5.80 | 13.20 | 0.40 | 0.2990 | 0.3085 | 0.3037 |
| Weed | 3.79 | 20.76 | 16.97 | 0.5000 | 0.7591 | 0.6029 | 12.20 | 12.60 | 26.20 | 0.2741 | 0.4884 | 0.3281 |
| Soil | 0 | 0 | 37.72 | 1.0000 | 0.6848 | 0.8129 | 0.80 | 0 | 28.80 | 0.9730 | 0.5199 | 0.6776 |
| GNDVI | ||||||||||||
| Vine | 17.00 | 22.60 | 9.60 | 0.3455 | 0.8947 | 0.4985 | Flight 1 | |||||
| Weed | 1.60 | 2.60 | 29.40 | 0.0774 | 0.1032 | 0.0884 | ||||||
| Soil | 0.40 | 0 | 16.80 | 0.9767 | 0.3011 | 0.4603 | ||||||
| NGRDI | GLI | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Vine | Weed | Soil | Precision | Recall | F1-Score | Vine | Weed | Soil | Precision | Recall | F1- Score | |
| Vine | 28.00 | 0.60 | 1.40 | 0.9333 | 0.9272 | 0.9302 | 26.08 | 0.19 | 0.19 | 0.9858 | 0.8081 | 0.8882 |
| Weed | 2.20 | 11.80 | 6.60 | 0.5728 | 0.9219 | 0.7066 | 6.19 | 4.69 | 1.31 | 0.3846 | 0.4237 | 0.4032 |
| Soil | 0 | 0.40 | 49.00 | 0.9919 | 0.8596 | 0.9211 | 0 | 6.19 | 55.16 | 0.8991 | 0.9735 | 0.9348 |
| NDVI | NDRE | |||||||||||
| Vine | 31.33 | 2.21 | 0.20 | 0.9286 | 0.8814 | 0.9043 | 15.00 | 1.60 | 1.00 | 0.8523 | 0.4261 | 0.5682 |
| Weed | 4.22 | 10.64 | 29.12 | 0.2420 | 0.8281 | 0.3746 | 19.80 | 10.60 | 45.40 | 0.1398 | 0.8413 | 0.2398 |
| Soil | 0 | 0 | 22.29 | 1.0000 | 0.4319 | 0.6033 | 0.40 | 0.40 | 5.80 | 0.8788 | 0.1111 | 0.1973 |
| GNDVI | ||||||||||||
| Vine | 24.61 | 2.56 | 5.12 | 0.7622 | 0.8065 | 0.7837 | Flight 2 | |||||
| Weed | 5.91 | 6.69 | 53.15 | 0.1018 | 0.7234 | 0.1785 | ||||||
| Soil | 0 | 0 | 1.97 | 1.0000 | 0.0327 | 0.0633 | ||||||
| NDVI | NGRDI | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Vine | Weed | Soil | Precision | Recall | F1-Score | Vine | Weed | Soil | Precision | Recall | F1- Score | |
| Vine | 49.00 | 1.60 | 1.80 | 0.9356 | 0.9648 | 0.9500 | 50.00 | 0.40 | 0.60 | 0.9804 | 0.9294 | 0.9542 |
| Weed | 1.60 | 5.40 | 5.80 | 0.4219 | 0.5870 | 0.4909 | 3.00 | 2.60 | 1.80 | 0.3514 | 0.4643 | 0.4000 |
| Soil | 0.20 | 2.20 | 32.00 | 0.9302 | 0.8081 | 0.8649 | 0.80 | 2.60 | 38.20 | 0.9183 | 0.9409 | 0.9294 |
| GLI | NDRE | |||||||||||
| Vine | 46.40 | 0 | 0 | 1.0000 | 0.8345 | 0.9098 | 37.10 | 1.41 | 1.81 | 0.9200 | 0.6790 | 0.7813 |
| Weed | 8.20 | 4.20 | 1.00 | 0.3134 | 0.5250 | 0.3925 | 17.54 | 4.23 | 7.06 | 0.1469 | 0.5833 | 0.2346 |
| Soil | 1.00 | 3.80 | 35.40 | 0.8806 | 0.9725 | 0.9243 | 0 | 1.61 | 29.23 | 0.9477 | 0.7672 | 0.8480 |
| GNDVI | ||||||||||||
| Vine | 55.40 | 2.80 | 2.60 | 0.9112 | 0.9685 | 0.9390 | Flight 3 | |||||
| Weed | 1.80 | 3.40 | 24.80 | 0.1133 | 0.5484 | 0.1878 | ||||||
| Soil | 0 | 0 | 9.20 | 1.0000 | 0.2514 | 0.4017 | ||||||
| GLI | NDVI | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Vine | Weed | Soil | Precision | Recall | F1-Score | Vine | Weed | Soil | Precision | Recall | F1- Score | |
| Vine | 39.60 | 1.40 | 0.40 | 0.9565 | 0.9474 | 0.9519 | 37.40 | 4.40 | 0 | 0.8947 | 0.9444 | 0.9189 |
| Weed | 2.00 | 12.60 | 3.60 | 0.6923 | 0.8077 | 0.7456 | 2.00 | 12.00 | 1.20 | 0.7895 | 0.5660 | 0.6593 |
| Soil | 0.20 | 1.60 | 39.60 | 0.9554 | 0.9061 | 0.9301 | 0.20 | 4.80 | 38.00 | 0.8837 | 0.9694 | 0.9246 |
| NGRDI | NDRE | |||||||||||
| Vine | 27.60 | 0 | 0 | 1.0000 | 0.6479 | 0.7863 | 16.40 | 2.40 | 0.60 | 0.8454 | 0.4121 | 0.5541 |
| Weed | 15.00 | 15.20 | 1.00 | 0.4872 | 0.8085 | 0.6080 | 21.80 | 16.40 | 10.20 | 0.3388 | 0.7664 | 0.4699 |
| Soil | 0 | 3.60 | 37.60 | 0.9126 | 0.9741 | 0.9424 | 1.60 | 2.60 | 28.00 | 0.8696 | 0.7216 | 0.7887 |
| GNDVI | ||||||||||||
| Vine | 22.40 | 3.40 | 4.20 | 0.7467 | 0.5685 | 0.6455 | Flight 4 | |||||
| Weed | 17.00 | 16.80 | 31.20 | 0.2585 | 0.8317 | 0.3944 | ||||||
| Soil | 0 | 0 | 5.00 | 1.0000 | 0.1238 | 0.2203 | ||||||
| SVM | RT | KNN | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | Precision | Recall | F1- Score | |
| Vine | 0.9254 | 0.7209 | 0.8105 | 0.8372 | 0.8090 | 0.8229 | 0.8684 | 0.7674 | 0.8148 |
| Weed | 0.5340 | 0.9483 | 0.6832 | 0.4271 | 0.8367 | 0.5655 | 0.5028 | 0.8824 | 0.6406 |
| Soil | 0.9956 | 0.7584 | 0.8610 | 0.9775 | 0.6933 | 0.8112 | 0.9837 | 0.7724 | 0.8654 |
| Metric | Model A (NGRDI) | Model B (SVM) | Model C (RT) | Model D (KNN) | ANOVA F-Statistic | ANOVA p-Value |
|---|---|---|---|---|---|---|
| Precision | 0.9589 | 0.2704 | 0.4733 | 0.4425 | 0.1047 | 0.9550 |
| Recall | 0.0661 | 0.2949 | 0.3497 | 0.0735 | 0.2415 | 0.8651 |
| F1-Score | 0.0548 | 0.5332 | 0.0769 | 0.4129 | 0.4279 | 0.7386 |
| Metric | Model A (NGRDI) | Model B (SVM) | Model C (RT) | Model D (KNN) |
|---|---|---|---|---|
| Precision—Mean | 0.8516 | 0.8183 | 0.7473 | 0.7850 |
| Precision—Standard Deviation | 0.1503 | 0.2487 | 0.2860 | 0.2511 |
| Precision—95% CI (Lower) | 0.4781 | 0.2005 | 0.0368 | 0.1613 |
| Precision—95% CI (Upper) | 1.2250 | 1.4362 | 1.4578 | 1.4087 |
| Recall—Mean | 0.8438 | 0.8092 | 0.7797 | 0.8074 |
| Recall—Standard Deviation | 0.0969 | 0.1219 | 0.0761 | 0.0650 |
| Recall—95% CI (Lower) | 0.6032 | 0.5063 | 0.5907 | 0.6459 |
| Recall—95% CI (Upper) | 1.0844 | 1.1121 | 0.9686 | 0.9689 |
| F1-Score—Mean | 0.8383 | 0.7849 | 0.7332 | 0.7736 |
| F1-Score—Standard Deviation | 0.0959 | 0.0916 | 0.1454 | 0.1179 |
| F1-Score—95% CI (Lower) | 0.6001 | 0.5573 | 0.3721 | 0.4807 |
| F1-Score—95% CI (Upper) | 1.0765 | 1.0125 | 1.0943 | 1.0665 |
| SVM | RT | KNN | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | Precision | Recall | F1-Score | |
| Vine | 0.9690 | 0.7440 | 0.8418 | 0.9764 | 0.8105 | 0.8857 | 1.0000 | 0.7941 | 0.8852 |
| Weed | 0.1458 | 0.9545 | 0.2530 | 0.2560 | 0.8205 | 0.3902 | 0.2056 | 0.9565 | 0.3385 |
| Soil | 1.0000 | 0.7323 | 0.8454 | 0.9597 | 0.7727 | 0.8561 | 0.9922 | 0.8339 | 0.9062 |
| Metric | Model A (NGRDI) | Model B (SVM) | Model C (RT) | Model D (KNN) | Significance Test | Statistic | p-Value |
|---|---|---|---|---|---|---|---|
| Precision | 0.2473 | 0.0611 | 0.0388 * | 0.0163 * | Kruskal–Wallis | 0.6304 | 0.8894 |
| Recall | 0.1347 | 0.0894 | 0.3813 | 0.4533 | ANOVA | 1.0853 | 0.4090 |
| F1-Score | 0.0687 | 0.0101 * | 0.1018 | 0.0623 | Kruskal–Wallis | 2.8974 | 0.4077 |
| Metric | Model A (NGRDI) | Model B (SVM) | Model C (RT) | Model D (KNN) |
|---|---|---|---|---|
| Precision—Mean | 0.83247 | 0.7049 | 0.7307 | 0.7326 |
| Precision—Standard Deviation | 0.2270 | 0.4845 | 0.4112 | 0.4564 |
| Precision—95% CI (Lower) | 0.2689 | −0.4986 | −0.2907 | −0.4012 |
| Precision—95% CI (Upper) | 1.3964 | 1.9084 | 1.7521 | 1.8664 |
| Recall—Mean | 0.9029 | 0.8103 | 0.8012 | 0.8615 |
| Recall—Standard Deviation | 0.0376 | 0.1250 | 0.0252 | 0.0846 |
| Recall—95% CI (Lower) | 0.8095 | 0.4996 | 0.7386 | 0.6512 |
| Recall—95% CI (Upper) | 0.9963 | 1.1209 | 0.8639 | 1.0718 |
| F1-Score—Mean | 0.8526 | 0.6467 | 0.7107 | 0.7100 |
| F1-Score—Standard Deviation | 0.1266 | 0.3410 | 0.2779 | 0.3219 |
| F1-Score—95% CI (Lower) | 0.5383 | −0.2003 | 0.0203 | −0.0896 |
| F1-Score—95% CI (Upper) | 1.1670 | 1.4938 | 1.4011 | 1.5095 |
| SVM | RT | KNN | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | Precision | Recall | F1-Score | |
| Vine | 0.9569 | 0.9208 | 0.9385 | 0.9474 | 0.7795 | 0.8553 | 0.9225 | 0.9084 | 0.9154 |
| Weed | 0.4157 | 0.9024 | 0.5692 | 0.2621 | 0.8636 | 0.4021 | 0.3810 | 0.9143 | 0.5378 |
| Soil | 0.9936 | 0.7990 | 0.8857 | 0.9795 | 0.7079 | 0.8218 | 1.0000 | 0.7783 | 0.8753 |
| Metric | Model A (NDVI) | Model B (SVM) | Model C (RT) | Model D (KNN) | Teste Used | Statistics | p-Value |
|---|---|---|---|---|---|---|---|
| Precision | 0.0175 * | 0.1084 | 0.0757 | 0.0012 * | Kruskal–Wallis | 0.431 | 0.9331 |
| Recall | 0.8126 | 0.2685 | 0.9115 | 0.0733 | ANOVA | 0.5596 | 0.6564 |
| F1-Score | 0.3344 | 0.2532 | 0.1268 | 0.1849 | ANOVA | 0.1210 | 0.9452 |
| Metric | Model A (NDVI) | Model B (SVM) | Model C (RT) | Model D (KNN) |
|---|---|---|---|---|
| Precision—Mean | 0.7626 | 0.7887 | 0.7297 | 0.7678 |
| Precision—Standard Deviation | 0.2950 | 0.3236 | 0.4052 | 0.3372 |
| Precision—95% CI (Lower) | 0.0297 | −0.0151 | −0.2770 | −0.0699 |
| Precision—95% CI (Upper) | 1.4955 | 1.5925 | 1.7363 | 1.6056 |
| Recall—Mean | 0.7866 | 0.8741 | 0.7837 | 0.8670 |
| Recall—Standard Deviation | 0.1898 | 0.0657 | 0.0779 | 0.0769 |
| Recall—95% CI (Lower) | 0.3151 | 0.7110 | 0.5901 | 0.6760 |
| Recall—95% CI (Upper) | 1.2582 | 1.0372 | 0.9773 | 1.0580 |
| F1-Score—Mean | 0.7686 | 0.7978 | 0.6931 | 0.7762 |
| F1-Score—Standard Deviation | 0.2442 | 0.1997 | 0.2525 | 0.2074 |
| F1-Score—95% CI (Lower) | 0.1619 | 0.3017 | 0.0657 | 0.2609 |
| F1-Score—95% CI (Upper) | 1.3753 | 1.2939 | 1.3204 | 1.2914 |
| SVM | RT | KNN | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | Precision | Recall | F1-Score | |
| Vine | 1.0000 | 0.8744 | 0.9330 | 0.9505 | 0.8872 | 0.9178 | 0.9880 | 0.8333 | 0.9041 |
| Weed | 0.6077 | 0.9753 | 0.7488 | 0.5615 | 0.8111 | 0.6636 | 0.5646 | 0.9326 | 0.7034 |
| Soil | 0.9796 | 0.8727 | 0.9231 | 0.9468 | 0.8279 | 0.8834 | 0.9600 | 0.8451 | 0.9023 |
| Metric | Model A (GLI) | Model B (SVM) | Model C (RT) | Model D (KNN) | Kruskal–Wallis H | p-Value |
|---|---|---|---|---|---|---|
| Precision | 0.0069 * | 0.0882 | 0.0158 * | 0.0012 * | 1.6209 | 0.6547 |
| Recall | 0.5574 | 0.0276 * | 0.4043 | 0.2081 | 1.9231 | 0.5885 |
| F1-Score | 0.1849 | 0.0081 * | 0.2388 | 0.0149 * | 2.5897 | 0.4593 |
| Metric | Model A (GLI) | Model B (SVM) | Model C (RT) | Model D (KNN) |
|---|---|---|---|---|
| Precision—Mean | 0.8681 | 0.8624 | 0.8196 | 0.8375 |
| Precision—Standard Deviation | 0.1522 | 0.2208 | 0.2235 | 0.2368 |
| Precision—95% CI (Lower) | 0.4899 | 0.3138 | 0.2643 | 0.2493 |
| Precision—95% CI (Upper) | 1.2462 | 1.4110 | 1.3749 | 1.4257 |
| Recall—Mean | 0.8871 | 0.9075 | 0.8421 | 0.8703 |
| Recall—Standard Deviation | 0.0718 | 0.0588 | 0.0400 | 0.0542 |
| Recall—95% CI (Lower) | 0.7088 | 0.7615 | 0.7428 | 0.7356 |
| Recall—95% CI (Upper) | 1.0653 | 1.0534 | 0.9414 | 1.0051 |
| F1-Score—Mean | 0.8762 | 0.8713 | 0.8216 | 0.8366 |
| F1-Score—Standard Deviation | 0.1128 | 0.1061 | 0.1379 | 0.1154 |
| F1-Score—95% CI (Lower) | 0.5961 | 0.6078 | 0.4790 | 0.5500 |
| F1-Score—95% CI (Upper) | 1.1563 | 1.1348 | 1.1642 | 1.1232 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Macedo, F.L.; Nóbrega, H.; de Freitas, J.G.R.; Pinheiro de Carvalho, M.A.A. Assessment of Vegetation Indices Derived from UAV Imagery for Weed Detection in Vineyards. Remote Sens. 2025, 17, 1899. https://doi.org/10.3390/rs17111899
Macedo FL, Nóbrega H, de Freitas JGR, Pinheiro de Carvalho MAA. Assessment of Vegetation Indices Derived from UAV Imagery for Weed Detection in Vineyards. Remote Sensing. 2025; 17(11):1899. https://doi.org/10.3390/rs17111899
Chicago/Turabian StyleMacedo, Fabrício Lopes, Humberto Nóbrega, José G. R. de Freitas, and Miguel A. A. Pinheiro de Carvalho. 2025. "Assessment of Vegetation Indices Derived from UAV Imagery for Weed Detection in Vineyards" Remote Sensing 17, no. 11: 1899. https://doi.org/10.3390/rs17111899
APA StyleMacedo, F. L., Nóbrega, H., de Freitas, J. G. R., & Pinheiro de Carvalho, M. A. A. (2025). Assessment of Vegetation Indices Derived from UAV Imagery for Weed Detection in Vineyards. Remote Sensing, 17(11), 1899. https://doi.org/10.3390/rs17111899