
Lightweight and Stable Multi-Feature Databases for Efficient Geometric Localization of Remote Sensing Images



Abstract
1. Introduction
- Feature descriptor limitations: The stable feature class focuses on typical feature point neighborhoods, excluding all imaging conditions in the training set.
- Feature descriptor redundancy: After training and storage, redundant scene descriptors persist in the database, with floating-point descriptors consuming more space.
- Feature form singularity: Limited point features miss out on leveraging the universality of feature databases.
- Stable feature database construction: Building the stable feature database by combining the iterative matching filtering strategy and AP to store non-redundant descriptors under multiple imaging conditions, thus enhancing matching stability.
- Lightweight feature descriptor: LDAHash is employed to derive binary descriptors for high-capacity floating-point descriptors, thereby effectively reducing storage demands.
- Feature enrichment in the database: The introduction of multi-scale region features and RIFT to the stable feature databases enriches the type of feature database and extends the applicable scenarios.
2. Materials and Methods
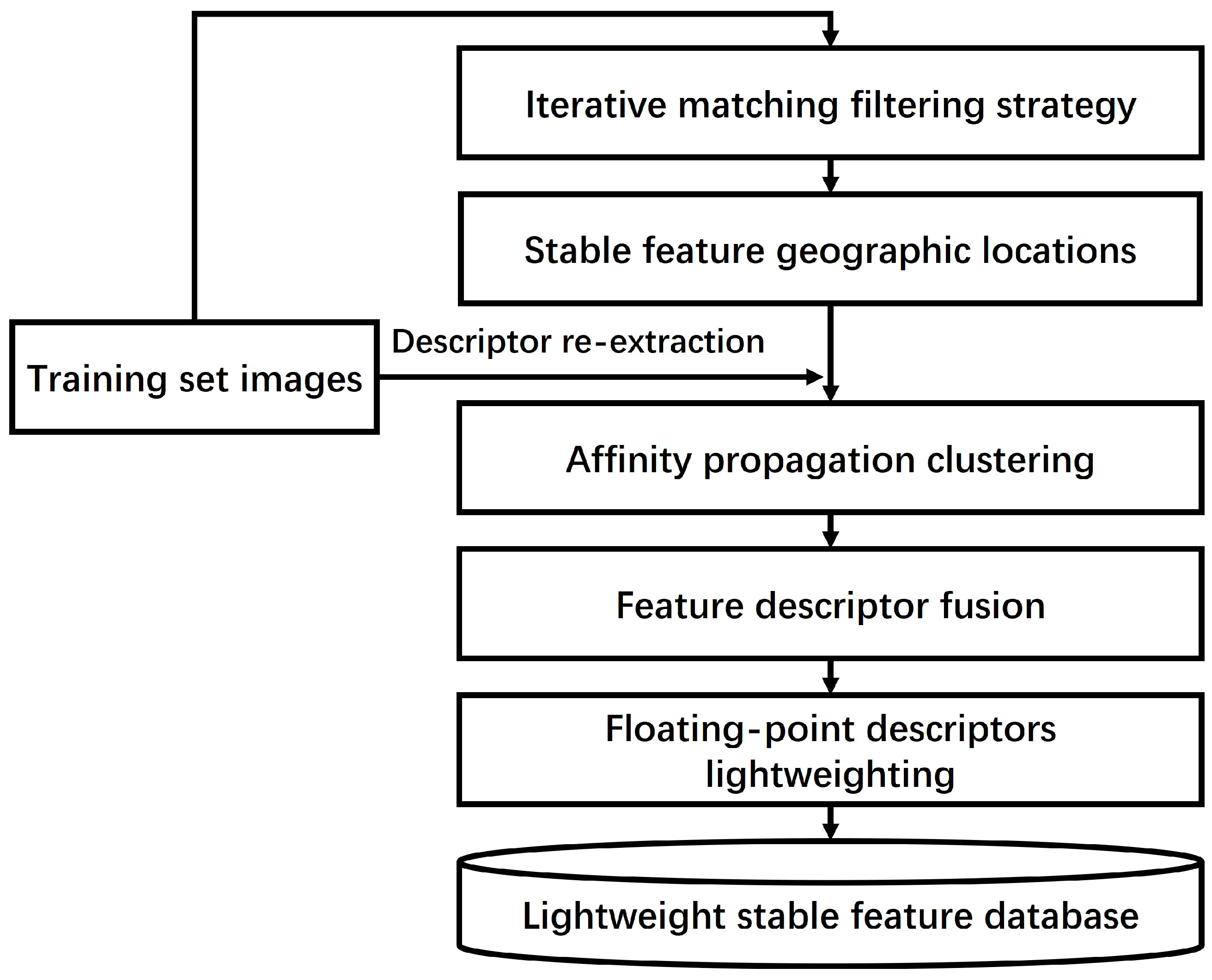
2.1. Stable Feature Database Construction Based on Iterative Matching Filtering Strategy and Affinity Propagation
2.1.1. Stable Feature Filtering Based on an Iterative Matching Filtering Strategy
| Algorithm 1: Feature Database Construction |
 |
2.1.2. Same-Location Descriptor Clustering and Fusion Based on AP
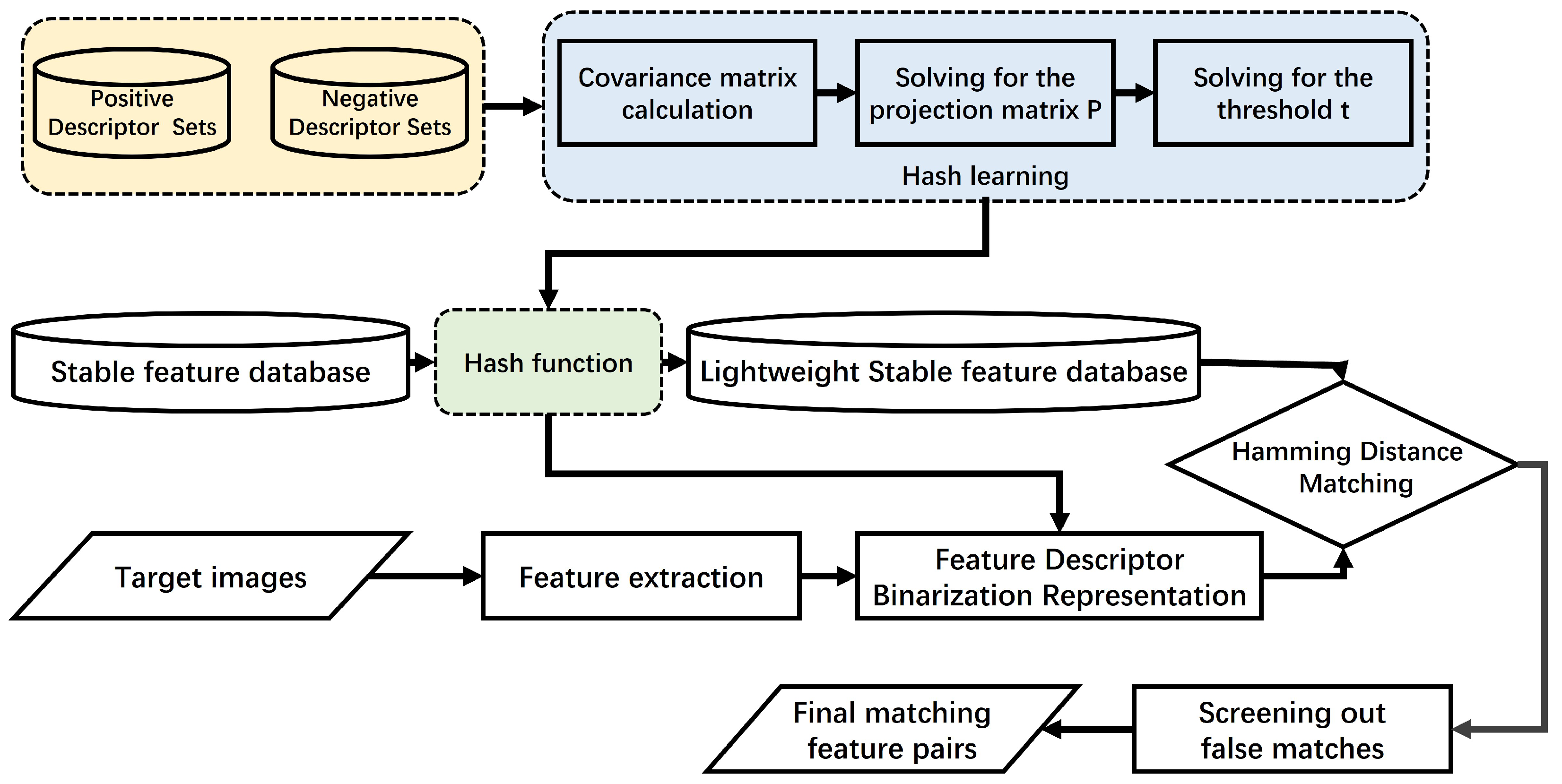
2.2. LDAHash-Based Floating-Point Descriptor Lightweighting
2.2.1. LDAHash
2.2.2. Projection Matrix P Solution
2.2.3. Threshold Vector t Solution
3. Experiments and Results
3.1. Image Data
3.2. Experimental Setup and Evaluation Criterion
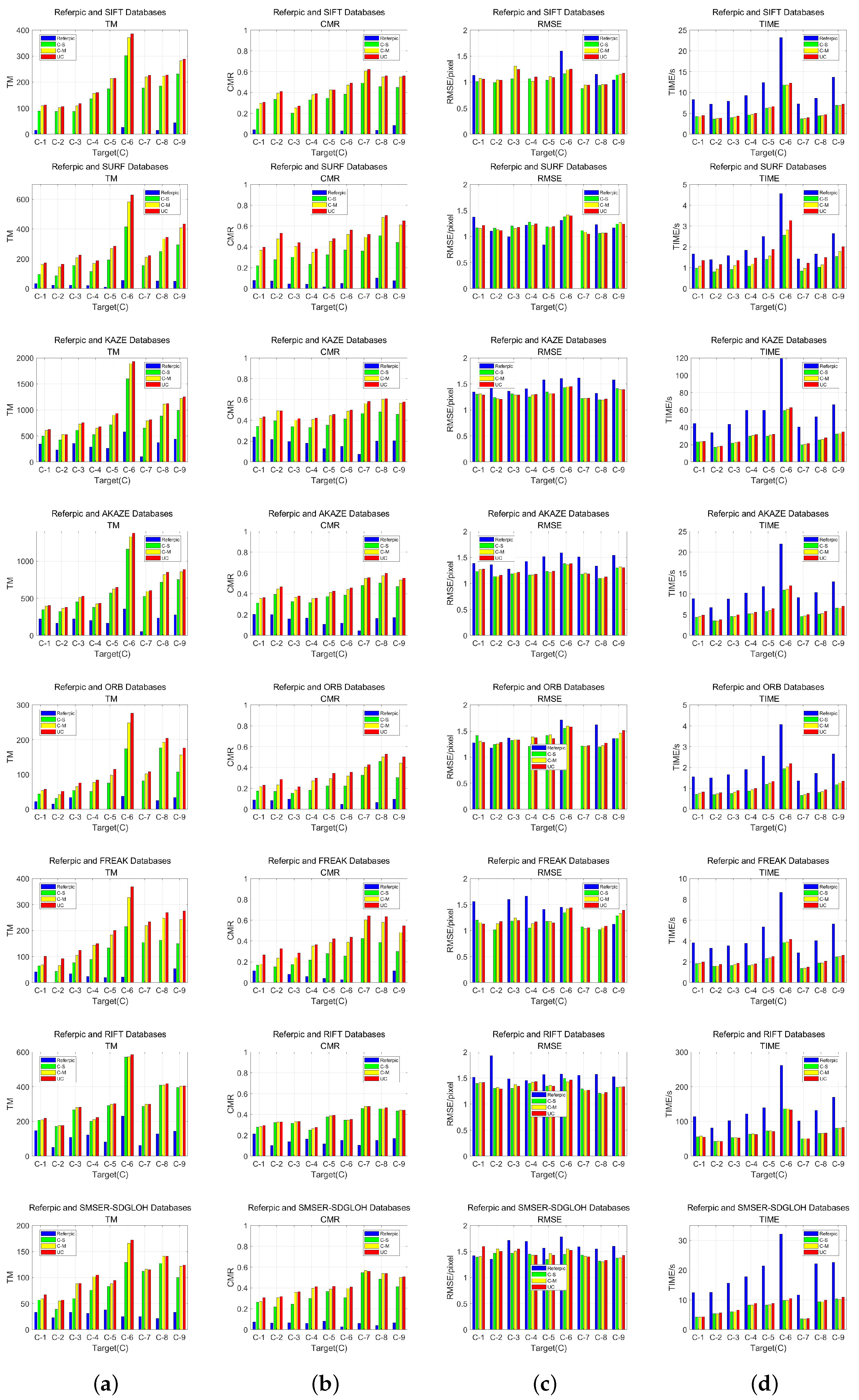
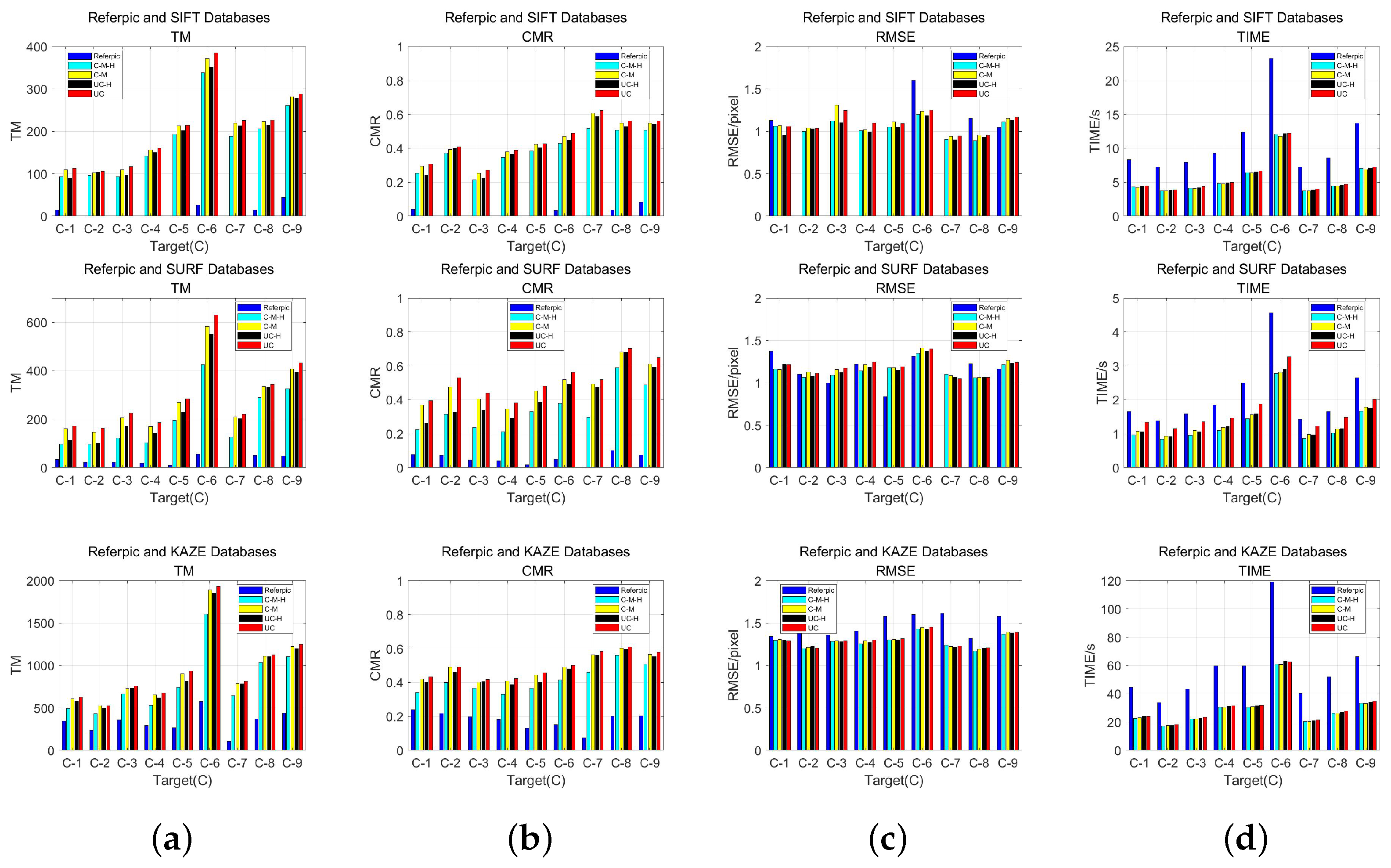
- Correct Matching Ratio (CMR): CMR in this paper is defined as the ratio of the total number of matches (TM) obtained after the false match filtering process to the total number of features () extracted from the feature database. Higher CMR indicates better matching of matching methods. CMR in this paper is calculated at the feature class level. When multiple descriptors in a feature class have matches, they are treated as a single match, considering only the total number of matches for each feature class.
- Root Mean Square Error (RMSE): RMSE is used to reflect the geometric localization accuracy of the feature matching method. Where denotes the coordinates of the matched features in the reference image or feature database and denotes the corresponding coordinates of the matched points in the target image after geometric correction. The smaller RMSE denotes a higher degree of geometric localization accuracy.
- TIME: TIME is the total time spent on feature extraction and matching between the reference image or feature database and the target image, reflecting the efficiency of the matching method.
3.3. Experiment Analysis
3.3.1. Matching of Stable Feature Databases
3.3.2. Matching of Lightweight and Stable Feature Databases
4. Discussion
5. Conclusions
- Feature stability: The stability of the features stored in the database is somewhat improved through the implementation of the training set filtering strategy.
- Descriptions richness: Utilizing AP to obtain multiple imaging condition descriptors at the same point to enhance matching possibilities.
- Storage efficiency: AP reduces redundancy in the feature databases, while LDAHash converts floating-point descriptors into binary representations, resulting in significant space savings.
- Universality of multiple features: Our feature databases can incorporate various features, including point features and region features. This flexibility allows for a more comprehensive reference in practical applications.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Du, Q.; Nekovei, R. Fast real-time onboard processing of hyperspectral imagery for detection and classification. J. Real-Time Image Process. 2009, 4, 273–286. [Google Scholar] [CrossRef]
- Long, T.; Jiao, W.; He, G.; Yin, R.; Wang, G.; Zhang, Z. Block Adjustment With Relaxed Constraints From Reference Images of Coarse Resolution. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7815–7828. [Google Scholar] [CrossRef]
- Lai, G.; Zhang, Y.; Tong, X.; Wu, Y. Method for the Automatic Generation and Application of Landmark Control Point Library. IEEE Access 2020, 8, 112203–112219. [Google Scholar] [CrossRef]
- Pi, Y.; Xie, B.; Yang, B.; Zhang, Y.; Li, X.; Wang, M. On-orbit geometric calibration of Linear push-broom optical satellite based on sparse GCPs. J. Geod. Geoinf. Sci. 2020, 3, 64. [Google Scholar]
- Wang, T.; Zhang, G.; Li, D.; Tang, X.; Jiang, Y.; Pan, H.; Zhu, X. Planar block adjustment and orthorectification of ZY-3 satellite images. Photogramm. Eng. Remote Sens. 2014, 80, 559–570. [Google Scholar] [CrossRef]
- Liu, D.; Zhou, G.; Zhang, D.; Zhou, X.; Li, C. Ground control point automatic extraction for spaceborne georeferencing based on FPGA. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3350–3366. [Google Scholar] [CrossRef]
- Wang, M.; Zhang, Z.; Zhu, Y.; Dong, Z.; Li, Y. Embedded GPU implementation of sensor correction for on-board real-time stream computing of high-resolution optical satellite imagery. J. Real-Time Image Process. 2018, 15, 565–581. [Google Scholar] [CrossRef]
- Salazar, C.; Gonzalez-Llorente, J.; Cardenas, L.; Mendez, J.; Rincon, S.; Rodriguez-Ferreira, J.; Acero, I.F. Cloud Detection Autonomous System Based on Machine Learning and COTS Components On-Board Small Satellites. Remote Sens. 2022, 14, 5597. [Google Scholar] [CrossRef]
- Yang, J.; Zhao, Z. A fast geometric rectification of remote sensing imagery based on feature ground control point database. WSEAS Trans. Comput. 2009, 8, 195–204. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Van Gool, L. Surf: Speeded up robust features. In Proceedings of the Computer Vision–ECCV 2006: 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Proceedings, Part I 9. Springer: Berlin/Heidelberg, Germany, 2006; pp. 404–417. [Google Scholar]
- Ji, S.; Zhang, Y.; Dong, Y.; Fan, D. Spaceborne lightweight image control points generation method. Acta Geod. Et Cartogr. Sin. 2022, 51, 413–425. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Kelman, A.; Sofka, M.; Stewart, C.V. Keypoint descriptors for matching across multiple image modalities and non-linear intensity variations. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–7. [Google Scholar]
- Schowengerdt, R.A. CHAPTER 8—Image Registration and Fusion. In Remote Sensing (Third Edition); Schowengerdt, R.A., Ed.; Academic Press: Burlington, VT, USA, 2007; pp. 355–385, XXIV–XXVI. [Google Scholar] [CrossRef]
- Feng, R.; Du, Q.; Li, X.; Shen, H. Robust registration for remote sensing images by combining and localizing feature-and area-based methods. ISPRS J. Photogramm. Remote Sens. 2019, 151, 15–26. [Google Scholar] [CrossRef]
- Sedaghat, A.; Mokhtarzade, M.; Ebadi, H. Uniform robust scale-invariant feature matching for optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2011, 49, 4516–4527. [Google Scholar] [CrossRef]
- Alcantarilla, P.F.; Bartoli, A.; Davison, A.J. KAZE features. In Proceedings of the Computer Vision–ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Proceedings, Part VI 12. Springer: Berlin/Heidelberg, Germany, 2012; pp. 214–227. [Google Scholar]
- Alcantarilla, P.F.; Solutions, T. Fast explicit diffusion for accelerated features in nonlinear scale spaces. IEEE Trans. Patt. Anal. Mach. Intell 2011, 34, 1281–1298. [Google Scholar]
- Mikolajczyk, K.; Schmid, C. A performance evaluation of local descriptors. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1615–1630. [Google Scholar] [CrossRef] [PubMed]
- Tola, E.; Lepetit, V.; Fua, P. Daisy: An efficient dense descriptor applied to wide-baseline stereo. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 815–830. [Google Scholar]
- Sedaghat, A.; Ebadi, H. Remote sensing image matching based on adaptive binning SIFT descriptor. IEEE Trans. Geosci. Remote Sens. 2015, 53, 5283–5293. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Leutenegger, S.; Chli, M.; Siegwart, R.Y. BRISK: Binary robust invariant scalable keypoints. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2548–2555. [Google Scholar]
- Alahi, A.; Ortiz, R.; Vandergheynst, P. Freak: Fast retina keypoint. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 510–517. [Google Scholar]
- Feng, R.; Shen, H.; Bai, J.; Li, X. Advances and opportunities in remote sensing image geometric registration: A systematic review of state-of-the-art approaches and future research directions. IEEE Geosci. Remote Sens. Mag. 2021, 9, 120–142. [Google Scholar] [CrossRef]
- Ye, Y.; Shan, J.; Bruzzone, L.; Shen, L. Robust registration of multimodal remote sensing images based on structural similarity. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2941–2958. [Google Scholar] [CrossRef]
- Fan, J.; Wu, Y.; Li, M.; Liang, W.; Cao, Y. SAR and optical image registration using nonlinear diffusion and phase congruency structural descriptor. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5368–5379. [Google Scholar] [CrossRef]
- Li, J.; Hu, Q.; Ai, M. RIFT: Multi-modal image matching based on radiation-variation insensitive feature transform. IEEE Trans. Image Process. 2019, 29, 3296–3310. [Google Scholar] [CrossRef] [PubMed]
- Viswanathan, D.G. Features from accelerated segment test (fast). In Proceedings of the 10th Workshop on Image Analysis for Multimedia Interactive Services, London, UK, 6–8 May 2009; pp. 6–8. [Google Scholar]
- Harris, C.; Stephens, M. A combined corner and edge detector. In Proceedings of the Alvey Vision Conference, Manchester, UK, September 1988; Citeseer: Princeton, NJ, USA, 1988; Volume 15, pp. 147–152. [Google Scholar]
- Tuytelaars, T.; Mikolajczyk, K. Local invariant feature detectors: A survey. Found. Trends® Comput. Graph. Vis. 2008, 3, 177–280. [Google Scholar] [CrossRef]
- Tuytelaars, T.; Van Gool, L.; Mirmehdi, M.; Thomas, B.T. Wide baseline stereo matching based on local, affinely invariant regions. In Proceedings of the BMVC, Bristol, UK, 11–14 September 2000; British Machine Vision Association: Durham, UK, 2000. [Google Scholar]
- Tuytelaars, T.; Van Gool, L. Matching widely separated views based on affine invariant regions. Int. J. Comput. Vis. 2004, 59, 61–85. [Google Scholar] [CrossRef]
- Matas, J.; Chum, O.; Urban, M.; Pajdla, T. Robust wide-baseline stereo from maximally stable extremal regions. Image Vis. Comput. 2004, 22, 761–767. [Google Scholar] [CrossRef]
- Liu, L.; Tuo, H.; Xu, T.; Jing, Z. Multi-spectral image registration and evaluation based on edge-enhanced MSER. Imaging Sci. J. 2014, 62, 228–235. [Google Scholar] [CrossRef]
- Martins, P.; Carvalho, P.; Gatta, C. On the completeness of feature-driven maximally stable extremal regions. Pattern Recognit. Lett. 2016, 74, 9–16. [Google Scholar] [CrossRef]
- Zhao, Z.; Wang, F.; You, H. Robust Region Feature Extraction with Salient MSER and Segment Distance-weighted GLOH for Remote Sensing Image Registration. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 17, 2475–2488. [Google Scholar] [CrossRef]
- Ordóñez, Á.; Acción, Á.; Argüello, F.; Heras, D.B. HSI-MSER: Hyperspectral Image Registration Algorithm Based on MSER and SIFT. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 12061–12072. [Google Scholar] [CrossRef]
- Śluzek, A. Improving performances of MSER features in matching and retrieval tasks. In Proceedings of the Computer Vision–ECCV 2016 Workshops, Amsterdam, The Netherlands, 8–10 and 15–16 October 2016; Proceedings, Part III 14. Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Zhang, Q.; Wang, Y.; Wang, L. Registration of images with affine geometric distortion based on maximally stable extremal regions and phase congruency. Image Vis. Comput. 2015, 36, 23–39. [Google Scholar] [CrossRef]
- Zhang, Y.; Guo, Y.; Gu, Y. Robust feature matching and selection methods for multisensor image registration. In Proceedings of the 2009 IEEE International Geoscience and Remote Sensing Symposium, Cape Town, South Africa, 12–17 July 2009; Volume 3, p. III-255. [Google Scholar]
- Zhao, Z.; Long, H.; You, H. An Optical Remote Sensing Image Matching Method Based on the Simple and Stable Feature Database. Appl. Sci. 2023, 13, 4632. [Google Scholar] [CrossRef]
- Frey, B.J.; Dueck, D. Clustering by passing messages between data points. Science 2007, 315, 972–976. [Google Scholar] [CrossRef] [PubMed]
- Strecha, C.; Bronstein, A.; Bronstein, M.; Fua, P. LDAHash: Improved matching with smaller descriptors. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 66–78. [Google Scholar] [CrossRef] [PubMed]
- Cheng, L.; Pian, Y.; Chen, Z.; Jiang, P.; Liu, Y.; Chen, G.; Du, P.; Li, M. Hierarchical filtering strategy for registration of remote sensing images of coral reefs. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 3304–3313. [Google Scholar] [CrossRef]
- Jiang, X.; Ma, J.; Fan, A.; Xu, H.; Lin, G.; Lu, T.; Tian, X. Robust feature matching for remote sensing image registration via linear adaptive filtering. IEEE Trans. Geosci. Remote Sens. 2020, 59, 1577–1591. [Google Scholar]
- Ghiasi, Y.; Duguay, C.R.; Murfitt, J.; Asgarimehr, M.; Wu, Y. Potential of GNSS-R for the Monitoring of Lake Ice Phenology. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 17, 660–673. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Single Feature Storage Content | Description |
|---|---|
| Feature Properties | geographic coordinate, response, angle, size, octave |
| Update Parameters | number of matches (M), number of unmatched matches (), number of consecutive matches (), number of consecutive unmatched matches (), feature class label |
| Feature Descriptor | multi-dimensional feature vector |
| Image | Source | Number | Date | Size (Pixel × Pixel) | Resolution (m) |
|---|---|---|---|---|---|
| Reference (A) | Google Earth | 1 | 2016 | 53,120 × 49,152 | 1.19 |
| Training (B) | GF-2 | 50 | 2016–2022 | 27,620 × 29,200 | 0.81 |
| Target (C) | JL-1 (C-1 C-2 C-3) | 3 | 2019–2020 | 28,651 × 28,720 | 0.75 |
| GF-1 (C-4 C-5 C-6) | 3 | 2019–2021 | 18,236 × 18,190 | 2 | |
| GF-2 (C-7 C-8 C-9) | 3 | 2019–2021 | 27,620 × 29,200 | 0.81 |
| Database Type | SIFT | SURF | KAZE | AKAZE | ORB | FREAK | RIFT | SMSER-SDGLOH-4 m |
|---|---|---|---|---|---|---|---|---|
| Unclustered (UC) | 16.90 | 26.90 | 92.00 | 14.50 | 2.58 | 5.29 | 63.00 | 12.90 |
| Clustered Multi-descriptor (C-M) | 8.42 | 12.70 | 46.80 | 5.29 | 0.86 | 1.46 | 33.60 | 5.99 |
| Clustered Single-descriptor (C-S) | 2.18 | 3.32 | 11.50 | 0.99 | 0.19 | 0.31 | 7.76 | 1.63 |
| Database Type | SIFT | SURF | KAZE |
|---|---|---|---|
| Unclustered (UC) | 16.90 | 26.90 | 92.00 |
| Unclustered-Hash (UC-H) | 1.83 | 2.43 | 9.37 |
| Clustered Multi-descriptor (C-M) | 8.42 | 12.70 | 46.80 |
| Clustered Multi-descriptor-Hash (C-M-H) | 0.60 | 0.83 | 3.50 |
| Feature Attributes | Regions | Points |
|---|---|---|
| Feature Composition | a set of interconnected pixel points | discrete points |
| Distribution Density | sparse | dense |
| Registration Accuracy | relatively lower | higher |
| Stability | small variation | susceptible to noise |
| Application | rough localization of a wide range of primary points | fine and dense localization |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Z.; Wang, F.; You, H. Lightweight and Stable Multi-Feature Databases for Efficient Geometric Localization of Remote Sensing Images. Remote Sens. 2024, 16, 1237. https://doi.org/10.3390/rs16071237
Zhao Z, Wang F, You H. Lightweight and Stable Multi-Feature Databases for Efficient Geometric Localization of Remote Sensing Images. Remote Sensing. 2024; 16(7):1237. https://doi.org/10.3390/rs16071237
Chicago/Turabian StyleZhao, Zilu, Feng Wang, and Hongjian You. 2024. "Lightweight and Stable Multi-Feature Databases for Efficient Geometric Localization of Remote Sensing Images" Remote Sensing 16, no. 7: 1237. https://doi.org/10.3390/rs16071237
APA StyleZhao, Z., Wang, F., & You, H. (2024). Lightweight and Stable Multi-Feature Databases for Efficient Geometric Localization of Remote Sensing Images. Remote Sensing, 16(7), 1237. https://doi.org/10.3390/rs16071237