

MSGFNet: Multi-Scale Gated Fusion Network for Remote Sensing Image Change Detection



Abstract
1. Introduction
- We propose a novel end-to-end CD network, namely the multi-scale gated fusion network (MSGFNet). The MSGFNet is designed with a weight-sharing Siamese architecture tailored to be compatible with the CD task;
- To improve the details of boundaries and detect the complete change targets, we propose an MSGFM comprising an MSPF unit and a GWAF unit. The MSGFM adaptively fuses bi-temporal multi-scale features based on gate mechanisms to obtain discriminative fusion features;
- To confirm the efficacy of the MSGFNet, we employed the LEVIR-CD, WHU-CD, and SYSU-CD datasets for our comparison experiments. The results demonstrate that the MSGFNet outperforms several state-of-the-art (SOTA) methods. Additionally, the MSGFM was validated through ablation studies.
2. Related Work
2.1. CNN-Based Methods
2.2. Transformer-Based Methods
2.3. Hybrid-Based Methods
3. Materials and Methods
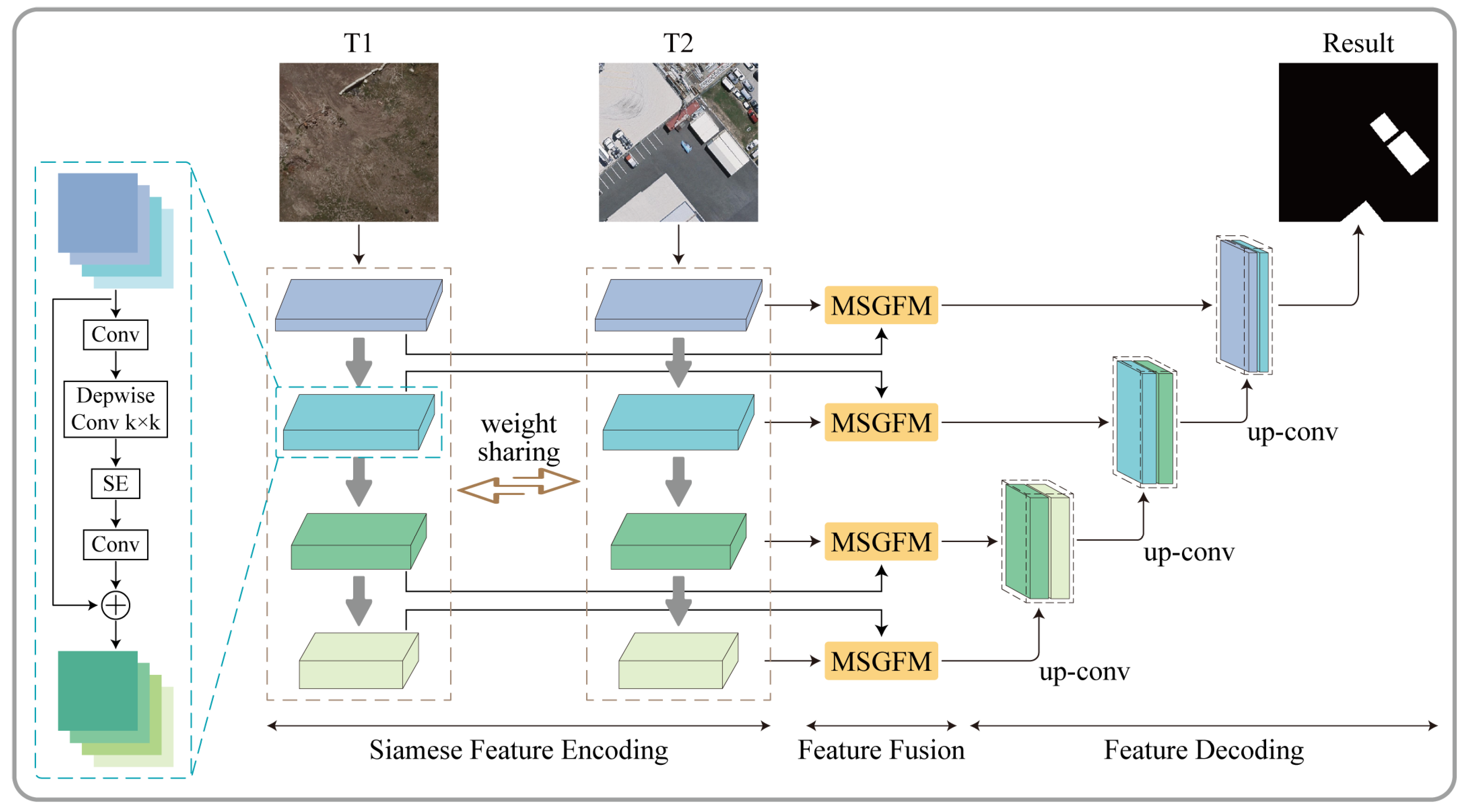
3.1. Framework
3.2. Siamese Feature Encoder
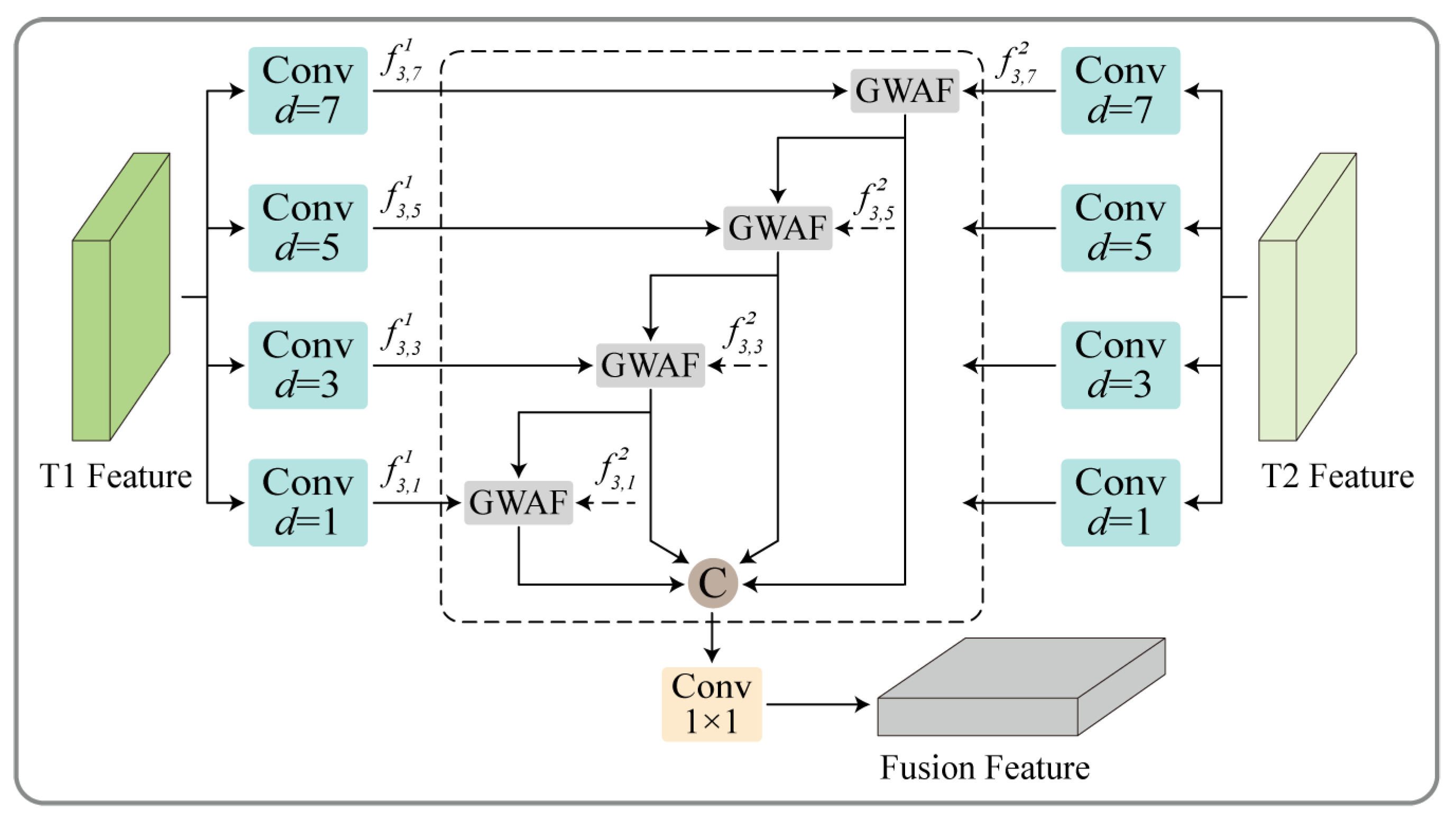
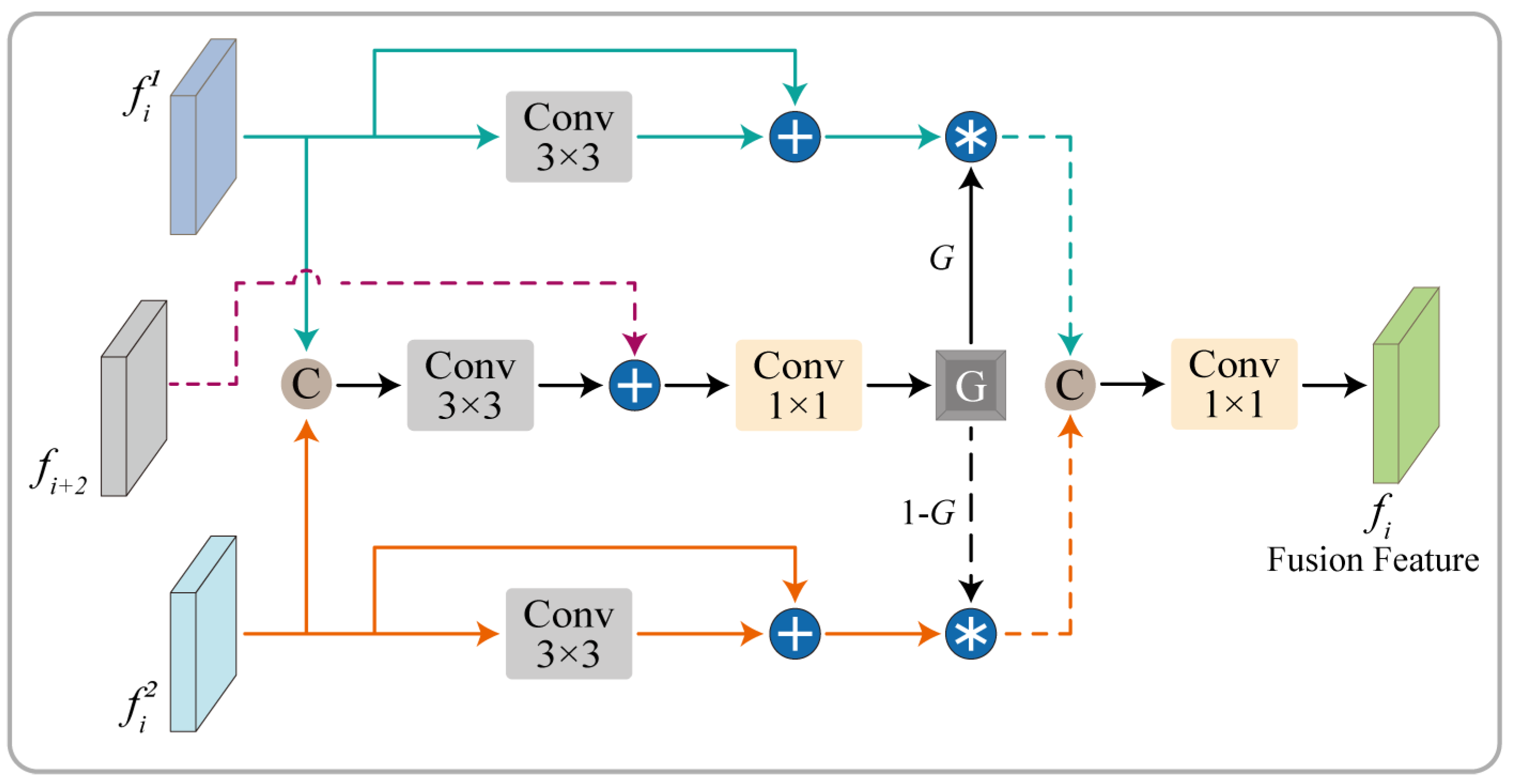
3.3. Multi-Scale Gated Fusion Module
3.3.1. Multi-Scale Progressive Fusion Unit
3.3.2. Gated Weight Adaptive Fusion Unit
3.4. Decoder
3.5. Details of Loss Function
4. Results
4.1. Datasets
4.1.1. WHU-CD
4.1.2. LEVIR-CD
4.1.3. SYSU-CD

4.2. Evaluation Metrics
4.3. Comparison Methods
- FC-EF [57]: FC-EF stands as a milestone method, utilizing a classic U-Net architecture. In this method, the bi-temporal images are concatenated along the feature direction before being input into the network.
- FC-Siam-Diff [57]: FC-Siam-diff is a CD method with a Siamese CNN architecture. This network first extracts multi-level features from bi-temporal images and then uses the feature difference as the feature fusion module to generate change information.
- STANet [55]: STANet is a metric-based method. This method suggests using a spatiotemporal attention module based on self-attention mechanisms to model the spatial and temporal relationships to obtain significant information about changed features.
- DSIFNet [58]: DSIFNet is a deeply supervised image fusion method. This method proposes an attention module to integrate multilevel feature information and employs the deep supervision strategy to optimize the network and improve its performance.
- SNUNet [20]: SNUNet is a combination of the NestedUNet and Siamese networks. This method alleviates the localization information loss by using a dense connection between the encoder and decoder. Furthermore, an ensemble channel attention module is built to refine the change features at different semantic levels.
- BITNet [59]: BITNet is a combination of a transformer and a CNN. This network first extracts semantic features by using the CNN, and then uses the transformer to model the global feature into a set of tokens, strengthening the contextual information of the changed features.
- ChangeFormer [34]: ChangeFormer is a purely transformer-based change detection method. This method uses a Siamese transformer to build the bi-temporal image features and then uses the multi-layer perceptual to decode the difference features.
- LightCDNet [60]: LightCDNet employs a lightweight MobileNetV2 to extract multilevel features and introduces a multi-temporal feature fusion module to fuse the corresponding level features. Finally, deconvolutional layers are utilized to recover the change map.
4.4. Experimental Details
4.5. Results
4.5.1. Experimental Analysis on the WHU-CD Dataset
4.5.2. Experimental Analysis on the LEVIR-CD Dataset
4.5.3. Experimental Analysis on the SYSU-CD Dataset
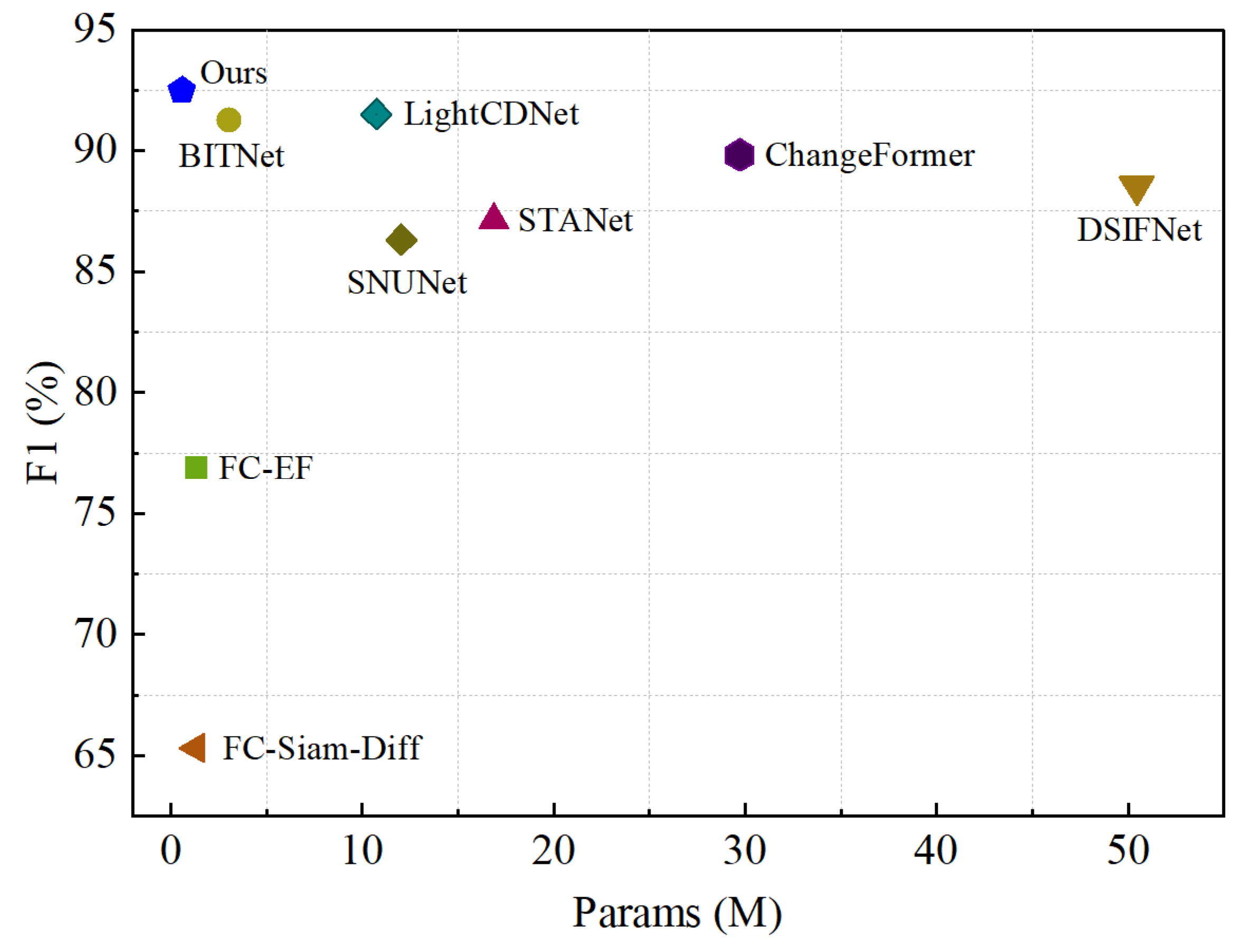
4.5.4. Model Size and Computational Complexity
4.6. Ablation Studies
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lu, D.; Mausel, P.; Brondízio, E.; Moran, E. Change Detection Techniques. Int. J. Remote Sens. 2004, 25, 2365–2401. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L.; Zhu, T. Building Change Detection from Multitemporal High-Resolution Remotely Sensed Images Based on a Morphological Building Index. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 105–115. [Google Scholar] [CrossRef]
- Shi, Q.; Liu, M.; Marinoni, A.; Liu, X. UGS-1m: Fine-Grained Urban Green Space Mapping of 31 Major Cities in China Based on the Deep Learning Framework. Earth Syst. Sci. Data 2023, 15, 555–577. [Google Scholar] [CrossRef]
- Gao, F.; Dong, J.; Li, B.; Xu, Q.; Xie, C. Change Detection from Synthetic Aperture Radar Images Based on Neighborhood-Based Ratio and Extreme Learning Machine. J. Appl. Remote Sens. 2016, 10, 046019. [Google Scholar] [CrossRef]
- Fang, H.; Du, P.; Wang, X.; Lin, C.; Tang, P. Unsupervised Change Detection Based on Weighted Change Vector Analysis and Improved Markov Random Field for High Spatial Resolution Imagery. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6002005. [Google Scholar] [CrossRef]
- Wu, J.; Li, B.; Qin, Y.; Ni, W.; Zhang, H. An Object-Based Graph Model for Unsupervised Change Detection in High Resolution Remote Sensing Images. Int. J. Remote Sens. 2021, 42, 6209–6227. [Google Scholar] [CrossRef]
- Fung, T. An Assessment of TM Imagery for Land-Cover Change Detection. IEEE Trans. Geosci. Remote Sens. 1990, 28, 681–684. [Google Scholar] [CrossRef]
- Thonfeld, F.; Feilhauer, H.; Braun, M.; Menz, G. Robust Change Vector Analysis (RCVA) for Multi-Sensor Very High Resolution Optical Satellite Data. Int. J. Appl. Earth Obs. Geoinf. 2016, 50, 131–140. [Google Scholar] [CrossRef]
- Wu, C.; Du, B.; Zhang, L. Slow Feature Analysis for Change Detection in Multispectral Imagery. IEEE Trans. Geosci. Remote Sens. 2014, 52, 2858–2874. [Google Scholar] [CrossRef]
- Wang, M.; Han, Z.; Yang, P.; Zhu, B.; Hao, M.; Fan, J.; Ye, Y. Exploiting Neighbourhood Structural Features for Change Detection. Remote Sens. Lett. 2023, 14, 346–356. [Google Scholar] [CrossRef]
- Celik, T. Unsupervised Change Detection in Satellite Images Using Principal Component Analysis and K-Means Clustering. IEEE Geosci. Remote Sens. Lett. 2009, 6, 772–776. [Google Scholar] [CrossRef]
- Chen, H.; Wu, C.; Du, B.; Zhang, L.; Wang, L. Change Detection in Multisource VHR Images via Deep Siamese Convolutional Multiple-Layers Recurrent Neural Network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 2848–2864. [Google Scholar] [CrossRef]
- Zhu, B.; Yang, C.; Dai, J.; Fan, J.; Qin, Y.; Ye, Y. R₂FD₂: Fast and Robust Matching of Multimodal Remote Sensing Images via Repeatable Feature Detector and Rotation-Invariant Feature Descriptor. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5606115. [Google Scholar] [CrossRef]
- Ye, Y.; Zhu, B.; Tang, T.; Yang, C.; Xu, Q.; Zhang, G. A Robust Multimodal Remote Sensing Image Registration Method and System Using Steerable Filters with First- and Second-Order Gradients. ISPRS J. Photogramm. Remote Sens. 2022, 188, 331–350. [Google Scholar] [CrossRef]
- Ye, Y.; Tang, T.; Zhu, B.; Yang, C.; Li, B.; Hao, S. A Multiscale Framework with Unsupervised Learning for Remote Sensing Image Registration. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5622215. [Google Scholar] [CrossRef]
- Tao, H.; Duan, Q.; An, J. An Adaptive Interference Removal Framework for Video Person Re-Identification. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 5148–5159. [Google Scholar] [CrossRef]
- Ye, Y.; Wang, M.; Zhou, L.; Lei, G.; Fan, J.; Qin, Y. Adjacent-Level Feature Cross-Fusion With 3-D CNN for Remote Sensing Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5618214. [Google Scholar] [CrossRef]
- Zhou, Y.; Feng, Y.; Huo, S.; Li, X. Joint Frequency-Spatial Domain Network for Remote Sensing Optical Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5627114. [Google Scholar] [CrossRef]
- Zhang, C.; Wang, L.; Cheng, S.; Li, Y. SUMLP: A Siamese U-Shaped MLP-Based Network for Change Detection. Appl. Soft Comput. 2022, 131, 109766. [Google Scholar] [CrossRef]
- Fang, S.; Li, K.; Shao, J.; Li, Z. SNUNet-CD: A Densely Connected Siamese Network for Change Detection of VHR Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 8007805. [Google Scholar] [CrossRef]
- Hu, Q.; Wang, D.; Yang, C. PPG-Based Blood Pressure Estimation Can Benefit from Scalable Multi-Scale Fusion Neural Networks and Multi-Task Learning. Biomed. Signal Process. Control 2022, 78, 103891. [Google Scholar] [CrossRef]
- Xiang, X.; Tian, D.; Lv, N.; Yan, Q. FCDNet: A Change Detection Network Based on Full-Scale Skip Connections and Coordinate Attention. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6511605. [Google Scholar] [CrossRef]
- Li, J.; Hu, M.; Wu, C. Multiscale Change Detection Network Based on Channel Attention and Fully Convolutional BiLSTM for Medium-Resolution Remote Sensing Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 9735–9748. [Google Scholar] [CrossRef]
- Jiang, K.; Zhang, W.; Liu, J.; Liu, F.; Xiao, L. Joint Variation Learning of Fusion and Difference Features for Change Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4709918. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 24 May 2019; pp. 6105–6114. [Google Scholar]
- Wen, D.; Huang, X.; Bovolo, F.; Li, J.; Ke, X.; Zhang, A.; Benediktsson, J.A. Change Detection From Very-High-Spatial-Resolution Optical Remote Sensing Images: Methods, Applications, and Future Directions. IEEE Geosci. Remote Sens. Mag. 2021, 9, 68–101. [Google Scholar] [CrossRef]
- Sun, S.; Mu, L.; Wang, L.; Liu, P. L-UNet: An LSTM Network for Remote Sensing Image Change Detection. IEEE Geosci. Remote Sens. Lett. 2022, 19, 8004505. [Google Scholar] [CrossRef]
- Peng, D.; Zhang, Y.; Guan, H. End-to-End Change Detection for High Resolution Satellite Images Using Improved UNet++. Remote Sens. 2019, 11, 1382. [Google Scholar] [CrossRef]
- Dai, Y.; Zhao, K.; Shen, L.; Liu, S.; Yan, X.; Li, Z. A Siamese Network Combining Multiscale Joint Supervision and Improved Consistency Regularization for Weakly Supervised Building Change Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 4963–4982. [Google Scholar] [CrossRef]
- Ye, Y.; Zhou, L.; Zhu, B.; Yang, C.; Sun, M.; Fan, J.; Fu, Z. Feature Decomposition-Optimization-Reorganization Network for Building Change Detection in Remote Sensing Images. Remote Sens. 2022, 14, 722. [Google Scholar] [CrossRef]
- Wang, M.; Zhu, B.; Zhang, J.; Fan, J.; Ye, Y. A Lightweight Change Detection Network Based on Feature Interleaved Fusion and Bistage Decoding. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 2557–2569. [Google Scholar] [CrossRef]
- Li, Z.; Tang, C.; Liu, X.; Zhang, W.; Dou, J.; Wang, L.; Zomaya, A.Y. Lightweight Remote Sensing Change Detection with Progressive Feature Aggregation and Supervised Attention. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5602812. [Google Scholar] [CrossRef]
- Zhou, F.; Xu, C.; Hang, R.; Zhang, R.; Liu, Q. Mining Joint Intraimage and Interimage Context for Remote Sensing Change Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4403712. [Google Scholar] [CrossRef]
- Bandara, W.G.C.; Patel, V.M. A Transformer-Based Siamese Network for Change Detection. In Proceedings of the IGARSS 2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 207–210. [Google Scholar]
- Song, X.; Hua, Z.; Li, J. PSTNet: Progressive Sampling Transformer Network for Remote Sensing Image Change Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 8442–8455. [Google Scholar] [CrossRef]
- Fang, S.; Li, K.; Li, Z. Changer: Feature Interaction Is What You Need for Change Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5610111. [Google Scholar] [CrossRef]
- Zhang, C.; Wang, L.; Cheng, S.; Li, Y. SwinSUNet: Pure Transformer Network for Remote Sensing Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5224713. [Google Scholar] [CrossRef]
- Song, L.; Xia, M.; Weng, L.; Lin, H.; Qian, M.; Chen, B. Axial Cross Attention Meets CNN: Bibranch Fusion Network for Change Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 32–43. [Google Scholar] [CrossRef]
- Song, X.; Hua, Z.; Li, J. LHDACT: Lightweight Hybrid Dual Attention CNN and Transformer Network for Remote Sensing Image Change Detection. IEEE Geosci. Remote Sens. Lett. 2023, 20, 7506005. [Google Scholar] [CrossRef]
- Feng, Y.; Xu, H.; Jiang, J.; Liu, H.; Zheng, J. ICIF-Net: Intra-Scale Cross-Interaction and Inter-Scale Feature Fusion Network for Bitemporal Remote Sensing Images Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4410213. [Google Scholar] [CrossRef]
- Song, X.; Hua, Z.; Li, J. Remote Sensing Image Change Detection Transformer Network Based on Dual-Feature Mixed Attention. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5920416. [Google Scholar] [CrossRef]
- Chu, S.; Li, P.; Xia, M.; Lin, H.; Qian, M.; Zhang, Y. DBFGAN: Dual Branch Feature Guided Aggregation Network for Remote Sensing Image. Int. J. Appl. Earth Obs. Geoinf. 2023, 116, 103141. [Google Scholar] [CrossRef]
- Tang, X.; Zhang, T.; Ma, J.; Zhang, X.; Liu, F.; Jiao, L. WNet: W-Shaped Hierarchical Network for Remote-Sensing Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5615814. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. ISBN 978-3-319-24573-7. [Google Scholar]
- Liang, S.; Hua, Z.; Li, J. Enhanced Self-Attention Network for Remote Sensing Building Change Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 4900–4915. [Google Scholar] [CrossRef]
- Chouhan, A.; Sur, A.; Chutia, D. DRMNet: Difference Image Reconstruction Enhanced Multiresolution Network for Optical Change Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4014–4026. [Google Scholar] [CrossRef]
- Zhu, Q.; Guo, X.; Li, Z.; Li, D. A Review of Multi-Class Change Detection for Satellite Remote Sensing Imagery. Geo Spat. Inf. Sci. 2022, 1–15. [Google Scholar] [CrossRef]
- Zhang, X.; Yue, Y.; Gao, W.; Yun, S.; Su, Q.; Yin, H.; Zhang, Y. DifUnet++: A Satellite Images Change Detection Network Based on Unet++ and Differential Pyramid. IEEE Geosci. Remote Sens. Lett. 2022, 19, 8006605. [Google Scholar] [CrossRef]
- Zhu, S.; Song, Y.; Zhang, Y.; Zhang, Y. ECFNet: A Siamese Network with Fewer FPs and Fewer FNs for Change Detection of Remote-Sensing Images. IEEE Geosci. Remote Sens. Lett. 2023, 20, 6001005. [Google Scholar] [CrossRef]
- Cheng, Y.; Cai, R.; Li, Z.; Zhao, X.; Huang, K. Locality-Sensitive Deconvolution Networks with Gated Fusion for RGB-D Indoor Semantic Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1475–1483. [Google Scholar]
- Saha, S.; Shahzad, M.; Ebel, P.; Zhu, X.X. Supervised Change Detection Using Prechange Optical-SAR and Postchange SAR Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 8170–8178. [Google Scholar] [CrossRef]
- Fu, Z.; Li, J.; Chen, Z.; Ren, L.; Hua, Z. DAFT: Differential Feature Extraction Network Based on Adaptive Frequency Transformer for Remote Sensing Change Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 5061–5076. [Google Scholar] [CrossRef]
- Barkur, R.; Suresh, D.; Lal, S.; Reddy, C.S.; Diwakar, P.G. RSCDNet: A Robust Deep Learning Architecture for Change Detection from Bi-Temporal High Resolution Remote Sensing Images. IEEE Trans. Emerg. Top. Comput. Intell. 2023, 7, 537–551. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Lu, M. Fully Convolutional Networks for Multisource Building Extraction from an Open Aerial and Satellite Imagery Data Set. IEEE Trans. Geosci. Remote Sens. 2019, 57, 574–586. [Google Scholar] [CrossRef]
- Chen, H.; Shi, Z. A Spatial-Temporal Attention-Based Method and a New Dataset for Remote Sensing Image Change Detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Shi, Q.; Liu, M.; Li, S.; Liu, X.; Wang, F.; Zhang, L. A Deeply Supervised Attention Metric-Based Network and an Open Aerial Image Dataset for Remote Sensing Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5604816. [Google Scholar] [CrossRef]
- Daudt, R.C.; Le Saux, B.; Boulch, A. Fully Convolutional Siamese Networks for Change Detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar]
- Zhang, C.; Yue, P.; Tapete, D.; Jiang, L.; Shangguan, B.; Huang, L.; Liu, G. A Deeply Supervised Image Fusion Network for Change Detection in High Resolution Bi-Temporal Remote Sensing Images. ISPRS J. Photogramm. Remote Sens. 2020, 166, 183–200. [Google Scholar] [CrossRef]
- Chen, H.; Qi, Z.; Shi, Z. Remote Sensing Image Change Detection with Transformers. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5607514. [Google Scholar] [CrossRef]
- Yang, H.; Chen, Y.; Wu, W.; Pu, S.; Wu, X.; Wan, Q.; Dong, W. A Lightweight Siamese Neural Network for Building Change Detection Using Remote Sensing Images. Remote Sens. 2023, 15, 928. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Pre | Recall | F1 | IoU | |
|---|---|---|---|---|---|
| CNN-based | FC-EF | 79.33 | 74.58 | 76.88 | 62.45 |
| FC-Siam-Diff | 67.55 | 63.21 | 65.31 | 48.75 | |
| STANet | 86.11 | 88.14 | 87.11 | 77.17 | |
| DSIFNet | 85.89 | 91.31 | 88.52 | 79.40 | |
| SNUNet | 82.63 | 90.33 | 86.31 | 75.92 | |
| LightCDNet | 92.00 | 91.00 | 91.50 | 84.30 | |
| Transformer-based | ChangeFormer | 89.36 | 90.28 | 89.82 | 81.60 |
| Hybrid-based | BITNet | 92.71 | 89.83 | 91.25 | 84.30 |
| CNN-based | MSGFNet | 91.88 | 93.06 | 92.46 | 85.98 |
| Methods | Pre | Recall | F1 | IoU | |
|---|---|---|---|---|---|
| CNN-based | FC-EF | 85.87 | 82.22 | 83.35 | 72.43 |
| FC-Siam-Diff | 88.59 | 80.72 | 85.37 | 74.48 | |
| STANet | 83.81 | 91.00 | 87.30 | 77.40 | |
| DSIFNet | 87.30 | 88.57 | 88.42 | 78.09 | |
| SNUNet | 90.55 | 89.28 | 89.91 | 81.67 | |
| LightCDNet | 91.30 | 88.00 | 89.60 | 81.20 | |
| Transformer-based | ChangeFormer | 92.05 | 88.80 | 90.40 | 82.48 |
| Hybrid-based | BITNet | 89.24 | 89.37 | 89.31 | 80.68 |
| CNN-based | MSGFNet | 92.12 | 89.63 | 90.86 | 83.25 |
| Methods | Pre | Recall | F1 | IoU | |
|---|---|---|---|---|---|
| CNN-based | FC-EF | 80.16 | 70.69 | 75.13 | 60.17 |
| FC-Siam-Diff | 78.34 | 66.13 | 70.17 | 55.11 | |
| STANet | 73.33 | 82.73 | 77.75 | 63.59 | |
| DSIFNet | 79.32 | 73.85 | 77.46 | 62.94 | |
| SNUNet | 82.16 | 71.33 | 76.36 | 61.76 | |
| LightCDNet | 83.01 | 74.90 | 78.75 | 64.98 | |
| Transformer-based | ChangeFormer | 77.16 | 78.51 | 77.83 | 63.71 |
| Hybrid-based | BITNet | 80.40 | 77.09 | 78.72 | 64.90 |
| CNN-based | MSGFNet | 83.34 | 77.65 | 80.39 | 67.22 |
| Methods | Params/M | FLOPs/G | F1 | |
|---|---|---|---|---|
| CNN-based | FC-EF | 1.35 | 3.58 | 76.88 |
| FC-Siam-Diff | 1.35 | 4.73 | 65.31 | |
| STANet | 16.89 | 6.43 | 87.11 | |
| DSIFNet | 50.46 | 50.77 | 88.52 | |
| SNUNet | 12.03 | 54.83 | 86.31 | |
| LightCDNet | 10.75 | 21.54 | 91.50 | |
| Transformer-based | ChangeFormer | 29.75 | 21.18 | 89.82 |
| Hybrid-based | BITNet | 3.04 | 8.75 | 91.25 |
| CNN-based | MSGFNet | 0.58 | 3.99 | 92.46 |
| Methods | Pre | Recall | F1 | IoU |
|---|---|---|---|---|
| Base | 90.14 | 85.05 | 87.52 | 77.81 |
| Base + GWAF | 90.66 | 88.39 | 89.51 | 80.47 |
| Base + MSPF | 91.69 | 88.83 | 90.23 | 82.21 |
| Base + MSPF + GWAF | 92.12 | 89.63 | 90.86 | 83.25 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Wang, M.; Hao, Z.; Wang, Q.; Wang, Q.; Ye, Y. MSGFNet: Multi-Scale Gated Fusion Network for Remote Sensing Image Change Detection. Remote Sens. 2024, 16, 572. https://doi.org/10.3390/rs16030572
Wang Y, Wang M, Hao Z, Wang Q, Wang Q, Ye Y. MSGFNet: Multi-Scale Gated Fusion Network for Remote Sensing Image Change Detection. Remote Sensing. 2024; 16(3):572. https://doi.org/10.3390/rs16030572
Chicago/Turabian StyleWang, Yukun, Mengmeng Wang, Zhonghu Hao, Qiang Wang, Qianwen Wang, and Yuanxin Ye. 2024. "MSGFNet: Multi-Scale Gated Fusion Network for Remote Sensing Image Change Detection" Remote Sensing 16, no. 3: 572. https://doi.org/10.3390/rs16030572
APA StyleWang, Y., Wang, M., Hao, Z., Wang, Q., Wang, Q., & Ye, Y. (2024). MSGFNet: Multi-Scale Gated Fusion Network for Remote Sensing Image Change Detection. Remote Sensing, 16(3), 572. https://doi.org/10.3390/rs16030572