Dilated Spectral–Spatial Gaussian Transformer Net for Hyperspectral Image Classification


Abstract
1. Introduction
2. Methodology
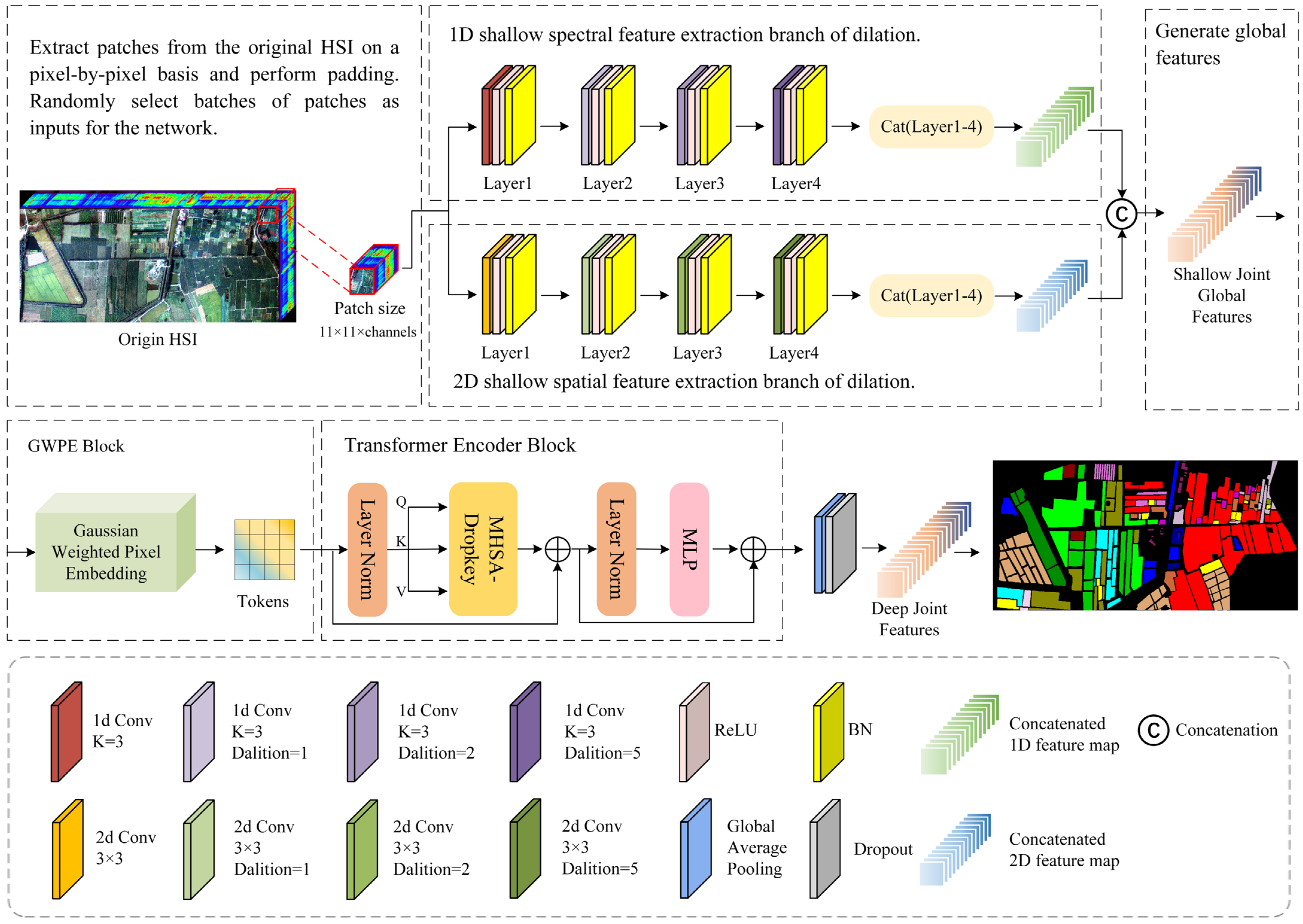
2.1. DSSGT Framework
2.2. Shallow Feature Extraction Backbone
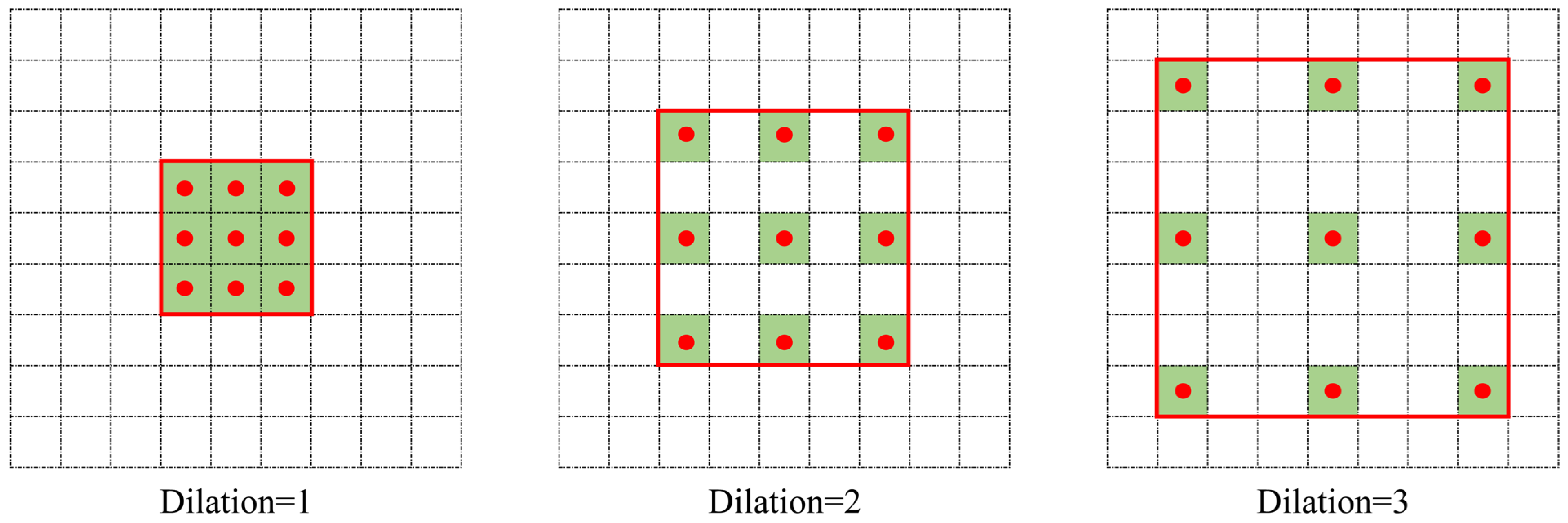
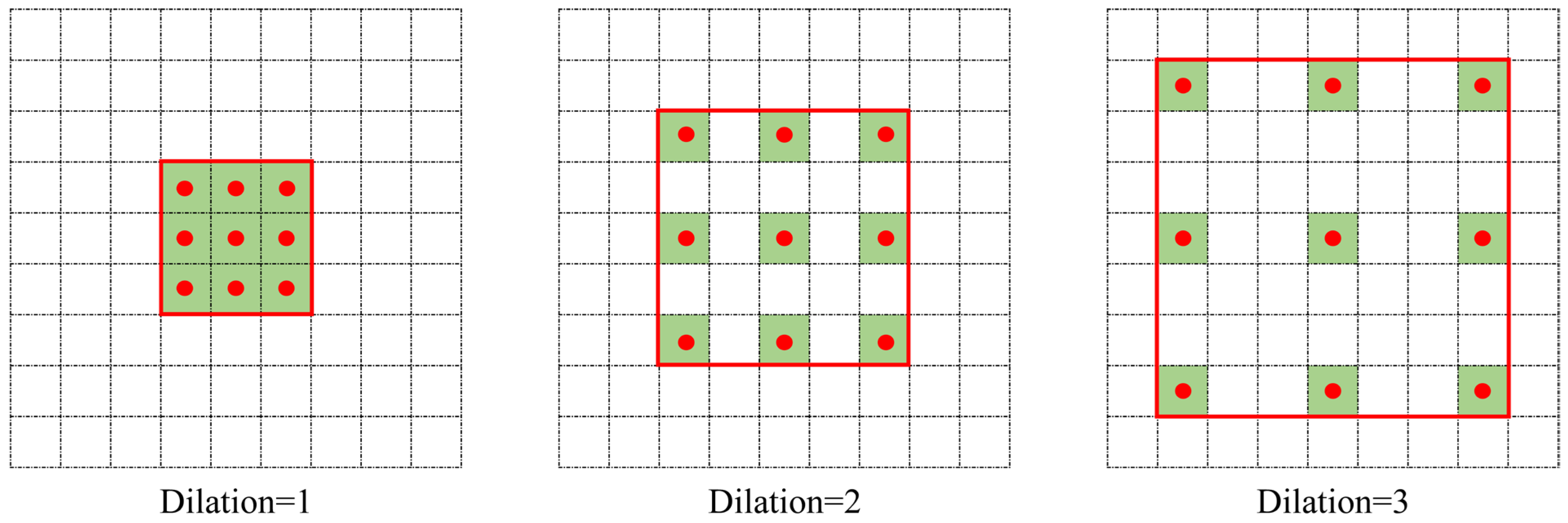
2.2.1. Convolution of One- and Two-Dimensional Dilation
2.2.2. Dilated Spectral–Spatial Feature Extraction
2.3. Deep Feature Fusion Backbone
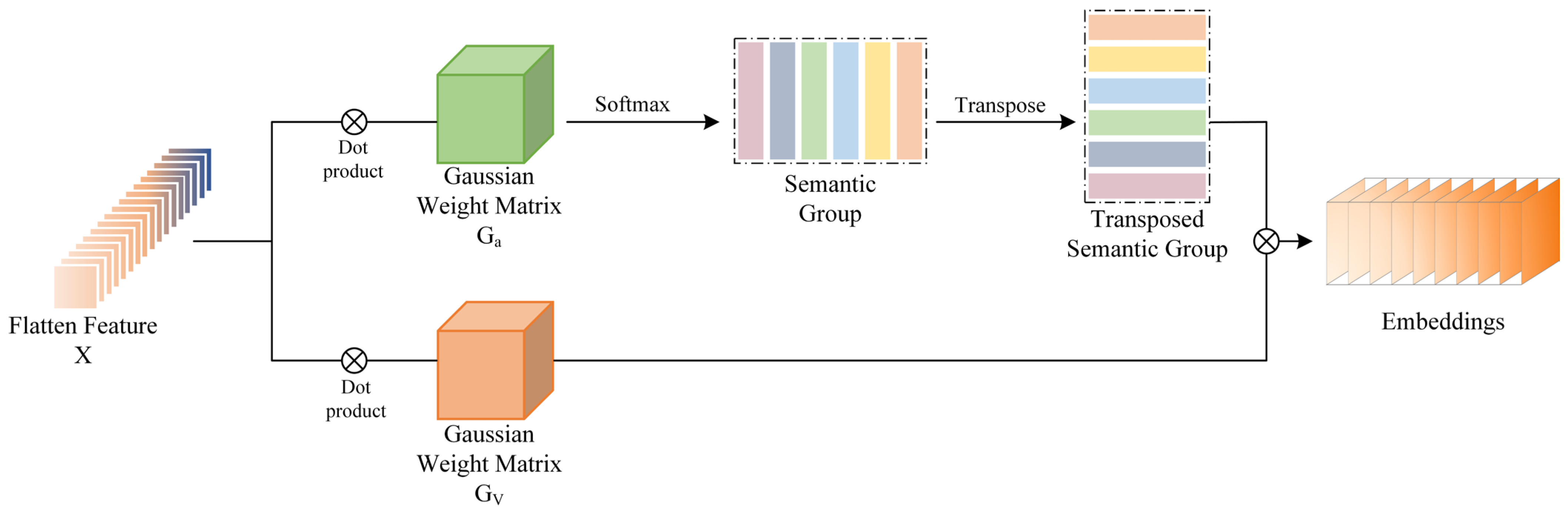
2.3.1. Gaussian Weighted Pixel Embedding
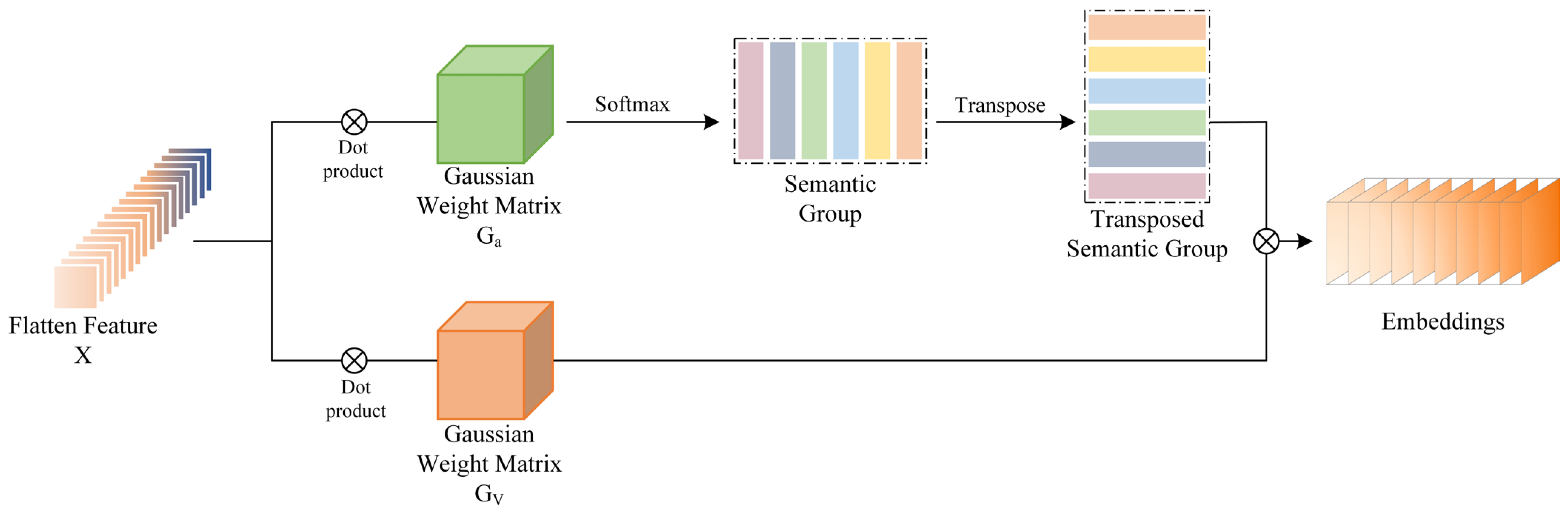
2.3.2. Transformer Encoder Block
3. Experiment and Analysis
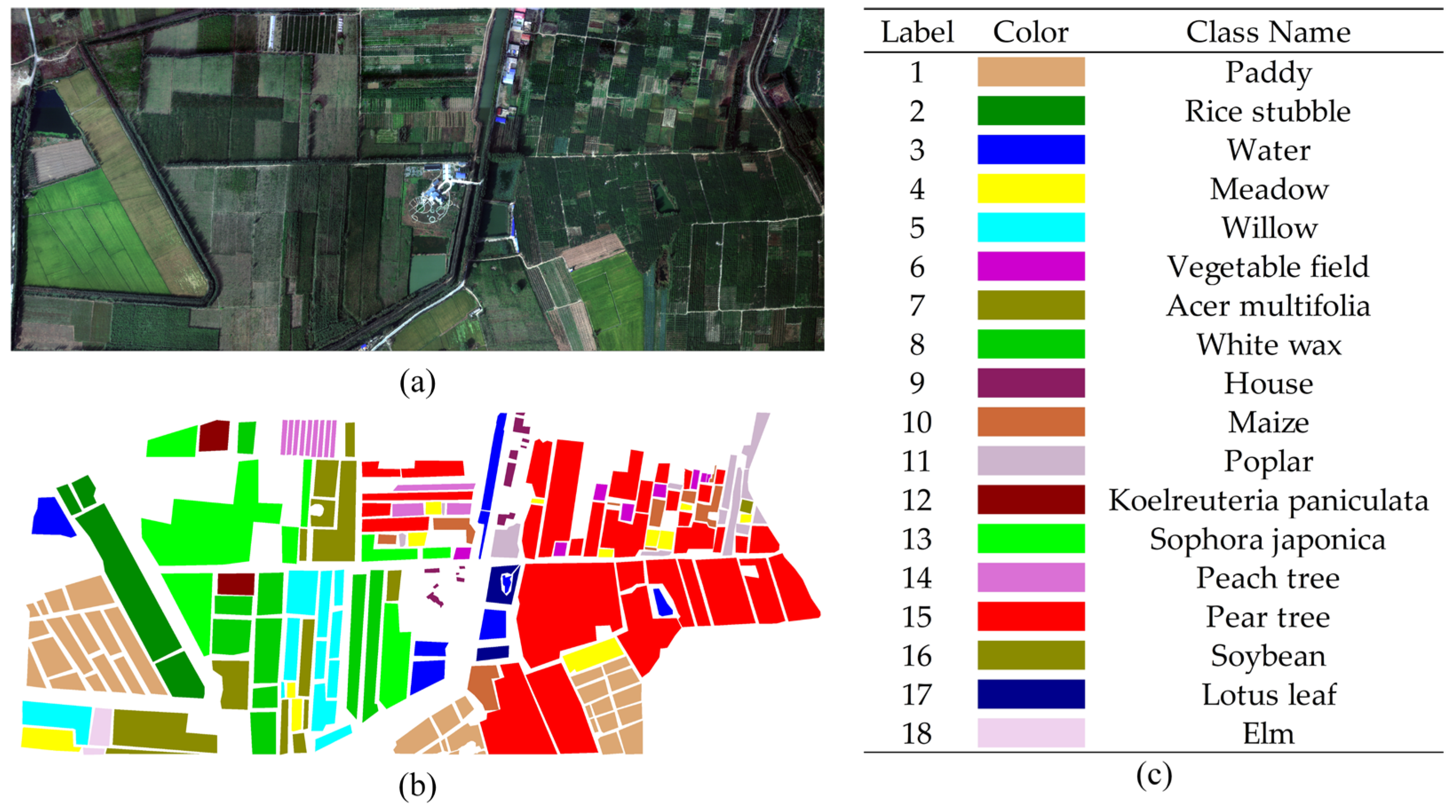
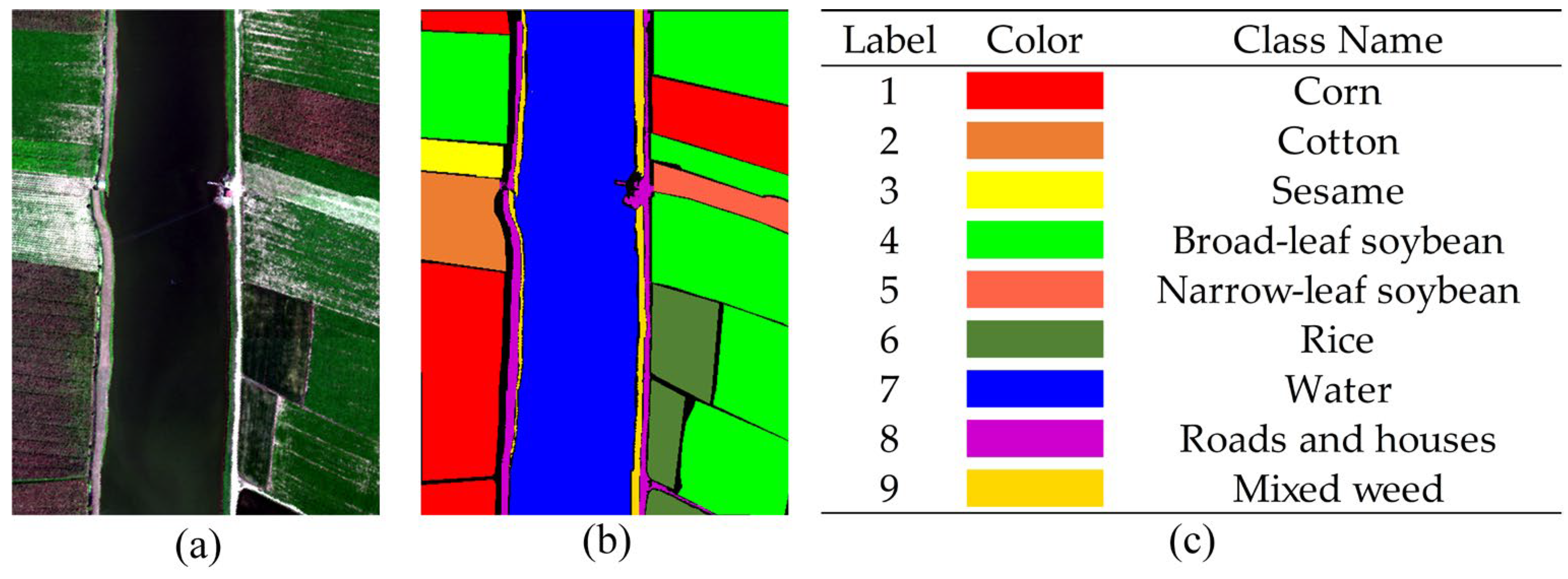
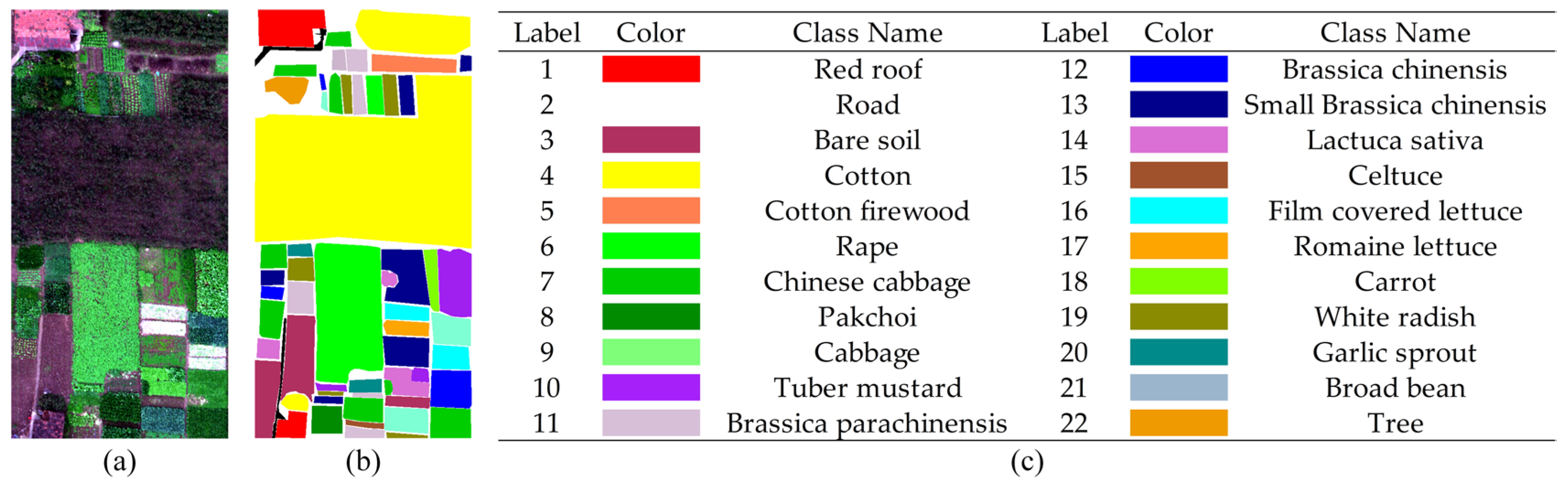
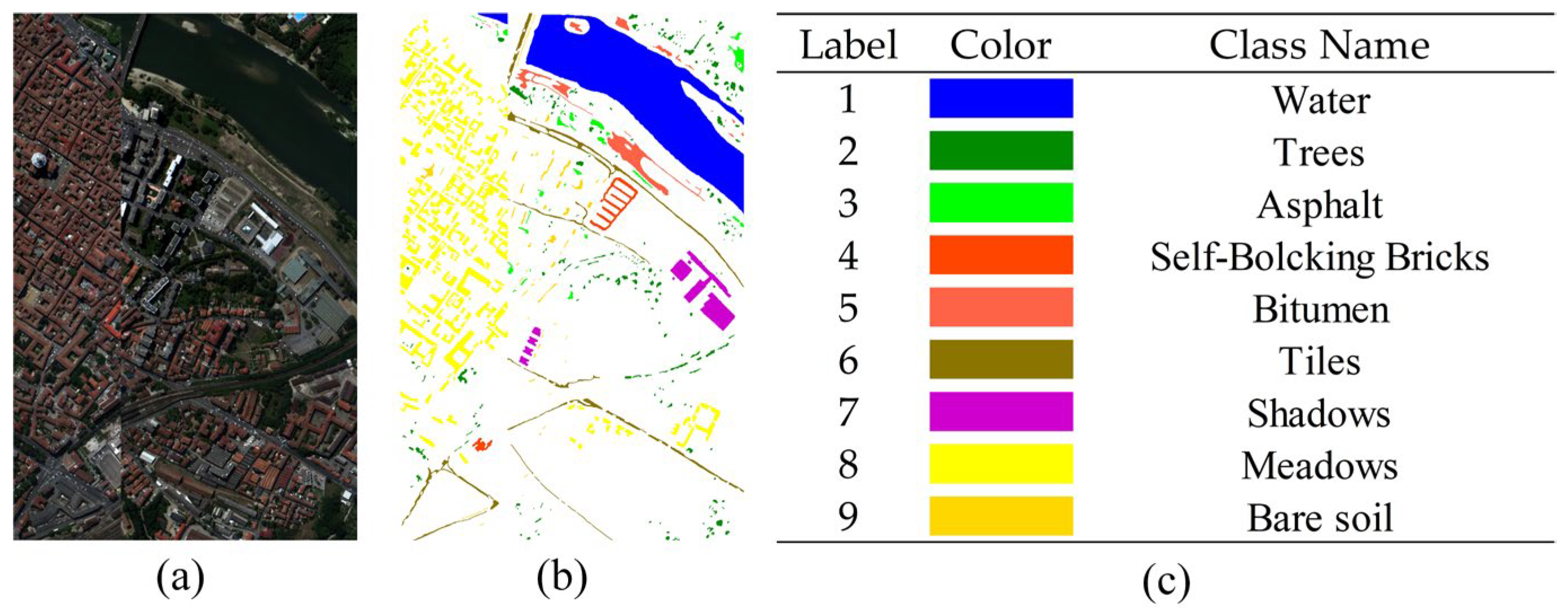
3.1. Data Description
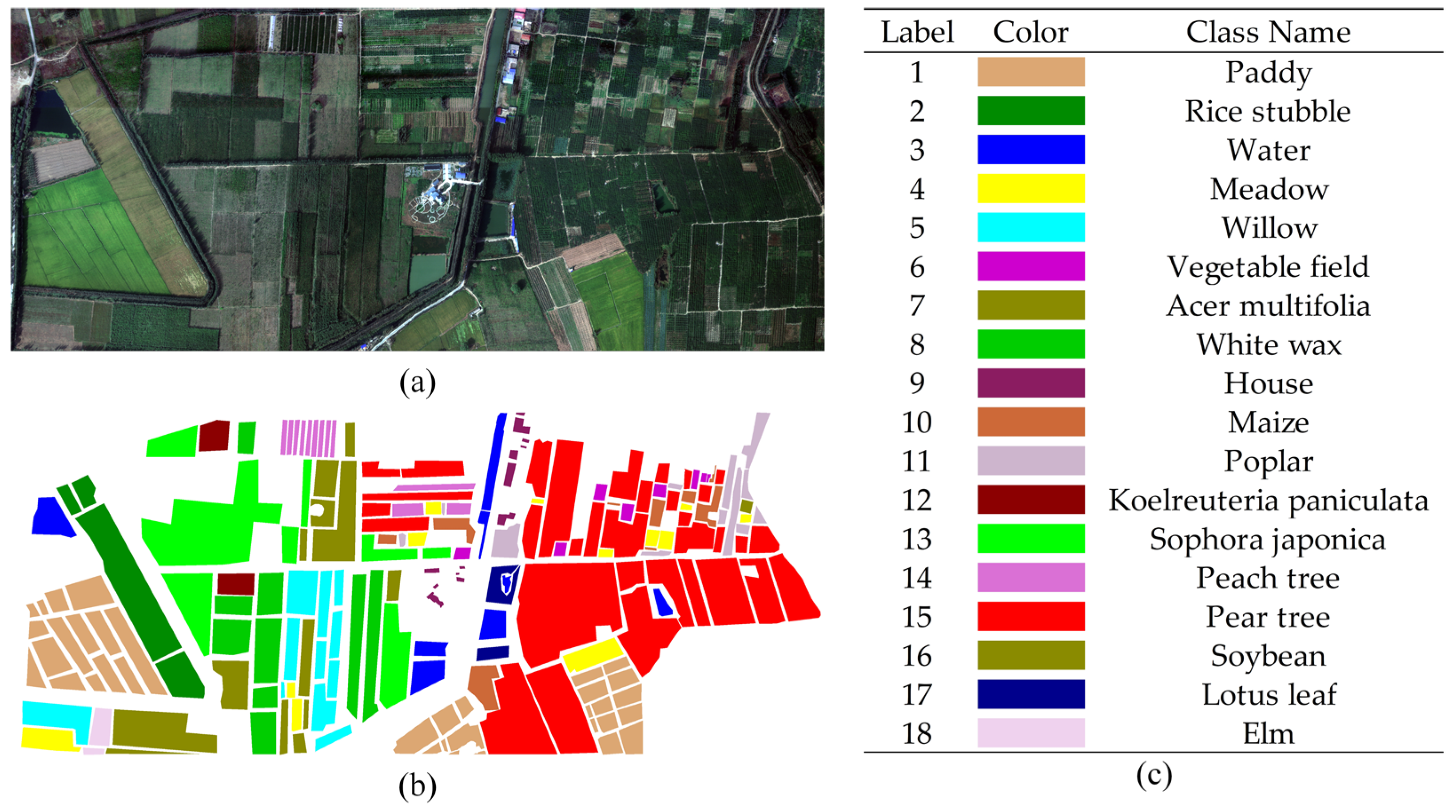
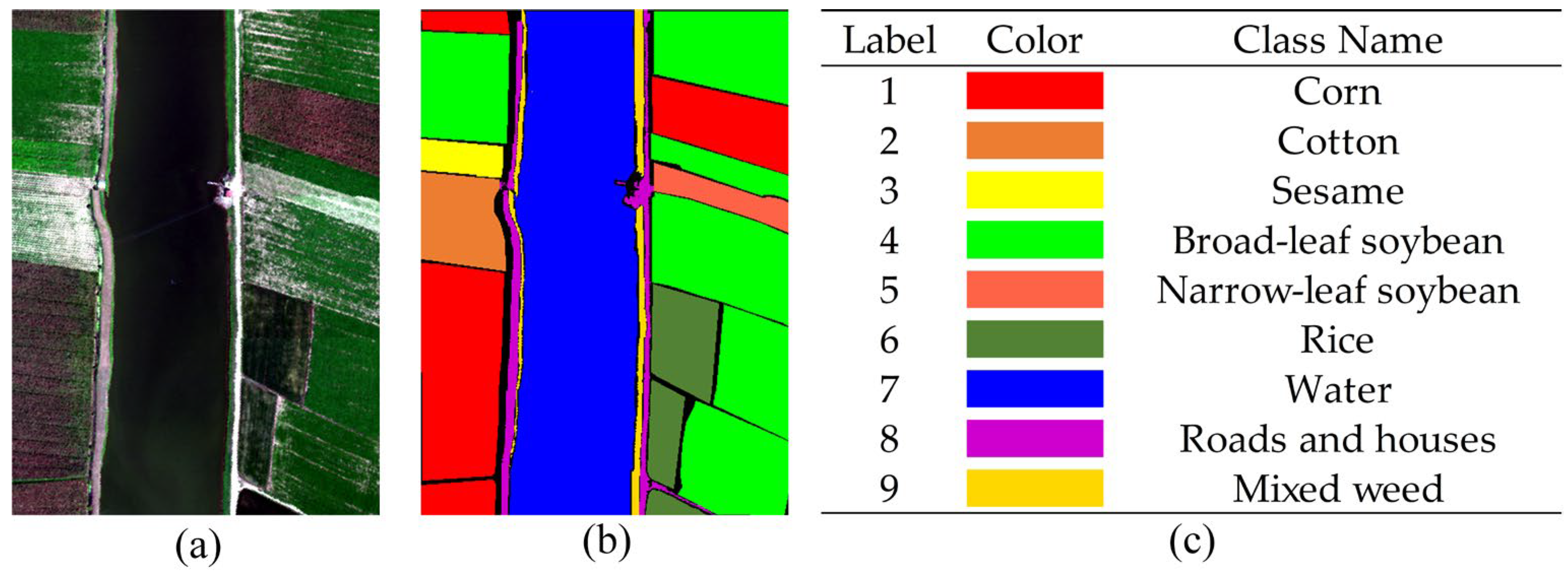
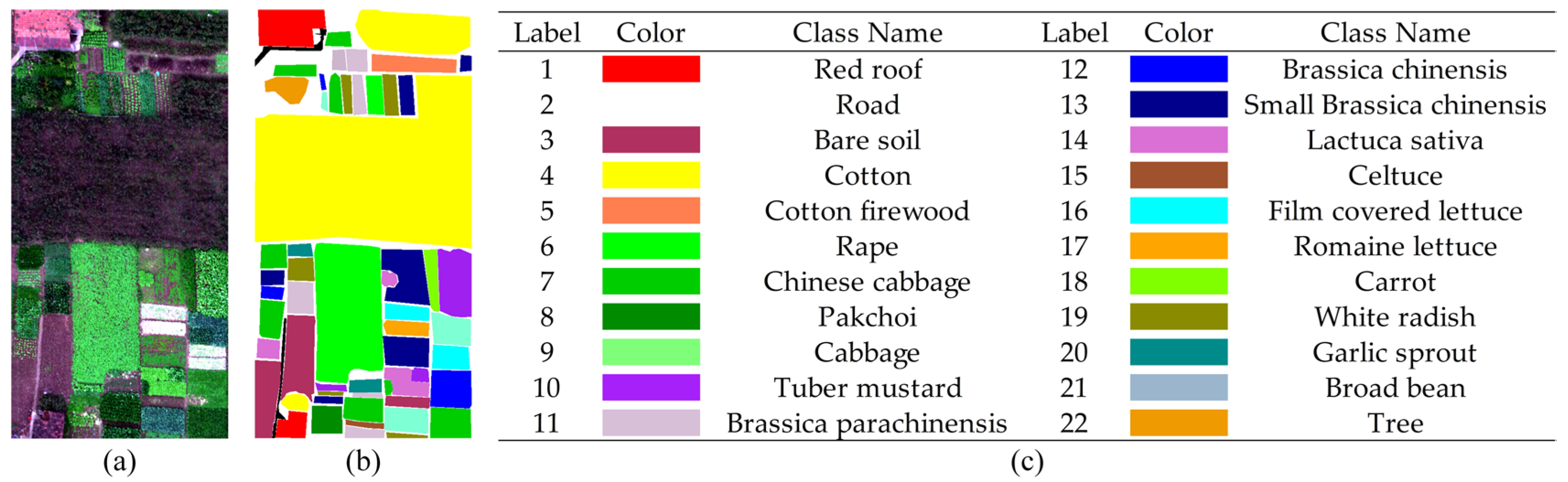

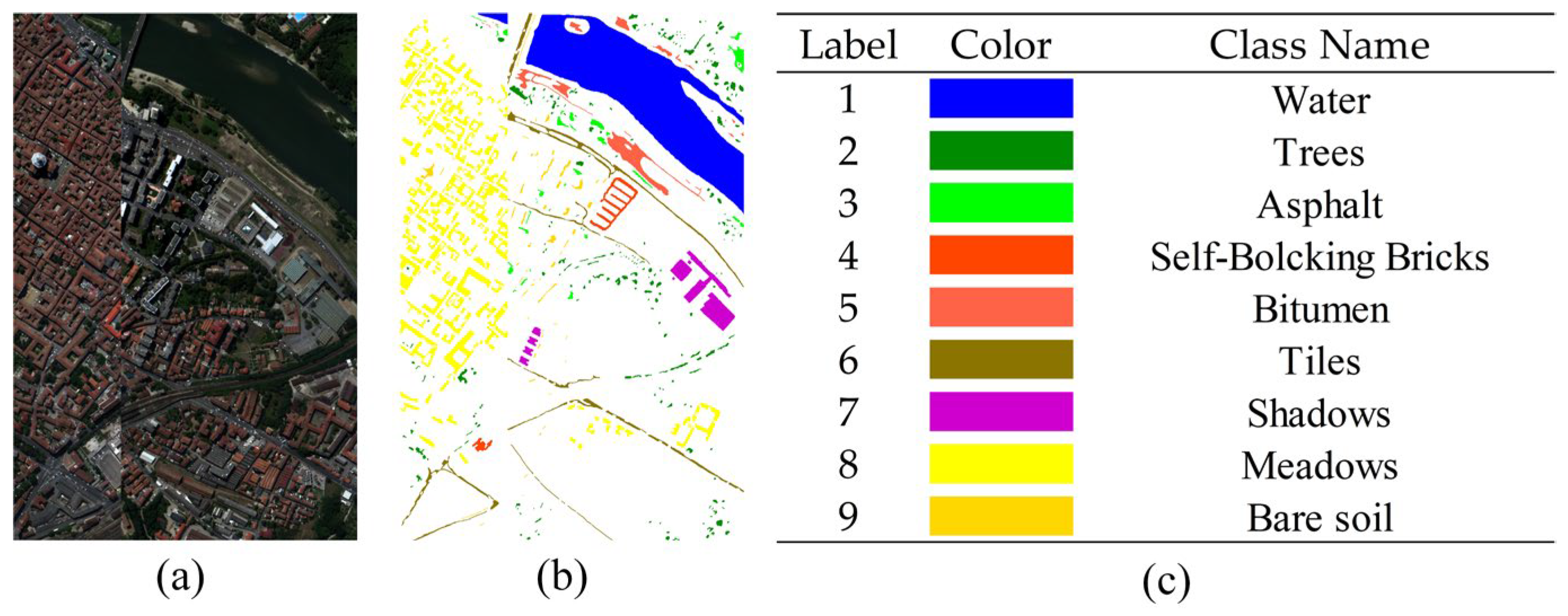
3.2. Experimental Setup
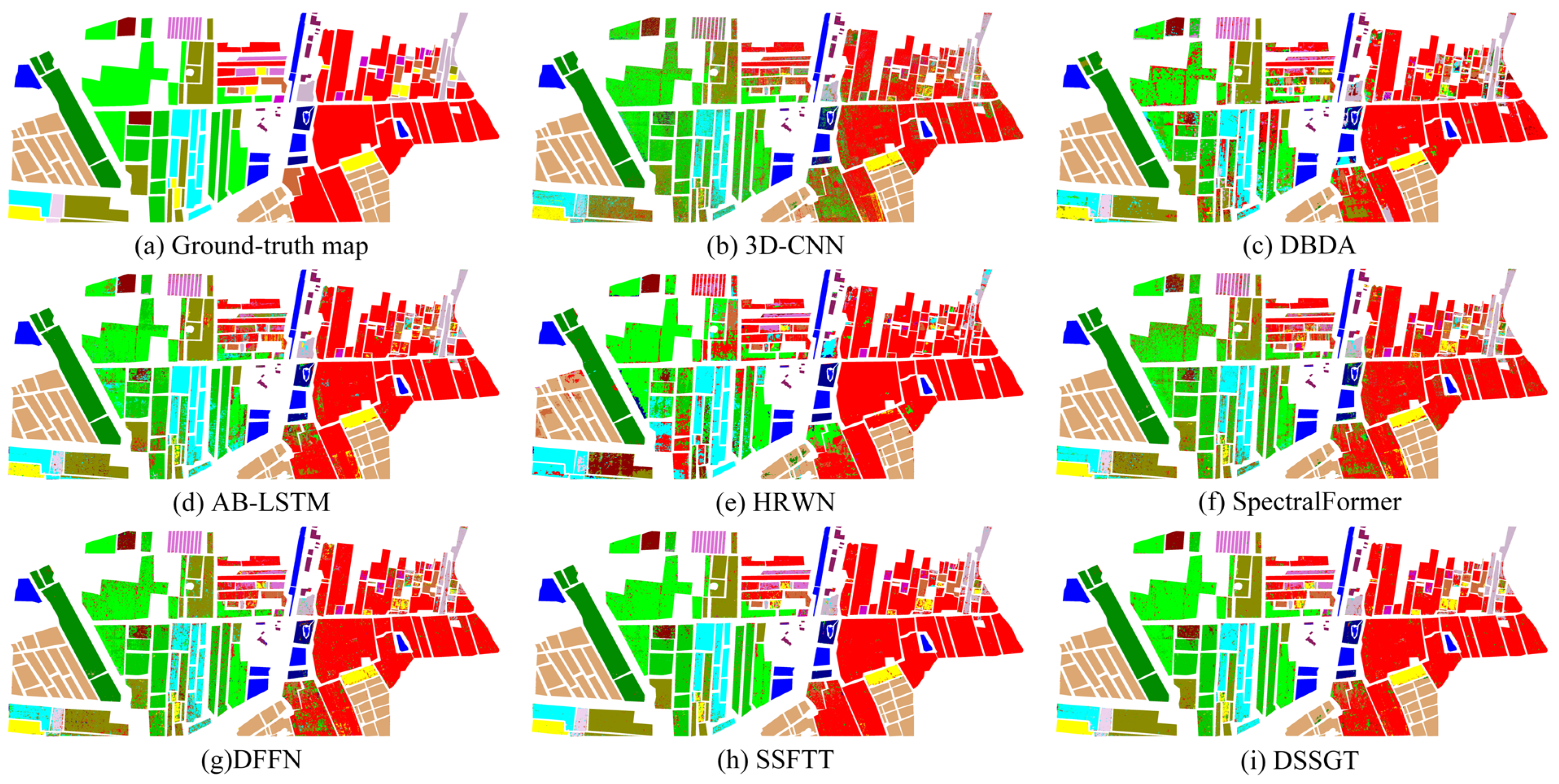
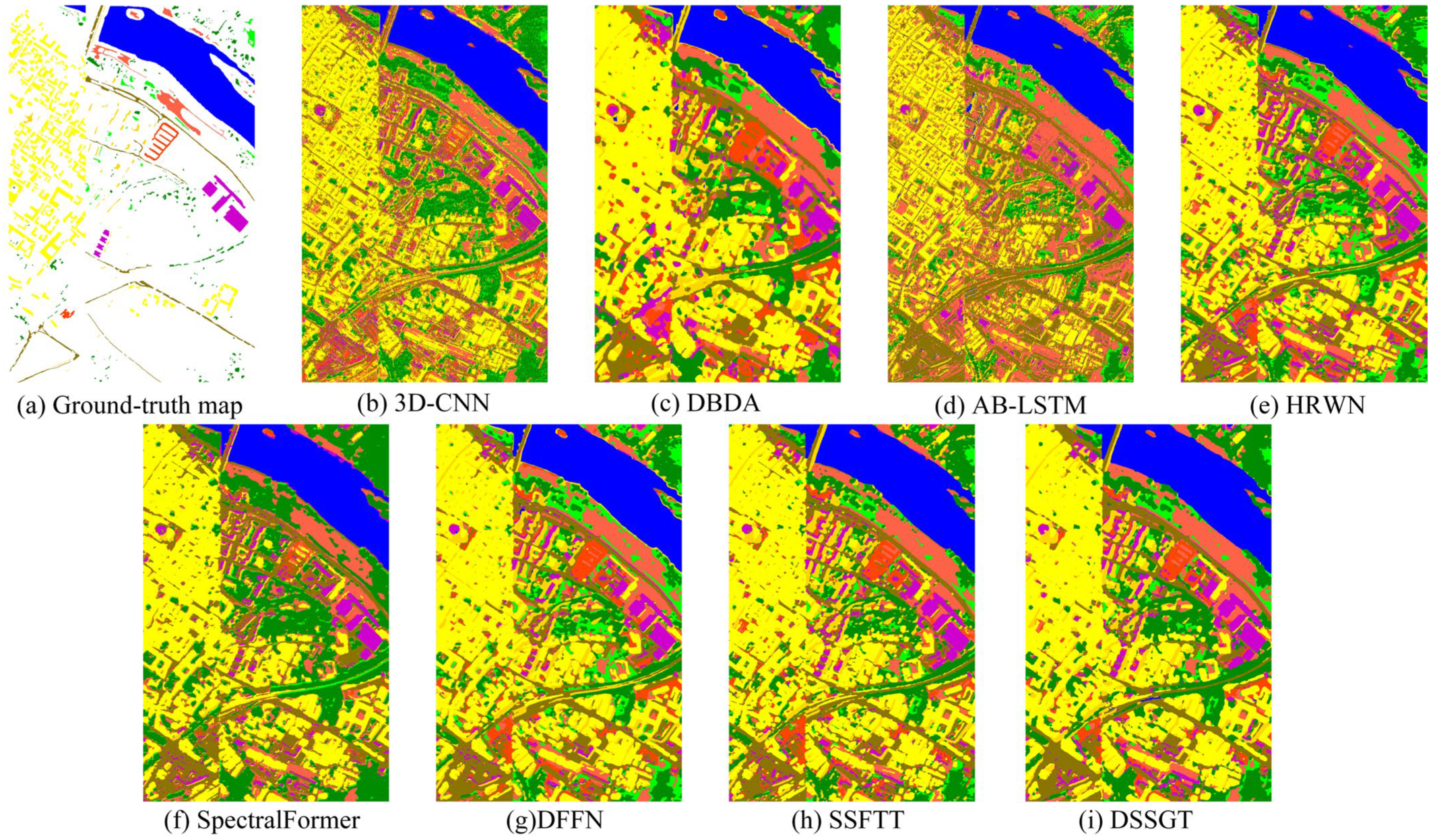
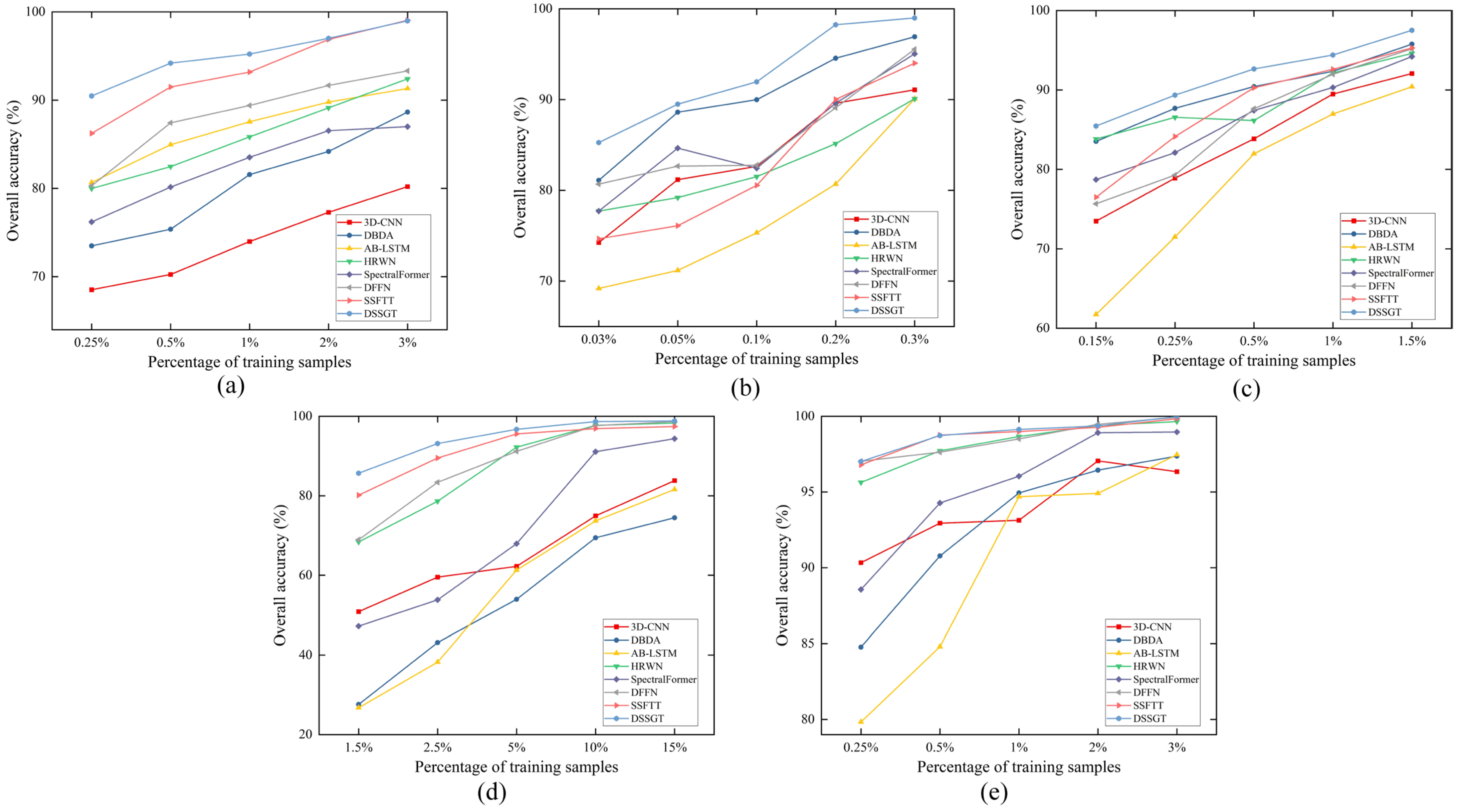
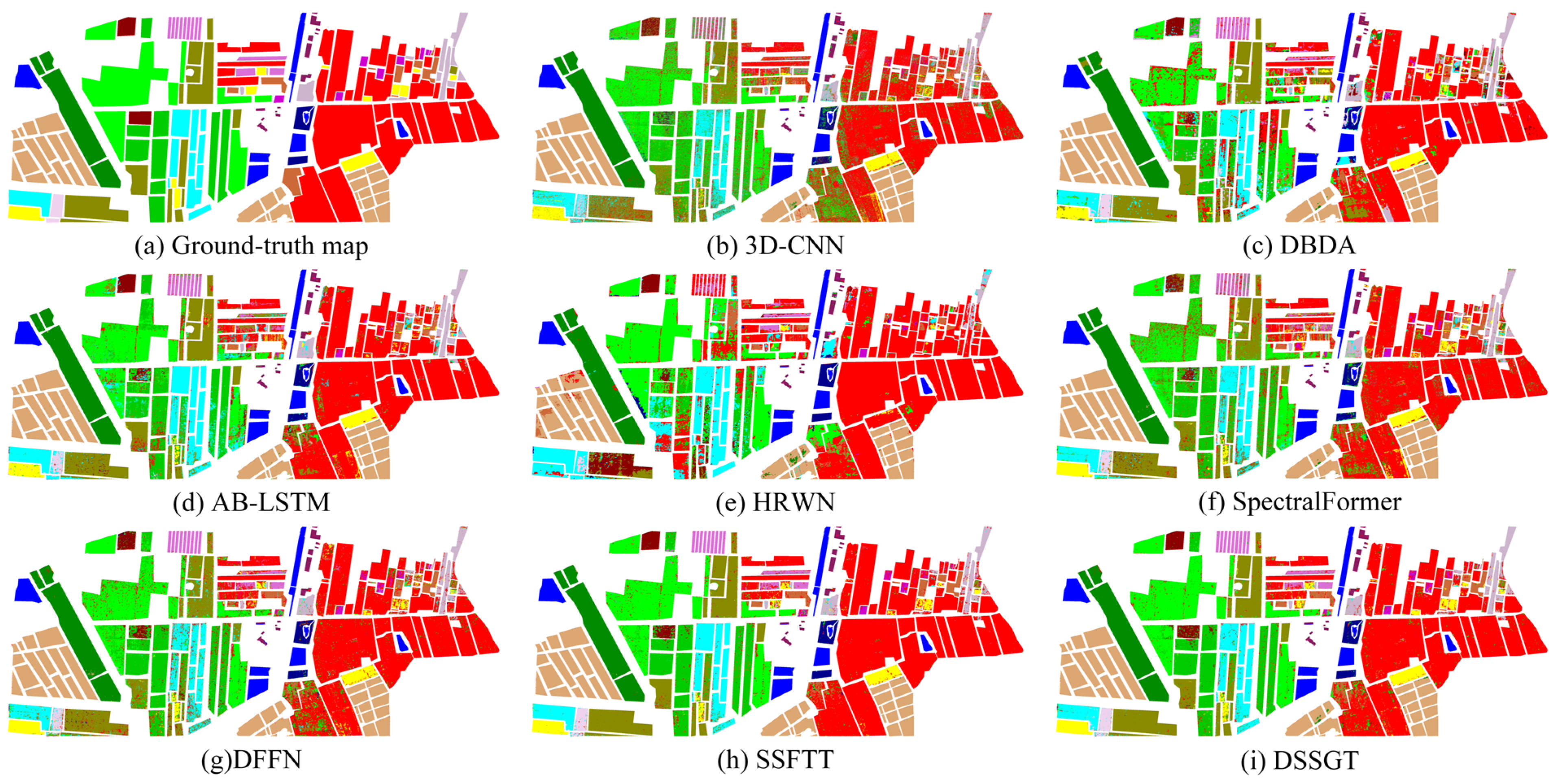
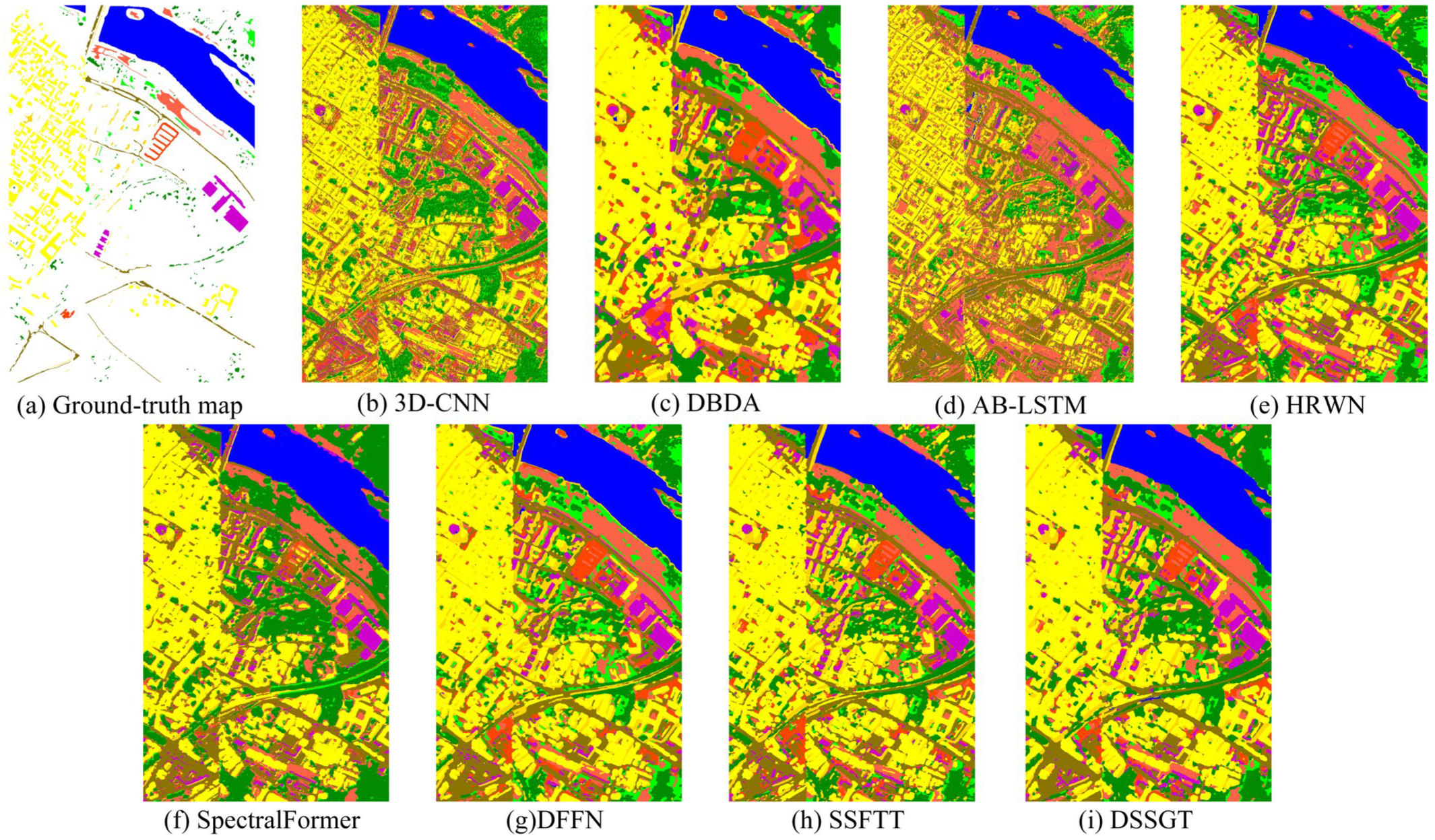
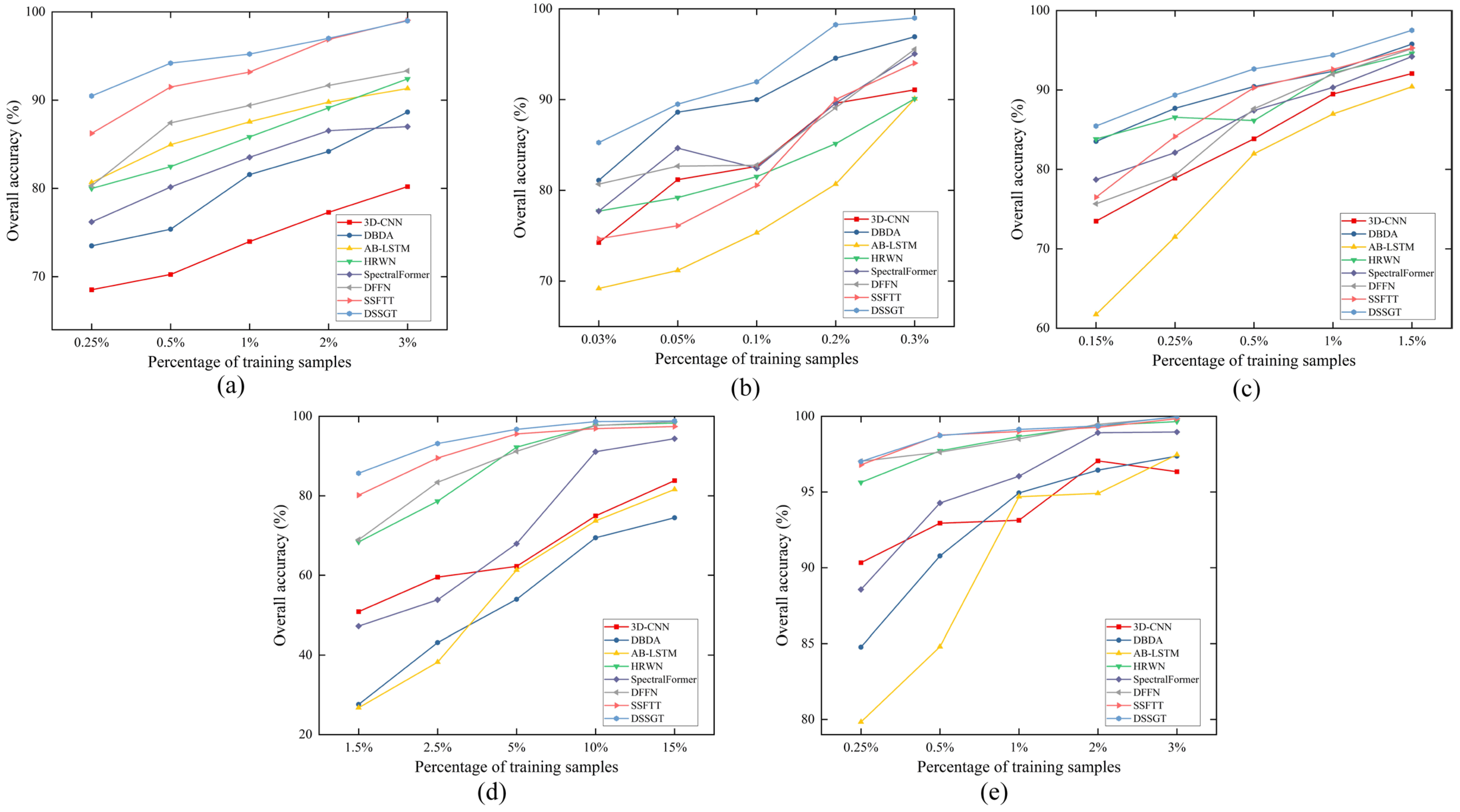
3.3. Experimental Results
3.4. Discussion
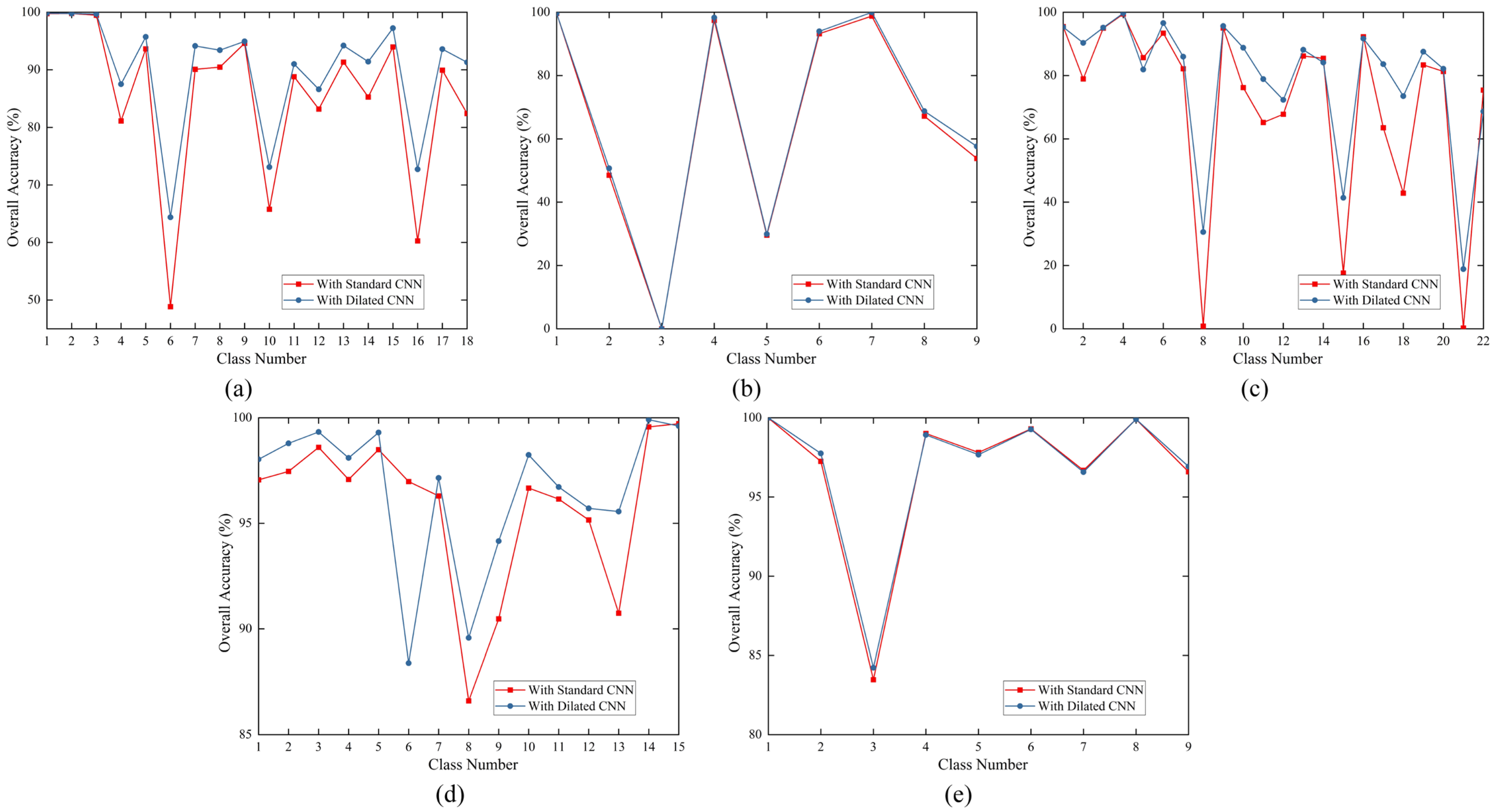
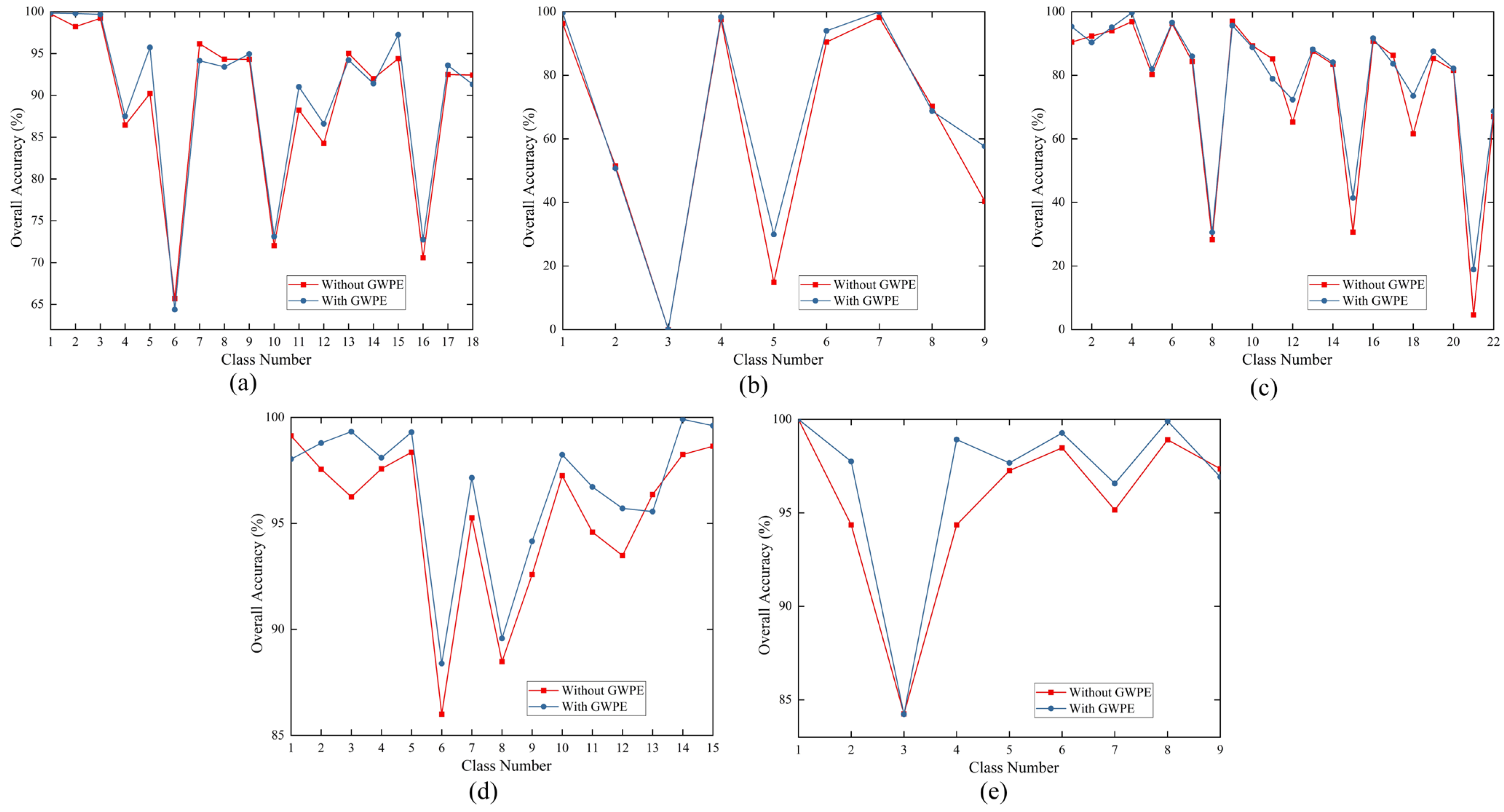
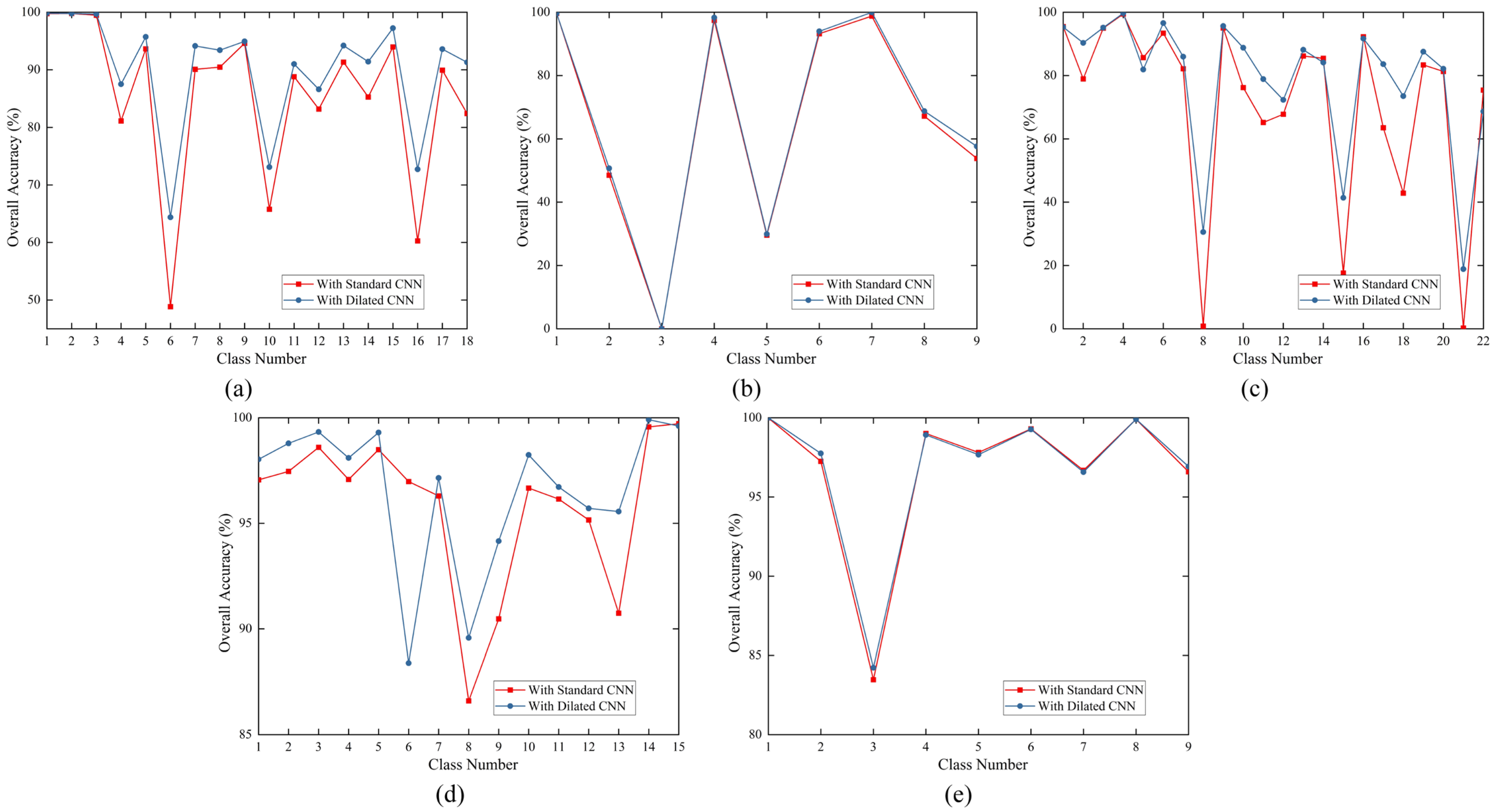
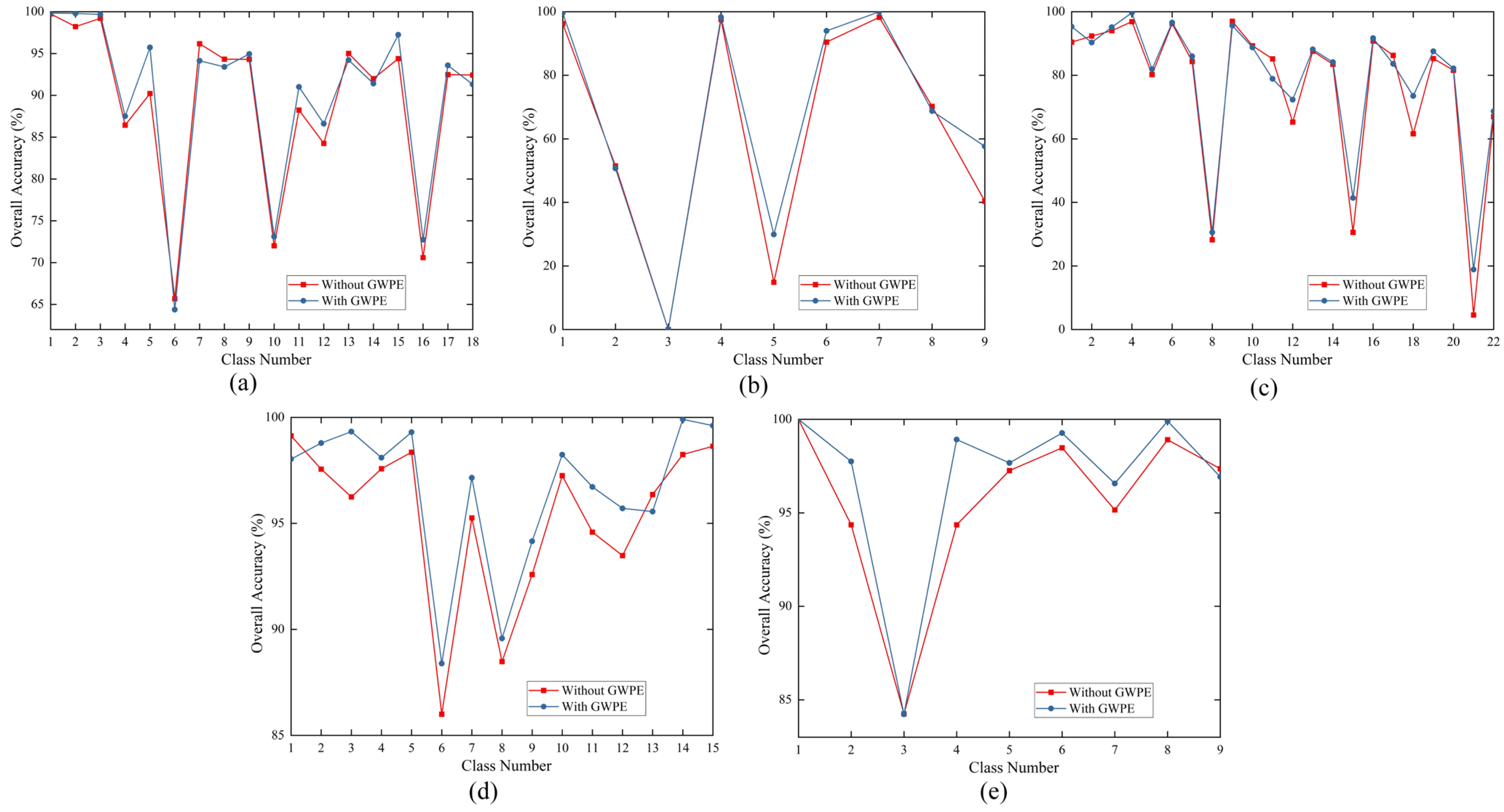
3.4.1. Ablation Experiments
3.4.2. Robustness Evaluation
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, M.; Zhao, J.; Zheng, J.; Wu, R. Review of Hyperspectral Imaging in Quality and Safety Inspections of Agricultural and Poultry Products. Trans. Chin. Soc. Agric. Mach. 2005, 36, 139–143. [Google Scholar]
- Wu, D.; Sun, D.-W. Advanced applications of hyperspectral imaging technology for food quality and safety analysis and assessment: A review—Part I: Fundamentals. Innov. Food Sci. Emerg. Technol. 2013, 19, 1–14. [Google Scholar] [CrossRef]
- Cui, R.; Yu, H.; Xu, T.; Xing, X.; Cao, X.; Yan, K.; Chen, J. Deep Learning in Medical Hyperspectral Images: A Review. Sensors 2022, 22, 9790. [Google Scholar] [CrossRef]
- Gerdes, N.; Hoff, C.; Hermsdorf, J.; Kaierle, S.; Overmeyer, L. Hyperspectral imaging for prediction of surface roughness in laser powder bed fusion. Int. J. Adv. Manuf. Technol. 2021, 115, 1249–1258. [Google Scholar] [CrossRef]
- Dong, X.; Yan, B.; Gan, F.; Li, N. Progress and prospectives on engineering application of hyperspectral remote sensing for geology and mineral resources. In Proceedings of the Fifth Symposium on Novel Optoelectronic Detection Technology and Application, Xi’an, China, 24–26 October 2018; SPIE: Bellingham, WA, USA, 2019. [Google Scholar]
- Luo, H.; Kan, Y.; Wang, L.; Fang, J.; Dai, S. Hyperspectral remote sensing for crop diseases and pest dectection. Guandong Agric. Sci. 2012, 39, 76–80. [Google Scholar]
- Sun, L.; He, C.; Zheng, Y.; Tang, S. SLRL4D: Joint Restoration of Subspace Low-Rank Learning and Non-Local 4-D Transform Filtering for Hyperspectral Image. Remote Sens. 2020, 12, 2979. [Google Scholar] [CrossRef]
- Wang, R.; Li, H.-C.; Liao, W.; Huang, X.; Philips, W. Centralized Collaborative Sparse Unmixing for Hyperspectral Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 1949–1962. [Google Scholar] [CrossRef]
- Mou, L.; Ghamisi, P.; Zhu, X.X. Deep Recurrent Neural Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3639–3655. [Google Scholar] [CrossRef]
- Ge, H.; Tang, Y.; Bi, Z.; Zhan, T.; Xu, Y.; Song, A. MMSRC: A Multidirection Multiscale Spectral-Spatial Residual Network for Hyperspectral Multiclass Change Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 9254–9265. [Google Scholar] [CrossRef]
- Hou, Z.; Li, W.; Li, L.; Tao, R.; Du, Q. Hyperspectral Change Detection Based on Multiple Morphological Profiles. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5507312. [Google Scholar] [CrossRef]
- Chen, H.; Du, X.; Liu, Z.; Cheng, X.; Zhou, Y.; Zhou, B. Target Recognition Algorithm for Fused Hyperspectral Image by Using Combined Spectra. Spectrosc. Lett. 2015, 48, 251–258. [Google Scholar] [CrossRef]
- Haitao, L.I.; Haiyan, G.U.; Bing, Z.; Lianru, G.A.O. Research on Hyperspectral Remote Sensing Image Classification Based on MNF and SVM. Remote Sens. Inf. 2007, 12–15, 25. [Google Scholar]
- Ma, X.; Yan, W.; Bian, H.; Sun, B.; Wang, P. Hyperspectral Remote Sensing Classification Based on SVM with End-member Extraction. In Proceedings of the MIPPR 2013: Remote Sensing Image Processing, Geographic Information Systems, and Other Applications, Wuhan, China, 26–27 October 2013; SPIE: Bellingham, WA, USA, 2013. [Google Scholar]
- Li, Y.; Wang, H.; Lv, X. The Comparison of Several Classification Algorithms and Case Analysis. In Proceedings of the International Conference on Graphic and Image Processing (ICGIP 2012), Singapore, 5–7 October 2012; SPIE: Bellingham, WA, USA, 2013. [Google Scholar]
- Zeng, Y.; Yang, Y.; Zhao, L. Nonparametric classification based on local mean and class statistics. Expert Syst. Appl. 2009, 36, 8443–8448. [Google Scholar] [CrossRef]
- Dalla Mura, M.; Villa, A.; Benediktsson, J.A.; Chanussot, J.; Bruzzone, L. Classification of Hyperspectral Images by Using Extended Morphological Attribute Profiles and Independent Component Analysis. IEEE Geosci. Remote Sens. Lett. 2011, 8, 542–546. [Google Scholar] [CrossRef]
- Su, H.; Sheng, Y.; Du, P.; Chen, C.; Liu, K. Hyperspectral image classification based on volumetric texture and dimensionality reduction. Front. Earth Sci. 2015, 9, 225–236. [Google Scholar] [CrossRef]
- Wang, Z.; Du, B.; Zhang, L.; Zhang, L. Based on Texture Feature and Extend Morphological Profile Fusion for Hyperspectral Image Classification. Acta Photonica Sin. 2014, 43, 0810002. [Google Scholar] [CrossRef]
- Licciardi, G.; Marpu, P.R.; Chanussot, J.; Benediktsson, J.A. Linear Versus Nonlinear PCA for the Classification of Hyperspectral Data Based on the Extended Morphological Profiles. IEEE Geosci. Remote Sens. Lett. 2012, 9, 447–451. [Google Scholar] [CrossRef]
- Ren, Y.; Liao, L.; Maybank, S.J.; Zhang, Y.; Liu, X. Hyperspectral Image Spectral-Spatial Feature Extraction via Tensor Principal Component Analysis. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1431–1435. [Google Scholar] [CrossRef]
- Liu, J. Hyperspectral Remote Sensing Image Terrain Classification Based on Direct LDA. Comput. Sci. 2011, 38, 274–277. [Google Scholar]
- Yang, M.; Fan, Y.; Li, B. Research on dimensionality reduction and classification of hyperspectral images based on LDA and ELM. J. Electron. Meas. Instrum. 2020, 34, 190–196. [Google Scholar]
- Hu, W.; Huang, Y.; Wei, L.; Zhang, F.; Li, H. Deep Convolutional Neural Networks for Hyperspectral Image Classification. J. Sens. 2015, 2015, 258619. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, X.; Ye, Y.; Lau, R.Y.K.; Lu, S.; Li, X.; Huang, X. Synergistic 2D/3D Convolutional Neural Network for Hyperspectral Image Classification. Remote Sens. 2020, 12, 2033. [Google Scholar] [CrossRef]
- Shi, C.; Liao, D.; Zhang, T.; Wang, L. Hyperspectral Image Classification Based on Expansion Convolution Network. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5528316. [Google Scholar] [CrossRef]
- Li, J.; Zhao, X.; Li, Y.; Du, Q.; Xi, B.; Hu, J. Classification of Hyperspectral Imagery Using a New Fully Convolutional Neural Network. IEEE Geosci. Remote Sens. Lett. 2018, 15, 292–296. [Google Scholar] [CrossRef]
- He, N.; Paoletti, M.E.; Mario Haut, J.; Fang, L.; Li, S.; Plaza, A.; Plaza, J. Feature Extraction with Multiscale Covariance Maps for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 755–769. [Google Scholar] [CrossRef]
- Roy, S.K.; Krishna, G.; Dubey, S.R.; Chaudhuri, B.B. HybridSN: Exploring 3-D–2-D CNN Feature Hierarchy for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2020, 17, 277–281. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: New York, NY, USA, 2016; pp. 770–778. [Google Scholar]
- Song, W.; Li, S.; Fang, L.; Lu, T. Hyperspectral Image Classification with Deep Feature Fusion Network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3173–3184. [Google Scholar] [CrossRef]
- Feng, F.; Zhang, Y.; Zhang, J.; Liu, B. Small Sample Hyperspectral Image Classification Based on Cascade Fusion of Mixed Spatial-Spectral Features and Second-Order Pooling. Remote Sens. 2022, 14, 505. [Google Scholar] [CrossRef]
- Meng, Z.; Zhao, F.; Liang, M.; Xie, W. Deep Residual Involution Network for Hyperspectral Image Classification. Remote Sens. 2021, 13, 3055. [Google Scholar] [CrossRef]
- Wang, S.; Liu, Z.; Chen, Y.; Hou, C.; Liu, A.; Zhang, Z. Expansion Spectral-Spatial Attention Network for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 6411–6427. [Google Scholar] [CrossRef]
- Zhao, C.; Zhu, W.; Feng, S. Hyperspectral Image Classification Based on Kernel-Guided Deformable Convolution and Double-Window Joint Bilateral Filter. IEEE Geosci. Remote Sens. Lett. 2022, 19, 5506505. [Google Scholar] [CrossRef]
- Zhao, Z.; Xu, X.; Li, J.; Li, S.; Plaza, A. Gabor-Modulated Grouped Separable Convolutional Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5518817. [Google Scholar] [CrossRef]
- Xu, F.; Zhang, G.; Song, C.; Wang, H.; Mei, S. Multiscale and Cross-Level Attention Learning for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5501615. [Google Scholar] [CrossRef]
- Wang, X.; Tan, K.; Du, P.; Pan, C.; Ding, J. A Unified Multiscale Learning Framework for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4508319. [Google Scholar] [CrossRef]
- Wang, L.; Zhu, T.; Kumar, N.; Li, Z.; Wu, C.; Zhang, P. Attentive-Adaptive Network for Hyperspectral Images Classification with Noisy Labels. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5505514. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Duan, C.; Yang, Y.; Wang, X. Classification of Hyperspectral Image Based on Double-Branch Dual-Attention Mechanism Network. Remote Sens. 2020, 12, 582. [Google Scholar] [CrossRef]
- Cai, W.; Ning, X.; Zhou, G.; Bai, X.; Jiang, Y.; Li, W.; Qian, P. A Novel Hyperspectral Image Classification Model Using Bole Convolution with Three-Direction Attention Mechanism: Small Sample and Unbalanced Learning. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5500917. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Gao, F.; Huang, H.; Yue, Z.; Li, D.; Ge, S.S.; Lee, T.H.; Zhou, H. Cross-Modality Features Fusion for Synthetic Aperture Radar Image Segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5214814. [Google Scholar] [CrossRef]
- Zhong, H.-F.; Sun, Q.; Sun, H.-M.; Jia, R.-S. NT-Net: A Semantic Segmentation Network for Extracting Lake Water Bodies from Optical Remote Sensing Images Based on Transformer. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5627513. [Google Scholar] [CrossRef]
- Zhang, C.; Su, J.; Ju, Y.; Lam, K.-M.; Wang, Q. Efficient Inductive Vision Transformer for Oriented Object Detection in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5616320. [Google Scholar] [CrossRef]
- Zhou, Y.; Chen, S.; Zhao, J.; Yao, R.; Xue, Y.; El Saddik, A. CLT-Det: Correlation Learning Based on Transformer for Detecting Dense Objects in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4708915. [Google Scholar] [CrossRef]
- Sun, L.; Zhao, G.; Zheng, Y.; Wu, Z. Spectral–Spatial Feature Tokenization Transformer for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5522214. [Google Scholar] [CrossRef]
- Zhang, J.; Meng, Z.; Zhao, F.; Liu, H.; Chang, Z. Convolution Transformer Mixer for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6014205. [Google Scholar] [CrossRef]
- Cao, X.; Lin, H.; Guo, S.; Xiong, T.; Jiao, L. Transformer-Based Masked Autoencoder with Contrastive Loss for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5524312. [Google Scholar] [CrossRef]
- Li, B.; Wang, Q.-W.; Liang, J.-H.; Zhu, E.-Z.; Zhou, R.-Q. SquconvNet: Deep Sequencer Convolutional Network for Hyperspectral Image Classification. Remote Sens. 2023, 15, 983. [Google Scholar] [CrossRef]
- Qiu, Z.; Xu, J.; Peng, J.; Sun, W. Cross-Channel Dynamic Spatial-Spectral Fusion Transformer for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5528112. [Google Scholar] [CrossRef]
- Zhao, Z.; Hu, D.; Wang, H.; Yu, X. Convolutional Transformer Network for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6009005. [Google Scholar] [CrossRef]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding Convolution for Semantic Segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV 2018), Lake Tahoe, NV, USA, 12–15 March 2018; IEEE: New York, NY, USA, 2018; pp. 1451–1460. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Ben Hamida, A.; Benoit, A.; Lambert, P.; Ben Amar, C. 3-D Deep Learning Approach for Remote Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4420–4434. [Google Scholar] [CrossRef]
- Mei, S.; Li, X.; Liu, X.; Cai, H.; Du, Q. Hyperspectral Image Classification Using Attention-Based Bidirectional Long Short-Term Memory Network. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5509612. [Google Scholar] [CrossRef]
- Zhao, X.; Tao, R.; Li, W.; Li, H.-C.; Du, Q.; Liao, W.; Philips, W. Joint Classification of Hyperspectral and LiDAR Data Using Hierarchical Random Walk and Deep CNN Architecture. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7355–7370. [Google Scholar] [CrossRef]
- Hong, D.; Han, Z.; Yao, J.; Gao, L.; Zhang, B.; Plaza, A.; Chanussot, J. SpectralFormer: Rethinking Hyperspectral Image Classification with Transformers. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5518615. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label | Train | Test | Methods | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 3D-CNN | DBDA | AB-LSTM | HRWN | SpectralFormer | DFFN | SSFTT | DSSGT | |||
| 1 | 3117 | 305,486 | 99.03 ± 0.15 | 99.33 ± 0.23 | 99.86 ± 0.06 | 97.62 ± 3.20 | 99.63 ± 0.09 | 99.24 ± 0.54 | 99.65 ± 0.19 | 99.84 ± 0.06 |
| 2 | 1580 | 154,928 | 97.44 ± 1.65 | 98.67 ± 0.67 | 99.88 ± 0.10 | 99.51 ± 0.67 | 99.72 ± 0.05 | 99.43 ± 0.33 | 99.69 ± 0.19 | 99.79 ± 0.09 |
| 3 | 990 | 97,089 | 96.50 ± 2.19 | 99.48 ± 0.12 | 99.59 ± 0.15 | 99.70 ± 0.12 | 99.28 ± 0.19 | 99.83 ± 0.06 | 99.67 ± 0.14 | 99.68 ± 0.06 |
| 4 | 797 | 78,165 | 62.00 ± 7.55 | 60.77 ± 6.65 | 66.92 ± 8.63 | 57.99 ± 37.07 | 68.59 ± 5.37 | 80.49 ± 0.82 | 84.35 ± 2.61 | 87.51 ± 2.85 |
| 5 | 1541 | 151,047 | 75.33 ± 6.60 | 85.92 ± 3.21 | 91.78 ± 2.95 | 94.64 ± 3.96 | 79.88 ± 6.51 | 85.22 ± 4.11 | 93.02 ± 0.43 | 95.72 ± 1.34 |
| 6 | 221 | 21,746 | 21.20 ± 3.30 | 27.31 ± 8.92 | 14.56 ± 10.44 | 40.90 ± 16.76 | 28.18 ± 11.87 | 48.78 ± 3.28 | 52.91 ± 4.94 | 64.38 ± 5.38 |
| 7 | 2391 | 234,377 | 58.81 ± 3.77 | 83.61 ± 2.46 | 88.22 ± 4.39 | 61.40 ± 35.94 | 81.80 ± 3.46 | 85.68 ± 4.52 | 93.32 ± 0.86 | 94.14 ± 1.31 |
| 8 | 2171 | 212,807 | 45.65 ± 11.14 | 69.88 ± 6.46 | 80.01 ± 1.30 | 69.38 ± 21.58 | 74.96 ± 1.31 | 86.93 ± 1.93 | 92.70 ± 1.62 | 93.41 ± 0.72 |
| 9 | 180 | 17,640 | 87.70 ± 2.88 | 88.81 ± 2.07 | 92.91 ± 1.76 | 92.76 ± 5.84 | 80.93 ± 7.02 | 93.31 ± 0.90 | 94.98 ± 0.99 | 94.94 ± 1.10 |
| 10 | 583 | 57,163 | 27.42 ± 1.36 | 34.81 ± 3.05 | 43.05 ± 7.87 | 45.35 ± 15.32 | 30.46 ± 10.73 | 60.96 ± 5.11 | 64.42 ± 8.42 | 73.11 ± 4.00 |
| 11 | 666 | 65,346 | 65.97 ± 5.00 | 76.82 ± 9.22 | 85.84 ± 2.79 | 70.29 ± 32.02 | 80.31 ± 2.22 | 86.79 ± 3.56 | 88.26 ± 1.87 | 91.01 ± 4.65 |
| 12 | 344 | 33,761 | 49.42 ± 7.55 | 45.92 ± 14.36 | 60.83 ± 11.57 | 76.59 ± 9.04 | 53.05 ± 1.69 | 74.16 ± 4.67 | 81.90 ± 5.44 | 86.61 ± 2.37 |
| 13 | 3340 | 327,389 | 67.50 ± 8.79 | 71.19 ± 7.07 | 82.56 ± 7.19 | 86.24 ± 4.39 | 77.05 ± 2.56 | 86.28 ± 2.39 | 91.52 ± 2.20 | 94.22 ± 1.08 |
| 14 | 534 | 52,410 | 34.84 ± 9.53 | 60.05 ± 13.57 | 67.78 ± 8.28 | 71.52 ± 22.07 | 49.36 ± 8.40 | 80.96 ± 1.84 | 88.42 ± 0.75 | 91.42 ± 0.12 |
| 15 | 9130 | 894,799 | 82.29 ± 1.37 | 85.83 ± 1.42 | 92.37 ± 0.64 | 95.53 ± 1.85 | 89.20 ± 1.40 | 91.59 ± 0.54 | 94.62 ± 0.97 | 97.24 ± 0.57 |
| 16 | 28 | 2802.8 | 6.41 ± 2.97 | 13.29 ± 10.33 | 0.00 ± 0.00 | 45.69 ± 33.02 | 8.86 ± 11.31 | 69.58 ± 2.54 | 67.95 ± 12.14 | 72.73 ± 6.43 |
| 17 | 251 | 24,598 | 50.42 ± 15.44 | 72.87 ± 13.58 | 80.46 ± 8.41 | 92.39 ± 7.39 | 75.74 ± 5.86 | 88.47 ± 2.89 | 92.54 ± 0.76 | 93.59 ± 0.34 |
| 18 | 174 | 17,140 | 31.18 ± 13.48 | 52.79 ± 37.44 | 53.57 ± 25.98 | 51.69 ± 25.02 | 68.97 ± 5.88 | 80.79 ± 10.65 | 91.50 ± 0.68 | 91.31 ± 1.67 |
| OA | 73.98 ± 1.83 | 81.57 ± 1.38 | 87.55 ± 1.87 | 85.84 ± 7.88 | 83.53 ± 0.85 | 89.40 ± 1.27 | 93.19 ± 0.40 | 95.22 ± 0.26 | ||
| AA | 58.84 ± 2.87 | 68.19 ± 2.26 | 72.23 ± 4.88 | 74.95 ± 12.9 | 69.22 ± 2.90 | 83.25 ± 1.83 | 87.30 ± 0.82 | 90.04 ± 1.41 | ||
| K × 100 | 68.91 ± 2.36 | 78.15 ± 1.66 | 85.18 ± 2.27 | 82.92 ± 9.67 | 80.32 ± 0.97 | 87.41 ± 1.53 | 91.91 ± 0.49 | 94.31 ± 0.32 | ||
| Train Times (s)/epoch | 36.73 | 56.14 | 8.12 | 6.40 | 35.52 | 8.89 | 9.90 | 7.72 | ||
| Label | Train | Test | Methods | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 3D-CNN | DBDA | AB-LSTM | HRWN | SpectralFormer | DFFN | SSFTT | DSSGT | |||
| 1 | 34 | 34,166 | 90.43 ± 2.37 | 99.01 ± 0.20 | 73.74 ± 7.27 | 85.80 ± 3.66 | 89.09 ± 1.84 | 93.68 ± 5.26 | 88.63 ± 7.88 | 99.65 ± 0.37 |
| 2 | 8 | 8290 | 53.79 ± 7.42 | 52.87 ± 12.63 | 0.00 ± 0.00 | 43.82 ± 2.77 | 55.94 ± 9.10 | 41.14 ± 5.16 | 34.12 ± 18.57 | 50.72 ± 4.52 |
| 3 | 3 | 3002 | 1.25 ± 1.61 | 13.07 ± 26.14 | 0.00 ± 0.00 | 0.00 ± 0.00 | 0.03 ± 0.07 | 0.00 ± 0.00 | 0.00 ± 0.00 | 0.00 ± 0.00 |
| 4 | 63 | 62,580 | 90.05 ± 4.48 | 98.22 ± 0.27 | 98.07 ± 3.43 | 93.60 ± 1.25 | 92.60 ± 2.75 | 98.20 ± 0.39 | 94.61 ± 3.12 | 98.31 ± 0.37 |
| 5 | 4 | 4109 | 8.02 ± 5.31 | 31.98 ± 19.53 | 0.00 ± 0.00 | 25.33 ± 5.98 | 0.87 ± 1.49 | 34.29 ± 5.54 | 0.00 ± 0.00 | 29.9 ± 17.78 |
| 6 | 11 | 11,735 | 29.11 ± 10.25 | 85.10 ± 7.55 | 0.00 ± 0.00 | 12.79 ± 3.03 | 15.00 ± 5.51 | 3.99 ± 3.22 | 13.10 ± 13.04 | 93.97 ± 3.22 |
| 7 | 67 | 66,386 | 98.09 ± 0.78 | 97.86 ± 0.49 | 99.32 ± 0.96 | 98.39 ± 0.22 | 99.27 ± 0.36 | 99.76 ± 0.22 | 99.54 ± 0.46 | 99.96 ± 0.05 |
| 8 | 7 | 7053 | 56.11 ± 10.58 | 71.83 ± 4.33 | 0.00 ± 0.00 | 46.22 ± 2.04 | 54.49 ± 3.25 | 25.21 ± 2.53 | 44.72 ± 25.29 | 68.76 ± 9.47 |
| 9 | 5 | 5177 | 53.61 ± 9.24 | 15.83 ± 4.63 | 0.00 ± 0.00 | 46.60 ± 2.59 | 45.49 ± 12.00 | 16.48 ± 7.48 | 0.10 ± 0.15 | 57.65 ± 5.63 |
| OA | 82.64 ± 2.00 | 89.99 ± 0.70 | 75.32 ± 6.01 | 81.51 ± 0.48 | 82.44 ± 0.93 | 82.77 ± 0.91 | 80.55 ± 3.48 | 91.96 ± 0.55 | ||
| AA | 53.58 ± 1.29 | 62.86 ± 4.09 | 30.13 ± 4.03 | 50.28 ± 1.24 | 50.31 ± 1.61 | 45.86 ± 1.46 | 41.65 ± 4.38 | 66.55 ± 2.13 | ||
| K × 100 | 76.78 ± 2.54 | 89.69 ± 0.97 | 64.95 ± 9.33 | 75.09 ± 0.77 | 76.33 ± 1.21 | 96.51 ± 1.31 | 73.39 ± 4.82 | 89.25 ± 0.74 | ||
| Train Times (s)/epoch | 0.25 | 0.51 | 0.07 | 0.05 | 0.32 | 0.07 | 0.08 | 0.07 | ||
| Label | Train | Test | Methods | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 3D-CNN | DBDA | AB-LSTM | HRWN | SpectralFormer | DFFN | SSFTT | DSSGT | |||
| 1 | 70 | 13,900 | 86.84 ± 1.06 | 94.17 ± 0.66 | 91.21 ± 2.29 | 95.51 ± 0.61 | 94.79 ± 1.58 | 95.56 ± 1.03 | 96.11 ± 0.86 | 95.31 ± 1.09 |
| 2 | 17 | 3475 | 57.75 ± 5.14 | 78.26 ± 3.97 | 32.05 ± 19.05 | 88.21 ± 2.77 | 56.13 ± 5.12 | 82.25 ± 4.27 | 67.35 ± 14.61 | 90.31 ± 2.13 |
| 3 | 109 | 21,602 | 94.08 ± 0.31 | 94.71 ± 1.27 | 94.26 ± 1.60 | 93.3 ± 1.09 | 94.12 ± 1.22 | 93.79 ± 1.53 | 96.08 ± 0.78 | 95.12 ± 0.50 |
| 4 | 816 | 161,652 | 99.80 ± 0.04 | 99.47 ± 0.07 | 99.35 ± 0.23 | 99.34 ± 0.21 | 99.60 ± 0.12 | 99.13 ± 0.11 | 99.44 ± 0.38 | 99.70 ± 0.09 |
| 5 | 31 | 6153 | 46.47 ± 5.76 | 75.14 ± 2.63 | 46.02 ± 12.04 | 74.66 ± 4.27 | 71.52 ± 5.60 | 83.17 ± 11.05 | 75.99 ± 11.37 | 81.93 ± 1.99 |
| 6 | 222 | 44,109 | 93.54 ± 0.57 | 95.21 ± 1.44 | 90.11 ± 2.60 | 91.79 ± 2.30 | 91.81 ± 1.03 | 91.26 ± 2.14 | 94.93 ± 1.55 | 96.58 ± 1.37 |
| 7 | 120 | 23,859 | 74.48 ± 4.40 | 87.44 ± 3.14 | 81.54 ± 5.91 | 77.2 ± 10.38 | 80.44 ± 5.27 | 82.02 ± 5.37 | 86.49 ± 4.41 | 85.98 ± 3.35 |
| 8 | 20 | 4010 | 11.38 ± 1.63 | 16.77 ± 12.62 | 0.35 ± 0.42 | 7.60 ± 4.26 | 0.20 ± 0.34 | 8.44 ± 6.64 | 0.59 ± 0.94 | 30.57 ± 13.8 |
| 9 | 54 | 10,707 | 84.84 ± 1.49 | 92.70 ± 2.37 | 82.46 ± 10.84 | 93.16 ± 3.02 | 94.34 ± 0.89 | 92.27 ± 2.39 | 94.91 ± 1.04 | 95.66 ± 1.45 |
| 10 | 61 | 12,266 | 68.35 ± 2.42 | 80.25 ± 6.11 | 59.85 ± 12.37 | 73.20 ± 5.60 | 73.50 ± 4.49 | 65.70 ± 2.76 | 83.33 ± 1.39 | 88.78 ± 2.22 |
| 11 | 55 | 10,905 | 45.78 ± 10.93 | 78.05 ± 6.31 | 31.08 ± 19.63 | 39.64 ± 10.53 | 66.85 ± 9.02 | 46.66 ± 6.26 | 62.98 ± 6.56 | 78.89 ± 10.69 |
| 12 | 44 | 8861 | 51.02 ± 3.86 | 62.95 ± 4.41 | 41.78 ± 8.44 | 49.59 ± 5.85 | 47.77 ± 8.72 | 65.72 ± 3.68 | 65.45 ± 1.42 | 72.34 ± 3.99 |
| 13 | 112 | 22,280 | 79.16 ± 1.64 | 78.29 ± 2.42 | 73.51 ± 4.92 | 67.54 ± 11.02 | 81.39 ± 3.60 | 77.13 ± 6.06 | 85.4 ± 1.91 | 88.15 ± 3.63 |
| 14 | 36 | 7281 | 46.30 ± 4.10 | 77.31 ± 4.30 | 48.99 ± 5.09 | 60.61 ± 5.65 | 59.99 ± 8.02 | 69.57 ± 11.73 | 85.15 ± 2.34 | 84.13 ± 3.15 |
| 15 | 5 | 990 | 4.70 ± 0.81 | 40.3 ± 22.16 | 0.00 ± 0.00 | 9.60 ± 4.83 | 1.40 ± 2.80 | 7.90 ± 10.63 | 6.50 ± 8.37 | 41.40 ± 24.84 |
| 16 | 36 | 7187 | 82.60 ± 2.96 | 87.08 ± 1.44 | 85.88 ± 9.47 | 93.02 ± 2.57 | 97.12 ± 1.47 | 85.91 ± 7.96 | 93.42 ± 3.88 | 91.67 ± 4.18 |
| 17 | 15 | 2980 | 58.47 ± 2.89 | 86.98 ± 3.53 | 18.01 ± 22.10 | 52.76 ± 10.86 | 2.16 ± 3.16 | 73.16 ± 20.10 | 55.61 ± 26.61 | 83.62 ± 3.91 |
| 18 | 16 | 3183 | 19.32 ± 2.90 | 64.70 ± 8.12 | 11.51 ± 11.11 | 29.95 ± 15.45 | 31.14 ± 20.37 | 43.55 ± 18.07 | 26.35 ± 21.47 | 73.50 ± 8.27 |
| 19 | 43 | 8623 | 63.74 ± 3.59 | 79.06 ± 5.70 | 58.48 ± 17.28 | 80.83 ± 4.85 | 85.05 ± 6.20 | 79.89 ± 2.13 | 84.71 ± 3.52 | 87.53 ± 3.83 |
| 20 | 17 | 3450 | 19.51 ± 6.24 | 76.79 ± 15.34 | 8.35 ± 14.71 | 74.26 ± 7.18 | 67.86 ± 16.71 | 75.04 ± 4.64 | 89.47 ± 3.41 | 82.15 ± 4.88 |
| 21 | 6 | 1312 | 2.49 ± 0.70 | 0.53 ± 1.06 | 0.00 ± 0.00 | 20.08 ± 10.8 | 0.00 ± 0.00 | 10.11 ± 5.10 | 0.00 ± 0.00 | 18.87 ± 9.70 |
| 22 | 20 | 4000 | 9.23 ± 2.45 | 79.53 ± 5.27 | 32.92 ± 27.25 | 66.51 ± 5.29 | 79.33 ± 5.98 | 74.63 ± 6.62 | 80.30 ± 2.54 | 68.66 ± 12.83 |
| OA | 83.85 ± 0.58 | 90.42 ± 0.31 | 81.96 ± 0.91 | 86.15 ± 0.52 | 87.41 ± 0.79 | 87.63 ± 0.71 | 90.28 ± 0.44 | 92.64 ± 0.92 | ||
| AA | 54.54 ± 1.51 | 73.89 ± 2.44 | 49.44 ± 2.94 | 65.38 ± 1.46 | 62.57 ± 2.50 | 68.31 ± 7.74 | 69.57 ± 1.74 | 78.68 ± 3.33 | ||
| K × 100 | 79.27 ± 0.77 | 87.85 ± 0.41 | 77.02 ± 1.19 | 82.45 ± 0.65 | 84.34 ± 0.99 | 84.34±0.91 | 87.68 ± 0.55 | 90.67 ± 1.18 | ||
| Train Times (s)/epoch | 2.55 | 5.21 | 0.63 | 0.51 | 3.05 | 0.61 | 0.73 | 0.48 | ||
| Label | Train | Test | Methods | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 3D-CNN | DBDA | AB-LSTM | HRWN | SpectralFormer | DFFN | SSFTT | DSSGT | |||
| 1 | 68 | 1236 | 80.79 ± 4.83 | 70.97 ± 5.35 | 93.16 ± 0.28 | 95.61 ± 1.04 | 90.63 ± 3.50 | 95.42 ± 2.35 | 97.48 ± 0.52 | 98.03 ± 0.45 |
| 2 | 72 | 1308 | 78.47 ± 4.66 | 75.54 ± 3.25 | 86.70 ± 1.61 | 97.45 ± 0.97 | 74.28 ± 4.65 | 95.05 ± 3.15 | 97.51 ± 1.01 | 98.79 ± 0.67 |
| 3 | 39 | 715 | 59.38 ± 10.55 | 28.39 ± 15.0 | 58.60 ± 27.27 | 99.50 ± 0.42 | 78.07 ± 4.05 | 98.43 ± 0.74 | 99.19 ± 0.65 | 99.33 ± 0.70 |
| 4 | 63 | 1137 | 76.48 ± 4.77 | 66.03 ± 13.97 | 91.47 ± 2.02 | 94.18 ± 1.09 | 71.36 ± 7.95 | 89.27 ± 2.92 | 97.61 ± 0.70 | 98.10 ± 1.53 |
| 5 | 64 | 1168 | 68.46 ± 9.23 | 86.66 ± 6.28 | 91.82 ± 4.07 | 96.85 ± 0.70 | 94.86 ± 1.85 | 96.80 ± 1.54 | 98.63 ± 0.85 | 99.30 ± 0.41 |
| 6 | 16 | 305 | 42.23 ± 7.85 | 21.05 ± 21.0 | 45.25 ± 22.62 | 55.54 ± 2.88 | 5.31 ± 3.58 | 81.57 ± 12.51 | 98.03 ± 3.14 | 88.39 ± 3.67 |
| 7 | 73 | 1328 | 71.67 ± 5.37 | 47.98 ± 13.72 | 88.06 ± 2.75 | 94.67 ± 0.56 | 82.95 ± 3.23 | 92.56 ± 2.61 | 96.07 ± 2.21 | 97.15 ± 1.21 |
| 8 | 67 | 1218 | 48.88 ± 9.99 | 43.73 ± 7.75 | 25.70 ± 9.85 | 85.17 ± 2.53 | 54.58 ± 3.22 | 83.12 ± 2.34 | 88.83 ± 1.96 | 89.57 ± 1.51 |
| 9 | 77 | 1398 | 59.38 ± 5.28 | 55.35 ± 9.22 | 63.91 ± 12.27 | 84.88 ± 1.73 | 73.03 ± 4.92 | 86.31 ± 3.86 | 89.54 ± 2.94 | 94.16 ± 1.40 |
| 10 | 71 | 1281 | 50.88 ± 12.04 | 45.84 ± 31.09 | 28.45 ± 0.90 | 94.80 ± 1.98 | 71.74 ± 7.90 | 84.82 ± 10.57 | 98.10 ± 0.92 | 98.24 ± 0.64 |
| 11 | 78 | 1409 | 48.30 ± 5.96 | 21.82 ± 12.40 | 53.41 ± 23.53 | 89.96 ± 1.59 | 46.25 ± 12.74 | 92.08 ± 2.60 | 95.71 ± 1.16 | 96.72 ± 1.85 |
| 12 | 71 | 1286 | 45.79 ± 10.97 | 47.99 ± 18.36 | 22.67 ± 18.39 | 91.23 ± 1.90 | 45.63 ± 16.34 | 89.41 ± 5.49 | 92.53 ± 3.70 | 95.71 ± 1.46 |
| 13 | 31 | 568 | 62.57 ± 10.6 | 32.82 ± 21.04 | 23.50 ± 4.67 | 87.57 ± 2.82 | 10.35 ± 2.02 | 86.90 ± 3.02 | 93.56 ± 2.74 | 95.56 ± 2.39 |
| 14 | 25 | 461 | 51.50 ± 10.72 | 50.80 ± 14.14 | 3.80 ± 3.80 | 96.92 ± 0.56 | 60.78 ± 10.49 | 97.83 ± 2.25 | 99.26 ± 0.38 | 99.91 ± 0.17 |
| 15 | 39 | 718 | 73.70 ± 12.53 | 85.21 ± 8.91 | 88.37 ± 7.87 | 98.41 ± 0.34 | 95.60 ± 1.57 | 99.86 ± 0.22 | 98.11 ± 1.42 | 99.61 ± 0.64 |
| OA | 62.23 ± 5.73 | 53.96 ± 5.79 | 61.31 ± 0.80 | 92.21 ± 0.29 | 67.94 ± 1.03 | 91.17 ± 1.11 | 95.57 ± 0.70 | 96.72 ± 0.46 | ||
| AA | 61.23 ± 5.36 | 52.01 ± 5.17 | 57.66 ± 2.42 | 90.85 ± 0.43 | 63.7 ± 1.31 | 91.30 ± 1.34 | 96.01 ± 0.82 | 96.57 ± 0.55 | ||
| K × 100 | 59.14 ± 6.19 | 50.24 ± 6.22 | 58.06 ± 0.92 | 91.58 ± 0.31 | 65.25 ± 1.12 | 90.46 ± 1.21 | 95.21 ± 0.76 | 96.46 ± 0.49 | ||
| Train Times (s)/epoch | 0.56 | 3.95 | 0.18 | 0.18 | 0.54 | 0.25 | 0.22 | 0.18 | ||
| Label | Train | Test | Methods | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 3D-CNN | DBDA | AB-LSTM | HRWN | SpectralFormer | DFFN | SSFTT | DSSGT | |||
| 1 | 659 | 64,651 | 99.47 ± 0.18 | 99.65 ± 0.28 | 99.68 ± 0.13 | 99.89 ± 0.04 | 99.88 ± 0.05 | 99.90 ± 0.05 | 100 ± 0.00 | 100 ± 0.00 |
| 2 | 75 | 7446 | 92.37 ± 0.96 | 89.45 ± 3.07 | 90.59 ± 7.33 | 96.59 ± 0.52 | 99.23 ± 0.73 | 94.75 ± 2.06 | 97.86 ± 1.25 | 97.75 ± 1.11 |
| 3 | 20 | 3028 | 66.44 ± 10.87 | 56.57 ± 22.45 | 52.85 ± 12.84 | 86.18 ± 2.11 | 17.75 ± 17.52 | 85.69 ± 3.73 | 82.89 ± 4.06 | 84.23 ± 5.60 |
| 4 | 26 | 2631 | 45.63 ± 9.64 | 84.35 ± 13.10 | 22.87 ± 20.74 | 96.34 ± 1.33 | 64.92 ± 17.86 | 98.60 ± 1.47 | 93.55 ± 3.39 | 98.92 ± 0.93 |
| 5 | 65 | 6452 | 82.47 ± 5.52 | 86.37 ± 5.28 | 91.36 ± 5.80 | 94.87 ± 1.13 | 93.57 ± 1.12 | 93.24 ± 2.09 | 97.47 ± 0.44 | 97.67 ± 0.48 |
| 6 | 92 | 9063 | 74.06 ± 5.89 | 83.93 ± 9.07 | 97.76 ± 0.89 | 96.84 ± 0.67 | 92.82 ± 3.41 | 98.34 ± 0.99 | 98.42 ± 0.76 | 99.27 ± 0.04 |
| 7 | 72 | 7141 | 79.44 ± 2.66 | 84.80 ± 4.34 | 75.43 ± 7.02 | 94.58 ± 0.52 | 91.91 ± 2.08 | 92.77 ± 0.83 | 96.40 ± 0.72 | 96.57 ± 0.34 |
| 8 | 428 | 41,969 | 97.08 ± 1.29 | 99.00 ± 0.34 | 98.67 ± 1.09 | 99.86 ± 0.02 | 99.70 ± 0.20 | 99.84 ± 0.02 | 99.91 ± 0.04 | 99.91 ± 0.03 |
| 9 | 28 | 2805 | 84.06 ± 3.27 | 72.92 ± 16.28 | 90.15 ± 4.80 | 98.70 ± 0.22 | 84.73 ± 6.56 | 97.08 ± 1.44 | 99.22 ± 0.60 | 96.92 ± 1.10 |
| OA | 93.13 ± 1.23 | 94.94 ± 0.96 | 94.69 ± 1.10 | 98.66 ± 0.07 | 96.04 ± 0.49 | 98.50 ± 0.18 | 98.99 ± 0.17 | 99.13 ± 0.05 | ||
| AA | 80.11 ± 2.97 | 84.12 ± 4.67 | 79.93 ± 2.84 | 95.98 ± 0.28 | 82.72 ± 3.03 | 95.58 ± 0.54 | 96.19 ± 0.64 | 96.80 ± 0.37 | ||
| K × 100 | 90.27 ± 1.73 | 92.83 ± 1.37 | 92.47 ± 1.55 | 98.11 ± 0.11 | 94.68 ± 1.71 | 97.87 ± 0.25 | 98.57 ± 0.24 | 98.77 ± 0.07 | ||
| Train Times (s)/epoch | 0.70 | 4.53 | 0.21 | 0.27 | 0.67 | 0.40 | 0.28 | 0.24 | ||
| Component | Indicators | |||||
|---|---|---|---|---|---|---|
| Standard CNN | Dilated CNN | GWPE | OA (%) | AA (%) | K × 100 | |
| MV | √ | ✕ | √ | 93.89 | 86.49 | 91.99 |
| ✕ | √ | ✕ | 92.15 | 84.59 | 89.20 | |
| ✕ | √ | √ | 95.22 | 90.04 | 94.31 | |
| WHU-LongKou | √ | ✕ | √ | 91.64 | 66.13 | 88.84 |
| ✕ | √ | ✕ | 90.21 | 66.12 | 88.08 | |
| ✕ | √ | √ | 91.96 | 66.55 | 89.25 | |
| WHU-HongHu | √ | ✕ | √ | 90.20 | 71.93 | 87.61 |
| ✕ | √ | ✕ | 91.20 | 78.89 | 89.95 | |
| ✕ | √ | √ | 92.64 | 78.68 | 90.67 | |
| Houston | √ | ✕ | √ | 95.49 | 95.80 | 95.13 |
| ✕ | √ | ✕ | 96.12 | 95.90 | 96.46 | |
| ✕ | √ | √ | 96.72 | 96.57 | 96.46 | |
| PC | √ | ✕ | √ | 99.10 | 96.67 | 98.72 |
| ✕ | √ | ✕ | 99.01 | 96.60 | 98.22 | |
| ✕ | √ | √ | 99.13 | 96.80 | 98.77 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Wang, S.; Zhang, W. Dilated Spectral–Spatial Gaussian Transformer Net for Hyperspectral Image Classification. Remote Sens. 2024, 16, 287. https://doi.org/10.3390/rs16020287
Zhang Z, Wang S, Zhang W. Dilated Spectral–Spatial Gaussian Transformer Net for Hyperspectral Image Classification. Remote Sensing. 2024; 16(2):287. https://doi.org/10.3390/rs16020287
Chicago/Turabian StyleZhang, Zhenbei, Shuo Wang, and Weilin Zhang. 2024. "Dilated Spectral–Spatial Gaussian Transformer Net for Hyperspectral Image Classification" Remote Sensing 16, no. 2: 287. https://doi.org/10.3390/rs16020287
APA StyleZhang, Z., Wang, S., & Zhang, W. (2024). Dilated Spectral–Spatial Gaussian Transformer Net for Hyperspectral Image Classification. Remote Sensing, 16(2), 287. https://doi.org/10.3390/rs16020287