
ESL-YOLO: Small Object Detection with Effective Feature Enhancement and Spatial-Context-Guided Fusion Network for Remote Sensing

Abstract
1. Introduction
- (1)
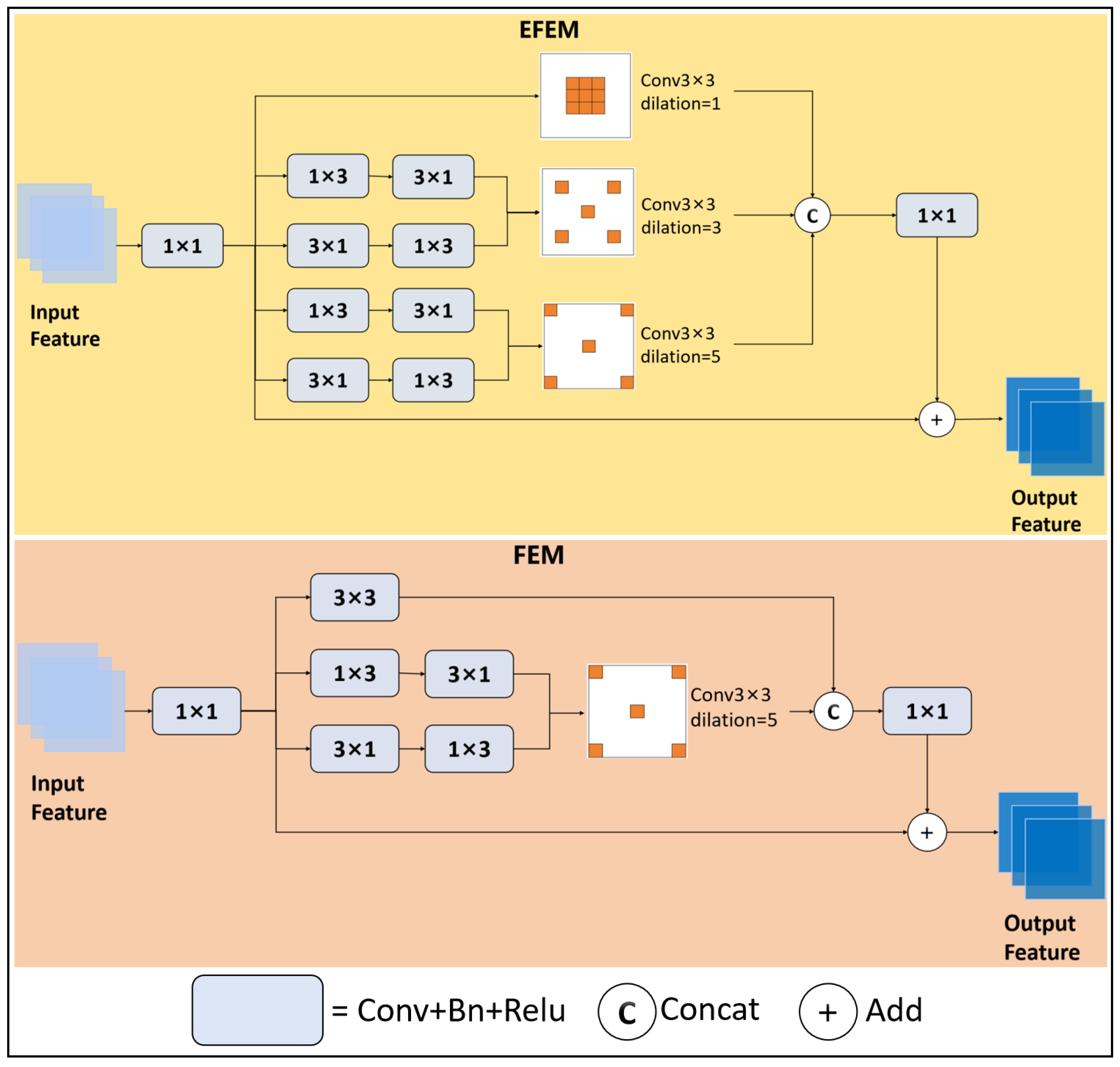
- We present EFEM, an effective feature enhancement module designed to address the issue of insufficient small object information. By integrating local features across various scales, this module enhances the perception of small objects and boosts detection accuracy.
- (2)
- We propose a novel multi-scale feature fusion architecture, SCGBiFPN, which integrates shallow features abundant in spatial context information to reduce spatial information loss for small objects. The addition of skip connections facilitates smoother feature transmission across different levels, retaining more spatial and semantic information.
- (3)
- We are the first to incorporate LAPM, a background suppression module, into the YOLO model, effectively diminishing the impact of complex backgrounds and significantly enhancing small object detection performance.
2. Related Works
2.1. Feature Enhancement Method
2.2. Feature Fusion Method
2.3. Background Suppression Method
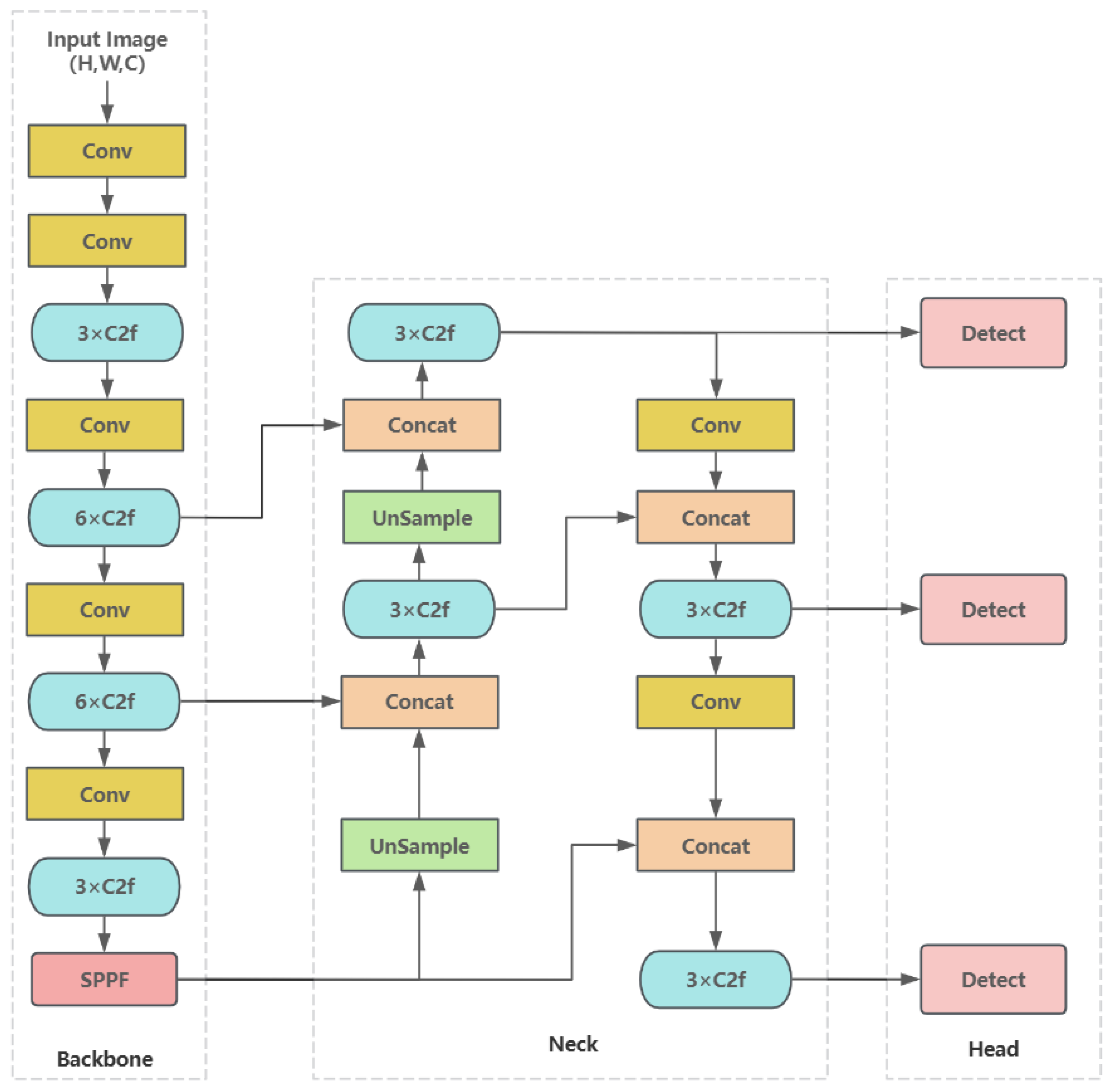
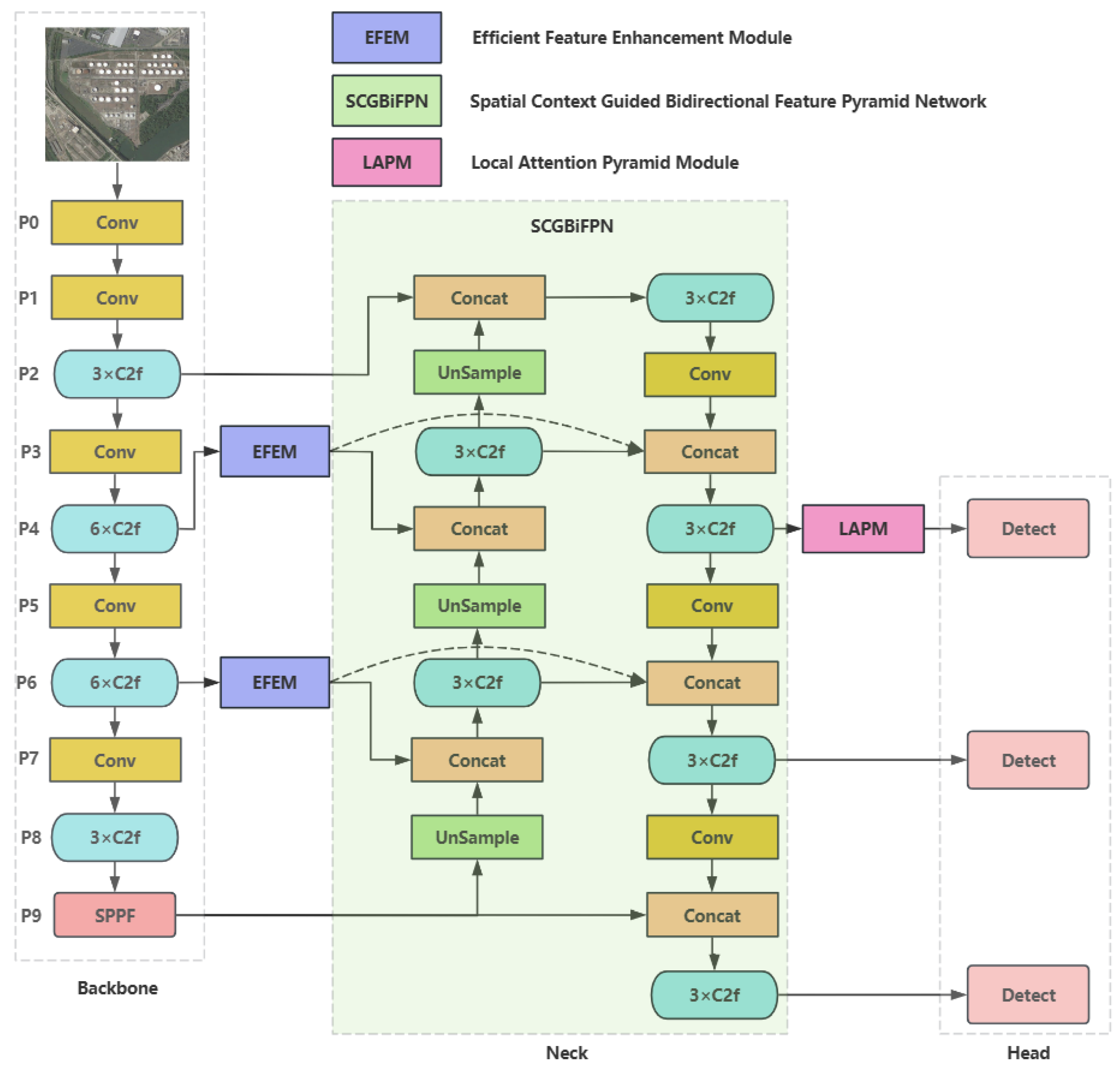
3. Materials and Methods
3.1. Effective Feature Enhancement Module
3.2. Spatial-Context-Guided Bidirectional Feature Pyramid Network
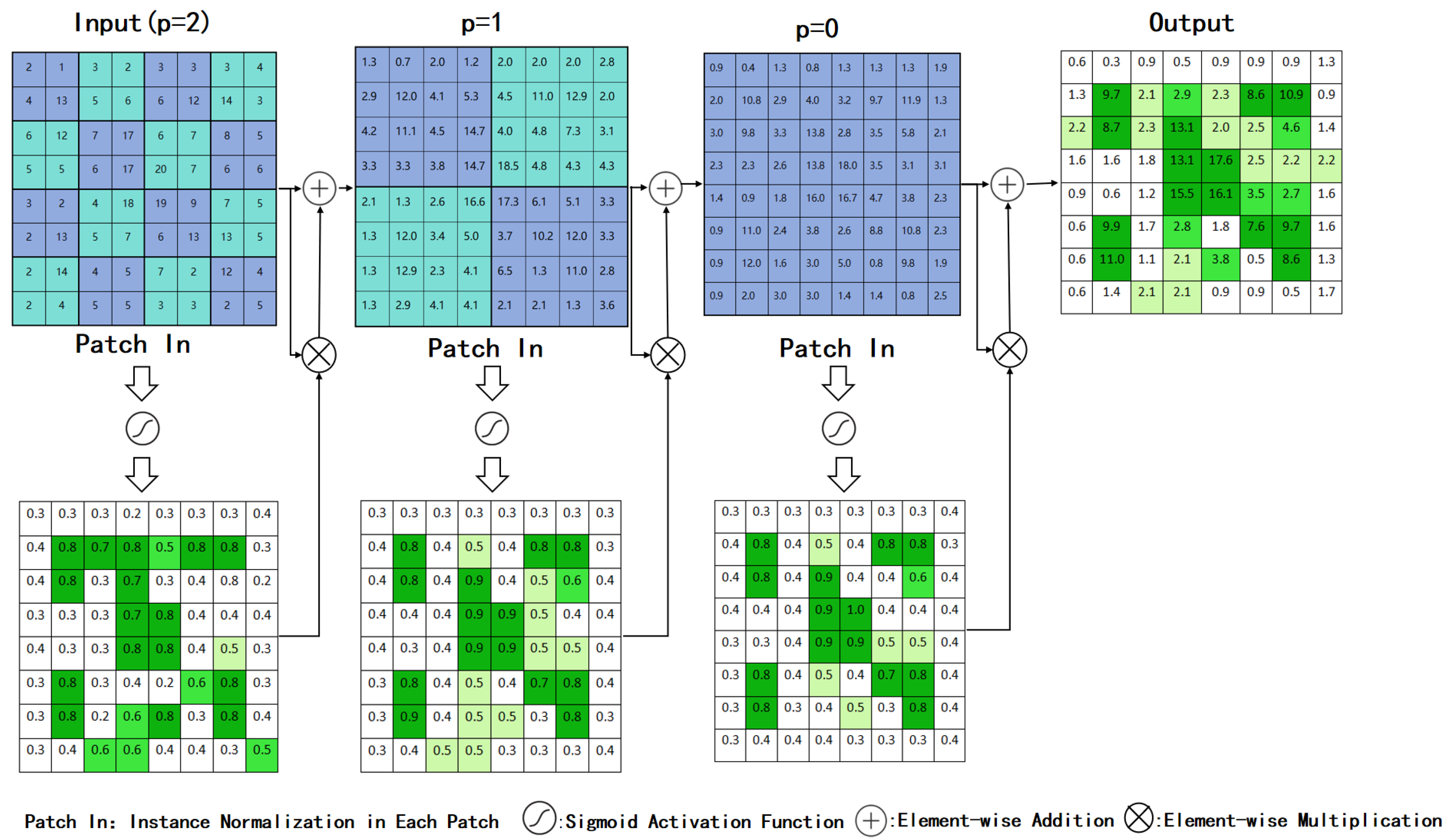
3.3. Local Attention Pyramid Module
4. Experimental Section
4.1. Experimental Details and Evaluation Metrics
4.2. Experimental Datasets Description
4.3. Ablation Experiments
4.4. Comparative Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tong, K.; Wu, Y.; Zhou, F. Recent advances in small object detection based on deep learning: A review. Image Vis. Comput. 2020, 97, 103910. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Mei, S.; Li, X.; Liu, X.; Cai, H.; Du, Q. Hyperspectral image classification using attention-based bidirectional long short-term memory network. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–12. [Google Scholar] [CrossRef]
- Cheng, G.; Yuan, X.; Yao, X.; Yan, K.; Zeng, Q.; Xie, X.; Han, J. Towards large-scale small object detection: Survey and benchmarks. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 13467–13488. [Google Scholar] [CrossRef]
- Shen, C.; Qian, J.; Wang, C.; Yan, D.; Zhong, C. Dynamic sensing and correlation loss detector for small object detection in remote sensing images. IEEE Trans. Geosci. Remote. Sens. 2024, 62, 5627212. [Google Scholar] [CrossRef]
- Han, J.; Zhang, D.; Cheng, G.; Guo, L.; Ren, J. Object detection in optical remote sensing images based on weakly supervised learning and high-level feature learning. IEEE Trans. Geosci. Remote. Sens. 2014, 53, 3325–3337. [Google Scholar] [CrossRef]
- Zhang, B.; Wu, Y.; Zhao, B.; Chanussot, J.; Hong, D.; Yao, J.; Gao, L. Progress and challenges in intelligent remote sensing satellite systems. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 1814–1822. [Google Scholar] [CrossRef]
- Han, Y.; Duan, B.; Guan, R.; Yang, G.; Zhen, Z. LUFFD-YOLO: A Lightweight Model for UAV Remote Sensing Forest Fire Detection Based on Attention Mechanism and Multi-Level Feature Fusion. Remote Sens. 2024, 16, 2177. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer International Publishing: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Shi, T.; Gong, J.; Hu, J.; Zhi, X.; Zhang, W.; Zhang, Y.; Zhang, P.; Bao, G. Feature-enhanced CenterNet for small object detection in remote sensing images. Remote Sens. 2022, 14, 5488. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. arXiv 2015, arXiv:1504.08083. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J. You Only Look Once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 726–731. [Google Scholar]
- Redmon, J. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 1–12. [Google Scholar]
- Sunkara, R.; Luo, T. No more strided convolutions or pooling: A new CNN building block for low-resolution images and small objects. In Machine Learning and Knowledge Discovery in Databases, ECML PKDD 2022, Grenoble, France, 19–23 September 2022; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2022; Volume 13715, pp. 503–518. [Google Scholar] [CrossRef]
- Cheng, G.; Lang, C.; Wu, M.; Xie, X.; Yao, X.; Han, J. Feature enhancement network for object detection in optical remote sensing images. J. Remote Sens. 2021, 2021, 9805389. [Google Scholar] [CrossRef]
- Yi, H.; Liu, B.; Zhao, B.; Liu, E. Small object detection algorithm based on improved YOLOv8 for remote sensing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 17, 1734–1747. [Google Scholar] [CrossRef]
- Zhang, K.; Shen, H. Multi-stage feature enhancement pyramid network for detecting objects in optical remote sensing images. Remote Sens. 2022, 14, 579. [Google Scholar] [CrossRef]
- Li, W.; Shi, M.; Hong, Z. SCAResNet: A ResNet variant optimized for tiny object detection in transmission and distribution towers. IEEE Geosci. Remote Sens. Lett. 2023, 20, 6011105. [Google Scholar] [CrossRef]
- Tang, S.; Zhang, S.; Fang, Y. HIC-YOLOv5: Improved YOLOv5 for small object detection. In Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024; pp. 6614–6619. [Google Scholar]
- Wang, Z.; Men, S.; Bai, Y.; Yuan, Y.; Wang, J.; Wang, K.; Zhang, L. Improved Small Object Detection Algorithm CRL-YOLOv5. Sensors 2024, 24, 6437. [Google Scholar] [CrossRef]
- Guo, M.H.; Lu, C.Z.; Hou, Q.; Liu, Z.; Cheng, M.M.; Hu, S.M. Segnext: Rethinking convolutional attention design for semantic segmentation. Adv. Neural Inf. Process. Syst. 2022, 35, 1140–1156. [Google Scholar]
- Li, Y.; Hou, Q.; Zheng, Z.; Cheng, M.M.; Yang, J.; Li, X. Large selective kernel network for remote sensing object detection. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 1117–1126. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. NAS-FPN: Learning scalable feature pyramid architecture for object detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7036–7045. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and efficient object detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10792. [Google Scholar]
- Wang, H.; Liu, C.; Cai, Y.; Chen, L.; Li, Y. YOLOv8-QSD: An improved small object detection algorithm for autonomous vehicles based on YOLOv8. IEEE Trans. Instrum. Meas. 2024, 73, 2513916. [Google Scholar] [CrossRef]
- Zhang, M.; Wang, Z.; Song, W.; Zhao, D.; Zhao, H. Efficient Small-Object Detection in Underwater Images Using the Enhanced YOLOv8 Network. Appl. Sci. 2024, 14, 1095. [Google Scholar] [CrossRef]
- Li, Y.; Zhou, Z.; Qi, G.; Hu, G.; Zhu, Z.; Huang, X. Remote Sensing Micro-Object Detection under Global and Local Attention Mechanism. Remote Sens. 2024, 16, 644. [Google Scholar] [CrossRef]
- Jiang, L.; Yuan, B.; Du, J.; Chen, B.; Xie, H.; Tian, J.; Yuan, Z. MFFSODNet: Multi-Scale Feature Fusion Small Object Detection Network for UAV Aerial Images. IEEE Trans. Instrum. Meas. 2024, 73, 5015214. [Google Scholar] [CrossRef]
- Li, X.; Wei, Y.; Li, J.; Duan, W.; Zhang, X.; Huang, Y. Improved YOLOv7 Algorithm for Small Object Detection in Unmanned Aerial Vehicle Image Scenarios. Appl. Sci. 2024, 14, 1664. [Google Scholar] [CrossRef]
- Liu, D.; Zhang, J.; Qi, Y.; Wu, Y.; Zhang, Y. Tiny object detection in remote sensing images based on object reconstruction and multiple receptive field adaptive feature enhancement. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5616213. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Zhu, P.; Chen, P.; Tang, X.; Li, C.; Jiao, L. Foreground refinement network for rotated object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Wang, C.; Bai, X.; Wang, S.; Zhou, J.; Ren, P. Multiscale visual attention networks for object detection in VHR remote sensing images. IEEE Geosci. Remote. Sens. Lett. 2018, 16, 310–314. [Google Scholar] [CrossRef]
- Ma, W.; Li, N.; Zhu, H.; Jiao, L.; Tang, X.; Guo, Y.; Hou, B. Feature split–merge–enhancement network for remote sensing object detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Fan, X.; Hu, Z.; Zhao, Y.; Chen, J.; Wei, T.; Huang, Z. A small ship object detection method for satellite remote sensing data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 11886–11898. [Google Scholar] [CrossRef]
- Dong, Y.; Yang, H.; Liu, S.; Gao, G.; Li, C. Optical remote sensing object detection based on background separation and small object compensation strategy. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024. Early Access. [Google Scholar] [CrossRef]
- Zhao, Z.; Du, J.; Li, C.; Fang, X.; Xiao, Y.; Tang, J. Dense Tiny Object Detection: A Scene Context Guided Approach and a Unified Benchmark. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5606913. [Google Scholar] [CrossRef]
- Shim, S.H.; Hyun, S.; Bae, D.; Heo, J.P. Local attention pyramid for scene image generation. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 432–441. [Google Scholar]
- Zhang, Y.; Ye, M.; Zhu, G.; Liu, Y.; Guo, P.; Yan, J. FFCA-YOLO for small object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5611215. [Google Scholar] [CrossRef]
- Wang, J.; Yang, W.; Guo, H.; Zhang, R.; Xia, G.S. Tiny object detection in aerial images. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 3271–3277. [Google Scholar]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2011–2020. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Mark Liao, H.Y. Yolov9: Learning what you want to learn using programmable gradient information. In Computer Vision—ECCV 2024, 18th European Conference, Milan, Italy, 29 September–4 October 2024; Springer: Cham, Switzerland, 2024; pp. 1–21. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Wang, J.; Xu, C.; Yang, W.; Yu, L. A normalized Gaussian Wasserstein distance for tiny object detection. arXiv 2021, arXiv:2110.13389. [Google Scholar]
- Ma, M.; Pang, H. SP-YOLOv8s: An improved YOLOv8s model for remote sensing image tiny object detection. Appl. Sci. 2023, 13, 8161. [Google Scholar] [CrossRef]
- Huo, B.; Li, C.; Zhang, J.; Xue, Y.; Lin, Z. SAFF-SSD: Self-attention combined feature fusion-based SSD for small object detection in remote sensing. Remote Sens. 2023, 15, 3027. [Google Scholar] [CrossRef]
- Bai, X.; Li, X. STODNet: Sparse Convolution for Super Tiny Object Detection from Remote Sensing Image. In Proceedings of the IGARSS 2024—2024 IEEE International Geoscience and Remote Sensing Symposium, Athens, Greece, 7–12 July 2024; pp. 7760–7764. [Google Scholar]
- Zhang, F.; Zhou, S.; Wang, Y.; Wang, X.; Hou, Y. Label Assignment Matters: A Gaussian Assignment Strategy for Tiny Object Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5633112. [Google Scholar] [CrossRef]
- Xu, C.; Ding, J.; Wang, J.; Yang, W.; Yu, H.; Yu, L.; Xia, G.S. Dynamic coarse-to-fine learning for oriented tiny object detection. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 8652–8661. [Google Scholar]
- Lee, H.; Song, M.; Koo, J.; Seo, J. Hausdorff distance matching with adaptive query denoising for rotated detection transformer. arXiv 2023, arXiv:2305.07598. [Google Scholar]
- Ren, B.; Xu, B.; Pu, Y.; Wang, J.; Deng, Z. Improving Detection in Aerial Images by Capturing Inter-Object Relationships. arXiv 2024, arXiv:2404.04140. [Google Scholar]
- Cai, X.; Lai, Q.; Wang, Y.; Wang, W.; Sun, Z.; Yao, Y. Poly kernel inception network for remote sensing detection. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 27706–27716. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| EFEM | SCGBiFPN | LAPM | P (%) | R (%) | (%) | (%) | Test Speed (ms) | Params (MB) |
|---|---|---|---|---|---|---|---|---|
| 0.51 | 0.427 | 0.418 | 0.186 | 2.4 | 11.13 | |||
| ✓ | 0.59 | 0.494 | 0.478 | 0.21 | 3.0 | 11.68 | ||
| ✓ | 0.607 | 0.522 | 0.511 | 0.23 | 2.6 | 11.41 | ||
| ✓ | 0.506 | 0.489 | 0.456 | 0.199 | 2.5 | 11.13 | ||
| ✓ | ✓ | 0.605 | 0.526 | 0.517 | 0.238 | 3.6 | 11.96 | |
| ✓ | ✓ | ✓ | 0.622 | 0.531 | 0.518 | 0.235 | 3.6 | 11.96 |
| Method | P | R | |
|---|---|---|---|
| FEM | 0.564 | 0.49 | 0.47 |
| EFEM | 0.59 | 0.494 | 0.478 |
| Method | P | R | |
|---|---|---|---|
| BiFPN | 0.547 | 0.486 | 0.479 |
| SCGBiFPN | 0.607 | 0.522 | 0.511 |
| Model | P | R | Test Speed (ms) | Params (MB) | ||
|---|---|---|---|---|---|---|
| YOLOv5s | 0.522 | 0.478 | 0.455 | 0.205 | 4.9 | 9.11 |
| YOLOv6s | 0.486 | 0.37 | 0.397 | 0.161 | 11.6 | 16.30 |
| YOLOv8s | 0.51 | 0.427 | 0.418 | 0.186 | 2.4 | 11.13 |
| YOLOv9s | 0.584 | 0.484 | 0.472 | 0.211 | 2.8 | 7.17 |
| YOLOv10s | 0.547 | 0.494 | 0.469 | 0.212 | 2.1 | 8.04 |
| YOLOv11s | 0.572 | 0.474 | 0.46 | 0.207 | 2.2 | 9.42 |
| M-CenterNet | - | - | 0.407 | 0.145 | - | - |
| DetectoRS + NWD | - | - | 0.493 | 0.208 | - | - |
| SAFF-SSD | - | - | 0.499 | 0.211 | - | - |
| SP-YOLOv8s | 0.592 | 0.467 | 0.483 | 0.227 | 27.7 | 10.24 |
| STODNet | - | - | 0.415 | - | 17.73 | 37.6 |
| TTFNet + GA (Darknet-53) | - | - | 0.503 | 0.217 | 29.15 | - |
| ESL-YOLO (ours) | 0.622 | 0.531 | 0.518 | 0.235 | 3.6 | 11.96 |
| Model | P | R | Test Speed (ms) | Params (MB) | ||
|---|---|---|---|---|---|---|
| YOLOv5s | 0.759 | 0.689 | 0.742 | 0.517 | 4.7 | 9.11 |
| YOLOv6s | 0.767 | 0.654 | 0.711 | 0.485 | 4.9 | 16.30 |
| YOLOv8s | 0.797 | 0.668 | 0.736 | 0.517 | 3.2 | 11.13 |
| YOLOv9s | 0.771 | 0.697 | 0.747 | 0.525 | 5.6 | 7.17 |
| YOLOv10s | 0.72 | 0.697 | 0.73 | 0.511 | 4.2 | 8.04 |
| YOLOv11s | 0.782 | 0.685 | 0.738 | 0.516 | 5.4 | 9.42 |
| DCFL | - | - | 0.710 | - | - | 36.1 |
| RHINO (Swin-tiny) | - | - | 0.735 | - | - | - |
| Transformer-based Model | - | - | 0.717 | - | - | - |
| PKINet-S | - | - | 0.715 | - | - | 13.7 |
| ESL-YOLO (ours) | 0.758 | 0.704 | 0.747 | 0.534 | 6.7 | 11.96 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, X.; Qiu, Y.; Zhang, G.; Lei, T.; Jiang, P. ESL-YOLO: Small Object Detection with Effective Feature Enhancement and Spatial-Context-Guided Fusion Network for Remote Sensing. Remote Sens. 2024, 16, 4374. https://doi.org/10.3390/rs16234374
Zheng X, Qiu Y, Zhang G, Lei T, Jiang P. ESL-YOLO: Small Object Detection with Effective Feature Enhancement and Spatial-Context-Guided Fusion Network for Remote Sensing. Remote Sensing. 2024; 16(23):4374. https://doi.org/10.3390/rs16234374
Chicago/Turabian StyleZheng, Xiangyue, Yijuan Qiu, Gang Zhang, Tao Lei, and Ping Jiang. 2024. "ESL-YOLO: Small Object Detection with Effective Feature Enhancement and Spatial-Context-Guided Fusion Network for Remote Sensing" Remote Sensing 16, no. 23: 4374. https://doi.org/10.3390/rs16234374
APA StyleZheng, X., Qiu, Y., Zhang, G., Lei, T., & Jiang, P. (2024). ESL-YOLO: Small Object Detection with Effective Feature Enhancement and Spatial-Context-Guided Fusion Network for Remote Sensing. Remote Sensing, 16(23), 4374. https://doi.org/10.3390/rs16234374