
Synthetic Training Datasets for Architectural Conservation: A Deep Learning Approach for Decay Detection




Abstract

1. Introduction
Challenges in Training Data Generation
- (1)
- Demonstrating the reliability of synthetic dataset-based approaches for semantic segmentation of decay;
- (2)
- Contributing to the development of automated tools for monitoring and preserving architectural heritage—specifically, in the case of the presented paper, 20th-century concrete heritage—aligning with the latest ICOMOS guidelines [26] and cutting-edge digital documentation strategies in the conservation field.
2. Materials and Methods
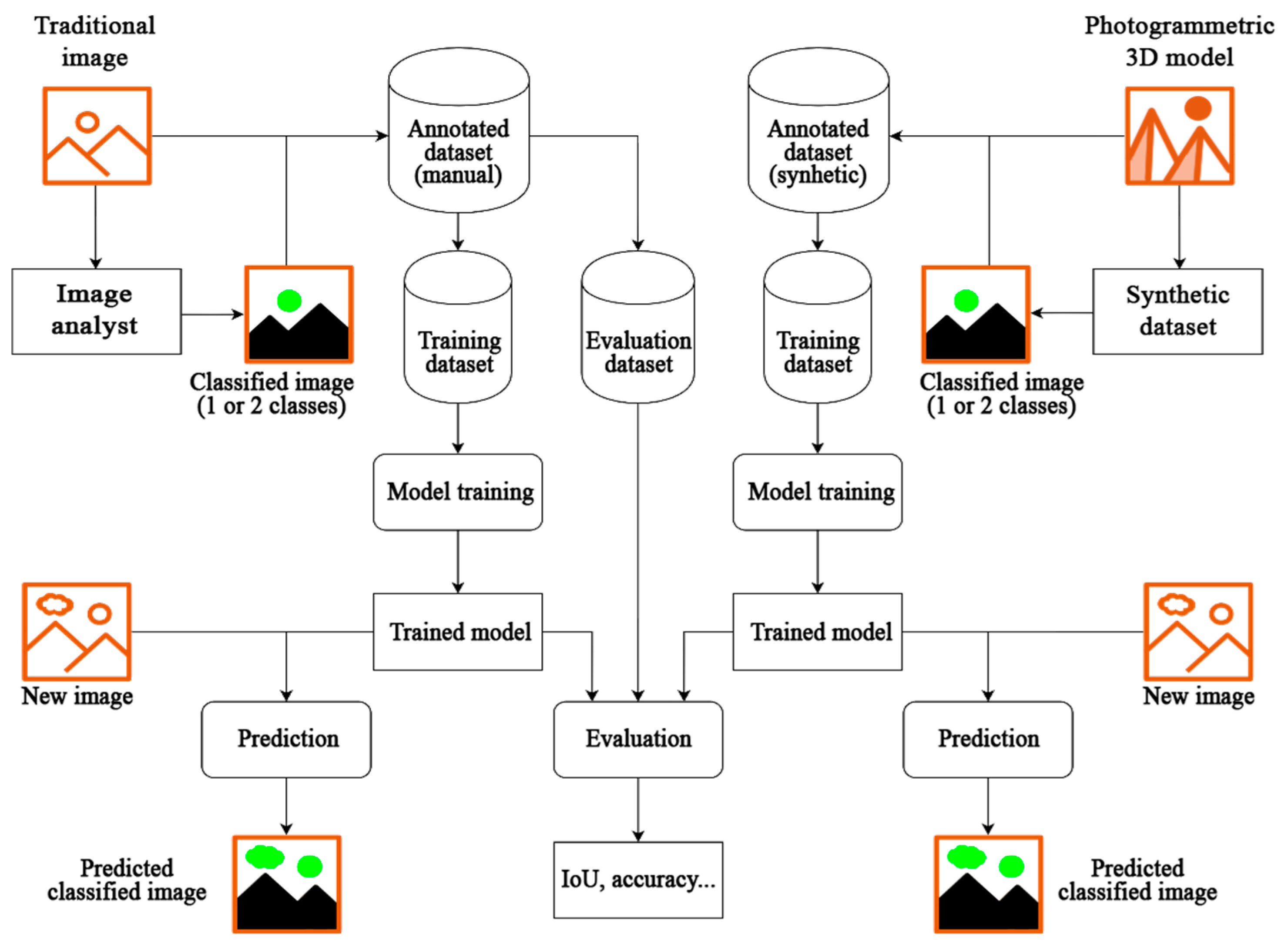
2.1. Research Goals, Aims, and Design
- A first neural network has been trained using traditional images acquired through traditional methods with the aim of generating a predictive model able to detect the object of interest in the images (single class scenario);
- A second neural network has been trained using synthetic images with the aim of generating a predictive model able to detect the object of interest in the images (single class scenario);
- A third neural network has been trained using synthetic images with the aim of generating a predictive model able to detect not only the object of interest in the images, but also deterioration (multiclass scenario).
- Dilated (Atrous) Convolutions, which allow the capture of information at various scales, thus preserving the details while enlarging the receptive field.
- Atrous Spatial Pyramid Pooling (ASPP), which employs parallel convolutions at different rates, improves the segmentation accuracy.
- The chosen backbone network extracts the features from the input image;
- The Dilated Convolutions and the ASPP are applied to the extracted features to extract multi-scale context;
- The processed features are upsampled to match the original resolution;
- The upsampled features are used to classify the pixels and generate the final segmentation map.
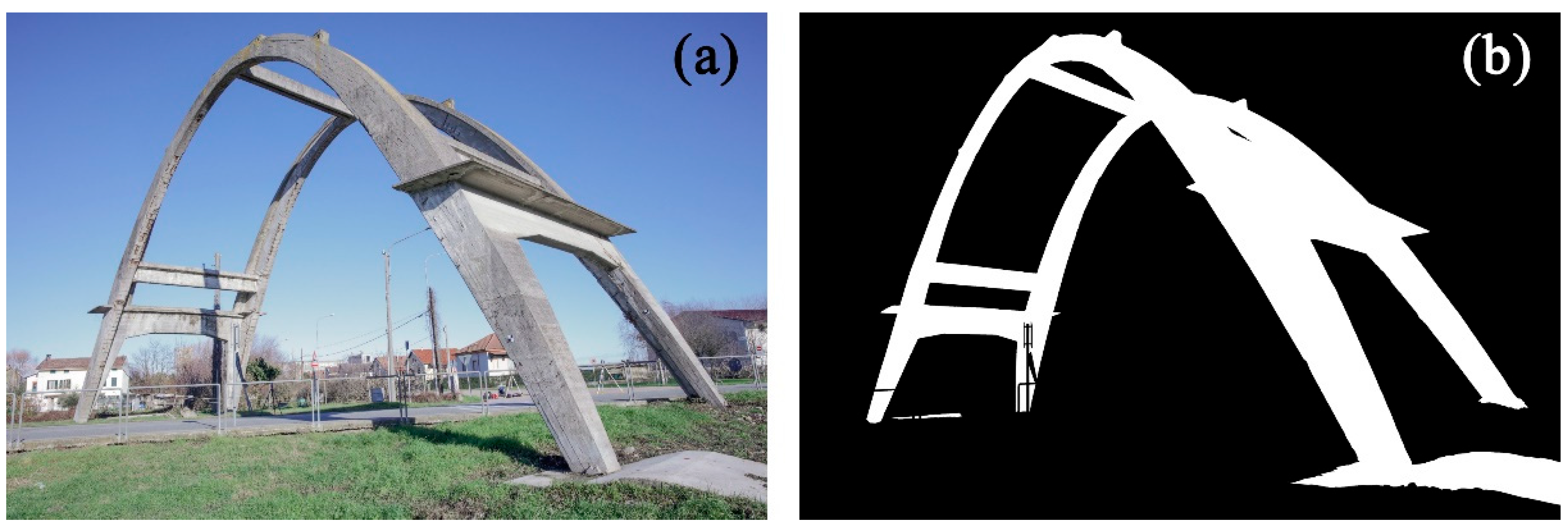
2.2. Case Study: The Parabolic Concrete Arch of Morano Sul Po
2.3. Primary Data Acquisition and Generation of the Training Dataset (Manual Approach)
- -
- Interior orientation and relative orientation using Multi View Stereo (MVS) and Structure-from-Motion (SfM) techniques;
- -
- Absolute orientation (for this reason, a set of 28 points was measured using a total station);
- -
- Accuracy evaluation (for this reason, a second set composed by 6 points was acquired);
- -
- Depht maps generation and dense point cloud generation;
- -
- 3D mesh generation.
2.4. Generation of ‘Synthetic’ Training Datasets from Photogrammetric Models
2.4.1. Single Class Scenario
- The 3D mesh of the arch with the context (road, vegetation, sidewalk, etc.) for the generation of the rendered images. Regarding the training dataset, the context can provide some learning features (e.g., radiometric features of elements belonging to the background, geometric features, etc.) useful for the neural network training.
- The 3D mesh of the arch without the context (in this case, every element except the arch has been manually deleted, to facilitate the automatic extraction of the labels).
2.4.2. Multi-Class Scenario: Concrete Degradation Detection
- -
- Mesh generation;
- -
- UV map generation for texture mapping;
- -
- Manual (multi-class) segmentation of the UV map (the segmented classes are: 0—background, 1—concrete, 2—exposed iron);
- -
- Reprojection of the classified texture;
- -
- Automatic generation of the synthetic rendered training dataset;
- -
- Automatic generation of the rendered multi-class labels;
- -
- Reclassification procedure to convert the rendered multi-class labels into a properly formatted ground truth for the training;
- -
- Neural network training (the training will be referred to in the next paragraphs as Training C).
2.5. Neural Network Training
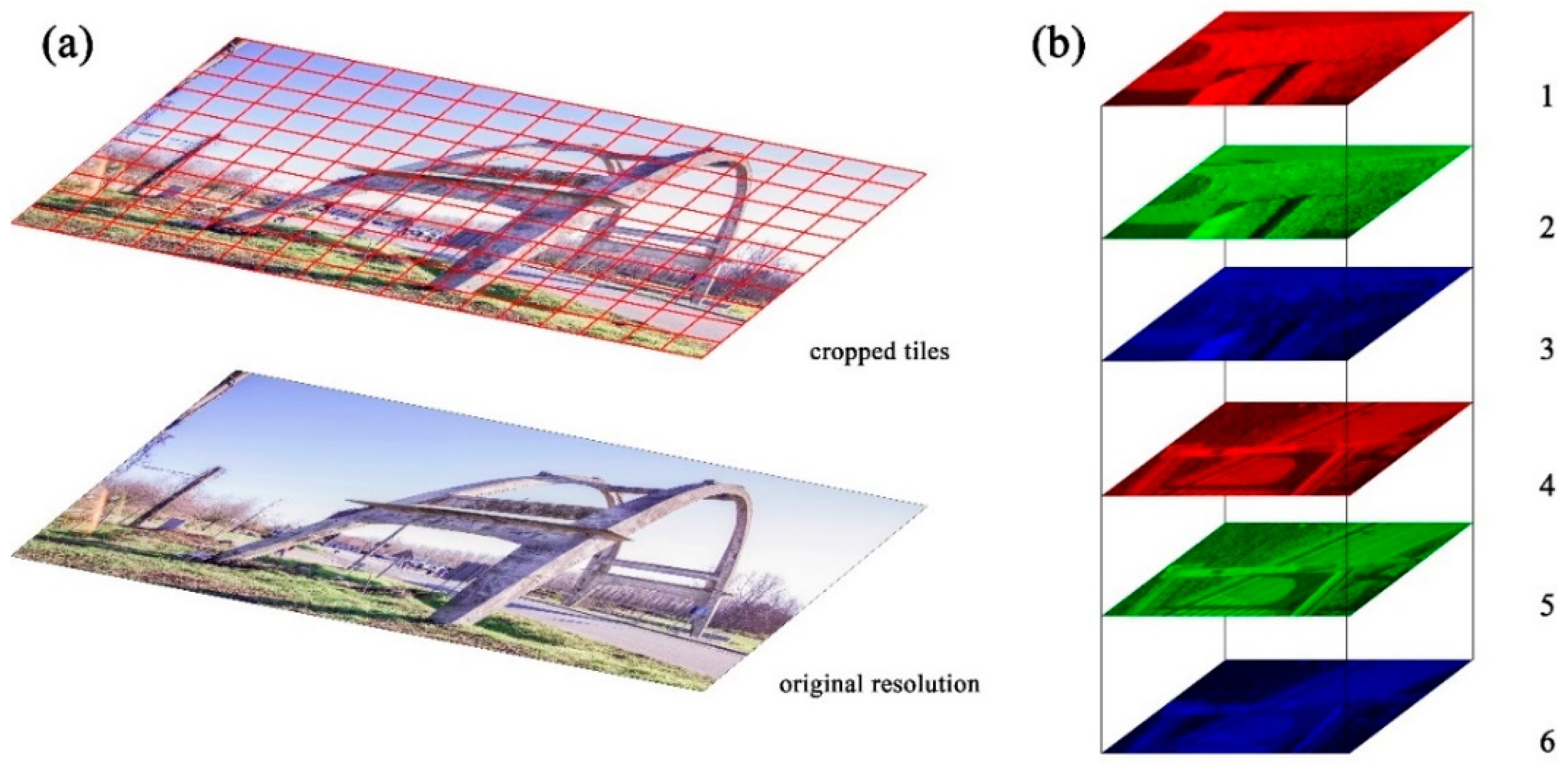
2.5.1. Dataset Preparation
- -
- First band: cropped tile (original resolution), Red band;
- -
- Second band: cropped tile (original resolution), Green band;
- -
- Third band: cropped tile (original resolution), Blue band;
- -
- Fourth band: downsampled image, Red band;
- -
- Fifth band: downsampled image, Green band;
- -
- Sixth band: downsampled image, Blue band.
2.5.2. Data Augmentation
- Random brightness change: the brightness of the image is randomly changed by uniformly increasing/decreasing the pixel values up to ±10 (with pixel values going from 0 to 255 on unsigned 8-bit integers);
- Horizontal flip;
- Random rotation: the image is rotated with a random angle up to 30°. The resulting blank areas are filled using the nearest neighbour interpolation;
- Random background change: the pixels labelled as background are replaced with a random image;
- Random occlusion: a square of random side (up to 30% of the image side) is filled with black at a random position.
2.5.3. Model Training
3. Results
3.1. Generation of the Predictive Models
3.1.1. Neural Networks Training Using Synthetic Dataset (Single Class Scenario)
3.1.2. Neural Network Training Using Synthetic Dataset (Multiclass Scenario)
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Betti, M.; Bonora, V.; Galano, L.; Pellis, E.; Tucci, G.; Vignoli, A. An Integrated Geometric and Material Survey for the Conservation of Heritage Masonry Structures. Heritage 2021, 4, 585–611. [Google Scholar] [CrossRef]
- Adamopoulos, E.; Rinaudo, F. Close-Range Sensing and Data Fusion for Built Heritage Inspection and Monitoring—A Review. Remote Sens. 2021, 13, 3936. [Google Scholar] [CrossRef]
- Rodriguez Polania, D.; Tondolo, F.; Osello, A.; Piras, M.; Di Pietra, V.; Grasso, N. Bridges monitoring and assessment using an integrated BIM methodology. Innov. Infrastruct. Solut. 2025, 10, 59. [Google Scholar] [CrossRef]
- Ioannides, M.; Patias, P. The Complexity and Quality in 3D Digitisation of the Past: Challenges and Risks. In 3D Research Challenges in Cultural Heritage III; Ioannides, M., Patias, P., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2023; p. 13125. [Google Scholar]
- Ioannides, M. Study on Quality in 3D Digitisation of Tangible Cultural Heritage: Mapping Parameters, Formats, Standards, Benchmarks, Methodologies, and Guidelines: Final Study Report; EU Study VIGIE 2020/654; Cyprus University of Technology: Limassol, Cyprus, 2022. [Google Scholar]
- UNESCO. Charter on the Preservation of the Digital Heritage; UNESCO: Paris, France, 2009. [Google Scholar]
- UNESCO. The UNESCO/PERSIST Guidelines for the Selection of Digital Heritage for Long-Term Preservation; UNESCO: Paris, France, 2016. [Google Scholar]
- Grilli, E.; Remondino, F. Classification of 3D Digital Heritage. Remote Sens. 2019, 11, 847. [Google Scholar] [CrossRef]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Mishra, M.; Barman, T.; Ramana, G.V. Artificial intelligence-based visual inspection system for structural health monitoring of cultural heritage. J. Struct. Health Monit. 2022, 14, 103–120. [Google Scholar] [CrossRef]
- Borin, P.; Cavazzini, F. Condition assessment of RC bridges. Integrating Machine Learning, photogrammetry and BIM. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-2/W15, 201–208. [Google Scholar]
- Lee, J.; Min Yu, J. Automatic surface damage classification developed based on deep learning for wooden architectural heritage. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2023, X-M-1-2023, 151–157. [Google Scholar]
- Bai, Y.; Zha, B.; Sezen, H.; Yilmaz, A. Deep cascaded neural networks for automatic detection of structural damage and cracks from images. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, V-2-2020, 411–417. [Google Scholar]
- Ali, L.; Alnajjar, F.; Jassmi, H.A.; Gocho, M.; Khan, W.; Serhani, M.A. Performance Evaluation of Deep CNN-Based Crack Detection and Localization Techniques for Concrete Structures. Sensors 2021, 21, 1688. [Google Scholar] [CrossRef]
- Savino, P.; Graglia, F.; Scozza, G.; Di Pietra, V. Automated corrosion surface quantification in steel transmission towers using UAV photogrammetry and deep convolutional neural networks. Comput.-Aided Civ. Infrastruct. Eng. 2025, 1–21. [Google Scholar] [CrossRef]
- Huang, X.; Duan, Z.; Hao, S.; Hou, J.; Chen, W.; Cai, L. A Deep Learning Framework for Corrosion Assessment of Steel Structures Using Inception v3 Model. Buildings 2025, 15, 512. [Google Scholar] [CrossRef]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.-T.; et al. Segment Anything. arXiv 2023, arXiv:2304.02643v1. [Google Scholar]
- Matrone, F.; Lingua, A.; Pierdicca, R.; Malinverni, E.S.; Paolanti, M.; Grilli, E.; Remondino, F.; Murtiyoso, A.; Landes, T. A benchmark for large-scale heritage point cloud semantic segmentation. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, XLIII-B2-2020, 1419–1426. [Google Scholar]
- Zhang, K.; Mea, C.; Fiorillo, F.; Fassi, F. Classification And Object Detection For Architectural Pathology: Practical Tests with Training Set. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2024, XLVIII-2/W4-2024, 477–484. [Google Scholar]
- de Melo, C.M.; Torralba, A.; Guibas, L.; DiCarlo, J.; Chellappa, R.; Hodgins, J. Next-generation deep learning based on simulators and synthetic data. Trends Cogn. Sci. 2021, 26, 174–187. [Google Scholar] [CrossRef]
- Tremblay, J.; Prakash, A.; Acuna, D.; Brophy, M.; Jampani, V.; Anil, C.; To, T.; Cameracci, E.; Boochoon, S.; Birchfield, S. Training Deep Learning Networks with Synthetic Data: Bridging the Reality Gap by Domain Randomization. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1082–1090. [Google Scholar]
- Agrafiotis, P.; Karantzalos, K.; Georgopoulos, A.; Skarlatos, D. Learning from Synthetic Data: Enhancing Refraction Correction Accuracy for Airborne Image-Based Bathymetric Mapping of Shallow Coastal Waters. PFG-J. Photogramm. Remote Sens. Geoinf. Sci. 2021, 89, 91–109. [Google Scholar] [CrossRef]
- Li, Z.; Snavely, N. Cgintrinsics: Better intrinsic image decomposition through physically-based rendering. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 371–387. [Google Scholar]
- Pellis, E.; Masiero, A.; Grussenmeyer, P.; Betti, M.; Tucci, G. Synthetic data generation and testing for the semantic segmentation of heritage buildings. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2023, XLVIII-M-2-2023, 1189–1196. [Google Scholar] [CrossRef]
- Patrucco, G.; Setragno, F. Enhancing automation of heritage processes: Generation of artificial training datasets from photogrammetric 3D models. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2023, XLVIII-M-2-2023, 1181–1187. [Google Scholar] [CrossRef]
- ICOMOS. The Cádiz Document: InnovaConcrete Guidelines for Conservation of Concrete Heritage; ICOMOS International: Charenton-le-Pont, France, 2022; Available online: https://isc20c.icomos.org/policy_items/complete-innovaconcrete/ (accessed on 12 May 2025).
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Patterns Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Jégou, S.; Drozdzal, M.; Vazquez, D.; Romero, A.; Bengio, Y. The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation. arXiv 2016, arXiv:1611.09326. [Google Scholar]
- ICOMOS. ISC20C, Approaches to the Conservation of Twentieth-Century Cultural Heritage Madrid–New Delhi Document. 2017. Available online: http://www.icomos-isc20c.org/madrid-document/ (accessed on 12 May 2025).
- Ramírez-Casas, J.; Gómez-Val, R.; Buill, F.; González-Sánchez, B.; Navarro Ezquerra, A. Forgotten Industrial Heritage: The Cement Factory from La Granja d’Escarp. Buildings 2025, 15, 372. [Google Scholar] [CrossRef]
- Ceravolo, R.; Invernizzi, S.; Lenticchia, E.; Matteini, I.; Patrucco, G.; Spanò, A. Integrated 3D Mapping and Diagnosis for the Structural Assessment of Architectural Heritage: Morano’s Parabolic Arch. Sensors 2023, 23, 6532. [Google Scholar] [CrossRef]
- Alicandro, M.; Dominici, D.; Pascucci, N.; Quaresima, R.; Zollini, S. Enhanced algorithms to extract decay forms of concrete infrastructures from UAV photogrammetric data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2024, XLVIII-1/W1-2023, 9–15. [Google Scholar] [CrossRef]
- Khan, M.A.-M.; Kee, S.-H.; Pathan, A.-S.K.; Nahid, A.-A. Image Processing Techniques for Concrete Crack Detection: A Scientometrics Literature Review. Remote Sens. 2023, 15, 2400. [Google Scholar] [CrossRef]
- Savino, P.; Tondolo, F. Automated classification of civil structure defects based on convolutional neural network. Front. Struct. Civ. Eng. 2021, 15, 305–317. [Google Scholar] [CrossRef]
- Patrucco, G.; Perri, S.; Spanò, A. TLS and image-based acquisition geometry for evaluating surface characterization. In Proceedings of the ARQUEOLÓGICA 2.0-9th International Congress & 3rd GEORES-GEOmatics and pREServation Lemma: Digital Twins for Advanced Cultural Heritage Semantic Digitization, Valencia, Spain, 26–28 April 2021; pp. 307–316. [Google Scholar]
- Patrucco, G.; Setragno, F. Multiclass semantic segmentation for digitization of movable heritage using deep learning techniques. Virtual Archaeol. Rev. 2021, 12, 85–98. [Google Scholar] [CrossRef]
- Patrucco, G.; Bambridge, P.; Giulio Tonolo, F.; Markey, J.; Spanò, A. Digital replicas of British Museum artefacts. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2023, XLVIII-M-2-2023, 1173–1180. [Google Scholar] [CrossRef]
- Granshaw, S.I. Photogrammetric terminology: Fourth edition. Photogramm. Rec. 2020, 35, 143–288. [Google Scholar] [CrossRef]
- Murtiyoso, A.; Grussenmeyer, P. Automatic point cloud noise masking in close range photogrammetry for buildings using AI-based semantic labelling. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2022, XLVI-2/W1-2022, 389–393. [Google Scholar] [CrossRef]
- Tarini, M. Volume-encoded UV-maps. ACM Trans. Graph. (TOG) 2016, 35, 1–13. [Google Scholar] [CrossRef]
- Donadio, E. 3D Photogrammetric Data Modeling and Optimization for Multipurpose Analysis and Representation of Cultural Heritage Assets. Ph.D. Thesis, Politecnico di Torino, Torino, Italy, 2018. [Google Scholar]
- Murtiyoso, A.; Pellis, E.; Grussenmeyer, P.; Landes, T.; Masiero, A. Towards semantic photogrammetry: Generating semantically rich point clouds from architectural close-range photogrammetry. Sensors 2022, 22, 966. [Google Scholar] [CrossRef]
- Mikołajczyk, A.; Grochowski, M. Data augmentation for improving deep learning in image classification problem. In Proceedings of the 2018 International Interdisciplinary PhD Workshop, Swinoujscie, Poland, 9–12 May 2018; pp. 117–122. [Google Scholar]
- Kingma, P.D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Boston, MA, USA, 2016. [Google Scholar]
- Ridnik, T.; Ben-Baruch, E.; Noy, A.; Zelnik-Manor, L. Imagenet-21k pretraining for the masses. arXiv 2021, arXiv:2104.10972. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Canon EOS 5DSR | |
|---|---|
| Sensor | 50.3 [MP] |
| Sensor size | Full frame, 36 × 24 [mm] |
| Image size | 8688 × 5792 [pixels] |
| Pixel size | 4.14 [μm] |
| Focal length of used lens | 25 [mm] |
| Used lens model | Zeiss ZE/ZF.2 Distagon T* 25 mm f/2 |
| ISO Range | 50–12,800 |
| Shutter speed | 30″—1/8000 s |
DJI Mavic Pro camera | |
|---|---|
| Sensor | CMOS 1/2.3″ |
| Effective pixels | 12.35 [MP] |
| Image size | 4000 × 3000 [pixels] |
| Pixel size | 1.53 [μm] |
| Lens | F/2.2, FoV 78.8° 5 mm (35 mm Equivalent: 26 mm) |
| ISO Range | 100–1600 |
| Shutter speed | 8–1/8000 s |
| X [m] | Y [m] | Z [m] | XYZ [m] | |
|---|---|---|---|---|
| GCPs [28] | 0.006 | 0.006 | 0.008 | 0.012 |
| CPs [6] | 0.009 | 0.004 | 0.009 | 0.013 |
| Training A (Traditional Digital Images) | |
|---|---|
| Accuracy | 99% |
| Mean IoU | 92% |
| Precision | 97% |
| Recall | 99% |
| F1-score | 98% |
| Training A (Traditional Digital Images) | Training B (Synthetic Data) | |
|---|---|---|
| Accuracy | 99% | 98% |
| Mean IoU | 92% | 90% |
| Precision | 97% | 96% |
| Recall | 99% | 99% |
| F1-score | 98% | 97% |
| Training A (Traditional Digital Images) | Training B (Synthetic Data) | |
|---|---|---|
| Accuracy | 84% | 78% |
| Mean IoU | 82% | 55% |
| Precision | 92% | 69% |
| Recall | 88% | 66% |
| F1-score | 90% | 67% |
| Training A | Training B | Training C | ||
|---|---|---|---|---|
| Single Class | Single Class | Class 1 | Class 2 | |
| Accuracy | 96% | 98% | 84% | 78% |
| Mean IoU | 92% | 90% | 82% | 55% |
| Precision | 97% | 96% | 92% | 69% |
| Recall | 99% | 99% | 88% | 66% |
| F1-score | 98% | 97% | 90% | 67% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Patrucco, G.; Setragno, F.; Spanò, A. Synthetic Training Datasets for Architectural Conservation: A Deep Learning Approach for Decay Detection. Remote Sens. 2025, 17, 1714. https://doi.org/10.3390/rs17101714
Patrucco G, Setragno F, Spanò A. Synthetic Training Datasets for Architectural Conservation: A Deep Learning Approach for Decay Detection. Remote Sensing. 2025; 17(10):1714. https://doi.org/10.3390/rs17101714
Chicago/Turabian StylePatrucco, Giacomo, Francesco Setragno, and Antonia Spanò. 2025. "Synthetic Training Datasets for Architectural Conservation: A Deep Learning Approach for Decay Detection" Remote Sensing 17, no. 10: 1714. https://doi.org/10.3390/rs17101714
APA StylePatrucco, G., Setragno, F., & Spanò, A. (2025). Synthetic Training Datasets for Architectural Conservation: A Deep Learning Approach for Decay Detection. Remote Sensing, 17(10), 1714. https://doi.org/10.3390/rs17101714