1. Introduction
In the electronic countermeasures field, the modulation classification of the radar intra-pulse signals is an important task, which provides the required information of the radar system, such as working mode, parameter setting, etc. [
1]. However, with the development of the multi-system radar and the other advanced radar technologies, the difficulty of radar signal detection increases [
2]. Many new types of radar signals are proposed; for example, the low probability intercept (LPI) radar signals are developed for anti-jamming and anti-interception, which have the properties of low power, frequency agility, and large time–width–bandwidth product [
3]. A limited number of high-quality labeled signals can be captured due to the lower probability of intercepting these radar signals. So, the accurate classification of signals based on limited labeled samples is valuable for the interference applications and so on [
4].
The traditional radar signal modulation classification methods usually extract features from the signals firstly, and then several thresholds for the feature parameters are set to classify the signals [
5,
6,
7,
8]. However, these methods mainly rely on the choice of signal features and the set thresholds, and they usually perform not very well or even fail to work in classifying the complex modulated signals or low signal-to-noise (SNR) signals. With highly developed artificial intelligence, significant achievements have been made in many applications, such as the image classification [
9], image retrieval [
10], natural language processing [
11], etc. Compared to the traditional signal modulation classification methods, the deep learning-based methods can automatically obtain better signal features without setting thresholds.
Many deep learning models for the signal modulation classification have been proposed, and most of them are based on the supervised learning (SL) [
12,
13,
14,
15]. In [
12], the convolutional neural network (CNN)-based model, AlexNet, is proposed, which uses the data augmentation and dropout operation to prevent the overfitting problem. Another CNN-based model, called OD-CNN, is proposed in [
13], which utilizes multi-feature fusion method to construct a more complete signal feature representation for reducing the noise and frequency offset influences. Moreover, refs. [
14,
15] apply the transformer model to the signal modulation classification for automatically learning the global dependencies of the signals, which helps the model adaptively concentrate on the key signal features and leads to robust performance. In [
16], the radar signal is preprocessed by the second-order short-time Fourier transformation, and then the modified CNN (MeNet) is applied to the classification. Some semi-supervised leaning (SSL) models are also proposed to increase the classification performance by predicting labels for the unlabeled samples, for example, the PLLW model in [
17].
To decrease the requirement of labeled samples, the self-supervised learning (SeSL) models are proposed [
18,
19]. These models usually first need to be trained by a great number of unlabeled samples, and then fine-tuned with a few labeled samples. Furthermore, the performance of these models is affected by the quantity of the image augmentations, but more augmentation means a greater amount of computation. Contrastive learning (CL) is a typical SeSL method, which learns the similarity and dissimilarity between samples by contrasting different views of the same sample [
20,
21]. The CL extracts the effective image features by comparison, and only limited labeled samples are needed to fine-tune the classifier for better classification performance. The signal modulation classification method in [
19] is based on the CL, but this method is easily affected by the quality of the unlabeled samples’ pseudo-labels.
A radar signal modulation classification, called SL-CL, which uses the CL strategy with the fully SL mode, is proposed in this paper, which adopts a two-stage training structure [
22]. In the first training stage, the supervised contrastive loss adapting to the labeled samples is constructed, which is improved from the CL loss for the unlabeled samples, then the encoder is constrained by this loss for representing the sample features better. With the extracted features of the first stage, the samples are classified by the linear classifier of the second stage. Due to the strong ability of capturing the sample features, the requirement for the labeled samples is relieved when a high classification accuracy is achieved.
In the proposed SL-CL model, the SeSL-type contrastive learning model is changed into an SL model, which enhances the classification accuracy by utilizing labeled samples for training. The loss function is reconstructed according to the change, which increases the feature capture ability. Furthermore, the two-stage training structure with two different losses is adopted instead of the one-stage one, which further increases the classification accuracy.
There are six sections in this paper. In
Section 2, The motivation and works related to the SL-CL model are presented. In
Section 3, the signal model and the method of data preprocessing are presented. Then, the structure and details of the SL-CL model are shown in
Section 4. Finally, the experiment performances of the SL-CL model are shown in
Section 5, where the parameter settings are analyzed and the comparisons with the other models are executed. The conclusion of this paper is given in
Section 6.
4. The Proposed SL-CL Model
4.1. Overview of the SL-CL Model
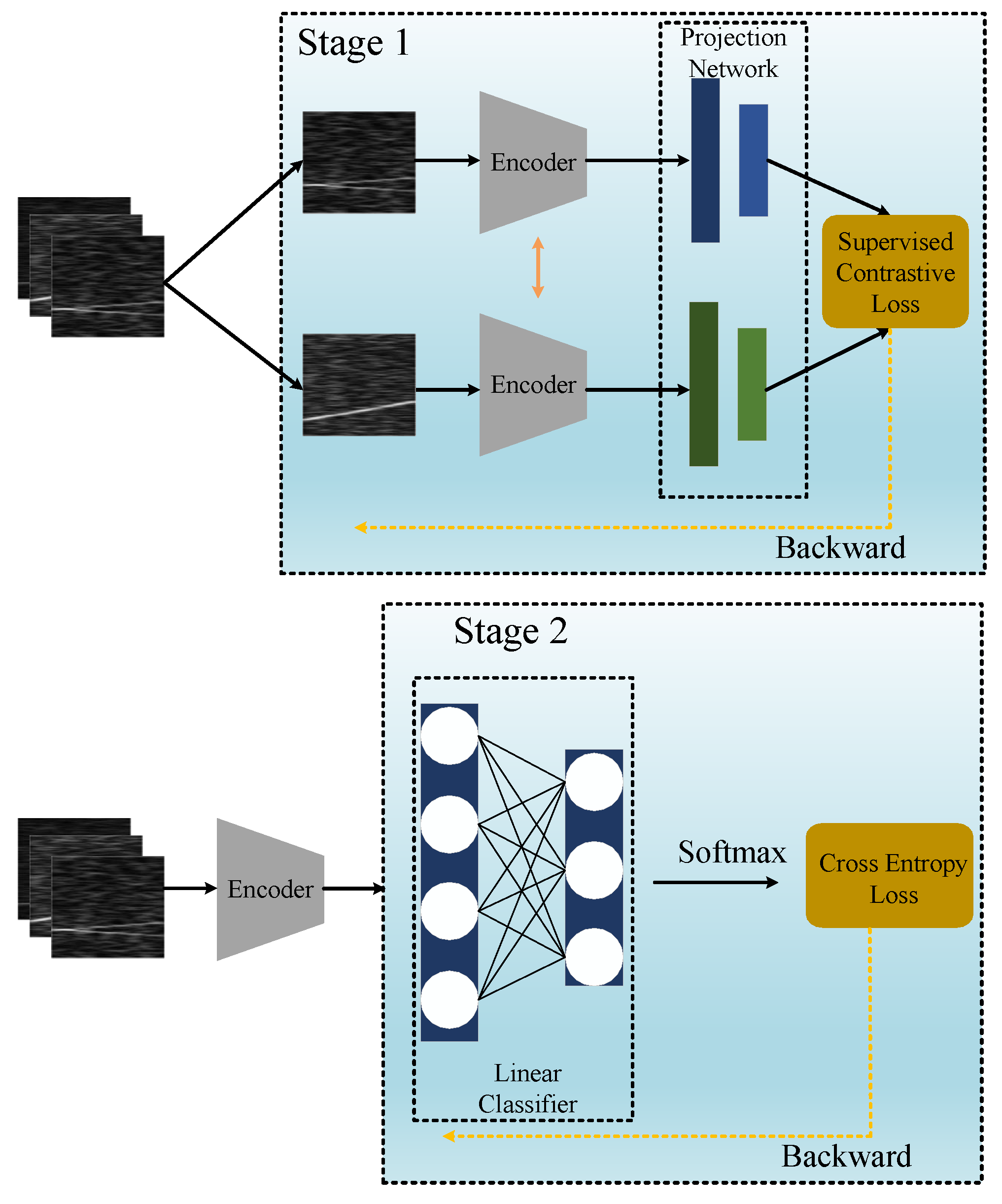
The architecture of the proposed SL-CL model is illustrated in
Figure 1, which contains two stages. The first stage mainly extracts the features of the signals using the CL method, while the second stage implies the classification according to the features produced in the first stage.
The first stage consists of an encoder and a projection network. The encoder maps the time frequency image x to a feature vector r. Then, the projection network projects r to another vector z to reduce its dimension. The multi-layer perception is taken as the projection network in this paper. The supervised contrastive loss function used in this stage reformulates the contrastive loss with a supervised form, which enhances the features extraction ability.
The second stage is a linear classifier, which is constrained by the cross-entropy loss. The feature vector r is taken as the input of the linear classifier, and the softmax operation is performed to generate the classification results.
4.2. Encoder Module
In the CL method, the encoder module is a key component for mapping the input samples to the embedding space, which extracts the feature representation of the samples for the subsequent tasks. The commonly used encoder modules include the CNN, ResNet, etc.
ResNet learns the residual mappings instead of the underlying mappings, which alleviates the gradient vanishing problem from skip connections. ResNet is taken as the encoder in the first stage of the SL-CL, whose representation is
where
x represents the input,
is the transformation applied by the weight layer, and
is the output.
ResNet contains multiple residual blocks. Each of the residual block includes multiple convolutional layers and skip connections, and is followed by a ReLU activation and a batch normalization operation. The general structure of the residual block is shown in
Figure 2, which may vary a little in different networks. For example, ResNet-50 uses bottleneck blocks with 1 × 1, 3 × 3, and 1 × 1 convolutional kernels instead of a convolution block.
4.3. Supervised Contrastive Loss
In the first stage of the SL-CL model, the supervised contrastive loss is adopted, which is suitable to the situation of limited labeled samples available. The process of constructing the supervised contrastive loss is shown below.
Firstly, the similarity function
of the general CL loss function in Equation (
1) is set as the inner production of vectors to cause the loss
to be written as
where
denotes the loss of the
ith sample,
I represents the set of samples,
denotes the set of samples excluding the current
ith sample,
,
, and
are the current sample vector, positive sample vector, and the vector of all the samples exclude the current
ith sample, respectively, and
is still the temperature scalar parameter.
In this equation, only one positive sample vector (
) is used to compare with the current sample vector (
). However, since the input samples of the SL-CL model are all labeled, there are multiple positive sample vectors, including the current sample. Thus, a more efficient loss is introduced, which fully uses all the positive sample vectors to compare with the current sample vector. This causes the current sample vector to be closer to all of the positive sample vectors, and the robustness of the model is enhanced. The supervised contrastive loss
is then written as
where
represents the loss of the
ith sample,
represents all of the sets of positive samples, including the current
ith sample,
is a positive sample vector, and
denotes the module value operation.
4.4. Two-Stage Training
The training process of the SL-CL is given below, where the supervised contrastive loss and cross-entropy loss are adopted in the first and second stages, respectively.
In the first stage, the labeled samples are input into the encoder, then the output is transported to the projection network. The loss is used to optimize the encoder and projection network.
After the first-stage training, the parameters of the encoder are fixed; meanwhile, the projection network is discarded. The output of the encoder is taken as the input of the second stage to train a linear classifier using the cross-entropy loss. The cross-entropy loss is expressed as follows:
where
denotes the ground truth labels, and
represents the predicted probabilities of the
ith sample.
There is another, much easier way to train the SL-CL model in one stage, which is an end-to-end training method. Only the cross-entropy loss is used to train both the encoder and linear classifier in the same procedure. However, this way of training performs worse than the two-stage training, which will be shown in the experiment section later.
5. Experiments and Analysis
5.1. Datasets
There are 12 types of radar signals used in the following experiments, and the settings of them are shown in
Table 5, where
represents a uniform random distribution and
denotes a random parameter set.
Figure 3 shows the time-frequency analysis of the signals at −5 dB.
5.2. Network Parameters and Training Strategies
In the proposed SL-CL model, the ResNet with 50 layers is taken as the encoder. The initial convolution layer is a 7 × 7 convolution kernel; then, a 3 × 3 max pooling layer follows. Subsequently, there are four residual blocks, which contain 3, 4, 6, and 3 residual units, respectively. Each unit is composed of a 1 × 1 convolution, a 3 × 3 convolution, and a 1 × 1 convolution. The output with size 1 × 1 × 2048 is through a global average pooling.
The SL-CL uses two-stage training, which includes the training of the encoder and linear classifier, respectively. The first-stage training uses the supervised contrast loss, and a projection network is added to reduce the dimension of the data. With the parameters are fixed and the projection network is abandoned in the first stage, the second-stage training uses the cross entropy loss to constrain the linear classifier.
5.3. Comparison Models
Seven comparison models are applied in this section. Among them, the OD-CNN [
33], ResNet [
34], VGG [
35], AlexNet [
36], and SL-CL-CE are all SL models, while the SIMCLR [
18] and PLLW [
17] are SeSL and SSL models, respectively. More details of the comparison models are given in
Table 6.
The OD-CNN model is composed of an omni-dimensional dynamic convolution, a classifier, and a deep residual network. The model utilizes the omni-dimensional dynamic convolution to extract features from the signals.
ResNet is a commonly used residual connection network, which is composed of multiple residual blocks. The network used in the following experiments contains 18 layers.
VGG and AlexNet are both typical CNNs, which are good at capturing the fine details and complex features of the images.
SIMCLR is a simple SeSL model for the visual representation. The similarity between the SIMCLR and the proposed SL-CL is that they all use two-stage training. But, the SIMCLR uses the CL loss while the SL-CL uses the supervised contrastive loss in the first stage of training.
The structure of the SL-CL-CE model is the same as that of the SL-CL, but it uses end-to-end training. The cross-entropy loss is taken in this model.
PLLW is an SSL classification model based on CNN. The model selects high reliable prediction to label the unlabeled samples.
5.4. Parameter Analysis
In the following experiments, 50 and 100 labeled samples per type of signals for training and testing of the SL models are available, where the total number of signals are 600 and 1200, respectively. For the SeSL model SIMCLR, 50 unlabeled samples per type of signals are provided for training besides the labeled samples. The number of unlabeled samples used in the SSL model PLLW is the same as that of the labeled samples. All the experiment results are taken as the average value of 10 trials. In this section, several parameters are analyzed with the SNR setting as 0 dB.
In the supervised contrastive loss function, the key parameter affecting the classification accuracy is the temperature scalar parameter
, which controls the smoothness or sharpness of the probability distribution of the classes. With different settings of
, the results can be seen in
Figure 4. It indicates that the classification accuracy increases as
increases from 0.01 to 0.07, then the accuracy decreases with
further increases. When
equals to 0.07, the highest accuracy is achieved. If
is too large, the relative distances between different samples will be reduced, which results in the decreasing of the discrimination between different samples. On the contrast, if
is too small, the relative distances between the same samples will be magnified, which results in the over-emphasis of the differences in the same sample. That is the reason of the best performance happens at a medium value of
.
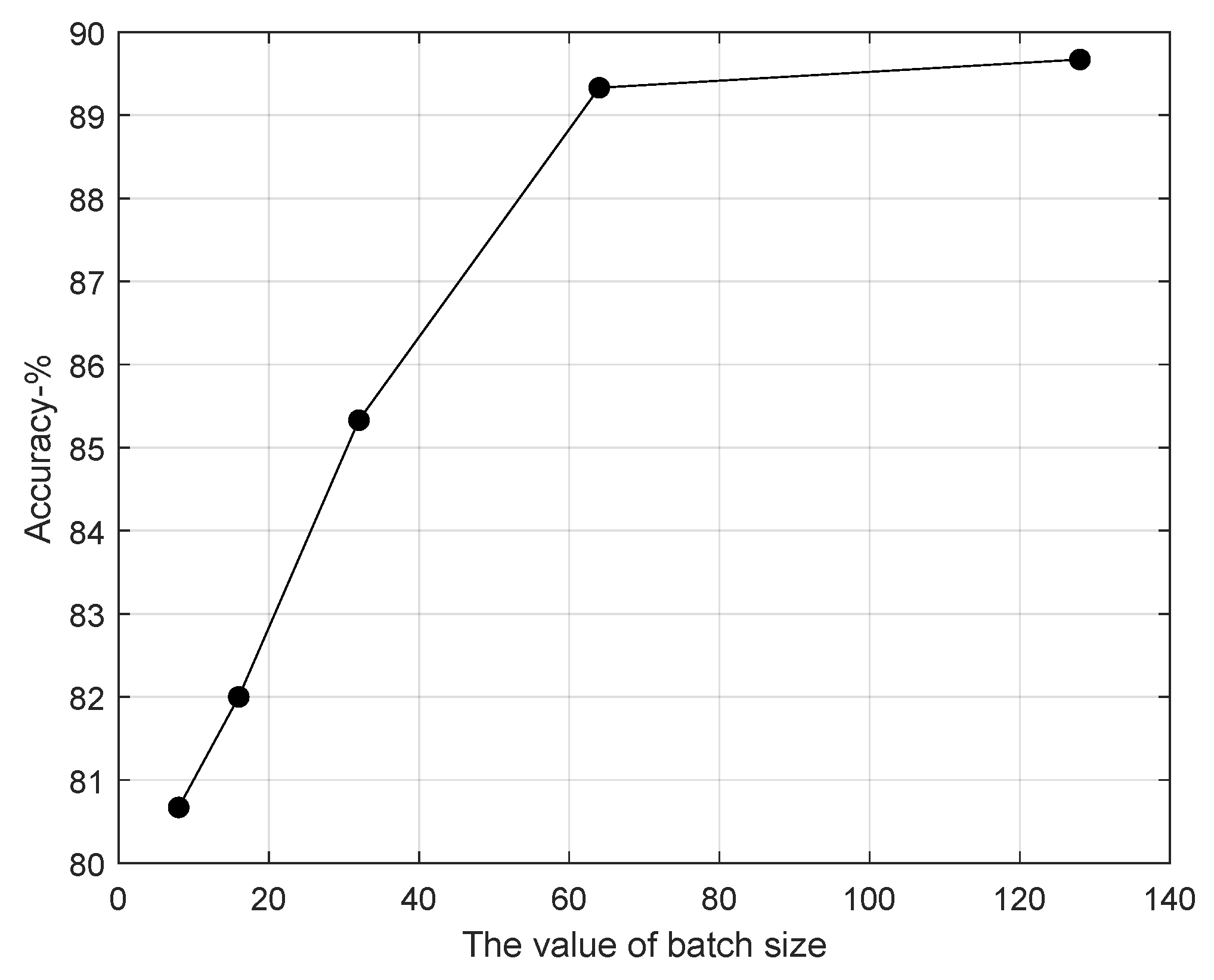
The batch size of the encoder is the number of samples processed simultaneously in the process of training. A larger batch size leads to higher training efficiency and more stable gradient estimation, but the memory requirement increases simultaneously. Meanwhile, a smaller batch size decreases the training efficiency and makes the the gradient estimation unstable. The classification results of varying batch sizes are shown in
Figure 5. It can be observed that the classification accuracy improves as the batch size increases, where the accuracy improves from 89.33% to 89.67% with the batch size increases from 64 to 128. However, the memory requirement increases significantly with the batch size increases. Considering the computation efficiency, we select the batch size 64 in the following experiments.
The number of layers of the encoder is also analyzed. A greater number of layers is better for capturing the complex features, but more parameters will be generated and the overfitting problem may happens. The experimental results of different settings of the number of layers are given in
Table 7. The best classification accuracy is achieved with a 50-layer encoder, which is 89.33%. The computation complexity or the time consuming increases with the number of layers increases, while the accuracy may decreases because of the overfitting problem. For example, the time consuming of a 101-layer encoder is nearly 5 s longer than that of the 50-layer encoder, but the accuracy of the 101-layer encoder is 5.33% less than the 50-layer encoder. So, the best setting of the number of layers is 50 in this experiment.
Additionally, the image resolution is an important factor for the classification. Although higher resolution of the image provides more detailed information, the time cost of training increases.
Table 8 presents the classification accuracy and time cost for different image resolutions, where
, batch size, and the number of layers are set as 0.07, 64 and 50, respectively. It can be observed that with the increasing of the image resolution, both the accuracy and time cost of training are all increased. The time costs per epoch with the image resolutions
and
are 25.88 and 89.86, respectively, which are much longer than that of the image resolution
; meanwhile, the accuracies increase only 0.34% and 0.53%, respectively. Therefore, considering both the classification accuracy and time cost, we choose the image resolution
in the following experiments.
The effect of the number of epochs to the classification accuracy is analyzed, and the results are shown in
Figure 6. The parameter settings are the same as the previous experiment. Since the second stage of training is a simple multi-layer perceptron, only the number of epochs of the first stage is tested. The number of epochs varies from 10 to 110 with an interval 10. It can be seen that the accuracy increases as the number of epochs increases. When the number of epochs reaches 110, the accuracy decreases a little, which is because too many epochs may cause over-fitting.
5.5. Performance Comparison
The comparison experiments of the SL-CL model are given below. The SL-CL is compared with the SIMCLR and SL-CL-CE models under different SNRs, and the performances are shown in
Figure 7. The SL-CL outperforms the other two models at all the SNRs. Compared to the CL loss that used in the SIMCLR, the supervised contrastive loss used in the SL-CL model makes the samples with the same label more compact, which leads to a higher classification accuracy. The only difference between the SL-CL-CE and SL-CL models is the one-stage and two-stage training structures. As the performance of the SL-CL is better than that of the SL-CL-CE, it indicates that the two-stage training plays a promoting role in the classification.
Then, the comparison experiments between the SL-CL model and the other comparison models are given in
Table 9,
Table 10 and
Table 11, in which the numbers of labeled samples for training are set as 25, 40, and 50, respectively. It can be observed that with the increasing of SNR, the overall classification accuracy increases accordingly. The classification accuracy of the SL-CL is always the highest among the comparison models at different SNRs and numbers of labeled samples. Even when the SNR is decreased as low as −5 dB, the accuracy of the SL-CL reaches 66.33% with 50 labeled training samples. The SIMCLR also uses two-stage training and CL method, but the first stage training uses the SeSL method. Although the cost of labeling is saved for the SIMCLR, the performance of classification decreases. In this experiment, the time costs of the SL-CL and SIMCLR are 10.7 s and 6.9 s per epoch, respectively. The time consumption of the SIMCLR is greater than that of the SL-CL, which indicates the SeSL model SIMCLR needs more time to process the pseudo-labels of the unlabeled samples. Besides the SIMCLR and SL-CL, the remaining models are all based on the one-stage training. Among these models, the performance of the SL-CL-CE is worse than the others, which is because the structure of the SL-CL-CE is the most complex one, which easily causes overfitting problem. The classification accuracy of the SSL model PLLW is much lower than that of the SL-CL, which is only a little higher than that of the SeSL model SIMCLR. As the PLLW chooses the labeled samples with higher confidence for training, it performs better than the SIMCLR using the unlabeled samples for training and the labeled samples for fine tuning. These models all perform worse than the SL-CL; the reason may be that they all use the single cross entropy loss while the SL-CL uses the supervised contrastive loss. As the feature capturing ability of the SL-CL is good, it performs well with a small number of labeled samples. With only 25 labeled samples per class and 5 dB SNR, the classification accuracy of the SL-CL is as high as 85.67%.
The confusion matrices are shown in
Figure 8, where the diagonal values of the matrices are the ratios of the correct classifications. The classification accuracy increases as the SNR increases; meanwhile, the diagonal value of the matrix is more close to 1. In addition, the signals P1 and P4 is the most confused pair compared to the other signal pairs, which are recognized as each other about 35% of the time at −5 dB SNR.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}