
Sparse SAR Imaging Algorithm in Marine Environments Based on Memory-Augmented Deep Unfolding Network


 ,
,
Abstract
1. Introduction
- (1)
- A sparse SAR imaging algorithm designed specifically for reconstructing sparse maritime scenes is introduced, employing the Memory-Augmented Deep Unfolding Network (MADUN). This architecture is characterized by two key modules—a gradient descent module and a proximal mapping module;
- (2)
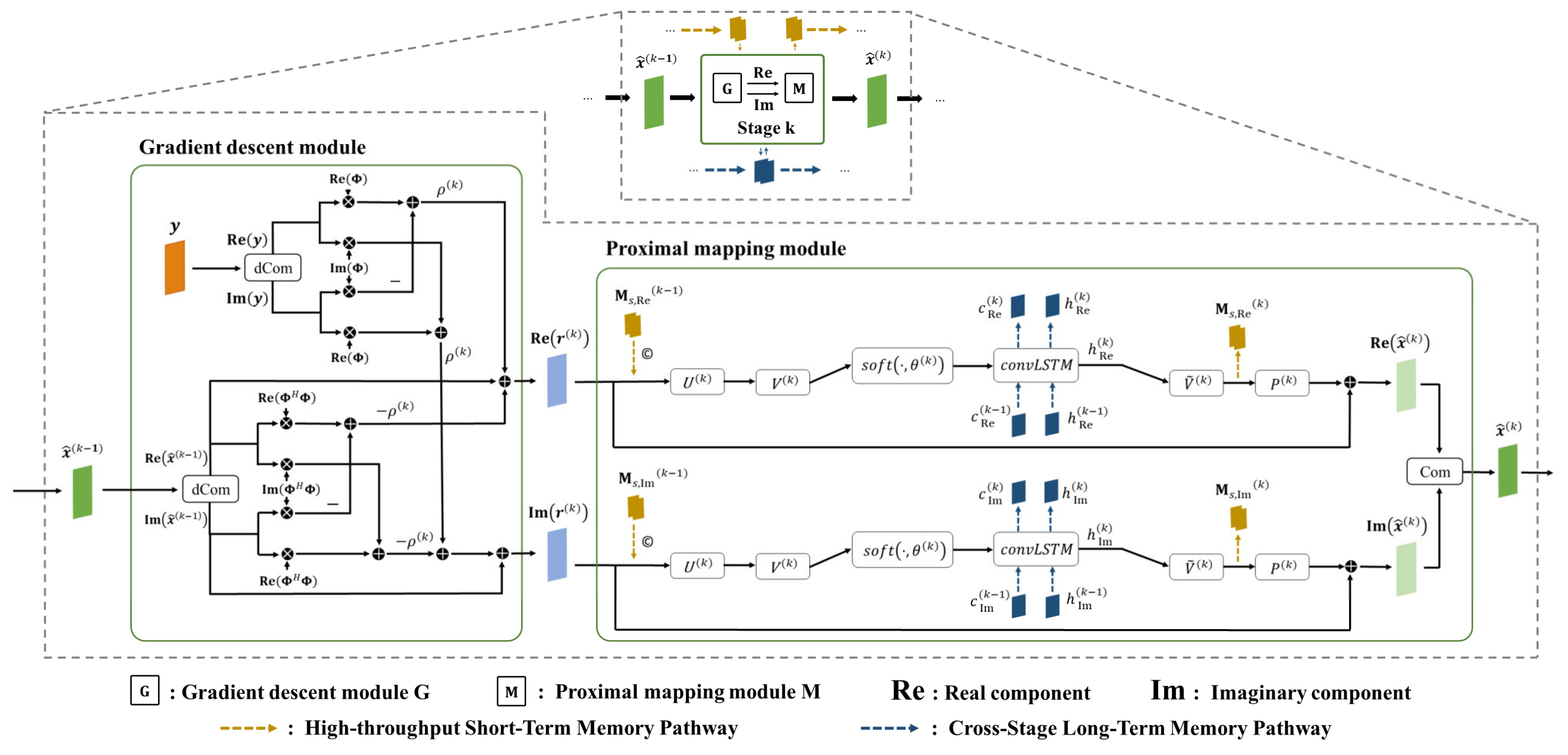
- A gradient descent module tailored to meet MADUN’s requirements for processing complex-valued signals is proposed. This is achieved by dividing the data into its real and imaginary components, thus enabling the more effective processing of complex-valued radar signals;
- (3)
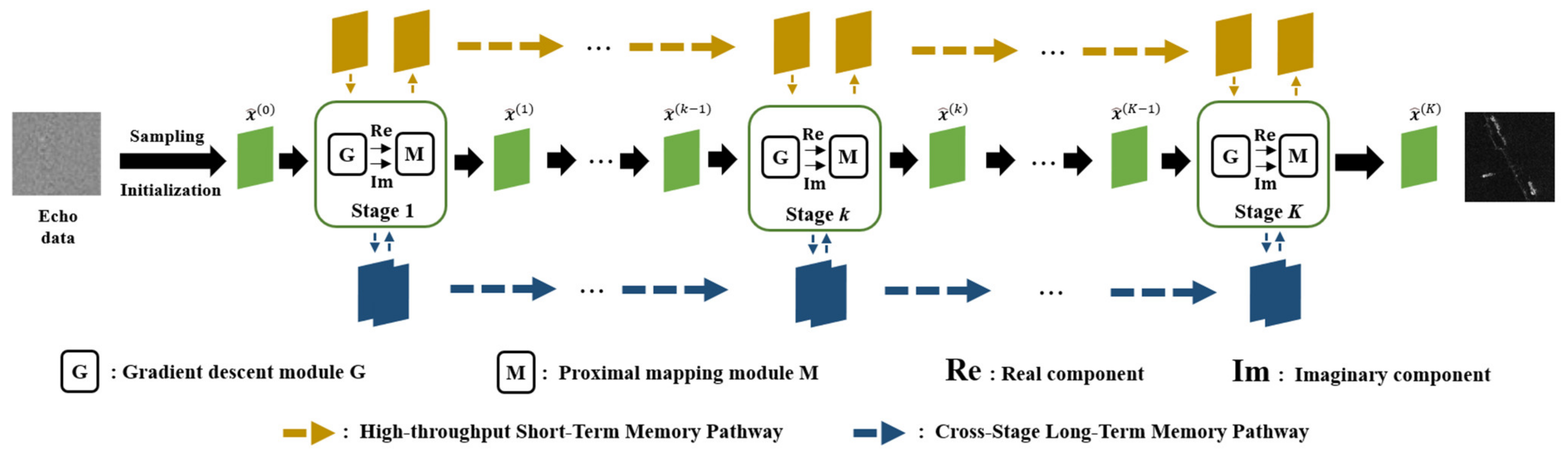
- By integrating High-throughput Short-term Memory (HSM) and Cross-stage Long-term Memory (CLM) enhancement mechanisms into the SAR imaging algorithm based on DUN, enhancing the proximal mapping module by improving the efficiency of multi-channel information transmission and strengthening the processing of long-distance dependencies between stages is achieved;
- (4)
- Extensive experiments have validated that our proposed MADUN-based sparse SAR imaging algorithm significantly outperforms traditional sparse reconstruction algorithms like ISTA and deep unfolding imaging methods such as ISTA-Net+ in reconstructing sparse marine scenes.
2. Materials and Methods
2.1. Sparse Imaging Model for SAR
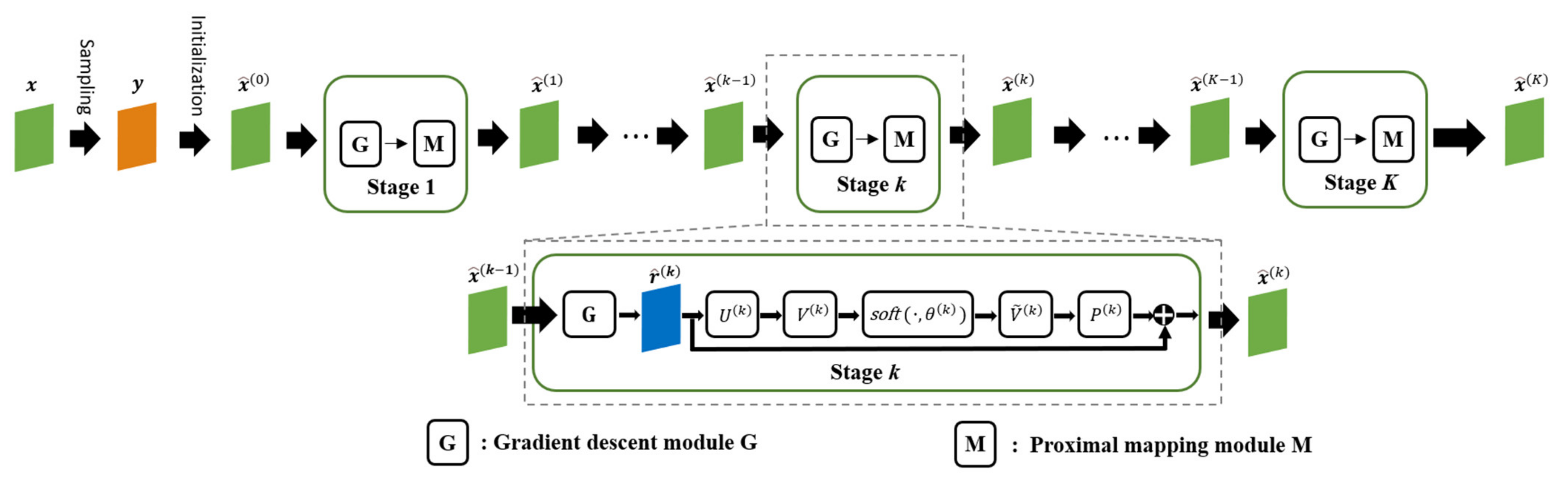
2.2. Deep Unfolding Network Based on ISTA
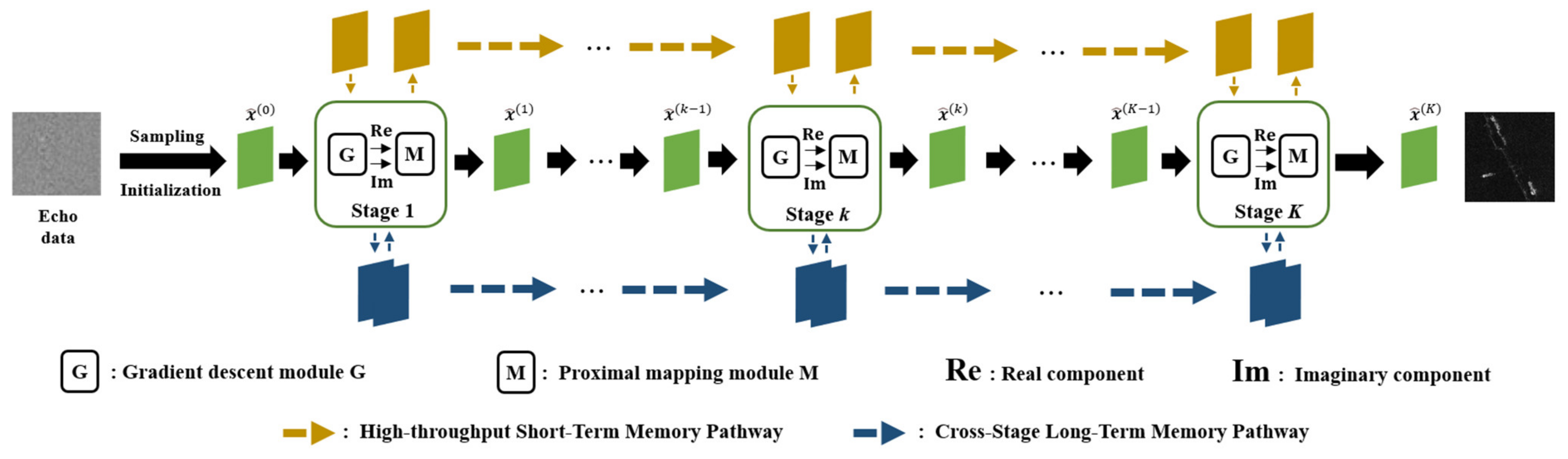
2.3. Sparse SAR Imaging Algorithm Based on Memory-Augmented Deep Unfolding Network
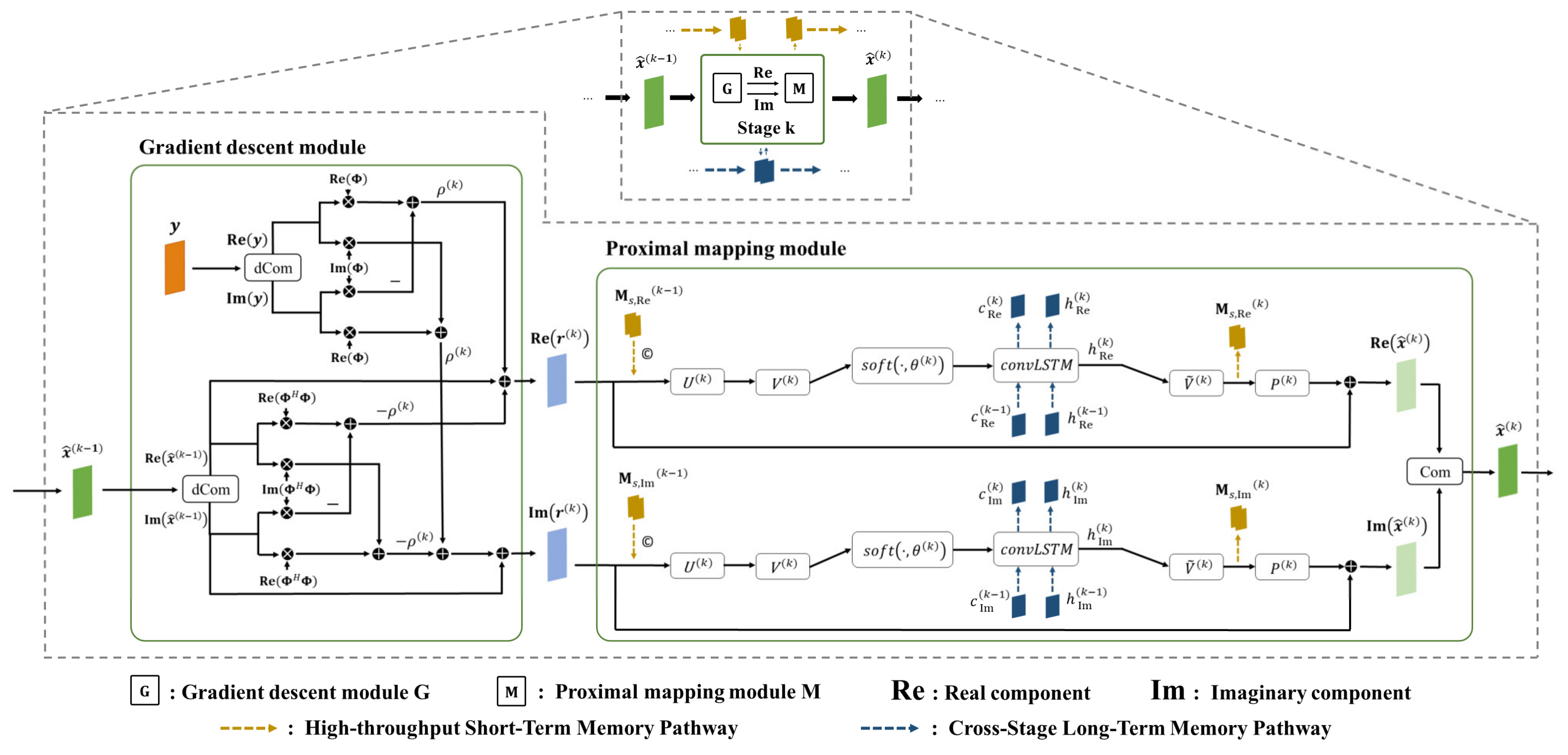
2.3.1. Gradient Descent Module
2.3.2. Proximal Mapping Module Combined with Memory Enhancement Mechanisms
2.4. Network Parameters and Loss Function
3. Results
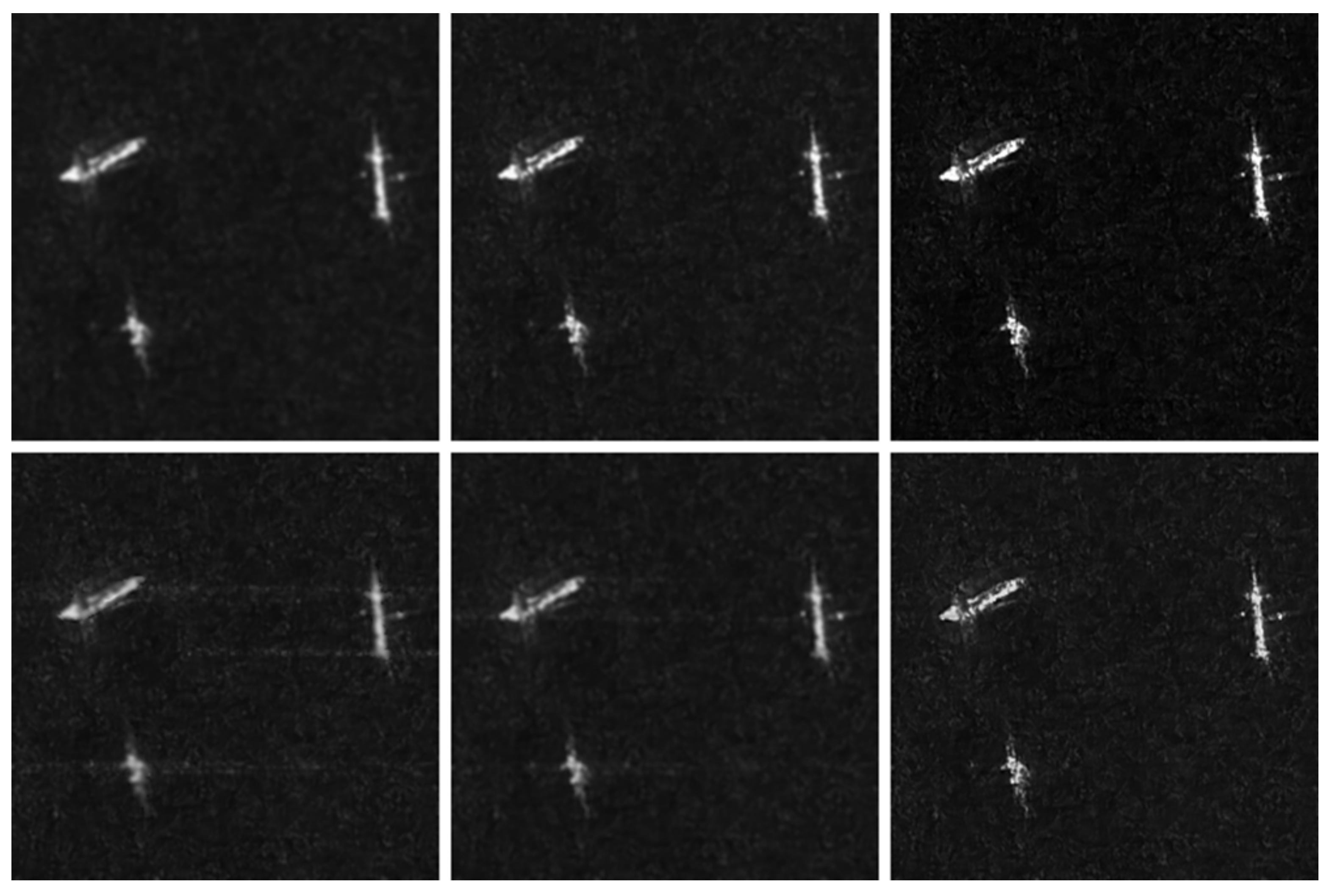
3.1. Simulated Experiments
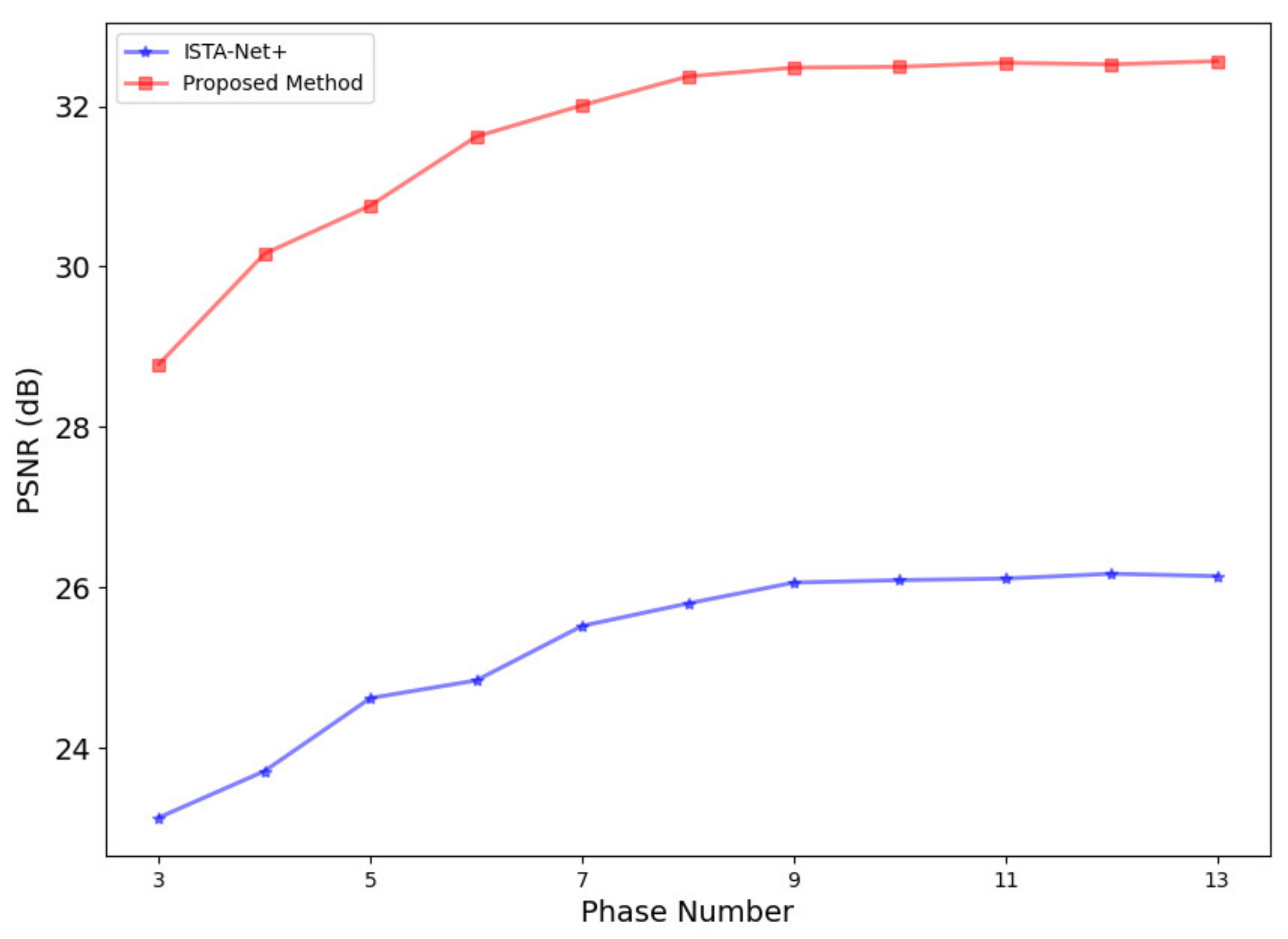
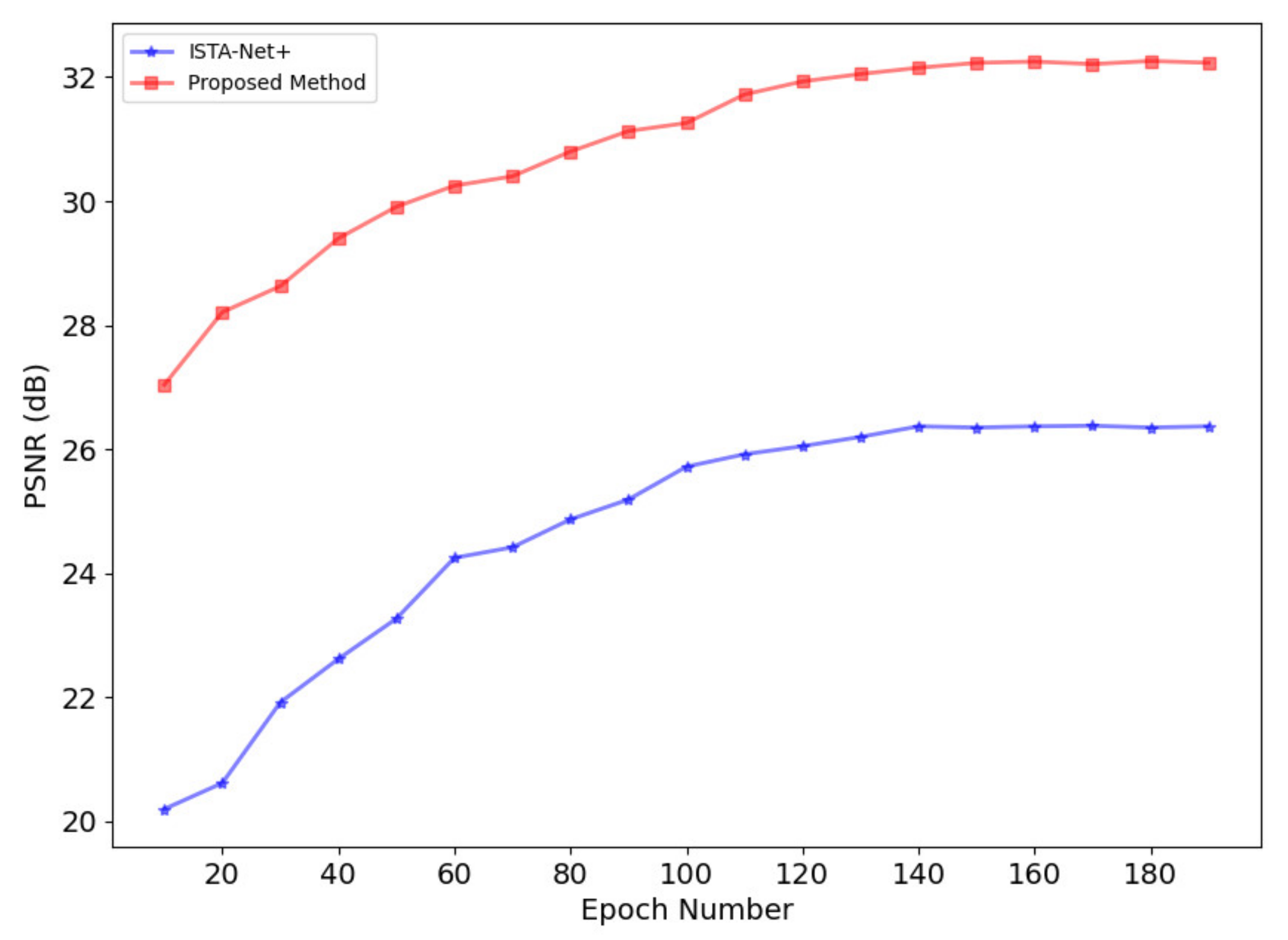
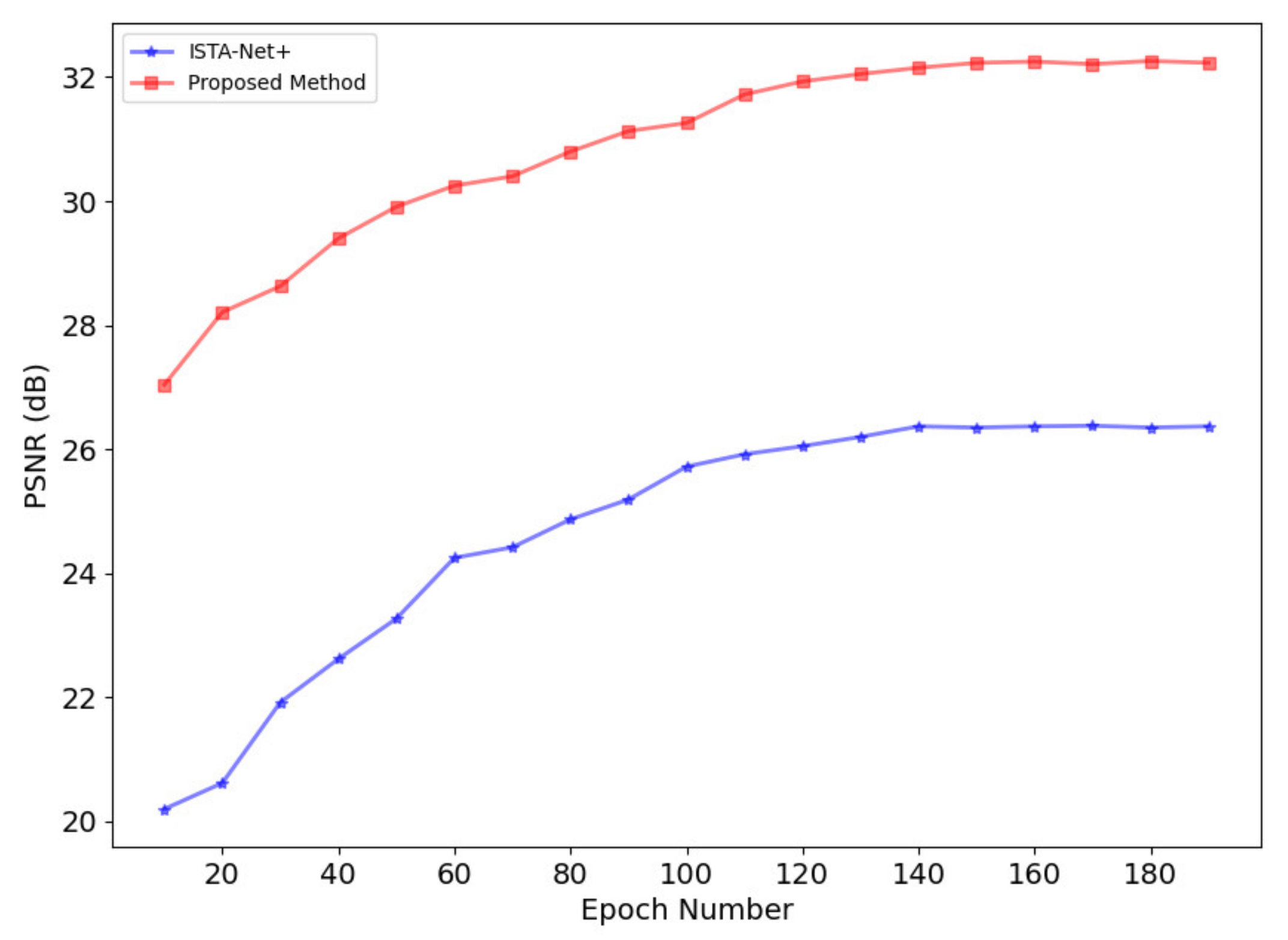
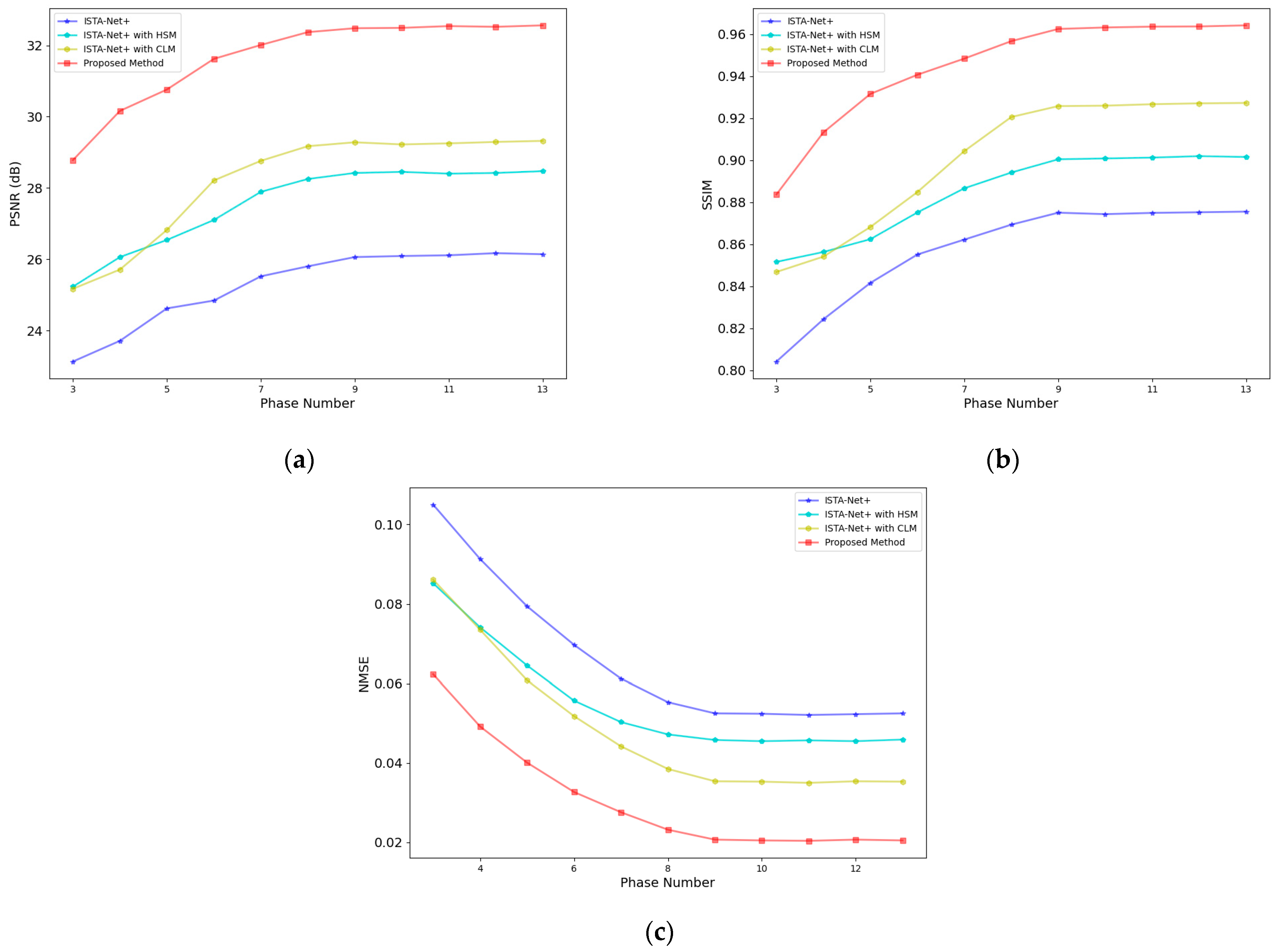
3.1.1. Optimization of Network Phases and Training Epochs
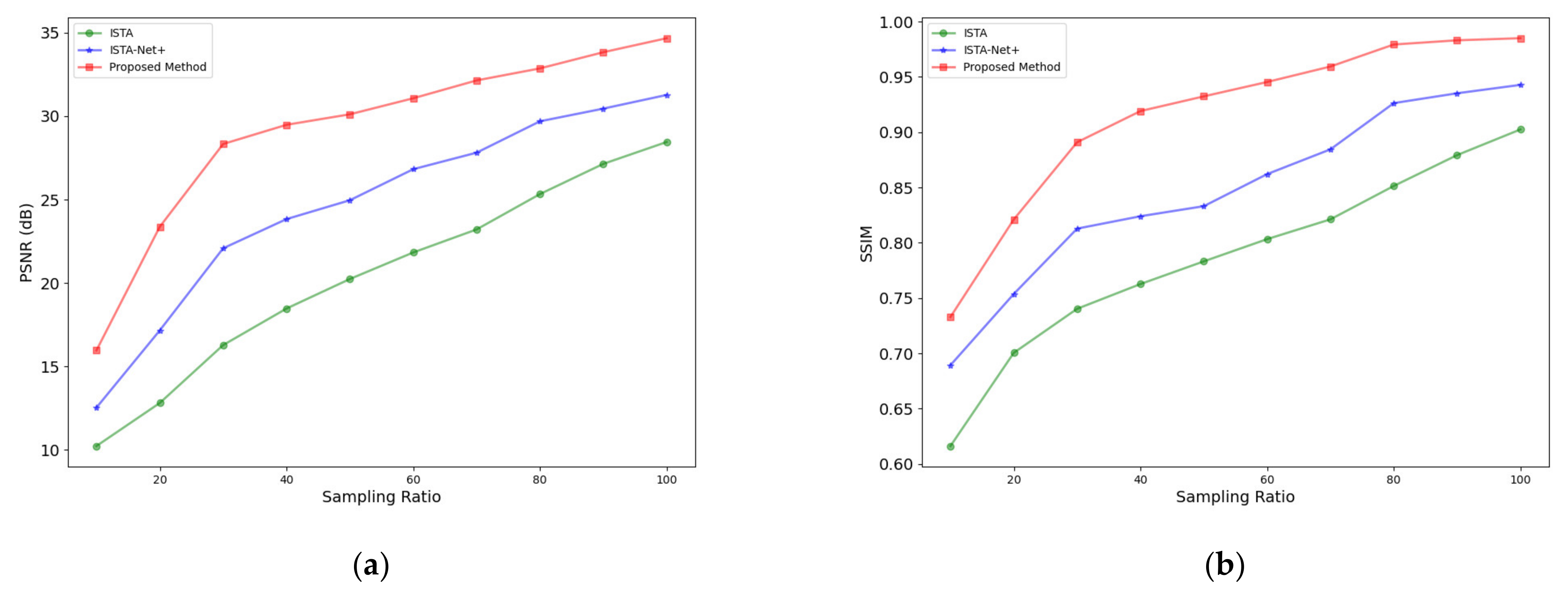
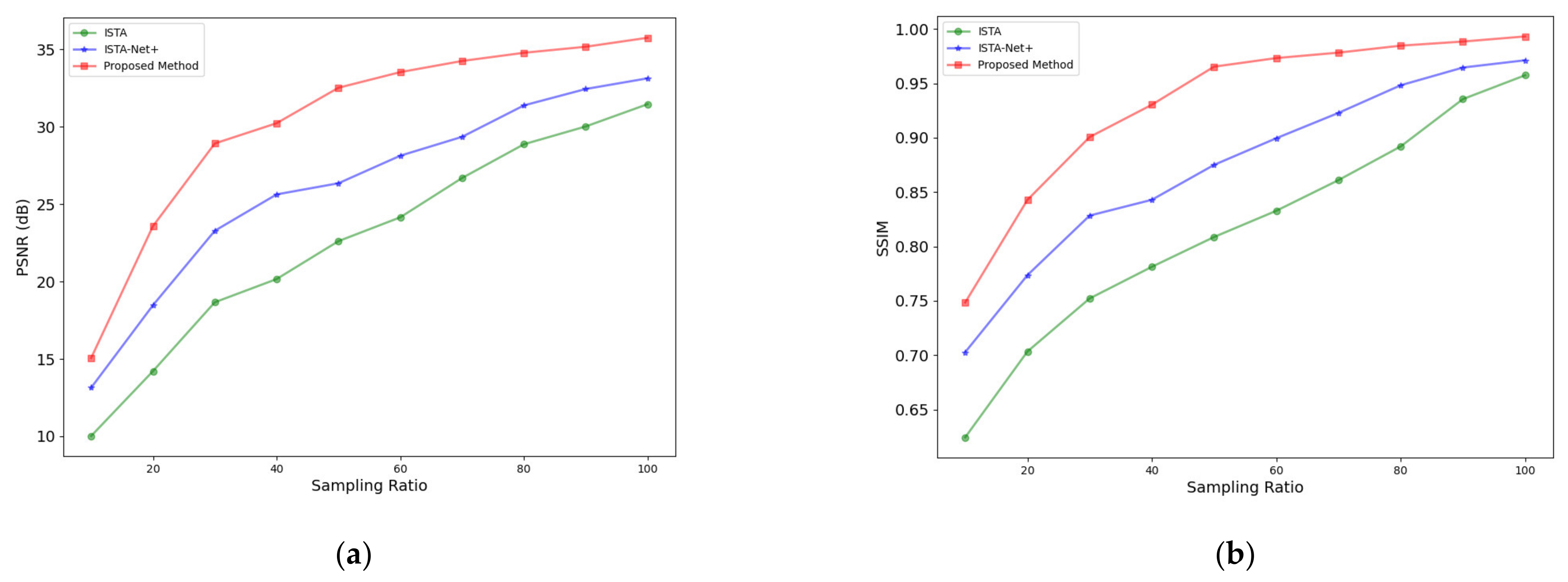
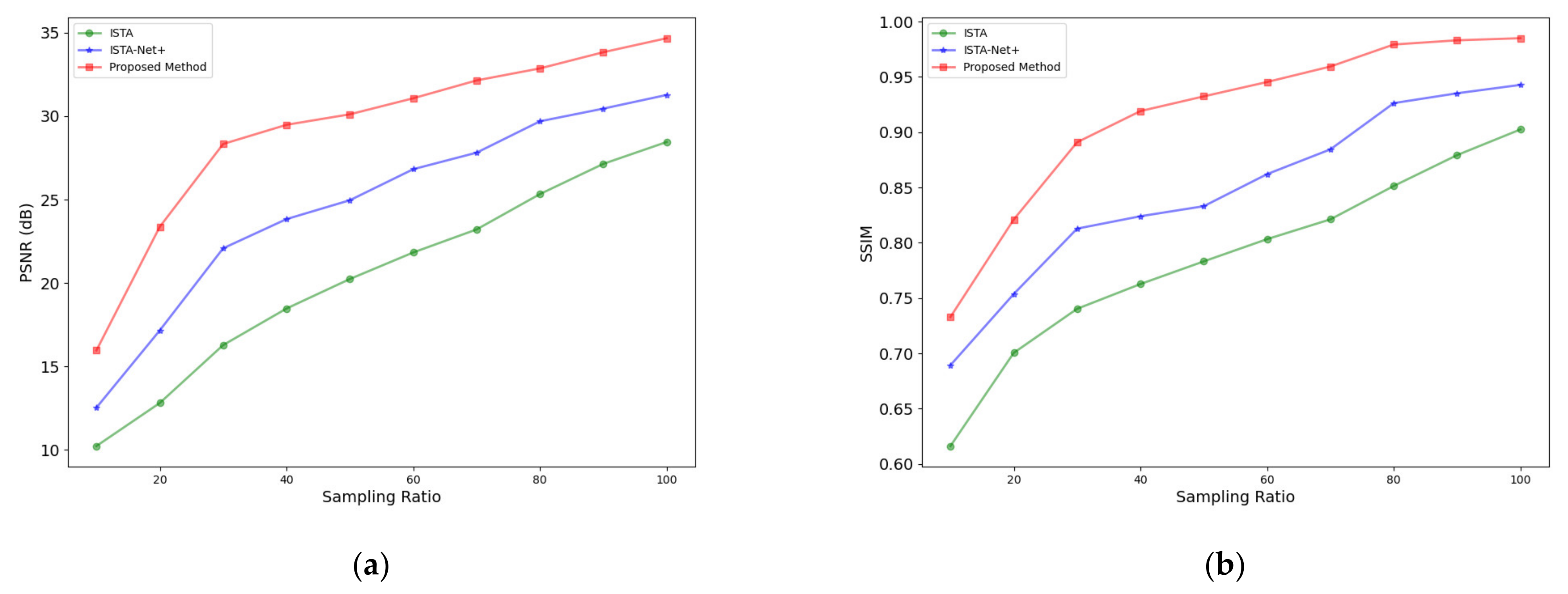
3.1.2. Results under Different Sampling Ratios
3.1.3. Evaluation of Phase Reconstruction Quality
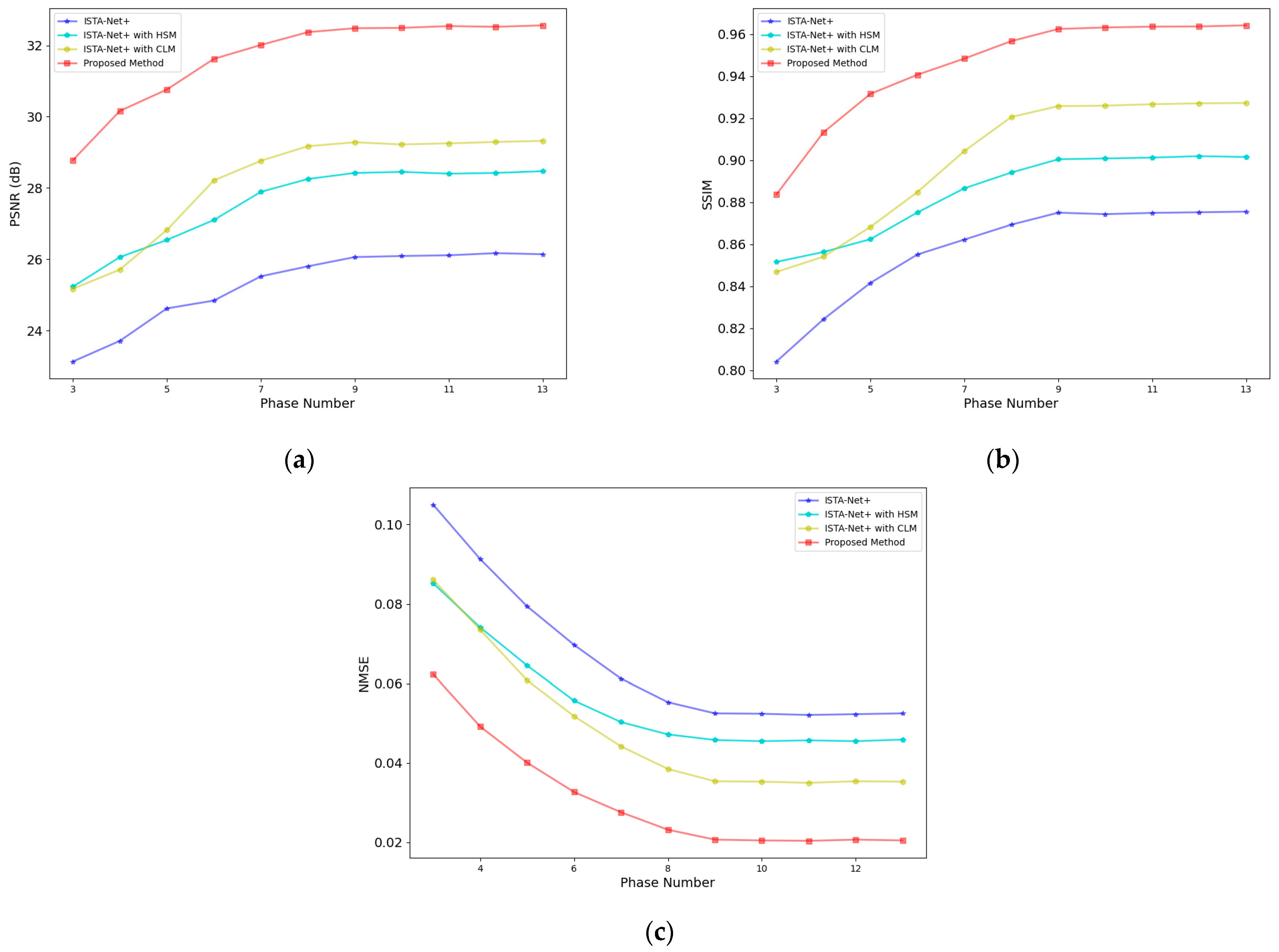
3.1.4. Ablation Experiments
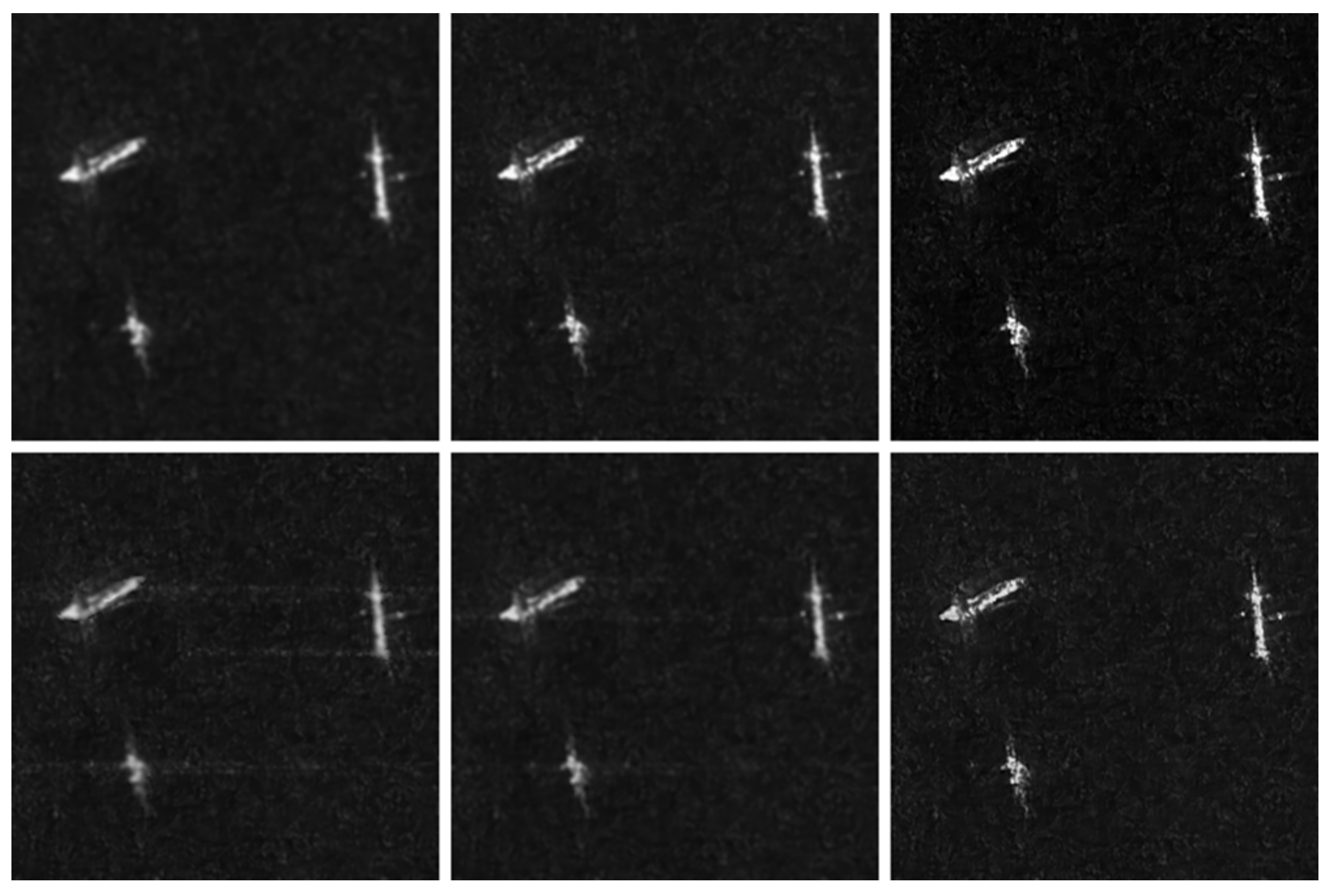
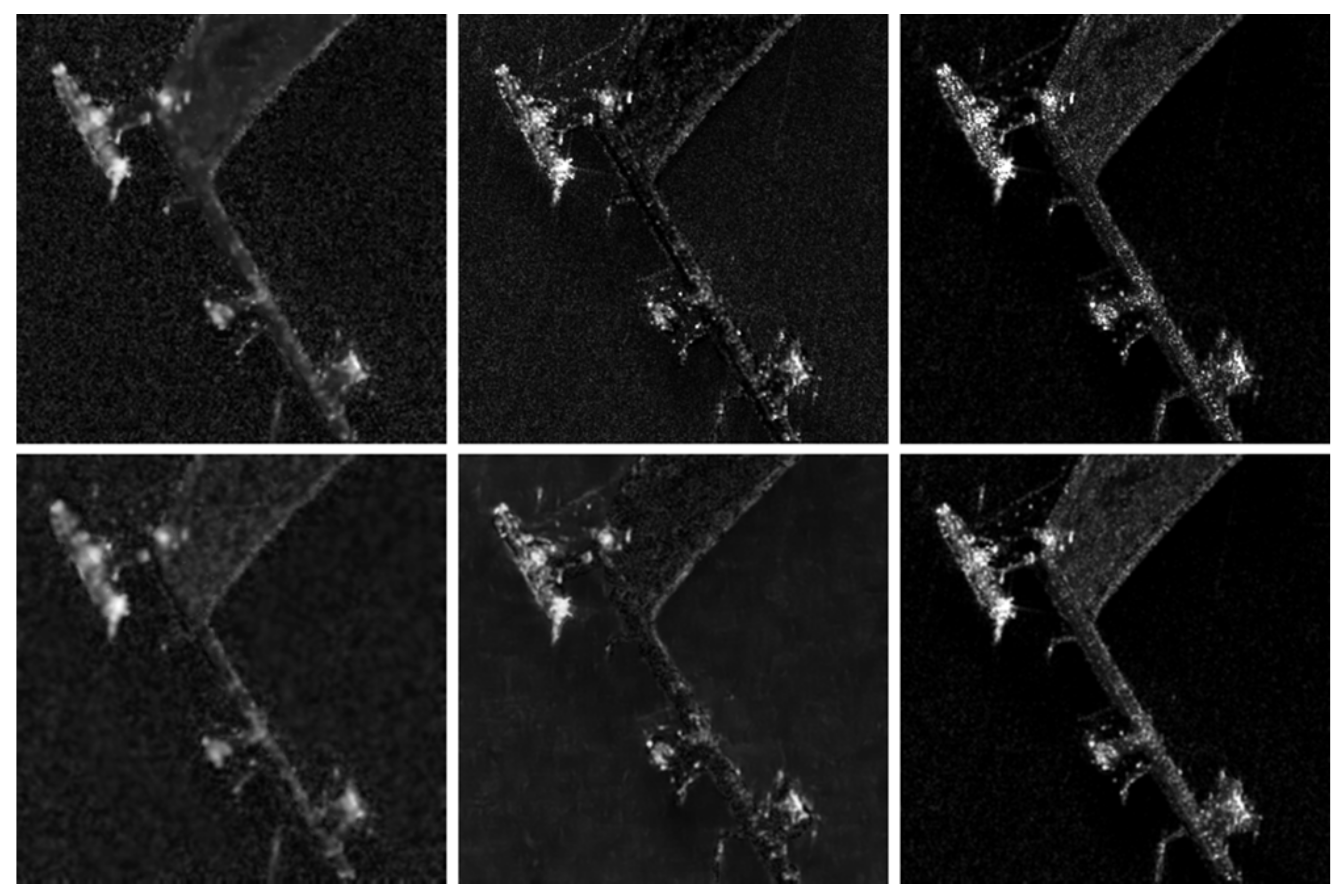
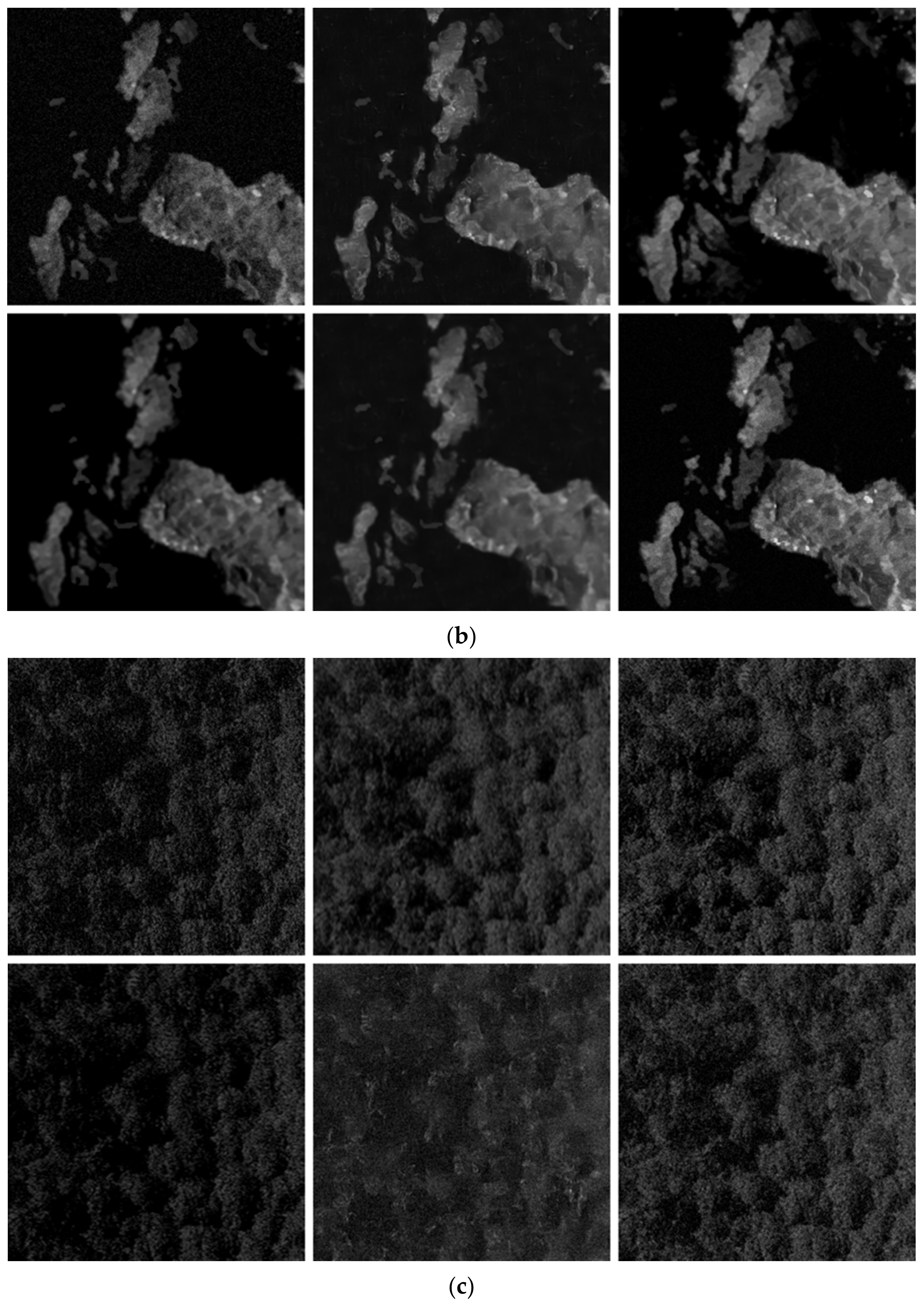
3.2. Measured Experiments
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wei, X.Y.; Zheng, W.; Xi, C.P.; Shang, S. Shoreline Extraction in SAR Image Based on Advanced Geometric Active Contour Model. Remote Sens. 2021, 13, 18. [Google Scholar] [CrossRef]
- Li, C.L.; Kim, D.J.; Park, S.; Kim, J.; Song, J. A self-evolving deep learning algorithm for automatic oil spill detection in Sentinel-1 SAR images. Remote Sens. Environ. 2023, 299, 14. [Google Scholar] [CrossRef]
- Donoho, D.L. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Dong, X.; Zhang, Y.H. SAR Image Reconstruction from Undersampled Raw Data Using Maximum A Posteriori Estimation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 1651–1664. [Google Scholar] [CrossRef]
- Xu, G.; Xia, X.G.; Hong, W. Nonambiguous SAR Image Formation of Maritime Targets Using Weighted Sparse Approach. IEEE Trans. Geosci. Remote Sens. 2018, 56, 1454–1465. [Google Scholar] [CrossRef]
- Monga, V.; Li, Y.L.; Eldar, Y.C. Algorithm Unrolling: Interpretable, Efficient Deep Learning for Signal and Image Processing. IEEE Signal Process Mag. 2021, 38, 18–44. [Google Scholar] [CrossRef]
- Zhang, J.; Chen, B.; Xiong, R.Q.; Zhang, Y.B. Physics-Inspired Compressive Sensing: Beyond deep unrolling. IEEE Signal Process Mag. 2023, 40, 58–72. [Google Scholar] [CrossRef]
- Zhao, Y.; Huang, W.K.; Quan, X.Y.; Ling, W.K.; Zhang, Z. Data-driven sampling pattern design for sparse spotlight SAR imaging. Electron. Lett. 2022, 58, 920–923. [Google Scholar] [CrossRef]
- Wei, Y.K.; Li, Y.C.; Ding, Z.G.; Wang, Y.; Zeng, T.; Long, T. SAR Parametric Super-Resolution Image Reconstruction Methods Based on ADMM and Deep Neural Network. IEEE Trans. Geosci. Remote Sens. 2021, 59, 10197–10212. [Google Scholar] [CrossRef]
- Hu, C.Y.; Li, Z.; Wang, L.; Guo, J.; Loffeld, O. Inverse Synthetic Aperture Radar Imaging Using a Deep ADMM Network. In Proceedings of the 20th International Radar Symposium (IRS), Ulm, Germany, 26–28 June 2019; pp. 1–9. [Google Scholar]
- Xiong, K.; Zhao, G.H.; Wang, Y.B.; Shi, G.M. SPB-Net: A Deep Network for SAR Imaging and Despeckling with Downsampled Data. IEEE Trans. Geosci. Remote Sens. 2021, 59, 9238–9256. [Google Scholar] [CrossRef]
- An, H.Y.; Jiang, R.L.; Wu, J.J.; Teh, K.C.; Sun, Z.C.; Li, Z.Y.; Yang, J.Y. LRSR-ADMM-Net: A Joint Low-Rank and Sparse Recovery Network for SAR Imaging. IEEE Trans. Geosci. Remote Sens. 2022, 60, 14. [Google Scholar] [CrossRef]
- Song, J.; Chen, B.; Zhang, J. Memory-Augmented Deep Unfolding Network for Compressive Sensing. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, Chengdu, China, 20–24 October 2021; pp. 4249–4258. [Google Scholar]
- Tibshirani, R. Regression Shrinkage and Selection Via the Lasso. J. R. Stat. Soc. Ser. B (Methodol.) 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Beck, A.; Teboulle, M. A Fast Iterative Shrinkage-Thresholding Algorithm for Linear Inverse Problems. SIAM J. Imag. Sci. 2009, 2, 183–202. [Google Scholar] [CrossRef]
- Li, C.B.; Yin, W.T.; Jiang, H.; Zhang, Y. An efficient augmented Lagrangian method with applications to total variation minimization. Comput. Optim. Appl. 2013, 56, 507–530. [Google Scholar] [CrossRef]
- Zhang, J.; Ghanem, B. ISTA-Net: Interpretable Optimization-Inspired Deep Network for Image Compressive Sensing. In Proceedings of the 31st IEaEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 1828–1837. [Google Scholar]
- Xu, G.; Zhang, B.J.; Yu, H.W.; Chen, J.L.; Xing, M.D.; Hong, W. Sparse Synthetic Aperture Radar Imaging from Compressed Sensing and Machine Learning: Theories, applications, and trends. IEEE Geosci. Remote Sens. Mag. 2022, 10, 32–69. [Google Scholar] [CrossRef]
- Shi, X.J.; Chen, Z.R.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. In Proceedings of the 29th Annual Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Sun, X.; Wang, Z.R.; Sun, Y.R. AIR-SARShip-1.0: High Resolution SAR Ship Detection Dataset. J. Radars 2019, 8, 852–862. [Google Scholar]
- Zhang, H.W.; Ni, J.C.; Li, K.M.; Luo, Y.; Zhang, Q. Nonsparse SAR Scene Imaging Network Based on Sparse Representation and Approximate Observations. Remote Sens. 2023, 15, 28. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Simulation | Sentinel-1 | GF-3 |
|---|---|---|---|
| Range FM rate | 1.3 MHz/µs | 1.93 MHz/µs | 1.33 MHz/µs |
| Center frequency | 5.4 GHz | 5.4 GHz | 5.4 GHz |
| Signal bandwidth | 60.5 MHz | 87.71 MHz | 60 MHz |
| Pulse duration | 45 µs | 45.5 µs | 45 µs |
| Pulse repetition frequency | 1200 Hz | 1871 Hz | 1150 Hz |
| Method | PSNR (dB)/SSIM | |
|---|---|---|
| η = 50% | η = 80% | |
| ISTA | 22.61/80.87% | 28.87/89.20% |
| ISTA-Net+ | 26.35/87.50% | 31.38/94.82% |
| Proposed Method | 32.52/96.53% | 34.78/98.46% |
| Method | PSNR (dB)/SSIM | |
|---|---|---|
| η = 50% | η = 80% | |
| ISTA | 20.24/78.32% | 25.33/85.14% |
| ISTA-Net+ | 24.96/83.31% | 29.69/92.63% |
| Proposed Method | 30.11/93.24% | 32.86/97.93% |
| Method | PSNR (dB)/SSIM/NMSE | |||
|---|---|---|---|---|
| K = 5 | K = 7 | K = 9 | K = 11 | |
| ISTA-Net+ | 24.62/84.16%/0.0794 | 25.52/86.22%/0.0612 | 26.06/87.50%/0.0525 | 26.11/87.45%/0.0521 |
| ISTA-Net+ with HSM | 26.54/86.24%/0.0645 | 27.89/88.66%/0.0503 | 28.42/90.04%/0.0458 | 28.4/90.01%/0.0457 |
| ISTA-Net+ with CLM | 26.82/86.82%/0.0608 | 28.76/90.43%/0.0442 | 29.28/92.57%/0.0354 | 29.25/92.58%/0.0350 |
| Proposed Method | 30.96/93.15%/0.0401 | 32.01/94.83%/0.0276 | 32.48/96.24%/0.0207 | 32.54/96.27%/0.0204 |
| Method | Time (ms) |
|---|---|
| ISTA-Net+ | 31.8 |
| ISTA-Net+ with HSM | 85.2 |
| ISTA-Net+ with CLM | 92.1 |
| Proposed Method | 156.7 |
| Scene | Sample Ratio (η) | ENT | ||
|---|---|---|---|---|
| ISTA | ISTA-Net+ | Proposed Method | ||
| Scene 1: Ship Scene | 80% | 3.51 | 2.82 | 2.35 |
| 50% | 4.22 | 3.47 | 2.87 | |
| Scene 2: Island Scene | 80% | 4.36 | 3.84 | 3.11 |
| 50% | 4.8 | 4.23 | 3.62 | |
| Scene 3: Wave Scene | 80% | 3.73 | 3.01 | 2.52 |
| 50% | 4.47 | 3.78 | 3.20 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Y.; Ou, C.; Tian, H.; Ling, B.W.-K.; Tian, Y.; Zhang, Z. Sparse SAR Imaging Algorithm in Marine Environments Based on Memory-Augmented Deep Unfolding Network. Remote Sens. 2024, 16, 1289. https://doi.org/10.3390/rs16071289
Zhao Y, Ou C, Tian H, Ling BW-K, Tian Y, Zhang Z. Sparse SAR Imaging Algorithm in Marine Environments Based on Memory-Augmented Deep Unfolding Network. Remote Sensing. 2024; 16(7):1289. https://doi.org/10.3390/rs16071289
Chicago/Turabian StyleZhao, Yao, Chengwen Ou, He Tian, Bingo Wing-Kuen Ling, Ye Tian, and Zhe Zhang. 2024. "Sparse SAR Imaging Algorithm in Marine Environments Based on Memory-Augmented Deep Unfolding Network" Remote Sensing 16, no. 7: 1289. https://doi.org/10.3390/rs16071289
APA StyleZhao, Y., Ou, C., Tian, H., Ling, B. W.-K., Tian, Y., & Zhang, Z. (2024). Sparse SAR Imaging Algorithm in Marine Environments Based on Memory-Augmented Deep Unfolding Network. Remote Sensing, 16(7), 1289. https://doi.org/10.3390/rs16071289