
Causal Meta-Reinforcement Learning for Multimodal Remote Sensing Data Classification


Abstract

1. Introduction
- (1)
- Causal meta-reinforcement learning (CMRL) is proposed, which simulates the human feedback learning mechanism, causal inference mechanism, and knowledge induction mechanism to fully mine multimodal complementary information, accurately capture true causal relationships, and reasonably induce cross-task shared knowledge;
- (2)
- Escaping the limitations of implicit optimization of fusion features, a reinforcement learning environment was customized for the classification of multimodal remote sensing data. Through the interaction feedback between intelligent agents and multimodal data, full mining of multimodal complementary information was achieved;
- (3)
- Surpassing the traditional learning model of establishing statistical associations between data and labels, causal reasoning was introduced for the first time into multimodal remote sensing data classification tasks. Causal distribution prediction actions, classification rewards, and causal intervention rewards were designed to encourage intelligent agents to capture pure causal factors and cut out false statistical associations between non-causal factors and labels;
- (4)
- The shortcomings of the optimization mode that minimizes the empirical risk of the model on training data under sparse training samples were revealed, and a targeted bi-layer optimization mechanism based on meta-learning was proposed. By encouraging agents to induce cross-task shared knowledge during scenario simulation, their generalization ability on unseen test data was improved.
2. Relate Work
2.1. Reinforcement Learning
2.2. Causal Learning
2.3. Meta-Learning
3. Method
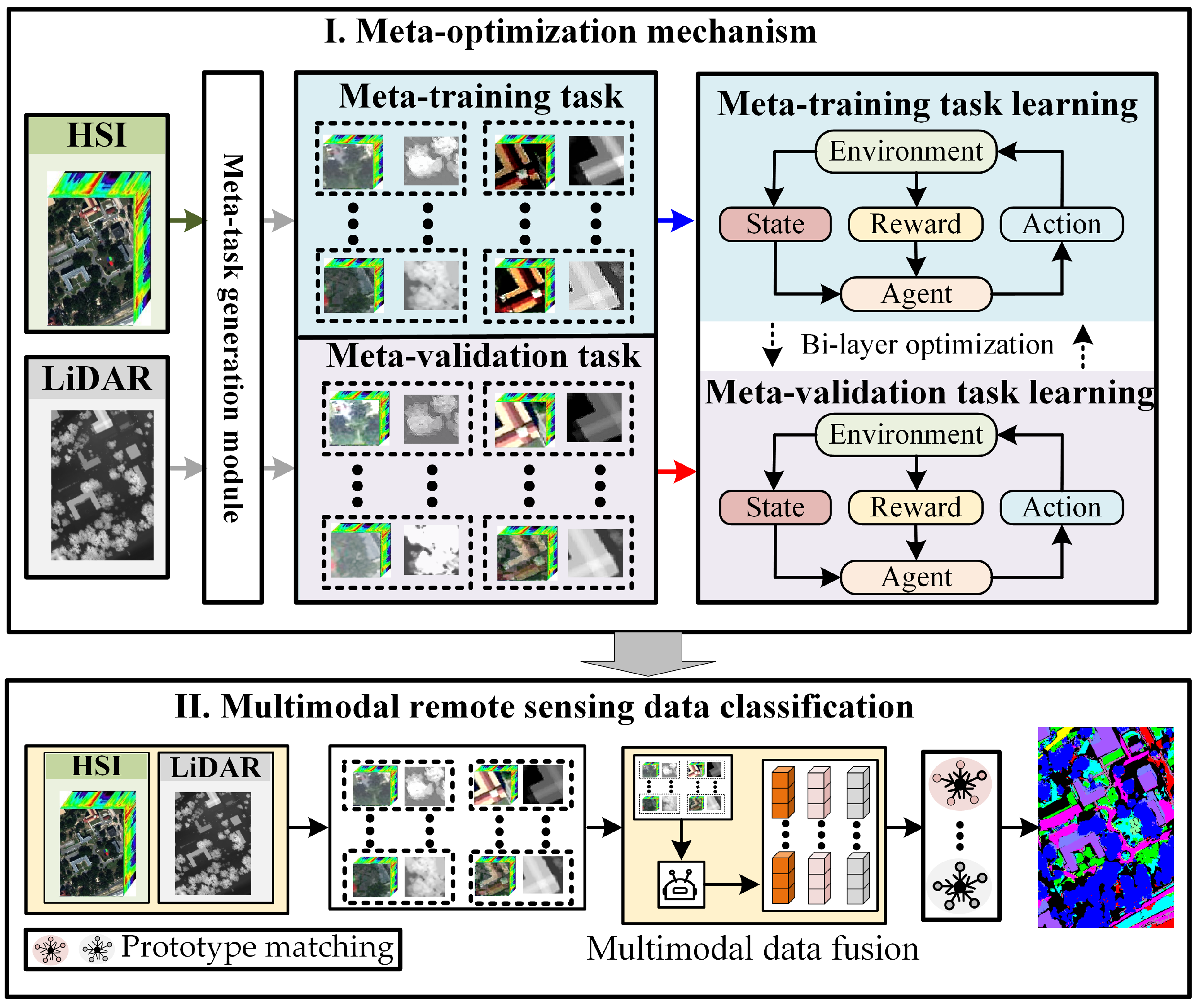
3.1. Framework of CMRL
3.1.1. Meta-Optimization Mechanisms
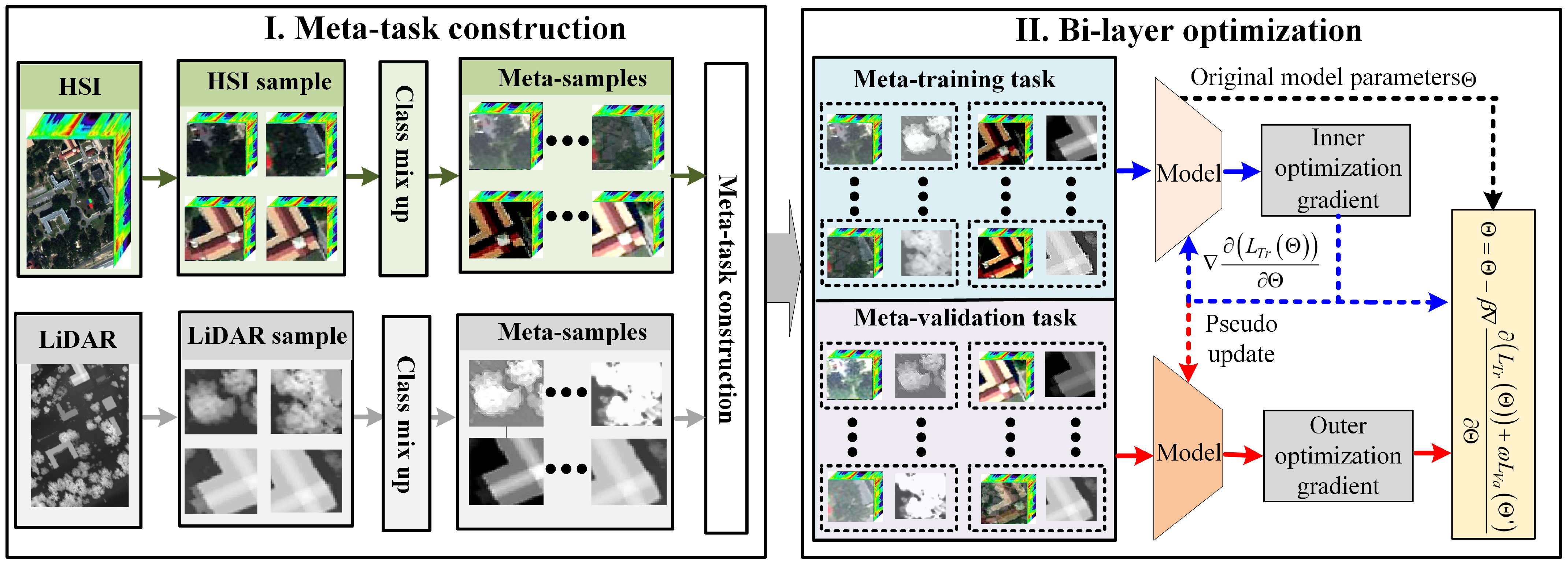
- (1)
- Meta-task construction: First, multimodal data are input into the meta-task generation module, where meta-samples are generated based on a class mixing strategy. Then, an equal number of meta-samples from each class are randomly selected to construct meta-training tasks and meta-validation tasks;
- (2)
- Bi-layer optimization: First, in the inner optimization, calculate the model’s meta-training loss on meta-training tasks, pseudo-update the model based on this loss, and save the optimization gradients of the meta-training tasks. Then, in the outer optimization, calculate the meta-validation loss of the model after pseudo-updates on meta-validation tasks, and perform meta-updates on the model considering both meta-training and meta-validation losses.
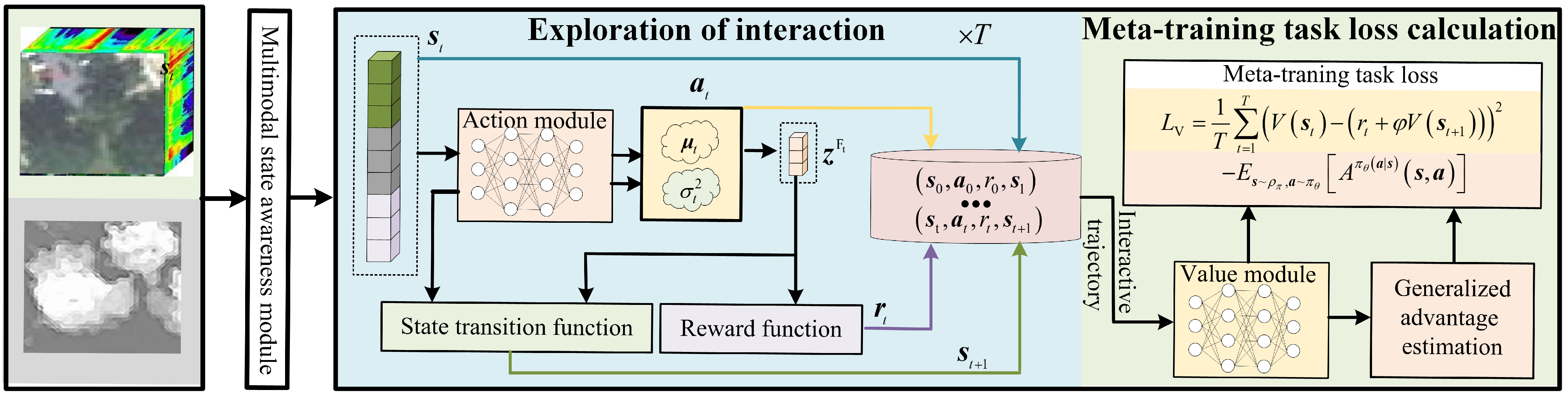
3.1.2. Meta-Training Task Learning
- (1)
- Exploration of interaction: First, input multimodal data from the meta-training task into the multimodal state perception module to obtain the state , where t represents the time step. Then, input into the action module to obtain causal distribution predictions , and obtain causal fusion features by sampling from the causal distribution. Next, use the state transition function to update the state to and calculate classification rewards and causal intervention rewards to obtain the total reward . Finally, repeat the above process until a predefined number of interactions is reached, obtaining an interaction trajectory;
- (2)
- Meta-training task loss calculation: First, estimate the state values for each time step in the interaction trajectory using a state value network. Then, calculate the value loss by computing the difference between the state value estimate and the future expected rewards. Simultaneously, use the generalized advantage estimation (GAE) [48] algorithm based on the state value estimate to obtain the advantage function. Calculate the policy loss based on the advantage function. Finally, compute the meta-training loss.
3.1.3. Meta-Validation Task Learning
3.2. Modeling Multimodal Remote Sensing Data Classification as an MDP
3.2.1. State and State Transition Function
3.2.2. Designing Actions and Rewards Based on Causal Intervention
- (1)
- Predicting actions from causal distribution
- (2)
- Classification rewards
- (3)
- Causal intervention reward
- (4)
- Total reward
3.3. Policy Gradient-Based Reinforcement Learning
3.4. Knowledge Induction Mechanism
3.4.1. Meta-Task Construction
3.4.2. Bi-Layer Optimization
4. Experiment
4.1. Dataset
- (1)
- MUUFL Dataset [51]: The MUUFL dataset was collected at the University of Southern Mississippi in Gulfport, covering 11 classes of ground objects. The data were acquired in November 2010 using Gemini LiDAR and CASI-1500 equipment. These devices were synchronized on the same flight platform to collect hyperspectral image data and LiDAR data simultaneously, ensuring spatial and temporal consistency between the two types of data. Both the hyperspectral images and LiDAR data consist of 325 × 220 pixels with a spatial resolution of 1 m. The hyperspectral images have 64 bands, and the LiDAR data record precise elevation information of the terrain. Dataset available at: https://github.com/GatorSense/MUUFLGulfport (accessed on 21 January 2024).
- (2)
- Houston Dataset [52]: Funded by the National Science Foundation of the United States and collected by the Airborne Laser Mapping Center, the Houston dataset covers 15 classes of ground objects in and around the University of Houston campus. This multimodal dataset primarily consists of two parts: hyperspectral data and LiDAR data. Both types of data have the same spatial resolution of 2.5 m and include 349 × 1905 pixels. The HSI covers 144 spectral bands from 380 nm to 1050 nm. The LiDAR data records precise elevation information of the terrain. Dataset available at: http://dase.grss-ieee.org/ (accessed on 21 January 2024).
- (3)
- Trento Dataset [53]: The Trento dataset was collected in the rural areas south of Trento, Italy, encompassing 6 classes of ground objects, including various natural features and artificial agricultural structures. This dataset integrates hyperspectral images captured by an airborne hyperspectral imager and LiDAR data obtained from an aerial laser scanning system. Both modalities have a consistent spatial resolution and consist of 166 × 600 pixels. The hyperspectral images include 63 spectral bands, and the LiDAR data records precise elevation information of the terrain. Dataset available at: https://github.com/tyust-dayu/Trento (accessed on 21 January 2024).
4.2. Experimental Setting
4.3. Comparative Experiments
- (1)
- Compared to the unimodal methods, multimodal methods exhibited a higher classification accuracy. This was because, due to the phenomena of “different objects have the same spectra” and “the same objects have different spectra” in HSI, some samples may have had low class distinguishability, making it difficult for the unimodal methods that only use HSI to achieve satisfactory performance. In contrast, the multimodal methods could combine LiDAR information to enhance the model’s ability to differentiate features when such phenomena occurred;
- (2)
- Compared to the multimodal decision fusion methods, the multimodal feature fusion methods demonstrated a higher classification performance. This is because the multimodal decision fusion methods integrate the output information of the classifiers. When noise exists in multimodal data, the noise interference from different modalities might accumulate during the decision-making process, leading to inaccurate class predictions. On the other hand, multimodal feature fusion methods can establish deep interactions between multimodal data, more effectively mining class-distinguishing information;
- (3)
- CMRL showed the highest classification performance across all three datasets, demonstrating its superiority in multimodal remote sensing data classification tasks. In particular, it showed a clear classification advantage for challenging classes like “mixed ground surface” and “sidewalk.” The former often contains complex noise information, while the latter is frequently obscured by structures such as buildings and trees, presenting significant intra-class variability and blurred inter-class boundaries. The superior performance of CMRL can be attributed to the following factors: On one hand, its feedback learning mechanism and causal inference mechanism allow the agent to fully understand which information in the multimodal data has a causal relationship with the labels. This enables the agent to cut off false statistical associations between non-causal factors (like noise information and obstructed heterogeneous ground features) and labels, achieving precise mining of real causal effects. On the other hand, the knowledge induction mechanism of CMRL enables the agent to learn cross-task shared knowledge, which can help it achieve higher generalization performance on unseen multimodal data.
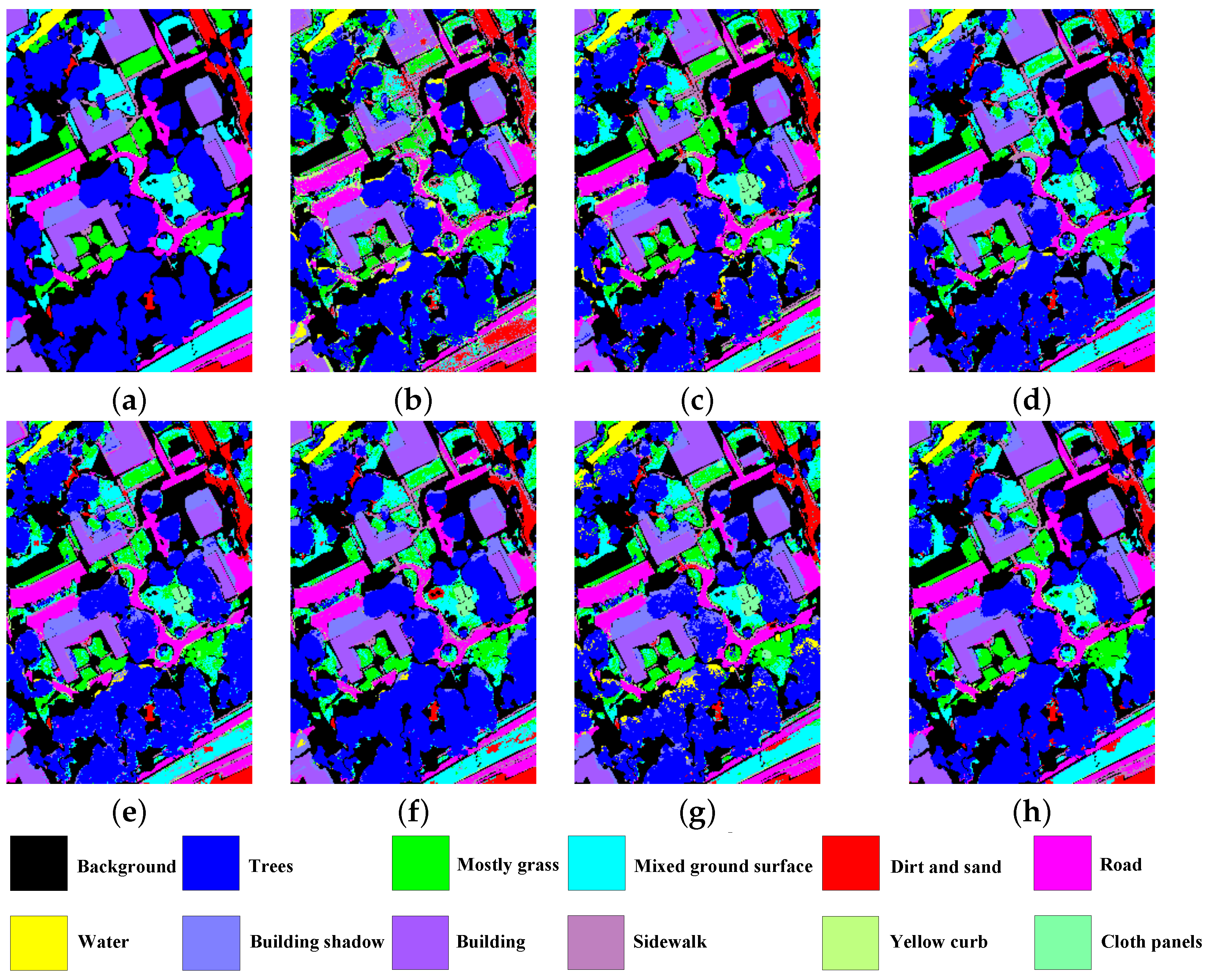
4.4. Visual Analysis
4.4.1. Classification Accuracy Maps
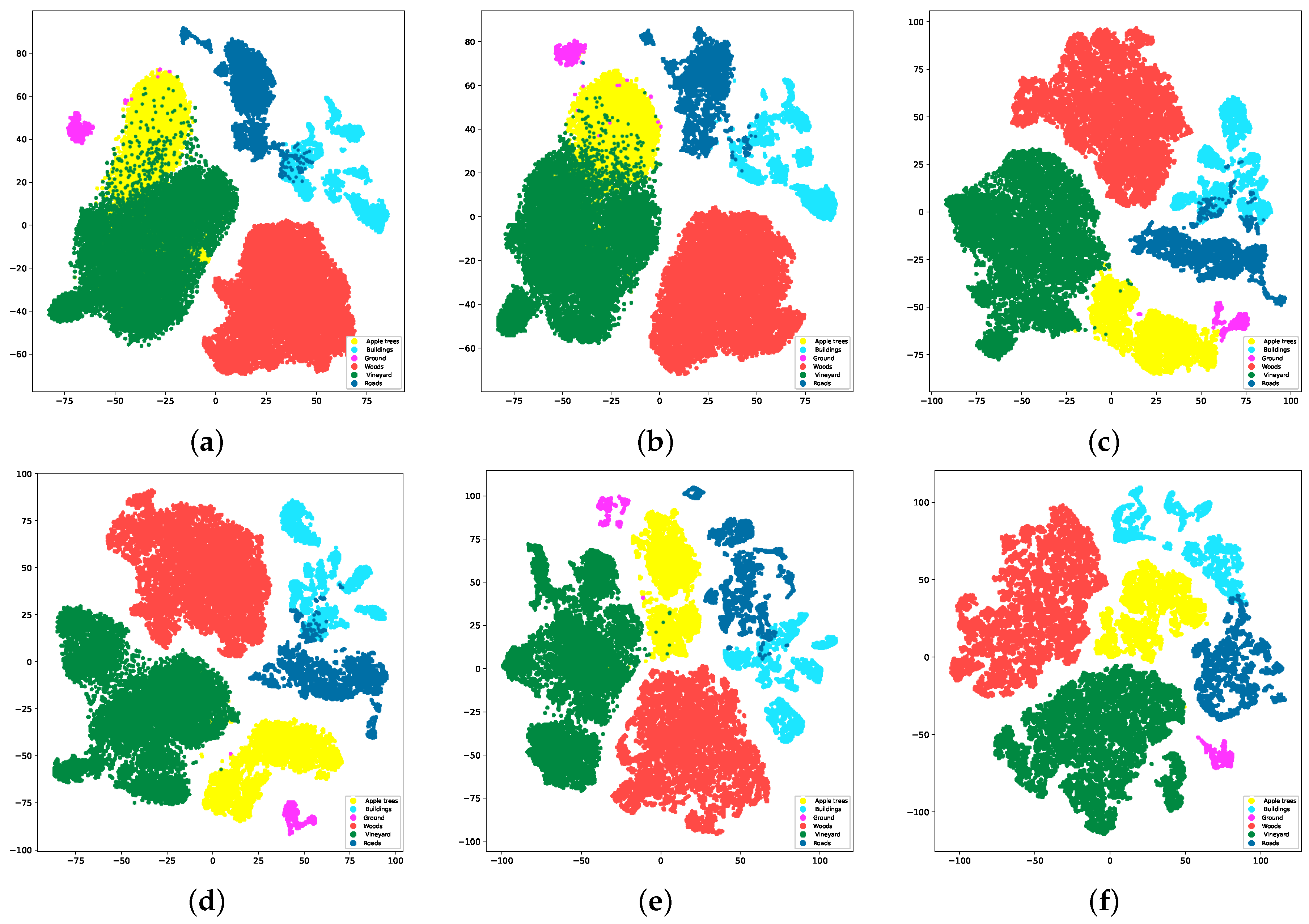
4.4.2. t-SNE Maps
4.4.3. Ablation Study
- (1)
- Compared to Baseline-A, Baseline-B improved the classification performance on three datasets by 2.81%, 2.21%, and 2.23%, respectively. This was because the feedback learning mechanism of reinforcement learning allows the agent to interact with a custom environment to understand the complex association mechanisms between its actions (predictions about the causal distribution) and the multimodal remote sensing data classification task. It can adjust and optimize action strategies based on immediate feedback from rewards. This iterative feedback structure enhances the model’s ability to capture task-relevant complementary information in multimodal data. The experimental performance also validated the effectiveness of the feedback learning mechanism of reinforcement learning in multimodal remote sensing data classification tasks;
- (2)
- Compared to Baseline-B, Baseline-C improved the classification performance on three datasets by 1.08%, 0.91%, and 1.42%, respectively. This was because the causal reasoning mechanism of causal learning helps the model identify causal and non-causal factors in multimodal data. This mechanism effectively reduces the influence of spectral noise in HSI by disrupting the false statistical association between non-causal factors and labels through causal intervention, helping the model establish a true causal relationship between multimodal data and labels. The experimental performance also validated the effectiveness of the causal reasoning mechanism of causal learning in multimodal remote sensing data classification tasks;
- (3)
- Compared to Baseline-C, CMRL improved the classification performance on three datasets by 2.24%, 2.03%, and 1.23%, respectively. This was because the knowledge induction mechanism of meta-learning helps the model reveal cross-task shared knowledge applicable to unseen multimodal data from a large number of similar yet different meta-tasks. This effectively alleviates the issue of the limited model generalization capability caused by data distribution bias between training and test samples. The experimental performance also validated the effectiveness of the knowledge induction mechanism of meta-learning in multimodal remote sensing data classification tasks.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, Y.; Li, W.; Zhang, M.; Wang, S.; Tao, R.; Du, Q. Graph information aggregation cross-domain few-shot learning for hyperspectral image classification. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 1912–1925. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Wang, W.; Wang, J.; Cai, Y.; Yang, Z.; Li, J. Hyper-LGNet: Coupling local and global features for hyperspectral image classification. Remote Sens. 2022, 14, 5251. [Google Scholar] [CrossRef]
- Datta, D.; Mallick, P.K.; Reddy, A.V.N.; Mohammed, M.A.; Jaber, M.M.; Alghawli, A.S.; Al-qaness, M.A.A. A hybrid classification of imbalanced hyperspectral images using ADASYN and enhanced deep subsampled multi-grained cascaded forest. Remote Sens. 2022, 14, 4853. [Google Scholar] [CrossRef]
- Xing, C.; Cong, Y.; Duan, C.; Wang, Z.; Wang, M. Deep network with irregular convolutional kernels and self-expressive property for classification of hyperspectral images. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 10747–10761. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Q.; Deng, W.; Zheng, Z.; Zhong, Y.; Guan, Q.; Lin, W.; Zhang, L.; Li, D. A spectral-spatial-dependent global learning framework for insufficient and imbalanced hyperspectral image classification. IEEE Trans. Cybern. 2021, 52, 11709–11723. [Google Scholar] [CrossRef] [PubMed]
- Ding, Y.; Chong, Y.; Pan, S.; Wang, Y.; Nie, C. Spatial-spectral unified adaptive probability graph convolutional networks for hyperspectral image classification. IEEE Trans. Neural Netw. Learn. Syst. 2021, 34, 3650–3664. [Google Scholar] [CrossRef] [PubMed]
- Ren, Q.; Tu, B.; Liao, S.; Chen, S. Hyperspectral image classification with iformer network feature extraction. Remote Sens. 2022, 14, 4866. [Google Scholar] [CrossRef]
- Dong, W.; Yang, T.; Qu, J.; Zhang, T.; Xiao, S.; Li, Y. Joint contextual representation model-informed interpretable network with dictionary aligning for hyperspectral and LiDAR classification. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 6804–6818. [Google Scholar] [CrossRef]
- Gao, H.; Feng, H.; Zhang, Y.; Xu, S.; Zhang, B. AMSSE-Net: Adaptive multiscale spatial–spectral enhancement network for classification of hyperspectral and LiDAR data. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5531317. [Google Scholar] [CrossRef]
- Zhang, T.; Xiao, S.; Dong, W.; Qu, J.; Yang, Y. A mutual guidance attention-based multi-level fusion network for hyperspectral and LiDAR classification. IEEE Geosci. Remote Sens. Lett. 2021, 19, 5509105. [Google Scholar] [CrossRef]
- Song, L.; Feng, Z.; Yang, S.; Zhang, X.; Jiao, L. Discrepant bi-directional interaction fusion network for hyperspectral and LiDAR data classification. IEEE Geosci. Remote Sens. Lett. 2023, 20, 5510605. [Google Scholar] [CrossRef]
- Xue, Z.; Yu, X.; Tan, X.; Liu, B.; Yu, A.; Wei, X. Multiscale deep learning network with self-calibrated convolution for hyperspectral and LiDAR data collaborative classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5514116. [Google Scholar] [CrossRef]
- Roy, S.K.; Deria, A.; Hong, D.; Ahmad, M.; Plaza, A.; Chanussot, J. Hyperspectral and LiDAR data classification using joint CNNs and morphological feature learning. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5530416. [Google Scholar] [CrossRef]
- Wang, J.; Li, J.; Shi, Y.; Lai, J.; Tan, X. AM3Net: Adaptive mutual-learning-based multimodal data fusion network. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 5411–5426. [Google Scholar] [CrossRef]
- Du, X.; Zheng, X.; Lu, X.; Wang, X. Hyperspectral and LiDAR representation with spectral-spatial graph network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 9231–9245. [Google Scholar] [CrossRef]
- Oh, I.; Rho, S.; Moon, S.; Son, S.; Lee, H.; Chung, J. Creating pro-level AI for a real-time fighting game using deep reinforcement learning. IEEE Trans. Games 2021, 14, 212–220. [Google Scholar] [CrossRef]
- Donge, V.S.; Lian, B.; Lewis, F.L.; Davoudi, A. Multi-agent graphical games with inverse reinforcement learning. IEEE Trans. Control Netw. Syst. 2022, 10, 841–852. [Google Scholar] [CrossRef]
- Justesen, N.; Bontrager, P.; Togelius, J.; Risi, S. Deep learning for video game playing. IEEE Trans. Games 2019, 12, 1–20. [Google Scholar]
- Matarese, M.; Sciutti, A.; Rea, F.; Rossi, S. Toward robots’ behavioral transparency of temporal difference reinforcement learning with a human teacher. IEEE Trans. Hum. Mach. Syst. 2021, 51, 578–589. [Google Scholar] [CrossRef]
- Zhang, L.; Hou, Z.; Wang, J.; Liu, Z.; Li, W. Robot navigation with reinforcement learned path generation and fine-tuned motion control. IEEE Robot. Autom. 2023, 8, 4489–4496. [Google Scholar] [CrossRef]
- Garaffa, L.C.; Basso, M.; Konzen, A.A.; de Freitas, E.P. Reinforcement learning for mobile robotics exploration: A survey. IEEE Trans. Neural Netw. Learn. Sys. 2023, 8, 3796–3810. [Google Scholar] [CrossRef]
- Wu, J.; Huang, Z.; Lv, C. Uncertainty-aware model-based reinforcement learning: Methodology and application in autonomous driving. IEEE Trans. Intell. Veh. 2022, 8, 194–203. [Google Scholar] [CrossRef]
- Shu, H.; Liu, T.; Mu, X.; Cao, D. Driving tasks transfer using deep reinforcement learning for decision-making of autonomous vehicles in unsignalized intersection. IEEE Trans. Veh. Technol. 2021, 71, 41–52. [Google Scholar] [CrossRef]
- Zhu, Z.; Zhao, H. A survey of deep RL and IL for autonomous driving policy learning. IEEE Trans. Intell. Transp. Syst. 2021, 23, 14043–14065. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [PubMed]
- Vinyals, O.; Babuschkin, I.; Czarnecki, W.M.; Mathieu, M.; Dudzik, A.; Chung, J.; Choi, D.H.; Powell, R.; Ewalds, T.; Georgiev, P.; et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 2019, 575, 350–354. [Google Scholar]
- Wang, X.; Gu, Y.; Cheng, Y.; Liu, A.; Chen, C.P. Approximate policy-based accelerated deep reinforcement learning. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 1820–1830. [Google Scholar] [CrossRef] [PubMed]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef]
- Bai, Z.; Hao, P.; Shangguan, W.; Cai, B.; Barth, M.J. Hybrid reinforcement learning-based eco-driving strategy for connected and automated vehicles at signalized intersections. IEEE Trans. Intell. Transp. Syst. 2022, 23, 15850–15863. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [PubMed]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double Q-learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 2094–2100. [Google Scholar]
- Baek, J.; Kaddoum, G. Online partial offloading and task scheduling in SDN-fog networks with deep recurrent reinforcement learning. IEEE Internet Things J. 2022, 9, 11578–11589. [Google Scholar] [CrossRef]
- Kohl, N.; Stone, P. Policy gradient reinforcement learning for fast quadrupedal locomotion. In Proceedings of the IEEE International Conference on Robotics and Automation, New Orleans, LA, USA, 26 April–1 May 2004; pp. 2619–2624. [Google Scholar]
- Lilicrap, T.; Hunt, J.; Pritzel, A.; Hess, N.; Erez, T.; Silver, D.; Wiestra, D. Continuous control with deep reinforcement learning. In Proceedings of the International Conference on Representation Learning, San Juan, PR, USA, 2–4 May 2016; pp. 1–14. [Google Scholar]
- Cheng, Y.; Huang, L.; Wang, X. Authentic boundary proximal policy optimization. IEEE Trans. Cybern. 2021, 52, 9428–9438. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Xiao, L.; Cao, X.; Foroosh, H. Multiple adverse weather conditions adaptation for object detection via causal intervention. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 46, 1742–1756. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, F.; Chen, Z.; Wu, Y.-C.; Hao, J.; Chen, G.; Heng, P.-A. Contrastive-ace: Domain generalization through alignment of causal mechanisms. IEEE Trans. Image Process. 2023, 32, 235–250. [Google Scholar] [CrossRef]
- Liu, Y.; Li, G.; Lin, L. Cross-modal causal relational reasoning for event-level visual question answering. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 11624–11641. [Google Scholar] [PubMed]
- Lin, J.; Wang, K.; Chen, Z.; Liang, X.; Lin, L. Towards causality-aware inferring: A sequential discriminative approach for medical diagnosis. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 13363–13375. [Google Scholar] [CrossRef]
- Zhang, Y.-F.; Zhang, Z.; Li, D.; Jia, Z.; Wang, L.; Tan, T. learning domain invariant representations for generalizable person re-identification. IEEE Trans. Image Process. 2023, 32, 509–523. [Google Scholar] [CrossRef]
- Nag, S.; Raychaudhuri, D.S.; Paul, S.; Roy-Chowdhury, A.K. Reconstruction Guided Meta-Learning for Few Shot Open Set Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 15394–15405. [Google Scholar] [CrossRef] [PubMed]
- Hospedales, T.; Antoniou, A.; Micaelli, P.; Storkey, A. Meta-learning in neural networks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 5149–5169. [Google Scholar]
- Coskun, H.; Zia, M.Z.; Tekin, B.; Bogo, F.; Navab, N.; Tombari, F.; Sawhney, H.S. Domain-specific priors and meta learning for few-shot first-person action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 6659–6673. [Google Scholar] [CrossRef]
- Yu, B.; Li, X.; Li, W.; Zhou, J.; Lu, J. Discrepancy-aware meta-learning for zero-shot face manipulation detection. IEEE Trans. Image Process. 2023, 32, 3759–3773. [Google Scholar] [CrossRef] [PubMed]
- Ye, H.-J.; Han, L.; Zhan, D.-C. Revisiting unsupervised meta-learning via the characteristics of few-shot tasks. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 3721–3737. [Google Scholar] [CrossRef]
- Lv, Q.; Chen, G.; Yang, Z.; Zhong, W.; Chen, C.Y.-C. Meta learning with graph attention networks for low-data drug discovery. IEEE Trans. Neural Netw. Learn. Sys. 2023, 1–13. [Google Scholar] [CrossRef]
- Wang, H.; Wang, X.; Cheng, Y. Graph meta transfer network for heterogeneous few-shot hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5501112. [Google Scholar] [CrossRef]
- Schulman, J.; Moritz, P.; Levine, S.; Jordan, M.I.; Abbeel, P. High-dimensional continuous control using generalized advantage estimation. arXiv 2015, arXiv:1506.02438. [Google Scholar]
- Jiao, P.; Guo, X.; Jing, X.; He, D.; Wu, H.; Pan, S.; Gong, M.; Wang, W. Temporal network embedding for link prediction via vae joint attention mechanism. IEEE Trans. Neural Netw. Learn. Sys. 2022, 33, 7400–7413. [Google Scholar] [CrossRef]
- Wang, S.; Li, L.; Li, X.; Zhang, J.; Zhao, L.; Su, X.; Chen, F. textcolorredA denoising network based on frequency-spectral- spatial-feature for hyperspectral image. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2023, 16, 6693–6710. [Google Scholar] [CrossRef]
- Peng, Y.; Zhang, Y.; Tu, B.; Zhou, C.; Li, Q. Multiview hierarchical network for hyperspectral and LiDAR data classification. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2022, 15, 1454–1469. [Google Scholar] [CrossRef]
- Debes, C.; Merentitis, A.; Heremans, R.; Hahn, J.; Frangiadakis, N.; van Kasteren, T.; Liao, W.; Bellens, R.; Pižurica, A.; Gautama, S.; et al. Hyperspectral and LiDAR data fusion: Outcome of the 2013 GRSS data fusion contest. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2014, 7, 2405–2418. [Google Scholar] [CrossRef]
- Shen, X.; Deng, X.; Geng, J.; Jiang, W. SFE-FN: A shuffle feature enhancement-based fusion network for hyperspectral and LiDAR classification. IEEE Geosci. Remote Sens. Lett. 2023, 20, 5501605. [Google Scholar] [CrossRef]
- Wu, H.; Prasad, S. Convolutional recurrent neural networks for hyperspectral data classification. Remote Sens. 2017, 9, 298. [Google Scholar] [CrossRef]
- Zhao, X.; Tao, R.; Li, W.; Li, H.-C.; Du, Q.; Liao, W.; Philips, W. Joint classification of hyperspectral and LiDAR data using hierarchical random walk and deep CNN architecture. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7355–7370. [Google Scholar] [CrossRef]
- Xu, X.; Li, W.; Ran, Q.; Du, Q.; Gao, L.; Zhang, B. Multisource remote sensing data classification based on convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 937–949. [Google Scholar] [CrossRef]
- Zhang, M.; Li, W.; Du, Q.; Gao, L.; Zhang, B. Feature extraction for classification of hyperspectral and LiDAR data using patch-to-patch CNN. IEEE Trans. Cybern. 2020, 50, 100–111. [Google Scholar] [CrossRef] [PubMed]
- Lu, T.; Ding, K.; Fu, W.; Li, S.; Guo, A. Coupled adversarial learning for fusion classification of hyperspectral and LiDAR data. Inf. Fusion 2023, 93, 118–131. [Google Scholar] [CrossRef]
- Roy, S.K.; Deria, A.; Hong, D.; Rasti, B.; Plaza, A.J.; Chanussot, J. Multimodal fusion transformer for remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5515620. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MUUFL Dataset | Houston Dataset | Trento Dataset | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Class Name | Train | Validate | Test | Class Name | Train | Validate | Test | Class Name | Train | Validate | Test |
| Trees | 20 | 3472 | 19,754 | Healthy grass | 20 | 158 | 1073 | Apple trees | 20 | 594 | 3420 |
| Mostly grass | 20 | 625 | 4250 | Stressed grass | 20 | 160 | 1074 | Buildings | 20 | 425 | 2458 |
| Mixed ground surface | 20 | 1017 | 5845 | Synthetic grass | 20 | 75 | 602 | Ground | 20 | 63 | 396 |
| Dirt and sand | 20 | 259 | 1547 | Trees | 20 | 158 | 1066 | Woods | 20 | 1355 | 7748 |
| Road | 20 | 988 | 5679 | Soil | 20 | 158 | 1064 | Vineyard | 20 | 1560 | 8921 |
| Building shadow | 20 | 55 | 391 | Water | 20 | 21 | 284 | Roads | 20 | 466 | 2688 |
| Building | 20 | 320 | 1893 | Residential | 20 | 160 | 1088 | ||||
| Sidewalk | 20 | 921 | 5299 | Commercial | 20 | 158 | 1066 | ||||
| Building shadow | 20 | 193 | 1172 | Road | 20 | 159 | 1073 | ||||
| Yellow curb | 20 | 12 | 151 | Highway | 20 | 155 | 872 | ||||
| Cloth panels | 20 | 23 | 226 | Railway | 20 | 158 | 1057 | ||||
| Parking lot 1 | 20 | 156 | 1057 | ||||||||
| Parking lot 2 | 20 | 43 | 406 | ||||||||
| Tennis court | 20 | 27 | 381 | ||||||||
| Running track | 20 | 28 | 612 | ||||||||
| Class | CRNN | HRWN | TBCNN | PTPCNN | CALC | MFT | CMRL |
|---|---|---|---|---|---|---|---|
| Trees (20/23,246) | 76.65 | 77.25 | 81.90 | 84.06 | 85.50 | 84.74 | 89.78 |
| Mostly grass (20/4270) | 71.15 | 74.94 | 76.07 | 81.08 | 80.12 | 79.60 | 85.34 |
| Mixed ground surface (20/6882) | 51.68 | 64.60 | 66.05 | 53.29 | 70.75 | 60.52 | 67.36 |
| Dirt and sand (20/1826) | 71.43 | 88.48 | 78.41 | 84.22 | 92.25 | 82.56 | 83.44 |
| Road (20/6687) | 76.36 | 84.43 | 87.15 | 89.46 | 77.53 | 80.32 | 89.88 |
| Water (20/466) | 99.78 | 99.78 | 99.10 | 97.31 | 95.96 | 100 | 98.66 |
| Building shadow (20/2233) | 80.98 | 89.20 | 91.32 | 87.75 | 94.80 | 91.59 | 87.30 |
| Building (20/6240) | 90.42 | 85.02 | 91.46 | 90.90 | 89.84 | 90.69 | 92.09 |
| Sidewalk (20/1385) | 56.56 | 68.13 | 72.89 | 61.98 | 74.14 | 67.18 | 75.60 |
| Yellow curb (20/183) | 66.87 | 86.50 | 90.80 | 91.41 | 90.18 | 93.87 | 95.09 |
| Cloth panels (20/269) | 94.78 | 95.58 | 95.18 | 92.77 | 97.99 | 97.19 | 95.98 |
| OA (%) | 74.31 | 78.19 | 81.44 | 82.39 | 83.17 | 81.34 | 86.27 |
| AA (%) | 76.06 | 83.08 | 84.58 | 84.02 | 86.28 | 84.39 | 87.32 |
| Kappa (%) | 67.87 | 72.54 | 76.44 | 77.54 | 78.44 | 76.25 | 82.20 |
| Class | CRNN | HRWN | TBCNN | PTPCNN | CALC | MFT | CMRL |
|---|---|---|---|---|---|---|---|
| Healthy grass (20/1251) | 87.41 | 84.08 | 94.96 | 93.50 | 96.18 | 97.40 | 96.91 |
| Stressed grass (20/1254) | 87.93 | 77.07 | 80.63 | 93.03 | 96.35 | 95.38 | 98.46 |
| Synthetic grass (20/697) | 94.39 | 100 | 99.71 | 100 | 100 | 100 | 99.85 |
| Trees (20/1244) | 91.75 | 93.87 | 95.92 | 92.89 | 95.10 | 96.65 | 98.53 |
| Soil (20/1242) | 98.61 | 97.55 | 99.26 | 95.91 | 96.56 | 94.11 | 96.24 |
| Water (20/325) | 89.18 | 97.71 | 100 | 96.39 | 99.02 | 100 | 100 |
| Residential (20/1268) | 84.06 | 84.86 | 83.33 | 91.27 | 94.23 | 94.23 | 94.55 |
| Commercial (20/1244) | 88.07 | 85.87 | 84.56 | 86.93 | 86.60 | 93.55 | 93.30 |
| Road (20/1252) | 72.16 | 75.73 | 75.89 | 79.30 | 85.63 | 78.25 | 90.26 |
| Highway (20/1227) | 63.22 | 74.48 | 88.73 | 77.71 | 94.86 | 96.27 | 92.46 |
| Railway (20/1235) | 62.39 | 94.73 | 85.35 | 92.76 | 99.34 | 88.48 | 97.61 |
| Parking lot 1 (20/1233) | 85.41 | 90.03 | 87.88 | 90.68 | 88.54 | 94.64 | 87.80 |
| Parking lot 2 (20/469) | 81.74 | 94.21 | 95.77 | 99.11 | 97.55 | 99.33 | 99.55 |
| Tennis court (20/428) | 99.76 | 100 | 98.28 | 99.51 | 100 | 100 | 100 |
| Running track (20/660) | 97.03 | 95.63 | 98.59 | 100 | 99.69 | 99.22 | 100 |
| OA (%) | 83.97 | 87.79 | 89.46 | 91.08 | 94.50 | 94.03 | 95.51 |
| AA (%) | 85.54 | 89.72 | 91.26 | 92.60 | 95.17 | 95.17 | 96.37 |
| Kappa (%) | 82.68 | 86.80 | 88.61 | 90.36 | 94.01 | 93.55 | 95.14 |
| Class | CRNN | HRWN | TBCNN | PTPCNN | CALC | MFT | CMRL |
|---|---|---|---|---|---|---|---|
| Apple trees (20/4034) | 77.03 | 96.61 | 96.21 | 97.29 | 98.73 | 96.56 | 99.10 |
| Buildings (20/2903) | 95.42 | 92.09 | 96.07 | 96.01 | 96.29 | 93.65 | 97.50 |
| Ground (20/479) | 93.25 | 97.82 | 99.78 | 97.60 | 98.48 | 100 | 99.35 |
| Woods (20/9123) | 99.45 | 100 | 97.10 | 99.82 | 99.99 | 99.99 | 99.35 |
| Vineyard (20/10,501) | 77.45 | 80.20 | 84.50 | 99.35 | 99.64 | 99.31 | 99.05 |
| Roads (20/3174) | 89.09 | 88.62 | 92.42 | 94.20 | 97.53 | 97.97 | 98.35 |
| OA(%) | 87.23 | 90.67 | 92.05 | 98.33 | 99.06 | 98.48 | 99.41 |
| AA(%) | 88.62 | 92.56 | 94.35 | 97.38 | 98.44 | 97.92 | 99.02 |
| Kappa(%) | 83.22 | 87.76 | 89.55 | 97.78 | 98.75 | 97.97 | 99.21 |
| Component | Baseline-A | Baseline-B | Baseline-C | CMRL |
|---|---|---|---|---|
| RL | 🗸 | 🗸 | 🗸 | 🗸 |
| CL | x | x | 🗸 | 🗸 |
| ML | x | x | x | 🗸 |
| Dataset | Baseline-A | Baseline-B | Baseline-C | CMRL |
|---|---|---|---|---|
| MUUFL | 80.14 | 82.95 | 84.03 | 86.27 |
| Houston | 90.36 | 92.57 | 93.48 | 95.51 |
| Trento | 94.53 | 96.76 | 98.18 | 99.41 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, W.; Wang, X.; Wang, H.; Cheng, Y. Causal Meta-Reinforcement Learning for Multimodal Remote Sensing Data Classification. Remote Sens. 2024, 16, 1055. https://doi.org/10.3390/rs16061055
Zhang W, Wang X, Wang H, Cheng Y. Causal Meta-Reinforcement Learning for Multimodal Remote Sensing Data Classification. Remote Sensing. 2024; 16(6):1055. https://doi.org/10.3390/rs16061055
Chicago/Turabian StyleZhang, Wei, Xuesong Wang, Haoyu Wang, and Yuhu Cheng. 2024. "Causal Meta-Reinforcement Learning for Multimodal Remote Sensing Data Classification" Remote Sensing 16, no. 6: 1055. https://doi.org/10.3390/rs16061055
APA StyleZhang, W., Wang, X., Wang, H., & Cheng, Y. (2024). Causal Meta-Reinforcement Learning for Multimodal Remote Sensing Data Classification. Remote Sensing, 16(6), 1055. https://doi.org/10.3390/rs16061055