1. Introduction
The advancement of sensor technology has facilitated the acquisition of substantial multi-platform and multi-modal remote sensing data [
1,
2,
3]. Among the most critical types of imagery in remote sensing are optical and synthetic aperture radar (SAR) images, which have been increasingly studied. Optical sensors, characterized by their extensive spectral capabilities, can capture data across various bands, including visible light, near infrared, and short-wave infrared [
4]. However, optical imagery is vulnerable to weather conditions. In contrast, SAR employs microwave imaging [
5], which is impervious to weather influences, enabling continuous operation under all weather conditions and offering a certain degree of penetration [
6]. However, SAR images are more difficult to interpret due to the complexity of the imaging mechanism. Consequently, merging optical data with SAR data effectively can improve multiple Earth observation activities, like classifying land cover [
7], change detection [
8], target extraction [
9], and so on.
Since deep learning technology has been applied to the field of remote sensing image classification [
10], innovative network architectures have been developed to enhance the efficiency of deep learning techniques, including convolutional neural networks (CNNs), [
11], recurrent neural networks (RNNs) [
12], graph neural networks (GNNs) [
13], and generative adversarial networks (GANs) [
14]. In earlier studies, due to the backwardness of earth observation capabilities and sensor technology, researchers usually focused on the classification of single-source remote sensing images. The authors of [
15] use deep learning technology, and a real-valued parameter convolutional neural network is proposed to directly classify complex-valued SAR data. Nonetheless, convolutional neural networks have limitations that prevent them from effectively extracting texture features. The authors of [
16] address the issue of classifying heterogeneous SAR images using transfer learning. Although it can learn effective domain invariant features, the model cannot be widely used, because SAR images themselves lack rich spectral information. Recently, some methods have been proposed to combine multimodal data to improve classification performance. The authors of [
17] first designed CNN to extract deep features of multi-source images simultaneously and then used SVM instead of SoftMax to obtain classification results. However, the single-branch design makes this method unable to extract spectral information and texture features simultaneously. In [
18], Jiaxin Lu et al. proposed a superpixel segmentation algorithm, which first uses the PCA method to extract optical and SAR features and then uses a multiscale superpixel segmentation algorithm for lithology classification. However, due to the limitations of the PCA algorithm, the model may ignore some effective features or extract too many redundant features. In [
19], Xuchu Yu et al. employed both the transformer’s ability to model long-range features and the convolutional neural network’s ability to extract local features at the same time, used the spectral transformer structure to extract the global spectral dependency in hyperspectral images, dynamically integrated spectral and spatial features through the feature coupling module, and finally, designed a multilevel network architecture to extract hierarchical features. However, the parallel feature extraction architecture adopted by the dynamic coupling strategy results in a lack of direct interaction between multimodal features, which may ignore the correlation between cross-modal features. At the same time, the fusion position is late, which may lead to information loss or insufficient fusion, and a more complex fusion mechanism is required to fully utilize the information.
The joint classification of optical and SAR images [
20] can be divided into the following two stages: the first stage is feature extraction, and the second stage is feature fusion. Therefore, how to effectively and accurately extract spectral and spatial features and fuse them is crucial for the classification task. The authors of [
21] utilized parallel multiscale spectral and spatial attention modules along residual paths to emphasize discriminative features and suppress redundancy, followed by a multilevel convolutional fusion module to refine integration. However, this methods lacks explicit mechanisms for cross-modal feature interaction at the propagation stage, relying mainly on attention within a single modality. The authors of [
22] employed dual encoders to process SAR and optical features separately, integrated a detail attention module for fine structure enhancement, and introduced a compound loss function to reduce noise and address class imbalance. It processed SAR and optical data in isolated encoders and enhanced details post-encoding but lacked an explicit mechanism for mutual feature refinement across domains.
Although the above methods are very helpful for optical and SAR image classification, there are still some problems. Studies have shown that the interaction between optical and SAR features can effectively compensate for the limitations of their respective features, thereby effectively improving classification accuracy. Most existing studies rely on fixed or separate attention mechanisms to extract features from different modalities. However, these approaches often treat modalities independently or in parallel, without dynamically assessing the usefulness of features during extraction. This leads to the following two major issues: redundant or noisy features are preserved, and the lack of interaction between SAR and optical features at the early stage weakens cross-modal complementarity. Moreover, fusion strategies in existing networks are typically implemented as a late-stage integration step. These methods do not establish strong dependencies between spatial and spectral domains or between modalities in a progressive manner. They lack the dynamic modulation or feedback to adaptively guide fusion based on the relevance and informativeness of the features. Therefore, to address the above issues, we introduce a feature propagation strategy that constrains the scale factor of BN through a statistical prediction interval, allowing the early filtering of redundant information and replacing it with complementary information from other modalities. This cross-modal interaction during feature extraction enhances the discriminative ability. At the same time, we combine spatial attention, channel attention, and multiscale axial attention in the feature fusion stage to form a tightly integrated fusion strategy that captures global context and fine-grained features more effectively than traditional fusion blocks. The significant contributions of this research are as follows:
- (1)
A combined classification model is developed for classifying optical and SAR images. The feature propagation block is used to extract the spectral spatial features of optical and SAR images. The weight-sharing method is used to reduce the number of training parameters, improve the training performance of the model, and enhance the generalization ability.
- (2)
Using a statistical prediction interval to limit the scale factor of the BN layer is conducive to extracting complementary features and reducing redundant information, giving full play to the complementary advantages of optics and SAR.
- (3)
A feature fusion module is designed to help the model concentrate on detailed features and to build long-range dependencies, integrating the advantages of optics and SAR and further improving the classification ability of the model.
The rest of the paper is organized as follows:
Section 2 presents the specific details of the proposed SPIFFNet. Experimental results and data on three datasets are analyzed in
Section 3. A discussion is presented in
Section 4. In
Section 5, we summarize our paper Some additional information on data distribution is given in
Appendix A 2. Proposed Framework
This section provides a detailed overview of SPIFFNet.
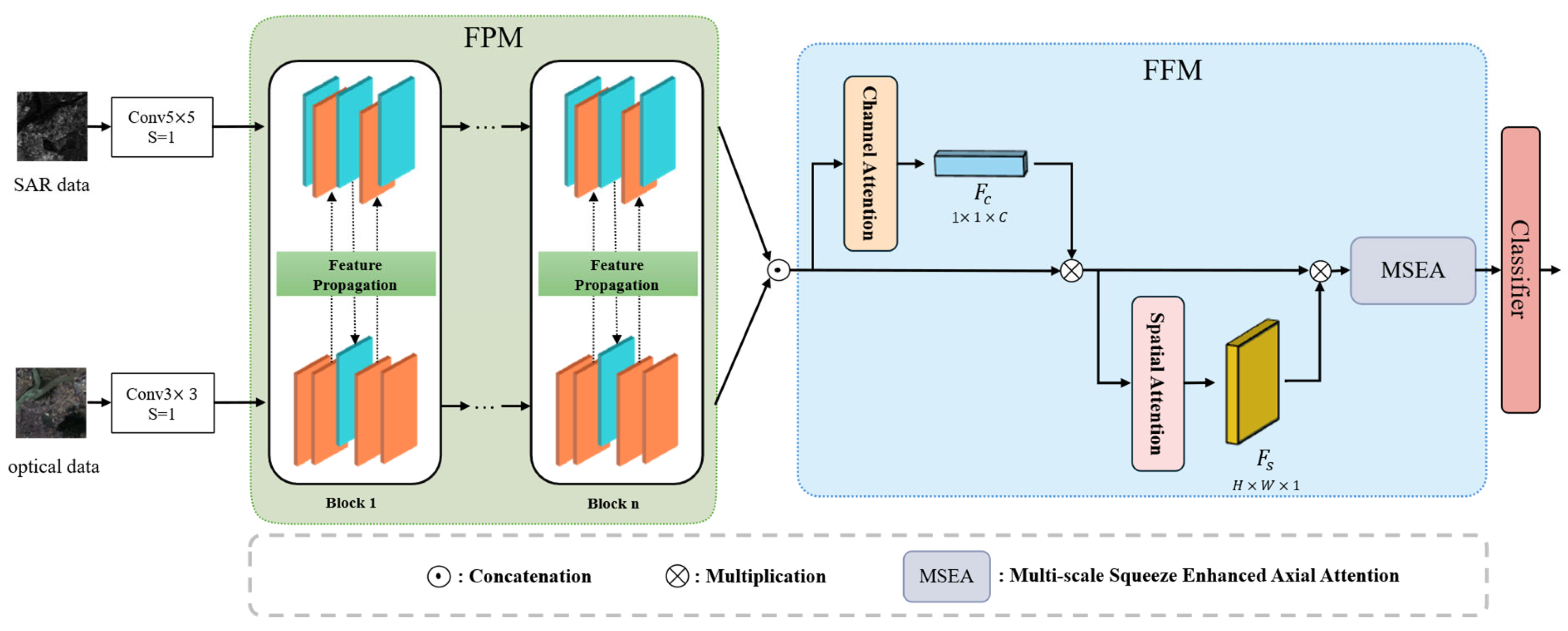
Figure 1 illustrates the architecture of the proposed SPIFFNet framework, which is composed of two primary components, FPM and FFM. First, n blocks are used to extract features from SAR data and optical data, respectively, and the two types of data are interacted based on the statistical prediction interval method, which is feature propagation. Secondly, CA, SA, and MSEA constitute FFM. The channel refinement features
extracted by channel attention and the spatial refinement features
extracted by the spatial attention module are multiplied with the input features to further enhance both types of features. Subsequently, MSEA is employed to cross-learn and fuse the two types of features, so that the optical and SAR features form complementary strengths. Finally, the classification results are obtained using a SoftMax classifier.
2.1. Feature Propagation Module
2.1.1. Feature Extraction Based on Block
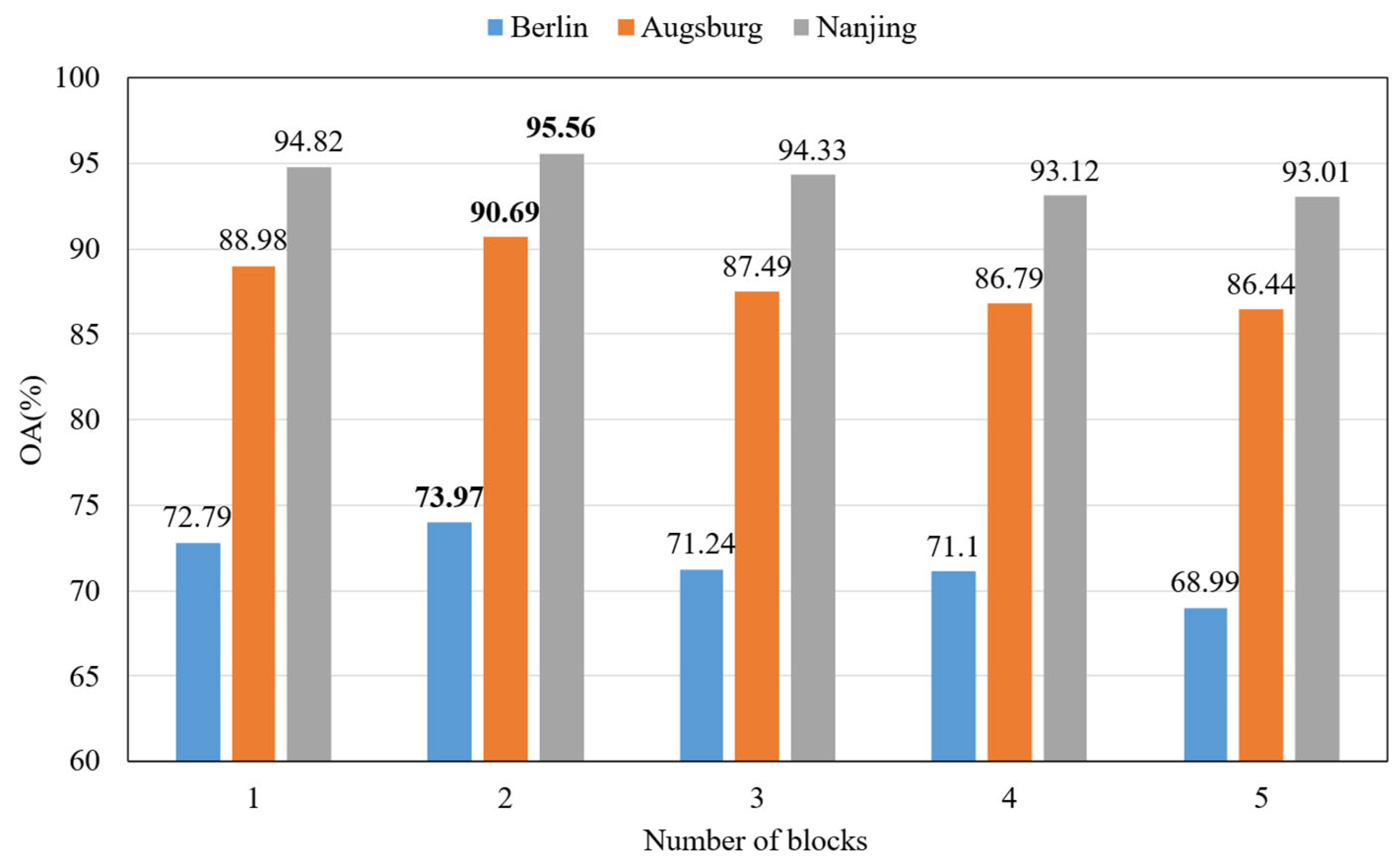
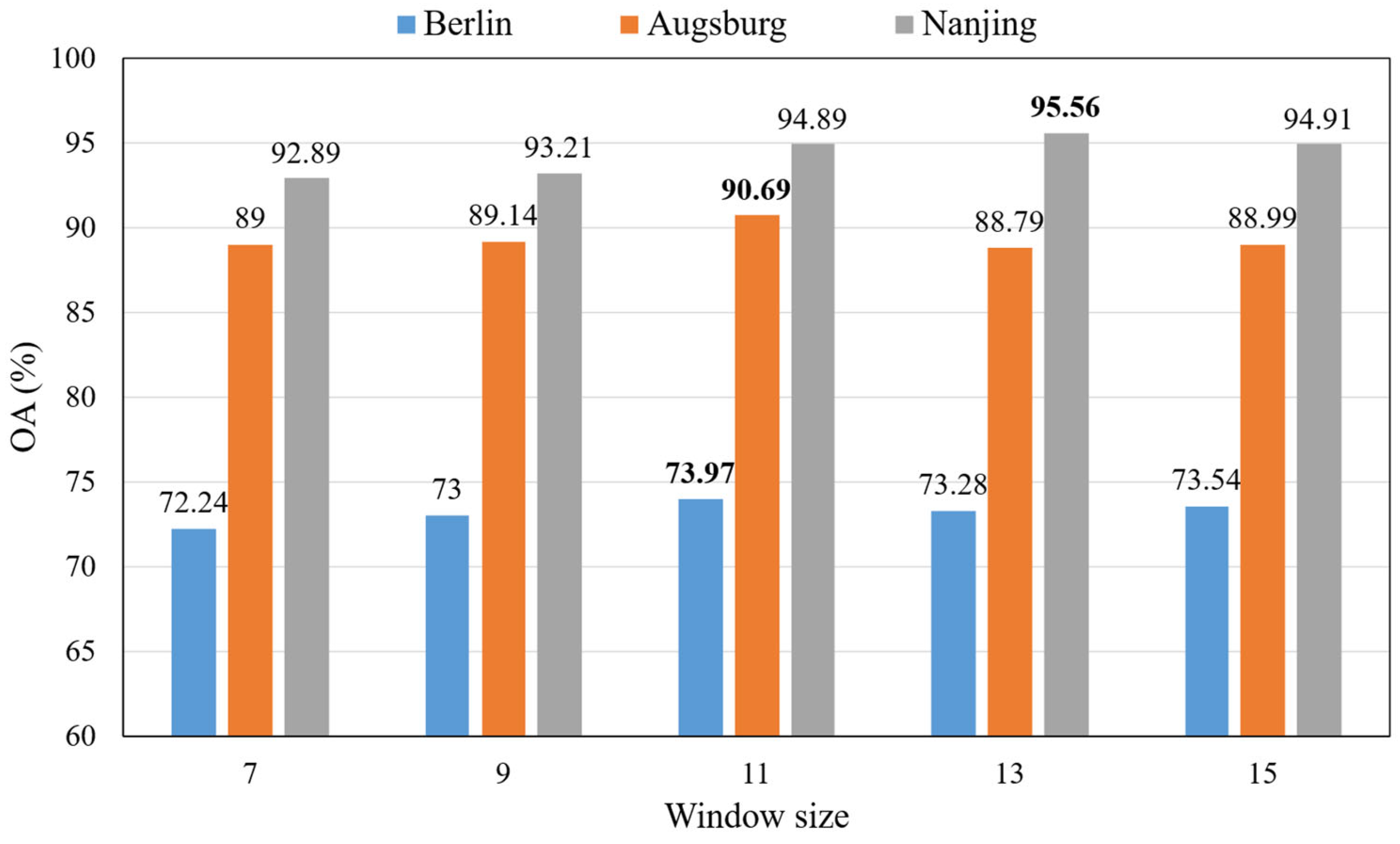
In order to facilitate the extraction of classification features, we used a size spatial neighbourhood window to represent the central pixel. Therefore, the input SAR image and optical image can be described as and , where represents the window size, and and are the channel number of SAR and optical data.
The
and
of the first layer of the SPIFFNet are employed to adjust the optical and SAR data to the same dimensions. Optical images usually contain rich colors and detailed features [
23], and smaller convolution kernels can better capture local features and subtle changes, while SAR images usually have strong noise and complex textures [
24], and using slightly larger convolution kernels can help the network better capture the overall structural and textural information, while reducing the effect of noise. Therefore, we choose
and
to extract optical and SAR features, respectively. The size of the original image patch remains unchanged with
and
, with only the channel number being modified. Afterwards, n blocks are used to extract spectral and spatial features. These blocks share common weights. This design can greatly reduce the number of parameters that need to be learned and reduce the risk of overfitting [
25].
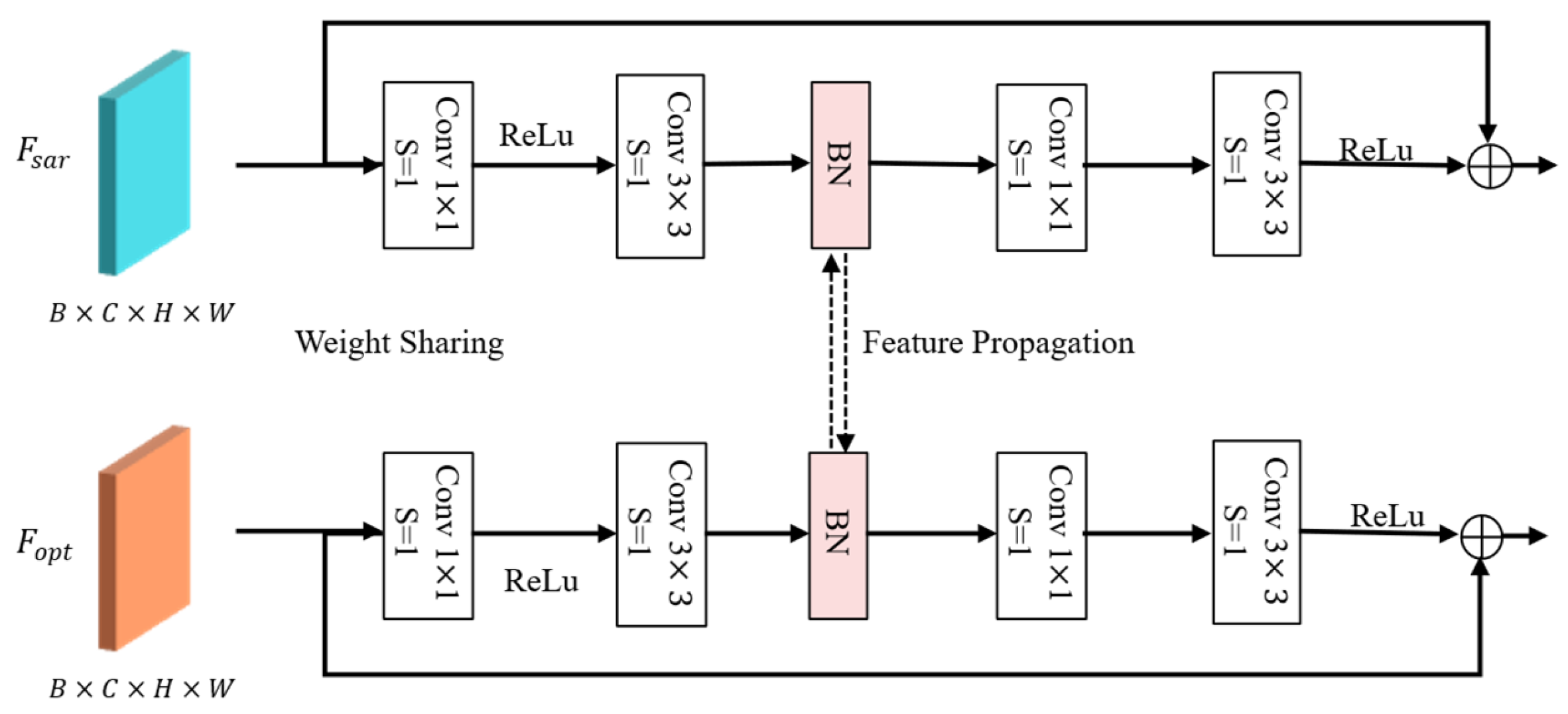
Figure 2 illustrates the detailed structure of the block, which includes multiple convolutional layers with varying kernel sizes and batch normalization layers. We use the ReLu activation function, because it is simple to implement and performs well in various classification tasks. In the BN layer, feature propagation is achieved by limiting the scale factor of the independent BN layer. The parameters of the BN layer do not share weights and are trained independently. In addition, the block also uses residual operations to overcome the gradient fading [
26] problem caused by the increase in the number of model layers. Therefore, while retaining the characteristics of the two types of data, the classification performance of the model is improved.
In addition, we used the stochastic gradient descent (SGD) optimization algorithm, which can search for the best parameters to minimize the loss function. In order to deal with the problem of the imbalanced number of training samples, we used the weighted cross-entropy loss function. At the same time, in order to avoid overfitting the model, we also added the
regularization term to the loss function [
27]. The loss function at the end can be described as follows:
where
represents the weight of label
, calculated according to the proportion of label
within the total sample. For example, when the total number of samples is
, and there are
different labels, the number of samples with label
is represented as
, then
.
and
represent the true label and the output of the model, respectively.
and
are the number of data sources and BN layers.
is the regularization constant, and
is the scale factor of the BN layer.
2.1.2. Feature Propagation Based on Statistical Prediction Interval
One of the reasons why deep learning network models are difficult to train is that the model contains many hidden layers. As training progresses, the parameters of each layer are modified and optimized, resulting in a continuous change in the input distribution of the hidden layer, which causes each hidden layer to encounter covariate shift [
28]. However, batch normalization, a popular and effective technique, can consistently accelerate the convergence of deep networks [
29]. BN transforms
according to the following expression:
where
represents the SAR or optical feature of the input. After BN operation,
.
is the mean of
, and
is the variance of
.
is a small constant to ensure that the denominator is not 0.
and
are the scale factor and shift factor, respectively.
During the training process, the change range of the middle layer should not be too drastic, and the BN operation makes the distribution of each layer actively centered. Therefore, we limited the scale factor. In fact, too large or too small a scale factor will have a bad effect on the convergence of the model. If the loss function is too large, the model parameters will be updated too quickly, so that the optimal solution cannot be found. If the loss function is too small, the model parameters will be updated too slowly and may fall into the local optimization [
30], which will be analyzed in detail in
Section 2.3. Following the standard in batch normalization [
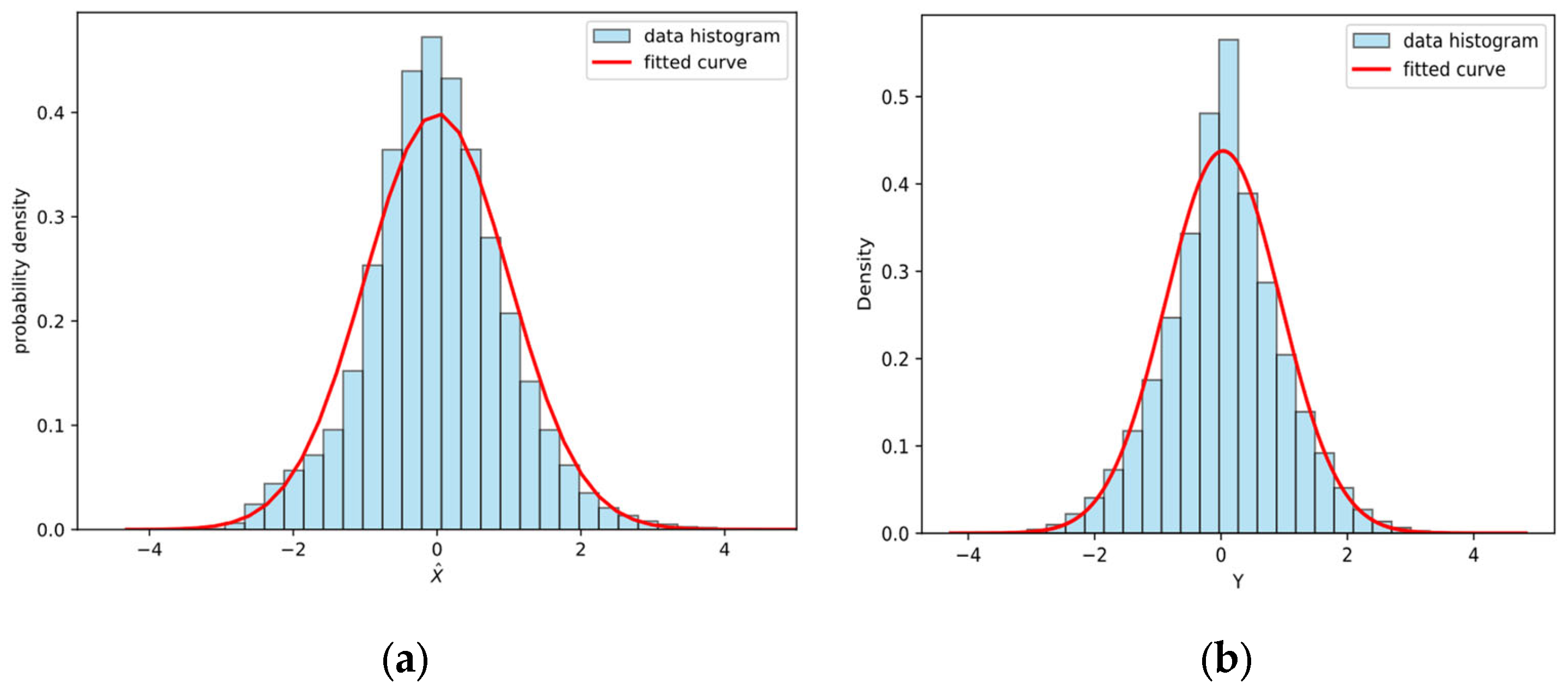
31], the feature activations after BN are considered to be approximately following a standard normal distribution. At the same time, we analyzed the post-BN distribution of our features and observed that they approximately follow a normal-like shape (see
Figure A1 in
Appendix A). Equation (2) shows that
follows a standard normal distribution, that is,
. Because
follows a standard normal distribution,
also follows a normal distribution. From Equation (3), we can obtain the mean of
as
and the variance as
.
Therefore, we can obtain
and define the sample mean and sample variance as follows:
where
is the total number of sample.
and
are the sample mean and sample variance, respectively.
For the sample mean
and sample variance
of a Gaussian random variable
, it follows from [
32] that they satisfy, as follows:
where
and
are independent of each other.
represents
distribution with degree of freedom
.
Figure 3 shows the probability density of the
distribution with
degrees of freedom. Point
is the upper
quantile of
. Therefore, the probability of the shaded area is calculated as follows:
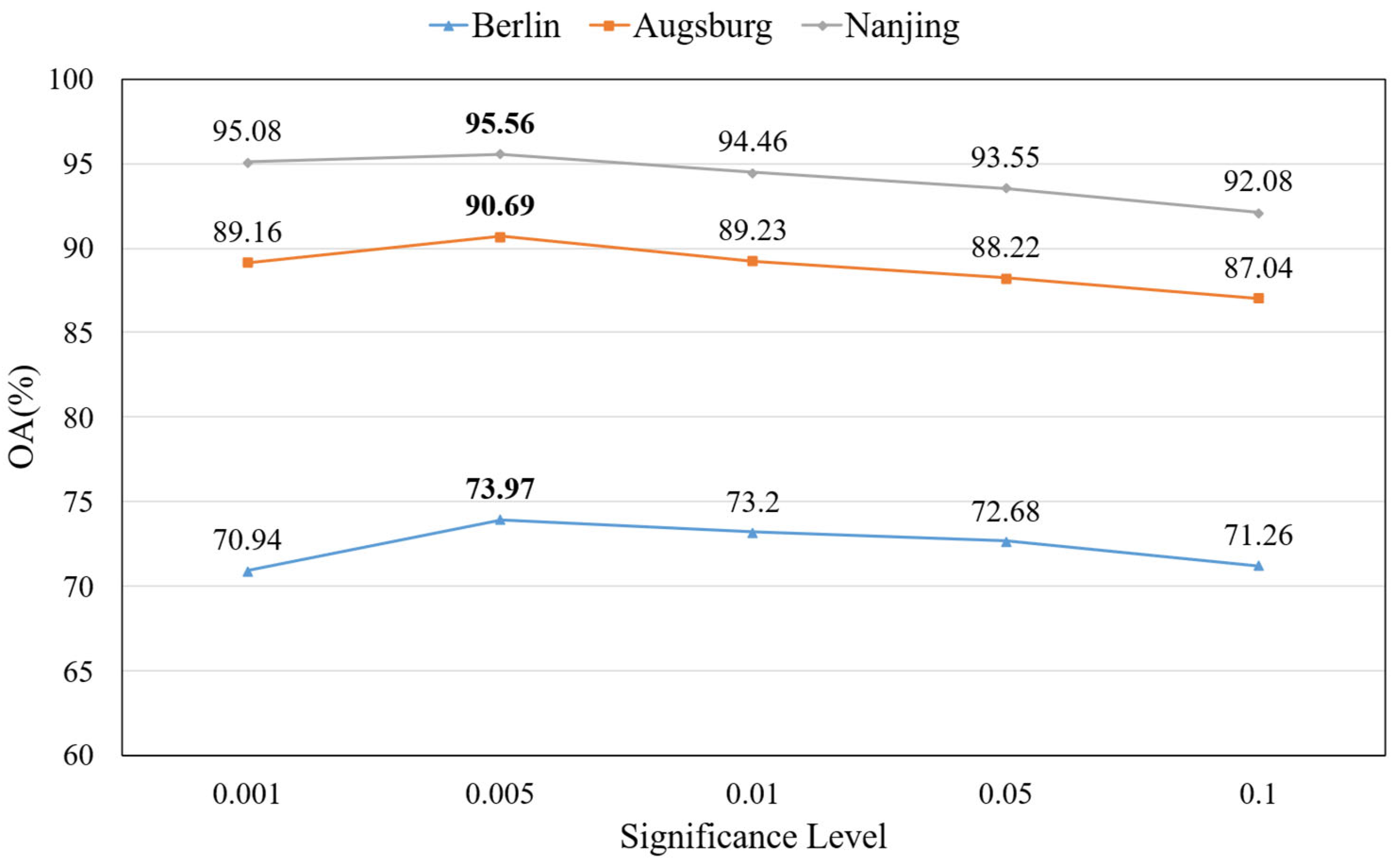
The range of the scale factor is calculated by the statistical prediction interval method. Equation (6) shows a confidence interval of the variance of the Gaussian variable with a confidence level of , that is, the confidence interval of scale factor . represents the significance level.
During model training, the scale factor
for each channel is learned along with other model parameters, as the input features pass through the BN layer. The scale factor of each channel of the SAR or optical feature is compared to the scale factor interval range obtained from Equation (6). If the
of the current channel is within the interval range, that is,
, then the feature of the current channel is considered to contribute to the subsequent classification and is a useful feature, and if the
of the current channel is too large or too small, resulting in exceeding this interval range, that is,
, then the feature of the current channel is detrimental to the subsequent classification of the model, which is analysed in detail in
Section 2.3. Therefore, it can be considered that the features of the current channel are redundant features, and the current features should be replaced with features from another data source, which is the process of feature propagation. Taking optical characteristics as an example, the specific process of feature propagation is described as follows:
2.2. Feature Fusion Module
After using block for feature propagation, the features between optical and SAR fully interacted, while retaining their advantages. In order to facilitate the subsequent classification, we designed a feature fusion module to combine optical and SAR features, capture global and detailed features, and improve the performance and generalization ability of the model [
33]. Initially, the FFM extracts both channel and spatial attention, from the perspectives of channel and space, respectively, to further augment the interaction between optical and SAR data. Then, the MSEA module is used to cross-learn and fuse the two types of features, so that the two types of data complement each other and, thus, improve classification accuracy.
2.2.1. Channel Attention and Spatial Attention
The framework of CA and SA is shown in
Figure 4. With the development of deep learning, pooling operations have been increasingly used. Pooling operations can usually reduce the scale of data and aggregate information [
34].
As the number of neural network layers increases, the receptive field of each neuron will become larger due to the pooling operation. Pooling operations include maximum pooling and average pooling [
35]. Channel attention and spatial attention use both pooling operations at the same time, aggregating the information extracted by the two in different ways and using convolution operations to refine the extracted features further. Ultimately, the channel attention feature map and the spatial attention feature map are derived and subsequently combined with the input feature map through element-wise multiplication.
For channel attention, the calculation process is as follows:
where
is the input feature, and
is sigmoid activation function. The
and
pooling operations here are along the
and
directions and do not change the size of
, so
.
where
is the input feature of spatial attention.
represents concatenating
and
in the channel dimension. The
and
pooling operations here are along the
directions and do not change the size of
and
, so
.
2.2.2. Multiscale Squeeze Enhanced Axial Attention
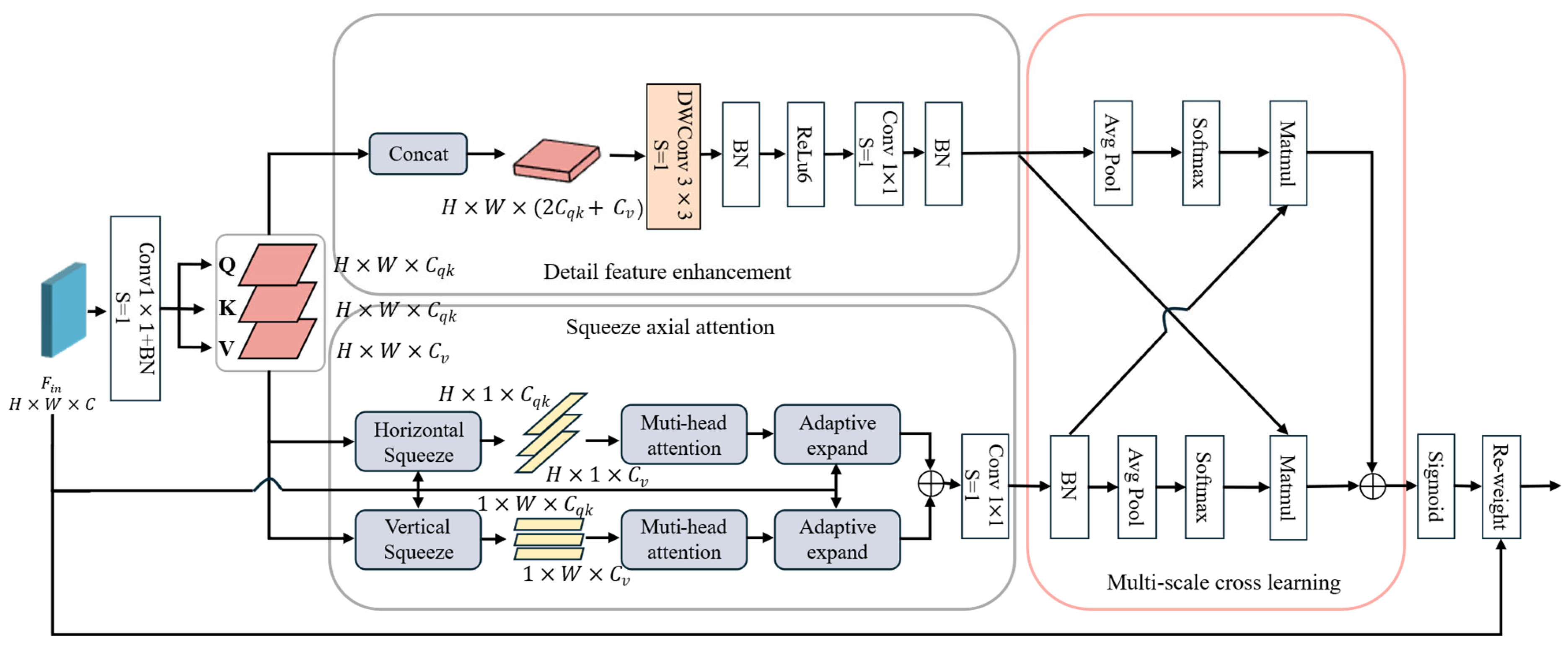
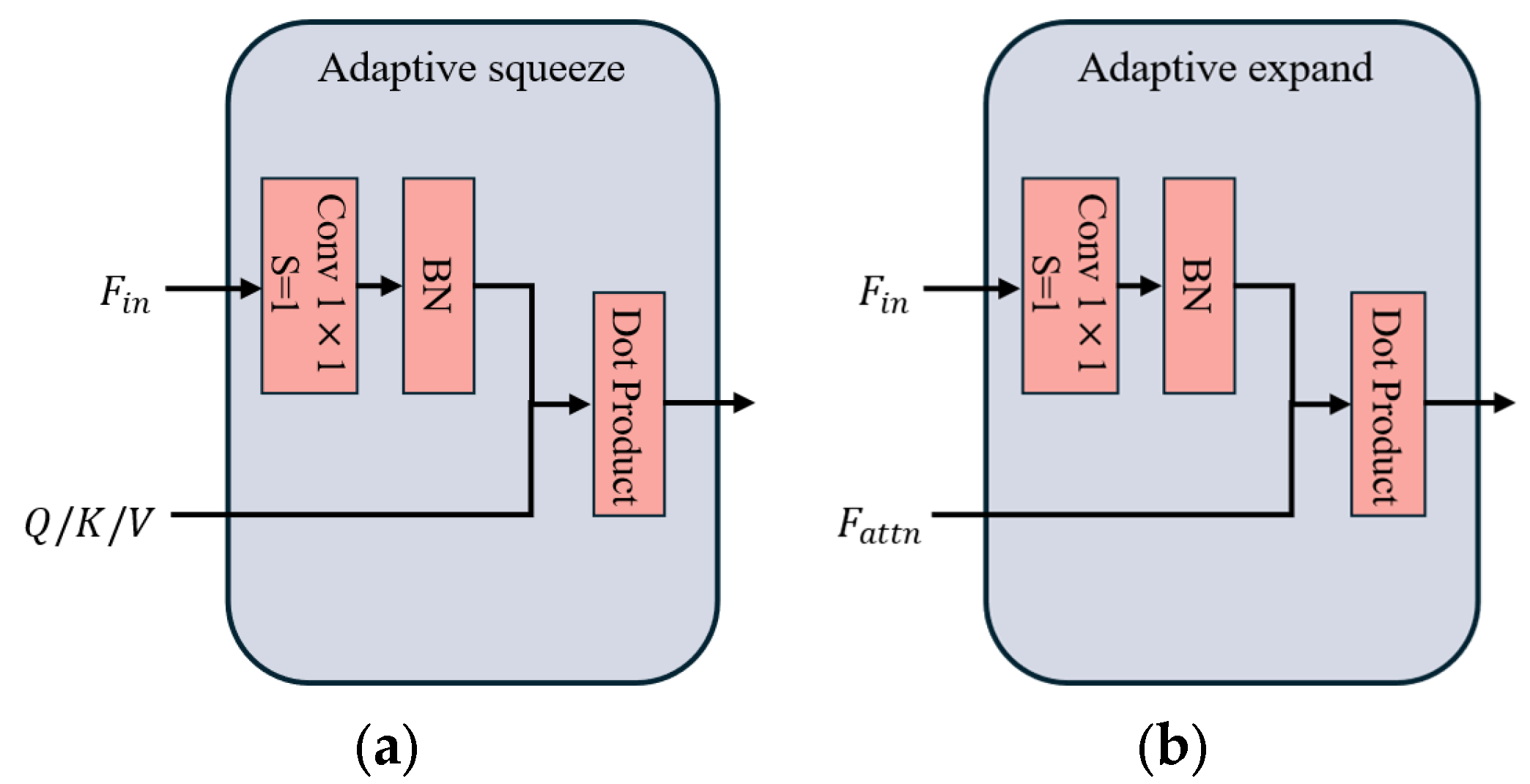
To effectively and accurately fuse and extract more features that are beneficial to classification, inspired by the literature [
36], we designed a multiscale squeeze enhanced axial attention, which is shown in
Figure 5. In this paper, firstly, the input features passed through a convolution layer and a batch normalization layer to obtain three feature matrices of
, and
. MSEA is improved based on squeezing axial attention similar to the self-attention mechanism. The self-attention mechanism involves the operation between query, key, and value, so its linear complexity is high [
37]. With ongoing advancements in remote sensing technology, the data to be processed by the model are also increasing, which makes the calculation cost of the self-attention mechanism increase significantly [
38]. Therefore, squeeze axial attention reduces the dimension of data through adaptive squeeze and expansion operations and adds position information, thus improving the calculation speed and accuracy of the model. In contrast to the pooling operation used for compression and broadcasting for expansion, adaptive squeezing and expanding operations enable the model to gather spatial information in an input-adaptive manner, while avoiding significant increases in computational costs. The specific implementation process is shown in
Figure 6.
The calculation of squeeze axial attention can be expressed as:
where
,
, and
are the result of horizontal squeeze, and
,
, and
are the result of vertical squeeze.
In order to extract more detailed features, the squeeze axial attention adds a detail feature enhancement branch. The depthwise separable convolution with
convolution kernel is used to capture multiscale feature representation and extract detail features with a large receptive field [
39]. After the feature extraction of the two branches, the features of the two branches need to be efficiently integrated to improve the classification effect of the integrated features [
40]. In contrast to existing methods that often rely on single-scale feature interaction or simple concatenation for multimodal fusion, the core innovation of our approach lies in the introduction of a multiscale cross learning fusion mechanism. This design allows features extracted at different scales to interact, complementing global semantic cues with fine-grained spatial information. Such cross-scale interactions significantly enhance the robustness of feature representations, especially when dealing with heterogeneous data sources, such as SAR and optical imagery, which often exhibit modality-specific noise and resolution discrepancies. Therefore, we added multiscale cross learning at the end, using two-dimensional global average pooling to encode global information and establish long-range dependencies and using cross-learning to aggregate two different spatial attention weights. Finally, the learned attention was fused into the input features through the Re-weight method to achieve feature fusion. The Re-weight operation is calculated as follows:
where
denotes the input feature for MSEA, while
signifies the attention weight.
2.3. Analysis of Scale Factor
In this paper, we employ the method of statistical prediction interval to impose constraints on the scale factor. In the event that the features of the current channel exceed the specified interval, we regard these features as superfluous information, which will have a detrimental impact on the subsequent classification. To prove that the scale factor is too large or too small, it has a bad effect on the extraction of optical and SAR features. From (1) and (2), the gradient of
can be calculated as follows:
From (12), the size of the scale factor affects the parameter update of the optical and SAR feature extraction model. At the same time, there is no shift factor in the gradient of , so we only limit the scale factor . When the scale factor is too large, that is , this denotes that the loss function is especially sensitive to shifts in the current input feature. The process of feature extraction is intended to capture the distinctive features of optical and SAR. At this stage, the update speed of the parameters is too fast, which will make feature extraction difficult. Conversely, when the scale factor is too minimal, that is , then , indicating that the current feature does not affect the update of the model parameters. Therefore, the current feature is considered to be a redundant feature, and feature propagation should be performed.
4. Discussion
In the process of advancing the classification task of multi-source remote sensing images, optical and synthetic aperture radar (SAR) synergistic classification has demonstrated great potential. For the scene in the same area, multi-source remote sensing images can demonstrate multiple grey-scale features and texture detail features of the scene, and thus, multi-source remote sensing images have the advantage of displaying the feature characteristics of the landforms in multiple perspectives, compared with imaging from a single data source. However, due to the different imaging mechanisms, the susceptibility of optical images to weather and the inherent coherent patch noise of SAR, which makes the features of the two differ greatly, it is a complex and challenging problem to extract the two types of features efficiently and to fuse them for classification reasonably and accurately. To cope with these challenges, our work effectively overcomes these problems by starting from both feature extraction and feature fusion, deeply extracting the respective advantageous features through a feature propagation strategy, and then, fusing the spatial and channel features of the two types of data from a multiscale perspective.
Firstly, SPIFFNet adopts the statistical prediction interval method to limit the scale factor of the BN layer in the feature propagation process, and this strategy effectively reduces the redundant information and achieves the information interaction between different modal data. However, the method is sensitive to the setting of the scale factor range, and different datasets may require different hyperparameter tuning, which limits the generalizability of the model to some extent. Future research can consider introducing an adaptive statistical prediction interval method, so that the model can dynamically adjust the constraint range of scale factors according to the data distribution, thus improving the generalization ability. Second, in the feature fusion stage, SPIFFNet combines channel attention (CA), spatial attention (SA), and multiscale compression-enhanced axial attention (MSEA) to enhance the complementarity of optical and SAR data. Although this multilevel feature fusion strategy effectively improves the classification performance, its computational complexity is relatively high, which may bring computational bottlenecks, especially in large-scale remote sensing data processing. Therefore, future research can explore lightweight attention mechanisms, such as the introduction of separable convolution or knowledge distillation techniques, in order to reduce the computational cost, while maintaining high classification accuracy. In addition, currently, SPIFFNet is mainly based on deep learning framework for end-to-end training, while remote sensing classification tasks are often affected by data quality, noise interference, and other factors, so we can try to combine traditional methods, such as image segmentation, boundary detection, etc., to further enhance the model’s robustness and interpretability.
Another issue of concern is the expandability of multimodal data fusion. Currently, SPIFFNet is mainly aimed at the joint classification of optical and SAR data, while in practical remote sensing tasks, hyperspectral (HSI) and LiDAR data are also rich in spatial and spectral information, which can provide more comprehensive feature characteristics. Therefore, future research can explore how to extend SPIFFNet to more multimodal data fusion tasks, such as using a multimodal transformer or graph neural networks (GNNs) for heterogeneous data modelling, in order to further improve the classification accuracy and information utilization. In addition, remote sensing data often have the problem of category imbalance, and even though this paper employs a weighted cross-entropy loss function to mitigate this issue, category skewing may still occur in extreme imbalance cases. Generative adversarial networks (GANs) or data enhancement strategies can be introduced in the future to improve the classification performance of small sample categories.
5. Conclusions
In this work, a statistical prediction interval-guided feature fusion network is proposed for the joint classification of optical and SAR images. We utilized the statistical prediction interval to constrain the scaling factors of the BN layers, which helped to determine the feature propagation strategy. This reduced redundancy, while enhancing the interaction between multi-source information. During the feature fusion stage, channel and spatial attention mechanisms were employed to extract channel and spatial information, followed by multi-source data fusion through multiscale squeezing to enhance axial attention for cross-scale learning. Additionally, to address the issue of class imbalance, we introduced a weighted cross-entropy loss function. Comprehensive evaluations across three datasets demonstrated the promising performance of the proposed SPIFFNet.
However, in practical model deployment and application, SPIFFNet may face certain limitations. For instance, during feature propagation, the current channel scaling factor was used to determine whether the information is redundant, directly replacing the current feature with another feature. This strategy might still exhibit some shortcomings when dealing with an increasing number of data sources. Therefore, future research should explore more effective propagation mechanisms to further advance multi-source remote sensing image classification.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}