
PU-CTG: A Point Cloud Upsampling Network Using Transformer Fusion and GRU Correction




Abstract
1. Introduction
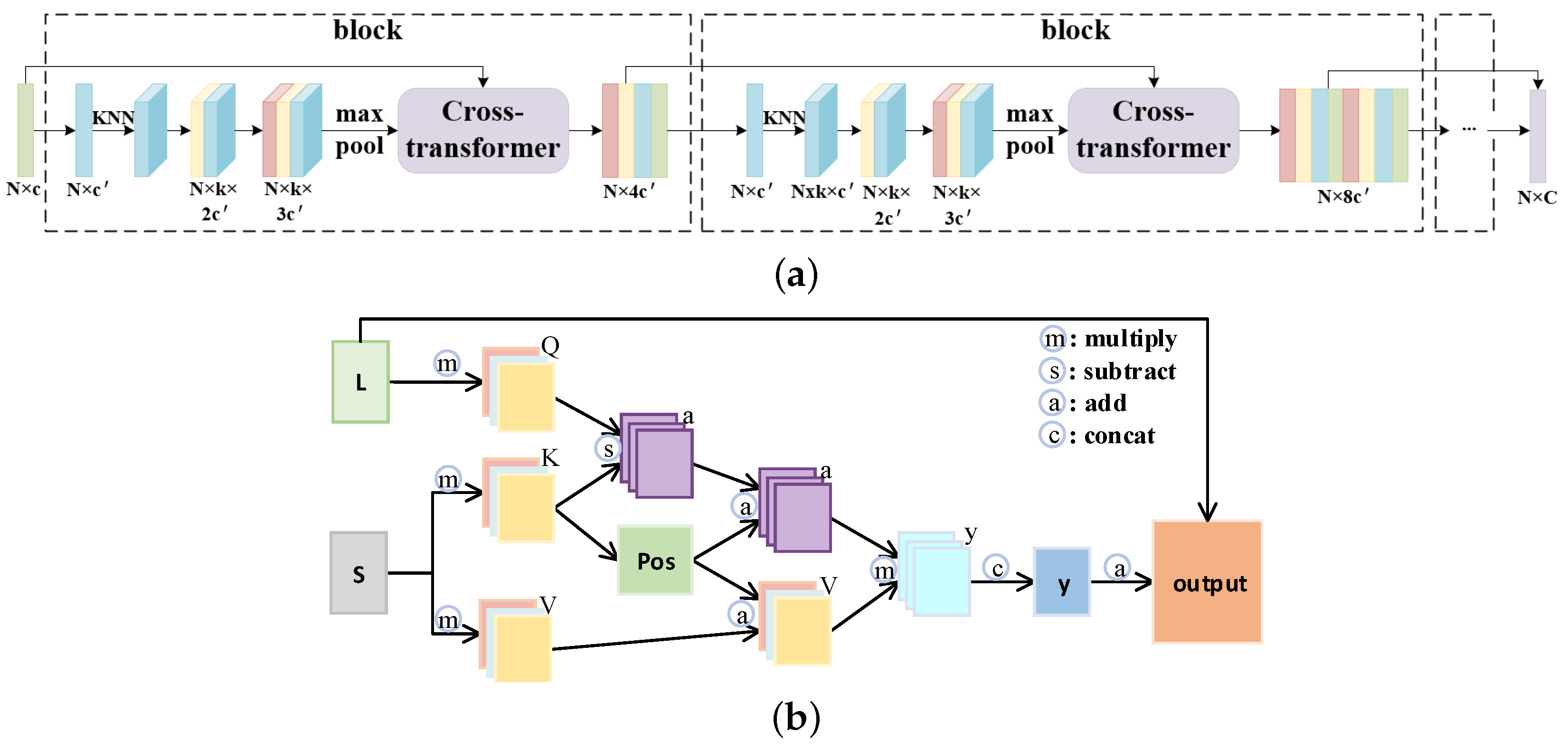
- We propose a multiscale feature extraction and fusion (MEF) unit based on a cross-transformer module containing an attention mechanism and position encoding. The features at different scales are input simultaneously for effective integration so that the detailed information can be further captured.
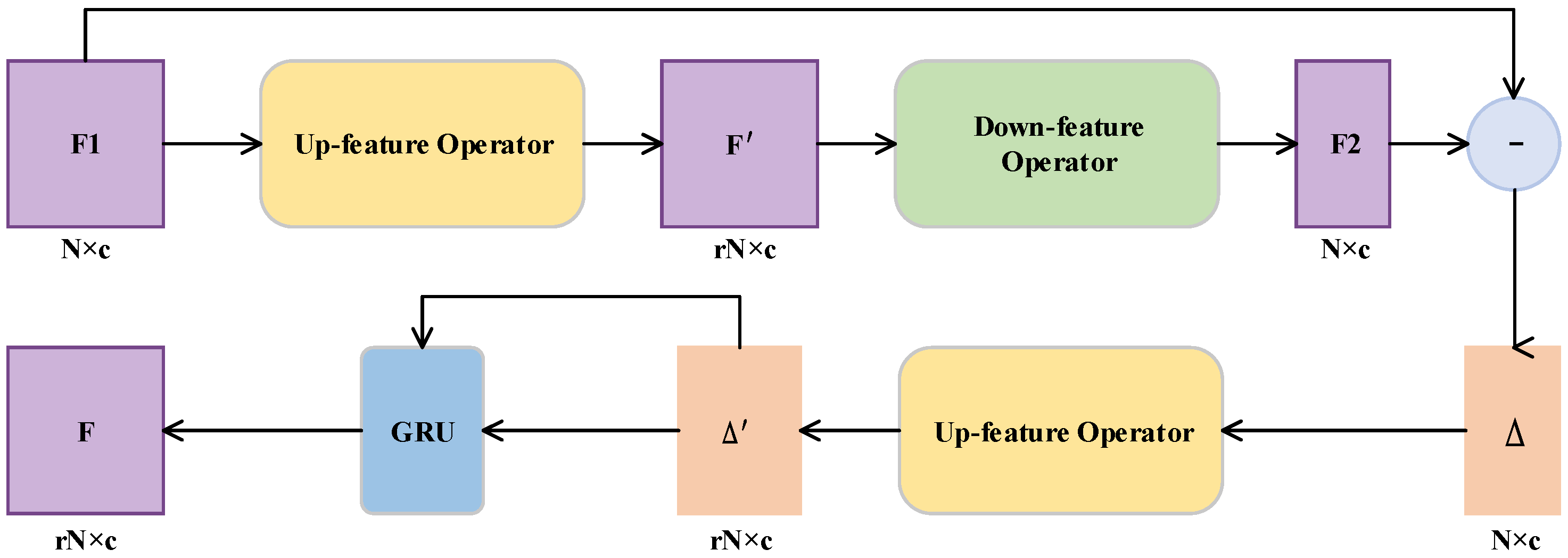
- We introduce a gated recurrent network (GRU) with error correction for the expanded features. This can keep critical information in the calibration to promote the formation of fine-grained features.
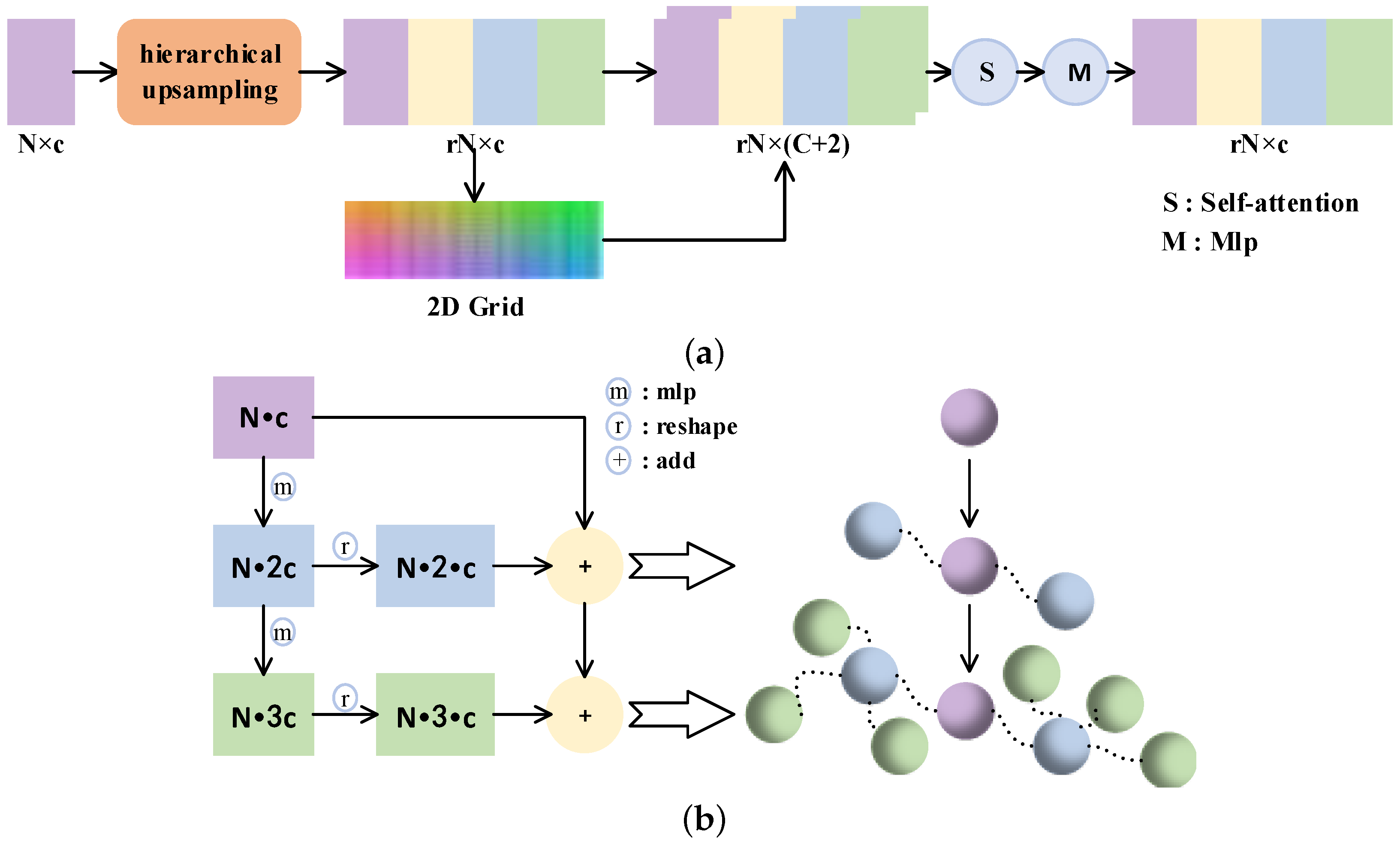
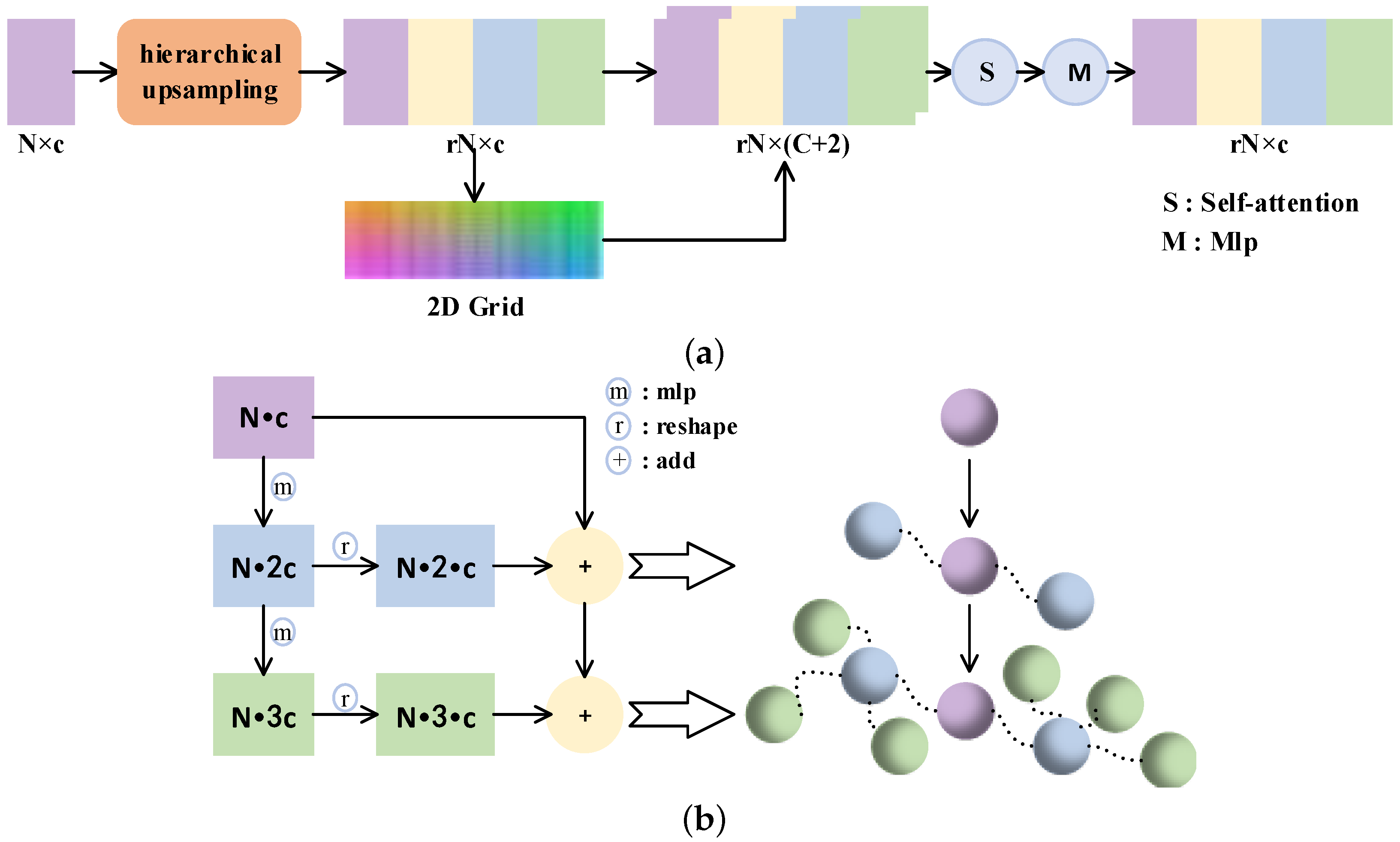
- We design the up-feature operation, which employs a simple hierarchical upsampling and folding operation [20] to increase the number of points. The operation seeks to enhance the diversity of generated points.
- The proposed method is evaluated on benchmark datasets, and the experimental results show the effectiveness of our method. Finally, we demonstrate the assistance of upsampling in point cloud classification.
2. Related Work
2.1. Optimization-Based Point Cloud Upsampling
2.2. Learning-Based Point Cloud Upsampling
3. Overall Architecture of PU-CTG
3.1. Multiscale Feature Extraction and Fusion (MEF) Unit
3.2. Up-Down-Up Expansion Unit
3.2.1. Up-Feature Operator
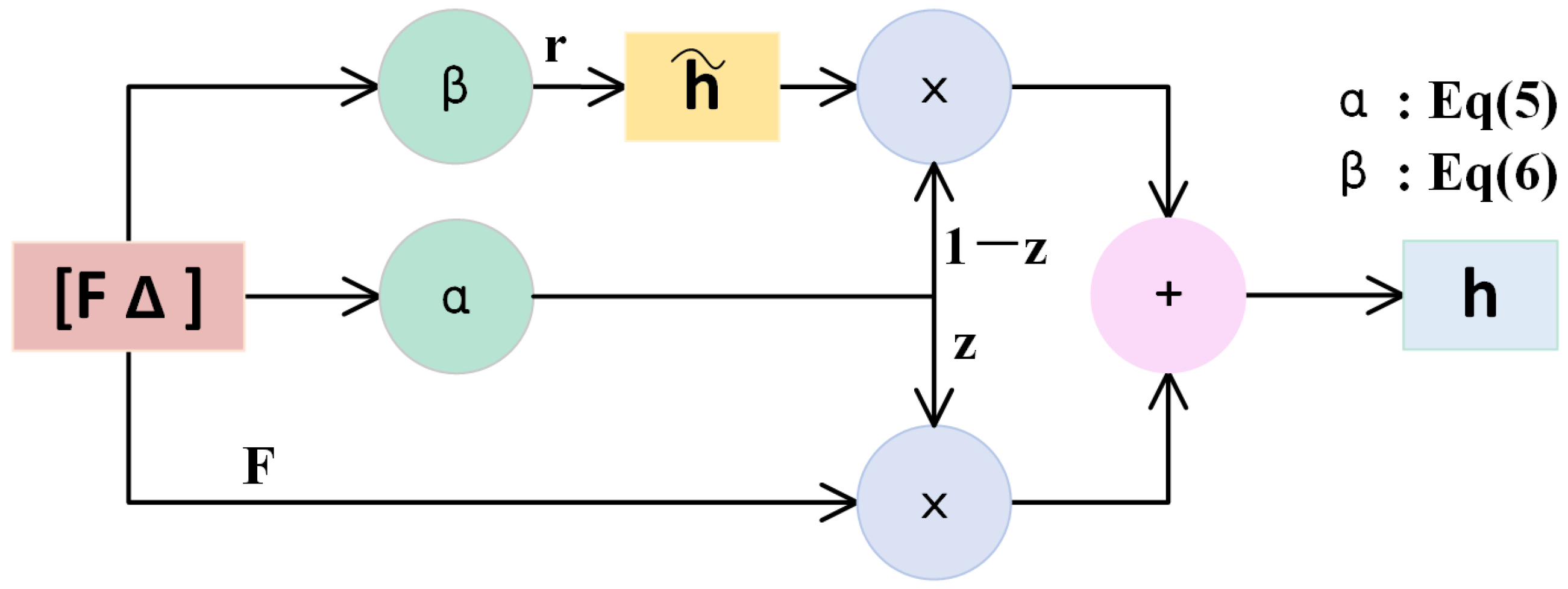
3.2.2. Gated Recurrent Unit (GRU)
4. Experimental Results and Discussion
4.1. Experimental Setup and Datasets
4.2. Loss Function
4.3. Experimental Results and Evaluation
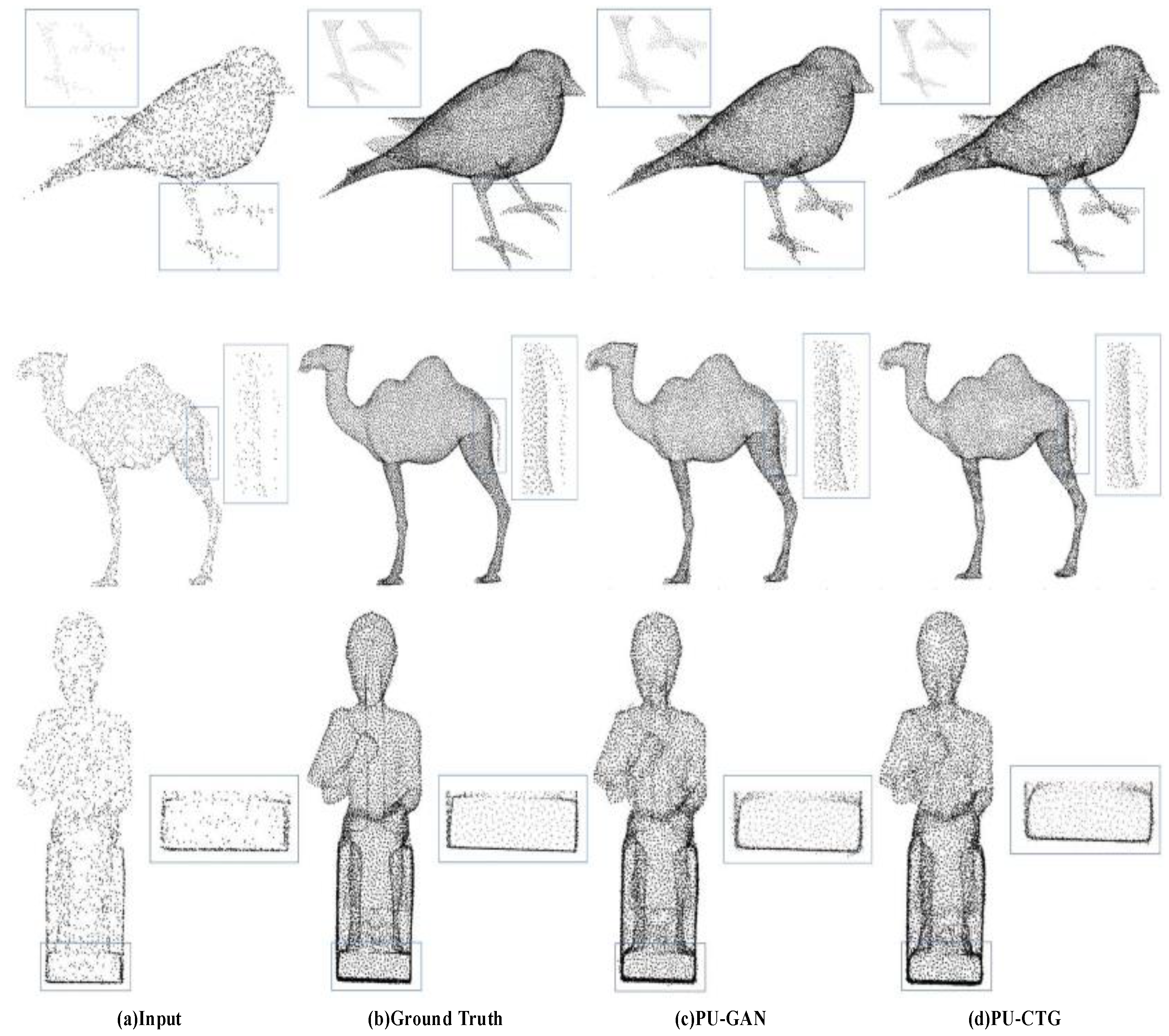
4.3.1. Quantitative and Qualitative Results on PU-GAN’s Dataset
4.3.2. Quantitative Results on the PU1K Dataset
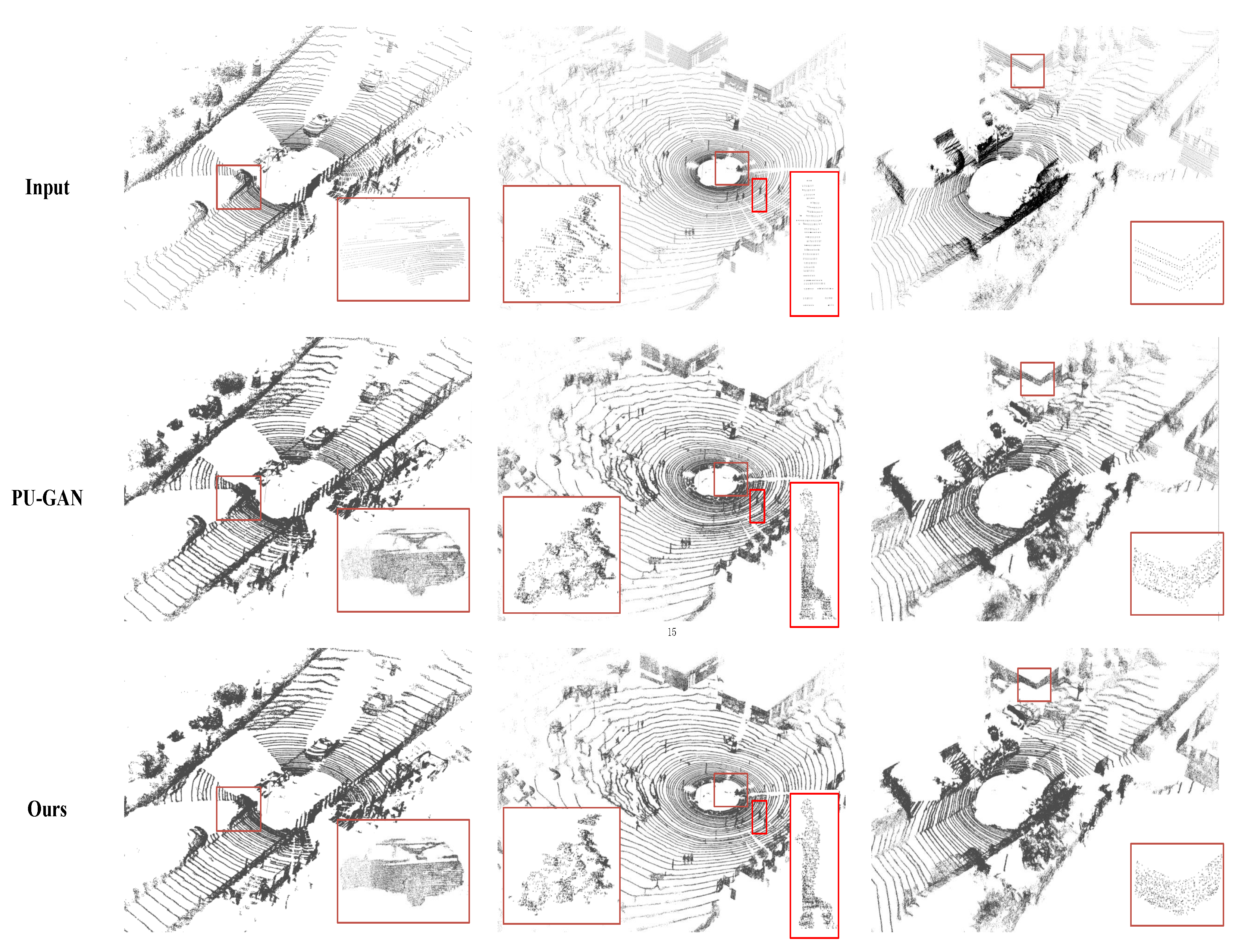
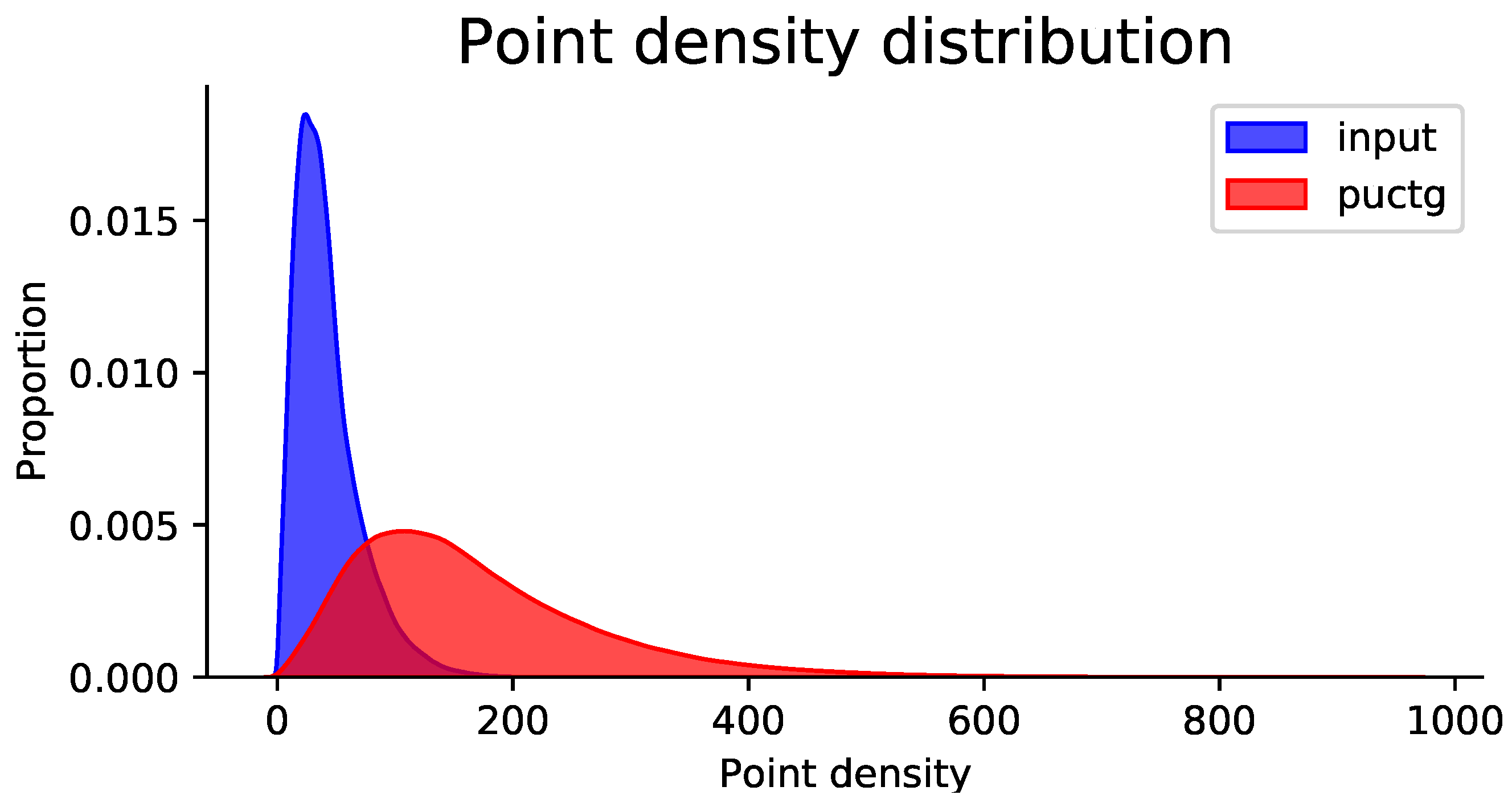
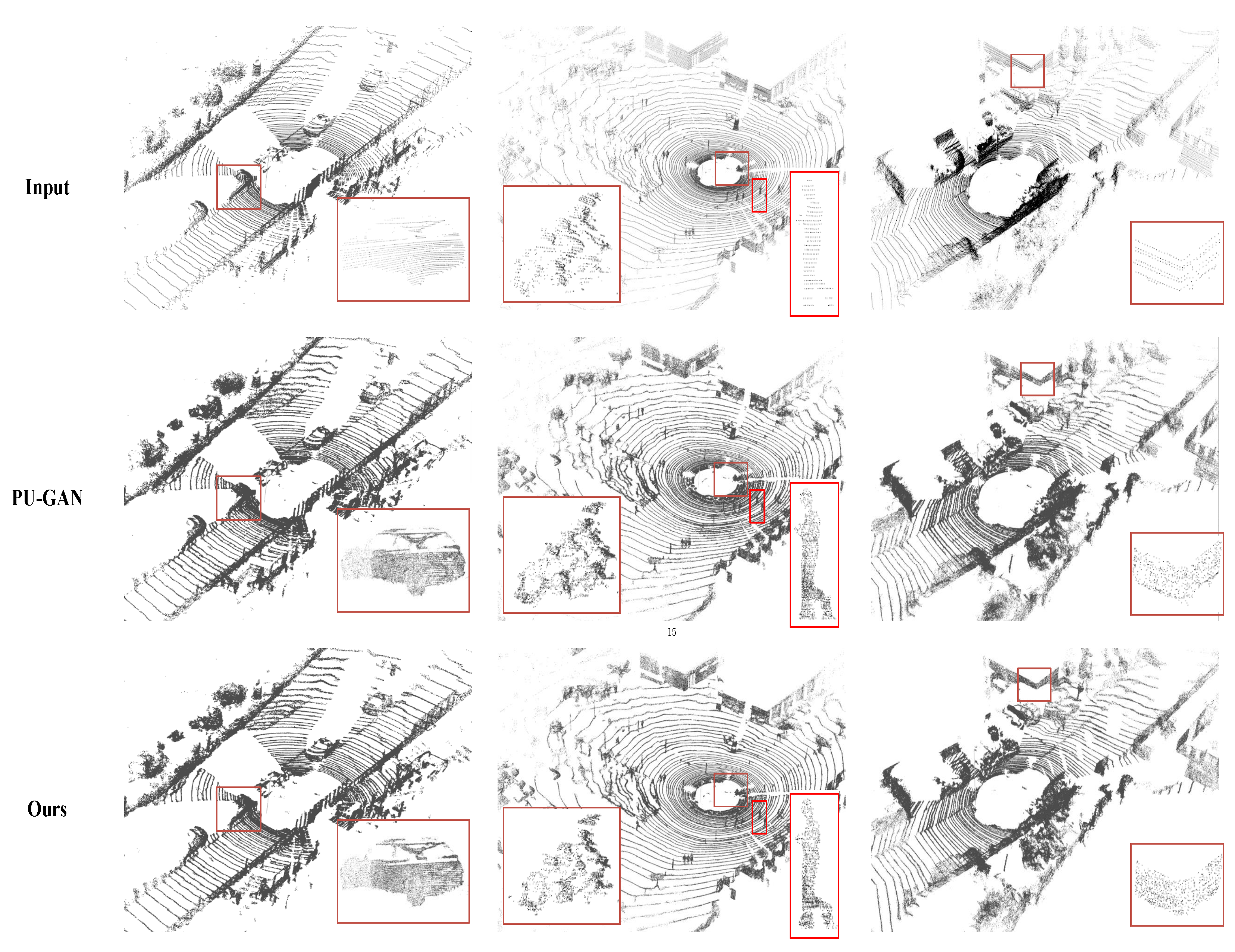
4.4. Upsampling Real-Scanned Data
4.5. Ablation Study
4.6. Discussion of Point Cloud Classification
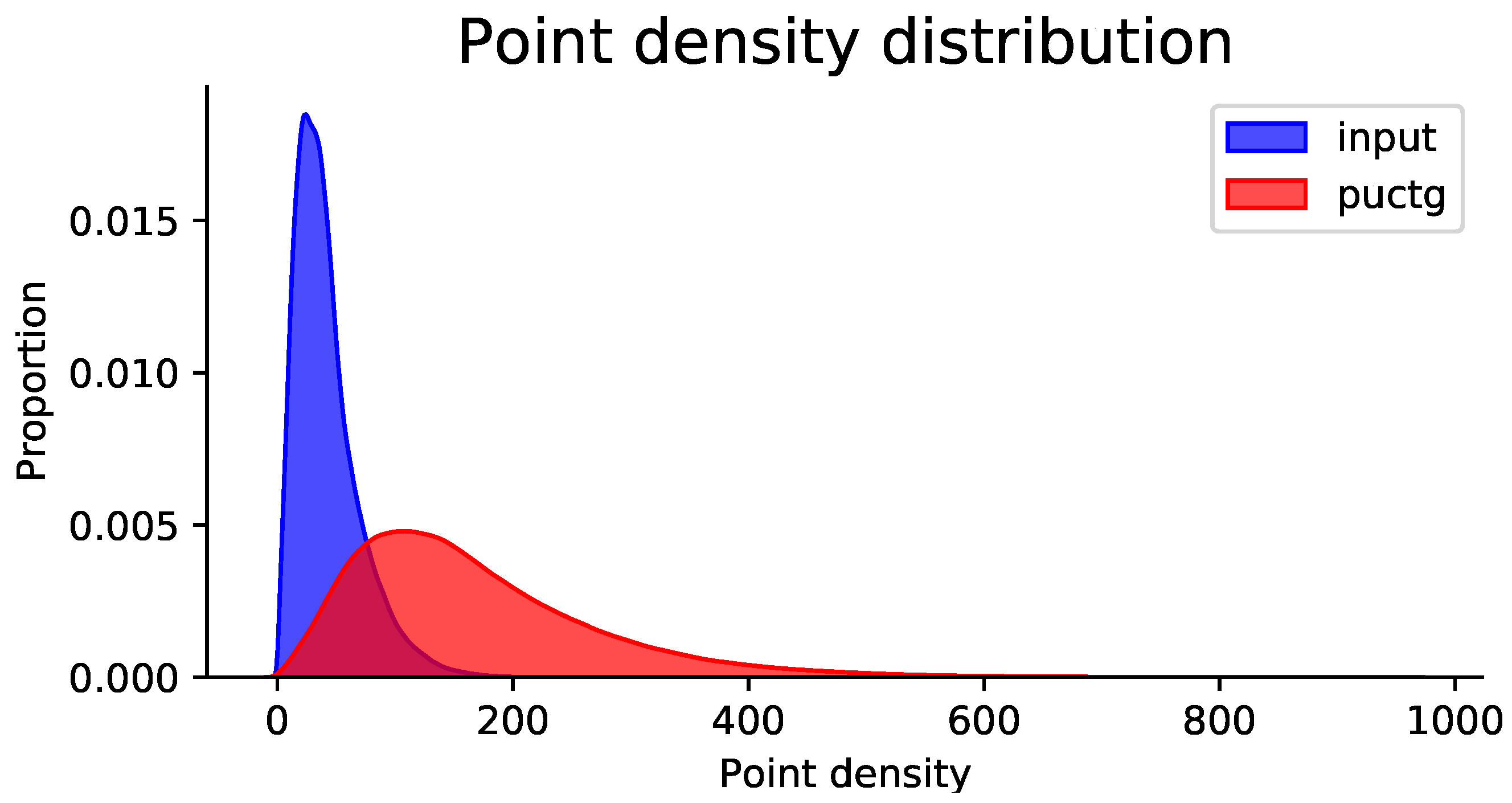
4.7. Effects of Additive Noise and Input Sizes
4.7.1. Upsampling Point Sets of Varying Noise Levels
4.7.2. Upsampling Point Sets of Varying Sizes
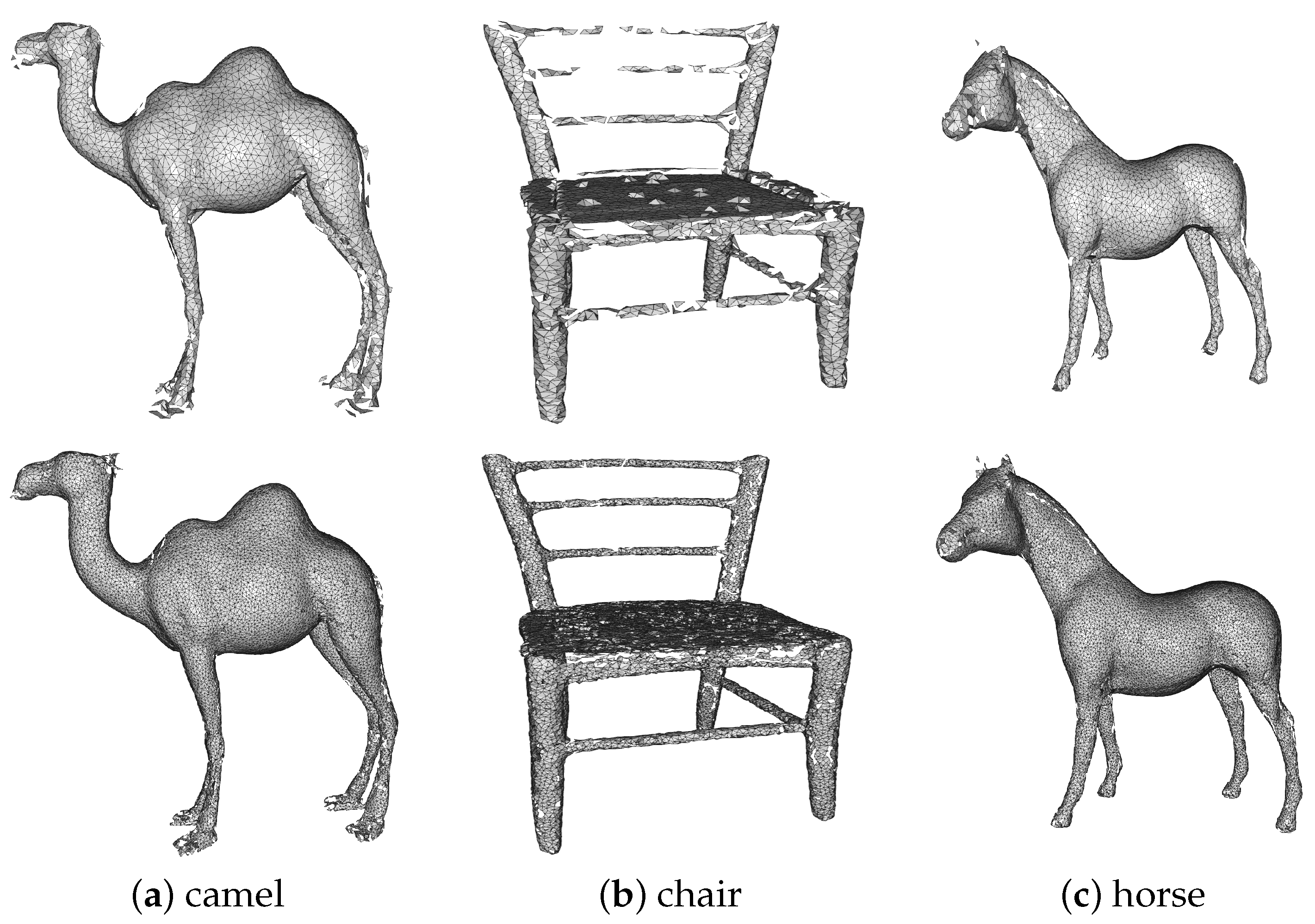
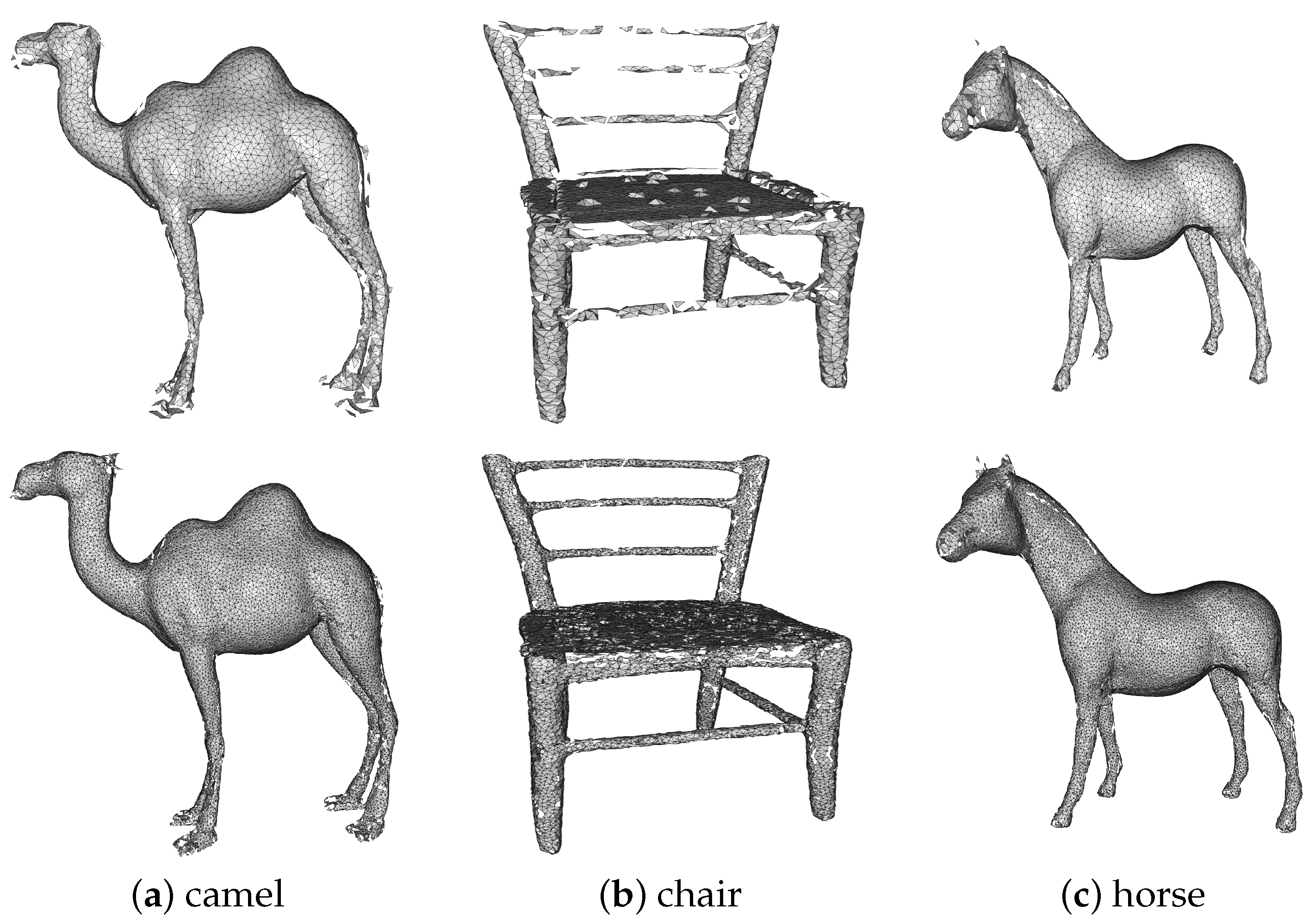
4.8. Effects of Generating 3D Meshes
4.9. Limitations
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, Z.; Sun, L.; Zhong, R.; Chen, D.; Zhang, L.; Li, X.; Wang, Q.; Chen, S. Hierarchical Aggregated Deep Features for ALS Point Cloud Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 1686–1699. [Google Scholar] [CrossRef]
- Qiu, S.; Anwar, S.; Barnes, N. Dense-resolution network for point cloud classification and segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 11–17 October 2021; pp. 3813–3822. [Google Scholar]
- Shahzad, M.; Zhu, X.X. Reconstruction of building façades using spaceborne multiview TomoSAR point clouds. In Proceedings of the 2013 IEEE International Geoscience and Remote Sensing Symposium-IGARSS, Melbourne, Australia, 21–26 July 2013; pp. 624–627. [Google Scholar]
- Shahzad, M.; Zhu, X.X. Robust reconstruction of building facades for large areas using spaceborne TomoSAR point clouds. IEEE Trans. Geosci. Remote Sens. 2014, 53, 752–769. [Google Scholar] [CrossRef]
- Li, Z.; Shan, J. RANSAC-based multi primitive building reconstruction from 3D point clouds. ISPRS J. Photogramm. Remote Sens. 2022, 185, 247–260. [Google Scholar] [CrossRef]
- Wang, F.; Zhou, G.; Hu, H.; Wang, Y.; Fu, B.; Li, S.; Xie, J. Reconstruction of LoD-2 Building Models Guided by Façade Structures from Oblique Photogrammetric Point Cloud. Remote Sens. 2023, 15, 400. [Google Scholar] [CrossRef]
- Yu, Y.; Li, J.; Guan, H.; Wang, C.; Yu, J. Semiautomated extraction of street light poles from mobile LiDAR point-clouds. IEEE Trans. Geosci. Remote Sens. 2014, 53, 1374–1386. [Google Scholar] [CrossRef]
- Wu, C.; Lin, Y.; Guo, Y.; Wen, C.; Shi, Y.; Wang, C. Vehicle Completion in Traffic Scene Using 3D LiDAR Point Cloud Data. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 7495–7498. [Google Scholar]
- Dai, J.; Zhang, Y.; Bi, D.; Lan, J. MUAN: Multiscale Upsampling Aggregation Network for 3-D Point Cloud Segmentation. IEEE Geosci. Remote Sens. Lett. 2022, 19, 7004805. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Wang, Z.; Zhang, L.; Zhang, L.; Li, R.; Zheng, Y.; Zhu, Z. A deep neural network with spatial pooling (DNNSP) for 3-D point cloud classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4594–4604. [Google Scholar] [CrossRef]
- Li, M.; Hu, Y.; Zhao, N.; Guo, L. LPCCNet: A lightweight network for point cloud classification. IEEE Geosci. Remote Sens. Lett. 2019, 16, 962–966. [Google Scholar] [CrossRef]
- Li, Y.; Ma, L.; Zhong, Z.; Cao, D.; Li, J. TGNet: Geometric graph CNN on 3-D point cloud segmentation. IEEE Trans. Geosci. Remote Sens. 2019, 58, 3588–3600. [Google Scholar] [CrossRef]
- Wang, F.; Zhang, X.; Jiang, Y.; Kong, L.; Wei, X. PatchCNN: An explicit convolution operator for point clouds perception. IEEE Geosci. Remote Sens. Lett. 2020, 18, 726–730. [Google Scholar] [CrossRef]
- Li, Y.; Li, X.; Zhang, Z.; Shuang, F.; Lin, Q.; Jiang, J. DenseKPNET: Dense kernel point convolutional neural networks for point cloud semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5702913. [Google Scholar] [CrossRef]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 2017, 30, 5105–5114. [Google Scholar]
- Yu, L.; Li, X.; Fu, C.W.; Cohen-Or, D.; Heng, P.A. Pu-net: Point cloud upsampling network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2790–2799. [Google Scholar]
- Wang, Y.; Wu, S.; Huang, H.; Cohen-Or, D.; Sorkine-Hornung, O. Patch-based progressive 3D point set upsampling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5958–5967. [Google Scholar]
- Li, R.; Li, X.; Fu, C.W.; Cohen-Or, D.; Heng, P.A. PU-GAN: A point cloud upsampling adversarial network. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7203–7212. [Google Scholar]
- Yang, Y.; Feng, C.; Shen, Y.; Tian, D. Foldingnet: Point cloud auto-encoder via deep grid deformation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 206–215. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Qian, G.; Abualshour, A.; Li, G.; Thabet, A.; Ghanem, B. PU-GCN: Point cloud upsampling using graph convolutional networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11683–11692. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets Robotics: The KITTI Dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Zhu, J.; Gehrung, J.; Huang, R.; Borgmann, B.; Sun, Z.; Hoegner, L.; Hebel, M.; Xu, Y.; Stilla, U. TUM-MLS-2016: An annotated mobile LiDAR dataset of the TUM city campus for semantic point cloud interpretation in urban areas. Remote Sens. 2020, 12, 1875. [Google Scholar] [CrossRef]
- Wu, T.; Pan, L.; Zhang, J.; Wang, T.; Liu, Z.; Lin, D. Density-aware chamfer distance as a comprehensive metric for point cloud completion. arXiv 2021, arXiv:2111.12702. [Google Scholar]
- Alexa, M.; Behr, J.; Cohen-Or, D.; Fleishman, S.; Levin, D.; Silva, C.T. Computing and rendering point set surfaces. IEEE Trans. Vis. Comput. Graph. 2003, 9, 3–15. [Google Scholar] [CrossRef]
- Lipman, Y.; Cohen-Or, D.; Levin, D.; Tal-Ezer, H. Parameterization-free projection for geometry reconstruction. ACM Trans. Graph. 2007, 26, 22-es. [Google Scholar] [CrossRef]
- Huang, H.; Li, D.; Zhang, H.; Ascher, U.; Cohen-Or, D. Consolidation of unorganized point clouds for surface reconstruction. ACM Trans. Graph. 2009, 28, 1–7. [Google Scholar] [CrossRef]
- Huang, H.; Wu, S.; Gong, M.; Cohen-Or, D.; Ascher, U.; Zhang, H. Edge-aware point set resampling. ACM Trans. Graph. 2013, 32, 1–12. [Google Scholar] [CrossRef]
- Preiner, R.; Mattausch, O.; Arikan, M.; Pajarola, R.; Wimmer, M. Continuous projection for fast L1 reconstruction. ACM Trans. Graph. 2014, 33, 1–13. [Google Scholar] [CrossRef]
- Wu, S.; Huang, H.; Gong, M.; Zwicker, M.; Cohen-Or, D. Deep points consolidation. ACM Trans. Graph. 2015, 34, 1–13. [Google Scholar] [CrossRef]
- Fan, H.; Su, H.; Guibas, L.J. A point set generation network for 3D object reconstruction from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 605–613. [Google Scholar]
- Lin, C.H.; Kong, C.; Lucey, S. Learning efficient point cloud generation for dense 3D object reconstruction. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Groueix, T.; Fisher, M.; Kim, V.G.; Russell, B.C.; Aubry, M. A papier-mâché approach to learning 3D surface generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 216–224. [Google Scholar]
- Zhang, W.; Jiang, H.; Yang, Z.; Yamakawa, S.; Shimada, K.; Kara, L.B. Data-driven upsampling of point clouds. Comput. Aided Des. 2019, 112, 1–13. [Google Scholar] [CrossRef]
- Yu, L.; Li, X.; Fu, C.W.; Cohen-Or, D.; Heng, P.A. Ec-net: An edge-aware point set consolidation network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 386–402. [Google Scholar]
- Zhao, Y.; Li, G.; Xie, W.; Jia, W.; Min, H.; Liu, X. GUN: Gradual upsampling network for single image super-resolution. IEEE Access 2018, 6, 39363–39374. [Google Scholar] [CrossRef]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Wu, J.; Zhang, C.; Xue, T.; Freeman, B.; Tenenbaum, J. Learning a probabilistic latent space of object shapes via 3D generative-adversarial modeling. Adv. Neural Inf. Process. Syst. 2016, 29, 82–90. [Google Scholar]
- Qian, Y.; Hou, J.; Kwong, S.; He, Y. PUGeo-Net: A geometry-centric network for 3D point cloud upsampling. In Proceedings of the European Conference on Computer Vision, Virtual, 23–28 August 2020; pp. 752–769. [Google Scholar]
- Wen, X.; Xiang, P.; Han, Z.; Cao, Y.P.; Wan, P.; Zheng, W.; Liu, Y.S. PMP-Net++: Point cloud completion by transformer-enhanced multi-step point moving paths. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 852–867. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Shajahan, D.A.; Varma, M.; Muthuganapathy, R. Point transformer for shape classification and retrieval of urban roof point clouds. IEEE Geosci. Remote Sens. Lett. 2021, 19, 6501105. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Chang, A.X.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. Shapenet: An information-rich 3D model repository. arXiv 2015, arXiv:1512.03012. [Google Scholar]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. KPConv: Flexible and Deformable Convolution for Point Clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3D shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]







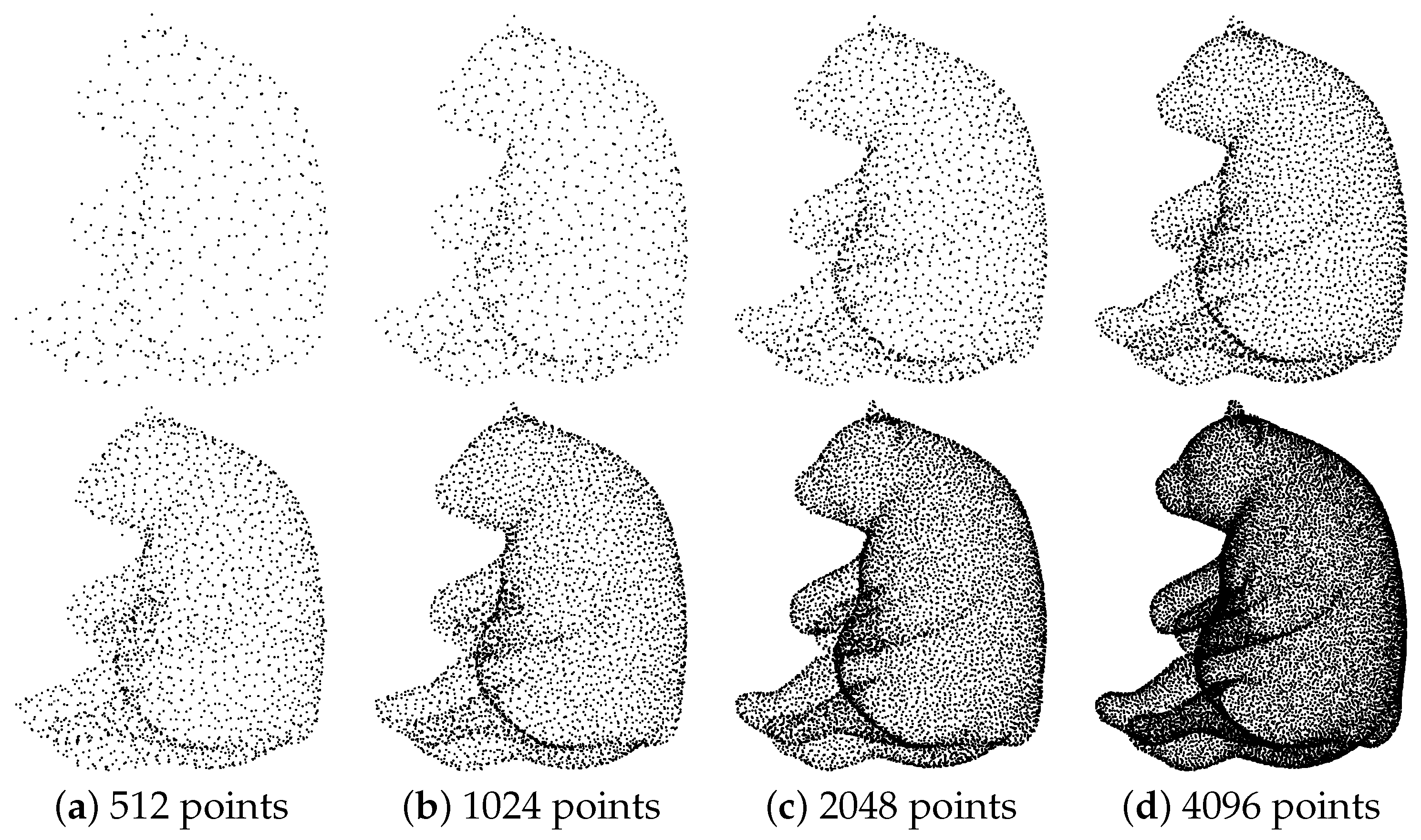

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
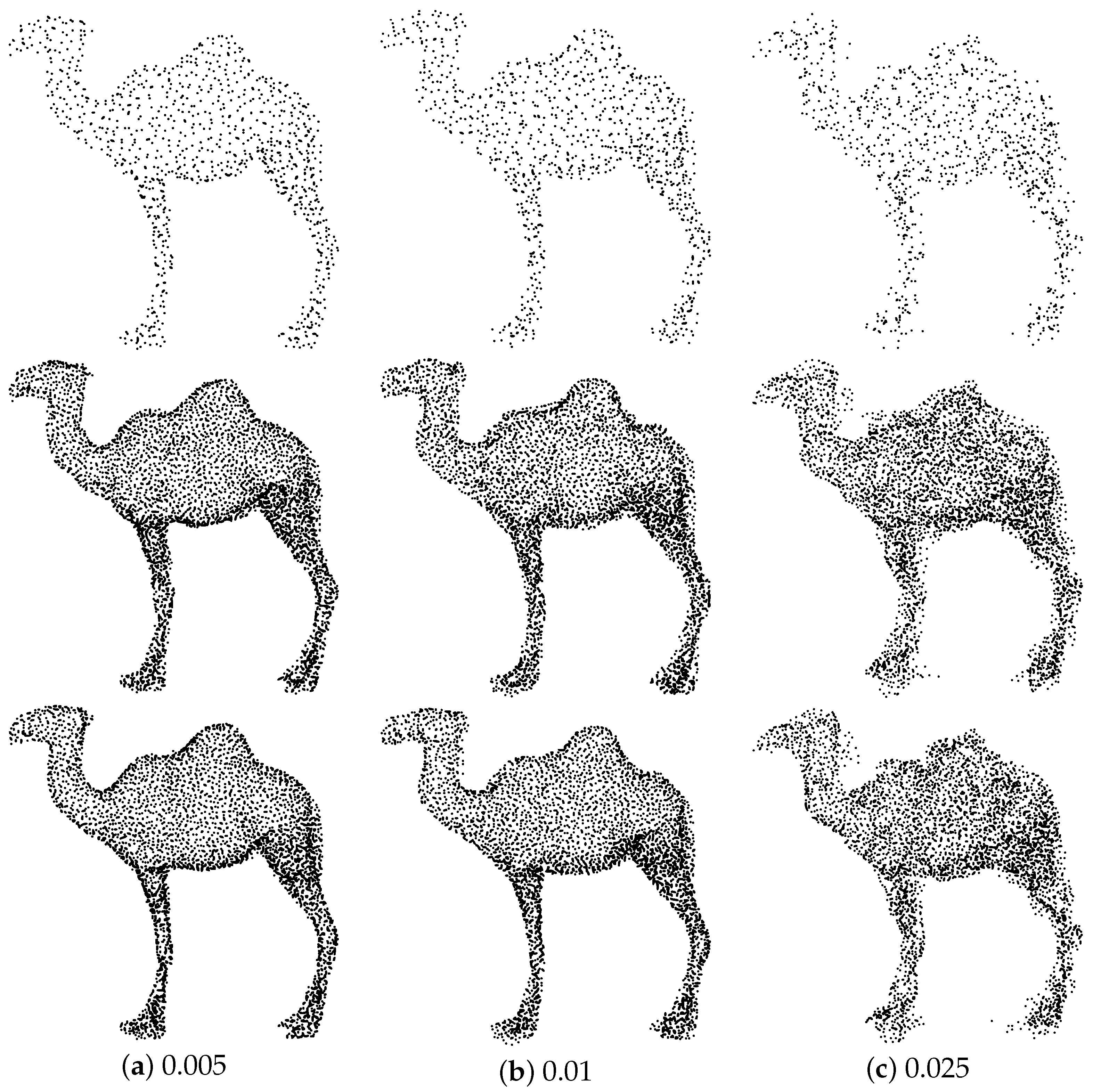{kind=link}
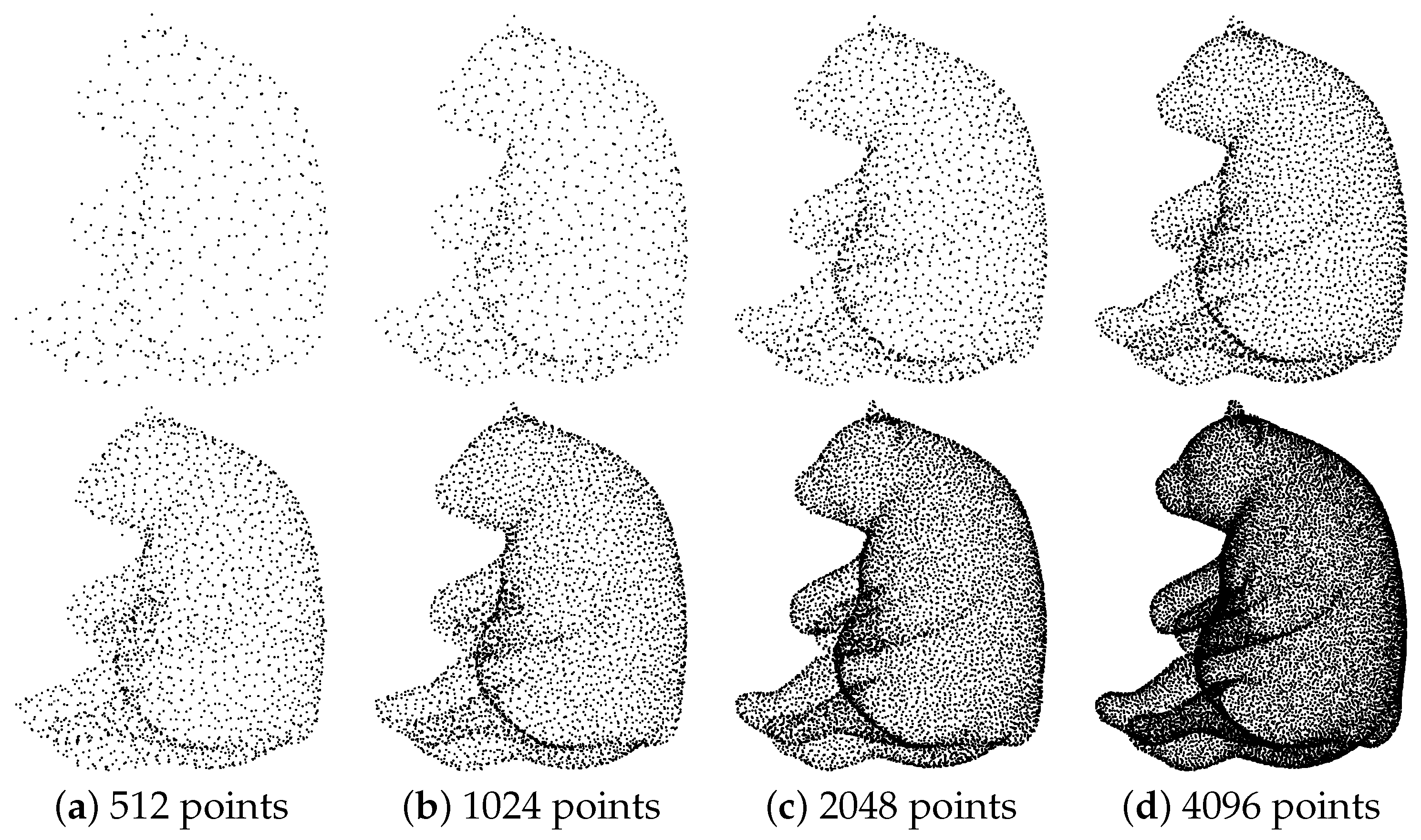{kind=link}
{kind=link}
| Methods | P2F (10) | CD (10) | HD (10) | Time(s) |
|---|---|---|---|---|
| EAR [29] | 5.82 | 0.52 | 7.37 | - |
| PU-Net [17] | 6.84 | 0.72 | 8.94 | 0.35 |
| MPU [18] | 3.96 | 0.49 | 6.11 | - |
| PU-GAN [19] | 2.33 | 0.28 | 4.64 | 0.63 |
| PU-CTG | 2.36 | 0.24 | 3.45 | 0.52 |
| Methods | CD (10) | HD (10) |
|---|---|---|
| PU-Net [17] | 1.16 | 15.17 |
| MPU [18] | 0.94 | 13.33 |
| PU-CTG | 0.69 | 10.50 |
| CD (10) | HD (10) | |
|---|---|---|
| MEF | 0.30 | 4.21 |
| GRU | 0.29 | 4.50 |
| Hierarchical Upsampling | 0.29 | 4.76 |
| DCD | 0.26 | 4.71 |
| Full Pipeline | 0.24 | 3.45 |
| Methods | Level = 0.005 | Level = 0.01 | Level = 0.015 | Level = 0.025 | ||||
|---|---|---|---|---|---|---|---|---|
| CD (10) | HD (10) | CD (10) | HD (10) | CD (10) | HD (10) | CD (10) | HD (10) | |
| PU-GAN | 1.13 | 7.48 | 1.33 | 9.76 | 1.64 | 12.29 | 2.23 | 20.45 |
| PU-CTG | 0.97 | 6.25 | 1.13 | 7.76 | 1.36 | 9.60 | 2.02 | 16.80 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, T.; Lin, Y.; Cheng, B.; Ai, G.; Yang, J.; Fang, L. PU-CTG: A Point Cloud Upsampling Network Using Transformer Fusion and GRU Correction. Remote Sens. 2024, 16, 450. https://doi.org/10.3390/rs16030450
Li T, Lin Y, Cheng B, Ai G, Yang J, Fang L. PU-CTG: A Point Cloud Upsampling Network Using Transformer Fusion and GRU Correction. Remote Sensing. 2024; 16(3):450. https://doi.org/10.3390/rs16030450
Chicago/Turabian StyleLi, Tianyu, Yanghong Lin, Bo Cheng, Guo Ai, Jian Yang, and Li Fang. 2024. "PU-CTG: A Point Cloud Upsampling Network Using Transformer Fusion and GRU Correction" Remote Sensing 16, no. 3: 450. https://doi.org/10.3390/rs16030450
APA StyleLi, T., Lin, Y., Cheng, B., Ai, G., Yang, J., & Fang, L. (2024). PU-CTG: A Point Cloud Upsampling Network Using Transformer Fusion and GRU Correction. Remote Sensing, 16(3), 450. https://doi.org/10.3390/rs16030450