1. Introduction
Implicit Neural Representations (INRs) are a novel area of research that can continuously represent a signal, in contrast to traditional discrete representations, such as images represented by grid-sampled discrete pixels [
1]. The core concept of INRs is to employ Multi-Layer Perceptron (MLP) networks to learn the implicit parameterization of continuous functions [
2]. For example, given a 2D image, the network learns a continuous function that relates pixel coordinates to pixel values, using the pixel coordinates
as input to train the network to output the corresponding values (
for RGB and
for grayscale) [
3]. Based on the capability of INRs to express continuous functions, their recent success in various applications, such as surface representation, volume rendering, and image compression, highlights INRs’ versatility and effectiveness in modern computational tasks [
4]. To enhance the model’s ability to learn and represent signals, prior works have utilized different activation functions and initialization methods for the INR model [
5], demonstrating that suitable initialization techniques can significantly improve the model’s capacity to capture high-frequency information.
Synthetic Aperture Radar (SAR) is a system that achieves high-resolution ground imaging through radar technology [
6,
7]. Its working principle involves emitting pulse electromagnetic waves and receiving the signals reflected from the surface of the target to obtain reflection information [
8,
9]. Compared to traditional optical imaging technologies, SAR can function effectively even under extreme weather conditions, such as fog or rain [
10], demonstrating greater stability and resistance to interference [
11]. This makes it widely applicable in areas such as remote sensing, military reconnaissance, and geological exploration [
12]. However, for high-precision imaging tasks, SAR often requires the fusion of data from multiple perspectives or different radar frequencies, which poses challenges for traditional deep-learning methods, particularly in terms of generalization ability and the accurate capture of high-frequency features [
13]. Due to the unique noise characteristics and imaging mechanism of SAR images, many studies have attempted to use neural networks with various techniques for tasks such as object detection [
14] and image denoising [
15,
16] on SAR images, achieving significant progress in these areas.
An image signal, such as an SAR image, is essentially a discrete signal made up of a finite set of coordinates and their corresponding pixel values, which represents the conventional method of expressing images. In contrast to this conventional representation, INR offers a new continuous representation with the following advantages. Firstly, compared to traditional methods, INR decouples the image signal from the number of discrete pixels, allowing for sampling at arbitrary spatial resolutions and providing what can be described as different resolutions. Secondly, as INR is based on neural networks for signal representation, the memory requirements are independent of spatial resolution and are closely related to the neural network itself. Extensive research has examined continuous representations of various image types, including natural images [
17], hyperspectral images [
18], and CT images [
19]. However, despite the widespread use of SAR images across various tasks, their continuous representations have not yet been explored through INR. This work pioneers the use of INRs for SAR images to address this gap.
In our preliminary investigation, we find that directly applying existing INR methods to represent SAR images poses challenges in capturing fine details. Based on previous research [
17,
20,
21], proper model weight initialization is essential in learning INR and plays a decisive role in the model’s capability to capture signal details. Inspired by the effectiveness of weight initialization in improving model performance, we explore the possibility of activating the model weights before target training. However, the challenge with activating model weights is that the information from the target image cannot be utilized at this stage. Consequently, we propose a self-activation method that utilizes the loss function on the model output to activate the model weights by exploiting the cross-pixel relationships within the model output.
The loss function used in our self-activation method comprises two opposing components: anti-smoothness sub-loss and smoothness sub-loss, both of which adjust the cross-pixel relationships of the model’s original output through image gradients before learning the target image. Specifically, the smoothness loss reduces the output image gradient, decreasing the differences between neighboring pixels and smoothing the output. In contrast, the anti-smoothness loss increases the output image gradient, enhancing the differences between neighboring pixels, which makes the output coarse. By alternately adjusting the model’s output with two opposing loss functions, the goal of activating the INR model is achieved. We demonstrate that the shift-invariance of the INR model’s Neural Tangent Kernel (NTK) can be enhanced through our model’s self-activation method, significantly improving its ability to capture high-frequency components and its overall representational capacity. Extensive experimental results demonstrate that self-activating the INR model with the two proposed opposing loss functions can significantly enhance its performance in representing SAR images.
Overall, our contributions are summarized as follows:
We investigate learning INR for SAR images and find that activating model weights before training can facilitate the model capture of fine details.
We propose a self-activation method to initialize the INR model weights, which does not require any information from the target image as input.
We conduct extensive experiments on SAR images, demonstrating that our proposed self-activation method improves model performance by a non-trivial margin.
3. Background and Method
Formulation of INR. Implicit Neural Representations (INRs) have garnered significant attention for their ability to continuously represent signals and have been applied to computer vision tasks such as image generation [
43], novel view synthesis [
44], and 3D reconstruction [
45], exhibiting remarkable visual performance. Specifically, INR provides a novel approach to parameterizing signals, using continuous functions to map signal domains to attribute values at each coordinate, in contrast to traditional, typically discrete signal representations. By inputting continuous spatial coordinates such as image coordinates, or 3D space coordinates, Implicit Neural Representations (INRs) predict the corresponding output signal values, which can include pixel values or signal amplitudes. We utilize a Multi-Layer Perceptron (MLP) [
46] as an INR function model,
, to perform the mapping:
This mapping enables the transformation of input dimensions,
, which represent the spatial coordinates, into output dimensions,
, which represent the predicted pixel values or signal amplitudes. In this context,
denotes the learnable parameters of the network MLP. By optimizing
, the MLP gradually approximates the target function,
, by multi-layer, which can be formulated as follows,
where
is the output of the hidden layer in the
n-th layer of the MLP,
is the nonlinear activation function, and
and
are the MLP parameters with the
nth layer. The output of each layer,
, is the result of a linear transformation on the previous layer’s output,
, followed by the addition of weights,
, and biases,
, and finally passed through the nonlinear activation function,
. This layer-by-layer linear transformation and nonlinear activation enable the network to learn more complex mapping relationships.
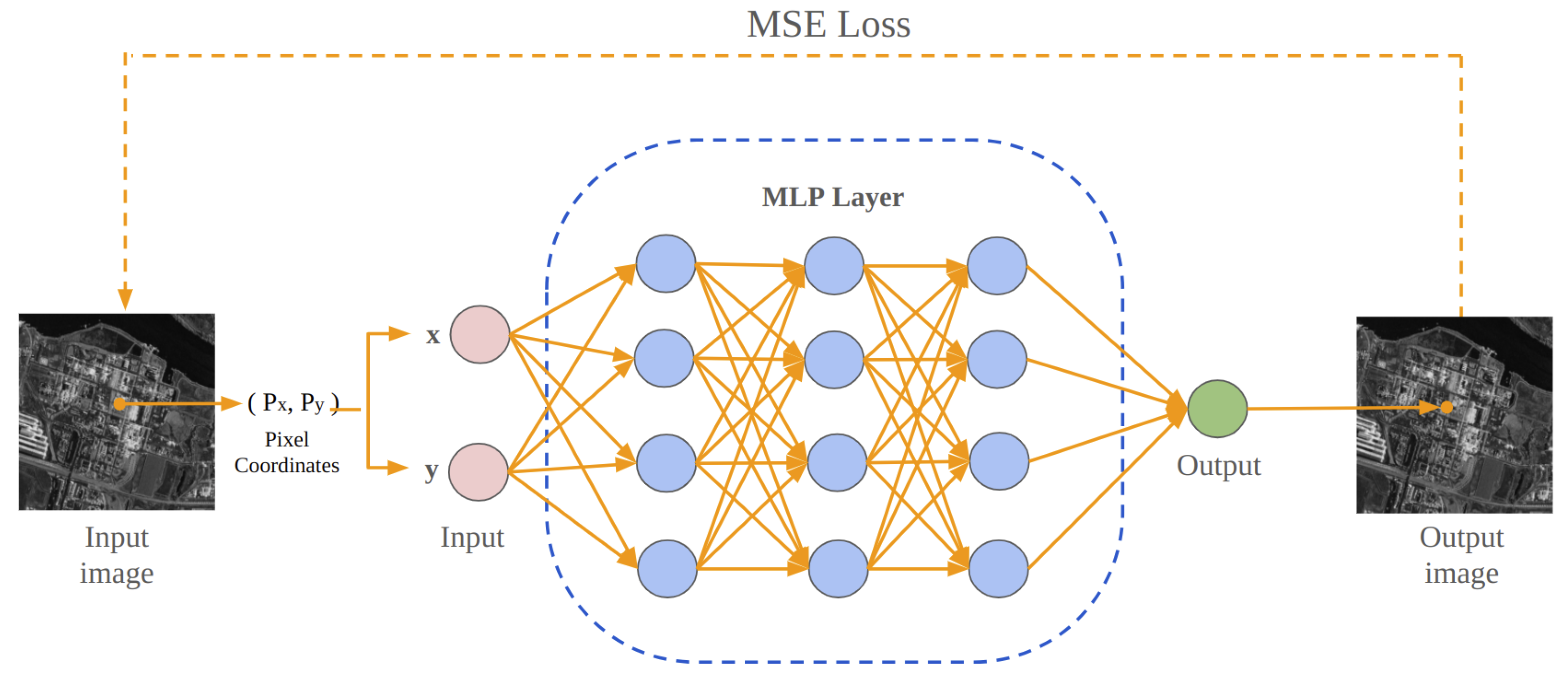
For representing an image,
I, the neural network learns a continuous function,
, which takes pixel coordinates
as input and generates corresponding output RGB values,
. This mapping can be expressed as
By continuously optimizing the parameters
and
, the neural network model
gradually approximates the target image of I. As shown in
Figure 1, to fit and reconstruct the image signal, MLP models are typically trained using Mean Squared Error (MSE) loss, which quantifies the average squared differences between predicted and true values:
where
W and
H represent the target image’s width and height, and
O denotes the model’s output image.
Seminal INR methods. Sinusoidal Representation Network (SIREN) [
20] is a seminal INR model that proposes periodic activation functions with a principled initialization scheme and demonstrates that SIREN is suitable for signal representation. In SIREN, modeling
as an
M-layer MLP, let
and
represent the input and output of the
i-th MLP layer, respectively. SIREN aims to optimize a neural network,
, to represent these relationships as accurately as possible, which can be formulated as follows:
where
refers to the network parameters to be optimized,
N is the number of MLP layers, and
is an experienced parameter for controlling the frequency. SIREN employs the non-monotonic periodic sin function, which requires careful initialization to ensure that input values fall within
. Otherwise, it may face convergence issues and fail to achieve high accuracy. The weights,
, are often initialized from
, where
d is the number of inputs per neuron.
The Wavelet Implicit Neural Representations (WIRE) model shows that, in addition to the sine function, the Gabor wavelet can achieve optimal time-frequency compactness. WIRE employs the continuous complex Gabor wavelet as its activation function, which can be expressed as follows,
where
and
s controls the frequency and width. WIRE also requires weight initialization like SIREN, and both SIREN-like weight initialization from
and normal initialization from
can yield competitive results when fitting signals. Moreover, both Gauss [
47] and FINER [
17] apply initialization methods tailored to their respective INR models, further demonstrating the importance of initialization for continuous signal representation.
3.1. Our Proposed Method
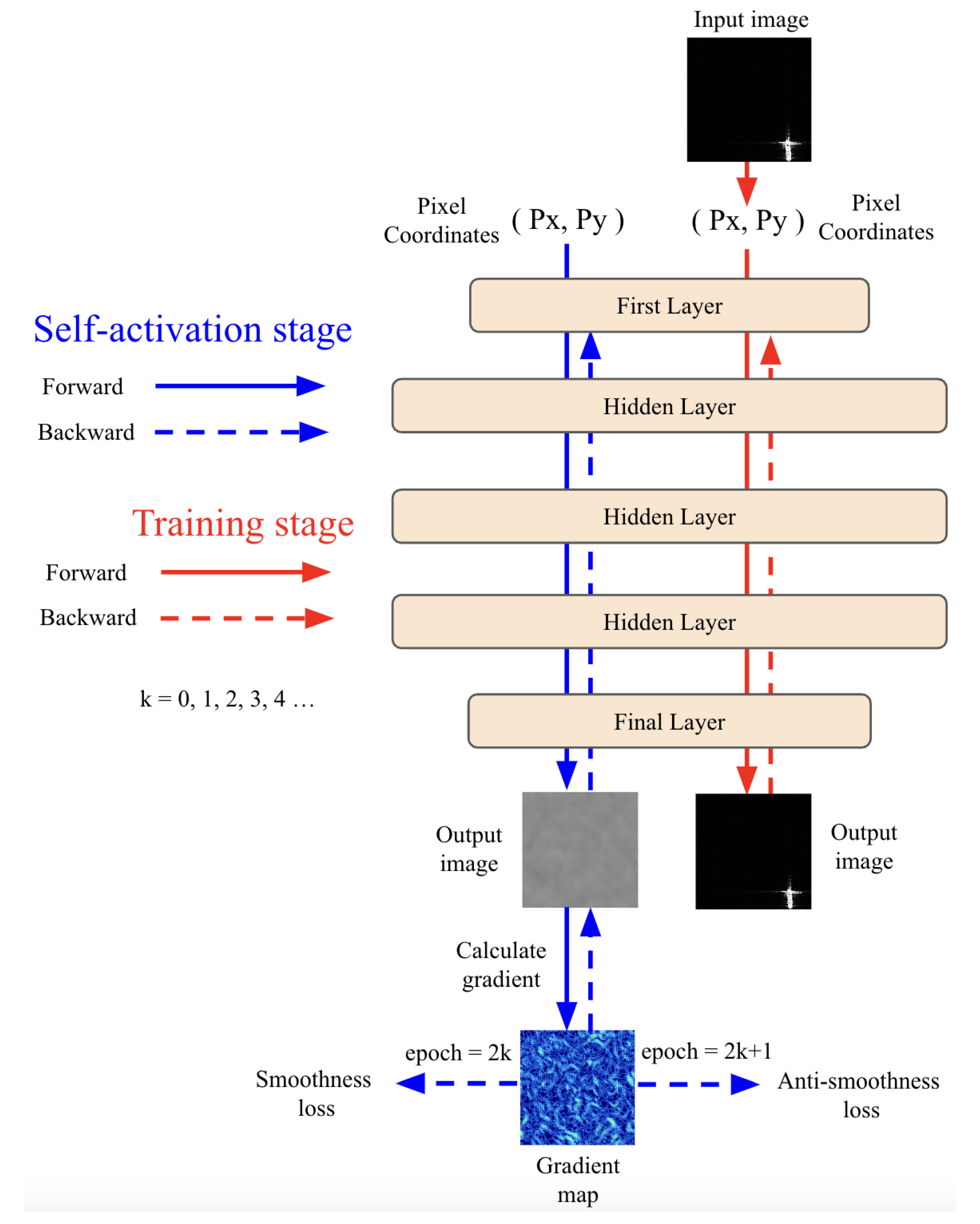
Our proposed method with the self-activation stage is illustrated in
Figure 2. Instead of directly learning the Implicit Neural Representations (INRs) for the target SAR image, we first initialize the INR model using a self-activation method that does not rely on any information from the target image during training. In the self-activation stage, we alternately apply two opposing functions to the model’s output. Upon completing the self-activation stage, we use the activated model to learn the representation of the SAR image.
Self-Activated INR
In INR models for signal learning tasks, previous works highlight the importance of proper model weight initialization for effectively fitting and capturing the fine details of images. Inspired by the effectiveness of network initialization in improving INR model performance, we explore the possibility of activating the model weights before target training. Since the model is activated prior to learning the target signal, it is not possible to make a model learn any information from the target image during this stage. Consequently, we propose a self-activation method that utilizes the loss function on the model output to activate the model weights by leveraging the cross-pixel relationships within the output.
In the self-activation method, the two opposing loss functions are calculated based on the gradient maps of the model’s output image. The gradient map of an image reflects the variation in pixel values and serves as an effective representation of cross-pixel relationships. In the gradient map,
, pixels in coarse regions with significant differences from neighboring pixels exhibit larger gradient values, while pixels in smooth areas, where values are similar to neighboring pixels, show smaller gradient values. We employ the Sobel operator to approximate the image gradient, which is a convolution-based discrete method utilizing two Sobel kernels,
and
, formulated as follows:
Using the Sobel operator, we calculate the gradient maps of the model’s output image, which does not incorporate any knowledge from the target but instead relies on the model’s vanilla initialization. As shown in
Figure 3, we observe that the model’s output is not a flattened image but rather a nearly gray image with complex textures, presenting distinct cross-pixel relationships.
Based on the gradient maps of the model’s output image, we alternately apply two opposing loss functions during the self-activation stage: a smoothness loss to increase the image gradient and an anti-smoothness loss to reduce it, thereby exploiting cross-pixel relationships to activate the INR model. The anti-smoothness and smoothness loss function alternate across different training epochs,
e: the anti-smoothness loss function is applied during even-numbered epochs, while the smoothness loss function is applied during odd-numbered epochs. To calculate the smoothness loss, we acquire the gradient map of the model’s original output, compute the average gradient across the entire image, and take this value as the loss, which can be formulated as follows:
Consequently, the smoothness loss function reduces the difference in pixel values with their neighbors in the output image, which restores cross-pixel relationships. The anti-smoothness loss function also computes the average gradient across the entire image, but unlike the first loss function we take the negative of this value and use it as the loss, which can be formulated as follows:
The anti-smoothness loss function increases the difference between a pixel’s value and its neighbors in the output image, thereby disturbing the relationships between pixels. Therefore, our final opposite loss function, which alternately applies smoothness and anti-smoothness loss, can be formulated as follows:
where
is a scaling coefficient with a default value set to 0.2. Based on our INR model in the self-activation stage, we learn the network parameters,
, of the target image function,
, which can be formulated as follows:
Here, p represents the number of epochs of the self-activation stage, which utilizes the training frequency of . We self-activate the INR model using the opposite loss function for p epochs and then utilize this self-activated model to learn the continuous representation of SAR images.
3.2. Analysis by Neural Tangent Kernel
Our work applies such pre-activation to Image INR and introduces a novel self-activation method by mitigating access to the target image during the pre-training stage. After pre-training, the model weights enter into a mode that is more appropriate for capturing high-frequency details, which are essential for guaranteeing high performance in image INRs. To illustrate this, we use the Neural Tangent Kernel (NTK) [
48] to analyze the network’s weights. Specifically, the network’s capability to learn signals is closely tied to the NTK’s diagonal characteristics, where strong diagonal dominance promotes shift invariance and accelerates the capture of fine-detail components. Let
denote the computational graph of a given neural network, where
x represents the input and
represents the network parameters. The neural tangent kernel is defined as
where
is the element in the
i-th row and
j-th column of the empirical NTK matrix, corresponding to the
i-th sample
and the
j-th sample
. According to references [
49], NTKs with stronger diagonal characteristics exhibit better translation invariance. This implies that the coordinates in the training set are nearly decoupled from one another during the training process, facilitating more effective signal learning.
We define a signal with a one-dimensional coordinate of size 1024 as our learning target and visualize the corresponding NTKs both with and without the self-activation stage of the INR model, as illustrated in
Figure 4. Our analysis reveals that the diagonal property of the NTK is significantly enhanced with the self-activated INR model. This indicates that incorporating the self-activation stage in the INR model provides better shift invariance compared to directly learning the target signal, along with an enhanced ability to capture high-frequency components.
5. Discussion
The Equivalent Number of Looks (ENL) is a widely used metric in SAR imaging to assess model output quality [
59,
60,
61]. For image representation, a model output’s ENL closer to the ground-truth ENL indicates better representation, especially in areas with fine details. We compare the ENL of the target image on the SIREN model, both with and without the self-activation method, as shown in
Table 8. With our self-activation stage, the model output achieves an ENL of 4.39, which is closer to the ground-truth value of 4.21, compared to the ENL of 4.88 obtained without the self-activation method.
The Kullback–Leibler (KL) distance is a commonly used metric in SAR imaging to evaluate the similarity between the ground truth and generated outputs [
62,
63], with lower values indicating closer alignment. As shown in
Table 9, we compare the KL distance of SIREN outputs with and without the self-activation method. With self-activation applied, we observe a decrease in the KL distance of the model’s reconstruction from 0.0189 to 0.0103 compared to the baseline SIREN.
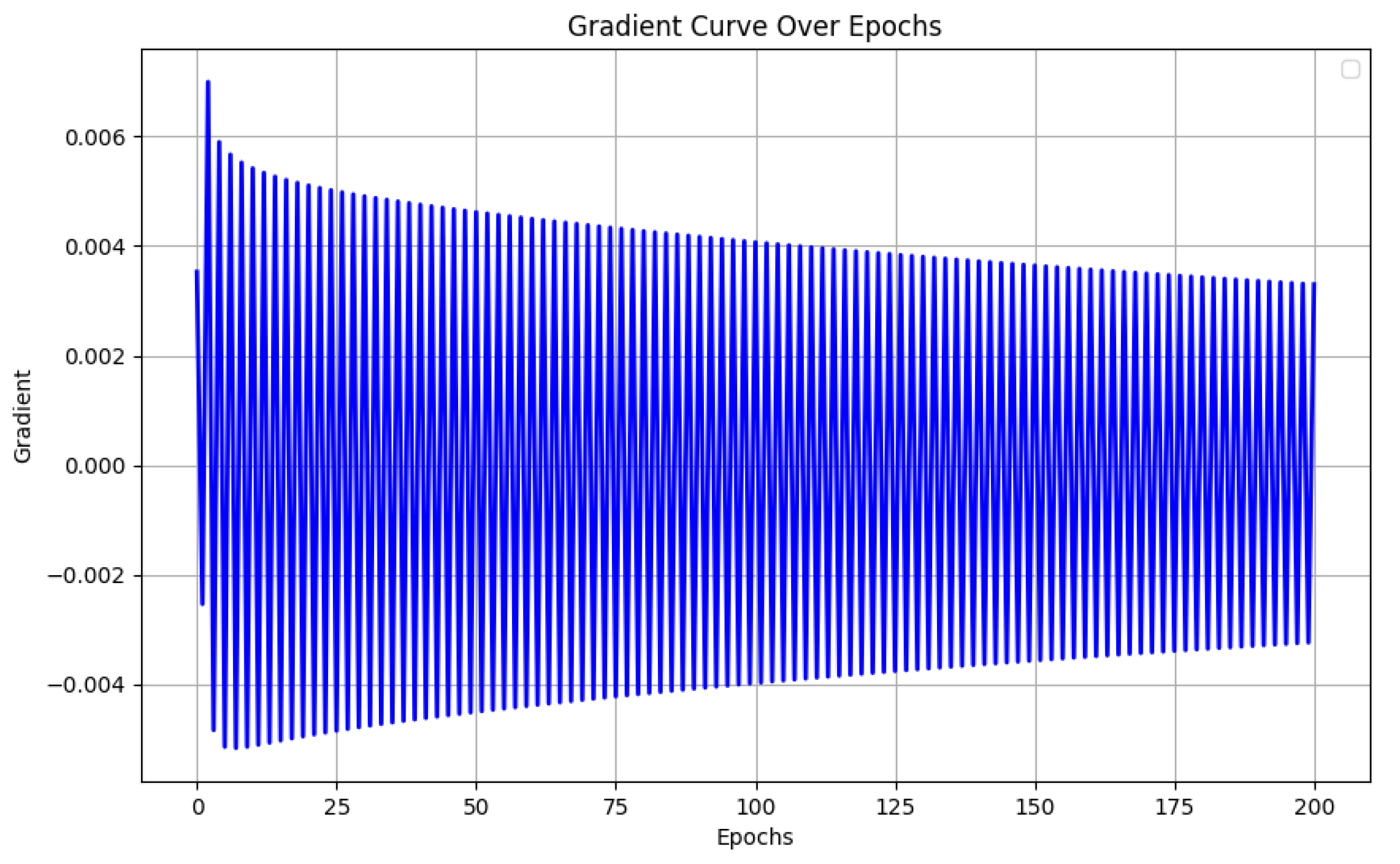
Since our two opposing loss functions alter the gradient of the model’s output image, imbalances may manifest as either exploding gradients or gradients that drop to zero. We prevent this by using opposite loss functions with equal loss weights. We find that this practice is sufficient for guaranteeing stable gradients even after 200 epochs. Empirically, we find that, after 200 epochs, the magnitude of the gradient only has a moderate drop (see
Figure 9). This moderate drop can be further mitigated by applying a slightly higher loss weight to the anti-smooth loss component. However, we note that mitigating this moderate drop by sophisticated search on the loss weight yields a very marginal performance boost. Therefore, we stick to using the strategy of equal loss weights for its simplicity and effectiveness.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}