
Carrier-Free Ultra-Wideband Sensor Target Recognition in the Jungle Environment


 ,
, 
Abstract
1. Introduction
- (1)
- We propose an enhanced scheme for identifying a target sensor on carrier-free UWB jungle vehicles and model four types of vehicle targets in the jungle composite electromagnetic environment for a carrier-free UWB sensor.
- (2)
- We use the MTF Markov transfer field method to convert a one-dimensional echo signal into a two-dimensional image, which can reflect the internal dynamics and correlations in the signal and improve the accuracy and robustness of image classification.
- (3)
- An improved REPVGG network is proposed with two areas of improvement. Firstly, the self-attention module is embedded in stage 0 and stage 4. The self-attention module in stage 0 can help the network to extract more integral features. In stage 4, the network embedded in the self-attention module can better adapt to the variability in different input image features and has better generalization performance. Secondly, we combine the sparsemax loss and cross-entropy loss functions to improve the classification accuracy.
2. Related Works
2.1. Carrier-Free Ultra-WideBand Sensor
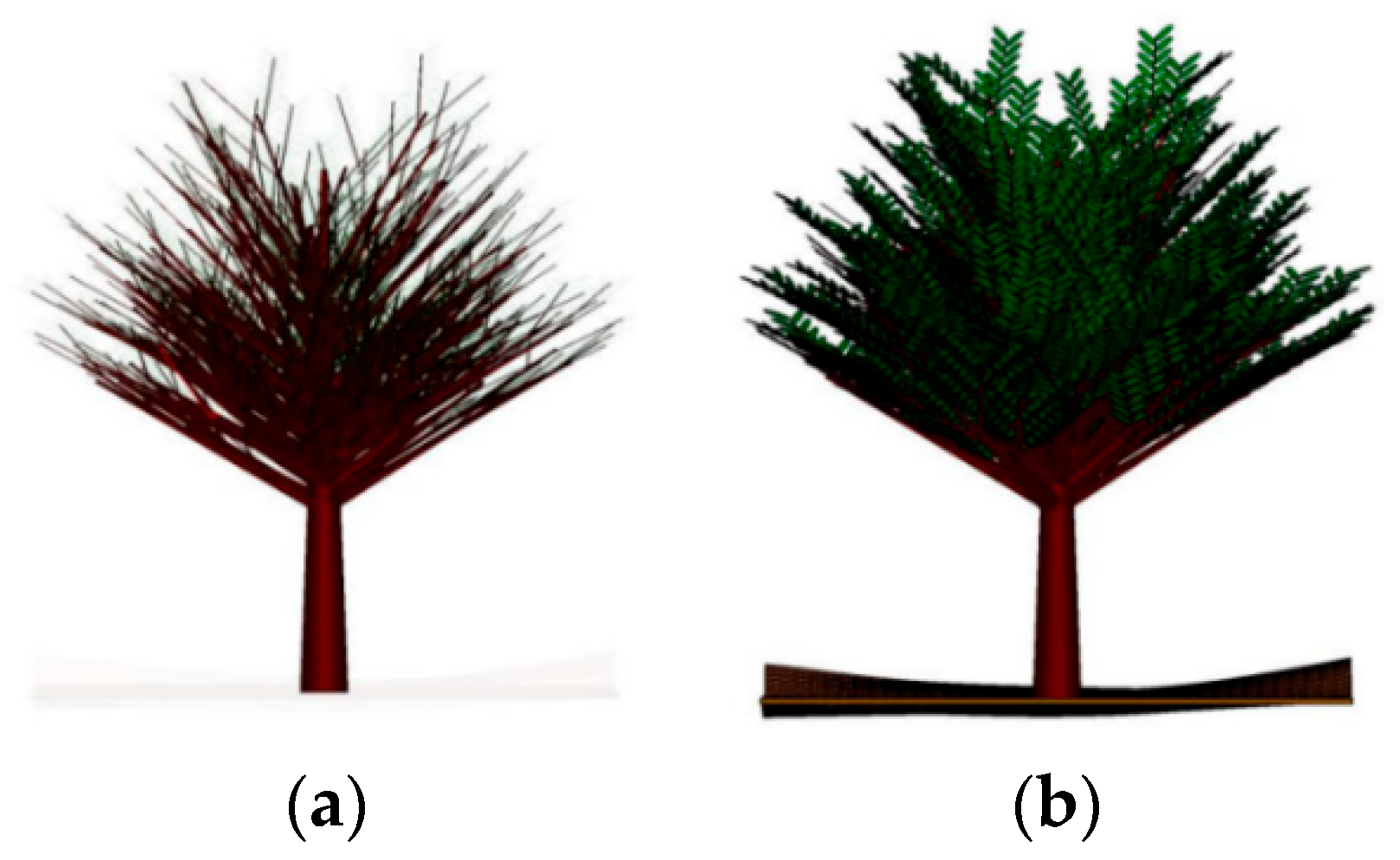
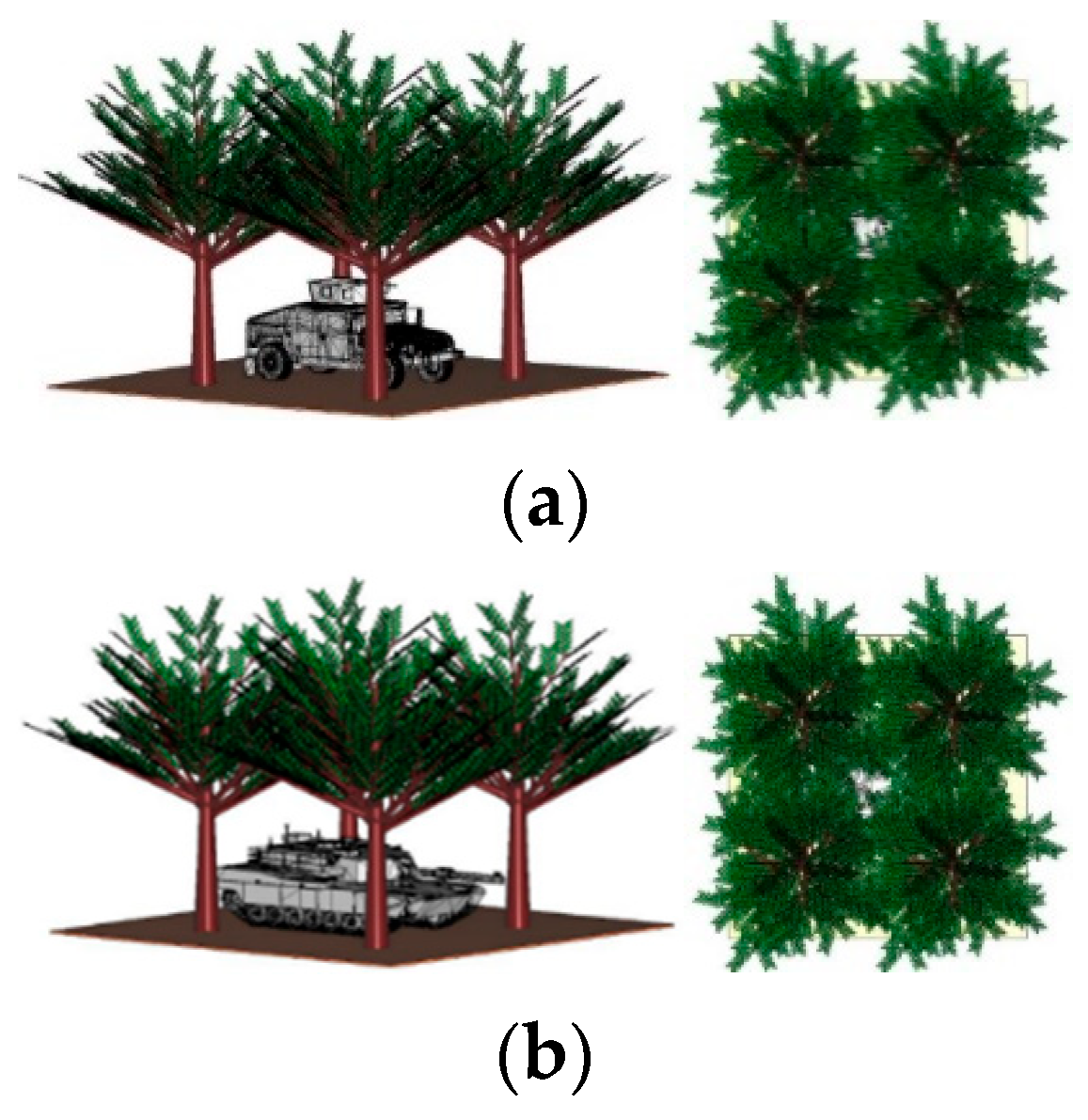
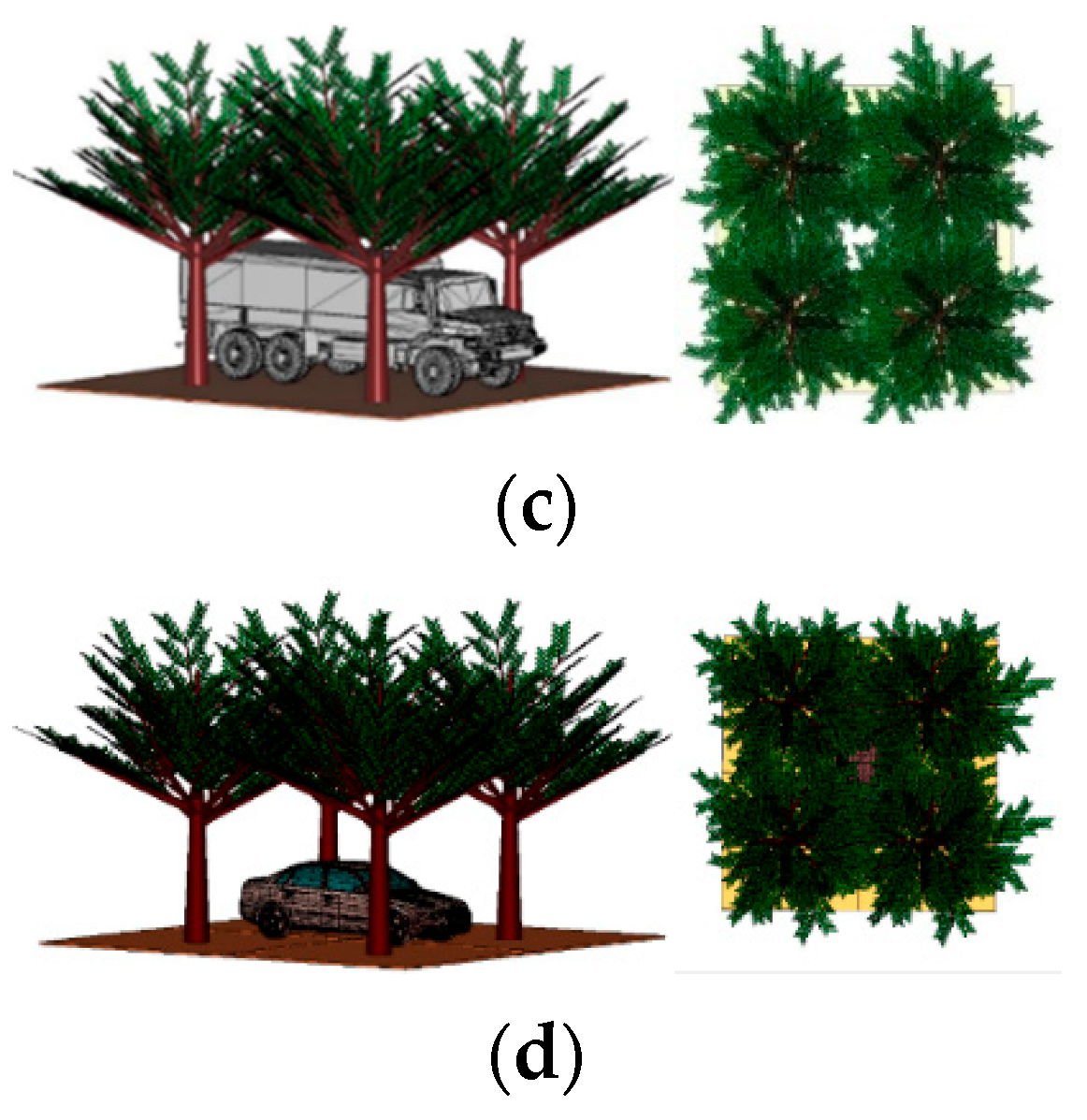
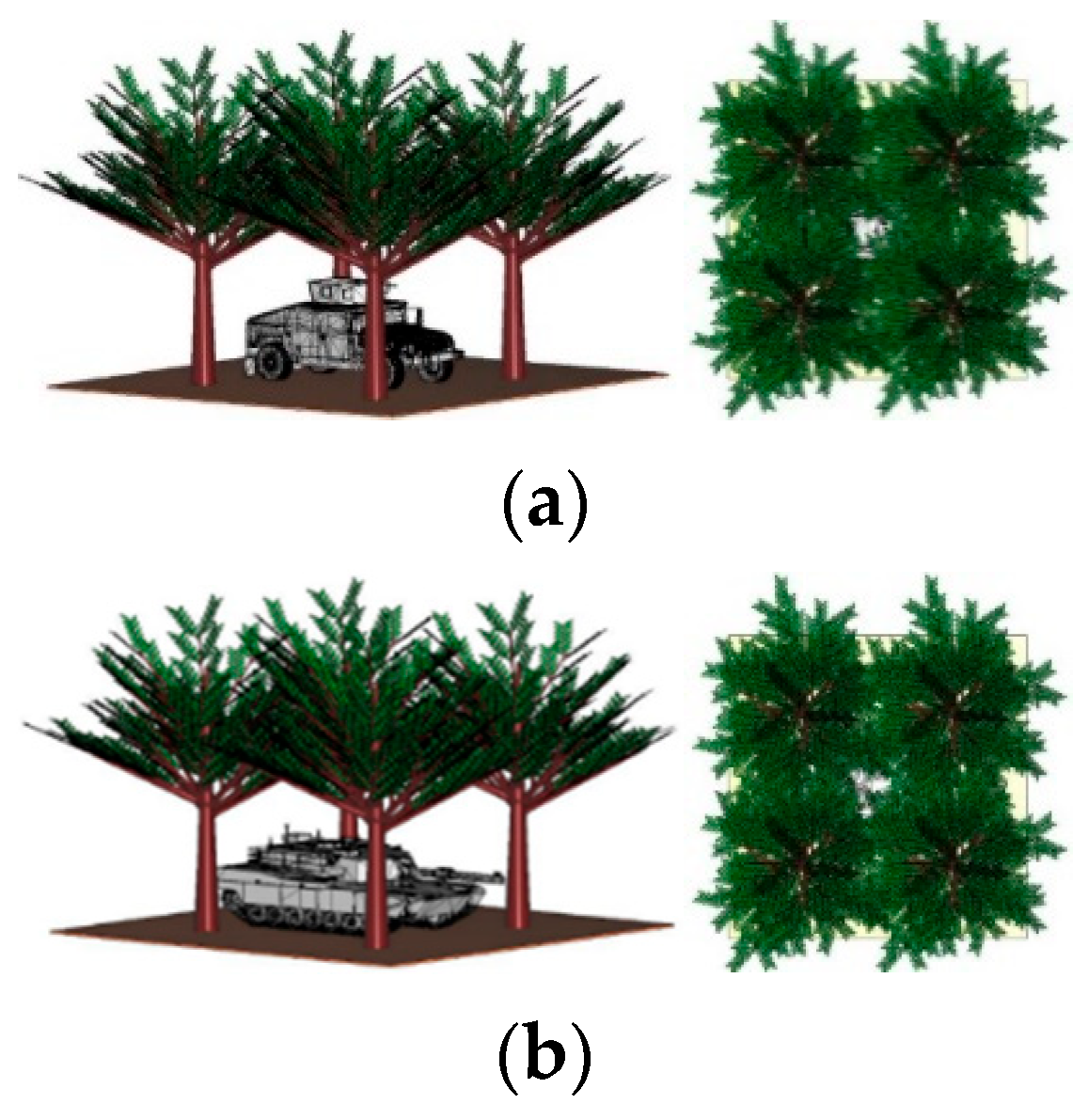
2.2. Modeling the Electromagnetic Environment of Jungle Vehicle Targets
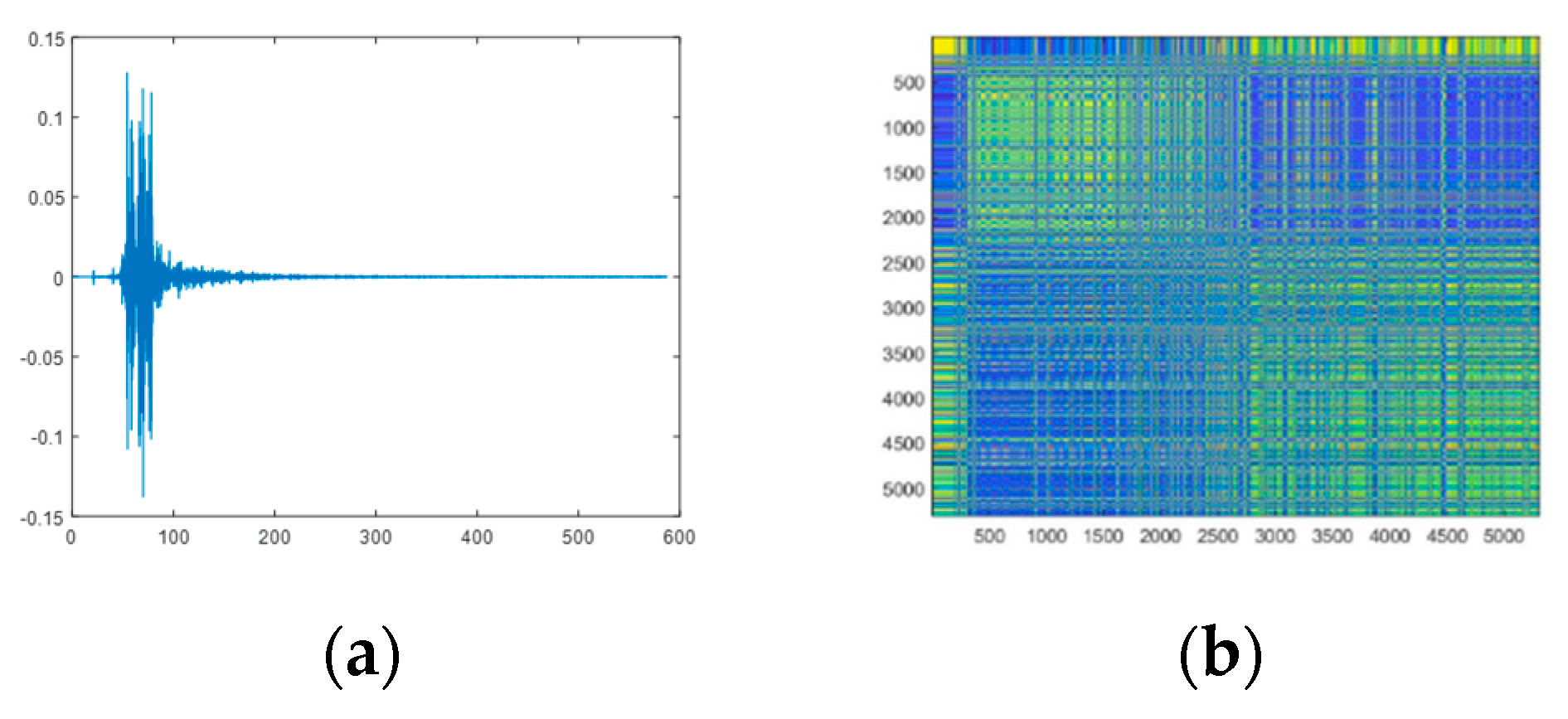
2.3. Markov Transfer Field
3. The Improved RepVGG Network
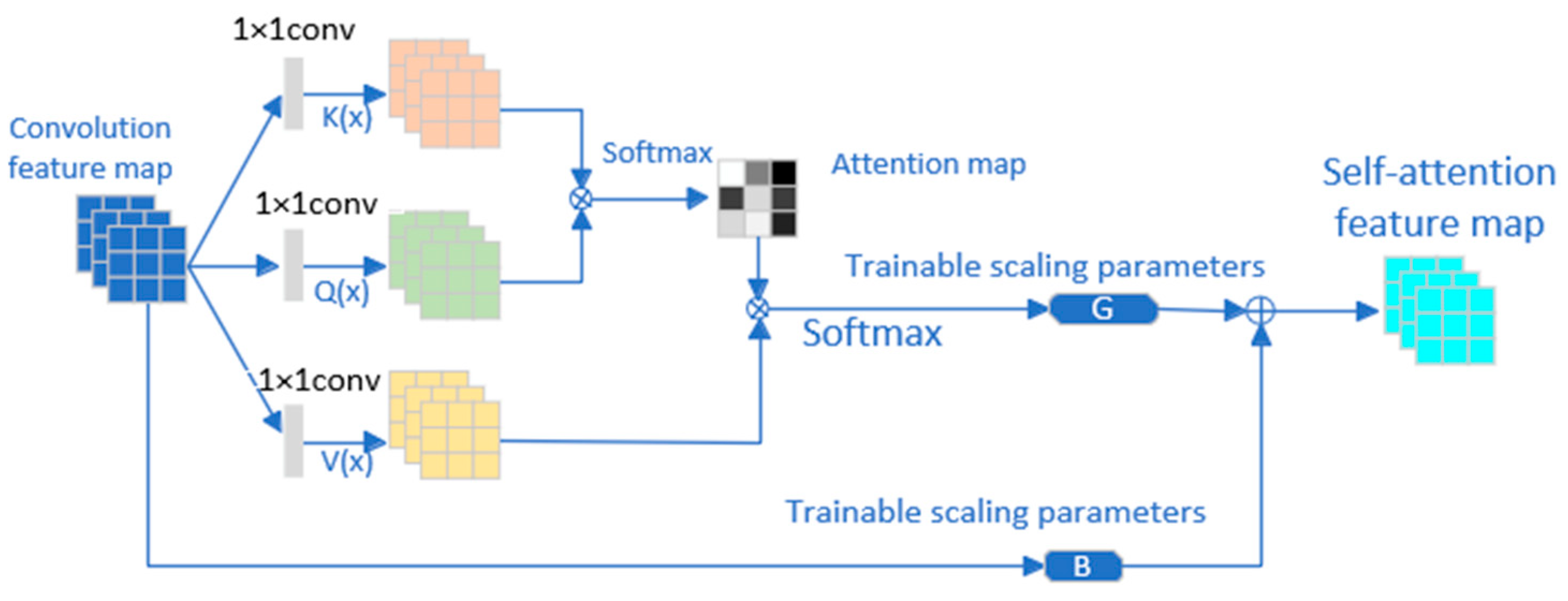
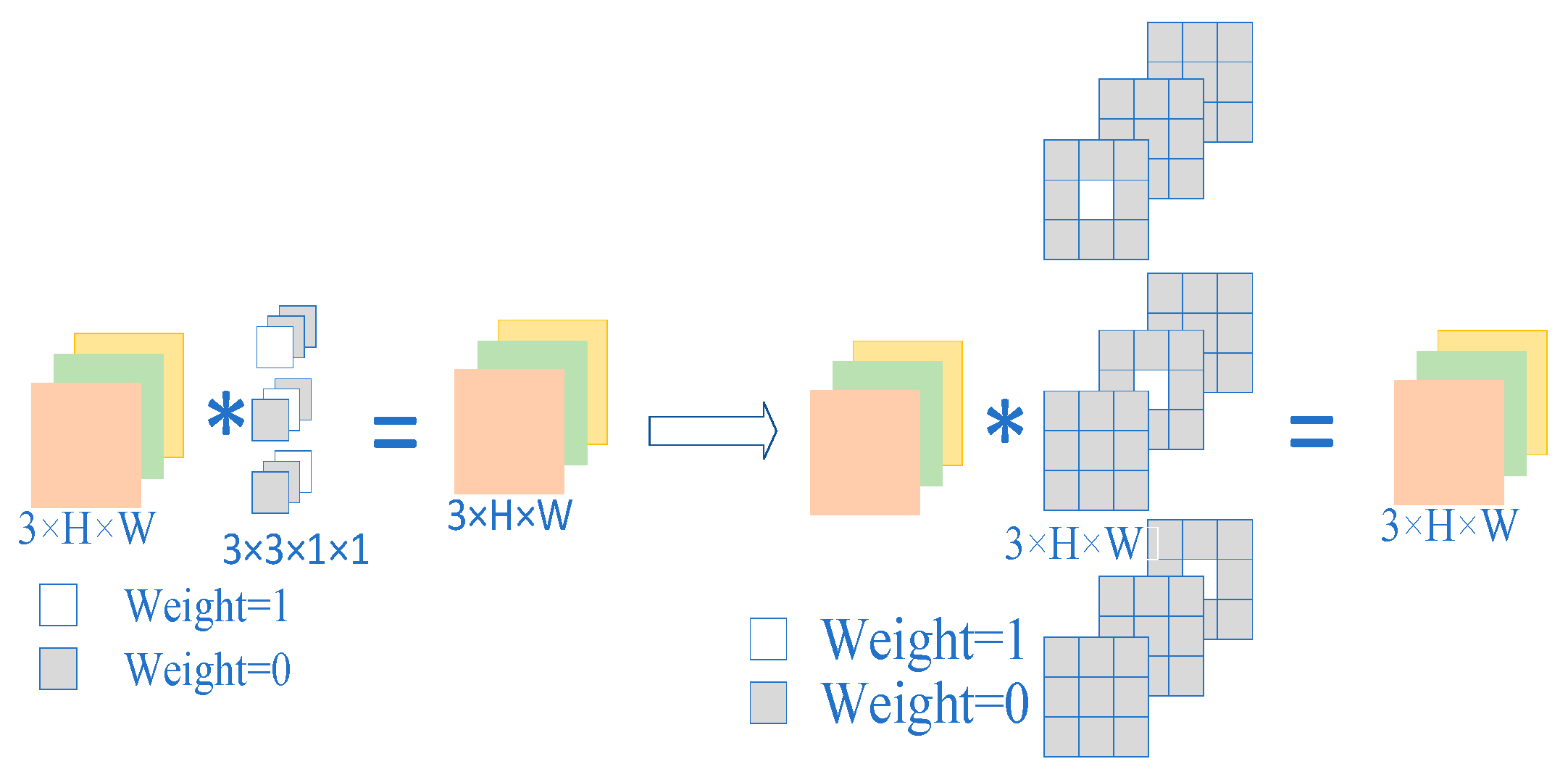
3.1. Self-Attention Module
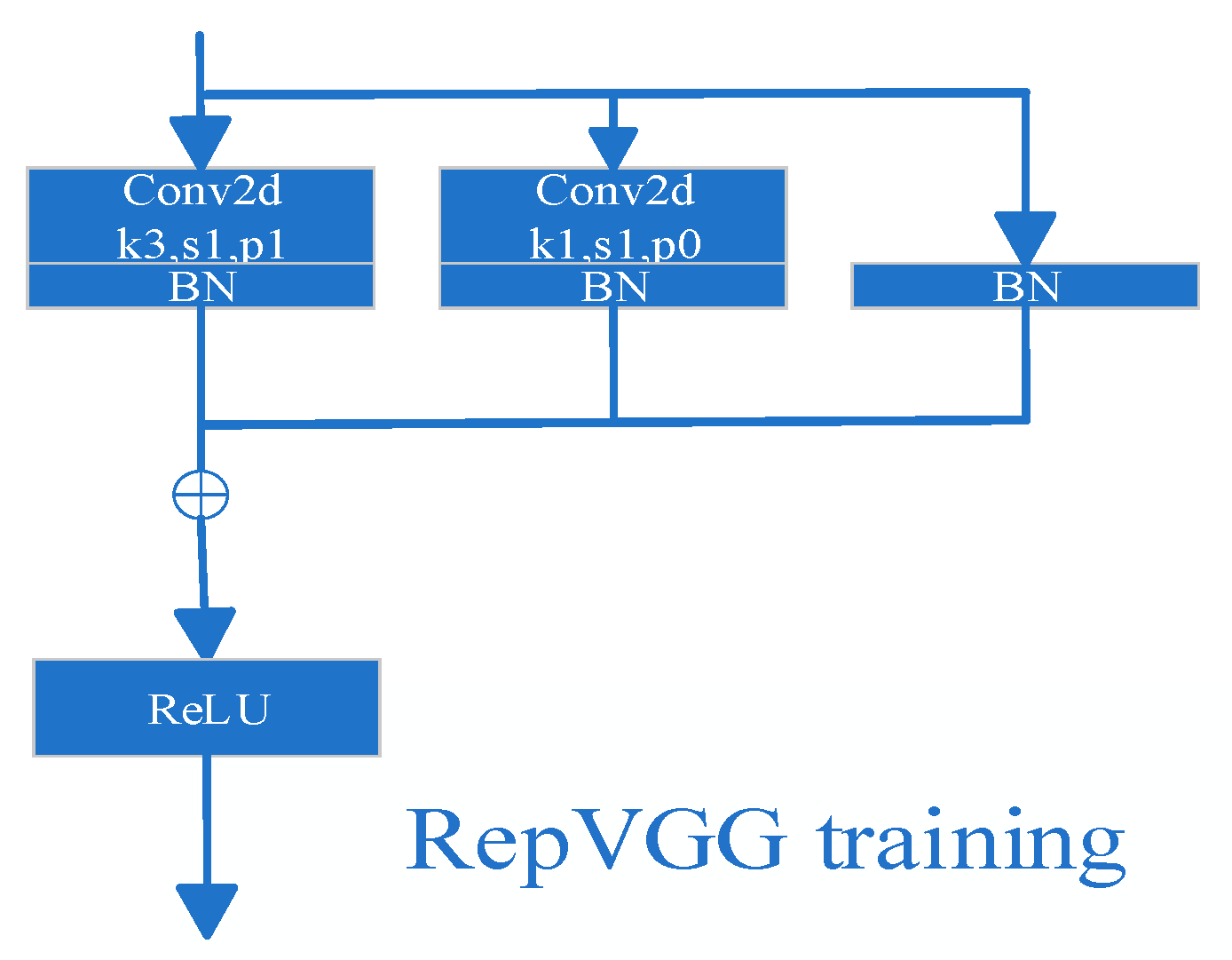
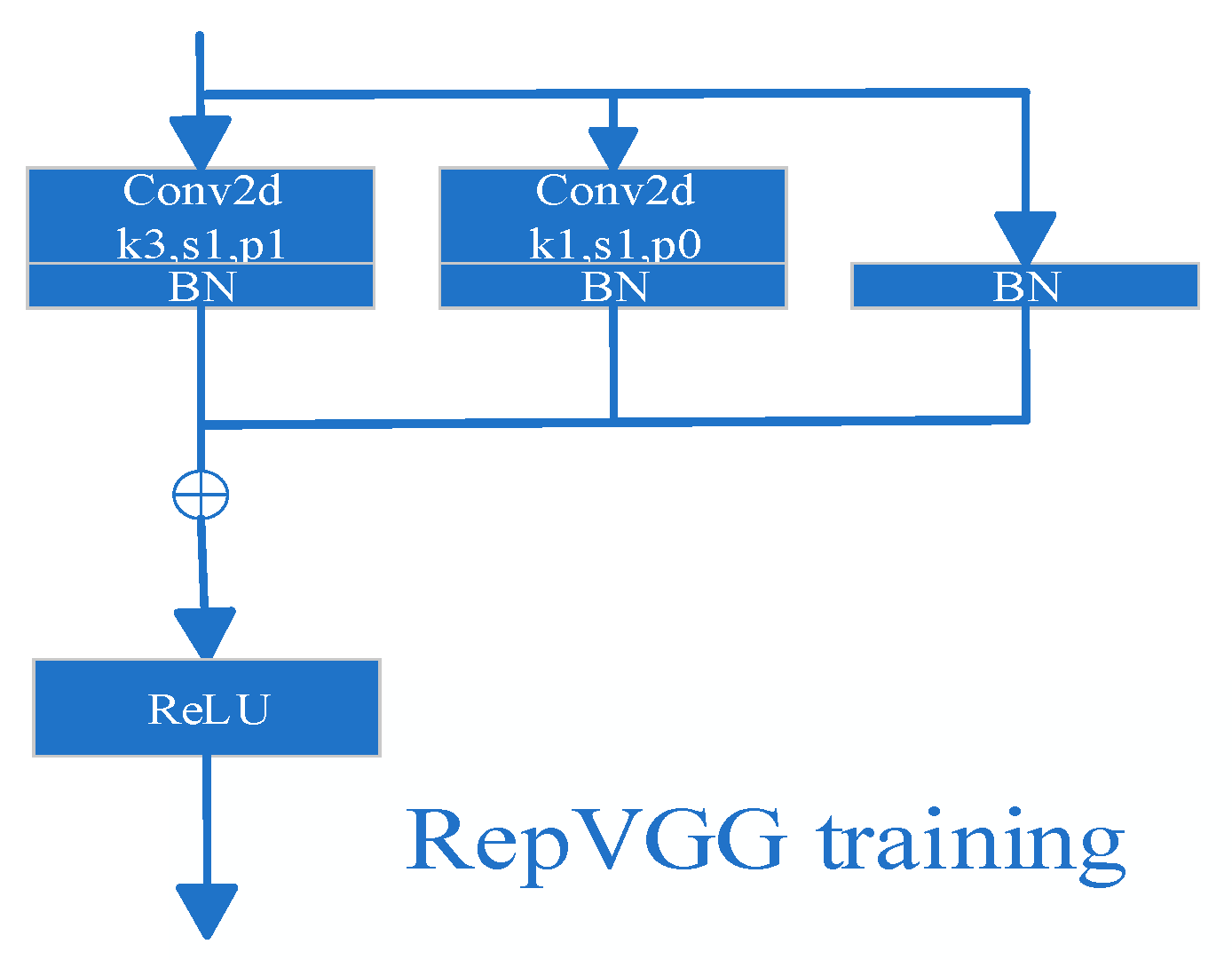
3.2. Framework and Parameters of the RepVGG
3.3. Improved Loss Function
| Algorithm 1 RepVGG with a Modified Loss Function. |
| Step 1: Calculate the softmax value of the model classification outputs. |
| Step 2: Calculate the output of sparsity. where is the number of categories. |
| Step 3: Weighted summation. |
4. Experiment and Results
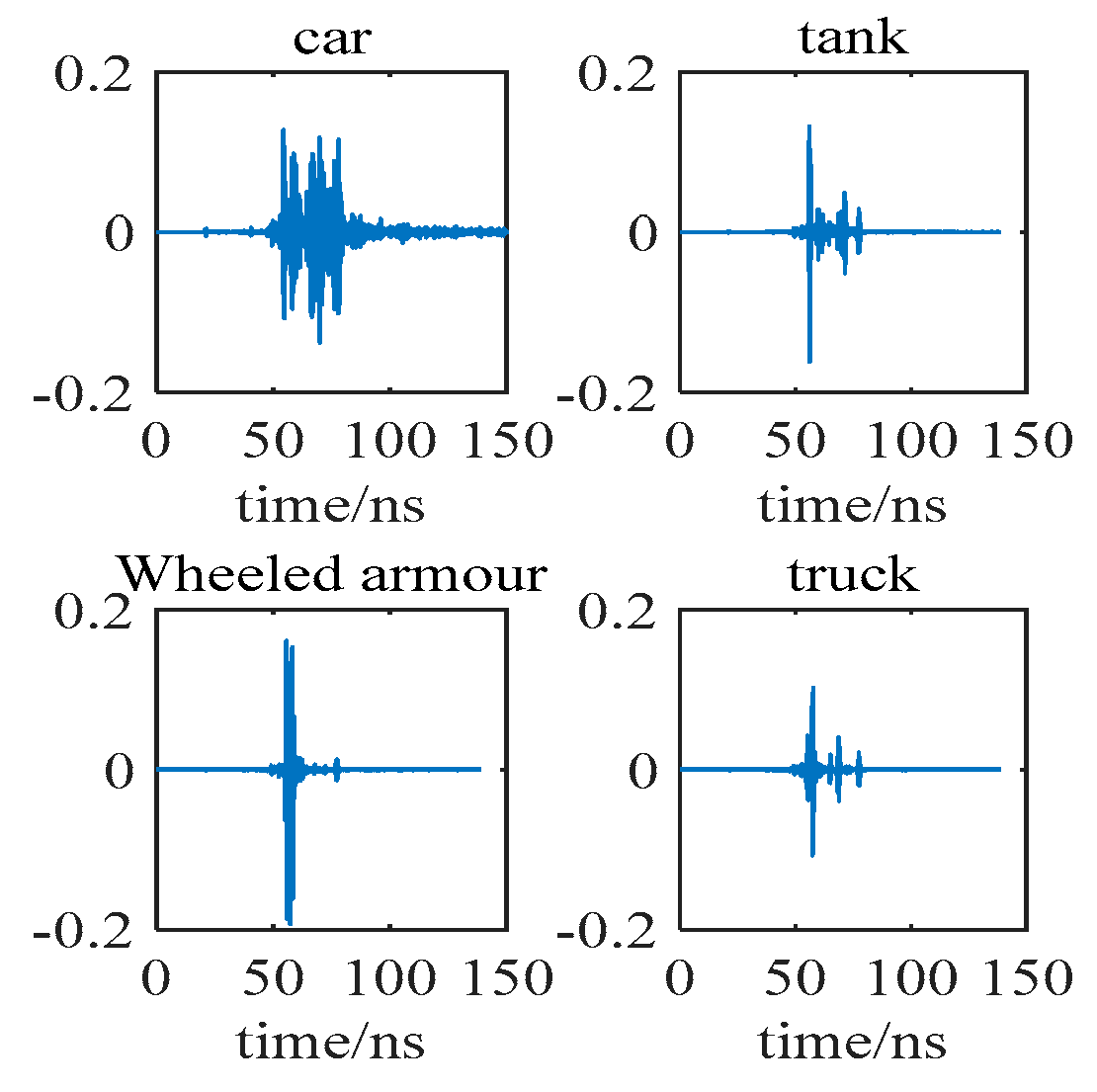
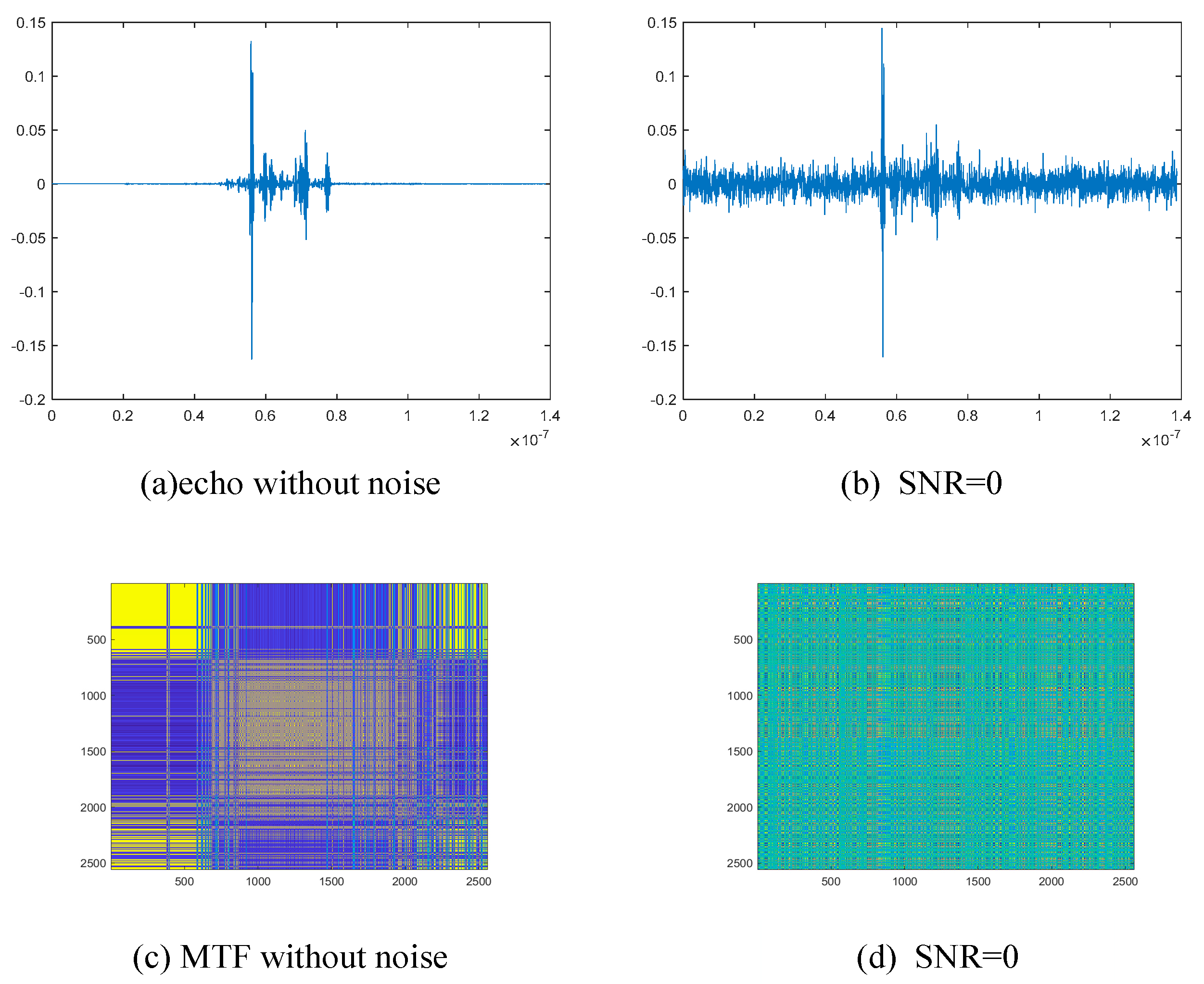
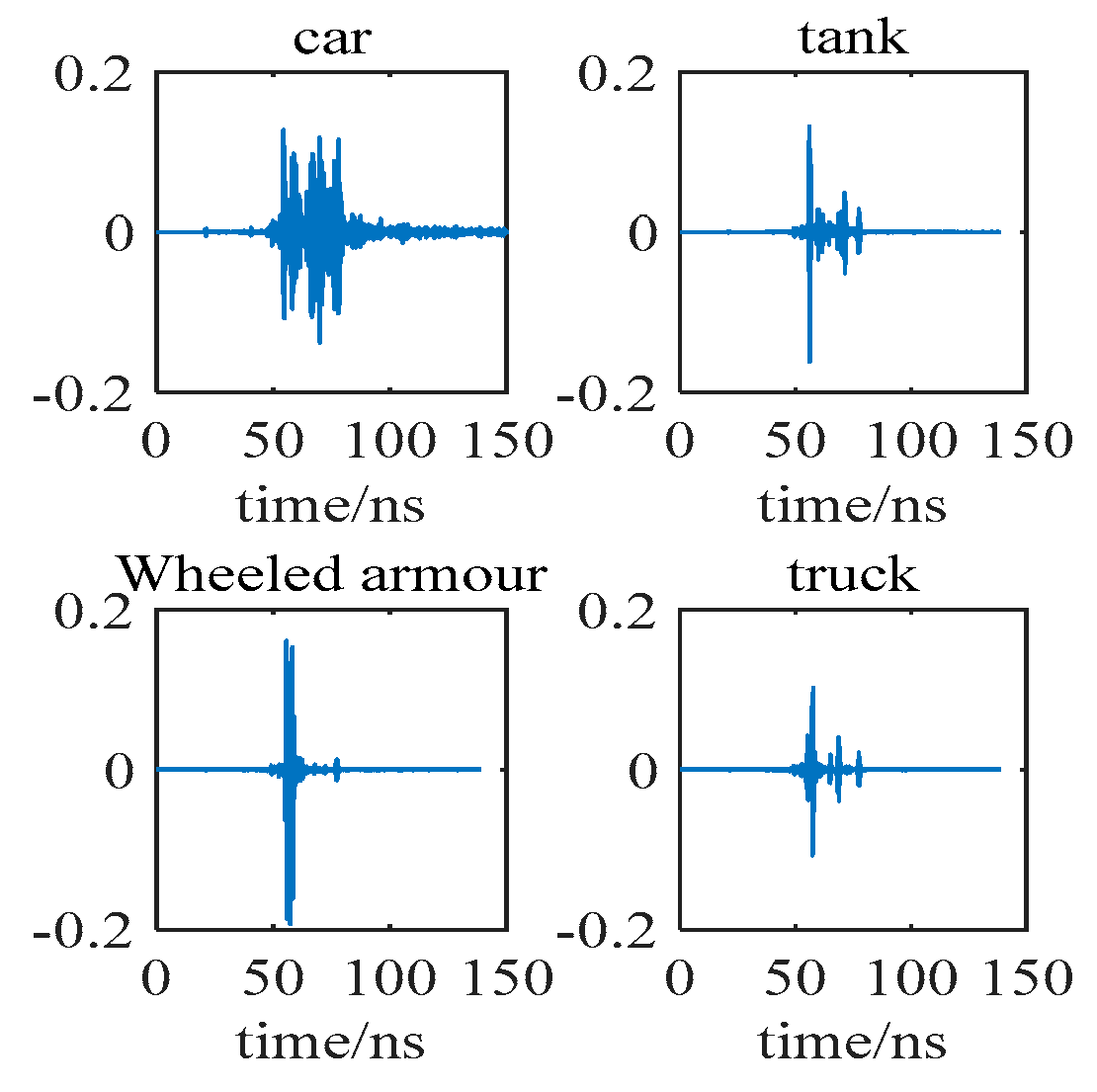
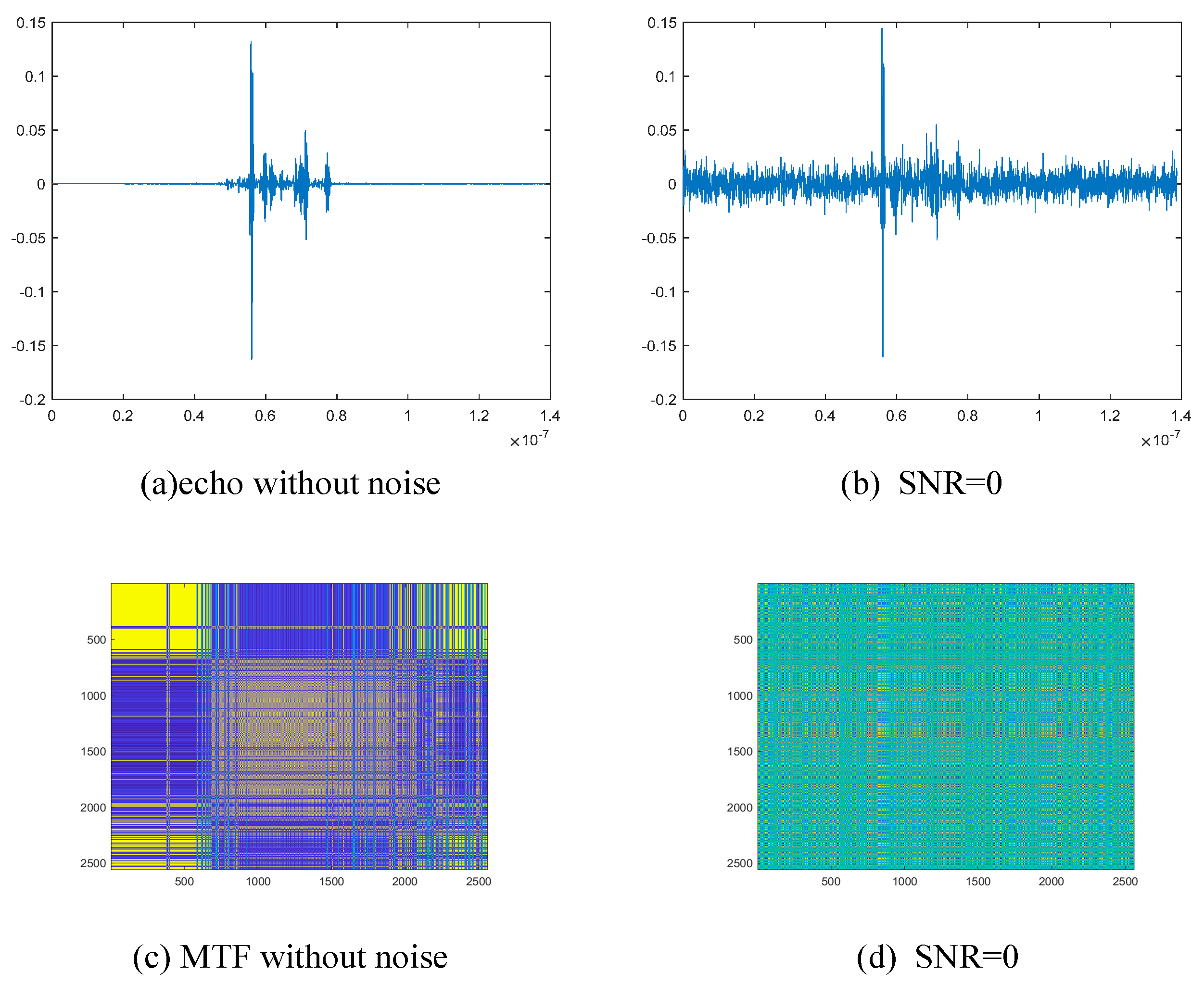
4.1. Dataset Description and Experimental Details
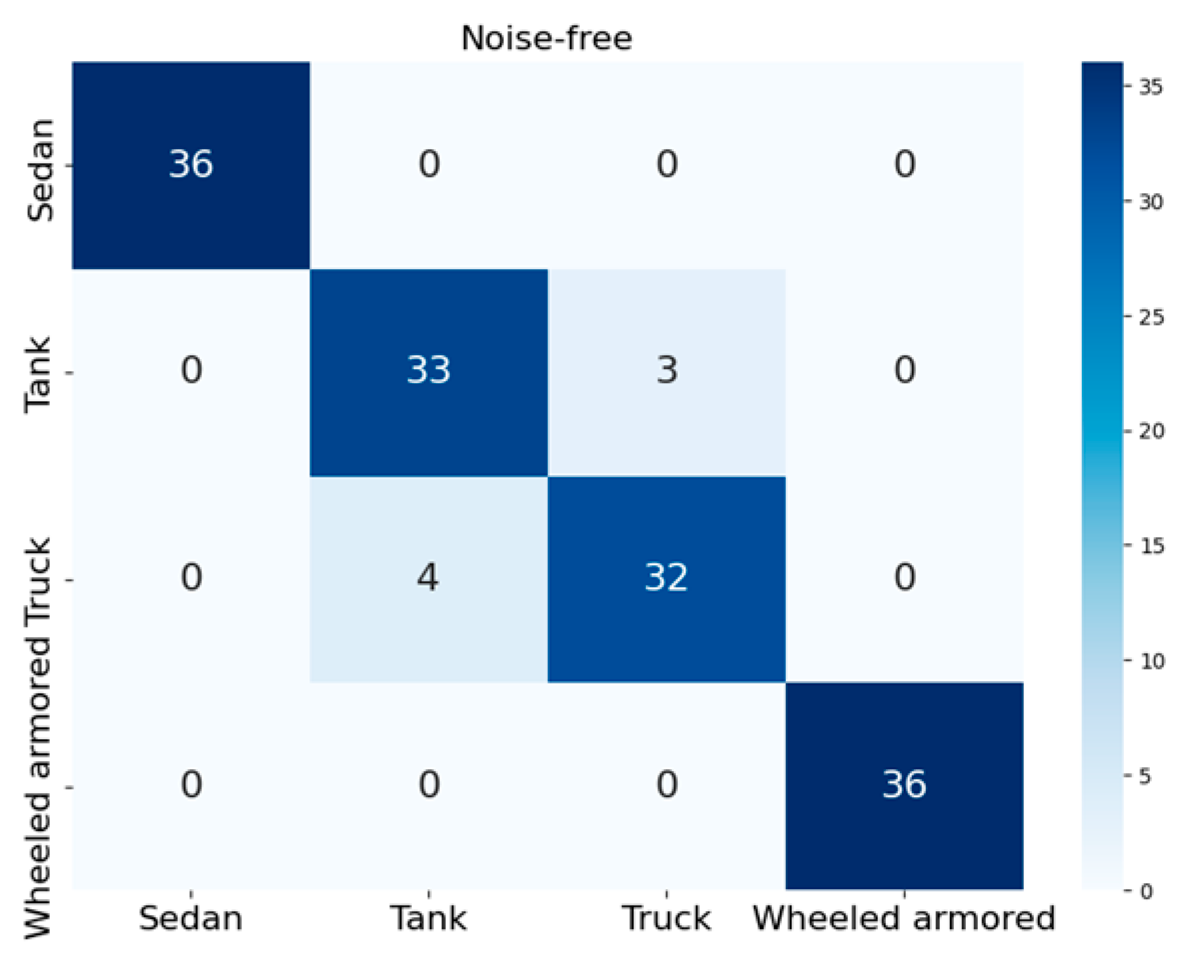
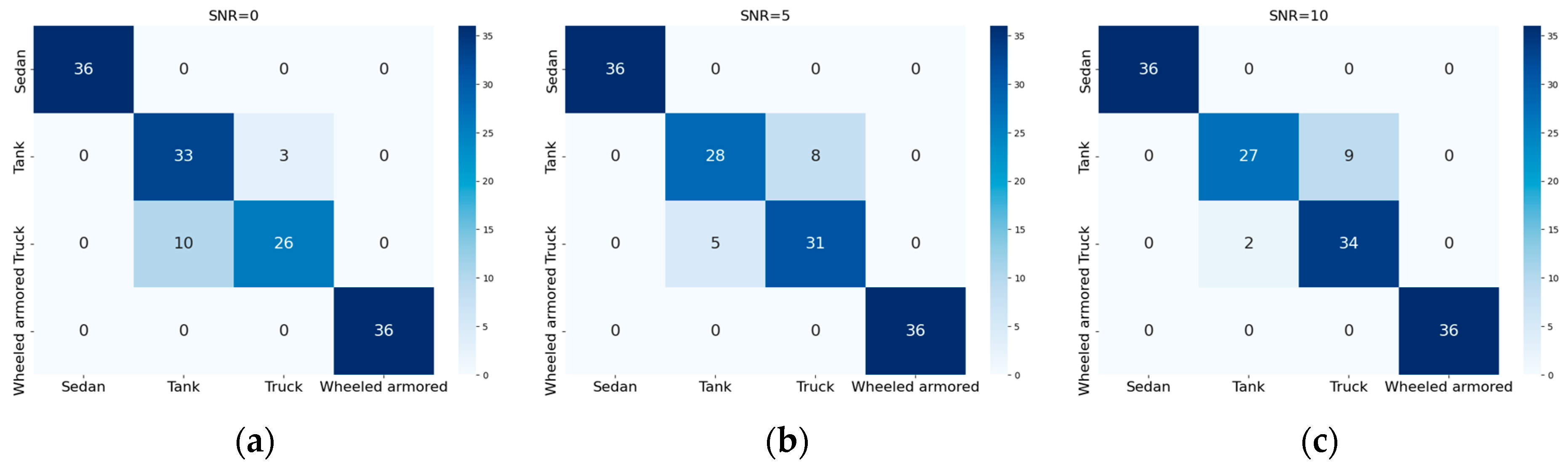
4.2. Performance Analysis of the Improved RepVGG
4.3. Network Performance Comparison
4.3.1. Recognition Performance Comparison
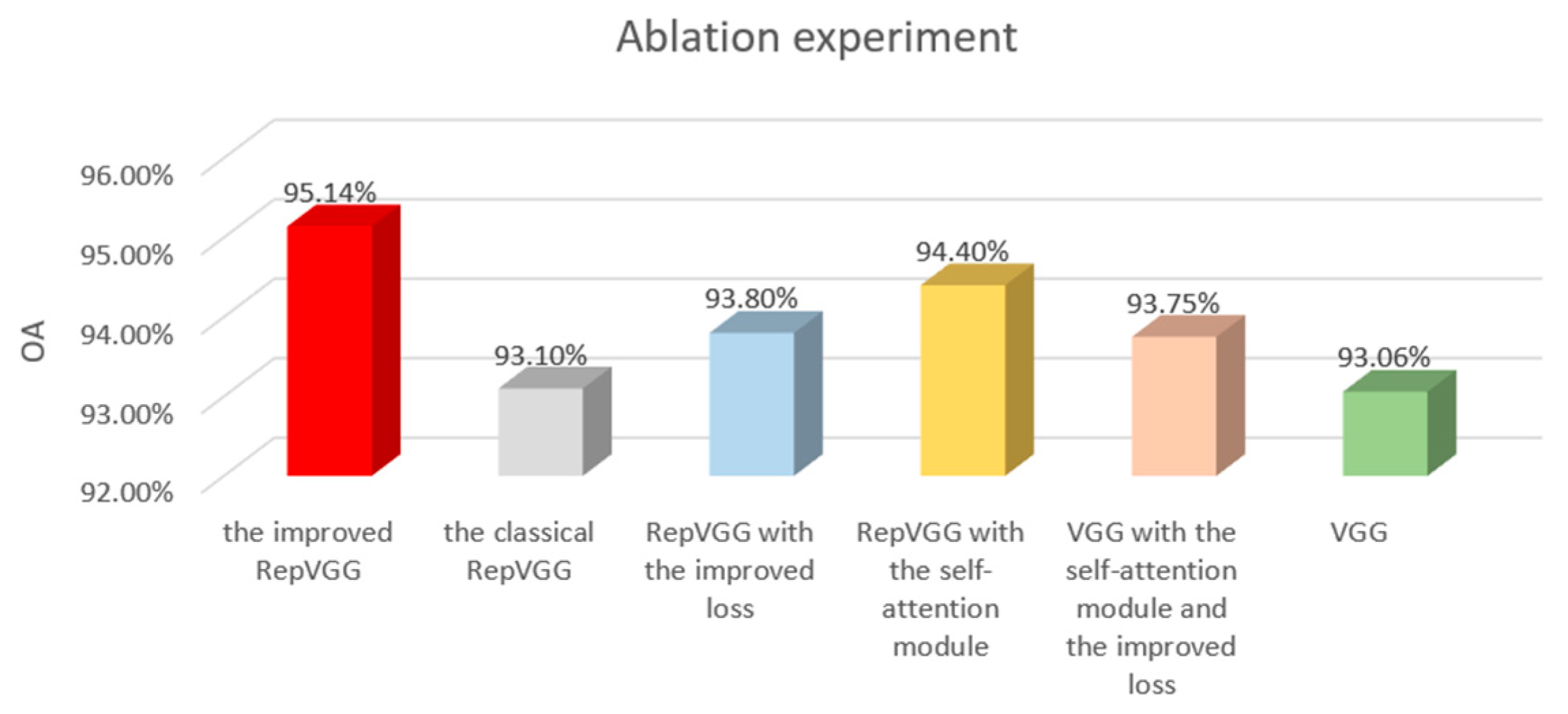
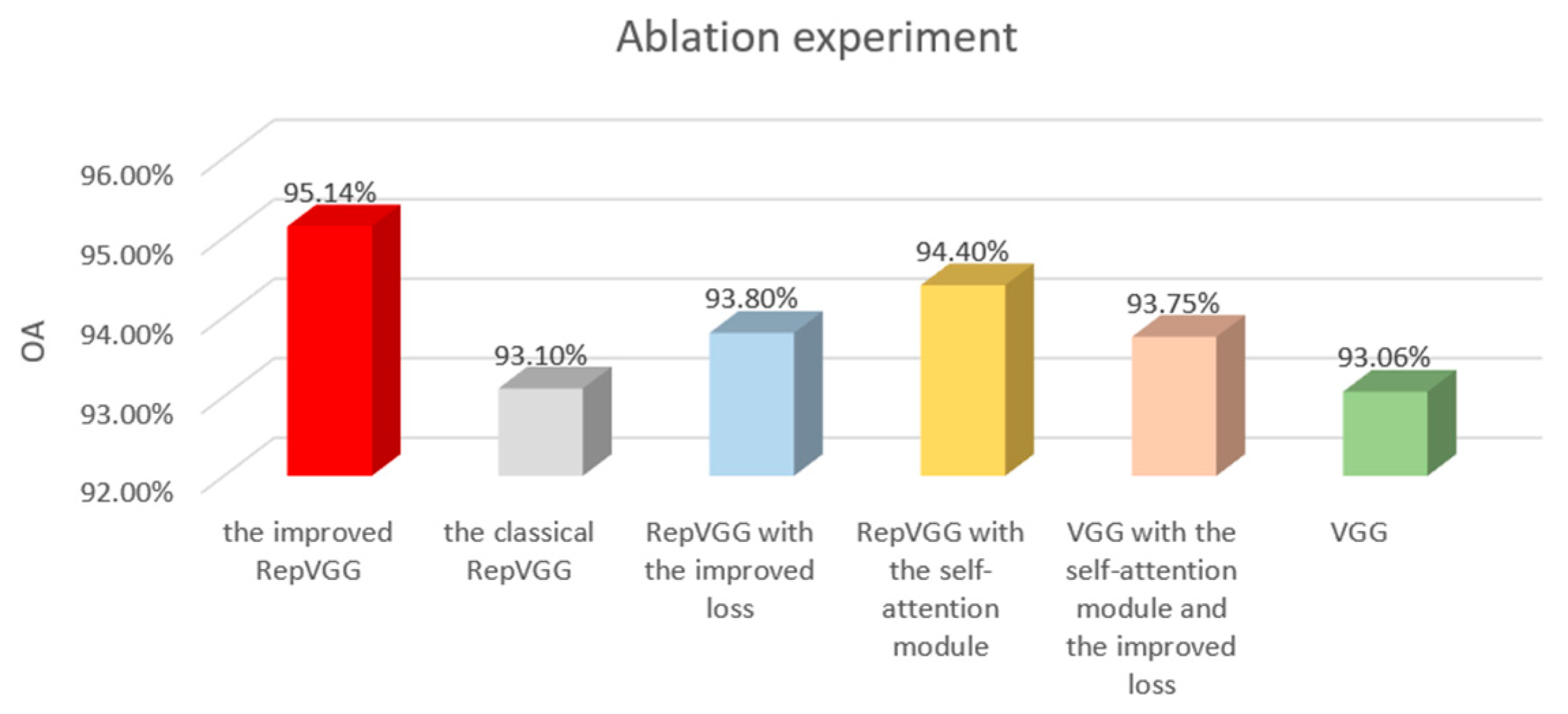
4.3.2. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, X.; Xiao, Z.; Zhu, Y.; Zhang, S.; Chen, S. Carrier-Free UWB Sensor Small-Sample Terrain Recognition Based on Improved ACGAN With Self-Attention. IEEE Sens. J. 2022, 22, 8050–8058. [Google Scholar] [CrossRef]
- Shen, Y.; Chen, X.; Rhee, W.; Wang, Z. A second-order multi-bit ΔΣ TDC for high resolution IR-UWB radar systems. In Proceedings of the 2014 IEEE International Wireless Symposium (IWS 2014), Xi’an, China, 24–26 March 2014; pp. 1–4. [Google Scholar]
- Tsang, T.K.K.; El-Gamal, M.N. Ultra-wideband (UWB) communications systems: An overview. In Proceedings of the 3rd International IEEE-NEWCAS Conference, Quebec, QC, Canada, 19–22 June 2005; pp. 381–386. [Google Scholar]
- Naveena, M.; Singh, D.K.; Singh, H. Design of UHF band UWB antenna for foliage penetration application. In Proceedings of the 2017 IEEE International Conference on Antenna Innovations & Modern Technologies for Ground, Aircraft and Satellite Applications (iAIM), Bangalore, India, 24–26 November 2017; pp. 1–3. [Google Scholar]
- Kim, S.Y.; Han, H.G.; Kim, J.W.; Lee, S.; Kim, T.W. A Hand Gesture Recognition Sensor Using Reflected Impulses. IEEE Sens. J. 2017, 17, 2975–2976. [Google Scholar] [CrossRef]
- Ye, S.; Chen, J.; Liu, L.; Zhang, C.; Fang, G. A novel compact UWB ground penetrating radar system. In Proceedings of the 2012 14th International Conference on Ground Penetrating Radar (GPR), Shanghai, China, 4–8 June 2012; pp. 71–75. [Google Scholar]
- Anabuki, M.; Okumura, S.; Sakamoto, T.; Saho, K.; Sato, T.; Yoshioka, M.; Inoue, K.; Fukuda, T.; Sakai, H. High-resolution imaging and separation of multiple pedestrians using UWB Doppler radar interferometry with adaptive beamforming technique. In Proceedings of the 2017 11th European Conference on Antennas and Propagation (EUCAP), Paris, France, 19–24 March 2017; pp. 469–473. [Google Scholar]
- Numan, P.E.; Park, H.; Lee, J.; Kim, S. Machine Learning-Based Joint Vital Signs and Occupancy Detection With IR-UWB Sensor. IEEE Sens. J. 2023, 23, 7475–7482. [Google Scholar] [CrossRef]
- Ni, Y.; Chen, H. Detection of underwater carrier-free pulse based on time-frequency analysis. J. Netw. 2013, 8, 205. [Google Scholar] [CrossRef]
- Li, C.; Yang, S.-T.; Ling, H. ISAR imaging of a windmill—Measurement and simulation. In Proceedings of the 8th European Conference on Antennas and Propagation (EuCAP 2014), The Hague, The Netherlands, 6–11 April 2014; pp. 1–5. [Google Scholar]
- Bai, Z.; Zhang, W.; Xu, S.; Liu, W.; Kwak, K. On the performance of multiple access DS-BPAM UWB system in data and image transmission. In Proceedings of the IEEE International Symposium on Communications and Information Technology, ISCIT 2005, Beijing, China, 12–14 October 2005; pp. 851–854. [Google Scholar]
- Zhang, S.; Pan, X.; Mu, H. A multi-pedestrian cooperative navigation and positioning method based on UWB technology. In Proceedings of the 2020 IEEE International Conference on Artificial Intelligence and Information Systems (ICAIIS), Dalian, China, 20–22 March 2020; pp. 260–264. [Google Scholar]
- Wang, X.; Zhang, S.; Chen, S.; Hou, L.; Zhu, L. An Antijamming Method Based on Multichannel Singular Spectrum Analysis and Affinity Propagation for UWB Ranging Sensors. IEEE Sens. J. 2023, 23, 11869–11878. [Google Scholar] [CrossRef]
- Xia, Z.; Wang, P.; Dong, G.; Liu, H. Radar HRRP Open Set Recognition Based on Extreme Value Distribution. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5102416. [Google Scholar] [CrossRef]
- Li, X.; Ouyang, W.; Pan, M.; Lv, S.; Ma, Q. Continuous Learning Method of Radar HRRP Based on CVAE-GAN. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5107819. [Google Scholar] [CrossRef]
- Zhang, Y.; Kong, Y. Target Recognition of HRRP Based on CNN with Multi-Axis Attention and Residual Connections. In Proceedings of the 2022 IEEE 24th Int Conf on High Performance Computing & Communications; 8th Int Conf on Data Science & Systems; 20th Int Conf on Smart City; 8th Int Conf on Dependability in Sensor, Cloud & Big Data Systems & Application (HPCC/DSS/SmartCity/DependSys), Hainan, China, 18–20 December 2022; pp. 2338–2344. [Google Scholar]
- Zhang, Y.-P.; Zhang, L.; Kang, L.; Wang, H.; Luo, Y.; Zhang, Q. Space Target Classification with Corrupted HRRP Sequences Based on Temporal–Spatial Feature Aggregation Network. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5100618. [Google Scholar] [CrossRef]
- Kong, Y.; Feng, D.; Zhang, J. Radar HRRP Target Recognition Based on Composite Deep Networks. In Proceedings of the 2022 International Applied Computational Electromagnetics Society Symposium (ACES-China), Xuzhou, China, 28–31 July 2022; pp. 1–5. [Google Scholar]
- Wang, X.; Wang, P.; Song, Y.; Li, J. Recognition of HRRP sequence based on TCN with attention and elastic net regularization. In Proceedings of the 2022 International Conference on Image Processing, Computer Vision and Machine Learning (ICICML), Xi’an, China, 28–30 October 2022; pp. 346–351. [Google Scholar]
- Zhu, Y.; Zhang, S.; Li, X.; Zhao, H.; Zhu, L.; Chen, S. Ground Target Recognition Using Carrier-Free UWB Radar Sensor with a Semi-Supervised Stacked Convolutional Denoising Autoencoder. IEEE Sens. J. 2021, 21, 20685–20693. [Google Scholar] [CrossRef]
- Zhu, L.; Sun, Y.; Zhang, S. Multi-Angle Recognition of Vehicles Based on Carrier-Free UWB Sensor and Deep Residual Shrinkage Learning. IEEE Microw. Wirel. Compon. Lett. 2022, 32, 927–930. [Google Scholar] [CrossRef]
- Zhu, Y.; Chen, S.; Li, X.; Zhang, S.; Zhu, L. Multi-Task Self-Supervised Learning for Vehicle Classification Based on Carrier-Free UWB Radars. IEEE Trans. Instrum. Meas. 2022, 71, 2515312. [Google Scholar] [CrossRef]
- Lyu, C.; Huo, Z.; Cheng, X.; Jiang, J. Alimasi and H. Liu. Distributed Optical Fiber Sensing Intrusion Pattern Recognition Based on GAF and CNN. J. Light. Technol. 2020, 38, 4174–4182. [Google Scholar] [CrossRef]
- Tian, M.; Li, Q.; Xv, C.; Yang, Y.; Li, Z. Coal-rock Interface Recognition Method Based on GAF-deep Learning. In Proceedings of the 2021 IEEE 5th Conference on Energy Internet and Energy System Integration (EI2), Taiyuan, China, 22–24 October 2021; pp. 4029–4033. [Google Scholar]
- Wu, J.; Zhong, Y.; Chen, A. Radio Modulation Classification Using STFT Spectrogram and CNN. In Proceedings of the 2021 7th International Conference on Computer and Communications (ICCC), Chengdu, China, 10–13 December 2021; pp. 178–182. [Google Scholar]
- Ong, K.L.; Lee, C.P.; Lim, H.S.; Lim, K.M.; Alqahtani, A. Mel-MViTv2: Enhanced Speech Emotion Recognition with Mel Spectrogram and Improved Multiscale Vision Transformers. IEEE Access 2023, 11, 108571–108579. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Bello, I.; Zoph, B.; Vaswani, A.; Shlens, J.; Le, Q.V. Attention augmented convolutional networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3286–3295. [Google Scholar]
- Sun, L.; Zou, H.; Wei, J.; Li, M.; Cao, X.; He, S.; Liu, S. Semantic Segmentation of High-Resolution Remote Sensing Images Based on Sparse Self-Attention. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 3492–3495. [Google Scholar]
- Chowdhury, T.; Rahnemoonfar, M. Self Attention Based Semantic Segmentation on a Natural Disaster Dataset. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 2798–2802. [Google Scholar]
- Chen, Q.; Dai, X.; Song, X.; Liu, G. ITSC Fault Diagnosis for Five Phase Permanent Magnet Motors by Attention Mechanisms and Multiscale Convolutional Residual Network. IEEE Trans. Ind. Electron. 2024, 71, 9737–9746. [Google Scholar] [CrossRef]
- Wang, J.; Guo, J.; Xu, Z. Cross-view Gait Recognition Model Combining Multi-Scale Feature Residual Structure and Self-attention Mechanism. IEEE Access 2023, 11, 127769–127782. [Google Scholar] [CrossRef]
- Fu, X.; Liu, J.; Yu, P. Multi-scale Convolutional Neural Networks Based on Self-attention And Residual Network for Industrial Equipment Fault Diagnosis. In Proceedings of the 2023 CAA Symposium on Fault Detection, Supervision and Safety for Technical Processes (SAFEPROCESS), Yibin, China, 22–24 September 2023; pp. 1–6. [Google Scholar]
- Wang, G.; Tang, L.; Yang, Z.; Yan, L.; Liu, P.; Qu, H. Deep CNN-RNN with Self-Attention Model for Electric IoT Traffic Classification. In Proceedings of the 2023 4th International Conference on Big Data & Artificial Intelligence & Software Engineering (ICBASE), Nanjing, China, 25–27 August 2023; pp. 363–368. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. RepVGG: Making VGG-style ConvNets Great Again. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13728–13737. [Google Scholar]
- Cordonnier, J.B.; Loukas, A.; Jaggi, M. On the relationship between self-attention and convolutional layers. arXiv 2019, arXiv:1911.03584. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Layers | Layer Composition |
|---|---|
| Canopy layer | Scatterers of leaves, stems, and branches |
| Trunk layer | Scatterers of trunks perpendicular to the ground |
| Ground layer | Soil surface with corresponding dielectric constant |
| Vehicle Type | Vehicle Size |
|---|---|
| wheeled armored vehicle | 4 m × 2 m × 2 m |
| tracked vehicle | 7 m × 2.2 m × 2.2 m |
| van truck | 8.5 m × 2.5 m × 2.7 m |
| sedan | 4.58 m × 1.77 m × 1.42 m |
| Stage/Type | The Number of RepVGG Blocks | The Number of Self-Attention Modules | Input Size | Input Channels | Output Size | Output Channels | Stride |
|---|---|---|---|---|---|---|---|
| Stage 0 | 1 | 1 | 256 × 256 | 3 | 128 × 128 | 64 | 2 |
| Stage 1 | 1 | 0 | 128 × 128 | 64 | 64 × 64 | 320 | 2 |
| Stage 2 | 1 | 0 | 64 × 64 | 320 | 32 × 32 | 512 | 2 |
| Stage 3 | 1 | 0 | 32 × 32 | 512 | 16 × 16 | 768 | 2 |
| Stage 4 | 1 | 0 | 16 × 16 | 768 | 8 × 8 | 1280 | 2 |
| Self-attention | - | 1 | 8 × 8 | 1280 | 8 × 8 | 1280 | 1 |
| AdaptiveAvgPool2d | - | - | 8 × 8 | 1280 | 1 × 1 | 1280 | - |
| Linear | - | - | 1 × 1 | 1280 | 1 | 4 | - |
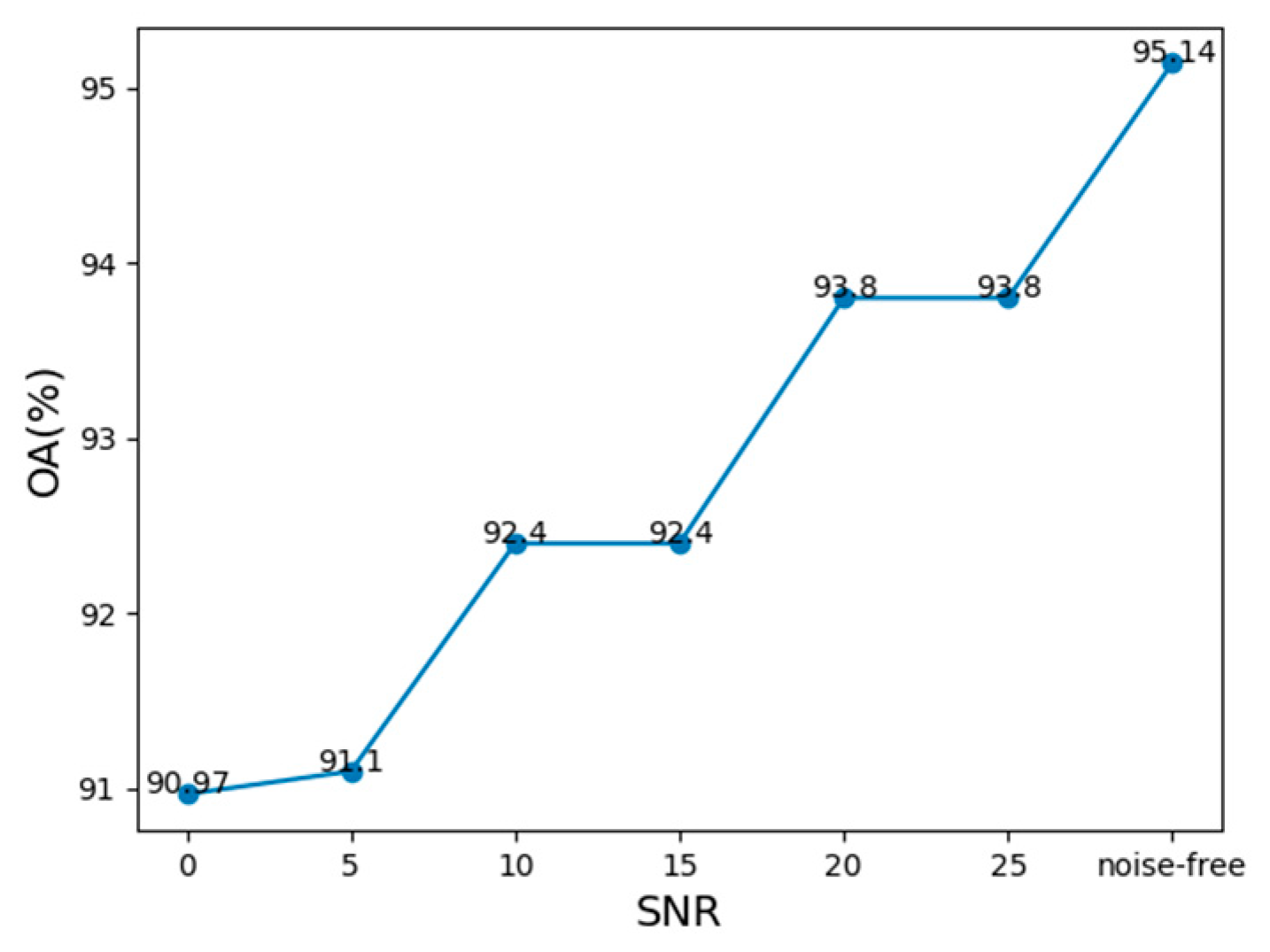
| OA | The Improved RepVGG | DenseNet | Inception | LeNet | ResNet | VGG |
|---|---|---|---|---|---|---|
| SNR = 0 | 90.97% | 79.86% | 85.42% | 86.81% | 79.86% | 87.50% |
| SNR = 5 | 91.10% | 83.33% | 85.42% | 86.81% | 80.56% | 88.89% |
| SNR = 10 | 92.40% | 85.42% | 85.42% | 90.28% | 86.81% | 88.89% |
| SNR = 15 | 92.40% | 87.5% | 86.11% | 91.67% | 86.11% | 88.89% |
| SNR = 20 | 93.80% | 87.5% | 86.11% | 92.36% | 88.89% | 90.97% |
| SNR = 25 | 93.80% | 90.97% | 88.89% | 92.36% | 90.28% | 93.06% |
| Noise-free | 95.14% | 91.18% | 92.36% | 94.44% | 90.48% | 93.06% |
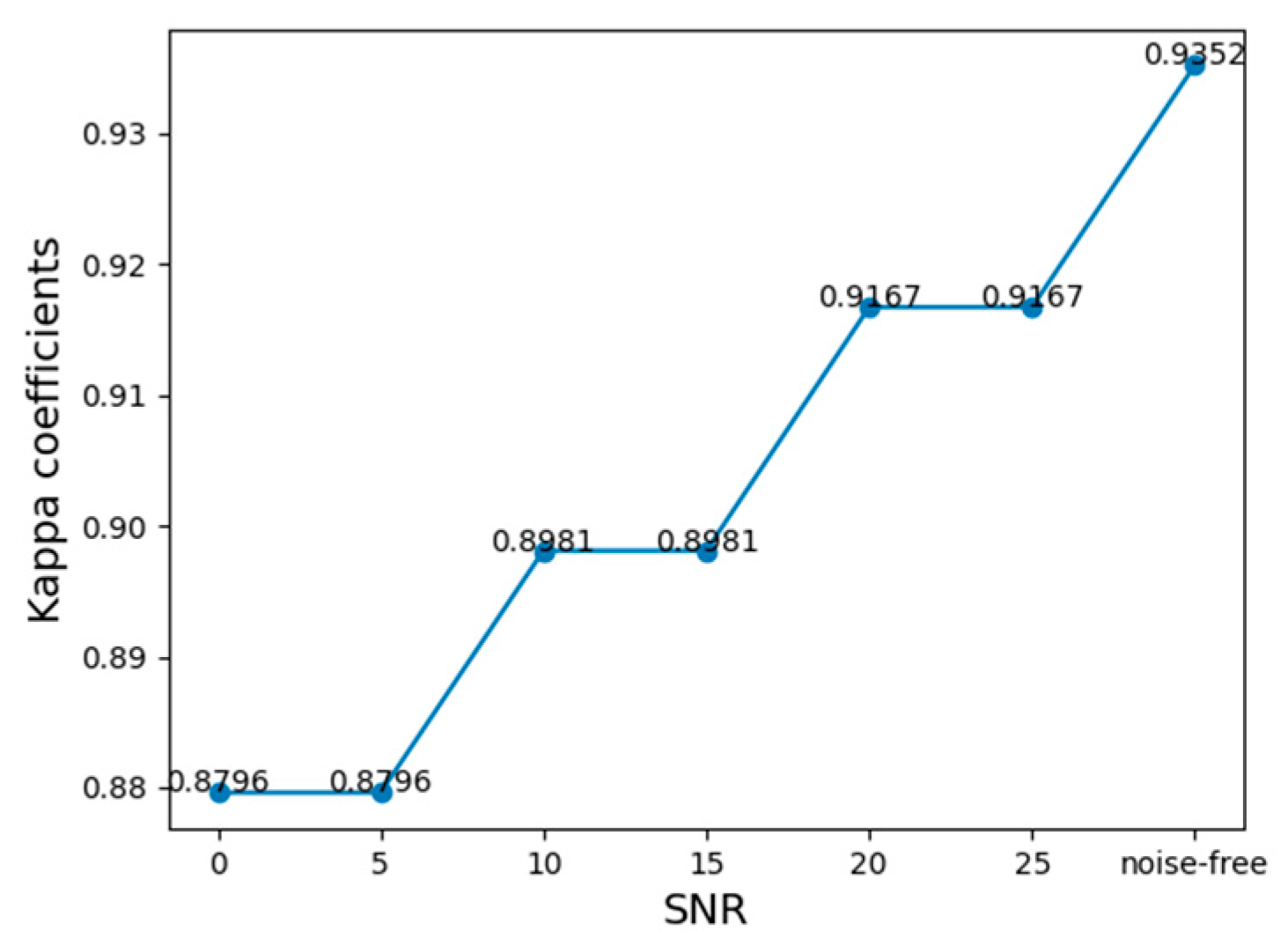
| Kappa Coefficient | The Improved RepVGG | DenseNet | Inception | LeNet | ResNet | VGG |
|---|---|---|---|---|---|---|
| SNR = 0 | 0.8796 | 0.731 | 0.806 | 0.824 | 0.731 | 0.833 |
| SNR = 5 | 0.8796 | 0.778 | 0.806 | 0.824 | 0.741 | 0.852 |
| SNR = 10 | 0.8981 | 0.806 | 0.806 | 0.87 | 0.824 | 0.852 |
| SNR = 15 | 0.8981 | 0.833 | 0.815 | 0.889 | 0.815 | 0.843 |
| SNR = 20 | 0.9167 | 0.833 | 0.815 | 0.889 | 0.852 | 0.88 |
| SNR = 25 | 0.9167 | 0.88 | 0.852 | 0.889 | 0.87 | 0.907 |
| Noise-free | 0.9352 | 0.882 | 0.898 | 0.926 | 0.873 | 0.907 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Zhang, S.; Zhu, L.; Chen, S.; Hou, L.; Li, X.; Chen, K. Carrier-Free Ultra-Wideband Sensor Target Recognition in the Jungle Environment. Remote Sens. 2024, 16, 1549. https://doi.org/10.3390/rs16091549
Li J, Zhang S, Zhu L, Chen S, Hou L, Li X, Chen K. Carrier-Free Ultra-Wideband Sensor Target Recognition in the Jungle Environment. Remote Sensing. 2024; 16(9):1549. https://doi.org/10.3390/rs16091549
Chicago/Turabian StyleLi, Jianchao, Shuning Zhang, Lingzhi Zhu, Si Chen, Linsheng Hou, Xiaoxiong Li, and Kuiyu Chen. 2024. "Carrier-Free Ultra-Wideband Sensor Target Recognition in the Jungle Environment" Remote Sensing 16, no. 9: 1549. https://doi.org/10.3390/rs16091549
APA StyleLi, J., Zhang, S., Zhu, L., Chen, S., Hou, L., Li, X., & Chen, K. (2024). Carrier-Free Ultra-Wideband Sensor Target Recognition in the Jungle Environment. Remote Sensing, 16(9), 1549. https://doi.org/10.3390/rs16091549