MFFP-Net: Building Segmentation in Remote Sensing Images via Multi-Scale Feature Fusion and Foreground Perception Enhancement


Abstract
1. Introduction
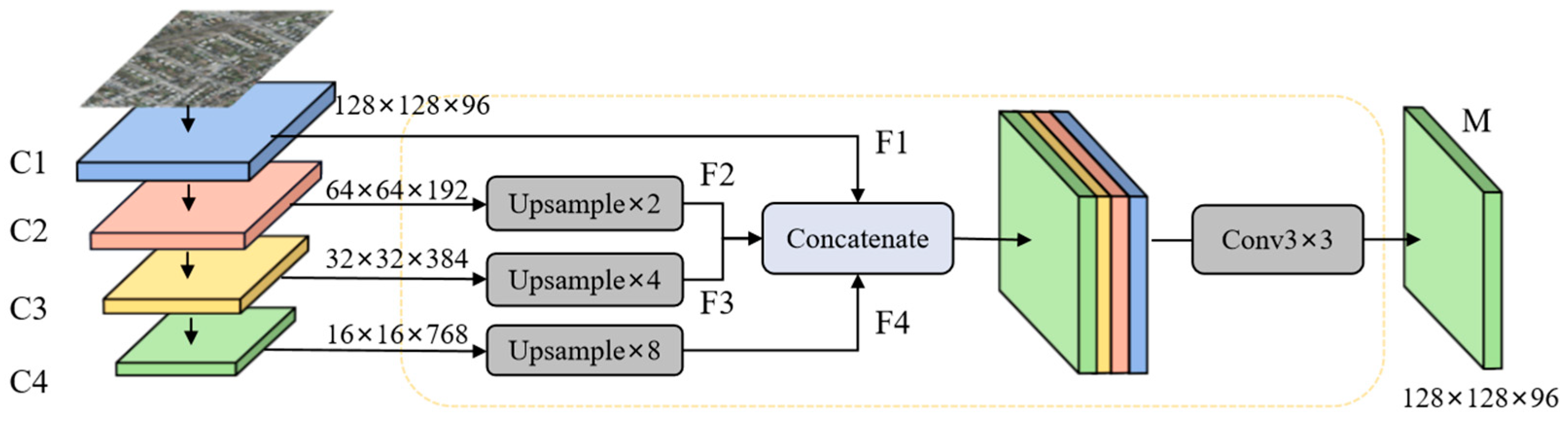
- A Multi-Scale Feature Fusion (MFF) module is proposed to improve the utilization efficiency of small target details in shallow features by constructing a hierarchical feature fusion mechanism, so that the network can pay more attention to shallow features containing more small target information.
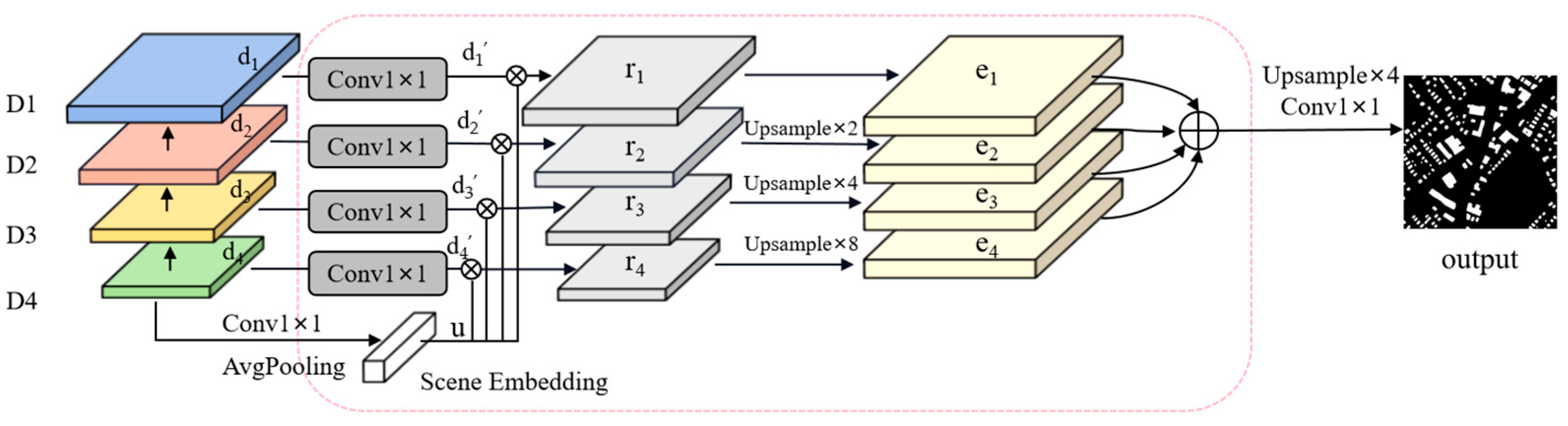
- A Foreground Perception Enhancement (FPE) module is proposed, which introduces a scene-constrained affinity learning mechanism that dynamically constructs pixel-wise spatial–semantic correlations within predicted foreground regions. By integrating pyramid scene embedding and convolution-based relation mapping, FPE clearly models the intra-class context dependency relationship. Compared with the traditional framework, it can effectively reduce the false alarms caused by intra-class variance.
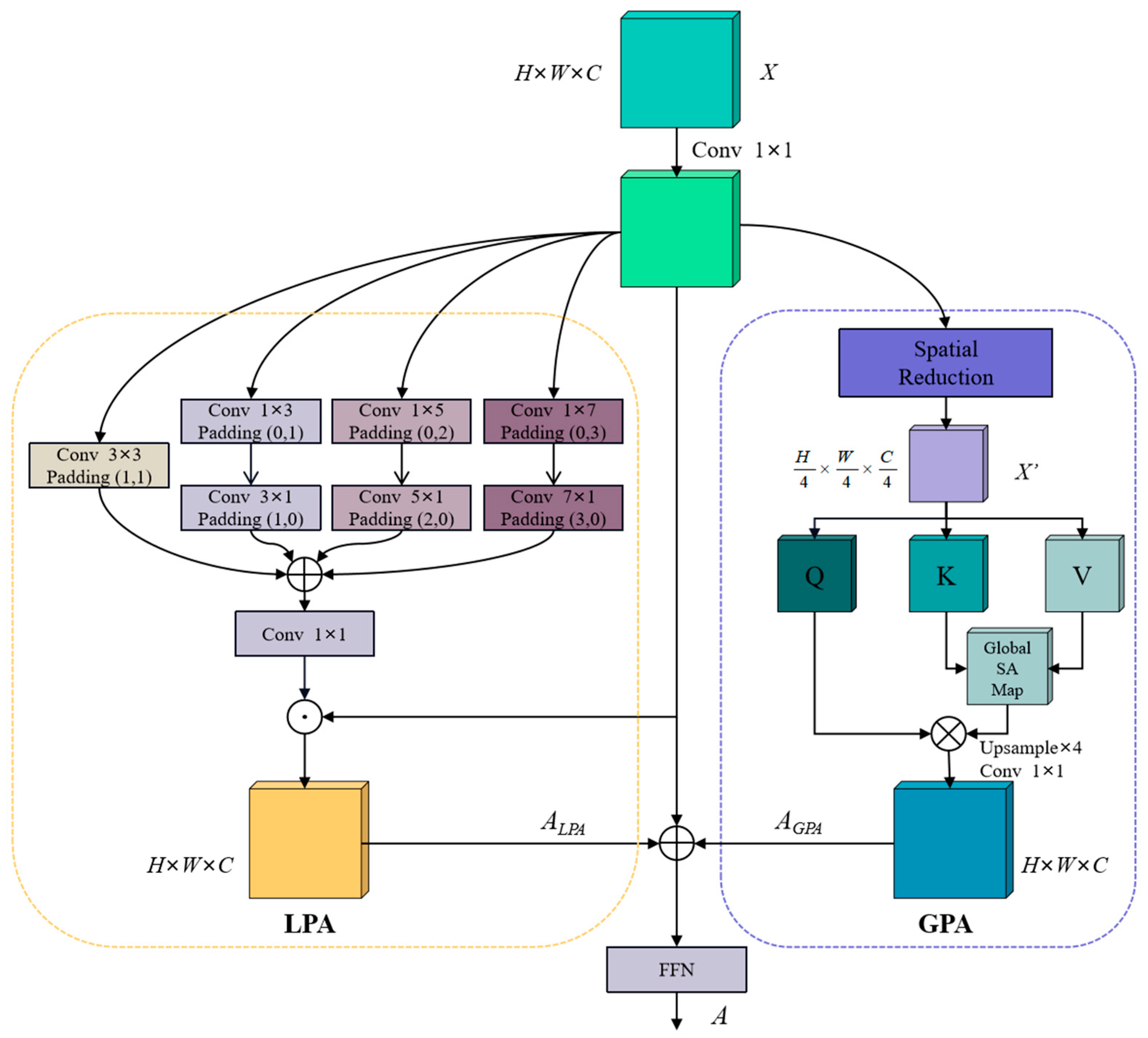
- A hybrid architecture in the form of a Dual-Path Attention (DPA) mechanism is designed, which combines the sparse self-attention (SA) of global context modeling with local attention based on strip convolution. This design strategically combines local details with global context dependency, reducing the computational complexity of the traditional SA and simultaneously improving the segmentation performance.
2. Related Works
3. Method
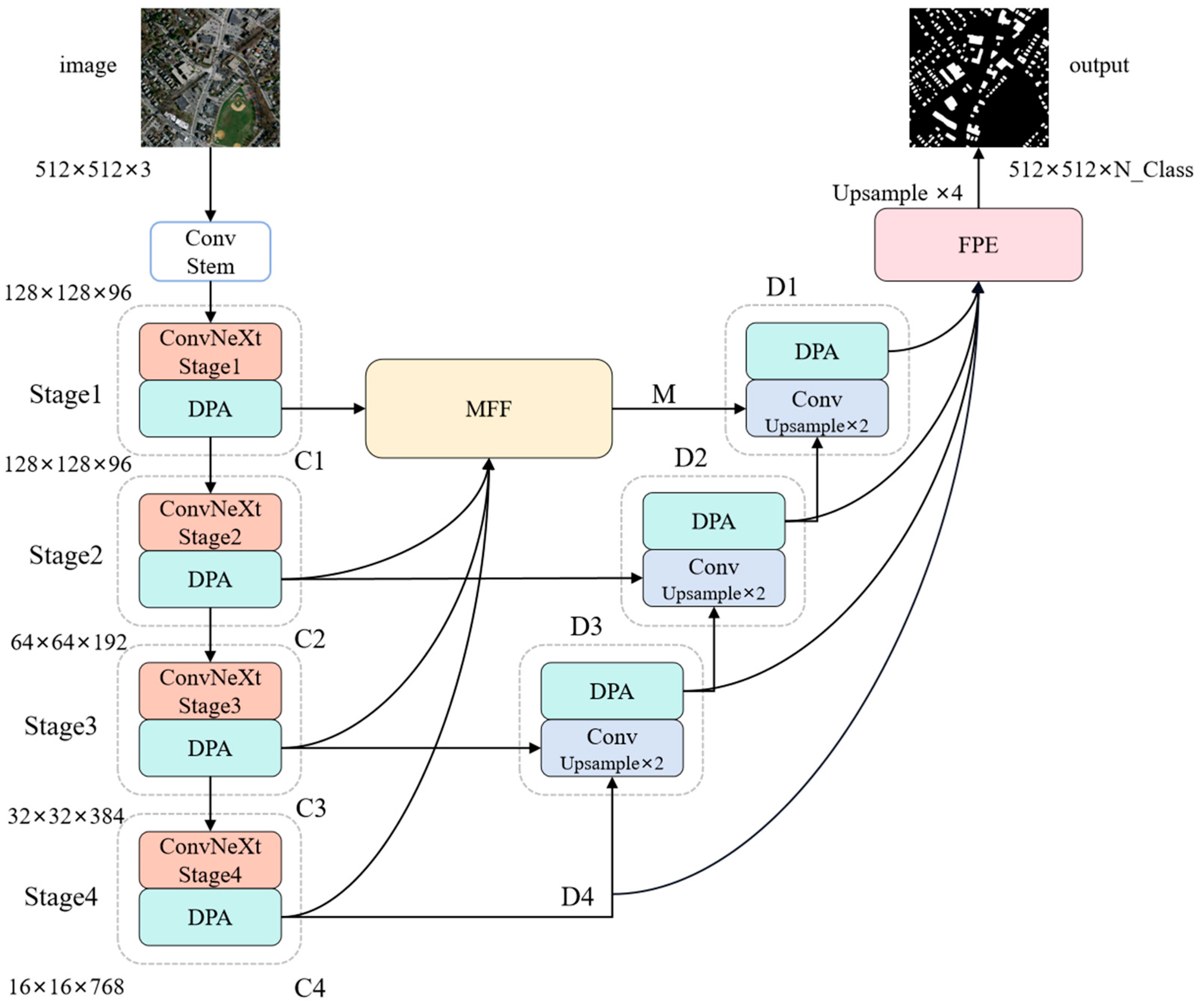
3.1. The Overall Structure of MFFP-Net
3.2. Dual-Path Attention (DPA)
3.3. Multi-Scale Feature Fusion (MFF)
3.4. Foreground Perception Enhancement (FPE)
4. Experiments
4.1. Datasets
- Massachusetts: The Massachusetts Building dataset is a collection of 151 aerial RGB images of different buildings in a 340-square-kilometer area of Boston, with a size of 1500 × 1500 pixels and a ground sampling distance of 1 m. The dataset contains both urban and suburban scenarios, where the buildings vary in size, shape, texture, and color, so the dataset is very challenging and is suitable for verifying the validity of the module. In this experiment, 131 images are used for training, 4 for verification, and 10 for testing. We expand the images to 1536 × 1536 pixels and then crop them to 512 × 512 pixels.
- Inria: The Inria Aerial Image Labeling dataset consists of a total of 360 images collected from different scenes in 5 cities, each with a size of 5000 × 5000 pixels. Following official recommendations, 155 of the images are used for training, 25 for verification, and the rest for testing. We expand the original 5000 × 5000-pixel images to 5120 × 5120 pixels and then crop them into 512 × 512-pixel images.
- WHU: The Wuhan University Building dataset contains two kinds of images: aerial images and satellite images. The WHU aerial image subset covers buildings in an area of more than 450 square kilometers and contains a total of about 22,000 building targets, each with a size of 512 × 512 pixels and a spatial resolution of 0.3 m. The dataset has a total of 8189 images, of which 4736 are used for training, 1036 for verification, and 2416 for testing.
4.2. Experimental Setup and Evaluation Metrics
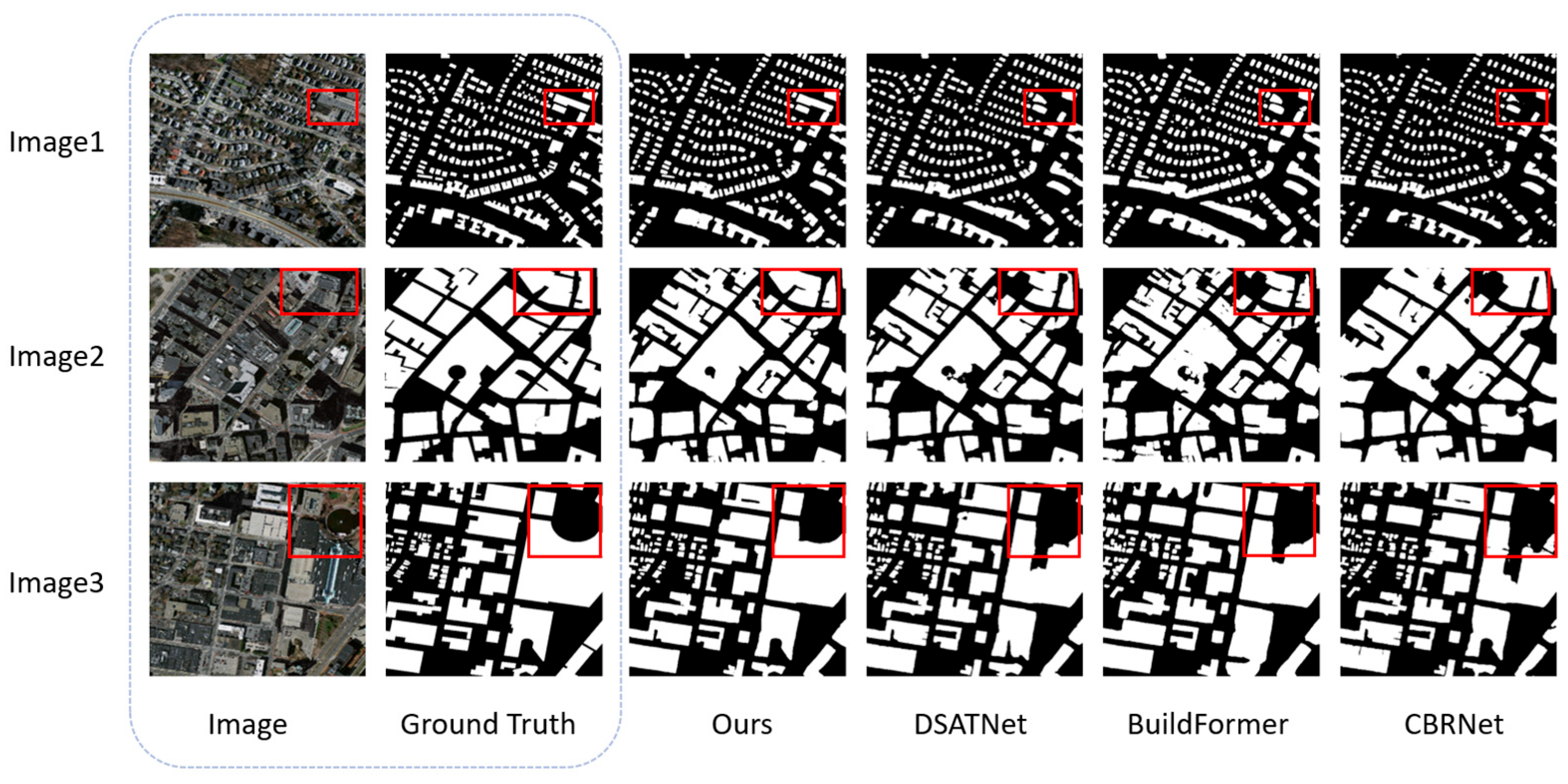
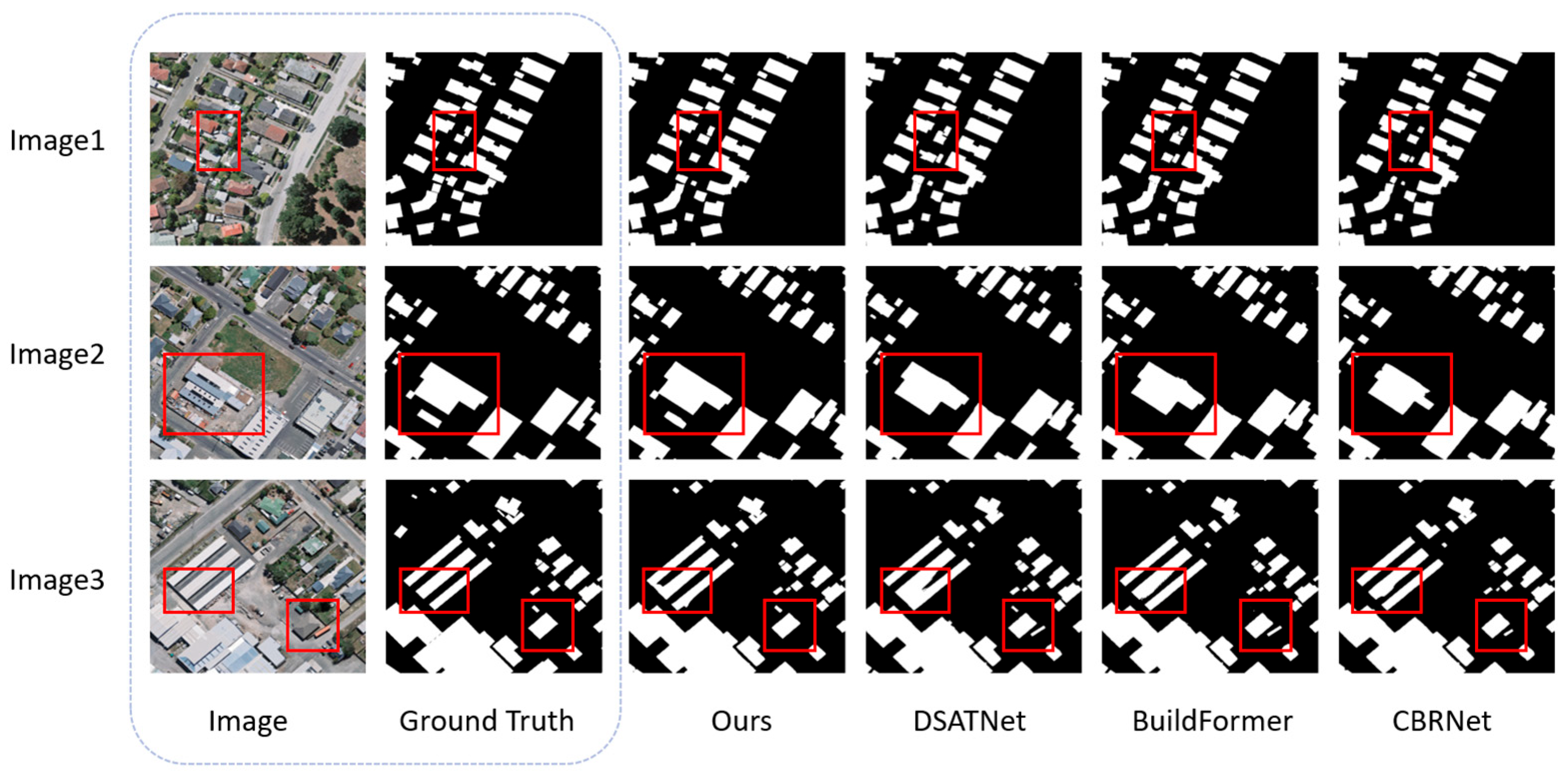
4.3. Performance Comparison
4.4. Ablation Study
4.4.1. Ablation of Different Modules
4.4.2. Ablation Experiment of DPA
5. Discussion
5.1. Model Parameters and FLOPs
5.2. The Cost–Performance Balance in Building Segmentation
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sahoo, P.; Soltani, S.; Wong, A. A survey of thresholding techniques. Comput. Vis. Image Underst. 1988, 41, 233–260. [Google Scholar] [CrossRef]
- Adams, R.; Bischof, L. Seeded region growing. IEEE Trans. Pattern Anal. Mach. Intell. 1994, 16, 641–647. [Google Scholar] [CrossRef]
- Reuter, M.; Biasotti, S.; Giorgi, D.; Patane, G.; Spagnuolo, M. Discrete Laplace–Beltrami operators for shape analysis and segmentation. Comput. Graph. 2009, 33, 381–390. [Google Scholar] [CrossRef]
- Kattenborn, T.; Leitloff, J.; Schiefer, F.; Hinz, S. Review on Convolutional Neural Networks (CNN) in vegetation remote sensing. ISPRS J. Photogramm. Remote Sens. 2021, 173, 24–49. [Google Scholar] [CrossRef]
- Chen, G.; Tan, X.; Guo, B.; Zhu, K.; Liao, P.; Wang, T.; Wang, Q.; Zhang, X. SDFCNv2: An Improved FCN Framework for Remote Sensing Images Semantic Segmentation. Remote Sens. 2021, 13, 4902. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Los Angeles, CA, USA, 16–20 June 2019. [Google Scholar]
- Guo, H.; Du, B.; Zhang, L.; Su, X. A coarse-to-fine boundary refinement network for building footprint extraction from remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2022, 183, 240–252. [Google Scholar] [CrossRef]
- Yan, G.; Jing, H.; Li, H.; Guo, H.; He, S. Enhancing Building Segmentation in Remote Sensing Images: Advanced Multi-Scale Boundary Refinement with MBR-HRNet. Remote Sens. 2023, 15, 3766. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhong, Y.; Wang, J.; Ma, A.; Zhang, L. FarSeg++: Foreground-Aware Relation Network for Geospatial Object Segmentation in High Spatial Resolution Remote Sensing Imagery. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 13715–13729. [Google Scholar] [CrossRef]
- Ma, D.; Liu, B.; Huang, Q.; Zhang, Q. MwdpNet: Towards improving the recognition accuracy of tiny targets in high-resolution remote sensing image. Sci. Rep. 2023, 13, 13890. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Xie, Y.; Yao, W.; Zhang, Y.; Wang, X.; Yang, Y.; Tang, L. U-MGA: A Multi-Module Unet Optimized with Multi-Scale Global Attention Mechanisms for Fine-Grained Segmentation of Cultivated Areas. Remote Sens. 2025, 17, 760. [Google Scholar] [CrossRef]
- Wei, S.; Ji, S.; Lu, M. Toward Automatic Building Footprint Delineation from Aerial Images Using CNN and Regularization. IEEE Trans. Geosci. Remote Sens. 2020, 58, 2178–2189. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Lu, M. Fully Convolutional Networks for Multisource Building Extraction from an Open Aerial and Satellite Imagery Data Set. IEEE Trans. Geosci. Remote Sens. 2019, 57, 574–586. [Google Scholar] [CrossRef]
- Chen, M.; Mao, T.; Wu, J.; Du, R.; Zhao, B.; Zhou, L. SAU-Net: A Novel Network for Building Extraction from High-Resolution Remote Sensing Images by Reconstructing Fine-Grained Semantic Features. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 6747–6761. [Google Scholar] [CrossRef]
- Guo, N.; Jiang, M.; Hu, X.; Su, Z.; Zhang, W.; Li, R.; Luo, J. NPSFF-Net: Enhanced Building Segmentation in Remote Sensing Images via Novel Pseudo-Siamese Feature Fusion. Remote Sens. 2024, 16, 3266. [Google Scholar] [CrossRef]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.; Zhou, Y. TransUNet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Strudel, R.; Garcia, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for Semantic Segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 7242–7252. [Google Scholar]
- Zhang, C.; Jiang, W.; Zhang, Y.; Wang, W.; Zhao, Q.; Wang, C. Transformer and CNN Hybrid Deep Neural Network for Semantic Segmentation of Very-High-Resolution Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–20. [Google Scholar] [CrossRef]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-Unet: Unet-Like Pure Transformer for Medical Image Segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 205–218. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Panboonyuen, T.; Jitkajornwanich, K.; Lawawirojwong, S.; Srestasathiern, P.; Vateekul, P. Transformer-Based Decoder Designs for Semantic Segmentation on Remotely Sensed Images. Remote Sens. 2021, 13, 5100. [Google Scholar] [CrossRef]
- Wang, L.; Fang, S.; Meng, X.; Li, R. Building Extraction with Vision Transformer. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Zhang, R.; Wan, Z.; Zhang, Q.; Zhang, G. DSAT-Net: Dual Spatial Attention Transformer for Building Extraction from Aerial Images. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Li, J.; Cheng, S. AFENet: An Attention-Focused Feature Enhancement Network for the Efficient Semantic Segmentation of Remote Sensing Images. Remote Sens. 2024, 16, 4392. [Google Scholar] [CrossRef]
- Zhao, W.; Xia, M.; Weng, L.; Hu, K.; Lin, H.; Zhang, Y.; Liu, Z. SPNet: Dual-Branch Network with Spatial Supplementary Information for Building and Water Segmentation of Remote Sensing Images. Remote Sens. 2024, 16, 3161. [Google Scholar] [CrossRef]
- Xiang, X.; Gong, W.; Li, S.; Chen, J.; Ren, T. TCNet: Multiscale Fusion of Transformer and CNN for Semantic Segmentation of Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 3123–3136. [Google Scholar] [CrossRef]
- Zhang, R.; Zhang, Q.; Zhang, G. SDSC-UNet: Dual Skip Connection ViT-Based U-Shaped Model for Building Extraction. IEEE Trans. Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction Without Convolutions. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 568–578. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Params | FLOPs | Massachusetts | ||||
|---|---|---|---|---|---|---|---|
| IoU | F1 | Precision | Recall | ||||
| CNN-Based Structure | CBR-Net [11] | 22.68 M | 185.87 G | 74.55 | 84.36 | 86.50 | 84.36 |
| MBR-HRNet [12] | 31.02 M | 68.71 G | 70.97 | 83.53 | 86.40 | 80.85 | |
| MA-FCN [16] | − | − | 73.80 | 84.93 | 87.07 | 82.89 | |
| SiU-Net [17] | − | − | − | − | − | − | |
| SAU-Net [18] | − | − | 74.18 | 85.18 | 86.34 | 84.01 | |
| NPSFF-Net [19] | 13.21 M | 219.96 G | 71.88 | 83.64 | 84.03 | 83.24 | |
| CNN–Transformer Hybrid Structure | Segmenter [21] | 31.87 M | 126.12 G | 73.65 | 84.83 | 86.38 | 83.38 |
| TransUNet [20] | 105.91 M | 168.92 G | 75.31 | 85.92 | 87.70 | 84.21 | |
| Swin-Unet [23] | 84.02 M | 97.69 G | 75.98 | 86.35 | 86.40 | 86.31 | |
| TCNet [25] | 34.88 M | 91.88 G | 76.21 | 84.29 | 85.17 | 86.82 | |
| BuildFormer [26] | 40.52 M | 117.12 G | 75.74 | 86.19 | 87.52 | 84.90 | |
| DSATNet † [27] | 48.50 M | 57.75 G | 75.32 | 85.92 | 87.39 | 84.49 | |
| MFFP-Net (ours) | 62.90 M | 90.70 G | 76.30 | 86.57 | 87.78 | 85.37 | |
| Method | WHU | Inria | |||||||
|---|---|---|---|---|---|---|---|---|---|
| IoU | F1 | Precision | Recall | IoU | F1 | Precision | Recall | ||
| CNN-Based Structure | CBR-Net [11] | − | − | − | − | 81.10 | 89.56 | 89.93 | 89.20 |
| MBR-HRNet [12] | 91.31 | 95.18 | 95.48 | 94.88 | − | − | − | − | |
| MA-FCN [16] | 90.70 | 95.15 | 95.20 | 95.10 | − | − | − | − | |
| SiU-Net [17] | 88.40 | 93.85 | 93.80 | 93.90 | − | − | − | − | |
| SAU-Net [18] | 91.12 | 95.37 | 95.61 | 95.11 | − | − | − | − | |
| NPSFF-Net [19] | − | − | − | − | − | − | − | − | |
| CNN–Transformer Hybrid Structure | Segmenter [21] | 87.78 | 93.49 | 93.65 | 93.34 | 80.72 | 89.33 | 90.38 | 88.30 |
| TransUNet [20] | 87.91 | 93.57 | 93.45 | 93.69 | 80.77 | 89.36 | 90.44 | 88.32 | |
| Swin-Unet [23] | 89.50 | 94.46 | 94.53 | 94.38 | 76.27 | 86.54 | 86.87 | 86.21 | |
| TCNet [25] | 91.16 | 95.55 | 95.15 | 95.55 | − | − | − | − | |
| BuildFormer [26] | 91.44 | 95.53 | 95.65 | 95.40 | 81.44 | 89.77 | 90.75 | 88.81 | |
| DSATNet † [27] | 91.41 | 95.51 | 95.82 | 95.20 | 82.56 | 90.45 | 91.76 | 89.17 | |
| MFFP-Net (ours) | 91.85 | 95.75 | 96.08 | 95.42 | 83.17 | 90.81 | 92.21 | 89.50 | |
| MFF | FPE | DPA | IoU | F1 | |
|---|---|---|---|---|---|
| No. 1 | √ | √ | 76.18 | 86.47 | |
| No. 2 | √ | √ | 75.97 | 86.35 | |
| No. 3 | √ | √ | 75.60 | 86.10 | |
| No. 4 | √ | √ | √ | 76.30 | 86.56 |
| Method | IoU | F1 |
|---|---|---|
| MFFP-Net w/o DPA | 75.60 | 86.10 |
| MFFP-Net w/o GPA | 75.98 | 86.35 |
| MFFP-Net w/o LPA | 75.70 | 86.17 |
| MFFP-Net | 76.30 | 86.56 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, H.; Huang, Q.; Liao, H.; Nong, G.; Wei, W. MFFP-Net: Building Segmentation in Remote Sensing Images via Multi-Scale Feature Fusion and Foreground Perception Enhancement. Remote Sens. 2025, 17, 1875. https://doi.org/10.3390/rs17111875
Xu H, Huang Q, Liao H, Nong G, Wei W. MFFP-Net: Building Segmentation in Remote Sensing Images via Multi-Scale Feature Fusion and Foreground Perception Enhancement. Remote Sensing. 2025; 17(11):1875. https://doi.org/10.3390/rs17111875
Chicago/Turabian StyleXu, Huajie, Qiukai Huang, Haikun Liao, Ganxiao Nong, and Wei Wei. 2025. "MFFP-Net: Building Segmentation in Remote Sensing Images via Multi-Scale Feature Fusion and Foreground Perception Enhancement" Remote Sensing 17, no. 11: 1875. https://doi.org/10.3390/rs17111875
APA StyleXu, H., Huang, Q., Liao, H., Nong, G., & Wei, W. (2025). MFFP-Net: Building Segmentation in Remote Sensing Images via Multi-Scale Feature Fusion and Foreground Perception Enhancement. Remote Sensing, 17(11), 1875. https://doi.org/10.3390/rs17111875