1. Introduction
The advancement of electronic technologies has intensified the competition between radar jamming and anti-jamming in modern electronic warfare [
1,
2]. As an essential component of the battlefield, cognitive radar systems [
3] provide critical capabilities for real-time target detection, situational awareness, and threat monitoring. However, the continuous refinement of active jamming technologies poses serious threats to radar [
4,
5]. In complex electromagnetic environments, a radar system’s ability to reliably detect and track real targets is significantly influenced by the system’s anti-jamming capabilities. Accurate identification of jamming types is crucial for implementing effective countermeasures, such as adaptive beamforming, frequency hopping, and optimized power allocation. Traditional jamming recognition methods, which rely heavily on expert knowledge and predefined features, are increasingly insufficient to meet the demands of modern electronic warfare. Consequently, the development of accurate and efficient jamming recognition methods has become a critical area of research in the advancement of cognitive radar electronic countermeasure technologies.
Radar active jamming can be classified into two categories according to different operational mechanisms: suppressive jamming [
6] and deceptive jamming [
7]. Suppressive jamming employs high-power noise signals to overwhelm the radar receivers, effectively masking the real targets. Deceptive jamming generates false targets by modulating and forwarding the intercepted radar transmission signals. These deceptive jamming signals exhibit enhanced coherence with radar signals, significantly disrupting the target detection and tracking processes of the enemy radar system.
However, existing recognition methods primarily focus on relatively simple electromagnetic environments, where both the jamming-to-noise ratio (JNR) and jamming-to-signal ratio (JSR) are stably high. In practical complex electromagnetic environments, JNR is highly variable and often low, posing a significant threat to radar target detection. Moreover, high-power noise can obscure meaningful jamming features, resulting in significant performance degradation of existing methods, which typically rely on one-dimensional raw echo data, frequency-domain data, or two-dimensional time–frequency representations of jamming signals as input.
To address the limited recognition performance in complex electromagnetic environments due to insufficient feature extraction and utilization of jamming signals, this paper proposes a novel and effective solution: a jamming recognition framework based on multi-domain feature fusion. Firstly, the pulse compression time–frequency (PC-TF) and the range-Doppler (RD) domain data are utilized to obtain robust feature representations of the jamming signals. Subsequently, a novel dual-channel feature fusion network architecture is designed, combining an efficient single-modality feature extraction and a two-stage dual-modality fusion to achieve superior jamming recognition performance. The main contributions of this work are summarized as follows:
Dual-Domain Representation: To improve the recognition performance and robustness of the network model, we employ PC-TF domain and RD domain data as parallel inputs, which enrich the feature space and improve the representation of jamming signals under low JNR conditions. These modalities not only provide robust features of jamming signals but also offer complementary information.
Two-Stage Fusion Strategy: To fully exploit the complementary information, a dual-modal feature fusion module based on a cross-attention mechanism is introduced to integrate the features from two modalities. Additionally, an adaptive decision fusion mechanism is proposed to further integrate the decisions from the input with the fused modalities, leading to more robust and accurate outputs.
Integrated Recognition Architecture: We develop MDFNet, an end-to-end framework that integrates three synergistic components: a multi-order feature extraction module, cross-modal feature fusion module, and adaptive decision fusion module. This cascaded architecture achieves progressive enhancement of jamming features, significantly improving recognition reliability in complex electromagnetic environments.
Comparative experiments conducted on a radar active jamming dataset demonstrate that our proposed method delivers enhanced robustness compared to existing recognition approaches across various JNR conditions, validating its effectiveness and superiority. The overall recognition accuracy of MDFNet is 96.05%. Ablation studies further emphasize the complementary nature of the two modalities and the efficacy of the designed network modules.
2. Related Work
Current research on jamming recognition can generally be classified into two categories: conventional manual feature extraction methods and advanced deep neural network (DNN)-driven methods. Traditional approaches generally employ various transformation techniques to extract features of different domains of jamming signals, including the time domain, frequency domain [
8], bispectral domain [
9], wavelet domain [
10], and fourier domain [
11]. These features are then processed by classifiers such as SVM [
12], decision trees [
13], and bayesian decision theory [
14] to identify the type of jamming. Although manually extracted expert features have clear physical interpretations, these approaches primarily depend on limited expert knowledge, which restricts its applicability and adaptability.
The advent of deep learning has revolutionized radar jamming recognition by automating feature extraction and eliminating the necessary of extensive expert knowledge. Some studies have focused on specialized architectures for specific jamming types, for instance, an efficient channel attention (ECA)-based one-dimensional residual neural network for interrupted sampling repeater jamming [
15] and fast–slow time-domain joint frequency response feature-based models for dense false target jamming [
16].
For multi-type jamming classification, some studies directly use raw echo signals as input to classification models, such as a 1D-CNN-based network designed for small-sample constraints [
17], while complex-valued CNN (CV-CNN) and pruning-based CV-CNN (F-CV-CNN) [
18] enable rapid recognition. In [
19], an integrated multi-label classification system is introduced for compound jamming scenarios, employing end-to-end architectural design. In [
20], a residual convolutional autoencoder-open world recognition (RCAE-OWR) algorithm is proposed to recognize unknown jamming patterns. Similarly, Ref. [
21] further develops transformer architectures with two specialized variants: the RadarCL-TR framework enhancing robustness against noisy samples through complementary labeling, and the RadarSSL-PL-TR framework addressing performance optimization with unlabeled datasets. However, these methods often exhibit reduced robustness under low JNR conditions due to the susceptibility of time-domain features to noise. Additionally, variations in radar waveform parameters can further limit their generalizability by altering the signal length.
Subsequent studies have leveraged image classification networks for jamming signal recognition by employing time–frequency representations of the signals as network inputs. Early research relied on convolutional neural networks (CNNs). For example, a simple CNN was utilized to identify the types of separated jamming signals [
22]. In [
23], deep networks and the open set recognition (OSR) models were combined to not only classify known jamming types but also to detect or reject unknown patterns. Subsequent studies introduced diverse attention mechanisms to improve the representational capacity of the models. In [
24], the multi-head self-attention (MSA) mechanism was employed to merge global and local representations in the jamming time–frequency images. In [
25], a spatial attention mechanism was integrated to enhance the representation of key areas within the features. A wavelet attention module was introduced to better capture time–frequency texture features [
26]. A lightweight neural network MobileViT was combined with a coordinate attention mechanism for improving performance [
27]. Similarly, an efficient hybrid attention (EHA) mechanism was combined with ShuffleNet v2 to construct a high-performance recognition model [
28]. In [
29], a convolutional embedding module (CEM) and a hybrid attention module (HAM) were integrated to extract spatial and location information. Other studies have explored transfer learning on pre-train models, thereby improving recognition performance under small-sample conditions. For example, an enhanced prototypical network with supervised pretraining and self-supervised fine-tuning was proposed [
30], which was pretrained on the open-source Omniglot dataset to bolster the encoder’s geometric recognition ability. Additionally, a few-shot learning (FSL) method integrated transfer learning (TL) with a dual graph convolutional network (DGCN) [
31], which utilized the mini-ImageNet dataset for pre-training. Furthermore, certain studies have applied object detection models to identify jamming signals directly from time–frequency images, like YOLO v5 [
32,
33]. Furthermore, several studies have extracted features from multiple domains of the time–frequency spectrogram, including the real part, imaginary part, magnitude, and phase [
34,
35,
36].
Recent advances in jamming recognition attempt to overcome single-domain limitations through multi-modal fusion strategies. Researchers have developed hybrid architectures that integrate complementary information across different transform domains: deep fusion CNN [
37] was proposed to combines time-domain data with time–frequency data through concatenate operation, while the multiscale attention network (MANet) [
38] synchronously processes time-domain data and frequency-domain data using cross-domain attention mechanisms. Further innovations include branch-structured networks that jointly analyze time–frequency images and fractional fourier transform (FRFT) images through attention-based fusion modules [
11], as well as fusing feature images from the time–frequency domain and wavelet transform domain through gated recurrent unit (GRU)-based architectures [
39].
3. Jamming Signal Model and Processing
3.1. Jamming Signal Models
This section provides an overview of the common types of active jamming based on the principles of jamming signals and presents their mathematical models. This paper establishes jamming signal models based on linear frequency modulation (LFM) radar waveforms, with the mathematical representation provided in Equation (
1).
where
denotes the center frequency, with
(pulse width) and
B (pulse bandwidth) determining the chirp rate
.
3.1.1. Suppressive Jamming
Suppressive jamming can be categorized into coherent and non-coherent suppression jamming. Coherent suppression jamming modulates radar signals with noise, while non-coherent suppression jamming directly transmits high-power noise signals. As a representative noise frequency modulation technique, spot noise (SN) jamming is characterized by Equation (
2).
where
,
, and
denote the amplitude, center carrier frequency, and frequency modulation rate, respectively;
is the Gaussian white noise with variance
;
is the noise modulation bandwidth. The essential spectral constraints are given by
Smart noise jamming (SNJ) operates by multiplying or convolving time-delayed radar signals with narrowband Gaussian noise, including noise product (NP) jamming and noise convolution (NC) jamming. The expressions are given by
where
denotes the time delay, and “⊗” denotes the convolution operation.
3.1.2. Deceptive Jamming
Deceptive jamming operates by intercepting, modulating, and forwarding radar signals to generate false targets. Recent advancements in digital radio frequency memory (DRFM) technology have enabled the implementation of sophisticated jamming techniques, whose operational principles and mathematical models will be analyzed in the following sections.
Dense false target (DFT) jamming generates a cluster of deceptive false targets by forwarding intercepted radar signal with multiple regular time delays. This process is mathematically modeled by
where
denotes the time delay of the real target, and
m and
denote the forwarding times and delay of the
ith false target, respectively.
Intermittent sampling repeater (ISR) jamming generates false targets by periodically sampling and forwarding slices of radar pulse signals. It can be categorized into two operational modes: direct repeater (ISDR) and repetitive repeater (ISRR), with mathematical models:
where
N and
M denote the number of slices and times each slice is retransmitted,
denote the sampling time of each slice, and
denote the time interval between two sampling slices.
Chopping and interleaving (CI) jamming operates through two sequential stages. The chopping stage divides radar signals into equal-duration slices via periodic sampling. Each slice is then divided into several sub-pulses during interleaving, where the first sub-pulse replicates the sampled signal segment and subsequent sub-pulses replicate the first sub-pulse. The mathematical model is given as
where
m and
n denote the number of slice and sub-pulses,
and
denote the sampling period and sampling time of the sub-pulse, and
is the impulse function.
Smeared Spectrum (SMSP) jamming operates through N-time interval sampling of intercepted radar signals. Each sub-pulse has a 1/N pulse width and N-times chirp rate of the original signal. These sub-pulses repeat N times sequentially, forming an SMSP signal with matched pulse width. The expression is given as
Comb Spectrum (COMB) jamming operates through time-domain multiplication between the COMB signal and the radar signal. The frequency spectrum of the COMB signal features a comb-like structure with equally spaced frequency components. The mathematical expression is
where
denotes the frequency of the
ith comb spectrum signal.
Deceptive pull-off jamming applies time or frequency modulation to intercepted radar signals, generating range or velocity deception. Range gate pull-off (RGPO) jamming, velocity gate pull-off (VGPO) jamming, and range-velocity gate pull-off (RVGPO) jamming are three common types of pull-off deceptive jamming, with the following expressions:
where
and
denote the time delay and the Doppler shift
3.2. Jamming Signal Processing
3.2.1. Pulse Compression
Certain jamming signals display subtle differences in time domain. Under low JNR conditions, noise can obscure the time-domain features, thereby impairing effective jamming recognition. Since most types of jamming signals are coherent with radar transmission signals, this paper employs a pulse compression technique to improve processing gains [
40], which can enhance both the SNR and the JNR. Pulse compression involves matched filtering of the time-domain data, with the filter’s transfer function defined according to the maximum SNR principle as follows:
where
denotes the frequency spectrum of the radar transmission signal
, and
denotes the complex conjugate of
. Given
as the time-domain representation of
, the pulse-compressed signal can be derived as follows:
After pulse compression processing, the time-domain signal is transformed into the range domain. As shown in Equation (
18), the envelope of the pulse-compressed signal
is a sinc function, where the peak’s position corresponds to the target’s range.
3.2.2. Time–Frequency Transformation
For enhanced feature extraction, each pulse-compression signal sample undergoes time–frequency analysis via the Short-Time Fourier Transform (STFT). The process can be defined as
where
denotes the window function.
Following the principle of stationary phase, where the time–frequency relationship is governed by
, the amplitude response of the pulse-compressed time–frequency signal is formulated as
As indicated in Equation (
20), the result appears as a two-dimensional sinc peak in time–frequency domain. The position of the peak in time domain is determined by the target range, with a mainlobe width of
, and a mainlobe width of
in frequency domain.
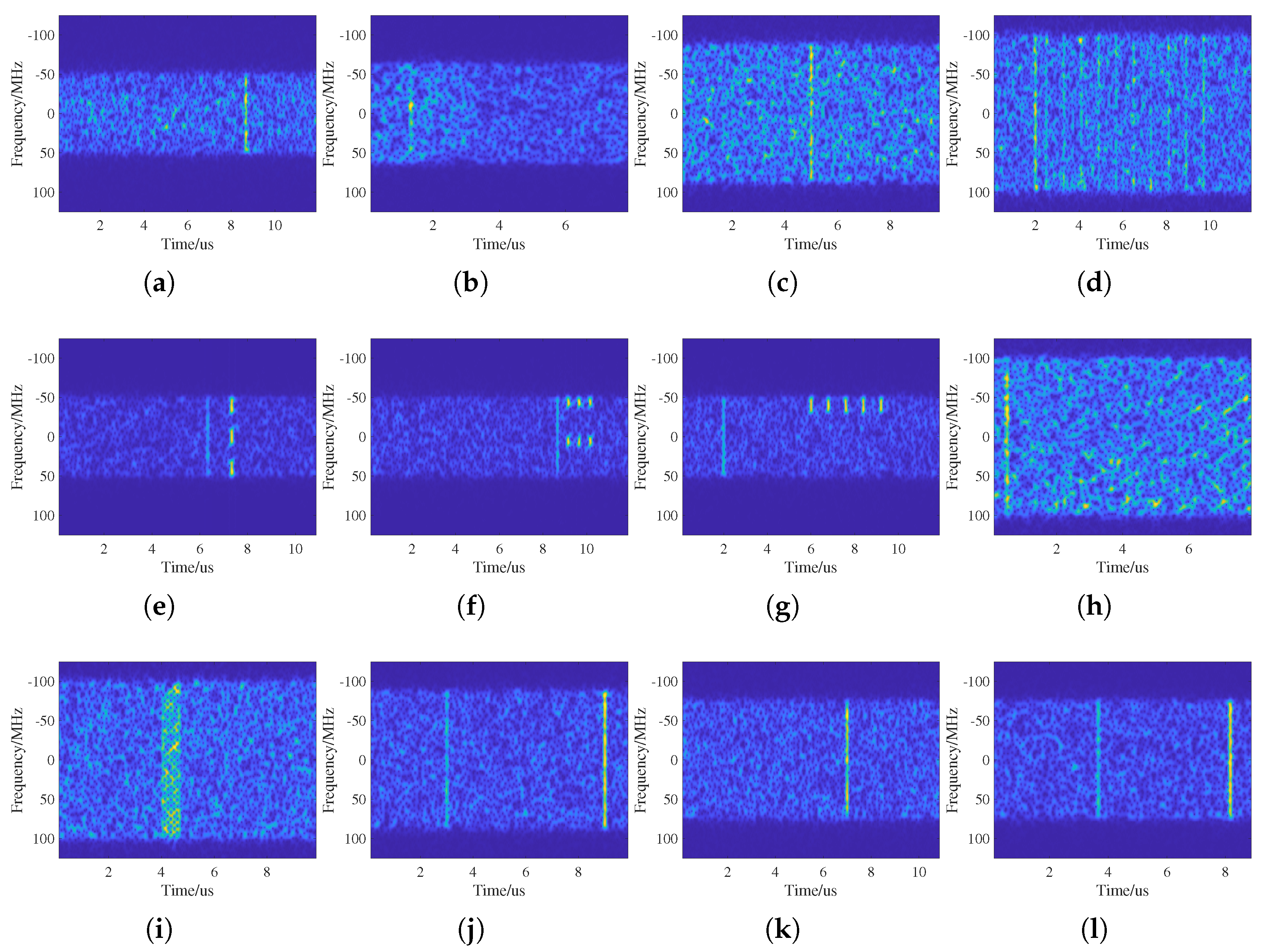
Figure 1 illustrates the pulse compression time–frequency characteristics of 12 classes of jamming signals.
3.2.3. Coherent Integration
To extract range-Doppler information, coherent integration is performed on
n consecutive pulse-compressed signals. The accumulated output for the
ith range gate is mathematically expressed as
where
is the sample number of each pulse repetition period.
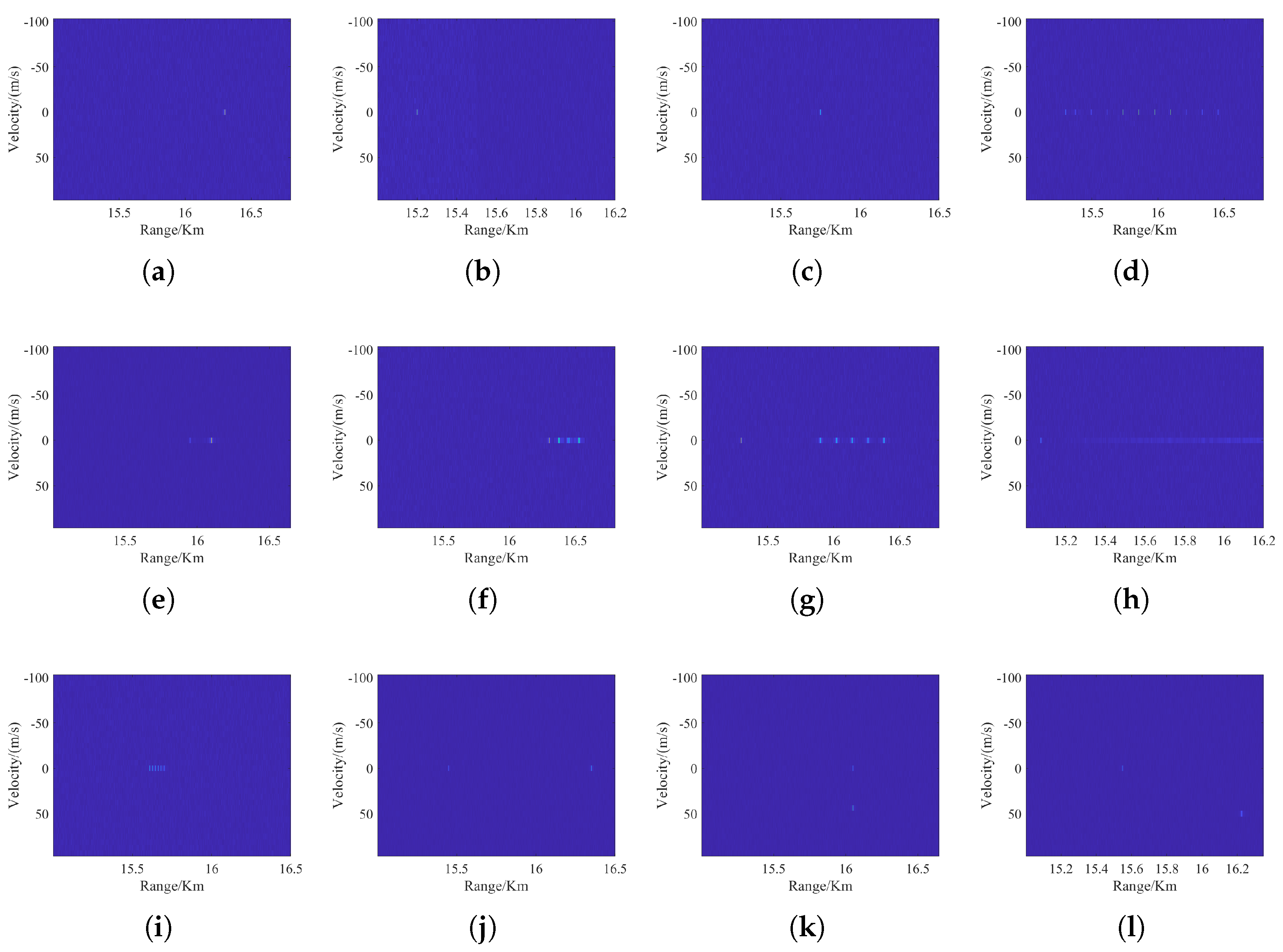
Figure 2 illustrates the range-Doppler characteristics of the 12 classes of jamming signals.
4. Methodology
4.1. Overview
The proposed framework, MDFNet, as shown in
Figure 3, employs a dual-branch architecture. The inputs, dual-modal images of jamming signals have been preprocessed as described in
Section 3.2, including PC-TF images and RD images. The framework sequentially executes three key stages: (1) single-modal feature extraction, (2) dual-modal feature fusion (DMFF), and (3) adaptive decision fusion (ADF). Firstly, single-modal feature extraction is performed on the PC-TF and RD images, respectively, defined as follows:
where
and
are the input PC-TF images and RD images, and
and
are the feature maps of the PC-TF branch and the RD branch, respectively.
denotes the feature extraction function with parameters
and
.
Subsequently, the feature maps
and
go through a dual-modal feature fusion to aggregate complementary information, following the formulation in Equation (
23).
where
denotes the fused features, and
represents the fusion operator with parameter
.
Finally, three parallel classifier heads process the fused features along with original modality features. To optimize information utilization, the adaptive decision fusion module dynamically integrates outputs from all branches, ultimately producing robust recognition results. This process can be expressed as follows:
where
and
denote the classification head function and adaptive decision fusion function.
4.2. Feature Extraction Module
As illustrated in
Figure 1 and
Figure 2, the PC-TF and RD images contain distinct features that characterize jamming signals. The PC-TF images are rich in content and contain valuable global features, whereas the RD images exhibit sparse features that are more effective for local representation. Consequently, this paper employs MogaNet [
41], which possesses multi-order feature representation capabilities as the backbone network for effective feature extraction.
MogaNet is a pure convolutional network characterized by a four-stage hierarchical architecture. Each stage integrates an embedding stem with N Moga blocks, where each block comprises a spatial aggregation (SA) block and a channel aggregation (CA) block. The embedding stem adjusts the resolution of the input images or feature maps, embedding them into dimensions. For an input image with a resolution of , the features are progressively downsampled across the four stages to resolutions of , , , and , respectively. The SA block is designed to extract both local and global features across different orders, while the CA block enhances feature representation in channel-wise. These two modules ensure that features are effectively utilized and optimized in both spatial and channel aspects.
The spatial aggregation (SA) block performs multi-order interactive aggregation of contextual features, as illustrated in
Figure 4a. This block consists of two cascaded modules: the feature decomposition (FD) module and the multi-order gated aggregation (Moga) module, which can be expressed as follows:
The
function first applies a
to the normalized input for linear transformation along the channel dimension. A global average pooling (GAP) operation is then employed to extract global contextual information. The GAP results are subsequently subtracted from the original features to derive richer feature representations. The resulting features are scaled by a factor
and activated by the GELU function, enhancing the distinction between local and global features for better aggregation. The detailed operations of FD module are given as follows:
The
function comprises two branches: the aggregation branch
and the context branch
, with parameter
and
, respectively. The
branch uses a
to perform linear adjustments along the channel dimension, preserving the original features while applying lightweight transformations to minimize information loss. The
branch focuses on multi-scale feature extraction, employing depth-wise convolutions (DWConv) layers with dilation ratios
d to encode multi-order contextual features. Specifically, the
branch first employs a
to extract low-order features
. Then,
Y are decomposed along the channel dimension into
. Subsequently,
and
are further processed by DWConv layers. Finally, the outputs are concatenated with
to form the multi-order context
. The process is defined as follows:
The SiLU activation function is employed to adaptively aggregate the multi-scale features output from the two branches. The equation is expressed as follows:
The channel aggregation (CA) block further processes the aggregated features by reallocating and adaptively weighting the channel-wise features, as shown in
Figure 4b. Specifically, the CA block first applies a normalization layer and a
to linearly transform the input features and adjust the channel dimensions. Then, a
and the GELU activation function are utilized to enhance spatial features. The channel aggregation module reallocates and gathers channel-wise information; ultimately, another
is applied to adjust the channel dimensions of the aggregated features, maintaining it the same as the input. The process formulated through the following expression:
The
function reallocates the channel-wise features through channel-reducing projection
, a non-linear activation, and weighted aggregation, which improves the model efficiency and generalization capability while maintaining a low computational cost. It is defined as follows:
where
denotes scaling factor, which can adaptively adjust the weights of channel-wise features with complementary interactions
. Finally, these are added to the original features to achieve higher channel-wise efficiency and better representation ability.
As the backbone network of the proposed framework, MogaNet encodes multi-order interactions to enhance multi-order feature representation and generalization capabilities, enabling efficient feature extraction in multi-modal jamming recognition.
4.3. Dual-Modal Feature Fusion Module
Compared to single-modal recognition methods [
26,
42], dual-modal data fusion offers significant advantages by leveraging complementary information across different domains. For jamming recognition, how to fuse dual-modal jamming images is critical and challenging. Building upon the success of transformers in multi-modal tasks [
43,
44], our method introduces a dual-modal feature fusion (DMFF) module [
45], which captures cross-modal information from a global perspective via the cross-attention mechanism.
Figure 3 demonstrates that the DMFF module consists of three specialized operations: spatial feature fhrinking (SFS), cross-modal feature enhancement (CFE), and fusion operation.
The SFS module compresses feature maps to reduce computational costs while preserving critical information. By adaptively integrating average and max pooling without additional parameters, it effectively reduces spatial dimensions. The process is defined as follows:
where
represents feature maps, and
and
denote the scaling factor and learnable parameter ranging from 0 to 1, respectively.
The CFE module captures cross-modal complementary information while enhancing long-term dependency modeling in fused features. For the feature maps
and
extracted by the backbone network, the CFE module convert them into a set of tokens. Spatial correlations are encoded through adaptive positional embeddings, which are learnable parameters jointly optimized with the network. The dual CFE modules independently enhance cross-modal features (without parameter sharing), capturing complementary information as formalized by
where
and
denote the PC-TF and RD feature tokens, and
and
denote the enhanced features after CFE.
Figure 5 demonstrates the workflow of the CFE module in enhancing RD domain features through cross-modal interaction. The module projects RD modality tokens into two matrices (
and
) and PC-TF tokens into
as follows:
where
,
, and
are the learnable weight parameters.
Next, the scaled dot-product attention operation [
46] is applied to the input query
and
pairs. The attention weights are derived by computing the query-key dot products scaled by
, followed by softmax normalization. The output vector is computed as follows:
where
denotes the dimension of
. This paper employs the cross-attention mechanism with eight parallel attention layers to enable simultaneous integration of PC-TF and RD feature spaces.
The vector
is projected back into the original feature space using weight matrix
and combined with the input tokens via residual connections. A two-layer feed-forward network (FFN) then applies nonlinear transformations to enhance feature representations in Equation (
36):
To adaptively learn from the data from different branches, the two residual connections apply the learnable coefficients , , , and .
Finally, bilinear interpolation recalibrates
and
to match the input feature dimensions. These recalibrated feature maps are then combined with the input feature maps via residual connections, producing enhanced features
and
, which are fused through
4.4. Adaptive Decision Fusion Module
The DMFF module effectively integrates complementary information from PC-TF and RD modalities. However, there is a risk of losing modality-specific discriminative features during fusion. To mitigate this limitation, we propose an adaptive decision fusion (ADF) module that dynamically optimizes fusion strategies. The ADF first conducts a vote among the three decisions derived from the PC-TF, RD, and DMFF. If the majority voting consensus threshold is unsatisfied, the highest-confidence decision is selected. This mechanism adaptively balances modality-specific details with fused representations while maintaining computational efficiency, as detailed in Algorithm 1.
| Algorithm 1 Adaptive Decision Fusion (ADF) |
| | Input: Decision based on {PC−TF, RD, DMFF}
Output: Final decision
|
Procedure:
Collect decisions in Voting_Result
Count each decision’s votes
if a majority exists then
Set Final_Decision to the majority decision
else
Set Final_Decision to the decision with the highest confidence
end if
return Final_Decision |
5. Experiments and Results
This section presents the dataset parameter settings, experimental details, and evaluation metrics. We conduct jamming signal recognition experiments using our proposed framework, alongside comparative experiments with other models and ablation studies. The recognition performance evaluation and experimental results analysis are subsequently elaborated.
5.1. Dataset Description
Due to the absence of publicly available datasets, we construct a radar active jamming (RAJ) dataset. This dataset contains 12 types of jamming, including SN, NP, NC, DFT, ISDR, ISRR, CI, SMSP, COMB, RGPO, VGPO, and RVGPO, which are simulated by the mathematical model in
Section 3.1. Detailed simulation parameters are provided in
Table 1. The simulation operates at a sampling rate of 250 MHz with a 16 us sampling time. The signals go through the processing flow described in
Section 3.2 to generate PC-TF and RD images. All images are resized to 224 × 224 pixels. The dataset contains 19,200 samples per jamming type, partitioned into training/validation/test subsets at 2:1:1 proportions. The test subset is further stratified by JNR levels, with 400 samples per jamming class at each JNR. The JNR of the dataset varies from −20 dB to 2 dB with 2 dB intervals. The dataset accounts for both mainlobe and sidelobe jamming scenarios. Given the radar antenna’s sinc-function response (exhibiting approximately 13.2 dB gain between the main lobe and first side lobe), the JSR is configured from −2 dB to 13 dB in 1 dB increments. To account for radar signal variability, bandwidth (100–200 MHz) and pulse width (4–8 us) are randomized to simulate the real-world operational conditions.
5.2. Experimental Details and Evaluation Metrics
The training process uses the Adam optimizer [
47] with an initial learning rate
, batch size of 64, and 100 training epochs. All experiments are implemented by PyTorch (version 2.5.1, developed by Meta Platforms Inc., Menlo Park, CA, USA) framework on two NVIDIA V100 GPUs. Recognition performance is evaluated through overall accuracy (OA), precision, recall, F1-score, and kappa coefficient, calculated following standard formulations, as in Equation (
38).
where
N and
K denote the total sample counts and class number of test datasets, with confusion matrix-derived metrics: true positives (TPs), false positives (FPs), true negatives (TNs), and false negatives (FNs).
represents overall accuracy, while
and
indicate the actual and predicted sample counts of the
kth class.
5.3. Performance Analysis of MDFNet
This section presents a comprehensive evaluation of the recognition performance of our proposed MDFNet.
Figure 6 displays the recognition accuracy, precision, recall, and F1-scores for each jamming type across varied JNR levels. As shown in
Figure 6a, deceptive jamming achieves 100% recognition accuracy consistently at JNR levels from
and 2 dB, retaining values above 96% even below
dB. Among suppressive jamming types, NP jamming achieves accuracy greater than 98% for JNR above
dB but sharply declines to 87.25% at
dB. In contrast, SN and NC exhibit stronger JNR dependency: SN maintains accuracy above 85% with JNR
dB but declines to 41% at
dB, while NC achieves accuracy greater than 90% with JNR
dB, declining progressively to approximately 57% at
dB. The reduced recognition accuracy for SN and NC jamming signals arises from two inherent limitations. Firstly, under identical noise bandwidth configurations, SN and NC jamming exhibit highly similar characteristics in both PC-TF and RD domains. Secondly, as noise-modulated jamming types, SN and NC jamming demonstrate weaker noise robustness than deceptive jamming in both domains due to the absence of pulse compression gain and coherent integration gain.
To analyze classification capability, confusion matrices in
Figure 7 illustrate the classification results at JNR
dB,
dB, and 0 dB. At 0 dB and
dB, classification errors mainly occur between SN and NC, with confusion intensifying as JNR decreases. This can be attributed to the inherent similarity between these noise-suppression jamming types, especially when their noise modulation bandwidth parameters are similar or identical. At
dB, significant confusion occurs between the three suppressive jamming types (SN, NP, and NC), while 2.6% of DFT samples are misclassified as suppressive jamming due to feature degradation caused by high-intensity noise. A similar confusion (1.2% misclassification rate) occurs between RGPO and RVGPO, caused by two factors: (1) high parameter similarity in range-delayed false targets, and (2) obscuration of discriminative Doppler-dimension features under strong noise.
In summary, deceptive jamming recognition demonstrates stable performance (100% accuracy when JNR dB with % degradation at dB). While suppressive jamming recognition exhibits performance degradation under extreme noise conditions due to their operational mechanisms, the framework achieves % average accuracy across all jamming types when JNR dB. These results verify that our proposed method can achieve both superior recognition accuracy and noise robustness.
To evaluate the generalization capability of MDFNet, we collected field jamming data from an experimental radar system and a jamming simulator. Limited by hardware, the field dataset only contains six jamming types (DFT, ISDR, ISRR, CI, RGPO, and RVGPO) with parameters partially overlapping but distinct from the simulation dataset. The JSR is set ranging from 0 dB to 12 dB with 4 dB intervals, while JNR is coarsely configured at three levels: 0 dB,
dB, and
dB. Each jamming type contains 240 samples. The confusion matrices in
Figure 8 demonstrate classification performance across different JNR levels. At 0 dB and
dB, all six jamming types achieve 100% recognition accuracy. At
dB, 3.8% of RVGPO samples are misclassified as RGPO and 1.2% of ISRR samples as CI due to excessive background noise. Overall, MDFNet maintains satisfactory recognition performance on the field dataset, effectively validating its generalization capability.
5.4. Network Performance Comparison
5.4.1. Recognition Performance Comparison
This section compares our MDFNet with four state-of-the-art methods: MobileViT_CA [
27], SSWANet [
26], MANet [
38], and DCNet [
39]. MobileViT_CA and SSWANet are single-modal recognition methods, whereas MANet and DCNet utilize dual-modal architectures. As demonstrated in
Table 2, MDFNet achieves the highest recognition accuracy for 11 out of 12 jamming types. Specifically, MDFNet demonstrates improvements of 3.43–12.19% in average accuracy, 2.62–10.29% in precision, 3.43–12.19% in recall, 3.38–12.65% in F1-score, and 3.74–13.29% in kappa over the other methods. These improvements validate the efficacy of the dual-modal fusion framework in advancing recognition performance.
Figure 9 further compares recognition performance across varied JNR levels. The proposed method consistently outperforms others across multiple evaluation metrics under all JNR conditions. When JNR level is relatively high (
dB to 2 dB), MDFNet maintains an accuracy greater than 98%, whereas MobileViT_CA and SSWANet achieve only 92.6% and 93%, respectively. Dual-modal methods MANet and DCNet attain peak accuracies about 97%. Even under challenging JNR conditions (
dB to
dB), MDFNet maintains accuracy greater than 92%, while MobileViT_CA and SSWANet degrade below 90% at at
dB and
dB, respectively. MANet and DCNet also fall below 90% when JNR drops to
dB. At an extremely low JNR of
dB, MDFNet’s average accuracy remains at 88.98%, which is approximately 12.86% and 18.19% higher than that of MANet and DCNet, respectively. In contrast, MobileViT_CA and SSWANet achieve only 59.19% and 48.58% accuracy, respectively. These results strongly demonstrate the superior noise robustness of our MDFNet.
5.4.2. Model Complexity
To evaluate practical deployment feasibility,
Table 3 quantifies computational complexity through three metrics: learnable parameters, floating-point operations per second (FLOPs), and inference time. Our MDFNet employs 6.47 M parameters, 52% fewer than DCNet, and 1.62G FLOPs, 11% lower than that of DCNet. Single-modal baselines MobileViT_CA and SSWANet, based on lightweight MobileViT and SqueezeNet backbones, exhibit fewer parameters and FLOPs. MANet’s 1D convolution-based dual-modal processing further reduces computational demands. Although SSWANet has the fewest FLOPs, its wavelet attention module increases the inference latency. The inference time of MDFNet is 24.1 ms, outperforming MobileViT_CA by 49% and SSWANet by 4.1%. These results verify that MDFNet achieves a favorable trade-off between computational efficiency and recognition performance.
5.5. Ablation Experiments
To validate the contributions of dual-domain inputs and proposed modules, we conducted ablation studies through two experimental configurations.
Table 4 compares performance when exclusively using PC-TF or RD as model inputs. Without the RD branch, average accuracy, precision, recall, F1-score, and kappa are reduced by 9.59%, 8.64%, 9.59%, 9.7%, and 10.46%, respectively. Similarly, without the PC-TF branch, these metrics are reduced by 5.83%, 5.2%, 5.83%, 5.75%, and 6.35%. As illustrated in
Figure 10a, recognition accuracy comparisons under varied JNR levels reveal that the recognition performance of the PC-TF domain degrades substantially when the JNR falls below
dB. While the RD domain maintains stability, its overall accuracy remains limited due to false target similarity in the RD domain. MDFNet utilizes the advantages of dual-domain inputs, thus achieving superior recognition performance over the entire JNR range, which indicates that each domain contributes to the performance enhancement.
In the DMFF ablation experiment, the DMFF module was replaced by a concatenation operation. In the ADF ablation experiment, the ADF module was removed, using only the features fused by DMFF for final decision-making.
Table 4 demonstrates that without DMFF, average accuracy, precision, recall, F1-score, and Kappa dropped by 2.64%, 2.26%, 2.64%, 2.61%, and 2.88%, respectively, while without ADF, these metrics dropped by 1.18%, 1.07%, 1.18%, 1.27%, and 1.29%.
Figure 10b shows that the drop in recognition accuracy becomes evident as the JNR decreases, particularly in DMFF-ablated configurations where the accuracy drops by 12% at JNR
dB. In summary, these experimental results clearly demonstrate the effectiveness of the proposed DMFF and ADF modules in enhancing the performance of our MDFNet.
6. Discussion
MDFNet achieves superior recognition performance and noise robustness through complementary feature fusion from PC-TF and RD domains. This dual-domain synergy addresses two critical challenges: (1) feature complementarity under diverse jamming parameters, and (2) enhanced robustness under low JNR conditions. The complementary synergy between PC-TF and RD domains resembles the operational robustness achieved by infrared and visible image fusion in all-weather surveillance systems, enabling radar systems to maintain reliable performance in complex electromagnetic environments. Experimental results reveal confusion between noise-suppression jamming types and accuracy degradation under low JNR conditions, primarily due to feature obscuration by background noise. However, for practical countermeasure applications, SN and NC jamming could be categorized collectively without compromising anti-jamming decisions. Performance degradation caused by dynamic jamming parameters and complex electromagnetic environments could be mitigated through an expanded real-world data collection for model refinement.
With 6.47 M parameters and 24.1 ms per-frame inference time on NVIDIA V100 GPU, MDFNet demonstrates feasible deployment potential in embedded radar processors. Actual implementation depends on specific hardware architectures, where platforms like NVIDIA Jetson AGX Xavier would enhance practicality. Additionally, the proposed method supports real-time processing with frame-by-frame execution in low-pulse repetition frequency (PRF) modes while requiring multi-frame interval processing for medium/high PRF operational scenarios.
Modern target detection radars such as pulse-Doppler radar and frequency-modulated continuous wave (FMCW) radar universally adopt standard signal processing workflows, including pulse compression, dechirping processing, and coherent integration. The proposed dual-domain feature construction method inherently aligns with these conventional radar processing chains. This compatibility ensures that our method introduces minimal additional computational overhead during data preprocessing, enabling both exceptional recognition performance and practical deployability.
7. Conclusions
To address the problem of jamming recognition in cognitive radar under complex electromagnetic environments, this paper proposes a novel framework MDFNet that integrates multi-domain features through a two-stage fusion strategy. First, PC-TF and RD domain images are adopted as dual-modal inputs, capturing jamming signal characteristics across complementary dimensions: PC-TF domain images represent range–frequency features, while RD domain images represent range–velocity features. Leveraging information from both domains enhances the learning capability of discriminative features. Second, MDFNet employs MogaNet as the backbone network, leveraging its multi-order feature representation to extract modality-specific patterns. A dual cross-attention transformer module then integrates and enhances the cross-modal complementary features, followed by an adaptive decision fusion module that further fuses modality-specific and cross-modality information for improved stability. Extensive experiments on the RAJ dataset validate the superiority of MDFNet. MDFNet maintains average accuracy % across JNR levels from dB to 2 dB and outperforms four SOTA existing methods in all JNR conditions. Ablation experiments verify the complementarity of the PC-TF and RD domains as well as the contributions of the DMFF and ADF modules.
In conclusion, the proposed two-stage fusion framework MDFNet, leveraging complementary PC-TF and RD domain features, achieves robust recognition of 12 types of active jamming under varied JNR conditions. This work establishes a new paradigm for reliable jamming recognition in complex electromagnetic environments, offering a practical solution for cognitive radar systems.
Author Contributions
Conceptualization, X.C. and C.W.; methodology, X.C.; validation, X.C.; formal analysis, X.C.; investigation, X.C.; data curation, X.C. and C.W.; writing—original draft preparation, X.C.; writing—review and editing, Y.L.; visualization, X.C.; supervision, Y.L.; project administration, C.W. and Y.L.; funding acquisition, Y.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was funded by the National Natural Science Foundation of China under Grant #62176247 and the Fundamental Research Funds for the Central Universities.
Data Availability Statement
The data are not publicly available due to the fact that they currently include privileged information.
Conflicts of Interest
The author Cheng Wang is employed by Beijing Raying Technology, Co., Ltd. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Kari, S.S.; Raj, A.A.B.; Balasubramanian, K. Evolutionary Developments of Today’s Remote Sensing Radar Technology—Right From the Telemobiloscope: A review. IEEE Geosci. Remote Sens. Mag. 2024, 12, 67–107. [Google Scholar] [CrossRef]
- Zhou, H.; Wang, Z.; Wu, R.; Xu, X.; Guo, Z. Jamming Recognition Algorithm Based on Variational Mode Decomposition. IEEE Sens. J. 2023, 23, 17341–17349. [Google Scholar] [CrossRef]
- Haykin, S.; Xue, Y.; Setoodeh, P. Cognitive Radar: Step Toward Bridging the Gap Between Neuroscience and Engineering. Proc. IEEE 2012, 100, 3102–3130. [Google Scholar] [CrossRef]
- Lang, W.; Mei, S.; Liu, Y.; Zhou, F.; Yang, X. A Periodic Multiple Phases Modulation Active Deception Jamming for Multistatic Radar System. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 3435–3451. [Google Scholar] [CrossRef]
- Zakerhaghighi, M.R.; Mivehchy, M.; Sabahi, M.F. Implementation and Assessment of Jamming Effectiveness Against an FMCW Tracking Radar Based on a Novel Criterion. IEEE Trans. Aerosp. Electron. Syst. 2020, 56, 4723–4733. [Google Scholar] [CrossRef]
- Wu, M.; Lin, Y.; Cheng, D.; Song, D.; Rao, B.; Wang, W. Using lightweight denoising network to suppress multiple barrage jamming in range-Doppler domain. IET Radar Sonar Navig. 2024, 18, 2308–2324. [Google Scholar] [CrossRef]
- Lou, M.; Yang, J.; Li, Z.; Ren, H.; An, H.; Wu, J. Joint Optimal and Adaptive 2-D Spatial Filtering Technique for FDA-MIMO SAR Deception Jamming Separation and Suppression. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5238414. [Google Scholar] [CrossRef]
- Su, D.; Gao, M. Research on Jamming Recognition Technology Based on Characteristic Parameters. In Proceedings of the 2020 IEEE 5th International Conference on Signal and Image Processing (ICSIP), Nanjing, China, 23–25 October 2020; pp. 303–307. [Google Scholar] [CrossRef]
- Wang, K.; Dong, Z.; Wan, T.; Jiang, K.; Xiong, W.; Fang, X. Research on Radar Active Deception Jamming Identification Method Based on RESNET and Bispectrum Features. In Proceedings of the 2021 International Conference on Computer Engineering and Application (ICCEA), Kunming, China, 25–27 June 2021; pp. 491–495. [Google Scholar] [CrossRef]
- Peng, R.; Dong, P.; Meng, C. Deceptive Jamming Recognition Based on Wavelet Entropy And RBF Neural Network. J. Phys. Conf. Ser. 2020, 1486, 022003. [Google Scholar] [CrossRef]
- Zhou, H.; Wang, L.; Guo, Z. Recognition of Radar Compound Jamming Based on Convolutional Neural Network. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 7380–7394. [Google Scholar] [CrossRef]
- Yao, D.; Liu, Z.; Li, F.; Li, Y. Distorted SAR target recognition with virtual SVM and AP-HOG feature. IET Int. Radar Conf. 2020, 2020, 734–739. [Google Scholar] [CrossRef]
- Tian, L.; Zeng, Z.; Li, Z.; Liu, C. Radar signal recognition method based on Random Forest model. In Proceedings of the 2022 3rd International Conference on Big Data, Artificial Intelligence and Internet of Things Engineering (ICBAIE), Xi’an, China, 15–17 July 2022; pp. 98–102. [Google Scholar] [CrossRef]
- Zhou, H.; Dong, C.; Wu, R.; Xu, X.; Guo, Z. Feature Fusion Based on Bayesian Decision Theory for Radar Deception Jamming Recognition. IEEE Access 2021, 9, 16296–16304. [Google Scholar] [CrossRef]
- Zhang, W.; Luo, K.; Zhao, Z.; Yang, J. A feature extraction and recognition method for interrupted sampling repeater jamming. AEU-Int. J. Electron. Commun. 2024, 176, 155156. [Google Scholar] [CrossRef]
- Peng, R.; Wei, W.; Sun, D.; Tan, S.; Wang, G. Dense False Target Jamming Recognition Based on Fast–Slow Time Domain Joint Frequency Response Features. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 9142–9159. [Google Scholar] [CrossRef]
- Shao, G.; Chen, Y.; Wei, Y. Convolutional Neural Network-Based Radar Jamming Signal Classification with Sufficient and Limited Samples. IEEE Access 2020, 8, 80588–80598. [Google Scholar] [CrossRef]
- Zhang, H.; Yu, L.; Chen, Y.; Wei, Y. Fast Complex-Valued CNN for Radar Jamming Signal Recognition. Remote Sens. 2021, 13, 2867. [Google Scholar] [CrossRef]
- Meng, Y.; Yu, L.; Wei, Y. Multi-Label Radar Compound Jamming Signal Recognition Using Complex-Valued CNN with Jamming Class Representation Fusion. Remote Sens. 2023, 15, 5180. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhao, Z.; Bu, Y. Radar Active Jamming Recognition under Open World Setting. Remote Sens. 2023, 15, 4107. [Google Scholar] [CrossRef]
- Zhang, M.; Chen, Y.; Zhang, Y. Weakly Supervised Transformer for Radar Jamming Recognition. Remote Sens. 2024, 16, 2541. [Google Scholar] [CrossRef]
- Zhou, H.; Wang, L.; Ma, M.; Guo, Z. Compound radar jamming recognition based on signal source separation. Signal Process. 2024, 214, 109246. [Google Scholar] [CrossRef]
- Zhou, Y.; Shang, S.; Song, X.; Zhang, S.; You, T.; Zhang, L. Intelligent Radar Jamming Recognition in Open Set Environment Based on Deep Learning Networks. Remote Sens. 2022, 14, 6220. [Google Scholar] [CrossRef]
- Lang, B.; Gong, J. JR-TFViT: A Lightweight Efficient Radar Jamming Recognition Network Based on Global Representation of the Time–Frequency Domain. Electronics 2022, 11, 2794. [Google Scholar] [CrossRef]
- Xiao, Y.; Zhou, J.; Yu, Y.; Guo, L. Active jamming recognition based on bilinear EfficientNet and attention mechanism. IET Radar Sonar Navig. 2021, 15, 957–968. [Google Scholar] [CrossRef]
- Wu, Z.; Wang, T.; Cao, Y.; Zhang, M.; Yang, L. Radar active deception jamming recognition based on Siamese squeeze wavelet attention network. IET Radar Sonar Navig. 2023, 17, 1886–1898. [Google Scholar] [CrossRef]
- Zou, W.; Xie, K.; Lin, J. Light-weight deep learning method for active jamming recognition based on improved MobileViT. IET Radar Sonar Navig. 2023, 17, 1299–1311. [Google Scholar] [CrossRef]
- Lv, Q.; Fan, H.; Liu, J.; Zhao, Y.; Xing, M.; Quan, Y. Multilabel Deep Learning-Based Lightweight Radar Compound Jamming Recognition Method. IEEE Trans. Instrum. Meas. 2024, 73, 2521115. [Google Scholar] [CrossRef]
- Yang, J.; Bai, Z.; Xian, Z.; Xiang, H.; Li, J.; Hu, H.; Dai, J.; Hao, X. Hybrid Attention Module and Transformer Based Fuze DRFM Jamming Signal Recognition. IEEE Commun. Lett. 2024, 28, 2091–2095. [Google Scholar] [CrossRef]
- Xiao, S.; Zhang, S.; Jiang, M.; Wang, W.Q. PSPNet: Pretraining and Self-Supervised Fine-Tuning-Based Prototypical Network for Radar Active Deception Jamming Recognition with Few Shots. IEEE Geosci. Remote Sens. Lett. 2024, 21, 3506105. [Google Scholar] [CrossRef]
- Wu, Z.; Wang, T.; Cao, Y.; Zhang, M.; Guo, W.; Yang, L. Transfer Learning-Based Dual GCN for Radar Active Deceptive Jamming Few-Shot Recognition. IEEE Trans. Aerosp. Electron. Syst. 2024, 61, 2185–2197. [Google Scholar] [CrossRef]
- Zhang, J.; Liang, Z.; Zhou, C.; Liu, Q.; Long, T. Radar Compound Jamming Cognition Based on a Deep Object Detection Network. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 3251–3263. [Google Scholar] [CrossRef]
- Peng, R.; Wu, X.; Wang, G.; Sun, D.; Yang, Z.; Li, H. Intelligent Recognition and Information Extraction of Radar Complex Jamming Based on Time-Frequency Features. J. Syst. Eng. Electron. 2024, 35, 1148–1166. [Google Scholar] [CrossRef]
- Lv, Q.; Quan, Y.; Feng, W.; Sha, M.; Dong, S.; Xing, M. Radar Deception Jamming Recognition Based on Weighted Ensemble CNN With Transfer Learning. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5107511. [Google Scholar] [CrossRef]
- Luo, Z.; Cao, Y.; Yeo, T.S.; Wang, Y.; Wang, F. Few-Shot Radar Jamming Recognition Network via Time-Frequency Self-Attention and Global Knowledge Distillation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5105612. [Google Scholar] [CrossRef]
- Luo, Z.; Cao, Y.; Yeo, T.S.; Wang, F. Few-Shot Radar Jamming Recognition Network via Complete Information Mining. IEEE Trans. Aerosp. Electron. Syst. 2024, 60, 3625–3638. [Google Scholar] [CrossRef]
- Shao, G.; Chen, Y.; Wei, Y. Deep Fusion for Radar Jamming Signal Classification Based on CNN. IEEE Access 2020, 8, 117236–117244. [Google Scholar] [CrossRef]
- Hou, L.; Zhang, S.; Wang, C.; Li, X.; Chen, S.; Zhu, L.; Zhu, Y. Jamming Recognition of Carrier-Free UWB Cognitive Radar Based on MANet. IEEE Trans. Instrum. Meas. 2023, 72, 8504413. [Google Scholar] [CrossRef]
- Chen, H.; Chen, H.; Lei, Z.; Zhang, L.; Li, B.; Zhang, J.; Wang, Y. Compound Jamming Recognition Based on a Dual-Channel Neural Network and Feature Fusion. Remote Sens. 2024, 16, 1325. [Google Scholar] [CrossRef]
- Richards, M.A. Fundamentals of Radar Signal Processing; Mcgraw-Hill: New York, NY, USA, 2005; Volume 1. [Google Scholar]
- Li, S.; Wang, Z.; Liu, Z.; Tan, C.; Lin, H.; Wu, D.; Chen, Z.; Zheng, J.; Li, S.Z. MogaNet: Multi-order Gated Aggregation Network. arXiv 2024, arXiv:2211.03295. [Google Scholar] [CrossRef]
- Mehta, S.; Rastegari, M. MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar] [CrossRef]
- Wei, X.; Zhang, T.; Li, Y.; Zhang, Y.; Wu, F. Multi-Modality Cross Attention Network for Image and Sentence Matching. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10938–10947. [Google Scholar] [CrossRef]
- Yu, H.; Gao, J.; Zhou, S.; Li, C.; Shi, J.; Guo, F. Cross-Modality Target Detection Using Infrared and Visible Image Fusion for Robust Objection recognition. Comput. Electr. Eng. 2025, 123, 110133. [Google Scholar] [CrossRef]
- Shen, J.; Chen, Y.; Liu, Y.; Zuo, X.; Fan, H.; Yang, W. ICAFusion: Iterative cross-attention guided feature fusion for multispectral object detection. Pattern Recognit. 2024, 145, 109913. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.M.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. arXiv 2017, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}