
JointNet4BCD: A Semi-Supervised Joint Learning Neural Network with Decision Fusion for Building Change Detection


Abstract
1. Introduction
- (1)
- To unleash the potential of single-temporal change detection methods, this paper proposes a single-temporal semi-supervised joint learning method called JointNet4BCD. By jointly training a semi-supervised building extraction task and a semi-supervised building change detection task, the proposed model enhances the ability of potential pivotal feature extraction and representation, which is efficient for insufficient labeling in the semi-supervised learning manner.
- (2)
- To further enhance the effectiveness of the proposed semi-supervised joint learning method, we design a decision fusion block. The accuracy of the building change detection results is increased by fusing the building extraction results and the change detection results at the decision level, while consistency regularization boosts the robustness of the decision fusion effect.
- (3)
- Comprehensive experiments conducted on two widely used high-resolution RS datasets show that our model achieves notable improvements in the accuracy of building change detection and outperforms multiple state-of-the-art methods.
2. Related Work
2.1. Traditional Change Detection Methods
2.2. Deep Learning-Based Change Detection Methods
2.3. Semi-Supervised Change Detection Methods
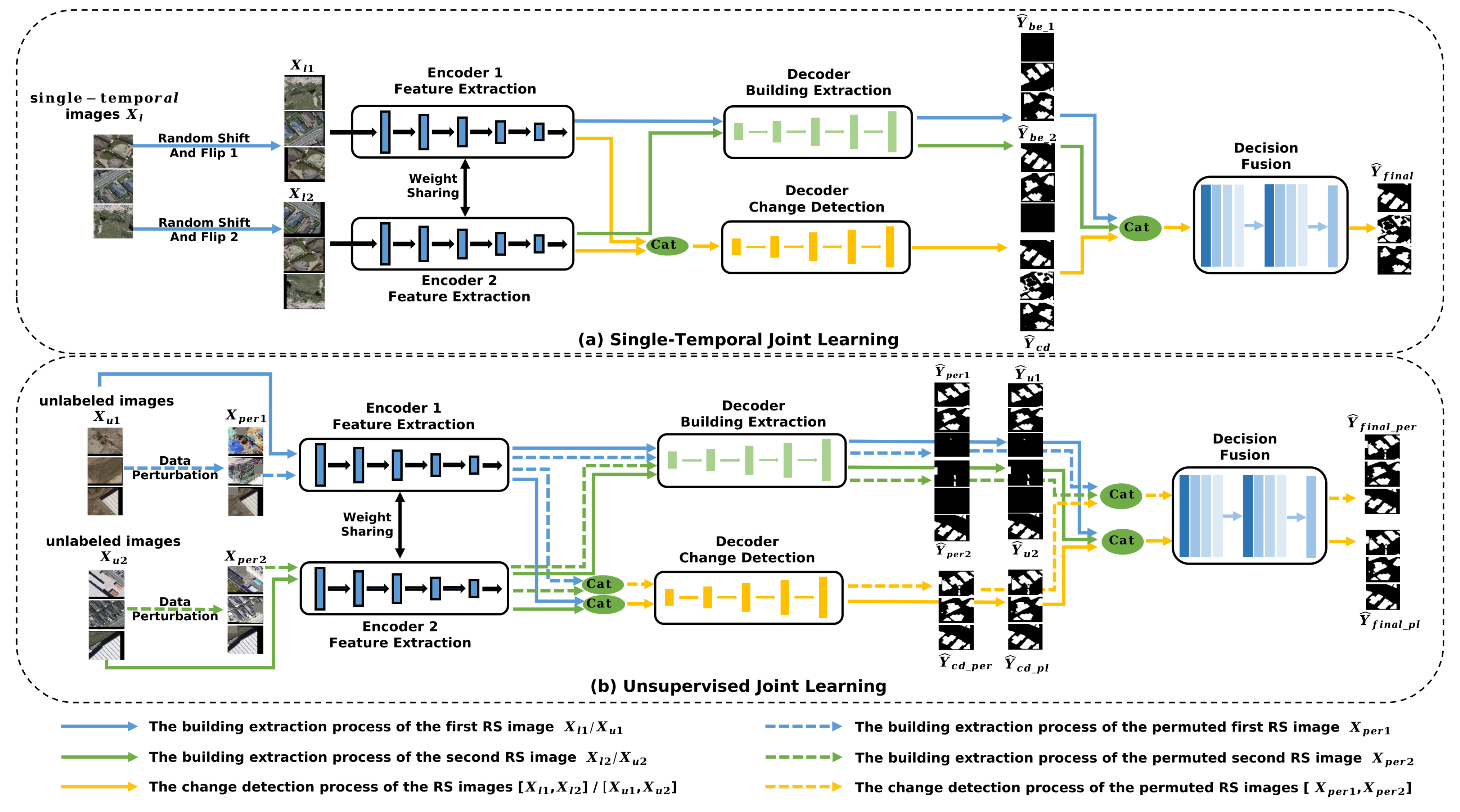
3. Methods
3.1. Single-Temporal Joint Learning
3.2. Unsupervised Joint Learning
3.3. Backbone Network
3.4. Decision Fusion Block
3.5. Loss Calculation
4. Experiments
4.1. Datasets
- The LEVIR dataset, accessible at https://justchenhao.github.io/LEVIR/ (last accessed on 26 October 2022), is a comprehensive remote sensing dataset designed for building change detection (BCD). It consists of 637 very-high-resolution (VHR) images from Google Earth, each with a size of 1024 × 1024 pixels and a resolution of 0.5 m per pixel. The dataset includes bi-temporal images captured across 20 different locations in Texas, USA, between the years 2002 and 2018. It focuses on detecting changes in land use, especially in buildings, covering a diverse array of structures such as high-rise apartments, small garages, cottage homes, and large warehouses. The images present many pseudo-changes due to seasonal influences, and the buildings exhibit varied geometric features, making the dataset particularly challenging. In order to cope with GPU memory limitations, the image pairs were divided into sections of 256 × 256 pixels and then randomly distributed into training and test sets. The training set contains 7120 images, whereas the test set includes 1024 images. Recognizing that 2000 images from the LEVIR dataset are adequate for training a high-precision change detection model and to reduce training duration, we created the LEVIR2000 dataset, which is composed of 2000 randomly selected images from the original LEVIR dataset.
- The WHU dataset (https://study.rsgis.whu.edu.cn/pages/download/building_dataset.html, accessed on 26 October 2022) consists of remote sensing imagery and change maps from the same region in Christchurch, New Zealand, captured in 2012 and 2016. Each image has a resolution of 0.075 m per pixel and dimensions of 32,507 × 15,345 pixels, with the primary focus being changes in buildings. To accommodate GPU memory constraints, we divided the images into segments of 256 × 256 pixels, creating a training set with 2000 image pairs and a test set with 996 image pairs. The WHU dataset is considered challenging due to the significant variation and the highly heterogeneous distribution of the changes in the buildings.
4.2. Evaluation Metrics
4.3. Experimental Setting and Baselines
- KPCA-MNet [15]: KPCA-MNet is an unsupervised change detection method that utilizes a deep Siamese network composed of weight-shared kernel principal component analysis (KPCA) convolutional layers to extract high-level spatial–spectral feature maps. The change detection results are obtained through threshold segmentation.
- SNUNet-ECAM [42]: A fully supervised method for remote sensing change detection, combining elements of a Siamese network with a nested UNet design. It utilizes an ensemble channel attention mechanism (ECAM) to effectively fuse the outputs from four nested UNets of varying depths.
- BIT-CD [50]: As a fully supervised remote sensing change detection method that utilizes a transformer-based approach, BIT-CD introduces the bi-temporal image transformer (BIT) to model contexts efficiently and effectively within the spatial–temporal domain.
- s4GAN [57]: By employing a feature matching loss, s4GAN, which is a semi-supervised semantic segmentation method, can minimize the gap between the segmentation maps predicted and the actual ones from semi-supervised data.
- semiCDNet [22]: A semi-supervised change detection method that leverages GANs, using two discriminators to ensure better consistency in segmentation and entropy maps across both labeled and unlabeled data.
- SemiSANet [23]: As a semi-supervised method for change detection, SemiSANet utilizes consistency regularization to attain high accuracy in CD results, particularly in situations where labels are limited.
- FPA [55]: FPA introduces a novel semisupervised change detection framework that effectively utilizes unlabeled remote sensing image pairs through class-aware feature alignment and pixelwise prediction alignment, achieving state-of-the-art performance across multiple benchmark datasets.
- PUF [56]: PUF is a progressive uncertainty-aware and uncertainty-guided framework, enhancing semi-supervised change detection performance by decoding and quantifying aleatoric uncertainty in remote sensing images.
- ChangStar [24]: ChangeStar represents the first fully supervised approach that relies completely on single-temporal remote sensing images paired with building extraction labels to train a robust change detection model.
4.4. Comparison Experiments
4.4.1. Prediction on LEVIR2000 Dataset
4.4.2. Prediction on WHU Dataset
4.5. Ablation Studies
5. Discussion
5.1. Performance and Efficiency
5.2. Critical Considerations and Limitations
5.3. Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bai, T.; Wang, L.; Yin, D.; Sun, K.; Chen, Y.; Li, W.; Li, D. Deep learning for change detection in remote sensing: A review. Geo Spat. Inf. Sci. 2023, 26, 262–288. [Google Scholar] [CrossRef]
- Cheng, G.; Huang, Y.; Li, X.; Lyu, S.; Xu, Z.; Zhao, H.; Zhao, Q.; Xiang, S. Change detection methods for remote sensing in the last decade: A comprehensive review. Remote Sens. 2024, 16, 2355. [Google Scholar] [CrossRef]
- Madasa, A.; Orimoloye, I.R.; Ololade, O.O. Application of geospatial indices for mapping land cover/use change detection in a mining area. J. Afr. Earth Sci. 2021, 175, 104108. [Google Scholar] [CrossRef]
- Khan, A.; Aslam, S.; Aurangzeb, K.; Alhussein, M.; Javaid, N. Multiscale modeling in smart cities: A survey on applications, current trends, and challenges. Sustain. Cities Soc. 2022, 78, 103517. [Google Scholar] [CrossRef]
- Lv, Z.; Wang, F.; Cui, G.; Benediktsson, J.A.; Lei, T.; Sun, W. Spatial–spectral attention network guided with change magnitude image for land cover change detection using remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Li, Z.; Tang, C.; Liu, X.; Li, C.; Li, X.; Zhang, W. MS-Former: Memory-Supported Transformer for Weakly Supervised Change Detection with Patch-Level Annotations. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5625213. [Google Scholar] [CrossRef]
- Cao, Y.; Huang, X.; Weng, Q. A multi-scale weakly supervised learning method with adaptive online noise correction for high-resolution change detection of built-up areas. Remote Sens. Environ. 2023, 297, 113779. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, M.; Shi, W. CS-WSCDNet: Class Activation Mapping and Segment Anything Model-Based Framework for Weakly Supervised Change Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5624812. [Google Scholar] [CrossRef]
- Zhang, H.; Chen, K.; Liu, C.; Chen, H.; Zou, Z.; Shi, Z. CDMamba: Remote Sensing Image Change Detection with Mamba. arXiv 2024, arXiv:2406.04207. [Google Scholar]
- Ding, L.; Zhang, J.; Guo, H.; Zhang, K.; Liu, B.; Bruzzone, L. Joint spatio-temporal modeling for semantic change detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5610814. [Google Scholar] [CrossRef]
- Huang, Y.; Li, X.; Du, Z.; Shen, H. Spatiotemporal enhancement and interlevel fusion network for remote sensing images change detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5609414. [Google Scholar] [CrossRef]
- Zuo, Y.; Li, L.; Liu, X.; Gao, Z.; Jiao, L.; Liu, F.; Yang, S. Robust Instance-Based Semi-Supervised Learning Change Detection for Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4404815. [Google Scholar] [CrossRef]
- Yang, Y.; Tang, X.; Ma, J.; Zhang, X.; Pei, S.; Jiao, L. ECPS: Cross Pseudo Supervision Based on Ensemble Learning for Semi-Supervised Remote Sensing Change Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5612317. [Google Scholar] [CrossRef]
- Sun, C.; Chen, H.; Du, C.; Jing, N. SemiBuildingChange: A Semi-Supervised High-Resolution Remote Sensing Image Building Change Detection Method with a Pseudo Bi-Temporal Data Generator. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5622319. [Google Scholar] [CrossRef]
- Wu, C.; Chen, H.; Du, B.; Zhang, L. Unsupervised change detection in multitemporal vhr images based on deep kernel pca convolutional mapping network. IEEE Trans. Cybern. 2021, 52, 12084–12098. [Google Scholar] [CrossRef]
- Wu, C.; Du, B.; Zhang, L. Fully convolutional change detection framework with generative adversarial network for unsupervised, weakly supervised and regional supervised change detection. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 9774–9788. [Google Scholar] [CrossRef]
- Zhao, M.; Hu, X.; Zhang, L.; Meng, Q.; Chen, Y.; Bruzzone, L. Beyond Pixel-Level Annotation: Exploring Self-Supervised Learning for Change Detection with Image-Level Supervision. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5614916. [Google Scholar] [CrossRef]
- Chen, H.; Peng, S.; Du, C.; Li, J.; Wu, S. SW-GAN: Road extraction from remote sensing imagery using semi-weakly supervised adversarial learning. Remote Sens. 2022, 14, 4145. [Google Scholar] [CrossRef]
- Yang, S.; Hou, S.; Zhang, Y.; Wang, H.; Ma, X. Change detection of high-resolution remote sensing image based on semi-supervised segmentation and adversarial learning. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1055–1058. [Google Scholar]
- Zhao, G.; Peng, Y. Semisupervised SAR image change detection based on a siamese variational autoencoder. Inf. Process. Manag. 2022, 59, 102726. [Google Scholar] [CrossRef]
- Yang, F.; Zhang, H.; Tao, S. Semi-supervised classification via full-graph attention neural networks. Neurocomputing 2022, 476, 63–74. [Google Scholar] [CrossRef]
- Peng, D.; Bruzzone, L.; Zhang, Y.; Guan, H.; Ding, H.; Huang, X. SemiCDNet: A semisupervised convolutional neural network for change detection in high resolution remote-sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5891–5906. [Google Scholar] [CrossRef]
- Sun, C.; Wu, J.; Chen, H.; Du, C. SemiSANet: A Semi-Supervised High-Resolution Remote Sensing Image Change Detection Model Using Siamese Networks with Graph Attention. Remote Sens. 2022, 14, 2801. [Google Scholar] [CrossRef]
- Zheng, Z.; Ma, A.; Zhang, L.; Zhong, Y. Change is everywhere: Single-temporal supervised object change detection in remote sensing imagery. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; 2021; pp. 15193–15202. [Google Scholar]
- Ridd, M.K.; Liu, J. A comparison of four algorithms for change detection in an urban environment. Remote Sens. Environ. 1998, 63, 95–100. [Google Scholar] [CrossRef]
- Falco, N.; Marpu, P.R.; Benediktsson, J.A. A toolbox for unsupervised change detection analysis. Int. J. Remote Sens. 2016, 37, 1505–1526. [Google Scholar] [CrossRef]
- Chen, G.; Hay, G.J.; Carvalho, L.M.; Wulder, M.A. Object-based change detection. Int. J. Remote Sens. 2012, 33, 4434–4457. [Google Scholar] [CrossRef]
- Xu, Y.; Li, J.; Du, C.; Chen, H. NBR-Net: A Non-rigid Bi-directional Registration Network for Multi-temporal Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5620715. [Google Scholar]
- Xu, Y.; Chen, H.; Du, C.; Li, J. MSACon: Mining Spatial Attention-Based Contextual Information for Road Extraction. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–17. [Google Scholar] [CrossRef]
- Chen, H.; Li, Z.; Wu, J.; Xiong, W.; Du, C. SemiRoadExNet: A semi-supervised network for road extraction from remote sensing imagery via adversarial learning. ISPRS J. Photogramm. Remote Sens. 2023, 198, 169–183. [Google Scholar] [CrossRef]
- Song, J.; Li, J.; Chen, H.; Wu, J. MapGen-GAN: A fast translator for remote sensing image to map via unsupervised adversarial learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2341–2357. [Google Scholar] [CrossRef]
- Song, J.; Li, J.; Chen, H.; Wu, J. RSMT: A Remote Sensing Image-to-Map Translation Model via Adversarial Deep Transfer Learning. Remote Sens. 2022, 14, 919. [Google Scholar] [CrossRef]
- Li, Z.; Chen, H.; Wu, J.; Li, J.; Jing, N. SegMind: Semi-supervised remote sensing image semantic segmentation with Masked Image modeling and contrastive learning method. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4408917. [Google Scholar] [CrossRef]
- Yang, L.; Chen, H.; Yang, A.; Li, J. EasySeg: An Error-Aware Domain Adaptation Framework for Remote Sensing Imagery Semantic Segmentation via Interactive Learning and Active Learning. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4407518. [Google Scholar] [CrossRef]
- Lv, Z.; Huang, H.; Gao, L.; Benediktsson, J.A.; Zhao, M.; Shi, C. Simple multiscale UNet for change detection with heterogeneous remote sensing images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Chen, T.; Lu, Z.; Yang, Y.; Zhang, Y.; Du, B.; Plaza, A. A Siamese Network Based U-Net for Change Detection in High Resolution Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 2357–2369. [Google Scholar]
- Moustafa, M.S.; Mohamed, S.A.; Ahmed, S.; Nasr, A.H. Hyperspectral change detection based on modification of UNet neural networks. J. Appl. Remote Sens. 2021, 15, 028505. [Google Scholar] [CrossRef]
- Sun, C.; Du, C.; Wu, J.; Chen, H. SUDANet: A Siamese UNet with Dense Attention Mechanism for Remote Sensing Image Change Detection. In Pattern Recognition and Computer Vision, Proceedings of the 5th Chinese Conference, PRCV 2022, Shenzhen, China, 4–7 November 2022; Proceedings, Part IV; Springer: Berlin/Heidelberg, Germany, 2022; pp. 78–88. [Google Scholar]
- Lv, Z.; Huang, H.; Sun, W.; Lei, T.; Benediktsson, J.A.; Li, J. Novel enhanced UNet for change detection using multimodal remote sensing image. IEEE Geosci. Remote Sens. Lett. 2023, 20, 2505405. [Google Scholar] [CrossRef]
- Tang, Y.; Cao, Z.; Guo, N.; Jiang, M. A Siamese Swin-Unet for image change detection. Sci. Rep. 2024, 14, 4577. [Google Scholar]
- Shao, R.; Du, C.; Chen, H.; Li, J. SUNet: Change Detection for Heterogeneous Remote Sensing Images from Satellite and UAV Using a Dual-Channel Fully Convolution Network. Remote Sens. 2021, 13, 3750. [Google Scholar] [CrossRef]
- Fang, S.; Li, K.; Shao, J.; Li, Z. SNUNet-CD: A densely connected siamese network for change detection of VHR images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Zhang, C.; Yue, P.; Tapete, D.; Jiang, L.; Shangguan, B.; Huang, L.; Liu, G. A deeply supervised image fusion network for change detection in high resolution bi-temporal remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 166, 183–200. [Google Scholar] [CrossRef]
- Chen, H.; Shi, Z. A spatial-temporal attention-based method and a new dataset for remote sensing image change detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Li, Z.; Cao, S.; Deng, J.; Wu, F.; Wang, R.; Luo, J.; Peng, Z. STADE-CDNet: Spatial–temporal attention with difference enhancement-based network for remote sensing image change detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–17. [Google Scholar] [CrossRef]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Islam, S.; Elmekki, H.; Elsebai, A.; Bentahar, J.; Drawel, N.; Rjoub, G.; Pedrycz, W. A comprehensive survey on applications of transformers for deep learning tasks. Expert Syst. Appl. 2024, 241, 122666. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Aleissaee, A.A.; Kumar, A.; Anwer, R.M.; Khan, S.; Cholakkal, H.; Xia, G.S.; Khan, F.S. Transformers in remote sensing: A survey. Remote Sens. 2023, 15, 1860. [Google Scholar] [CrossRef]
- Chen, H.; Qi, Z.; Shi, Z. Remote sensing image change detection with transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5607514. [Google Scholar] [CrossRef]
- Li, Q.; Zhong, R.; Du, X.; Du, Y. TransUNetCD: A hybrid transformer network for change detection in optical remote-sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–19. [Google Scholar]
- Zhou, Y.; Wang, F.; Zhao, J.; Yao, R.; Chen, S.; Ma, H. Spatial-temporal based multihead self-attention for remote sensing image change detection. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6615–6626. [Google Scholar]
- Noman, M.; Fiaz, M.; Cholakkal, H.; Narayan, S.; Anwer, R.M.; Khan, S.; Khan, F.S. Remote sensing change detection with transformers trained from scratch. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4704214. [Google Scholar]
- Han, K.; Sheng, V.S.; Song, Y.; Liu, Y.; Qiu, C.; Ma, S.; Liu, Z. Deep semi-supervised learning for medical image segmentation: A review. In Expert Systems with Applications; Elsevier: Amsterdam, The Netherlands, 2024; p. 123052. [Google Scholar]
- Zhang, X.; Huang, X.; Li, J. Semisupervised change detection with feature-prediction alignment. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–16. [Google Scholar] [CrossRef]
- Shen, J.; Zhang, C.; Zhang, M.; Li, Q.; Wang, Q. Learning Remote Sensing Aleatoric Uncertainty for Semi-Supervised Change Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5635413. [Google Scholar]
- Mittal, S.; Tatarchenko, M.; Brox, T. Semi-supervised semantic segmentation with high-and low-level consistency. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1369–1379. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Number of Labeled Images | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 15 | 20 | 30 | |||||||||||||
| F1 | Kappa | IoU | TIME | F1 | Kappa | IoU | TIME | F1 | Kappa | IoU | TIME | F1 | Kappa | IoU | TIME | |
| KPCA-MNet | 0.0972 | 0.7214 | 0.0511 | 440 s | 0.0972 | 0.7214 | 0.0511 | 440 s | 0.0972 | 0.7214 | 0.0511 | 440 s | 0.0972 | 0.7214 | 0.0511 | 440 s |
| SNUNet-ECAM | 0.2755 | 0.2570 | 0.1597 | 0.13 s | 0.3390 | 0.3192 | 0.2041 | 0.17 s | 0.3335 | 0.3121 | 0.2001 | 0.23 s | 0.3375 | 0.3076 | 0.2030 | 0.37 s |
| BIT-CD | 0.2294 | 0.2074 | 0.1295 | 0.42 s | 0.1504 | 0.1351 | 0.0813 | 0.52 s | 0.1911 | 0.1793 | 0.1056 | 0.81 s | 0.3274 | 0.3106 | 0.1957 | 1.07 s |
| s4GAN | 0.3295 | 0.2882 | 0.1973 | 99 s | 0.4767 | 0.4479 | 0.3129 | 107 s | 0.5626 | 0.5404 | 0.3914 | 115 s | 0.5430 | 0.3076 | 0.2030 | 140 s |
| semiCDNet | 0.3842 | 0.3502 | 0.2378 | 90 s | 0.4769 | 0.4568 | 0.3131 | 112 s | 0.6007 | 0.5863 | 0.4293 | 147 s | 0.6049 | 0.5903 | 0.4336 | 178 s |
| semiSANet | 0.7002 | 0.6876 | 0.5387 | 85 s | 0.7132 | 0.7014 | 0.5543 | 90 s | 0.7376 | 0.7272 | 0.5843 | 97 s | 0.7300 | 0.7204 | 0.5749 | 113 s |
| ChangeStar | 0.7207 | 0.7081 | 0.5633 | 25 min | 0.7207 | 0.7081 | 0.5633 | 25 min | 0.7207 | 0.7081 | 0.5633 | 25 min | 0.7207 | 0.7081 | 0.5633 | 25 min |
| FPA | 0.5294 | 0.5106 | 0.3600 | 57 s | 0.5686 | 0.5473 | 0.3972 | 52 s | 0.5613 | 0.5421 | 0.3901 | 61 s | 0.6696 | 0.6565 | 0.5033 | 57 s |
| PUF | 0.6163 | 0.6185 | 0.4454 | 135 s | 0.6402 | 0.6327 | 0.4708 | 135 s | 0.6416 | 0.6229 | 0.4724 | 135 s | 0.8030 | 0.7736 | 0.6709 | 135 s |
| JointNet4BCD | 0.8393 | 0.8326 | 0.7232 | 125 s | 0.8403 | 0.8333 | 0.7245 | 131 s | 0.8449 | 0.8385 | 0.7315 | 144 s | 0.8493 | 0.8428 | 0.7380 | 152 s |
| Method | Number of Labeled Images | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 15 | 20 | 30 | |||||||||||||
| F1 | Kappa | IoU | TIME | F1 | Kappa | IoU | TIME | F1 | Kappa | IoU | TIME | F1 | Kappa | IoU | TIME | |
| KPCA-MNet | 0.2087 | 0.7210 | 0.1165 | 440 s | 0.2087 | 0.7210 | 0.1165 | 440 s | 0.2087 | 0.7210 | 0.1165 | 440 s | 0.2087 | 0.7210 | 0.1165 | 440 s |
| SNUNet-ECAM | 0.3228 | 0.2594 | 0.1924 | 0.13 s | 0.5110 | 0.4486 | 0.3432 | 0.17 s | 0.5287 | 0.4674 | 0.3594 | 0.23 s | 0.5444 | 0.4883 | 0.3740 | 0.37 s |
| BIT-CD | 0.3849 | 0.2840 | 0.2382 | 0.42 s | 0.5393 | 0.4735 | 0.3691 | 0.52 s | 0.5830 | 0.5368 | 0.4114 | 0.81 s | 0.5907 | 0.5451 | 0.4191 | 1.07 s |
| s4GAN | 0.6364 | 0.5924 | 0.4667 | 99 s | 0.5898 | 0.5351 | 0.4182 | 107 s | 0.6197 | 0.5674 | 0.4490 | 115 s | 0.5763 | 0.5182 | 0.4048 | 140 s |
| semiCDNet | 0.6251 | 0.5765 | 0.4547 | 90 s | 0.6265 | 0.5892 | 0.4561 | 112 s | 0.6335 | 0.5853 | 0.4636 | 147 s | 0.6331 | 0.5952 | 0.4631 | 178 s |
| semiSANet | 0.5316 | 0.4870 | 0.3620 | 85 s | 0.7603 | 0.7331 | 0.6132 | 90 s | 0.7778 | 0.7568 | 0.6364 | 97 s | 0.7812 | 0.7595 | 0.6410 | 113 s |
| ChangeStar | 0.6704 | 0.6358 | 0.5042 | 25 min | 0.6704 | 0.6358 | 0.5042 | 25 min | 0.6704 | 0.6358 | 0.5042 | 25 min | 0.6704 | 0.6358 | 0.5042 | 25 min |
| FPA | 0.5716 | 0.5401 | 0.4002 | 57 s | 0.5838 | 0.5537 | 0.4122 | 58 s | 0.6021 | 0.5694 | 0.4307 | 63 s | 0.8168 | 0.7981 | 0.6904 | 63 s |
| PUF | 0.5468 | 0.3464 | 0.3763 | 140 s | 0.6372 | 0.4599 | 0.4676 | 142 s | 0.8294 | 0.8024 | 0.7085 | 142 s | 0.8692 | 0.8466 | 0.7687 | 143 s |
| JointNet4BCD | 0.8345 | 0.8271 | 0.7159 | 125 s | 0.8487 | 0.8325 | 0.7371 | 131 s | 0.8664 | 0.8537 | 0.7644 | 144 s | 0.8730 | 0.8597 | 0.7746 | 152 s |
| Method | Semi | Joint | DIM | Number of Labeled Images | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 15 | 20 | 30 | ||||||||||||
| F1 | Kappa | IoU | F1 | Kappa | IoU | F1 | Kappa | IoU | F1 | Kappa | IoU | ||||
| JointNet4BCD | × | × | × | 0.3367 | 0.2945 | 0.2024 | 0.4878 | 0.4588 | 0.3225 | 0.5768 | 0.5573 | 0.4053 | 0.5918 | 0.5700 | 0.4203 |
| ✓ | × | × | 0.7553 | 0.7457 | 0.6068 | 0.7988 | 0.7900 | 0.6651 | 0.8138 | 0.8055 | 0.6860 | 0.8329 | 0.8257 | 0.7136 | |
| ✓ | ✓ | × | 0.8300 | 0.8228 | 0.7093 | 0.8322 | 0.8247 | 0.7126 | 0.8411 | 0.8341 | 0.7257 | 0.8411 | 0.8344 | 0.7258 | |
| ✓ | ✓ | ✓ | 0.8393 | 0.8326 | 0.7232 | 0.8403 | 0.8333 | 0.7245 | 0.8449 | 0.8385 | 0.7315 | 0.8493 | 0.8428 | 0.7380 | |
| Method | Semi | Joint | DIM | Number of Labeled Images | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 15 | 20 | 30 | ||||||||||||
| F1 | Kappa | IoU | F1 | Kappa | IoU | F1 | Kappa | IoU | F1 | Kappa | IoU | ||||
| JointNet4BCD | × | × | × | 0.6616 | 0.6254 | 0.4943 | 0.6268 | 0.5811 | 0.4564 | 0.6648 | 0.6237 | 0.4979 | 0.6583 | 0.6191 | 0.4907 |
| ✓ | × | × | 0.6882 | 0.6510 | 0.5246 | 0.7620 | 0.7340 | 0.6155 | 0.8317 | 0.8131 | 0.7119 | 0.8393 | 0.8216 | 0.7230 | |
| ✓ | ✓ | × | 0.8306 | 0.8123 | 0.7103 | 0.8412 | 0.8242 | 0.7260 | 0.8582 | 0.8427 | 0.7517 | 0.8681 | 0.8539 | 0.7669 | |
| ✓ | ✓ | ✓ | 0.8345 | 0.8271 | 0.7159 | 0.8487 | 0.8325 | 0.7371 | 0.8664 | 0.8537 | 0.7644 | 0.8730 | 0.8597 | 0.7746 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.; Sun, C.; Li, J.; Du, C. JointNet4BCD: A Semi-Supervised Joint Learning Neural Network with Decision Fusion for Building Change Detection. Remote Sens. 2024, 16, 4569. https://doi.org/10.3390/rs16234569
Chen H, Sun C, Li J, Du C. JointNet4BCD: A Semi-Supervised Joint Learning Neural Network with Decision Fusion for Building Change Detection. Remote Sensing. 2024; 16(23):4569. https://doi.org/10.3390/rs16234569
Chicago/Turabian StyleChen, Hao, Chengzhe Sun, Jun Li, and Chun Du. 2024. "JointNet4BCD: A Semi-Supervised Joint Learning Neural Network with Decision Fusion for Building Change Detection" Remote Sensing 16, no. 23: 4569. https://doi.org/10.3390/rs16234569
APA StyleChen, H., Sun, C., Li, J., & Du, C. (2024). JointNet4BCD: A Semi-Supervised Joint Learning Neural Network with Decision Fusion for Building Change Detection. Remote Sensing, 16(23), 4569. https://doi.org/10.3390/rs16234569