Abstract
Object detection in remote sensing images has received significant attention for a wide range of applications. However, traditional unimodal remote sensing images, whether based on visible light or infrared, have limitations that cannot be ignored. Visible light images are susceptible to ambient lighting conditions, and their detection accuracy can be greatly reduced. Infrared images often lack rich texture information, resulting in a high false-detection rate during target identification and classification. To address these challenges, we propose a novel multimodal fusion network detection model, named ACDF-YOLO, basedon the lightweight and efficient YOLOv5 structure, which aims to amalgamate synergistic data from both visible and infrared imagery, thereby enhancing the efficiency of target identification in remote sensing imagery. Firstly, a novel efficient shuffle attention module is designed to assist in extracting the features of various modalities. Secondly, deeper multimodal information fusion is achieved by introducing a new cross-modal difference module to fuse the features that have been acquired. Finally, we combine the two modules mentioned above in an effective manner to achieve ACDF. The ACDF not only enhances the characterization ability for the fused features but also further refines the capture and reinforcement of important channel features. Experimental validation was performed using several publicly available multimodal real-world and remote sensing datasets. Compared with other advanced unimodal and multimodal methods, ACDF-YOLO separately achieved a 95.87% and 78.10% mAP0.5 on the LLVIP and VEDAI datasets, demonstrating that the deep fusion of different modal information can effectively improve the accuracy of object detection.
1. Introduction
In recent years, visible light remote sensing images have been widely used for object detection in automatic driving, intelligent medical care, urban planning, and military reconnaissance. However, several challenges remain, such as susceptibility to weather and lighting conditions, occlusion, and limited spectral information. Clouds and haze can scatter and absorb light, reducing the image quality and target visibility. Variations in lighting conditions, especially at night or under poor lighting, degrade image quality and make target details difficult to discern. Obstructions in the line of sight also hinder target identification. Moreover, a narrow electromagnetic band limits the ability of visible light to provide rich spectral information for accurate classification and recognition. These challenges highlight the need for algorithms with higher detection accuracy and robustness, particularly given the limited improvement in the resolution of visible light remote sensing images.
The majority of algorithms employed for target detection in visible light scenes can be broadly categorized into two distinct types based on the specific detection steps involved, namely two-stage and single-stage detection algorithms. Two-stage detection algorithms generate a candidate frame and then detect fine-grained targets. Representative algorithms include fast R-CNN [1], faster R-CNN [2], and task-aligned one-stage object detection (TOOD) [3]. Single-stage algorithms do not need candidate regions and directly predict the location and class of the target. Representative algorithms include the you only look once (YOLO) series [4]. In addition, there has been some related research on detection algorithms [5] based on the Transformer algorithm [6]. The effectiveness of these algorithms in visible image target detection has motivated researchers to continue to focus on and improve them.
To further enhance the performance of object detection in visible light scenes, researches have focused on various aspects of image processing, feature augmentation, backbone networks, and lightweight models. For example, a framework for greater realizability in remote sensing picture super-resolution was composed of a joint nonlocal tensor and Bayesian tensor factorization [7]. Subsequently, the construction of a model that leveraged super-resolution information to enhance target detection performance was achieved by merging target detection with remote sensing super-resolution pictures [8]. Cheng et al. focused on enhanced feature representation by proposing a dual attention feature enhancement (DAFE) module and a context feature enhancement (CFE) module, which were applied to Faster R-CNN, using the publicly available DIOR and DOTA datasets [9]. Additionally, a more lightweight algorithm, LSKNet, leveraged a priori knowledge to extract contextual information using large convolutional kernels and a spatial selection mechanism as backbone, yielding outstanding results on multiple datasets [10]. The comparably light LVGG demonstrated good accuracy in categorizing outcomes across various datasets [11]. Additionally, it is noteworthy that there has been some advancement in the use of human–computer interaction in the realm of remote sensing imaging [12,13].
In addition to visible light images, target detection in infrared images has also received widespread attention. Based on the medical image segmentation network U-Net [14], Wu et al. developed UIU-Net by nesting U-Nets of different sizes, reaching the pinnacle of infrared small target detection algorithms [15]. However, these algorithms inevitably have a large number of parameters and lengthy training time. So there is considerable interest in single-stage algorithms that offer faster detection times. For instance, for addressing the issues of elevated false alarms in the detection of infrared image targets, YOLO-FIRI incorporates a shallow cross-stage partial connectivity module and an enhanced attention module, significantly improving the algorithm’s accuracy on public datasets [16]. GT-YOLO improved upon the YOLO algorithm by fusing an attention mechanism, introducing SPD-Conv, which is better suited to small targets and low resolution, and incorporating Soft-NMS [17]. This algorithm was demonstrated to be effective on an infrared nearshore ship dataset. Additionally, MGSFA-Net was developed considering the importance of the scattering features of SAR ships, combining segmentation and k-nearest neighbor algorithms to obtain local graph features [18]. Additionally, the YOLO and vision Transformer architectures have both produced positive outcomes [19].
It is evident from the research above that, when identified separately, each of the two modes has benefits and drawbacks. The higher resolution and rich detail and color information of visible light target detection provide benefits for the research of target detection in remote sensing images, but the dependence of the image quality on light makes the image detection effect poor under conditions of low light, as well as poor external environments. In contrast, infrared images excel in detecting thermal targets with high pixel values and demonstrate the ability to penetrate obstacles (e.g., detecting pedestrians obscured by stone pillars), even at night. However, infrared images typically exhibit low spatial resolution, resulting in unclear target details and edges. Furthermore, the varied and complex shapes and sizes of targets significantly increase the detection difficulty, and the low contrast between targets and backgrounds further diminishes visibility. Therefore, numerous studies have been conducted around fusing these modalities to obtain more information, aiding in accurate identification and enabling all-weather operation.
Existing research divides inter-modal fusion into three categories: CNN-based approaches, Transformer-based methods, and GAN-based methods. Fusion also comprises pixel-level fusion, feature-level fusion, and decision-level fusion approaches. The YOLOrs algorithm uses a new midlevel fusion architecture that adapts to multimodal aerial images, which not only helps detect the target in real time but also helps predict the target direction [20]. However, decision-level fusion increases the computational complexity of the model, since it combines two modalities that are run through the complete network structure individually before being fused. SuperYOLO was developed for fusing images in a pixel-level manner in front of a backbone network, and an encoder and decoder were used as auxiliary branches for super-resolution features of different classes [21]. These algorithms have performed at an advanced level on publicly available datasets. In addition to direct pixel-level fusion, dynamic and adaptive fusion have also been employed to increase multimodal detection performance [22,23]. Additionally, the PIAFusion network utilizes a cross-modal differential sensing module for fusion and considers the impact of light from various angles, emphasizing its significance in fusion algorithm design [24].
The CFT model utilizes a Transformer encoder for cross-modality fusion, achieving a high degree of intra-modal and inter-modal fusion, with significant advantages in detection on multiple datasets [25]. C2Former, which also utilizes a Transformer structure, addressed the error in the modalities and the lack of precision in the fusion, and reduces the dimensionality, yielding robust detection results [26]. A two-stage training strategy fusion algorithm was also developed to train the same autoencoder structure using different modal data, and to train the newly proposed cross-attention strategy and decoder to generate a combined image, with experimental findings affirming the method’s efficacy [27]. The merging of multiscale and multimodal data has demonstrated good performance in remote sensing [28]. To improve fusion quality, one study segmented the images of both modalities into a common region with feature decomposition [29]. ASFusion also involves decomposition but decomposes the structural blocks, and the visible light is adaptively and visually enhanced prior to decomposition [30]. In addition, generative and adversarial networks (GAN) have also received attention from researchers in the field of multimodal fusion [31]. The algorithms FusionGAN [32], MHW-GAN [33], and DDcGAN [34] employ a generator and discriminator to further enhance the intricacy of the fusion procedure.
Although infrared images are not as useful as visible images with respect to color, texture, and other features, they are very advantageous for detection in bad weather. Previous studies have shown that the fusion of data from the two modalities can help to obtain comprehensive features and improve the detection performance compared with using a single modality. Therefore, this paper proposes a new detection method, attentive and cross-differential fusion (ACDF)-YOLO, based on the fusion of visible and infrared images. ACDF-YOLO successfully addresses the issues related to inadequate multimodal fusion and poor detection of targets. The key contributions of this paper can be encapsulated thus:
(1) Derived from the YOLOv5 network configuration, an algorithm capable of fusing visible and infrared images for detection is proposed, named ACDF-YOLO. Visible and infrared images are combined, which not only yields more detailed feature data by merging the two modal datasets, but also addresses the issue of restricted detection precision caused by inadequate features. The module was verified through comparison experiments with current advanced algorithms and ablation experiments, and the overall detection performance after fusing the modalities was higher than that of the other algorithms.
(2) We propose a fusion module for attention, named efficient shuffle attention (ESA). Depthwise separable convolution and shuffle modules are added to the fusion operation process of infrared and visible images to obtain more fully fused features and to focus on the correlation and importance between different modalities under attention, increasing the benefits of fusion. The detection results achieved 77.11% for mAP0.5 and 74.34% for recall on the VEDAI dataset.
(3) We propose a cross-modal difference module (CDM) to represent the differences between different modalities, capturing the correlations and complementary features between modalities. This module also performs a de-redundancy operation on the information shared by the two modalities when they are fused, which provides richer and more accurate information for the subsequent detection. Based on differential fusion, the experimental mAP0.5 value increased to 78.1%, demonstrating the module’s usefulness.
The remainder of this paper is organized as follows: In Section 2, we discuss the related work covered in the paper. Section 3 describes the proposed ACDF module and the overall network structure. Section 4 and Section 5 provide further details of the experiments, to demonstrate the superiority of the algorithm from an experimental point of view. Section 6 summarizes this research.
2. Related Work
In addition to the detection framework for different modalities, the related work on module design in our study is extensive. The following is arranged around three major linked challenges involved in the design of efficient shuffle attention, namely depthwise separable convolution, ShuffleNet, and efficient channel attention.
2.1. Depthwise Separable Convolution
Convolution is a fundamental operation in deep neural networks and is commonly used for feature extraction. The standard convolution utilizes several multi-channel convolution kernels to process multiple channels of input. In contrast, depthwise separable convolution differs from ordinary convolution by combining depthwise and pointwise convolution. The kernel for depthwise convolution is single-channel and has to be convolved for each channel, thus obtaining an output feature map with the same number of channels as the input feature map. This process changes the width and height without adjusting the channel count. The pointwise convolution is needed to validate the information from the small number of output feature maps. Tracing back to its roots reveals the use of a convolution kernel for dimensionalization. Depthwise separable convolution groups convolutions into feature dimensions, performs independent depth-by-depth convolutions for each channel, and aggregates all channels using convolutions before output.
Google’s Xception [35] and MobileNet [36] models significantly advanced the field of separable convolution. Accordingly, a series of models have been developed for fusing network structures with deep separable convolution, which have been experimentally validated. In terms of computational volume and efficiency, depthwise separable convolution surpasses ordinary convolution.
2.2. ShuffleNet
Pointwise group convolution is used in ShuffleNet [37], similarly to the group convolution in AlexNet [38], but they use different convolution kernel sizes. A convolution kernel of size is used in ShuffleNetV1. Its modular unit implementation replaces all convolutions with a pointwise group convolution operation and performs a mixing operation of the channels after the first pointwise group convolution. These two operations allow the model to maintain accuracy, while significantly reducing the computational cost. Thus, they are important for the porting and application of the model in industry. Related experiments demonstrated the significant superiority of ShuffleNet in downstream tasks [37], such as the classification task, exhibiting lower error than MobileNet [36], and regarding the real-world speedup ratio on mobile devices, it greatly outperformed that of the AlexNet network.
ShuffleNetV2 introduced a new channel separation operation, to avoid using either dense convolution or large group convolution sets, while maintaining a larger number of channels. This is achieved by splitting the c feature channels into c1 and c-c1 channels (i.e., splitting the original input into two branches) [39]. The two branches are connected after performing different operations, and after connection, the channel mashup in ShuffleNetV1 is used to realize the interaction of information between different channels. ShuffleNetV2 has a smaller model size than ShuffleNetV1, which is more suitable for resource-constrained devices and applications.
2.3. Efficient Channel Attention
Efficient channel attention (ECA) [40] is an improved attention mechanism based on SENet [41]. Specifically, the fully connected layer from SENet is removed, and a convolutional kernel is used for processing. The model’s overall parameters are also further trimmed. Theoretically, not every channel’s information is useful, and the operation of the fully connected layer for each channel’s set of information increases the parameter burden. Moreover, in cases where the input features are substantial, the fully connected layer’s parameter count is extremely large, and thus the SENet model is prone to overfitting for small datasets. The ECA mechanism utilizes the cross-channel information capturing ability of convolution to effectively avoid these problems.
ECA improves the model’s feature expression ability by enhancing the focus of the model on different channels in a way that modifies each channel’s relevance in an adaptable manner. Meanwhile, ECA helps the model to distinguish features of different categories or attributes by weighting the features of different channels, thus highlighting the important channels, suppressing the unimportant channels, and enhancing the model’s performance in regression or classification [40]. Compared with other attention mechanisms, ECA enhances the model’s efficiency without incurring substantial computational or memory burdens.
3. Methodology
3.1. Overall Structure
As is widely known, YOLO-DCAM recognizes individual trees in UAV RGB images with rich edges and realistic tree characteristics, demonstrating the benefit of visible light and the efficiency of detection [42]. However, in order to achieve all-weather detection, a visible light picture is unable to gather edge information from individual trees in the middle of the night, or even recognize hidden individual trees in the image, reducing the overall detection effectiveness. Similarly, an infrared picture can still perform well in highly exposed, unevenly lit, and dark situations within a dataset, but it lacks rich information such as color and accumulates incomplete features [43].
The architecture of the ACDF-YOLO network designed in this study is shown in Figure 1, comprising a multimodal target detection model that is both efficient and accurate. Based on the requirement of real-time performance and the consideration of a lightweight network structure, we employ the widely used and high-performance YOLO algorithm as our basic framework. Among the many YOLO versions, we adopt YOLOv5 as the backbone of our model, because it has a small number of parameters. In order to avoid adding repetitive parameters, in the fusion strategy, we do not use the decision-level fusion method, but choose the intermediate layer fusion method, which does not require additional parameters, and this fusion method is more effective than fusion through the direct addition of the previous period. At the same time, we supplement the residual connection in the ACDF structure to reduce information loss during the convolution process, in order to achieve fusion of the two modes of data.
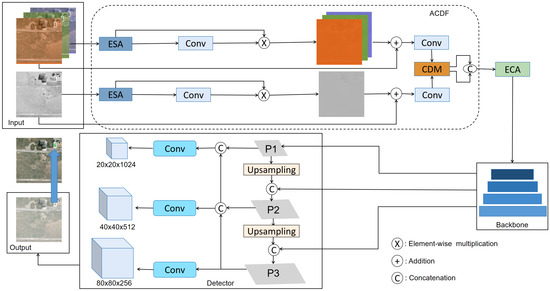
Figure 1.
Architecture of the ACDF-YOLO network. Here, the constructed ACDF module includes the suggested efficient shuffle attention (ESA) and cross-modal difference module (CDM).
The input layer, fusion stage, backbone, and detection header are the four main parts of ACDF-YOLO. To streamline the presentation and concentrate on the key parts of the structure, we omit many convolutional details in Figure 1. In the design of the fusion stage, we specifically considered the handling of different modalities. Traditional fusion strategies tend to fuse the modalities after the respective backbone network, or in the neck or even the head of the detector, increasing the number of model parameters and providing a limited improvement in detection accuracy. For this reason, we fuse the two modalities before the backbone network, avoiding an unnecessary increase in network branches.
In the fusion phase, we use the designed ACDF module, which amalgamates two principal segments: an attention section and a CDM. After the visible and infrared images are input, they are preprocessed by the ESA mechanism, then multiplied element-by-element with the result of the convolutional processing, followed by residual concatenation to preserve the preliminary information. Subsequently, this information is fed into the CDM to further emphasize inter-modal differences, and the attention given to local features is enhanced by performing stitching operations in combination with the ECA mechanism. Through this series of operations, we obtain deeply fused and improved features. It is possible to depict the entire procedure using Equations (1)–(3), where denotes the features obtained from the visible image after branching, denotes the features of the infrared image after branching, and denotes the fused features.
The backbone adopts the structure of YOLOv5, a choice based on the advantages of its cross-stage partial connectivity structure, which reduces the amount of computation and the number of parameters, without sacrificing the capacity to effectively extract features. Furthermore, the inclusion of a spatial pyramid pooling module improves the model’s multi-scale target detection performance by boosting the model’s capacity to recognize targets of various sizes. In the detection head part, we utilize a feature pyramid and path aggregation network structure to fuse low-level features with high-level semantic information, which further enhances the context awareness of the model, thus strengthening its reliability and precision in target detection.
3.2. Attention Module
Various attentional mechanisms have been demonstrated in the investigation of multimodal fusion, considering the ease of operation, as well as effectiveness. Prior to feature fusion, we incorporate our ESA mechanism into the respective branches of the two modalities. We note the advantage of ECA in improving the model’s capability to depict the channel dimension. ECA empowers the model to concentrate on key channel characteristics by dynamically adjusting the channel’s dimensions, enhancing both its representational efficiency and performance. Moreover, we considered that the ECA mechanism, although it is lightweight, requires some additional parameters to learn the attention weights between channels. Therefore, we modified it to obtain the ESA mechanism.
In ShuffleNet, effective feature extraction is possible because of the depthwise separable convolution and channel shuffle functions. Depthwise separable convolution reduces the computational requirements and performs feature extraction in the channel dimension, whereas the channel shuffle operation enhances the interaction between features, breaks the information isolation between channels, and improves the diversity and richness of features. Meanwhile, channel shuffle can reduce redundant and unnecessary features through the operations of shuffling and compressing channels, which improves the efficiency, helps generalize the model, and reduces the demand for computational resources. In addition, ESA enhances the model’s expressive ability in the channel dimension, allowing the model to extract key features more effectively and learn more discriminative feature representations from complex data inputs. Furthermore, depthwise separable convolution decreases the amount of processing and number of model parameters. With the newly added branch, the features are processed in the spatial dimension, and the inter-channel interactions are continuously enhanced in the form of blending. Using the new ESA formed by the addition of this branch is expected to further increase the network’s effectiveness and performance, while minimizing the computational complexity and parameter count.
The ESA structure is illustrated in Figure 2. The input is received from the upper layer and contains the channel and spatial details of the image. Subsequently, the input is subjected to global average pooling to compress the spatial dimension information into global features at the channel level, where the kernel size of the convolution is computed using a formula, and the feature map is obtained using the one-dimensional convolution kernel. At the same time, the input is adjusted through the branch of depthwise separable convolution and shuffle to improve the information flow between different channel groups, encourage inter-feature cross-learning, magnify the model’s representational abilities, and perform a summation operation for the two acquired features to gain a richer feature representation. Finally, the fused features of the two branches are multiplied element-by-element to avoid information loss during the series of operations.
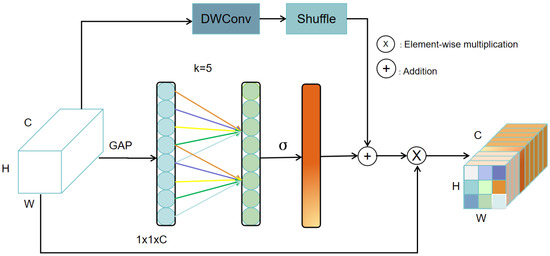
Figure 2.
Structure of the ESA mechanism.
3.3. Cross-Modal Difference Module
After enhancing the features of each modality in the two-branch process, we introduce the CDM and make further improvements. The CDM can determines and enhance the differences in features, which is a unique advantage of multimodal data processing. It determines differences between modalities through a series of explicit computations and operations, thus enhancing the model’s sensitivity to important features. The CDM focuses on extracting and enhancing the differences between different input features, which is important for tasks that rely on the differences between modalities. The difference module not only extracts features that differ across modalities but also extracts features that are common to them, thus enhancing the generalization capabilities when the model is confronted with different data.
The CDM structure is shown in Figure 3. We denote the features of visible and infrared images by Fv and Fi, respectively. Using this structure, we first perform the phase subtraction operation on the infrared features and the visible light features to highlight the dissimilarity between the two modalities. In this way, the model can recognize the features that are more significant in one modality and less significant in the other modality. Immediately following this, global average pooling is performed in both the X and Y directions (i.e., horizontally and vertically) for the phase subtraction, which helps to extract global contextual information at a macroscopic level and reduces the computational load, while preserving the discrete features. The outcomes in both directions are then further processed through shared convolution to extract comprehensive global information and avoid overfitting. Then, the results are summed and nonlinearly transformed by an activation function. This approach refines the feature information. A subsequent multiplication operation avoids the loss of valid information and reweights the initial disparity features of the modalities, thus highlighting important feature regions. The final cross-sum operation combines the initial modal information and the modal disparity information after a series of operations to form the final fused features, namely Fv′ and Fi′.
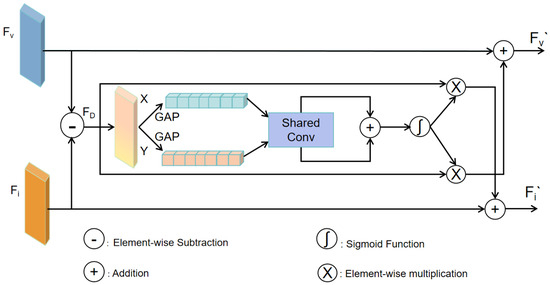
Figure 3.
Structure of the proposed CDM.
Overall, this module serves the following purposes: enhancing modal differences, which helps to capture features that are particularly important to the task; extracting global contextual information, which provides the model with a broader perspective to understand the content of the image; enhancing feature representation, which enhances the model’s capacity for generalization by learning more intricate feature representations; highlighting important features, which improves the accuracy of detection; and retaining the integrated information, which is useful for combining the initial features with the processed features, so that the final fused feature signature contains the inter-modal difference information and retains the distinct information of the respective modalities.
4. Experimentation
4.1. Experimental Datasets
The LLVIP dataset was created specifically for low-light image processing applications [44], providing data in both visible and infrared modalities, with precise temporal and spatial alignment between the data in both modalities. The dataset contains a total of 30,976 images, forming 15,488 pairs of visible and infrared images. They mostly contain nighttime scenes, with fewer daytime scenes, involving indoor scenes, urban roads, etc. The lighting conditions of the scenes vary from low light to completely dark. In addition, the detailed annotation information facilitates supervised research. Utilization of the LLVIP dataset spans areas such as enhancing images in dim lighting, identifying targets, integrating multiple modes, and overseeing security. For the consideration of training time and complexity, we selected 5000 pairs from this dataset for the experimental dataset in the algorithmic study of this paper.
The VEDAI dataset also contains both visible and infrared image modalities, and it has become the first choice for target detection experiments using multi-modal remote sensing images. This dataset, accessible to the public and tailored for identifying vehicles in aerial photographs, seeks to advance studies and applications within the domains of remote sensing image analysis, vehicle detection, and computer vision. Furthermore, images with different resolutions, such as 9, 15, and 30 cm/pixel, are considered for evaluating and comparing the performance of the algorithms at different resolutions. The images contain a variety of backgrounds from different environments, including urban, rural, and desert settings, as well as various weather conditions, which helps to strengthen the generalizability of the model. The dataset contains a total of 1246 different images, which are distributed among eight different target categories, and the distributions of the images in each category are shown in Table 1. Each image contains both infrared and visible modalities.

Table 1.
Distribution of images in the VEDAI dataset.
4.2. Experimental Settings
Experiments were conducted using the YOLOv5s structure in the PyTorch framework, and Table 2 displays the corresponding parameter configurations. Since the dataset had been separated into training and testing sets, we did not need to set the proportion of the experimental dataset. The whole network was trained for 300 rounds with a momentum of 0.9, a weight decay of 0.0005, and an initial learning rate of . We set a lower learning rate, which helped the model to perform more detailed parameter tuning at the later training stage and improved the model’s generalizability. The weight decay prevents the model from overfitting with a regularization technique. For the value of momentum, we chose the commonly used 0.9, to help the model converge quickly and reduce oscillations.
Table 2.
Experimental configuration details.
Average precision (AP), recall, and average detection accuracy are commonly used to assess experimental results and compare the performance of different models. Herein, we used these indicators as evaluation criteria, but when calculating the mean AP (mAP), we calculated both mAP0.5 and mAP0.5:0.95. The average detection precision under two confidence thresholds was used to evaluate the experimental results more comprehensively. The formula for accuracy is shown in Equation (4), where P denotes precision, denotes the number of vehicles that were correctly detected, denotes the count of other non-vehicle categories that were detected as vehicles, and denotes the number of vehicles that were not noticed in the image. Equation (5) allows us to determine the recall rate based on the provided information, where R denotes the rate of recall.
By combining precision and recall, we can obtain the image precision and recall, and by performing an integration operation on it, we can obtain the value of average precision. The more closely the AP value approaches 1, the more accurately this category is detected; a value close to 0 indicates that the model is poor at detecting this category. The calculation of AP is expressed as follows:
Each category’s mAP value was subsequently computed (Equation (7)). In multi-category detection, we not only considered the detection effect of a single category but also the detection effect of the whole dataset. Therefore, mAP is often used in the evaluation of multi-category detection. Different standards are used due to different confidence thresholds, and the commonly used mAP0.5 refers to the average detection accuracy when the confidence threshold is 0.5, which is used as the evaluation index in most experiments. The more stringent mAP0.5:0.95 indicates the average accuracy within the range of confidence thresholds from 0.5 to 0.95.
5. Results
To confirm the effectiveness of ACDF-YOLO in multimodal fusion target detection, we carried out numerous experiments using the LLVIP and VEDAI datasets, comparing several versions of the YOLO model (including YOLOv3, YOLOv4, and YOLOv5s) with the existing multimodal fusion models (YOLOrs. SuperYOLO).
The experimental results of the LLVIP dataset are shown in Table 3, which lists the values obtained from the different methods for the different modalities, including the precision, recall, mAP0.5, and mAP0.5:0.95. Most of the algorithms achieved an increase in precision and recall with the use of modal fusion, but some algorithms exhibited precision values that were similar for infrared and visible images before and after fusion. Overall, fusion appeared to provide significant performance gains for unimodal visible images. These results demonstrated the effectiveness of multimodal fusion for the LLVIP dataset, especially for improving the detection accuracy of visible images. However, the relatively small performance gains for infrared images may have been due to the nature of the infrared images themselves in the target detection task.
Table 3.
Detection results for the LLVIP dataset.
To visualize the result of multimodal fusion for the detection of single-category data in the LLVIP dataset, we compare the detection results of several algorithms in Figure 4. Here, we selected three representative images for detection. The image in the first row has more uniform illumination, whereas the second row shows pedestrian targets under dim lighting, and there is an overlap between targets in the last row. The first column represents the ground truth, and the other columns represent the results of each algorithm. For first row, YOLOv3 detected the unlabeled pedestrian target, whereas YOLOv5s and YOLOrs mislabeled the two pedestrians next to the stone column as three pedestrians. YOLOv4, SuperYOLO, and our algorithm detected the targets with improved confidence. For the detection of pedestrians in (b), YOLOv3, YOLOv4, and YOLOv5s incorrectly treated the tree branch in the lower right corner and the crosswalk as pedestrians, and their confidence level was more than 0.5, whereas YOLOrs, SuperYOLO, and our algorithm correctly labeled the targets without misdetections. This also shows that the direct splicing of the two modal fusion methods by the YOLO series algorithms was not as effective as the fusion methods used in YOLOrs, SuperYOLO, or our algorithm. For the detection of the target in the last row, only our algorithm correctly detected the target, whereas the other algorithms contained omissions and misdetections. Our algorithm could detect overlapping targets because the CDM obtained the fusion information more reliably.

Figure 4.
Comparison of multimodal detection effects for different algorithms using the LLVIP dataset. (a) Ground truth, (b) ground truth, (c) ground truth, (d) YOLOv3, (e) YOLOv3, (f) YOLOv3, (g) YOLOv4, (h) YOLOv4, (i) YOLOv4, (j) YOLOv5s, (k) YOLOv5s, (l) YOLOv5s, (m) YOLOrs, (n) YOLOrs, (o) YOLOrs, (p) SuperYOLO, (q) SuperYOLO, (r) SuperYOLO, (s) ACDF-YOLO, (t) ACDF-YOLO, (u) ACDF-YOLO.
The experimental results for the VEDAI are listed in Table 4, containing the percentages for the precision, recall, and average detection accuracy corresponding to different thresholds for each model. In most cases, the detection performance was higher for visible images than infrared images, which may have been a result of the rich color and texture information in the visible images. In addition, multimodal fusion provided an improvement in mAP0.5 and mAP0.5:0.95 for almost all models, suggesting that the infrared and visible light information effectively complemented each other and the combination improved the overall detection performance.
Table 4.
Detection results for the VEDAI dataset.
Our model performed well in multimodal detection for the Car, Pickup, Camping, Other, and Boat categories, ranking first among all the models. For mAP0.5 and mAP0.5:0.95, our model achieved 78.10% and 47.88%, respectively, outperforming the other models. By combining an ESA mechanism and CDM, our model not only exhibited high performance in a single modality but also exhibited a significant performance enhancement in multimodal fusion scenarios, especially for the detection precision and recall. The experimental results also emphasize the key role of multimodal fusion techniques in enhancing the target detection performance of remote sensing images.
To visualize the effectiveness of our model using the VEDAI dataset, we compare the detection results of our algorithm with those of the other algorithms in Figure 5a–c, corresponding to three different images, and each column corresponds to the detection effect graphs of each algorithm. The YOLOv3, YOLOv4, YOLOv5s, and YOLOrs algorithms had misdetections in image Figure 5a, which are marked with red arrows. Among them, YOLOv4 and YOLOv5s also contained unlabeled targets, which are marked with black arrows. Both SuperYOLO and our algorithm could detect the targets correctly, but our algorithm had a significantly higher detection confidence for the Camping van. For Figure 5b, several algorithms missed the Boat, which we mark with yellow arrows. YOLOrs and SuperYOLO also detected nonexistent targets, marked with black arrows. For Figure 5c, the unimproved YOLO algorithms all missed the target, whereas the algorithms that incorporated multimodality all detected the target, with subtle differences in their confidence of detection.


Figure 5.
Comparison of the multimodal detection results for the selected algorithms using the VEDAI dataset. (a) Ground truth, (b) ground truth, (c) ground truth, (d) YOLOv3, (e) YOLOv3, (f) YOLOv3, (g) YOLOv4, (h) YOLOv4, (i) YOLOv4, (j) YOLOv5s, (k) YOLOv5s, (l) YOLOv5s, (m) YOLOrs, (n) YOLOrs, (o) YOLOrs, (p) SuperYOLO, (q) SuperYOLO, (r) SuperYOLO, (s) ACDF-YOLO, (t) ACDF-YOLO, (u) ACDF-YOLO.
5.1. Ablation Experiment
To further demonstrate the efficacy of ESA and the CDM, we designed ablation experiments to demonstrate how each module influenced the model’s total efficacy. In the first set of experiments, we directly fed data from both modalities into the YOLOv5s network model, and in the second set of experiments, we integrated the ESA mechanism into both branches of the model. We first added ESA to the two branches and spliced them after branch processing, where the splicing enhanced the representation of local features with the help of ECA. The third set of experiments incorporated the CDM on top of ESA, with the goal of boosting the model’s efficiency by refining and improving the distinctions in features among the various modalities. A comparison of the experimental results is shown in Table 5, revealing the enhancement in energy absorption. After applying ESA, the overall precision of the model decreased slightly, but the recall was significantly improved. Despite the slight increase in training time, the mAP value also increased. After adding the CDM, the precision, recall, and mAP were all enhanced, while the training time was slightly reduced, indicating that the CDM optimized the training efficiency, while improving the performance of the model. Although the entire model resulted in an increase in the number of parameters, the increase in the number of parameters was within acceptable bounds when compared to GFLOPs.
Table 5.
Comparison of experimental results for each module combination.
To showcase the efficacy of our proposed algorithm in terms of feature visualization, we carried out additional visualization analyses. As illustrated in Figure 6, the first column depicts the model’s input graph, featuring the van and the camping area in white. The second column displays the original feature map, while the third column presents the heat maps generated after processing through the backbone networks of YOLOv5s and ACDF-YOLO, respectively. The region focused on by the YOLOv5s network lacks targets, whereas ACDF-YOLO clearly identified a broader range of targets compared to YOLOv5s, thereby demonstrating the effectiveness of our algorithm.

Figure 6.
Feature visualization of the backbone for YOLOv5s and ACDF-YOLO. (a) Input RGB image, (b) feature of RGB image, (c) heatmap of YOLOv5s, (d) input IR image, (e) feature of IR image, (f) heatmap of ACDF-YOLO.
5.2. Choice of Attention
In our efforts to design efficient multimodal fusion modules, the selection and experimental study of different attentional mechanisms became a critical aspect. After a series of experimental comparisons, we proposed the ESA mechanism combined with the existing ECA mechanism. We selected triplet attention [45], ECA, and the Gaussian context transformer (GCT) [46] attention mechanism as the focus of our study and applied them on two separate branches for experimental validation of the attention schemes that promoted the model’s performance.
The performance of various attention mechanisms was compared and analyzed by examining the AP value, precision, recall, and mAP value. Triplet attention considers both spatial and channel dimensions, instead of limiting itself to feature weighting in a single dimension, which theoretically bolsters the model’s ability to gather important information. However, based on our experimental results, triplet attention did not show the expected benefits in the context of this study. In contrast, GCT utilizes a Gaussian context converter to directly map global environmental information onto attentional activation, which is unique, in that it achieves significant feature reinforcement without using a learning process [46]. In the theoretical analysis, GCT was expected to provide more effective feature fusion, but the experimental results did not support this. Line graphs of the different attention mechanisms are shown in Figure 7, revealing their relative performance across the various categories of detection and evaluation metrics. Although triplet attention and GCT performed well for some aspects, our proposed ESA mechanism achieved an optimal performance for most categories and key detection evaluation metrics. Notably, under the more stringent detection threshold requirements, the ESA mechanism still provided a significant performance improvement, further validating its effectiveness and reliability.
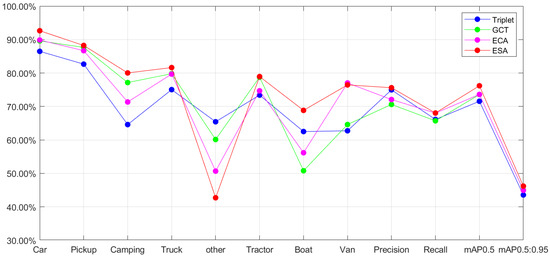
Figure 7.
Different attention results using the VEDAI dataset.
Through this series of experimental validations and comparative analyses, we not only demonstrated that the introduction of the ESA mechanism maximally enhanced the multimodal fusion model, but also emphasized the importance of integrating spatial and channel information when designing advanced attention models. In summary, our experimental results supported the ESA mechanism as a key module for improving the performance of multimodal fusion models.
5.3. Differential Module Insertion Position
In this study, we also carefully designed a CDM and identified its optimal insertion position in the multimodal fusion framework. To determine the impact of the CDM insertion position on model performance, we conducted a series of experimental comparative analyses, which informed the design of the final ACDF module.
In this part of the study, we focus on the changes in model performance when CDMs were inserted at different locations under the same experimental conditions. Specifically, the CDM was inserted into the ESA (Figure 8, referred to as method ADFa) and into branches before fusion (Figure 9, referred to as method ADFb). To compare the performance between these two structures with different insertion positions, we summarize the experimental results in Figure 10.
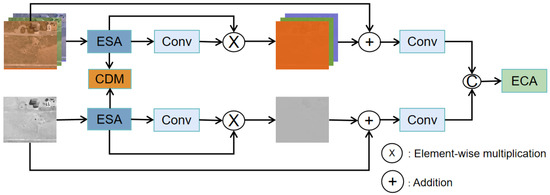
Figure 8.
Structure of ADFa, inserting the CDM into the ESA.
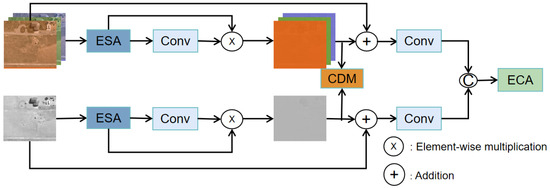
Figure 9.
Structure of ADFb, inserting the CDM into the branches before fusion.
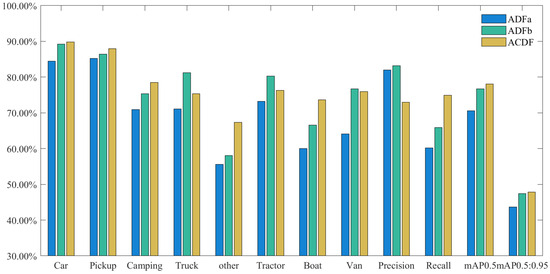
Figure 10.
Results for thedifferent CDM insertion positions using the VEDAI dataset.
We found that ADFb outperformed ADFa and the ACDF module in the detection task for specific categories (e.g., Truck, Tractor, and Van). However, even though method ADFb led in detection accuracy for certain categories, its overall recall was relatively low, implying that it may have a high misdetection rate in practical applications. Considering that a low recall can severely limit the usability of a model in real-world scenarios, we attempted to find a balance where a relatively high recall can be maintained, while ensuring a high detection precision.
Based on the above considerations, we chose the ACDF module as the core component of our multimodal fusion model. The ACDF module not only excels in overall average detection accuracy but also achieves a better balance between accuracy and recall. Owing to this design, our model can provide high accuracy, while reducing the missed detection of targets, making it more suitable for application in a wide range of real-world scenarios.
6. Conclusions
To overcome the limitations and challenges associated with target detection using single-modal remote sensing images, we comprehensively investigated the utilization of different modal data information and designed and implemented an innovative multimodal fusion framework, namely ACDF, which integrates a novel attention mechanism with a CDM to enhance the data interpretation, including feature representation and difference information, from two modalities. This combination improves the overall performance of the model through a series of operations, with proper placement. The core of the ACDF framework lies in its ability to recognize and leverage the complementary data found in both infrared and visible photos and to optimize the integration of features and the saliency of inter-modal differences. This fusion method significantly increases the accuracy and robustness of target identification, while bolstering the model’s capacity to capture target properties. Combining the ACDF model with the lightweight and powerful YOLOv5 framework enables real-time target detection in complex scenes, while keeping the computational cost and resource consumption low. This new multimodal fusion target detection architecture not only represents a breakthrough compared to the unimodal limitation in remote sensing image analysis, but also provides new perspectives and solutions for future multimodal image processing and analysis tasks. We plan to follow this study with further research on lightweight and expanding receptive field target detection algorithms for remote sensing images, in conjunction with new architectures in this area.
Author Contributions
Methodology, software, and writing—original draft preparation, X.F. and M.G.; investigation and data curation, Y.L. and R.Y.; modification and editing, L.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported in part by the National Natural Science Foundation of China (62006072), the Key Technologies Research and Development Program of Henan Province (222102210108, 242102311015), the Ministry of Education Key Laboratory Open Funded Project for Grain Information Processing and Control (KFJJ2022013), the Innovative Funds Plan of Henan University of Technology (2022ZKCJ11), and the Cultivation Programme for Young Backbone Teachers in Henan University of Technology.
Data Availability Statement
The LLVIP dataset can be found at https://bupt-ai-cz.github.io/LLVIP/ and accessed on 13 April 2024. The VEDAI dataset can be found at https://downloads.greyc.fr/vedai/ and accessed on 3 May 2024.
Acknowledgments
The authors would like to thank the editors and reviewers for their advice.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Feng, C.; Zhong, Y.; Gao, Y.; Scott, M.; Huang, W. TOOD: Task-aligned One-stage Object Detection. In Proceedings of the International Conference on Computer Vision 2021, Montreal, BC, Canada, 17 October 2021. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Ye, F.; Wu, Z.B.; Jia, X.P.; Chanussot, J.; Xu, Y.; Wei, Z.H. Bayesian Nonlocal Patch Tensor Factorization for Hyperspectral Image Super-Resolution. IEEE Trans. Image Process 2023, 32, 5877–5892. [Google Scholar] [CrossRef]
- He, C.X.; Xu, Y.; Wu, Z.B.; Wei, Z.H. Connecting Low-Level and High-Level Visions: A Joint Optimization for Hyperspectral Image Super-Resolution and Target Detection. IEEE Trans. Geosci. Remote. Sens. 2024, 62, 5514116. [Google Scholar] [CrossRef]
- Cheng, G.; Lang, C.; Wu, M.; Xie, X.; Yao, X.; Han, J. Feature Enhancement Network for Object Detection in Optical Remote Sensing Images. J. Remote. Sens. 2021, 2021, 9805389. [Google Scholar] [CrossRef]
- Li, Y.; Hou, Q.; Zheng, Z.; Cheng, M.; Yang, J.; Li, X. Large Selective Kernel Network for Remote Sensing Object Detection. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–3 October 2023; pp. 16748–16759. [Google Scholar]
- Fei, X.; Wu, S.; Miao, J.; Wang, G.; Sun, L. Lightweight-VGG: A Fast Deep Learning Architecture Based on Dimensionality Reduction and Nonlinear Enhancement for Hyperspectral Image Classification. Remote Sens. 2024, 16, 259. [Google Scholar] [CrossRef]
- Sun, L.; Zhang, H.; Zheng, Y.H.; Wu, Z.B.; Ye, Z.L.; Zhao, H.X. MASSFormer: Memory-Augmented Spectral-Spatial Transformer for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote. Sens. 2024, 62, 5516415. [Google Scholar] [CrossRef]
- Wu, Z.; Sun, J.; Zhang, Y.; Zhu, Y.; Li, J.; Plaza, A.; Benediktsson, J.A.; Wei, Z. Scheduling-Guided Automatic Processing of Massive Hyperspectral Image Classification on Cloud Computing Architectures. IEEE Trans. Cybern. 2021, 51, 3588–3601. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Lecture Notes in Computer Science, Medical Image Computing and Computer-Assisted Intervention-MICCAI 2015, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Wu, X.; Hong, D.F.; Chanussot, J. UIU-Net: U-Net in U-Net for Infrared Small Object Detection. IEEE Trans. Image Process. 2023, 32, 364–376. [Google Scholar] [CrossRef]
- Li, S.S.; Li, Y.J.; Li, Y.; Li, M.J.; Xu, X.R. YOLO-FIRI: Improved YOLOv5 for Infrared Image Object Detection. IEEE Access 2021, 9, 141861–141875. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, B.R.; Huo, L.L.; Fan, Y.S. GT-YOLO: Nearshore Infrared Ship Detection Based on Infrared Images. J. Mar. Sci. Eng. 2024, 12, 213. [Google Scholar] [CrossRef]
- Zhang, X.H.; Feng, S.J.; Zhao, C.X.; Sun, Z.Z.; Zhang, S.Q.; Ji, K.F. MGSFA-Net: Multiscale Global Scattering Feature Association Network for SAR Ship Target Recognition. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2024, 17, 4611–4625. [Google Scholar] [CrossRef]
- Zhao, X.F.; Xia, Y.T.; Zhang, W.W.; Zheng, C.; Zhang, Z.L. YOLO-ViT-Based Method for Unmanned Aerial Vehicle Infrared Vehicle Target Detection. Remote Sens. 2023, 15, 3778. [Google Scholar] [CrossRef]
- Sharma, M.; Dhanaraj, M.; Karnam, S.; Chachlakis, D.G.; Ptucha, R.; Markopoulos, P.P.; Saber, E. YOLOrs: Object Detection in Multimodal Remote Sensing Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2021, 14, 1497–1508. [Google Scholar] [CrossRef]
- Zhang, J.; Lei, J.; Xie, W.; Fang, Z.; Li, Y.; Du, Q. SuperYOLO: Super resolution assisted object detection in multimodal remote sensing imagery. IEEE Trans. Geosci. Remote. Sens. 2023, 61, 5605415. [Google Scholar] [CrossRef]
- Yang, J.; Yu, M.; Li, S.; Zhang, J.; Hu, S. Long-Tailed Object Detection for Multimodal Remote Sensing Images. Remote Sens. 2023, 15, 4539. [Google Scholar] [CrossRef]
- Cheng, X.L.; Geng, K.K.; Wang, Z.W.; Wang, J.H.; Sun, Y.X.; Ding, P.B. SLBAF-Net: Super-Lightweight bimodal adaptive fusion network for UAV detection in low recognition environment. Multimed. Tools Appl. 2023, 82, 47773–47792. [Google Scholar] [CrossRef]
- Tang, L.F.; Yuan, J.T.; Zhang, H.; Jiang, X.Y.; Ma, J.Y. PIAFusion: A progressive infrared and visible image fusion network based on illumination aware. Inform. Fusion 2022, 83, 79–92. [Google Scholar] [CrossRef]
- Fang, Q.; Han, D.; Wang, Z. Cross-Modality Fusion Transformer for Multispectral Object Detection. Ssrn Electron. J. 2022. [Google Scholar] [CrossRef]
- Yuan, M.; Wei, X. C2Former: Calibrated and Complementary Transformer for RGB-Infrared Object Detection. IEEE Trans. Geosci. Remote. Sens. 2024, 62, 5403712. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.J. CrossFuse: A novel cross attention mechanism based infrared and visible image fusion approach. Inform. Fusion 2024, 103, 102147. [Google Scholar] [CrossRef]
- Sun, L.; Wang, X.Y.; Zheng, Y.H.; Wu, Z.B.; Fu, L.Y. Multiscale 3-D–2-D Mixed CNN and Lightweight Attention-Free Transformer for Hyperspectral and LiDAR Classification. IEEE Trans. Geosci. Remote. Sens. 2024, 62, 2100116. [Google Scholar] [CrossRef]
- Chen, W.Y.; Miao, L.J.; Wang, Y.H.; Zhou, Z.Q.; Qiao, Y.J. Infrared-Visible Image Fusion through Feature-Based Decomposition and Domain Normalization. Remote Sens. 2024, 16, 969. [Google Scholar] [CrossRef]
- Zhou, Y.Q.; He, K.J.; Xu, D.; Tao, D.P.; Lin, X.; Li, C.Z. ASFusion: Adaptive visual enhancement and structural patch decomposition for infrared and visible image fusion. Eng. Appl. Artif. Intel. 2024, 132, 107905. [Google Scholar] [CrossRef]
- Zeng, X.; Long, L. Generative Adversarial Networks. In Beginning Deep Learning with TensorFlow; Apress: Berkeley, CA, USA, 2022; pp. 553–599. [Google Scholar]
- Ma, J.Y.; Yu, W.; Liang, P.W.; Li, C.; Jiang, J.J. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inform. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Zhao, C.; Yang, P.; Zhou, F.; Yue, G.; Wang, S.; Wu, H.; Lei, B.; Wang, T.; Chen, C. MHW-GAN: Multidiscriminator Hierarchical Wavelet Generative Adversarial Network for Multimodal Image Fusion. IEEE Trans. Neural Netw. Learn. Syst. 2023; early access. [Google Scholar] [CrossRef]
- Xu, H.; Liang, P.; Yu, W.; Jiang, J.; Ma, J. Learning a Generative Model for Fusing Infrared and Visible Images via Conditional Generative Adversarial Network with Dual Discriminators. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence IJCAI-19, Macao, China, 10–16 August 2019. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Communications of the ACM 2017, Los Angeles, CA, USA, 21–25 August 2017; pp. 84–90. [Google Scholar] [CrossRef]
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the Computer Vision–ECCV 2018, Lecture Notes in Computer Science, Munich, Germany, 8–14 September 2018; pp. 122–138. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Cheng, D.C.; Meng, G.F.; Cheng, G.L.; Pan, C.H. SeNet: Structured Edge Network for Sea-Land Segmentation. IEEE Geosci. Remote. Sens. Lett. 2017, 14, 247–251. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, H.; Liu, Y.; Zhang, H.; Zheng, D. Tree-Level Chinese Fir Detection Using UAV RGB Imagery and YOLO-DCAM. Remote Sens. 2024, 16, 335. [Google Scholar] [CrossRef]
- Jiang, C.C.; Ren, H.Z.; Ye, X.; Zhu, J.S.; Zeng, H.; Nan, Y.; Sun, M.; Ren, X.; Huo, H.T. Object detection from UAV thermal infrared images and videos using YOLO models. Int. J. Appl. Earth Obs. 2022, 112, 102912. [Google Scholar] [CrossRef]
- Jia, X.; Zhu, C.; Li, M.; Tang, W.; Zhou, W. LLVIP: A Visible-infrared Paired Dataset for Low-light Vision. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Misra, D.; Nalamada, T.; Arasanipalai, A.; Hou, Q. Rotate to Attend: Convolutional Triplet Attention Module. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual Event, 5–9 January 2021. [Google Scholar]
- Ruan, D.; Wang, D.; Zheng, Y.; Zheng, N.; Zheng, M. Gaussian Context Transformer. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).