
Adaptive and Anti-Drift Motion Constraints for Object Tracking in Satellite Videos


Abstract
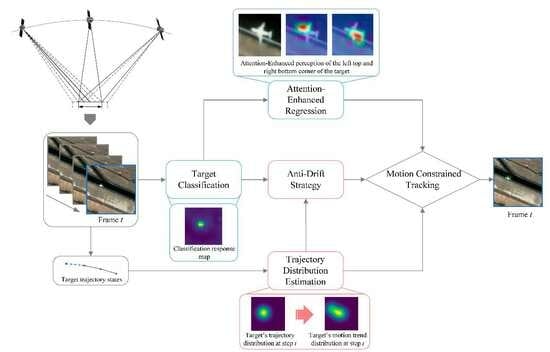
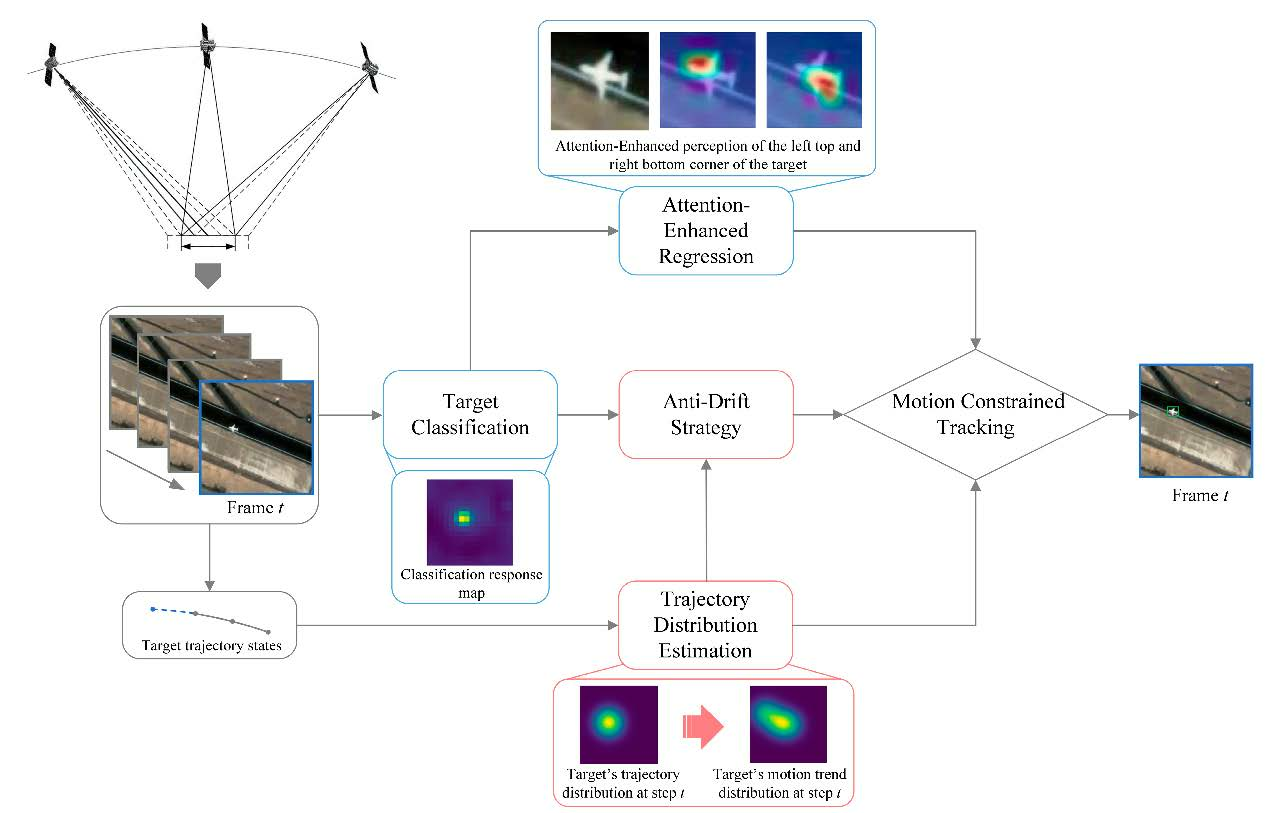
1. Introduction
- We propose an attention-enhanced bounding box regression branch to improve the baseline tracker’s performance in satellite video scenes. Instead of dense sampling proposals, we focus on the regions of interest in the search area and integrate a dual spatial and channel attention mechanism to enhance the tracker’s perception ability of the target.
- We design a learnable motion model based on LSTM to realize trajectory distribution estimation. The model effectively utilizes the historical trajectory of the target to extract short-term motion features for estimating the trajectory as well as the motion trend distribution. It serves to compensate for the common issue of limited appearance features in satellite video scenes.
- We propose an anti-drift module for satellite video single object tracking, which models the difference between the observation distribution and motion trend distribution of the target to detect drift. By incorporating this module, we appropriately introduce motion constraints during the tracking process, effectively solving the drift problem and improving overall tracking performance.
2. Related Literature
2.1. Correlation Filter-Based Object Tracking
2.2. Siamese Network-Based Object Tracking
2.3. Transformer-Based Object Tracking
2.4. Single Object Tracking in Satellite Video
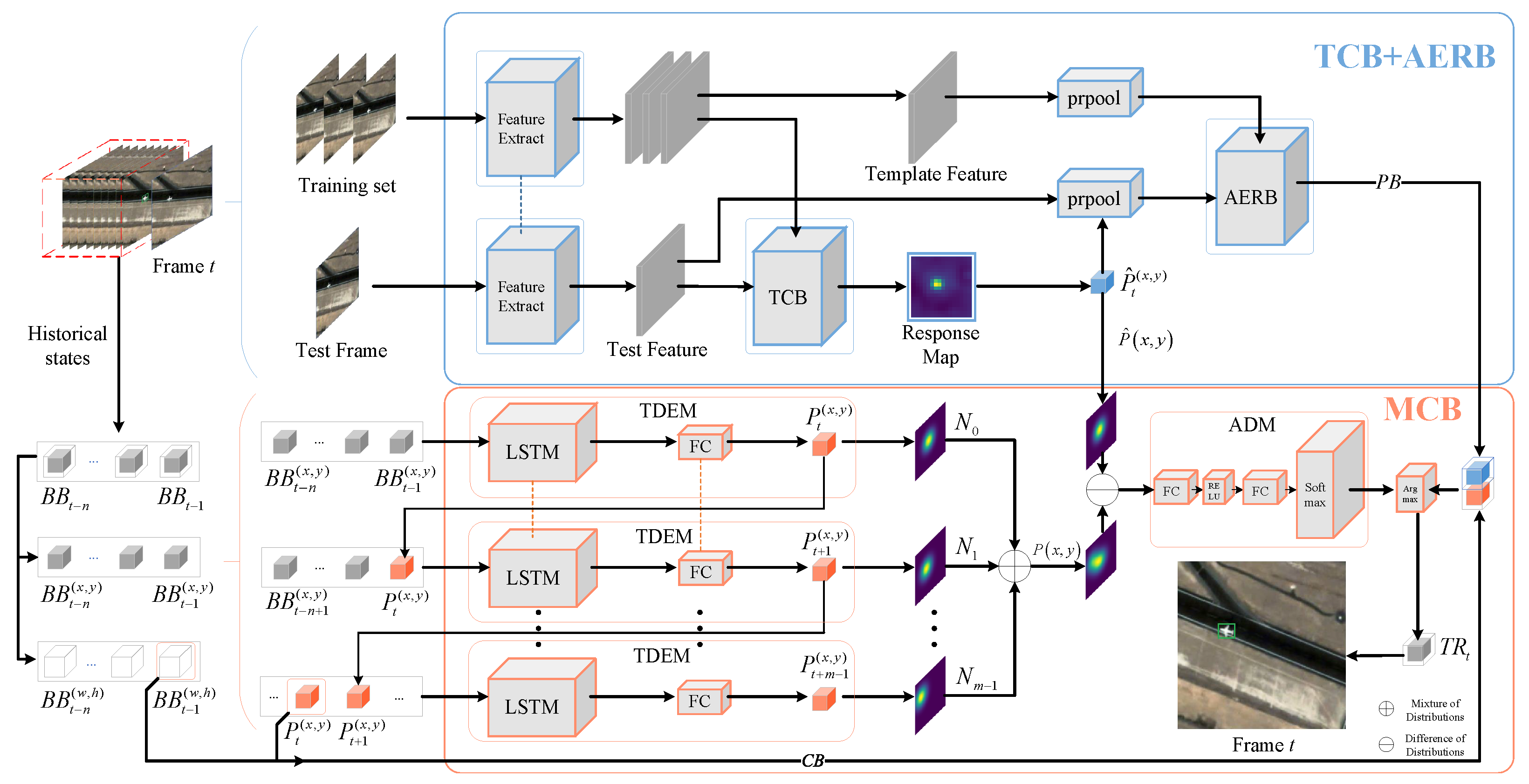
3. Methodology
3.1. Target Classification Branch
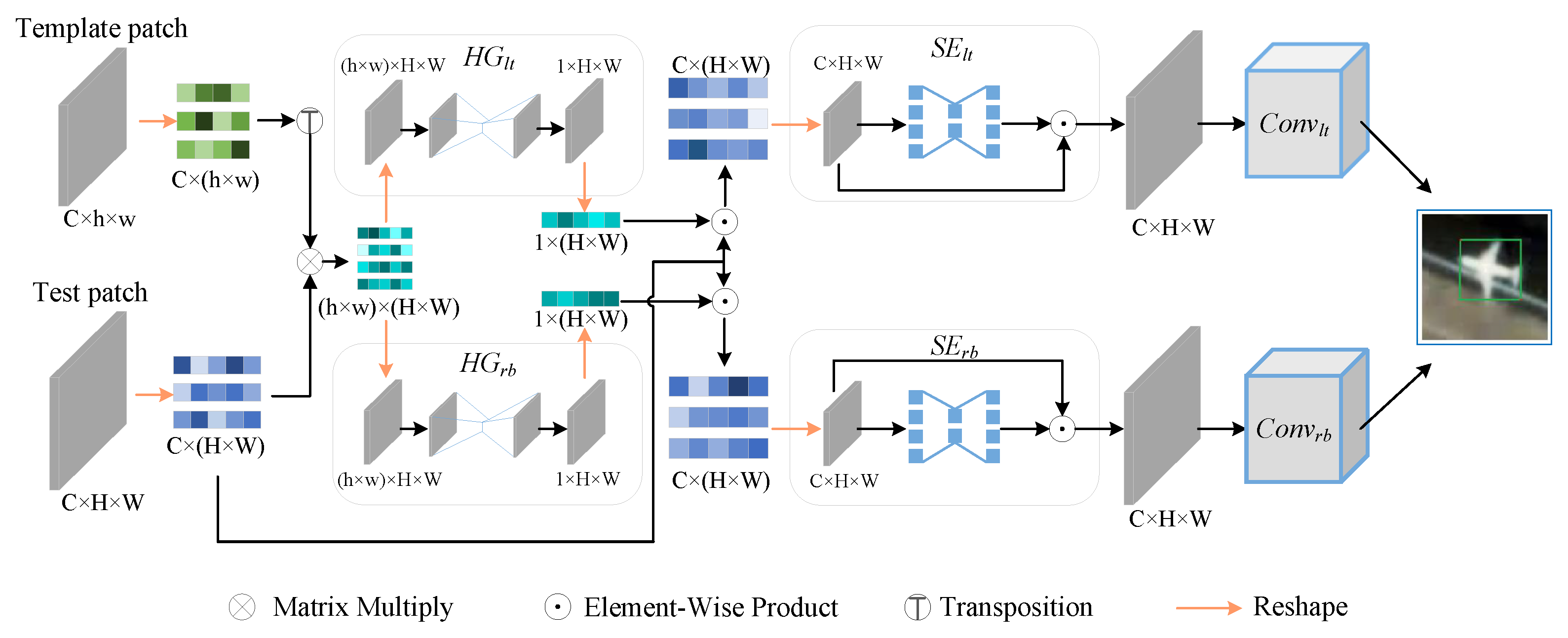
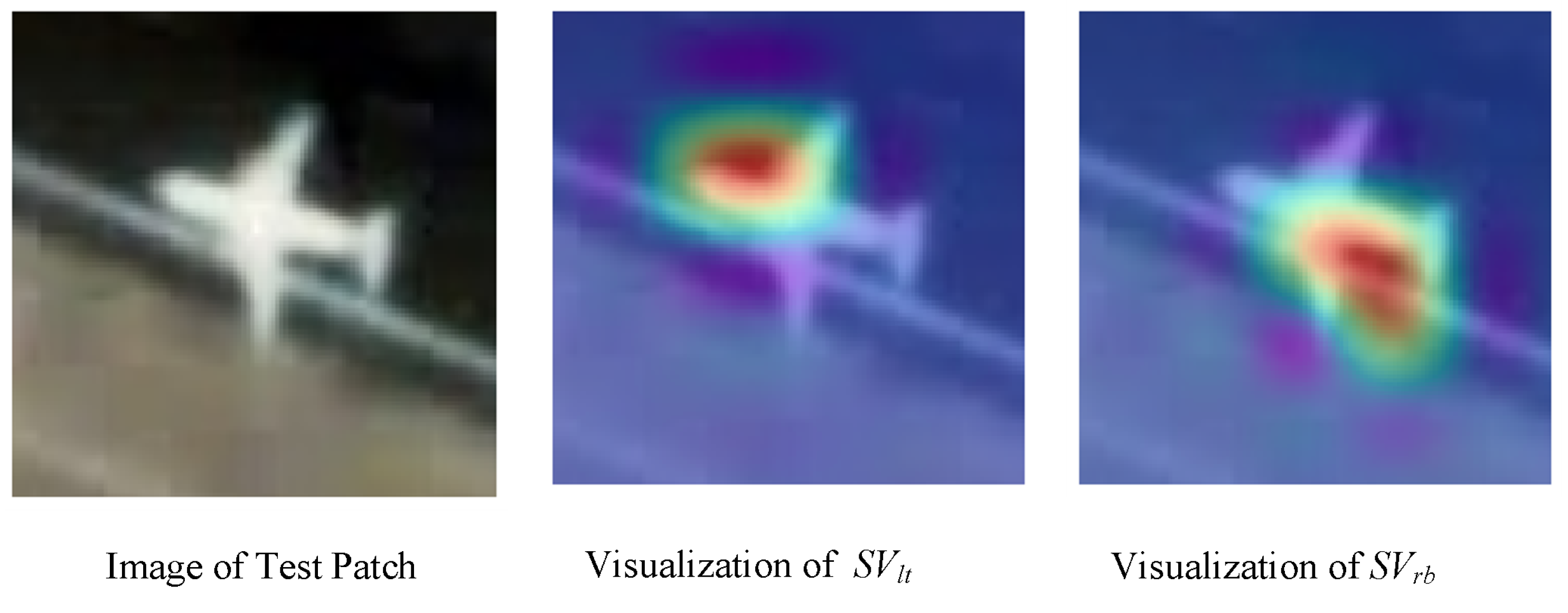
3.2. Attention-Enhanced Regression Branch
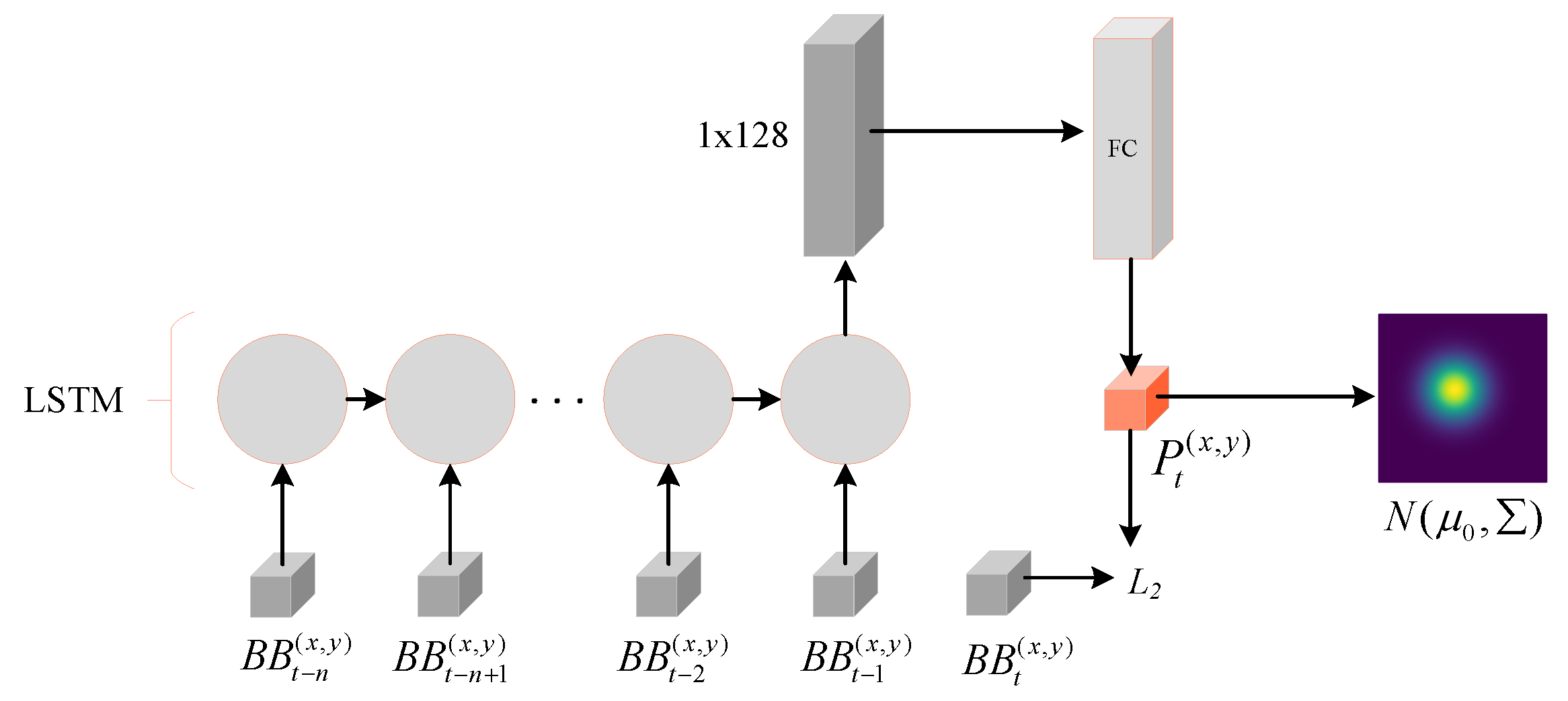
3.3. Trajectory Distribution Estimation Strategy
3.4. Anti-Drift Strategy
| Algorithm 1 The procedure of motion constraint for tracking. |
| Input: : The historical trajectory segment of the target; : The target observation center in Frame t; : The covariance matrix of the trajectory distribution; : The prediction of the target bounding box by the AERB; : The prior information about the bounding box; Output: : The tracking result of Frame t;
|
4. Experiments and Results Analysis
4.1. Experimental Settings
4.1.1. Datasets
4.1.2. Evaluation Metrics
4.1.3. Implementation Details
4.2. Ablation Study
4.2.1. Study on Key Components
4.2.2. Study on Attention-Enhanced Regression Branch
4.2.3. Study on Motion Constraint Branch
4.2.4. Study on Trajectory Distribution Estimation Strategy
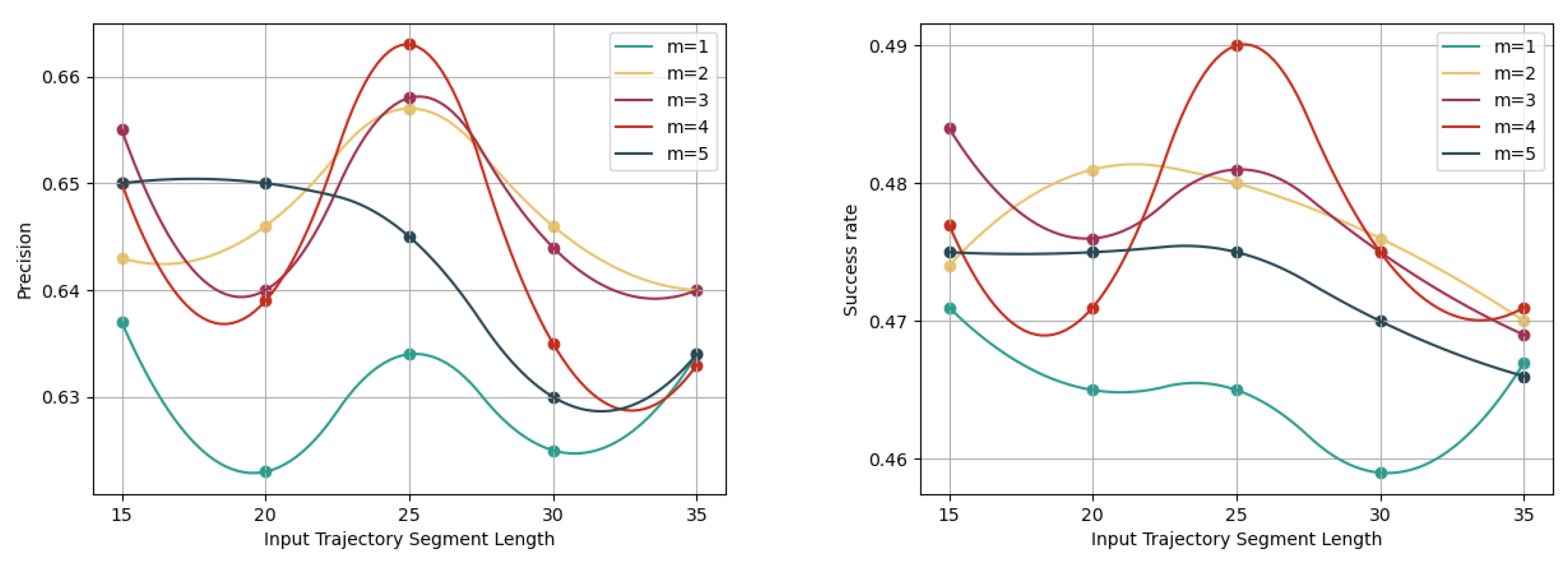
4.2.5. Study on Distribution Hyperparameter
4.3. Results and Analysis
4.3.1. Overall Results
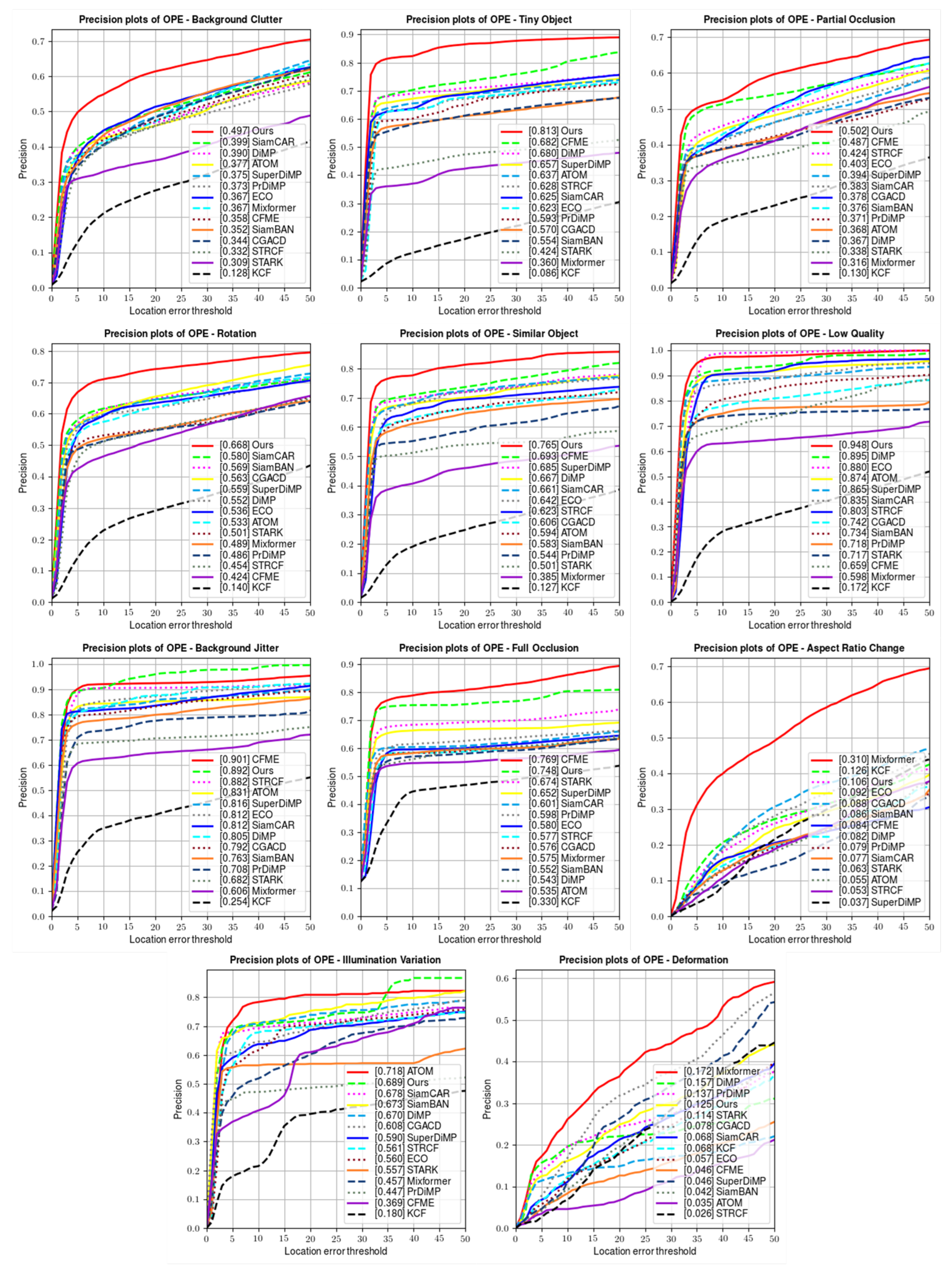
4.3.2. Against Different Challenges
4.3.3. Qualitative Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tsakanikas, V.; Dagiuklas, T. Video surveillance systems-current status and future trends. Comput. Electr. Eng. 2018, 70, 736–753. [Google Scholar] [CrossRef]
- Singha, J.; Roy, A.; Laskar, R.H. Dynamic hand gesture recognition using vision-based approach for human–computer interaction. Neural Comput. Appl. 2018, 29, 1129–1141. [Google Scholar] [CrossRef]
- Grigorescu, S.; Trasnea, B.; Cocias, T.; Macesanu, G. A survey of deep learning techniques for autonomous driving. J. Field Robot. 2020, 37, 362–386. [Google Scholar] [CrossRef]
- Wilson, D.; Alshaabi, T.; Van Oort, C.; Zhang, X.; Nelson, J.; Wshah, S. Object Tracking and Geo-Localization from Street Images. Remote Sens. 2022, 14, 2575. [Google Scholar] [CrossRef]
- d’Angelo, P.; Kuschk, G.; Reinartz, P. Evaluation of Skybox Video and Still Image products. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2014, XL-1, 95–99. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote Sensing Image Scene Classification: Benchmark and State of the Art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Cui, K.; Xiang, J.; Zhang, Y. Mission planning optimization of video satellite for ground multi-object staring imaging. Adv. Space Res. 2018, 61, 1476–1489. [Google Scholar] [CrossRef]
- Xian, Y.; Petrou, Z.I.; Tian, Y.; Meier, W.N. Super-Resolved Fine-Scale Sea Ice Motion Tracking. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5427–5439. [Google Scholar] [CrossRef]
- Melillos, G.; Themistocleous, K.; Papadavid, G.; Agapiou, A.; Prodromou, M.; Michaelides, S.; Hadjimitsis, D.G. Integrated use of field spectroscopy and satellite remote sensing for defence and security applications in Cyprus. In Proceedings of the Conference on Detection and Sensing of Mines, Explosive Objects, and Obscured Targets XXI, Baltimore, MD, USA, 18–21 April 2016. [Google Scholar] [CrossRef]
- Alvarado, S.T.; Fornazari, T.; Cóstola, A.; Morellato, L.P.C.; Silva, T.S.F. Drivers of fire occurrence in a mountainous Brazilian cerrado savanna: Tracking long-term fire regimes using remote sensing. Ecol. Indic. 2017, 78, 270–281. [Google Scholar] [CrossRef]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual object tracking using adaptive correlation filters. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2544–2550. [Google Scholar] [CrossRef]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-Speed Tracking with Kernelized Correlation Filters. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 583–596. [Google Scholar] [CrossRef]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H.S. Fully-Convolutional Siamese Networks for Object Tracking. In Proceedings of the Computer Vision—ECCV 2016 Workshops, Amsterdam, The Netherlands, 8–16 October 2016; pp. 850–865. [Google Scholar] [CrossRef]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. SiamRPN++: Evolution of Siamese Visual Tracking With Very Deep Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4277–4286. [Google Scholar] [CrossRef]
- Yan, B.; Peng, H.; Fu, J.; Wang, D.; Lu, H. Learning Spatio-Temporal Transformer for Visual Tracking. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 10428–10437. [Google Scholar] [CrossRef]
- Cui, Y.; Jiang, C.; Wang, L.; Wu, G. MixFormer: End-to-End Tracking with Iterative Mixed Attention. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 13598–13608. [Google Scholar] [CrossRef]
- Bhat, G.; Danelljan, M.; Van Gool, L.; Timofte, R. Learning Discriminative Model Prediction for Tracking. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6181–6190. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. Exploiting the Circulant Structure of Tracking-by-Detection with Kernels. In Proceedings of the European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; pp. 702–715. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar] [CrossRef]
- Li, Y.; Zhu, J. A Scale Adaptive Kernel Correlation Filter Tracker with Feature Integration. In Proceedings of the Computer Vision—ECCV 2014 Workshops, Zurich, Switzerland, 6–12 September 2015; pp. 254–265. [Google Scholar] [CrossRef]
- van de Weijer, J.; Schmid, C.; Verbeek, J.; Larlus, D. Learning Color Names for Real-World Applications. IEEE Trans. Image Process. 2009, 18, 1512–1523. [Google Scholar] [CrossRef]
- Galoogahi, H.K.; Fagg, A.; Lucey, S. Learning Background-Aware Correlation Filters for Visual Tracking. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1144–1152. [Google Scholar] [CrossRef]
- Danelljan, M.; Robinson, A.; Khan, F.S.; Felsberg, M. Beyond Correlation Filters: Learning Continuous Convolution Operators for Visual Tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 472–488. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar] [CrossRef]
- Danelljan, M.; Bhat, G.; Khan, F.S.; Felsberg, M. ECO: Efficient Convolution Operators for Tracking. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6931–6939. [Google Scholar] [CrossRef]
- Valmadre, J.; Bertinetto, L.; Henriques, J.; Vedaldi, A.; Torr, P.H.S. End-to-End Representation Learning for Correlation Filter Based Tracking. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5000–5008. [Google Scholar] [CrossRef]
- Danelljan, M.; Van Gool, L.; Timofte, R. Probabilistic Regression for Visual Tracking. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 7181–7190. [Google Scholar] [CrossRef]
- Danelljan, M.; Bhat, G.; Mayer, C.; Paul, M. pytracking. Available online: https://github.com/visionml/pytracking (accessed on 21 January 2024).
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High Performance Visual Tracking with Siamese Region Proposal Network. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8971–8980. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Z.; Wang, Q.; Li, B.; Wu, W.; Yan, J.; Hu, W. Distractor-Aware Siamese Networks for Visual Object Tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 103–119. [Google Scholar] [CrossRef]
- Guo, D.; Wang, J.; Cui, Y.; Wang, Z.; Chen, S. SiamCAR: Siamese Fully Convolutional Classification and Regression for Visual Tracking. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 6268–6276. [Google Scholar] [CrossRef]
- Chen, Z.; Zhong, B.; Li, G.; Zhang, S.; Ji, R.; Tang, Z.; Li, X. SiamBAN: Target-Aware Tracking With Siamese Box Adaptive Network. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 5158–5173. [Google Scholar] [CrossRef] [PubMed]
- Du, F.; Liu, P.; Zhao, W.; Tang, X. Correlation-Guided Attention for Corner Detection Based Visual Tracking. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 6835–6844. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Chen, X.; Yan, B.; Zhu, J.; Wang, D.; Yang, X.; Lu, H. Transformer Tracking. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 8122–8131. [Google Scholar] [CrossRef]
- Cao, Z.; Huang, Z.; Pan, L.; Zhang, S.; Liu, Z.; Fu, C. TCTrack: Temporal Contexts for Aerial Tracking. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 14778–14788. [Google Scholar] [CrossRef]
- Du, B.; Sun, Y.; Cai, S.; Wu, C.; Du, Q. Object Tracking in Satellite Videos by Fusing the Kernel Correlation Filter and the Three-Frame-Difference Algorithm. IEEE Geosci. Remote Sens. Lett. 2018, 15, 168–172. [Google Scholar] [CrossRef]
- Liu, Y.; Liao, Y.; Lin, C.; Jia, Y.; Li, Z.; Yang, X. Object Tracking in Satellite Videos Based on Correlation Filter with Multi-Feature Fusion and Motion Trajectory Compensation. Remote Sens. 2022, 14, 777. [Google Scholar] [CrossRef]
- Du, B.; Cai, S.; Wu, C. Object Tracking in Satellite Videos Based on a Multiframe Optical Flow Tracker. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2019, 12, 3043–3055. [Google Scholar] [CrossRef]
- Xuan, S.; Li, S.; Han, M.; Wan, X.; Xia, G.S. Object Tracking in Satellite Videos by Improved Correlation Filters With Motion Estimations. IEEE Trans. Geosci. Remote Sens. 2020, 58, 1074–1086. [Google Scholar] [CrossRef]
- Li, Y.; Bian, C.; Chen, H. Object Tracking in Satellite Videos: Correlation Particle Filter Tracking Method With Motion Estimation by Kalman Filter. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Shao, J.; Du, B.; Wu, C.; Gong, M.; Liu, T. HRSiam: High-Resolution Siamese Network, Towards Space-Borne Satellite Video Tracking. IEEE Trans. Image Process. 2021, 30, 3056–3068. [Google Scholar] [CrossRef]
- Hu, Z.; Yang, D.; Zhang, K.; Chen, Z. Object Tracking in Satellite Videos Based on Convolutional Regression Network With Appearance and Motion Features. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2020, 13, 783–793. [Google Scholar] [CrossRef]
- Yang, J.; Pan, Z.; Wang, Z.; Lei, B.; Hu, Y. SiamMDM: An Adaptive Fusion Network With Dynamic Template for Real-Time Satellite Video Single Object Tracking. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–19. [Google Scholar] [CrossRef]
- Chen, Y.; Tang, Y.; Yin, Z.; Han, T.; Zou, B.; Feng, H. Single Object Tracking in Satellite Videos: A Correlation Filter-Based Dual-Flow Tracker. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2022, 15, 6687–6698. [Google Scholar] [CrossRef]
- Jiang, B.; Luo, R.; Mao, J.; Xiao, T.; Jiang, Y. Acquisition of Localization Confidence for Accurate Object Detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 816–832. [Google Scholar] [CrossRef]
- Newell, A.; Yang, K.; Deng, J. Stacked Hourglass Networks for Human Pose Estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 483–499. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Guo, Y.; Yin, Q.; Hu, Q.; Zhang, F.; Xiao, C.; Zhang, Y.; Wang, H.; Dai, C.; Yang, J.; Zhou, Z.; et al. The First Challenge on Moving Object Detection and Tracking in Satellite Videos: Methods and Results. In Proceedings of the 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 4981–4988. [Google Scholar] [CrossRef]
- Zhao, M.; Li, S.; Xuan, S.; Kou, L.; Gong, S.; Zhou, Z. SatSOT: A Benchmark Dataset for Satellite Video Single Object Tracking. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Wu, Y.; Lim, J.; Yang, M.H. Object Tracking Benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1834–1848. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar] [CrossRef]
- Li, F.; Tian, C.; Zuo, W.; Zhang, L.; Yang, M.H. Learning Spatial-Temporal Regularized Correlation Filters for Visual Tracking. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4904–4913. [Google Scholar] [CrossRef]
- Danelljan, M.; Bhat, G.; Khan, F.S.; Felsberg, M. ATOM: Accurate Tracking by Overlap Maximization. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4655–4664. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute | Definition |
|---|---|
| BC | background clutter: the background has similar appearance to the target |
| IV | illumination variation: the illumination of the target region changes significantly |
| LQ | low quality: the image is in low quality and the target is difficult to be distinguished |
| ROT | rotation: the target rotates in the video |
| POC | partial occlusion: the target is partially occluded in the video |
| FOC | full occlusion: the target is temporally fully occluded in the video |
| TO | tiny object: at least one ground truth bounding box has less than 25 pixels |
| SOB | similar object: there are objects of similar shape or same type around the target |
| BJT | background jitter: background jitter occurs by the shaking of satellite camera |
| DEF | deformation: non-rigid object deformation |
| ARC | aspect ratio change: the ratio of the box aspect ratio of the first and the current frame is outside the range [0.5, 2] |
| Tracker | TCB | AERB | MCB | Prec. (%) | Succ. (%) |
|---|---|---|---|---|---|
| Baseline | ✓ | - | - | 56.7 | 41.9 |
| TCB + AERB | ✓ | ✓ | - | 61.6 | 46.2 |
| TCB + MCB | ✓ | - | ✓ | 60.5 | 42.9 |
| TCB + AERB + MCB | ✓ | ✓ | ✓ | 66.3 | 49.0 |
| Tracker | S | C | Prec. (%) | Succ. (%) |
|---|---|---|---|---|
| TCB + MCB | - | - | 60.5 | 42.9 |
| TCB + MCB + S | ✓ | - | 61.7 | 45.2 |
| TCB + MCB + S + C | ✓ | ✓ | 66.3 | 49.0 |
| Tracker | TDEM | ADM | Prec. (%) | Succ. (%) |
|---|---|---|---|---|
| TCB + AERB | - | - | 61.6 | 46.2 |
| TCB + AERB + TDEM/0.1 | ✓ | - | 60.9 | 45.6 |
| TCB + AERB + TDEM/0.2 | ✓ | - | 61.3 | 45.9 |
| TCB + AERB + TDEM/0.3 | ✓ | - | 63.5 | 47.2 |
| TCB + AERB + TDEM/0.4 | ✓ | - | 62.2 | 46.3 |
| TCB + AERB + MCB | ✓ | ✓ | 66.3 | 49.0 |
| Prec. (%) | Succ. (%) | FPS | |
|---|---|---|---|
| 0.07 | 65.8 | 48.3 | 25.29 |
| 0.06 | 64.6 | 47.6 | 25.49 |
| 0.05 | 66.3 | 49.0 | 25.05 |
| 0.04 | 63.9 | 47.2 | 24.85 |
| 0.03 | 64.1 | 47.4 | 24.84 |
| Tracker | Method | Feature | SatSOT | SatVideoDT | ||
|---|---|---|---|---|---|---|
| Prec. (%) | Succ.(%) | Prec. (%) | Succ. (%) | |||
| KCF | CF | HOG | 21.5 | 22.2 | 8.7 | 3.2 |
| STRCF | CF | HOG | 52.3 | 36.8 | 56.1 | 20.6 |
| ECO | CF | CNN | 55.2 | 36.8 | 44.8 | 15.0 |
| CFME | CF | HOG | 54.6 | 41.8 | 35.6 | 19.0 |
| ATOM | DCF | CNN | 55.6 | 39.4 | 40.9 | 19.0 |
| DiMP | DCF | CNN | 56.7 | 41.9 | 52.9 | 26.2 |
| PrDiMP | DCF | CNN | 49.8 | 35.8 | 44.0 | 20.6 |
| SuperDiMP | DCF | CNN | 57.3 | 42.6 | 54.2 | 27.6 |
| SiamBAN | SN | CNN | 57.2 | 41.6 | 50.5 | 23.8 |
| SiamCAR | SN | CNN | 58.6 | 43.2 | 52.8 | 26.4 |
| CGACD | SN | CNN | 56.5 | 42.2 | 38.1 | 16.4 |
| STARK | TF | CNN | 51.1 | 36.6 | 47.4 | 25.0 |
| Mixformer | TF | TF | 54.0 | 43.6 | 51.9 | 27.7 |
| Ours | DCF | CNN | 66.3 | 49.0 | 60.9 | 32.6 |
| Video Name | Challenge Attributes |
|---|---|
| Car_24 | FOC, POC, ROT |
| Car_34 | FOC, TO, SOB, ROT, BC |
| Car_40 | TO, POC, ROT, BC |
| Car_53 | SOB, TO |
| Plane_09 | ROT |
| Train_08 | BC, ARC |
| Train_01 | BC, DEF, ARC, ROT |
| Car_50 | BC, ROT, LQ, POC, SOB |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, J.; Ji, S. Adaptive and Anti-Drift Motion Constraints for Object Tracking in Satellite Videos. Remote Sens. 2024, 16, 1347. https://doi.org/10.3390/rs16081347
Fan J, Ji S. Adaptive and Anti-Drift Motion Constraints for Object Tracking in Satellite Videos. Remote Sensing. 2024; 16(8):1347. https://doi.org/10.3390/rs16081347
Chicago/Turabian StyleFan, Junyu, and Shunping Ji. 2024. "Adaptive and Anti-Drift Motion Constraints for Object Tracking in Satellite Videos" Remote Sensing 16, no. 8: 1347. https://doi.org/10.3390/rs16081347
APA StyleFan, J., & Ji, S. (2024). Adaptive and Anti-Drift Motion Constraints for Object Tracking in Satellite Videos. Remote Sensing, 16(8), 1347. https://doi.org/10.3390/rs16081347