
Link Aggregation for Skip Connection–Mamba: Remote Sensing Image Segmentation Network Based on Link Aggregation Mamba

Abstract
1. Introduction
- We propose a SSM-based link aggregation method, LASC-Mamba, to facilitate semantic exchange between the encoder and decoder. This approach enhances the cross-scale representation capability during the skip-layer stages in remote sensing segmentation networks.
- During the decoding phase, a dual-pathway Mix-Mamba is employed to activate insensitive information across different spatial and sequential dimensions, thereby augmenting the capability for high-level image understanding.
- Comparative and ablation experiments are conducted on two public remote sensing image segmentation datasets. The results demonstrate that our method outperforms traditional CNN- and transformer-based segmentation approaches.
2. Related Work
2.1. U-Net-like Network
2.2. Hybrid Architecture of CNN and Transformer
2.3. Mamba Structure
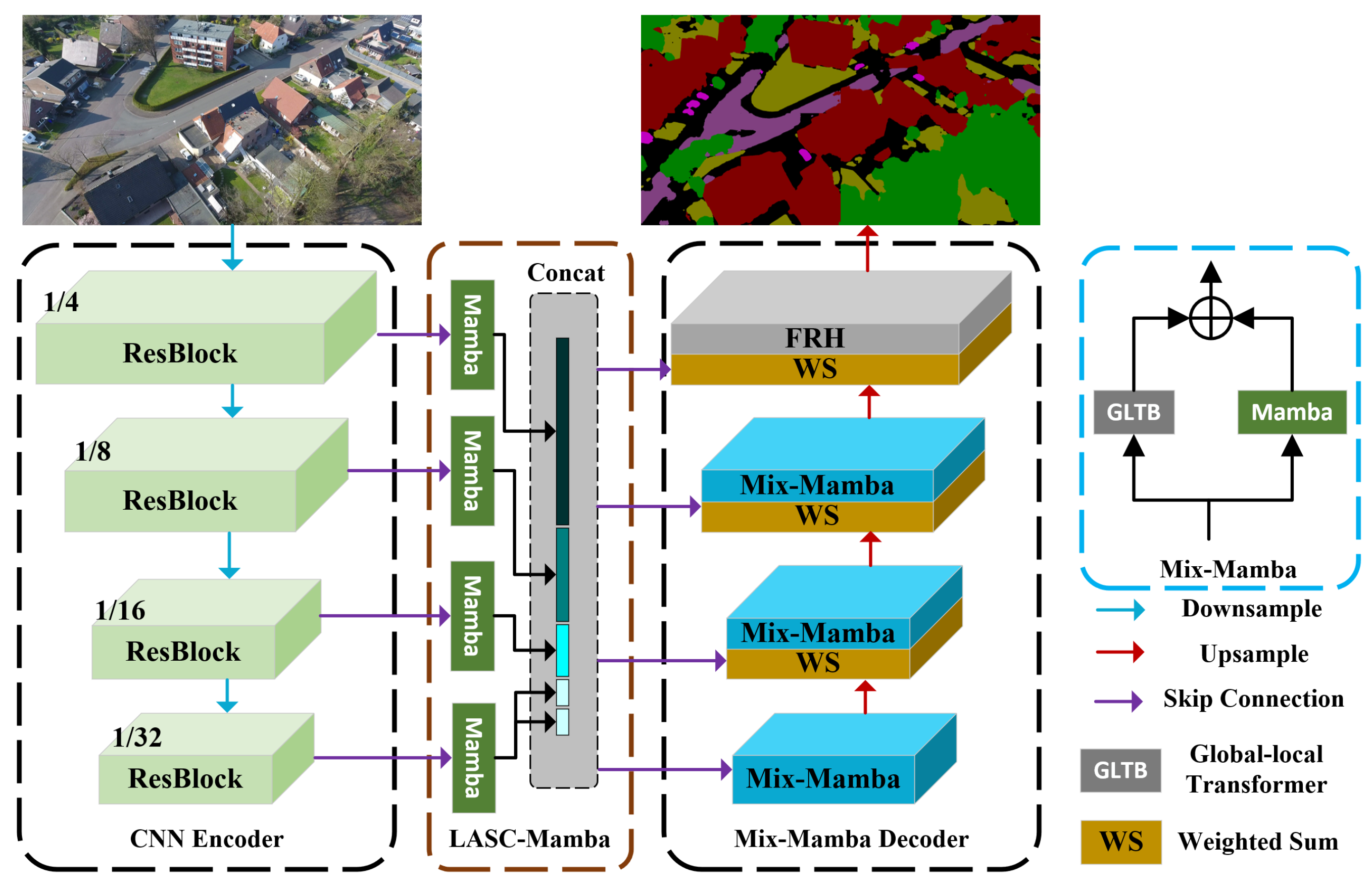
3. Method
3.1. Network Architectures
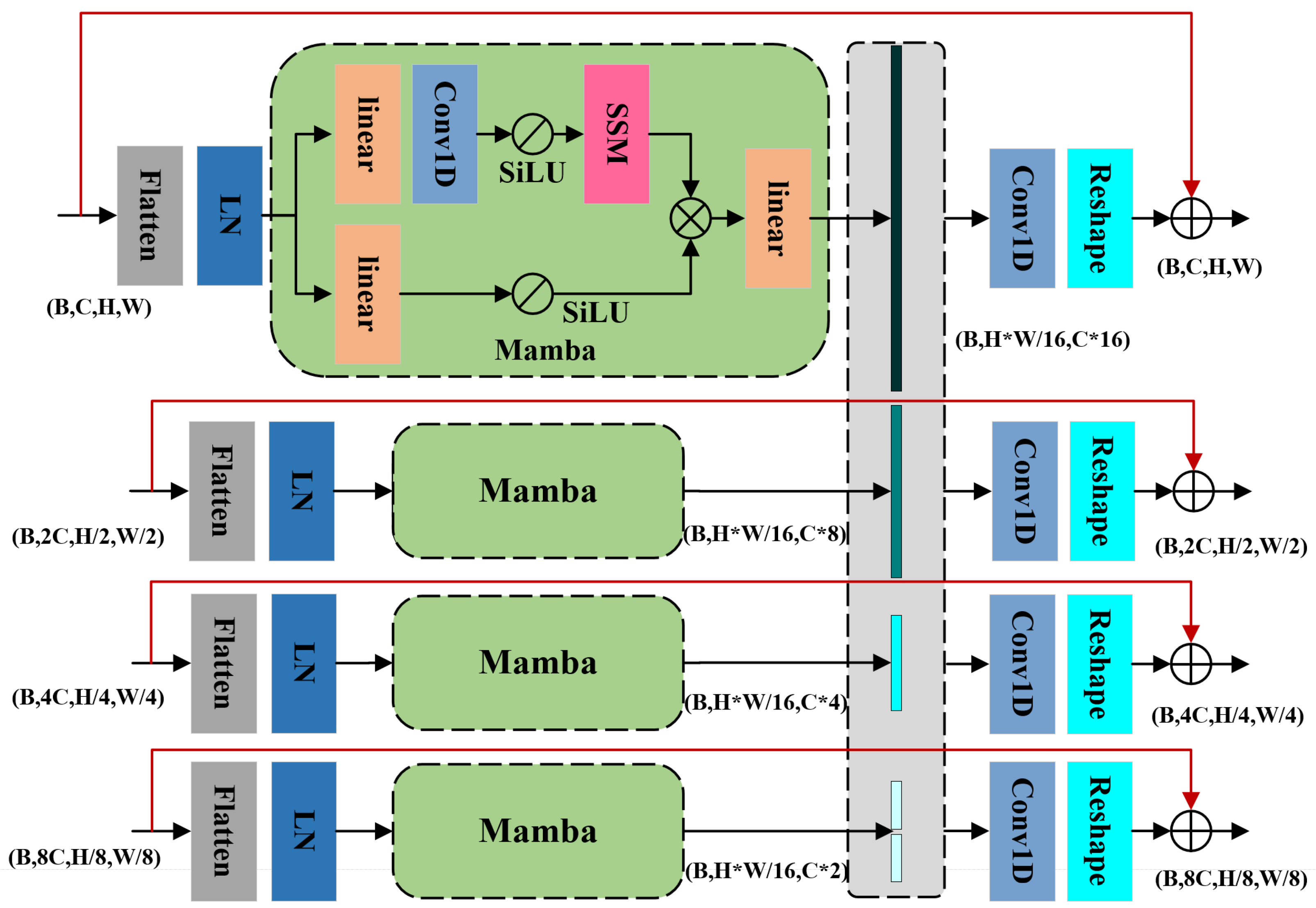
3.2. Link Aggregation for Skip Connection Mamba (LASC-Mamba)
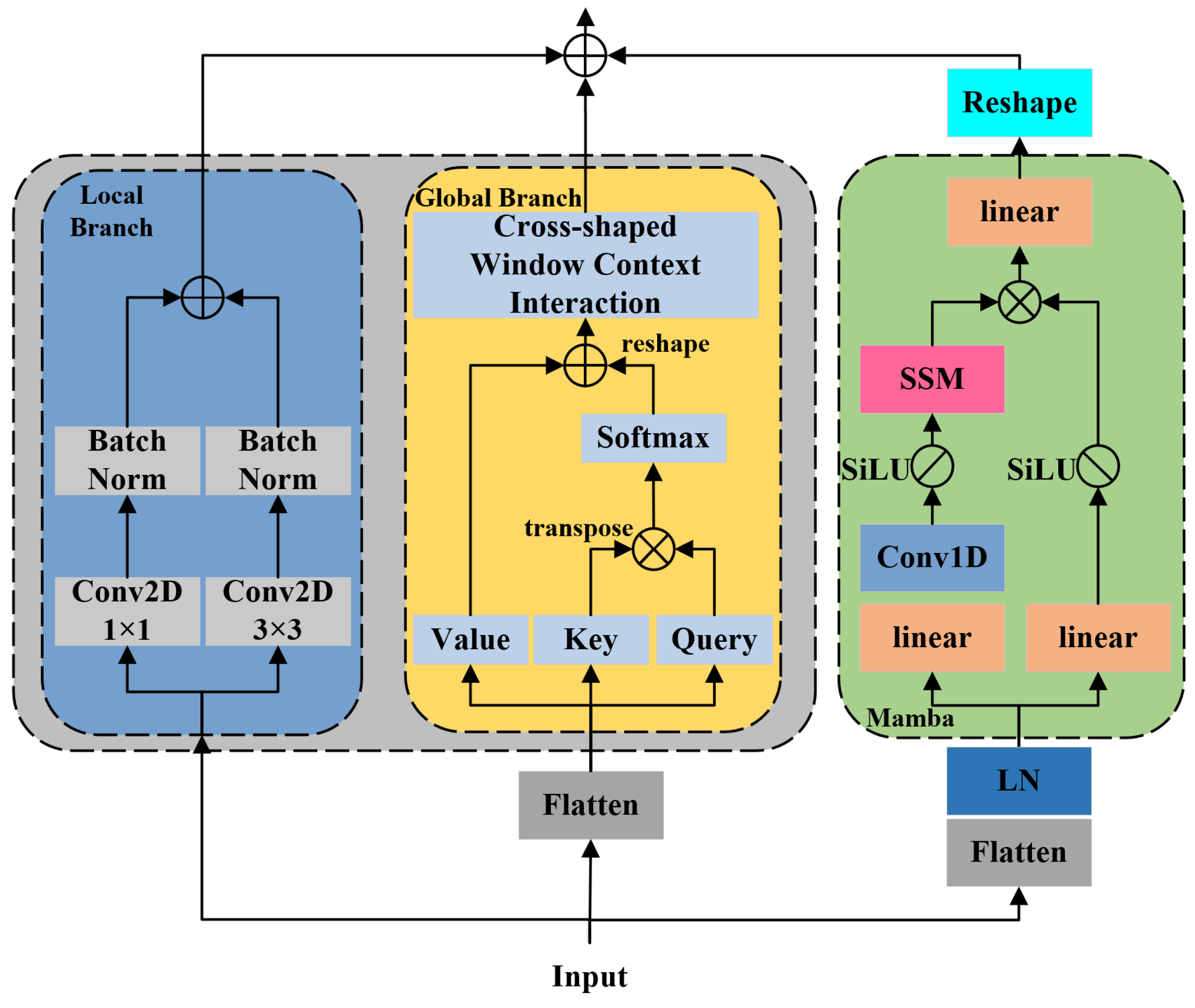
3.3. Mix-Mamba
4. Experiments
4.1. Dataset
4.2. Training Detail
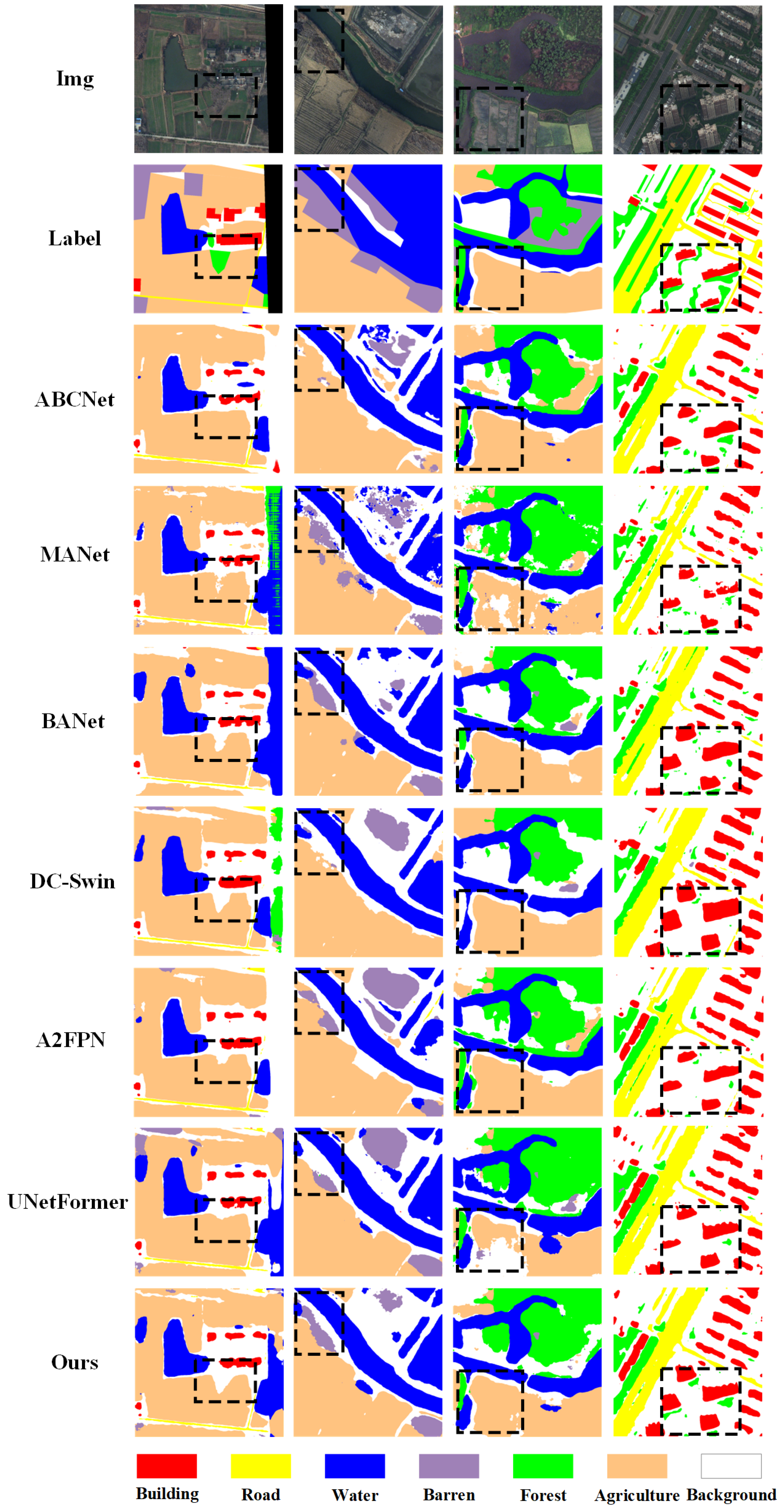
4.3. Comparison with Other Methods
4.4. Ablation Study
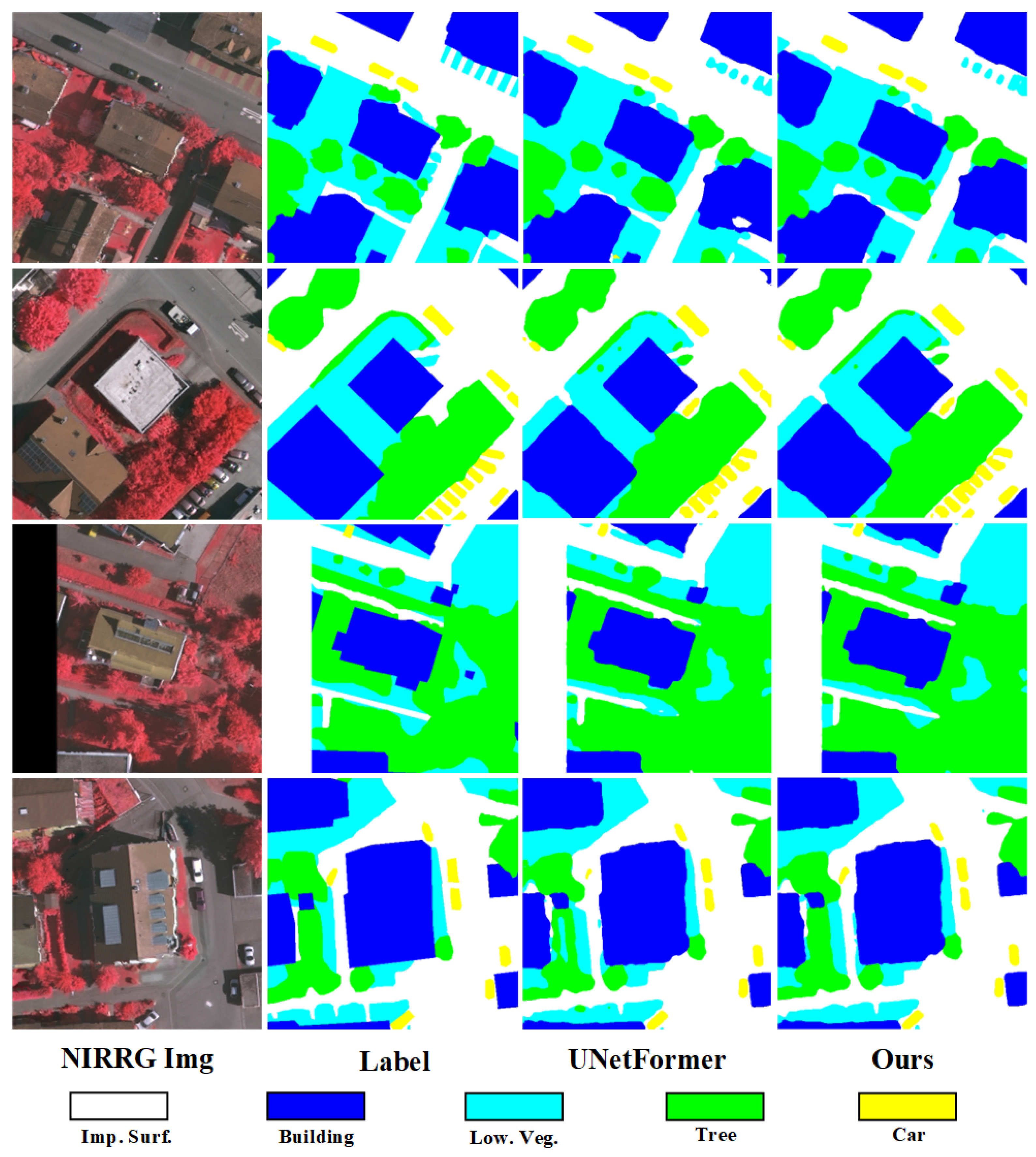
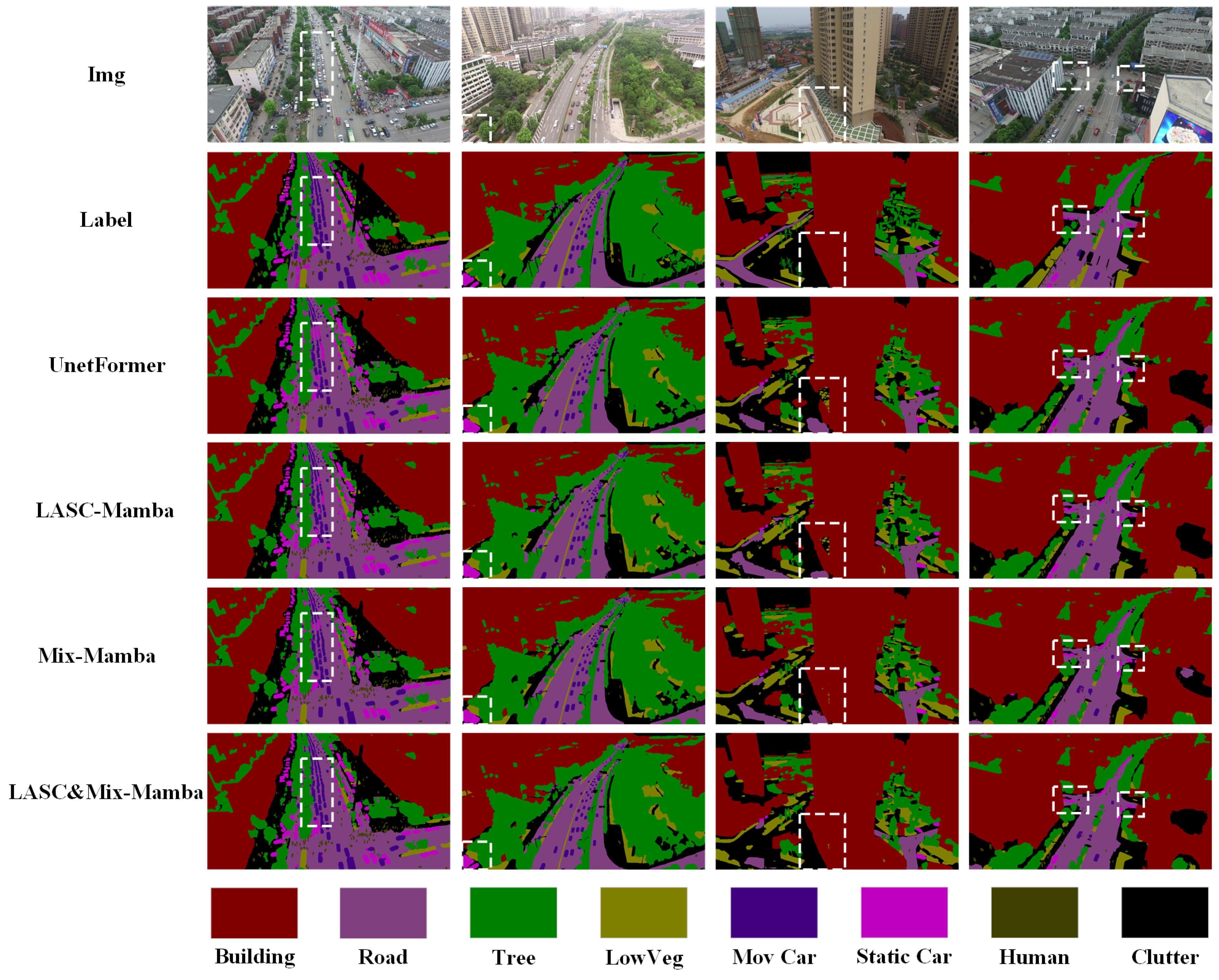
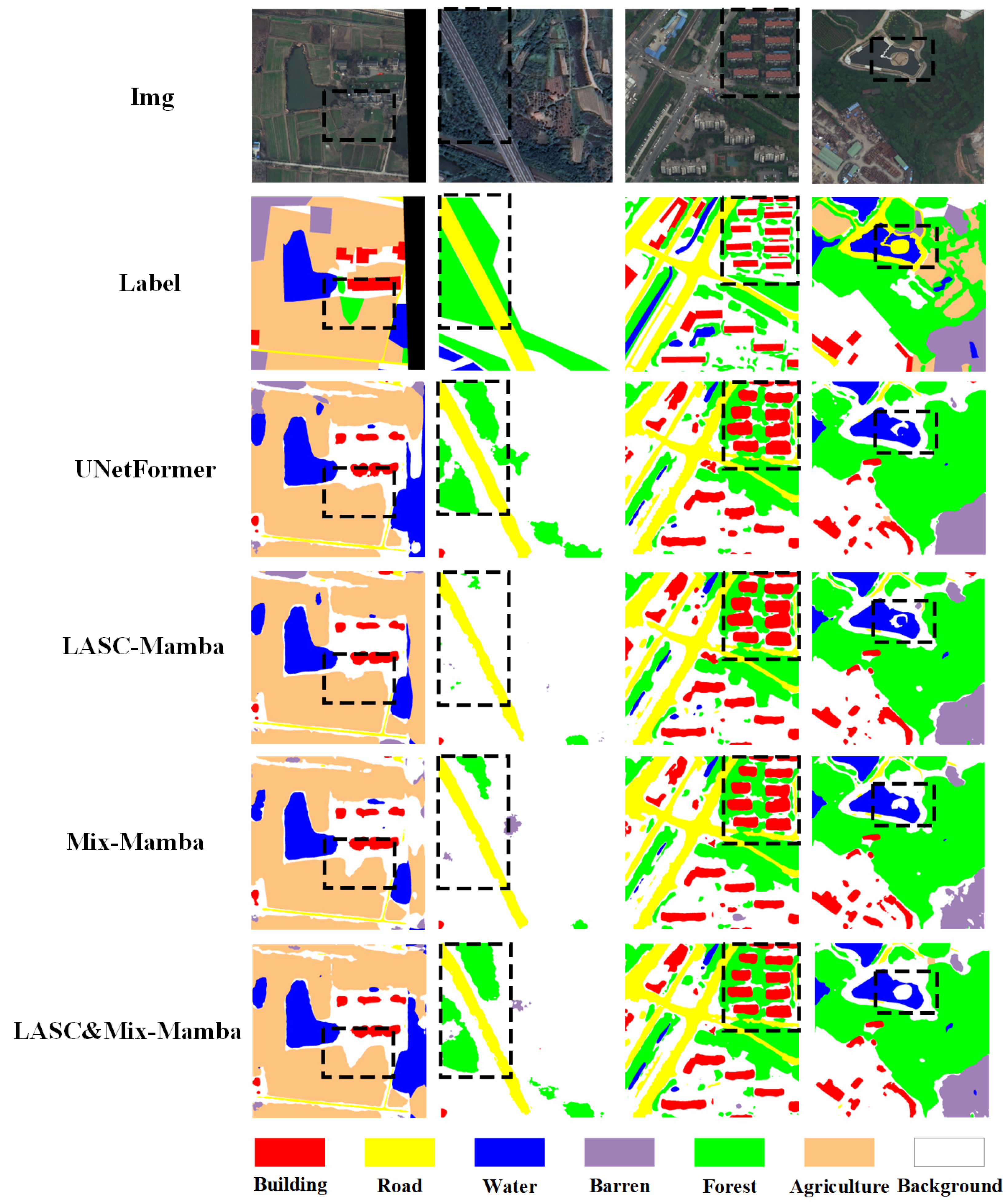
4.5. Further Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xing, J.; Sieber, R.; Caelli, T. A scale-invariant change detection method for land use/cover change research. ISPRS J. Photogramm. Remote Sens. 2018, 141, 252–264. [Google Scholar] [CrossRef]
- Yin, H.; Pflugmacher, D.; Li, A.; Li, Z.; Hostert, P. Land use and land cover change in Inner Mongolia-understanding the effects of China’s re-vegetation programs. Remote Sens. Environ. 2018, 204, 918–930. [Google Scholar] [CrossRef]
- Shao, P.; Yi, Y.; Liu, Z.; Dong, T.; Ren, D. Novel multiscale decision fusion approach to unsupervised change detection for high-resolution images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 2503105. [Google Scholar] [CrossRef]
- Samie, A.; Abbas, A.; Azeem, M.M.; Hamid, S.; Iqbal, M.A.; Hasan, S.S.; Deng, X. Examining the impacts of future land use/land cover changes on climate in Punjab province, Pakistan: Implications for environmental sustainability and economic growth. Environ. Sci. Pollut. Res. 2020, 27, 25415–25433. [Google Scholar] [CrossRef] [PubMed]
- Lobo Torres, D.; Queiroz Feitosa, R.; Nigri Happ, P.; Elena Cué La Rosa, L.; Marcato, J., Jr.; Martins, J.; Ola Bressan, P.; Gonçalves, W.N.; Liesenberg, V. Applying fully convolutional architectures for semantic segmentation of a single tree species in urban environment on high resolution UAV optical imagery. Sensors 2020, 20, 563. [Google Scholar] [CrossRef]
- Hoeser, T.; Bachofer, F.; Kuenzer, C. Object detection and image segmentation with deep learning on Earth observation data: A review—Part II: Applications. Remote Sens. 2020, 12, 3053. [Google Scholar] [CrossRef]
- Chai, B.; Nie, X.; Zhou, Q.; Zhou, X. Enhanced Cascade R-CNN for Multi-scale Object Detection in Dense Scenes from SAR Images. IEEE Sens. J. 2024, 24, 20143–20153. [Google Scholar] [CrossRef]
- Zhang, C.; Wang, L.; Yang, R. Semantic segmentation of urban scenes using dense depth maps. In Proceedings of the Computer Vision–ECCV 2010: 11th European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; Proceedings, Part IV 11. Springer: Berlin/Heidelberg, Germany, 2010; pp. 708–721. [Google Scholar]
- Schmitt, M.; Prexl, J.; Ebel, P.; Liebel, L.; Zhu, X.X. Weakly supervised semantic segmentation of satellite images for land cover mapping—Challenges and opportunities. arXiv 2020, arXiv:2002.08254. [Google Scholar] [CrossRef]
- Kherraki, A.; Maqbool, M.; El Ouazzani, R. Traffic scene semantic segmentation by using several deep convolutional neural networks. In Proceedings of the 2021 3rd IEEE Middle East and North Africa COMMunications Conference (MENACOMM), Virtual, 3–5 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Boudissa, M.; Kawanaka, H.; Wakabayashi, T. Semantic segmentation of traffic landmarks using classical computer vision and U-Net model. Proc. J. Phys. Conf. Ser. 2022, 2319, 012031. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Wang, J.; HQ Ding, C.; Chen, S.; He, C.; Luo, B. Semi-supervised remote sensing image semantic segmentation via consistency regularization and average update of pseudo-label. Remote Sens. 2020, 12, 3603. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 205–218. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. 2021. Available online: http://arxiv.org/abs/2102.04306 (accessed on 11 June 2024).
- Wang, L.; Li, R.; Duan, C.; Zhang, C.; Meng, X.; Fang, S. A novel transformer based semantic segmentation scheme for fine-resolution remote sensing images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6506105. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Panboonyuen, T.; Jitkajornwanich, K.; Lawawirojwong, S.; Srestasathiern, P.; Vateekul, P. Transformer-based decoder designs for semantic segmentation on remotely sensed images. Remote Sens. 2021, 13, 5100. [Google Scholar] [CrossRef]
- Xu, Z.; Zhang, W.; Zhang, T.; Yang, Z.; Li, J. Efficient transformer for remote sensing image segmentation. Remote Sens. 2021, 13, 3585. [Google Scholar] [CrossRef]
- Adams, R.; Bischof, L. Seeded region growing. IEEE Trans. Pattern Anal. Mach. Intell. 1994, 16, 641–647. [Google Scholar] [CrossRef]
- Mary Synthuja Jain Preetha, M.; Padma Suresh, L.; John Bosco, M. Image segmentation using seeded region growing. In Proceedings of the 2012 International Conference on Computing, Electronics and Electrical Technologies (ICCEET), Nagercoil, India, 21–22 March 2012; pp. 576–583. [Google Scholar] [CrossRef]
- Athanasiadis, T.; Mylonas, P.; Avrithis, Y.; Kollias, S. Semantic image segmentation and object labeling. IEEE Trans. Circuits Syst. Video Technol. 2007, 17, 298–312. [Google Scholar] [CrossRef]
- Liu, Z.; Li, X.; Luo, P.; Loy, C.C.; Tang, X. Deep learning markov random field for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1814–1828. [Google Scholar] [CrossRef]
- Vemulapalli, R.; Tuzel, O.; Liu, M.Y.; Chellapa, R. Gaussian conditional random field network for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3224–3233. [Google Scholar]
- Strudel, R.; Garcia, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 7262–7272. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS J. Photogramm. Remote Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Zhang, Q.; Geng, G.; Yan, L.; Zhou, P.; Li, Z.; Li, K.; Liu, Q. P-MSDiff: Parallel Multi-Scale Diffusion for Remote Sensing Image Segmentation. arXiv 2024, arXiv:2405.20443. [Google Scholar]
- Chen, K.; Zou, Z.; Shi, Z. Building extraction from remote sensing images with sparse token transformers. Remote Sens. 2021, 13, 4441. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Gu, A.; Dao, T. Mamba: Linear-Time Sequence Modeling with Selective State Spaces. 2023. Available online: http://arxiv.org/abs/2312.00752 (accessed on 11 June 2024).
- Zhu, L.; Liao, B.; Zhang, Q.; Wang, X.; Liu, W.; Wang, X. Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model. 2024. Available online: http://arxiv.org/abs/2401.09417 (accessed on 11 June 2024).
- Liu, Y.; Tian, Y.; Zhao, Y.; Yu, H.; Xie, L.; Wang, Y.; Ye, Q.; Liu, Y. VMamba: Visual State Space Model. 2024. Available online: http://arxiv.org/abs/2401.10166 (accessed on 11 June 2024).
- Lieber, O.; Lenz, B.; Bata, H.; Cohen, G.; Osin, J.; Dalmedigos, I.; Safahi, E.; Meirom, S.; Belinkov, Y.; Shalev-Shwartz, S.; et al. Jamba: A hybrid transformer-mamba language model. arXiv 2024, arXiv:2403.19887. [Google Scholar]
- Xu, J. HC-Mamba: Vision MAMBA with Hybrid Convolutional Techniques for Medical Image Segmentation. arXiv 2024, arXiv:2405.05007. [Google Scholar]
- Chen, S.; Atapour-Abarghouei, A.; Zhang, H.; Shum, H.P. MxT: Mamba × Transformer for Image Inpainting. arXiv 2024, arXiv:2407.16126. [Google Scholar]
- Wang, Y.; Liu, Y.; Deng, D.; Wang, Y. Reunet: An Efficient Remote Sensing Image Segmentation Network. In Proceedings of the 2023 International Conference on Machine Learning and Cybernetics (ICMLC), Adelaide, Australia, 9–11 July 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 63–68. [Google Scholar]
- Cao, Y.; Liu, S.; Peng, Y.; Li, J. DenseUNet: Densely connected UNet for electron microscopy image segmentation. IET Image Process. 2020, 14, 2682–2689. [Google Scholar] [CrossRef]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 20 September 2018; Proceedings 4. Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.W.; Wu, J. Unet 3+: A full-scale connected unet for medical image segmentation. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1055–1059. [Google Scholar]
- Zhang, C.; Wang, R.; Chen, J.W.; Li, W.; Huo, C.; Niu, Y. A Multi-Branch U-Net for Water Area Segmentation with Multi-Modality Remote Sensing Images. In Proceedings of the IGARSS 2023-2023 IEEE International Geoscience and Remote Sensing Symposium, Pasadena, CA, USA, 16–21 July 2023; pp. 5443–5446. [Google Scholar] [CrossRef]
- Yue, K.; Yang, L.; Li, R.; Hu, W.; Zhang, F.; Li, W. TreeUNet: Adaptive tree convolutional neural networks for subdecimeter aerial image segmentation. ISPRS J. Photogramm. Remote Sens. 2019, 156, 1–13. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Beal, J.; Kim, E.; Tzeng, E.; Park, D.H.; Zhai, A.; Kislyuk, D. Toward transformer-based object detection. arXiv 2020, arXiv:2012.09958. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Mehta, S.; Rastegari, M. Mobilevit: Light-weight, general-purpose, and mobile-friendly vision transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar]
- Gu, A.; Goel, K.; Ré, C. Efficiently modeling long sequences with structured state spaces. arXiv 2021, arXiv:2111.00396. [Google Scholar]
- Gu, A.; Dao, T.; Ermon, S.; Rudra, A.; Ré, C. Hippo: Recurrent memory with optimal polynomial projections. Adv. Neural Inf. Process. Syst. 2020, 33, 1474–1487. [Google Scholar]
- Xiao, Y.; Yuan, Q.; Jiang, K.; Chen, Y.; Zhang, Q.; Lin, C.W. Frequency-Assisted Mamba for Remote Sensing Image Super-Resolution. arXiv 2024, arXiv:2405.04964. [Google Scholar]
- Zhang, H.; Chen, K.; Liu, C.; Chen, H.; Zou, Z.; Shi, Z. CDMamba: Remote Sensing Image Change Detection with Mamba. arXiv 2024, arXiv:2406.04207. [Google Scholar]
- Zhu, Q.; Cai, Y.; Fang, Y.; Yang, Y.; Chen, C.; Fan, L.; Nguyen, A. Samba: Semantic segmentation of remotely sensed images with state space model. arXiv 2024, arXiv:2404.01705. [Google Scholar] [CrossRef]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Lyu, Y.; Vosselman, G.; Xia, G.S.; Yilmaz, A.; Yang, M.Y. UAVid: A semantic segmentation dataset for UAV imagery. ISPRS J. Photogramm. Remote Sens. 2020, 165, 108–119. [Google Scholar] [CrossRef]
- Wang, J.; Zheng, Z.; Ma, A.; Lu, X.; Zhong, Y. LoveDA: A remote sensing land-cover dataset for domain adaptive semantic segmentation. arXiv 2021, arXiv:2110.08733. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Wang, L.; Li, R.; Wang, D.; Duan, C.; Wang, T.; Meng, X. Transformer meets convolution: A bilateral awareness network for semantic segmentation of very fine resolution urban scene images. Remote Sens. 2021, 13, 3065. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Zhang, C.; Duan, C.; Wang, L.; Atkinson, P.M. ABCNet: Attentive bilateral contextual network for efficient semantic segmentation of Fine-Resolution remotely sensed imagery. ISPRS J. Photogramm. Remote Sens. 2021, 181, 84–98. [Google Scholar] [CrossRef]
- He, P.; Jiao, L.; Shang, R.; Wang, S.; Liu, X.; Quan, D.; Yang, K.; Zhao, D. MANet: Multi-Scale Aware-Relation Network for Semantic Segmentation in Aerial Scenes. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5624615. [Google Scholar] [CrossRef]
- Wu, H.; Huang, P.; Zhang, M.; Tang, W.; Yu, X. CMTFNet: CNN and Multiscale Transformer Fusion Network for Remote-Sensing Image Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 2004612. [Google Scholar] [CrossRef]
- Liu, M.; Dan, J.; Lu, Z.; Yu, Y.; Li, Y.; Li, X. CM-UNet: Hybrid CNN-Mamba UNet for Remote Sensing Image Semantic Segmentation. arXiv 2024, arXiv:2405.10530. [Google Scholar]
- Ma, X.; Zhang, X.; Pun, M.O. RS 3 Mamba: Visual State Space Model for Remote Sensing Image Semantic Segmentation. IEEE Geosci. Remote Sens. Lett. 2024, 21, 6011405. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Background | Building | Road | Water | Barren | Forest | Agriculture | mIoU |
|---|---|---|---|---|---|---|---|---|
| ABCNet | 41.8 | 56.6 | 50.7 | 77.1 | 14.9 | 45.2 | 54.2 | 48.6 |
| MANet | 41.8 | 55.1 | 53.4 | 75.5 | 14.6 | 44.4 | 55.1 | 48.5 |
| BANet | 43.7 | 51.5 | 51.1 | 76.9 | 16.6 | 44.9 | 62.5 | 49.6 |
| TransUNet | 43.0 | 56.1 | 53.7 | 78.0 | 9.3 | 44.9 | 56.9 | 48.9 |
| Segmenter | 38.0 | 50.7 | 48.7 | 77.4 | 13.3 | 43.5 | 58.2 | 47.1 |
| A2FPN | 42.7 | 57.6 | 54.3 | 78.0 | 14.1 | 45.0 | 54.9 | 49.5 |
| DC-Swin | 43.3 | 54.3 | 54.3 | 78.7 | 14.9 | 45.3 | 59.6 | 50.0 |
| UNetFormer | 44.7 | 58.8 | 54.9 | 79.6 | 20.1 | 46.0 | 62.5 | 52.4 |
| CM-Unet | 54.6 | 64.1 | 55.5 | 68.1 | 29.6 | 42.9 | 50.4 | 52.2 |
| RS3Mamba | 39.7 | 58.8 | 57.9 | 61.0 | 37.2 | 39.7 | 34.0 | 50.9 |
| Ours | 46.1 | 58.4 | 55.6 | 79.9 | 19.2 | 47.6 | 63.2 | 52.9 |
| Method | Building | Road | Tree | LowVeg. | Mov Car | Static Car | Human | Clutter | mIoU | mF1 | OA |
|---|---|---|---|---|---|---|---|---|---|---|---|
| BANet | 90.04 | 75.66 | 78.11 | 68.42 | 70.17 | 64.12 | 42.68 | 62.27 | 68.93 | 80.88 | 86.95 |
| DC-Swin | 92.67 | 78.95 | 77.73 | 67.08 | 69.27 | 64.59 | 37.27 | 65.91 | 69.2 | 80.80 | 87.90 |
| A2FPN | 90.83 | 77.45 | 77.97 | 68.66 | 67.07 | 64.9 | 46.91 | 63.21 | 69.62 | 81.48 | 87.3 |
| LSKNet-T | 91.80 | 73.83 | 79.09 | 69.47 | 75.85 | 69.43 | 46.85 | 60.72 | 70.89 | 82.32 | 87.34 |
| MANet | 91.77 | 78.10 | 78.59 | 69.14 | 72.20 | 69.48 | 48.50 | 65.28 | 71.63 | 82.92 | 87.99 |
| UNetFormer | 90.64 | 76.45 | 77.52 | 67.76 | 71.22 | 67.38 | 46.62 | 62.70 | 70.00 | 81.64 | 87.21 |
| Ours | 92.45 | 82.94 | 82.35 | 58.56 | 79.84 | 70.47 | 50.64 | 63.74 | 72.63 | 84.63 | 88.55 |
| Method | Imp. Surf. | Building | Low.veg. | Tree | Car | mF1 | mIoU | OA |
|---|---|---|---|---|---|---|---|---|
| DANet | 90.0 | 93.9 | 82.2 | 87.3 | 44.5 | 79.6 | 69.4 | 88.2 |
| ABCNet | 92.7 | 95.2 | 84.5 | 89.7 | 85.3 | 89.5 | 81.3 | 90.7 |
| BANet | 92.2 | 95.2 | 83.8 | 89.9 | 86.8 | 89.6 | 81.4 | 90.5 |
| Segmenter | 89.8 | 93.0 | 81.2 | 88.9 | 67.6 | 84.1 | 73.6 | 88.1 |
| ESDINet | 92.7 | 95.5 | 84.5 | 90.0 | 87.2 | 90.0 | 82.0 | 90.9 |
| UNetFormer | 92.7 | 95.3 | 84.9 | 90.6 | 88.5 | 90.4 | 82.7 | 90.4 |
| CMTFNet | 90.6 | 94.2 | 81.9 | 87.6 | 82.8 | 87.4 | 78.0 | 88.7 |
| RS3Mamba | 96.7 | 95.5 | 84.4 | 90.0 | 86.9 | 90.7 | 83.3 | 93.2 |
| Ours | 96.7 | 96.0 | 86.1 | 89.5 | 84.7 | 90.6 | 83.2 | 93.5 |
| UNetFormer | LASC-Mamba | Mix-Mamba | Building | Road | Tree | LowVeg. | Mov Car | Static Car | Human | Clutter | mIoU |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ✔ | - | - | 90.64 | 76.45 | 77.52 | 67.76 | 71.22 | 67.38 | 46.62 | 62.70 | 70.0 |
| ✔ | ✔ | - | 91.18 | 78.18 | 78.13 | 68.92 | 72.50 | 68.96 | 47.57 | 64.18 | 71.20 |
| ✔ | - | ✔ | 91.35 | 78.79 | 78.37 | 68.24 | 73.01 | 70.29 | 47.99 | 65.20 | 71.66 |
| ✔ | ✔ | ✔ | 92.45 | 82.94 | 82.35 | 58.56 | 79.84 | 70.47 | 50.64 | 63.74 | 72.63 |
| UNetFormer | LASC-Mamba | Mix-Mamba | Background | Building | Road | Water | Barren | Forest | Agriculture | mIoU |
|---|---|---|---|---|---|---|---|---|---|---|
| ✔ | - | - | 44.7 | 58.8 | 54.9 | 79.6 | 20.1 | 46.0 | 62.5 | 52.4 |
| ✔ | ✔ | - | 46.7 | 57.8 | 57.3 | 80.9 | 15.8 | 47.5 | 63.7 | 52.8 |
| ✔ | - | ✔ | 46.1 | 58.3 | 58.5 | 79.6 | 18.5 | 46.9 | 61.5 | 52.8 |
| ✔ | ✔ | ✔ | 46.1 | 58.4 | 55.5 | 79.9 | 19.2 | 47.6 | 63.2 | 52.9 |
| Method | FLOPs (G) | Param. (M) |
|---|---|---|
| ABCNet | 7.81 | 13.39 |
| CMTFNet | 17.14 | 30.07 |
| UNetformer | 5.87 | 11.69 |
| RS3Mamba | 31.65 | 43.32 |
| CM-UNet | 6.01 | 12.89 |
| Ours | 7.89 | 15.63 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Q.; Geng, G.; Zhou, P.; Liu, Q.; Wang, Y.; Li, K. Link Aggregation for Skip Connection–Mamba: Remote Sensing Image Segmentation Network Based on Link Aggregation Mamba. Remote Sens. 2024, 16, 3622. https://doi.org/10.3390/rs16193622
Zhang Q, Geng G, Zhou P, Liu Q, Wang Y, Li K. Link Aggregation for Skip Connection–Mamba: Remote Sensing Image Segmentation Network Based on Link Aggregation Mamba. Remote Sensing. 2024; 16(19):3622. https://doi.org/10.3390/rs16193622
Chicago/Turabian StyleZhang, Qi, Guohua Geng, Pengbo Zhou, Qinglin Liu, Yong Wang, and Kang Li. 2024. "Link Aggregation for Skip Connection–Mamba: Remote Sensing Image Segmentation Network Based on Link Aggregation Mamba" Remote Sensing 16, no. 19: 3622. https://doi.org/10.3390/rs16193622
APA StyleZhang, Q., Geng, G., Zhou, P., Liu, Q., Wang, Y., & Li, K. (2024). Link Aggregation for Skip Connection–Mamba: Remote Sensing Image Segmentation Network Based on Link Aggregation Mamba. Remote Sensing, 16(19), 3622. https://doi.org/10.3390/rs16193622