
Spatial-Spectral Linear Extrapolation for Cross-Scene Hyperspectral Image Classification



Abstract
1. Introduction
- 1.
- This study proposes a HSI linear data augmentation framework, which is designed with a complementary spatial-spectral linear transformation, to reduce the risk of feature contamination from nonlinear neurons and promote the generalization of neural networks to target domains with distribution shift.
- 2.
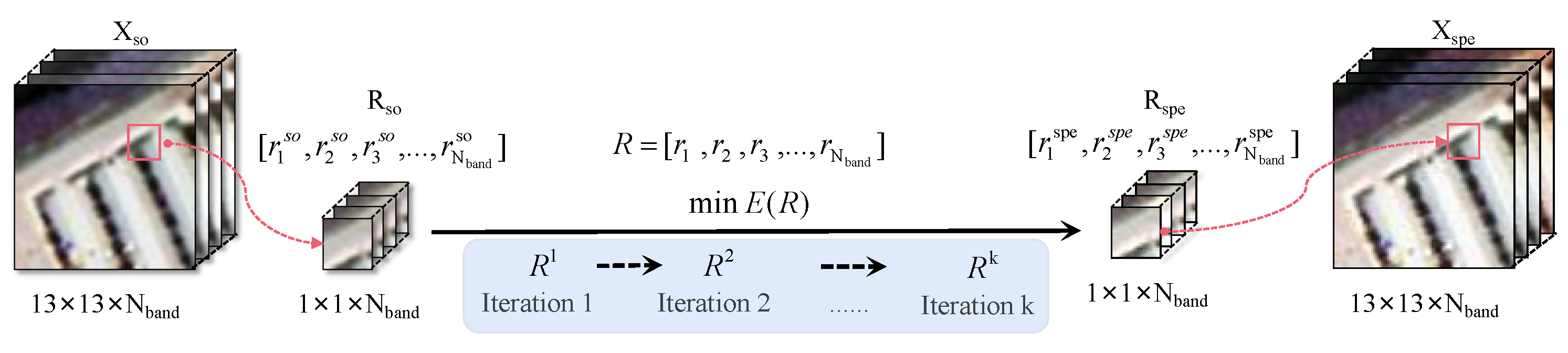
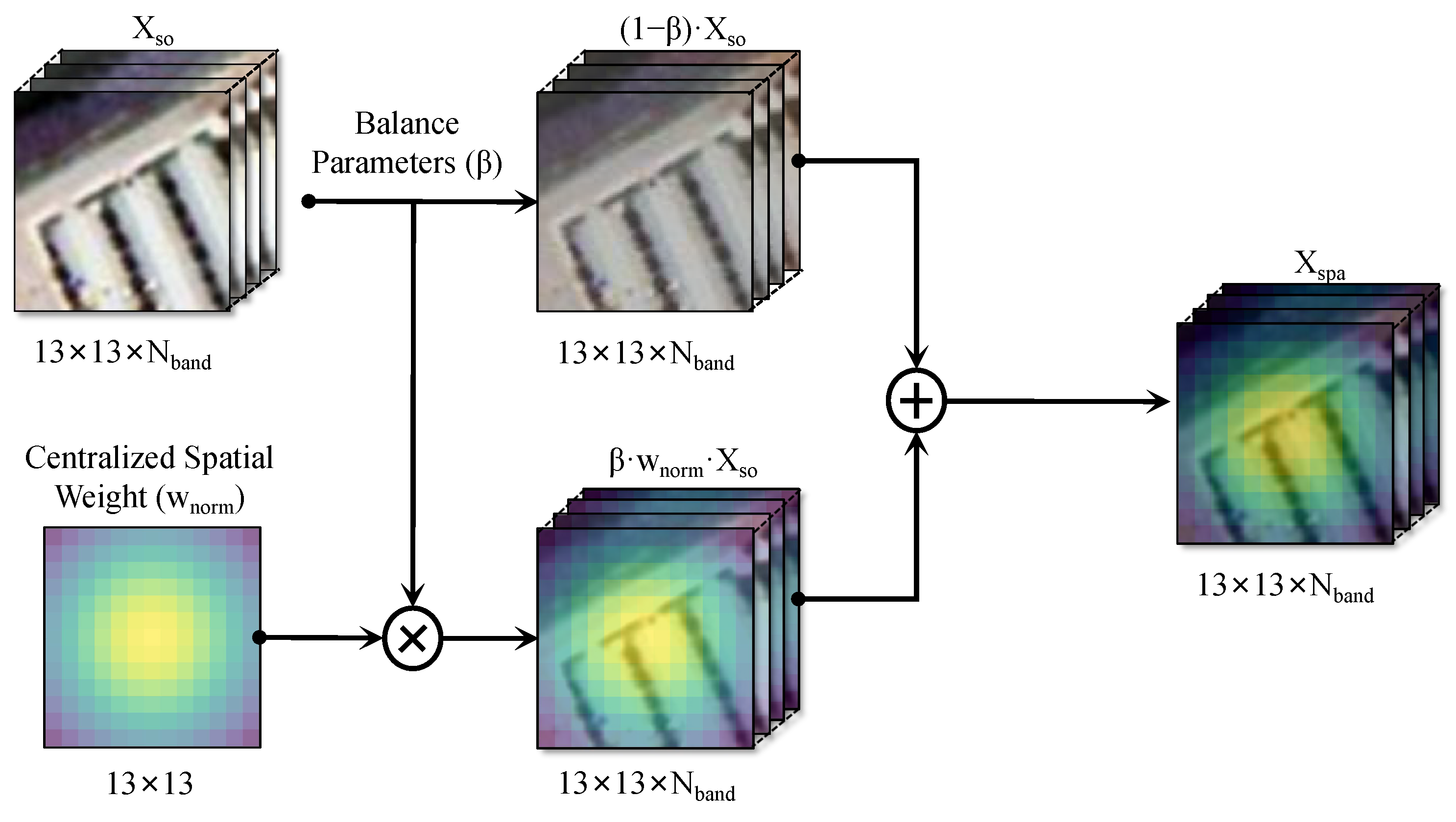
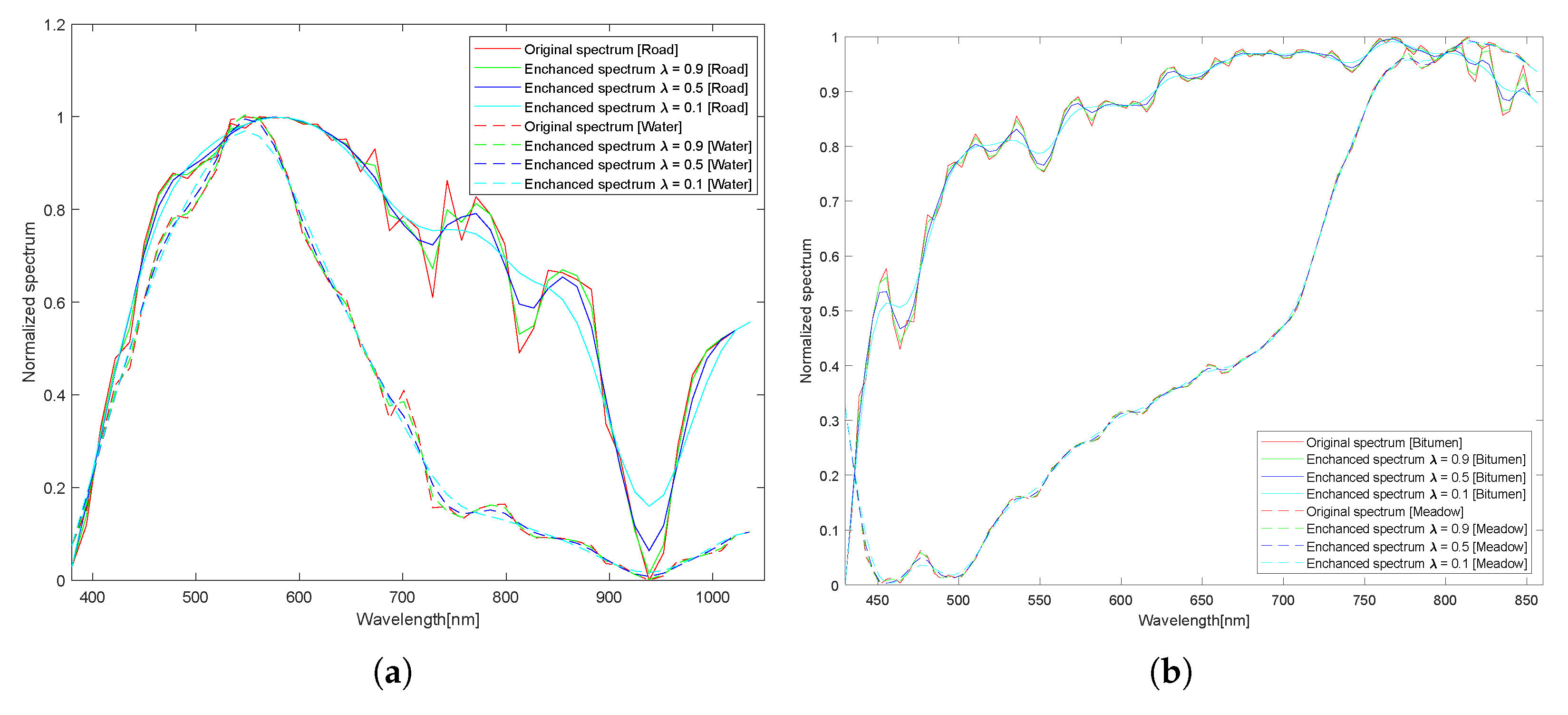
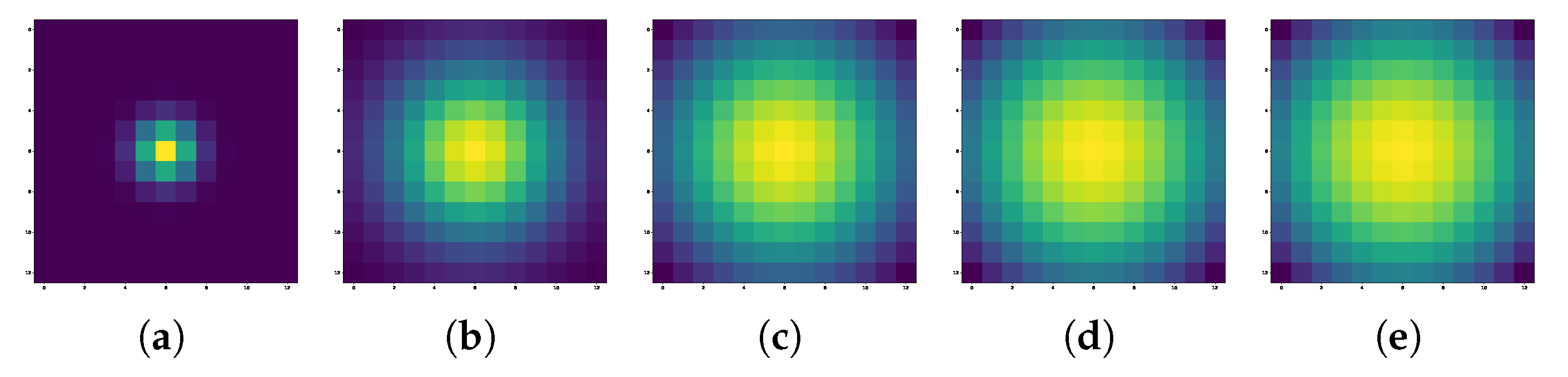
- Considering the information distribution characteristics of HSIs, and inspired by the weakening effect of water vapor absorption and Rayleigh scattering on band reflectivity, a spectral linear extrapolation based on a MRF is designed to simulate spectral drift. Further considering the co-occurrence phenomenon [45] of patch images in space, spatial weights are designed in combination with the label certainty of the central pixel to construct a linear spatial extrapolation. Benefiting from the above spatial-spectral linear transformation, the sample diversity outside the convex hull boundary of the source domain is enriched.
- 3.
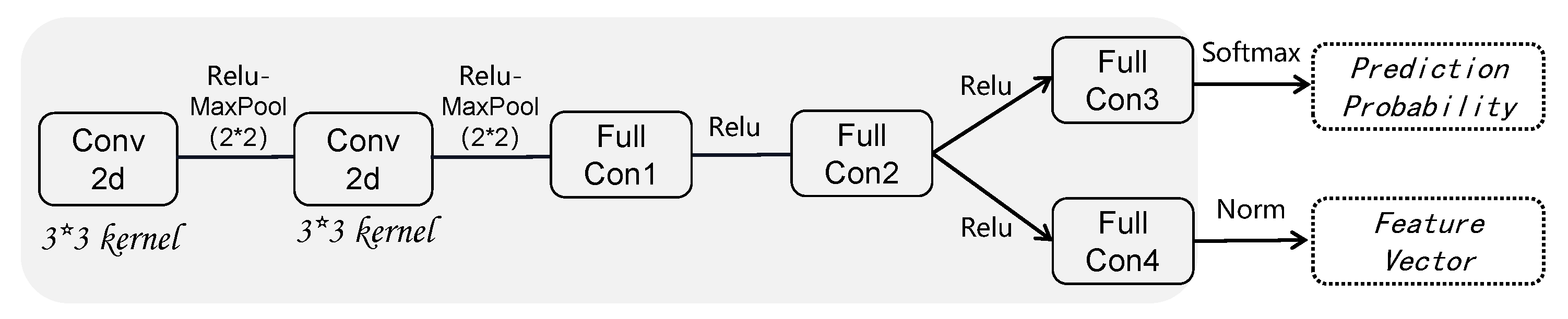
- To prevent a CNN-based discriminator from learning redundant or meaningless features for linear synthetic domains, this study introduces feature-level supervised contrastive learning to unify the invariant representation by constraining the aggregate distribution of low-dimensional features between domains.
2. Related Work
2.1. Feature Contamination
2.2. Mixed Sample Data Augmentation
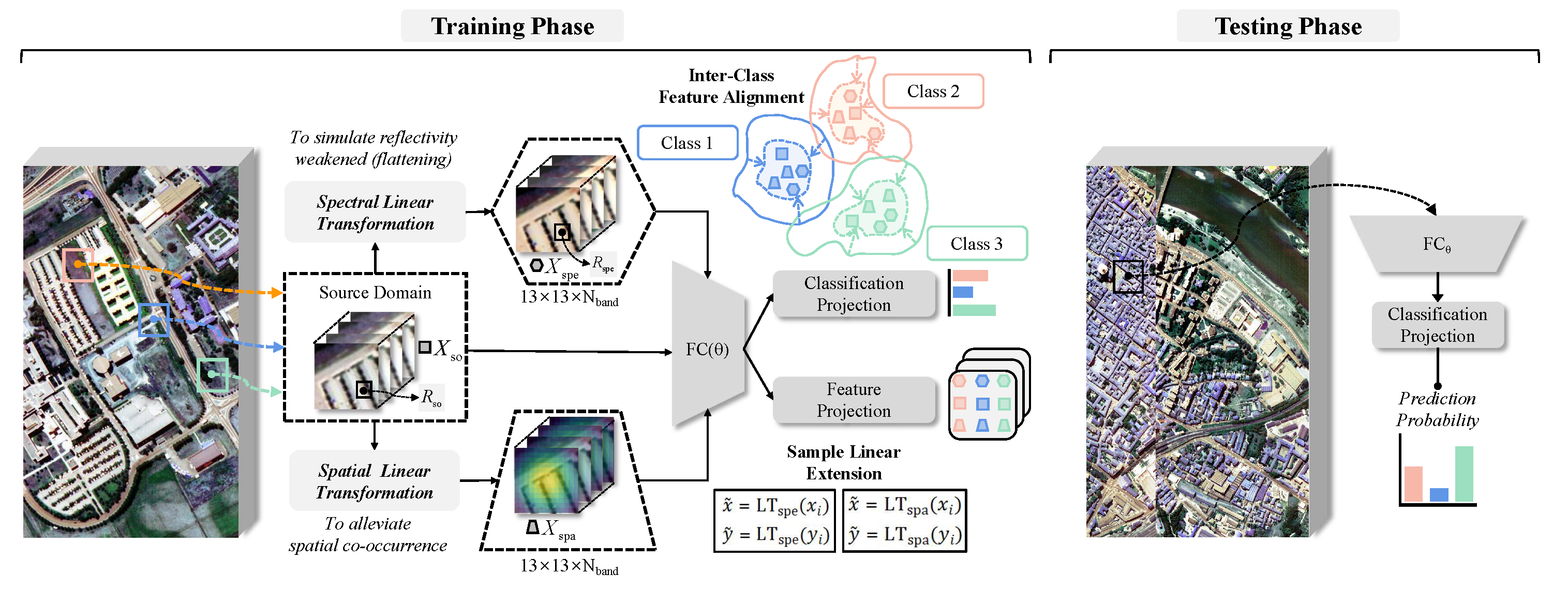
3. Proposed Domain Generalization Method
3.1. Spectral Linear Transformation
| Algorithm 1 Calculating |
|
3.2. Spatial Linear Transformation
3.3. Training Phase
3.4. Generalization Performance
4. Experimental Results and Discussion
4.1. Experimental Data
4.1.1. Houston Dataset
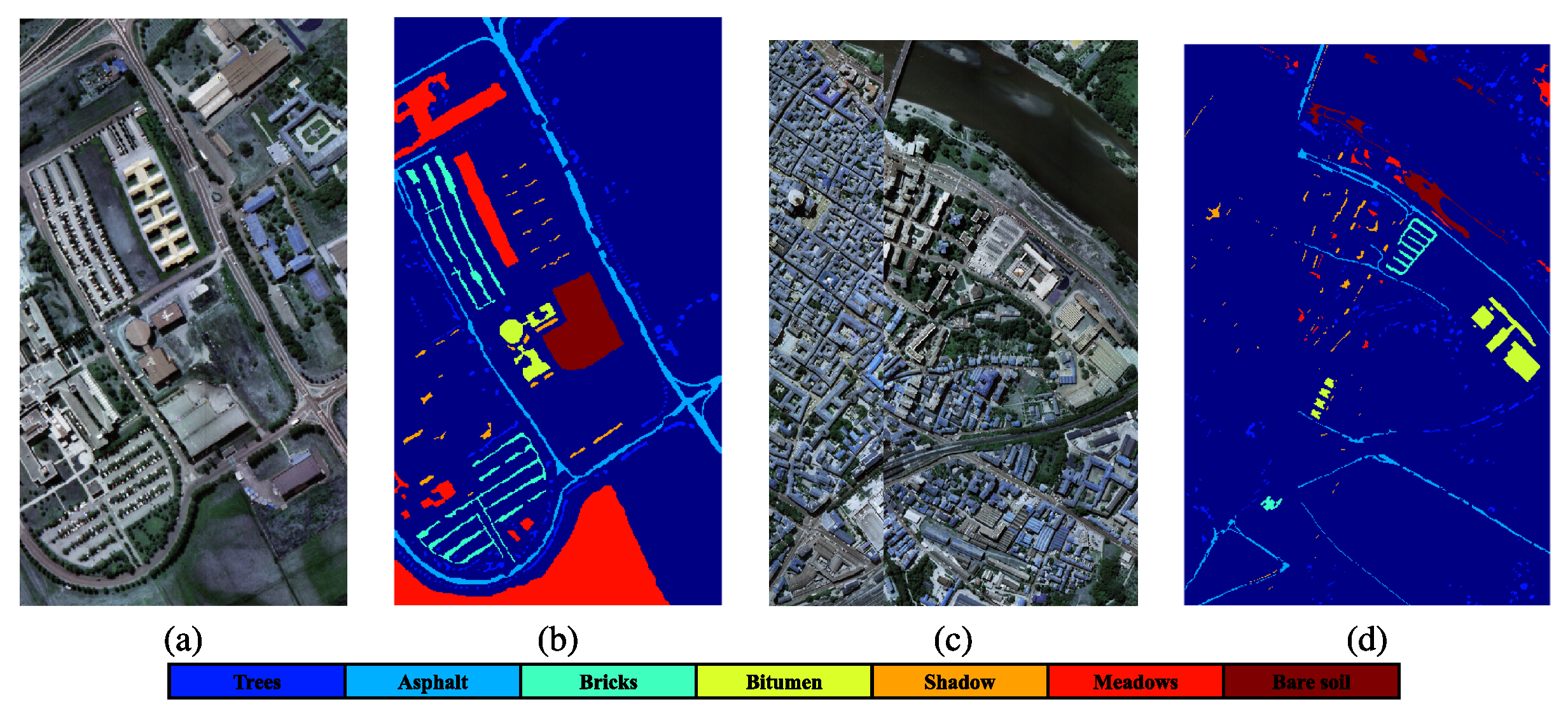
4.1.2. Pavia Dataset
4.1.3. Shanghai-Hangzhou Dataset
4.1.4. Hyrank Dataset
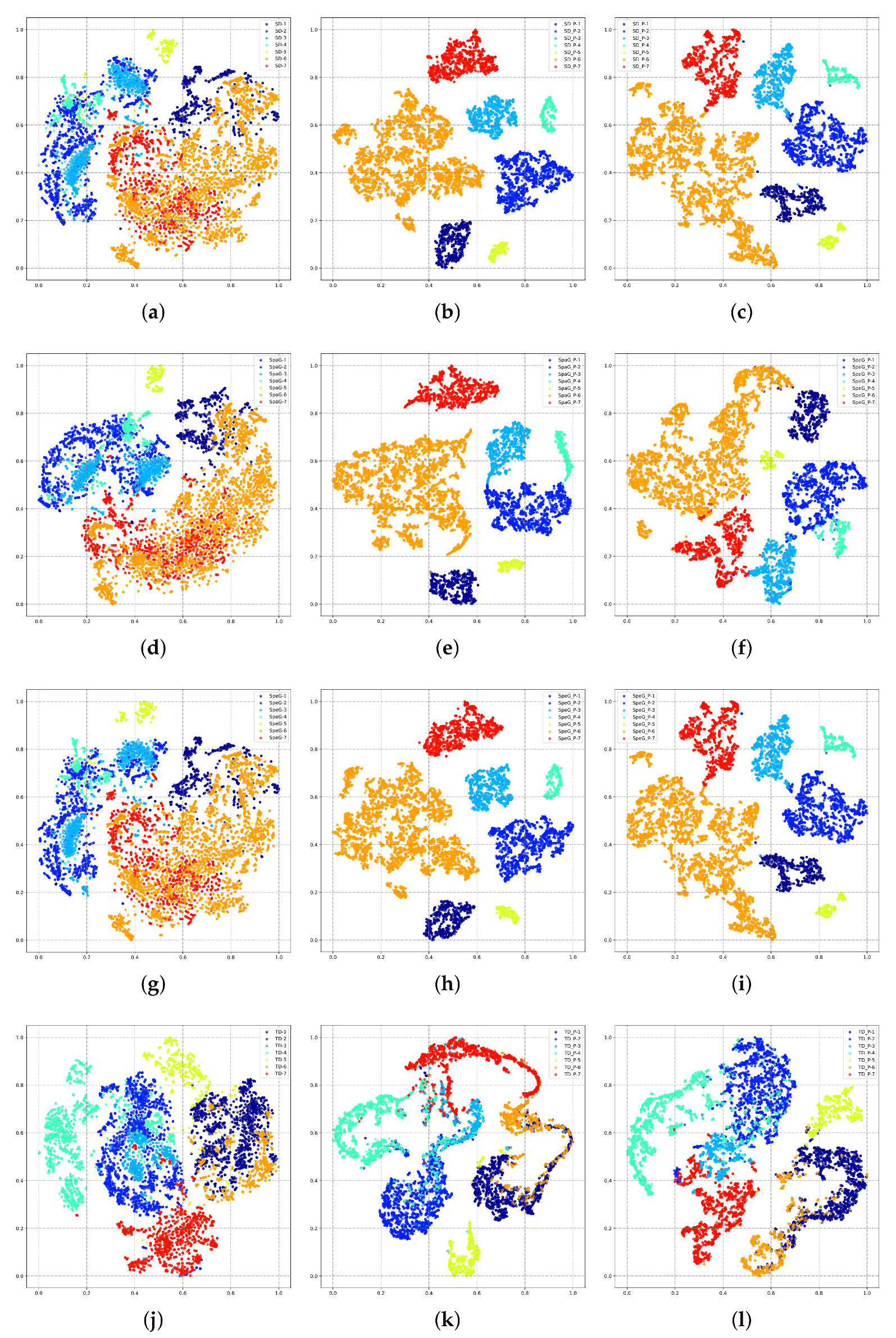
4.2. Ablation Study
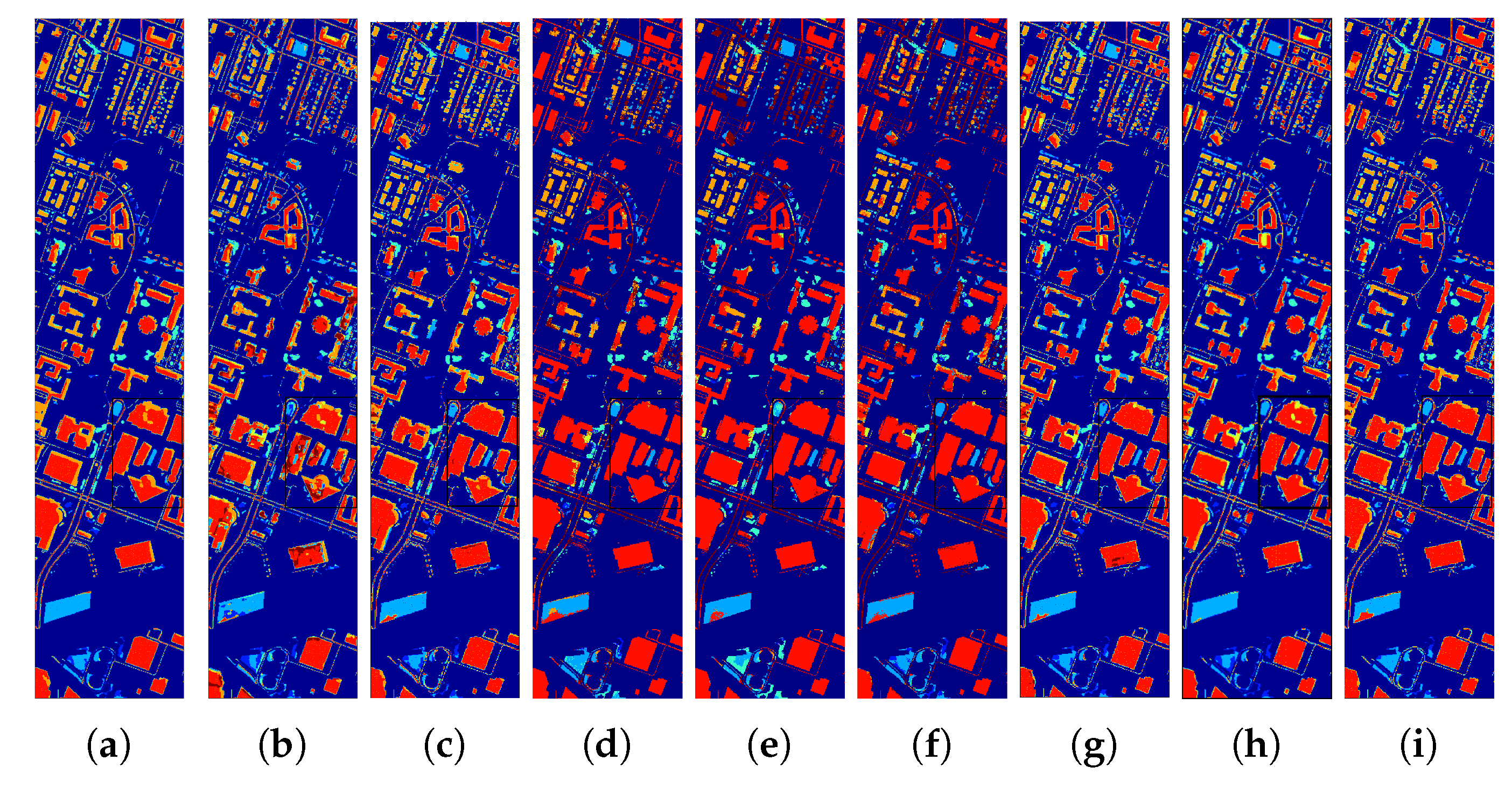
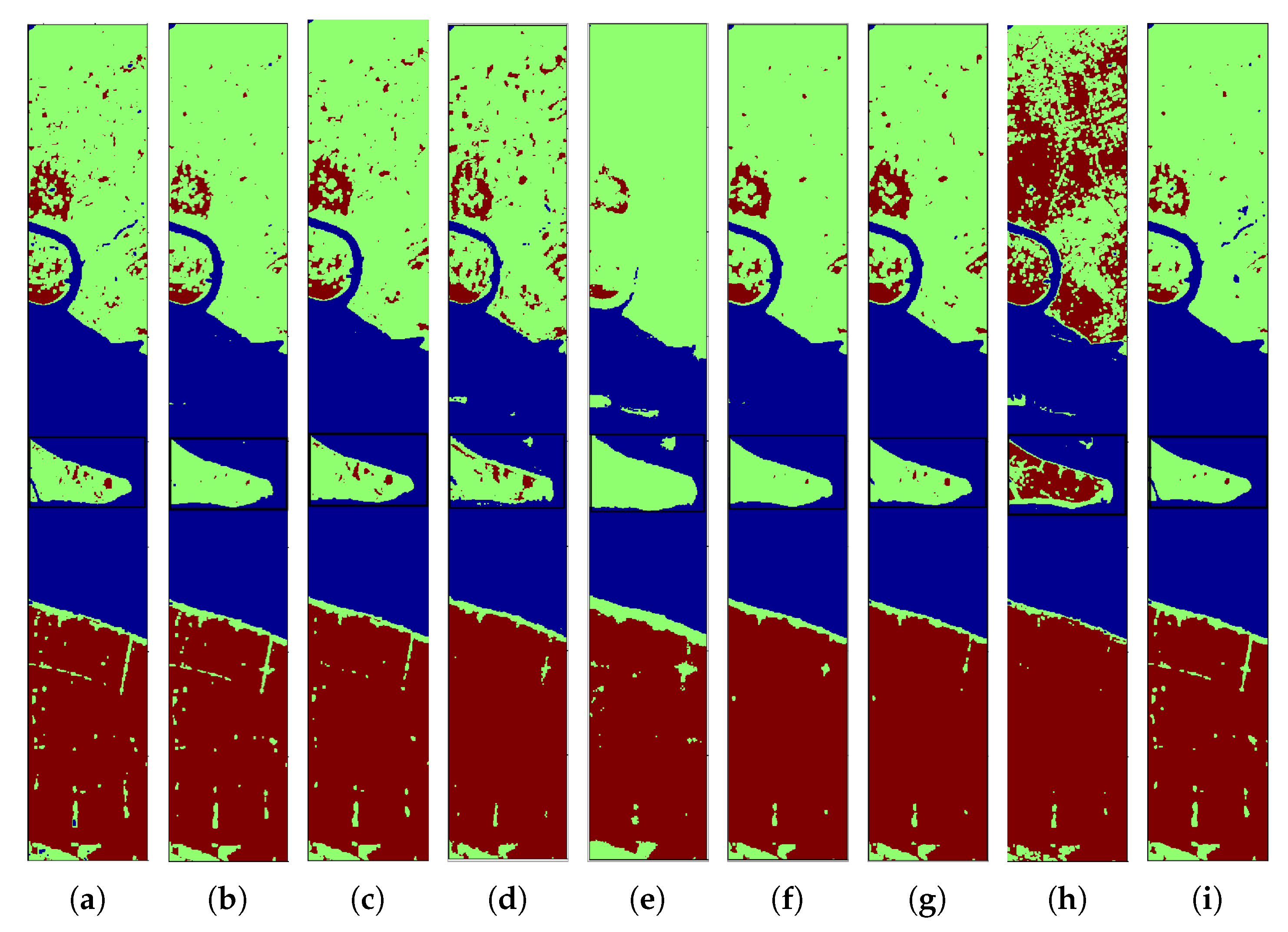
4.3. Performance in Cross-Scene HSI Classification
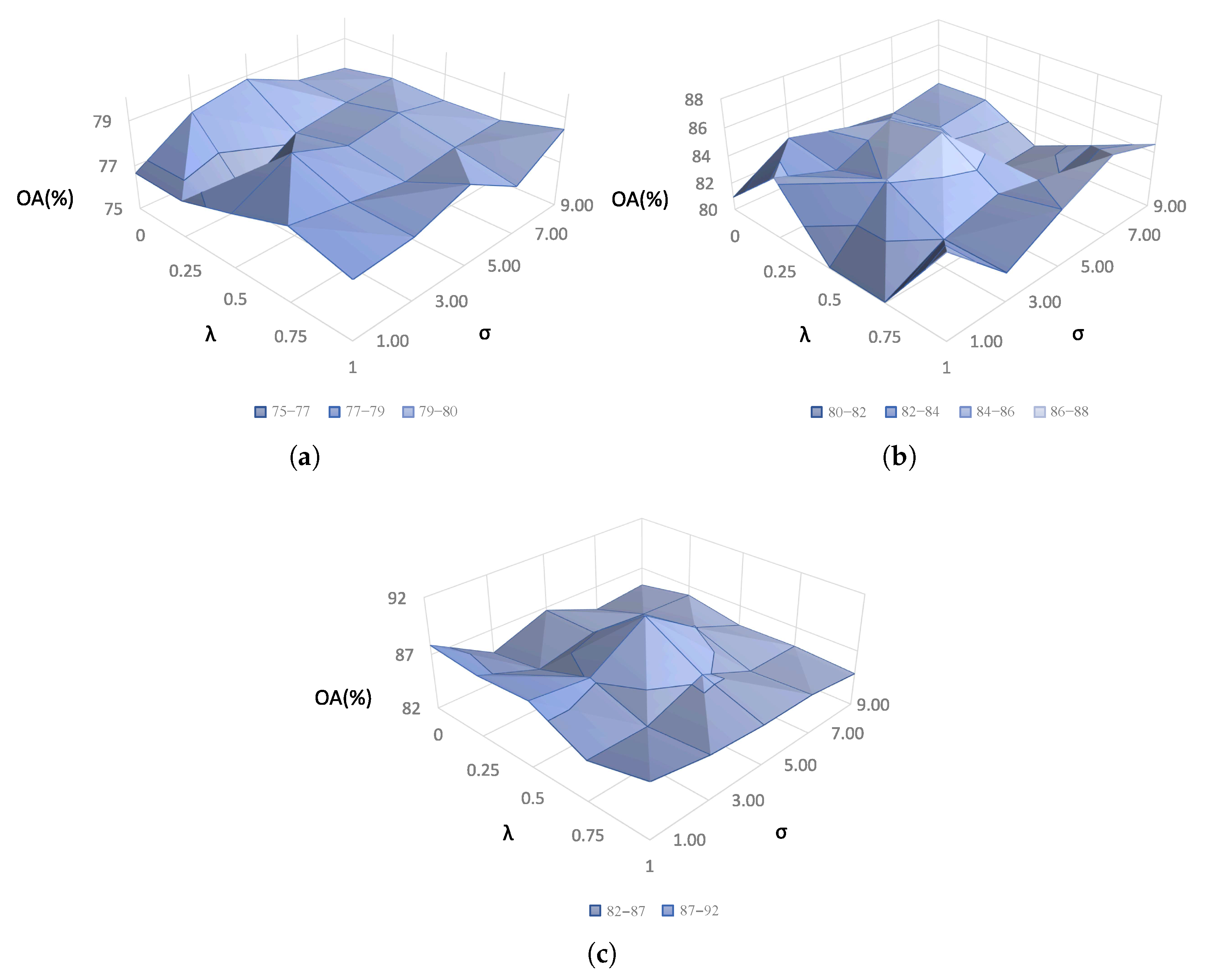
4.4. Parameter Sensitivity Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Xu, Y.; Du, B.; Zhang, L. Self-Attention Context Network: Addressing the Threat of Adversarial Attacks for Hyperspectral Image Classification. IEEE Trans. Image Process. 2021, 30, 8671–8685. [Google Scholar] [CrossRef] [PubMed]
- Wu, H.; Prasad, S. Semi-Supervised Deep Learning Using Pseudo Labels for Hyperspectral Image Classification. IEEE Trans. Image Process. 2018, 27, 1259–1270. [Google Scholar] [CrossRef] [PubMed]
- Dong, Y.; Liu, Q.; Du, B.; Zhang, L. Weighted Feature Fusion of Convolutional Neural Network and Graph Attention Network for Hyperspectral Image Classification. IEEE Trans. Image Process. 2022, 31, 1559–1572. [Google Scholar] [CrossRef] [PubMed]
- Zhou, S.; Wu, H.; Xue, Z. Grouped subspace linear semantic alignment for hyperspectral image transfer learning. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4412116. [Google Scholar] [CrossRef]
- Xu, Y.; Wu, S.; Wang, B.; Yang, M.; Wu, Z.; Yao, Y.; Wei, Z. Two-stage fine-grained image classification model based on multi-granularity feature fusion. Pattern Recognit. 2024, 146, 110042. [Google Scholar] [CrossRef]
- Zhang, M.; Wang, Z.; Wang, X.; Gong, M.; Wu, Y.; Li, H. Features kept generative adversarial network data augmentation strategy for hyperspectral image classification. Pattern Recognit. 2023, 142, 109701. [Google Scholar] [CrossRef]
- Hong, D.; Han, Z.; Yao, J.; Gao, L.; Zhang, B.; Plaza, A.; Chanussot, J. SpectralFormer: Rethinking hyperspectral image classification with transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5518615. [Google Scholar] [CrossRef]
- He, X.; Chen, Y.; Lin, Z. Spatial-Spectral Transformer for Hyperspectral Image Classification. Remote Sens. 2021, 13, 498. [Google Scholar] [CrossRef]
- Xie, J.; Hua, J.; Chen, S.; Wu, P.; Gao, P.; Sun, D.; Lyu, Z.; Lyu, S.; Xue, X.; Lu, J. HyperSFormer: A Transformer-Based End-to-End Hyperspectral Image Classification Method for Crop Classification. Remote Sens. 2023, 15, 3491. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, W.; Sun, W.; Tao, R.; Du, Q. Single-Source Domain Expansion Network for Cross-Scene Hyperspectral Image Classification. IEEE Trans. Image Process. 2023, 32, 1498–1512. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, M.; Li, W.; Wang, S.; Tao, R. Language-Aware Domain Generalization Network for Cross-Scene Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–12. [Google Scholar] [CrossRef]
- Peng, J.; Sun, W.; Ma, L.; Du, Q. Discriminative transfer joint matching for domain adaptation in hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2019, 16, 972–976. [Google Scholar] [CrossRef]
- Ma, L.; Luo, C.; Peng, J.; Du, Q. Unsupervised manifold alignment for cross-domain classification of remote sensing images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1650–1654. [Google Scholar] [CrossRef]
- Ma, L.; Crawford, M.M.; Zhu, L.; Liu, Y. Centroid and covariance alignment-based domain adaptation for unsupervised classification of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2018, 57, 2305–2323. [Google Scholar] [CrossRef]
- Matasci, G.; Volpi, M.; Kanevski, M.; Bruzzone, L.; Tuia, D. Semisupervised Transfer Component Analysis for Domain Adaptation in Remote Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3550–3564. [Google Scholar] [CrossRef]
- Sun, B.; Feng, J.; Saenko, K. Return of Frustratingly Easy Domain Adaptation. arXiv 2015, arXiv:1511.05547. [Google Scholar] [CrossRef]
- Ye, M.; Qian, Y.; Zhou, J.; Tang, Y.Y. Dictionary Learning-Based Feature-Level Domain Adaptation for Cross-Scene Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 1544–1562. [Google Scholar] [CrossRef]
- Persello, C.; Bruzzone, L. Kernel-Based Domain-Invariant Feature Selection in Hyperspectral Images for Transfer Learning. IEEE Trans. Geosci. Remote Sens. 2016, 54, 2615–2626. [Google Scholar] [CrossRef]
- Liu, T.; Zhang, X.; Gu, Y. Unsupervised Cross-Temporal Classification of Hyperspectral Images With Multiple Geodesic Flow Kernel Learning. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9688–9701. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, W.; Zhang, M.; Qu, Y.; Tao, R.; Qi, H. Topological structure and semantic information transfer network for cross-scene hyperspectral image classification. IEEE Trans. Neural Netw. Learn. Syst. 2021, 34, 2817–2830. [Google Scholar] [CrossRef]
- Wang, P.; Zhang, Z.; Lei, Z.; Zhang, L. Sharpness-Aware Gradient Matching for Domain Generalization. In Proceedings of the IEEE Comput Soc Conf Comput Vision Pattern Recognit, Vancouver, BC, Canada, 18–22 June 2023; pp. 3769–3778. [Google Scholar]
- Wang, J.; Lan, C.; Liu, C.; Ouyang, Y.; Qin, T.; Lu, W.; Chen, Y.; Zeng, W.; Yu, P. Generalizing to unseen domains: A survey on domain generalization. IEEE Trans. Knowl. Data Eng. 2022, 35, 8052–8072. [Google Scholar] [CrossRef]
- Qiao, F.; Zhao, L.; Peng, X. Learning to learn single domain generalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12556–12565. [Google Scholar]
- Liu, A.H.; Liu, Y.C.; Yeh, Y.Y.; Wang, Y.C.F. A unified feature disentangler for multi-domain image translation and manipulation. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar]
- Yue, X.; Zhang, Y.; Zhao, S.; Sangiovanni-Vincentelli, A.; Keutzer, K.; Gong, B. Domain randomization and pyramid consistency: Simulation-to-real generalization without accessing target domain data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 November–2 October 2019; pp. 2100–2110. [Google Scholar]
- Shankar, S.; Piratla, V.; Chakrabarti, S.; Chaudhuri, S.; Jyothi, P.; Sarawagi, S. Generalizing across domains via cross-gradient training. arXiv 2018, arXiv:1804.10745. [Google Scholar]
- Blanchard, G.; Deshmukh, A.A.; Dogan, Ü.; Lee, G.; Scott, C. Domain generalization by marginal transfer learning. J. Mach. Learn. Res. 2021, 22, 46–100. [Google Scholar]
- Ghifary, M.; Kleijn, W.B.; Zhang, M.; Balduzzi, D. Domain generalization for object recognition with multi-task autoencoders. In Proceedings of the IEEE international Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2551–2559. [Google Scholar]
- Motiian, S.; Piccirilli, M.; Adjeroh, D.A.; Doretto, G. Unified deep supervised domain adaptation and generalization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5715–5725. [Google Scholar]
- Ganin, Y.; Lempitsky, V. Unsupervised domain adaptation by backpropagation. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 1180–1189. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Arjovsky, M.; Bottou, L.; Gulrajani, I.; Lopez-Paz, D. Invariant risk minimization. arXiv 2019, arXiv:1907.02893. [Google Scholar]
- D’Innocente, A.; Caputo, B. Domain generalization with domain-specific aggregation modules. In Proceedings of the Pattern Recognition: 40th German Conference, GCPR 2018, Stuttgart, Germany, 9–12 October 2018; Proceedings 40. Springer: Berlin/Heidelberg, Germany, 2019; pp. 187–198. [Google Scholar]
- Li, D.; Yang, Y.; Song, Y.Z.; Hospedales, T. Learning to generalize: Meta-learning for domain generalization. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Li, L.; Gao, K.; Cao, J.; Huang, Z.; Weng, Y.; Mi, X.; Yu, Z.; Li, X.; Xia, B. Progressive Domain Expansion Network for Single Domain Generalization. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 224–233. [Google Scholar] [CrossRef]
- Wang, Z.; Luo, Y.; Qiu, R.; Huang, Z.; Baktashmotlagh, M. Learning to Diversify for Single Domain Generalization. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 814–823. [Google Scholar] [CrossRef]
- Wang, R.; Yi, M.; Chen, Z.; Zhu, S. Out-of-Distribution Generalization With Causal Invariant Transformations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 375–385. [Google Scholar]
- Dong, L.; Geng, J.; Jiang, W. Spectral–Spatial Enhancement and Causal Constraint for Hyperspectral Image Cross-Scene Classification. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–13. [Google Scholar] [CrossRef]
- Qin, B.; Feng, S.; Zhao, C.; Xi, B.; Li, W.; Tao, R. FDGNet: Frequency Disentanglement and Data Geometry for Domain Generalization in Cross-Scene Hyperspectral Image Classification. IEEE Trans. Neural Netw. Learn. Syst. 2024, 1–14. [Google Scholar] [CrossRef]
- Balestriero, R.; Pesenti, J.; LeCun, Y. Learning in high dimension always amounts to extrapolation. arXiv 2021, arXiv:2110.09485. [Google Scholar]
- Zhang, T.; Zhao, C.; Chen, G.; Jiang, Y.; Chen, F. Feature Contamination: Neural Networks Learn Uncorrelated Features and Fail to Generalize. arXiv 2024, arXiv:2406.03345. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond Empirical Risk Minimization. arXiv 2018, arXiv:1710.09412. [Google Scholar] [CrossRef]
- Zhou, K.; Yang, Y.; Qiao, Y.; Xiang, T. Domain Generalization with MixStyle. arXiv 2021, arXiv:2104.02008. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhong, Z.; Zhao, N.; Sebe, N.; Lee, G.H. Style-hallucinated dual consistency learning for domain generalized semantic segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 535–552. [Google Scholar]
- Lei, M.; Wu, H.; Lv, X.; Wang, X. ConDSeg: A General Medical Image Segmentation Framework via Contrast-Driven Feature Enhancement. arXiv 2024, arXiv:2412.08345. [Google Scholar] [CrossRef]
- Shah, H.; Tamuly, K.; Raghunathan, A.; Jain, P.; Netrapalli, P. The pitfalls of simplicity bias in neural networks. Adv. Neural Inf. Process. Syst. 2020, 33, 9573–9585. [Google Scholar]
- Pezeshki, M.; Kaba, O.; Bengio, Y.; Courville, A.C.; Precup, D.; Lajoie, G. Gradient starvation: A learning proclivity in neural networks. Adv. Neural Inf. Process. Syst. 2021, 34, 1256–1272. [Google Scholar]
- Chen, J.; Yang, Z.; Yang, D. Mixtext: Linguistically-informed interpolation of hidden space for semi-supervised text classification. arXiv 2020, arXiv:2004.12239. [Google Scholar]
- Bohren, C.F.; Huffman, D.R. Absorption and Scattering of Light by Small Particles; John Wiley & Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
- Bhatia, N.; Tolpekin, V.A.; Reusen, I.; Sterckx, S.; Biesemans, J.; Stein, A. Sensitivity of reflectance to water vapor and aerosol optical thickness. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 3199–3208. [Google Scholar] [CrossRef]
- Zhang, H.; Han, X.; Deng, J.; Sun, W. How to Evaluate and Remove the Weakened Bands in Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2025, 63, 1–15. [Google Scholar] [CrossRef]
- Blake, A.; Kohli, P.; Rother, C. Markov Random Fields for Vision and Image Processing; MIT Press: Cambridge, MA, USA, 2011. [Google Scholar]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised contrastive learning. Adv. Neural Inf. Process. Syst. 2020, 33, 18661–18673. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Kingma, D.P. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Debes, C.; Merentitis, A.; Heremans, R.; Hahn, J.; Frangiadakis, N.; van Kasteren, T.; Liao, W.; Bellens, R.; Pižurica, A.; Gautama, S.; et al. Hyperspectral and LiDAR Data Fusion: Outcome of the 2013 GRSS Data Fusion Contest. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2405–2418. [Google Scholar] [CrossRef]
- Le Saux, B.; Yokoya, N.; Hansch, R.; Prasad, S. 2018 IEEE GRSS Data Fusion Contest: Multimodal Land Use Classification [Technical Committees]. IEEE Geosci. Remote Sens. Mag. 2018, 6, 52–54. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, W.; Zhang, M.; Wang, S.; Tao, R.; Du, Q. Graph Information Aggregation Cross-Domain Few-Shot Learning for Hyperspectral Image Classification. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 1912–1925. [Google Scholar] [CrossRef]
- Karantzalos, K.; Karakizi, C.; Kandylakis, Z.; Antoniou, G. HyRANK Hyperspectral Satellite Dataset I, Version 001; Zenodo: Geneva, Switzerland, 2018. [CrossRef]
- Nam, H.; Lee, H.; Park, J.; Yoon, W.; Yoo, D. Reducing Domain Gap by Reducing Style Bias. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 8686–8695. [Google Scholar] [CrossRef]
- Chu, M.; Yu, X.; Dong, H.; Zang, S. Domain-Adversarial Generative and Dual Feature Representation Discriminative Network for Hyperspectral Image Domain Generalization. IEEE Trans. Geosci. Remote Sens. 2024, 32, 5533213. [Google Scholar] [CrossRef]
- Gao, J.; Ji, X.; Ye, F.; Chen, G. Invariant semantic domain generalization shuffle network for cross-scene hyperspectral image classification. Expert Syst. Appl. 2025, 273, 126818. [Google Scholar] [CrossRef]
- Zhao, H.; Zhang, J.; Lin, L.; Wang, J.; Gao, S.; Zhang, Z. Locally linear unbiased randomization network for cross-scene hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5526512. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Description |
|---|---|
| HSIC | Hyperspectral image classification |
| SD | Source domain |
| TD | Target domain |
| DA | Domain adaptation |
| DG | Domain generalization |
| SDG | Single domain generalization |
| SSLE | Spatial-spectral linear extrapolation |
| CRM | Conv2D-Relu-Maxpool2D |
| MRF | Markov random field |
| P | Projection head |
| Houston Dataset | Pavia Dataset | Hangzhou-Shanghai Dataset | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Class | Number of Samples | Class | Number of Samples | Class | Number of Samples | ||||||
| No. | Name |
Houston 2013
(Source) |
Houston 2018
(Target) | No. | Name |
PaviaU
(Source) |
PaviaC
(Target) | No. | Name |
Hangzhou
(Source) |
Shanghai
(Target) |
| 1 | Grass healthy | 345 | 1353 | 1 | Tree | 3064 | 7598 | ||||
| 2 | Grass stressed | 365 | 4888 | 2 | Asphalt | 6631 | 9248 | ||||
| 3 | Trees | 365 | 2766 | 3 | Brick | 3682 | 2685 | 1 | Water | 18,043 | 123,123 |
| 4 | Water | 285 | 22 | 4 | Bitumen | 1330 | 7287 | 2 | Land/Building | 77,450 | 161,689 |
| 5 | Residential buildings | 319 | 5347 | 5 | Shadow | 947 | 2863 | 3 | Plant | 40,207 | 83,188 |
| 6 | Non-residential buildings | 408 | 32,459 | 6 | Meadow | 18,649 | 3090 | ||||
| 7 | Road | 443 | 6365 | 7 | Bare soil | 5029 | 6584 | ||||
| Total | 2530 | 53,200 | Total | 39,332 | 39,355 | Total | 135,700 | 368,000 | |||
| HyRANK Dataset | |||
|---|---|---|---|
| Class | Number of Samples | ||
| No. | Name |
Dioni
(Source) |
Loukia
(Target) |
| C1 | Dense Urban Fabric | 1262 | 206 |
| C2 | Mineral Extraction Sites | 204 | 54 |
| C3 | Non Irrigated Arable Land | 614 | 426 |
| C4 | Fruit Trees | 150 | 79 |
| C5 | Olive Groves | 1768 | 1107 |
| C6 | Coniferous Forest | 361 | 422 |
| C7 | Dense Sclerophyllous Vegetation | 5035 | 2996 |
| C8 | Sparce Sclerophyllous Vegetation | 6374 | 2361 |
| C9 | Sparsely Vegetated Areas | 1754 | 399 |
| C10 | Rocks and Sand | 492 | 453 |
| C11 | Water | 1612 | 1393 |
| C12 | Coastal Water | 398 | 421 |
| Total | 20,024 | 10,317 | |
| CRM Backbone | Align | Houston2018 (Target) | PaviaCenter (Target) | ShangHai (Target) | ||
|---|---|---|---|---|---|---|
| ✓ | 74.43 ± 2.36 | 75.25 ± 5.51 | 83.81 ± 3.09 | |||
| ✓ | ✓ | 74.87 ± 1.15 | 79.44 ± 5.92 | 87.05 ± 3.18 | ||
| ✓ | ✓ | 74.52 ± 0.92 | 81.96 ± 2.61 | 87.56 ± 2.54 | ||
| ✓ | ✓ | ✓ | 75.27 ± 0.91 | 78.01 ± 3.76 | 88.62 ± 1.47 | |
| ✓ | ✓ | ✓ | ✓ | 78.85 ± 0.87 | 82.50 ± 1.41 | 90.85 ± 1.81 |
| Classification Algorithms | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mixed-Based Data Augmentation | SDG Methods in Computer Vision | SDG Methods for Cross-Scene HSI Classification | |||||||||
| Class | Mixup | MixStyle | StyleHall | SagNet | LDSDG | PDEN | SDENet | FDGNet | D3Net | ISDGSNet | Proposed |
| 1 | 41.88 ± 15.18 | 52.56 ± 2.02 | 47.23 ± 12.47 | 25.79 | 10.13 | 46.49 | 74.08 ± 22.42 | 49.42 ± 17.28 | 20.12 ± 10.36 | 48.25 ± 18.27 | 51.34 ± 11.43 |
| 2 | 89.30 ± 2.56 | 68.80 ± 2.18 | 79.84 ± 8.98 | 62.79 | 62.97 | 77.60 | 75.16 ± 3.99 | 76.18 ± 6.59 | 82.9 ± 6.18 | 73.10 ± 11.18 | 77.47 ± 7.41 |
| 3 | 72.44 ± 2.82 | 63.75 ± 10.04 | 65.58 ± 2.63 | 48.66 | 60.81 | 59.73 | 60.59 ± 2.98 | 62.89 ± 2.36 | 53.17 ± 7.51 | 64.06 ± 7.44 | 67.12 ± 2.29 |
| 4 | 100 ± 0.00 | 99.09 ± 26.48 | 100 ± 0.00 | 81.82 | 81.82 | 100 | 100.00 ± 0 | 100 ± 0 | 89.09 ± 9.96 | 100.00 ± 0 | 100 ± 0.00 |
| 5 | 81.74 ± 3.56 | 48.62 ± 6.66 | 77.60 ± 4.82 | 59.57 | 45.65 | 49.62 | 50.63 ± 11.97 | 68.44 ± 6.64 | 66.48 ± 8.87 | 73.51 ± 8.89 | 66.14 ± 6.76 |
| 6 | 81.44 ± 2.37 | 61.76 ± 2.20 | 79.85 ± 1.23 | 89.28 | 89.22 | 84.98 | 90.01 ± 3.17 | 87.80 ± 3.64 | 91.82 ± 1.53 | 88.14 ± 2.65 | 88.15 ± 0.86 |
| 7 | 45.42 ± 10.38 | 58.38 ± 6.69 | 59.84 ± 3.64 | 34.99 | 44.15 | 64.21 | 50.61 ± 1.49 | 52.85 ± 16.35 | 24.66 ± 4.47 | 52.18 ± 8.49 | 53.99 ± 6.93 |
| OA (%) | 76.42 ± 0.84 | 60.56 ± 2.19 | 75.66 ± 1.17 | 73.01 ± 1.81 | 74.23 ± 1.49 | 75.40 ± 1.76 | 78.04 ± 1.41 | 78.34 ± 1.68 | 76.58 ± 1.09 | 78.72 ± 1.91 | 78.85 ± 0.87 |
| Kappa | 61.71 ± 1.27 | 42.05 ± 2.49 | 61.08 ± 1.79 | 55.29 ± 3.50 | 55.42 ± 2.27 | 55.87 ± 2.92 | 61.86 ± 1.98 | 62.88 ± 4.58 | 57.30 ± 2.78 | 63.67 ± 3.87 | 63.66 ± 1.97 |
| Classification Algorithms | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mixed-Based Data Augmentation | SDG Methods in Computer Vision | SDG Methods for Cross-Scene HSI Classification | |||||||||
| Class | Mixup | MixStyle | StyleHall | SagNet | LDSDG | PDEN | SDENet | FDGNet | D3Net | ISDGSNet | Proposed |
| 1 | 91.10 ± 13.98 | 71.33 ± 8.56 | 84.44 ± 4.06 | 98.35 | 91.09 | 85.93 | 86.27 ± 1.39 | 86.44 ± 1.30 | 90.41 ± 4.84 | 89.87 ± 4.74 | 87.51 ± 2.67 |
| 2 | 82.42 ± 9.00 | 73.71 ± 9.46 | 82.44 ± 2.52 | 59.76 | 73.51 | 88.56 | 82.80 ± 3.01 | 83.25 ± 0.56 | 90.55 ± 1.99 | 88.36 ± 3.81 | 87.55 ± 2.22 |
| 3 | 45.87 ± 8.14 | 68.28 ± 14.51 | 72.52 ± 13.36 | 5.40 | 2.23 | 61.34 | 69.35 ± 6.22 | 70.83 ± 7.09 | 70.13 ± 14.92 | 51.89 ± 8.2 | 66.64 ± 9.02 |
| 4 | 63.50 ± 2.03 | 72.40 ± 6.40 | 87.22 ± 0.96 | 87.03 | 71.72 | 85.49 | 85.35 ± 1.8 | 84.94 ± 1.34 | 78.21 ± 6.12 | 70.44 ± 18.82 | 78.75 ± 8.71 |
| 5 | 82.15 ± 8.66 | 70.37 ± 10.25 | 80.28 ± 12.60 | 93.19 | 71.04 | 87.95 | 89.43 ± 2.83 | 86.54 ± 3.27 | 82.30 ± 8.47 | 91.11 ± 2.03 | 89.70 ± 3.55 |
| 6 | 70.92 ± 5.18 | 74.25 ± 3.53 | 73.59 ± 3.17 | 49.81 | 57.12 | 79.26 | 79.10 ± 1.27 | 72.71 ± 1.74 | 64.14 ± 5.38 | 71.92 ± 2.98 | 74.89 ± 3.01 |
| 7 | 72.93 ± 3.93 | 65.74 ± 6.69 | 84.96 ± 5.95 | 57.94 | 78.13 | 64.75 | 77.23 ± 5.03 | 81.27 ± 0.90 | 80.38 ± 9.21 | 74.53 ± 9.38 | 80.70 ± 4.52 |
| OA (%) | 79.59 ± 4.65 | 71.68 ± 1.42 | 82.60 ± 1.58 | 69.28 ± 1.11 | 70.88 ± 1.55 | 80.27 ± 1.38 | 82.28 ± 1.48 | 82.41 ± 0.59 | 82.47 ± 2.83 | 79.44 ± 4.72 | 82.50 ± 1.41 |
| Kappa | 70.55 ± 5.78 | 66.23 ± 1.54 | 79.11 ± 1.86 | 63.04 ± 1.67 | 64.06 ± 2.07 | 76.81 ± 1.92 | 78.76 ± 1.77 | 78.88 ± 0.69 | 78.85 ± 3.36 | 75.25 ± 5.63 | 78.98 ± 1.70 |
| Classification Algorithms | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mixed-Based Data Augmentation | SDG Methods in Computer Vision | SDG Methods for Cross-Scene HSI Classification | |||||||||
| Class | Mixup | MixStyle | StyleHall | SagNet | LDSDG | PDEN | SDENet | FDGNet | D3Net | ISDGSNet | Proposed |
| 1 | 94.16 ± 1.01 | 94.32 ± 1.38 | 94.81 ± 0.72 | 93.01 ± 1.69 | 89.26 ± 4.03 | 93.58 ± 1.34 | 93.89 ± 1.04 | 93.81 ± 0.47 | 93.73 ± 2.32 | 93.59 ± 1.06 | 94.13 ± 0.93 |
| 2 | 84.19 ± 7.41 | 80.49 ± 1.27 | 79.32 ± 11.24 | 73.10 ± 4.24 | 72.33 ± 7.08 | 77.00 ± 6.03 | 73.75 ± 7.52 | 59.65 ± 10.84 | 83.15 ± 8.84 | 79.41 ± 5.81 | 88.02 ± 4.06 |
| 3 | 85.65 ± 8.58 | 99.58 ± 0.05 | 97.71 ± 4.75 | 99.57 ± 0.19 | 99.40 ± 0.65 | 99.49 ± 0.22 | 99.57 ± 0.19 | 99.95 ± 0.05 | 91.36 ± 13.64 | 99.11 ± 1.06 | 93.30 ± 8.70 |
| OA (%) | 88.36 ± 2.45 | 89.43 ± 0.51 | 86.96 ± 3.55 | 88.56 ± 1.48 | 87.00 ± 1.08 | 90.02 ± 2.17 | 89.07 ± 2.36 | 80.19 ± 4.81 | 88.54 ± 2.79 | 88.61 ± 2.30 | 90.85 ± 1.81 |
| Kappa | 82.44 ± 3.57 | 83.99 ± 0.75 | 80.46 ± 5.15 | 78.62 ± 2.75 | 76.75 ± 2.78 | 81.23 ± 4.25 | 79.52 ± 4.47 | 70.92 ± 6.64 | 82.48 ± 4.07 | 82.77 ± 3.33 | 86.06 ± 2.66 |
| Classification Algorithms | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mixed-Based Data Augmentation | SDG Methods in Computer Vision | SDG Methods for Cross-Scene HSI Classification | |||||||||
| Class | Mixup | MixStyle | StyleHall | SagNet | LDSDG | PDEN | SDEnet | FDGNet | D3Net | ISDGSNet | Proposed |
| C1 | 21.52 ± 9.97 | 0 ± 0 | 27.86 ± 10.12 | 0.97 ± 1.29 | 0 ± 0 | 1.45 ± 1.46 | 26.69 ± 12.39 | 26.37 ± 9.83 | 26.80 ± 24.13 | 20.97 ± 13.26 | 21.94 ± 7.97 |
| C2 | 42.59 ± 39.02 | 17.28 ± 17.60 | 14.81 ± 15.87 | 0 ± 0 | 0 ± 0 | 0 ± 0 | 70.37 ± 48.15 | 16.04 ± 21.46 | 34.08 ± 23.19 | 60.37 ± 26.6 | 58.52 ± 13.13 |
| C3 | 56.88 ± 3.99 | 19.79 ± 18.76 | 45.30 ± 12.37 | 40.14 ± 34.95 | 0 ± 0 | 0 ± 0 | 10.95 ± 8.03 | 51.4 ± 15.14 | 37.51 ± 22.53 | 32.49 ± 25.54 | 64.79 ± 13.44 |
| C4 | 12.65 ± 1.27 | 0 ± 0 | 8.60 ± 4.68 | 11.39 ± 19.73 | 0 ± 0 | 0 ± 0 | 5.06 ± 5.80 | 18.14 ± 6.37 | 2.02 ± 3.3 | 9.87 ± 13.53 | 33.67 ± 17.71 |
| C5 | 0.57 ± 0.99 | 0.39 ± 0.60 | 4.71 ± 3.35 | 0.18 ± 0.31 | 2.8 ± 4.24 | 0.63 ± 0.81 | 37.48 ± 6.50 | 0.42 ± 0.29 | 6.85 ± 8.87 | 17.98 ± 18.07 | 31.76 ± 13.8 |
| C6 | 35.78 ± 2.17 | 10.66 ± 9.7 | 31.75 ± 4.60 | 25.12 ± 12.69 | 0 ± 0 | 0.23 ± 0.41 | 29.78 ± 17.01 | 33.09 ± 6.70 | 18.96 ± 16.64 | 25.83 ± 16.09 | 9.48 ± 5.59 |
| C7 | 78.41 ± 3.14 | 84.42 ± 1.87 | 75.05 ± 1.78 | 73.74 ± 15.07 | 84.47 ± 4.81 | 83.52 ± 1.30 | 77.67 ± 9.15 | 75.13 ± 0.23 | 76.52 ± 3.03 | 74.33 ± 1.54 | 69.72 ± 1.52 |
| C8 | 68.78 ± 7.85 | 62.12 ± 8.02 | 72.32 ± 3.71 | 54.3 ± 18.64 | 61.6 ± 6.65 | 66.38 ± 5.07 | 52.69 ± 8.39 | 73.13 ± 1.68 | 66.32 ± 1.97 | 63.31 ± 6.09 | 60.86 ± 4.66 |
| C9 | 32.83 ± 24.09 | 28.23 ± 42.83 | 55.94 ± 19.17 | 22.39 ± 7.00 | 42.35 ± 27.14 | 64.82 ± 10.18 | 74.77 ± 4.7 | 53.46 ± 24.60 | 73.13 ± 8.76 | 79.85 ± 4.71 | 76.39 ± 9.25 |
| C10 | 0 ± 0 | 1.10 ± 1.91 | 9.36 ± 20.92 | 1.473 ± 2.55 | 0 ± 0 | 26.34 ± 31.03 | 17.66 ± 26.84 | 0 ± 0 | 9.01 ± 8.62 | 4.24 ± 8.41 | 11.52 ± 10.12 |
| C11 | 100 ± 0 | 100 ± 0 | 100 ± 0 | 100 ± 0 | 100 ± 0 | 100 ± 0 | 100 ± 0 | 99.97 ± 0.04 | 100.00 ± 0 | 100.00 ± 0 | 100.00 ± 0 |
| C12 | 100 ± 0 | 4.51 ± 7.82 | 100 ± 0 | 100 ± 0 | 98.57 ± 1.56 | 63.51 ± 54.59 | 100 ± 0 | 100 ± 0 | 99.81 ± 0.42 | 99.86 ± 0.32 | 100.00 ± 0.42 |
| OA (%) | 61.99 ± 1.47 | 59.94 ± 1.00 | 62.88 ± 1.44 | 55.16 ± 2.34 | 58.09 ± 0.85 | 60.52 ± 1.60 | 62.50 ± 1.64 | 62.47 ± 0.75 | 62.03 ± 0.74 | 62.06 ± 1.22 | 62.69 ± 0.95 |
| Kappa | 52.83 ± 1.72 | 43.01 ± 1.44 | 54.11 ± 1.91 | 44.04 ± 2.74 | 45.99 ± 1.37 | 50.38 ± 1.75 | 54.35 ± 2.18 | 53.33 ± 086 | 52.93 ± 0.91 | 53.49 ± 1.71 | 54.72 ± 1.27 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, L.; Zhao, H.; Gao, S.; Wang, J.; Zhang, Z. Spatial-Spectral Linear Extrapolation for Cross-Scene Hyperspectral Image Classification. Remote Sens. 2025, 17, 1816. https://doi.org/10.3390/rs17111816
Lin L, Zhao H, Gao S, Wang J, Zhang Z. Spatial-Spectral Linear Extrapolation for Cross-Scene Hyperspectral Image Classification. Remote Sensing. 2025; 17(11):1816. https://doi.org/10.3390/rs17111816
Chicago/Turabian StyleLin, Lianlei, Hanqing Zhao, Sheng Gao, Junkai Wang, and Zongwei Zhang. 2025. "Spatial-Spectral Linear Extrapolation for Cross-Scene Hyperspectral Image Classification" Remote Sensing 17, no. 11: 1816. https://doi.org/10.3390/rs17111816
APA StyleLin, L., Zhao, H., Gao, S., Wang, J., & Zhang, Z. (2025). Spatial-Spectral Linear Extrapolation for Cross-Scene Hyperspectral Image Classification. Remote Sensing, 17(11), 1816. https://doi.org/10.3390/rs17111816