

A Framework for Subregion Ensemble Learning Mapping of Land Use/Land Cover at the Watershed Scale




Abstract

1. Introduction
2. Study Area and Data Preprocessing
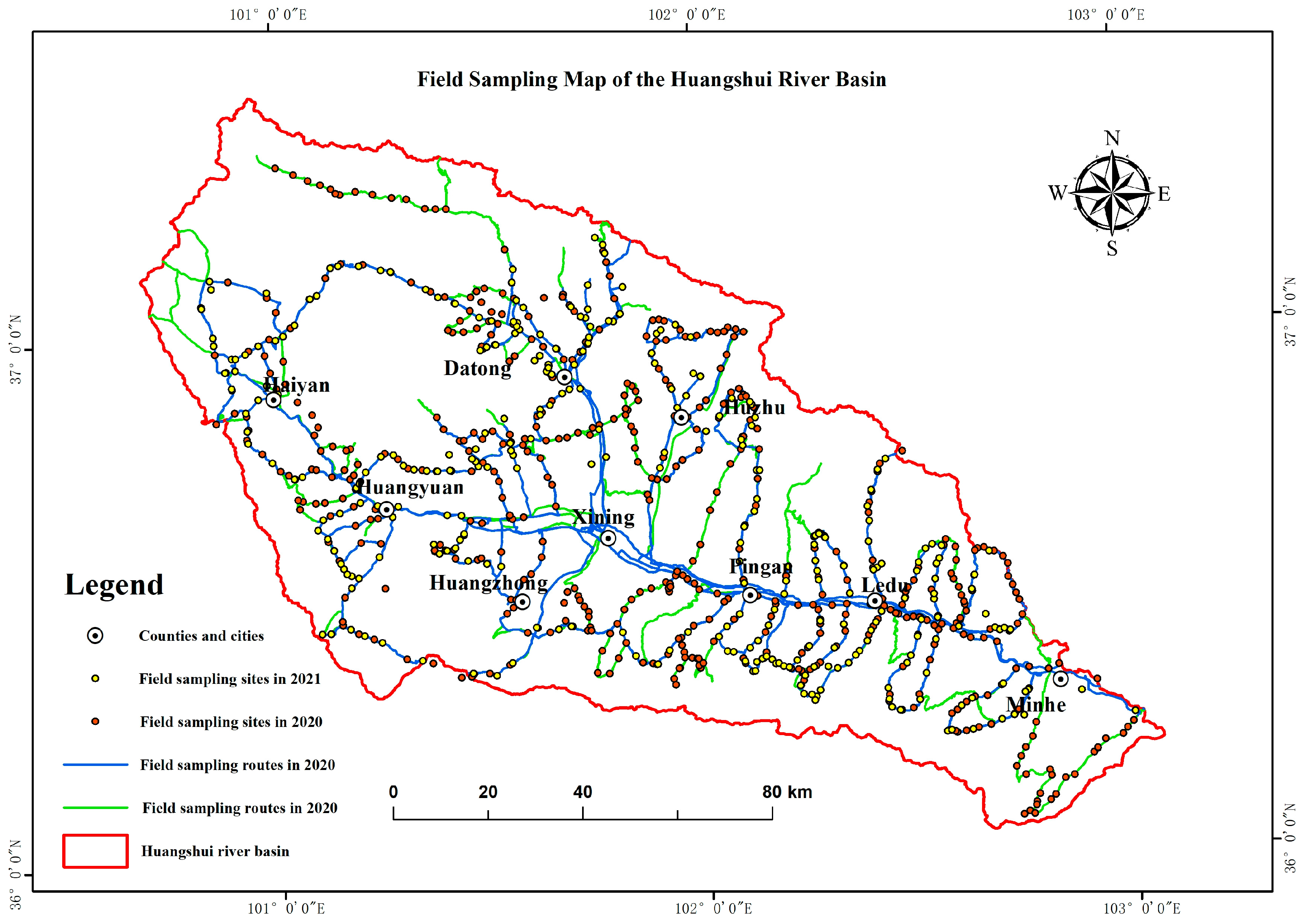
2.1. Overview of the Study Area
2.2. Data Sources
2.3. Classification System
3. Research Methodology
3.1. Random Forest
3.2. Improved LightGBM
3.3. Stacking
4. Results and Analysis
4.1. Classification Experimental Design
4.1.1. Samples Dataset
4.1.2. Model Parameterization
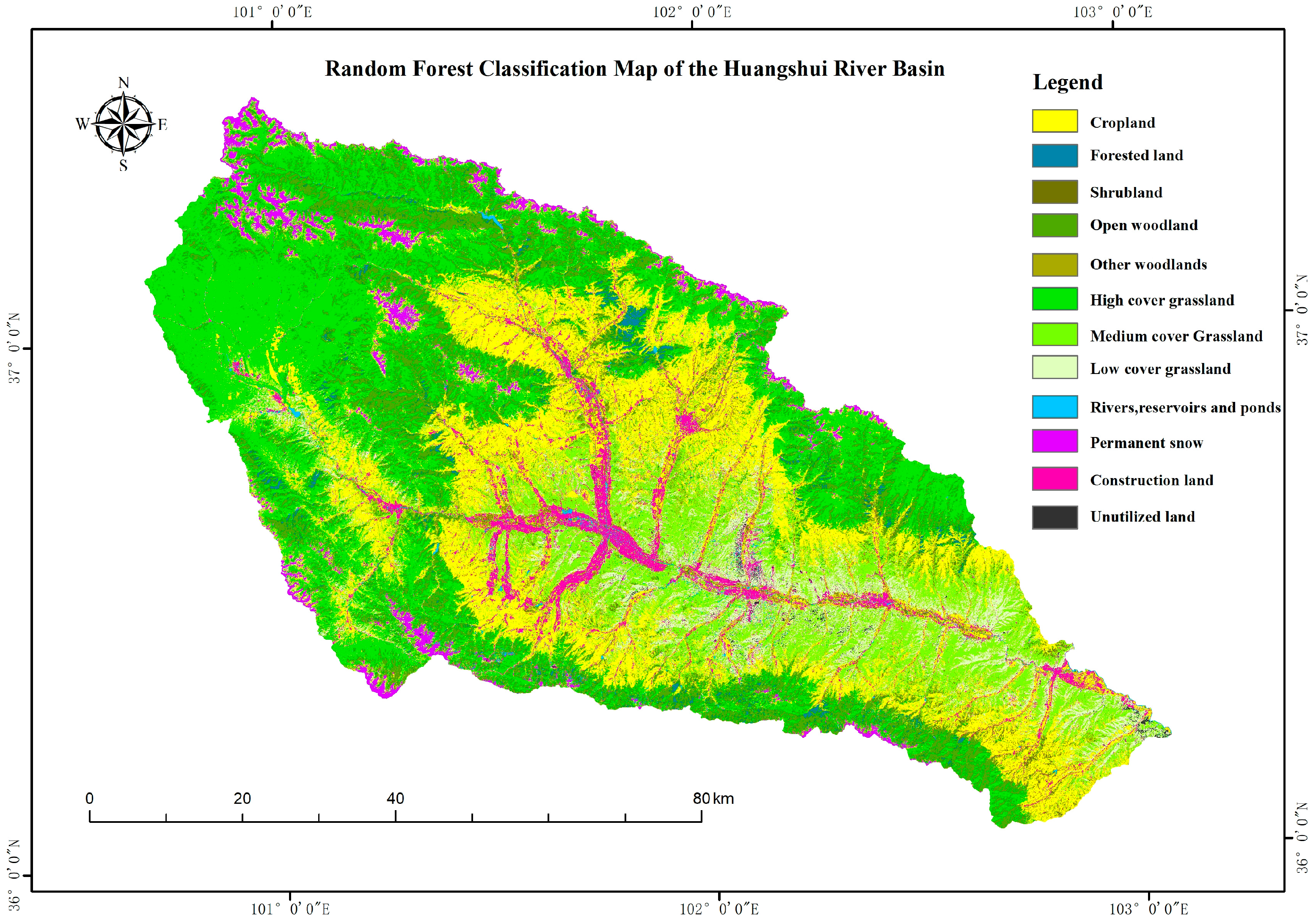
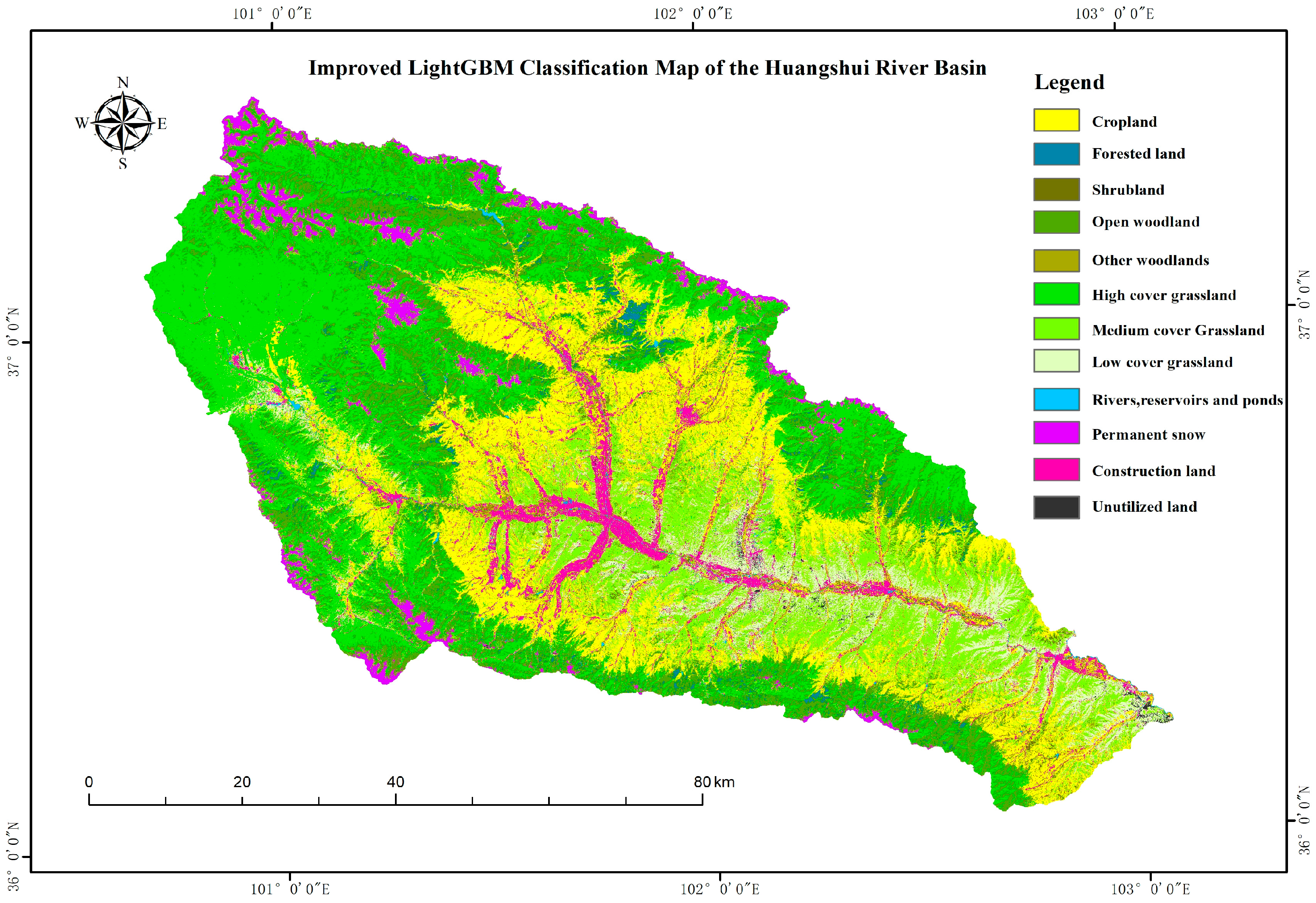
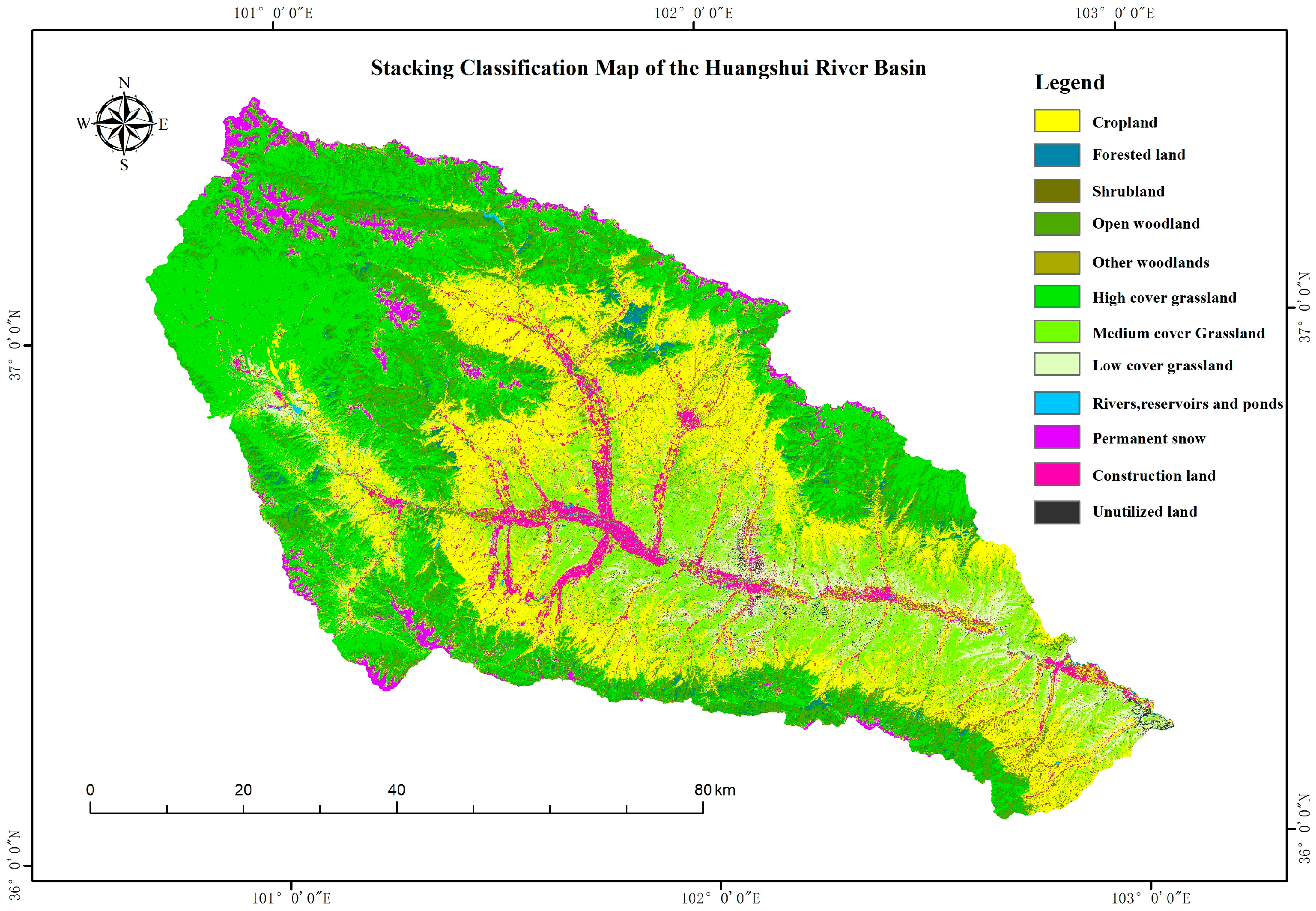
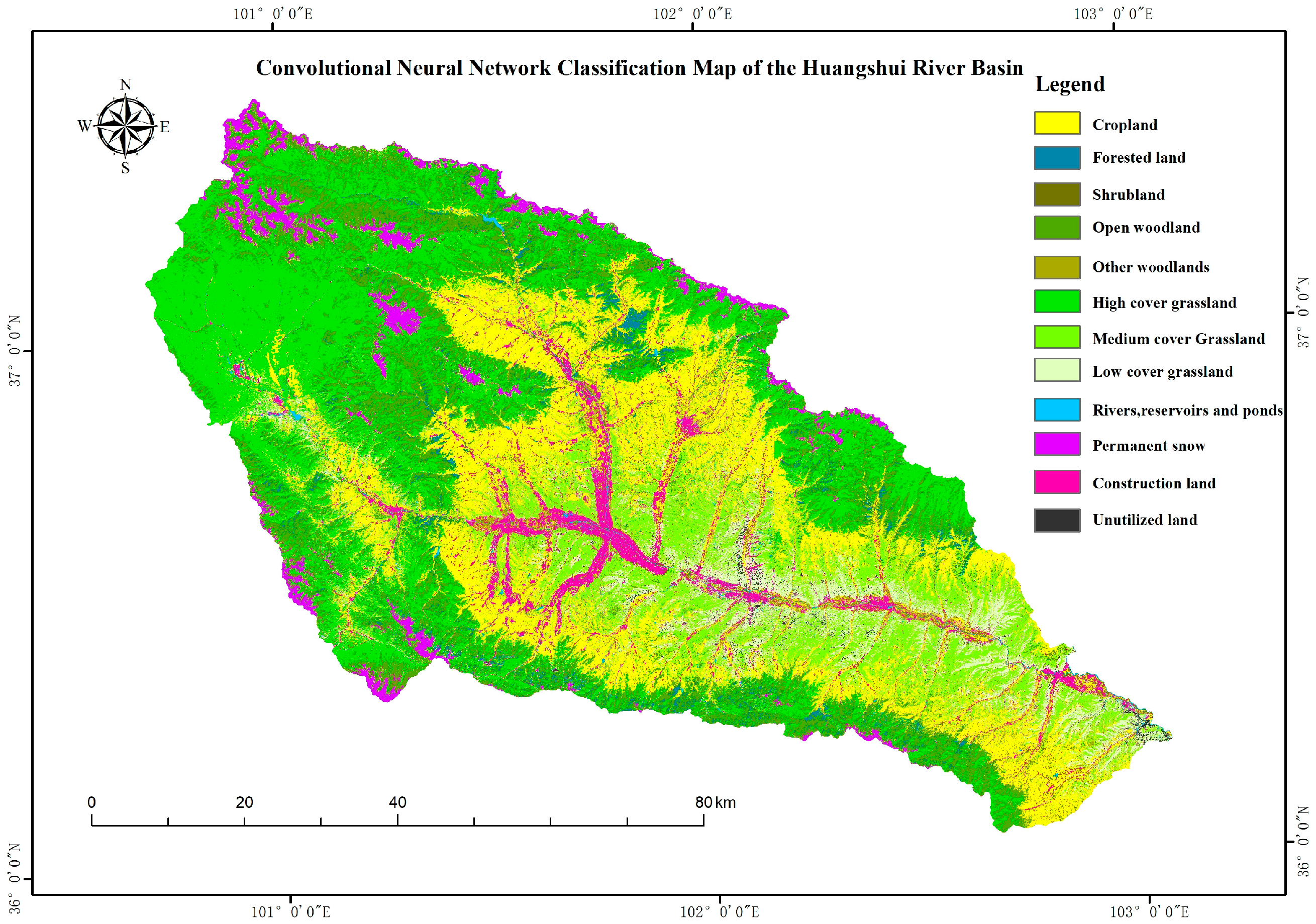
4.2. Classification Results
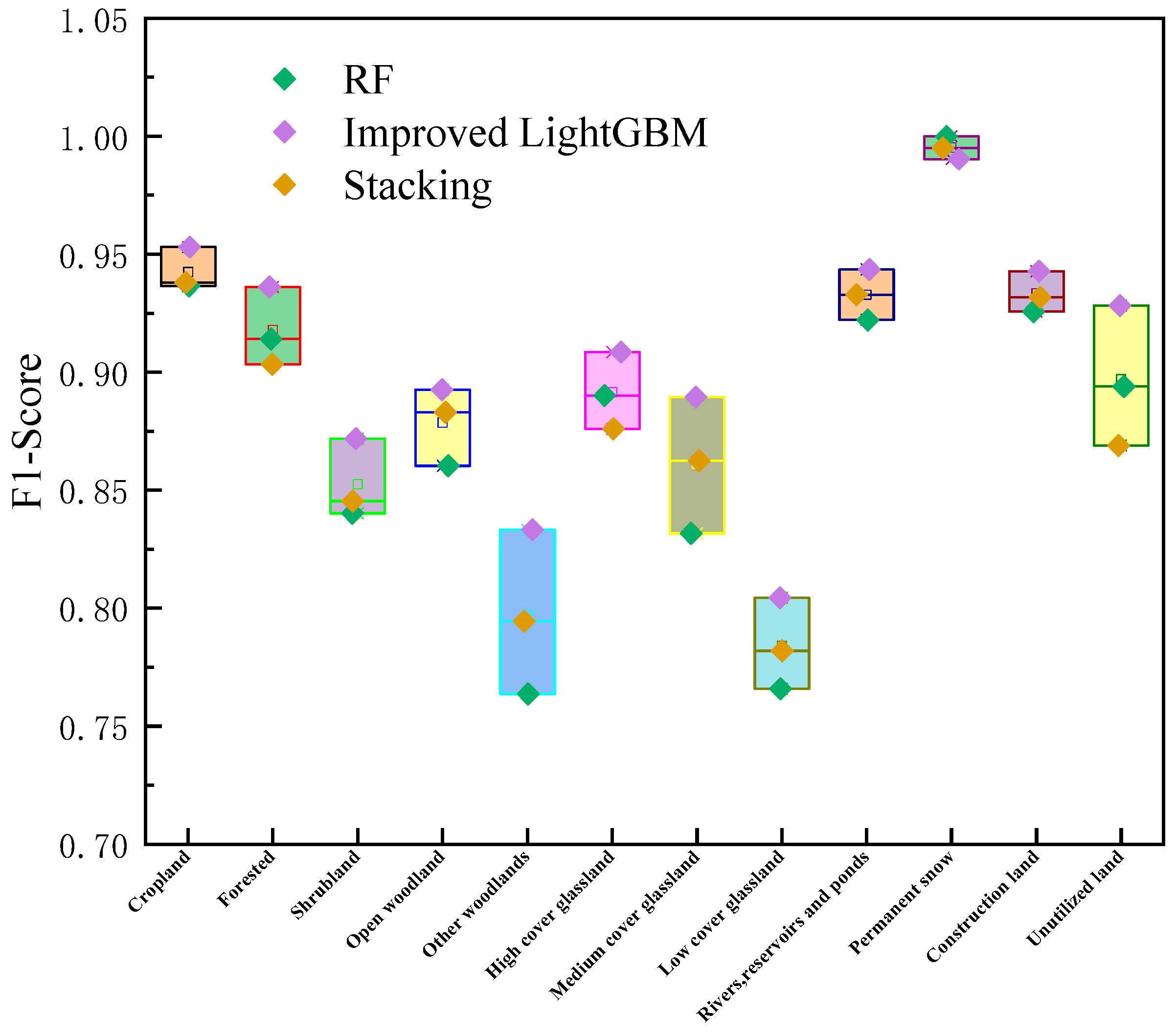
Assessment of Mapping Accuracy
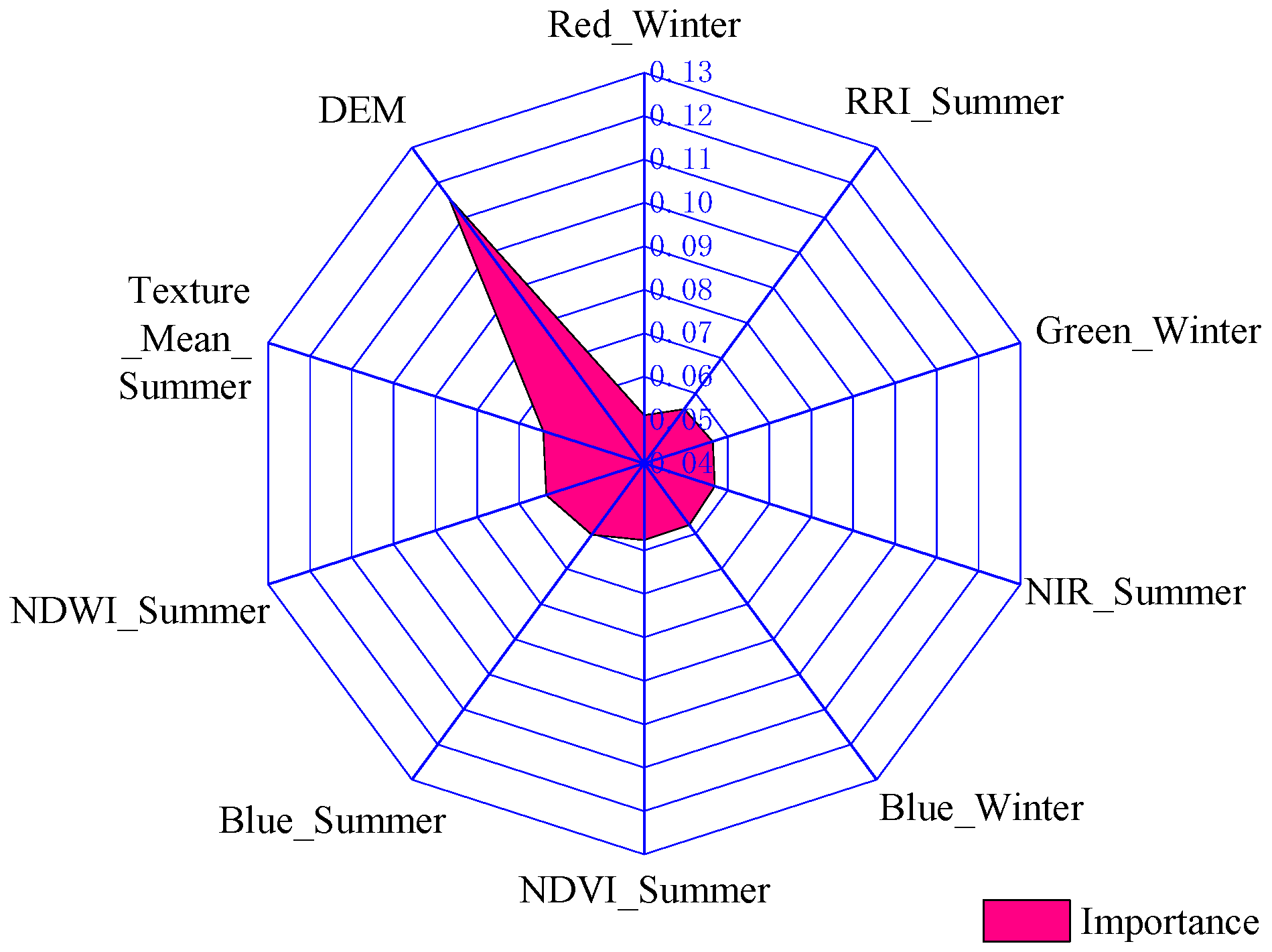
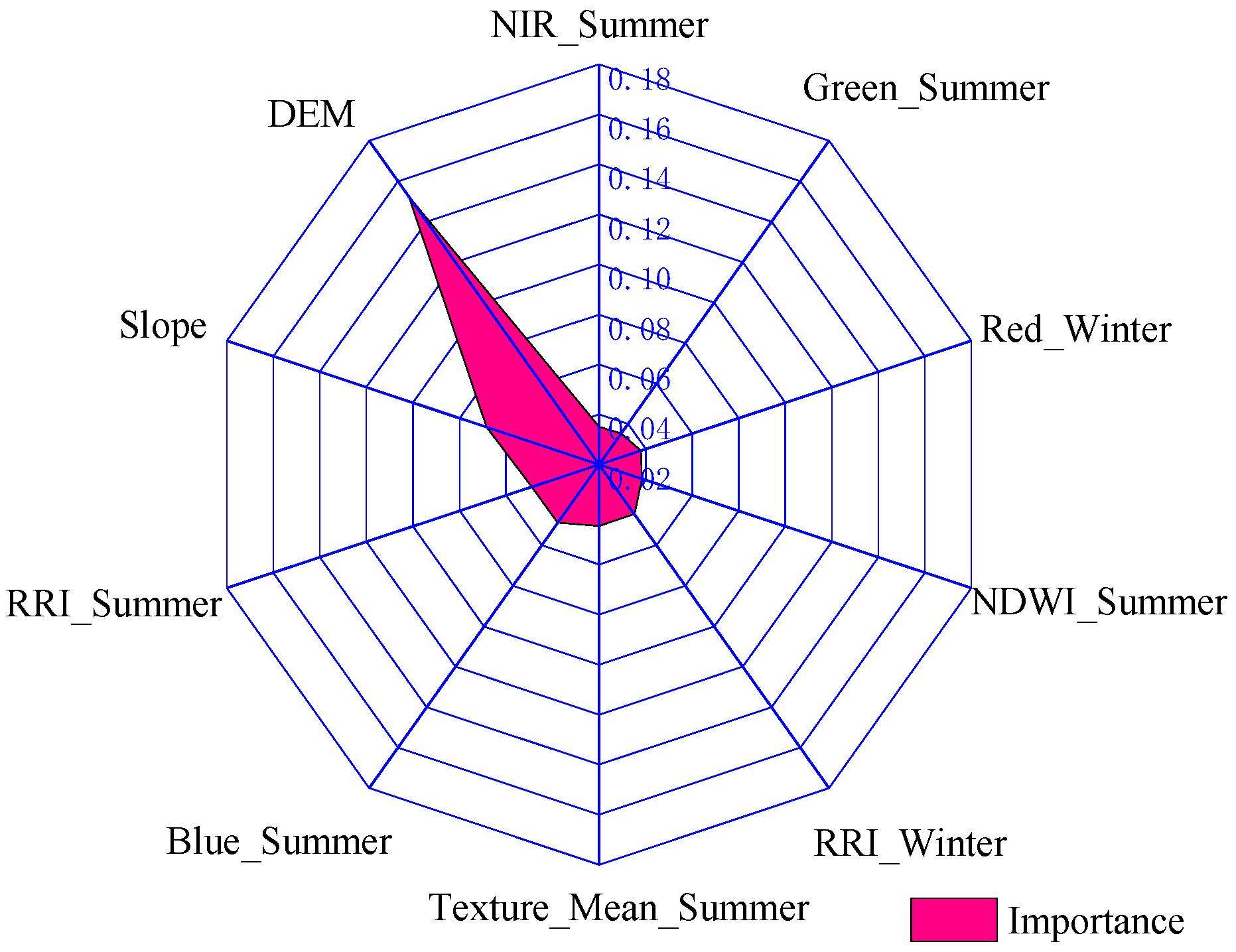
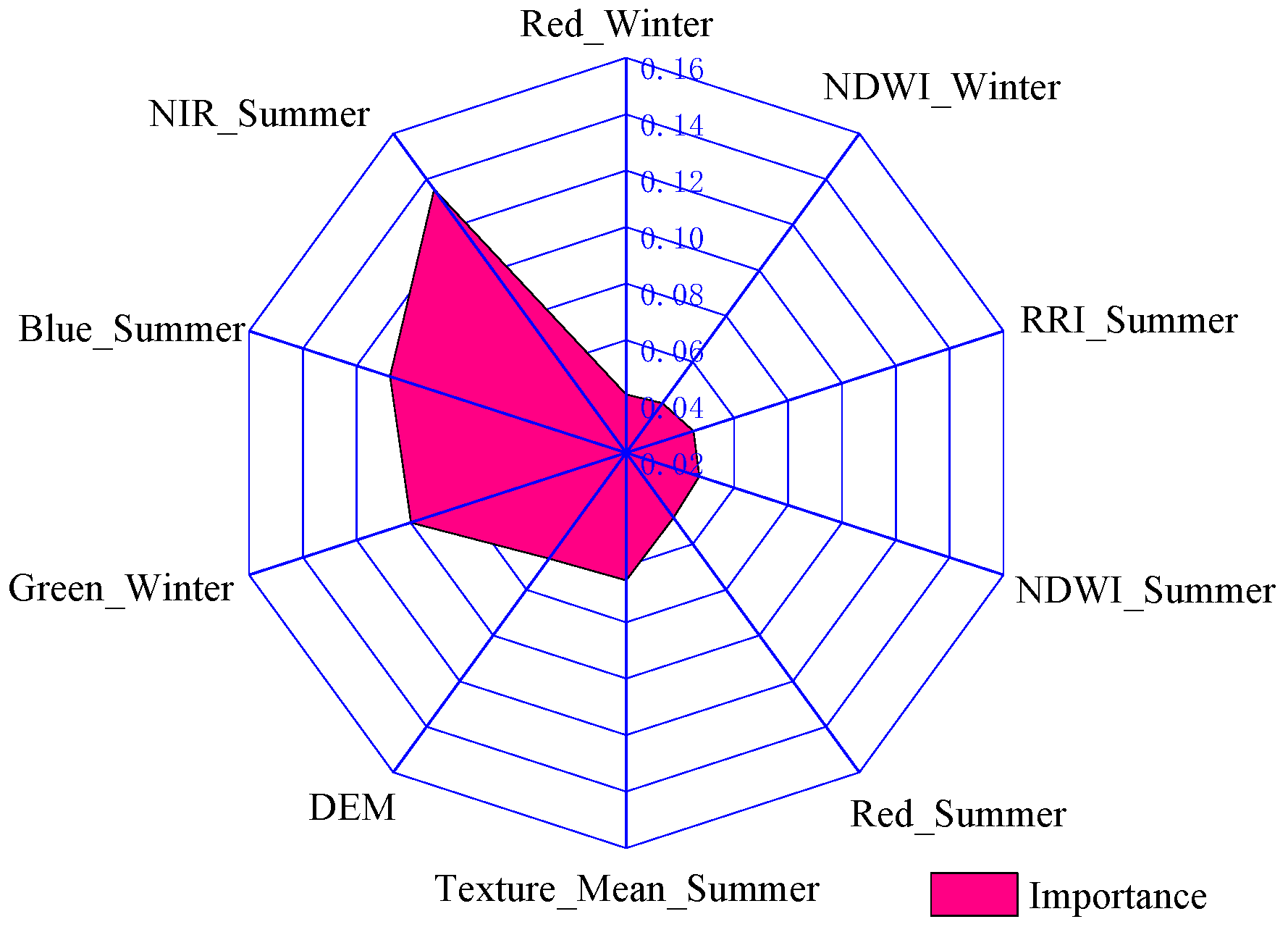
4.3. Analysis of Variable Significance
5. Discussion
5.1. Advantages of the Classification Framework
5.2. Effect of Different Methods on the Classification Results
5.3. Classification Efficiency and Accuracy
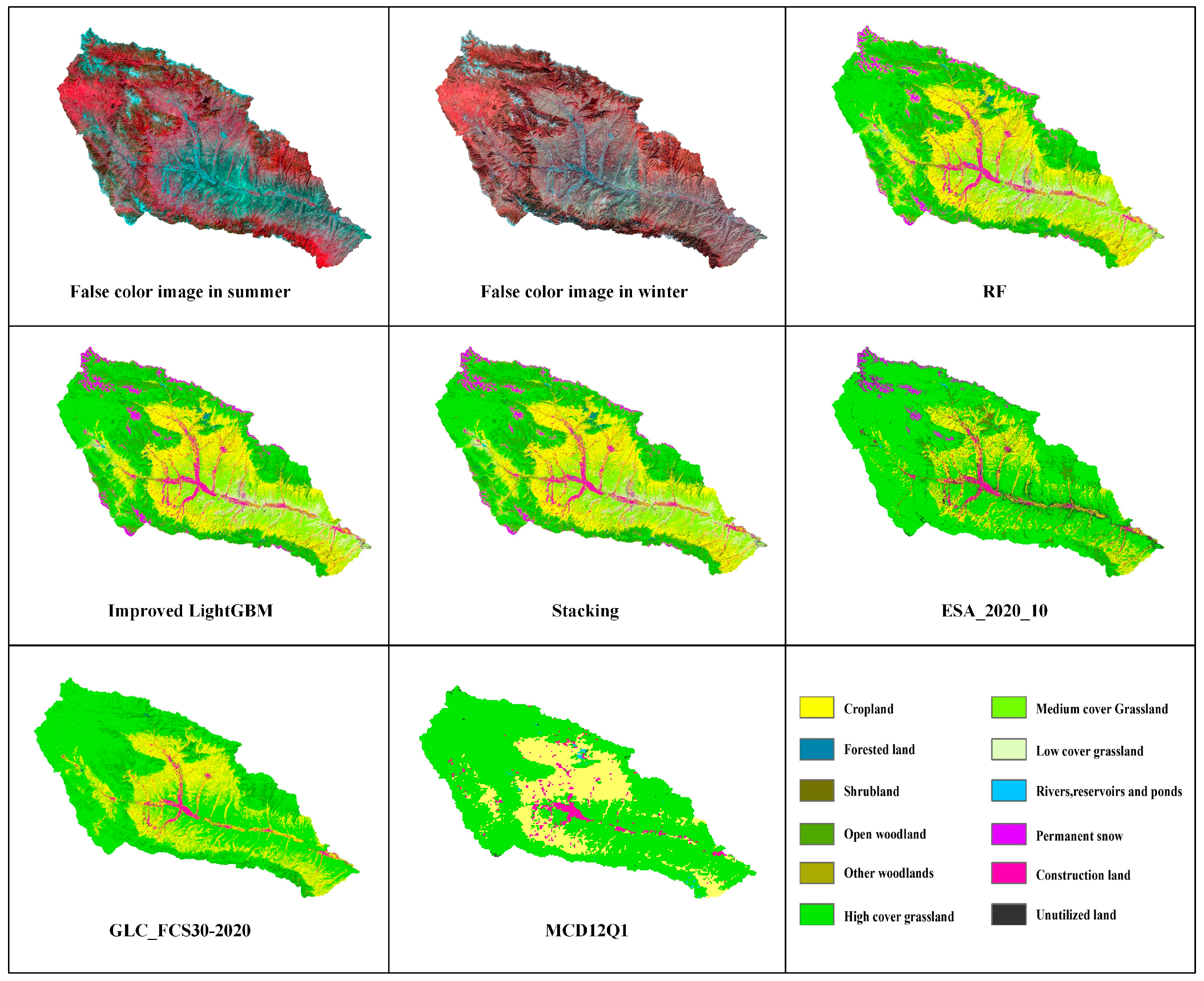
5.4. Comparison between Different Products
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Song, X.-P.; Hansen, M.C.; Stehman, S.V.; Potapov, P.V.; Tyukavina, A.; Vermote, E.F.; Townshend, J.R. Global land change from 1982 to 2016. Nature 2018, 560, 639–643. [Google Scholar] [CrossRef]
- Foley, J.A.; DeFries, R.; Asner, G.P.; Barford, C.; Bonan, G.; Carpenter, S.R.; Chapin, F.S.; Coe, M.T.; Daily, G.C.; Gibbs, H.K. Global consequences of land use. Science 2005, 309, 570–574. [Google Scholar] [CrossRef]
- Zhang, C.; Harrison, P.A.; Pan, X.; Li, H.; Sargent, I.; Atkinson, P.M. Scale Sequence Joint Deep Learning (SS-JDL) for land use and land cover classification. Remote Sens. Environ. 2020, 237, 111593. [Google Scholar] [CrossRef]
- Dang, V.H.; Hoang, N.D.; Nguyen, L.M.D.; Bui, D.T.; Samui, P. A novel GIS-based random forest machine algorithm for the spatial prediction of shallow landslide susceptibility. Forests 2020, 11, 118. [Google Scholar] [CrossRef]
- Szantoi, Z.; Geller, G.N.; Tsendbazar, N.E.; See, L.; Griffiths, P.; Fritz, S.; Gong, P.; Herold, M.; Mora, B.; Obregón, A. Addressing the need for improved land cover map products for policy support. Environ. Sci. Policy 2020, 112, 28–35. [Google Scholar] [CrossRef]
- Talukdar, S.; Singha, P.; Mahato, S.; Shahfahad; Pal, S.; Liou, Y.-A.; Rahman, A. Land-use land-cover classification by machine learning classifiers for satellite observations—A review. Remote Sens. 2020, 12, 1135. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef]
- Adam, E.; Mutanga, O.; Odindi, J.; Abdel-Rahman, E.M. Land-use/cover classification in a heterogeneous coastal landscape using Rapid Eye imagery: Evaluating the performance of random forest and support vector machines classifiers. Int. J. Remote Sens. 2014, 35, 3440–3458. [Google Scholar] [CrossRef]
- Camargo, F.F.; Sano, E.E.; Almeida, C.M.; Mura, J.C.; Almeida, T.A. A comparative assessment of machine learning techniques for land use and land cover classification of the Brazilian tropical savanna using ALOS-2/PALSAR-2 polarimetric images. Remote Sens. 2019, 11, 1600. [Google Scholar] [CrossRef]
- Li, X.; Chen, W.; Cheng, X.; Wang, L. A comparison of machine learning algorithms for mapping of complexsurface-mined and agricultural landscapes using ZiYuan-3 stereo satellite imagery. Remote Sens. 2016, 8, 514. [Google Scholar] [CrossRef]
- Rogan, J.; Franklin, J.; Stow, D.; Miller, J.; Woodcock, C.; Roberts, D. Mapping land-cover modifications over large areas: A comparison of machine learning algorithms. Remote Sens. Environ. 2008, 112, 2272–2283. [Google Scholar] [CrossRef]
- Ma, L.; Li, M.; Ma, X.; Cheng, L.; Du, P.; Liu, Y. A review of supervised object-based land-cover image classification. ISPRS J. Photogramm. Remote Sens. 2017, 130, 277–293. [Google Scholar] [CrossRef]
- Shen, H.F.; Lin, Y.H.; Tian, Q.J.; Xu, K.; Jiao, J. A comparison of multiple classifier combinations using different voting-weights for remote sensing image classification. Int. J. Remote Sens. 2018, 39, 3705–3722. [Google Scholar] [CrossRef]
- Wen, L.; Hughes, M. Coastal wetland mapping using ensemble learning algorithms: A comparative study of Bagging, Boosting and Stacking techniques. Remote Sens. 2020, 12, 1683. [Google Scholar] [CrossRef]
- Feng, S.; Li, W.; Xu, J.; Liang, T.; Ma, X.; Wang, W.; Yu, H. Land use/land cover mapping based on GEE for the monitoring of changes in ecosystem types in the upper Yellow River basin over the Tibetan Plateau. Remote Sens. 2022, 14, 5361. [Google Scholar] [CrossRef]
- Gislason, P.O.; Benediktsson, J.A.; Sveinsson, J.R. Random forests for land cover classification. Pattern Recognit. Lett. 2006, 27, 294–300. [Google Scholar] [CrossRef]
- Chan, J.C.W.; Paelinckx, D. Evaluation of random forest and adaboost tree-based ensemble classification and spectral band selection for ecotope mapping using airborne hyper-spectral imagery. Remote Sens. Environ. 2008, 112, 2999–3011. [Google Scholar] [CrossRef]
- Yang, L.; Mansaray, L.; Huang, J.; Wang, L. Optimal segmentation scale parameter, feature subset and classification algorithm for geographic object-based crop recognition using multisource satellite imagery. Remote Sens. 2019, 11, 514. [Google Scholar] [CrossRef]
- Abdullah, A.Y.M.; Masrur, A.; Adnan, M.S.G.; Baky, M.A.A.; Hassan, Q.K.; Dewan, A. Spatio-temporal patterns of land use/land cover change in the heterogeneous coastal region of bangladesh between 1990 and 2017. Remote Sens. 2019, 11, 790. [Google Scholar] [CrossRef]
- Tian, Z.; Wei, J.; Li, Z. How important is satellite-retrieved aerosol optical depth in deriving surface PM2.5 using machine learning. Remote Sens. 2023, 15, 3780. [Google Scholar] [CrossRef]
- Zhang, P.; Hu, S.G.; Li, W.D.; Zhang, C.; Cheng, P. Improving parcel-level mapping of smallholder crops from VHSR imagery: An ensemble machine-learning-based framework. Remote Sens. 2021, 13, 2146. [Google Scholar] [CrossRef]
- Zhang, X.; Zhao, T.; Xu, H.; Liu, W.; Wang, J.; Chen, X.; Liu, L. GLC_FCS30D: The first global 30 m land-cover dynamics monitoring product with a fine classification system for the period from 1985 to 2022 generated using dense-time-series Landsat imagery and the continuous change-detection method. Earth Syst. Sci. Data 2024, 16, 1353–1381. [Google Scholar] [CrossRef]
- Herold, M.; Mayaux, P.; Woodcock, C.E.; Baccini, A.; Schmullius, C. Some challenges in global land cover mapping: An assessmentof agreement and accuracy in existing 1 km datasets. Remote Sens. Environ. 2008, 112, 2538–2556. [Google Scholar] [CrossRef]
- Kaptué Tchuenté, A.T.; Roujean, J.-L.; De Jong, S.M. Comparison and relative quality assessment of the GLC2000, GLOBCOVER, MODIS and ECOCLIMAP land cover data sets at the African continental scale. Int. J. Appl. Earth Obs. Geoinf. 2011, 13, 207–219. [Google Scholar] [CrossRef]
- Mou, X.L.; Li, H.; Huang, C.; Liu, Q.; Liu, G. Application progress of google earth engine in land use and land cover remote sensing information extraction. Remote Sens. Land Resour. 2021, 33, 1–10. [Google Scholar]
- Wang, F.F.; Liu, S.; Liu, Y.; Sun, Y.; Yu, L.; Wang, Q.; Dong, Y.; Beazley, R. Long-term dynamics of nitrogen flow in a typical agricultural and pastoral region on the Qinghai-Tibet Plateau and its optimization strategy. Environ. Pollut. 2021, 288, 117684. [Google Scholar] [CrossRef]
- Ghorbanian, A.; Zaghian, S.; Asiyabi, R.M.; Amani, M.; Mohammadzadeh, A.; Jamali, S. Mangrove ecosystem mapping using sentinel-1 and sentinel-2 satellite images and random forest algorithm in google earth engine. Remote Sens. 2021, 13, 2565. [Google Scholar] [CrossRef]
- Caballero, I.; Navarro, G. Monitoring cyanoHABs and water quality in Laguna Lake (Philippines) with sentinel-2 satellites during the 2020 Pacific typhoon season. Sci. Total Environ. 2021, 788, 147700. [Google Scholar] [CrossRef]
- Vizzari, M. Planet scope, sentinel-2, and sentinel-1 data integration for object-based land cover classification in google earth engine. Remote Sens. 2022, 14, 2628. [Google Scholar] [CrossRef]
- Pott, L.P.; Amado, T.J.C.; Schwalbert, R.A.; Corassa, G.M.; Ciampitti, I.A. Satellite-based data fusion crop type classification andmapping in Rio Grande do Sul, Brazil. ISPRS J. Photogramm. Remote Sens. 2021, 176, 196–210. [Google Scholar] [CrossRef]
- Verde, N.; Kokkoris, I.P.; Georgiadis, C.; Kaimaris, D.; Dimopoulos, P.; Mitsopoulos, I.; Mallinis, G. National scale land coverclassification for ecosystem services mapping and assessment, using multitemporal copernicus EO data and google earth engine. Remote Sens. 2020, 12, 3303. [Google Scholar] [CrossRef]
- Tuvdendorj, B.; Zeng, H.; Wu, B.; Elnashar, A.; Zhang, M.; Tian, F.; Nabil, M.; Nanzad, L.; Bulkhbai, A.; Natsagdorj, N. Performance and the optimal integration of sentinel-1/2 time-series features for crop classification in Northern Mongolia. Remote Sens. 2022, 14, 1830. [Google Scholar] [CrossRef]
- Fremout, T.; Cobián-De Vinatea, J.; Thomas, E.; Huaman-Zambrano, W.; Salazar-Villegas, M.; Limache-de la Fuente, D.; Bernardino, P.N.; Atkinson, R.; Csaplovics, E.; Muys, B. Site-specific scaling of remote sensing-based estimates of woody cover and aboveground biomass for mapping long-term tropical dry forest degradation status. Remote Sens. Environ. 2022, 276, 113040. [Google Scholar] [CrossRef]
- Amini, S.; Saber, M.; Rabiei-Dastjerdi, H.; Homayouni, S. Urban land use and land cover change analysis using random forest classification of landsat time series. Remote Sens. 2022, 14, 2654. [Google Scholar] [CrossRef]
- Tucker, C.J. Red and photographic infrared linear combinations for monitoring vegetation. Remote Sens. Environ. 1979, 8, 127–150. [Google Scholar] [CrossRef]
- Gao, B.-C. NDWI—A normalized difference water index for remote sensing of vegetation liquid water from space. Remote Sens. Environ. 1996, 58, 257–266. [Google Scholar] [CrossRef]
- Ji, H.; Li, X.; Wei, X.; Liu, W.; Zhang, L.; Wang, L. Mapping 10-m resolution rural settlements using multi-source remote sensing datasets with the google earth engine platform. Remote Sens. 2020, 12, 2832. [Google Scholar] [CrossRef]
- Johansen, K.; Phinn, S. Mapping structural parameters and species composition of riparian vegetation using IKONOS and Landsat ETM+ data in Australian tropical savannahs. Photogramm. Eng. Remote Sens. 2006, 72, 71–80. [Google Scholar] [CrossRef]
- Fassnacht, F.E.; Latifi, H.; Stere’nczak, K.; Modzelewska, A.; Lefsky, M.; Waser, L.T.; Straub, C.; Ghosh, A. Review of studies on tree species classification from remotely sensed data. Remote Sens. Environ. 2016, 186, 64–87. [Google Scholar] [CrossRef]
- Mohammadpour, P.; Viegas, D.X.; Viegas, C. Vegetation mapping with random forest using sentinel 2 and GLCM texture feature—A case study for Lousã Region, Portugal. Remote Sens. 2022, 14, 4585. [Google Scholar] [CrossRef]
- Yang, Y.; Yang, D.; Wang, X.; Zhang, Z.; Nawaz, Z. Testing accuracy of land cover classification algorithms in the qilian mountains based on gee cloud platform. Remote Sens. 2021, 13, 5064. [Google Scholar] [CrossRef]
- Mariana, B.; Lucian, D. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 21–31. [Google Scholar]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Zhang, J.; Xu, J.; Dai, X.; Ruan, H.; Liu, X.; Jing, W. Multi-source precipitation data merging for heavy rainfall events based on CoKriging and machine learning methods. Remote Sens. 2022, 14, 1750. [Google Scholar] [CrossRef]
- Chai, X.; Li, J.; Zhao, J.; Wang, W.; Zhao, X. LGB-PHY: An evaporation duct height prediction model based on physically constrained LightGBM algorithm. Remote Sens. 2022, 14, 3448. [Google Scholar] [CrossRef]
- Cheng, X.; Lei, H. Remote sensing scene image classification based on mmsCNN–HMM with stacking ensemble model. Remote Sens. 2022, 14, 4423. [Google Scholar] [CrossRef]
- Van Niel, T.G.; Mcvicar, T.; Datt, B. On the relationship between training sample size and data dimensionality: Monte Carlo analysis of broadband multi-temporal classification. Remote Sens. Environ. 2005, 98, 468–480. [Google Scholar] [CrossRef]
- Appel, M.; Lahn, F.; Buytaert, W.; Pebesma, E. Open and scalable analytics of large Earth observation datasets: From scenes to multidimensional arrays using SciDB and GDAL. ISPRS J. Photogramm. Remote Sens. 2018, 138, 47–56. [Google Scholar] [CrossRef]
- Zhang, H.; Tong, H.; Zuo, B.; Zhang, X. Quick browsing of massive remote sensing image based on GDAL. Comput. Eng. Appl. 2012, 48, 159–162. [Google Scholar]
- Congalton, R.G. A review of assessing the accuracy of classifications of remotely sensed data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Foody, G.M. Status of land cover classification accuracy assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I.H. Textural features for image classification. IEEE Trans. Syst. Man Cybern. 1973, SMC-3, 610–621. [Google Scholar] [CrossRef]
- Kupidura, P. The comparison of different methods of texture analysis for their efficacy for land use classification in satelliteimagery. Remote Sens. 2019, 11, 1233. [Google Scholar] [CrossRef]
- Burai, P.; Deák, B.; Valkó, O.; Tomor, T. Classification of herbaceous vegetation using airborne hyperspectral imagery. Remote Sens. 2015, 7, 2046–2066. [Google Scholar] [CrossRef]
- Ghayour, L.; Neshat, A.; Paryani, S.; Shahabi, H.; Shirzadi, A.; Chen, W.; Al-Ansari, N.; Geertsema, M.; Pourmehdi Amiri, M.; Gholamnia, M.; et al. Performance evaluation of Sentinel-2 and Landsat 8 OLI Data for Land Cover/Use Classification Using a Comparison between Machine Learning Algorithms. Remote Sens. 2021, 13, 1349. [Google Scholar] [CrossRef]
- Saboori, M.; Homayouni, S.; Shah-Hosseini, R.; Zhang, Y. Optimum feature and classifier selection for accurate urban land use/cover mapping from very high resolution satellite imagery. Remote Sens. 2022, 14, 2097. [Google Scholar] [CrossRef]
- Rapinel, S.; Mony, C.; Lecoq, L.; Clement, B.; Thomas, A.; Hubert-Moy, L. Evaluation of Sentinel-2 time-series for mapping floodplain grassland plant communities. Remote Sens. Environ. 2019, 223, 115–129. [Google Scholar] [CrossRef]
- Ji, Q.; Liang, W.; Fu, B.; Zhang, W.; Yan, J.; Lü, Y.; Yue, C.; Jin, Z.; Lan, Z.; Li, S. Mapping land use/cover dynamics of the Yellow River Basin from 1986 to 2018 supported by Google Earth Engine. Remote Sens. 2021, 13, 1299. [Google Scholar] [CrossRef]
- Dietterich, T.G. An experimental comparison of three methods for constructing ensembles of decision trees: Bagging, boosting, and randomization. Mach. Learn. 2000, 40, 139–157. [Google Scholar] [CrossRef]
- Ghimire, B.; Rogan, J.; Rodríguez-Galiano, V.F.; Panday, P.; Neeti, N. An evaluation of bagging, boosting, and random forests for land-cover classification in Cape Cod, Massachusetts, USA. GIScience Remote Sens. 2012, 49, 623–643. [Google Scholar] [CrossRef]
- Feng, L.; Zhang, Z.; Ma, Y.; Du, Q.; Williams, P.; Drewry, J.; Luck, B. Alfalfa yield prediction using UAV-based hyperspectral imagery and ensemble learning. Remote Sens. 2020, 12, 2028. [Google Scholar] [CrossRef]
- Shi, F.; Gao, X.; Li, R.; Zhang, H. Ensemble Learning for the Land Cover Classification of Loess Hills in the Eastern Qinghai–Tibet Plateau Using GF-7 Multitemporal Imagery. Remote Sens. 2024, 16, 2556. [Google Scholar] [CrossRef]
- Venter, Z.S.; Barton, D.N.; Chakraborty, T.; Simensen, T.; Singh, G. Global 10 m land use land cover datasets: A comparison of Dynamic World, World Cover and Esri Land Cover. Remote Sens. 2022, 14, 4101. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, Y.; Zhang, K. Automatic 10 m Forest Cover Mapping in 2020 at China’s Han River Basin by Fusing ESA Sentinel-1/Sentinel-2 Land Cover and Sentinel-2 near Real-Time Forest Cover Possibility. Forests 2023, 14, 1133. [Google Scholar] [CrossRef]
- Koyama, A.; Fukue, K.; Otake, Y.; Matsuoka, Y.; Hasegawa, T.; Hiyama, T.; Kato, H. Global land cover classification using modis surface reflectance prosucts. In Proceedings of the Asian Conference on Remote Sensing, Quezon City, Metro Manila, Philippines, 24–28 October 2015. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Wave Band | Descriptive | Quantities |
|---|---|---|---|
| Primary bands | Red | Composite images of summer and winter seasons. Spatial resolution 10 m | 8 |
| Green | |||
| Blue | |||
| NIR | |||
| Spectral indices | NDVI | Reflects vegetation growth Reflects the spatial distribution of water bodies Reflects spatial distribution of buildings | 6 |
| NDWI | |||
| RRI | |||
| Texture features | Second Moment | Extract the first principal component from the blue, green, red, and near-infrared bands and calculate the gray-level co-occurrence matrix from the first principal component, reflecting the texture information. | 16 |
| Entropy | |||
| Variance | |||
| Contrast | |||
| Mean | |||
| Dissimilarity | |||
| Homogeneity | |||
| Correlation | |||
| Topographic features | DEM | Reflects terrain elevation, slope, and aspect information | 3 |
| Aspect | |||
| Slope |
| LULC Types | Number of Samples (Number) | Training Samples (Number) | Validation Sample (Number) |
|---|---|---|---|
| Cropland | 2905 | 2019 | 886 |
| Forested land | 526 | 361 | 165 |
| Shrubland | 1044 | 734 | 310 |
| Open woodland | 853 | 594 | 259 |
| Other woodlands | 360 | 239 | 121 |
| High-cover grassland | 1298 | 932 | 366 |
| Medium-cover grassland | 1291 | 896 | 395 |
| Low-cover grassland | 767 | 535 | 232 |
| Rivers, reservoirs, and ponds | 821 | 570 | 251 |
| Permanent snow | 364 | 261 | 103 |
| Construction land | 1507 | 1084 | 423 |
| Unutilized land | 424 | 287 | 137 |
| Total | 12,160 | 8512 | 3648 |
| Classifiers | Parameters | Description | Tuning Ranges |
|---|---|---|---|
| RF | n_estimators | The number of trees, representing the number of iterations. | 1–500 |
| max_features | The number of features to consider when looking for the best split. | 1–15 | |
| max_depth | The maximum depth of each tree. | 1–10 | |
| min_samples_split | The minimum number of samples a node must have to be split. | 1–6 | |
| min_samples_leaf | The minimum number of samples a leaf node must have. | 1–6 | |
| Improve LightGBM | n_estimators | The number of trees, representing the number of iterations. | 1–500 |
| learning_rate | The learning rate, controlling the update magnitude of model parameters in each iteration. | 0.01–0.1 | |
| boosting_type | The parameter that specifies the type or strategy of the gradient boosting algorithm. | “gbdt” | |
| num_leaves | The number of leaf nodes. | 50–150 | |
| max_features | The number of features to consider when looking for the best split. | 1–10 | |
| max_depth | The maximum depth of each tree. | 1–10 | |
| min_samples_split | The minimum number of samples a node must have to be split. | 1–5 | |
| min_samples_leaf | The minimum number of samples a leaf node must have. | 1–5 | |
| L1 | Regularization parameter. | 0.1–0.5 | |
| L2 | Regularization parameter. | 0.1–0.5 | |
| Stacking | num_class | Number of classes. | 12 |
| learning_rate | The learning rate, controlling the update magnitude of model parameters in each iteration. | 0.01–0.1 | |
| n_estimators | The number of trees, representing the number of iterations. | 250 | |
| max_depth | The maximum depth of each tree. | 1–500 | |
| min_child_weight | Minimum node weight. | 1–10 | |
| L1 | Regularization parameter. | 0.1–0.5 | |
| L2 | Regularization parameter. | 0.1–0.5 |
| LULC Types | RF Algorithm | Improved LightGBM Algorithm | Stacking Algorithm | ||||||
|---|---|---|---|---|---|---|---|---|---|
| PA (%) | UA (%) | F1-Score | PA (%) | UA (%) | F1-Score | PA (%) | UA (%) | F1-Score | |
| Cropland | 95.03 | 92.32 | 0.94 | 96.16 | 94.46 | 0.95 | 95.82 | 91.88 | 0.94 |
| Forested land | 90.30 | 92.55 | 0.91 | 93.33 | 93.90 | 0.94 | 87.88 | 92.95 | 0.90 |
| Shrubland | 84.84 | 83.23 | 0.84 | 87.74 | 86.62 | 0.87 | 86.45 | 82.72 | 0.85 |
| Open woodland | 89.19 | 83.09 | 0.86 | 91.51 | 87.13 | 0.89 | 90.35 | 86.35 | 0.88 |
| Other woodlands | 69.42 | 84.85 | 0.76 | 78.51 | 88.79 | 0.83 | 71.90 | 88.78 | 0.79 |
| High-cover grassland | 87.43 | 90.65 | 0.89 | 89.62 | 92.13 | 0.91 | 86.89 | 88.33 | 0.88 |
| Medium-cover grassland | 85.06 | 81.36 | 0.83 | 90.63 | 87.32 | 0.89 | 86.58 | 85.93 | 0.86 |
| Low-cover grassland | 75.43 | 77.78 | 0.77 | 79.74 | 81.14 | 0.80 | 78.02 | 78.35 | 0.78 |
| Rivers, reservoirs, and ponds | 92.03 | 92.40 | 0.92 | 93.23 | 95.51 | 0.94 | 91.24 | 95.42 | 0.93 |
| Permanent snow | 100.00 | 100.00 | 1.00 | 100.00 | 98.10 | 0.99 | 100.00 | 99.04 | 1.00 |
| Construction land | 91.25 | 93.92 | 0.93 | 93.62 | 94.96 | 0.94 | 91.96 | 94.42 | 0.93 |
| Unutilized land | 86.13 | 92.91 | 0.89 | 89.78 | 96.09 | 0.93 | 84.67 | 89.23 | 0.87 |
| OA (%) | 88.76 | 91.47 | 89.39 | ||||||
| Kappa | 0.87 | 0.90 | 0.88 | ||||||
| LULC Types | RF-A | RF-B | ||||
|---|---|---|---|---|---|---|
| PA (%) | UA (%) | F1-Score | PA (%) | UA (%) | F1-Score | |
| Cropland | 94.51 | 90.91 | 0.93 | 94.30 | 93.52 | 0.94 |
| Forested land | 85.00 | 96.23 | 0.90 | 97.78 | 98.88 | 0.98 |
| Shrubland | 85.23 | 79.79 | 0.82 | 81.45 | 88.60 | 0.85 |
| Open woodland | 85.07 | 85.07 | 0.85 | 91.49 | 87.31 | 0.89 |
| Other woodlands | 74.67 | 82.35 | 0.78 | 73.17 | 90.91 | 0.81 |
| High-cover grassland | 87.04 | 87.40 | 0.87 | 87.30 | 90.16 | 0.89 |
| Medium-cover grassland | 81.08 | 83.33 | 0.82 | 90.79 | 84.87 | 0.88 |
| Low-cover grassland | 68.89 | 60.78 | 0.65 | 82.84 | 79.55 | 0.81 |
| Rivers, reservoirs, and ponds | 96.79 | 94.97 | 0.96 | 83.13 | 95.83 | 0.89 |
| Permanent snow | 97.33 | 98.65 | 0.98 | 93.33 | 97.67 | 0.95 |
| Construction land | 94.82 | 98.32 | 0.97 | 85.04 | 87.80 | 0.86 |
| Unutilized land | 44.44 | 100.00 | 0.62 | 93.50 | 95.83 | 0.95 |
| OA (%) | 89.51 | 89.94 | ||||
| Kappa | 0.8791 | 0.8819 | ||||
| LULC Types | Improved LightGBM-A | Improved LightGBM-B | ||||
|---|---|---|---|---|---|---|
| PA (%) | UA (%) | F1-Score | PA (%) | UA (%) | F1-Score | |
| Cropland | 94.51 | 92.26 | 0.93 | 95.48 | 95.16 | 0.95 |
| Forested land | 85.00 | 94.44 | 0.89 | 97.78 | 98.88 | 0.98 |
| Shrubland | 84.66 | 80.54 | 0.83 | 82.26 | 91.07 | 0.86 |
| Open woodland | 88.06 | 83.10 | 0.86 | 92.55 | 88.32 | 0.90 |
| Other woodlands | 72.00 | 85.71 | 0.78 | 70.73 | 85.29 | 0.77 |
| High-cover grassland | 87.04 | 86.69 | 0.87 | 90.48 | 91.20 | 0.91 |
| Medium-cover grassland | 83.78 | 80.52 | 0.82 | 93.97 | 87.57 | 0.91 |
| Low-cover grassland | 62.22 | 62.22 | 0.62 | 83.43 | 82.94 | 0.83 |
| Rivers, reservoirs, and ponds | 94.87 | 97.37 | 0.96 | 85.54 | 95.95 | 0.90 |
| Permanent snow | 98.67 | 100.00 | 0.99 | 100.00 | 100.00 | 1.00 |
| Construction land | 96.76 | 96.45 | 0.97 | 92.13 | 90.00 | 0.91 |
| Unutilized land | 44.44 | 66.67 | 0.53 | 90.24 | 96.52 | 0.93 |
| OA (%) | 89.64 | 91.62 | ||||
| Kappa | 0.8805 | 0.9016 | ||||
| LULC Types | Stacking-A | Stacking-B | ||||
|---|---|---|---|---|---|---|
| PA (%) | UA (%) | F1-Score | PA (%) | UA (%) | F1-Score | |
| Cropland | 93.90 | 90.86 | 0.92 | 96.15 | 93.33 | 0.95 |
| Forested land | 86.67 | 96.30 | 0.91 | 97.78 | 98.88 | 0.98 |
| Shrubland | 82.95 | 78.07 | 0.80 | 83.87 | 85.95 | 0.85 |
| Open woodland | 83.58 | 84.85 | 0.84 | 86.70 | 84.46 | 0.86 |
| Other woodlands | 69.33 | 83.87 | 0.76 | 53.66 | 73.33 | 0.62 |
| High-cover grassland | 86.23 | 85.89 | 0.86 | 86.51 | 93.16 | 0.90 |
| Medium-cover grassland | 85.14 | 79.75 | 0.82 | 94.92 | 88.99 | 0.92 |
| Low-cover grassland | 62.22 | 70.00 | 0.66 | 86.39 | 84.88 | 0.86 |
| Rivers, reservoirs, and ponds | 96.15 | 97.40 | 0.97 | 86.75 | 94.74 | 0.91 |
| Permanent snow | 98.67 | 98.67 | 0.99 | 97.78 | 100.00 | 0.99 |
| Construction land | 96.12 | 95.50 | 0.96 | 85.04 | 90.76 | 0.88 |
| Unutilized land | 44.44 | 66.67 | 0.53 | 91.06 | 96.55 | 0.94 |
| OA (%) | 89.02 | 90.78 | ||||
| Kappa | 0.8733 | 0.8916 | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, R.; Gao, X.; Shi, F. A Framework for Subregion Ensemble Learning Mapping of Land Use/Land Cover at the Watershed Scale. Remote Sens. 2024, 16, 3855. https://doi.org/10.3390/rs16203855
Li R, Gao X, Shi F. A Framework for Subregion Ensemble Learning Mapping of Land Use/Land Cover at the Watershed Scale. Remote Sensing. 2024; 16(20):3855. https://doi.org/10.3390/rs16203855
Chicago/Turabian StyleLi, Runxiang, Xiaohong Gao, and Feifei Shi. 2024. "A Framework for Subregion Ensemble Learning Mapping of Land Use/Land Cover at the Watershed Scale" Remote Sensing 16, no. 20: 3855. https://doi.org/10.3390/rs16203855
APA StyleLi, R., Gao, X., & Shi, F. (2024). A Framework for Subregion Ensemble Learning Mapping of Land Use/Land Cover at the Watershed Scale. Remote Sensing, 16(20), 3855. https://doi.org/10.3390/rs16203855