
Estimating Carbon Dioxide Emissions from Power Plant Water Vapor Plumes Using Satellite Imagery and Machine Learning

 , , , , ,
, , , , ,
Abstract
1. Introduction
2. Background
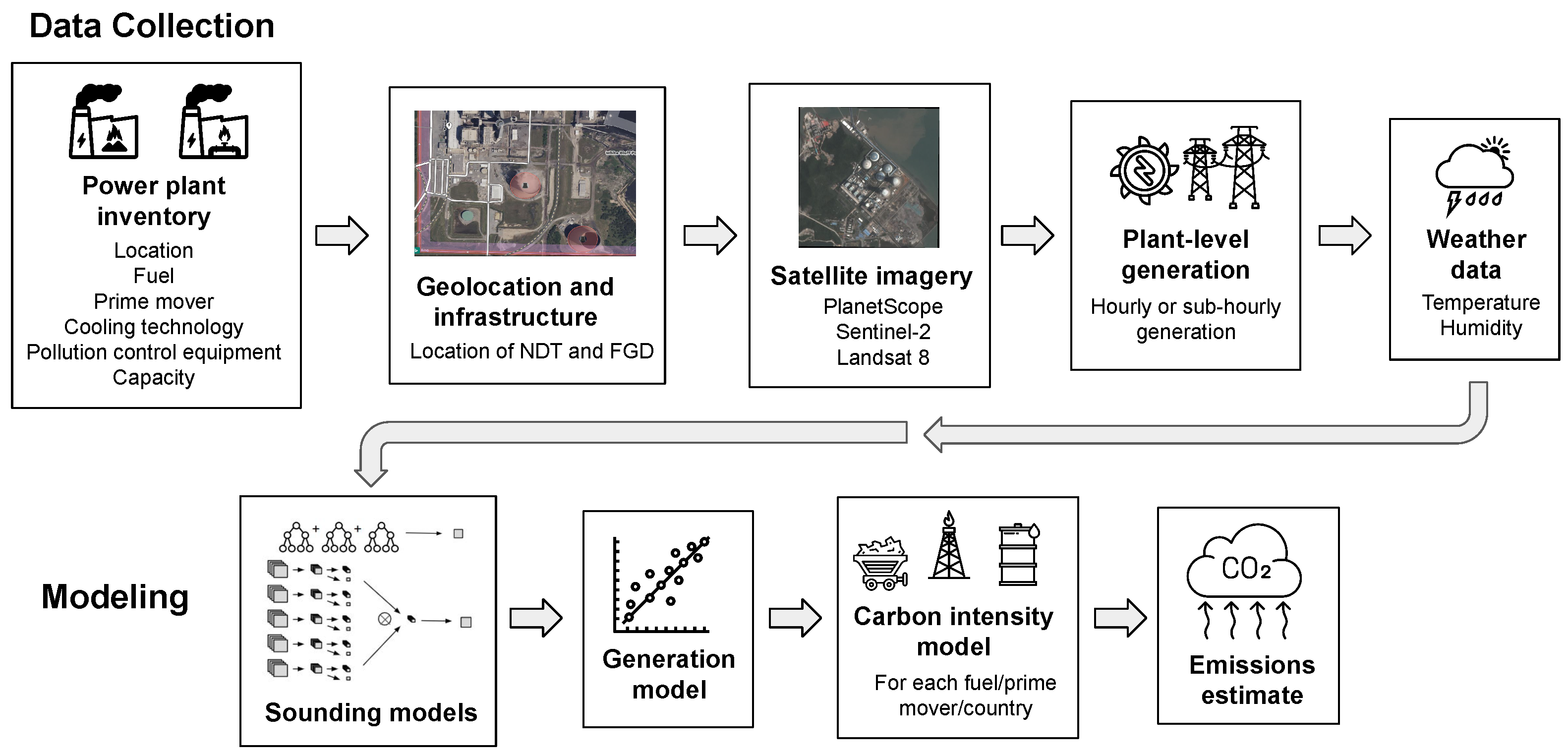
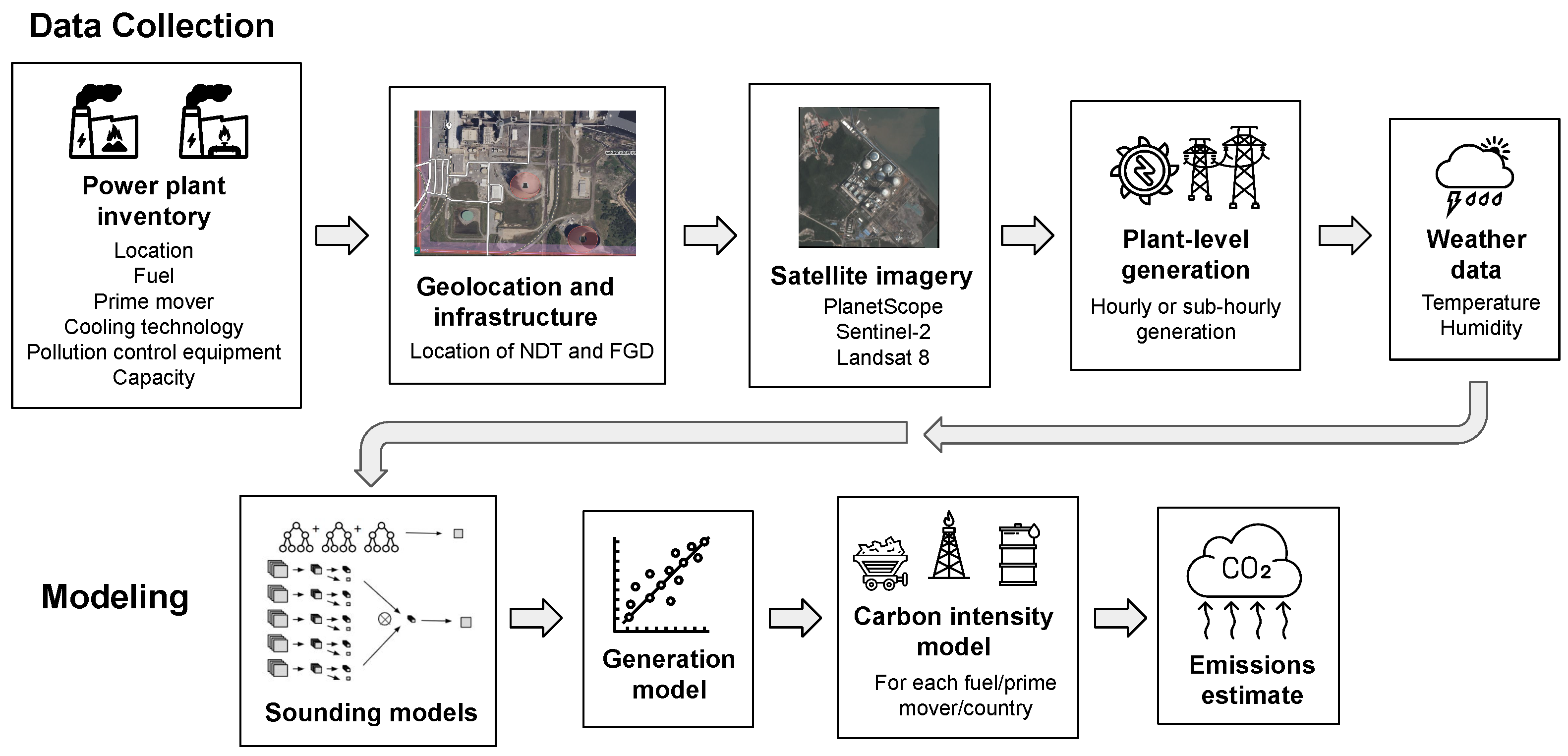
3. Materials and Methods
- Natural draft cooling towers (NDT): Plants using NDT have a large hyperbolic structure that allows vapor plumes to form during evaporative cooling.
- Wet flue gas desulfurization (FGD): After desulfurization, flue gases become saturated with water, increasing the visibility of plumes from the flue stack.
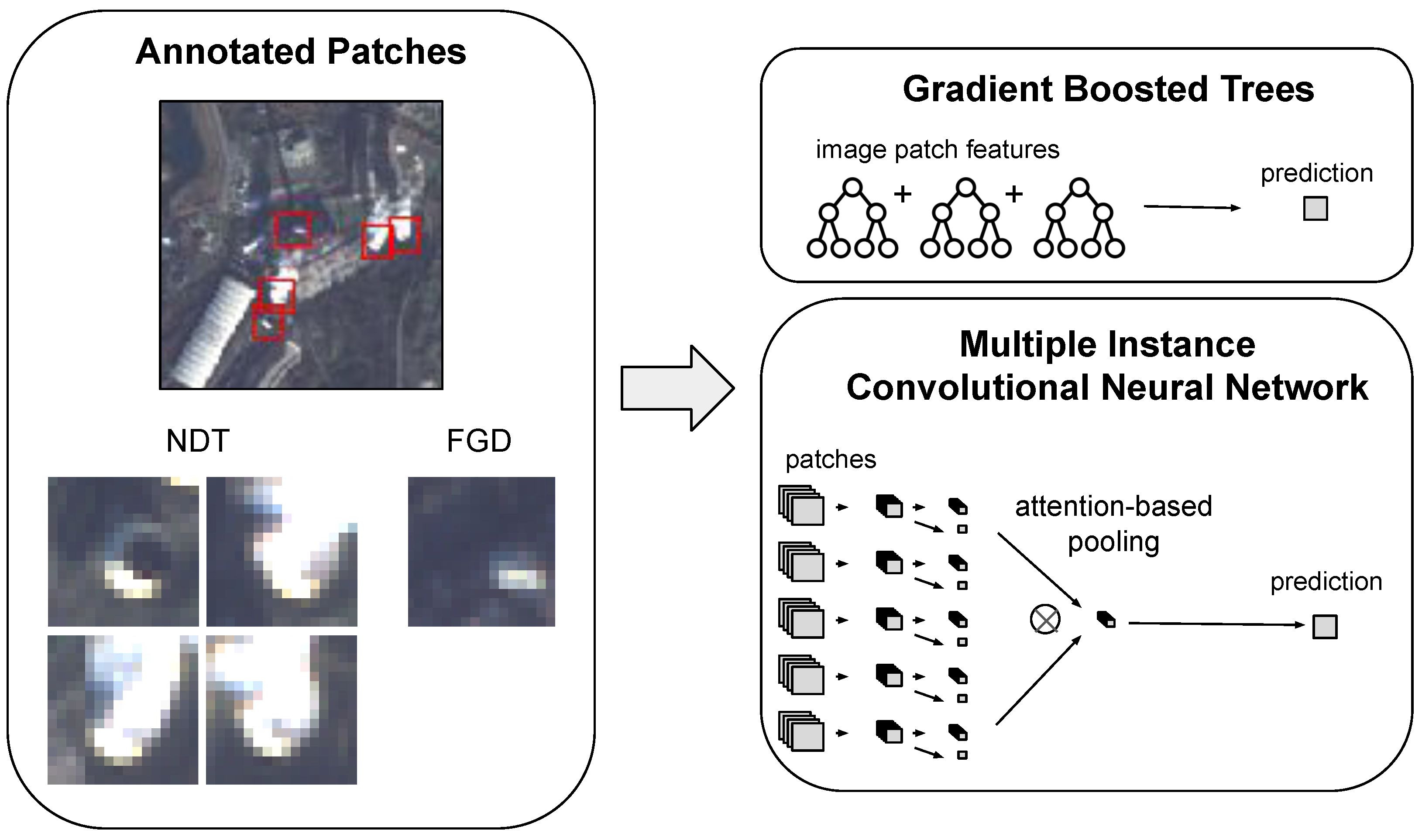
- In terms of size, NDT plumes are generally larger and wider than FGD plumes, making them easier to see in multi-spectral satellite imagery, as shown in Figure 1. A power plant may have one, both, or neither of these technologies. Due to the differing plume sizes and shapes from their sources, we created separate NDT and FGD models.
- Sounding-level models: consist of (A) a classification model to classify whether a plant was running or not (on/off), and (B) a regression model to predict the capacity factor (i.e., what proportion of the power plant’s generation capacity was being used to generate power, generally between 0 and 1), for a given a satellite image of that plant at a certain point in time.
- Generation models: aggregate the predictions from the sounding-level models into the estimates of a power plant capacity factor over the preceding 30 days.
3.1. Power Plant Datasets
- An accurate plant location for our satellite imagery.
- The location of FGD flue stacks and NDT cooling towers to focus our models on the relevant signals.
- Attributes of the power plant, including type, fuel, cooling technology, and air pollution control equipment to identify whether the plant is suitable for our models.
- Local weather data to decide whether temperature and humidity are conducive to vapor plume visibility.
- Plant capacity to determine whether the plant is of sufficient size to be modeled and to calculate the generation from the modeled capacity factor. This is used in conjunction with unit operating dates to find the plant capacity on any given date.
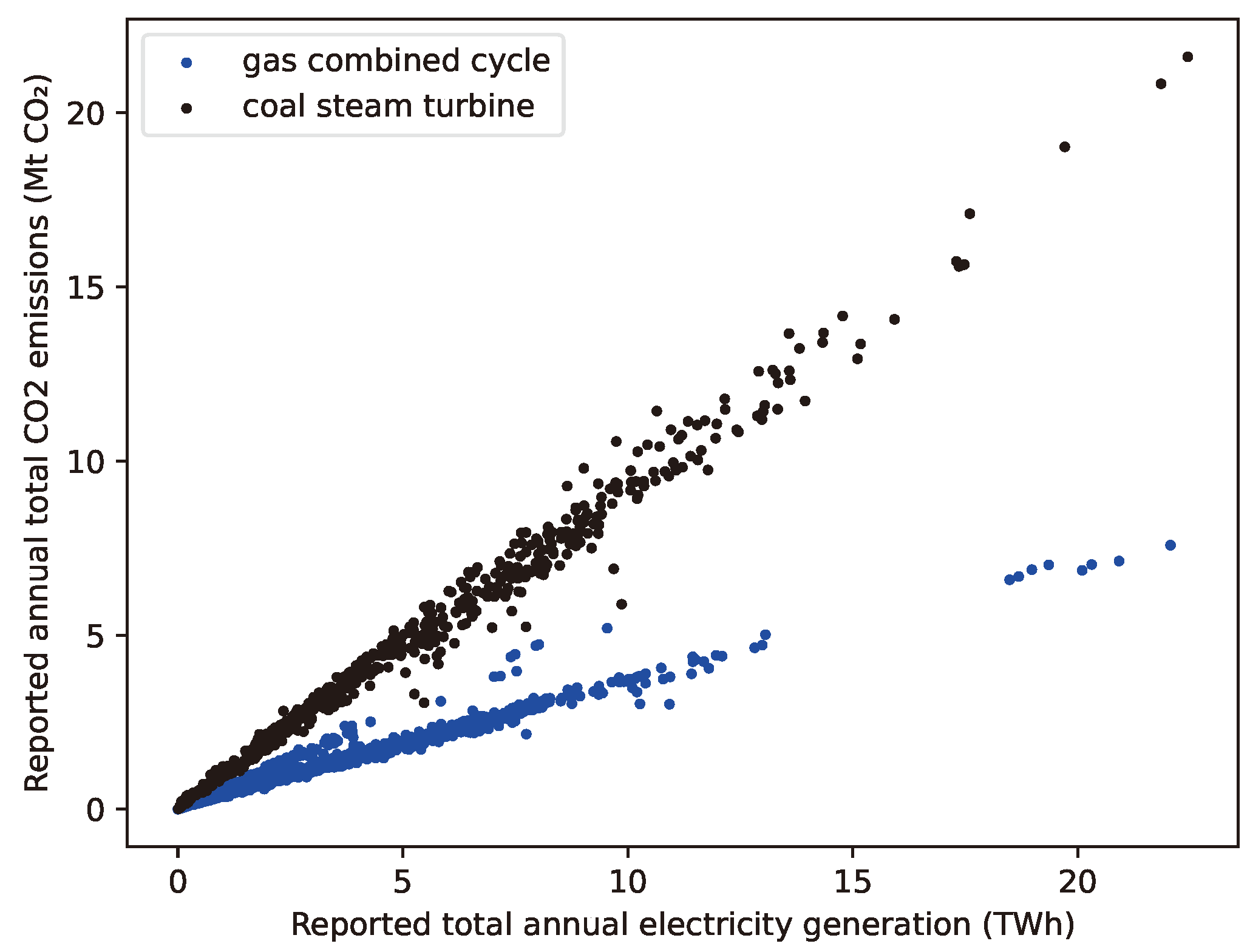
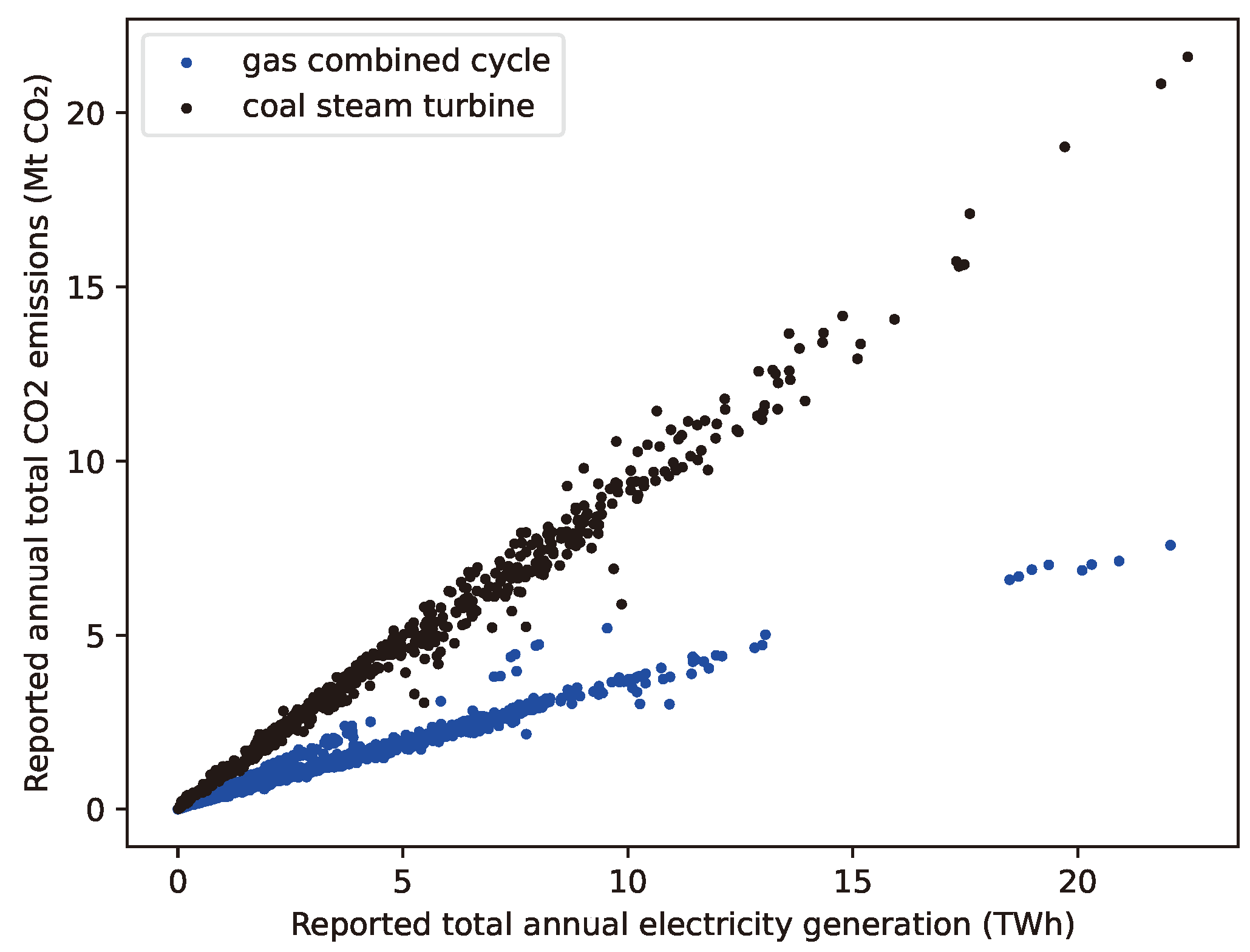
- Fuel and prime mover (i.e., steam or gas turbine) type to estimate the emissions factor.
3.2. Satellite Data and Processing
- Haze-optimized transformation (HOT), a linear combination of the blue and red bands:
- Whiteness [44], which consists of:where
- Normalized difference vegetation index (NDVI), a ratio between the red and near-infrared (NIR) bands,
- Normalized difference shortwave infrared, a ratio between the shortwave infrared (SWIR) bands,
- Normalized difference thermal infrared, a ratio between the shortwave infrared (TIR) bands,
3.3. Ground Truth Labels for Model Training
3.4. Plant and Image Selection
- Plant selection. The first set of filters was based on the capacity of the plant and whether it was using mostly NDT or FGD technology at the time:
- Coal must account for at least 50% of the plant’s operating capacity.
- For NDT models, ≥70% of the plant’s cooling was NDT.
- For FGD models, ≥90% of total generation and 100% of coal capacity was associated with wet FGD.
- At least one NDT tower or FGD-enabled flue stack has been annotated in OpenStreetMap or in our in-house annotations database.
- Capacity must be at least 500 MW.
- Exclude from training any plants with incomplete or erroneous generation and/or retirement date, for example, failure to report generation for operating units, reporting generation several months past retirement, or insufficient or inconsistently reported generation data. This criterion is applicable to training only.
- Because our modeling approach assumes that plants with wet FGD always run their pollution controls, we removed from training any operational plants that repeatedly exhibited sporadic or no visible FGD usage when the plant was reported “on”. For inference, this is harder to assess in the absence of reported generation data. We flagged operational plants with FGD where FGD plumes were never detected under the expected plume-favorable weather conditions (detailed later in this section) by our classification models, nor observed upon the manual inspection of 100 random images. We also flagged plants that exhibited other signals of operating (i.e., NDT plumes) with no FGD signal. There are two primary reasons for which an operational plant may fail to exhibit an FGD vapor plume signal when generating electricity under the appropriate temperature and humidity conditions:
- –
- Our power plant database has incorrect information suggesting that the power plant has a “wet” process when it is actually “dry”. This is possible for both NDT and FGD as either can be a “wet” or “dry” process; generally “dry” is more common in arid climates to conserve water.
- –
- The power plant fails to run its SOx pollution control equipment (the flue gas desulfurization, FGD), so there is no FGD plume. Note that this is only relevant for FGD plumes, not NDT, because some type of cooling is necessary to operate a power plant, whereas pollution controls are not strictly necessary to operate (rather, they represent additional requirements set by clean air regulations).
For inference on NDT plants, these criteria were relaxed by applying our models to all the plants that met the following criteria every year: a total capacity of at least 50 MW and any positive amount of NDT capacity, regardless of fuel type. Despite the loosened criteria, the vast majority of plants in our external validation sets for both electricity generation and emissions burn >50% coal. - Image selection. We also filtered based on the characteristics of each satellite image:
- Our FGD and NDT annotations are fully contained within the satellite image.
- The cloud mask over the plant indicated <20% cloud coverage. This threshold is set relatively high to avoid falsely excluding images containing large plumes, which are easily misclassified as clouds.
- For PlanetScope, we used the post-2018 UDM2 bands to keep only images with <80% heavy haze.
- For all PlanetScope images, we calculated the mean brightness and developed a cloudiness score based on HOT, whiteness, and NDVI, respectively, to filter out excessively dark or cloudy images.
- Images with known data quality issues were discarded, e.g., exhibiting plumes when generation has been zero for at least an hour. Appendix A.4 details the scenarios in which we excluded images due to quality issues.
- When there were images of the same location with the same timestamp, we kept a single copy, breaking ties with the following: (1) largest area surrounding the plant contained; (2) least cloudy area; (3) latest download timestamp; and (4) random selection.
- Weather filters. Ambient temperature and relative humidity were obtained for each plant as detailed in Appendix A.3. Images were excluded from FGD models when ambient weather conditions were unfavorable for plume visibility. At high temperatures and/or low relative humidity, the water vapor in the flue stack does not readily condense, plume visibility is reduced, and our models have no signal to detect. The warmer the temperature, the more humid it needs to be for water vapor plumes to be visible, eventually becoming very faint at high temperatures regardless of the humidity. At colder temperatures, however, even very dry conditions will still result in a visible plume. Therefore, we used empirically derived cutoff rules for plume visibility:
- Exclude images in which the ambient temperature is ≥14 °C and relative humidity is ≤26%.
- Exclude images in which the ambient temperature is ≥24 °C and relative humidity is ≤36%.
- Exclude images in which the ambient temperature is ≥32 °C.
3.5. Sounding Models
3.5.1. Gradient-Boosted Decision Trees
3.5.2. Convolutional Neural Networks
- RESISC: a ResNet50 CNN [45] pre-trained on the RESISC dataset, which consists of aerial RGB images labeled by land cover and scene classes [46]. The RESISC dataset is particularly relevant because it includes a cloud class, enabling the model to capture distinguishing features of clouds—and, likely, plumes. This model uses the RGB channels only.
- BigEarthNet: with a VGG16 CNN [47] pre-trained on the BigEarthNet dataset, which consists of Sentinel-2 images labeled by land cover class [48]. This model uses 10 bands from Sentinel-2, excluding the lowest resolution bands of 1, 9, and 10. We were not able to apply this model to PlanetScope but did adapt it for Landsat 8 by matching the band wavelengths as closely as possible and pairing the remaining bands even if the wavelengths are different. While this dataset enabled the model to learn a more diverse set of spectral characteristics, it only contained cloud-free images; our model must learn plume features during fine-tuning.
3.6. Generation Ensemble Models
3.7. Emissions Estimation
3.8. Model Training with Cross-Validation
3.9. Model Inference
4. Results
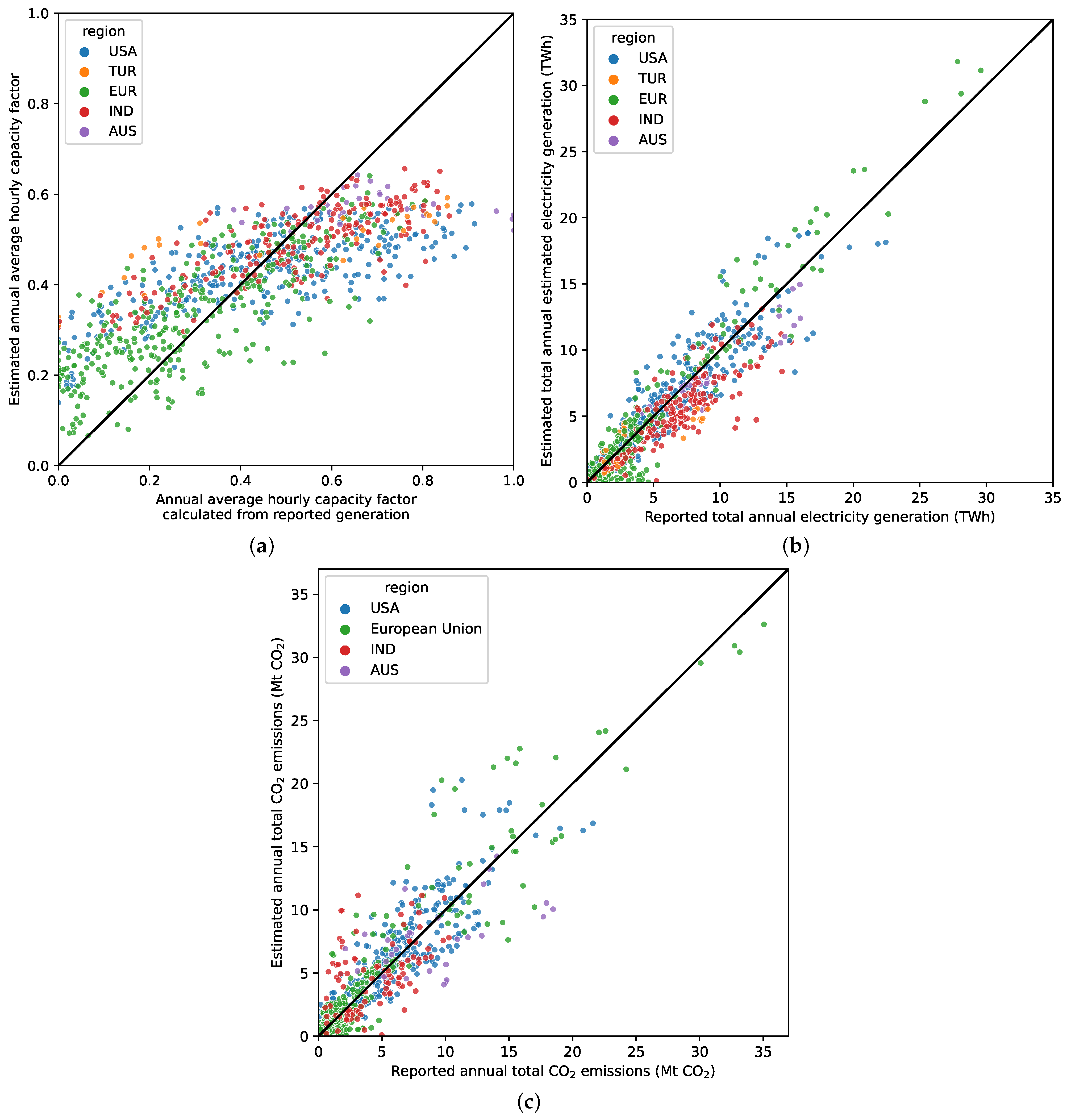
4.1. Sounding Model Validation
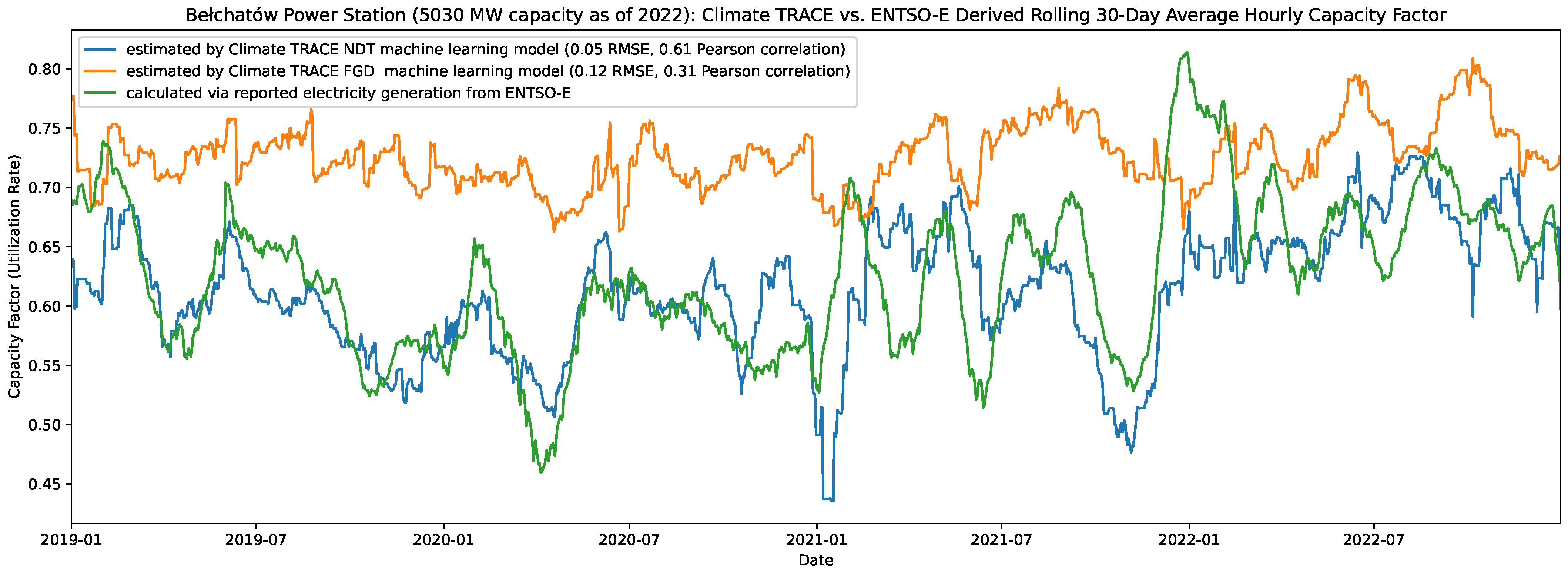
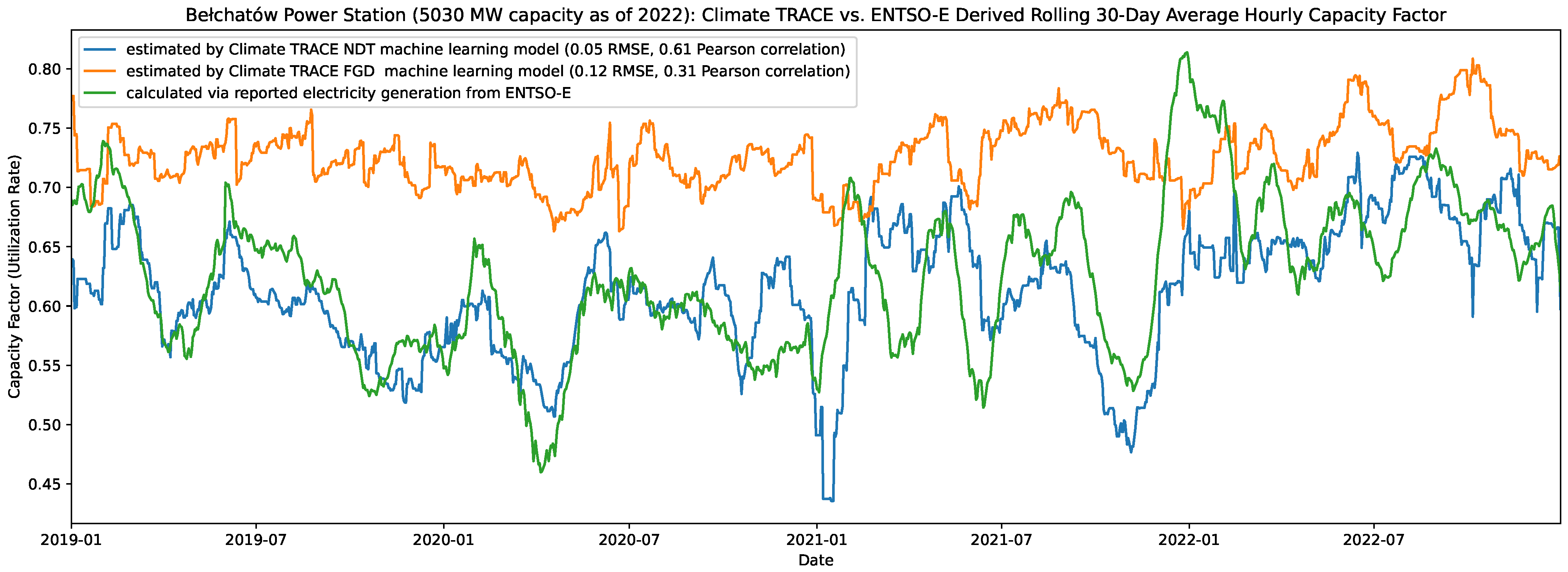
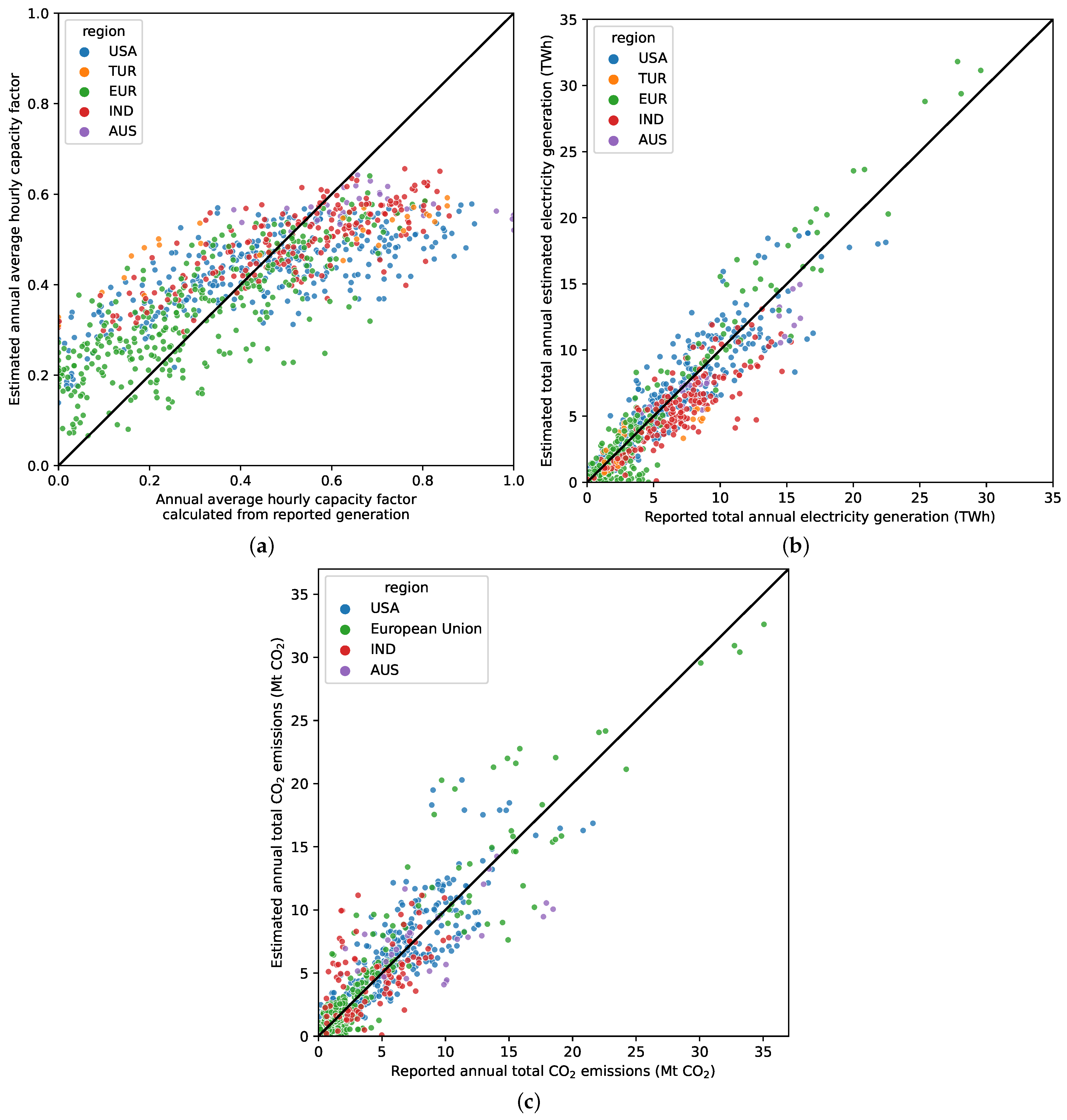
4.2. Generation Model Validation
4.3. Annual Validation
5. Discussion
- FGD usage. Because our models assume continuous wet FGD usage, if a plant is mislabeled and has dry FGD instead of wet or does not run its FGD continuously, our models will tend to underpredict emissions. We manually filtered out the most obvious examples of plants that showed no FGD signal but had other signs of activity from our FGD models. However, there could be plants we missed and therefore underestimated their emissions.
- Changing plant characteristics. For simplicity, our current filtering approach is not time-dependent and assumes fixed plant characteristics; however, plants may change over time and add or remove FGD or NDT units. A plant may meet FGD or NDT criteria one year and not another, yet we treat all years the same. To address this issue for the time being, we filtered out plants that did not meet the filtering criteria for one or more years during the period of analysis (2015–2022 inclusive). However, we did not exclude plants that only failed the filter for one year because they retired midway through that year.
- Satellite overpass time. The satellites’ local overpass times are during the daytime and in the morning, averaging around mid-morning or ∼11 a.m. local time for all three sensors: Landsat 8, Sentinel-2, and PlanetScope. Therefore, all soundings, and thus all predictions, are based on images from this time window. If a power plant generates more/less electricity at times when the satellites do not capture the plant, our generation estimates are biased low/high, respectively. Furthermore, since our generation model is currently restricted to training on the US, Australia, and Europe (ENTSO-E), it may simply learn how mid-morning power plant snapshots predict rolling 30-day average generation in those regions (especially the US and Europe, as 93% of training plants are in these regions). Our method can, therefore, over- or under-predict in regions of the world where dispatch patterns differ significantly from those in the training regions. We are working to remedy this source of bias by both expanding our training set to include more regions and by investigating additional proxy signals to augment our current NDT and FGD signals with a more complete view of each power plant.
- Weather influencing signal visibility. The primary proxy signal we currently use to estimate capacity factor is the water vapor plume, whose size is sensitive to temperature, humidity, and wind speed: cold and wet conditions favor large plumes, dry and hot conditions result in smaller or fainter plumes, and higher wind speeds elongate plumes. Wind is not currently taken into account in our models because we did not find it to be a significant factor in differentiating the model performance, perhaps in part due to the lack of precise wind data for specific power plant locations. To address the temperature and humidity, however, we currently employ a temperature and humidity filter for FGD models, since FGD plumes are especially at risk of disappearing under hot and dry conditions compared to their larger NDT counterparts. Still, this means that regions that are too hot and dry to pass the filter will lack observations for models to ingest, such that we are forced to make predictions based off less data. However, even if observations pass the filters, regions that are hotter and drier on average are at risk of underprediction. Adding additional proxy signals that are not as sensitive to local weather will reduce this bias, and this is an area we are actively working on.
- More satellite images in recent years. The majority of PlanetScope satellites were launched in 2017 or later, with more satellites added through 2022. Furthermore, Sentinel-2B was launched in 2017. This makes satellite-derived estimates in the years 2015–2017 less accurate due to the limited satellite coverage and observations. Because there is less confidence on ML predictions prior to 2019, we restricted asset-level reporting on the Climate TRACE website to 2019–2022, while ML predictions on 2015–2018 are only used for aggregating into country totals.
6. Conclusions
- Improving our regression models by better understanding the relationship between plume size, generation, and weather conditions;
- Creating mechanisms to estimate model bias;
- Including new and additional satellite measurements, e.g., thermal and SWIR, that can identify activity related to emissions;
- Sourcing additional reported data from regions outside the current training set to both validate and mitigate model bias;
- Investigating new proxy signals at plants that do not use NDT or FGD as well as signals widely applicable to other fuel sources;
- Increasing the precision of the carbon intensity modeling of individual power plants.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AVIRIS-NG | Next-Generation Airborne Visible/Infrared Imaging Spectrometer |
| CAMPD | Clean Air Markets Program Data |
| CNN | convolutional neural network |
| CO2 | carbon dioxide |
| CO2M | Copernicus CO2 Monitoring |
| CEMS | Continuous emissions monitoring systems |
| EDGAR | Emissions Database for Global Atmospheric Research |
| EIA | Energy Information Administration |
| ENTSO-E | European Network of Transmission System Operators for Electricity |
| EU | European Union |
| EU ETS | European Union Emissions Trading System |
| FGD | Flue gas desulfurization |
| GAO | Global Airborne Observatory |
| GEE | Google Earth Engine |
| GOSAT | Greenhouse Gases Observing Satellite |
| HOT | Haze-optimized transformation |
| LULUCF | Land Use, land-use change and forestry |
| mAP | Mean average precision |
| MBE | Mean bias error |
| ML | Machine learning |
| NDT | Natural draft wet cooling towers |
| NDVI | Normalized difference vegetation index |
| NIR | Near-infrared |
| OCO | Orbiting Carbon Observatory |
| OLI | Operational Land Imager |
| ODIAC | Open-source Data Inventory for Anthropogenic CO2 |
| PRISMA | Precursore Iperspettrale della Missione Applicativa |
| RMSE | Root mean squared error |
| ROI | Region of interest |
| SWIR | Shortwave infrared |
| TIR | Thermal infrared |
| TIRS | Thermal infrared sensor |
| TOA | Top of atmosphere |
| UDM2 | Usable data mask |
| US | United States |
| USGS | US Geological Survey |
Appendix A. Data Sources
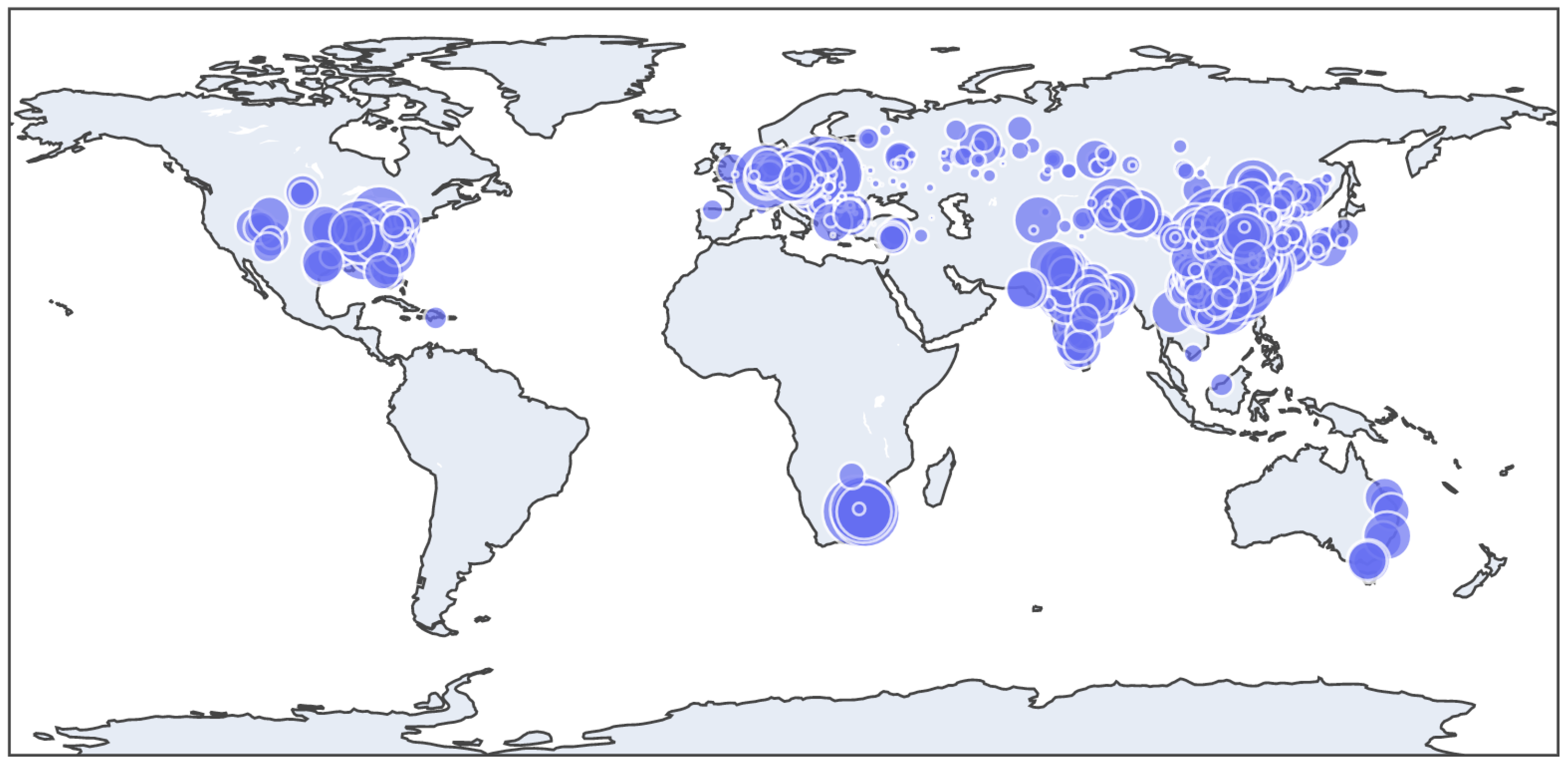
Appendix A.1. Global Fossil Power Plant Inventory

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Plant Metadata Used |
|---|---|
| US Energy Information Administration EIA-860, EIA-860m https://www.eia.gov/electricity/data/eia860/ (accessed on 1 June 2023) | Plant name Unit fuel type Location Unit capacity Unit operating dates Unit cooling type Unit pollution control tech SO2 |
| World Resources Institute (WRI) Global Power Plant Database (GPPD) https://datasets.wri.org/dataset/globalpowerplantdatabase (accessed on 1 July 2021) | Plant name Plant fuel type Location Plant capacity Plant operating dates |
| S&P Global/Platts World Electric Power Plant (WEPP) https://www.spglobal.com/marketintelligence/en/solutions/market-intelligence-platform (accessed on 1 March 2023) Note: The source level dataset is proprietary and is used internally only. | Unit fuel type Unit capacity Unit operating dates Unit cooling type Unit pollution control tech SO2 |
| Global Energy Monitor (GEM) Global Coal Plant Tracker (GCPT) and Global Gas Plant Tracker (GGPT) https://globalenergymonitor.org/ (accessed on 8 August 2023) | Plant name Unit fuel type Location Unit capacity Unit operating dates |
| Other sources (e.g., press releases, newspaper articles, company websites) | All |
Appendix A.2. Plant Validation and Infrastructure Mapping
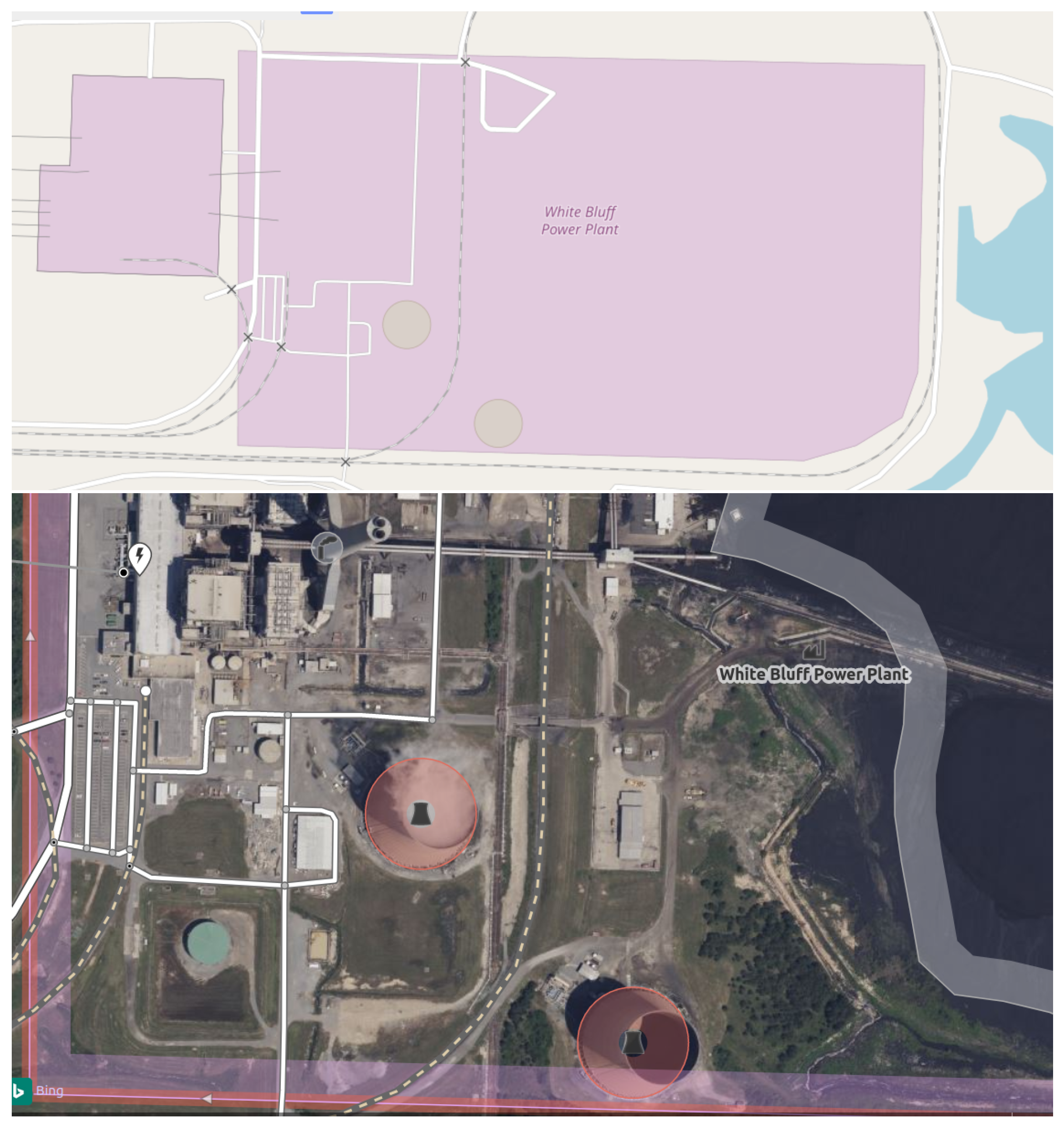
- Confirmed that there is a power plant at the provided coordinates.
- Verified that it is the correct plant by checking that plant information and visible technology (e.g., cooling equipment, coal piles) on the ground matches our information about the plant.
- Annotated all FGD flue stacks.
- Annotated all NDT cooling towers.
Appendix A.3. Weather Data
Appendix A.4. Plant-Level Electricity Generation Data
- Türkiye—Enerji Piyasaları İşletme A.Ş. (EPİAŞ), also known as Energy Exchange Istanbul (EXIST) (https://www.epias.com.tr, accessed on 1 June 2023). Reports hourly electricity generation data.
- India—National Power Portal (NPP) (https://npp.gov.in, accessed on 1 June 2023). Reports daily electricity generation data.
Appendix A.5. Plant-Level Emissions Data
- United States—US EPA Clean Air Markets Program Data (CAMPD) (https://campd.epa.gov, accessed on 1 June 2023);
- European Union–European Union Emissions Trading System (EU ETS); (https://www.eea.europa.eu/data-and-maps/data/european-union-emissions-trading-scheme-17/eu-ets-data-download-latest-version, accessed on 25 October 2023);
- Australia–Clean Energy Regulator (CER) National Greenhouse and Energy Reporting (NGER) Scheme (https://www.cleanenergyregulator.gov.au/NGER, accessed on 25 October 2023);
- India–Central Electricity Authority (CEA) (https://cea.nic.in, accessed on 25 October 2023).
- Note that, for Australia and India, emissions data are reported on the local fiscal year (1 July–30 June in Australia, 1 April–31 March in India). For comparability to annual-level ML-based predictions, emissions were converted to the Gregorian calendar year by rescaling based on sub-annual electricity data reported from NEM and NPP, respectively:
Appendix A.6. Annual Emissions Factors
- A base value (base_carbon_intensity) was gathered from the combination of the unit’s energy source (energy_source_type), e.g., coal, gas, oil, and prime mover technology (prime_mover_type), e.g., combined cycle, simple cycle. This factor accounts for the typical efficiency and fuel carbon content differences between fuel and prime mover types.
- If the combination of the energy source and prime mover did not have a value in the database, the average carbon intensity of the energy source was used.
- The final emissions factor was calculated by applying an energy source and country-specific calibration factor (country_calibration_factor), a scalar that was multiplied by the base value to account for average regional differences in power plant efficiency (due to age, technology level, and size), fuel quality, and the impact of ambient conditions on carbon intensity that are not currently modeled.
Appendix B. CNN Model and Training Details
- Patch size ;
- Backbone truncation layer [block2_pool, block3_pool, block4_pool];
- Attention heads ;
- Augmentation magnitude ;
- Weight decay ;
- Early stopping patience ;
- Batch size ;
- Learning rate ;
- Number of epochs ;
- Loss (for regression only) [mean squared error, huber].
Appendix C. Generation Model Features
- A sounding prediction p from the set of soundings P within a lookback window; represents the number of sounding predictions in the lookback window;
- A sounding model from the set of sounding models associated with a satellite s; represents the number of sounding models for satellite s;
- A classification sounding from sounding model : ;
- A regression sounding from sounding model : .
- Model-averaged regression and classification soundings: We averaged each sounding model’s capacity factor predictions, and separately, the ON-scores during the lookback window:This produced a feature for each sounding model for each satellite.
- Satellite-averaged regression and classification soundings: We averaged the capacity factor predictions and, separately, the ON scores from all sounding models associated with a satellite. This resulted in one ensembled capacity factor estimate and ON-score per image in the lookback window. These values were then averaged over the images to obtain a single value per lookback window:This produced a feature for each satellite.
- Weighted-average regression soundings: We weighed the capacity-factor-related predictions based on the corresponding classification soundings. First, we averaged the classification soundings from all sounding models associated with a satellite:This produced one ensembled ON-score per image in the lookback window. These values were then used to weigh the capacity-factor-related predictions. The further away from 0.5 the ensembled ON-score, the higher the weight, with a maximum weight of 1 and a minimum weight of 0. The resulting weighted regression scores were then averaged within the lookback window to obtain a single value. This was achieved for each model and for each satellite:This produced a feature for each model and one for each satellite.
- Mean thresholded classification soundings: These features indicate the percentage of ON-scores in the lookback window that were above 0.5:where I is an indicator function mapping to 1 if the condition is true and 0 otherwise. This resulted in a feature for each model and one for each satellite.
- Missing feature indicator (FGD only): This value indicates whether a feature was imputed, 1 if imputed, and 0 otherwise. Imputation was used more often for the FGD model due to the stricter temperature and humidity filter.
Appendix D. External Validation for Sounding Model
| Satellite | Model | Classification | Regression | |
|---|---|---|---|---|
| mAP [CI] | RMSE [CI] | MBE [CI] | ||
| PlanetScope | XGBoost | 0.779 [0.733, 0.837] | 0.221 [0.206, 0.233] | 0.004 [−0.017, 0.028] |
| PlanetScope | CNN-RESISC | 0.782 [0.721, 0.851] | 0.215 [0.198, 0.231] | −0.009 [−0.034, 0.020] |
| Sentinel-2 | XGBoost | 0.749 [0.708, 0.802] | 0.240 [0.223, 0.255] | −0.008 [−0.037, 0.024] |
| Sentinel-2 | CNN-RESISC | 0.752 [0.713, 0.808] | 0.231 [0.210, 0.250] | −0.040 [−0.068, −0.008] |
| Sentinel-2 | CNN-BigEarthNet | 0.738 [0.704, 0.795] | 0.232 [0.214, 0.248] | −0.014 [−0.041, 0.018] |
| Landsat 8 | XGBoost | 0.730 [0.689, 0.803] | 0.257 [0.230, 0.278] | 0.033 [ 0.000, 0.066] |
| Landsat 8 | CNN-RESISC | 0.717 [0.669, 0.772] | 0.271 [0.244, 0.294] | −0.017 [−0.053, 0.019] |
| Landsat 8 | CNN-BigEarthNet | 0.721 [0.683, 0.791] | 0.272 [0.243, 0.295] | −0.003 [−0.039, 0.039] |
| Satellite | Model | Classification | Regression | |
|---|---|---|---|---|
| mAP [CI] | RMSE [CI] | MBE [CI] | ||
| PlanetScope | XGBoost | 0.664 [0.531, 0.909] | 0.487 [0.463, 0.504] | −0.373 [−0.416, −0.323] |
| PlanetScope | CNN-RESISC | 0.778 [0.623, 0.943] | 0.394 [0.392, 0.395] | −0.299 [−0.303, −0.295] |
| Sentinel-2 | XGBoost | 0.615 [0.519, 0.766] | 0.455 [0.411, 0.492] | −0.350 [−0.407, −0.277] |
| Sentinel-2 | CNN-RESISC | 0.604 [0.523, 0.871] | 0.461 [0.416, 0.500] | −0.356 [−0.410, −0.292] |
| Sentinel-2 | CNN-BigEarthNet | 0.682 [0.529, 0.940] | 0.474 [0.444, 0.496] | −0.390 [−0.419, −0.346] |
| Landsat 8 | XGBoost | 0.586 [0.517, 0.765] | 0.519 [0.444, 0.584] | −0.406 [−0.516, −0.296] |
| Landsat 8 | CNN-RESISC | 0.550 [0.517, 0.714] | 0.509 [0.479, 0.543] | −0.400 [−0.477, −0.329] |
| Landsat 8 | CNN-BigEarthNet | 0.569 [0.568, 0.829] | 0.430 [0.408, 0.447] | −0.318 [−0.372, −0.260] |
References
- Paris Agreement to the United Nations Framework Convention on Climate Change; Number 16-1104, T.I.A.S. 2015. Available online: https://unfccc.int/sites/default/files/resource/parisagreement_publication.pdf (accessed on 6 June 2023).
- Ge, M.; Friedrich, J. 4 Charts Explain Greenhouse Gas Emissions by Countries and Sectors; World Resources Institute: Washington, DC, USA, 2020; Available online: https://www.wri.org/blog/2020/02/greenhouse-gas-emissions-by-country-sector (accessed on 6 June 2023).
- Climate Watch. Climate Watch Historical GHG Emissions; World Resources Institute: Washington, DC, USA, 2022; Available online: https://www.climatewatchdata.org/ghg-emissions (accessed on 1 July 2023).
- IEA (International Energy Agency). Greenhouse Gas Emissions from Energy Data Explorer; IEA: Paris, France, 2023; Available online: https://www.iea.org/data-and-statistics/data-tools/greenhouse-gas-emissions-from-energy-data-explore (accessed on 1 July 2023).
- Sloss, L.L. Efficiency and Emissions Monitoring and Reporting; IEA Clean Cloal Centre: Paris, France, 2011. [Google Scholar]
- Liu, F.; Duncan, B.N.; Krotkov, N.A.; Lamsal, L.N.; Beirle, S.; Griffin, D.; McLinden, C.A.; Goldberg, D.L.; Lu, Z. A methodology to constrain carbon dioxide emissions from coal-fired power plants using satellite observations of co-emitted nitrogen dioxide. Atmos. Chem. Phys. 2020, 20, 99–116. [Google Scholar] [CrossRef]
- Cusworth, D.H.; Duren, R.M.; Thorpe, A.K.; Eastwood, M.L.; Green, R.O.; Dennison, P.E.; Frankenberg, C.; Heckler, J.W.; Asner, G.P.; Miller, C.E. Quantifying Global Power Plant Carbon Dioxide Emissions With Imaging Spectroscopy. AGU Adv. 2021, 2, e2020AV000350. [Google Scholar] [CrossRef]
- Kuhlmann, G.; Broquet, G.; Marshall, J.; Clément, V.; Löscher, A.; Meijer, Y.; Brunner, D. Detectability of CO2 emission plumes of cities and power plants with the Copernicus Anthropogenic CO2 Monitoring (CO2M) mission. Atmos. Meas. Tech. 2019, 12, 6695–6719. [Google Scholar] [CrossRef]
- Vaughn, T.L.; Bell, C.S.; Pickering, C.K.; Schwietzke, S.; Heath, G.A.; Pétron, G.; Zimmerle, D.J.; Schnell, R.C.; Nummedal, D. Temporal variability largely explains top-down/bottom-up difference in methane emission estimates from a natural gas production region. Proc. Natl. Acad. Sci. USA 2018, 115, 11712–11717. [Google Scholar] [CrossRef] [PubMed]
- Cusworth, D.H.; Thorpe, A.K.; Miller, C.E.; Ayasse, A.K.; Jiorle, R.; Duren, R.M.; Nassar, R.; Mastrogiacomo, J.P.; Nelson, R.R. Two years of satellite-based carbon dioxide emission quantification at the world’s largest coal-fired power plants. Atmos. Chem. Phys. 2023, 23, 14577–14591. [Google Scholar] [CrossRef]
- Nassar, R.; Hill, T.G.; McLinden, C.A.; Wunch, D.; Jones, D.B.; Crisp, D. Quantifying CO2 emissions from individual power plants from space. Geophys. Res. Lett. 2017, 44, 10,045–10,053. [Google Scholar] [CrossRef]
- Nassar, R.; Mastrogiacomo, J.P.; Bateman-Hemphill, W.; Callum McCracken, J.P.; MacDonald, C.G.; Hill, T.; O’Dell, C.W.; Kiel, M.; Crisp, D. Advances in quantifying power plant CO2 emissions with OCO-2. Remote Sens. Environ. 2021, 264, 112579. [Google Scholar] [CrossRef]
- Hu, Y.; Shi, Y. Estimating CO2 emissions from large scale coal-fired power plants using OCO-2 observations and emission inventories. Atmosphere 2021, 12, 811. [Google Scholar] [CrossRef]
- Guo, W.; Shi, Y.; Liu, Y.; Su, M. CO2 emissions retrieval from coal-fired power plants based on OCO-2/3 satellite observations and a Gaussian plume model. J. Clean. Prod. 2023, 397, 136525. [Google Scholar] [CrossRef]
- Lin, X.; van der A, R.; de Laat, J.; Eskes, H.; Chevallier, F.; Ciais, P.; Deng, Z.; Geng, Y.; Song, X.; Ni, X.; et al. Monitoring and quantifying CO2 emissions of isolated power plants from space. Atmos. Chem. Phys. 2023, 23, 6599–6611. [Google Scholar] [CrossRef]
- Yang, D.; Zhang, H.; Liu, Y.; Chen, B.; Cai, Z.; Lü, D. Monitoring carbon dioxide from space: Retrieval algorithm and flux inversion based on GOSAT data and using CarbonTracker-China. Adv. Atmos. Sci. 2017, 34, 965–976. [Google Scholar] [CrossRef]
- Shim, C.; Han, J.; Henze, D.K.; Yoon, T. Identifying local anthropogenic CO2 emissions with satellite retrievals: A case study in South Korea. Int. J. Remote Sens. 2019, 40, 1011–1029. [Google Scholar] [CrossRef]
- Zheng, T.; Nassar, R.; Baxter, M. Estimating power plant CO2 emission using OCO-2 XCO2 and high resolution WRF-Chem simulations. Environ. Res. Lett. 2019, 14, 085001. [Google Scholar] [CrossRef]
- Yang, S.; Lei, L.; Zeng, Z.; He, Z.; Zhong, H. An Assessment of Anthropogenic CO2 Emissions by Satellite-Based Observations in China. Sensors 2019, 19, 1118. [Google Scholar] [CrossRef] [PubMed]
- Reuter, M.; Buchwitz, M.; Schneising, O.; Krautwurst, S.; O’Dell, C.W.; Richter, A.; Bovensmann, H.; Burrows, J.P. Towards monitoring localized CO2 emissions from space: Co-located regional CO2 and NO2 enhancements observed by the OCO-2 and S5P satellites. Atmos. Chem. Phys. 2019, 19, 9371–9383. [Google Scholar] [CrossRef]
- Nassar, R.; Moeini, O.; Mastrogiacomo, J.P.; O’Dell, C.W.; Nelson, R.R.; Kiel, M.; Chatterjee, A.; Eldering, A.; Crisp, D. Tracking CO2 emission reductions from space: A case study at Europe’s largest fossil fuel power plant. Front. Remote Sens. 2022, 3, 1028240. [Google Scholar] [CrossRef]
- Sierk, B.; Fernandez, V.; Bézy, J.L.; Meijer, Y.; Durand, Y.; Courrèges-Lacoste, G.B.; Pachot, C.; Löscher, A.; Nett, H.; Minoglou, K.; et al. The Copernicus CO2M mission for monitoring anthropogenic carbon dioxide emissions from space. In Proceedings of the International Conference on Space Optics—ICSO 2020, Online, France, 30 March–2 April 2021; International Society for Optics and Photonics: Bellingham, WA, USA, 2021; Volume 118523M. [Google Scholar]
- Kuhlmann, G.; Henne, S.; Meijer, Y.; Brunner, D. Quantifying CO2 Emissions of Power Plants With CO2 and NO2 Imaging Satellites. Front. Remote Sens. 2021, 2, 689838. [Google Scholar] [CrossRef]
- Keremedjiev, M.; Haag, J.; Shivers, S.; Guido, J.; Roth, K.; teja Nallapu, R.; Dockstader, S.; McGill, L.; Giuliano, P.; Duren, R.; et al. Carbon mapper phase 1: Two upcoming VNIR-SWIR hyperspectral imaging satellites. In Proceedings of the Algorithms, Technologies, and Applications for Multispectral and Hyperspectral Imaging XXVIII, Orlando, FL, USA, 3 April–13 June 2022; SPIE: Bellingham, WA, USA, 2022; Volume 12094, pp. 62–68. [Google Scholar]
- Krutz, D.; Walter, I.; Sebastian, I.; Paproth, C.; Peschel, T.; Damm, C.; Risse, S.; von Lukowicz, H.; Roiger, A.; Butz, A.; et al. CO2Image: The design of an imaging spectrometer for CO2 point source quantification. In Proceedings of the Infrared Remote Sensing and Instrumentation XXX, San Diego, CA, USA, 21–26 August 2022; SPIE: Bellingham, WA, USA, 2022; Volume 12233, pp. 36–44. [Google Scholar]
- Durand, Y.; Courrèges-Lacoste, G.B.; Pachot, C.; Fernandez, M.M.; Cabezudo, D.S.; Fernandez, V.; Lesschaeve, S.; Spilling, D.; Dussaux, A.; Serre, D.; et al. Copernicus CO2M: Status of the mission for monitoring anthropogenic carbon dioxide from space. In Proceedings of the International Conference on Space Optics—ICSO 2022, Dubrovnik, Croatia, 3–7 October 2022; SPIE: Bellingham, WA, USA, 2023; Volume 12777, pp. 1936–1950. [Google Scholar]
- Penman, J.; Gytarsky, M.; Hiraishi, T.; Krug, T.; Kruger, D.; Pipatti, R.; Buendia, L.; Miwa, K.; Ngara, T.; Tanabe, K.; et al. Good Practice Guidance for Land Use, Land-Use Change and Forestry; Institute for Global Environmental Strategies: Hayama, Japan, 2003. [Google Scholar]
- UNFCCC Resource Guide for Preparing the National Communications of non-Annex I Parties. Module 3: National Greenhouse Gas Inventories; United Nations Framework Convention on Climate Change. 2009. Available online: https://unfccc.int/files/national_reports/application/pdf/module_3_national_ghg.pdf (accessed on 13 July 2023).
- Gray, M.; Watson, L.; Ljungwaldh, S.; Morris, E. Nowhere to Hide: Using Satellite Imagery to Estimate the Utilisation of Fossil Fuel Power Plants; Carbon Tracker Initiative: London, UK, 2018; Available online: https://carbontracker.org/reports/nowhere-to-hide/ (accessed on 11 August 2023).
- Mommert, M.; Sigel, M.; Neuhausler, M.; Scheibenreif, L.M.; Borth, D. Characterization of Industrial Smoke Plumes from Remote Sensing Data. In Proceedings of the NeurIPS 2020 Workshop on Tackling Climate Change with Machine Learning, Online, 6–12 December 2020. [Google Scholar]
- Hanna, J.; Mommert, M.; Scheibenreif, L.M.; Borth, D. Multitask Learning for Estimating Power Plant Greenhouse Gas Emissions from Satellite Imagery. In Proceedings of the NeurIPS 2021 Workshop on Tackling Climate Change with Machine Learning, Online, 6–14 December 2021. [Google Scholar]
- Jain, A. Employing Deep Learning to Quantify Power Plant Greenhouse Gas Emissions via Remote Sensing Data. In Proceedings of the AAAI 2022 Fall Symposium: The Role of AI in Responding to Climate Challenges, Arlington, VA, USA, 17–19 November 2022. [Google Scholar]
- Couture, H.D.; O’Connor, J.; Mitchell, G.; Söldner-Rembold, I.; D’souza, D.; Karra, K.; Zhang, K.; Kargar, A.R.; Kassel, T.; Goldman, B. Towards tracking the emissions of every power plant on the planet. In Proceedings of the NeurIPS 2020 Workshop on Tackling Climate Change with Machine Learning, Online, 6–12 December 2020; Volume 3. [Google Scholar]
- Hobbs, M.; Kargar, A.R.; Couture, H.; Freeman, J.; Söldner-Rembold, I.; Ferreira, A.; Jeyaratnam, J.; O’Connor, J.; Lewis, J.; Koenig, H.; et al. Inferring carbon dioxide emissions from power plants using satellite imagery and machine learning. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Pasadena, CA, USA, 16–21 July 2023. [Google Scholar]
- Planet Imagery Product Specifications; Planet Labs: San Francisco, CA, USA, 2022; Available online: https://assets.planet.com/docs/Planet_Combined_Imagery_Product_Specs_letter_screen.pdf (accessed on 18 February 2024).
- Dos Reis, A.A.; Werner, J.P.; Silva, B.C.; Figueiredo, G.K.; Antunes, J.F.; Esquerdo, J.C.; Coutinho, A.C.; Lamparelli, R.A.; Rocha, J.V.; Magalhães, P.S. Monitoring pasture aboveground biomass and canopy height in an integrated crop–livestock system using textural information from PlanetScope imagery. Remote Sens. 2020, 12, 2534. [Google Scholar] [CrossRef]
- Moon, M.; Richardson, A.D.; Friedl, M.A. Multiscale assessment of land surface phenology from harmonized Landsat 8 and Sentinel-2, PlanetScope, and PhenoCam imagery. Remote Sens. Environ. 2021, 266, 112716. [Google Scholar] [CrossRef]
- Sentinel-2-Missions-Sentinel Online. Available online: https://sentinels.copernicus.eu/web/sentinel/home (accessed on 1 March 2023).
- Main-Knorn, M.; Pflug, B.; Louis, J.; Debaecker, V.; Müller-Wilm, U.; Gascon, F. Sen2Cor for sentinel-2. In Proceedings of the Image and Signal Processing for Remote Sensing XXIII, Warsaw, Poland, 11–14 September 2017; SPIE: Bellingham, WA, USA, 2017; Volume 10427, pp. 37–48. [Google Scholar]
- Shikwambana, L.; Ncipha, X.; Malahlela, O.E.; Mbatha, N.; Sivakumar, V. Characterisation of aerosol constituents from wildfires using satellites and model data: A case study in Knysna, South Africa. Int. J. Remote Sens. 2019, 40, 4743–4761. [Google Scholar] [CrossRef]
- Landsat 8|U.S. Geological Survey. Available online: https://www.usgs.gov/landsat-missions/landsat-8 (accessed on 1 March 2023).
- Marchese, F.; Genzano, N.; Neri, M.; Falconieri, A.; Mazzeo, G.; Pergola, N. A multi-channel algorithm for mapping volcanic thermal anomalies by means of Sentinel-2 MSI and Landsat-8 OLI data. Remote Sens. 2019, 11, 2876. [Google Scholar] [CrossRef]
- Mia, M.B.; Fujimitsu, Y.; Nishijima, J. Thermal activity monitoring of an active volcano using Landsat 8/OLI-TIRS sensor images: A case study at the Aso volcanic area in southwest Japan. Geosciences 2017, 7, 118. [Google Scholar] [CrossRef]
- Xiong, Q.; Wang, Y.; Liu, D.; Ye, S.; Du, Z.; Liu, W.; Huang, J.; Su, W.; Zhu, D.; Yao, X.; et al. A cloud detection approach based on hybrid multispectral features with dynamic thresholds for GF-1 remote sensing images. Remote Sens. 2020, 12, 450. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Sumbul, G.; Charfuelan, M.; Demir, B.; Markl, V. Bigearthnet: A large-scale benchmark archive for remote sensing image understanding. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019. [Google Scholar]
- Ilse, M.; Tomczak, J.; Welling, M. Attention-based Deep Multiple Instance Learning. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Hobbs, M.; Rouzbeh, A.; Couture, H.; Freeman, J.; Jeyaratnam, J.; Lewis, J.; Koenig, H.; Nakano, T.; Dalisay, C.; McCormick, C. Estimating Fossil Fuel Power Plant Carbon Dioxide Emissions Globally with Remote Sensing and Machine Learning. In Proceedings of the AGU23, San Francisco, CA, USA, 11–15 December 2023. [Google Scholar]
- Freeman, J.; Rouzbeh kargar, A.; Couture, H.D.; Jeyaratnam, J.; Lewis, J.; Hobbs, M.; Koenig, H.; Nakano, T.; Dalisay, C.; Davitt, A.; et al. Power Sector: Electricity Generation; Climate TRACE, International. 2023. Available online: https://github.com/climatetracecoalition/methodology-documents/tree/main/2023/Power (accessed on 16 November 2023).
- U.S. Energy Information Administration (EIA). Electric Power Annual 2022; U.S. Energy Information Administration: Washington, DC, USA, 2023. Available online: https://www.eia.gov/electricity/annual/pdf/epa.pdf (accessed on 10 October 2023).
- U.S. Energy Information Administration (EIA). Carbon Dioxide Emissions Coefficients; U.S. Energy Information Administration: Washington, DC, USA, 2023. Available online: https://www.eia.gov/environment/emissions/co2_vol_mass.php (accessed on 7 September 2023).




| Satellite | NDT Image Count | FGD Image Count | ||
|---|---|---|---|---|
| Before Filtering | After Filtering | Before Filtering | After Filtering | |
| PlanetScope | 69,533 | 54,136 | 108,038 | 69,462 |
| Sentinel-2 | 18,964 | 15,064 | 30,541 | 18,390 |
| Landsat 8 | 9040 | 7176 | 12,885 | 8235 |
| Approach | % Power Emissions | # Observations | # Plants | # Countries | Years |
|---|---|---|---|---|---|
| Climate TRACE ML | |||||
| Cross-val | 7% | 157,831 | 139 | 12 | 2015–2022 |
| External val (generation) | 2% | 107,440 | 101 | 16 | 2018–2022 |
| External val (CO2) | 7% | 162,588 | 207 | 17 | 2019–2022 |
| All inference | 32% | 1,198,167 | 1042 | 41 | 2015–2022 |
| Jain [32] | <1% | 2131 | 146 | 18 | 2019–2021 |
| Hanna et al. [31] | <1% | 1639 | 146 | 11 | 2020 |
| Lin et al. [15] inference | 4% | 106 | 78 | 15 | 2018–2021 |
| Lin et al. [15] validation | <1% | 50 | 22 | 1 | 2018–2021 |
| Cusworth et al. [7] | <1% | 28 | 21 | 4 | 2014–2020 |
| Nassar et al. [12] | <1% | 20 | 14 | 6 | 2014–2018 |
| Satellite | Model | NDT mAP [CI] | FGD mAP [CI] |
|---|---|---|---|
| PlanetScope | XGBoost | 0.956 [0.932, 0.987] | 0.886 [0.857, 0.911] |
| PlanetScope | CNN-RESISC | 0.930 [0.901, 0.963] | 0.885 [0.861, 0.916] |
| Sentinel-2 | XGBoost | 0.932 [0.904, 0.980] | 0.889 [0.858, 0.917] |
| Sentinel-2 | CNN-RESISC | 0.959 [0.941, 0.974] | 0.903 [0.880, 0.925] |
| Sentinel-2 | CNN-BigEarthNet | 0.933 [0.906, 0.966] | 0.839 [0.801, 0.873] |
| Landsat 8 | XGBoost | 0.899 [0.866, 0.942] | 0.878 [0.855, 0.904] |
| Landsat 8 | CNN-RESISC | 0.901 [0.866, 0.942] | 0.824 [0.793, 0.854] |
| Landsat 8 | CNN-BigEarthNet | 0.865 [0.826, 0.899] | 0.811 [0.784, 0.837] |
| Satellite | Model | NDT | FGD | ||
|---|---|---|---|---|---|
| RMSE [CI] | MBE [CI] | RMSE [CI] | MBE [CI] | ||
| PlanetScope | XGBoost | 0.209 [0.194, 0.221] | −0.021 [−0.034, −0.006] | 0.297 [0.285, 0.308] | −0.056 [−0.076, −0.037] |
| PlanetScope | CNN-RESISC | 0.196 [0.186, 0.206] | −0.024 [−0.037, −0.010] | 0.263 [0.244, 0.277] | −0.065 [−0.084, −0.045] |
| Sentinel-2 | XGBoost | 0.210 [0.198, 0.220] | −0.020 [−0.034, −0.006] | 0.270 [0.258, 0.281] | −0.029 [−0.049, −0.011] |
| Sentinel-2 | CNN-RESISC | 0.203 [0.192, 0.213] | −0.019 [−0.034, −0.004] | 0.267 [0.248, 0.282] | −0.048 [−0.066, −0.029] |
| Sentinel-2 | CNN-BigEarthNet | 0.220 [0.206, 0.233] | −0.025 [−0.041, −0.008] | 0.259 [0.246, 0.269] | 0.005 [−0.014, 0.025] |
| Landsat 8 | XGBoost | 0.243 [0.220, 0.260] | −0.011 [−0.032, 0.013] | 0.285 [0.271, 0.298] | −0.063 [−0.085, −0.042] |
| Landsat 8 | CNN-RESISC | 0.266 [0.249, 0.280] | −0.089 [−0.110, −0.068] | 0.299 [0.289, 0.309] | −0.036 [−0.054, −0.015] |
| Landsat 8 | CNN-BigEarthNet | 0.264 [0.247, 0.278] | −0.031 [−0.054, −0.006] | 0.301 [0.288, 0.313] | 0.025 [0.002, 0.050] |
| Plant | Validation | Plant | RMSE | MBE | ||
|---|---|---|---|---|---|---|
| Type | Type | Count | ML [CI] | Baseline | ML [CI] | Baseline |
| NDT | cross | 73 | 0.149 [0.129, 0.162] | 0.272 | −0.014 [−0.028, 0.002] | 0.000 |
| NDT | external | 104 | 0.199 [0.188, 0.210] | 0.273 | −0.075 [−0.091, −0.058] | 0.048 |
| FGD | cross | 97 | 0.196 [0.187, 0.205] | 0.270 | 0.012 [−0.007, 0.031] | 0.000 |
| FGD | external | 4 | 0.323 [0.216, 0.384] | 0.359 | −0.252 [−0.330, −0.127] | −0.272 |
| Region | Validation | Plant | RMSE | MBE | ||
|---|---|---|---|---|---|---|
| Type | Count | ML [CI] | Baseline | ML [CI] | Baseline | |
| US | cross | 78 | 0.17 [0.16, 0.18] | 0.22 | −0.02 [−0.05, 0.00] | −0.05 |
| US | external | 6 | 0.14 [0.12, 0.17] | 0.19 | 0.03 [−0.06, 0.12] | 0.04 |
| Europe (ENTSO-E) | cross | 59 | 0.12 [0.11, 0.13] | 0.20 | 0.04 [0.02, 0.06] | 0.05 |
| Europe (ENTSO-E) | external | 27 | 0.14 [0.12, 0.16] | 0.18 | 0.02 [−0.01, 0.05] | 0.10 |
| Australia | cross | 7 | 0.20 [0.08, 0.26] | 0.18 | −0.12 [−0.20, −0.04] | −0.10 |
| Australia | external | 1 | 0.09 [N/A] | 0.09 | −0.01 [N/A] | 0.04 |
| India | external | 50 | 0.14 [0.13, 0.15] | 0.20 | −0.03 [−0.05, −0.01] | 0.08 |
| Türkiye | external | 8 | 0.24 [ 0.21, 0.26] | 0.32 | 0.00 [−0.12, 0.10] | 0.13 |
| Region | Validation | Plant | RMSE (TWh) | MBE (TWh) | ||
|---|---|---|---|---|---|---|
| Type | Count | ML [CI] | Baseline | ML [CI] | Baseline | |
| US | cross | 78 | 1.68 [1.51, 1.84] | 2.99 | 0.06 [−0.16, 2.90] | −0.65 |
| US | external | 6 | 2.92 [0.68, 3.92] | 3.90 | −0.66 [−2.17, 0.88] | 0.31 |
| Europe (ENTSO-E) | cross | 59 | 1.38 [1.09, 1.58] | 2.43 | 0.35 [0.15, 0.53] | −0.16 |
| Europe (ENTSO-E) | external | 27 | 1.39 [1.09, 1.61] | 1.27 | −0.55 [−0.82, −0.28] | 0.65 |
| Australia | cross | 7 | 2.05 [ 0.91, 2.60] | 2.19 | −1.46 [−2.08, −0.63] | −1.33 |
| Australia | external | 1 | 1.12 [N/A] | 0.94 | −0.49 [N/A] | 0.37 |
| India | external | 50 | 2.12 [1.78, 2.37] | 2.58 | −1.38 [−1.63, −1.12] | 0.98 |
| Türkiye | external | 8 | 2.08 [1.31, 2.57] | 2.80 | −0.94 [−1.91, 0.01] | 0.97 |
| Region | Validation | Plant | RMSE (Mt CO2) | MBE (Mt CO2) | ||
|---|---|---|---|---|---|---|
| Type | Count | ML [CI] | Baseline | ML [CI] | Baseline | |
| US | cross | 77 | 2.11 [1.73, 2.36] | 2.68 | 0.37 [ 0.08, 0.67] | −1.13 |
| US | external | 5 | 1.12 [0.37, 1.43] | 2.25 | −0.61 [−1.08, −0.10] | −0.56 |
| EU | cross | 58 | 2.27 [1.70, 2.68] | 3.04 | 0.57 [0.19, 0.97] | −0.18 |
| EU | external | 36 | 1.00 [0.76, 1.16] | 1.05 | −0.41 [−0.58, −0.23] | 0.25 |
| Australia | cross | 6 | 4.17 [2.91, 5.12] | 3.67 | −1.40 [−2.98, 0.34] | −0.84 |
| Australia | external | 1 | 3.23 [N/A] | 2.63 | −2.06 [N/A] | −1.21 |
| India | external | 24 | 2.74 [2.41, 3.01] | 4.06 | 0.33 [−0.02, 0.68] | 2.72 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Couture, H.D.; Alvara, M.; Freeman, J.; Davitt, A.; Koenig, H.; Rouzbeh Kargar, A.; O’Connor, J.; Söldner-Rembold, I.; Ferreira, A.; Jeyaratnam, J.; et al. Estimating Carbon Dioxide Emissions from Power Plant Water Vapor Plumes Using Satellite Imagery and Machine Learning. Remote Sens. 2024, 16, 1290. https://doi.org/10.3390/rs16071290
Couture HD, Alvara M, Freeman J, Davitt A, Koenig H, Rouzbeh Kargar A, O’Connor J, Söldner-Rembold I, Ferreira A, Jeyaratnam J, et al. Estimating Carbon Dioxide Emissions from Power Plant Water Vapor Plumes Using Satellite Imagery and Machine Learning. Remote Sensing. 2024; 16(7):1290. https://doi.org/10.3390/rs16071290
Chicago/Turabian StyleCouture, Heather D., Madison Alvara, Jeremy Freeman, Aaron Davitt, Hannes Koenig, Ali Rouzbeh Kargar, Joseph O’Connor, Isabella Söldner-Rembold, André Ferreira, Jeyavinoth Jeyaratnam, and et al. 2024. "Estimating Carbon Dioxide Emissions from Power Plant Water Vapor Plumes Using Satellite Imagery and Machine Learning" Remote Sensing 16, no. 7: 1290. https://doi.org/10.3390/rs16071290
APA StyleCouture, H. D., Alvara, M., Freeman, J., Davitt, A., Koenig, H., Rouzbeh Kargar, A., O’Connor, J., Söldner-Rembold, I., Ferreira, A., Jeyaratnam, J., Lewis, J., McCormick, C., Nakano, T., Dalisay, C., Lewis, C., Volpato, G., Gray, M., & McCormick, G. (2024). Estimating Carbon Dioxide Emissions from Power Plant Water Vapor Plumes Using Satellite Imagery and Machine Learning. Remote Sensing, 16(7), 1290. https://doi.org/10.3390/rs16071290