
A Deformable Split Fusion Method for Object Detection in High-Resolution Optical Remote Sensing Image


Abstract

1. Introduction
- The receptive field range required for remote sensing objects of different sizes differs, and some studies need to process high-resolution features efficiently from a global perspective;
- The object features observed in feature maps at different scales and levels are different, and some studies cannot effectively handle the different background information required for detecting different objects;
- To improve the accuracy of remote sensing rotated object detection, it is necessary to simultaneously learn rich prior knowledge, improve the representation method of oriented bounding boxes, and search for better feature fusion methods.
- Before sending feature maps at different levels into FPN [29], we select convolutional kernels of different sizes for feature extraction. As the network deepens, the size of the convolutional kernels gradually increases, thereby better processing high-resolution object information and rich contextual information;
- We propose a deformable split fusion method, which consists of two parts: a deformable split module and a space fusion module. This method helps the model dynamically extract contextual information based on different remote sensing objects, improving the model’s detection accuracy for remote sensing objects;
- This paper proposes a novel remote sensing object detection framework called RoI Transformer-DSF. It conducts extensive comparative experiments and ablation studies on the benchmark DOTAv1.0 and FAIR1M datasets, corroborating the performance enhancement of the proposed method.
2. Related Work
2.1. RoI Transformer
2.2. Multi-Scale Feature Fusion
2.3. Attention Mechanism
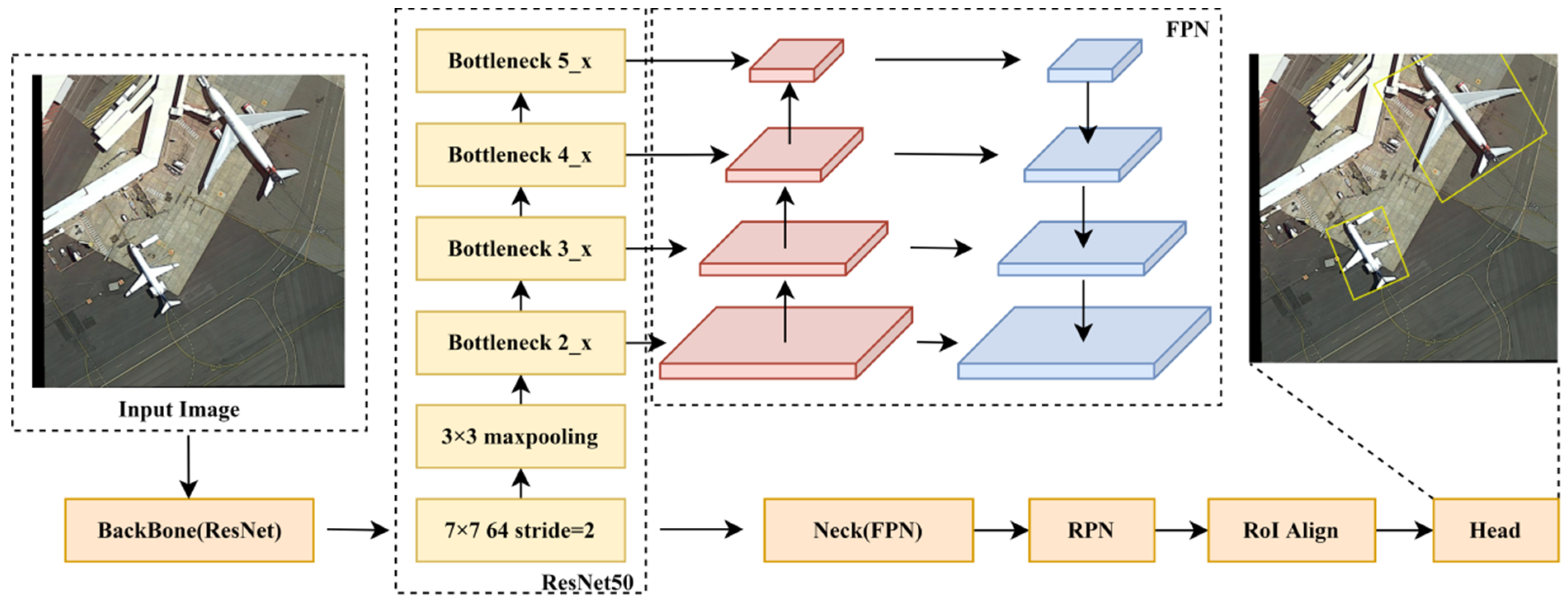
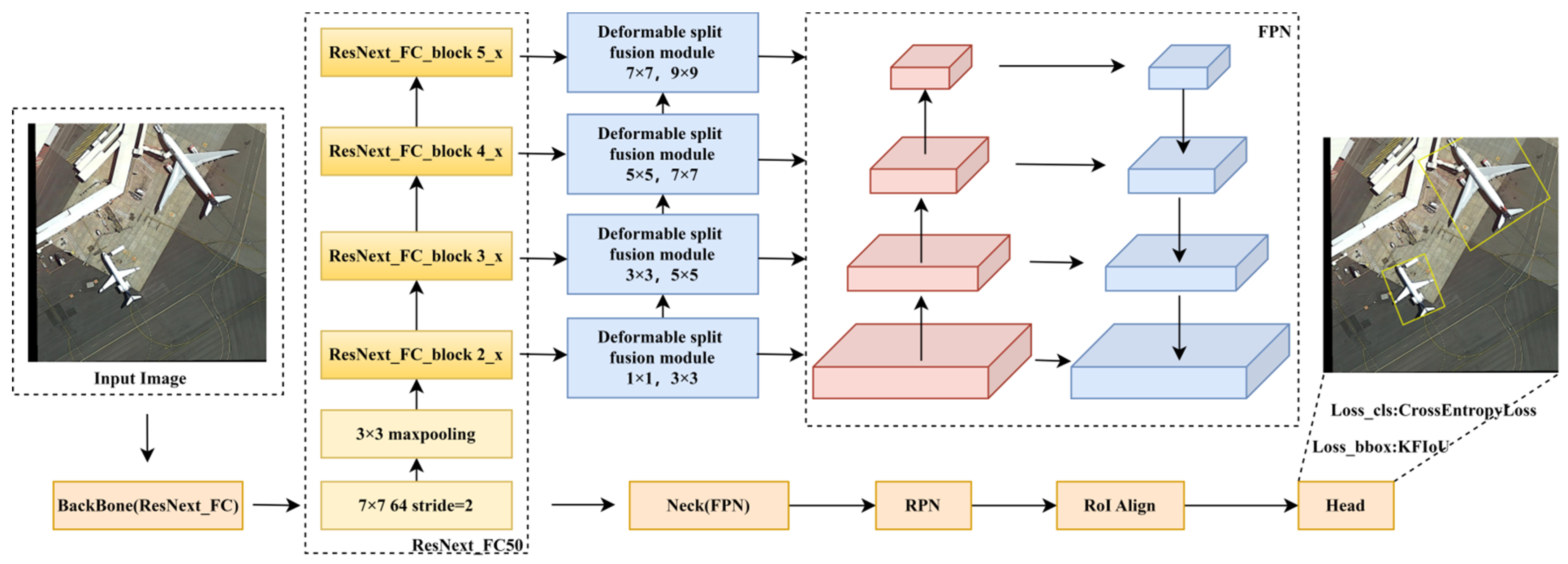
3. Our Work
3.1. Deformable Split Module
3.2. Space Fusion Module
3.3. ResNext_FC_Block
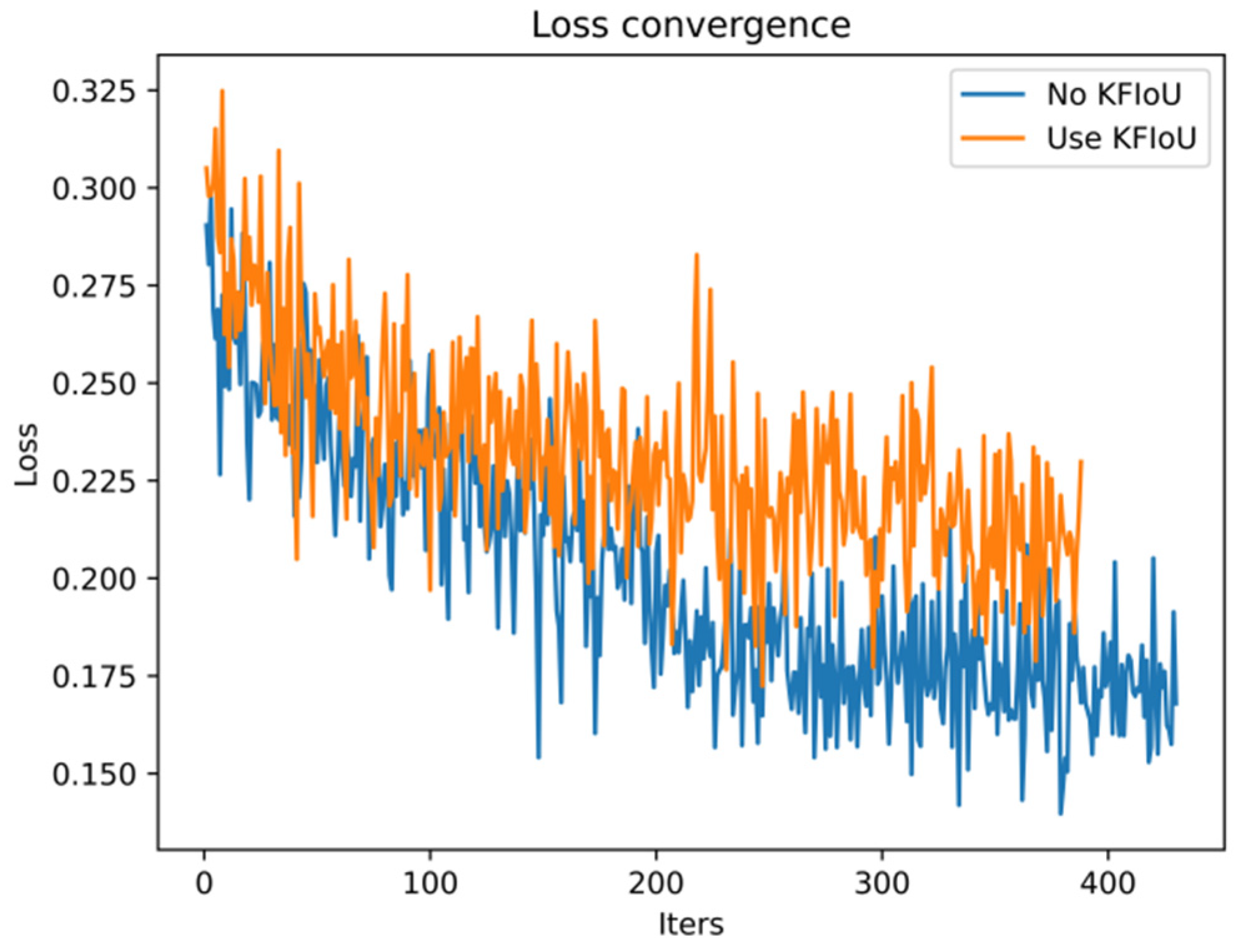
3.4. Optimize the Loss Function
4. Experiment and Result Analysis
4.1. Experimental Environment and Parameter Configuration
4.2. Datasets
4.3. Experimental Evaluation Indicators
4.4. Analysis of Experimental Results
4.4.1. DOTA Dataset Comparison Experiment
4.4.2. FAIR1M Dataset Comparison Experiment
4.5. Ablation Experiment
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| DSM | Deformable split module |
| SFM | Space fusion module |
| DSF | Deformable split fusion |
| RoI | Region of Interest |
| SAR | Synthetic Aperture Radar |
| FPN | Feature pyramid network |
| KFIoU | SkewIoU based on Kalman Filtering |
| CNN | Convolutional Neural Network |
| SA-S | Shape adaptive selection |
| SA-M | Shape adaptive measurement |
| FAM | Feature Alignment Module |
| ODM | Orientation Detection Module |
| CAM | Channel attention module |
| SAM | Spatial attention module |
| ARN | Anchor refinement network |
| AP | Average precision |
| IoU | Intersection over union |
| R | Recall |
| P | Precision |
| YOLO | You only look once |
| SSD | Single shot multibox detector |
| mAP | Mean average precision |
| MLP | Multi-layer perceptron |
| BN | Batch Normalization |
| SGD | Stochastic gradient descent |
| C | Channel Weight branch |
| S | Spatial Weight branch |
References
- Fei, X.; Guo, M.; Li, Y.; Yu, R.; Sun, L. ACDF-YOLO: Attentive and Cross-Differential Fusion Network for Multimodal Remote Sensing Object Detection. Remote Sens. 2024, 16, 3532. [Google Scholar] [CrossRef]
- He, X.; Liang, K.; Zhang, W.; Li, F.; Jiang, Z.; Zuo, Z.; Tan, X. DETR-ORD: An Improved DETR Detector for Oriented Remote Sensing Object Detection with Feature Reconstruction and Dynamic Query. Remote Sens. 2024, 16, 3516. [Google Scholar] [CrossRef]
- Liu, Z.; He, G.; Dong, L.; Jing, D.; Zhang, H. Task-Sensitive Efficient Feature Extraction Network for Oriented Object Detection in Remote Sensing Images. Remote Sens. 2024, 16, 2271. [Google Scholar] [CrossRef]
- Liu, C.; Zhang, S.; Hu, M.; Song, Q. Object Detection in Remote Sensing Images Based on Adaptive Multi-Scale Feature Fusion Method. Remote Sens. 2024, 16, 907. [Google Scholar] [CrossRef]
- Mei, S.; Lian, J.; Wang, X.; Su, Y.; Ma, M.; Chau, L.-P. A Comprehensive Study on the Robustness of Image Classification and Object Detection in Remote Sensing: Surveying and Benchmarking. arXiv 2023, arXiv:2306.12111. [Google Scholar]
- Cheng, A.; Xiao, J.; Li, Y.; Sun, Y.; Ren, Y.; Liu, J. Enhancing Remote Sensing Object Detection with K-CBST YOLO: Integrating CBAM and Swin-Transformer. Remote Sens. 2024, 16, 2885. [Google Scholar] [CrossRef]
- Pan, M.; Xia, W.; Yu, H.; Hu, X.; Cai, W.; Shi, J. Vehicle Detection in UAV Images via Background Suppression Pyramid Network and Multi-Scale Task Adaptive Decoupled Head. Remote Sens. 2023, 15, 5698. [Google Scholar] [CrossRef]
- Wang, W.; Cai, Y.; Luo, Z.; Liu, W.; Wang, T.; Li, Z. SA3Det: Detecting Rotated Objects via Pixel-Level Attention and Adaptive Labels Assignment. Remote Sens. 2024, 16, 2496. [Google Scholar] [CrossRef]
- Chen, J.; Lin, Q.; Huang, H.; Yu, Y.; Zhu, D.; Fu, G. HVConv: Horizontal and Vertical Convolution for Remote Sensing Object Detection. Remote Sens. 2024, 16, 1880. [Google Scholar] [CrossRef]
- Zhao, Q.; Wu, Y.; Yuan, Y. Ship Target Detection in Optical Remote Sensing Images Based on E2YOLOX-VFL. Remote Sens. 2024, 16, 340. [Google Scholar] [CrossRef]
- Guan, Q.; Liu, Y.; Chen, L.; Zhao, S.; Li, G. Aircraft Detection and Fine-Grained Recognition Based on High-Resolution Remote Sensing Images. Electronics 2023, 12, 3146. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the NIPS’15: Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; p. 28. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.-S.; Lu, Q. Learning RoI transformer for oriented object detection in aerial images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2849–2858. [Google Scholar]
- Yang, X.; Yan, J.; Feng, Z.; He, T. R3det: Refined single-stage detector with feature refinement for rotating object. Proc. AAAI Conf. Artif. Intell. 2021, 35, 3163–3171. [Google Scholar] [CrossRef]
- Han, J.; Ding, J.; Li, J.; Xia, G.-S. Align deep features for oriented object detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5602511. [Google Scholar] [CrossRef]
- Han, J.; Ding, J.; Xue, N.; Xia, G.-S. Redet: A rotation-equivariant detector for aerial object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2786–2795. [Google Scholar]
- Guo, Z.; Liu, C.; Zhang, X.; Jiao, J.; Ji, X.; Ye, Q. Beyond bounding-box: Convex-hull feature adaptation for oriented and densely packed object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8792–8801. [Google Scholar]
- Xie, X.; Cheng, G.; Wang, J.; Yao, X.; Han, J. Oriented R-CNN for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3520–3529. [Google Scholar]
- Yang, X.; Yan, J.; Ming, Q.; Wang, W.; Zhang, X.; Tian, Q. Rethinking rotated object detection with gaussian wasserstein distance loss. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 18–24 July 2021; pp. 11830–11841. [Google Scholar]
- Yang, X.; Yang, X.; Yang, J.; Ming, Q.; Wang, W.; Tian, Q.; Yan, J. Learning high-precision bounding box for rotated object detection via kullback-leibler divergence. Adv. Neural Inf. Process. Syst. 2021, 34, 18381–18394. [Google Scholar]
- Hou, L.; Lu, K.; Xue, J.; Li, Y. Shape-adaptive selection and measurement for oriented object detection. Proc. AAAI Conf. Artif. Intell. 2022, 36, 923–932. [Google Scholar] [CrossRef]
- Li, W.; Chen, Y.; Hu, K.; Zhu, J. Oriented reppoints for aerial object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1829–1838. [Google Scholar]
- Yang, X.; Zhou, Y.; Zhang, G.; Yang, J.; Wang, W.; Yan, J.; Zhang, X.; Tian, Q. The KFIoU loss for rotated object detection. arXiv 2022, arXiv:2201.12558. [Google Scholar]
- Hou, L.; Lu, K.; Yang, X.; Li, Y.; Xue, J. G-rep: Gaussian representation for arbitrary-oriented object detection. Remote Sens. 2023, 15, 757. [Google Scholar] [CrossRef]
- Chen, Y.; Yuan, X.; Wu, R.; Wang, J.; Hou, Q.; Cheng, M.-M. YOLO-MS: Rethinking Multi-Scale Representation Learning for Real-time Object Detection. arXiv 2023, arXiv:2308.05480. [Google Scholar]
- Li, Y.; Hou, Q.; Zheng, Z.; Cheng, M.-M.; Yang, J.; Li, X. Large Selective Kernel Network for Remote Sensing Object Detection. arXiv 2023, arXiv:2303.09030. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Liu, C.; Yu, S.; Yu, M.; Wei, B.; Li, B.; Li, G. Adaptive smooth L1 loss: A better way to regress scene texts with extreme aspect ratios. In Proceedings of the 2021 IEEE Symposium on Computers and Communications (ISCC), Athens, Greece, 5–8 September 2021; IEEE: New York, NY, USA, 2021; pp. 1–7. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xu, X.; Jiang, Y.; Chen, W.; Huang, Y.; Zhang, Y.; Sun, X. Damo-yolo: A report on real-time object detection design. arXiv 2022, arXiv:2211.15444. [Google Scholar]
- Park, H.J.; Kang, J.W.; Kim, B.G. ssFPN: Scale Sequence (S 2) Feature-Based Feature Pyramid Network for Object Detection. Sensors 2023, 23, 4432. [Google Scholar] [CrossRef] [PubMed]
- Luo, Y.; Cao, X.; Zhang, J.; Guo, J.; Shen, H.; Wang, T.; Feng, Q. CE-FPN: Enhancing channel information for object detection. Multimed. Tools Appl. 2022, 81, 30685–30704. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Y.; Shao, Z.; Hoffmann, N. Global attention mechanism: Retain information to enhance channel-spatial interactions. arXiv 2021, arXiv:2112.05561. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Xia, G.-S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]
- Sun, X.; Wang, P.; Yan, Z.; Xu, F.; Wang, R.; Diao, W.; Chen, J.; Li, J.; Feng, Y.; Xu, T.; et al. FAIR1M: A benchmark dataset for fine-grained object recognition in high-resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2022, 184, 116–130. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Block | mAP0.5 (%) |
|---|---|---|
| RoI Transformer | ResNet_block (original) | 80.53 |
| ResNext_block | 80.72 | |
| ResNext_FC_block (our) | 81.19 |
| Algorithm | Loss Set | mAP0.5 (%) |
|---|---|---|
| RoI Transformer | CrossEntropy Loss+SmoothL1 Loss (original) | 80.53 |
| Focal Loss+SmoothL1 Loss | 80.62 | |
| Focal Loss+KFIoU Loss | 80.77 | |
| CrossEntropy Loss+KFIoU Loss | 81.03 |
| Algorithm | Size | mAP0.5 (%) | APmax (%) | APmin (%) | Recallmax (%) | Recallmin (%) |
|---|---|---|---|---|---|---|
| RoI Transformer | 1024 × 1024 | 80.53 | 90.9 | 62.3 | 99.6 | 72.2 |
| SASM | 1024 × 1024 | 70.81 | 90.7 | 42.6 | 96.8 | 71.3 |
| ReDet | 1024 × 1024 | 78.75 | 90.9 | 61.3 | 97.7 | 75.5 |
| R3Det | 1024 × 1024 | 75.37 | 90.9 | 56.0 | 96.4 | 74.2 |
| Faster Rcnn | 1024 × 1024 | 78.60 | 90.8 | 59.1 | 97.7 | 69.6 |
| Rotated RetinaNet | 1024 × 1024 | 77.57 | 90.8 | 52.6 | 99.2 | 73.6 |
| Rotate RepPoints | 1024 × 1024 | 66.18 | 90.0 | 34.4 | 96.5 | 68.9 |
| KFIoU | 1024 × 1024 | 79.88 | 90.9 | 62.6 | 99.2 | 78.3 |
| GWD | 1024 × 1024 | 79.41 | 90.9 | 62.0 | 98.9 | 83.5 |
| S2ANet | 1024 × 1024 | 79.58 | 90.9 | 62.6 | 99.2 | 78.0 |
| RoI Transformer-DSF | 1024 × 1024 | 83.53 | 90.7 | 69.1 | 99.6 | 77.7 |
| Class | Gts | Dets | Recall (%) | AP (%) |
|---|---|---|---|---|
| plane | 4449 | 6840 | 96.4 | 90.7 |
| ship | 18,537 | 24,711 | 95.9 | 89.9 |
| storage tank | 4740 | 6986 | 77.7 | 72.1 |
| baseball diamond | 358 | 1666 | 91.9 | 84.6 |
| tennis course | 1512 | 2668 | 98.4 | 90.7 |
| basketball course | 266 | 1383 | 99.6 | 87.9 |
| ground track field | 212 | 1194 | 97.2 | 86.1 |
| harbor | 4167 | 8415 | 92.6 | 86.8 |
| bridge | 785 | 3983 | 85.3 | 71.8 |
| large vehicle | 8819 | 21,201 | 98.3 | 88.3 |
| small vehicle | 10,579 | 25,238 | 92.3 | 83.3 |
| helicopter | 122 | 1682 | 99.2 | 88.5 |
| roundabout | 275 | 1911 | 86.9 | 79.0 |
| soccer ball field | 251 | 1860 | 95.6 | 84.1 |
| swimming pool | 732 | 2625 | 86.2 | 69.1 |
| Algorithm | SASM | ReDet | R3Det | Faster Rcnn | Rotated RetinaNet | Rotated RepPoints | KFIoU | GWD | S2ANet | RoI Transformer | RoI Transformer-DSF |
|---|---|---|---|---|---|---|---|---|---|---|---|
| plane | 90.10 | 90.50 | 90.30 | 90.20 | 90.50 | 90.00 | 90.60 | 90.60 | 90.60 | 90.50 | 90.70 |
| ship | 81.00 | 89.40 | 88.30 | 88.70 | 88.00 | 78.40 | 89.40 | 89.40 | 89.10 | 89.80 | 89.90 |
| storage tank | 73.20 | 71.50 | 69.60 | 63.20 | 69.00 | 71.90 | 78.60 | 79.10 | 78.70 | 71.10 | 72.10 |
| baseball diamond | 77.70 | 87.60 | 82.30 | 86.60 | 88.10 | 76.90 | 85.40 | 85.20 | 86.20 | 86.90 | 84.60 |
| tennis course | 90.70 | 90.90 | 90.90 | 90.80 | 90.80 | 90.90 | 90.90 | 90.90 | 90.90 | 90.90 | 90.70 |
| basketball course | 79.10 | 88.50 | 83.50 | 88.30 | 84.60 | 74.30 | 89.70 | 88.50 | 89.40 | 89.20 | 87.90 |
| ground track field | 75.60 | 80.30 | 84.10 | 85.10 | 80.60 | 74.30 | 80.30 | 80.10 | 75.70 | 83.60 | 86.10 |
| harbor | 74.60 | 79.20 | 75.70 | 78.20 | 72.80 | 54.80 | 78.10 | 77.90 | 77.70 | 79.30 | 86.80 |
| bridge | 53.40 | 61.30 | 57.40 | 59.10 | 52.60 | 45.50 | 62.60 | 62.00 | 62.60 | 62.30 | 71.80 |
| large vehicle | 81.00 | 86.40 | 79.70 | 83.10 | 82.80 | 59.10 | 86.80 | 87.00 | 86.40 | 86.20 | 88.30 |
| small vehicle | 58.50 | 69.70 | 71.30 | 72.30 | 71.30 | 61.90 | 71.80 | 72.40 | 72.10 | 73.20 | 83.30 |
| helicopter | 42.60 | 76.40 | 56.00 | 78.00 | 78.30 | 34.40 | 71.80 | 69.70 | 73.30 | 79.00 | 88.50 |
| roundabout | 71.30 | 73.50 | 75.90 | 76.30 | 81.20 | 70.70 | 83.00 | 81.10 | 84.00 | 78.30 | 79.00 |
| soccer ball field | 53.00 | 74.30 | 60.20 | 70.90 | 65.50 | 50.50 | 72.00 | 71.00 | 72.40 | 79.60 | 84.10 |
| swimming pool | 60.20 | 61.90 | 65.30 | 68.10 | 67.50 | 59.80 | 67.10 | 66.30 | 64.80 | 68.10 | 69.10 |
| mAP (%) | 70.81 | 78.75 | 75.37 | 78.60 | 77.57 | 66.18 | 79.88 | 79.41 | 79.58 | 80.53 | 83.53 |
| Algorithm | Size | mAP0.5 (%) | APmax (%) | APmin (%) | Recallmax (%) | Recallmin (%) |
|---|---|---|---|---|---|---|
| RoI Transformer | 1024 × 1024 | 42.27 * | 75.6 | 1.0 | 94.4 | 14.3 |
| SASM | 1024 × 1024 | 33.33 * | 63.8 | 0.4 | 98.5 | 67.9 |
| ReDet | 1024 × 1024 | 41.99 * | 70.6 | 5.3 | 94.9 | 17.9 |
| R3Det | 1024 × 1024 | 41.82 * | 83.9 | 0.3 | 98.9 | 64.3 |
| Faster Rcnn | 1024 × 1024 | 41.76 * | 83.6 | 2.8 | 96.7 | 13.2 |
| Rotated RetinaNet | 1024 × 1024 | 38.31 * | 77.6 | 0.2 | 98.8 | 67.9 |
| GWD | 1024 × 1024 | 42.28 * | 81.6 | 0.2 | 98.3 | 67.9 |
| S2ANet | 1024 × 1024 | 42.95 * | 86.3 | 0.3 | 97.8 | 67.9 |
| RoI Transformer-DSF | 1024 × 1024 | 44.14 | 81.1 | 0.2 | 98.2 | 64.3 |
| Class | Gts | Dets | Recall (%) | AP (%) |
|---|---|---|---|---|
| Boeing737 | 2370 | 11,627 | 96.8 | 38.3 |
| Boeing747 | 1100 | 4003 | 97.6 | 81.1 |
| Boeing777 | 375 | 4865 | 97.6 | 20.7 |
| Boeing787 | 869 | 5998 | 96.9 | 51.5 |
| ARJ21 | 174 | 9883 | 95.4 | 12.0 |
| C919 | 28 | 8151 | 64.3 | 0.2 |
| A220 | 2687 | 12,525 | 98.2 | 45.5 |
| A321 | 1378 | 9329 | 96.4 | 58.1 |
| A330 | 696 | 5556 | 95.5 | 49.7 |
| A350 | 442 | 4096 | 92.1 | 56.8 |
| Other-airplane | 5192 | 18,033 | 95.4 | 71.7 |
| Algorithm | SASM | ReDet | R3Det | Faster Rcnn | Rotated RetinaNet | GWD | S2ANet | RoI Transformer | RoI Transformer-DSF |
|---|---|---|---|---|---|---|---|---|---|
| Boeing737 | 38.10 | 38.00 | 37.40 | 35.20 | 34.70 | 38.80 | 38.60 | 40.50 | 38.30 |
| Boeing747 | 57.70 | 77.90 | 84.20 | 83.60 | 77.50 | 81.60 | 86.30 | 75.60 | 81.10 |
| Boeing777 | 13.30 | 15.30 | 16.40 | 15.80 | 14.90 | 18.70 | 14.10 | 20.70 | 20.70 |
| Boeing787 | 39.30 | 45.60 | 47.40 | 43.40 | 43.60 | 46.90 | 46.30 | 53.60 | 51.50 |
| ARJ21 | 7.70 | 10.50 | 6.0 | 7.0 | 3.5 | 4.1 | 11.00 | 12.30 | 12.00 |
| C919 | 0.40 | 5.30 | 0.30 | 2.80 | 0.20 | 0.20 | 0.30 | 1.0 | 0.20 |
| A220 | 35.90 | 41.00 | 43.10 | 41.00 | 42.90 | 45.00 | 44.60 | 41.90 | 45.50 |
| A321 | 46.60 | 55.40 | 57.60 | 56.00 | 56.80 | 56.80 | 60.80 | 47.70 | 58.10 |
| A330 | 40.30 | 52.50 | 41.90 | 48.30 | 30.90 | 39.20 | 39.30 | 46.40 | 49.70 |
| A350 | 23.50 | 49.90 | 50.30 | 54.00 | 48.00 | 61.40 | 58.30 | 55.30 | 56.80 |
| Other-airplane | 63.80 | 70.60 | 75.40 | 72.10 | 68.40 | 72.20 | 72.80 | 70.00 | 71.70 |
| mAP (%) | 33.33 | 41.99 | 41.82 | 41.76 | 38.31 | 42.28 | 42.95 | 42.27 | 44.14 |
| Algorithm | ResNext_FC | DSM | SFM | KFIoU | mAP0.5 (%) |
| RoI Transformer | 80.53 | ||||
| RoI Transformer+ResNext_FC | √ | 81.19 | |||
| RoI Transformer+DSM | √ | 81.47 | |||
| RoI Transformer+SFM | √ | 80.65 | |||
| RoI Transformer+KFIoU | √ | 81.03 | |||
| RoI Transformer+ResNext_FC+DSM | √ | √ | 82.35 | ||
| RoI Transformer+DSM+SFM | √ | √ | 81.69 | ||
| RoI Transformer+SFM+KFIoU | √ | √ | 81.33 | ||
| RoI Transformer+ResNext_FC+DSM+SFM | √ | √ | √ | 83.16 | |
| RoI Transformer+DSM+SFM+KFIoU | √ | √ | √ | 82.86 | |
| RoI Transformer-DSF(ours) | √ | √ | √ | √ | 83.53 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guan, Q.; Liu, Y.; Chen, L.; Li, G.; Li, Y. A Deformable Split Fusion Method for Object Detection in High-Resolution Optical Remote Sensing Image. Remote Sens. 2024, 16, 4487. https://doi.org/10.3390/rs16234487
Guan Q, Liu Y, Chen L, Li G, Li Y. A Deformable Split Fusion Method for Object Detection in High-Resolution Optical Remote Sensing Image. Remote Sensing. 2024; 16(23):4487. https://doi.org/10.3390/rs16234487
Chicago/Turabian StyleGuan, Qinghe, Ying Liu, Lei Chen, Guandian Li, and Yang Li. 2024. "A Deformable Split Fusion Method for Object Detection in High-Resolution Optical Remote Sensing Image" Remote Sensing 16, no. 23: 4487. https://doi.org/10.3390/rs16234487
APA StyleGuan, Q., Liu, Y., Chen, L., Li, G., & Li, Y. (2024). A Deformable Split Fusion Method for Object Detection in High-Resolution Optical Remote Sensing Image. Remote Sensing, 16(23), 4487. https://doi.org/10.3390/rs16234487