1. Introduction
The exploration of geothermal resources is currently an important demand for energy departments in various countries. Due to the renewable and clean nature of geothermal resources, the demand for exploring geothermal resources is increasing year by year. At present, the development methods of geothermal resources such as [
1,
2] still rely on geological exploration, expert evaluation, on-site inspections, and other means, which require high costs. Exploring geothermal anomalies in ground areas through satellite remote sensing images is an extremely efficient means. The satellite remote sensing images captured by the current Landsat satellite series are widely used. The Operational Land Imager (OLI), Thermal Mapper (TM), and Thermal Infrared Sensor (TIRS) carried by the Landsat series satellites can return radiation values from multiple bands in the captured area. These radiation values can be used to calculate LST retrieval images of the captured area. In addition to exploring geothermal resources, the Landsat series satellites have also played an important role in other work. The application of Landsat series satellites in tasks such as agricultural monitoring and urban heat island effects analysis was demonstrated in [
3,
4,
5,
6]. In [
7], Guo et al. used Landsat8 satellite images to monitor the water quality in the waters of Shenzhen, China. In [
8], Habib et al. proposed a system with automatic image processing and parameter calculation modules, which can calculate the water consumption of crops in the water consumption model pixel by pixel. In [
9], Gemitzi et al. performed LST on the northeastern region of Greece, and a threshold-based algorithm was developed to search for existing or potential geothermal reservoirs in the image. In [
10], Chou et al. introduced Long Short-Term Memory (LSTM) for predicting changes in Earth’s climate over time, demonstrating the application of machine learning techniques in time-sensitive tasks. In recent years, Hyperspectral images have widely been used [
11,
12].
Land surface temperature retrieval is mainly based on the surface thermal radiation observed by the thermal infrared sensor. After subtracting the atmospheric influence, the surface thermal radiant intensity can be obtained, and then the surface temperature can be obtained through thermal radiant intensity conversion. However, the use of LST images for geothermal resource exploration requires images with high resolution. Because remote sensing images are limited by sensor parameters, the natural environment, and other factors, they often carry certain noise and information loss, which will make the image fuzzy and thus affect the use of images. The purpose of image super-resolution is to improve the overall image quality and recover the lost information. At present, the main challenges of image super-resolution are excessive smoothness, excessive sharpening and the difficulty in eliminating noise in pursuit of a high index. The objective of this paper is to improve image quality while reducing sharpening and noise so as to facilitate further exploration of geothermal areas.
The super-resolution task of this article is aimed at LST retrieval images. The goal is to restore the image quality, that is, to restore the low-resolution image that has lost information to its initial state (high-resolution) through mathematical modeling. Since LST images require multiple operations of infrared band satellite remote sensing images and other reasons, such as flight altitude, size of instantaneous field of view (IFOV), and so on, the information in the images will be lost greatly during the operation process, resulting in a decrease in the resolution of the images, which will cause difficulties for subsequent searches for geothermal anomaly areas. We conducted indices and vision effects testing on the proposed model and compared it with the previous CNN models. The experimental results show that the proposed model outperformed the previous CNN models in terms of experimental indices and visual effects.
Image super-resolution is an important task in recent years, which has received widespread attention in the field of computer vision and has been widely applied in various tasks [
13,
14]. The past single-image super-resolution methods were mainly based on pixel adjacent area interpolation methods, such as Gaussian process regression [
15], random forest [
16], and the method for restoring image quality through interpolation—Bicubic interpolation. These methods are based on the information of the image itself to restore the image. Although these operations can appropriately restore the image quality, there is still a great loss of information that cannot be restored when processing temperature retrieval images.
The super-resolution method based on deep learning technology is now widely used. In [
17], Wang et al. summarized the application of deep learning theory in today’s super-resolution tasks. Nowadays, there are two super-resolution methods that have aroused widespread interest among researchers: single-image super-resolution (SISR) and reference-based image super-resolution (RefSR). For SISR, in the Super-Resolution Convolutional Neural Network (SRCNN) [
18], Dong et al. set a precedent for the application of deep learning in image super-resolution, which improved the performance of image super-resolution compared to traditional methods, such as Bicubic. In the Super-Resolution Generative Adversarial Network (SRGAN) [
19], Christian et al. introduced the concept of GAN [
20] into the task of super-resolution of a single image, making the restoration effect of details in the high-frequency part of the image better. In Enhanced-SRGAN (ESRGAN) [
21], Wang et al. introduced the Residual-in-Residual Dense Block (RRDB) based on SRGAN, which improves the super-resolution restoration effect of a single image. In SR3 [
22], Chitwan et al. used the diffusion model to complete the SISR, which spliced the low-resolution image upsampled to the target resolution with the high-resolution image added with noise and used it as a conditional input for super-resolution. In [
23], Moser et al. discussed the latest applications of diffusion models in the field of super-resolution. In [
24,
25], the authors explained the application of super-resolution technology in the field of remote sensing. These methods make it difficult to restore low-resolution images well in situations where there is a significant loss of image information. We conducted metric testing on the proposed model and compared it with previous CNN models. The experimental results show that our proposed new model outperforms the previous CNN model in terms of experimental indices and visual effects.
And reference-based image super-resolution can reduce the impact of information loss in low-resolution images on super-resolution work. In [
26], Zhang et al. introduced a neural texture transfer module into super-resolution based on reference image
, solving the problem of difficulty in improving the super-resolution performance in SISR tasks. In [
27], Yang et al. first introduced the attention mechanism [
28] into super-resolution tasks, improving the performance of image super-resolution tasks based on reference images. At present, the super-resolution of remote sensing images is mainly based on SRCNN [
18] and SRGAN [
19], such as CycleCNN [
29] and Edge-Enhanced-SRGAN (EESRGAN) [
30]. Although these methods can effectively perform super-resolution reconstruction on remote sensing images, there is still a large amount of lost information that cannot be restored when processing temperature retrieval images.
However, LST images have a high demand for image information restoration. With previous methods, due to the lack of image preprocessing, directly performing super-resolution processing on images does not perform well. The significant loss of image information leads to many visual problems in super-resolution images, such as the loss of high-frequency information and the loss of image brightness. Therefore, introducing reference image information is crucial.
The current super-resolution methods of LST images such as [
31] mainly improved the resolution by modeling the probability distribution of the image and analyzing and fusing the spectrum. The effect achieved by these methods is similar to Bicubic interpolation. Although the reconstructed image and Ground Truth’s indices can reach a considerable level, the overall image quality and high-frequency details of the image are still largely lost. In addition, in the process of super-resolution, the previous diffusion model method, due to the lack of reference information in the denoising network, leads to poor indices and visual effects of the image super-resolution task, and the loss information of the image still cannot be recovered.
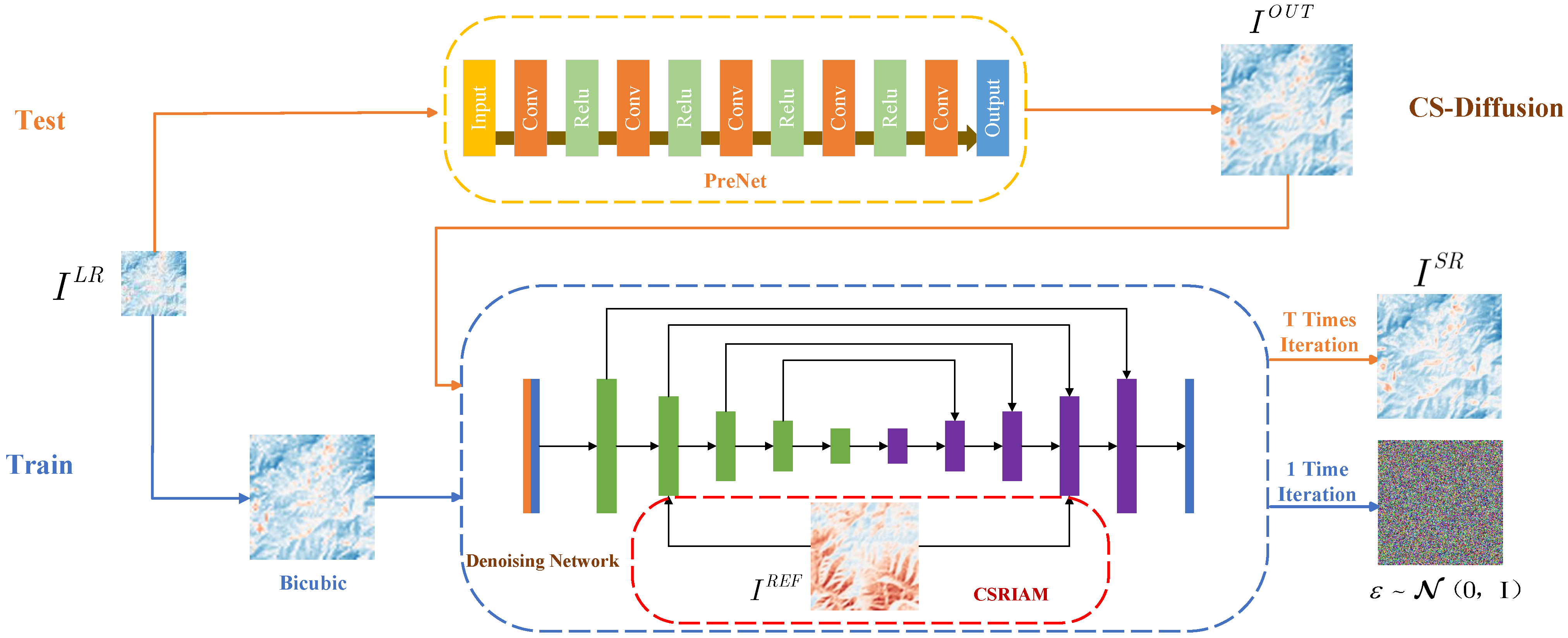
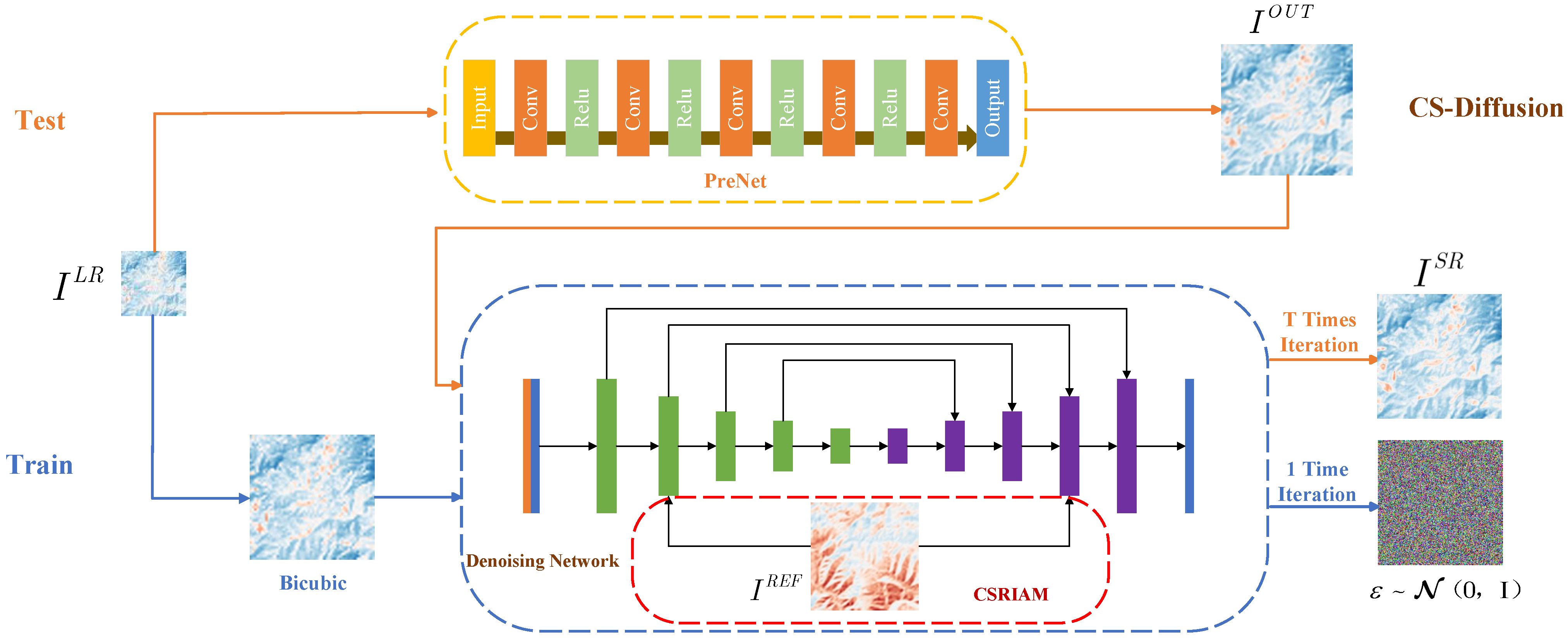
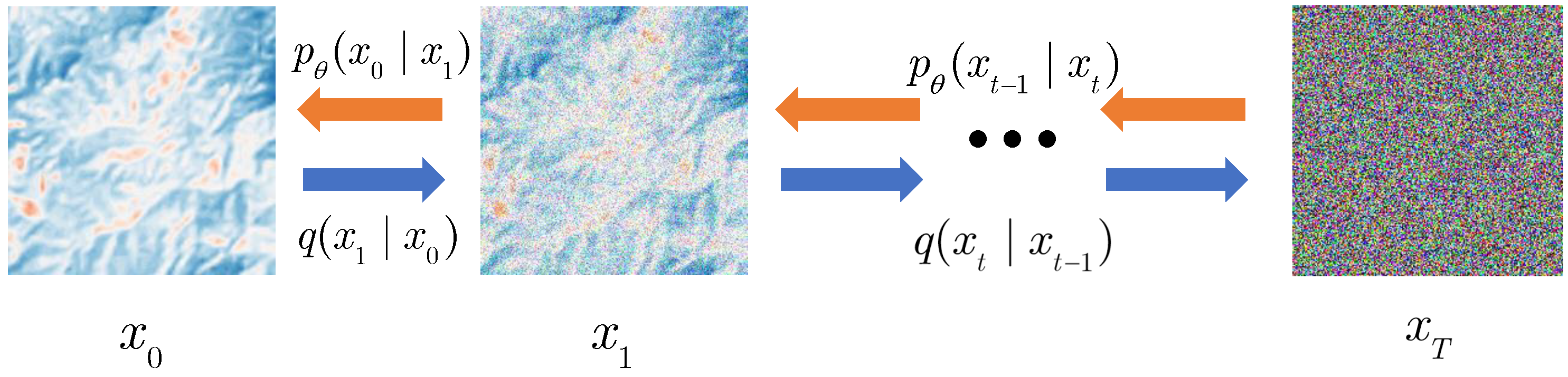
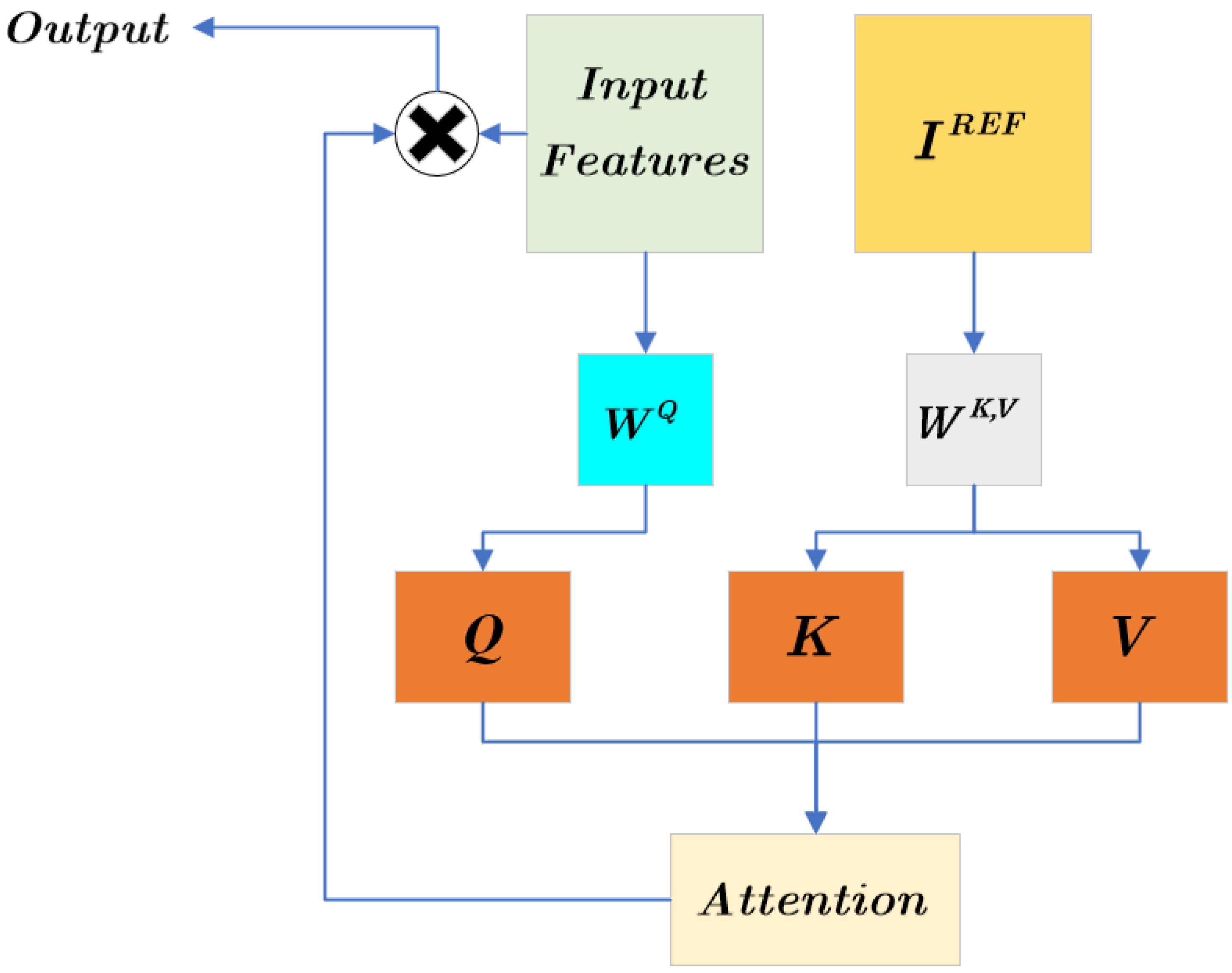
To address these issues, we proposed the Cross-Scale Diffusion (CS-Diffusion) method, which combines the advantages of super-resolution based on reference images and enables the network to learn features of reference images at different scales. Image super-resolution based on reference images can extract features from high-resolution reference images and be used to improve image quality. Our CS-Diffusion method introduces cross-scale reference images. First, due to the limitations of the Bicubic method itself, it is unable to perform good information recovery on low-resolution images. Therefore, we introduced Pre-Super-Resolution Net (PreNet), which can preliminarily restore the quality of the LR image. Based on the SR3 [
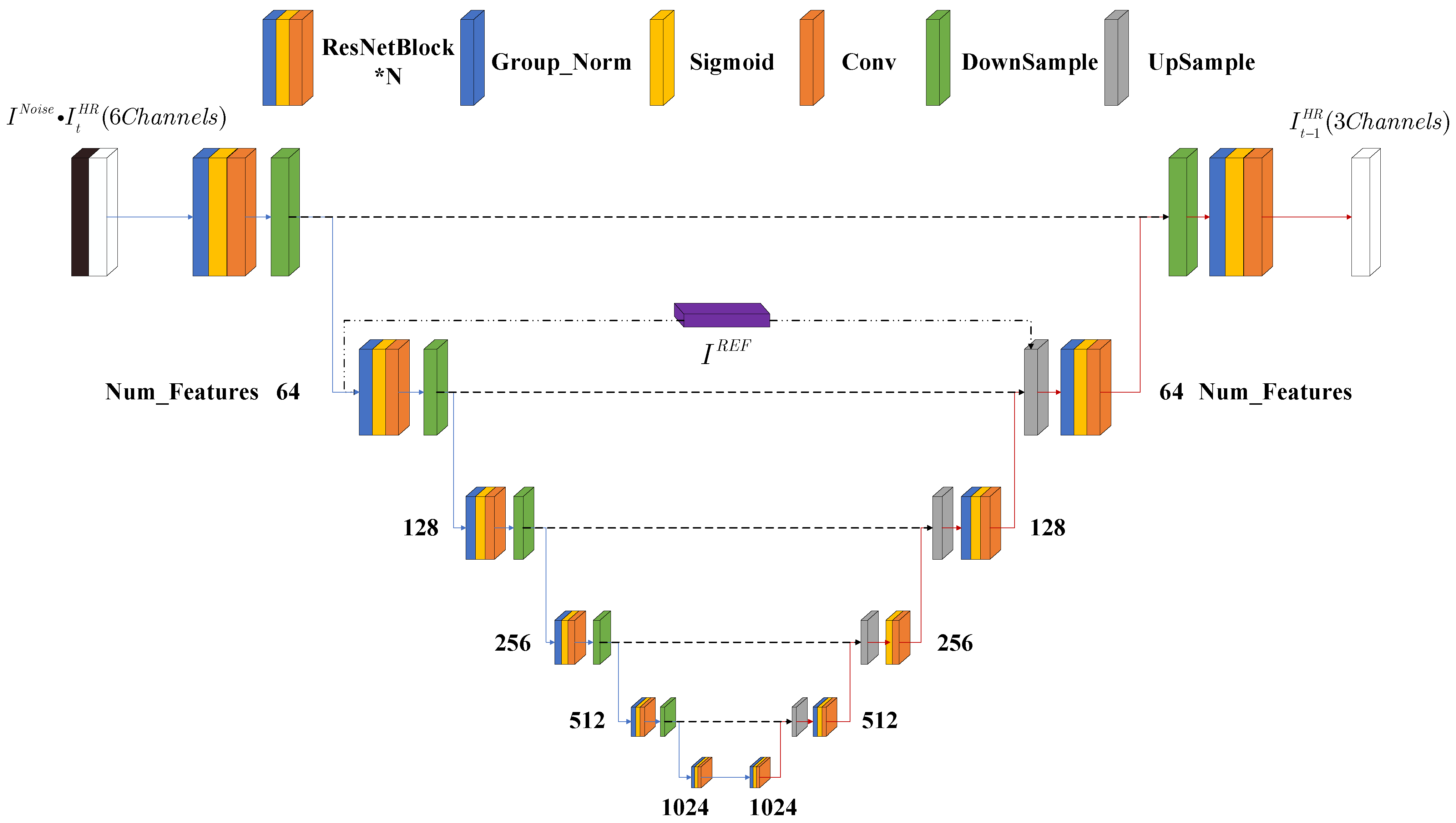
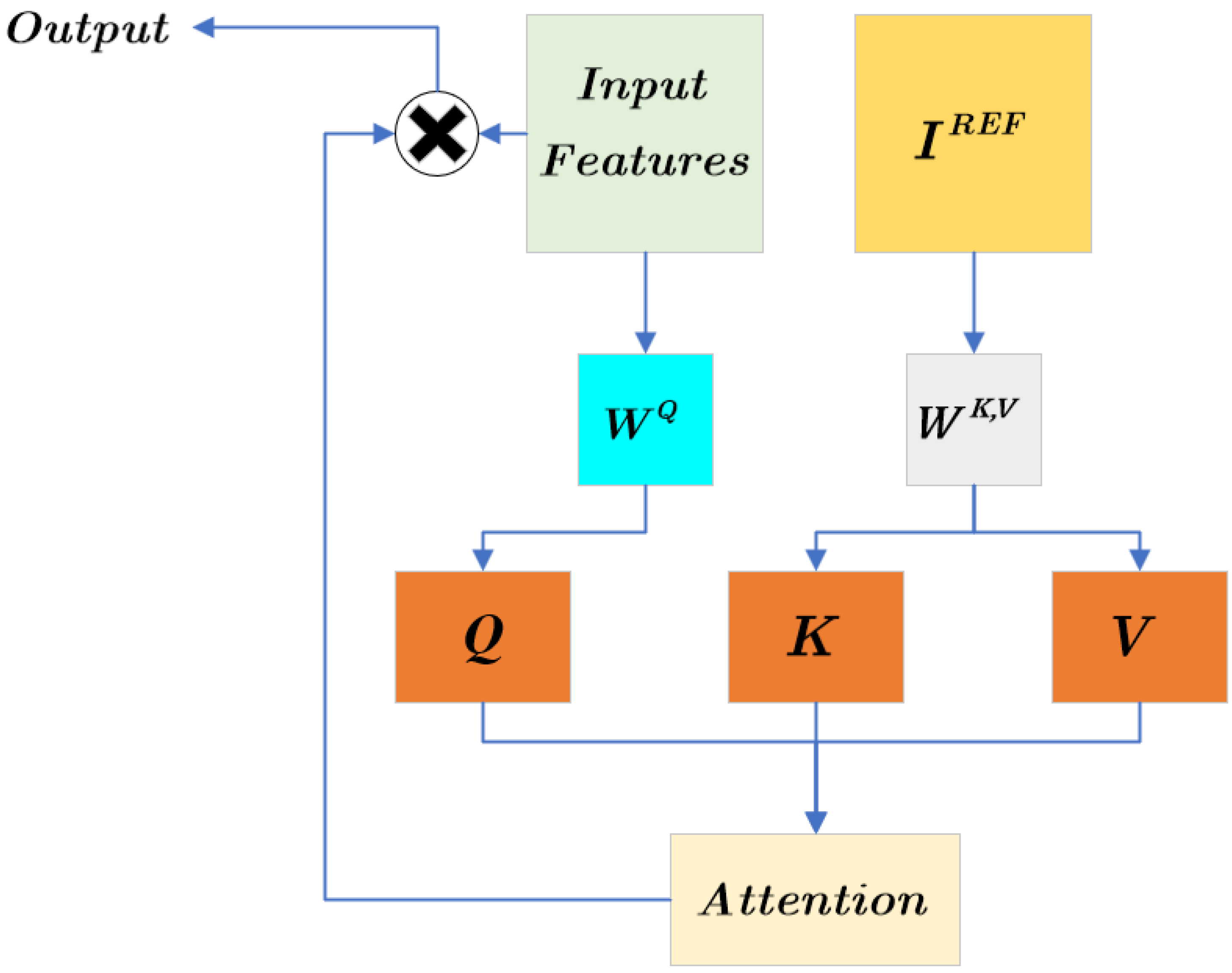
22], we replaced its conditional input (Low-resolution image with Bicubic interpolation to target resolution) in the SR3 method with the output of our PreNet, whose inputs are low-resolution images; after that, we concatenated it with high-resolution images with noise. We used the same dataset to train PreNet to have the ability of pre-super-resolution. Finally, after the training of the diffusion model, we found that the super-resolution effect of LST retrieval images was greatly improved. Meanwhile, we proposed the Cross-Scale Reference Image Attention Mechanism, which could fuse the downsampled feature image and the high-resolution reference image, and reduce the information loss caused by the downsampling process. After the introduction of this mechanism, the noise of the super-resolution image was greatly reduced, and the recovery effect on geothermal anomaly points was greatly improved.
The main contributions of this article are as follows:
1. We proposed a network PreNet, which takes a low-resolution image as its input, and its output is used as the conditional input of the diffusion model. This method enhanced the effect of image reconstruction, resulting in an improvement in indices.
2. In response to the problem of information loss in U-Net downsampling, we proposed the Cross-Scale Reference Image Attention Mechanism to provide high-resolution reference features for the U-Net feature maps, greatly enhancing the information recovery ability of denoising networks.
In the next section, we introduce the proposed cross-scale diffusion method. PreNet is discussed in
Section 2.1. The main structure of the denoising network is discussed in
Section 2.2. The structure of the Cross-Scale Reference Image Attention Mechanism is discussed in
Section 2.2.4.
Figure 1 shows the overall framework of our CS-Diffusion method, using two types of logic for training and testing.
3. Experimental Results and Discussions
3.1. Dataset Preparation
The commonly used image super-resolution datasets currently include COCO [
39], CUFED5 [
40], and ImageNet [
41]. These datasets are composed of a large number of high-resolution images, which can be a good source of data for super-resolution tasks. However, for the super-resolution reconstruction task of LST images, the above datasets cannot effectively represent the characteristics of such images. Therefore, we used satellite remote sensing images to create SAT (Satellite And Temperature) datasets. In
Figure 5, we present some images from the SAT dataset:
The data used in this article are all from the Landsat8 satellite. Its OLI land imager consists of 9 bands with a spatial resolution of 30 m. The thermal infrared sensor TIRS consists of two separate thermal infrared bands with a resolution of 100 m. The wavelength ranges of the two thermal infrared bands are Band10 (10.60∼11.19
m) and Band11 (11.50∼12.51
m). The thermal infrared band can record the amount of thermal radiation released from the ground and its diffusion range.
Table 1 lists the specific information of the remote sensing image data we used, including region names, Data IDs, center longitude and latitude, and image capture times.
We used ENVI 5.3 to perform temperature retrieval on the original remote sensing images. Firstly, we used Landsat8 data for radiometric calibration. Then, we performed OLI (Operational Land Imager) atmospheric correction to eliminate the influence of atmospheric and lighting factors on ground reflection; NDVI (Normalized Difference Vegetation Index) calculation to detect vegetation growth status, vegetation coverage, and eliminate some radiation errors; and surface specific radiance calculation to obtain the temporal information of land surface. Finally, we calculated the blackbody radiance to obtain the land surface temperature image.
Our SAT dataset comes from four typical geothermal resource concentration areas in Eryuan, Midu, Lancang, and Ning’er, Yunnan Province, China, with a total of four high-resolution remote sensing images. The download path for images is
http://www.gscloud.cn/. We selected satellite remote sensing images with cloud cover of less than
for temperature retrieval, which can minimize the impact of weather factors on the experimental results. After retrieval of the land surface temperature using the ENVI platform, they were cut into 96 × 96 patches, including 14,976
and 14,976
. We used 182 sheets 224 × 224 patches as our test set to conduct comparative experimental tests on the performance of various models. Before sending the image into the network, we normalized it to facilitate network processing.
3.2. Training Details and Parameters Setting
The hardware platform we used is Intel Core i9-13900K + NVIDIA GeForce RTX 4090. The software platform is Python 3.10.11 + PyTorch 2.0.1 + CUDA 11.8 + CUDNN 8.2.1. The test indices for the comparative experiment are Peak Signal-to-Noise Ratio (PSNR), Structural Similarity (SSIM) [
42], Learned Perceptual Image Patch Similarity (LPIPS) [
43], and Frechet Inception Distance score (FID) [
44], and the vision effects were taken as the reference indicator.
The formula for Peak Signal-to-Noise Ratio(PSNR) is as follows:
where
is the maximum pixel value of the image, and MSE is defined as follows:
where
H and
W represent the height and width of the image,
represents the pixel value of the test image, and
represents the pixel value of the target image.
Structural Similarity (SSIM) is an indicator that measures the similarity between two images and satisfies
, which is defined as follows:
where
represents the comparison of image brightness,
represents the comparison of the image contrast,
represents the comparison of the image structure,
represents the mean,
represents the standard deviation,
represents the covariance,
are constants, preventing the denominator from being 0, and
are usually taken as 1.
The formula of Learned Perceptual Image Patch Similarity (LPIPS) is as follows:
where
l means the layer of the feature map,
means the neural network used to calculate the indicator,
means the pixels of SR, and
means the pixels of HR.
The formula of the Frechet Inception Distance score (FID) is as follows:
where
means the trace of the matrix.
We used 182 images for super-resolution testing on each model, with each image size of . The corresponding low-resolution images were downsampled to different resolutions—: , : —and the average PSNR, SSIM, LPIPS, and FID were taken as the final indices for each model.
We selected the parameters according to the common diffusion model training details. In order to converge to the optimal network parameters, we set a lower learning rate and a higher training epochs, and the details of the experimental parameters are as follows.
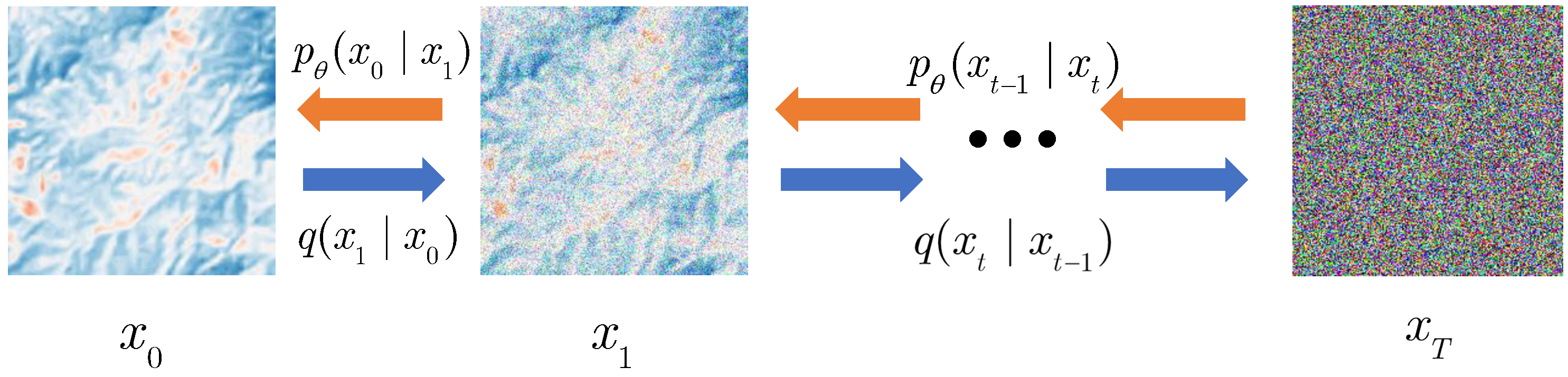
The number of iterations of the diffusion model was set to T = 2000, and the size of the Cross-Scale Reference Image Attention Mechanism was set to 48 (training) and 112 (testing).
The number of residual blocks N corresponding to each feature of U-Net was set to 3, and the number of channels in U-Net was set to . The Batchsize was set to 16, we used the Adam optimizer, and the initial learning rate was 0.0001. The model converged after 600,000 iterations (300 epochs) of training on our dataset.
In addition, we also trained 300 epochs when training other models, and used the same dataset for training and testing. We selected Bicubic, SRCNN [
18], SRGAN [
19], ESRGAN [
21], RCAN [
45], HAT [
46], and BebyGAN [
47] as the comparative experimental models for SISR; TTSR [
27] as the comparative experimental model based on reference image
; and SR3 [
22], IDM [
48], and SRDiff [
49] as the diffusion-based comparative experimental models.
3.3. Benchmark Comparison and Ablation
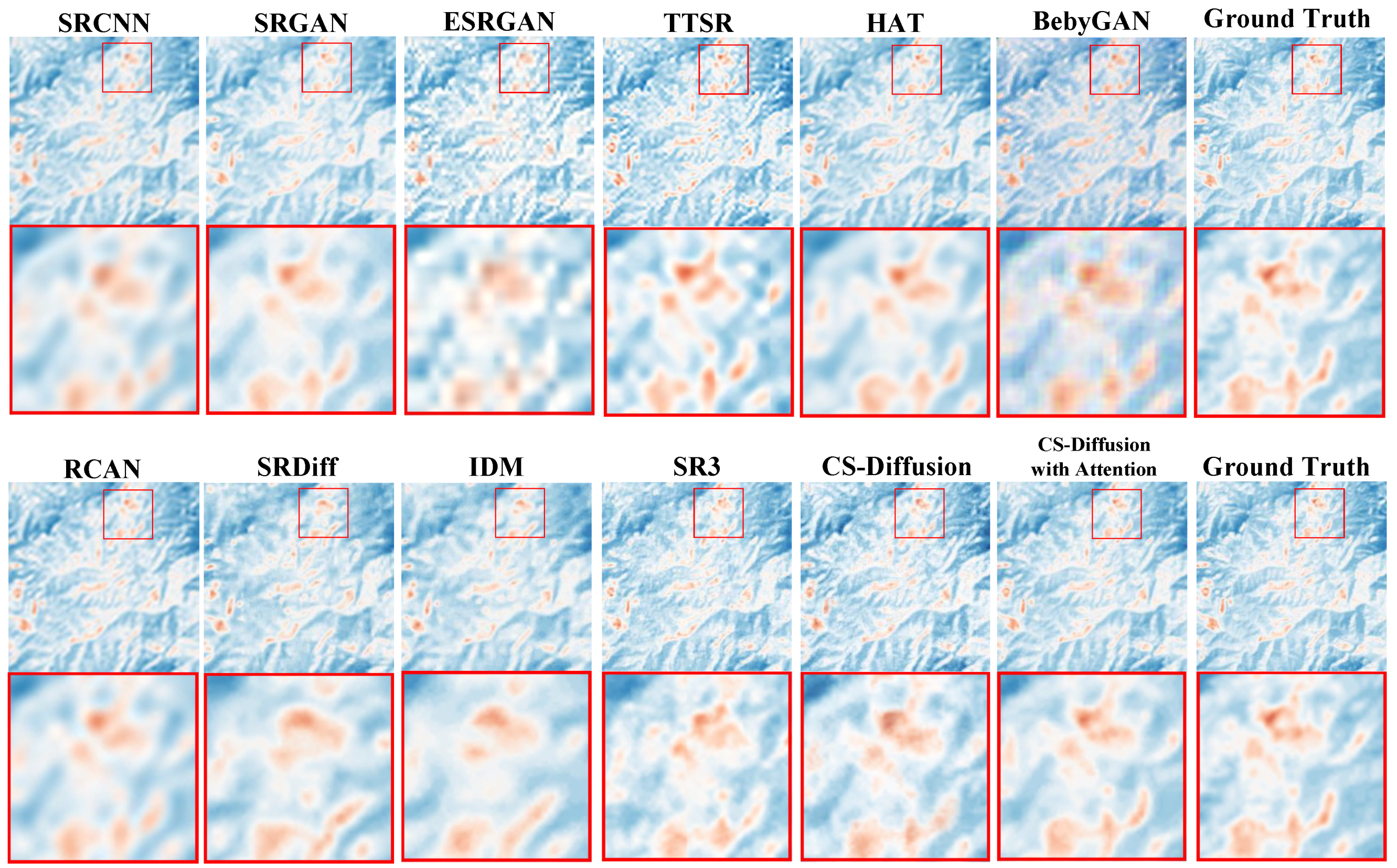
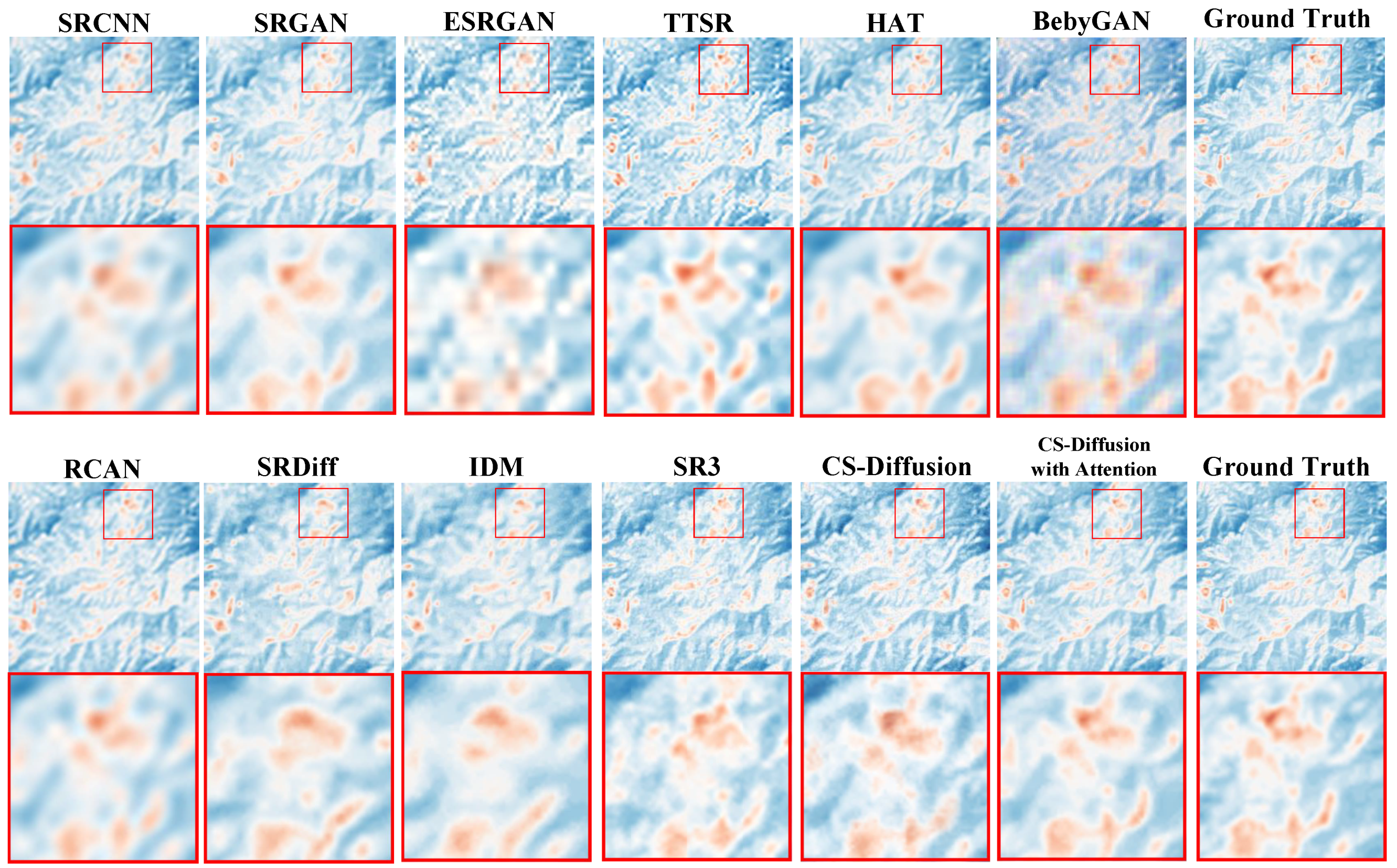
We trained each model using the SAT dataset, performed 4× and 8× super-resolution, and tested the super-resolution visual effect of the model. The indices results of the comparative experiment are shown in
Table 2, and the comparison of the experimental effects is shown in
Figure 6. We found that although the model based on CNN can achieve higher PSNR and SSIM [
42], and the model based on GAN [
20] and Diffusion [
35] can achieve higher LPIPS [
43] and FID [
44], it can be found from the experimental results in
Figure 6 that high indices are not equivalent to excellent super-resolution visual effects, and the overall appearance of the image is also an important indicator. It can be observed that methods based on MSE optimization often lack high-frequency details of images, while methods based on generative adversarial networks are limited by interpolation methods, leading to block phenomena in images.
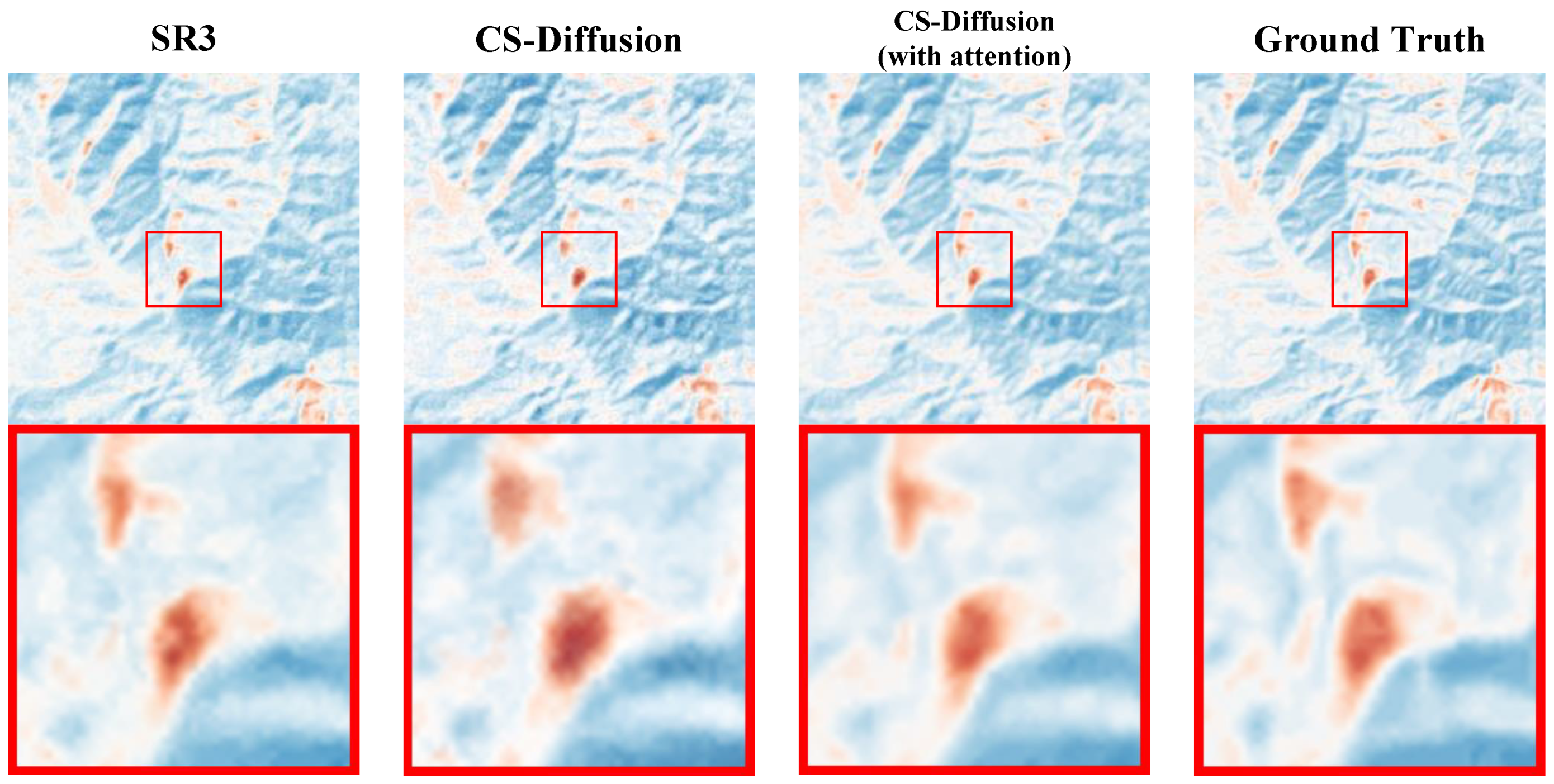
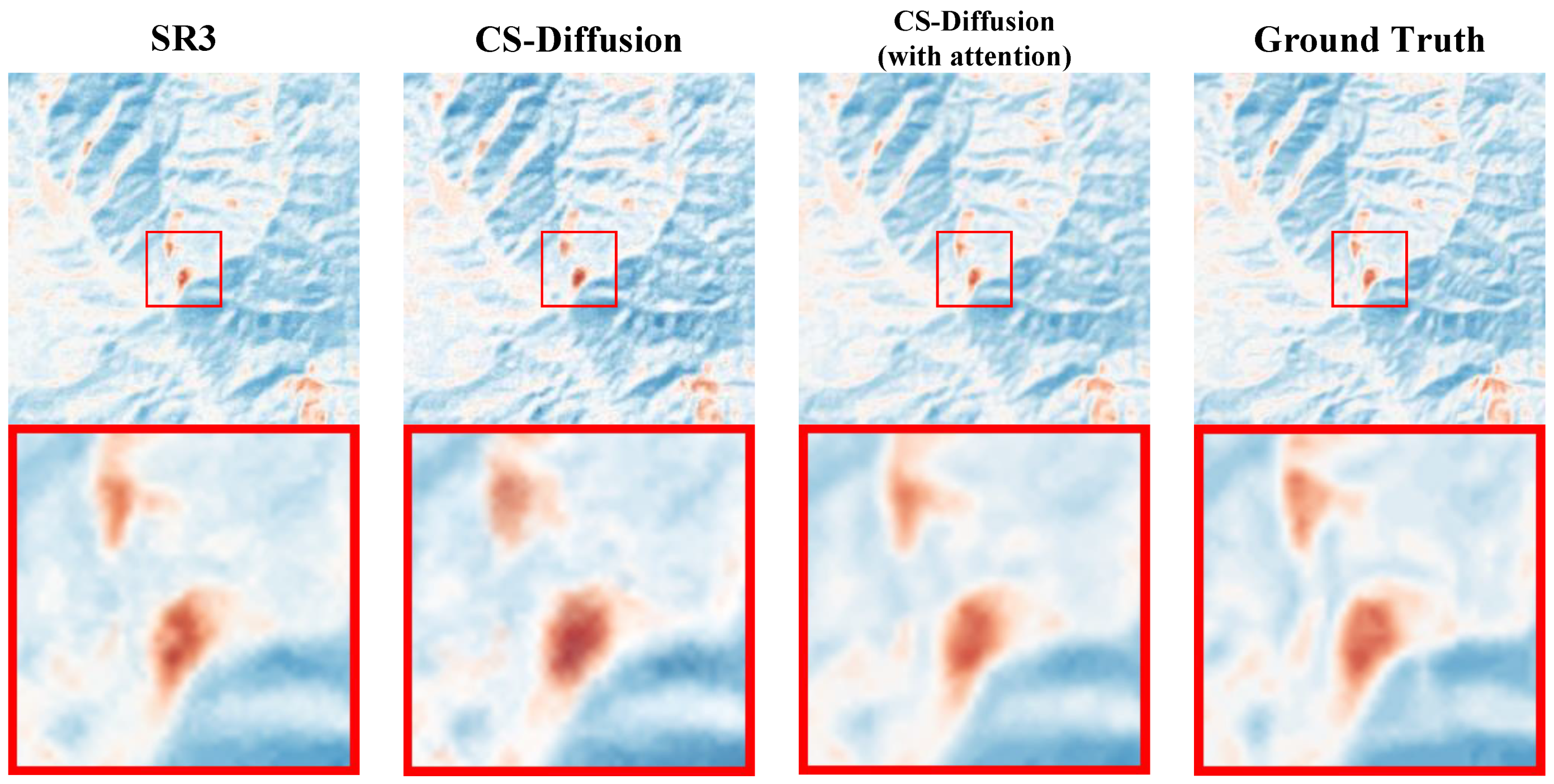
In the ablation experiment, we selected the SR3 [
22] method as the baseline. According to the experimental comparison results, we demonstrated that introducing PreNet during testing can improve indices and visual effects compared to the SR3 method, which means our CS-Diffusion method (SR3 + PreNet) can greatly improve the super-resolution performance. The introduction of CSRIAM further improves the indices and eliminates the problem of white noise in the image. The specific visual effect can be seen in
Figure 7.
In
Table 3 and
Figure 7, we demonstrate the progress of our CS-Diffusion method based on the SR3 method. We found that the SR3 method will leave a portion of white noise on the reconstructed image, which is reflected in the form of white noise on the image. Although the addition of PreNet’s CS-Diffusion will, to some extent, solve this problem, there will still be some white noise present. After adding the Cross-Scale Reference Image Attention Mechanism, we effectively solved the problem of white noise on the image, resulting in an overall improvement in the quality of the reconstructed image and a more complete recovery of some geothermal anomalous areas.
According to the comparative test results, we found that our method can achieve the optimal effect in all comparison models on PSNR, SSIM and LPIPS, and can also be very close to the optimal performance on FID. Our method combines the advantages of reference-based super-resolution and diffusion models: excellent restoration of image quality, while reducing the excessive smoothing and over-sharpening of images. On this basis, noise removal in visual effects can be achieved (as shown in
Figure 6).
3.4. Parameter Comparison Experiment
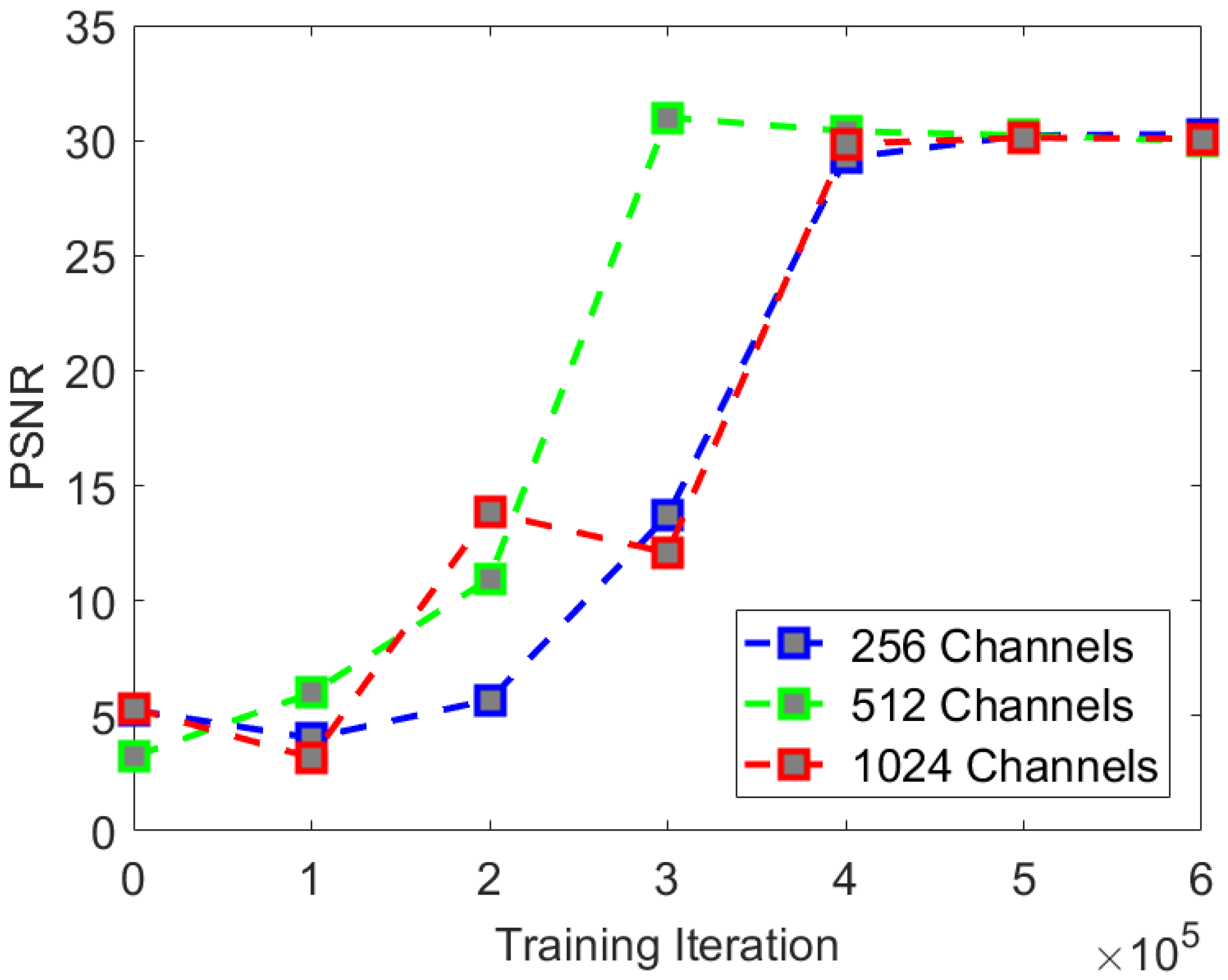
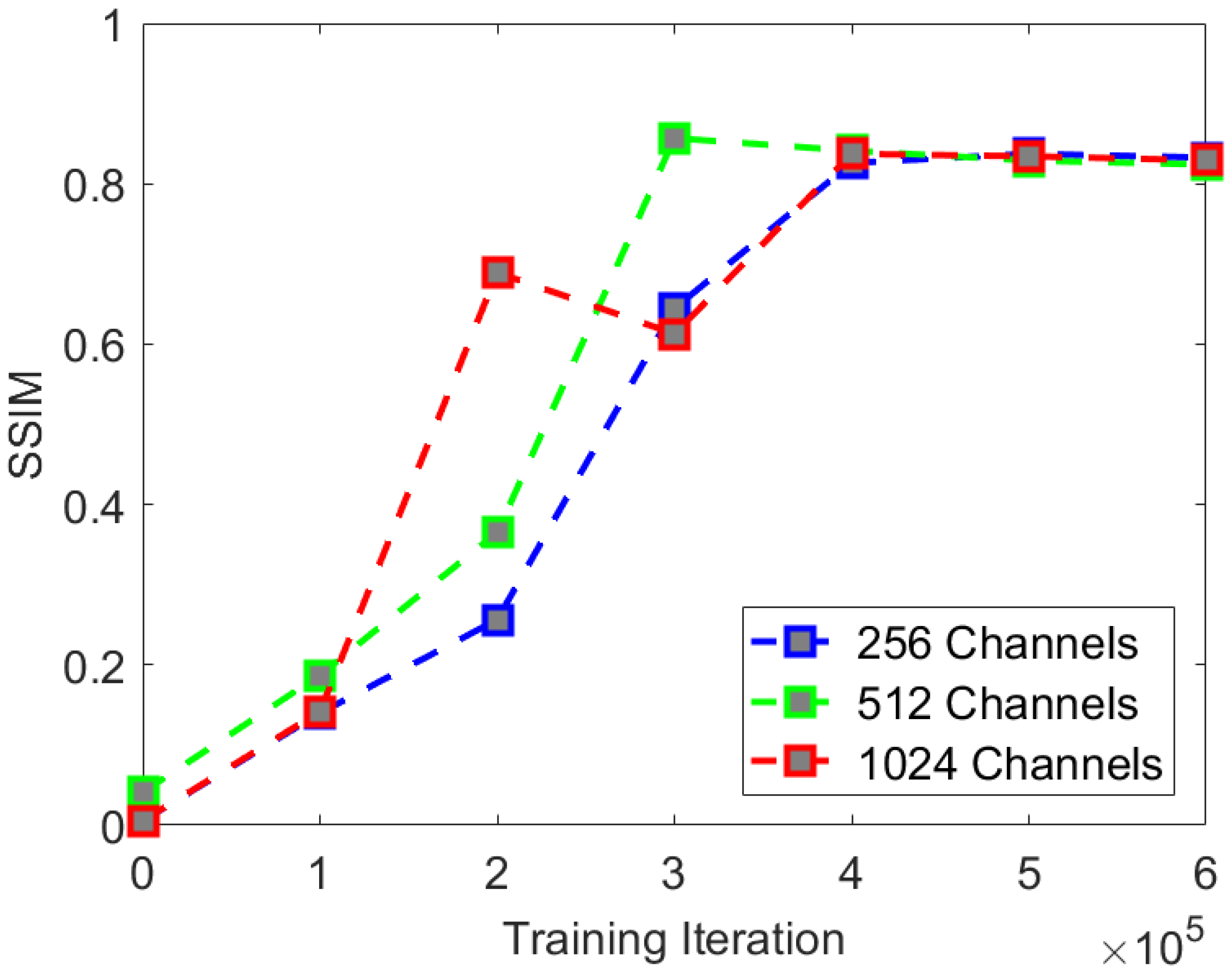
To explore the effects of network depth, number of iterations, and noise schedule on experimental results, we conducted multiple comparative experiments using the CS-Diffusion method. We found that the PSNR and SSIM can reflect whether the model converges. So we chose these two indices as the symbol of the rate of convergence. When conducting comparative experimental tests, our PSNR and SSIM were obtained by calculating the mean of the indices from the first three images in the test set.
In the comparative experiment of network depth, we adopted three U-Net network depths:
. The comparative experimental indices are shown in
Table 4.
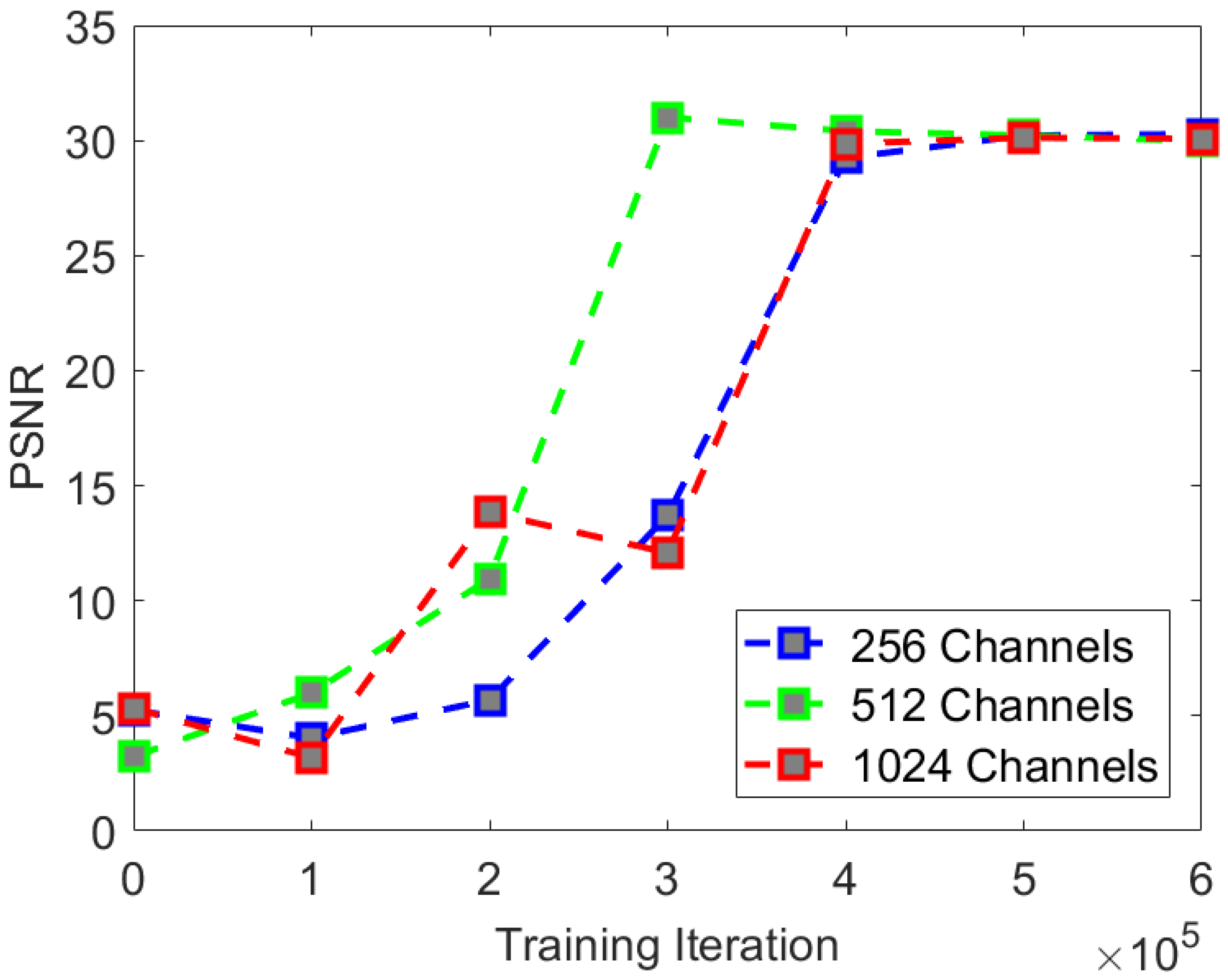
We found that with the increase in network depth, i.e., network parameters, there was a certain improvement in experimental indices. The network converges fastest at the depth of 512, but the optimal indices in the experiment are best at the depth of 1024. The rate of convergence of PSNR and SSIM is shown in
Figure 8 and
Figure 9. The comparison of visual effects is shown in
Figure 10.
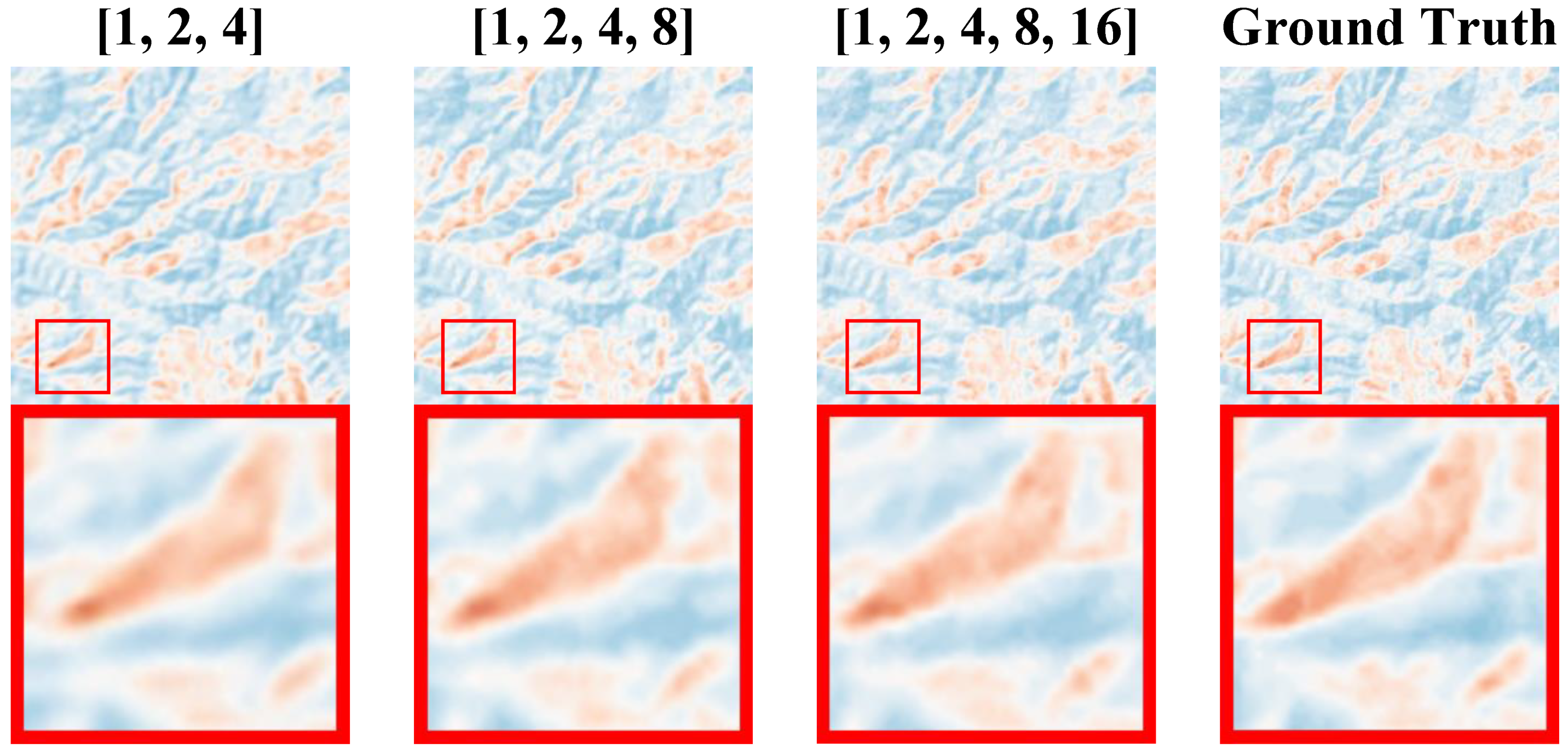
We found that when the network depth was [1, 2, 4, 8], the rate of convergence of the PSNR index was the fastest, and it could finally converge to an effect similar to the network depth [1, 2, 4, 8, 16]. It is difficult for the human eye to see the difference in the visual effect comparison. Therefore, when applying the CS-Diffusion model, we can sacrifice the metrics appropriately in exchange for training a model that is easier to converge and has smaller network parameters.
The rate of convergence of the SSIM index is similar to that of the PSNR index. Although we can improve the SSIM index with the increase in the network depth, there will not be much change in the visual effect. Therefore, we believe that the network depth of the CS-Diffusion model is the most cost-effective choice [1, 2, 4, 8].
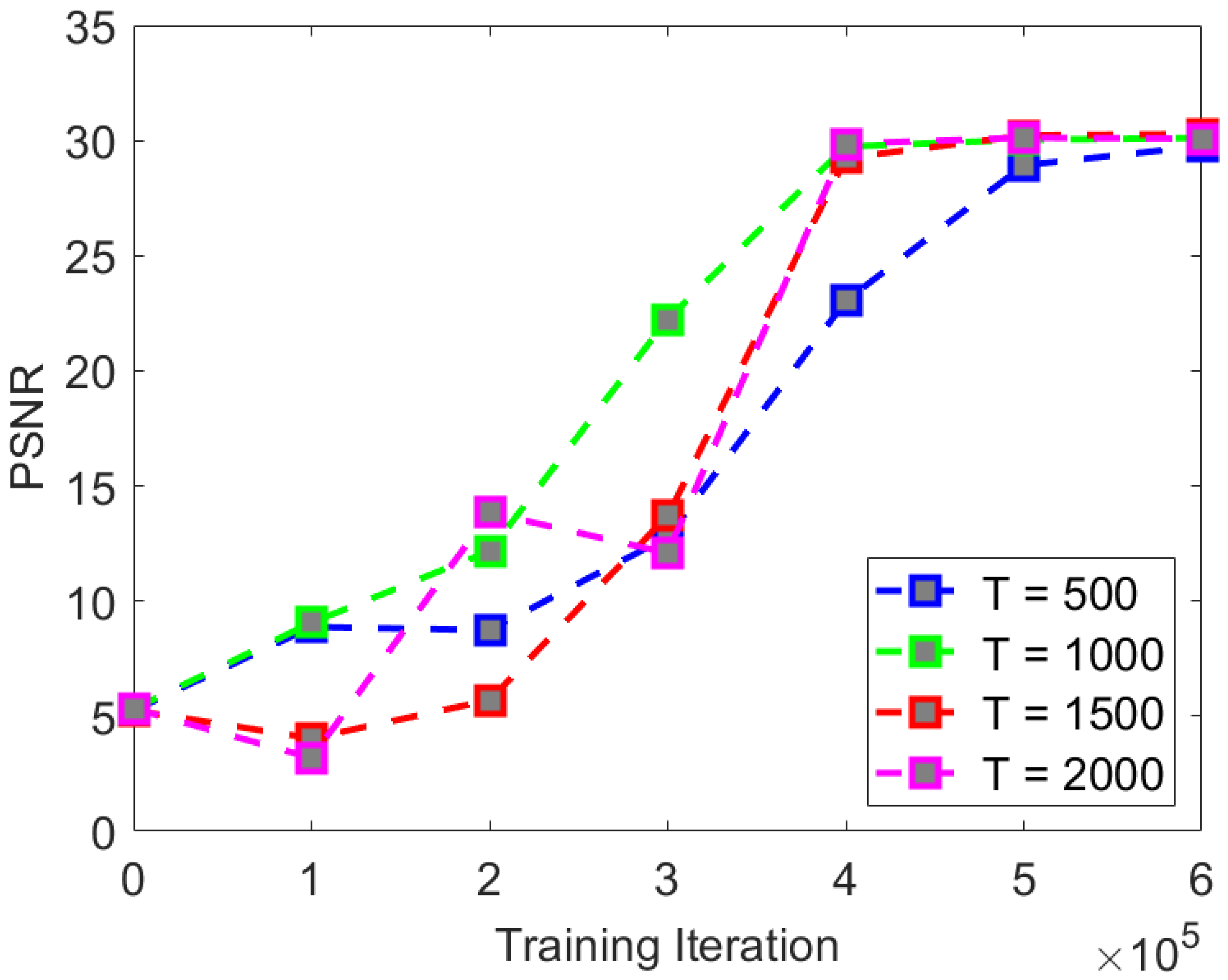
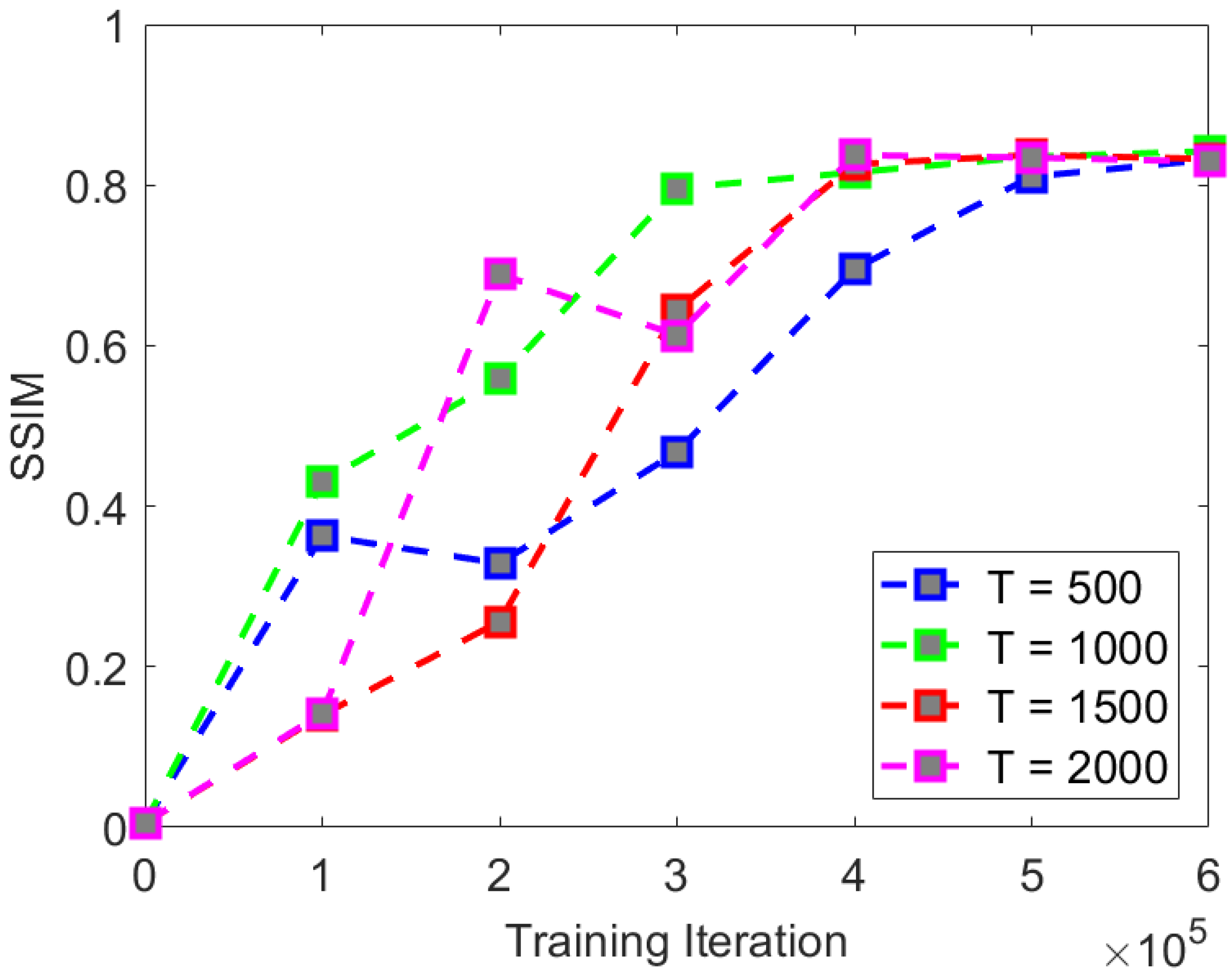
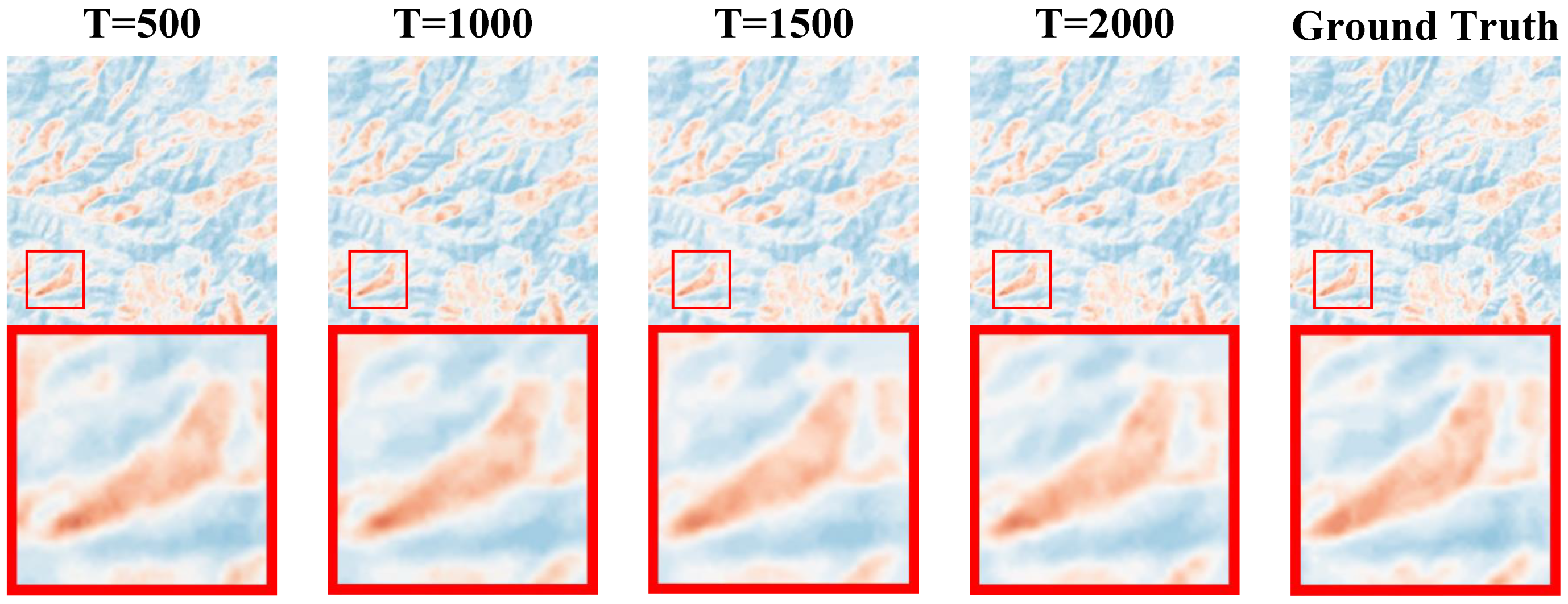
For the comparative experiment of iteration times, we adopted T = 500, 1000, 1500, and 2000 iteration times to compare the experimental indices and visual effects. The comparative experimental indices are shown in
Table 5.
According to the experimental comparison, it can be seen that as the number of iterations increases, the experimental indices show a certain improvement. The rate of convergence of PSNR and SSIM is shown in
Figure 11 and
Figure 12. The comparison of the visual effects is shown in
Figure 13. But as T grows, the time consumed by the testing process will increase significantly.
We found that when the number of iterations T is too small (i.e., T = 500), the PSNR and SSIM metrics cannot converge to good results. We believe that this is due to the small number of iterations, which leads to the inability to completely remove noise from the image. When the number of iterations is 1000, the rate of convergence and final convergence effect of both PSNR and SSIM indexes are better than those of other iterations. Therefore, we believe that T = 1000 is a good choice for the iteration number T of the CS-Diffusion method. As
T increases as shown in
Figure 13, the visual effect of the comparative experiment also improves, and the noise in the reconstructed image is reduced accordingly.
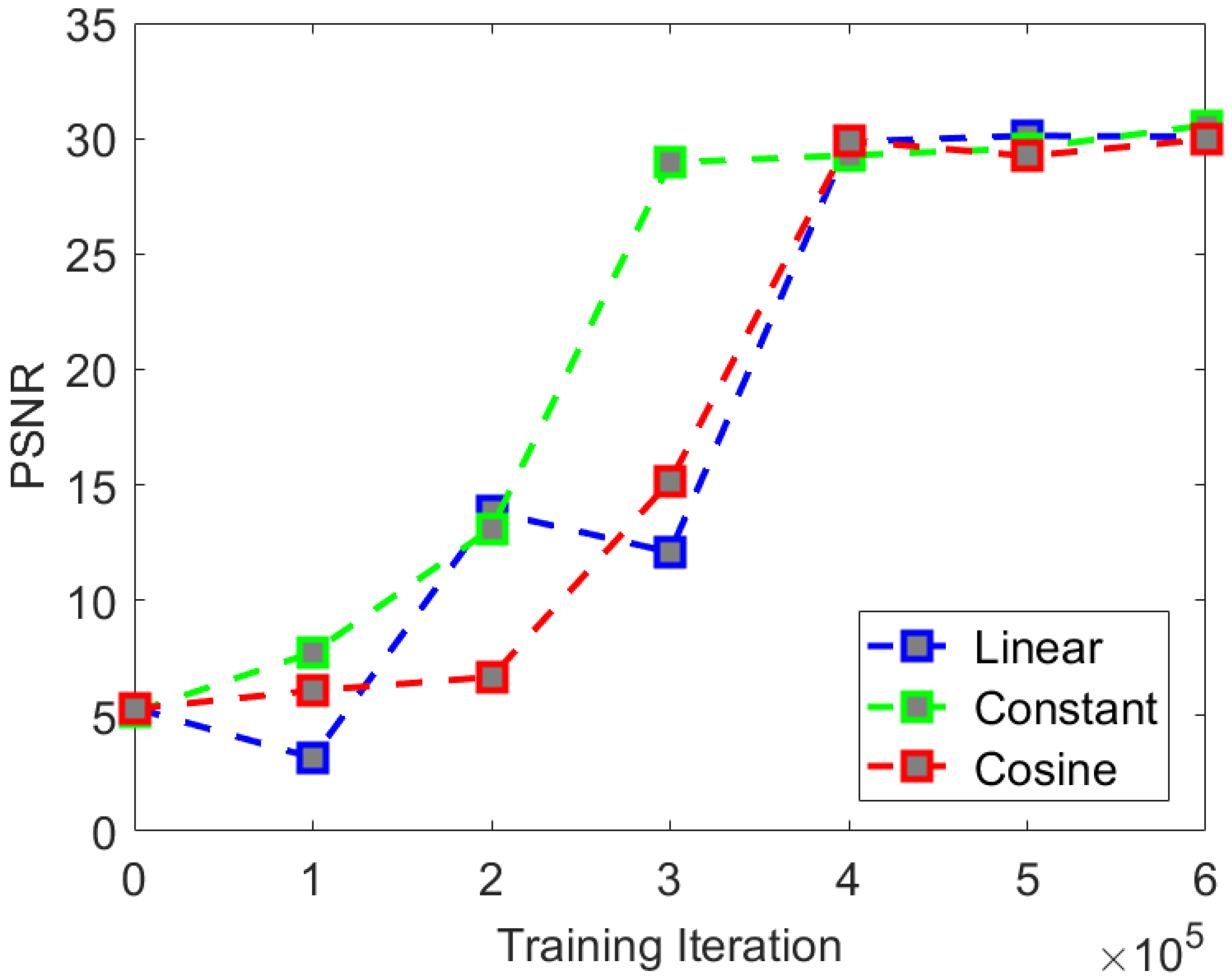
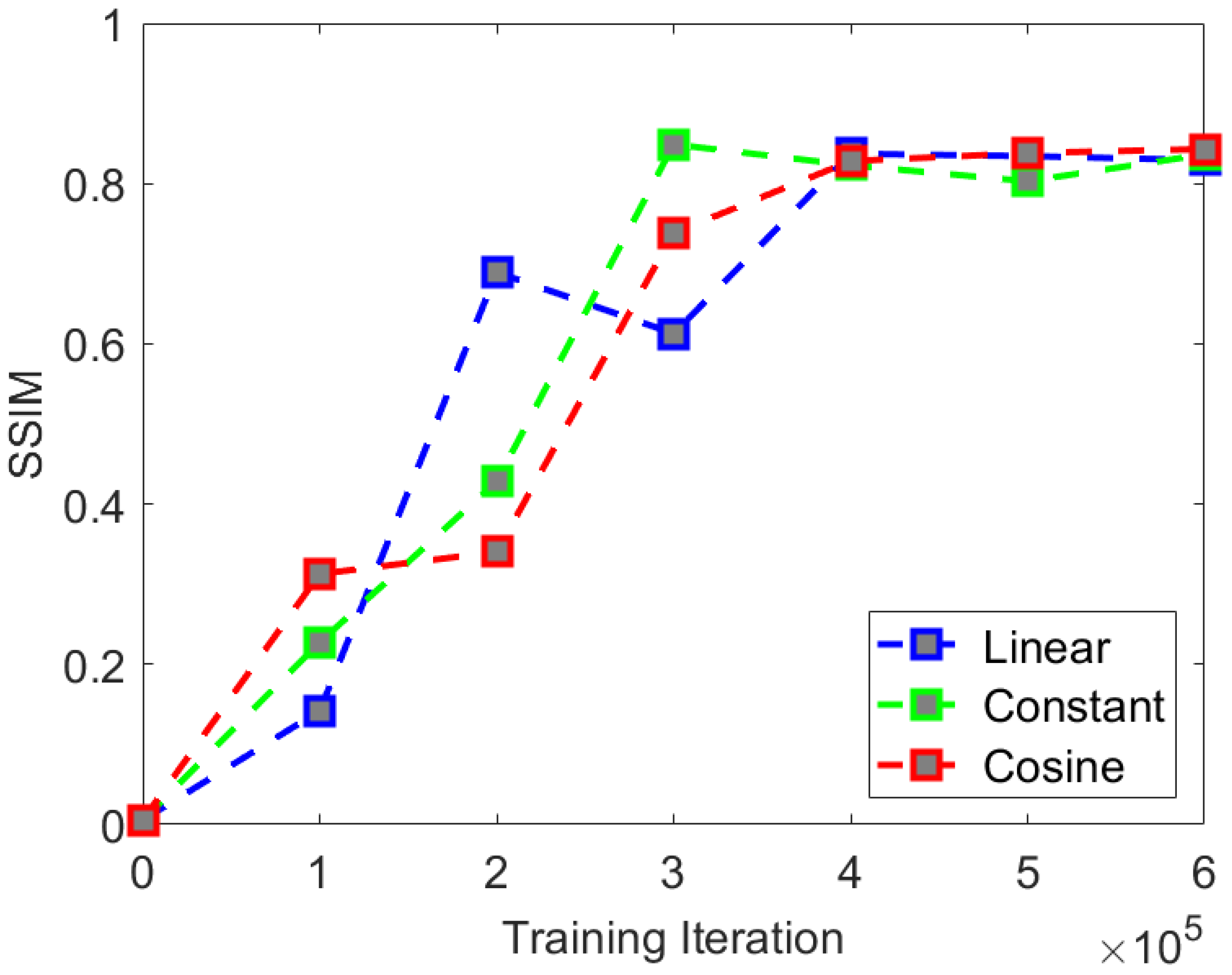
We selected three different noise schedules for comparative experiments. The relationship between linear variance
and iteration rounds
t is as follows:
where
T is the number of iterations;
and
refer to the lower and upper bounds of
;
; and
.
The relationship between constant variance
and iteration round
t is as follows:
where
C is a constant, and
.
The relationship between cosine variance
and iteration number
t is as follows:
where c is a constant and its function is to prevent the denominator from being 0, which can lead to calculation errors.
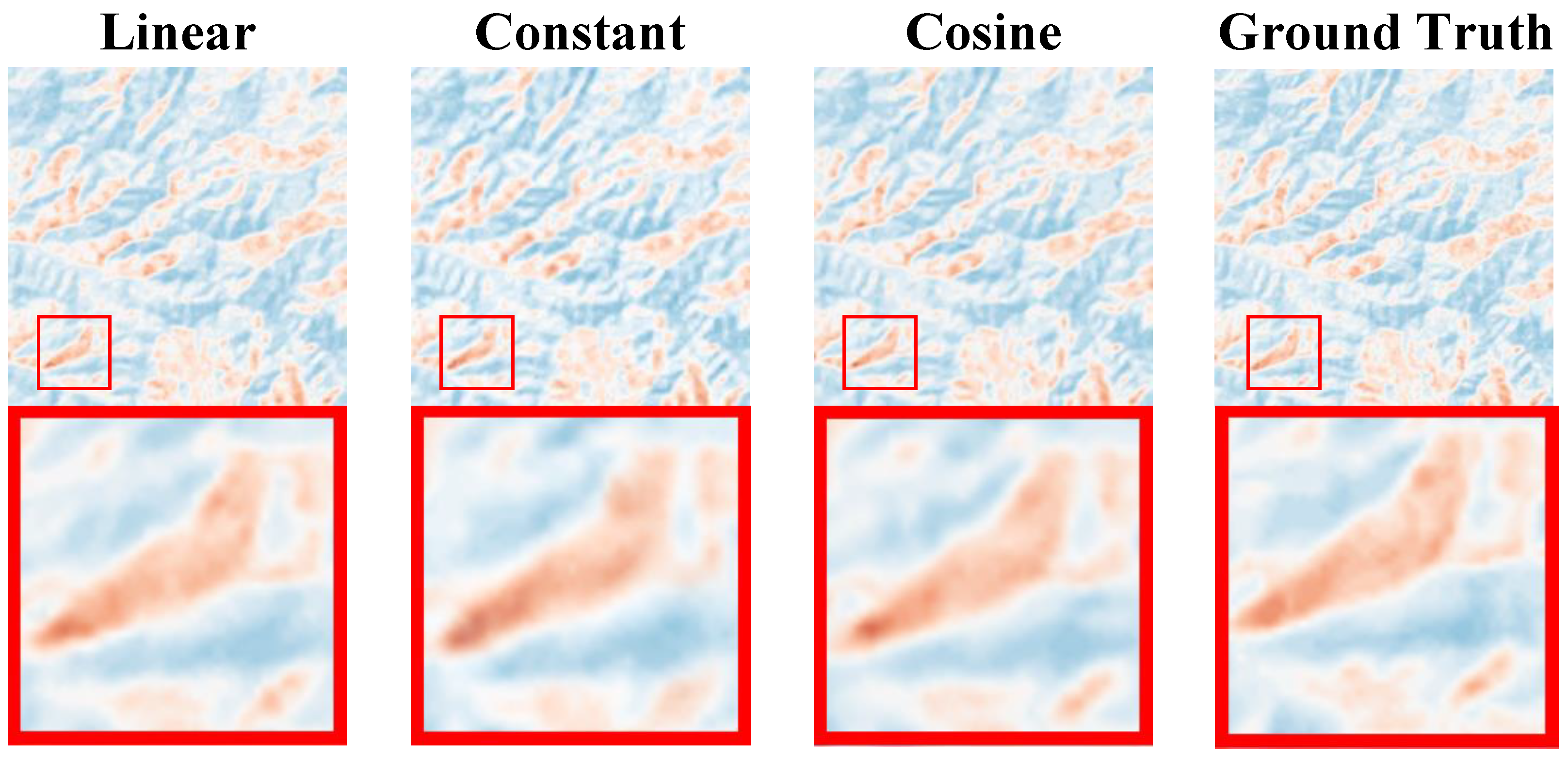
The comparative experimental indices are shown in
Table 6.
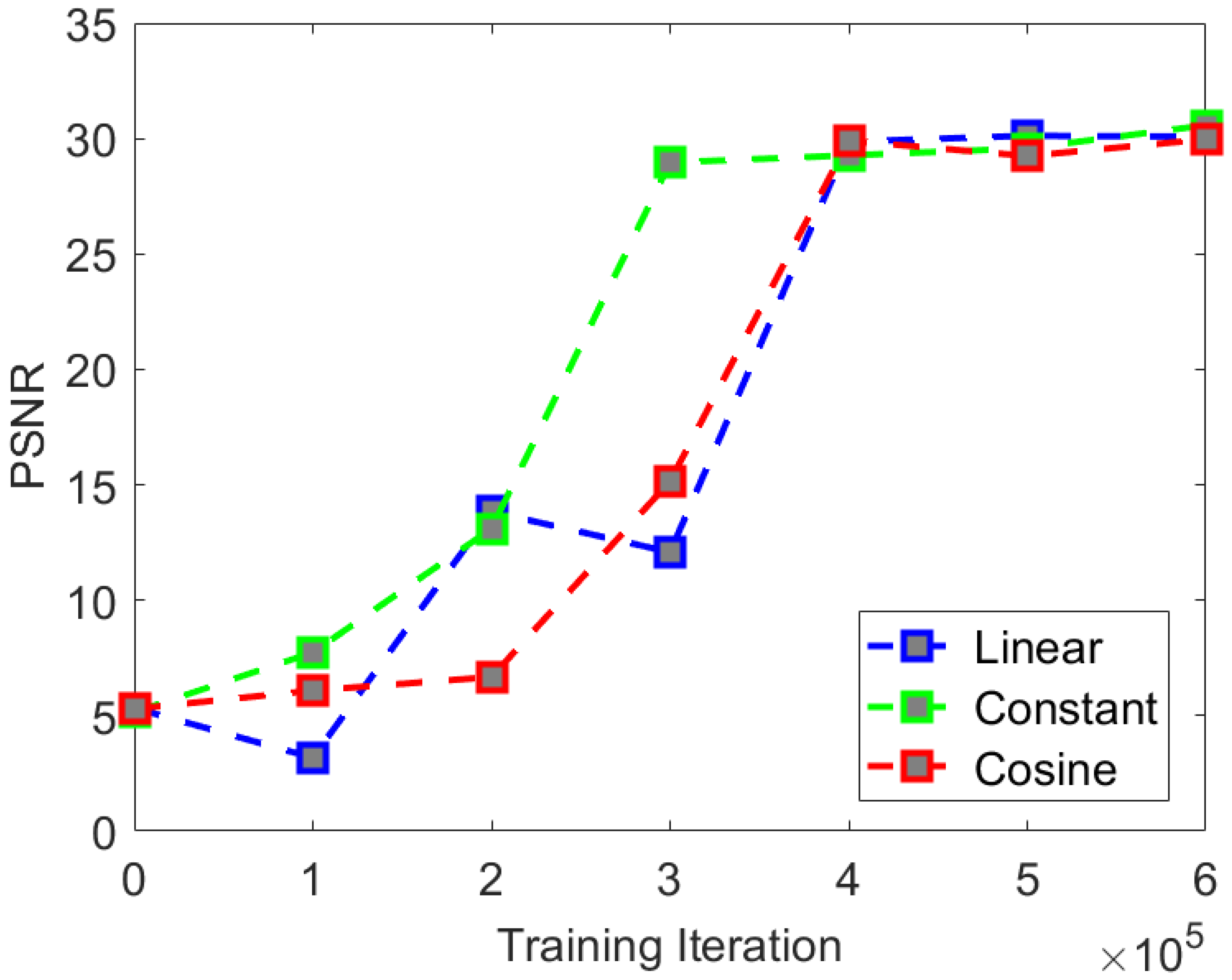
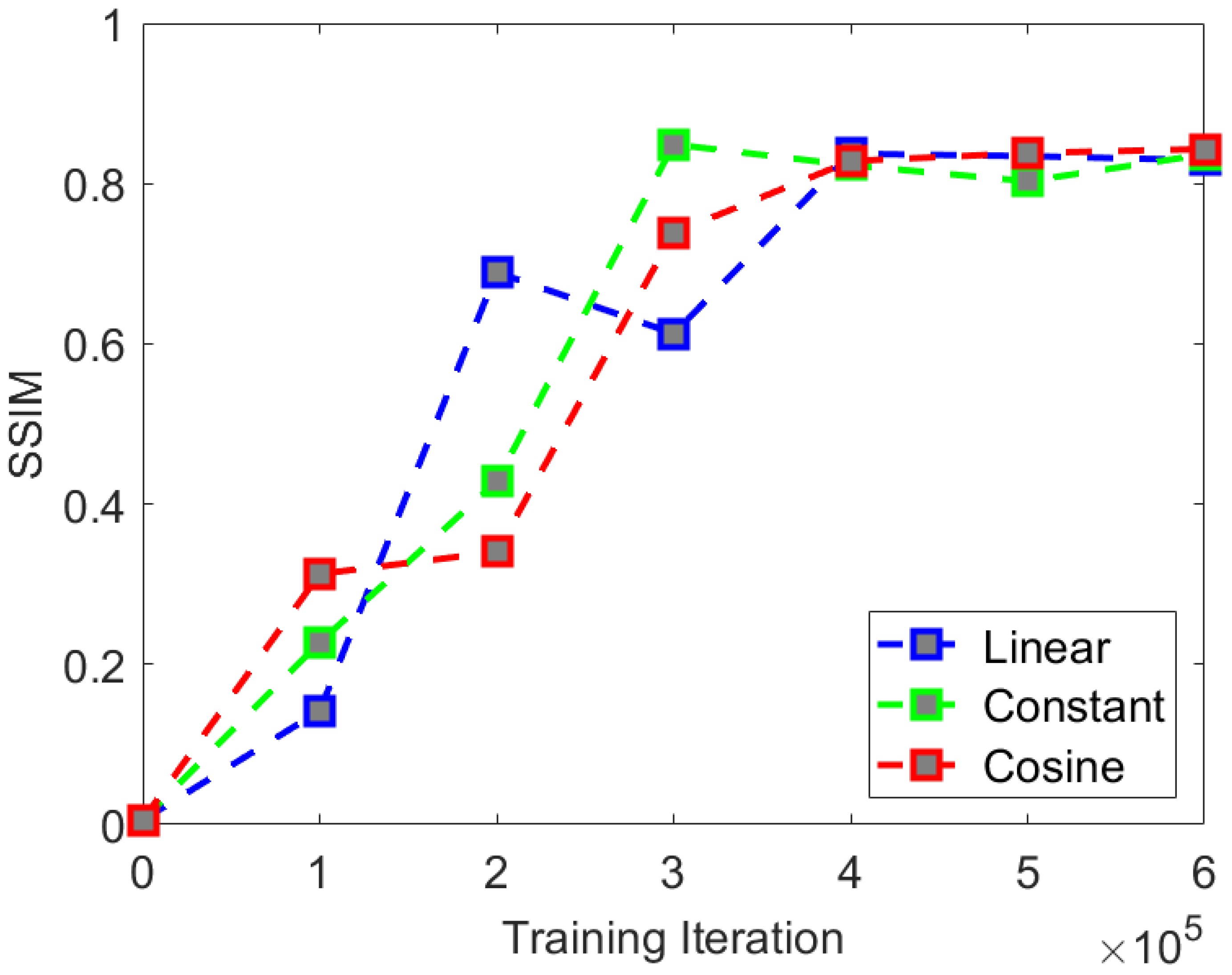
We found that in the comparative experiment, the three types of noise showed little difference in experimental indices. Although both experimental indices were not optimal under cosine noise, there was no significant difference in the visual effect compared to the other two types of noise. The rate of convergence of PSNR and SSIM are shown in
Figure 14 and
Figure 15. The comparison of visual effects is shown in
Figure 16.
We found that in terms of the comparison of the rate of convergence of the experimental indices when using constant noise, the rate of convergence of the PSNR and SSIM indices is the fastest and can achieve a good final convergence effect. Therefore, we believe that the optimal noise selection for the CS-Diffusion method is constant noise.
Through comparative experiments on visual effects, we found that selecting the type of noise has little impact on the visual effects. Therefore, when training the CS-Diffusion model, we can give priority to the constant noise with a faster rate of convergence.
Through the above experiments, it can be found that we can adjust the experimental results by selecting different network parameters and the type of noise used during training. Different network parameters also have a significant impact on the super-resolution time. We also found that as the number of iterations T increases, the super-resolution effect improves. However, when T increases to a certain extent, the effect no longer shows a significant improvement but instead increases the time cost of super-resolution. At the same time, we found that as the depth of the network increases, the experimental effect will also improve but only within a certain range. Beyond this range, it will cause a sharp increase in the time cost of training and testing. In
Section 3.5, a comparative experiment is conducted on the super-resolution time consumption between our model and other existing models.
3.5. Algorithm Time Consumption
Algorithms based on diffusion models are often time-consuming; this is due to the limitations of the diffusion model itself. In super-resolution tasks, the diffusion model needs to undergo T iterations to obtain SR images. Therefore, compared to the number of network parameters, the size of T is a direct factor affecting the algorithm’s time consumption. Our CS-Diffusion method can ensure the super-resolution effect while reducing T. Compared to SR3, we are able to reduce T to 300 without affecting the quality of SR images, greatly reducing the algorithm time consumption. We tested the time (in minutes) required for each model to perform 4× and 8× super-resolution on 182 images of size 224 × 224 in our test set. In
Table 7, we show the time consumption of different models. We found that the models based on diffusion cost more time than the models based on CNN, but they can achieve better visual and indicator effects when dealing with time-insensitive super-resolution tasks, while methods based on diffusion models can achieve better results.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}