1. Introduction
Object detection in remote sensing images (RSIs) has attracted significant research attention in recent years [
1,
2], primarily due to its critical role in identifying and localizing specific objects including vehicles, vessels, and aircraft in aerial images. It has been extensively applied to domains such as satellite positioning and atmospheric monitoring. Compared to the traditional horizontal bounding box generation method, remote sensing object detection focuses more on producing bounding boxes that are precisely aligned with the orientation of objects. As a result, numerous researchers have devoted efforts to developing various oriented bounding box (OBB) detectors [
3,
4], aiming to improve codes of OBBs [
5,
6,
7] and enhance the accuracy of angle prediction [
8,
9,
10,
11]. However, as for the feature extracting of objection detection, the unique characteristics of remote sensing images in feature extraction have not yet been fully explored.
Remote sensing images are typically captured from an aerial perspective at a high resolution, which results in a wide range of object scales, from small entities such as vehicles and ships to large structures like football fields and ring roads. The accuracy of object recognition in these images depends not only on the appearances of the objects themselves but also on extensive contextual information. Surrounding environments provide valuable cues regarding the shape, orientation, and other characteristics of an object. Thus, some studies employed explicit data augmentation techniques [
12,
13,
14] to enhance the robustness of contextual feature representation; meanwhile, other studies focused on multi-scale feature integration [
15,
16] for extracting rich multi-scale contextual information. However, due to the significant scale variations in objects in remote sensing images and the presence of numerous high-aspect-ratio objects, where a high-aspect-ratio object refers to a target with an aspect ratio significantly greater than 1 (e.g., ships, bridges, etc.), such an object’s elongated form imposes a special demand on receptive field design. This variation reduces the accuracy of CNN- and transformer-based methods in object recognition and detection. The primary reasons are as follows. (a) In remote sensing image recognition, CNNs are constrained by the limited sizes of their local receptive fields. This limitation makes it difficult to effectively capture contextual information for high-aspect-ratio objects in high-resolution remote sensing images. In addition, irrelevant information from surrounding areas is included, increasing the likelihood of misdetections and omissions, ultimately leading to misclassification. (b) In remote sensing object detection, achieving a balance between robust local contextual feature extraction and precise global context modeling is essential for optimal detection performance. The advantage of transformers is the ability to establish long-range dependencies through self-attention mechanisms. However, directly applying traditional transformer models to remote sensing object detection can result in slow convergence, leading to a series of negative impacts on detection performance. Additionally, this approach has high computational complexity, which significantly slows down inference speed, reducing the FPS and limiting real-time applications.
In recent years, large-kernel convolutional networks have been introduced into the field of remote sensing object detection. By expanding the receptive field, these networks effectively capture broader contextual information and have achieved promising results. A notable example is LSKNet [
17], which incorporates a series of large convolutions combined with a spatial selection mechanism to capture long-range contextual information. PKINet [
18] further extends LSKNet by employing a parallel large-square convolution structure, enhancing the model’s ability to handle object scale variations. However, despite the expansion of the receptive field, these models primarily extract features within square-shaped windows. This limitation makes it difficult to effectively capture the contextual information of high-aspect-ratio objects. To address this issue, the large strip convolutions proposed in [
19] have demonstrated strong capability in detecting objects with various aspect ratios. These convolutions exhibit excellent feature representation learning abilities in remote sensing object detection. Additionally, the dilated large-kernel convolutions used in [
17,
18] may overlook dependencies between distant objects within the receptive field. Transformer-based models mitigate this limitation through their global self-attention mechanism. However, this attention mechanism comes with significantly high computational complexity, leading to reduced inference speed, making them less suitable for real-time remote sensing applications.
Recently, the state space model (SSM) Mamba [
20], equipped with a selective scanning mechanism, has demonstrated both superior performance in long-range interactions and linear computational complexity. These advantages enable it to effectively address the computational inefficiency of transformers in long-sequence state space modeling. Existing SSM-based models typically employ a multi-scan strategy, involving steps such as forward, backward, horizontal, and vertical scanning, to ensure that every part of an image can establish connections with others. However, the repetitive extraction of similar sequence patterns within the selective scanning strategy exacerbates information redundancy. Encouragingly, a multi-granularity strategy, by capturing spatial dependencies at different levels of granularity, offers a promising solution to this challenge. Therefore, exploring efficient selective scanning mechanisms is crucial for improving SSM-based approaches.
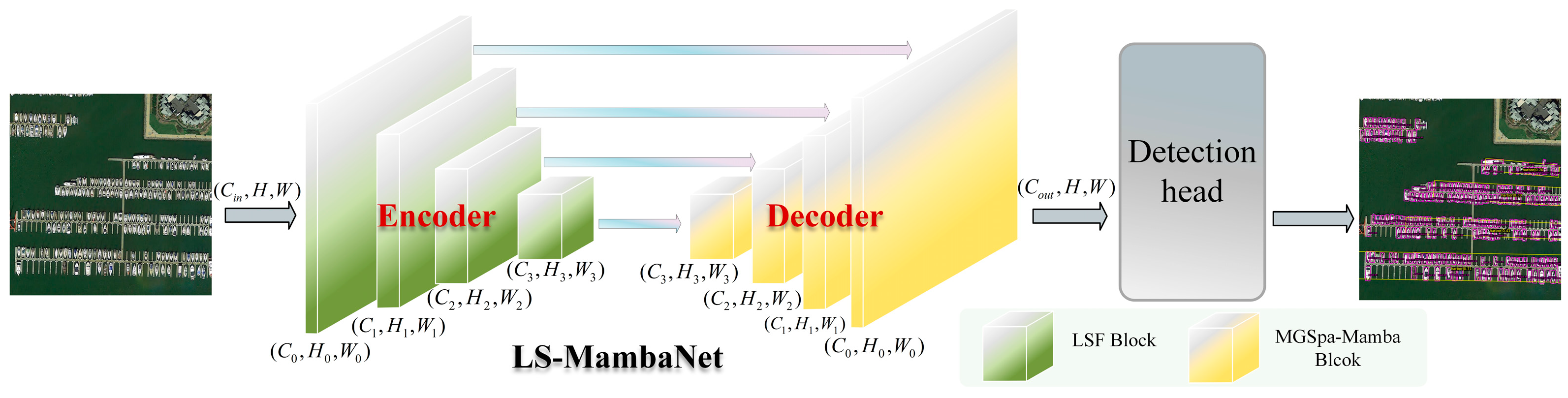
Remote sensing images often exhibit significant object scale variation and high-aspect-ratio characteristics, which pose substantial challenges for accurate object detection. Effectively capturing both local details and long-range contextual information under these conditions has become a critical research problem. To address this, we propose LS-MambaNet, a general-purpose backbone network specifically designed to tackle the unique difficulties of remote sensing object detection, particularly those caused by large variations in object scales and elongated shapes.
In summary, the main contributions of this paper are as follows:
To address the issue that traditional CNN methods are limited by fixed square receptive fields and struggle to effectively capture the contextual information of high-aspect-ratio objects in remote sensing images, the LSF Block is proposed. This module enhances the model’s ability to extract context from high-aspect-ratio objects by combining a grouping fusion strategy based on large-kernel convolutions with large strip convolutions in orthogonal directions.
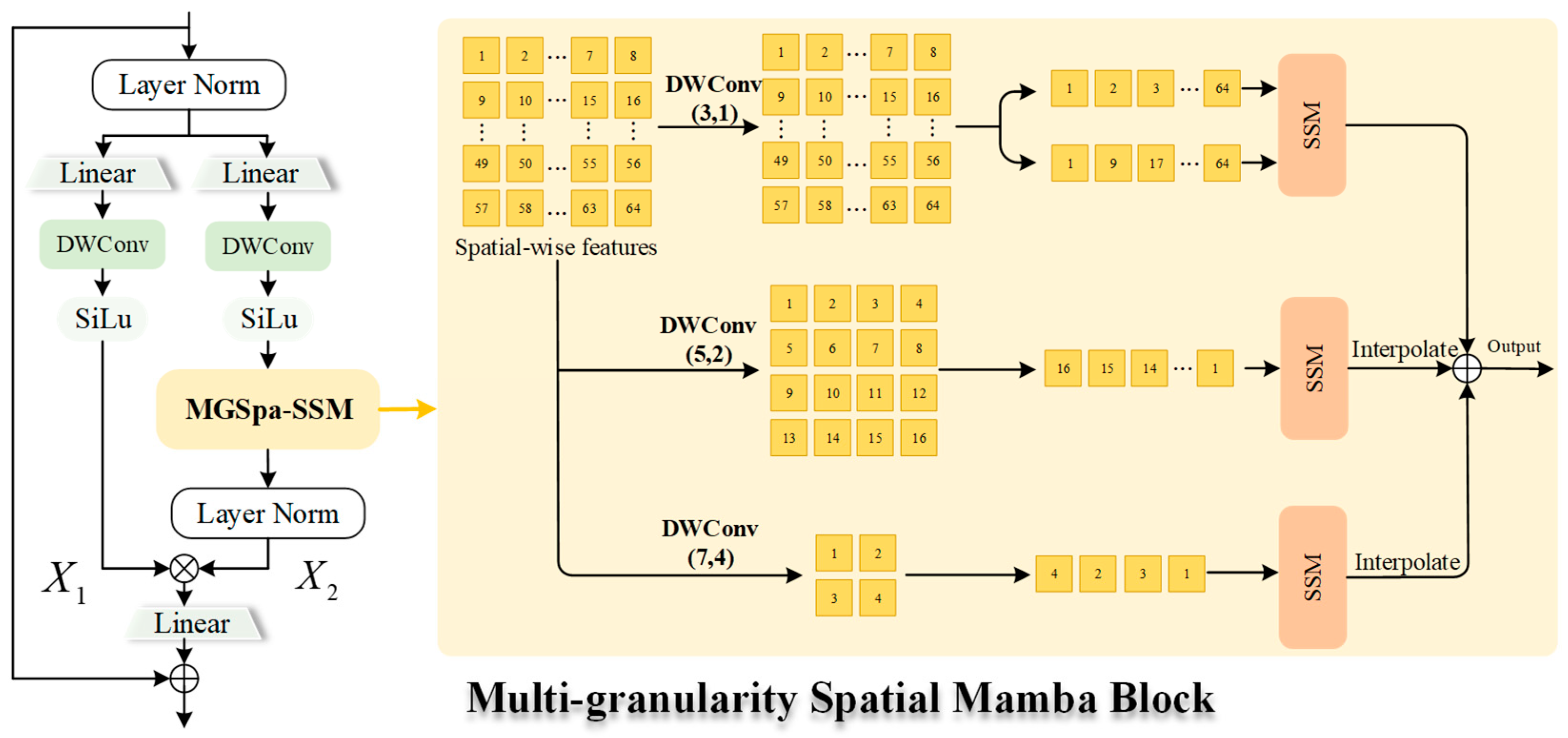
The MGSpa-Mamba Block has been designed not only to reduce computational costs but also to enhance inference speed, thereby improving the FPS, especially when processing high-resolution remote sensing images. This block adopts a multi-granularity scanning strategy to reduce information redundancy across multiple scanning paths and lower computational costs, thereby ensuring the efficient modeling of spatial dependencies.
The proposed LS-MambaNet model achieves state-of-the-art detection performance while significantly improving the FPS, advancing remote sensing object detection to a higher level. On the DOTA1.0 and HRSC2016 datasets, LS-MambaNet demonstrates outstanding detection accuracy and inference efficiency.
4. Experiments
This section presents extensive experiments to evaluate the effectiveness and performance of the model in remote sensing object detection. First, the datasets used in the experiments are briefly introduced. Next, the experimental setup and evaluation metrics are explained. Finally, the results of ablation studies and comparative experiments are provided, followed by an analysis of the observed phenomena and trends.
4.1. Datasets
DOTA-v1.0 [
1] is a large-scale optical remote sensing image object detection dataset, consisting of 2806 remote sensing images with sizes ranging from 800 × 800 to 4000 × 4000. It includes 188,282 instances across 15 categories, such as ‘airplane’ (PL), ‘baseball diamond’ (BD), ‘bridge’ (BR), and ‘ground track field’ (GTF), each annotated with horizontal bounding boxes (HBBs) and oriented bounding boxes (OBBs). The dataset is divided into training (50%), testing (33%), and validation sets, with the remainder allocated for the test set.
HRSC2016 [
2] is a high-resolution remote sensing dataset that is collected for ship detection. It consists of 1061 images: 436 images are for training data, 444 images are for testing data, and the rest are validation data. It contains 2976 ship instances.
4.2. Implementation Details and Evaluation Metrics
In our experiments, we evaluate the oriented object detection model using the DOTA-v1.0 and HRSC2016 datasets. To ensure a fair comparison, we adhere to the dataset processing methods used in other mainstream studies [
6,
17]. For DOTA-v1.0, we utilize a multi-scale approach during training and testing by resizing images to three different scales (0.5, 1.0, 1.5) and then dividing each resized image into overlapping 1024 × 1024 patches with a 500-pixel overlap. For HRSC2016, images are resized by setting the longer edge to 800 pixels while preserving their aspect ratio. The backbone network is first pre-trained on the ImageNet-1K dataset and subsequently fine-tuned on the remote sensing benchmark. To compare with SOTA results, we adopt a 300-epoch pretraining strategy for the backbone to improve the primary results’ accuracy. For ablation studies, we reduce the pretraining epochs to 100 to enhance experimental efficiency. Unless otherwise mentioned, LS-MambaNet is built by default in the framework of Oriented RCNN. Models are trained on training and validation sets and evaluated on the test set. We employ the AdamW optimizer for training, with 36 epochs allocated for HRSC2016 and 12 epochs for DOTA-v1.0. The initial learning rate is 0.0004 for HRSC2016 and 0.0002 for DOTA-v1.0. In both experiments on these two datasets, the learning rate is tuned using cosine scheduling and a warm-up strategy, where the weights decay to 0.05. LS-MambaNet is implemented under the MMRotate framework. The training of LS-MambaNet is conducted on four RTX 4090 GPUs (batch size: 8) in an Ubuntu 22.04 environment while testing uses a single RTX 4090 GPU. All reported FLOPs are calculated with 1024 × 1024 input images, and mean average precision (mAP) is used to measure the accuracy of the compared methods.
Table 1 lists the detailed configuration of LS-MambaNet used in this paper.
Our experimental evaluation metrics include mean average precision (mAP), frames per second (FPS), model parameter count (Params), and model floating point operations (FLOPs).
mAP is a comprehensive metric obtained by averaging the AP values. It uses an integration approach to calculate the area under the precision–recall curve for all classes. Therefore, mAP can be calculated thus:
Here, p represents precision, r represents recall, and N is the number of categories.
FPS refers to the number of frames processed by the model in one second. A higher FPS value indicates faster inference speed. The calculation formula is as follows:
Here, Latency refers to the model’s computation time, which is the average time required for the model to process a single image.
The Params value and the FLOPs are calculated by feeding the model with the same batch of images. The Params value refers to the total number of parameters in the model while FLOPs measure the computational complexity, representing the number of floating-point operations required to process the given input.
4.3. Comparison with the State-of-the-Art
Results for DOTA-v1.0: We compare LS-MambaNet with 12 state-of-the-art methods on the DOTA-v1.0 dataset. The reported DOTA results are obtained by submitting the predicted outcomes to the official evaluation server. As shown in
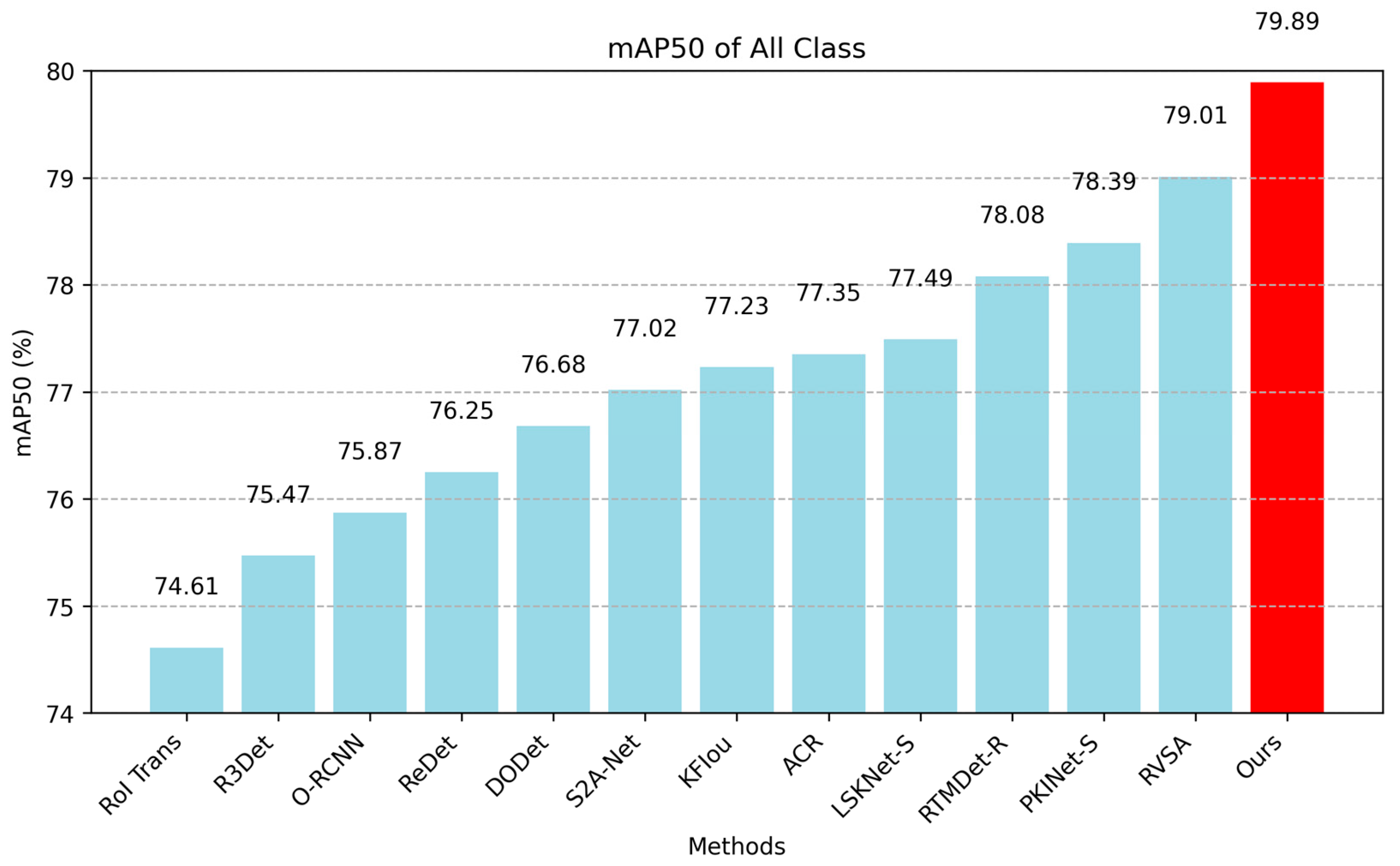
Table 2, our LS-MambaNet achieves state-of-the-art performance, with an mAP of 79.89%, improving by 1.5% and 1.81% compared to Pkinet-S and LSKnet-S, respectively. This demonstrates the effectiveness and efficiency of the proposed LS-MambaNet model, which shows high recognition capability for complex objects in remote sensing images.
Figure 4 and
Figure 5 display the line charts for detection accuracy by category and the bar charts for overall detection accuracy, respectively.
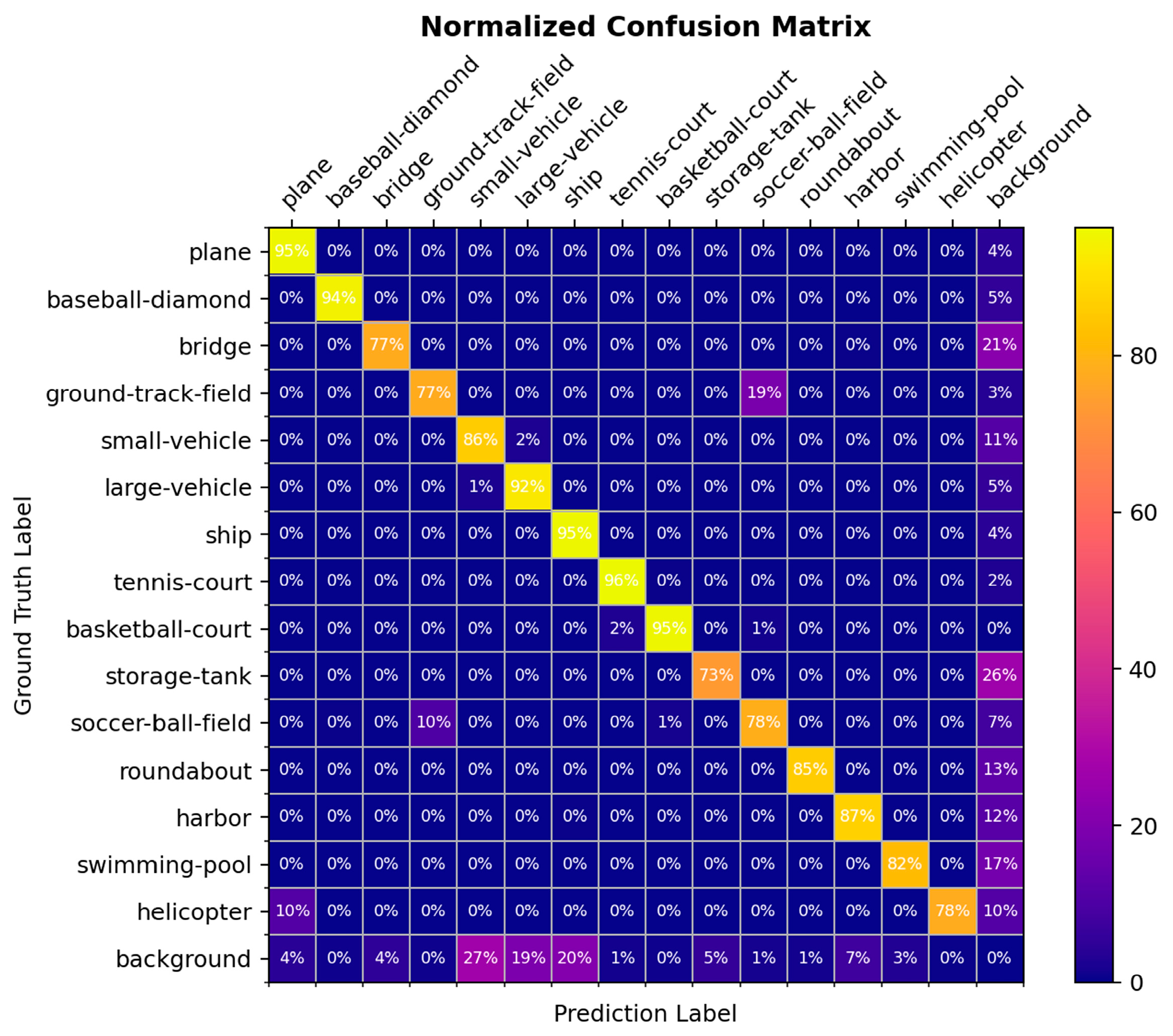
Figure 6 presents the confusion matrix generated by the model on the DOTA-v1.0 test set, where the rows represent the true categories and the columns represent the predicted categories. The diagonal elements from the top-left to bottom-right represent the accuracy with which the model correctly classifies each category.
Results for HRSC2016: The ship instances in HRSC2016 exhibit significant variations in the aspect ratio, arbitrary orientation, and instance size within the same category, posing a great challenge to the detector’s generalization and accuracy. We evaluate the performance of LS-MambaNet on the HRSC2016 dataset against nine state-of-the-art methods. As shown in
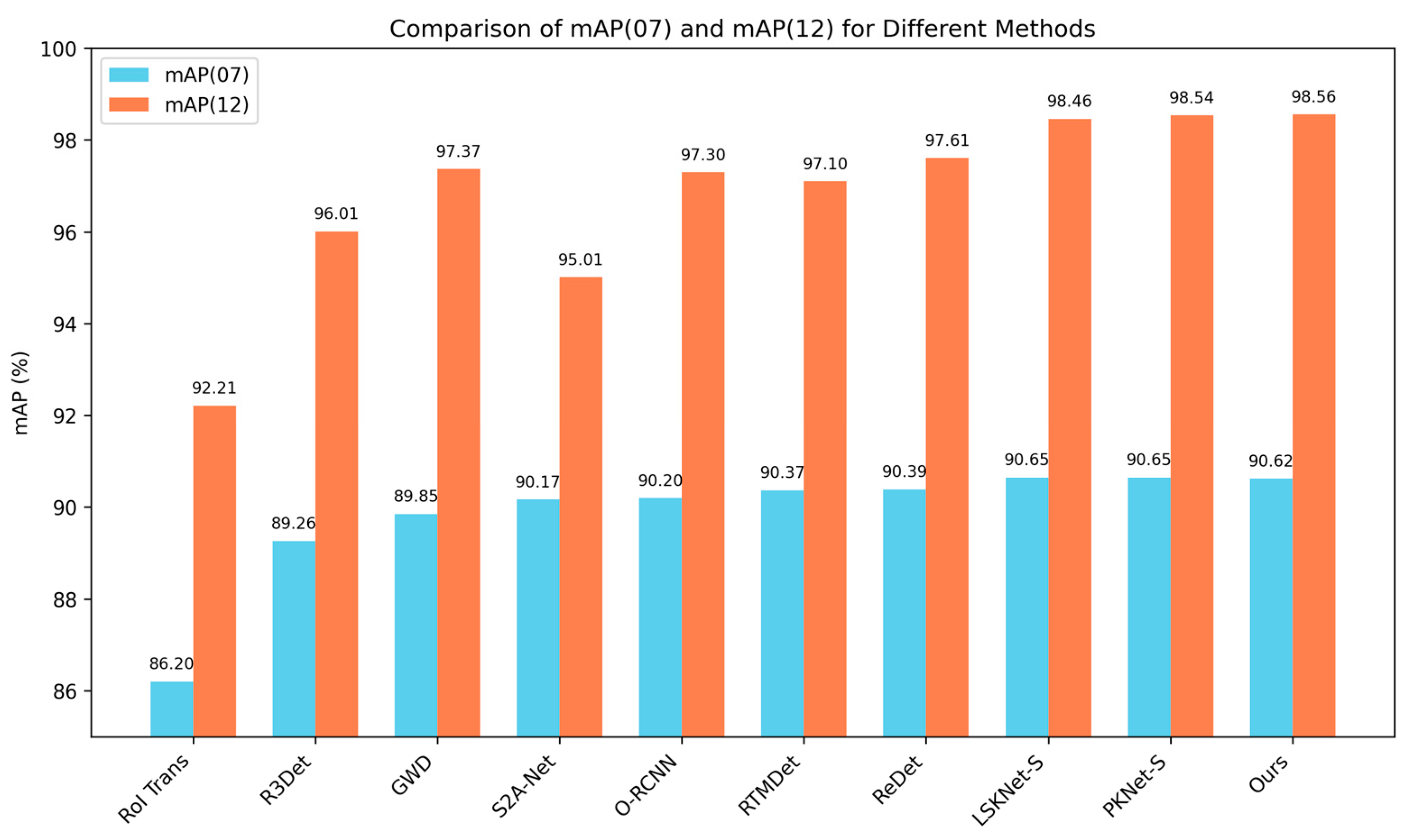
Table 3, the mAP values under PASCAL VOC 2007 and VOC 2012 metrics are 90.62% and 98.46%, respectively. This demonstrates that, compared to other methods, LS-MambaNet has stronger robustness in recognizing objects with large scale variations.
Figure 7 shows the bar charts of the mAP (07) and mAP (12) metrics for the comparison methods on the HRSC2016 dataset.
Overall, the experimental results demonstrate that the proposed method not only achieves significant performance improvements on the DOTA-V1.0 dataset but also delivers excellent detection performance on the HRSC2016 dataset. Our LS-MambaNet enhances the accuracy of remote sensing object detection under normal conditions, primarily due to the following reasons: (1) In the LS-MambaNet model, the LSF Block combines a grouping fusion strategy with large strip convolutions to adaptively adjust the receptive field of features. This enhances the model’s ability to extract spatial features for high-aspect-ratio objects and effectively captures their contextual information. (2) The MGSpa-Mamba Block is proposed, and this optimizes computational efficiency through a multi-granularity strategy and reduces functional redundancy across different scanning paths, thereby more efficiently modeling the global contextual information of the detection targets. The results of the DOTA1.0 dataset and HRSC2016 dataset detection visualizations are shown in
Figure 8 and
Figure 9, respectively.
4.4. Ablation Study
Our proposed LS-MambaNet consists of two key components: the LSF Block and the MGSpa-Mamba Block. Therefore, we conduct the following experiments and compare the results using O-RCNN [
6] as the baseline model.
4.4.1. Analysis of the Grouping Fusion Strategy in the LSF Block
As shown in
Table 4, we investigate the kernel design of the grouped fusion strategy in LSF. The results indicate that using only small kernels (1 × 1 and 3 × 3) in the grouping strategy leads to suboptimal detection performance due to limited texture information extraction capability. Subsequently, we adopt (1,3,5,7) as the grouping kernel structure, with kernel sizes ranging from 1 × 1 to 7 × 7. Under this configuration, the model achieves the best performance, with an mAP of 79.89% and the highest FPS of 22.9. Further testing reveals that when the grouped kernels are adjusted to (3,5,7,9), the additional expansion of large kernels not only increases the computational complexity and parameter size (with an increase of 1.06M parameters) but also leads to a drop in the FPS from 22.9 to 19.2 and a 0.56% decrease in the mAP. This suggests that an excessively large grouped kernel strategy may introduce background noise, leading to performance degradation while also negatively impacting the inference speed.
These findings demonstrate that the (1,3,5,7) grouping fusion strategy achieves the best trade-off between speed and accuracy, maximizing both the FPS and mAP. It effectively captures multi-scale contextual information while avoiding excessive computational overhead, making it the optimal choice for balancing detection precision and inference efficiency.
4.4.2. Analysis of the Strip Convolution in the LSF Block
Firstly, we analyze the impact of different kernel sizes in strip convolutions on model performance, as shown in
Table 5. The two parameters in the first column represent the kernel sizes of the horizontal and vertical strip convolutions, respectively. Experimental results indicate that smaller kernels (e.g., 3 × 3 and 5 × 5) struggle to effectively capture long-range dependencies, especially when handling elongated objects in vertical and horizontal directions, leading to a decline in detection accuracy. In contrast, larger kernels (e.g., 7 × 7 and 11 × 11) improve detection accuracy by capturing more distant contextual information, thereby enhancing overall model performance. Specifically, a kernel size of (11,11) achieves the highest mAP (79.89%) while also maintaining the best inference speed (22.9 FPS), demonstrating its efficiency in both accuracy and computational performance.
Notably, while increasing the kernel size from (3,3) to (5,5) improves FPS from 20.5 to 22.6, the FPS fluctuates slightly when moving to (7,7) (21.5 FPS) before reaching its peak at (11,11) (22.9 FPS). This trend suggests that moderately increasing the kernel size enhances both inference speed and detection performance by efficiently capturing long-range dependencies without introducing excessive computational overhead. Based on these findings, we adopt a strip convolution with a kernel size of (11,11) as it provides the optimal trade-off between accuracy and speed, ensuring robust performance in remote sensing object detection.
4.4.3. Analysis of the MGSpa-Mamba Block
Table 6 presents the impact of changing the number of downsampling paths on the detection performance of the DOTA1.0 dataset. The results show that when the network architecture adopts a mixed configuration of two original resolution paths and two downsampling paths, the model achieves optimal detection performance, with parameter, FPS, and mAP values of 1.79 M, 22.9, and 79.89%, respectively. This configuration strikes the best balance between feature redundancy and the efficient retention of key details by preserving fine-grained semantic information in the high-resolution feature maps while leveraging downsampling paths to capture long-range spatial dependencies, thereby validating the effectiveness of the multi-scale scanning strategy. In contrast, when the number of downsampling paths exceeds two (i.e., three or four), the detection performance systematically declines. Specifically, the mAP drops to 78.17% with three paths and to 77.33% with four paths. A similar trend is observed in the FPS: while the FPS slightly decreases from 22.9 to 21.2 when increasing the number of paths from two to three, it rebounds to 22.1 at four paths, indicating that aggressive downsampling does not consistently lead to faster inference. This phenomenon reveals the dynamic balance mechanism between model complexity and feature fidelity. Excessive downsampling, although reducing the computational load, leads to the irreversible loss of high-frequency feature information, which negatively impacts small object detection accuracy.
Under limited computational resource constraints, an optimal balance point for downsampling paths exists, which, in this experiment, is determined to be two downsampling paths. This balance avoids wasting dense computational resources while effectively maintaining the richness of feature space, achieving both high detection accuracy and the best inference speed (22.9 FPS). Additionally, the paper finds that the effect of multi-granularity fusion strategies on the number of parameters exhibits non-linear characteristics. When the number of downsampling paths exceeds two, the reduction in parameters does not correlate proportionally with performance enhancement, offering new optimization directions for future lightweight model designs.
4.4.4. Synergy Analysis Between LSF and MGSpa-Mamba
In addition to intra-module parameter tuning, we further investigate the individual and combined contributions of the LSF Block and the MGSpa-Mamba Block to the overall performance. Specifically, three experimental comparison sets are specifically designed: (1) baseline + LSF only, (2) baseline + MGSpa-Mamba only, and (3) full LS-MambaNet (both modules). The results for the DOTA-v1.0 dataset are shown in
Table 7.
From the results, we observe that introducing the LSF Block alone improves the baseline by +1.94% mAP while the MGSpa-Mamba Block alone brings a +2.18% gain. When both modules are incorporated, the final performance reaches 79.89% mAP, demonstrating a cumulative improvement of +4.02% over the baseline. Specifically, the LSF module effectively expands the local sensing field through large-band convolution, which is especially adapted to the feature extraction of high-aspect-ratio targets; the MGSpa-Mamba module improves the long-range contextual relationship modeling capability through multi-granularity state modeling. The two complement each other so that the model can extract local and global information more comprehensively in remote sensing images, thus realizing more accurate target detection.
Although our LS-MambaNet significantly improves the detection accuracy, we observe a moderate decrease in the FPS compared to the baseline model. This phenomenon is mainly attributed to the additional computational complexity introduced by the LSF Block and the MGSpa-Mamba Block.
Specifically, the LSF Block incorporates multiple grouped convolutions with different kernel sizes and employs strip convolutions (e.g., 11 × 1 and 1 × 11) to enhance the receptive field, resulting in a slight increase in the number of per-layer operations. The MGSpa-Mamba Block adopts a multi-granularity spatial modeling strategy, where features are processed across multiple downsampled paths with selective state space scanning, thereby increasing the processing steps and memory access overhead. While these modules introduce more computations, they enable the network to capture richer spatial context and long-range dependencies, which are crucial for remote sensing object detection.
Overall, despite a decrease in the FPS (from 25.4 FPS to 22.9 FPS), the trade-off is reasonable given the significant improvement in the mAP (+4.02%), and LS-MambaNet still maintains competitive inference efficiency compared to other state-of-the-art methods.
4.4.5. Performance Analysis of the LS-MambaNet Backbone in Different Detection Frameworks
For fair comparison, all detection frameworks have been trained using the same hyperparameter settings, including the optimizer, learning rate schedule, batch size, and data preprocessing methods, following the settings described in
Section 4.2.
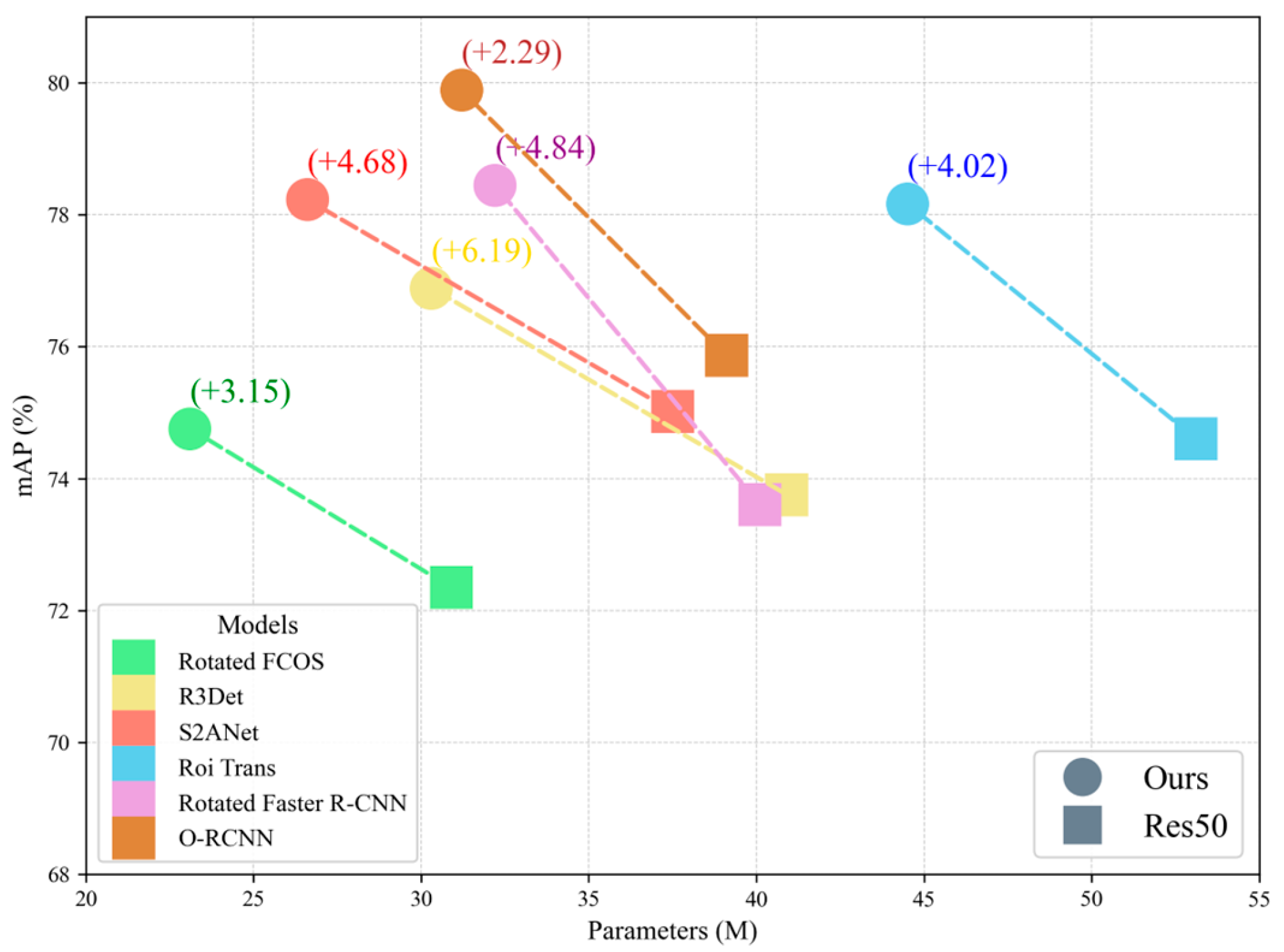
To validate the generalizability and effectiveness of the proposed LS-MambaNet backbone, we conduct evaluations across various remote sensing object detection frameworks, including both two-stage frameworks (RoI Transformer, Rotated Faster R-CNN, and O-RCNN) as well as single-stage frameworks (Rotated FCOS, R3Det, and S2A-Net). As shown in
Table 8 the experimental results demonstrate that LS-MambaNet significantly improves detection performance compared to the classic ResNet-50 backbone. This proves that LS-MambaNet is widely applicable across different detection frameworks, not limited to a specific framework, and exhibits generalizability in various detection tasks.
Figure 10 further illustrates the mAP and parameter results of our LS-MambaNet across these detection frameworks.
5. Conclusions
Due to the significant scale variation and high-aspect-ratio characteristics of remote sensing images, designing a network architecture that efficiently captures comprehensive contextual information has become an important and challenging research topic. To address this, this paper proposes a universal backbone network, LS-MambaNet, aimed at tackling the challenges posed by large object scale variations and high aspect ratios in remote sensing object detection. In this work, we have introduced a universal backbone network, LS-MambaNet, to address issues such as large object scale variations and high aspect ratios in remote sensing object detection. We propose the Large Strip Convolution Fusion Block, which uses a grouping fusion strategy and large strip convolutions to adaptively adjust the receptive field for feature extraction. This effectively captures contextual information from multi-scale features, especially excelling in remote sensing images that contain many high-aspect-ratio objects. Additionally, to alleviate the performance bottleneck caused by functional redundancy in selective scanning strategies, we propose the Multi-Granularity Spatial Mamba Block. This module adopts a multi-granularity scanning strategy, which effectively reduces computational costs and mitigates functional redundancy across different scanning paths, thus efficiently modeling the global contextual information of detection targets.
Experimental results demonstrate that LS-MambaNet achieves a 79.89% mAP and 22.9 FPS on the DOTA-v1.0 dataset, outperforming the baseline by +4.02% in accuracy while maintaining efficient inference. On the HRSC2016 dataset, our model reaches a 90.63% mAP, demonstrating strong generalization capability across diverse remote sensing scenarios. Although the proposed network has achieved satisfactory results in addressing the insufficient contextual information extraction during the detection of high-aspect-ratio objects in remote sensing images, there are still limitations and several directions for future exploration:
The experiments have only validated general remote sensing datasets such as DOTA1.0 and HRSC2016 and have not tested the model’s robustness in special scenarios (such as cloud or fog obstruction or nighttime infrared images) or with new sensor data (such as SAR and hyperspectral images).
The current multi-granularity scanning strategy uses fixed granularity window divisions. Future work could dynamically adjust the scanning paths based on target size or local image complexity, which would lead to a more refined modeling of small targets or dense areas.
Future work could explore the application of the method in 3D remote sensing object detection frameworks, incorporating Digital Surface Model (DSM) data and extending strip convolutions to the height dimension for building height estimation and 3D object detection.
There is potential for constructing a multi-modal Mamba architecture, integrating multi-source data such as visible light, SAR, LiDAR, etc., and enhancing detection robustness in complex environments through cross-modal interaction modules (such as cross-attention).
LS-MambaNet may still face challenges in extreme scenarios such as those involving dense small objects or cloud occlusion, which we aim to address through dynamic receptive field adjustment and multi-modal feature integration in future work.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}