1. Introduction
Hyperspectral imaging (HSI), a pioneering remote sensing technology, has proven its distinct benefits across various domains in recent years. This technology surpasses traditional imaging by offering richer, more detailed data for precise object identification and analysis. It achieves this by capturing continuous spectral information ranging from visible light to near-infrared bands. The evolution of HSI has not only revolutionized traditional Earth observation and environmental monitoring but also demonstrated its exceptional application value in urban planning, disaster management, and agriculture [
1,
2,
3,
4]. However, the intricate and high-dimensional nature of hyperspectral data poses significant challenges to effective data analysis and processing. This complexity necessitates ongoing research to discover more efficient data processing and analysis methods.
In the initial stages, traditional methods such as support vector machines (SVMs) [
5,
6], random forests (RFs) [
7], k-NN [
8], and PCA [
9] were commonly employed for hyperspectral image classification. Among these, the SVM model, despite its compactness, struggled with identifying an appropriate nonlinear kernel function. RF, by integrating multiple decision trees, exhibited superior generalization capabilities but demanded substantial computational resources. While k-NN offered flexibility by adjusting the k value to suit different problems, it often underperformed with category-imbalanced datasets. PCA, based on linear assumptions, found it challenging to handle nonlinear data structures. Furthermore, these traditional methods typically relied on manually designed features and lacked the capacity to extract deep features, rendering them often ineffective for hyperspectral image classification tasks.
In recent years, the swift advancement of deep learning technology has significantly propelled hyperspectral image classification technology. The goal is to harness the capabilities of sophisticated neural network architectures for more robust and efficient classification. Early deep learning methods, such as stacked autoencoders (SAEs) and deep belief networks (DBNs) [
10], set the groundwork by emphasizing feature extraction through fully connected layers. However, these methods’ reliance on fully connected layers led to a large number of network parameters and necessitated diverse training data.
To mitigate these issues, the convolutional neural network (CNN) [
11] was introduced into HSI classification. Qing et al. [
12] proposed a multiscale residual convolutional neural network model, MRA-NET, for hyperspectral image classification, focusing on efficient channel attention network fusion. Bhatti et al. [
13] introduced the local similarity projection Gabor filter (LSPGF) algorithm for hyperspectral image classification, combining dimensionality reduction via local similarity projection and 2D Gabor filtering with CNN-based feature extraction. Several researchers have employed 3D CNNs for hyperspectral image classification tasks. Yue et al. [
14] proposed an HSI classification method based on adaptive spatial pyramid constraint (ASPC), which leverages the global spatial neighborhood information of labeled samples to enhance the model’s generalization ability in scenarios with limited training data. Zhu et al. [
15] integrated global convolutional long short-term memory and a global joint attention mechanism to address the challenge of insufficient and imbalanced sample data, introducing the SSDGL framework for HSI classification. Despite their success, these methods still grapple with the challenge that CNNs are local and translation-invariant, potentially failing to capture long-range dependencies in hyperspectral data. The self-attention mechanism, a key feature of the transformer architecture, allows the model to dynamically weigh and integrate information from the entire input spectrum [
16]. The transformer model’s self-attention mechanism enables it to capture long-range dependencies in the data, and transformers are permutation-invariant, making them more suitable for processing unordered feature sets [
17]. Sun et al. [
18] proposed a spectral–spatial feature tag transformer (SSFTT) method for HSI classification, which captures spectral–spatial features and high-level semantic features, outperforming several state-of-the-art methods. Yang et al. [
19] proposed a hyperspectral image transformer (HiT) classification network that embeds convolution operations into the transformer structure to capture subtle spectral differences and convey local spatial context information.
Despite substantial advancements in HSI classification using deep learning, these methods continue to face challenges. End-to-end supervised learning often necessitates a large number of labeled samples to optimize deep models. To mitigate these issues, strategies such as lightweight modeling [
20], active learning [
21], and self-supervised pretraining modeling (SSL) have been introduced. These methods aim to enhance generalization capabilities and utilize unlabeled raw data, which are more readily available than labeled samples. In this paper, we introduce a spectral transformer-based self-supervised learning algorithm (S3L) for HSI classification when labeled data are scarce. The goal is to optimize the performance of hyperspectral image classification. This method comprises two stages: pretraining and fine-tuning. In the pretraining stage, a mask mechanism is employed to learn the spatial representation of HSI, and the spectral features are modeled through the spectral transformer module. In the fine-tuning stage, labeled data are used to optimize pretraining weights and enhance classification accuracy. Experimental results on multiple public datasets demonstrate that the proposed method achieves state-of-the-art performance.
The main contributions are summarized as follows:
1. We propose a unique spectral transformer structure specifically designed to capture and model the complex relationships between different spectral bands in hyperspectral images. This structure enhances the model’s sensitivity to spectral information, allowing it to more accurately capture subtle changes in HSI data.
2. We adopt a pretraining and fine-tuning strategy, using a mask mechanism and a spectral transformer to learn the spatial representation of HSI from unlabeled data. This approach enhances the sequence dependence of spectral features and learns robust spatial representation of the hyperspectral image by introducing a mask mechanism.
3. Experimental results on multiple public datasets demonstrate that the proposed S3L outperforms other methods, achieving state-of-the-art performance.
In the subsequent sections, we delve into the specifics of the proposed S3L.
Section 2 reviews previous work.
Section 3 provides a detailed introduction to the S3L. In
Section 4, we carry out comparative and ablation experiments and analyze the results to further validate the effectiveness of the proposed S3L. Finally,
Section 5 offers a comprehensive summary of the entire text.
3. Methodology
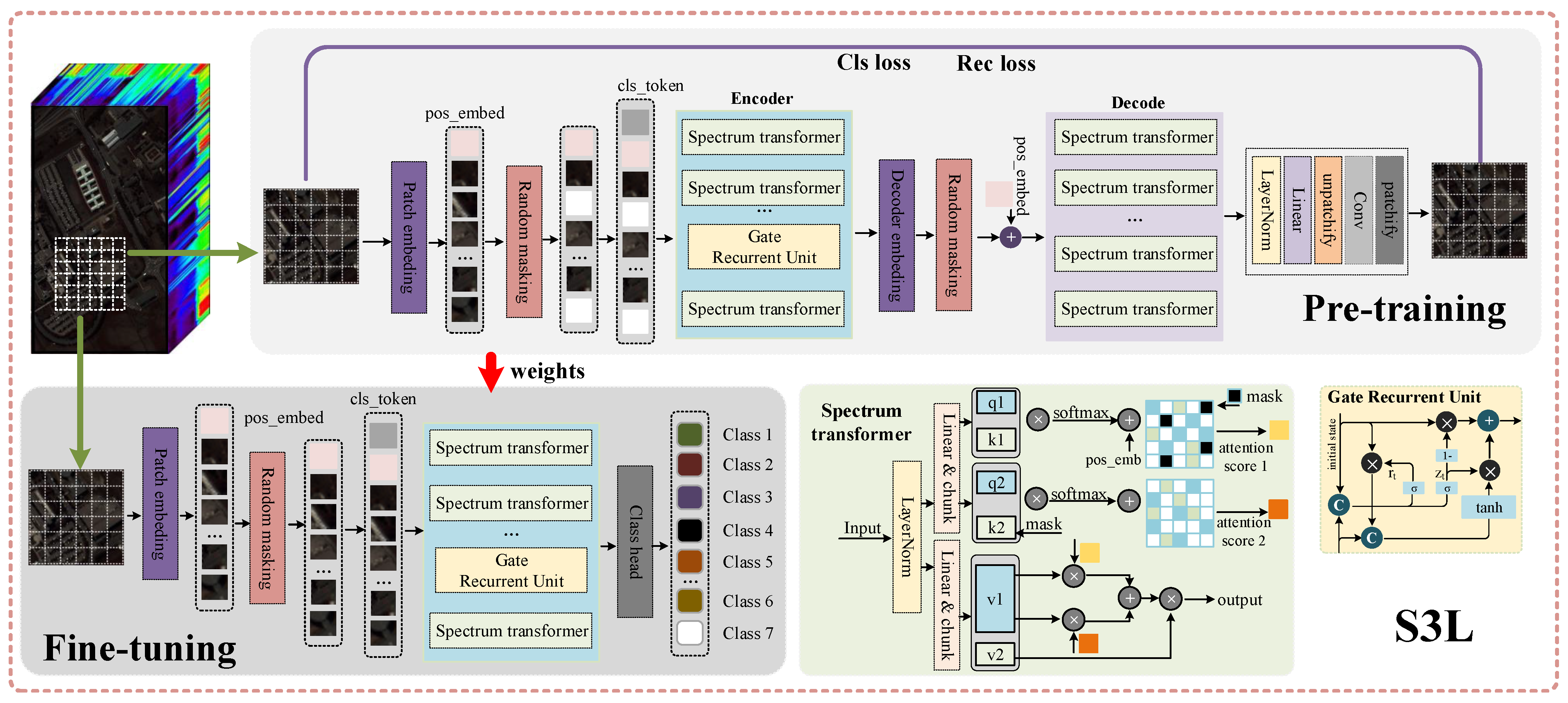
In order to achieve efficient classification performance with limited HSI annotation data, we propose a self-supervised learning algorithm, S3L (spectral–spatial self-learning), which deeply processes spectral features. The design of S3L is inspired by current state-of-the-art techniques in self-supervised learning, particularly their effectiveness in processing high-dimensional feature spaces. The overall architecture of this algorithm is shown in
Figure 1. At the core of S3L is its unique spectral transformer architecture, specifically designed to parse and learn from the complexity and high dimensionality of HSI data. The introduction of the spectral transformer structure aims to enhance the model’s sensitivity to spectral information and capture subtle changes in HSI data more accurately. The S3L algorithm is divided into two main stages: pretraining and fine-tuning. In the pretraining stage, we adopt an innovative approach that does not rely on labeled data but introduces a mask mechanism to learn a robust spatial representation of hyperspectral images. The goal of this stage is to enable the model to autonomously learn and understand the intrinsic structure and characteristics of HSI data without explicit label guidance. Concurrently, the introduction of the spectral transformer enables the model to conduct in-depth modeling of spectral features in HSI data, capturing richer and more detailed information. To further enhance the model’s sequential dependence on spectral features, we innovatively couple the gated recurrent unit (GRU) module with the transformer’s encoder module. This coupling not only improves the model’s ability to process time series data but also enhances its ability to understand and represent spectral features. In this way, S3L can handle spatiotemporal dynamic changes in HSI data more effectively, providing more accurate classification performance.
Throughout the pretraining process, we continually optimize and adjust the model’s parameters through a comprehensive optimization strategy, encompassing both classification and reconstruction functions. This strategy ensures that the model can glean as much effective information as possible during the pretraining phase, laying a solid foundation for the subsequent fine-tuning phase. Upon entering the fine-tuning phase, we introduce limited labeled data to further refine and optimize the model weights obtained during the pretraining phase. The goal of this stage is to enable the model to adapt more accurately to specific classification tasks and further enhance the accuracy of hyperspectral image classification. Through the robust feature representation obtained in the pretraining stage coupled with the fine adjustments in the fine-tuning stage, S3L can significantly improve the overall performance of classification tasks.
In the following section, we first delve into the details of the spectral transformer module in S3L, explaining its design concept and working mechanism. We then explore the pretraining and fine-tuning process of S3L and how these two stages interact with and complement each other to advance the hyperspectral image classification task.
3.1. Spectrum Transformer
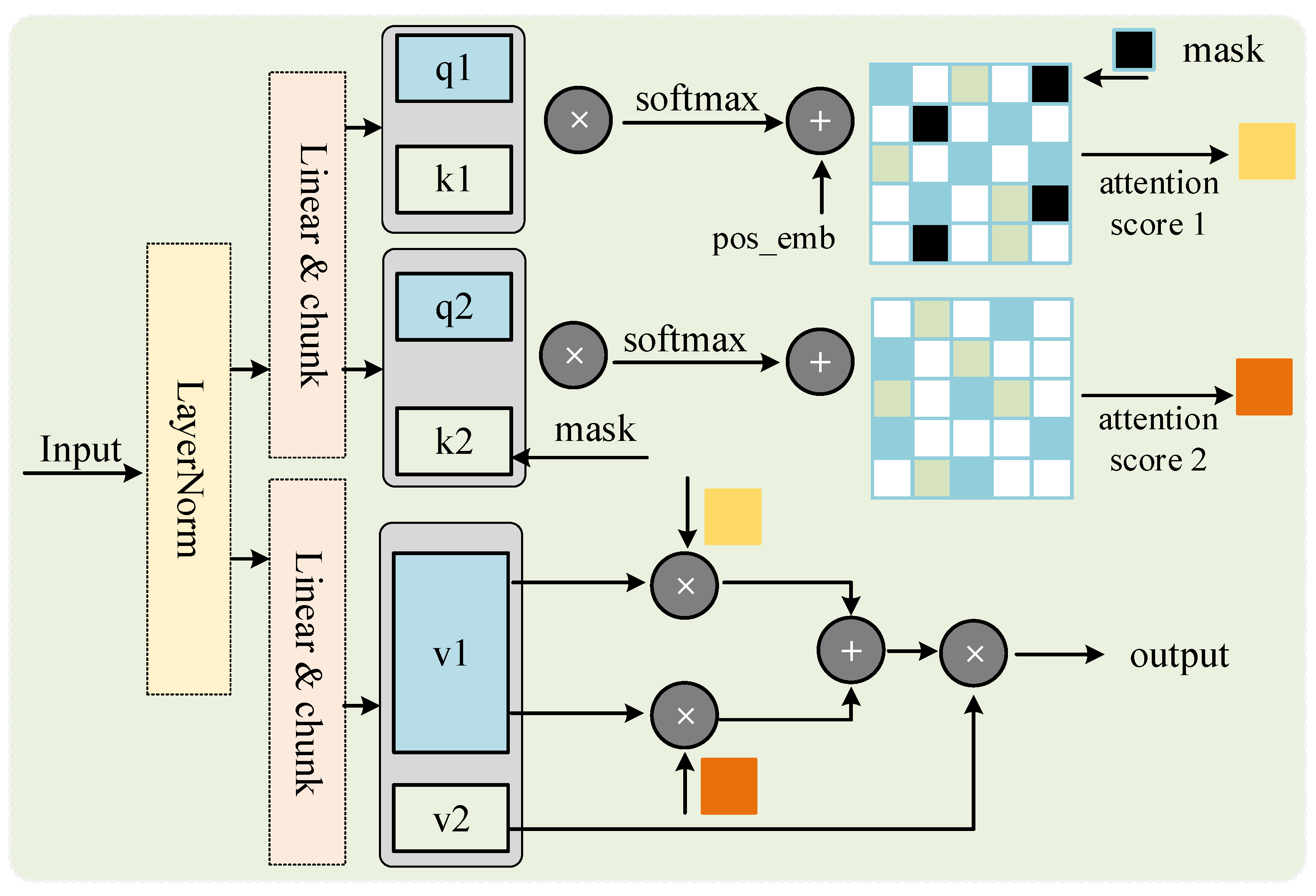
Masked image modeling in self-supervised learning methods is a transformative technology, particularly crucial in HSI classification. Existing masking methods primarily focus on modeling spatial features, often overlooking the importance of spectral features. To address this, we propose a unique spectral transformer structure specifically designed to capture and model the complex relationships between different spectral bands in hyperspectral images, as depicted in
Figure 2.
Specifically, for the input hyperspectral feature matrix, we first normalize it to eliminate scale differences between different bands. Next, we perform carefully designed partitioning and splicing operations on the spectral features. This not only preserves the integrity of the spatial features but also significantly enhances the model’s ability to capture spectral sequential feature dependencies when processing input shifts by introducing changes in spectral dimensions. We further linearly map the normalized feature vectors to recalibrate the spectral dimensions, a step that critically influences the model’s ability to understand and process spectral data.
By further dividing, we obtain two components,
v and
, which play a central role in the model. Additionally, the feature vector generates
and
through another linear mapping, two components crucial in the transformer architecture. We further divide them, resulting in different linear components (such as
,
,
, and
), and through multiple position shifts, we enable the model to more deeply understand and model the complex interactions between spectral features. For
, we adopt an innovative random masking strategy. By setting the value of the mask part to zero, the model can ignore certain noncritical parts and focus on more important information. We also introduce rotational position encoding to enhance the model’s understanding of sequential relationships in hyperspectral sequence data. Next, the input data are padded to fit the needs of the transformer model and facilitate parallel processing of spectral features. This step enables the model to efficiently capture different granularity levels in the spectral data. Simultaneously, the mask is also padded accordingly to ensure its consistency with the input data length. The core of the transformer model lies in its attention mechanism. We obtain the final similarity matrix by calculating the similarity between
and
and adjusting it using the relative position deviation. These attention weights are then applied to the feature variables
V, producing the output matrix
. For
and
, we adopt a similar approach to obtain the feature output
. By weighting information at different locations, the model is able to obtain a more accurate and richer data representation. Finally, by weighted combination of
and
, we obtain the final feature output. This approach enables the model to effectively handle complex relationships between adjacent pixels and spectral features, further enhancing the performance of S3L. The entire implementation process of the spectral transformer demonstrates in detail how to effectively improve the accuracy of hyperspectral image classification through carefully designed structures and strategies. The detailed execution process is shown in Algorithm 1.
| Algorithm 1 Spectrum transformer |
- 1:
Input: Hyperspectral feature matrix x - 2:
Output: Processed feature matrix - 3:
Normalize x to obtain - 4:
if is true then - 5:
Split and concatenate to introduce spectral dimension variations - 6:
end if - 7:
Apply linear mapping to , split into v and - 8:
Generate query and key from , split into , , , and - 9:
if mask exists then - 10:
Apply masking to , setting masked values to 0 - 11:
Apply rotary position encoding to , , , to enhance sequence understanding - 12:
end if - 13:
Pad input data for suitable reorganization and chunking - 14:
Apply the same padding to the mask to match the input data length - 15:
Compute similarity between queries and keys with relative position bias - 16:
Apply attention mechanism to v to produce output matrices and - 17:
Weight and combine and to obtain the final feature output - 18:
Enhance performance by processing relationships between adjacent pixels and spectral features - 19:
return Final feature output
|
3.2. Self-Supervised Pretraining
During the pretraining phase, our goal is to extract robust spatial and spectral features from hyperspectral images using a self-supervised learning approach, which does not require labeled data. We achieve this by implementing a masking mechanism that randomly occludes parts of the input hyperspectral images, creating an information bottleneck. This compels the model to predict the occluded region’s content based solely on the surrounding unoccluded context, thereby enhancing the model’s understanding of spatial and spectral dependencies in the data. The entire procedure is delineated in Algorithm 2.
Drawing inspiration from the work of Sun et al. [
49], a variety of dimensionality reduction techniques were explored, including linear discriminant analysis (LDA), independent component analysis (ICA), local linear embedding (LLE), and principal component analysis (PCA). LDA is designed to enhance the separation between classes, yet it may falter with hyperspectral data where class distinctions are subtle. ICA aims to identify independent components, a challenge in hyperspectral imagery due to the often-correlated spectral signatures of materials. LLE prioritizes preserving the local structure of data, potentially overlooking broader trends. Conversely, PCA focuses on capturing components with significant variance, effectively mitigating noise by discarding low-variance elements. This attribute of PCA not only addresses the noise issue prevalent in hyperspectral imagery but also adeptly manages the sparsity associated with high-dimensional data spaces. To effectively handle noise and redundant information in hyperspectral images, we employ the principal component analysis (PCA) algorithm for data preprocessing. PCA linearly transforms the original hyperspectral data
into a new coordinate system, the basis of which is the data’s principal component direction. The PCA-processed data are denoted as
, where
L signifies the number of spectral channels postdimensionality reduction. We then use a sliding window of size
to divide
into
N small blocks of size
. Each small block is represented as
, where
.
| Algorithm 2 Pretraining process for hyperspectral image classification |
- 1:
Initialize model parameters . - 2:
for each training epoch do - 3:
for each batch in the training set do - 4:
Generate a masked version of the input . - 5:
Transfer to the computation device (e.g., GPU). - 6:
Compute the reconstruction loss . - 7:
if labelled data is available then - 8:
Compute the classification loss . - 9:
end if - 10:
Calculate the total loss . - 11:
Update the model parameters to minimize L. - 12:
end for - 13:
Update the learning rate. - 14:
end for - 15:
Save the model state.
|
For these small patches P, we apply random mask operations and add positional encoding. The processed data are then passed through the encoder and decoder, which are composed of spectral transformers in sequence. In the encoder’s penultimate layer, we incorporate a GRU network structure to capture the sequential dependence of spectral features while maintaining the capture of global dependencies. This is necessary as our proposed spectral transformer performs multiple splits and calibrations when handling spectral dimensions, which may overlook the spectral continuity between adjacent pixels.
To optimize the entire pretraining process, we use two loss functions: classification loss (Cls loss) and reconstruction loss (Rec loss). The classification loss aims to preserve the model’s discriminative ability during pretraining, even when faced with incomplete spectral information. This is achieved by making accurate class predictions on unoccluded parts of the image, thereby enhancing the model’s ability to infer global information from partial data. The classification loss is expressed as
where
is the true class label and
is the class probability predicted by the model.
The reconstruction loss is designed to aid the model in learning the complex structure of hyperspectral images, deeply exploring spatial–spectral features by reconstructing the mask area, and identifying subtle spectral differences of different ground objects. This enables comprehensive characterization of hyperspectral images, capturing more spatial and spectral details. The reconstruction loss is expressed as mean square error (MSE):
where
is the pixel value of the original image and
is the pixel value of the reconstructed image.
3.3. Fine-Tuning
Following the initial deep learning and feature extraction in the pretraining phase, the model undergoes further refinement to enhance its performance in specific classification tasks. Fine-tuning primarily involves adjusting the pretrained weights using labeled data to align the learned features more accurately with the dataset’s specific categories. The network structure during the fine-tuning phase largely mirrors the pretrained model. The key distinction is the exclusive use of the encoder, omitting the decoder. The encoder employs the spectrum transformer to amalgamate and process spectral data, ensuring that the spatial and spectral features align with the labeled data. This method preserves the original spatial and spectral representation during refinement, enhancing its consistency with the labeled data.
A classification head is incorporated during the fine-tuning process, positioned at the model’s end. This component transforms the rich spectral–spatial features into category probability distributions. It is optimized to map learned representations to specific categories effectively, thereby minimizing classification errors. The classification head also strikes a balance between the generalized representation acquired during pretraining and the detailed information necessary for precise classification, ensuring the model’s final output accurately predicts hyperspectral image class labels. It is important to note that a lower learning rate is maintained throughout the fine-tuning process. This strategy preserves the general features acquired during pretraining while facilitating necessary model adjustments for new classification tasks. Consequently, the fine-tuning process can optimize the model and make necessary adjustments while retaining its robust feature extraction capabilities, thereby enhancing the model’s performance in specific tasks. In summary, the fine-tuning phase is a refinement and enhancement of the pretraining phase. It fine-tunes the learned features and adjusts the network structure to better suit specific classification tasks. This process not only boosts the model’s accuracy but also ensures its comprehensive understanding and effective processing of hyperspectral images. Through fine-tuning, our model exhibits superior performance across a range of complex classification scenarios.
4. Datasets and Experimental Setting
This section commences with an introduction to three publicly accessible datasets, followed by a quantitative and qualitative comparative analysis with other sophisticated methods. Subsequently, we perform a series of ablation experiments to evaluate and highlight the efficacy of each component within the S3L framework.
4.1. Datasets
Our research utilizes four renowned hyperspectral image datasets, Indian Pines (IN), University of Pavia (UP), Salinas (SA), and Houston 2013, to assess the performance of our proposed method. These datasets, widely recognized in the hyperspectral image processing domain, offer hyperspectral images with diverse characteristics, facilitating a thorough evaluation of our method’s effectiveness and generalizability.
Table 1 summarizes the basic information of the four datasets.
Table 2 and
Table 3 illustrate the training and test samples.
Indian Pines: The Indian Pines dataset, captured by the Airborne Visible/Infrared Imaging Spectroradiometer (AVIRIS) in 1992, represents a 145 × 145 pixel region in northwest Indiana’s Indian Pines area. It comprises 21,025 samples, initially with 224 spectral bands in the 0.4 to 2.5 µm range. However, due to water absorption and noise, 24 bands were discarded, leaving 200 usable bands. The spatial resolution is 20 m. The dataset, known for its diverse class representation, includes 16 different classes with a total of 10,249 labeled samples, primarily consisting of agricultural land and natural perennial vegetation.
Salinas: The Salinas dataset, collected by the AVIRIS sensor in California’s Salinas Valley, is characterized by a high spatial resolution of 3.7 m per pixel. The original dataset includes 224 bands with a spectral range from 400 to 2500 nm. After excluding 20 bands due to water absorption, 204 bands were retained for analysis. The dataset, covering an area of 512 × 217 pixels or a total of 111,104 samples, includes 16 different categories with 54,129 labeled samples, featuring diverse landscapes such as vegetable plots, bare soil, and vineyards.
University of Pavia: The University of Pavia dataset, also known as PaviaU, was collected by the ROSIS-03 sensor in the urban area of Pavia, Northern Italy. It boasts a high geometric resolution of 1.3 m, consisting of 610 × 340 pixels, with a total of 207,400 samples. Initially, 115 frequency bands were included, 12 of which were discarded due to noise, leaving 103 frequency bands for our experiments. The dataset features urban landscapes with nine categories and 42,776 labeled samples, including various urban surfaces such as asphalt, bricks, grass, and trees.
Houston 2013: The Houston 2013 dataset, captured using CASI-1500 sensors, encompasses the University of Houston campus and adjacent regions. It comprises 349 by 1905 pixels, featuring a comprehensive collection of 144 spectral bands. These bands span a spectral range from 380 nm to 1050 nm, with each pixel representing a spatial resolution of 2.5 m. The dataset is categorized into 15 distinct classes, encompassing various natural and human-made surfaces such as grass, trees, soil, and water, among others. It includes a total of 15,029 labeled pixels, facilitating detailed analysis and classification tasks.
4.2. Implementation Details
We employed the PyTorch 1.13.1 library to construct an experimental framework for hyperspectral image classification. The system used for this experiment was equipped with an NVIDIA GPU 4090 (Santa Clara, CA, USA), boasting 24 GB of memory, and operated within a Python 3.8 environment. In the experiment, we configured 20 training samples per category, set the window sizes to 27, and established a batch size of 512. We ran the model for 300 epochs with a learning rate of . Regarding the mask settings, we maintained a mask ratio of 0.8 and an MLP ratio of 2.0, and we assigned 128 to the number of hidden channels. The dimensions of both the model’s encoder and decoder were set to 128. However, they differed in complexity: the encoder consisted of two layers, while the decoder was more intricate with six layers. Each layer contained eight‘ attention heads. We set the temperature to 1.0 and the hierarchical loss rate to 0.005. The model was trained using the Adam optimizer. To minimize the effects of random sampling, we conducted the experiment multiple times, each time with different initial training samples.
4.3. Comparative Analysis
To assess the efficacy of our proposed method, we juxtapose it with eight distinct methods: HybridSN [
50], 3DAES [
51], SSFTT [
18], FDSSC [
52], DCFSL [
53], CLB [
54], and DBDA [
55]. HybridSN [
50] is a spectral–spatial 3D-CNN supplemented with a spatial 2D-CNN. This method jointly extracts spatial–spectral features from a multitude of spectral bands and further learns a spatial representation at a more abstract level. 3DAES [
51] is a semisupervised Siamese network that incorporates an autoencoder module and a Siamese network. This network explores information in large volumes of unlabeled data and rectifies it with a limited set of labeled samples. SSFTT [
18] captures spectral–spatial features and high-level semantic features using a spectral–spatial feature extraction module and a transformer encoder module. FDSSC [
52] is an end-to-end fast dense spectral–spatial convolution framework. It employs different convolution kernel sizes to extract spectral and spatial features, respectively, and utilizes a densely connected structure for deep learning of features. DCFSL [
53] employs a conditional adversarial domain adaptation strategy to address the few-shot learning and domain adaptation problems within a unified framework. CLB [
54] is an unsupervised framework that leverages contrastive learning methods and transformer models for hyperspectral image classification. DBDA [
55] is a dual-branch dual-attention mechanism network that captures a vast number of spectral and spatial features contained in HSI. It uses channel attention blocks and spatial attention blocks to refine and optimize the extracted feature maps.
4.3.1. Quantitative Analysis
Table 4 displays the quantitative experimental results of various methods on the IN dataset. The proposed method consistently outperforms other techniques across various indicators. Specifically, S3L achieves an OA of 93.45%, which is 1.8% higher than the closest competitor, DBDA, and significantly surpasses traditional methods such as HybridSN. In the AA domain, the proposed method again leads with 92.2%, slightly higher than SSFTT’s 91.68%. This underscores the balanced performance of the proposed method across different categories. SSFTT can achieve higher classification performance with limited labeled samples. For instance, the OA of the SSFTT method is improved by 9.58% over the HybridSN method and 3.83% over the 3DAES method. The addition of methods like CLB and DBDA, which utilize contrastive learning and attention mechanisms, respectively, are beneficial for handling classification boundary issues. As shown in the per-class accuracy results, our proposed method can handle boundary information better, achieving 100% accuracy for Classes 6, 9, and 14.
Table 5 showcases the experimental results on the SA dataset. The OA, AA, and Kappa values of the proposed S3L are 94.87%, 94.31%, and 92.46, respectively, which surpass the corresponding values of other methods. 3DAES and SSFTT also achieved competitive results, with OA values of 92.13% and 93.01%, AA values of 92.47% and 94.26%,and Kappa values of 92.68 and 92.34, respectively. The proposed S3L obtains additional semantic information by processing spectral and spatial data, effectively capturing and utilizing spectral and spatial features in hyperspectral images.
Table 6 presents the quantitative experimental results of various methods on the PU dataset. The proposed method, S3L, achieved an overall accuracy (OA) of 94.64% and an average accuracy (AA) of 92.78%, demonstrating its consistent performance across all categories and its effective integration of spectral and spatial features. The Kappa coefficient is 93.54, the second highest, indicating a high agreement between the predicted and actual class labels. Among other methods, 3DAES and SSFTT performed commendably, with overall accuracy rates of 91.56% and 90.65% respectively. FDSSC, known for its rapid and accurate feature learning, excelled in Class 1 and Class 6 but fell short in other categories. This discrepancy may be attributed to the method’s emphasis on speed, potentially compromising its accuracy in complex scenes. SSFTT and CLB also demonstrated notable performance, particularly in Class 2 and Class 3 for SSFTT, and Class 2 and Class 4 for CLB, indicating their effective feature extraction capabilities.
Table 7 presents a comparative analysis of the performance metrics for various methodologies applied to the Houston 2013 dataset. The method proposed in this study attains an overall accuracy (OA) of 86.50%, an average accuracy (AA) of 85.25%, and a Kappa coefficient of 85.85. Concurrently, the SSFTT and FDSSC methods demonstrate robust performance, with SSFTT excelling in Class 4 with a 90.98% accuracy rate, and FDSSC achieving the highest classification accuracy in Class 5 at 91.57%. Nonetheless, when juxtaposed with the outcomes from other datasets, a marginal decline in the performance of all evaluated methods on the Houston 2013 dataset is observed. This decrement can likely be attributed to the larger size and the more complex spatial and spectral characteristics of the Houston 2013 dataset compared to the others.
4.3.2. Qualitative Analysis
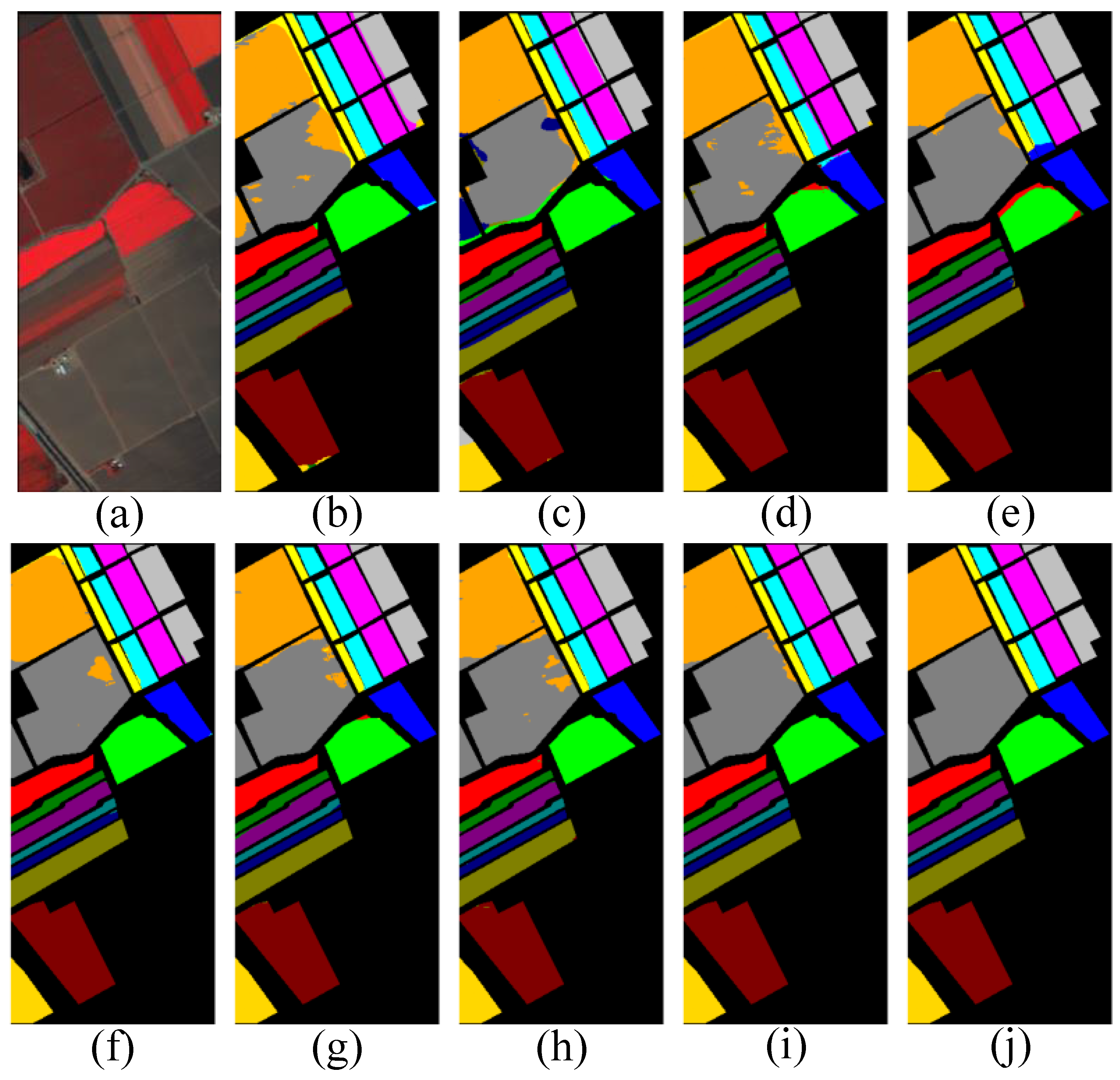
Figure 3 presents the visual results of the hyperspectral image classification task on the Indian Pines (IN) dataset. The classification results of different methods (HybridSN, 3DAES, SSFTT, FDSSC, DCFSL, CLB, and DBDA) and the ground truth are displayed in sections a–i. It is evident that the proposed method excels in preserving plot boundaries and minimizing classification errors, particularly in identifying complex surfaces such as Building–Grass–Trees–Drives and Stone–Steel–Towers. The classification results of the proposed method are more coherent and the color blocks are more compact, indicating higher classification accuracy and spatial continuity. For different types of crops, such as corn (Corn-notill, Corn-mintill, Corn) and soybeans (Soybean-notill, Soybean-mintill, Soybean-clean) with varying farming methods, the proposed method appears to distinguish more accurately between different farming statuses. This is reflected in the classification results in the figure, with clear color distinctions and fewer misclassifications. When analyzing large areas of single color such as wheat fields (Wheat) and fallow fields (Fallow, Fallow-rough plow, Fallow-smooth), the proposed method effectively reduces noise and misclassification areas, demonstrating smoother and more consistent classification results.
Figure 4 displays the visualization results of the hyperspectral image classification task on the Salinas Area (SA) dataset. The proposed method proves effective in identifying small plots and complex boundaries, such as vineyards (Grapes), lettuce (Lettuce-4wk to Lettuce-7wk), and Vineyard-untrained, accurately depicting the edges of plots. Compared to other methods, oversmoothing is reduced, thereby better preserving the spatial characteristics of the original features. Additionally, the results of the proposed method are more distinct in color distinction, reducing confusion and misclassification, especially between categories with similar colors, such as lettuce at different stages. Throughout the visualization outcomes, objects categorized as Grapes and Fallow-plow exhibit a higher propensity for misclassification.
Figure 5 illustrates the visualization results of the hyperspectral image classification task on the PU dataset. When classifying urban structures such as buildings, roads, and lanes, the proposed method produces more refined and coherent results, better preserving the structural features of the buildings, such as metal surfaces and brick distinctions. Furthermore, S3L effectively reduces noise, displaying a more uniform and consistent classification. Throughout the visualization outcomes, objects categorized as Meadows and Bare Soil exhibit a higher propensity for misclassification.
Figure 6 presents the comparative visualization outcomes for various methodologies applied to the Houston 2013 dataset, with inaccurately classified regions delineated by yellow boxes. The analysis reveals that HybridSN, DCFSL, and SSFTT exhibit a higher incidence of misclassifications, particularly with indistinct demarcations between Tennis Court and Running Track areas. Both CLB and the newly introduced S3L method encounter some classification inaccuracies within the Healthy Grass categories. Conversely, FDSSC and the novel S3L method demonstrate superior qualitative visualization outcomes. Notably, S3L stands out for its minimal misclassifications, distinct boundary delineations, and adeptness at accurately classifying small-area features as well as features possessing similar spectral signatures. Throughout the visualization outcomes, objects categorized as Stressed Grass and Water exhibit a higher propensity for misclassification.
Figure 7 presents the visualization curves of the proposed S3L method during training and validation on three hyperspectral datasets: IN, UP, and SA. For the IN dataset, the initial training loss of S3L is high, reflecting the uncertainty in the initial model. As the number of epochs increases, it eventually stabilizes around 0.2, indicating effective model convergence, with the validation accuracy stabilizing at approximately 91%. The training accuracy of S3L on the UP dataset approaches 100%, the validation accuracy nears 94%, and the final training loss is close to 0.1. The performance on the SA dataset mirrors that of the IN and UP datasets, with a similar pattern observed: the training loss significantly decreases and levels off, with the training set accuracy nearing 100% and the validation set accuracy approaching 93%.
4.4. Ablation Experiment
To validate the effectiveness of each proposed module, we designed several sets of ablation experiments. In Experiment 1, the spectral transformer module was replaced with the standard transformer module (Exp 1) to evaluate the performance of the standard transformer in processing hyperspectral data. In Experiment 2, the GRU module (Exp 2) was removed to analyze its contribution to the order dependence of captured spectral features. No pretraining was performed in Experiment 3 (Exp 3). The experimental results are displayed in
Table 8.
When replacing the spectral transformer module with the classic transformer module, performance deteriorates on all datasets. OA on the UP dataset dropped to 91.2%, and Kappa dropped to 0.905; on the IN dataset, OA dropped to 90.3%, and Kappa dropped to 0.895; and on the SA dataset, OA dropped to 88.5%, and Kappa dropped to 0.880. This demonstrates the critical role of the specialized design of the spectral transformer in processing hyperspectral data for the overall performance of the model. Classic transformers, while effective in various tasks, may not be as proficient as spectral transformers in capturing complex spectral dependencies in hyperspectral data.
In the experiment of removing the GRU module, although the performance decreased, the impact was less than that of Experiment 1. The OA on the UP dataset is 92.7% and the Kappa is 0.920; the IN dataset has an OA of 91.8% and a Kappa of 0.910; and the SA dataset has an OA of 89.9% and a Kappa of 0.895. This result illustrates the important role of the GRU module in the model, especially in capturing the order dependence of spectral features. However, the model can still maintain good performance even without the GRU module, indicating that other components (such as the spectral transformer) also play a significant role in the model.
The experimental results without pretraining performed the worst on all indicators. On the UP dataset, OA dropped to 87.3%, and Kappa dropped to 0.865; on the IN dataset, OA dropped to 86.5%, and Kappa dropped to 0.850; and on the SA dataset, OA dropped to 84.7%, and Kappa dropped to 0.835. This significant performance drop underscores the importance of the pretraining phase. Pretraining allows the model to learn robust feature representations without labeled data, providing a solid foundation for the fine-tuning phase.
5. Conclusions
This paper introduces a self-supervised learning algorithm, S3L, based on the spectral transformer for HSI classification. The S3L algorithm operates in two stages: pretraining and fine-tuning. During the pretraining stage, a mask mechanism is employed to learn the spatial representation of HSI, and spectral features are modeled through the spectral transformer module. In the fine-tuning stage, labeled data are utilized to optimize pretraining weights and enhance classification accuracy. Additionally, a GRU layer is integrated into the algorithm to strengthen the sequence dependence of spectral features. Experimental results on multiple datasets demonstrate that the S3L algorithm performs commendably when labeled samples are limited and is competitive with current advanced methods. Future work will explore the application of S3L in a broader range of remote sensing data classification tasks and further optimize the algorithm structure.
While the proposed method has demonstrated remarkable performance, it is not without its limitations. Compared to convolutional neural networks (CNNs), the self-supervised learning (S3L) approach, which leverages the transformer architecture, encounters certain deployment challenges. Primarily, the intricate self-attention mechanism inherent to transformers demands substantial memory during inference, posing significant demands on hardware resources. Additionally, the scarcity of hardware platforms capable of accelerating transformer models represents another critical issue that needs addressing. Moving forward, our research will focus on developing a lightweight transformer architecture and exploring hardware acceleration capabilities for transformer-based models. Furthermore, the training, fine-tuning, and testing processes have been confined to a single dataset. Future efforts will aim to extend these processes across diverse datasets, enhancing the method’s adaptability and robustness.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}