1. Introduction
Recently, due to ongoing improvements in remote sensing image technology, achieving high-quality semantic segmentation of these images has emerged as a fundamental and the most talked about task in remote sensing image processing. This technique is essential for applications including urban planning [
1], land cover classification [
2], and land use planning [
3].The main goal of semantic segmentation is to label each pixel of the input image with its category. However, the complex texture information and varying scales of remote sensing image categories make it difficult for traditional methods like random forests (RFs) [
4] and support vector machines (SVMs) [
5] to perform precise and efficient semantic segmentation, making this a highly challenging task.
With the successful and organic integration of convolutional neural networks (CNNs) into an increasing number of tasks [
6], their application in remote sensing semantic segmentation tasks has demonstrated excellent feature extraction and model representation capabilities. Particularly, the advent of the fully convolutional network (FCN) [
7] marked the first realization of end-to-end pixel-level segmentation. However, the roughness of the spatial recovery process in the FCN led to insufficiently detailed segmentation outcomes. To resolve this, Ronneberger et al. [
8] proposed UNet, which introduced skip connections to compensate for the loss of feature information and employed more upsampling operations to achieve finer segmentation results, thereby further enhancing segmentation accuracy. Nevertheless, UNet did not further refine the integration of low-level features from the encoder with high-level features from the decoder, resulting in the network’s inability to fully differentiate and utilize these features.
CNNs have demonstrated exceptional feature extraction and representation capabilities in image segmentation tasks, but the limited field of view of convolutional kernels also restricts their ability to process contextual information. To tackle this, Chen et al. [
9] developed atrous spatial pyramid pooling (ASPP), employing atrous convolutions at various sampling rates to parallelly capture multi-scale image context. Zhao et al. [
10] proposed the pyramid pooling module (PPM), which aggregates multi-scale features using regions of different sizes. However, the context information aggregated through pooling and atrous convolutions was relatively coarse, failing to effectively capture global context, and thus did not achieve the desired effect. With the successful application of transformers in the visual field, a new solution to this problem has emerged [
11,
12]. The visual transformer (ViT) [
13] utilizes the self-attention (SA) mechanism to enable a globally weighted representation of each position, thereby enhancing the model’s perception of global context and achieving significant results. However, its high computational cost becomes a major barrier when processing large-scale remote sensing images. Subsequently, the Swin transformer [
14] and HMANet [
15] have significantly improved the computational efficiency of self-attention on remote sensing images through strategies like windowing and pooling. Chen et al. [
16] points out that, although the enhanced ViT architecture has advantages in modeling long-term dependencies, it often overlooks local spatial features. More and more work [
17,
18,
19] is beginning to explore the organic integration of CNNs and transformers, but the focus of these efforts is on enhancing the feature extraction and modeling capabilities of segmentation models through the technical means of CNNs and transformers, without further refinement based on the characteristics of the tasks during the modeling process.
Remote sensing images usually contain rich feature information and usually cover multiple categories. Therefore, compared with general segmentation tasks that are single-target and relatively standardized in content, the remote sensing semantic segmentation model should take the characteristics of the task into more consideration, and the model and modules should be designed to fit the task more closely. Firstly, as shown in
Figure 1, remote sensing semantic segmentation often involves multiple categories, and the samples of different categories are imbalanced. These categories not only differ greatly in the overall number of pixel samples, with remote sensing images showing distinct characteristics in different areas [
20] (e.g., buildings occupy most of the area in urban regions, while rural regions have fewer buildings), but also show substantial fluctuations in the proportion of each category within local areas of images (e.g., the closer to the city center one goes, the more buildings and fewer trees there are). This imbalance in data and variability in content can lead to similarly imbalanced model performance. Secondly, although the deep features of the network contain rich semantic and category information, their low resolution limits the accuracy of feature representation, leading to blurry edges and details in the segmentation results. While the shallow features are rich in high-resolution detail information, they are relatively primitive and have a gap in expression with the high-level semantics of deep features. To achieve precise segmentation, effectively utilizing the detailed information from the shallow features of the network is particularly important. Therefore, the network’s category balance and the utilization of detailed information are aspects that should receive more attention in remote sensing semantic segmentation tasks. The following sections will explore these two aspects in detail.
On one hand, the general image segmentation networks [
7,
8] learn all the information as a whole during the segmentation process, and only comb the class information at the output of the model. Empirically, this kind of overall learning for remote sensing images with many and uneven categories easily leads to the learning ability of the model being biased towards the categories with a large proportion of samples, while the categories with fewer samples do not have enough feature space and parameters to be represented and learnt. Therefore, we believe that reducing the squeezing between categories during the learning process of the model and ensuring that each category has enough space to learn and represent is the key to dealing with remote sensing images with imbalanced categories and balancing the performance of the segmentation model. Recent studies [
15,
21,
22] have shown that there is a strong relationship between the channels of the feature map and the categories. Inspired by this, we propose category-based combing decoding. As shown in
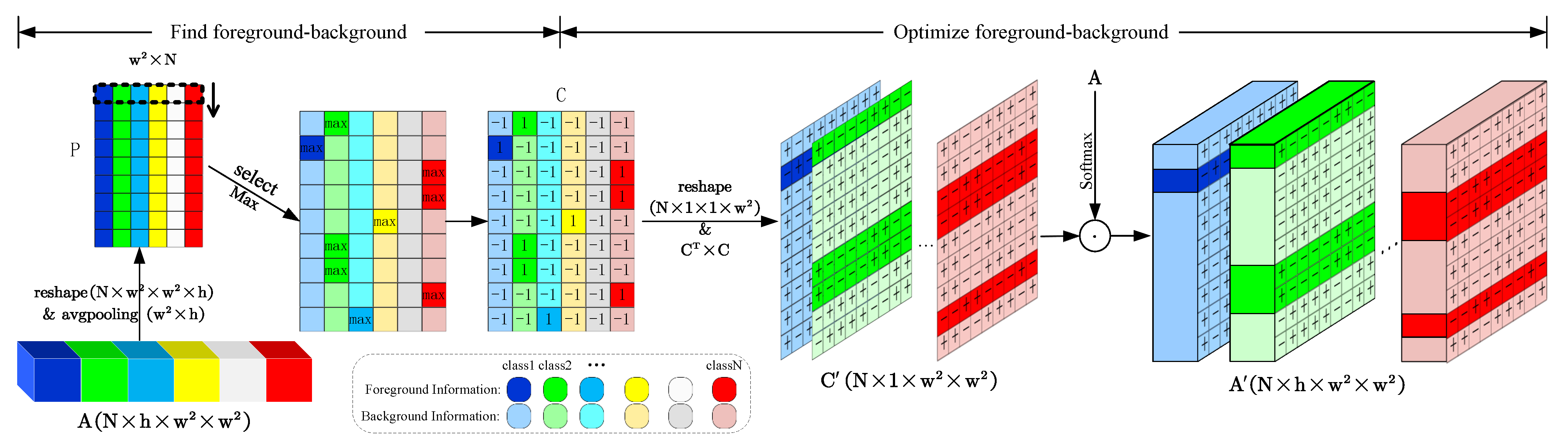
Figure 2, different from general feature processing, we group the features and deploy the modules according to categories, and each category is decoded in its own feature space, as a way to give the vulnerable categories enough space to learn and represent, and to allow features to be expressed in a clearer way. Additionally, considering that group split limits the utilization of information between groups, we propose the interactive foreground–background relationship optimization (IFBRO), which improves the representation of the foreground and background within each category through interactions between categories.
On the other hand, the feature information of remote sensing images is complex and variable, and the detail information in shallow features is indispensable for achieving accurate pixel-level segmentation. Although the low-level features contain rich detail information such as edges, colors, textures, etc., there are different feeling fields and feature expressions between them and the high-level features. Improper fusion of the two types of features can cause the information from shallow features to become noise within the deep features, interfering with the expression of high-level semantics. Some work [
18,
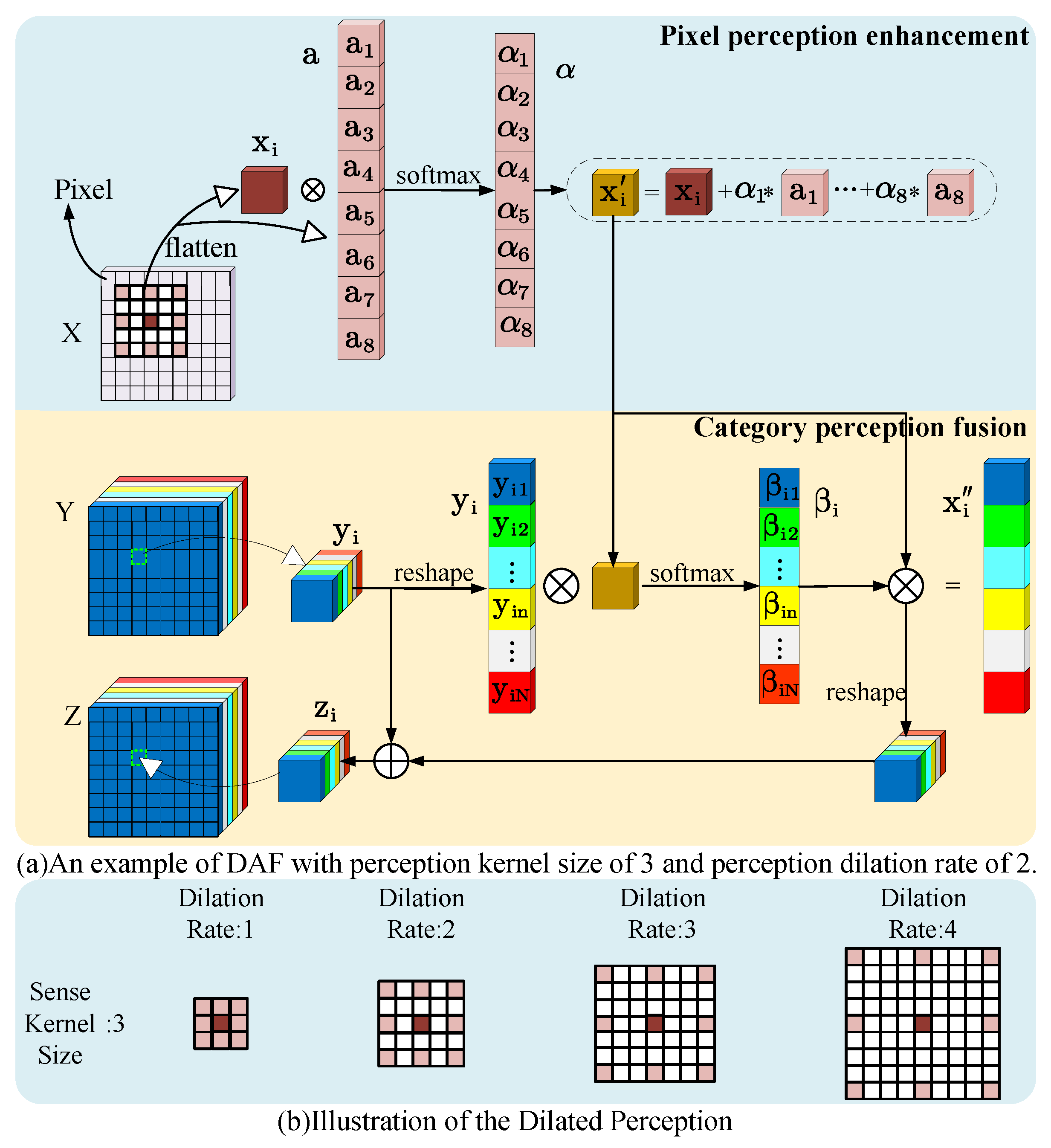
23] has demonstrated that while direct summing operations on these two features are quick, they lower segmentation accuracy. To better fuse the two different features, we propose perceptual fusion to align the fields of view of the two features and achieve pixel-level fine fusion.
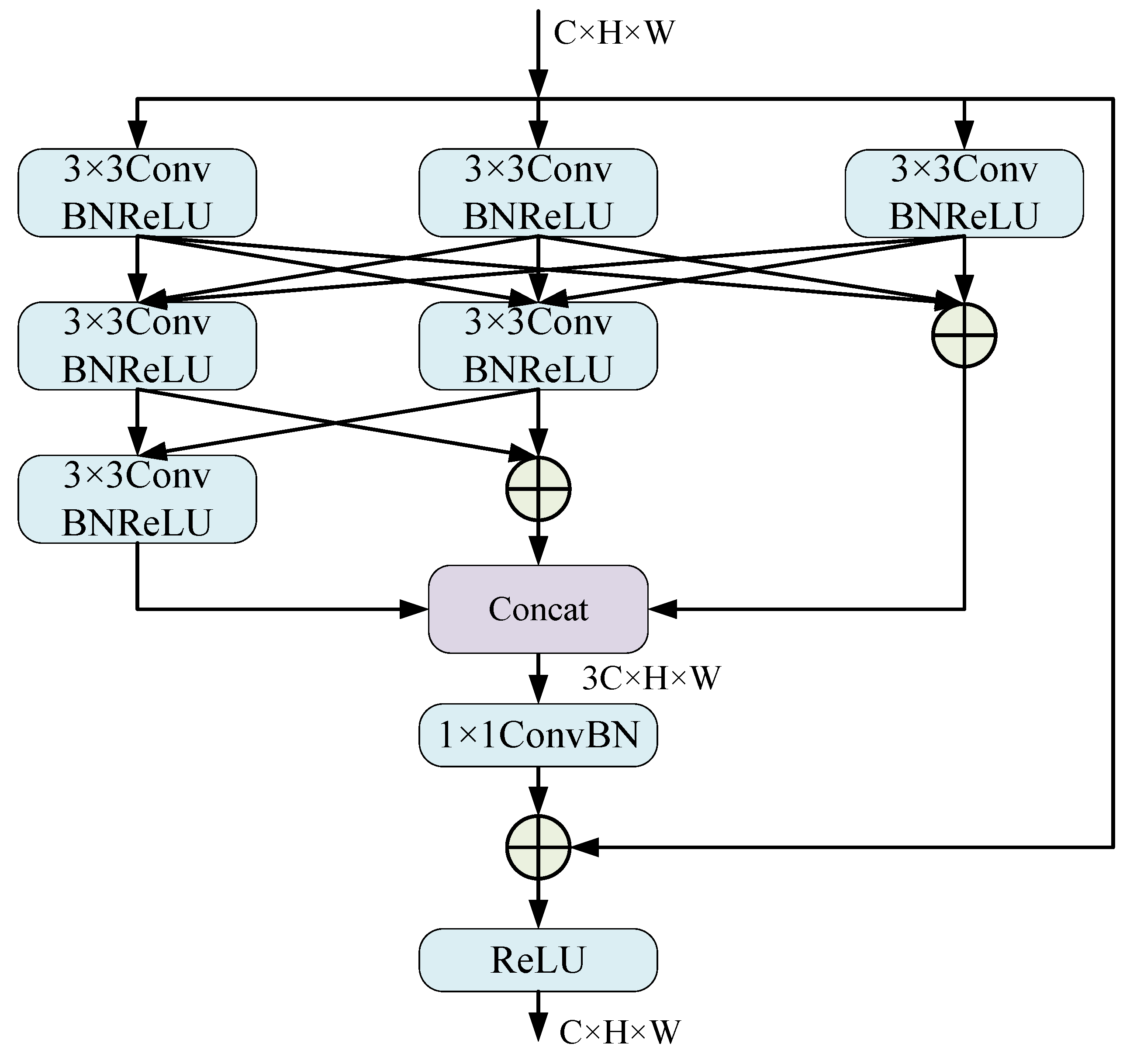
From the above two points, we introduce the category-based interactive attention and perception fusion network (CIAPNet), a novel semantic segmentation model for remote sensing images based on an encoder–decoder architecture. Unlike the traditional decoding approach, in order to enhance the network model’s ability to adapt to the category imbalance of remote sensing images, we propose the category-based transformer to reconstruct the encoder’s features in the form of categories. We use CGA as the attention module of the transformer to reconstruct the input features using self-attention grouped by categories, and optimize the self-attention weights for each category using IFBRO embedded in CGA to improve the representation relationship between foreground and background. In addition, we propose a detail-aware fusion (DAF) module to achieve fine fusion with deeper feature categories based on the perception of shallow features. Finally, we design a multi-scale representation (MSR) module deployed categorically as the feedforward network for CGA and DAF, using different scales of fields of view to enhance the descriptive capability of features at various scales. Our primary contributions are summarized as follows.
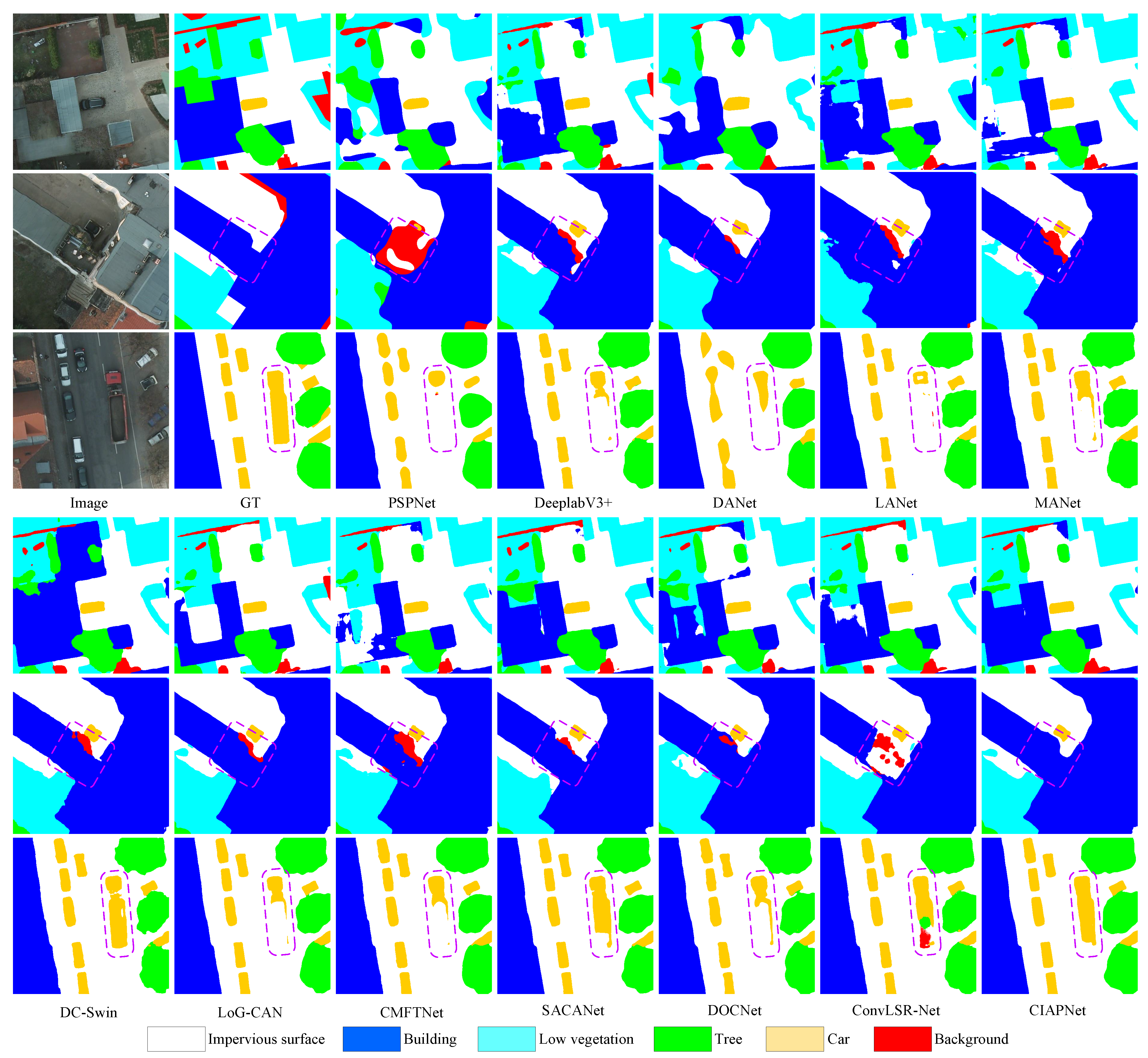
We propose a new CNN-coded transformer-decoded remote sensing semantic segmentation network CIAPNet based on the characteristics of remote sensing images. Information spaces are divided for each category, and the features of the backbone network are reconstructed by category, achieving balanced learning of the network across all categories. Experiments conducted on three varied remote sensing image datasets reveal that the method performs exceptionally well and the network adapts effectively to the category imbalance in remote sensing images.
We propose CGA that processes features by grouping them according to category, using multi-head self-attention to enable clearer categorical representation of the encoder’s features. An IFBRO module is embedded to interact with the attention information of different categories, distinguishing the foreground and background of each category and clarifying the representational relationship between them.
The DAF module is proposed to expand the perceptual field of shallow detailed features using dilated percept. Complete the semantic details of deep features based on the perception of context and categories from detail features. In addition, by introducing MSR deployed by category as the feedforward network, the expression capability of CGA and DAF for each category is further enhanced from a multi-level, multi-scale perspective.
6. Conclusions
In this paper, we propose a category-based semantic segmentation framework for remote sensing images, CIAPNet, which revisits traditional feature processing patterns. Unlike general holistic feature processing, we partition the feature space based on categories during the decoding phase and reconstruct the features for each category, balancing the model’s ability to learn and represent across categories, while ensuring features are more clearly represented by category. To ensure that categories with fewer samples receive sufficient resources for learning, we propose the CGA module, which processes features and deploys self-attention according to the Group block strategy, along with the category interaction module IFBRO to improve the foreground–background representation relationships across categories. Additionally, we introduce the DAF module to achieve semantic refinement at the pixel level of deep features using shallow features. Finally, we utilize the multi-perspective MSR module to enhance the network’s ability to describe multi-scale features. Experimental results on three datasets verify the effectiveness of our proposed CIAPNet, which also demonstrates outstanding balance. However, as the number of categories increases, this category-based feature processing approach also leads to an increase in the number of feature spaces, as well as the model parameters and computational load. In the future, we will further explore efficient category-based feature processing methods to ensure that the network achieves efficient remote sensing image segmentation while maintaining sensitivity and balance to categories.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}