




CDWMamba: Cloud Detection with Wavelet-Enhanced Mamba for Optical Satellite Imagery




Abstract

1. Introduction
- We propose CDWMamba, an encoder–decoder cloud detection network that integrates Mamba with discrete wavelet transform. Each encoder stage fuses wavelet-domain global features and spatial-domain local textures, enabling comprehensive context modeling with reduced computational cost.
- A wavelet-aware Mamba module is introduced, in which the low-frequency component incorporates state space modeling for global semantic understanding, while high-frequency components employ directional and rectangular convolutions to enhance edge sensitivity and spatial precision.
- Extensive experiments on Landsat-8 and Sentinel-2 datasets demonstrate that CDWMamba outperforms existing state-of-the-art methods, particularly under complex terrain and cloud morphology conditions.
2. Related Work
2.1. Attention Mechanisms for Remote Sensing Cloud Detection
2.2. Frequency-Domain and Multi-Scale Modeling in Remote Sensing
3. Methodology
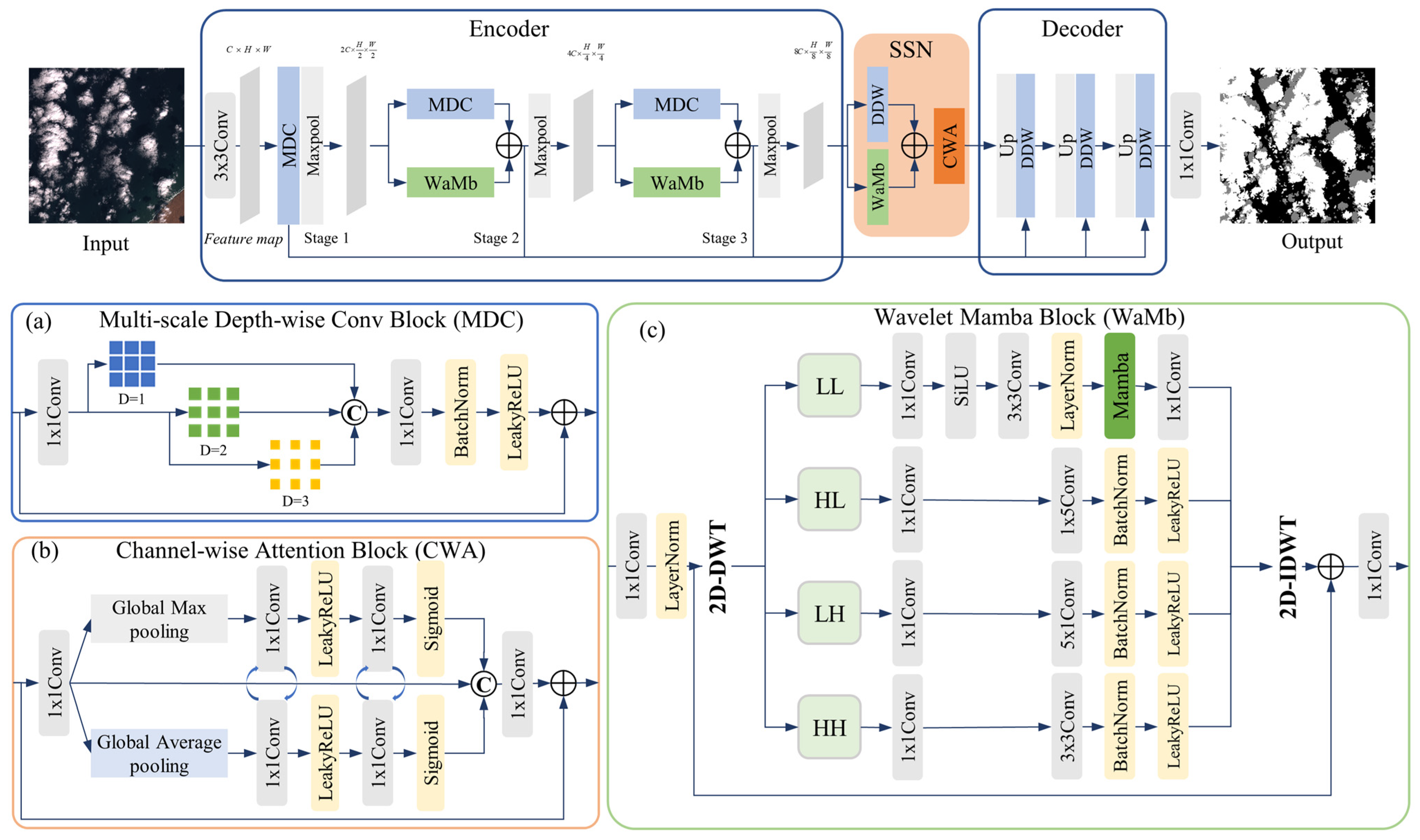
3.1. Overview of the CDWMamba Architecture
- Encoder. We employ three downsampling stages—Stage 1, Stage 2, and Stage 3—each of which processes its input feature through a pair of parallel blocks including WaMb and MDC. WaMb performs discrete wavelet decomposition, Mamba-based global modeling on the low-frequency band, directional convolution on high-frequency bands, and inverse wavelet reconstruction. MDC applies three parallel depth-wise 3 × 3 convolutions with different dilation ratios (D = 1, D = 2, and D = 3). In each stage, the outputs of these blocks were fused via addition and a 1 × 1 convolution:
- 2.
- SSN. At the coarsest resolution, we apply an SSN block that merges Stage 3 features along with a CWA and parallel MDC-WaMb. This produces a refined bottleneck feature .
- 3.
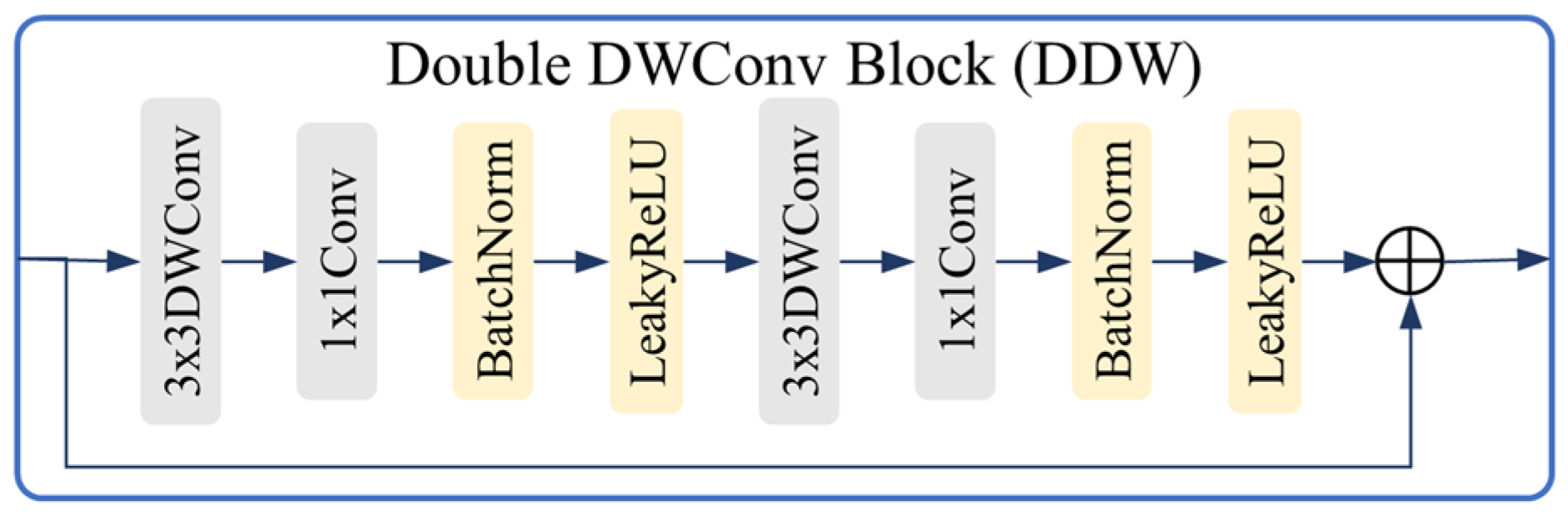
- Decoder. The decoder symmetrically upsamples the bottleneck feature in three stages. At each decoder stage, the input feature is firstly upsampled by a factor of 2 through bilinear interpolation; then, it is concatenated with from the corresponding encoder stage; finally, they are fused via Dual DWConv Block (DDC).
3.2. Wavelet-Mamba Block
3.2.1. Discrete Wavelet Decomposition
3.2.2. Mamba with State Space Model
| Algorithm 1 Pseudocode of Mamba module |
| Input: low-frequency feature Output: 1: 2: for i in [four directions] do 3: 4: end for 5: 6: Return: |
3.2.3. Global Modeling with Mamba
3.3. Multi-Scale Depth-Wise Convolution Block
3.4. Spatial–Spectral Bottleneck with Channel-Wise Attention
3.5. Decoder and Skip Connections
3.6. Loss Function and Evaluation Metrics
4. Experiments
4.1. Experimental Setup
4.2. Qualitative Comparison on Two Datasets
4.3. Quantitative Evaluations
5. Analysis
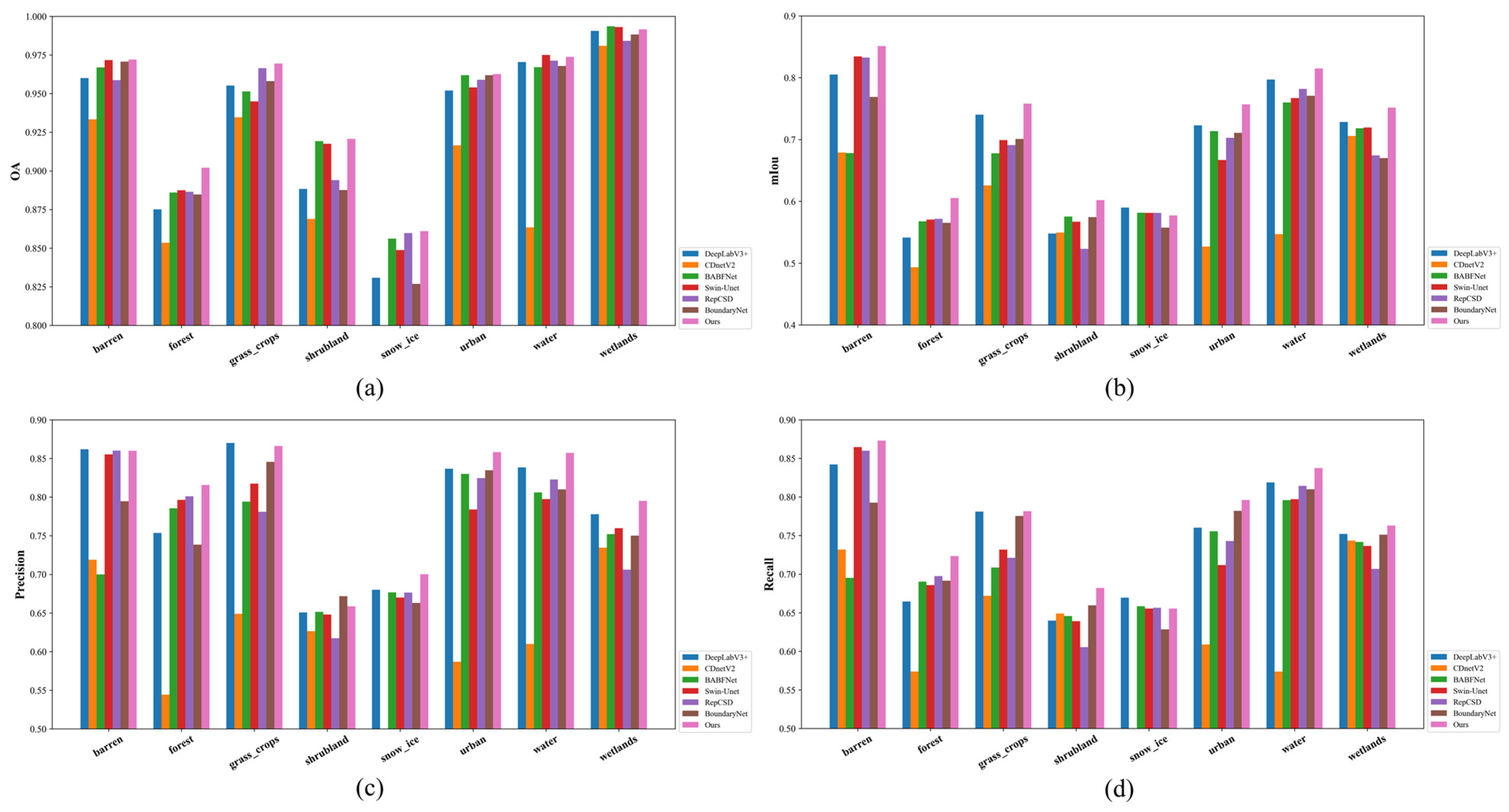
5.1. Performance Across Different Land Cover Types
5.2. Cloud Detection over Snow Surface
5.3. Ablation Study
5.3.1. Different Band Combinations
5.3.2. Ablation on Proposed Components
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wright, N.; Duncan, J.M.A.; Callow, J.N.; Thompson, S.E.; George, R.J. Clouds2mask: A Novel Deep Learning Approach for Improved Cloud and Cloud Shadow Masking in Sentinel-2 Imagery. Remote Sens. Environ. 2024, 306, 114122. [Google Scholar] [CrossRef]
- Skakun, S.; Wevers, J.; Brockmann, C.; Doxani, G.; Aleksandrov, M.; Batič, M.; Frantz, D.; Gascon, F.; Gómez-Chova, L.; Hagolle, O.; et al. Cloud Mask Intercomparison Exercise (Cmix): An Evaluation of Cloud Masking Algorithms for Landsat 8 and Sentinel-2. Remote Sens. Environ. 2022, 274, 112990. [Google Scholar] [CrossRef]
- Zhou, X.; Li, S.; Yang, J.; Wan, Y.; Sun, L.; Huang, Z. An Extended Cloud Shadow Detection Algorithm Supported by an A Priori Database. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4108116. [Google Scholar] [CrossRef]
- Meng, S.; Wang, X.; Hu, X.; Luo, C.; Zhong, Y. Deep Learning-Based Crop Mapping in the Cloudy Season Using One-Shot Hyperspectral Satellite Imagery. Comput. Electron. Agric. 2021, 186, 106188. [Google Scholar] [CrossRef]
- Lei, L.; Wang, X.; Zhong, Y.; Zhao, H.; Hu, X.; Luo, C. Docc: Deep One-Class Crop Classification Via Positive and Unlabeled Learning for Multi-Modal Satellite Imagery. Int. J. Appl. Earth Obs. Geoinf. 2021, 105, 102598. [Google Scholar] [CrossRef]
- Soja, M.J.; Persson, H.J.; Ulander, L.M.H. Estimation of Forest Biomass from Two-Level Model Inversion of Single-Pass Insar Data. IEEE Trans. Geosci. Remote Sens. 2015, 53, 5083–5099. [Google Scholar] [CrossRef]
- Villa, P.; Bresciani, M.; Braga, F.; Bolpagni, R. Comparative Assessment of Broadband Vegetation Indices over Aquatic Vegetation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 3117–3127. [Google Scholar] [CrossRef]
- Yang, J.; Li, S.; Gong, W.; Min, Q.; Mao, F.; Pan, Z. A Fast Cloud Geometrical Thickness Retrieval Algorithm for Single-Layer Marine Liquid Clouds Using Oco-2 Oxygen a-Band Measurements. Remote Sens. Environ. 2021, 256, 112305. [Google Scholar] [CrossRef]
- Li, S.; Song, G.; Xing, J.; Dong, J.; Zhang, M.; Fan, C.; Meng, S.; Yang, J.; Dong, L.; Gong, W. Unraveling Overestimated Exposure Risks through Hourly Ozone Retrievals from Next-Generation Geostationary Satellites. Nat. Commun. 2025, 16, 3364. [Google Scholar] [CrossRef]
- Ding, Y.; Li, S.; Xing, J.; Li, X.; Ma, X.; Song, G.; Teng, M.; Yang, J.; Dong, J.; Meng, S. Retrieving Hourly Seamless Pm2.5 Concentration across China with Physically Informed Spatiotemporal Connection. Remote Sens. Environ. 2024, 301, 113901. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhong, Y.; Ma, A.; Zhang, L. Single-Temporal Supervised Learning for Universal Remote Sensing Change Detection. Int. J. Comput. Vis. 2024, 132, 5582–5602. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Object-Based Cloud and Cloud Shadow Detection in Landsat Imagery. Remote Sens. Environ. 2012, 118, 83–94. [Google Scholar] [CrossRef]
- Qiu, S.; Zhu, Z.; He, B. Fmask 4.0: Improved Cloud and Cloud Shadow Detection in Landsats 4–8 and Sentinel-2 Imagery. Remote Sens. Environ. 2019, 231, 111205. [Google Scholar] [CrossRef]
- Zhai, H.; Zhang, H.; Zhang, L.; Li, P. Cloud/Shadow Detection Based on Spectral Indices for Multi/Hyperspectral Optical Remote Sensing Imagery. ISPRS J. Photogramm. Remote Sens. 2018, 144, 235–253. [Google Scholar] [CrossRef]
- Li, Z.; Shen, H.; Cheng, Q.; Liu, Y.; You, S.; He, Z. Deep Learning Based Cloud Detection for Medium and High Resolution Remote Sensing Images of Different Sensors. ISPRS J. Photogramm. Remote Sens. 2019, 150, 197–212. [Google Scholar] [CrossRef]
- Chai, D.; Newsam, S.; Zhang, H.K.; Qiu, Y.; Huang, J. Cloud and Cloud Shadow Detection in Landsat Imagery Based on Deep Convolutional Neural Networks. Remote Sens. Environ. 2019, 225, 307–316. [Google Scholar] [CrossRef]
- Kanu, S.; Khoja, R.; Lal, S.; Raghavendra, B.S.; Cs, A. Cloudx-Net: A Robust Encoder-Decoder Architecture for Cloud Detection from Satellite Remote Sensing Images. Remote Sens. Appl. Soc. Environ. 2020, 20, 100417. [Google Scholar] [CrossRef]
- Shao, Z.; Pan, Y.; Diao, C.; Cai, J. Cloud Detection in Remote Sensing Images Based on Multiscale Features-Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4062–4076. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, Y.; Wang, H.; Wu, J.; Li, Y. CNN Cloud Detection Algorithm Based on Channel and Spatial Attention and Probabilistic Upsampling for Remote Sensing Image. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5404613. [Google Scholar] [CrossRef]
- Huang, H.; Roy, D.P.; De Lemos, H.; Qiu, Y.; Zhang, H.K. A global Swin-Unet Sentinel-2 Surface Reflectance-Based Cloud and Cloud Shadow Detection Algorithm for the Nasa Harmonized Landsat Sentinel-2 (Hls) Dataset. Sci. Remote Sens. 2025, 11, 100213. [Google Scholar] [CrossRef]
- Zheng, L.; Wang, C.; Kong, L. Linear Complexity Randomized Self-Attention Mechanism. Presented at the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 27011–27041. [Google Scholar]
- Xu, X.; He, W.; Xia, Y.; Zhang, H.; Wu, Y.; Jiang, Z.; Hu, T. TANet: Thin Cloud-Aware Network for Cloud Detection in Optical Remote Sensing Image. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5611416. [Google Scholar] [CrossRef]
- Aleissaee, A.A.; Kumar, A.; Anwer, R.M.; Khan, S.; Cholakkal, H.; Xia, G.-S.; Khan, F.S. Transformers in Remote Sensing: A Survey. Remote Sens. 2023, 15, 1860. [Google Scholar] [CrossRef]
- Zhu, L.; Liao, B.; Zhang, Q.; Wang, X.; Liu, W.; Wang, X. Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model. In Proceedings of the 41st International Conference on Machine Learning, Vienna, Austria, 21–27 July 2024; p. 2584. [Google Scholar]
- Gao, F.; Jin, X.; Zhou, X.; Dong, J.; Du, Q. MSFMamba: Multiscale Feature Fusion State Space Model for Multisource Remote Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5504116. [Google Scholar] [CrossRef]
- Zi, Y.; Ding, H.; Xie, F.; Jiang, Z.; Song, X. Wavelet Integrated Convolutional Neural Network for Thin Cloud Removal in Remote Sensing Images. Remote Sens. 2023, 15, 781. [Google Scholar] [CrossRef]
- Zhang, X.; Li, S.; Tan, Z.; Li, X. Enhanced Wavelet Based Spatiotemporal Fusion Networks Using Cross-Paired Remote Sensing Images. ISPRS J. Photogramm. Remote Sens. 2024, 211, 281–297. [Google Scholar] [CrossRef]
- Li, H.; Shi, J.; Li, L.; Tuo, X.; Qu, K.; Rong, W. Novel Wavelet Threshold Denoising Method to Highlight the First Break of Noisy Microseismic Recordings. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5910110. [Google Scholar] [CrossRef]
- Pan, H.; Jing, Z.; Leung, H.; Li, M. Hyperspectral Image Fusion and Multitemporal Image Fusion by Joint Sparsity. IEEE Trans. Geosci. Remote Sens. 2021, 59, 7887–7900. [Google Scholar] [CrossRef]
- Álvarez-Cortés, S.; Serra-Sagristà, J.; Bartrina-Rapesta, J.; Marcellin, M.W. Regression Wavelet Analysis for near-Lossless Remote Sensing Data Compression. IEEE Trans. Geosci. Remote Sens. 2020, 58, 790–798. [Google Scholar] [CrossRef]
- Li, Q.; Yang, X.; Li, B.; Wang, J. Self-Supervised Multiscale Contrastive and Attention-Guided Gradient Projection Network for Pansharpening. Sensors 2025, 25, 2560. [Google Scholar] [CrossRef]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. Presented at the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018; pp. 833–851. [Google Scholar]
- Guo, J.; Yang, J.; Yue, H.; Tan, H.; Hou, C.; Li, K. Cdnetv2: Cnn-Based Cloud Detection for Remote Sensing Imagery with Cloud-Snow Coexistence. IEEE Trans. Geosci. Remote Sens. 2021, 59, 700–713. [Google Scholar] [CrossRef]
- Zhao, C.; Zhang, X.; Kuang, N.; Luo, H.; Zhong, S.; Fan, J. Boundary-Aware Bilateral Fusion Network for Cloud Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5403014. [Google Scholar] [CrossRef]
- Guangbin, Z.; Xianjun, G.; Shuhao, R.; Yuanwei, Y.; Lishan, L.; Yan, Z. Accurate and Lightweight Cloud Detection Method Based on Cloud and Snow Coexistence Region of High-Resolution Remote Sensing Images. Acta Geod. Cartogr. Sin. 2023, 52, 93. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | OA | mIoU | Precision | Recall |
|---|---|---|---|---|
| DeepLabV3+ | 0.9316 | 0.6923 | 0.7792 | 0.7471 |
| CDnetV2 | 0.8530 | 0.5513 | 0.6006 | 0.6156 |
| BABFNet | 0.9392 | 0.6591 | 0.7503 | 0.7117 |
| Swin-Unet | 0.9366 | 0.6757 | 0.7666 | 0.7278 |
| RepCSD | 0.9351 | 0.6701 | 0.7620 | 0.7258 |
| BoundaryNet | 0.9310 | 0.6795 | 0.7649 | 0.7366 |
| Ours | 0.9403 | 0.6925 | 0.7849 | 0.7458 |
| Method | OA | mIoU | Precision | Recall |
|---|---|---|---|---|
| DeepLabV3+ | 0.9365 | 0.7808 | 0.8558 | 0.8082 |
| CDnetV2 | 0.9276 | 0.6852 | 0.7489 | 0.7232 |
| BABFNet | 0.9491 | 0.7878 | 0.8483 | 0.8116 |
| Swin-Unet | 0.9465 | 0.74 | 0.7907 | 0.7681 |
| RepCSD | 0.9486 | 0.7575 | 0.8078 | 0.7804 |
| BoundaryNet | 0.9458 | 0.7785 | 0.8345 | 0.8026 |
| Ours | 0.9632 | 0.8333 | 0.8813 | 0.8562 |
| Input Configuration | Band Combination | OA | mIoU | Precision | Recall |
|---|---|---|---|---|---|
| Case 1 | Coastal + BGR + NIR (Bands 1–5) | 0.9241 | 0.6652 | 0.7638 | 0.7232 |
| Case 2 | Case 1 + SWIR1, SWIR2, Cirrus (Bands 6, 7, 9) | 0.9344 | 0.6817 | 0.7761 | 0.7346 |
| Case 3 | Case 2 + TIRS1, TIRS2 (Bands 10, 11) | 0.9403 | 0.6925 | 0.7849 | 0.7458 |
| Ablation Setting | OA | mIoU | Precision | Recall |
|---|---|---|---|---|
| w/o Mamba | 0.9317 | 0.6632 | 0.7604 | 0.71369 |
| w/o Wavelet (Mamba in spatial domain) | 0.9332 | 0.6701 | 0.7658 | 0.7252 |
| w/o MDC | 0.9325 | 0.6682 | 0.7611 | 0.71958 |
| w/o SSN Attention | 0.9350 | 0.6759 | 0.7701 | 0.7283 |
| w/o Directional Conv on High-Freq | 0.9364 | 0.6827 | 0.7773 | 0.7361 |
| Full Model | 0.9403 | 0.6925 | 0.7849 | 0.7458 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meng, S.; Gong, W.; Li, S.; Song, G.; Yang, J.; Ding, Y. CDWMamba: Cloud Detection with Wavelet-Enhanced Mamba for Optical Satellite Imagery. Remote Sens. 2025, 17, 1874. https://doi.org/10.3390/rs17111874
Meng S, Gong W, Li S, Song G, Yang J, Ding Y. CDWMamba: Cloud Detection with Wavelet-Enhanced Mamba for Optical Satellite Imagery. Remote Sensing. 2025; 17(11):1874. https://doi.org/10.3390/rs17111874
Chicago/Turabian StyleMeng, Shiyao, Wei Gong, Siwei Li, Ge Song, Jie Yang, and Yu Ding. 2025. "CDWMamba: Cloud Detection with Wavelet-Enhanced Mamba for Optical Satellite Imagery" Remote Sensing 17, no. 11: 1874. https://doi.org/10.3390/rs17111874
APA StyleMeng, S., Gong, W., Li, S., Song, G., Yang, J., & Ding, Y. (2025). CDWMamba: Cloud Detection with Wavelet-Enhanced Mamba for Optical Satellite Imagery. Remote Sensing, 17(11), 1874. https://doi.org/10.3390/rs17111874