
A Multi-Scale Content-Structure Feature Extraction Network Applied to Gully Extraction


Abstract
1. Introduction
2. Study Area and Data
2.1. Study Area
2.2. Data Preparation
3. Methods
3.1. Overall Structure
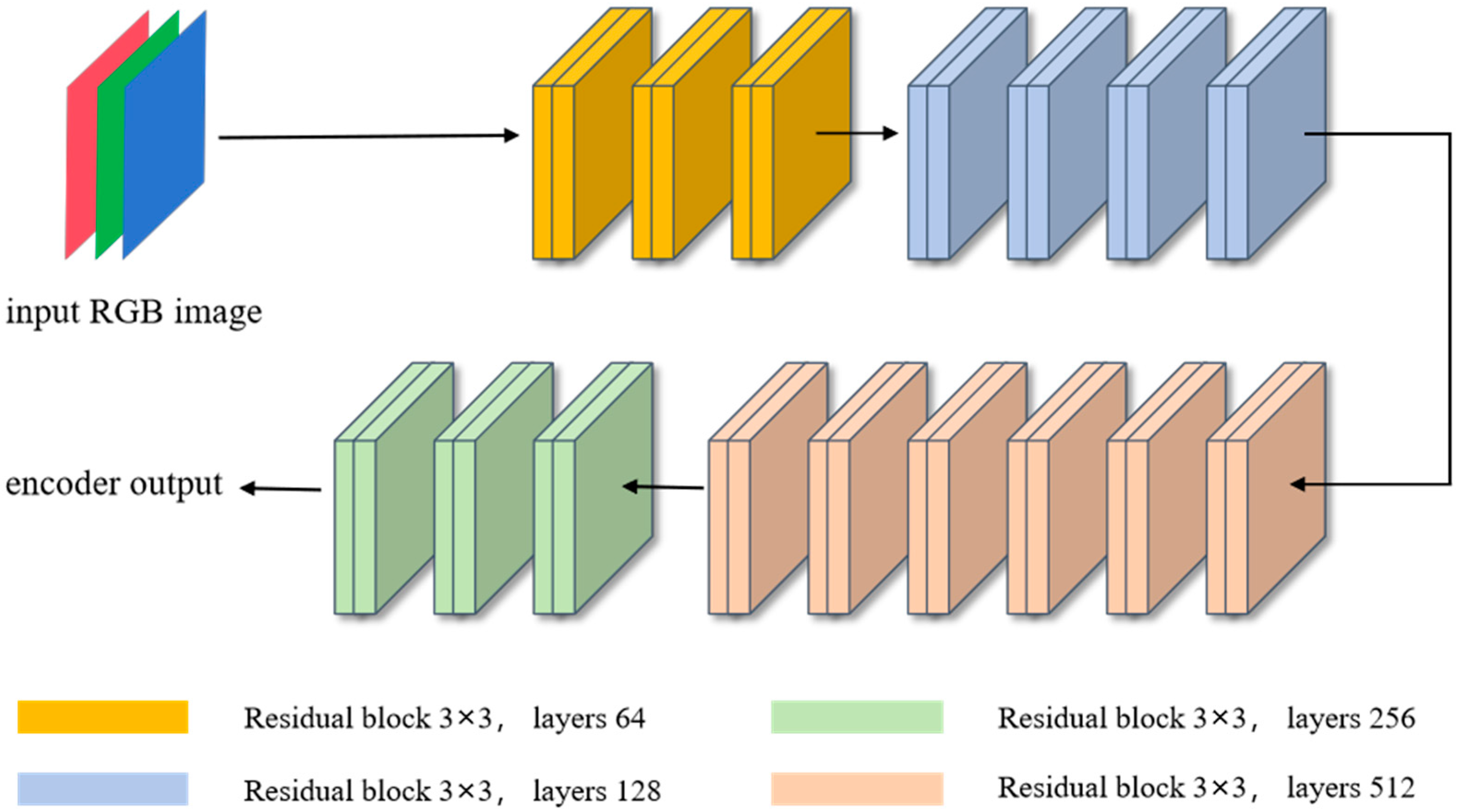
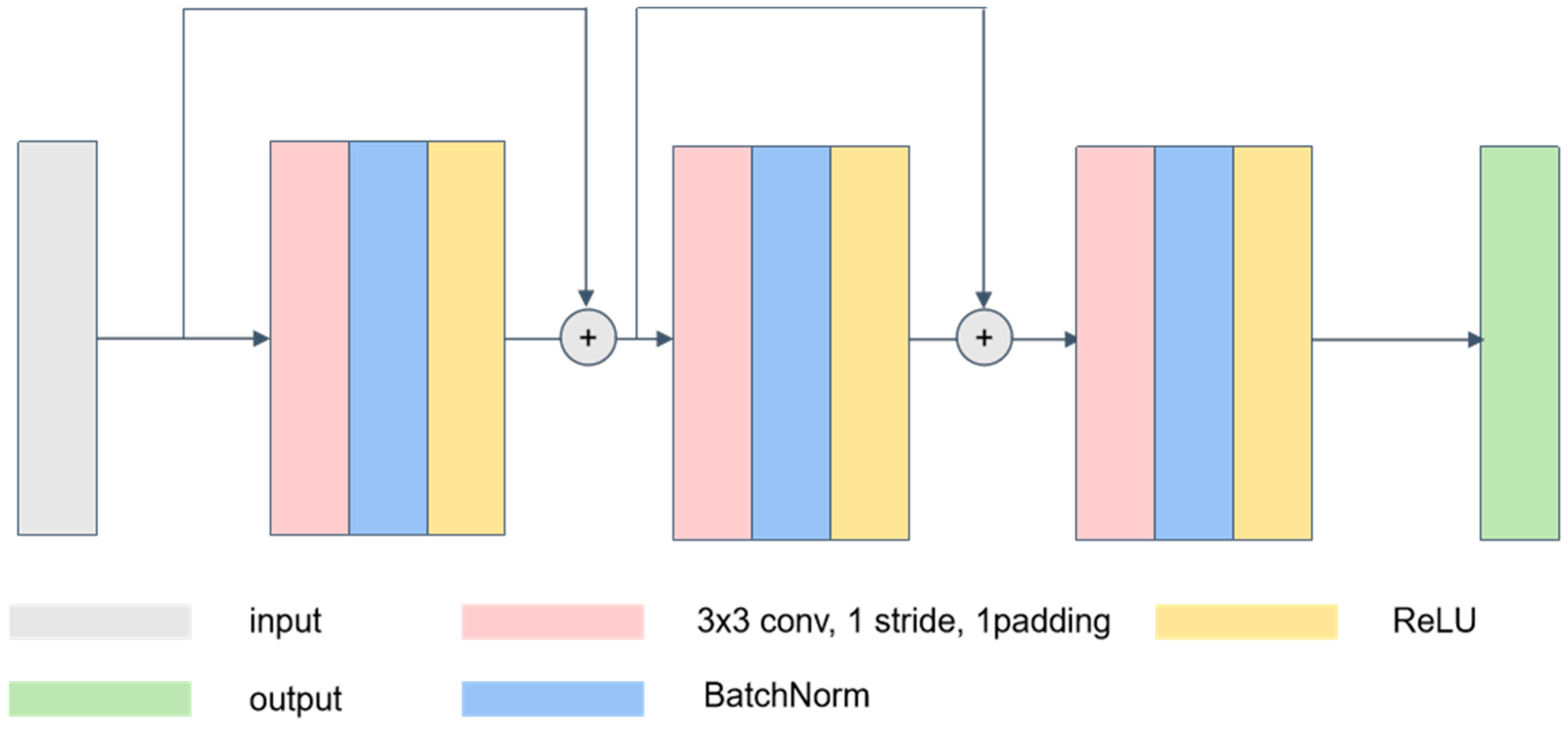
3.2. Multi-Scale Structure Extraction Module
3.3. Multi-Scale Content Extraction Module
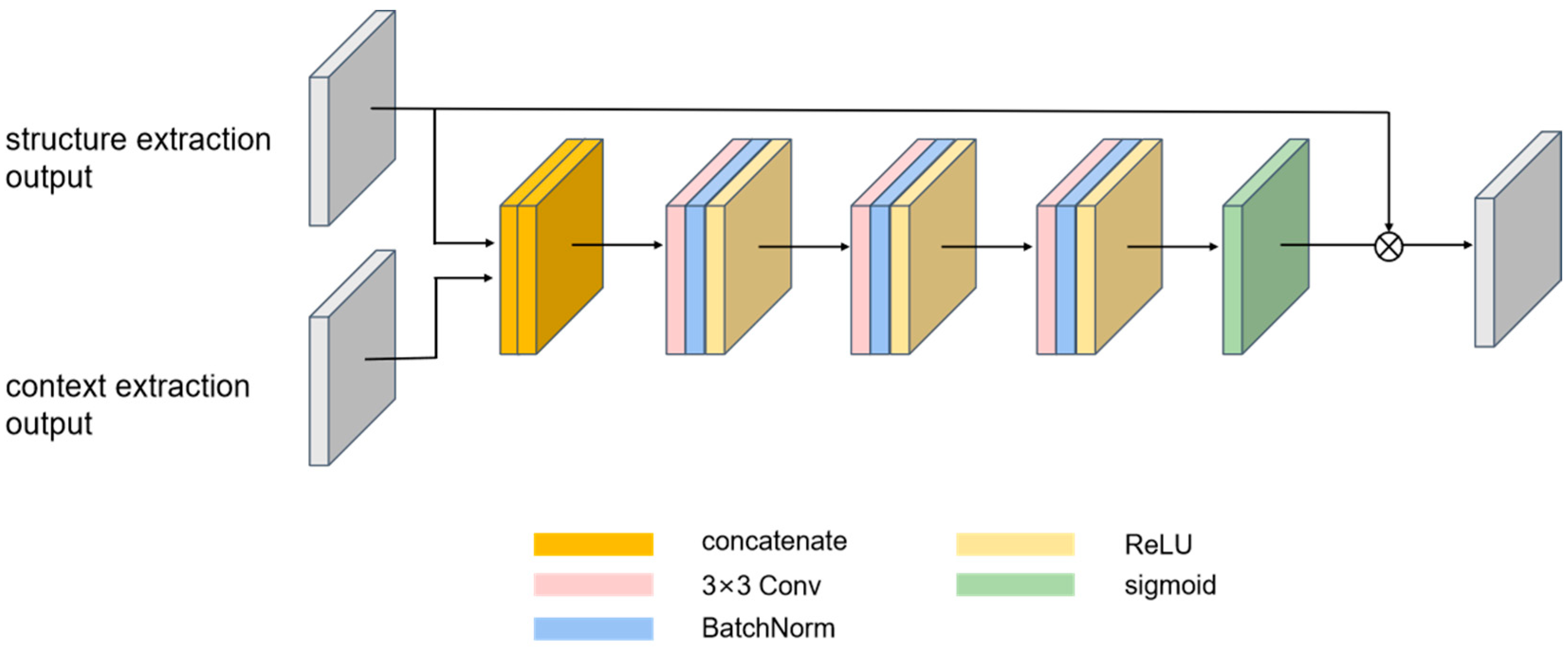
3.4. Structure-Content Fusion Network
3.5. Muti-Scale Feature Fusion Module
3.6. Data Augmentation
3.7. Evaluation Metrics
4. Results
4.1. Implementation Details
4.2. Analysis and Discussion of the Experimental Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| UAV | Unmanned Aerial Vehicle |
| GPS | Global Positioning System |
| OBIA | Object-Based Image Analysis |
| NorToM | Normalized Terrain Method |
| InSAR | Interferometric Synthetic Aperture Radar |
| REA | Relative Elevation Algorithm |
| DEM | Digital Elevation Model |
| HRI | High-Resolution Remote Imagery |
| LiDAR | Light Detection and Ranging |
| OOA | Object-Oriented Image Analysis |
| IoU | Intersection over Union |
| GEI | Google Earth Image |
References
- Luo, L.; Ma, J.; Li, F.; Jiao, H.; Strobl, J.; Zhu, A.; Dai, Z.; Liu, S. Simulation of loess gully evolution based on geographic cellular automata. Earth Surf. Process. Landf. 2021, 47, 756–777. [Google Scholar] [CrossRef]
- Poesen, J.; Nachtergaele, J.; Verstraeten, G.; Valentin, C. Gully erosion and environmental change: Importance and research needs. CATENA 2002, 50, 91–133. [Google Scholar] [CrossRef]
- Valentin, C.; Poesen, J.; Li, Y. Gully erosion: Impacts, factors and control. CATENA 2005, 63, 132–153. [Google Scholar] [CrossRef]
- Zaimes, G.N.; Schultz, R.C. Assessing riparian conservation land management practice impacts on gully erosion in Iowa. Environ. Manag. 2012, 49, 1009–1021. [Google Scholar] [CrossRef] [PubMed]
- Zakerinejad, R.; Maerker, M. An integrated assessment of soil erosion dynamics with special emphasis on gully erosion in the Mazayjan basin, southwestern Iran. Nat. Hazards 2015, 79, 25–50. [Google Scholar] [CrossRef]
- Garosi, Y.; Sheklabadi, M.; Conoscenti, C.; Pourghasemi, H.R.; Van Oost, K. Assessing the performance of GIS- based machine learning models with different accuracy measures for determining susceptibility to gully erosion. Sci. Total. Environ. 2019, 664, 1117–1132. [Google Scholar] [CrossRef]
- Chen, R.; Zhou, Y.; Wang, Z.; Li, Y.; Li, F.; Yang, F. Towards accurate mapping of loess waterworn gully by integrating google earth imagery and DEM using deep learning. Int. Soil Water Conserv. Res. 2024, 12, 13–28. [Google Scholar] [CrossRef]
- Borrelli, P.; Poesen, J.; Vanmaercke, M.; Ballabio, C.; Hervás, J.; Maerker, M.; Scarpa, S.; Panagos, P. Monitoring gully erosion in the European Union: A novel approach based on the Land Use/Cover Area frame survey (LUCAS). Int. Soil Water Conserv. Res. 2021, 10, 17–28. [Google Scholar] [CrossRef]
- Ding, H.; Liu, K.; Chen, X.; Xiong, L.; Tang, G.; Qiu, F.; Strobl, J. Optimized segmentation based on the weighted aggregation method for loess bank gully mapping. Remote Sens. 2020, 12, 793. [Google Scholar] [CrossRef]
- Ionita, I.; Fullen, M.A.; Zgłobicki, W.; Poesen, J. Gully erosion as a natural and human-induced hazard. Nat. Hazards 2015, 79, 1–5. [Google Scholar] [CrossRef]
- Vanmaercke, M.; Poesen, J.; Van Mele, B.; Demuzere, M.; Bruynseels, A.; Golosov, V.; Bezerra, J.F.R.; Bolysov, S.; Dvinskih, A.; Frankl, A.; et al. How fast do gully headcuts retreat? Earth-Sci. Rev. 2016, 154, 336–355. [Google Scholar] [CrossRef]
- Wu, Y.; Cheng, H. Monitoring of gully erosion on the Loess Plateau of China using a global positioning system. CATENA 2005, 63, 154–166. [Google Scholar] [CrossRef]
- Shruthi, R.B.; Kerle, N.; Jetten, V. Object-based gully feature extraction using high spatial resolution imagery. Geomorphology 2011, 134, 260–268. [Google Scholar] [CrossRef]
- Liu, K.; Ding, H.; Tang, G.; Zhu, A.-X.; Yang, X.; Jiang, S.; Cao, J. An object-based approach for two-level gully feature mapping using high-resolution DEM and imagery: A case study on hilly loess plateau region, China. Chin. Geogr. Sci. 2017, 27, 415–430. [Google Scholar] [CrossRef]
- Wang, B.; Zhang, Z.; Wang, X.; Zhao, X.; Yi, L.; Hu, S. Object-based mapping of gullies using optical images: A case study in the black soil region, Northeast of China. Remote Sens. 2020, 12, 487. [Google Scholar] [CrossRef]
- Castillo, C.; Taguas, E.V.; Zarco-Tejada, P.; James, M.R.; Gómez, J.A. The normalized topographic method: An automated procedure for gully mapping using GIS. Earth Surf. Process. Landf. 2014, 39, 2002–2015. [Google Scholar] [CrossRef]
- Knight, J.; Spencer, J.; Brooks, A.; Phinn, S.R. Large-area, high-resolution remote sensing based mapping of alluvial gully erosion in Australia’s tropical rivers. In Proceedings of the 5th Australian Stream Management Conference, Albury, NSW, Australia, 12 January 2007; pp. 199–204. [Google Scholar]
- Chen, K.; Wang, C.; Lu, M.; Dai, W.; Fan, J.; Li, M.; Lei, S. Integrating Topographic Skeleton into Deep Learning for Terrain Reconstruction from GDEM and Google Earth Image. Remote Sens. 2023, 15, 4490. [Google Scholar] [CrossRef]
- Lu, P.; Zhang, B.; Wang, C.; Liu, M.; Wang, X. Erosion Gully Networks Extraction Based on InSAR Refined Digital Elevation Model and Relative Elevation Algorithm—A Case Study in Huangfuchuan Basin, Northern Loess Plateau, China. Remote Sens. 2024, 16, 921. [Google Scholar] [CrossRef]
- Zeng, T.; Guo, Z.; Wang, L.; Jin, B.; Wu, F.; Guo, R. Tempo-spatial landslide susceptibility assessment from the perspective of human engineering activity. Remote Sens. 2023, 15, 4111. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, L.; Yin, K.; Luo, H.; Li, J. Landslide identification using machine learning. Geosci. Front. 2020, 12, 351–364. [Google Scholar] [CrossRef]
- Shahabi, H.; Jarihani, B.; Piralilou, S.T.; Chittleborough, D.; Avand, M.; Ghorbanzadeh, O. A Semi-automated object-based gully networks detection using different machine learning models: A case study of bowen catchment, Queensland, Australia. Sensors 2019, 19, 4893. [Google Scholar] [CrossRef] [PubMed]
- D’Oleire-Oltmanns, S.; Marzolff, I.; Tiede, D.; Blaschke, T. Detection of gully-affected areas by applying object-based image analysis (OBIA) in the region of Taroudannt, Morocco. Remote Sens. 2014, 6, 8287–8309. [Google Scholar] [CrossRef]
- Eustace, A.; Pringle, M.; Witte, C. Give me the dirt: Detection of gully extent and volume using high-resolution lida. In Innovations in Remote Sensing and Photogrammetry; Springer: Berlin/Heidelberg, Germany, 2009; pp. 255–269. [Google Scholar]
- Liu, B.; Zhang, B.; Feng, H.; Wu, S.; Yang, J.; Zou, Y.; Siddique, K.H. Ephemeral gully recognition and accuracy evaluation using deep learning in the hilly and gully region of the Loess Plateau in China. Int. Soil Water Conserv. Res. 2022, 10, 371–381. [Google Scholar] [CrossRef]
- Zhu, P.; Xu, H.; Zhou, L.; Yu, P.; Zhang, L.; Liu, S. Automatic mapping of gully from satellite images using asymmetric non-local LinkNet: A case study in Northeast China. Int. Soil Water Conserv. Res. 2024, 12, 365–378. [Google Scholar] [CrossRef]
- Gafurov, A.M.; Yermolayev, O.P. Automatic gully detection: Neural networks and computer vision. Remote. Sens. 2020, 12, 1743. [Google Scholar] [CrossRef]
- Wilkinson, S.N.; Kinsey-Henderson, A.E.; Hawdon, A.A.; Hairsine, P.B.; Bartley, R.; Baker, B. Grazing impacts on gully dynamics indicate approaches for gully erosion control in northeast Australia. Earth Surf. Process. Landf. 2018, 43, 1711–1725. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. Proc. IEEE Conf. Comput. Vis. Pattern Recognit. 2016, 43, 770–778. [Google Scholar]
- Philipp, G.; Song, D.; Carbonell, J.G. The exploding gradient problem demystified-definition, prevalence, impact, origin, tradeoffs, and solutions. arXiv 2017, arXiv:1712.05577. [Google Scholar]
- Balduzzi, D.; Frean, M.; Leary, L.; Lewis, J.P.; Ma, K.W.-D.; McWilliams, B. The shattered gradients problem: If resnets are the answer, then what is the question? In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 28 February 2017; pp. 342–350. [Google Scholar]
- Taki, M. Deep residual networks and weight initialization. arXiv 2017, arXiv:1709.02956. [Google Scholar]
- Nagi, J.; Ducatelle, F.; Di Caro, G.A.; Cireşan, D.; Meier, U.; Giusti, A.; Nagi, F.; Schmidhuber, J.; Gambardella, L.M. Max-pooling convolutional neural networks for vision-based hand gesture recognition. In Proceedings of the 2011 IEEE International Conference on Signal and Image Processing Applications (ICSIPA), Kuala Lumpur, Malaysia, 16–18 November 2011; pp. 342–347. [Google Scholar]
- Guo, C.; Fan, B.; Zhang, Q.; Xiang, S.; Pan, C. Augfpn: Improving multi-scale feature learning for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12595–12604. [Google Scholar]
- Chen, M.; Shi, X.; Zhang, Y.; Wu, D.; Guizani, M. Deep feature learning for medical image analysis with convolutional autoencoder neural network. IEEE Trans. Big Data 2017, 7, 750–758. [Google Scholar] [CrossRef]
- Han, Z.; Lu, H.; Liu, Z.; Vong, C.-M.; Liu, Y.-S.; Zwicker, M.; Han, J.; Chen, C.L.P. 3D2SeqViews: Aggregating sequential views for 3D global feature learning by CNN with hierarchical attention aggregation. IEEE Trans. Image Process. 2019, 28, 3986–3999. [Google Scholar] [CrossRef] [PubMed]
- Gao, M.; Qi, D.; Mu, H.; Chen, J. A Transfer residual neural network based on ResNet-34 for detection of wood knot defects. Forests 2021, 12, 212. [Google Scholar] [CrossRef]
- Gao, L.; Zhang, X.; Yang, T.; Wang, B.; Li, J. The Application of ResNet-34 Model Integrating Transfer Learning in the Recognition and Classification of Overseas Chinese Frescoes. Electronics 2023, 12, 3677. [Google Scholar] [CrossRef]
- Zhuang, Q.; Gan, S.; Zhang, L. Human-computer interaction based health diagnostics using ResNet34 for tongue image classification. Comput. Methods Programs Biomed. 2022, 226, 107096. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z. Resnet-based model for autonomous vehicles trajectory prediction. In Proceedings of the 2021 IEEE International Conference on Consumer Electronics and Computer Engineering (ICCECE), Guangzhou, China, 15–17 January 2021; pp. 565–568. [Google Scholar]
- Venerito, V.; Angelini, O.; Cazzato, G.; Lopalco, G.; Maiorano, E.; Cimmino, A.; Iannone, F. A convolutional neural network with transfer learning for automatic discrimination between low and high-grade synovitis: A pilot study. Intern. Emerg. Med. 2021, 16, 1457–1465. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar]
- Gangrade, S.; Sharma, P.C.; Sharma, A.K.; Singh, Y.P. Modified DeeplabV3+ with multi-level context attention mechanism for colonoscopy polyp segmentation. Comput. Biol. Med. 2024, 170, 108096. [Google Scholar] [CrossRef]
- Pecoraro, R.; Basile, V.; Bono, V. Local Multi-Head Channel Self-Attention for Facial Expression Recognition. Information 2022, 13, 419. [Google Scholar] [CrossRef]
- Dutta, A.K.; Raparthi, M.; Alsaadi, M.; Bhatt, M.W.; Dodda, S.B.; Prashant, G.C.; Sandhu, M.; Patni, J.C. Deep learning-based multi-head self-attention model for human epilepsy identification from EEG signal for biomedical traits. Multimed. Tools Appl. 2024, 1–23. [Google Scholar] [CrossRef]
- Liu, J.; Chen, S.; Wang, B.; Zhang, J. Attention as relation: Learning supervised multi-head self-attention for relation extraction. In Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, Vienna, Austria, 11–17 July 2020; pp. 3787–3793. [Google Scholar]
- Yu, X.; Zhang, D.; Zhu, T.; Jiang, X. Novel hybrid multi-head self-attention and multifractal algorithm for non-stationary time series prediction. Inf. Sci. 2022, 613, 541–555. [Google Scholar] [CrossRef]
- Azam, M.F.; Younis, M.S. Multi-horizon electricity load and price forecasting using an interpretable multi-head self-attention and EEMD-based framework. IEEE Access 2021, 9, 85918–85932. [Google Scholar] [CrossRef]
- Qin, C.; Huang, G.; Yu, H.; Wu, R.; Tao, J.; Liu, C. Geological information prediction for shield machine using an enhanced multi-head self-attention convolution neural network with two-stage feature extraction. Geosci. Front. 2023, 14, 101519. [Google Scholar] [CrossRef]
- Jin, Y.; Tang, C.; Liu, Q.; Wang, Y. Multi-head self-attention-based deep clustering for single-channel speech separation. IEEE Access 2020, 8, 100013–100021. [Google Scholar] [CrossRef]
- Xiao, L.; Hu, X.; Chen, Y.; Xue, Y.; Chen, B.; Gu, D.; Tang, B. Multi-head self-attention based gated graph convolutional networks for aspect-based sentiment classification. Multimed. Tools Appl. 2020, 81, 19051–19070. [Google Scholar] [CrossRef]
- Vasanthi, P.; Mohan, L. Multi-Head-Self-Attention based YOLOv5X-transformer for multi-scale object detection. Multimed. Tools Appl. 2023, 83, 36491–36517. [Google Scholar] [CrossRef]
- Li, C.; Ma, K. Entity recognition of Chinese medical text based on multi-head self- attention combined with BILSTM-CRF. Math. Biosci. Eng. 2021, 19, 2206–2218. [Google Scholar] [CrossRef]
- Gao, Z.; Zhao, X.; Cao, M.; Li, Z.; Liu, K.; Chen, B.M. Synergizing low rank representation and deep learning for automatic pavement crack detection. IEEE Trans. Intell. Transp. Syst. 2023, 24, 10676–10690. [Google Scholar] [CrossRef]
- Zeng, N.; Wu, P.; Wang, Z.; Li, H.; Liu, W.; Liu, X. A Small-sized object detection oriented multi-scale feature fusion approach with application to defect detection. IEEE Trans. Instrum. Meas. 2022, 71, 1–14. [Google Scholar] [CrossRef]
- Huang, L.; Chen, C.; Yun, J.; Sun, Y.; Tian, J.; Hao, Z.; Yu, H.; Ma, H. Multi-scale feature fusion convolutional neural network for indoor small target detection. Front. Neurorobotics 2022, 16, 881021. [Google Scholar] [CrossRef]
- Huo, X.; Sun, G.; Tian, S.; Wang, Y.; Yu, L.; Long, J.; Zhang, W.; Li, A. HiFuse: Hierarchical multi-scale feature fusion network for medical image classification. Biomed. Signal Process. Control 2024, 87, 105534. [Google Scholar] [CrossRef]
- Zhong, J.; Zhu, J.; Huyan, J.; Ma, T.; Zhang, W. Multi-scale feature fusion network for pixel-level pavement distress detection. Autom. Constr. 2022, 141, 104436. [Google Scholar] [CrossRef]
- Liu, X.; Yang, L.; Chen, J.; Yu, S.; Li, K. Region-to-boundary deep learning model with multi-scale feature fusion for medical image segmentation. Biomed. Signal Process. Control 2022, 71, 103165. [Google Scholar] [CrossRef]
- Zhang, Y.; Lu, Y.; Zhu, W.; Wei, X.; Wei, Z. Traffic sign detection based on multi-scale feature extraction and cascade feature fusion. J. Supercomput. 2022, 79, 2137–2152. [Google Scholar] [CrossRef]
- Mumuni, A.; Mumuni, F. Data augmentation: A comprehensive survey of modern approaches. Array 2022, 16, 100258. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Garcea, F.; Serra, A.; Lamberti, F.; Morra, L. Data augmentation for medical imaging: A systematic literature review. Comput. Biol. Med. 2023, 152, 106391. [Google Scholar] [CrossRef]
- Kebaili, A.; Lapuyade-Lahorgue, J.; Ruan, S. Deep learning approaches for data augmentation in medical imaging: A review. J. Imaging 2023, 9, 81. [Google Scholar] [CrossRef]
- Chlap, P.; Min, H.; Vandenberg, N.; Dowling, J.; Holloway, L.; Haworth, A. A review of medical image data augmentation techniques for deep learning applications. J. Med. Imaging Radiat. Oncol. 2021, 65, 545–563. [Google Scholar] [CrossRef]
- Zoph, B.; Cubuk, E.D.; Ghiasi, G.; Lin, T.-Y.; Shlens, J.; Le, Q.V. Learning data augmentation strategies for object detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 566–583. [Google Scholar]
- Maharana, K.; Mondal, S.; Nemade, B. A review: Data pre-processing and data augmentation techniques. Glob. Transit. Proc. 2022, 3, 91–99. [Google Scholar] [CrossRef]
- Wang, W.; Zhou, T.; Yu, F.; Dai, J.; Konukoglu, E.; Van Gool, L. Exploring cross-image pixel contrast for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Beijing, China, 28 January 2021; pp. 7303–7313. [Google Scholar]
- Zhang, B.; Tian, Z.; Tang, Q.; Chu, X.; Wei, X.; Shen, C.; Liu, Y. Segvit: Semantic segmentation with plain vision transformers. Adv. Neural Inf. Process. Syst. 2022, 35, 4971–4982. [Google Scholar]
- Li, R.; Zheng, S.; Zhang, C.; Duan, C.; Su, J.; Wang, L.; Atkinson, P.M. Multiattention network for semantic segmentation of fine-resolution remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Qi, Y.; He, Y.; Qi, X.; Zhang, Y.; Yang, G. Dynamic snake convolution based on topological geometric constraints for tubular structure segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 17 July 2023; pp. 6047–6056. [Google Scholar]
- Wu, H.; Huang, P.; Zhang, M.; Tang, W.; Yu, X. CMTFNet: CNN and multiscale transformer fusion network for remote-sensing image semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–12. [Google Scholar] [CrossRef]
- Loey, M.; Manogaran, G.; Khalifa, N.E.M. A deep transfer learning model with classical data augmentation and CGAN to detect COVID-19 from chest CT radiography digital images. Neural Comput. Appl. 2020. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wng, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | F1 Score | Recall | IoU |
|---|---|---|---|
| DeepLabV3+ | 0.728 | 0.756 | 0.552 |
| PSPNet | 0.718 | 0.692 | 0.539 |
| UNet | 0.708 | 0.637 | 0.510 |
| Ours | 0.745 | 0.777 | 0.586 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, F.; Jin, J.; Li, L.; Li, H.; Zhang, Y. A Multi-Scale Content-Structure Feature Extraction Network Applied to Gully Extraction. Remote Sens. 2024, 16, 3562. https://doi.org/10.3390/rs16193562
Dong F, Jin J, Li L, Li H, Zhang Y. A Multi-Scale Content-Structure Feature Extraction Network Applied to Gully Extraction. Remote Sensing. 2024; 16(19):3562. https://doi.org/10.3390/rs16193562
Chicago/Turabian StyleDong, Feiyang, Jizhong Jin, Lei Li, Heyang Li, and Yucheng Zhang. 2024. "A Multi-Scale Content-Structure Feature Extraction Network Applied to Gully Extraction" Remote Sensing 16, no. 19: 3562. https://doi.org/10.3390/rs16193562
APA StyleDong, F., Jin, J., Li, L., Li, H., & Zhang, Y. (2024). A Multi-Scale Content-Structure Feature Extraction Network Applied to Gully Extraction. Remote Sensing, 16(19), 3562. https://doi.org/10.3390/rs16193562