

Remote Sensing Image Segmentation Network That Integrates Global–Local Multi-Scale Information with Deep and Shallow Features

Abstract
1. Introduction
- We propose a novel semantic segmentation network, GLDSFNet, which improves the recognition of objects at multiple scales by effectively integrating global context, multi-scale local features, shallow details, and deep semantics within the decoder.
- We design the GLMFFM, composed of GCFEM and MDCM, to simultaneously extract and fuse global contextual information and multi-scale local features, enhancing the overall feature representation capacity.
- We introduce the SDFFM, which enables mutual guidance between deep and shallow features. By preserving and fusing their complementary characteristics, SDFFM enhances the expressiveness of feature maps and boosts segmentation accuracy, especially for fine-grained object boundaries.
2. Related Work
2.1. CNN-Based Semantic Segmentation Methods
2.2. Transformer-Based Semantic Segmentation Methods
3. Materials and Methods
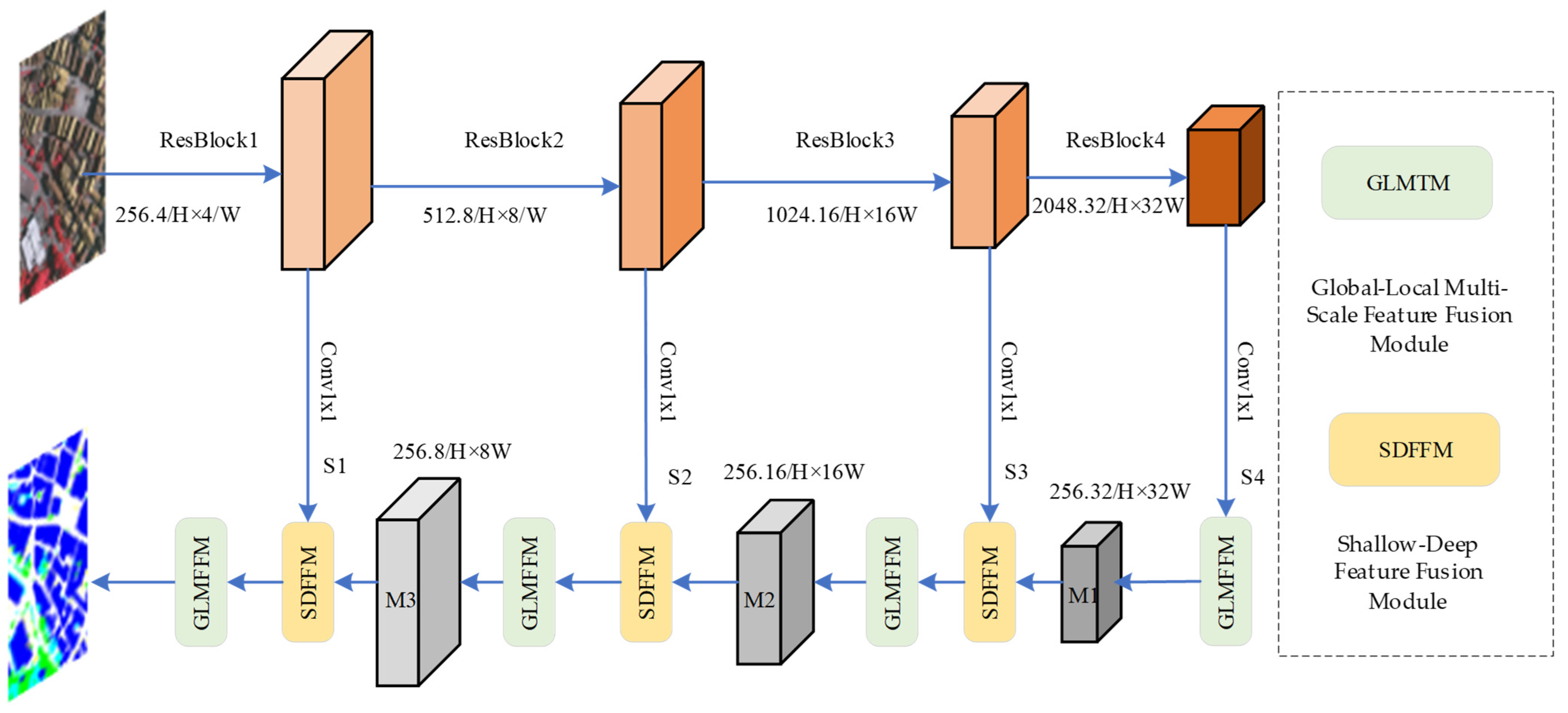
3.1. Overall Structure
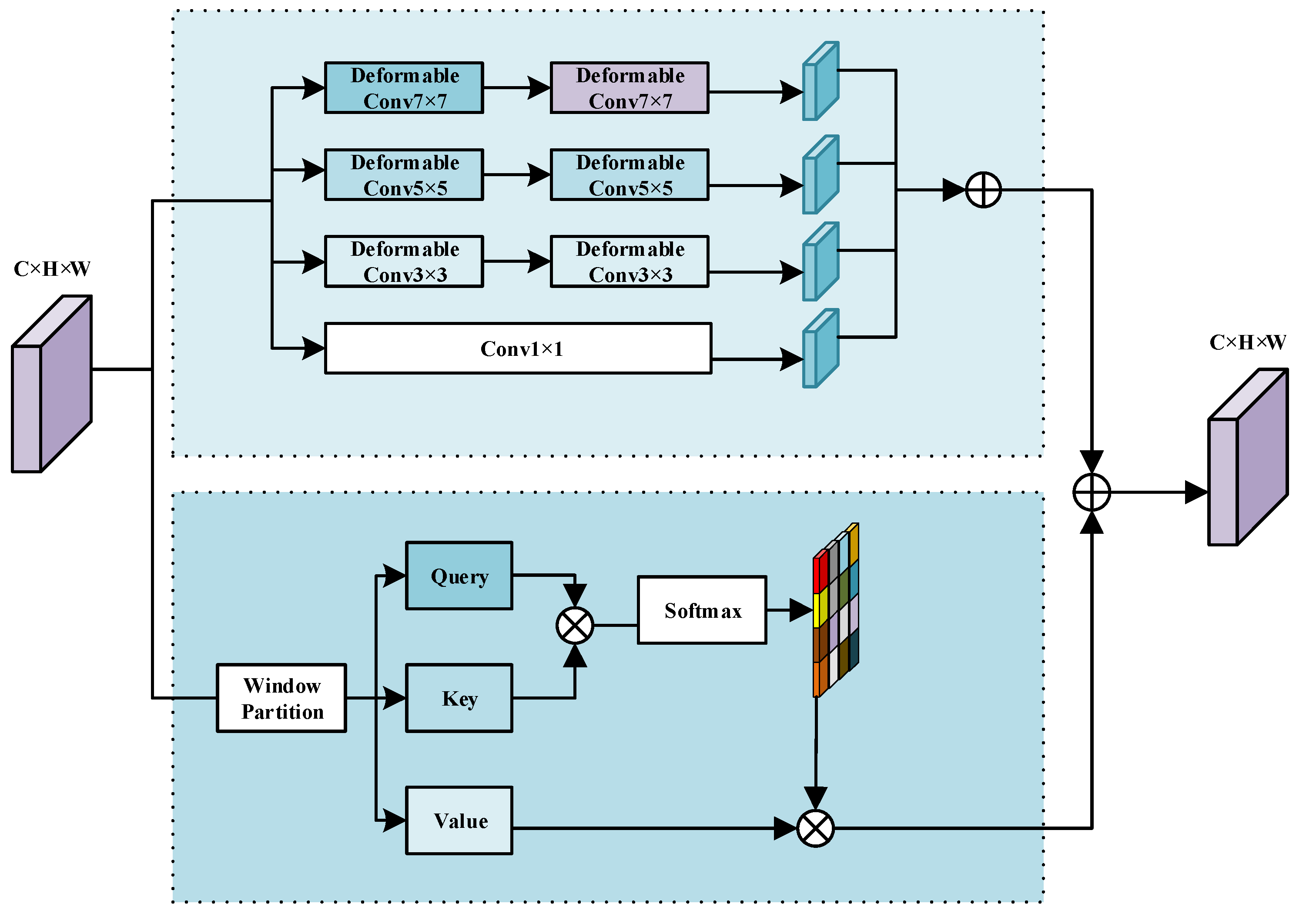
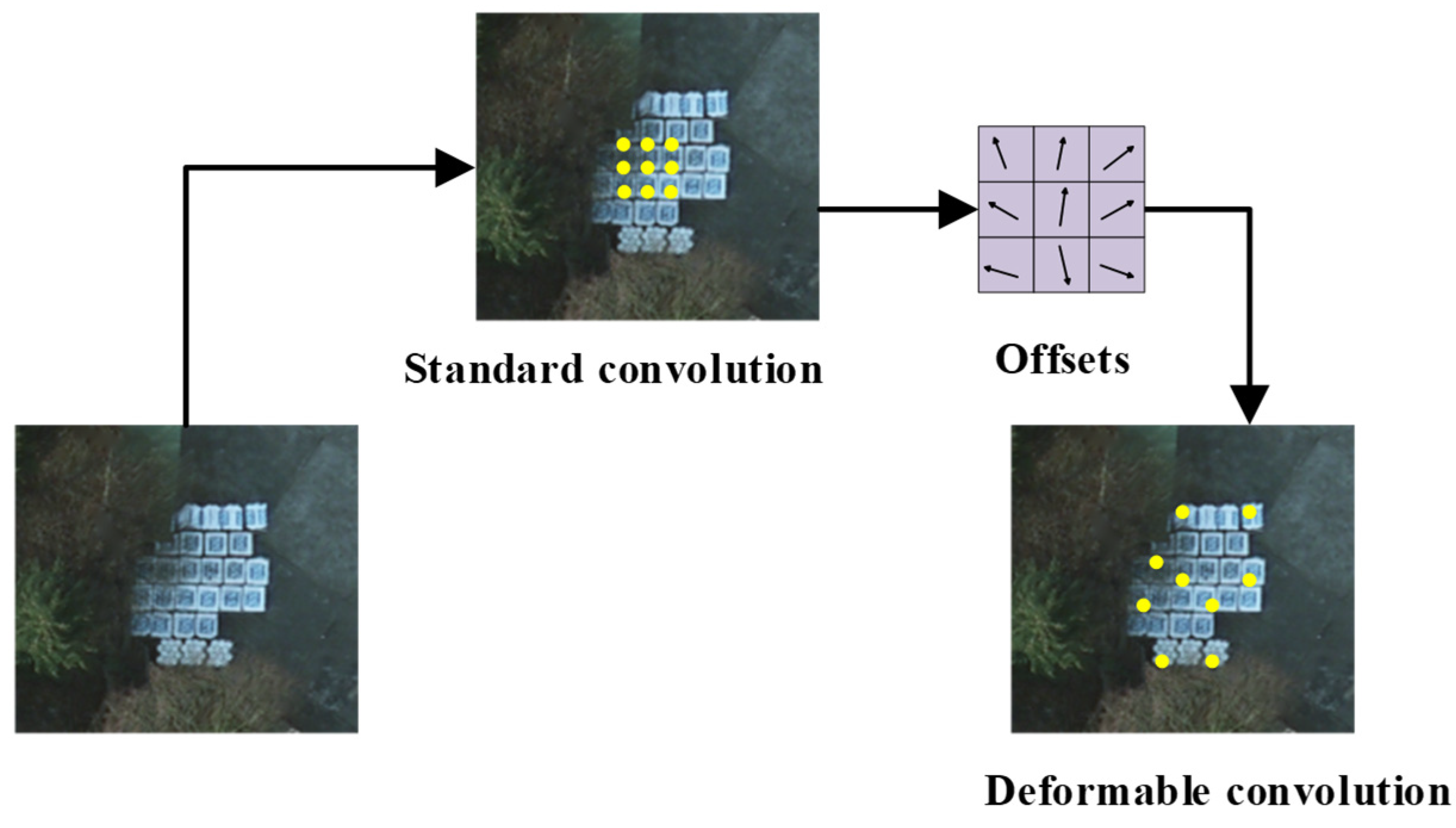
3.2. Global–Local Multi-Scale Feature Fusion Module
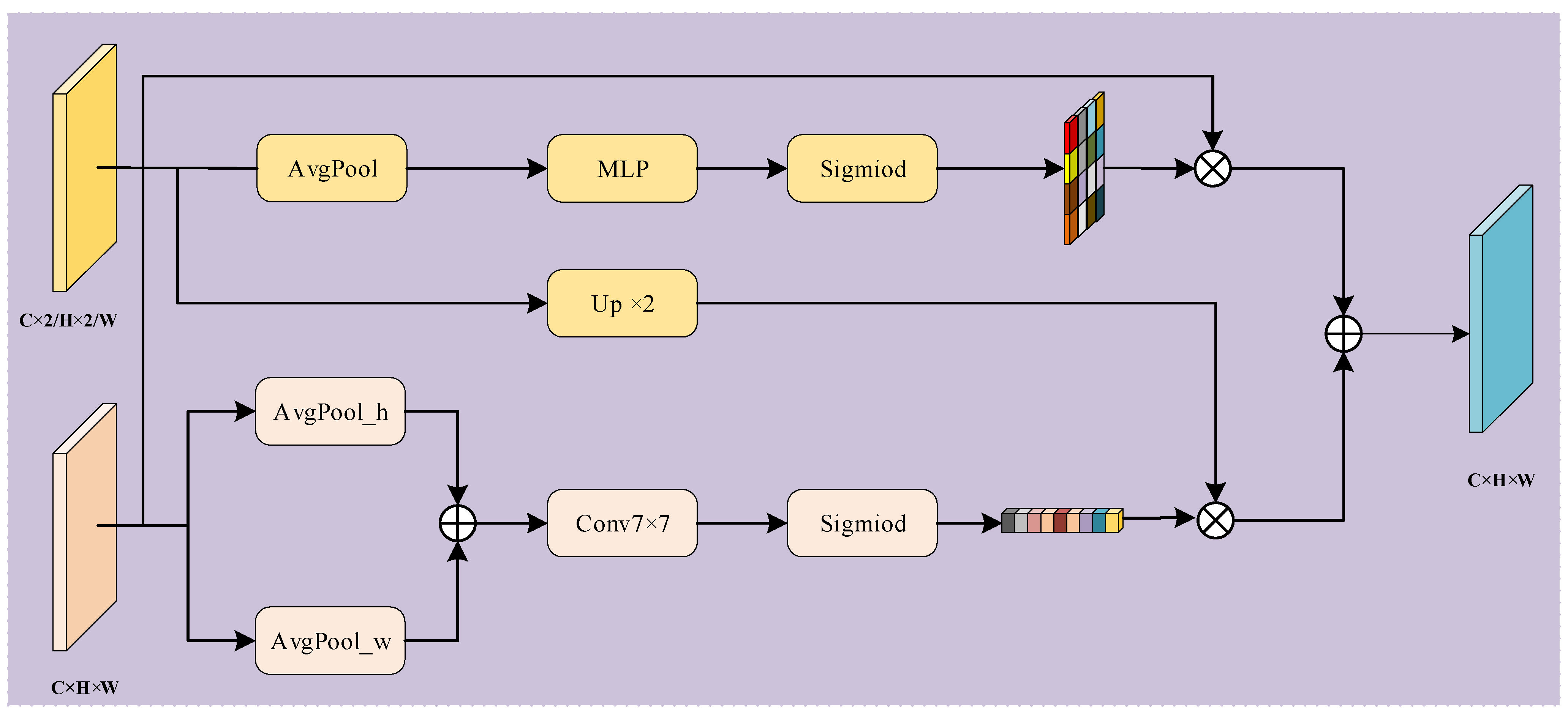
3.3. Shallow–Deep Feature Fusion Module
4. Results and Discussion
4.1. Dataset and Evaluation Metrics
4.2. Experimental Details
4.3. Ablation Experiments
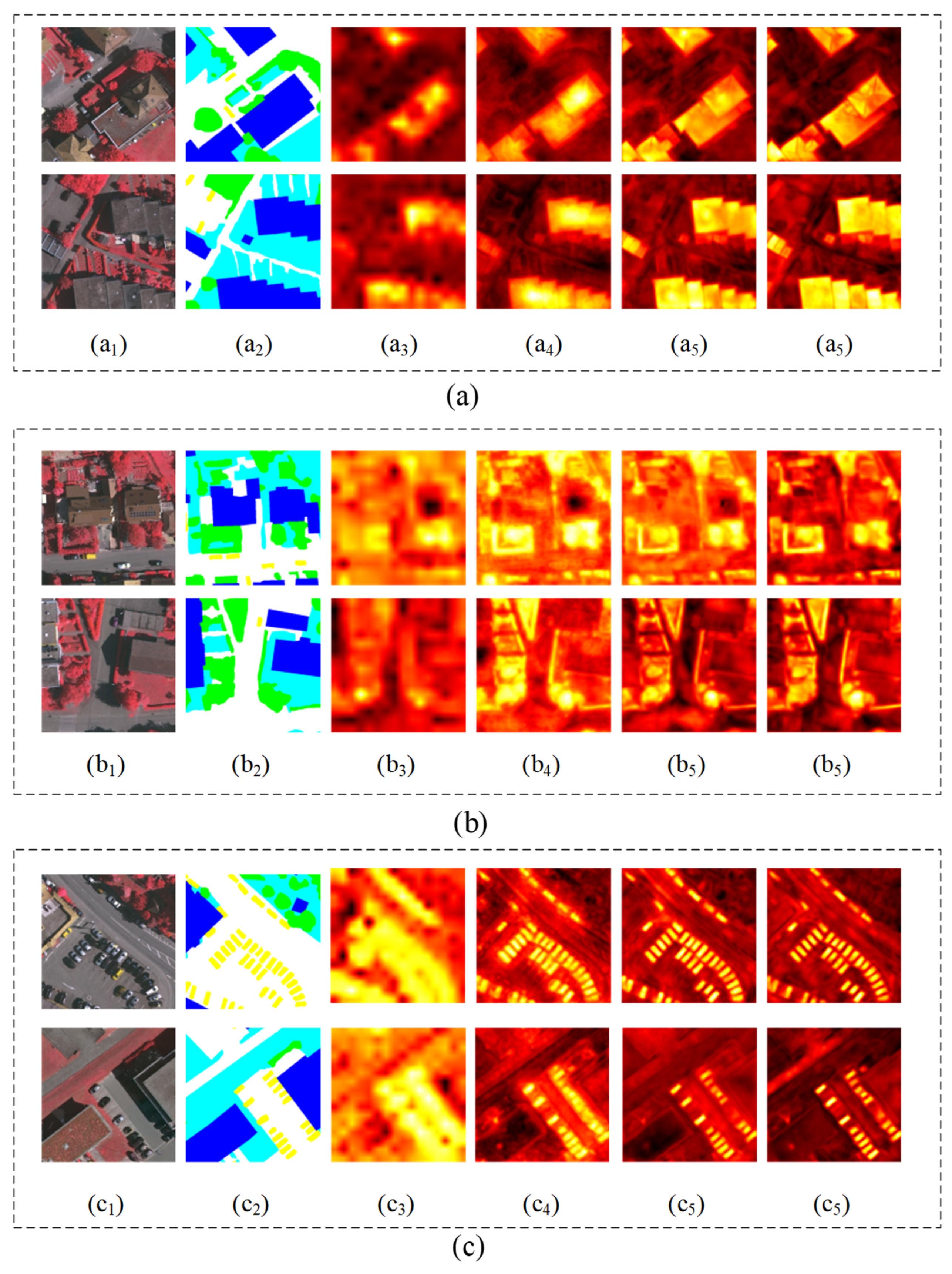
4.3.1. Effectiveness of Each Module of GLDSFNet
4.3.2. Effectiveness of GLMFFM
4.4. Comparative Experiments
4.4.1. Experimental Results on the ISPRS Vaihingen
4.4.2. Experimental Results on the ISPRS Potsdam
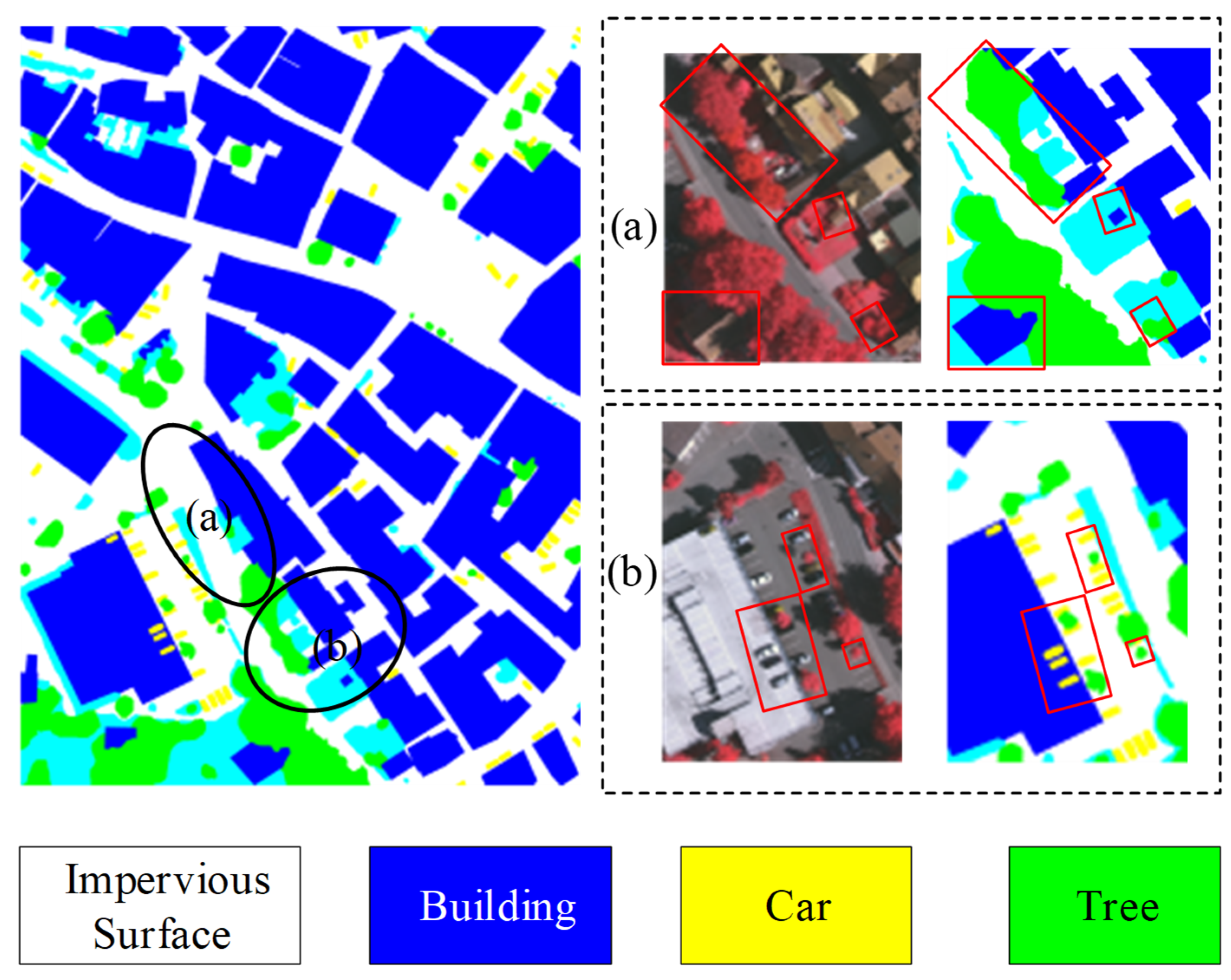
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, X.; Yong, X.; Li, T.; Tong, Y.; Gao, H.; Wang, X.; Xu, Z.; Fang, Y.; You, Q.; Lyu, X. A Spectral–Spatial Context-Boosted Network for Semantic Segmentation of Remote Sensing Images. Remote Sens. 2024, 16, 1214. [Google Scholar] [CrossRef]
- Xu, Y.; Bai, T.; Yu, W.; Chang, S.; Atkinson, P.M.; Ghamisi, P. AI Security for Geoscience and Remote Sensing: Challenges and Future Trends. IEEE Geosci. Remote Sens. Mag. 2023, 11, 60–85. [Google Scholar] [CrossRef]
- Ajibola, S.; Cabral, P. A Systematic Literature Review and Bibliometric Analysis of Semantic Segmentation Models in Land Cover Mapping. Remote Sens. 2024, 16, 2222. [Google Scholar] [CrossRef]
- Xiang, S.; Xie, Q.; Wang, M. Semantic Segmentation for Remote Sensing Images Based on Adaptive Feature Selection Network. IEEE Geosci. Remote Sens. Lett. 2022, 19, 8006705. [Google Scholar] [CrossRef]
- Wang, L.; Dong, S.; Chen, Y.; Meng, X.; Fang, S.; Fei, S. MetaSegNet: Metadata-Collaborative Vision-Language Representation Learning for Semantic Segmentation of Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5644211. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation; Spring: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 June 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 833–851. [Google Scholar]
- Yang, M.; Yu, K.; Zhang, C.; Li, Z.; Yang, K. DenseASPP for Semantic Segmentation in Street Scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3684–3692. [Google Scholar]
- He, J.; Deng, Z.; Qiao, Y. Dynamic Multi-Scale Filters for Semantic Segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3561–3571. [Google Scholar]
- Wang, G.; Zhai, Q.; Lin, J. Multi-Scale Network for Remote Sensing Segmentation. IET Image Process. 2022, 16, 1742–1751. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, C.; Li, R.; Duan, C.; Meng, X.; Atkinson, P.M. Scale-Aware Neural Network for Semantic Segmentation of Multi-Resolution Remote Sensing Images. Remote Sens. 2021, 13, 5015. [Google Scholar] [CrossRef]
- Li, S.; Yan, F.; Liu, Y.; Shen, Y.; Liu, L.; Wang, K. A Multi-Scale Rotated Ship Targets Detection Network for Remote Sensing Images in Complex Scenarios. Sci. Rep. 2025, 15, 2510. [Google Scholar] [CrossRef]
- Zou, Q.; Ni, L.; Zhang, T.; Wang, Q. Deep Learning Based Feature Selection for Remote Sensing Scene Classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2321–2325. [Google Scholar] [CrossRef]
- Ren, Y.; Zhu, C.; Xiao, S. Small Object Detection in Optical Remote Sensing Images via Modified Faster R-CNN. Appl. Sci. 2018, 8, 813. [Google Scholar] [CrossRef]
- Meng, W.; Shan, L.; Ma, S.; Liu, D.; Hu, B. DLNet: A Dual-Level Network with Self- and Cross-Attention for High-Resolution Remote Sensing Segmentation. Remote Sens. 2025, 17, 1119. [Google Scholar] [CrossRef]
- Zhang, C.; Jiang, W.; Zhang, Y.; Wang, W.; Zhao, Q.; Wang, C. Transformer and CNN Hybrid Deep Neural Network for Semantic Segmentation of Very-High-Resolution Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4408820. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Springenberg, J.T.; Riedmiller, M.; Brox, T. Discriminative Unsupervised Feature Learning with Convolutional Neural Networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems—Volume 1, Bali, Indonesia, 8–12 December 2021; MIT Press: Cambridge, MA, USA, 2014; Volume 1, pp. 766–774. [Google Scholar]
- Pereira, G.A.; Hussain, M. A Review of Transformer-Based Models for Computer Vision Tasks: Capturing Global Context and Spatial Relationships. arXiv 2024, arXiv:2408.15178. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Xu, X.; Yang, Z.; Zhang, S.; Li, S.; Luo, G.; Xu, Y. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 6881–6890. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Hwang, G.; Jeong, J.; Lee, S.J. SFA-Net: Semantic Feature Adjustment Network for Remote Sensing Image Segmentation. Remote Sens. 2024, 16, 3278. [Google Scholar] [CrossRef]
- Temenos, A.; Temenos, N.; Kaselimi, M.; Doulamis, A.; Doulamis, N. Interpretable Deep Learning Framework for Land Use and Land Cover Classification in Remote Sensing Using SHAP. IEEE Geosci. Remote Sens. Lett. 2023, 20, 8500105. [Google Scholar] [CrossRef]
- Bielecka, E.; Markowska, A.; Wiatkowska, B.; Calka, B. Sustainable Urban Land Management Based on Earth Observation Data—State of the Art and Trends. Remote Sens. 2025, 17, 1537. [Google Scholar] [CrossRef]
- Zhu, W.; He, W.; Li, Q. Hybrid AI and Big Data Solutions for Dynamic Urban Planning and Smart City Optimization. IEEE Access 2024, 12, 189994–190006. [Google Scholar] [CrossRef]
- Haack, B.; Bryant, N.; Adams, S. An Assessment of Landsat MSS and TM Data for Urban and Near-Urban Land-Cover Digital Classification. Remote Sens. Environ. 1987, 21, 201–213. [Google Scholar] [CrossRef]
- Li, D.; Zhang, J.; Liu, G. Autonomous Driving Decision Algorithm for Complex Multi-Vehicle Interactions: An Efficient Approach Based on Global Sorting and Local Gaming. IEEE Trans. Intell. Transp. Syst. 2024, 25, 6927–6937. [Google Scholar] [CrossRef]
- Li, R.; Wang, L.; Zhang, C.; Duan, C.; Zheng, S. A2-FPN for Semantic Segmentation of Fine-Resolution Remotely Sensed Images. Int. J. Remote Sens. 2022, 43, 1131–1155. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Duan, C.; Su, J.; Zhang, C. Multistage Attention ResU-Net for Semantic Segmentation of Fine-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 8009205. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Zhang, C.; Duan, C.; Su, J.; Wang, L.; Atkinson, P.M. Multiattention Network for Semantic Segmentation of Fine-Resolution Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5607713. [Google Scholar] [CrossRef]
- Zhu, S.; Zhang, B.; Wen, D.; Tian, Y. NCSBFF-Net: Nested Cross-Scale and Bidirectional Feature Fusion Network for Lightweight and Accurate Remote-Sensing Image Semantic Segmentation. Electronics 2025, 14, 1335. [Google Scholar] [CrossRef]
- Cheng, Y.; Wang, W.; Zhang, W.; Yang, L.; Wang, J.; Ni, H.; Guan, T.; He, J.; Gu, Y.; Tran, N.N. A Multi-Feature Fusion and Attention Network for Multi-Scale Object Detection in Remote Sensing Images. Remote Sens. 2023, 15, 2096. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Wang, L.; Li, R.; Duan, C.; Zhang, C.; Meng, X.; Fang, S. A Novel Transformer Based Semantic Segmentation Scheme for Fine-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6506105. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: A UNet-like Transformer for Efficient Semantic Segmentation of Remote Sensing Urban Scene Imagery. ISPRS J. Photogramm. Remote Sensg 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Wu, H.; Huang, P.; Zhang, M.; Tang, W.; Yu, X. CMTFNet: CNN and Multiscale Transformer Fusion Network for Remote-Sensing Image Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 2004612. [Google Scholar] [CrossRef]
- Wang, X.; Jiang, B.; Wang, X.; Luo, B. MTFNet: Mutual-Transformer Fusion Network for RGB-D Salient Object Detection. arXiv 2021, arXiv:2112.01177. [Google Scholar]
- Wu, H.; Zhang, M.; Huang, P.; Tang, W. CMLFormer: CNN and Multiscale Local-Context Transformer Network for Remote Sensing Images Semantic Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 7233–7241. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Params (M) | FLOPs (GFLOPs) | OA (%) | Mean F1 (%) | MIoU (%) |
|---|---|---|---|---|---|
| Resnet50 (baseline) | 23.52 | 21 | 85.46 | 80.35 | 68.55 |
| Baseline + SDFFM | 23.73 | 25 | 87.26 | 85.06 | 74.48 |
| Baseline + GCFEM | 25.56 | 30 | 86.76 | 84.74 | 73.97 |
| Baseline + MDCM | 44.35 | 129 | 87.03 | 85.53 | 75.11 |
| Baseline + GLMFFM | 44.92 | 131 | 87.36 | 85.68 | 75.34 |
| Baseline + GLMFFM + SDFFM | 45.41 | 135 | 87.64 | 85.86 | 75.64 |
| Module | Params (M) | LOPs (GFLOPs) | OA (%) | Mean F1 (%) | mIoU (%) |
|---|---|---|---|---|---|
| Resnet50 + GLTB | 28.24 | 44 | 84.74 | 83.75 | 73.97 |
| Resnet50 + MLTB | 26.17 | 32 | 86.87 | 84.81 | 74.09 |
| Renet50 + GLMFFM | 44.92 | 269 | 87.36 | 85.68 | 75.34 |
| Module | Params (M) | LOPs (GFLOPs) | OA (%) | Mean F1 (%) | mIoU (%) |
|---|---|---|---|---|---|
| Resnet50 + FPN | 23.60 | 24 | 86.74 | 84.83 | 74.10 |
| Resnet50 + AAM | 47.67 | 90 | 87.01 | 84.90 | 74.23 |
| Resnet50 + SDFFM | 23.73 | 25 | 87.26 | 85.06 | 74.48 |
| GLMFFM1 | GLMFFM2 | GLMFFM3 | GLMFFM4 | Params (M) | FLOPs (GFLOPs) | OA (%) | Mean F1 (%) | mIoU (%) |
|---|---|---|---|---|---|---|---|---|
| √ | 30.09 | 107 | 87.31 | 85.62 | 74.84 | |||
| √ | √ | 35.02 | 128 | 87.35 | 85.44 | 75.01 | ||
| √ | √ | √ | 40.31 | 133 | 87.45 | 85.72 | 75.41 | |
| √ | √ | √ | √ | 45.41 | 135 | 87.64 | 85.86 | 75.64 |
| Method | Per-Class FI Score (%)/Per-Class loU Score (%) | Indicators | ||||||
|---|---|---|---|---|---|---|---|---|
| Imp_Sur | Build | Low_veg | Tree | Car | OA (%) | MF1 (%) | MIoU (%) | |
| FCNs | 87.08/77.11 | 92.43/85.92 | 77.68/63.50 | 84.65/73.38 | 59.96/42.82 | 80.35 | 85.46 | 68.55 |
| U-Net | 87.82/78.28 | 91.59/84.49 | 77.78/63.64 | 84.55/73.23 | 72.50/56.86 | 82.84 | 85.60 | 71.29 |
| FPN | 88.83/79.91 | 93.16/87.20 | 78.74/64.93 | 85.33/74.42 | 78.06/64.02 | 84.83 | 86.73 | 74.10 |
| PSPNet | 88.20/78.89 | 92.83/86.62 | 78.88/65.13 | 85.41/74.53 | 76.46/61.89 | 84.36 | 86.53 | 73.41 |
| DeepLabV3+ | 88.85/79.94 | 93.08/87.06 | 78.58/64.72 | 85.29/74.35 | 76.85/62.40 | 84.49 | 86.61 | 73.64 |
| MAResU-Net | 85.12/74.09 | 92.99/86.90 | 78.40/64.48 | 85.47/74.63 | 78.60/64.74 | 84.84 | 86.62 | 74.10 |
| MANet | 88.83/79.90 | 92.99/86.89 | 78.68/64.85 | 85.62/74.85 | 78.91/65.17 | 85.00 | 86.78 | 74.33 |
| A2-FPN | 88.89/80.00 | 93.29/87.43 | 78.60/64.75 | 85.45/74.60 | 77.43/63.17 | 84.73 | 86.77 | 74.00 |
| UNetFormer | 89.04/80.24 | 93.34/87.51 | 79.23/65.60 | 85.50/74.67 | 79.29/65.69 | 85.28 | 87.00 | 74.74 |
| CMLFormer | 88.99/80.17 | 93.25/87.36 | 78.57/64.71 | 85.42/74.55 | 77.35/63.07 | 84.72 | 86.77 | 73.97 |
| GLDSFNet | 89.87/81.60 | 93.80/88.33 | 80.01/66.68 | 86.01/75.46 | 79.63/66.16 | 85.86 | 87.64 | 75.64 |
| Method | Per-Class FI Score (%)/Per-Class loU Score (%) | Indicators | ||||||
|---|---|---|---|---|---|---|---|---|
| Imp_Sur | Build | Low_veg | Tree | Car | OA (%) | MF1 (%) | MIoU (%) | |
| FCNs | 88.73/79.65 | 93.09/86.98 | 81.57/68.85 | 81.26/68.40 | 80.95/67.96 | 85.08 | 86.65 | 74.37 |
| U-Net | 90.91/83.35 | 94.63/89.72 | 90.49/82.67 | 83.35/71.42 | 91.59/84.50 | 88.31 | 88.98 | 80.33 |
| FPN | 90.73/83.07 | 94.92/90.39 | 83.76/72.10 | 83.72/71.91 | 88.59/79.53 | 88.25 | 88.90 | 79.40 |
| PSPNet | 91.96/85.18 | 95.94/92.35 | 84.74/73.53 | 85.41/74.57 | 89.85/81.59 | 89.61 | 90.18 | 81.45 |
| DeepLabV3+ | 92.15/85.45 | 90.45/82.62 | 85.32/74.45 | 85.25/74.38 | 90.41/82.50 | 89.88 | 90.39 | 81.88 |
| MAResU-Net | 92.45/86.09 | 96.37/93.07 | 85.56/74.70 | 85.06/74.05 | 91.55/84.37 | 90.21 | 90.55 | 82.46 |
| MANet | 92.25/85.73 | 96.26/92.95 | 85.58/74.71 | 85.21/74.20 | 91.99/85.19 | 90.28 | 90.51 | 82.56 |
| A2-FPN | 92.12/85.44 | 96.15/92.43 | 85.24/74.27 | 84.69/73.50 | 91.16/83.87 | 89.89 | 90.24 | 81.90 |
| UNetFormer | 92.30/85.79 | 96.25/92.94 | 85.47/74.57 | 84.97/73.89 | 91.61/84.46 | 90.13 | 90.47 | 82.33 |
| CMLFormer | 91.91/85.12 | 96.15/92.45 | 85.21/74.24 | 84.71/73.53 | 91.15/83.86 | 89.45 | 89.85 | 82.12 |
| GLDSFNet | 92.88/86.66 | 96.57/93.45 | 86.21/75.67 | 86.01/75.46 | 92.35/85.74 | 90.79 | 91.06 | 83.40 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, N.; Yang, R.; Zhao, Y.; Dai, Q.; Wang, L. Remote Sensing Image Segmentation Network That Integrates Global–Local Multi-Scale Information with Deep and Shallow Features. Remote Sens. 2025, 17, 1880. https://doi.org/10.3390/rs17111880
Chen N, Yang R, Zhao Y, Dai Q, Wang L. Remote Sensing Image Segmentation Network That Integrates Global–Local Multi-Scale Information with Deep and Shallow Features. Remote Sensing. 2025; 17(11):1880. https://doi.org/10.3390/rs17111880
Chicago/Turabian StyleChen, Nan, Ruiqi Yang, Yili Zhao, Qinling Dai, and Leiguang Wang. 2025. "Remote Sensing Image Segmentation Network That Integrates Global–Local Multi-Scale Information with Deep and Shallow Features" Remote Sensing 17, no. 11: 1880. https://doi.org/10.3390/rs17111880
APA StyleChen, N., Yang, R., Zhao, Y., Dai, Q., & Wang, L. (2025). Remote Sensing Image Segmentation Network That Integrates Global–Local Multi-Scale Information with Deep and Shallow Features. Remote Sensing, 17(11), 1880. https://doi.org/10.3390/rs17111880