
Design of a Multimodal Detection System Tested on Tea Impurity Detection


Abstract
1. Introduction
2. Design of the Multimodal Detection System
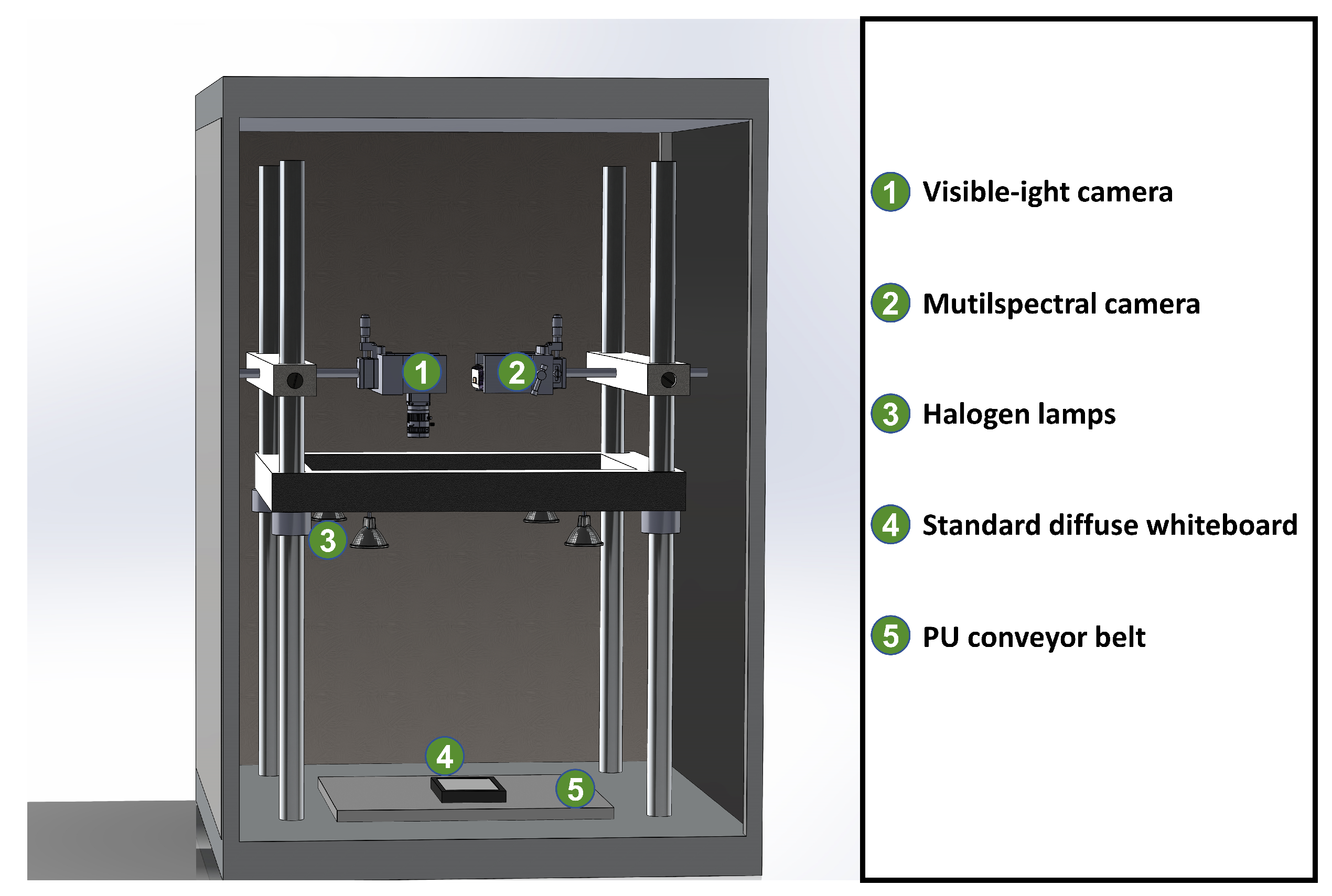
2.1. Multimodal Detection System
2.2. Image Correction And Registration
3. Materials and Methods
3.1. Sample Preparation
3.2. Feature Extraction
3.3. Modeling and Evaluation
4. Results
4.1. Feature Analysis
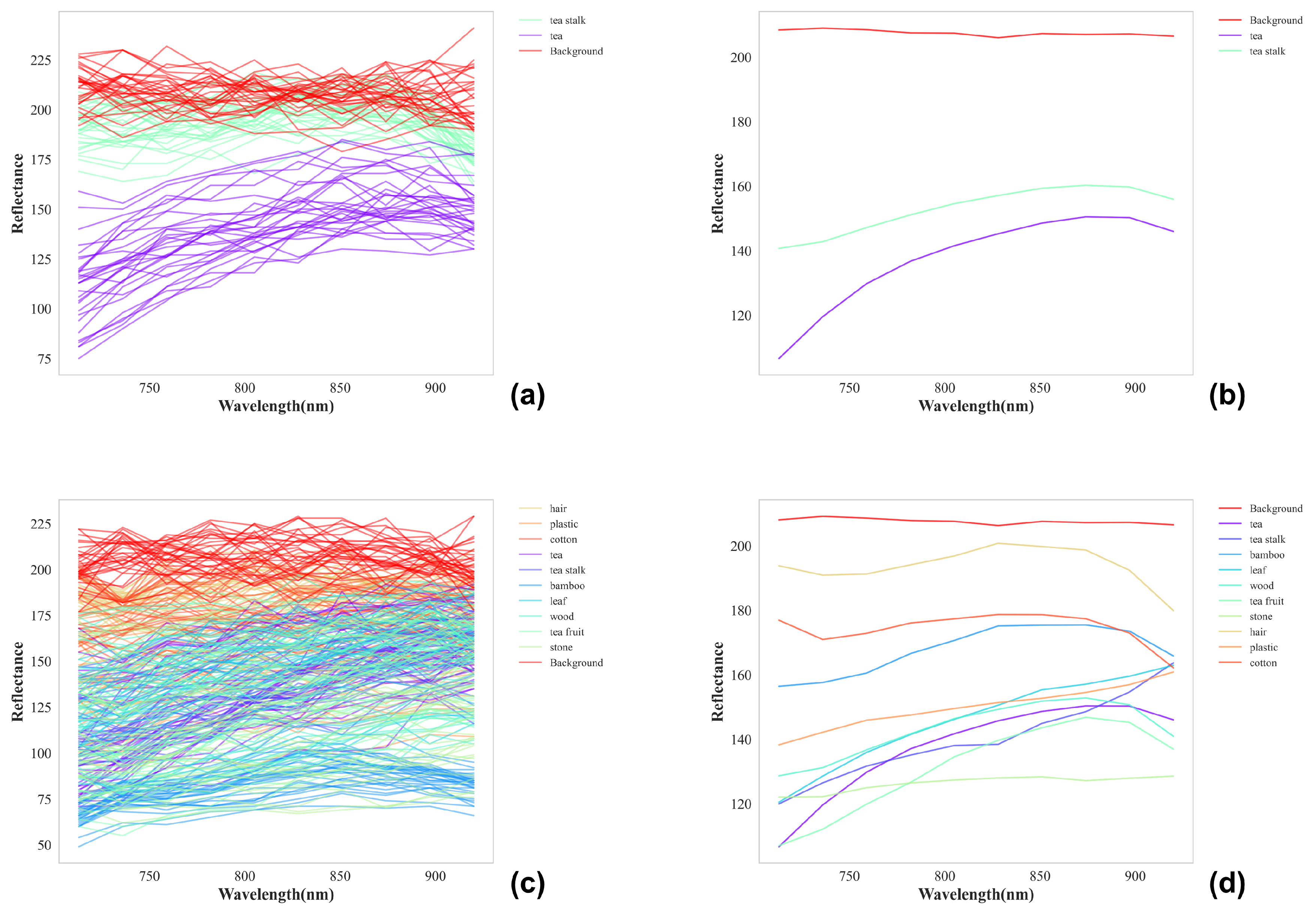
4.1.1. Spectral Analysis
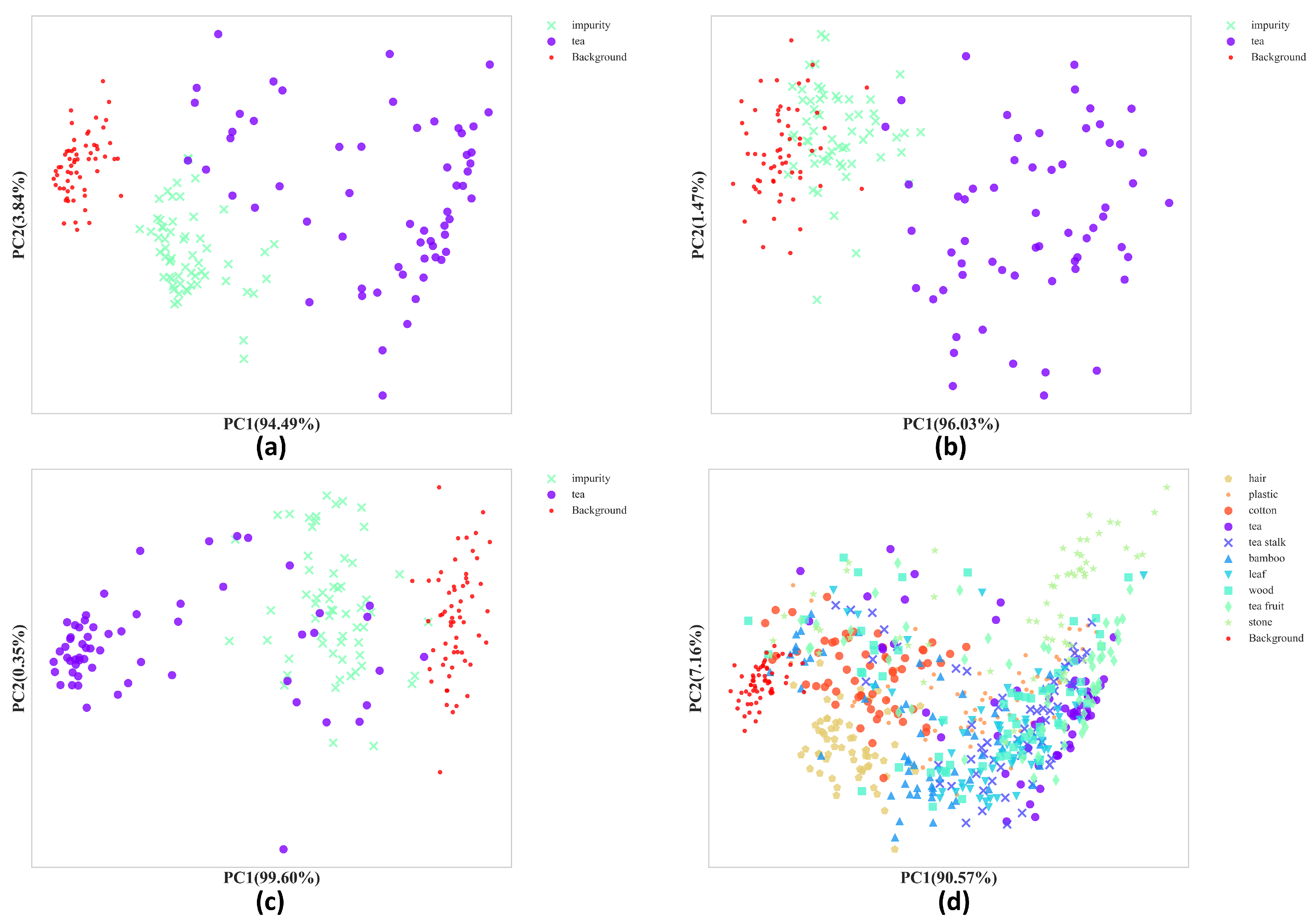
4.1.2. Principal Component Analysis (PCA)
4.2. Comparison of Different Models
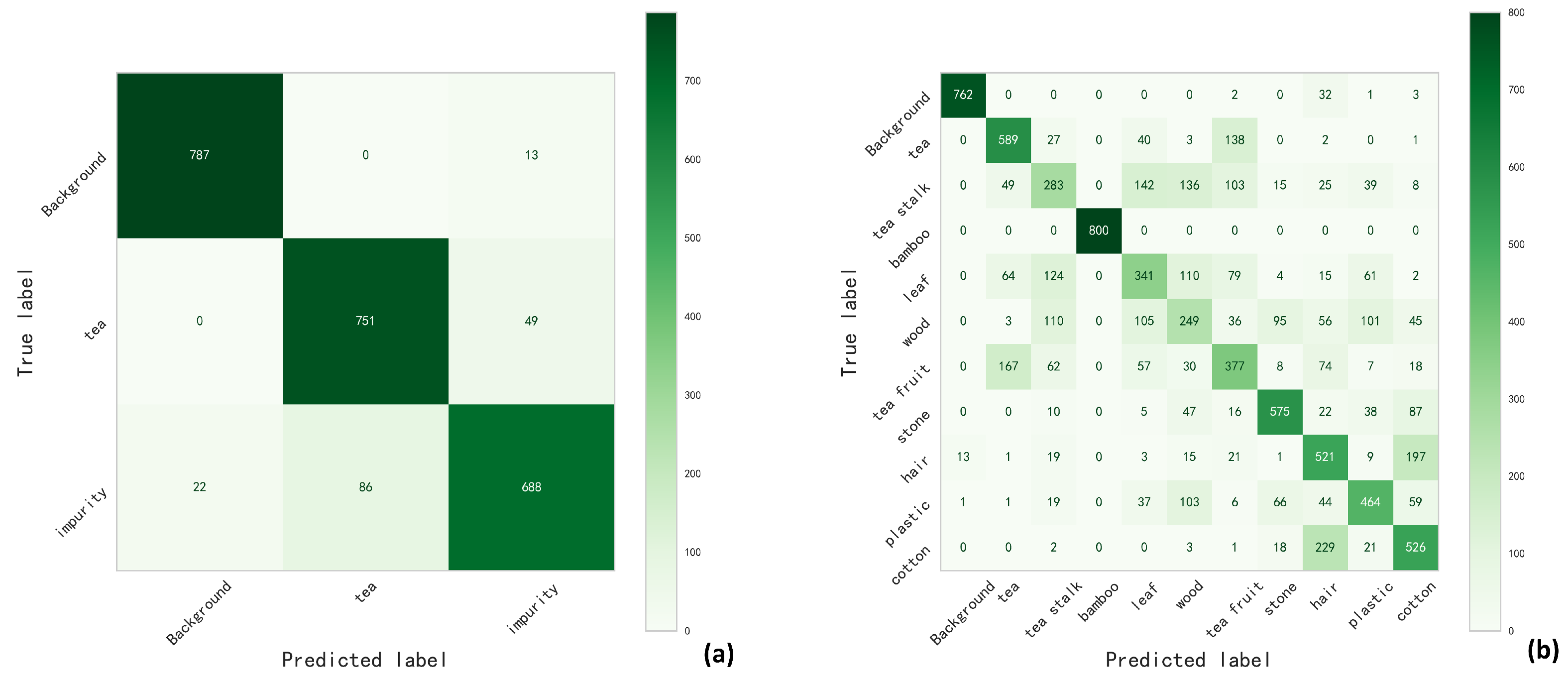
4.3. Classification Results and Post-Processing
4.4. Small Impurity Detection and Final Detection Results
4.5. Model Extrapolation Capability
5. Discussion and Prospect
- Increase the detection field of the multimodal detection system: The multispectral camera used in this study had fast imaging speed, and the image registration algorithm was simple and fast. The total imaging and image registration time was less than 3 s. Due to the limitation of the size of the correction whiteboard in the experiment, the actual detection field corresponding to the image after registration was about 20 cm × 20 cm. In practical applications, the size of the corrected whiteboard can be increased, which improves the detection field to a certain extent. A visible light camera with a slightly larger field of view than a multispectral camera was used in the experiment, but a visible light camera with a larger resolution and field of view can be selected for practical applications. However, the detection field captured by multispectral cameras is much smaller than that of visible light cameras, but multiple multispectral cameras can be used to increase the detection field. A visible light camera with a larger field of view and a higher resolution can be positioned at the center, while multiple multispectral cameras are installed in different directions at the same distance from the visible light cameras. Through this installation method, each multispectral camera can be paired with the same visible-light camera, thus effectively increasing the detection field.
- Improve the detection accuracy: In terms of the accuracy of the algorithm, it can be concluded from the detection results that there were problems such as the incomplete detection of the impurity object region and the deviation of the predicting box. This was mainly because the accuracy of pixel classification was not high enough, and some scattered impurity pixels were processed into other types of pixels in the post-processing, which caused the object area to become incomplete. Fortunately, despite the incomplete detection of the impurity object region, all the impurity regions could be detected. This means that an incomplete detection of the impurity object region does not affect the final detection accuracy of the impurity. In order to improve the accuracy of pixel classification, an instance segmentation based on deep learning method will be considered next. A total of 13 channels of multispectral data and visible light data were input into the network for training. Multiple image sources can provide more information, which can effectively improve the accuracy of network training results. In addition, several impurity objects were detected as the same impurity object due to overlapping or close proximity. In the subsequent process of automatic removal of impurities, this would cause some impurities to be missed. It can be solved by adding another round of impurity detection after the vibrator disperses the tea again, which can not only solve the missed detection caused by overlapping impurity objects but also solve the missed detection caused by impurities covered by tea. However, this will increase the time of detection, which needs to be balanced between accuracy and efficiency in practical applications.
- Comprehensively analyze the performance of the system: The multimodal detection system designed in this experiment can obtain more abundant information from multiple cameras, and more importantly, it can make up for the shortcomings of the low resolution of multispectral cameras. The whole system has a high imaging stability and fast imaging speed, which are very suitable for rapid detection. This study confirmed the advantages of this system in detecting tea impurities, which can not only improve the accuracy of pixel classification but also improve the ability to detect small objects. It can also be used for impurity detection of other samples, such as soybean impurity detection, rice impurity detection, grain impurity detection, and so on. It can also be used for crop growth detection and classification problems. In the future, we consider using this system to detect impurities in rice, in cocoa beans, in tobacco, and in wheat to verify the scalability of this system. This system can be used in cases where samples and all types of impurities can be distinguished by color or spectrum. The spectral band of the multispectral camera used in the experiment can be selected in the band from 713 nm to 920 nm. The optical fiber spectrometer can be used to detect the spectral characteristics of samples and impurities, and the appropriate band can be selected. If the detection requirements cannot be met within this band, it is recommended to choose other types of multispectral cameras, build the system by referring to the method in this paper, and then refer to the impurity detection algorithm adopted in this paper. This system is particularly suitable for projects that exclusively utilize multispectral cameras, as the additional information and higher resolution will enhance the results of these studies to varying degrees.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mukhi, S.E.; Varshini, R.T.; Sherley, S.E.F. Diagnosis of COVID-19 from Multimodal Imaging Data Using Optimized Deep Learning Techniques. SN Comput. Sci. 2023, 4, 212. [Google Scholar] [CrossRef] [PubMed]
- Nayak, M.; Tiyadi, J. Predicting the Onset of Diabetes Using Multimodal Data and a Novel Machine Learning Method; Technical Report. EasyChair. 2023. Available online: https://www.researchgate.net/profile/Jagannath-Tiyadi/publication/376595859_EasyChair_Preprint_Predicting_the_Onset_of_Diabetes_Using_Multimodal_Data_and_a_Novel_Machine_Learning_Method/links/657f14b78e2401526ddf2708/EasyChair-Preprint-Predicting-the-Onset-of-Diabetes-Using-Multimodal-Data-and-a-Novel-Machine-Learning-Method.pdf (accessed on 5 March 2024).
- Houria, L.; Belkhamsa, N.; Cherfa, A.; Cherfa, Y. Multimodal magnetic resonance imaging for Alzheimer’s disease diagnosis using hybrid features extraction and ensemble support vector machines. Int. J. Imaging Syst. Technol. 2023, 33, 610–621. [Google Scholar] [CrossRef]
- Spaide, R.F.; Curcio, C.A. Drusen characterization with multimodal imaging. Retina 2010, 30, 1441–1454. [Google Scholar] [CrossRef] [PubMed]
- Heintz, A.; Sold, S.; Wühler, F.; Dyckow, J.; Schirmer, L.; Beuermann, T.; Rädle, M. Design of a Multimodal Imaging System and Its First Application to Distinguish Grey and White Matter of Brain Tissue. A Proof-of-Concept-Study. Appl. Sci. 2021, 11, 4777. [Google Scholar] [CrossRef]
- Li, X.; Zhang, G.; Cui, H.; Hou, S.; Chen, Y.; Li, Z.; Li, H.; Wang, H. Progressive fusion learning: A multimodal joint segmentation framework for building extraction from optical and SAR images. ISPRS J. Photogramm. Remote Sens. 2023, 195, 178–191. [Google Scholar] [CrossRef]
- Quan, L.; Lou, Z.; Lv, X.; Sun, D.; Xia, F.; Li, H.; Sun, W. Multimodal remote sensing application for weed competition time series analysis in maize farmland ecosystems. J. Environ. Manag. 2023, 344, 118376. [Google Scholar] [CrossRef] [PubMed]
- Zhao, L.; Han, L.; Zhang, H.; Liu, Z.; Gao, F.; Yang, S.; Wang, Y. Study on recognition of coal and gangue based on multimode feature and image fusion. PLoS ONE 2023, 18, e0281397. [Google Scholar] [CrossRef] [PubMed]
- Chu, X.; Tang, L.; Sun, F.; Chen, X.; Niu, L.; Ren, C.; Li, Q. Defect detection for a vertical shaft surface based on multimodal sensors. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 8109–8117. [Google Scholar] [CrossRef]
- Saran, G.; Ganguly, A.; Tripathi, V.; Kumar, A.A.; Gigie, A.; Bhaumik, C.; Chakravarty, T. Multi-modal imaging-based foreign particle detection system on coal conveyor belt. Trans. Indian Inst. Met. 2022, 75, 2231–2240. [Google Scholar] [CrossRef]
- Jiang, L.; Xue, R.; Liu, D. Node-Loss Detection Methods for CZ Silicon Single Crystal Based on Multimodal Data Fusion. Sensors 2023, 23, 5855. [Google Scholar] [CrossRef]
- Maheshkar, V. Improved Detection of Recyclable Plastics Using Multi Modal Sensing and Machine Learning. Ph.D. Thesis, State University of New York at Buffalo, Buffalo, NY, USA, 2023. [Google Scholar]
- Villafana, T.; Edwards, G. Creation and reference characterization of Edo period Japanese woodblock printing ink colorant samples using multimodal imaging and reflectance spectroscopy. Herit. Sci. 2019, 7, 1–14. [Google Scholar] [CrossRef]
- Lee, J.H.; Kim, B.H.; Kim, M.Y. Machine learning-based automatic optical inspection system with multimodal optical image fusion network. Int. J. Control. Autom. Syst. 2021, 19, 3503–3510. [Google Scholar] [CrossRef]
- Tian, J.; Zhu, Z.; Wu, B.; Wang, L.; Liu, X. Bacterial and fungal communities in Pu’er tea samples of different ages. J. Food Sci. 2013, 78, M1249–M1256. [Google Scholar] [CrossRef] [PubMed]
- Lv, H.p.; Zhang, Y.j.; Lin, Z.; Liang, Y.r. Processing and chemical constituents of Pu-erh tea: A review. Food Res. Int. 2013, 53, 608–618. [Google Scholar] [CrossRef]
- Thike, A.; San, Z.M.; Oo, Z.M. Design and development of an automatic color sorting machine on belt conveyor. Int. J. Sci. Eng. Appl. 2019, 8, 176–179. [Google Scholar] [CrossRef]
- Momin, M.A.; Yamamoto, K.; Miyamoto, M.; Kondo, N.; Grift, T. Machine vision based soybean quality evaluation. Comput. Electron. Agric. 2017, 140, 452–460. [Google Scholar] [CrossRef]
- Mahirah, J.; Yamamoto, K.; Miyamoto, M.; Kondo, N.; Ogawa, Y.; Suzuki, T.; Habaragamuwa, H.; Ahmad, U. Monitoring harvested paddy during combine harvesting using a machine vision-Double lighting system. Eng. Agric. Environ. Food 2017, 10, 140–149. [Google Scholar] [CrossRef]
- Vithu, P.; Anitha, J.; Raimond, K.; Moses, J. Identification of dockage in paddy using multiclass SVM. In Proceedings of the 2017 International Conference on Signal Processing and Communication (ICSPC), Coimbatore, India, 28–29 July 2017; pp. 389–393. [Google Scholar]
- Mittal, S.; Dutta, M.K.; Issac, A. Non-destructive image processing based system for assessment of rice quality and defects for classification according to inferred commercial value. Measurement 2019, 148, 106969. [Google Scholar] [CrossRef]
- Senni, L.; Ricci, M.; Palazzi, A.; Burrascano, P.; Pennisi, P.; Ghirelli, F. On-line automatic detection of foreign bodies in biscuits by infrared thermography and image processing. J. Food Eng. 2014, 128, 146–156. [Google Scholar] [CrossRef]
- Zhang, H.; Li, D. Applications of computer vision techniques to cotton foreign matter inspection: A review. Comput. Electron. Agric. 2014, 109, 59–70. [Google Scholar] [CrossRef]
- Zhang, R.; Li, C.; Zhang, M.; Rodgers, J. Shortwave infrared hyperspectral reflectance imaging for cotton foreign matter classification. Comput. Electron. Agric. 2016, 127, 260–270. [Google Scholar] [CrossRef]
- Zhang, M.; Li, C.; Yang, F. Classification of foreign matter embedded inside cotton lint using short wave infrared (SWIR) hyperspectral transmittance imaging. Comput. Electron. Agric. 2017, 139, 75–90. [Google Scholar] [CrossRef]
- Shen, Y.; Yin, Y.; Zhao, C.; Li, B.; Wang, J.; Li, G.; Zhang, Z. Image recognition method based on an improved convolutional neural network to detect impurities in wheat. IEEE Access 2019, 7, 162206–162218. [Google Scholar] [CrossRef]
- Pan, S.; Zhang, X.; Xu, W.; Yin, J.; Gu, H.; Yu, X. Rapid On-site identification of geographical origin and storage age of tangerine peel by Near-infrared spectroscopy. Spectrochim. Acta Part A Mol. Biomol. 2022, 271, 120936. [Google Scholar] [CrossRef]
- Zhang, X.; Gao, Z.; Yang, Y.; Pan, S.; Yin, J.; Yu, X. Rapid identification of the storage age of dried tangerine peel using a hand-held near infrared spectrometer and machine learning. J. Infrared Spectrosc. 2022, 30, 31–39. [Google Scholar] [CrossRef]
- Yu, Z.; Cui, W. LSCA-net: A lightweight spectral convolution attention network for hyperspectral image processing. Comput. Electron. Agric. 2023, 215, 108382. [Google Scholar] [CrossRef]
- Yin, J.; Yang, Y.; Hong, W.; Cai, Y.; Yu, X. Portable smart spectrometer integrated with blockchain and big data technology. Appl. Sci. 2019, 9, 3279. [Google Scholar] [CrossRef]
- Liang, D.; Zhou, Q.; Ling, C.; Gao, L.; Mu, X.; Liao, Z. Research progress on the application of hyperspectral imaging techniques in tea science. J. Chemom. 2023, 37, e3481. [Google Scholar] [CrossRef]
- Sun, X.; Xu, C.; Luo, C.; Xie, D.; Fu, W.; Gong, Z.; Wang, X. Non-destructive detection of tea stalk and insect foreign bodies based on THz-TDS combination of electromagnetic vibration feeder. Food Qual. Saf. 2023, 7, fyad004. [Google Scholar] [CrossRef]
- Shen, Y.; Yin, Y.; Li, B.; Zhao, C.; Li, G. Detection of impurities in wheat using terahertz spectral imaging and convolutional neural networks. Comput. Electron. Agric. 2021, 181, 105931. [Google Scholar] [CrossRef]
- Sun, X.; Cui, D.; Shen, Y.; Li, W.; Wang, J. Non-destructive detection for foreign bodies of tea stalks in finished tea products using terahertz spectroscopy and imaging. Infrared Phys. Technol. 2022, 121, 104018. [Google Scholar] [CrossRef]
- Yu, X.; Zhao, L.; Liu, Z.; Zhang, Y. Distinguishing tea stalks of Wuyuan green tea using hyperspectral imaging analysis and Convolutional Neural Network. J. Agric. Eng. 2024. [Google Scholar] [CrossRef]
- Tang, L.; Zhao, M.; Shi, S.; Chen, J.; Li, J.; Li, Q.; Li, R. Tobacco Impurities Detection with Deep Image Segmentation Method on Hyperspectral Imaging. In Proceedings of the 2023 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), Zhengzhou, China, 14–17 November 2023; pp. 1–5. [Google Scholar]
- Yang, Z.; Ma, W.; Lu, J.; Tian, Z.; Peng, K. The Application Status and Trends of Machine Vision in Tea Production. Appl. Sci. 2023, 13, 10744. [Google Scholar] [CrossRef]
- Zhu, B.; Zhou, L.; Pu, S.; Fan, J.; Ye, Y. Advances and challenges in multimodal remote sensing image registration. IEEE J. Miniaturization Air Space Syst. 2023, 4, 165–174. [Google Scholar] [CrossRef]
- Peterson, L.E. K-nearest neighbor. Scholarpedia 2009, 4, 1883. [Google Scholar] [CrossRef]
- Song, Y.Y.; Ying, L. Decision tree methods: Applications for classification and prediction. Shanghai Arch. Psychiatry 2015, 27, 130. [Google Scholar] [PubMed]
- Rao, C.R. The use and interpretation of principal component analysis in applied research. Sankhyā Indian J. Stat. Ser. A 1964, 26, 329–358. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Yang, Y.; Zhang, X.; Yin, J.; Yu, X. Rapid and nondestructive on-site classification method for consumer-grade plastics based on portable NIR spectrometer and machine learning. J. Spectrosc. 2020, 2020, 1–8. [Google Scholar] [CrossRef]
- Jiang, L.; Cai, Z.; Wang, D.; Jiang, S. Survey of improving k-nearest-neighbor for classification. In Proceedings of the Fourth International Conference on Fuzzy Systems and Knowledge Discovery (FSKD 2007), Haikou, China, 24–27 August 2007; Volume 1, pp. 679–683. [Google Scholar]
- Biau, G.; Scornet, E. A random forest guided tour. Test 2016, 25, 197–227. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tea | Tea Stalk | Bamboo | Leaf | Wood | Tea Fruit | Stone | Hair | Plastic | Cotton |
|---|---|---|---|---|---|---|---|---|---|
 |  |  |  |  |  |  |  |  |  |
| Color image | |||||||||
 |  |  |  |  |  |  |  |  |  |
| Segmented image | |||||||||
| 92,070 | 53,324 | 36,186 | 67,934 | 29,387 | 36,431 | 13,986 | 24,069 | 26,122 | 20,720 |
| Number of pixels in ROI | |||||||||
| Model | Optimal Paremeters | |
|---|---|---|
| Spectral features | SVM | C: 100, kernel: linear |
| RF | max_features: sqrt, n_estimators: 100 | |
| KNN | n_neighbors: 10, p: 4, weights: distance | |
| DT | criterion: entropy, max_depth: 7, min_samples_leaf: 11 | |
| Combined features | SVM | C: 100, kernel: linear |
| RF | max_features: 0.8, n_estimators: 50 | |
| KNN | n_neighbors: 5, p: 3, weights: distance | |
| DT | criterion: entropy, max_depth: 10, min_samples_leaf: 41 |
| SVM | RF | KNN | DT | |
|---|---|---|---|---|
| Spectrum | 0.86 | 0.86 | 0.86 | 0.84 |
| Spectrum + RGB | 0.93 | 0.91 | 0.91 | 0.88 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kuang, Z.; Yu, X.; Guo, Y.; Cai, Y.; Hong, W. Design of a Multimodal Detection System Tested on Tea Impurity Detection. Remote Sens. 2024, 16, 1590. https://doi.org/10.3390/rs16091590
Kuang Z, Yu X, Guo Y, Cai Y, Hong W. Design of a Multimodal Detection System Tested on Tea Impurity Detection. Remote Sensing. 2024; 16(9):1590. https://doi.org/10.3390/rs16091590
Chicago/Turabian StyleKuang, Zhankun, Xiangyang Yu, Yuchen Guo, Yefan Cai, and Weibin Hong. 2024. "Design of a Multimodal Detection System Tested on Tea Impurity Detection" Remote Sensing 16, no. 9: 1590. https://doi.org/10.3390/rs16091590
APA StyleKuang, Z., Yu, X., Guo, Y., Cai, Y., & Hong, W. (2024). Design of a Multimodal Detection System Tested on Tea Impurity Detection. Remote Sensing, 16(9), 1590. https://doi.org/10.3390/rs16091590