Abstract
In recent years, advancements in remote sensing image observation technology have significantly enriched the surface feature information captured in remote sensing images, posing greater challenges for semantic information extraction from remote sensing imagery. While convolutional neural networks (CNNs) excel at understanding relationships between adjacent image regions, processing multidimensional data requires reliance on attention mechanisms. However, due to the inherent complexity of remote sensing images, most attention mechanisms designed for natural images underperform when applied to remote sensing data. To address these challenges in remote sensing image semantic segmentation, we propose a highly generalizable multi-branch attention fusion method based on shallow and deep features. This approach applies pixel-wise, spatial, and channel attention mechanisms to feature maps fused with shallow and deep features, thereby enhancing the network’s semantic information extraction capability. Through evaluations on the Cityscapes, LoveDA, and WHDLD datasets, we validate the performance of our method in processing remote sensing data. The results demonstrate consistent improvements in segmentation accuracy across most categories, highlighting its strong generalization capability. Specifically, compared to baseline methods, our approach achieves average mIoU improvements of 0.42% and 0.54% on the WHDLD and LoveDA datasets, respectively, significantly enhancing network performance in complex remote sensing scenarios.
1. Introduction
In recent years, with the advancement of Earth observation technology, the acquisition cost of remote sensing images has been significantly reduced, leading to their widespread applications in transportation, agriculture, forestry, fisheries, and other fields [1,2,3,4,5,6,7,8,9]. Simultaneously, rapid developments in optical sensor technology and continuous innovations in sensor-carrying platforms have diversified the types of remote sensing data. From RGB images to multispectral and hyperspectral data, and from 2D data to 3D point cloud data, the resolution of acquired remote sensing images has become increasingly higher, with these high-resolution images containing richer object-level information [10]. Early researchers often employed mathematical morphology analysis methods for feature extraction [11], while Fourier transforms and maximum likelihood classification could meet the requirements of different tasks [12]. Some researchers integrated machine learning methods with remote sensing [13]; compared to the former approaches, these methods often achieved superior speed and accuracy when processing data with complex feature spaces [14]. However, the semantic information extraction capabilities of these methods remain insufficient to meet current task demands, often failing to deliver satisfactory results when handling high-resolution data. At present, researchers predominantly focus on integrating deep learning with remote sensing tasks. For instance, in 2022, attention mechanisms were proven to enhance performance in few-shot learning tasks [15], and in 2023, a YOLOv8-based instance segmentation method utilizing multispectral remote sensing data was applied to tobacco plant counting [16]. Yet, as this integration deepens, new challenges have emerged.
Compared to natural images, remote sensing images are typically captured by satellite or UAV-mounted sensors from high altitudes. Influenced by factors such as flight altitude, sampling area, and acquisition time, remote sensing images generally exhibit characteristics including more diverse target categories, larger object scale variations, and more complex terrain patterns. These characteristics endow remote sensing images with richer semantic information, more severe class imbalance, and increased interference compared to natural images. Additionally, uncontrollable factors such as solar flares and wind speed further degrade data quality. These challenges collectively render semantic information extraction from remote sensing data significantly more difficult than from natural images, indicating that attention mechanisms designed for natural images cannot effectively interpret the semantics of remote sensing data.
To address these issues, researchers have proposed various methods. For instance, HRCNet enhances spatial information extraction in remote sensing images through a boundary-aware loss (BA loss) function and a boundary-aware (BA) module [17]. The ResUNet-a architecture introduces a gradient-driven Tanimoto loss to improve performance in aerial image semantic segmentation tasks [18]. Furthermore, numerous methods have been developed to enhance model performance in remote sensing tasks [19,20,21,22,23]. Despite their successful applications in specific domains, these approaches are often tailored to address singular limitations or specialized datasets. To date, no universally applicable method has been proposed for general remote sensing tasks.
To address the aforementioned challenges, we select remote sensing semantic segmentation—a critical component of RSIR (Remote Sensing Image Retrieval)—as our research focus. Our objective is to design a highly generalizable, plug-and-play attention mechanism that enhances feature extraction capabilities for remote sensing image data. To this end, we propose an attention method that integrates deep and shallow features of the model. Within the module, we employ a three-branch architecture incorporating pixel-wise, spatial, and channel attention mechanisms to further strengthen the model’s ability to extract semantic information from remote sensing images. This module enhances the network’s semantic understanding by simultaneously learning both deep and shallow features of the input image.
During testing, we selected the Cityscapes dataset, LoveDA dataset, and WHDLD dataset to evaluate the performance of the attention module under different scenarios and resolutions. This approach ultimately led to a significant improvement in the model’s performance on remote sensing datasets.
The main contributions of this paper are as follows:
- (1)
- We designed and proposed a multi-branch attention fusion method based on shallow and deep semantic information, specifically tailored for remote sensing data and exhibiting high generalization capability. Compared to the attention mechanisms employed in baseline methods, our approach demonstrates superior effectiveness while maintaining competitive inference speed. As illustrated in Figure 1, our method produces more intuitive results, with building regions exhibiting more precise boundaries and road regions showing enhanced connectivity.
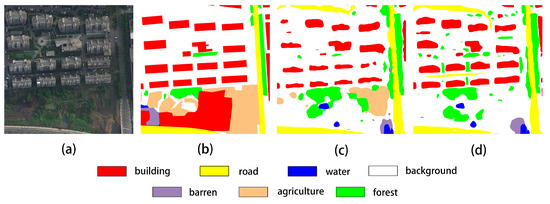 Figure 1. Comparative visualization of segmentation results. (a) Input image, (b) ground truth, (c) prediction result of the spatial attention method, (d) prediction result of our method.
Figure 1. Comparative visualization of segmentation results. (a) Input image, (b) ground truth, (c) prediction result of the spatial attention method, (d) prediction result of our method. - (2)
- We conducted comprehensive tests across multiple datasets, comparing the effects of applying our proposed attention mechanism to both natural image datasets and remote sensing datasets. The results reveal that this multi-branch attention mechanism exhibits superior performance on remote sensing imagery, achieving enhanced overall performance.
2. Related Work
This section discusses technologies relevant to our research, including semantic segmentation methods, the PP-LiteSeg network, and multi-branch feature fusion techniques.
2.1. Fully Convolutional Network (FCN)-Based Semantic Segmentation
Unlike region-based semantic segmentation approaches, FCN-based semantic segmentation [24] operates at the pixel level, aiming to assign a category label to each pixel in an image. In deep learning, FCNs typically support more flexible input scales, enabling broader applicability across scenarios. For instance, using SDFCNv2 [25], researchers addressed the differences between remote sensing images and natural scene images by proposing a Hybrid Basic Convolution (HBC) block and a Spatial-Channel Fusion Squeeze-and-Excitation (SCFSE) module. These components enhance the model’s feature extraction capability by expanding the receptive field while reducing parameters [26]. Subsequently, following the design principles of FCNs, researchers have proposed various improved methods.
2.2. PP-LiteSeg
In remote sensing tasks, models must not only meet accuracy requirements but also maintain inference speed. Therefore, we select the lightweight semantic segmentation network PP-LiteSeg [27] as the baseline model for our study. PP-LiteSeg is a meticulously designed lightweight network that successfully balances model performance with significantly improved inference efficiency, achieving an optimal trade-off between lightweight design and high efficiency.
PP-LiteSeg primarily consists of three components: an encoder, a Flexible and Lightweight Decoder (FLD), and a computationally efficient Simple Pyramid Pooling Module (SPPM). The encoder employs the lightweight feature extraction network STDC proposed in STDCSeg [28], with PP-LiteSeg offering two variants—STDC1 and STDC2—whose detailed differences are summarized in Table 1. The input image first undergoes multi-layer convolution in the encoder to generate shallow feature maps, which are then fed into the SPPM module for contextual information aggregation. The output from SPPM is further processed by the FLD module. Within FLD, researchers introduced a Unified Attention Fusion Module (UAFM), which effectively fuses low-level and high-level features by applying channel attention or spatial attention to feature maps, thereby enhancing the network’s representational capacity and segmentation performance.

Table 1.
Architectural details of PP-LiteSeg variants.
2.3. Multi-Branch Feature Fusion Techniques
In the field of artificial intelligence, multi-branch is a network design methodology distinct from single-branch architectures. In multi-branch structures, data can be processed in "parallel" streams without mutual interference, enabling specialized processing of specific data features. This design philosophy has been applied across diverse tasks including medical imaging, remote sensing, and deblurring. Using CMFNet [29], researchers proposed a multi-branch network architecture that mimics the parvocellular layers (P-cells), koniocellular layers (K-cells), and magnocellular layers (M-cells) in the visual neural system, thereby enhancing the model’s perception of image shape, color, and illumination variations.
3. Methods
Due to the large data volume and high complexity of remote sensing imagery, semantic segmentation models often struggle to extract sufficient effective information during training. Using PP-LiteSeg, researchers employ the Unified Attention Fusion Module (UAFM) (Figure 2a), which simultaneously inputs low-level and high-level features into the attention module to generate attention weights. This mechanism enables the attention module to integrate features across different receptive fields. Using CMFNet, the researchers enhance model performance by incorporating pixel attention, spatial attention, and channel attention mechanisms within a multi-branch architecture, simulating human visual cells (P-cells, K-cells, and M-cells), as illustrated in Figure 2b. However, the former approach utilizes only spatial attention in its module, while the latter significantly increases parameter count when integrated with U-Net architectures, resulting in suboptimal feature extraction capabilities. Therefore, inspired by CMFNet and PP-LiteSeg, we propose a multi-branch attention fusion method based on shallow and deep semantic information. As illustrated in Figure 2c, we adopt the three attention mechanisms (pixel, spatial, and channel attention) from CMFNet and hybridize them with the UAFM framework from PP-LiteSeg. This integration enables the module to concurrently apply multiple attention operations to both shallow and deep features. This design preserves the feature extraction capability of the module, and the additional parameters introduced by this design are constrained to approximately 2.6 M, ensuring compatibility with resource-sensitive remote sensing applications. Furthermore, we introduce a learnable weighting parameter that allows the network to dynamically adjust the contributions of different attention mechanisms.
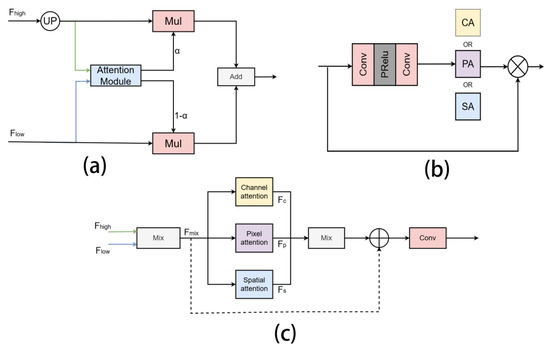
Figure 2.
Multi-branch attention fusion mechanism. (a) attention mechanism using PP-LiteSeg; (b) attention mechanism using CMFNet; (c) proposed fused attention method.
The main workflow of this module is formalized in Equation (1), where represent the outputs of the channel attention, pixel attention, and spatial attention mechanisms, respectively, and w denotes a learnable weight. As shown in Figure 2c, shallow features are first upsampled and convolved before being fused with deep features through a learnable fusion parameter. The fused features are then fed into three parallel branches for pixel attention, spatial attention, and channel attention processing, generating feature maps f1, f2 and f3. These feature maps are subsequently aggregated, and the combined output is passed through a 3 × 3 convolutional layer to produce the final feature map. This paper provides two versions of the method: V01 and V02. As indicated by the dashed lines in Figure 2c, the V02 method incorporates residual connections to reduce overfitting by adding the fused feature maps to the outputs of the multi-branch attention.
To more intuitively demonstrate the differences between the V01 and V02 methods, we implemented the proposed approach in a concrete network. Taking PP-LiteSeg as an example (as shown in Figure 3), we replaced its original UAFM mechanism with our proposed multi-branch attention fusion mechanism (MAFM)—a novel module specifically designed based on the method presented in this work. Using the building areas as a case study, we selected two representative sets of remote sensing images for heatmap analysis. As shown in Figure 4, in the first two image rows, the V01 method demonstrates significantly superior responses to the building regions compared to both the baseline method and the V02 method. This occurs because the first two rows exhibit image blurring and irregular building shapes, the blurred images contain more noise, and complex regional boundaries require learning richer features, posing substantial challenges to the network’s feature extraction capabilities. Consequently, the V01 method, with stronger learning capacity, outperforms other methods in these scenarios. In the last two rows, where the images are clearer and the building edges are more regular, the demands placed on feature extraction are reduced. Under these conditions, the V01 method exhibits imbalanced responses to target regions, while the V02 method achieves more balanced responses across all target areas in the images.
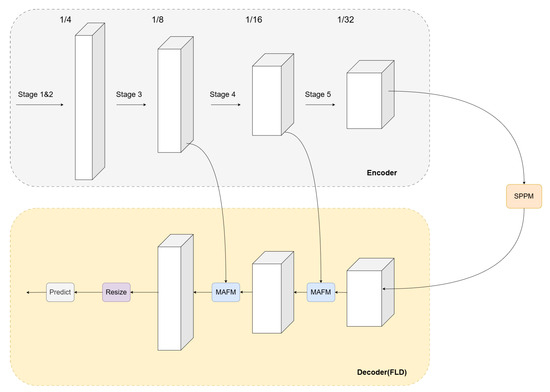
Figure 3.
A schematic diagram of module deployment. In this network, the MAFM module is deployed in the decoder section, designed to fuse shallow and deep features from the encoder, ultimately generating the attention-weighted output.
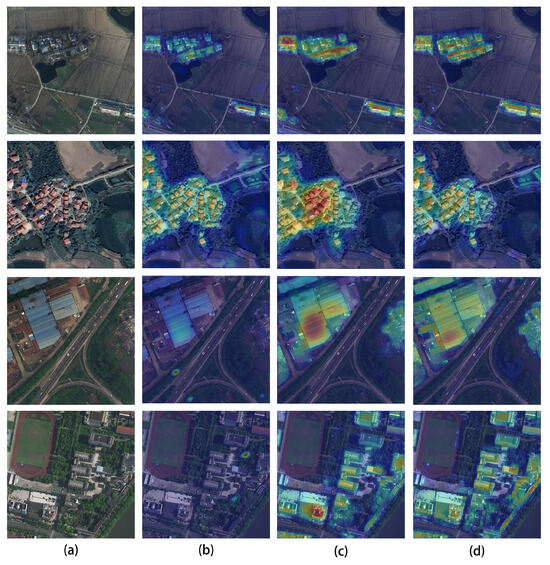
Figure 4.
Visual comparison of attention distributions. (a) Input image, (b) attention mechanism in PP-LiteSeg, (c) V01 attention method, and (d) V02 attention method.
4. Experiments
4.1. Datasets
4.1.1. Cityscapes
The Cityscapes dataset [30] is an urban scene dataset designed for semantic segmentation, constructed by collecting data from vehicles across 50 cities in Germany and neighboring countries. The dataset comprises 5000 high-quality manually annotated images with the following specifications:
- Training set: 2975 images (59.5%)
- Validation set: 500 images (10%)
- Test set: 1525 images (30.5%)
- Evaluation categories: 19 urban scene classes
- Resolution: 2048 × 1024 pixels
As shown in Figure 5, this dataset is utilized to test the performance of the attention mechanism in processing non-remote sensing data.

Figure 5.
Visual of Cityscapes dataset.
4.1.2. LoveDA
The LoveDA dataset [31] is a remote sensing dataset designed for domain adaptive semantic segmentation. Collected from 18 Chinese administrative regions, it contains two distinct scenarios:
- Urban subset:
- −
- Training images: 1156;
- −
- Validation images: 677;
- −
- Total: 1833 samples;
- −
- Spatial resolution: 0.3 m;
- −
- Spectral channels: RGB.
- Rural subset:
- −
- Training images: 1366;
- −
- Validation images: 992;
- −
- Total: 2358 samples;
- −
- Spatial resolution: 0.3 m;
- −
- Spectral channels: RGB.
As shown in Figure 6, the left portion displays urban data and their masks, while the right portion shows rural data and their masks. A comparison with Figure 5 reveals that the LoveDA dataset exhibits three characteristics: nadir-view acquisition perspective, semantically rich single images, and imbalanced urban-rural class distribution. These characteristics impose higher demands on the model’s feature extraction capability.

Figure 6.
Visual of LoveDA dataset. Left: Representative samples from urban areas; Right: Representative samples from rural areas.
4.1.3. WHDLD
The WHDLD dataset [32,33] is a densely annotated urban dataset with the following characteristics:
- Source: Wuhan metropolitan area, China;
- Total samples: 4,940 RGB images;
- Image dimensions: 256×256 pixels;
- Spatial resolution: 2 m;
- Land cover classes: 6 categories (buildings, roads, pavements, vegetation, bare soil, water).
- Compared with LoveDA, WHDLD features:
- Smaller spatial coverage per image;
- Lower spatial resolution;
- Higher class imbalance.
As shown in Figure 7, compared with LoveDA and Cityscapes datasets, this dataset features more detailed annotation masks. Specifically, the LoveDA annotations rely on simplified polygonal outlines composed of basic line segments, whereas the WHDLD dataset provides pixel-level annotations with finer granularity and superior data quality. Consequently, we adopted this dataset to rigorously evaluate model performance across varying annotation quality levels.

Figure 7.
Images of the WHDLD dataset.
4.2. Data Augmentation
In our experiments, we introduced randomized adjustments to the brightness, contrast, and saturation of all training data to simulate real-world imaging variations under different temporal and meteorological conditions. Additionally, considering the diversity of acquisition perspectives in practical scenarios, we applied random flipping and scaling to the training data. The combination of these data augmentation methods enables our attention module to focus on more diverse information, thereby enhancing the model’s generalization capability.
4.3. Evaluation Metrics
In this experiment, we adopt the mean Intersection over Union (mIoU) as the evaluation metric for model performance. mIoU is a critical assessment metric in semantic segmentation tasks. As shown in Equation (2), K represents the total number of classes, typically including all target categories to be segmented (potentially encompassing the background class), and denotes the Intersection over Union (IoU) for class c. This metric comprehensively evaluates the model’s predictive performance across all categories. During testing, higher mIoU values indicate superior model performance.
4.4. Experiments on Non-Remote Sensing Datasets
Application Experiment on Cityscapes Dataset
This experiment aimed to test the effectiveness of our proposed attention mechanism on natural image datasets. Specifically, we applied the V01 version of the multi-branch attention fusion module to pp-LiteSeg with the stdc1 backbone, and the V02 version to pp-LiteSeg with the stdc2 backbone. Both backbone networks were pre-trained. As shown in Figure 8, the convergence speed of the V01 method was comparable to the baseline under pre-training conditions, while the V02 method exhibited slightly slower convergence.
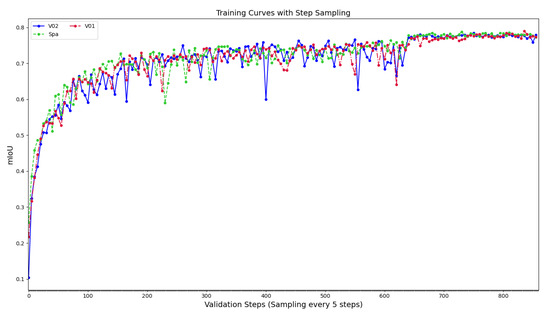
Figure 8.
mIoU variation in models under pre-training.
The experimental results are presented in Table 2. With the stdc1 backbone, our attention mechanism achieves 73. 37% on the mIoU test, outperforming the baseline result of 72.0%. However, with the stdc2 backbone, our method shows superior performance only in the validation set. These results indicate that, while the proposed attention mechanism provides modest improvements in general-purpose datasets, the performance gains are not substantial. Furthermore, the stdc2-based configuration is prone to overfitting.
Table 2.
Performance comparison of attention on WHDLD dataset.
4.5. Experiments on Remote Sensing Datasets
4.5.1. Performance Comparison on WHDLD Dataset
To validate the effectiveness of our method for remote sensing datasets, we conducted experiments using the WHDLD dataset. As shown in Table 3, under the STDC1 module, both the V01 attention mechanism and the V02 that use the residual connection attention mechanism outperformed the baseline in both validation and test datasets. Specifically, the V01 method achieved the best mIoU of 61.10%, surpassing the baseline by 0.79%. In the experiments using the STDC2 module, both V01 and V02 methods also outperformed the baseline on the validation and test sets. However, unlike the previous group of experiments, while the V01 method still achieved the best mIoU of 62.63% on the validation set, the V02 method outperformed it on the test set with an mIoU of 61.45%, which was 0.42% higher than the baseline. These improvements are primarily attributed to the application of an attention mechanism with stronger feature extraction capabilities in the network, while the use of residual connections helped maintain the network’s generalization ability as much as possible. Analyzing the results of the two groups of experiments, we found that at a 2 m resolution scale, our attention mechanism demonstrated a more pronounced improvement on lightweight networks. Meanwhile, within lightweight networks, the performance of the V02 method was inferior to that of V01. Furthermore, comparing our results with the baseline model, taking the experimental results of the STDC2 module as an example, the V02 method improved the recognition performance for the categories of buildings, roads, pavements, vegetation, bare soil, and water by 1.5%, 0.15%, 0.32%, 0.1%, 0.21%, and 0.24%, respectively. This indicates that our method can consistently enhance performance across all categories in this dataset, ultimately achieving better overall performance. In addition, the experimental data in Table 3 reveal that replacing the baseline’s backbone network from STDC1 to STDC2 increases the model parameters from 8.15 M to 12.38 M (a 4.23 M increase) while improving performance from 60.31% to 61.03% (a 0.73% increase). In contrast, our attention mechanism innovation achieves a higher performance of 61.10% (a 0.79% improvement) with only a 2.26 M increase in parameters. This demonstrates that a well-designed attention module can enhance network efficiency more effectively.
Table 3.
Performance comparison of attention on WHDLD dataset.
As shown in Figure 9, based on the comparison within the black dashed box, it can be observed that both the V01 and V02 methods outperform the original method in road recognition, with the detected road regions demonstrate improved spatial continuity. In the detection of building areas, the regions identified by the V02 method are more refined compared to the original attention mechanism. Additionally, as seen in the fifth image, the V02 method demonstrates superior performance in water body recognition compared to both the V01 method and the original method, avoiding large-scale misidentification of water body areas.
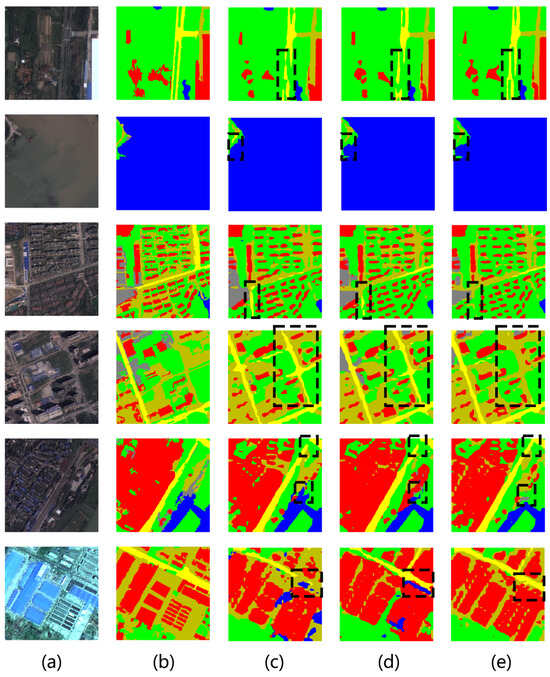
Figure 9.
Prediction visualization on the WHDLD dataset. The (a) input image, (b) ground truth, (c) prediction result of the spatial attention method, (d) prediction result of the V01 method, and (e) prediction result of the V02 method.
4.5.2. Performance Comparison on LoveDA Dataset
In this experiment, we trained the network using the LoveDA dataset with higher resolution and richer semantic information. The experimental results are shown in Table 4. In the experiments using the STDC1 backbone, the V01 method achieved the best performance for both the validation set (46.69%) and test set (50.73%), surpassing the baseline by 0.52%, while the V02 method underperformed on the test set. In the STDC2 backbone experiments, it can be observed that in the test set, the V02 method achieves segmentation accuracies of 44.14% (background), 55.30% (buildings), 55.54% (roads), 79.01% (water bodies), and 45.38% (forested areas), outperforming other methods. Compared to the baseline, the V02 method improves IoU for these categories by 0.35%, 4%, 1.3%, 1.72%, and 0.19%, respectively. Notably, the most significant improvements are observed for building segmentation, with roads and water bodies also showing substantial gains. Additionally, the V01 method attains a 16.91% IoU for the barren category, surpassing both V02 and the baseline by 2.26% and 1.03%, respectively. Overall, although the V01 method achieved the highest validation mIoU in both experimental groups, its test set superiority was limited to the lightweight backbone (STDC1). In contrast, the V02 method demonstrated more prominent performance (50.43% test mIoU) with the STDC2 backbone. This result aligns with earlier findings: the V01 method exhibited stronger feature extraction ability but suffered from severe overfitting, whereas the V02 method mitigated overfitting at the cost of slightly reduced feature extraction capacity. In addition, compared to backbone replacement, attention mechanism modifications yielded more efficient performance improvements.
Table 4.
Performance comparison of attention on LoveDA dataset.
Furthermore, observations on the recognition performance of farmland areas reveal that when identifying categories with blurred boundaries, the V01 method achieves only 58.16% mIoU. This indicates that ambiguous boundaries may cause the model to learn incorrect features. Critically, the V01 method, which lacks residual connections, is more prone to learning erroneous local features, thereby inducing severe overfitting. This issue demands particular attention.
As shown in Figure 10, both V01 and V02 methods achieve higher segmentation accuracy for categories with distinct boundaries (e.g., urban buildings and water bodies), but exhibit degraded performance for regions with ambiguous boundaries, such as farmland. Furthermore, the V02 method achieves superior road segmentation performance compared to other methods, with the segmented road regions demonstrating enhanced connectivity. Notably, these observations align precisely with the conclusions drawn in the preceding subsection.
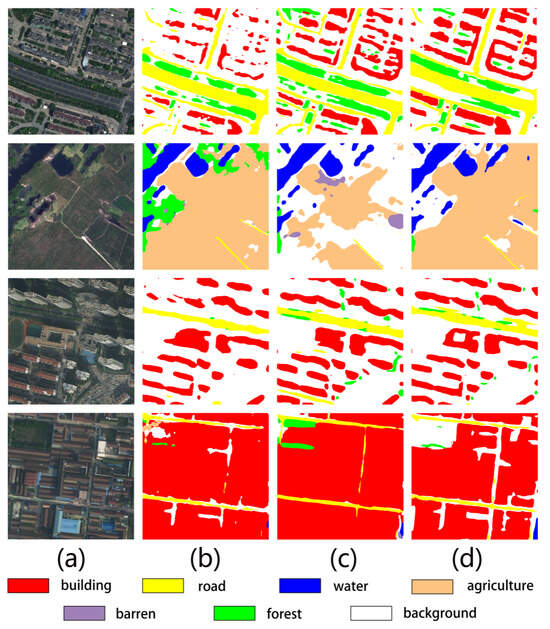
Figure 10.
Visualization of predictions on LoveDA dataset. (a) Input image, (b) baseline prediction (spatial attention mechanism), (c) V01 attention prediction, and (d) V02 attention prediction.
4.5.3. Comparative Experiments with Other Networks
In this experiment, we further reduce the volume of training data utilizing only the urban subset of the LoveDA dataset. The results are summarized in Table 5. The V02 method achieves IoU scores of 28.41% for barren land and 45.45% for forested areas, while the V01 method attains 63.04% and 61.90% IoU for buildings and roads, respectively. Notably, all models exhibit stronger performance on barren land segmentation in urban scenarios, with the V02 method delivering a 3.7% improvement over the original spatial attention mechanism. Remarkably, this enhancement is achieved without significant degradation in other categories, yielding a 0.65% overall mIoU gain.
Table 5.
Comparison results with other models.
5. Discussion
The proposed multi-branch attention fusion method effectively addresses challenges posed by multi-scale targets and complex scenes in remote sensing image segmentation. Experiments confirm that this approach improves mIoU while maintaining a manageable parameter scale.
While these findings are encouraging, our current implementation utilizes only lightweight pixel, spatial, and channel attention mechanisms, limiting its performance ceiling. Notably, while advanced attention mechanisms, such as Vision Transformer’s patch-based self-attention, lead to superior performance, they incur significantly higher computational costs. Future work will focus on distilling and integrating such high-performance attention modules while balancing model complexity.
Finally, the proposed method is not designed to achieve optimal performance across all tasks with a single configuration, but rather to adapt to diverse task requirements in a lighter-weight, more comprehensive, flexible, and efficient manner. As demonstrated by our V01 and V02 variants, where merely adding or removing residual connections, the model achieves notable improvements on both WHDLD and LoveDA datasets. Additionally, we plan to extend this framework to cross-modal data fusion scenarios, further enhancing its applicability in remote sensing analytics.
6. Conclusions
In this paper, we explore multi-attention fusion strategies and ultimately propose a multi-branch attention fusion mechanism tailored for remote sensing semantic segmentation. This mechanism comprehensively extracts features from remote sensing data by integrating channel, spatial, and pixel-wise attention operations. Experimental results demonstrate that while our attention mechanism offers limited improvements on natural image segmentation tasks, it significantly enhances recognition accuracy for most categories in remote sensing imagery and delivers robust overall performance gains. Unlike many models designed for single-category scenarios, our fused attention mechanism demonstrably excels in handling complex environmental data.
Author Contributions
Conceptualization, K.L. and Z.Q.; methodology, K.L. and Z.Q.; software, K.L. and H.L.; validation, Z.Q., X.W. and H.L.; formal analysis, Z.Q. and X.W.; investigation, X.W.; resources, Z.Q.; data curation, K.L.; writing—original draft preparation, K.L.; writing—review and editing, Z.Q.; visualization, H.L.; supervision, Z.Q.; project administration, Z.Q.; funding acquisition, Z.Q. All authors have read and agreed to the published version of this manuscript.
Funding
This work is supported by the projects of Natural Science Foundation of China (Grant No. 12163004), the Yunnan Fundamental Research Project (Grant No. 202301BD070001-008, 202401AS070009), the Key Research and Development Project of Yunnan Province (Grant No. 202402AD080002-5), and the Xingdian Talent Support Program (Grant No. YNWR-QNBJ-2019-286).
Data Availability Statement
The experimental data involved in this article will be provided by the authors upon request.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| BA | Boundary-aware |
| RSIR | Remote Sensing Image Retrieval |
| HBC | Hybrid Basic Convolution |
| FCN | Fully Convolutional Networks |
| SCFSE | Spatial-Channel Fusion Squeeze-and-Excitation |
| FCN | Fully Convolutional Networks |
| FLD | Flexible and Lightweight Decoder |
| SPPM | Simple Pyramid Pooling Module |
| UAFM | Unified Attention Fusion Module |
| MAFM | Multi-branch attention fusion mechanism (MAFM) |
| mIoU | Mean Intersection over Union |
References
- Zhu, L.; Suomalainen, J.; Liu, J.; Hyyppä, J.; Kaartinen, H.; Haggren, H. A Review: Remote Sensing Sensors. In Multi-Purposeful Application of Geospatial Data; Springer: Cham, Switzerland, 2018; Volume 19, pp. 1–19. [Google Scholar]
- Verstraete, M.M.; Pinty, B.; Myneni, R.B. Potential and Limitations of Information Extraction on the Terrestrial Biosphere from Satellite Remote Sensing. Remote Sens. Environ. 1996, 58, 201–214. [Google Scholar] [CrossRef]
- Salamí, E.; Barrado, C.; Pastor, E. UAV Flight Experiments Applied to the Remote Sensing of Vegetated Areas. Remote Sens. 2014, 6, 11051–11081. [Google Scholar] [CrossRef]
- Jin, W.; Ge, H.L.; Du, H.Q.; Xu, X.J. A Review on Unmanned Aerial Vehicle Remote Sensing and Its Application. Remote Sens. Inf. 2009, 1, 88–92. [Google Scholar]
- Feroz, S.; Abu Dabous, S. UAV-Based Remote Sensing Applications for Bridge Condition Assessment. Remote Sens. 2021, 13, 1809. [Google Scholar] [CrossRef]
- Yang, Z.; Yu, X.; Dedman, S.; Rosso, M.; Zhu, J.; Yang, J.; Xia, Y.; Tian, Y.; Zhang, G.; Wang, J. UAV Remote Sensing Applications in Marine Monitoring: Knowledge Visualization and Review. Sci. Total Environ. 2022, 838, 155939. [Google Scholar] [CrossRef]
- Holmgren, P.; Thuresson, T. Satellite Remote Sensing for Forestry Planning—A Review. Scand. J. For. Res. 1998, 13, 90–110. [Google Scholar] [CrossRef]
- Feng, Q.; Liu, J.; Gong, J. UAV Remote Sensing for Urban Vegetation Mapping Using Random Forest and Texture Analysis. Remote Sens. 2015, 7, 1074–1094. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, C.; Qiang, Z.; Xu, W.; Fan, J. A New Forest Growing Stock Volume Estimation Model Based on AdaBoost and Random Forest Model. Forests 2024, 15, 260. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.; Zhang, L.; Xu, F. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Soille, P.; Pesaresi, M. Advances in Mathematical Morphology Applied to Geoscience and Remote Sensing. IEEE Trans. Geosci. Remote Sens. 2002, 40, 2042–2055. [Google Scholar] [CrossRef]
- Richards, J.A.; Richards, J.A. Remote Sensing Digital Image Analysis, 6th ed.; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Atkinson, P.M.; Tatnall, A.R.L. Introduction Neural Networks in Remote Sensing. Int. J. Remote Sens. 1997, 18, 699–709. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of Machine-Learning Classification in Remote Sensing: An Applied Review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef]
- Lin, H.; Tse, R.; Tang, S.K.; Qiang, Z.P.; Pau, G. The Positive Effect of Attention Module in Few-Shot Learning for Plant Disease Recognition. In Proceedings of the 2022 5th International Conference on Pattern Recognition and Artificial Intelligence (PRAI), Chengdu, China, 19–21 August 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 114–120. [Google Scholar]
- Lin, H.; Chen, Z.; Qiang, Z.; Tang, S.-K.; Liu, L.; Pau, G. Automated Counting of Tobacco Plants Using Multispectral UAV Data. Agronomy 2023, 13, 2861. [Google Scholar] [CrossRef]
- Xu, Z.; Zhang, W.; Zhang, T.; Li, J. HRCNet: High-Resolution Context Extraction Network for Semantic Segmentation of Remote Sensing Images. Remote Sens. 2020, 13, 71. [Google Scholar] [CrossRef]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A Deep Learning Framework for Semantic Segmentation of Remotely Sensed Data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef]
- Zhang, Y.; Ye, M.; Zhu, G.; Liu, Y.; Guo, P.; Yan, J. FFCA-YOLO for Small Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5611215. [Google Scholar] [CrossRef]
- Liu, R.; Mi, L.; Chen, Z. AFNet: Adaptive Fusion Network for Remote Sensing Image Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2020, 59, 7871–7886. [Google Scholar] [CrossRef]
- Ding, L.; Tang, H.; Bruzzone, L. LANet: Local Attention Embedding to Improve the Semantic Segmentation of Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 426–435. [Google Scholar] [CrossRef]
- Zhang, J.; Qiang, Z.; Lin, H.; Chen, Z.; Li, K.; Zhang, S. Research on tobacco field semantic segmentation method based on multispectral unmanned aerial vehicle data and improved PP-LiteSeg model. Agronomy 2024, 14, 1502. [Google Scholar] [CrossRef]
- Lin, H.; Qiang, Z.; Tse, R.; Tang, S.-K.; Pau, G. A few-shot learning method for tobacco abnormality identification. Front. Plant Sci. 2024, 15, 1333236. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, G.; Tan, X.; Guo, B.; Zhu, K.; Liao, P.; Wang, T.; Wang, Q.; Zhang, X. SDFCNv2: An Improved FCN Framework for Remote Sensing Images Semantic Segmentation. Remote Sens. 2021, 13, 4902. [Google Scholar] [CrossRef]
- Mou, L.; Zhu, X.X. RiFCN: Recurrent Network in Fully Convolutional Network for Semantic Segmentation of High Resolution Remote Sensing Images. arXiv 2018, arXiv:1805.02091. [Google Scholar]
- Peng, J.; Liu, Y.; Tang, S.; Hao, Y.; Chu, L.; Chen, G.; Wu, Z.; Chen, Z.; Yu, Z.; Du, Y.; et al. Pp-liteseg: A Superior Real-Time Semantic Segmentation Model. arXiv 2022, arXiv:2204.02681. [Google Scholar]
- Fan, M.; Lai, S.; Huang, J.; Wei, X.; Chai, Z.; Luo, J. Rethinking Bisenet for Real-Time Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 9716–9725. [Google Scholar]
- Fan, C.M.; Liu, T.J.; Liu, K.H. Compound Multi-branch Feature Fusion for Real Image Restoration. arXiv 2022, arXiv:2206.02748. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Wang, J.; Zheng, Z.; Ma, A.; Lu, X.; Zhong, Y. LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation. arXiv 2021, arXiv:2110.08733. [Google Scholar]
- Shao, Z.; Yang, K.; Zhou, W. Performance Evaluation of Single-Label and Multi-Label Remote Sensing Image Retrieval Using a Dense Labeling Dataset. Remote Sens. 2018, 10, 964. [Google Scholar] [CrossRef]
- Shao, Z.; Zhou, W.; Deng, X.; Zhang, M.; Cheng, Q. Multilabel Remote Sensing Image Retrieval Based on Fully Convolutional Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 318–328. [Google Scholar] [CrossRef]
- Sun, K.; Zhao, Y.; Jiang, B.; Cheng, T.; Xiao, B.; Liu, D.; Mu, Y.; Wang, X.; Liu, W.; Wang, J. High-Resolution Representations for Labeling Pixels and Regions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- Zhu, W.; Jia, Y. High-Resolution Remote Sensing Image Land Cover Classification Based on EAR-HRNetV2. J. Phys. Conf. Ser. 2023, 2593, 012002. [Google Scholar] [CrossRef]
- Yao, M.; Zhang, Y.; Liu, G.; Pang, D. SSNet: A Novel Transformer and CNN Hybrid Network for Remote Sensing Semantic Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 3023–3037. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).