1. Introduction
Synthetic aperture radar (SAR) is a microwave remote sensor used to provide high-resolution images with all-day-and-night and all-weather operating characteristics that has been widely used in various military and civilian fields [
1,
2,
3]. Automatic target recognition (ATR) is a fundamental but also challenging task in the SAR domain [
4]. It consists of two key procedures: feature extraction and target classification, which are independent of each other in traditional SAR ATR methods. Moreover, traditional methods rely on hand-crafted features, which hinder the development of SAR ATR.
With the prosperous development and successful application of deep learning technologies in the field of remote sensing, studies on SAR ATR have shown significant breakthroughs [
5]. Numerous deep-learning-based SAR ATR methods have continued to emerge over the past few years and demonstrate their superiority to traditional methods. To name just a few, Chen et al. [
6] were among the first who applied a deep convolutional neural network (CNN) to SAR ATR tasks, laying a foundation for follow-up studies in this field. Kechagias-Stamatis and Aouf [
7] proposed an SAR ATR method by fusing deep learning and sparse coding that could achieve excellent recognition performance in different situations. Zhang et al. [
8] proposed a multi-view classification with semi-supervised learning for SAR target recognition. Pei et al. [
9] designed a two-stage algorithm based on contrastive learning for SAR image classification. Zhang et al. [
10] proposed a separability-measure-based CNN for SAR ATR, which can quantitatively analyze the interpretability of feature maps.
One of the biggest challenges for most deep-learning-based methods is that they are data-hungry and often require hundreds or thousands of training samples to achieve state-of-the-art accuracy [
11]. However, in real SAR ATR scenarios, the scarcity of labeled samples is a common problem due to the imaging mechanism of SAR. Under the situation where only a few labeled SAR images are available, which is termed as a few-shot problem, most existing deep-learning-based SAR ATR methods will suffer severe performance decline.
To face this challenge, a variety of few-shot learning (FSL) methods have been proposed in the past few years. Among them, prototypical network (ProtoNet) [
12], relation network (RelationNet) [
13], transductive propagation network (TPN) [
14], cross-attention network (CAN) and transductive CAN [
15], graph neural network (GNN) [
16], and edge-labeling GNN [
17] are some representatives in the field of computer vision. Subsequently, some FSL methods have been proposed specifically for SAR ATR under few-shot conditions [
18,
19,
20,
21,
22]. For instance, Liu et al. [
23] put forward a bi-similarity prototypical network with capsule-based embedding (BSCapNet) to solve the problem of few-shot SAR target recognition. Experiments on moving and stationary target acquisition and recognition (MSTAR) dataset show its effectiveness and superiority to some state-of-the-arts. Bi et al. [
24] proposed a contrastive domain adaptation based SAR target classification method to solve the problem of insufficient samples. Experimental results on MSTAR dataset demonstrate the effectiveness. Fu et al. [
25] proposed a metalearning framework for few-shot SAR ATR (MSAR). Yang et al. [
26] came up with mixed loss graph attention network (MGANet) for few-shot SAR target classification. Wang et al. [
27] presented a multitask representation learning network (MTRLN) for few-shot SAR ATR. Yu et al. [
28] presented a transductive prototypical attention network (TPAN). Ren et al. [
29] proposed adaptive convolutional subspace reasoning network (ACSRNet). Liao et al. [
30] put forward a model-agnostic meta-learning (MAML) for few-shot image classification. Although some significant achievements have been made, studies on few-shot SAR ATR are yet in their infancy and there remains considerable potential to be explored.
Our goal in this paper is to boost the achievements on few-shot SAR ATR and to further improve the recognition performance by proposing a new method named enhanced prototypical network with customized region-aware convolution (CRCEPN). Extensive evaluation experiments on both the MSTAR dataset, the OpenSARship dataset and the SAMPLE+ dataset verify the effectiveness as well as the superiority of the proposed method compared to some state-of-the-art methods for few-shot SAR ATR. The main contributions of this paper can be summarized as follows:
A feature-extraction network based on a customized and region-aware convolution (CRConv) is developed, which can adaptively adjust convolutional kernels and their receptive fields according to each sample’s own characteristics and the semantical similarity among spatial regions. Consequently, CRConv can adapt better to diverse SAR images and is more robust to variations in radar view, which augment its capacity to extract more informative and discriminative features. This greatly improves the recognition performance of the proposed method, especially under few-shot conditions;
To achieve accurate and robust target identity prediction for few-shot SAR ATR, an enhanced prototypical network is proposed. This network can effectively enhance the representation ability of the class prototypes by utilizing both support and query samples, thereby raising the classification accuracy;
A new loss function—namely, aggregation loss—is proposed to minimize the intra-class compactness. With the joint optimization of the aggregation loss and the cross-entropy loss, not only are the inter-class differences enlarged, but also the intra-class variations are reduced in the feature space. Thereby, highly discriminative features can be obtained for few-shot SAR ATR, thus improving the recognition performance, as supported by the experimental results.
The rest of this paper is organized as follows.
Section 2 details the framework and each key component of the proposed method. In
Section 3, extensive experiments on the MSTAR, the OpenSARship dataset, and the SAMPLE+ dataset are performed, and experimental results are analyzed in detail.
Section 4 concludes this work.
2. Methodology
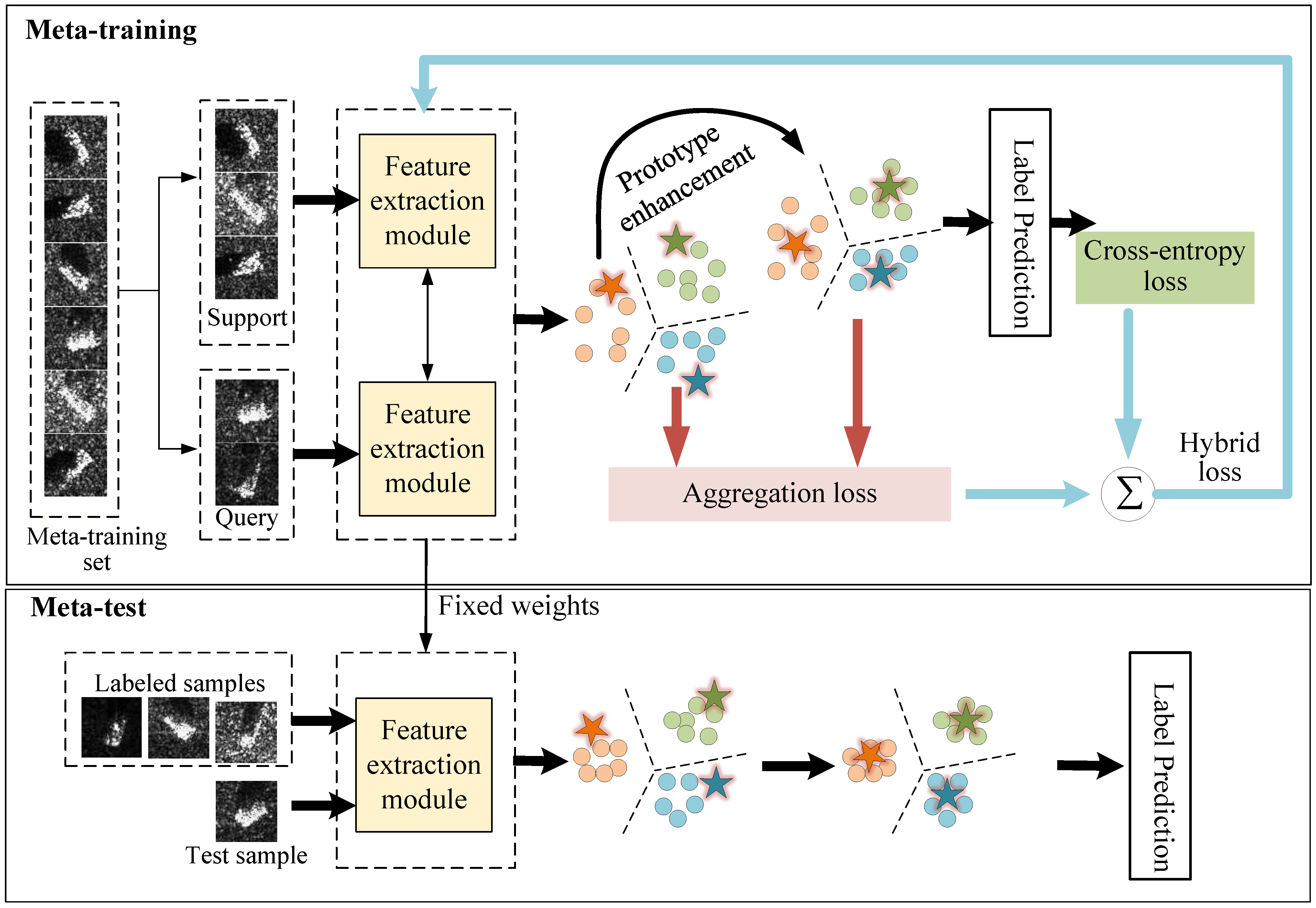
The overall framework of the proposed method is illustrated in
Figure 1. Following the idea of meta-learning, the proposed method consists of two stages, i.e., meta-training and meta-test. Below, three main components, including the feature-extraction module, classification module, and loss function, are elaborated.
2.1. Feature-Extraction Module
As a vital component of SAR ATR systems, feature extraction plays an important role in improving the effectiveness and robustness of the whole ATR system. The convolutional neural network (CNN) stands as a cornerstone in the development of deep learning technology, primarily due to its ability to efficiently process and extract rich features from images.
However, the traditional CNN is characterized by using standard static convolutional kernels, which exhibit two deficiencies in their nature. First, standard convolution performs in a kernel-sharing manner across the spatial domain, thus limiting its representation ability due to a single kernel’s poor capacity. Second, static convolutional kernels are randomly generated and shared among all input images, which is not effective for capturing each image’s uniqueness.
Owing to SAR image’s sensitivity to variations in radar view, different images of the same target may appear variable spatial information distribution, while images from different targets may appear similarly. Under few-shot condition, this problem may be more prominent. Consequently, standard static convolution may not be able to effectively extract discriminative features for few-shot SAR ATR [
29].
Inspired by a dynamic mechanism [
29,
31,
32,
33], a customized and region-aware convolution (CRConv) is introduced in this paper, and then the feature-extraction network is constructed by cascading four layers of CRConv. There are two distinct features in CRConv that are different from traditional convolution. First, different SAR images no longer share the same convolutional kernels in CRConv, but use their own unique kernels, that is, the convolutional kernels are customized for each image according to their own characteristics. Second, for each SAR image, different spatial regions may adopt different kernels and also different kernel sizes according to their semantical similarity, that is, the convolutional kernels are region-aware. This is useful since the target area and the background area usually display very different semantic information, and the center area and edge area of the target may also be semantically different.
Concretely, by generating multiple customized and region-aware convolutional kernels for each SAR image and dynamically assigning them to their corresponding spatial regions, CRConv is capable of capturing the specific feature of each sample and handling a variable spatial information distribution. It can, therefore, adapt better to diverse SAR images, which not only can augment its representation capacity but also makes it more robust to variations in radar view. It can, thus, be anticipated that the feature extraction network based on CRConv is effective to extract more informative and discriminative features for few-shot SAR ATR, thus improving the recognition performance.
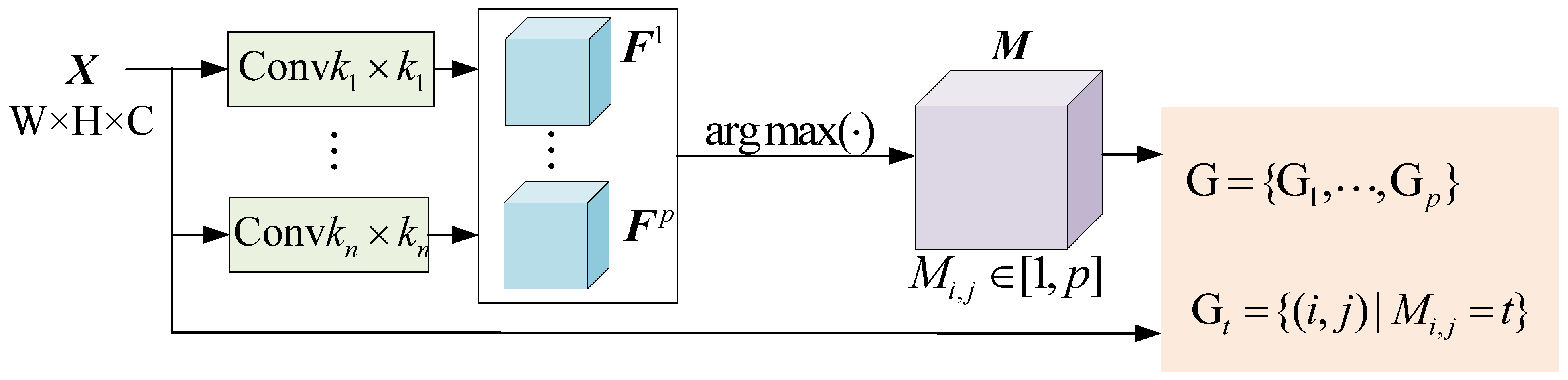
As shown in
Figure 2, CRConv comprises three main parts: dynamic region division, customized kernel generation, and dynamic convolution. During dynamic region division, each SAR image is divided into several regions across the spatial dimension according to their semantical similarity. During customized kernel generation, multiple customized kernels are generated specifically for each SAR image and each region. Dynamic convolution is finally performed between each individual region and its corresponding convolutional kernel. In the following, each part is elaborated.
2.1.1. Dynamic Region Division
The implementation procedure of dynamic region division is shown in
Figure 3. For each input image
, a group of standard convolutions with
n different sizes
are firstly applied to produce a set of feature maps,
where
,
m is the kernel number of each size, and
n is the number of different kernel sizes. One can see that, in CRConv, convolutional kernels with different receptive fields are used to adapt better to multiscale semantical features. This is different from [
31], where the kernel size is single.
Then, a region division map
is obtained by
where
outputs the index of maximum value and
represents spatial position. It is easy to see that the values in
vary from 1 to
p, i.e.,
, which can be expressed by one-hot-form. For instance, if
and
the one-hot-form is
.
To make the region division map learnable, in backward propagation, the softmax operation is applied to feature map
in order to approximate the one-hot-form of
[
31]:
Finally, based on the region division map, all spatial pixels of the input SAR image can be divided into
p regions:
with
2.1.2. Customized Kernel Generation
Figure 4 illustrates the implementation procedure of customized kernel generation, wherein multiple customized kernels are generated specifically for each SAR image and each region. As shown in
Figure 4, the input image
is first average-pooled such that it is down-sampled to
n different sizes,
. Then, a
convolution, including sigmoid as the activation function, is applied, followed by another
convolution with group =
m. Finally, a set of
p kernels are generated for each input–output channel pair, denoted as
.
Apparently, the convolutional kernels of CRConv are customized and region-aware, which can be adjusted adaptively according to each sample’s own characteristics and can make full use of the diversity of spatial information. As a result, the CRConv adapts better to diverse SAR images and is more robust to variations in radar view, which is helpful for improving the recognition performance, especially under few-shot conditions.
Moreover, utilizing multiscale kernels is able to further enhance the representation capacity of CRConv. Intuitively, by accommodating the features of varying scales, these kernels ensure that both fine-grained details and broader spatial patterns are effectively captured. This is particularly beneficial for SAR images, where targets may vary greatly in size and shape and background clutter may obscure critical details.
2.1.3. Dynamic Convolution
With the process of the above two parts, i.e., dynamic region division and customized kernel generation, the input image is divided into
p regions, each region corresponding to a customized convolutional kernel. Then, the convolution operation in CRConv can be expressed as
where
is the
c-th channel input,
is the
r-th channel output,
represents the convolutional kernels from the
c-th input to the
r-th output, and ∗ is a 2D convolution operation. From (
5), we see that, in CRConv, different regions use different customized convolutional kernels and, in each region, a standard convolution operation is performed. Specifically, spatial pixels in the region
use the convolutional kernel
.
2.2. Classification Module
Prototype learning is a popularly adopted and widely used classification method in the realm of few-shot learning. It has also been utilized for few-shot SAR ATR [
23]. To put it simply, the core of prototype learning involves the computation of a class prototype that essentially represents the average feature vector of all samples within a given class. Mathematically, the prototype for the
i-th class, denoted as
, is calculated by
where
represents the feature-extraction network,
is the support set belonging to the
i-th class,
N is the number of target categories, and
K is the number of labeled samples per category. The target identity of a sample in the query set,
, is then predicted according to the nearest distance between
and each class prototype.
Clearly, the true prototype may not be obtained accurately with only a few labeled samples under few-shot condition. Additionally, owing to an SAR image’s sensitivity to variations in radar view, the representation ability of the prototype for each SAR target will be further weakened, resulting in lowered classification accuracy [
29]. To improve the classification accuracy for few-shot SAR ATR, we develop an enhanced prototypical network, which can effectively enhance the representation ability of class prototype by utilizing both support and query samples.
Firstly, the initial probability of a query sample
z belonging to the
i-th class is predicted by
where
represents the similarity between
and
, which is obtained by an exponential mapping from the Euclidean distance, i.e.,
By using (
7) and (
8), we elaborately assign larger weights to samples that are more similar to initial class prototypes and smaller weights to samples that are less similar to initial class prototypes.
Then, an enhanced class prototype with augmented representative ability is generated based on both support and query sets as below:
Based on the class prototype obtained via (
9), the final probability of a query sample
z belonging to the
i-th class is calculated by
And the target identity of
z is predicted as
From the above process, one can see that, by utilizing both support and query samples dexterously, the proposed enhanced prototypical network can effectively enhance the representation ability of class prototype and achieve robust target identity prediction, which helps to raise the classification accuracy for few-shot SAR ATR.
2.3. Loss Function
The proposed method utilizes a hybrid loss function, which is composed of two distinct components: the cross-entropy loss and the aggregation loss.
The cross-entropy loss is utilized to train the model at the classification level, which can be expressed as
where
M is the total number of samples in the query set and
if
z belongs to the
i-th class; otherwise,
.
In order to promote the discriminative ability of the extracted features, we propose an aggregation loss, which is defined as
As can be seen from (
13), the aggregation loss can update the prototype of each class and simultaneously penalize the distances between initial and enhanced prototypes. Thereby, a hybrid loss which combines (
12) and (
13) is formulated to train the proposed model, i.e.,
where
is used for balancing the two losses.
On the one hand, the cross-entropy loss plays a crucial role in ensuring that the model can accurately classify input samples by minimizing the disparity between the predicted class probabilities and the actual class labels. It encourages the model to create clear boundaries between different classes, thereby enhancing inter-class separability. On the other hand, the aggregation loss focuses on the inner clustering within each class by minimizing the distances between initial and enhanced prototypes. Intuitively, the former forces the features of different classes staying apart, while the latter pulls features of the same class staying together. With the joint optimization of both losses, we train a robust network to obtain features with both inter-class separability and intra-class tightness as much as possible, which can beneficially improve the recognition performance of the proposed method.
3. Experimental Results and Analysis
3.1. Dataset Description
(1) MSTAR dataset: The MSTAR dataset was publicly released by the Defense Advanced Research Projects Agency (DARPA). It includes 10 categories of ground military targets: BMP2, BTR60, BTR70, T62, T72, D7, ZIL131, 2S1, BRDM2, and ZSU23/4. The SAR images of each target were collected using an X-band SAR in spotlight mode under three different depression angles (
,
, and
) over full aspect angles from
to
. All images are 128 × 128 pixels in size.
Figure 5 shows some optical images and the corresponding SAR images of 10 categories of targets from the MSTAR dataset.
Based on the idea of meta-learning, we split the MSTAR dataset into a meta-training set and a meta-test set. Referring to existing studies [
22,
23,
25,
27,
28], the SAR images of seven targets, including BMP2, BTR60, BTR70, T62, T72, D7, and ZIL131, collected at a
depression angle constitute the meta-training set, while the SAR images of the other three targets, i.e., 2S1, BRDM2, and ZSU23/4, collected at
,
and
depression angles act as the meta-test set.
Table 1 summarizes the detailed information.
(2) OpenSARShip dataset: The OpenSARShip dataset was publicly released by Shanghai Jiaotong University, which is widely used as a benchmark for evaluating SAR target detection and recognition algorithms. The dataset contains 11,346 SAR images from 17 categories of ship targets, and all images were derived from 41 Sentinel-1 images with 4 polarization modes. The resolution of each SAR image is 10 m × 10 m. In this paper, SAR images with vertical–vertical (VV) and vertical–horizontal (VH) polarization are utilized for experiments.
Figure 6 illustrates some optical and corresponding SAR images of six ship targets in the OpenSARShip dataset. Referring to previous work [
8,
21], the SAR images of three ship targets, i.e., Dredger, Fishing, and Tug, are used as the meta-training data, while the images of Bulk carrier, Container ship, and Tanker are used as the meta-test data.
Table 2 lists the number of each target in the meta-training set and meta-test set.
(3) SAMPLE+ dataset: The SAMPLE+ dataset [
34] is an extension of the original SAMPLE (Synthetic and Measured Paired Labeled Experiment) dataset, which combines synthetic and measured SAR data for algorithm development and testing. This dataset is widely used for evaluating SAR target detection and recognition algorithms, particularly for military vehicle identification. The SAMPLE+ dataset includes a variety of military vehicles, providing both training and testing subsets.
In this paper, we utilize the SAMPLE+ dataset for our experiments. The dataset is divided into meta-training and meta-test sets. The meta-training set consists of seven vehicle types: 2S1, BMP2, BTR70, M2, M35, M548, and ZSU23. The meta-test set includes three vehicle types: M1, M60, and T72. This division allows us to evaluate the model’s ability to generalize to new, unseen classes.
Table 3 lists the number of samples for each target in the meta-training set and meta-test set. This distribution ensures a balanced representation of different vehicle types for both training and evaluation purposes.
3.2. Experimental Detail
Following previous work [
22,
23,
25,
27,
28], we simulate two few-shot SAR ATR tasks, i.e., 3-way 1-shot and 3-way 5-shot, on the MSTAR dataset, the OpenSARShip dataset, and the SAMPLE+ dataset. On the MSTAR dataset, each few-shot task is conducted under five different experimental scenarios so as to evaluate the robustness of the proposed method.
Table 4 lists the detailed information of five different experimental scenarios. In the following experiments, each SAR image is cropped into 64 × 64 pixels in size. And each experiment is conducted for 1000 independent runs in order to obtain statistically significant results.
To demonstrate the superiority of the proposed method for few-shot SAR ATR tasks, several state-of-the-art few-shot methods are employed for performance comparison, including ProtoNet [
12], RelationNet [
13], TPN [
14], CAN and TCAN [
15], MSAR [
25], BSCapNet [
23], MTRLN [
27], TPAN [
28], 2SCNet [
22], ACSRNet [
29], SimCLR+OE [
11], GSPCL-Net, and MAML [
30]. To maintain fairness, the feature-extraction networks in RelationNet, TPN, CAN, TCAN, MSAR, and 2SCNet are kept the same as that in ProtoNet [
12], i.e., consisting of four convolutional layers. BSCapNet, MTRLN, TPAN, ACSRNet, and MAML are reproduced according to the settings in their original papers.
The Adam optimizer [
35] is adopted to optimize the proposed method, and the learning rate is set to 0.01. The hyperparameter
in (
14) is fine-tuned to 0.01 for a relatively optimum balance between the cross-entropy loss and the aggregation loss. In CRConv, four different sizes of convolutional kernels are generated, i.e.,
,
,
, and
, and the kernel number for each size is set to 4. This results in a total of 16 customized kernels for each SAR images, that is,
and
.
All experiments are implemented in the PyTorch framework, making use of its dynamic computational graph and its extensive library of tools for deep learning research. All experiments are conducted on a high-performance server equipped with a 16-core AMD Ryzen 9 7950X CPU and an NVIDIA GeForce RTX 3090 Ti GPU.
3.3. Recognition Results on the MSTAR Dataset
In this section, extensive experiments are conducted on the MSTAR dataset in order to evaluate the performance of the proposed method for few-shot SAR ATR tasks.
Table 5 lists the recognition results of the proposed method and other competitors under five different experimental scenarios.
Table 6 shows the confusion matrices of the average recognition accuracy of the proposed CRCEPN under different experimental scenarios.
As can be seen from
Table 5, the proposed CRCEPN consistently performs better than all competitors for either the 1-shot or 5-shot task under different experimental scenarios on the MSTAR dataset. One can also see that TPAN performs the second-best on the whole. Particularly, in the first four experiments for both few-shot tasks, the recognition rates of the proposed CRCEPN are about 2–9% higher than those of TPAN, and the performance improvements compared with other competitors are more remarkable. In the fifth experiment, where the depression variation between the meta-training set and the meta-test set is enlarged and, thus, the SAR ATR task is more challenging, the proposed CRCEPN still surpasses TPAN by about 5% for the 5-shot task and 2% for the 1-shot task. Overall, these experimental results manifest the effectiveness and superiority of the proposed CRCEPN for few-shot SAR ATR tasks.
It is worth noting that, in TPAN, a cross-feature spatial attention module is designed following the feature extractor to obtain more discriminative features [
28], while, in the proposed CRCEPN, we use only a feature extractor consisting of four layers of CRConv.
Interestingly, we have also included two self-supervised methods, SimCLR+OE and GSPCL-Net, for comparison in the 5-way-1-shot and 5-way-5-shot setting. It is important to note that these self-supervised methods were evaluated under a more challenging 5-way setting, which partially explains their lower performance. Additionally, the cross-domain nature of the problem poses significant challenges for self-supervised approaches, highlighting the advantages of meta-learning techniques in few-shot SAR ATR tasks.
Moreover, from the confusion matrices in
Table 6, one can see that the recognition performance of the proposed method on each target is relatively balanced under different experimental scenarios for both 1-shot and 5-shot tasks on the MSTAR dataset, which indicates huge potential of the proposed method for few-shot SAR target recognition.
3.4. Recognition Results on the OpenSARship Dataset
This section performs evaluation experiments on the OpenSARShip dataset so as to further verify the recognition performance of the the proposed method for few-shot SAR ATR tasks.
Table 7 lists the recognition results of each method for both 1-shot and 5-shot tasks on the OpenSARShip dataset.
It can be seen from the experimental results in
Table 7 that the proposed CRCEPN still exhibits the best performance for either the 1-shot or the 5-shot task on the challenging OpenSARShip dataset. In particular, the recognition rate of CRCEPN is 65% and 53% for 5-shot and 1-shot settings, respectively, which are about 5% and 6% higher than those of the second-best method, i.e., 2SCNet [
22] and ACSRNet [
29].
Table 8 lists the confusion matrices of the average recognition accuracy of the proposed CRCEPN on the OpenSARShip dataset. Likewise, it indicates that the recognition performance of the proposed method on each target is properly balanced for both 1-shot and 5-shot tasks.
From the above extensive experimental results on both the MSTAR dataset and the OpenSARShip dataset, we can state that the proposed method shows huge potential and significant superiority in solving the problem of few-shot SAR ATR compared with other state-of-the-art competitors.
3.5. Recognition Results on the SAMPLE+ Dataset
In order to further verify the recognition performance of the proposed method in the few-shot SAR ATR task, we conducted evaluation experiments on the SAMPLE+ dataset.
Table 9 lists the average recognition accuracy confusion matrix of the proposed CRCEPN method on the SAMPLE+ dataset. Similarly, it indicates that the proposed method achieves a proper balance in recognition performance for each target in both 1-shot and 5-shot tasks. From the extensive experimental results on the MSTAR dataset and the SAMPLE+ dataset, it can be seen that the proposed method shows great potential and significant advantages in addressing the few-shot SAR ATR problem.
3.6. Effectiveness Analysis
In this section, a series of experiments are designed and conducted to comprehensively evaluate the effectiveness of the proposed methods. First, ablation experiments are performed to investigate the efficacy of each component of the proposed CRCEPN, i.e., feature-extraction network based on CRConv, enhanced prototypical network (EPN), and hybrid loss (HL) function. Then, enumeration experiments are carried out to examine the influence of different values of the hyperparameter
on the recognition performance of the proposed method. Finally, two visualization methods, the t-SNE [
37] and the Grad-CAM [
38], are leveraged to display, respectively, the feature distributions and feature maps of the proposed method and several competitors.
3.6.1. Ablation Experiment
In this section, we quantitatively investigate the effectiveness of the feature-extraction network based on CRConv, enhanced prototypical network (EPN), and hybrid loss (HL) function for improving the recogntion performance of the proposed CRCEPN. Below, ablation experiments are carried out on all three dataset.
The basic architecture of the proposed method is similar to that of ProtoNet [
12], so we use ProtoNet as the baseline. ProtoNet also consists of three components: feature-extraction network based on standard convolution, prototypical network (PN), and cross-entropy loss (CL). By replacing one or more components of ProtoNet with the corresponding counterparts of CRCEPN, we obtain different variants, as shown in the first column of
Table 10, so as to evaluate the effectiveness of the corresponding components of CRCEPN. Specifically, ProtoNet-CRConv represents a variant where the standard convolution in ProtoNet is replaced by CRConv, ProtoNet-EPN means that PN is replaced by EPN, ProtoNet-EPN-HL means that PN and CL are replaced by EPN and HL, respectively, and so forth. Particularly, if all three components of ProtoNet are replaced correspondingly, it yields ProtoNet-CRConv-EPN-HL, which is just our proposed CRCEPN.
Table 10 gives the ablation experimental results on the MSTAR dataset under three different scenarios for both 1-shot and 5-shot tasks. From the results in
Table 10, one can observe the following three points:
(1) The recognition rates of ProtoNet-CRConv are about 9–18% higher than those of ProtoNet under each experimental scenario for either the 1-shot or 5-shot task. Also, ProtoNet-CRConv-EPN-HL (i.e., CRCEPN) outperforms ProtoNet-EPN-HL by about 9–17% in recognition rates. This demonstrates convincingly that the CRConv-based feature-extraction network is capable of extracting more informative and discriminative features for few-shot SAR ART, thus improving the recognition performance of the proposed method;
(2) By comparing ProtoNet-EPN with ProtoNet and ProtoNet-CRConv-EPN with ProtoNet-CRConv, one can see that the recognition rates are increased by about 0.4–6.6% and 0.3–1.7%, respectively. As such, we can state that the proposed enhanced prototypical network (EPN) is better than traditional prototypical network (PN) for solving the problems of few-shot SAR target recognition;
(3) Furthermore, the recognition rates of ProtoNet-EPN-HL exceed those of ProtoNet-EPN by 0.4–2.7%, and ProtoNet-CRConv-EPN-HL (i.e., CRCEPN) surpasses ProtoNet-CRConv-EPN by 0.4–3.9%, which indicate explicitly that the proposed hybrid loss (HL) function is beneficial to further enhancing the recognition performance.
The ablation experimental results on the OpenSARShip dataset are listed in
Table 11. As can be seen, similar results can be concluded for both 1-shot and 5-shot tasks. Broadly speaking, the CRConv-based feature-extraction network brings 2.5–6% improvement for the recognition rates, the enhanced prototypical network (EPN) gives 0.6–1.5%, and the hybrid loss (HL) function contributes about 0.1–3%.
The ablation experimental results on the SAMPLE+ dataset are listed in
Table 12.
From these above ablation experiments, we can state that each key component, that is, the feature-extraction network based on CRConv, enhanced prototypical network (EPN), and hybrid loss (HL) gives its own individual contribution to promoting the recognition performance of the proposed CRCEPN. And CRConv plays an explicitly dominant role in the performance improvement. These comprehensive evaluations on three datasets not only demonstrate the effectiveness of each key component of the proposed CRCEPN, but also partly indicate that the proposed method is relatively robust and is able to handle diversified few-shot SAR data.
3.6.2. Hyperparameter Analysis
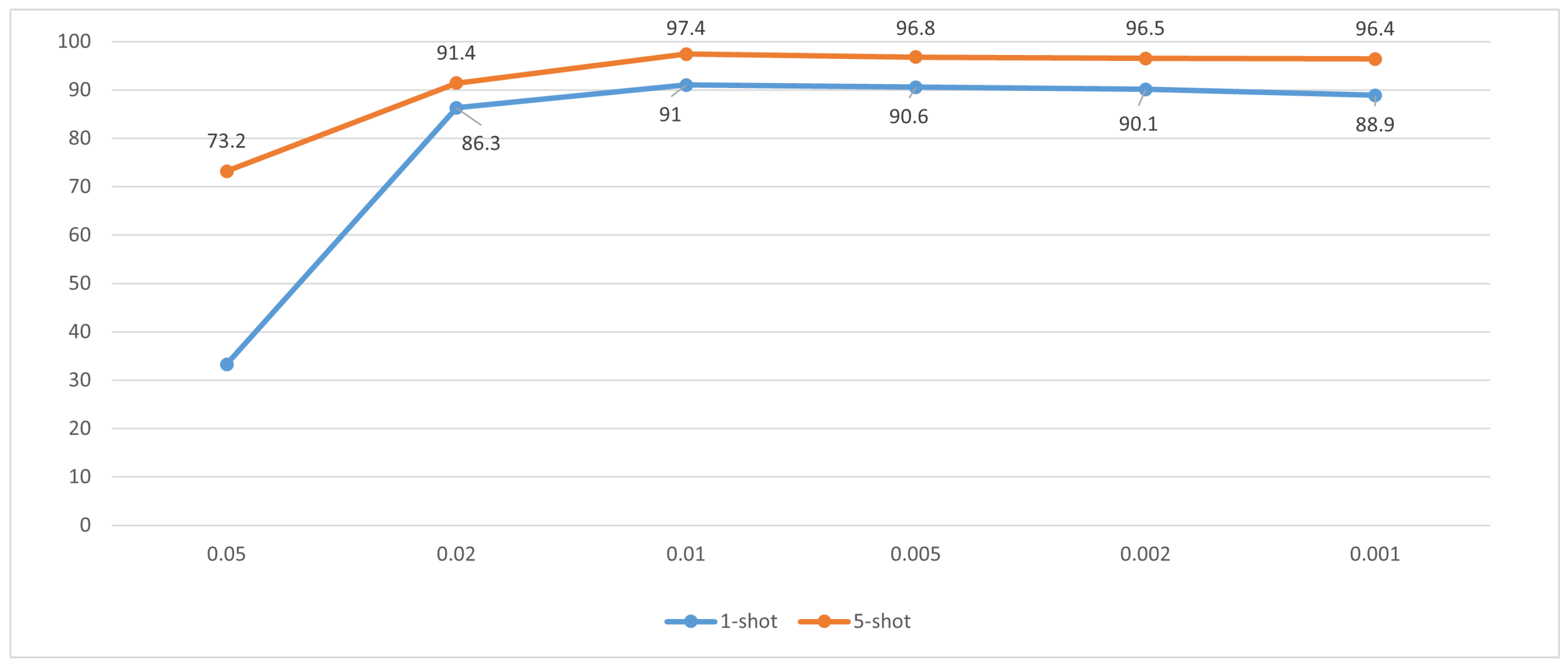
is a key parameter in the proposed method that is used to balance the importance of the cross-entropy loss and the aggregation loss in the hybrid loss function. In this section, we conduct enumeration experiments in order to investigate the influence of different values of on the recognition performance of the proposed method. The values of are set to {0.05, 0.02, 0.01, 0.005, 0.002, 0.001}. All experiments are conducted on the MSTAR dataset under the first scenario for both 1-shot and 5-shot tasks.
Figure 7 displays the recognition rates of the proposed method with different values of
. One can see from
Figure 7 that, for both few-shot tasks, as the value of
is decreased from 0.05 to 0.001, the recognition rate of the proposed method increases first and then decreases gradually. This indicates that an appropriate value of
is important for the proposed method. Specifically, in our experiments, the proposed method obtains the best recognition performance when
is set to 0.01. When
is greater than 0.01, the recognition rate shows significant degradation, while, as
decreases to 0, it also declines but slightly and gradually. As a matter of fact, if the value of
is greater than 0.05, the recognition performance of the proposed method drops dramatically.
As mentioned in
Section 2.3, the cross-entropy loss forces the features of different classes to stay as far apart as possible, while the aggregation loss pulls the features of the same class together as much as possible. A greater value of
means that the aggregation loss plays more of a role, while a smaller value of
means that the cross-entropy loss dominates the hybrid loss function. For SAR ATR problems, the ultimate goal is to distinguish one class from another, so it is perfectly reasonable that the cross-entropy loss plays a leading role while the aggregation loss acts as a supplement in the proposed method. That is to say, a reasonably smaller value of
is necessary for the proposed method to obtain satisfactory recognition performance.
3.6.3. Feature Distribution Visualization
In this section, the performance of the proposed method is further demonstrated from the perspective of feature distribution. Specifically, we employ the t-SNE tool [
37] in the Python 3.8 package to visualize the distribution of original SAR images as well as the features extracted by ProtoNet, TPAN, and our proposed CRCEPN. For this purpose, the SAR images of three targets in the MSTAR dataset for testing, i.e., 2S1, BRDM2, and ZSU23/4, collected at a
depression angle, are selected for visualization.
Figure 8a displays that the distribution of the original SAR images is widely scattered, exhibiting severe within-class dispersion and inter-class overlap. This underscores the inherent challenge in distinguishing between different targets based solely on the original SAR image data. By contrast,
Figure 8b shows that the features extracted by ProtoNet are broadly clustered, suggesting an improvement in the ability to separate different classes. However, the within-class dispersion is still relatively wide and a noticeable overlap remains between the features of BRDM2 and 2S1 (represented by purple and green dots, respectively; the yellow dots donote ZSU23/4). Then,
Figure 8c reveals that the feature space of TPAN is more separable than that of ProtoNet and the between-class overlap is reduced, suggesting an enhancement in the recognition performance of TPAN, which has been confirmed through the comparison experiments in
Section 3.3.
Finally,
Figure 8d demonstrates that the proposed CRCEPN can yield a more distinguishable feature space compared to TPAN, characterized by better both inter-class separability and intra-class compactness. This visualization result of feature distribution is also a perfect illustration to what we discussed in
Section 2.3, that is, with the joint optimization of both the cross-entropy loss and the aggregation loss, we train a robust network to obtain features with both inter-class separability and intra-class tightness. And this trait contributes directly to the superior recognition performance of the proposed CRCEPN for few-shot SAR ATR tasks, as is also verified by the experimental results in
Section 3.3.
3.6.4. Feature Map Visualization
In this section, we continue to investigate the effectiveness and superiority of the proposed method intuitively. For this purpose, a visualization method, i.e., Grad-CAM [
37], is utilized to display the extracted feature map of the proposed CRCEPN. ProtoNet and TPAN are still used as competitors. The visualization results are displayed in
Figure 9, where the first row contains the results of one image of T62 and the second row lists the results of one image of BTR60, both from the MSTAR dataset.
The results in
Figure 9b show that ProtoNet has relatively poor ability to focus on the target area in SAR images and the edge area of the target is blurred by surrounding backgrounds, which, as a result, gives very limited recognition performance.
Figure 9c indicates that TPAN can better locate the target area than ProtoNet and the edge of the target area is clearly visible, thus improving the recognition performance. This may benefit from the elaborately designed region-awareness-based feature extractor in TPAN [
28]. Nevertheless, one can also see from
Figure 9c in the second row that TPAN may possibly highlight some extra background area that is explicitly irrelevant to the target.
In comparison, we can see from
Figure 9d that the proposed CRCEPN can not only focus on the target area but also properly suppress the redundant background, which helps to obtain higher recognition performance than TPAN. This superiority mainly owes to the use of CRConv in CRCEPN, which can adaptively adjust convolutional kernels as well as their receptive fields according to each SAR image’s own characteristics and the semantical similarity of spatial regions, thereby augmenting the capability to extract more informative and discriminative features that significantly aid the target classification. This is very valuable for few-shot SAR target recognition, where the scarcity of labeled images may severely degrade a network’s representation ability. Thereby making the most of every piece of available information to amplify as much as possible the representation capacity of the network appears particularly important.
It is worth noting that while the focus of this study is on suppressing background information to highlight target features, the shadows in SAR images actually contain important information about the target’s height. In certain application scenarios, this shadow information may assist in target recognition and classification. Future research could consider how to selectively utilize this shadow information to further enhance recognition performance while maintaining the focus on the target.
3.6.5. Noise Impact Analysis
Based on references [
39,
40], we simulate SAR images at different noise levels using the MSTAR dataset. A parameter L is introduced to represent noise intensity, with smaller L values indicating stronger noise. In the experiments, L takes values from 1 to 5, increasing incrementally. This method allows for the evaluation of the impact of noise on recognition performance under controlled conditions. As shown in
Table 13, the recognition performance lowers as the noise intensity increases; however, the proposed method can still obtain relatively satisfactory results.
3.7. Computational Complexity Analysis
In this section, we analyze the computational complexity of the proposed method and compare with several state-of-the-art few-shot learning approaches, including ProtoNet [
12], RelationNet [
13], TPN [
14], BSCapNet [
23], and TPAN [
28]. The complexity analysis focuses on both time and space aspects, which are crucial for understanding the efficiency and scalability of the methods.
As shown in
Table 14, our CRCEPN method has a time complexity of
, which is higher than the other compared methods. This increased time complexity is primarily due to the more sophisticated feature-extraction and optimization processes in our approach, which contribute to its improved performance in few-shot learning tasks.
In terms of space complexity, CRCEPN requires parameters, which is comparable to BSCapNet and higher than the other methods. This increased space requirement is a result of our method’s need to store and process more complex feature representations and relational information between samples.
While our method has higher computational demands, it is important to note that this increased complexity translates to superior performance in few-shot learning tasks, as demonstrated in our experimental results. The additional computational cost allows CRCEPN to capture more subtle relationships between samples and classes, leading to better generalization in few-shot scenarios.
4. Conclusions
This paper proposes a new method called enhanced prototypical network with customized region-aware convolution (CRCEPN) to solve the problem of few-shot SAR target recognition, where scarcely a few labeled samples are available. The contributions of this paper include three aspects. First, a feature-extraction network with customized and region-aware convolutional kernels is developed to extract more informative and discriminative features for few-shot SAR target recognition, which can adapt better to diverse SAR images and remarkably improve the recognition performance of the proposed method. Second, an enhanced prototypical network is proposed to achieve more accurate and robust target identity prediction, which can effectively enhance the representation ability of class prototypes and, in turn, raise the classification accuracy, especially for the situation of few-shot SAR target recognition. Third, a new loss function—namely, aggregation loss—is proposed to pull features of the same class together as much as possible, and a hybrid loss is then designed to learn a feature space with both inter-class separability and intra-class tightness, which can further upgrade the recognition performance of the proposed method. Extensive experiments on the MSTAR dataset, the OpenSARship dataset, and the SAMPLE+ dataset demonstrate that the proposed method is superior to some state-of-the-art methods for few-shot SAR target recognition. In future research, we will further exploit the few-shot SAR ATR algorithm in dynamic environments where the number of target categories continues to increase.





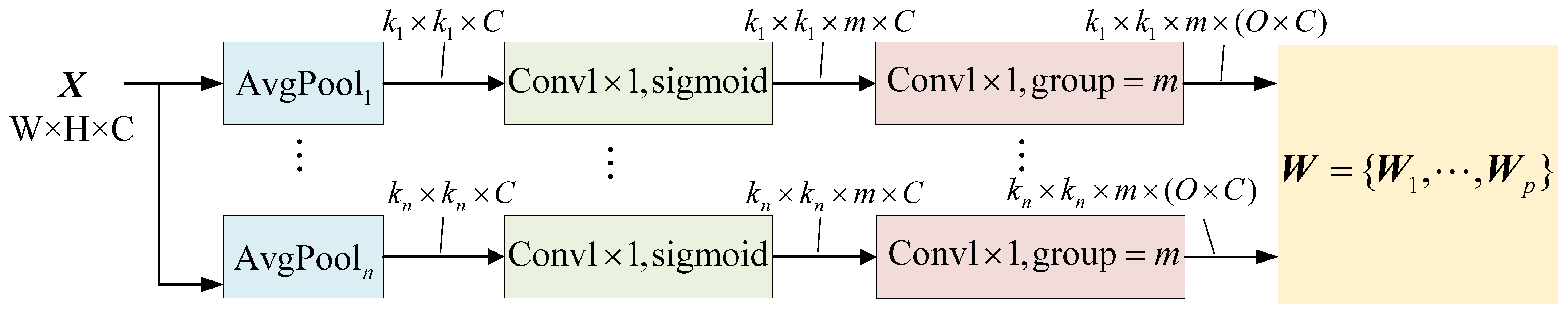





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}