
Multiscale Change Detection Domain Adaptation Model Based on Illumination–Reflection Decoupling


Abstract
1. Introduction
- Lack of a specific UDA framework for CD. Unlike other per-pixel segmentation models, CD models are bi-stream models designed specifically for bi-temporal data. The differential features generated by CD models have difficulty accurately representing bi-temporal data. In addition, the complexity of land cover in CD data leads to poor intra-class consistency in the features generated by CD models, increasing the difficulty of feature alignment;
- Imbalance in CD samples. The number of samples in unaltered areas significantly exceeds the number of samples in altered areas. This imbalance can cause CD-UDA models to converge to local optima, incorrectly identifying changed areas as unchanged. This in turn leads to the generation of incorrect pseudo-labels for the target domain.
- A high-performance feature extraction model with illumination–reflection feature decoupling (IRD) and fusion is proposed. The model consists of a module for extracting low-frequency illumination features, a module for extracting high-frequency reflection features, a module for fusing high-frequency and low-frequency features, and a module for decoding difference features. The IRD model can achieve high-performance supervised CD by decoupling the strongly coupled illumination and reflection features, and provides a backbone model for the UDA-CD strategy;
- A global marginal distribution domain alignment method for middle layer illumination features is proposed. Utilizing the IRD model to extract shared illumination features from multi-temporal data, this method represents bi-temporal data in both source and target domains, promoting global style alignment and stable model convergence between the domains;
- A conditional distribution domain alignment method for deep features is designed. By minimizing intra-domain disparities and maximizing inter-domain differences, this approach alleviates the issue of fitting features of different classes into the same feature space, due to the poor intra-class consistency of differential features;
- An easy-to-hard sample selection strategy based on the CD entropy threshold is proposed. Aiming to obtain reliable pseudo-labels with balanced high confidence, this strategy reduces the transfer failure caused by sample imbalance and promotes stable convergence in CD-UDA.
2. Domain Adaptation
3. Methodology
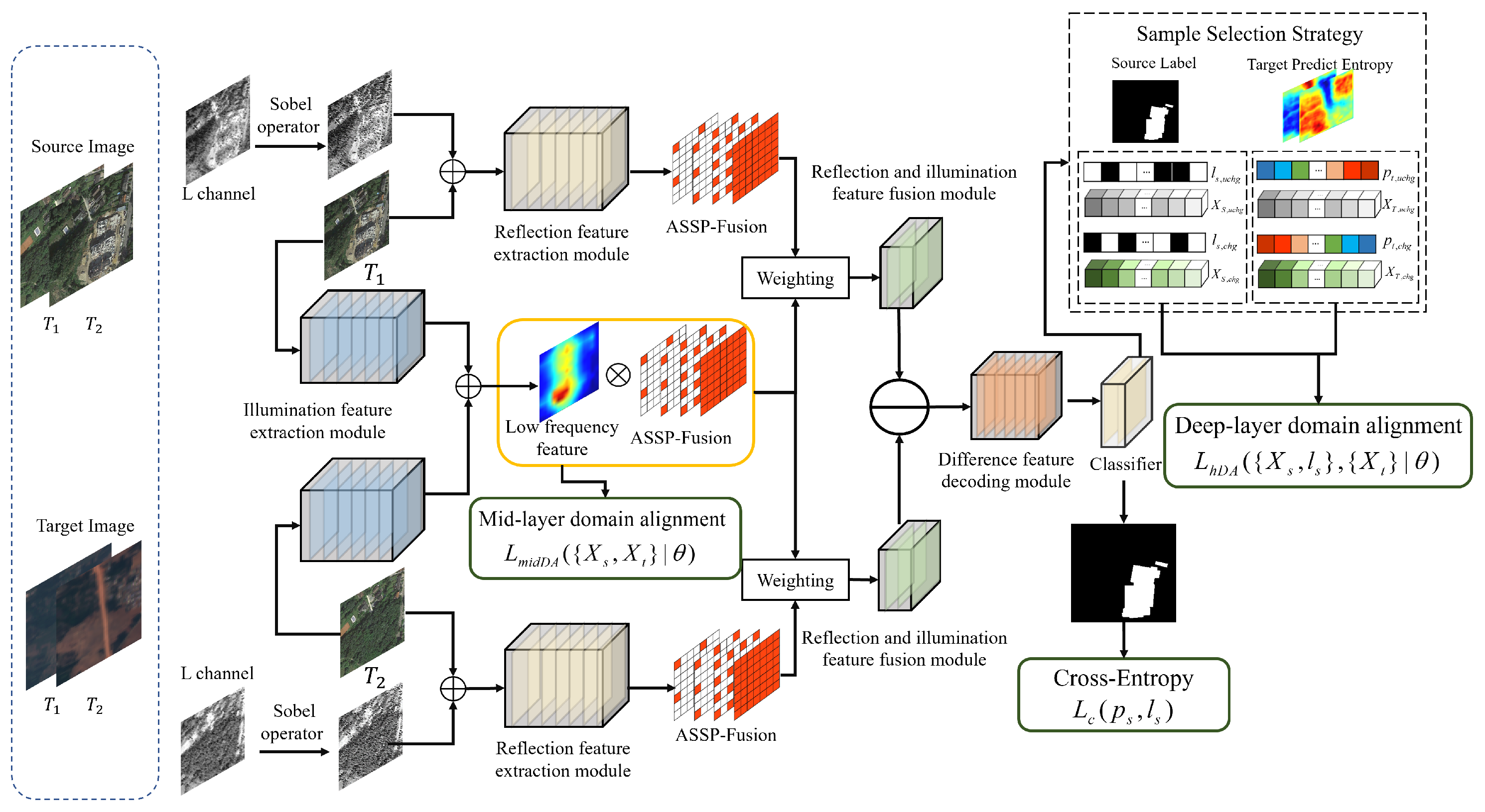
3.1. Structure of the Illumination–Reflection Decoupled Change Detection Multi-Scale Unsupervised Domain Adaptation Model (IRD-CD-UDA)
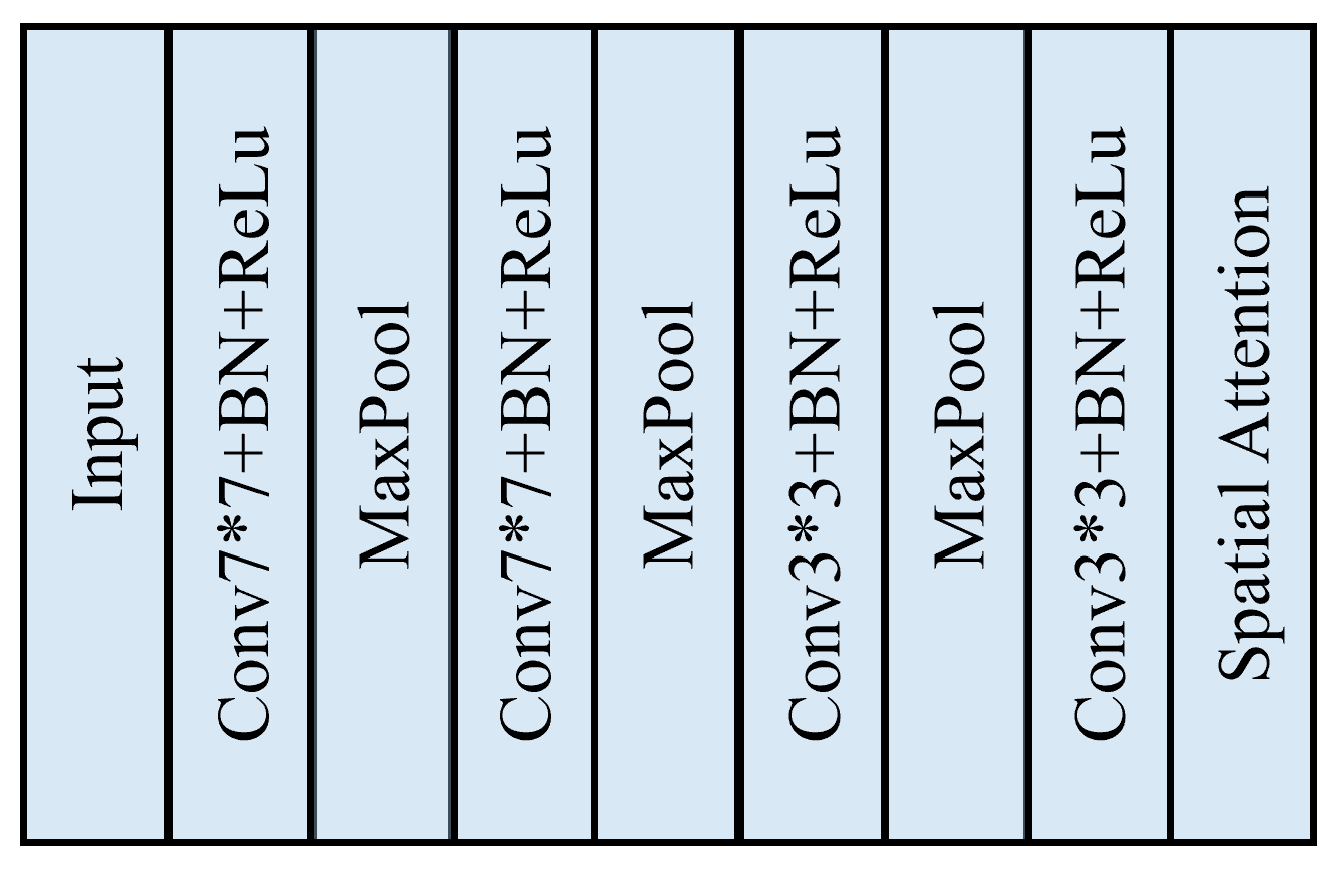
3.1.1. Illumination Feature Extraction Module
3.1.2. Reflection Feature Extraction Module
| Algorithm 1 Reflection feature extraction module |
| Require: multi-temporal images . High frequency weighting:
Output: |
3.1.3. Reflection and Illumination Feature Fusion Module
3.1.4. Differential Feature Decoding Module
3.2. Strategy of Change Detection Unsupervised Domain Adaptation Model (CD-UDA)
3.2.1. Marginal Distribution Domain Alignment of Illumination Feature
3.2.2. Conditional Distribution Domain Alignment of Classification Feature
3.2.3. Sample Selection Strategy
| Algorithm 2 Transferable sample selection strategy |
| Require: The transferable features from source and target domain . Initialization: Set the entropy threshold , sample number to be selected and . Transferable sample selection:
|
| Algorithm 3 Framework of the IRD-CD-UDA algorithm |
| Require: Multi-temporal data from source domain and target domain: . Initialization: randomly set parameter of IRD-CD follow the standard normal distribution. Normalization: . Pretraining based on :
|
4. Experiment
4.1. Experimental Setting and Datasets
4.2. Evaluation Metrics
4.3. Performance Evaluation of Change Detection
4.4. Ablation Experiment of Change Detection Unsupervised Domain Adaptation Model (CD-UDA)
- D0: Evaluate the UDA performance of the model when pre-trained with the source domain data, using only the mid-layer marginal distribution alignment (Section 3.2.1);
- D1: Evaluate the UDA performance of the model when pre-trained with the source domain data, using transferable features derived from the probabilistic easy-to-hard target domain sample selection strategy (Section 3.2.3) for the inter-domain marginal distribution alignment (Section 3.2.1) prior to the classification layer;
- D2: Building on D1, evaluate the UDA performance of the mid-layer marginal distribution alignment (Section 3.2.2).
4.5. Performance Evaluation of Change Detection Unsupervised Domain Adaptation Model (CD-UDA)
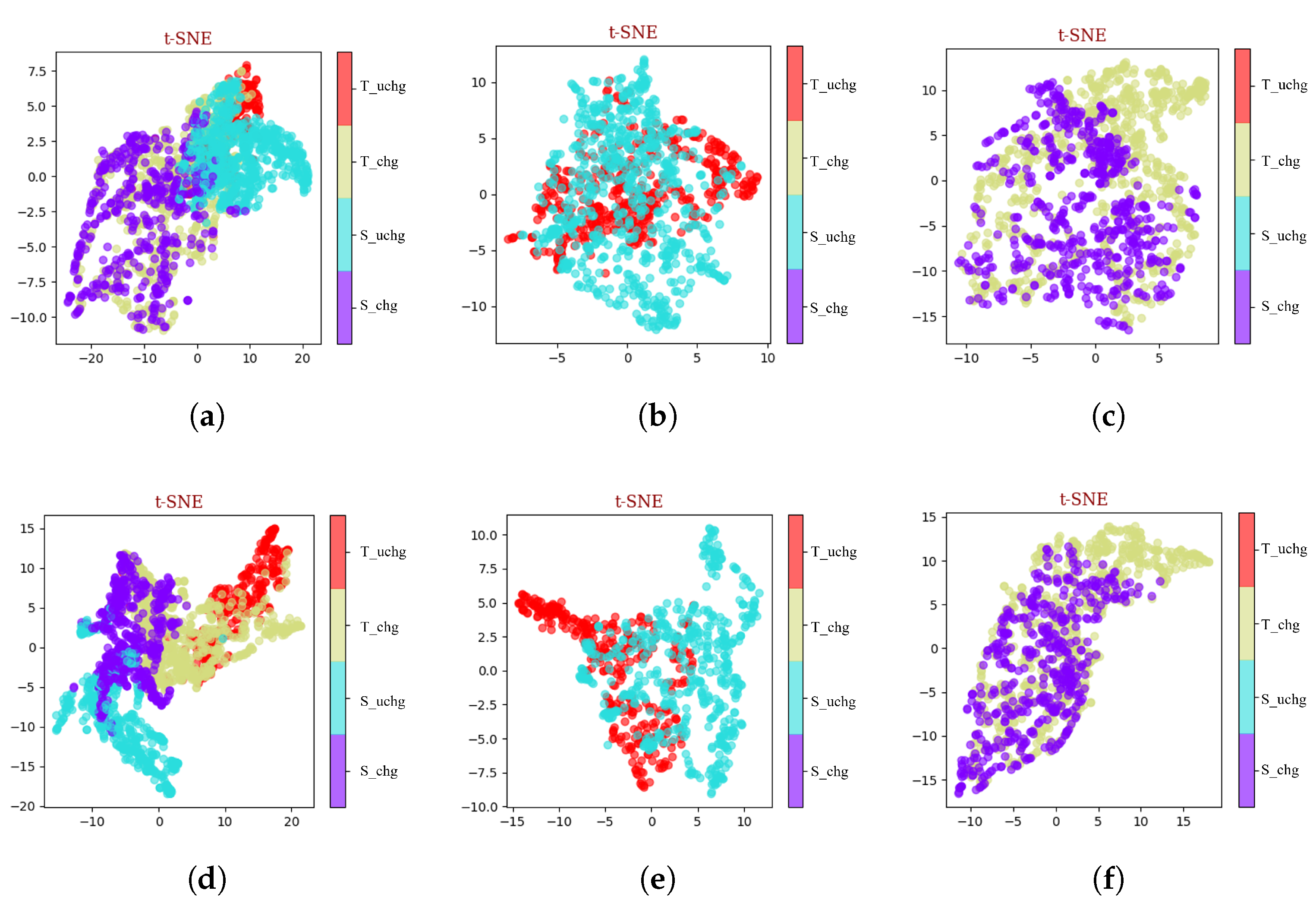
4.6. Visualization
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| CD | Change Detection |
| UDA | Unsupervised Domain Adaptation |
| IRD | Illumination-Reflection Feature Decoupling |
| ASSP | Atrous Apatial Pyramid Pooling |
References
- Shi, W.; Zhang, M.; Zhang, R.; Chen, S.; Zhan, Z. Change Detection Based on Artificial Intelligence: State-of-the-Art and Challenges. Remote Sens. 2020, 12, 1688. [Google Scholar] [CrossRef]
- Zhang, R.; Zhang, H.; Ning, X.; Huang, X.; Wang, J.; Cui, W. Global-aware siamese network for change detection on remote sensing images. ISPRS J. Photogramm. Remote Sens. 2023, 199, 61–72. [Google Scholar] [CrossRef]
- Wang, X.; Yan, X.; Tan, K.; Pan, C.; Ding, J.; Liu, Z.; Dong, X. Double U-Net (W-Net): A change detection network with two heads for remote sensing imagery. Int. J. Appl. Earth Obs. Geoinf. 2023, 122, 103456. [Google Scholar] [CrossRef]
- Li, S.; Wang, Y.; Cai, H.; Lin, Y.; Wang, M.; Teng, F. MF-SRCDNet: Multi-feature fusion super-resolution building change detection framework for multi-sensor high-resolution remote sensing imagery. Int. J. Appl. Earth Obs. Geoinf. 2023, 119, 103303. [Google Scholar] [CrossRef]
- Kumar, A.; Mishra, V.; Panigrahi, R.K.; Martorella, M. Application of Hybrid-Pol SAR in Oil-Spill Detection. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar] [CrossRef]
- Wu, C.; Du, B.; Zhang, L. Slow Feature Analysis for Change Detection in Multispectral Imagery. IEEE Trans. Geosci. Remote Sens. 2014, 52, 2858–2874. [Google Scholar] [CrossRef]
- Li, H.C.; Yang, G.; Yang, W.; Du, Q.; Emery, W.J. Deep nonsmooth nonnegative matrix factorization network with semi-supervised learning for SAR image change detection. ISPRS J. Photogramm. Remote Sens. 2020, 160, 167–179. [Google Scholar] [CrossRef]
- Zhang, X.; Su, H.; Zhang, C.; Gu, X.; Tan, X.; Atkinson, P.M. Robust unsupervised small area change detection from SAR imagery using deep learning. ISPRS J. Photogramm. Remote Sens. 2021, 173, 79–94. [Google Scholar] [CrossRef]
- Jiang, X.; Li, G.; Zhang, X.P.; He, Y. A Semisupervised Siamese Network for Efficient Change Detection in Heterogeneous Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–18. [Google Scholar] [CrossRef]
- Xie, S.; Zheng, Z.; Chen, L.; Chen, C. Learning Semantic Representations for Unsupervised Domain Adaptation. In Proceedings of the 35th International Conference on Machine Learning PMLR, Stockholm, Sweden, 10–15 July 2018; Dy, J., Krause, A., Eds.; Volume 80, pp. 5423–5432. [Google Scholar]
- Vega, P.J.S.; da Costa, G.A.O.P.; Feitosa, R.Q.; Adarme, M.X.O.; de Almeida, C.A.; Heipke, C.; Rottensteiner, F. An unsupervised domain adaptation approach for change detection and its application to deforestation mapping in tropical biomes. ISPRS J. Photogramm. Remote Sens. 2021, 181, 113–128. [Google Scholar] [CrossRef]
- Li, X.; Du, Z.; Huang, Y.; Tan, Z. A deep translation (GAN) based change detection network for optical and SAR remote sensing images. ISPRS J. Photogramm. Remote Sens. 2021, 179, 14–34. [Google Scholar] [CrossRef]
- Zhao, W.; Chen, X.; Ge, X.; Chen, J. Using Adversarial Network for Multiple Change Detection in Bitemporal Remote Sensing Imagery. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Li, J.; Zi, S.; Song, R.; Li, Y.; Hu, Y.; Du, Q. A Stepwise Domain Adaptive Segmentation Network With Covariate Shift Alleviation for Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M. Learning transferable features with deep adaptation networks. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 97–105. [Google Scholar]
- Geng, J.; Deng, X.; Ma, X.; Jiang, W. Transfer Learning for SAR Image Classification Via Deep Joint Distribution Adaptation Networks. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5377–5392. [Google Scholar] [CrossRef]
- Zhao, H.; Combes, R.; Zhang, K.; Gordon, G.J. On Learning Invariant Representation for Domain Adaptation. arXiv 2019, arXiv:1901.09453. [Google Scholar]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain Adaptation via Transfer Component Analysis. IEEE Trans. Neural Netw. 2011, 22, 199–210. [Google Scholar] [CrossRef]
- Zellinger, W.; Grubinger, T.; Lughofer, E.; Natschläger, T.; Saminger-Platz, S. Central moment discrepancy (cmd) for domain-invariant representation learning. arXiv 2017, arXiv:1702.08811. [Google Scholar]
- Sun, B.; Saenko, K. Deep coral: Correlation alignment for deep domain adaptation. In Proceedings of the Computer Vision–ECCV 2016 Workshops, Amsterdam, The Netherlands, 8–10 and 15–16 October 2016; Proceedings, Part III 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 443–450. [Google Scholar]
- Gretton, A.; Sejdinovic, D.; Strathmann, H.; Balakrishnan, S.; Pontil, M.; Fukumizu, K.; Sriperumbudur, B.K. Optimal kernel choice for large-scale two-sample tests. Adv. Neural Inf. Process. Syst. 2012, 25. [Google Scholar]
- Long, M.; Wang, J.; Ding, G.; Sun, J.; Yu, P.S. Transfer Feature Learning with Joint Distribution Adaptation. In Proceedings of the 2013 IEEE International Conference on Computer Vision (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 2200–2207. [Google Scholar] [CrossRef]
- Zhang, J.; Li, W.; Ogunbona, P. Joint Geometrical and Statistical Alignment for Visual Domain Adaptation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5150–5158. [Google Scholar] [CrossRef]
- Tzeng, E.; Hoffman, J.; Zhang, N.; Saenko, K.; Darrell, T. Deep domain confusion: Maximizing for domain invariance. arXiv 2014, arXiv:1412.3474. [Google Scholar]
- Long, M.; Zhu, H.; Wang, J.; Jordan, M.I. Deep transfer learning with joint adaptation networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 2208–2217. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.; Hao, S.; Feng, W.; Shen, Z. Balanced Distribution Adaptation for Transfer Learning. In Proceedings of the 2017 IEEE International Conference on Data Mining (ICDM), New Orleans, LA, USA, 18–21 November 2017; pp. 1129–1134. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.; Feng, W.; Yu, H.; Huang, M.; Yang, Q. Transfer learning with dynamic distribution adaptation. ACM Trans. Intell. Syst. Technol. (TIST) 2020, 11, 1–25. [Google Scholar] [CrossRef]
- Yan, H.; Ding, Y.; Li, P.; Wang, Q.; Xu, Y.; Zuo, W. Mind the Class Weight Bias: Weighted Maximum Mean Discrepancy for Unsupervised Domain Adaptation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 945–954. [Google Scholar] [CrossRef]
- Shen, J.; Qu, Y.; Zhang, W.; Yu, Y. Wasserstein distance guided representation learning for domain adaptation. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar] [CrossRef]
- Kang, G.; Jiang, L.; Yang, Y.; Hauptmann, A.G. Contrastive Adaptation Network for Unsupervised Domain Adaptation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4888–4897. [Google Scholar] [CrossRef]
- Chen, H.; Wu, C.; Du, B.; Zhang, L. DSDANet: Deep Siamese domain adaptation convolutional neural network for cross-domain change detection. arXiv 2020, arXiv:2006.09225v1. [Google Scholar]
- Ahmed, S.M.; Raychaudhuri, D.S.; Paul, S.; Oymak, S.; Roy-Chowdhury, A.K. Unsupervised Multi-source Domain Adaptation Without Access to Source Data. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 10098–10107. [Google Scholar] [CrossRef]
- Liang, J.; Hu, D.; Feng, J. Domain Adaptation with Auxiliary Target Domain-Oriented Classifier. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 16627–16637. [Google Scholar] [CrossRef]
- Yang, L.; Balaji, Y.; Lim, S.N.; Shrivastava, A. Curriculum manager for source selection in multi-source domain adaptation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XIV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 608–624. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Wu, H.; Zheng, S.; Zhang, J.; Huang, K. Fast end-to-end trainable guided filter. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1838–1847. [Google Scholar] [CrossRef]
- Weyermann, J.; Kneubühler, M.; Schläpfer, D.; Schaepman, M.E. Minimizing Reflectance Anisotropy Effects in Airborne Spectroscopy Data Using Ross–Li Model Inversion With Continuous Field Land Cover Stratification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 5814–5823. [Google Scholar] [CrossRef]
- Petro, A.B.; Sbert, C.; Morel, J.M. Multiscale Retinex. Image Process. Line 2014, 71–88. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Shi, Q.; Liu, M.; Li, S.; Liu, X.; Wang, F.; Zhang, L. A Deeply Supervised Attention Metric-Based Network and an Open Aerial Image Dataset for Remote Sensing Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Peng, D.; Bruzzone, L.; Zhang, Y.; Guan, H.; Ding, H.; Huang, X. SemiCDNet: A Semisupervised Convolutional Neural Network for Change Detection in High Resolution Remote-Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 5891–5906. [Google Scholar] [CrossRef]
- Chen, H.; Shi, Z. A spatial-temporal attention-based method and a new dataset for remote sensing image change detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Xie, B.; Yuan, L.; Li, S.; Liu, C.H.; Cheng, X. Towards Fewer Annotations: Active Learning via Region Impurity and Prediction Uncertainty for Domain Adaptive Semantic Segmentation. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 8058–8068. [Google Scholar] [CrossRef]
- Luo, X.; Li, X.; Wu, Y.; Hou, W.; Wang, M.; Jin, Y.; Xu, W. Research on Change Detection Method of High-Resolution Remote Sensing Images Based on Subpixel Convolution. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 1447–1457. [Google Scholar] [CrossRef]
- Caye Daudt, R.; Le Saux, B.; Boulch, A. Fully Convolutional Siamese Networks for Change Detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar] [CrossRef]
- Raza, A.; Huo, H.; Fang, T. EUNet-CD: Efficient UNet++ for Change Detection of Very High-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Basavaraju, K.S.; Sravya, N.; Lal, S.; Nalini, J.; Reddy, C.S.; Acqua, D. UCDNet: A Deep Learning Model for Urban Change Detection From Bi-Temporal Multispectral Sentinel-2 Satellite Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–10. [Google Scholar] [CrossRef]
- Cheng, G.; Wang, G.; Han, J. ISNet: Towards Improving Separability for Remote Sensing Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Maaten, L. Accelerating t-SNE using tree-based algorithms. J. Mach. Learn. Res. 2014, 15, 3221–3245. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Source | Ground Target Composition | : |
|---|---|---|---|
| SYSU [42] | Aerial images | Urban construction, suburbs, pre-construction, vegetation, road, ocean | 0.20:1 |
| GZ [43] | Google Earth | Water bodies, roads, farmland, bare land, forests, buildings, ships | 0.10:1 |
| LEVIR [44] | Google Earth | Buildings, including urban and rural scenes | 0.05:1 |
| Data | Method | OA | UAcc | CAcc | F1 | mIoU | Parp |
|---|---|---|---|---|---|---|---|
| GZ | DeepLab | 0.967 | 0.992 | 0.679 | 0.876 | 0.795 | 26.7M |
| FCSiamD | 0.980 | 0.991 | 0.870 | 0.933 | 0.884 | 2.1M | |
| EUNet | 0.968 | 0.999 | 0.627 | 0.872 | 0.794 | 2.3M | |
| UCDNet | 0.964 | 0.979 | 0.800 | 0.884 | 0.805 | 4.3M | |
| ISNet | 0.968 | 0.969 | 0.951 | 0.907 | 0.839 | 12.3M | |
| IRDNet | 0.985 | 0.989 | 0.933 | 0.909 | 0.908 | 6.3M | |
| LEVIR | DeepLab | 0.994 | 0.998 | 0.733 | 0.927 | 0.838 | 26.7M |
| FCSiamD | 0.995 | 0.998 | 0.789 | 0.921 | 0.863 | 2.1M | |
| EUNet | 0.992 | 0.997 | 0.637 | 0.856 | 0.775 | 2.3M | |
| UCDNet | 0.995 | 0.999 | 0.774 | 0.920 | 0.862 | 4.3M | |
| ISNet | 0.994 | 0.996 | 0.895 | 0.918 | 0.859 | 12.3M | |
| IRDNet | 0.996 | 0.998 | 0.847 | 0.936 | 0.886 | 6.3M | |
| SUYU | DeepLab | 0.895 | 0.953 | 0.687 | 0.824 | 0.732 | 26.7M |
| FCSiamD | 0.897 | 0.942 | 0.730 | 0.844 | 0.741 | 2.1M | |
| EUNet | 0.864 | 0.944 | 0.575 | 0.781 | 0.661 | 2.3M | |
| UCDNet | 0.888 | 0.918 | 0.780 | 0.840 | 0.734 | 4.3M | |
| ISNet | 0.893 | 0.954 | 0.670 | 0.832 | 0.726 | 12.3M | |
| IRDNet | 0.905 | 0.962 | 0.697 | 0.851 | 0.751 | 6.3M |
| D0 | D1 | D2 | Data | OA | UAcc | CAcc | F1 | mIoU |
|---|---|---|---|---|---|---|---|---|
| √ | × | × | 0.973 | 0.992 | 0.232 | 0.643 | 0.568 | |
| √ | √ | × | 0.964 | 0.989 | 0.257 | 0.646 | 0.577 | |
| √ | √ | √ | 0.974 | 0.990 | 0.305 | 0.673 | 0.597 | |
| √ | × | × | 0.796 | 0.992 | 0.076 | 0.511 | 0.434 | |
| √ | √ | × | 0.792 | 0.984 | 0.087 | 0.517 | 0.435 | |
| √ | √ | √ | 0.797 | 0.966 | 0.188 | 0.584 | 0.478 | |
| √ | × | × | 0.786 | 0.976 | 0.088 | 0.514 | 0.432 | |
| √ | √ | × | 0.785 | 0.981 | 0.065 | 0.496 | 0.421 | |
| √ | √ | √ | 0.777 | 0.958 | 0.111 | 0.524 | 0.434 | |
| √ | × | × | 0.941 | 0.994 | 0.138 | 0.597 | 0.534 | |
| √ | √ | × | 0.941 | 0.987 | 0.247 | 0.657 | 0.574 | |
| √ | √ | √ | 0.940 | 0.978 | 0.361 | 0.698 | 0.606 | |
| √ | × | × | 0.939 | 0.953 | 0.333 | 0.587 | 0.521 | |
| √ | √ | × | 0.843 | 0.845 | 0.769 | 0.551 | 0.472 | |
| √ | √ | √ | 0.951 | 0.966 | 0.348 | 0.614 | 0.548 | |
| √ | × | × | 0.671 | 0.654 | 0.924 | 0.524 | 0.400 | |
| √ | √ | × | 0.852 | 0.856 | 0.788 | 0.657 | 0.547 | |
| √ | √ | √ | 0.877 | 0.886 | 0.733 | 0.678 | 0.571 |
| 0.6 | 0.7 | 0.8 | 0.9 | |
|---|---|---|---|---|
| 0.534/0.509 | 0.608/0.549 | 0.613/0.608 | 0.615/0.556 | |
| 0.497/0.420 | 0.558/0.522 | 0.562/0.531 | 0.568/0.511 | |
| 0.488/0.418 | 0.485/0.417 | 0.502/0.419 | 0.497/0.418 | |
| 0.613/0.544 | 0.643/0.565 | 0.654/0.573 | 0.660/0.581 | |
| 0.542/0.499 | 0.579/0.531 | 0.582/0.532 | 0.610/0.553 | |
| 0.533/0.495 | 0.594/0.543 | 0.597/0.548 | 0.604/0.493 |
| 0.6 | 0.7 | 0.8 | 0.9 | |
|---|---|---|---|---|
| 0.583/0.536 | 0.655/0.580 | 0.673/0.597 | 0.658/0.584 | |
| 0.535/0.456 | 0.557/0.478 | 0.584/0.479 | 0.542/0.461 | |
| 0.485/0.416 | 0.497/0.418 | 0.523/0.434 | 0.510/0.428 | |
| 0.627/0.564 | 0.684/0.652 | 0.698/0.610 | 0.661/0.585 | |
| 0.596/0.529 | 0.615/0.551 | 0.614/0.548 | 0.614/0.549 | |
| 0.608/0.549 | 0.627/0.564 | 0.659/0.562 | 0.627/0.564 |
| Method | |||||
|---|---|---|---|---|---|
| DeepLab | 0.970 | 0.992 | 0.095 | 0.559 | 0.521 |
| FCSiamD | 0.973 | 0.994 | 0.087 | 0.551 | 0.522 |
| EUNet | 0.976 | 0.999 | 0.030 | 0.522 | 0.502 |
| UCDNet | 0.974 | 0.997 | 0.044 | 0.460 | 0.507 |
| ISNet | 0.969 | 0.988 | 0.218 | 0.621 | 0.558 |
| IRDNet | 0.974 | 0.991 | 0.176 | 0.609 | 0.552 |
| IRD-CD-UDA-Source | 0.969 | 0.988 | 0.930 | 0.899 | 0.909 |
| UCDNet-UDA | 0.966 | 0.998 | 0.052 | 0.541 | 0.513 |
| FCSiamD-UDA | 0.966 | 0.988 | 0.074 | 0.541 | 0.509 |
| DSDANet | 0.941 | 0.994 | 0.126 | 0.589 | 0.528 |
| IRD-CD-UDA | 0.974 | 0.990 | 0.305 | 0.673 | 0.597 |
| Method | |||||
|---|---|---|---|---|---|
| DeepLab | 0.794 | 0.996 | 0.053 | 0.491 | 0.422 |
| FCSiamD | 0.793 | 0.995 | 0.054 | 0.508 | 0.422 |
| EUNet | 0.790 | 0.993 | 0.044 | 0.482 | 0.415 |
| UCDNet | 0.789 | 0.998 | 0.020 | 0.532 | 0.404 |
| ISNet | 0.786 | 0.979 | 0.077 | 0.505 | 0.427 |
| IRDNet | 0.789 | 0.980 | 0.081 | 0.510 | 0.430 |
| IRD-CD-UDA-Source | 0.979 | 0.990 | 0.927 | 0.901 | 0.901 |
| UCDNet-UDA | 0.791 | 0.977 | 0.101 | 0.527 | 0.440 |
| FCSiamD-UDA | 0.785 | 0.991 | 0.039 | 0.485 | 0.408 |
| DSDANet | 0.788 | 0.992 | 0.039 | 0.477 | 0.412 |
| IRD-CD-UDA | 0.800 | 0.966 | 0.188 | 0.585 | 0.478 |
| Method | |||||
|---|---|---|---|---|---|
| DeepLab | 0.787 | 0.999 | 0.005 | 0.445 | 0.395 |
| FCSiamD | 0.788 | 0.999 | 0.011 | 0.451 | 0.399 |
| EUNet | 0.787 | 0.999 | 0.005 | 0.445 | 0.396 |
| UCDNet | 0.787 | 0.999 | 0.006 | 0.447 | 0.396 |
| ISNet | 0.789 | 0.997 | 0.023 | 0.462 | 0.405 |
| IRDNet | 0.786 | 0.999 | 0.004 | 0.444 | 0.395 |
| IRD-CD-UDA-Source | 0.989 | 0.991 | 0.851 | 0.928 | 0.881 |
| UCDNet-UDA | 0.792 | 0.997 | 0.040 | 0.479 | 0.415 |
| FCSiamD-UDA | 0.786 | 0.999 | 0.046 | 0.453 | 0.405 |
| DSDANet | 0.786 | 0.999 | 0.054 | 0.441 | 0.399 |
| IRD-CD-UDA | 0.787 | 0.958 | 0.112 | 0.524 | 0.434 |
| Method | |||||
|---|---|---|---|---|---|
| DeepLab | 0.933 | 0.978 | 0.258 | 0.613 | 0.564 |
| FCSiamD | 0.942 | 0.994 | 0.152 | 0.608 | 0.541 |
| EUNet | 0.928 | 0.967 | 0.338 | 0.665 | 0.576 |
| UCDNet | 0.941 | 0.994 | 0.131 | 0.593 | 0.531 |
| ISNet | 0.913 | 0.988 | 0.228 | 0.648 | 0.621 |
| IRD-CD-UDA-Source | 0.991 | 0.996 | 0.851 | 0.938 | 0.888 |
| IRDNet | 0.948 | 0.992 | 0.299 | 0.613 | 0.607 |
| IRD-CD-UDA-Source | 0.989 | 0.991 | 0.851 | 0.928 | 0.881 |
| UCDNet-UDA | 0.912 | 0.953 | 0.251 | 0.605 | 0.528 |
| FCSiamD-UDA | 0.917 | 0.959 | 0.288 | 0.629 | 0.547 |
| DSDANet | 0.927 | 0.968 | 0.304 | 0.652 | 0.566 |
| IRD-CD-UDA | 0.950 | 0.980 | 0.361 | 0.698 | 0.610 |
| Method | |||||
|---|---|---|---|---|---|
| DeepLab | 0.947 | 0.966 | 0.177 | 0.556 | 0.511 |
| FCSiamD | 0.950 | 0.969 | 0.207 | 0.571 | 0.521 |
| EUNet | 0.754 | 0.755 | 0.733 | 0.491 | 0.408 |
| UCDNet | 0.600 | 0.601 | 0.552 | 0.373 | 0.313 |
| ISNet | 0.847 | 0.851 | 0.676 | 0.574 | 0.470 |
| IRDNet | 0.875 | 0.880 | 0.664 | 0.567 | 0.493 |
| IRD-CD-UDA-Source | 0.901 | 0.958 | 0.691 | 0.844 | 0.749 |
| UCDNet-UDA | 0.901 | 0.922 | 0.272 | 0.537 | 0.486 |
| FCSiamD-UDA | 0.969 | 0.992 | 0.103 | 0.533 | 0.512 |
| DSDANet | 0.874 | 0.877 | 0.769 | 0.578 | 0.499 |
| IRD-CD-UDA | 0.951 | 0.966 | 0.348 | 0.614 | 0.548 |
| Method | |||||
|---|---|---|---|---|---|
| DeepLab | 0.800 | 0.800 | 0.792 | 0.596 | 0.493 |
| FCSiamD | 0.880 | 0.906 | 0.496 | 0.637 | 0.541 |
| EUNet | 0.536 | 0.508 | 0.957 | 0.438 | 0.310 |
| UCDNet | 0.752 | 0.766 | 0.537 | 0.461 | 0.431 |
| ISNet | 0.807 | 0.812 | 0.730 | 0.604 | 0.494 |
| IRDNet | 0.815 | 0.816 | 0.789 | 0.619 | 0.507 |
| IRD-CD-UDA-Source | 0.902 | 0.951 | 0.681 | 0.841 | 0.742 |
| UCDNet-UDA | 0.818 | 0.821 | 0.766 | 0.619 | 0.508 |
| FCSiamD-UDA | 0.877 | 0.886 | 0.733 | 0.668 | 0.570 |
| DSDANet | 0.781 | 0.777 | 0.843 | 0.597 | 0.481 |
| IRD-CD-UDA | 0.898 | 0.924 | 0.491 | 0.659 | 0.562 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, R.; Xie, J.; Yang, J.; Hong, Z.; Xu, Y.; Hou, H. Multiscale Change Detection Domain Adaptation Model Based on Illumination–Reflection Decoupling. Remote Sens. 2024, 16, 799. https://doi.org/10.3390/rs16050799
Fan R, Xie J, Yang J, Hong Z, Xu Y, Hou H. Multiscale Change Detection Domain Adaptation Model Based on Illumination–Reflection Decoupling. Remote Sensing. 2024; 16(5):799. https://doi.org/10.3390/rs16050799
Chicago/Turabian StyleFan, Rongbo, Jialin Xie, Jianhua Yang, Zenglin Hong, Yuqi Xu, and Hong Hou. 2024. "Multiscale Change Detection Domain Adaptation Model Based on Illumination–Reflection Decoupling" Remote Sensing 16, no. 5: 799. https://doi.org/10.3390/rs16050799
APA StyleFan, R., Xie, J., Yang, J., Hong, Z., Xu, Y., & Hou, H. (2024). Multiscale Change Detection Domain Adaptation Model Based on Illumination–Reflection Decoupling. Remote Sensing, 16(5), 799. https://doi.org/10.3390/rs16050799