

Mapping Gridded GDP Distribution of China Based on Remote Sensing Data and Machine Learning Methods
 ,
,
Abstract
1. Introduction
2. Study Area and Data
2.1. Study Area
2.2. Data
3. Methodology
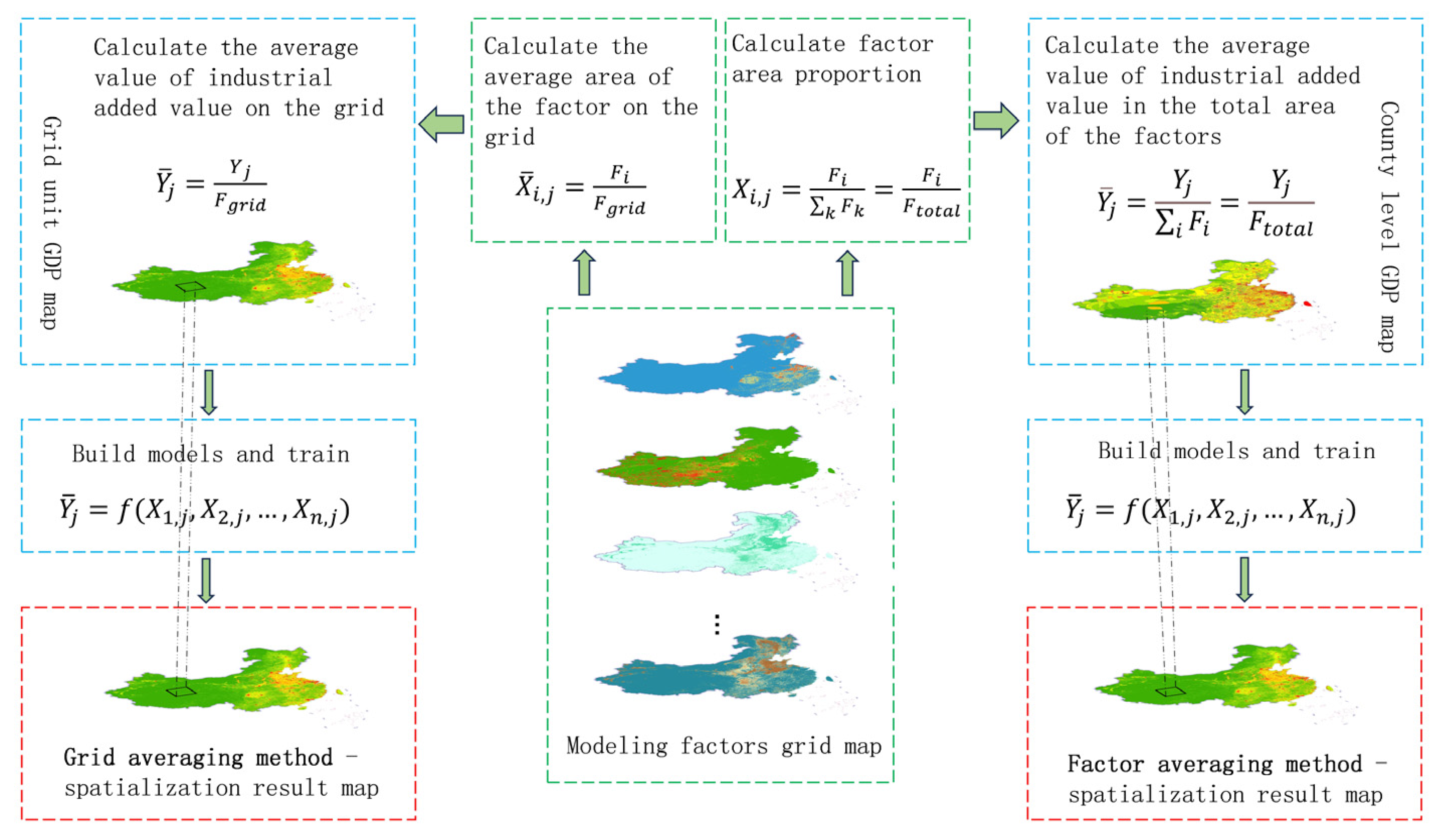
3.1. GDP Modeling Method
3.2. GDP Spatialization
3.3. Accuracy Assessment
4. Results
4.1. Model Performance Evaluation
4.2. Accuracy Assessment at Town-Level
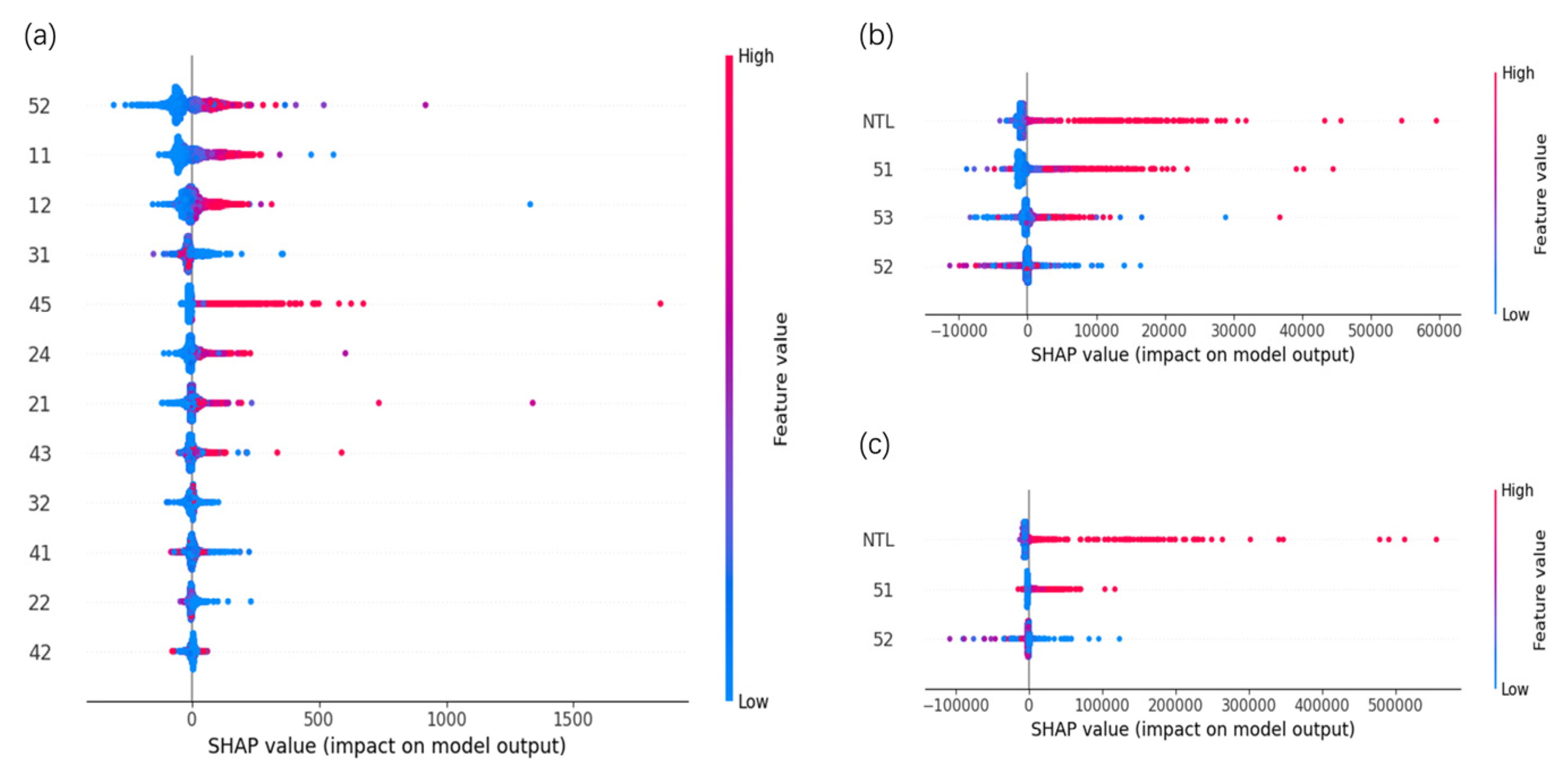
4.3. Feature Importance Analysis
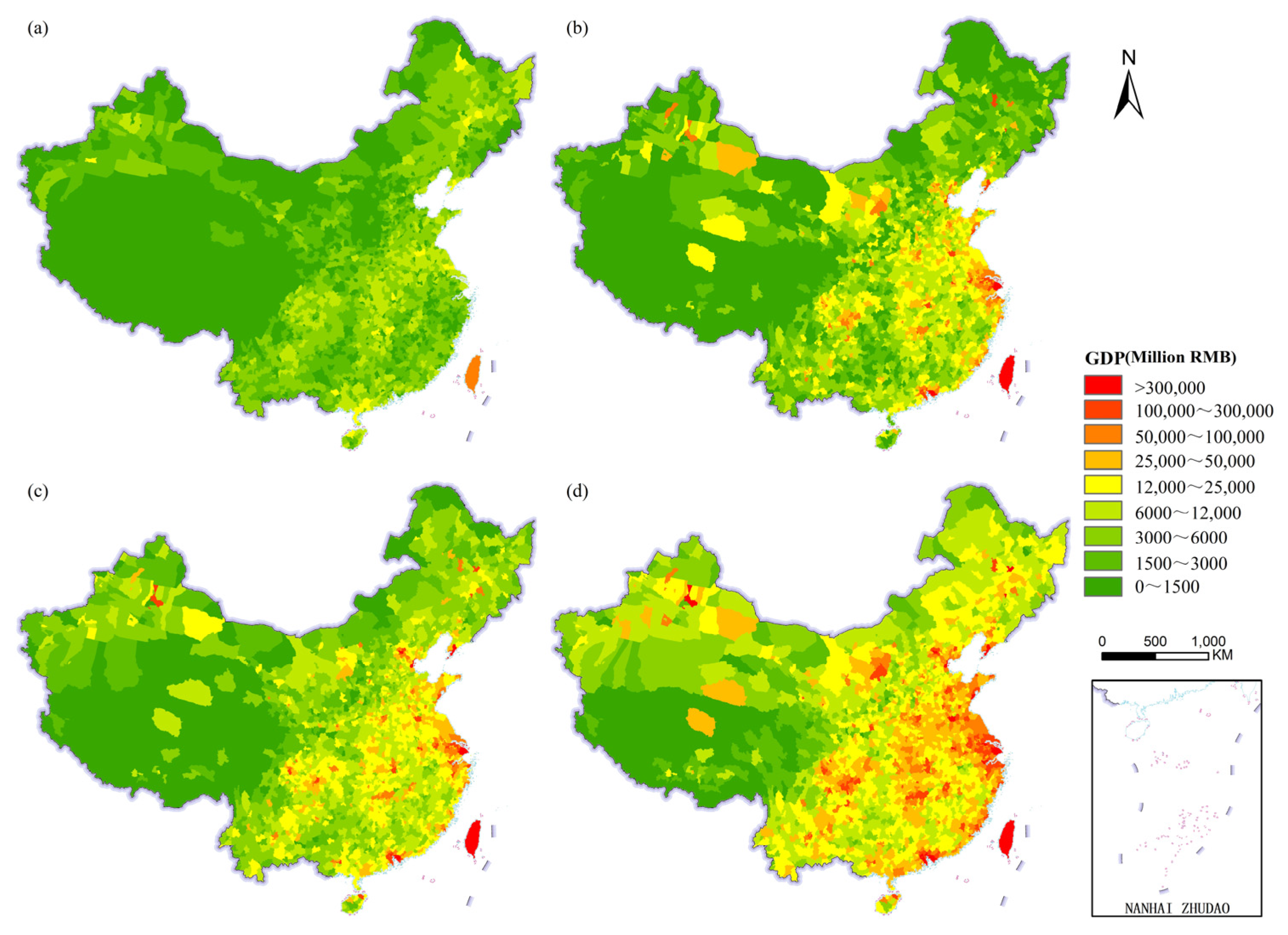
4.4. GDP Spatialization Results
4.4.1. Primary Industry Spatialization Results
4.4.2. Secondary Industry Spatialization Results
4.4.3. Tertiary Industry Spatialization Results
5. Discussion
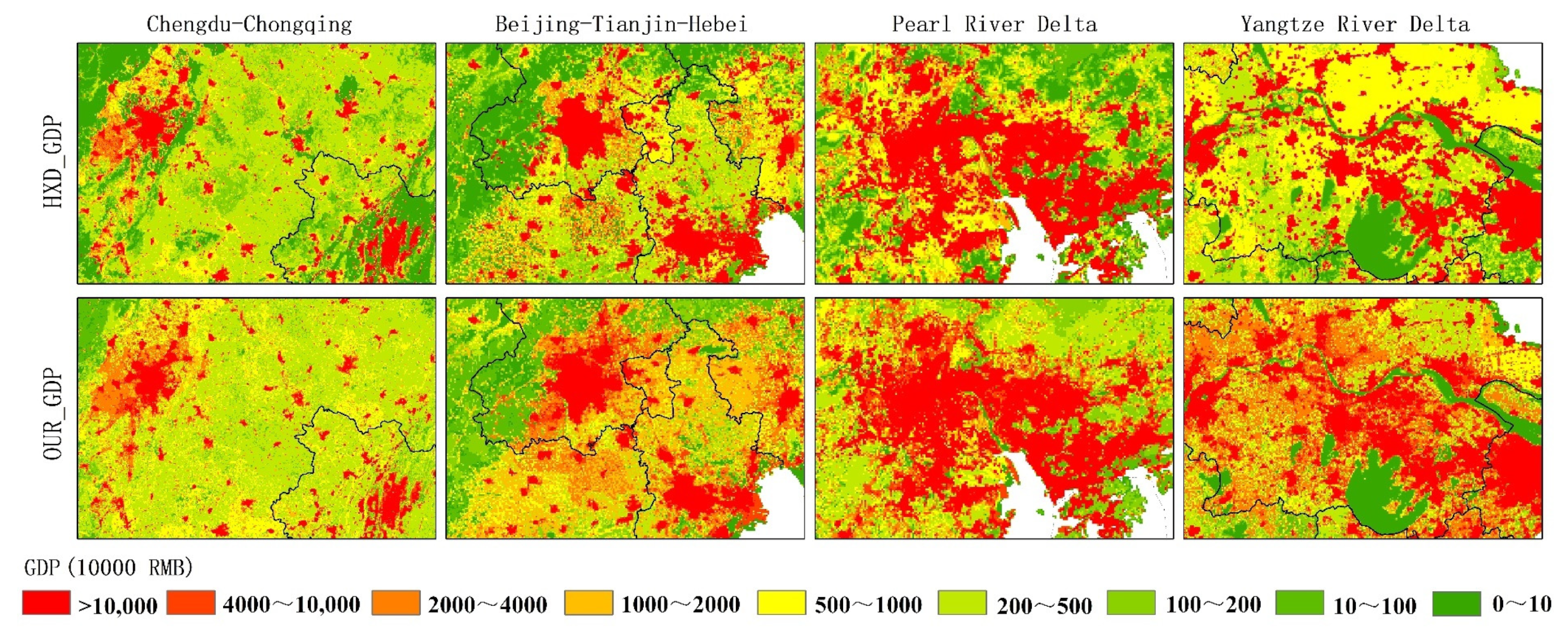
5.1. Comparison with Publicly Available GDP Datasets
5.2. Comparison of Modeling Methods
5.3. Comparison of the Three Industries
5.4. Limitations and Future Work
6. Conclusions
- (1)
- The modeling idea of the GAM has a better modeling effect. In the GAM, the R2 values of the models for the three industries are all higher than those of the FAM, indicating that the modeling approach of the GAM is superior to the FAM. Therefore, the GAM was chosen as the foundation for GDP spatialization modeling. Among the four models, RF and XGBoost exhibited significantly better modeling performance than LR and NN, suggesting that machine learning models are more suitable for constructing GDP spatialization models than linear regression and neural network models. Furthermore, for GDP1 and GDP2, the R2 values of XGBoost were higher than those of RF, demonstrating better modeling performance. However, for GDP3, RF showed better modeling performance than XGBoost. Therefore, the XGBoost model was used to construct the spatialization model for GDP1 and GDP2, while the RF model was used for GDP3. Finally, the three spatialization models were summed to obtain the overall GDP spatialization result.
- (2)
- The spatialization results of GDP are highly accurate and can precisely depict the internal differences within county-level administrative units. Using more refined scale town-level GDP statistical data to evaluate the accuracy of the GDP spatialization results, the findings indicate that it performs exceptionally well on the town-level validation dataset. Specifically, the R2 value reaches 0.78, demonstrating its reliable predictive capability. Additionally, the MAE and RMSE are relatively small. Therefore, the gridded total GDP derived from using the XGBoost model for GDP1 and GDP2, and the RF model for GDP3, exhibits good accuracy. Furthermore, when compared to publicly available GDP datasets, the two show consistent spatial distribution patterns and aggregation trends. Our GDP dataset provides a finer depiction of differences within county-level administrative units.
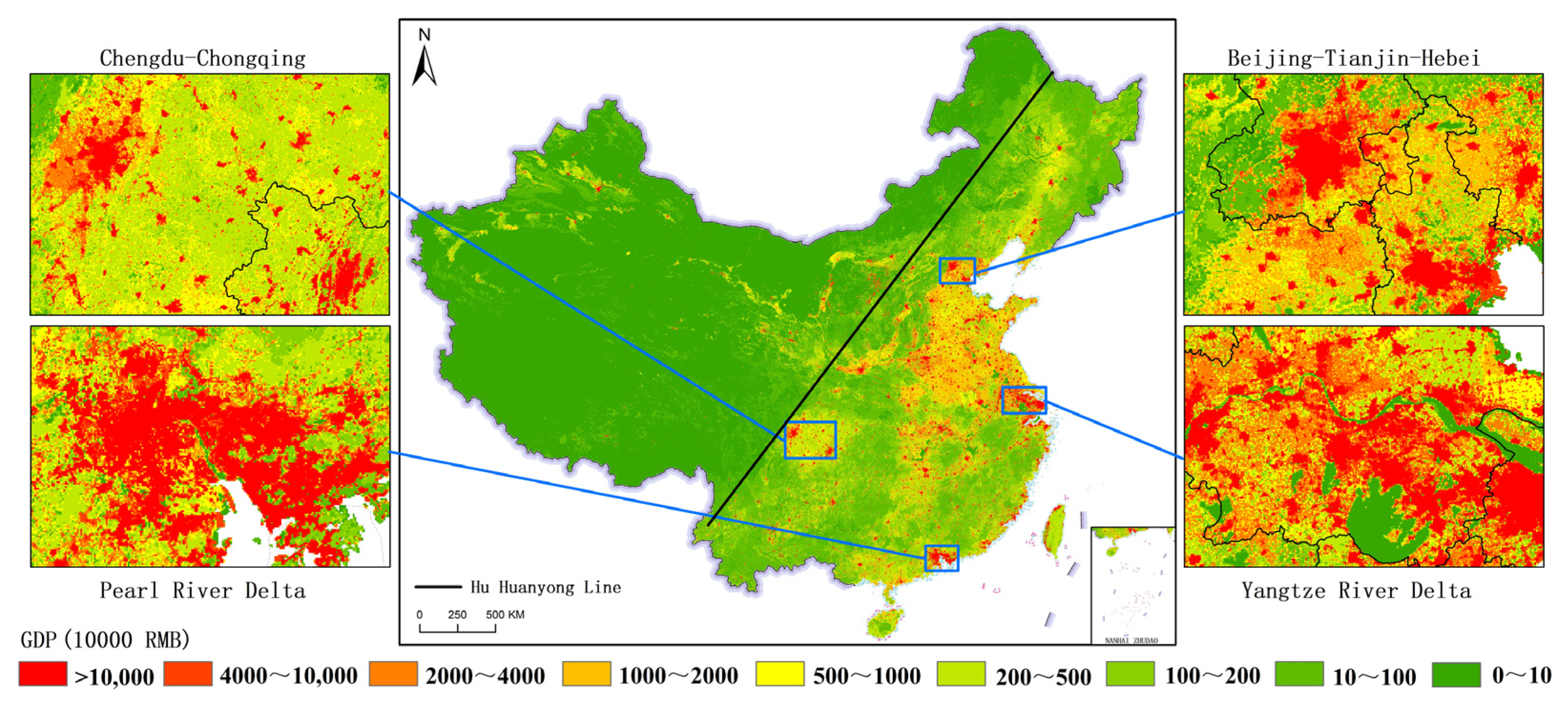
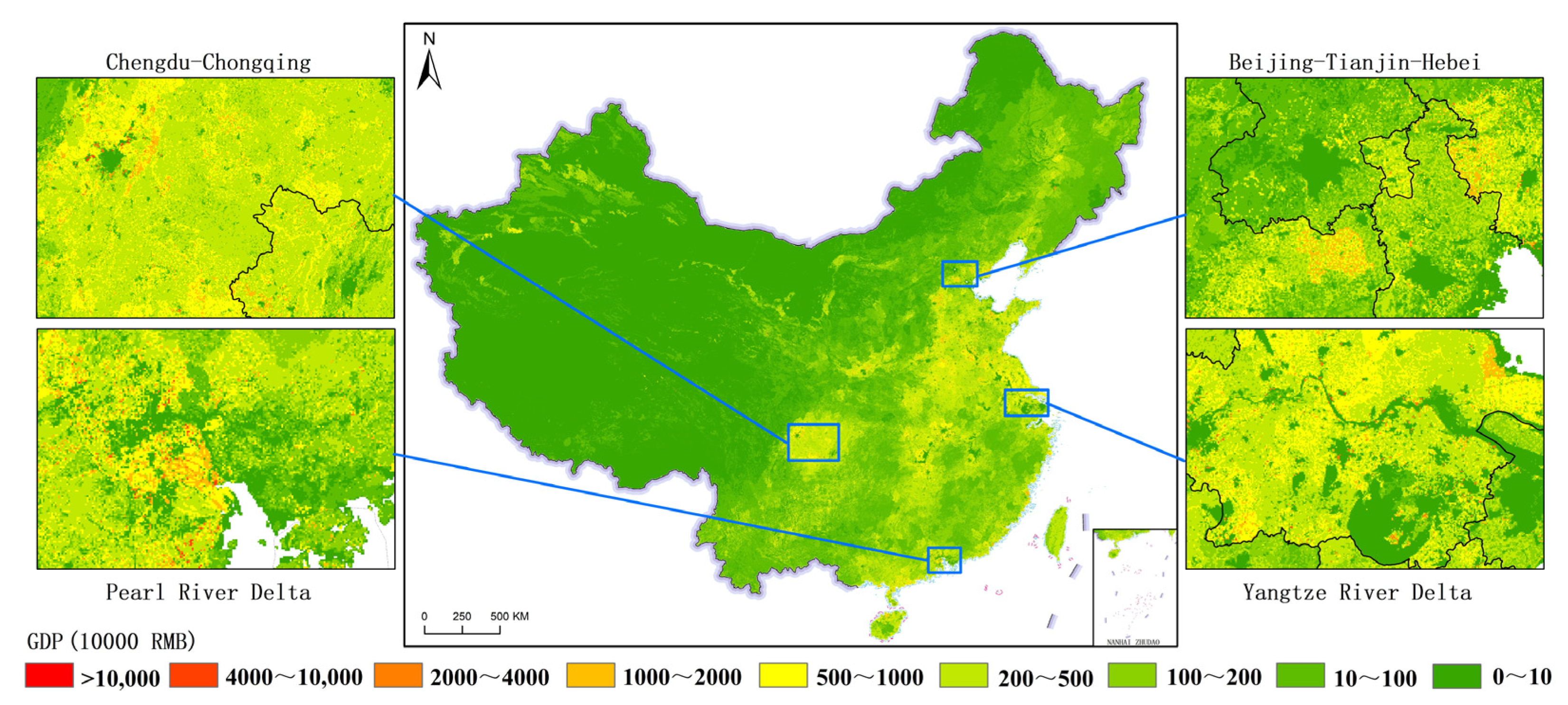
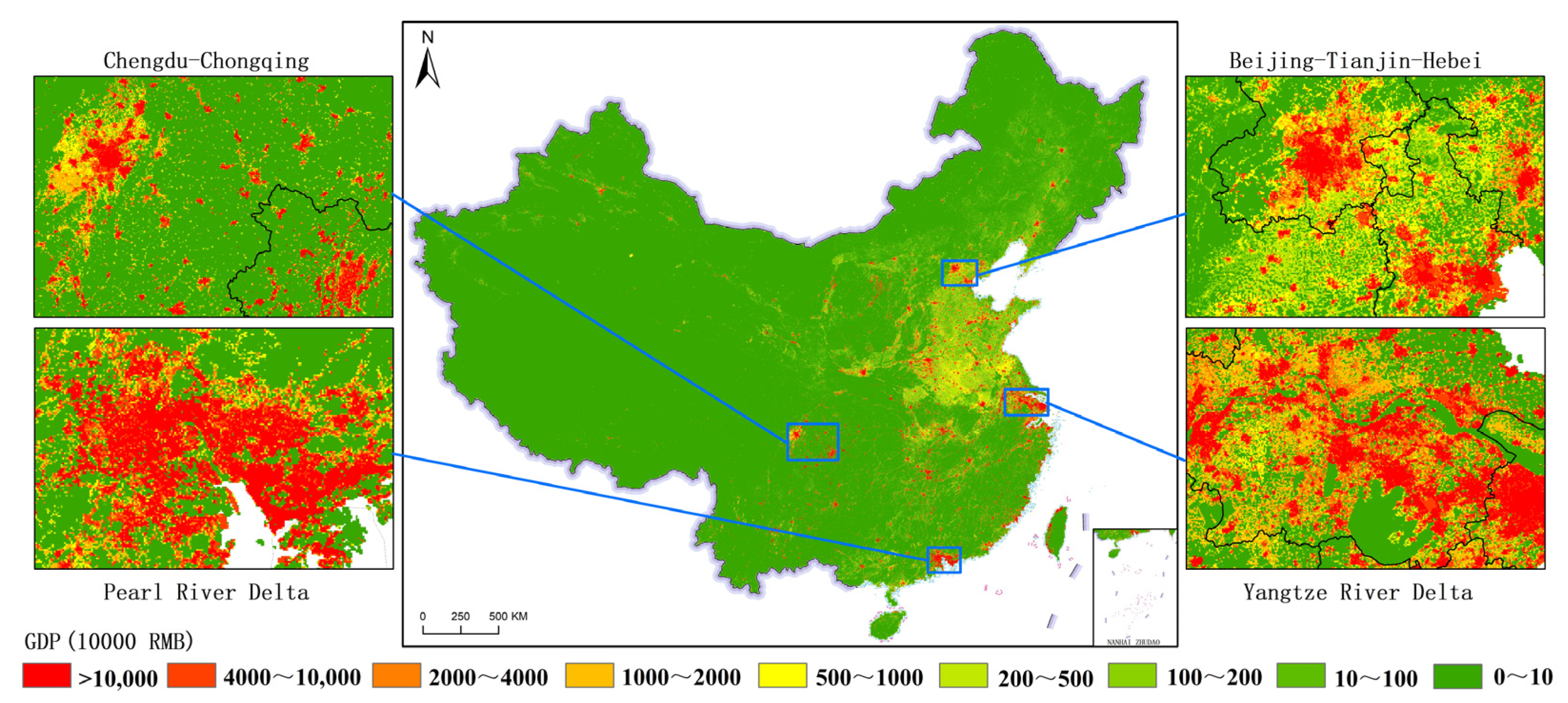
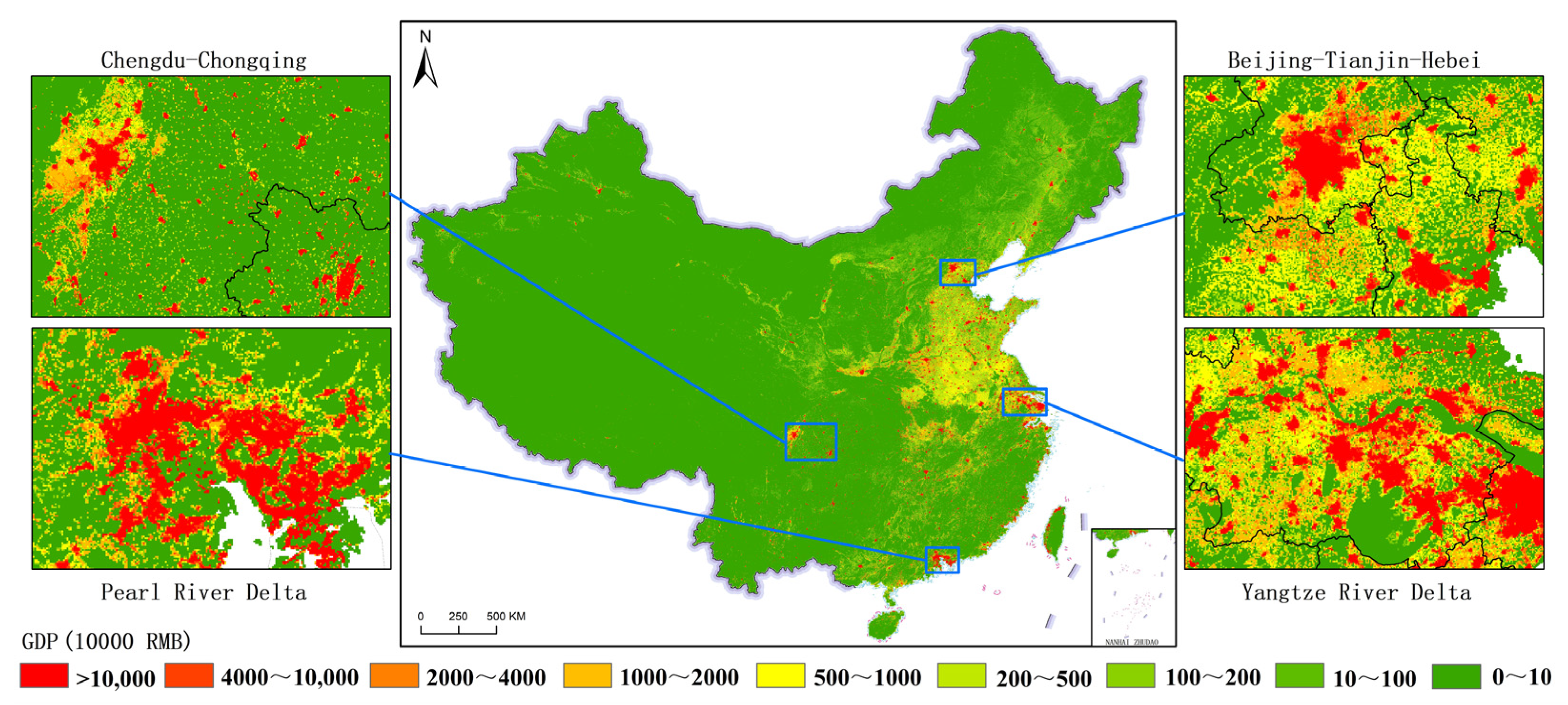
- (3)
- The spatial distribution differences in the three major industries are remarkable. On the whole, China’s GDP is divided by the “Hu Huanyong line”. The relatively high GDP is mainly distributed in the Huang–Huai–Hai Plain and the eastern coastal areas on the southeast side of the line, while the relatively low GDP is mainly distributed in most areas of Tibet, Qinghai, Xinjiang, and inner Mongolia on the northwest side of the line. Overall, the number of high-value GDP grids ranks as follows: tertiary industry > secondary industry > primary industry. Regarding the distribution of high-value GDP grids, primary industry is mainly located in suburban and rural areas. The secondary and tertiary industries are primarily distributed in large cities and their surroundings, with the former being more prevalent in suburban areas and the latter being more concentrated in city centers. The spatial distribution differences among the gridded GDP for the three industries are consistent with the actual distribution of real GDP.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Geiger, T. Continuous National Gross Domestic Product (GDP) Time Series for 195 Countries: Past Observations (1850–2005) Harmonized with Future Projections According to the Shared Socio-Economic Pathways (2006–2100). Earth Syst. Sci. Data 2018, 10, 847–856. [Google Scholar] [CrossRef]
- Henderson, J.V.; Storeygard, A.; Weil, D.N. Measuring Economic Growth from Outer Space. Am. Econ. Rev. 2012, 102, 994–1028. [Google Scholar] [CrossRef] [PubMed]
- Sutton, P.C.; Costanza, R. Global Estimates of Market and Non-Market Values Derived from Nighttime Satellite Imagery, Land Cover, and Ecosystem Service Valuation. Ecol. Econ. 2002, 41, 509–527. [Google Scholar] [CrossRef]
- Chen, X.; Nordhaus, W.D. Using Luminosity Data as a Proxy for Economic Statistics. Proc. Natl. Acad. Sci. USA 2011, 108, 8589–8594. [Google Scholar] [CrossRef]
- Wang, W.; Cheng, H.; Zhang, L. Poverty Assessment Using DMSP/OLS Night-Time Light Satellite Imagery at a Provincial Scale in China. Adv. Space Res. 2012, 49, 1253–1264. [Google Scholar] [CrossRef]
- Gu, H.; Chen, C.; Lu, Y.; Chu, Y.; Ma, Y. Construction of Regional Economic Development Model Based on Remote Sensing Data. IOP Conf. Ser. Earth Environ. Sci. 2019, 310, 052060. [Google Scholar] [CrossRef]
- Huang, Z.; Li, S.; Gao, F.; Wang, F.; Lin, J.; Tan, Z. Evaluating the Performance of LBSM Data to Estimate the Gross Domestic Product of China at Multiple Scales: A Comparison with NPP-VIIRS Nighttime Light Data. J. Clean. Prod. 2021, 328, 129558. [Google Scholar] [CrossRef]
- Liao, F.H.F.; Wei, Y.D. Dynamics, Space, and Regional Inequality in Provincial China: A Case Study of Guangdong Province. Appl. Geogr. 2012, 35, 71–83. [Google Scholar] [CrossRef]
- Chen, J.; Li, L. Regional Economic Activity Derived From MODIS Data: A Comparison With DMSP/OLS and NPP/VIIRS Nighttime Light Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3067–3077. [Google Scholar] [CrossRef]
- Chen, Y.; Wu, G.; Ge, Y.; Xu, Z. Mapping Gridded Gross Domestic Product Distribution of China Using Deep Learning with Multiple Geospatial Big Data. Ieee J. Stars 2022, 15, 1791–1802. [Google Scholar] [CrossRef]
- Kummu, M.; Taka, M.; Guillaume, J.H.A. Gridded Global Datasets for Gross Domestic Product and Human Development Index over 1990–2015. Sci. Data 2018, 5, 180004. [Google Scholar] [CrossRef] [PubMed]
- Yue, T.; Zhao, N.; Liu, Y.; Wang, Y.; Zhang, B.; Du, Z.; Fan, Z.; Shi, W.; Chen, C.; Zhao, M.; et al. A fundamental theorem for eco-environmental surface modelling and its applications. Sci. China (Earth Sci.) 2020, 63, 1092–1112. [Google Scholar] [CrossRef]
- Ye, T.; Zhao, N.; Yang, X.; Ouyang, Z.; Liu, X.; Chen, Q.; Hu, K.; Yue, W.; Qi, J.; Li, Z.; et al. Improved Population Mapping for China Using Remotely Sensed and Points-of-Interest Data within a Random Forests Model. Sci. Total Environ. 2019, 658, 936–946. [Google Scholar] [CrossRef]
- Elvidge, C.D.; Baugh, K.E.; Kihn, E.A.; Kroehl, H.W.; Davis, E.R.; Davis, C.W. Relation between Satellite Observed Visible-near Infrared Emissions, Population, Economic Activity and Electric Power Consumption. Int. J. Remote Sens. 1997, 18, 1373–1379. [Google Scholar] [CrossRef]
- Zhao, N.; Liu, Y.; Cao, G.; Samson, E.L.; Zhang, J. Forecasting China’s GDP at the Pixel Level Using Nighttime Lights Time Series and Population Images. GIScience Remote Sens. 2017, 54, 407–425. [Google Scholar] [CrossRef]
- Guo, B.; Hu, D.; Wang, S.; Lin, A.; Kuang, H. Estimation of Gridded Anthropogenic Heat Flux at the Optimal Scale by Integrating SDGSAT-1 Nighttime Lights and Geospatial Data. Int. J. Appl. Earth Obs. Geoinf. 2023, 125, 103596. [Google Scholar] [CrossRef]
- Li, X.; Xu, H.; Chen, X.; Li, C. Potential of NPP-VIIRS Nighttime Light Imagery for Modeling the Regional Economy of China. Remote Sens. 2013, 5, 3057–3081. [Google Scholar] [CrossRef]
- Guo, B.; Hu, D.; Zheng, Q. Potentiality of SDGSAT-1 Glimmer Imagery to Investigate the Spatial Variability in Nighttime Lights. Int. J. Appl. Earth Obs. Geoinf. 2023, 119, 103313. [Google Scholar] [CrossRef]
- Liu, S.; Liu, W.; Zhou, Y.; Wang, S.; Wang, Z.; Wang, Z.; Wang, Y.; Wang, X.; Hao, L.; Wang, F. Analysis of Economic Vitality and Development Equilibrium of China’s Three Major Urban Agglomerations Based on Nighttime Light Data. Remote Sens. 2024, 16, 4571. [Google Scholar] [CrossRef]
- Liu, S.; Zhou, Y.; Wang, F.; Wang, S.; Wang, Z.; Wang, Y.; Qin, G.; Wang, P.; Liu, M.; Huang, L. Lighting Characteristics of Public Space in Urban Functional Areas Based on SDGSAT-1 Glimmer Imagery:A Case Study in Beijing, China. Remote Sens. Environ. 2024, 306, 114137. [Google Scholar] [CrossRef]
- Deng, F.; Cao, L.; Li, F.; Li, L.; Man, W.; Chen, Y.; Liu, W.; Peng, C. Mapping China’s Changing Gross Domestic Product Distribution Using Remotely Sensed and Point-of-Interest Data with Geographical Random Forest Model. Sustainability 2023, 15, 8062. [Google Scholar] [CrossRef]
- Chen, Q.; Hou, X.; Zhang, X.; Ma, C. Improved GDP Spatialization Approach by Combining Land-Use Data and Night-Time Light Data: A Case Study in China’s Continental Coastal Area. Int. J. Remote Sens. 2016, 37, 4610–4622. [Google Scholar] [CrossRef]
- Liang, H.; Guo, Z.; Wu, J.; Chen, Z. GDP Spatialization in Ningbo City Based on NPP/VIIRS Night-Time Light and Auxiliary Data Using Random Forest Regression. Adv. Space Res. 2020, 65, 481–493. [Google Scholar] [CrossRef]
- Zhao, M.; Cheng, W.; Zhou, C.; Li, M.; Wang, N.; Liu, Q. GDP Spatialization and Economic Differences in South China Based on NPP-VIIRS Nighttime Light Imagery. Remote Sens. 2017, 9, 673. [Google Scholar] [CrossRef]
- Chen, T.; Zhou, Y.; Zou, D.; Wu, J.; Chen, Y.; Wu, J.; Wang, J. Deciphering China’s Socio-Economic Disparities: A Comprehensive Study Using Nighttime Light Data. Remote Sens. 2023, 15, 4581. [Google Scholar] [CrossRef]
- Li, F.; Mao, L.; Chen, Q.; Yang, X. Refined Estimation of Potential GDP Exposure in Low-Elevation Coastal Zones (LECZ) of China Based on Multi-Source Data and Random Forest. Remote Sens. 2023, 15, 1285. [Google Scholar] [CrossRef]
- Xu, Z.; Wang, Y.; Sun, G.; Chen, Y.; Ma, Q.; Zhang, X. Generating Gridded Gross Domestic Product Data for China Using Geographically Weighted Ensemble Learning. ISPRS Int. J. Geo-Inf. 2023, 12, 123. [Google Scholar] [CrossRef]
- Wu, N.; Yan, J.; Liang, D.; Sun, Z.; Ranjan, R.; Li, J. High-Resolution Mapping of GDP Using Multi-Scale Feature Fusion by Integrating Remote Sensing and POI Data. Int. J. Appl. Earth Obs. Geoinf. 2024, 129, 103812. [Google Scholar] [CrossRef]
- Chen, Z.; Wang, W.; Zong, H.; Yu, X. Precise GDP Spatialization and Analysis in Built-Up Area by Combining the NPP-VIIRS-like Dataset and Sentinel-2 Images. Sensors 2024, 24, 3405. [Google Scholar] [CrossRef]
- Ustaoglu, E.; Bovkır, R.; Aydınoglu, A.C. Spatial Distribution of GDP Based on Integrated NPS-VIIRS Nighttime Light and MODIS EVI Data: A Case Study of Turkey. Environ. Dev. Sustain. 2021, 23, 10309–10343. [Google Scholar] [CrossRef]
- Li, W.; Wu, M.; Niu, Z. Spatialization and Analysis of China’s GDP Based on NPP/VIIRS Data from 2013 to 2023. Appl. Sci. 2024, 14, 8599. [Google Scholar] [CrossRef]
- Murakami, D.; Yamagata, Y. Estimation of Gridded Population and GDP Scenarios with Spatially Explicit Statistical Downscaling. Sustainability 2019, 11, 2106. [Google Scholar] [CrossRef]
- Zhang, H.; Dong, G.; Li, B.; Xie, Z.; Miao, C.; Yang, F.; Gao, Y.; Meng, X.; Yang, D.; Liu, Y.; et al. Developing an Annual Global Sub-National Scale Economic Data from 1992 to 2021 Using Nighttime Lights and Deep Learning. Int. J. Appl. Earth Obs. Geoinf. 2024, 133, 104086. [Google Scholar] [CrossRef]
- Chen, Z.; Yu, B.; Yang, C.; Zhou, Y.; Yao, S.; Qian, X.; Wang, C.; Wu, B.; Wu, J. An Extended Time Series (2000–2018) of Global NPP-VIIRS-like Nighttime Light Data from a Cross-Sensor Calibration. Earth Syst. Sci. Data 2021, 13, 889–906. [Google Scholar] [CrossRef]
- Stevens, F.R.; Gaughan, A.E.; Linard, C.; Tatem, A.J. Disaggregating Census Data for Population Mapping Using Random Forests with Remotely-Sensed and Ancillary Data. PLoS ONE 2015, 10, e0107042. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 4768–4777. [Google Scholar]
- Han, X.; Zhou, Y.; Wang, S.; Wang, L.; Hou, Y. Spatialization Approach to 1 km Grid GDP Based on Remote Sensing. In Proceedings of the 2011 International Conference on Multimedia Technology, Hangzhou, China, 26–28 July 2011; pp. 739–742. [Google Scholar]
- Doll, C.N.H.; Muller, J.-P.; Morley, J.G. Mapping Regional Economic Activity from Night-Time Light Satellite Imagery. Ecol. Econ. 2006, 57, 75–92. [Google Scholar] [CrossRef]
- Wang, K.; Ji, X.; Liu, S.; Zhu, J.; Liu, K. Harnessing Big Data for Sustainable Urban Management: A Novel Approach to Gridded Urban GDP Dataset Development. J. Clean. Prod. 2024, 444, 141205. [Google Scholar] [CrossRef]
- Zhou, Y.; Ma, T.; Zhou, C.; Xu, T. Nighttime Light Derived Assessment of Regional Inequality of Socioeconomic Development in China. Remote Sens. 2015, 7, 1242–1262. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Primary Classification | Secondary Classification | GDP1 | GDP2 | GDP3 | ||
|---|---|---|---|---|---|---|
| 1 | Crop land | 11 | Paddy field | 0.59 | - | - |
| 12 | Dry land | 0.35 | - | - | ||
| 2 | Forest land | 21 | Forest land with trees | 0.15 | - | - |
| 22 | Shrub land | 0.08 | - | - | ||
| 23 | Sparse forest land | - | - | - | ||
| 24 | Other forest land | 0.23 | - | - | ||
| 3 | Grassland | 31 | High-coverage grassland | −0.07 | - | - |
| 32 | Medium-coverage grassland | −0.14 | - | - | ||
| 33 | Low-coverage grassland | - | - | - | ||
| 4 | Water and wetland | 41 | River and canal | 0.17 | - | - |
| 42 | Lake | −0.05 | - | - | ||
| 43 | Reservoir and pit pond | 0.35 | - | - | ||
| 44 | Permanent glacier and snow land | - | - | - | ||
| 45 | Tidal flat | 0.40 | - | - | ||
| 46 | Beach land | - | - | - | ||
| 5 | Construction land | 51 | Urban land | - | 0.81 | 0.76 |
| 52 | Rural residential area | 0.53 | 0.26 | 0.21 | ||
| 53 | Other construction land | - | 0.41 | - | ||
| 6 | Unused land | - | - | - | - | - |
| NTL | NTL | Nighttime light | - | 0.94 | 0.85 |
| Model | R2 | MAE | RMSE | |
|---|---|---|---|---|
| GDP1 | Linear regression | 0.16 | 0.02 | 0.04 |
| Random Forest | 0.64 | 0.01 | 0.02 | |
| Neural network | 0.19 | 0.02 | 0.04 | |
| XGBoost | 0.74 | 0.01 | 0.02 | |
| GDP2 | Linear regression | 0.15 | 1.14 | 2.27 |
| Random Forest | 0.71 | 0.60 | 1.34 | |
| Neural network | 0.16 | 1.14 | 2.27 | |
| XGBoost | 0.78 | 0.35 | 1.16 | |
| GDP3 | Linear regression | 0.42 | 1.93 | 4.90 |
| Random Forest | 0.71 | 0.91 | 3.44 | |
| Neural network | 0.47 | 1.70 | 4.66 | |
| XGBoost | 0.63 | 0.65 | 3.88 |
| Model | R2 | MAE | RMSE | |
|---|---|---|---|---|
| GDP1 | Linear regression | 0.32 | 0.91 | 1.88 |
| Random Forest | 0.83 | 0.41 | 0.94 | |
| Neural network | 0.52 | 0.88 | 1.58 | |
| XGBoost | 0.87 | 0.20 | 0.83 | |
| GDP2 | Linear regression | 0.55 | 16.66 | 58.63 |
| Random Forest | 0.82 | 8.41 | 36.92 | |
| Neural network | 0.55 | 16.48 | 58.46 | |
| XGBoost | 0.87 | 4.55 | 31.33 | |
| GDP3 | Linear regression | 0.50 | 113. 08 | 335.88 |
| Random Forest | 0.87 | 26.00 | 174.09 | |
| Neural network | 0.58 | 60.67 | 306.39 | |
| XGBoost | 0.66 | 32.11 | 276.43 |
| R2 | MAE | RMSE | |
|---|---|---|---|
| RF + XGBoost | 0.78 | 37.96 | 60.03 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, S.; Liu, W.; Zhou, Y.; Wang, S.; Wang, F.; Wang, Z. Mapping Gridded GDP Distribution of China Based on Remote Sensing Data and Machine Learning Methods. Remote Sens. 2025, 17, 1709. https://doi.org/10.3390/rs17101709
Liu S, Liu W, Zhou Y, Wang S, Wang F, Wang Z. Mapping Gridded GDP Distribution of China Based on Remote Sensing Data and Machine Learning Methods. Remote Sensing. 2025; 17(10):1709. https://doi.org/10.3390/rs17101709
Chicago/Turabian StyleLiu, Saimiao, Wenliang Liu, Yi Zhou, Shixin Wang, Futao Wang, and Zhenqing Wang. 2025. "Mapping Gridded GDP Distribution of China Based on Remote Sensing Data and Machine Learning Methods" Remote Sensing 17, no. 10: 1709. https://doi.org/10.3390/rs17101709
APA StyleLiu, S., Liu, W., Zhou, Y., Wang, S., Wang, F., & Wang, Z. (2025). Mapping Gridded GDP Distribution of China Based on Remote Sensing Data and Machine Learning Methods. Remote Sensing, 17(10), 1709. https://doi.org/10.3390/rs17101709