
SA-SatMVS: Slope Feature-Aware and Across-Scale Information Integration for Large-Scale Earth Terrain Multi-View Stereo


Abstract
1. Introduction
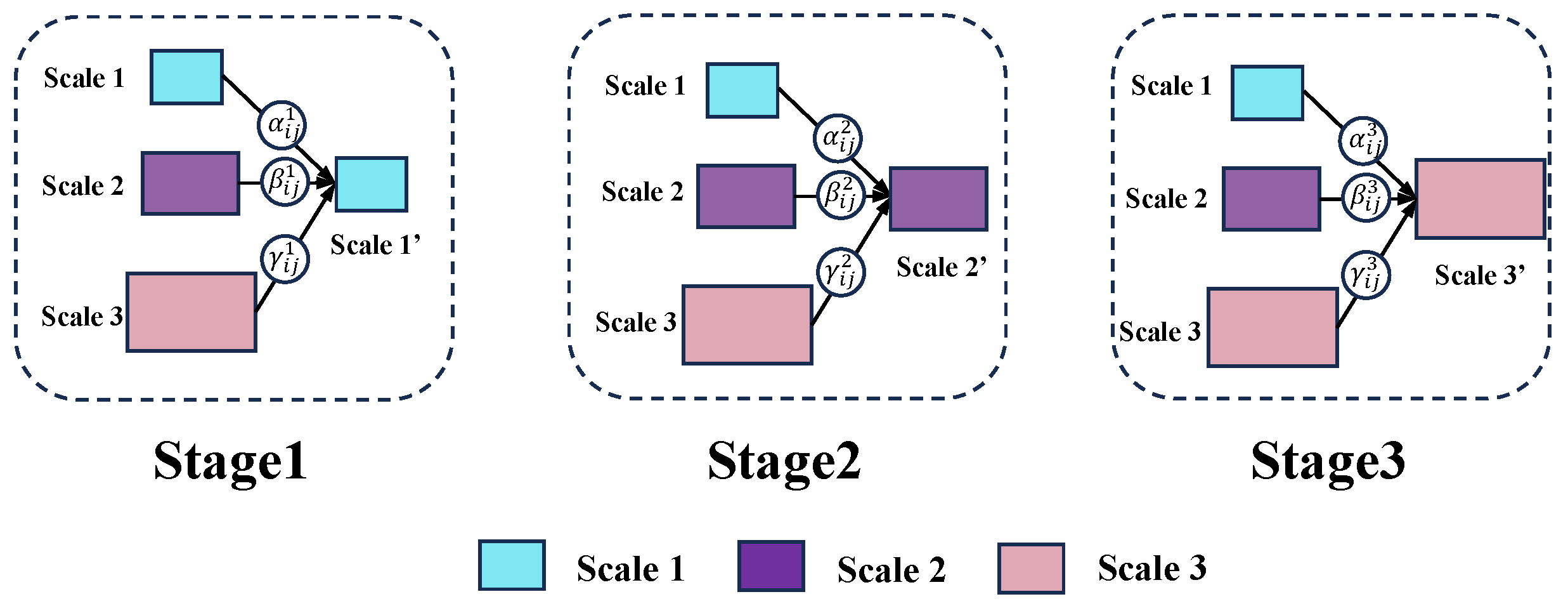
- We propose the adaptive spatial feature extraction network to better leverage local and global information at different scales, which can calculate the optimal fusion of feature maps at different scales.
- We leverage the probability volume to obtain the probability distribution and adopt the idea of an offset factor to implement the pixel-wise Laplacian-offset interval partition. This transforms the equidistant partition method—which overlooks the characteristics of the probability distribution—into a non-equidistant partition method.
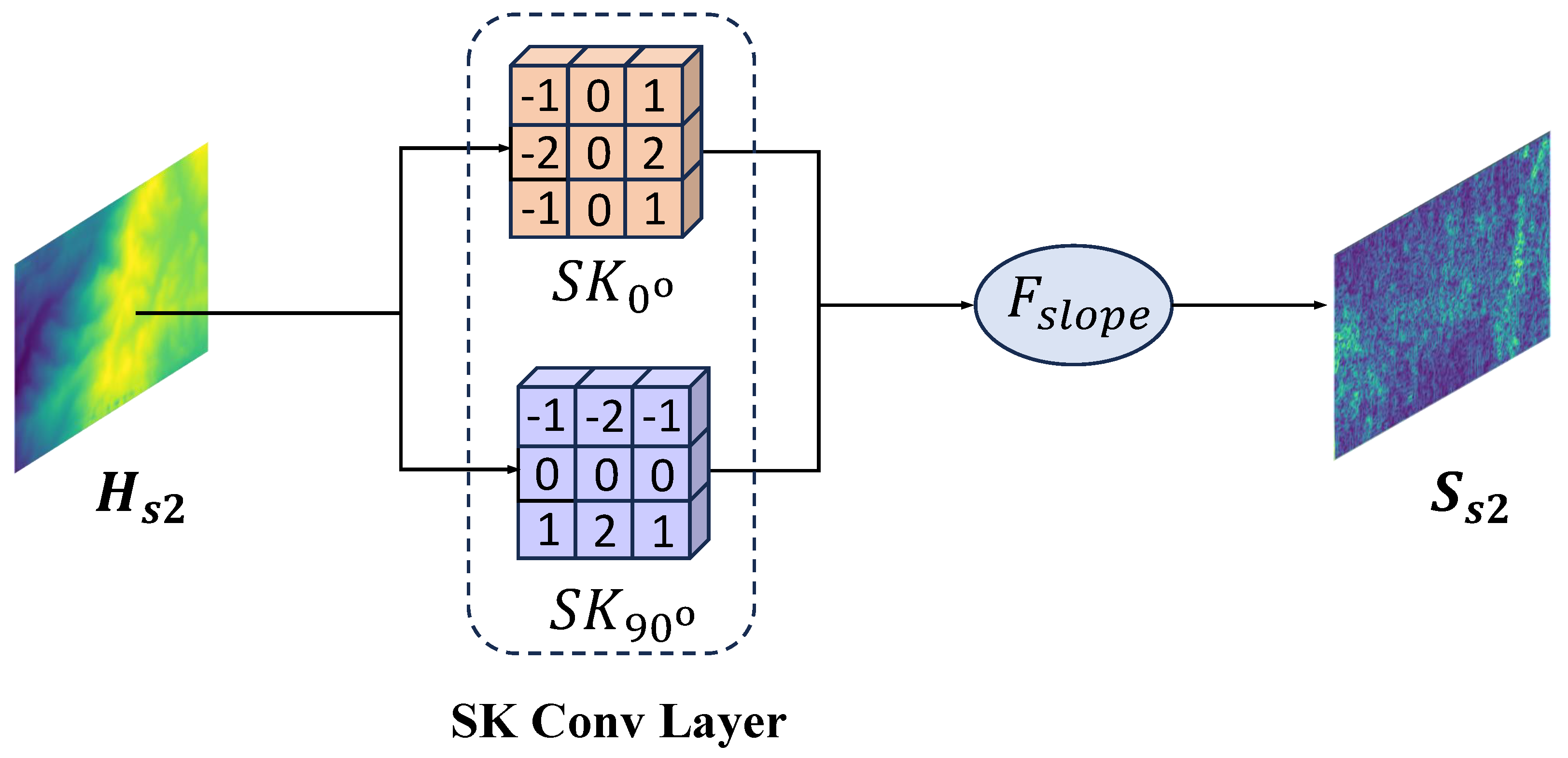
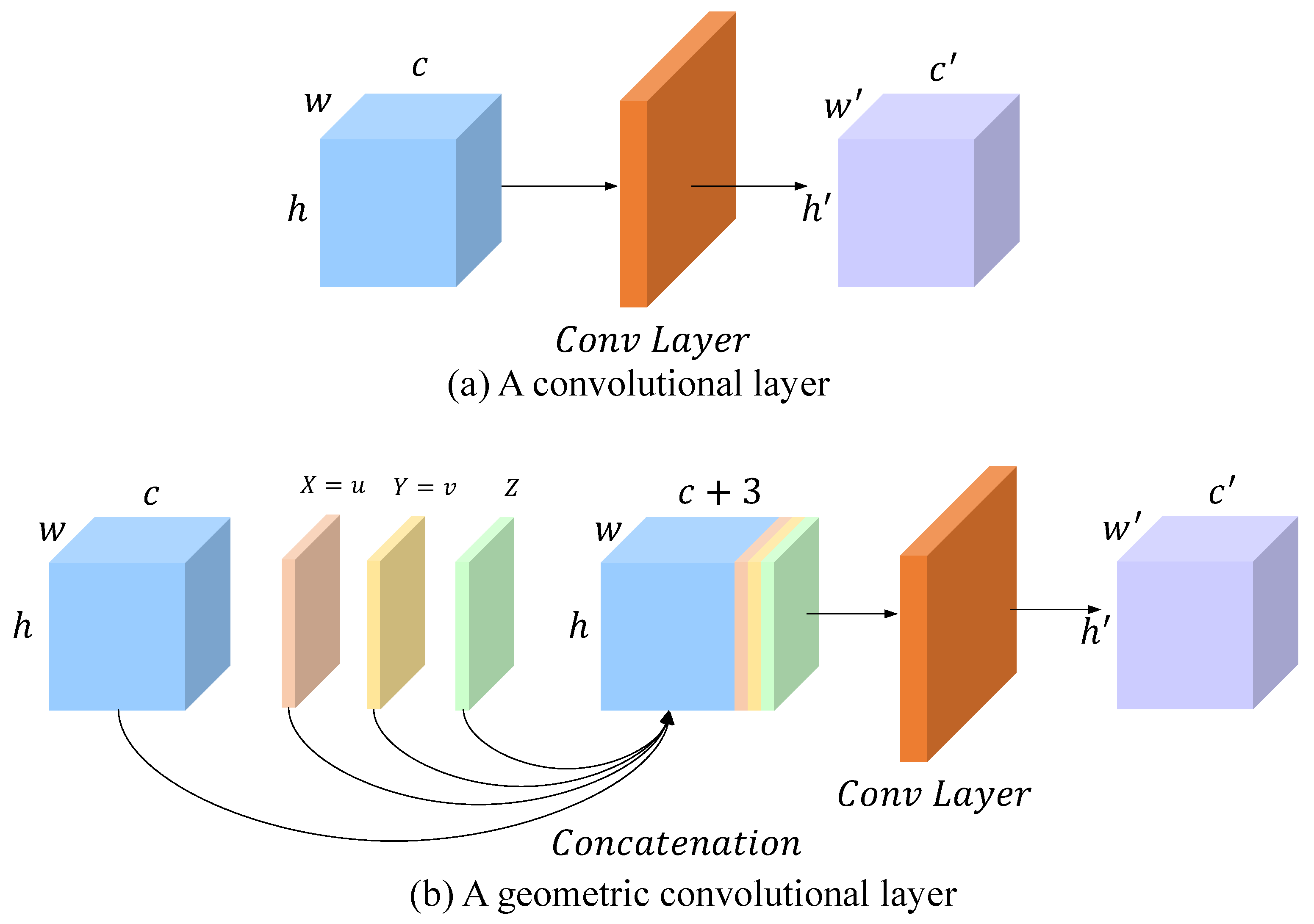
- We introduce the terrain-prior-guided feature fusion network to fully explore the inherent slope feature, which can increase the matching information. Apart from that, this enhances geometric awareness via the positional encoding of pixels. This can also incorporate geometric structural information into the feature-matching network.
- We conduct extensive experiments on the WHU-TLC dataset. The results of the experiments prove that our method achieves state-of-the-art performance.
2. Related Work
2.1. Close-Range Multi-View Stereo
2.2. Large-Scale Multi-View Stereo
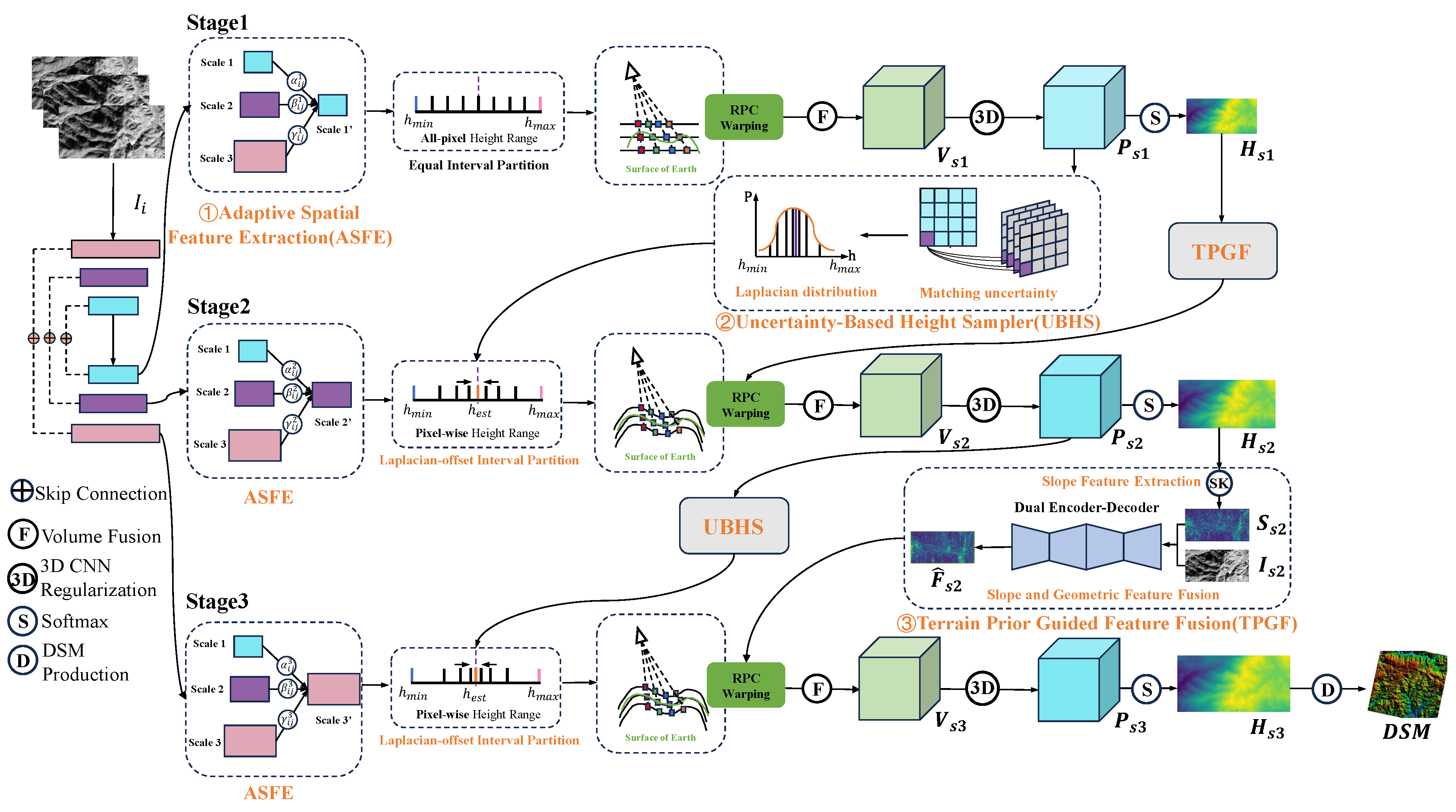
3. Methodology
3.1. Problem Definition
3.2. Framework
3.3. Adaptive Spatial Feature Extraction
3.4. Uncertainty-Based Height Sampler
3.5. Terrain-Prior-Guided Feature Fusion
3.6. Loss Function
4. Experiment
4.1. The Dataset
4.2. Evaluation Metrics
4.3. Implemented Details
4.4. Results
4.4.1. Analysis on Height Map
4.4.2. Analysis on DSM
4.5. Ablation Study
4.5.1. Ablation Study on the Novel Modules
4.5.2. Ablation Study on the Softmax Function
5. Limitations and Discussion
- In the realm of satellite multi-view stereo matching, the fusion of multi-modal data presents a notable challenge, underscoring a persistent issue in achieving optimal terrain reconstruction. Our approach adopts an encoder–decoder framework, enhanced with residual blocks, for the amalgamation of data across various modalities. Furthermore, we remain committed to investigating alternative strategies for data fusion, aiming to refine and expand the efficacy of our methodology in addressing the nuanced demands of satellite multi-view stereo matching.
- The acquisition of high-quality, high-resolution datasets plays a crucial role in facilitating more precise terrain reconstruction outcomes. Our methodology endeavors to mitigate these limitations by dynamically integrating features across various scales, effectively harnessing both local and global feature sets to enhance the reconstruction process. Moving forward, we anticipate the development of additional methodologies and strategies aiming to overcome these challenges, further advancing the field of terrain reconstruction.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kril, T.; Shekhunova, S. Terrain elevation changes by radar satellite images interpretation as a component of geo-environmental monitoring. In Proceedings of the Monitoring 2019. European Association of Geoscientists & Engineers, The Hague, The Netherlands, 8–12 September 2019; Volume 2019, pp. 1–5. [Google Scholar]
- Maksimovich, K.Y.; Garafutdinova, L. GIS-Based Terrain Morphometric Analysis for Environmental Monitoring Tasks. J. Agric. Environ. 2022, 21. [Google Scholar]
- Storch, M.; de Lange, N.; Jarmer, T.; Waske, B. Detecting Historical Terrain Anomalies with UAV-LiDAR Data Using Spline-Approximation and Support Vector Machines. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 3158–3173. [Google Scholar] [CrossRef]
- Shao, Z.; Yang, N.; Xiao, X.; Zhang, L.; Peng, Z. A multi-view dense point cloud generation algorithm based on low-altitude remote sensing images. Remote Sens. 2016, 8, 381. [Google Scholar] [CrossRef]
- Gao, J.; Liu, J.; Ji, S. Rational polynomial camera model warping for deep learning based satellite multi-view stereo matching. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2021, Montreal, BC, Canada, 11–17 October 2021; pp. 6148–6157. [Google Scholar]
- Zhou, L.; Zhang, Z.; Jiang, H.; Sun, H.; Bao, H.; Zhang, G. DP-MVS: Detail preserving multi-view surface reconstruction of large-scale scenes. Remote Sens. 2021, 13, 4569. [Google Scholar] [CrossRef]
- Gonçalves, G.; Gonçalves, D.; Gómez-Gutiérrez, Á.; Andriolo, U.; Pérez-Alvárez, J.A. 3D reconstruction of coastal cliffs from fixed-wing and multi-rotor uas: Impact of sfm-mvs processing parameters, image redundancy and acquisition geometry. Remote Sens. 2021, 13, 1222. [Google Scholar] [CrossRef]
- Kada, M.; McKinley, L. 3D building reconstruction from LiDAR based on a cell decomposition approach. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2009, 38, W4. [Google Scholar]
- Li, N.; Su, B. 3D-Lidar based obstacle detection and fast map reconstruction in rough terrain. In Proceedings of the 2020 5th International Conference on Automation, Control and Robotics Engineering (CACRE), Dalian, China, 19–20 September 2020; pp. 145–151. [Google Scholar]
- Do, P.N.B.; Nguyen, Q.C. A review of stereo-photogrammetry method for 3-D reconstruction in computer vision. In Proceedings of the 2019 19th International Symposium on Communications and Information Technologies (ISCIT), Ho Chi Minh City, Vietnam, 25–27 September 2019; pp. 138–143. [Google Scholar]
- Lorensen, W.E.; Cline, H.E. Marching cubes: A high resolution 3D surface construction algorithm. In Seminal Graphics: Pioneering Efforts That Shaped the Field; Association for Computing Machinery: New York, NY, USA, 1998; pp. 347–353. [Google Scholar]
- Newman, T.S.; Yi, H. A survey of the marching cubes algorithm. Comput. Graph. 2006, 30, 854–879. [Google Scholar] [CrossRef]
- Zhang, K.; Snavely, N.; Sun, J. Leveraging vision reconstruction pipelines for satellite imagery. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops 2019, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Toutin, T. Geometric processing of IKONOS Geo images with DEM. In Proceedings of the ISPRS Joint Workshop High Resolution from Space 2001, Hannover, Germany, 19–21 September 2001; pp. 19–21. [Google Scholar]
- Pham, N.T.; Park, S.; Park, C.S. Fast and efficient method for large-scale aerial image stitching. IEEE Access 2021, 9, 127852–127865. [Google Scholar] [CrossRef]
- Zarei, A.; Gonzalez, E.; Merchant, N.; Pauli, D.; Lyons, E.; Barnard, K. MegaStitch: Robust Large-scale image stitching. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–9. [Google Scholar] [CrossRef]
- Chen, L.; Zhao, Y.; Xu, S.; Bu, S.; Han, P.; Wan, G. Densefusion: Large-scale online dense pointcloud and dsm mapping for uavs. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 4766–4773. [Google Scholar]
- Qin, R.; Gruen, A.; Fraser, C. Quality assessment of image matchers for DSM generation–a comparative study based on UAV images. arXiv 2021, arXiv:2108.08369. [Google Scholar]
- Seitz, S.M.; Curless, B.; Diebel, J.; Scharstein, D.; Szeliski, R. A comparison and evaluation of multi-view stereo reconstruction algorithms. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 1, pp. 519–528. [Google Scholar]
- Yao, Y.; Luo, Z.; Li, S.; Fang, T.; Quan, L. Mvsnet: Depth inference for unstructured multi-view stereo. In Proceedings of the European Conference on Computer Vision (ECCV) 2018, Munich, Germany, 8–14 September 2018; pp. 767–783. [Google Scholar]
- Gu, X.; Fan, Z.; Zhu, S.; Dai, Z.; Tan, F.; Tan, P. Cascade cost volume for high-resolution multi-view stereo and stereo matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2020, Seattle, WA, USA, 13–19 June 2020; pp. 2495–2504. [Google Scholar]
- Cheng, S.; Xu, Z.; Zhu, S.; Li, Z.; Li, L.E.; Ramamoorthi, R.; Su, H. Deep stereo using adaptive thin volume representation with uncertainty awareness. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2020, Seattle, WA, USA, 13–19 June 2020; pp. 2524–2534. [Google Scholar]
- Weilharter, R.; Fraundorfer, F. Highres-mvsnet: A fast multi-view stereo network for dense 3d reconstruction from high-resolution images. IEEE Access 2021, 9, 11306–11315. [Google Scholar] [CrossRef]
- Gao, J.; Liu, J.; Ji, S. A general deep learning based framework for 3D reconstruction from multi-view stereo satellite images. ISPRS J. Photogramm. Remote Sens. 2023, 195, 446–461. [Google Scholar] [CrossRef]
- Bosch, M.; Kurtz, Z.; Hagstrom, S.; Brown, M. A multiple view stereo benchmark for satellite imagery. In Proceedings of the 2016 IEEE Applied Imagery Pattern Recognition Workshop (AIPR), Washington, DC, USA, 18–20 October 2016; pp. 1–9. [Google Scholar]
- Bosch, M.; Foster, K.; Christie, G.; Wang, S.; Hager, G.D.; Brown, M. Semantic stereo for incidental satellite images. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1524–1532. [Google Scholar]
- Cheng, L.; Guo, Q.; Fei, L.; Wei, Z.; He, G.; Liu, Y. Multi-criterion methods to extract topographic feature lines from contours on different topographic gradients. Int. J. Geogr. Inf. Sci. 2022, 36, 1629–1651. [Google Scholar] [CrossRef]
- Zhang, Y.; Yu, W.; Zhu, D. Terrain feature-aware deep learning network for digital elevation model superresolution. ISPRS J. Photogramm. Remote Sens. 2022, 189, 143–162. [Google Scholar] [CrossRef]
- Chen, P.H.; Yang, H.C.; Chen, K.W.; Chen, Y.S. MVSNet++: Learning depth-based attention pyramid features for multi-view stereo. IEEE Trans. Image Process. 2020, 29, 7261–7273. [Google Scholar] [CrossRef]
- Mi, Z.; Di, C.; Xu, D. Generalized binary search network for highly-efficient multi-view stereo. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2022, New Orleans, LA, USA, 18–24 June 2022; pp. 12991–13000. [Google Scholar]
- Zhang, S.; Xu, W.; Wei, Z.; Zhang, L.; Wang, Y.; Liu, J. ARAI-MVSNet: A multi-view stereo depth estimation network with adaptive depth range and depth interval. Pattern Recognit. 2023, 144, 109885. [Google Scholar] [CrossRef]
- Ma, X.; Wang, Z.; Li, H.; Zhang, P.; Ouyang, W.; Fan, X. Accurate monocular 3d object detection via color-embedded 3d reconstruction for autonomous driving. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2019, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6851–6860. [Google Scholar]
- Perez, J.; Sales, J.; Penalver, A.; Fornas, D.; Fernandez, J.J.; Garcia, J.C.; Sanz, P.J.; Marin, R.; Prats, M. Exploring 3-d reconstruction techniques: A benchmarking tool for underwater robotics. IEEE Robot. Autom. Mag. 2015, 22, 85–95. [Google Scholar] [CrossRef]
- Stereopsis, R.M. Accurate, dense, and robust multiview stereopsis. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1362–1376. [Google Scholar]
- Kutulakos, K.N.; Seitz, S.M. A theory of shape by space carving. Int. J. Comput. Vis. 2000, 38, 199–218. [Google Scholar] [CrossRef]
- Schönberger, J.L.; Zheng, E.; Frahm, J.M.; Pollefeys, M. Pixelwise view selection for unstructured multi-view stereo. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part III 14. pp. 501–518. [Google Scholar]
- Merrell, P.; Akbarzadeh, A.; Wang, L.; Mordohai, P.; Frahm, J.M.; Yang, R.; Nistér, D.; Pollefeys, M. Real-time visibility-based fusion of depth maps. In Proceedings of the ICCV 2007, Rio De Janeiro, Brazil, 14–21 October 2007. [Google Scholar]
- Schonberger, J.L.; Frahm, J.M. Structure-from-motion revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 4104–4113. [Google Scholar]
- Yang, J.; Mao, W.; Alvarez, J.M.; Liu, M. Cost volume pyramid based depth inference for multi-view stereo. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2020, Seattle, WA, USA, 14–19 June 2020; pp. 4877–4886. [Google Scholar]
- Liu, J.; Ji, S. A novel recurrent encoder-decoder structure for large-scale multi-view stereo reconstruction from an open aerial dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2020, Seattle, WA, USA, 14–19 June 2020; pp. 6050–6059. [Google Scholar]
- Li, J.; Huang, X.; Feng, Y.; Ji, Z.; Zhang, S.; Wen, D. A Hierarchical Deformable Deep Neural Network and an Aerial Image Benchmark Dataset for Surface Multiview Stereo Reconstruction. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–12. [Google Scholar] [CrossRef]
- Zhang, S.; Wei, Z.; Xu, W.; Zhang, L.; Wang, Y.; Zhang, J.; Liu, J. Edge aware depth inference for large-scale aerial building multi-view stereo. ISPRS J. Photogramm. Remote Sens. 2024, 207, 27–42. [Google Scholar] [CrossRef]
- Ding, X.; Hu, L.; Zhou, S.; Wang, X.; Li, Y.; Han, T.; Lu, D.; Che, G. Snapshot depth–spectral imaging based on image mapping and light field. EURASIP J. Adv. Signal Process. 2023, 2023, 24. [Google Scholar] [CrossRef]
- Liu, Z.; Chen, S.; Zhang, Z.; Qin, J.; Peng, B. Visual analysis method for unmanned pumping stations on dynamic platforms based on data fusion technology. EURASIP J. Adv. Signal Process. 2024, 2024, 29. [Google Scholar] [CrossRef]
- Li, R.; Zeng, X.; Yang, S.; Li, Q.; Yan, A.; Li, D. ABYOLOv4: Improved YOLOv4 human object detection based on enhanced multi-scale feature fusion. EURASIP J. Adv. Signal Process. 2024, 2024, 6. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- LeCun, Y.; Touresky, D.; Hinton, G.; Sejnowski, T. A theoretical framework for back-propagation. In Proceedings of the 1988 Connectionist Models Summer School; Morgan Kaufmann: Burlington, MA, USA, 1988; Volume 1, pp. 21–28. [Google Scholar]
- Kendall, A.; Gal, Y. What uncertainties do we need in bayesian deep learning for computer vision? Adv. Neural Inf. Process. Syst. 2017, 30, 5574–5584. [Google Scholar]
- Sobel, I.; Feldman, G. A 3 × 3 isotropic gradient operator for image processing. Pattern Classif. Scene Anal. 1968, 1968, 271–272. [Google Scholar]
- AS, R.A.; Gopalan, S. Comparative analysis of eight direction Sobel edge detection algorithm for brain tumor MRI images. Procedia Comput. Sci. 2022, 201, 487–494. [Google Scholar]
- Hu, M.; Wang, S.; Li, B.; Ning, S.; Fan, L.; Gong, X. Penet: Towards precise and efficient image guided depth completion. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 13656–13662. [Google Scholar]
- Tang, J.; Tian, F.P.; Feng, W.; Li, J.; Tan, P. Learning guided convolutional network for depth completion. IEEE Trans. Image Process. 2020, 30, 1116–1129. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liu, R.; Lehman, J.; Molino, P.; Petroski Such, F.; Frank, E.; Sergeev, A.; Yosinski, J. An intriguing failing of convolutional neural networks and the coordconv solution. Adv. Neural Inf. Process. Syst. 2018, 31, 9605–9616. [Google Scholar]
- Chen, Y.; Yang, B.; Liang, M.; Urtasun, R. Learning joint 2d-3d representations for depth completion. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2019, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 10023–10032. [Google Scholar]
- Zhang, Z.; Peng, R.; Hu, Y.; Wang, R. GeoMVSNet: Learning Multi-View Stereo With Geometry Perception. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2023, Vancouver, BC, Canada, 18–22 June 2023; pp. 21508–21518. [Google Scholar]
- Orhan, A.E.; Pitkow, X. Skip connections eliminate singularities. arXiv 2017, arXiv:1701.09175. [Google Scholar]
- Bjorck, N.; Gomes, C.P.; Selman, B.; Weinberger, K.Q. Understanding batch normalization. Adv. Neural Inf. Process. Syst. 2018, 31, 7705–7716. [Google Scholar]
- Agarap, A.F. Deep learning using rectified linear units (relu). arXiv 2018, arXiv:1803.08375. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | MAE (m) | <2.5 m (%) | <7.5 m (%) |
|---|---|---|---|
| SatMVS (RED-Net) | 1.836 | 82.06 | 96.63 |
| SatMVS (CasMVSNet) | 1.979 | 81.89 | 96.54 |
| SatMVS (UCS-Net) | 1.875 | 81.96 | 96.59 |
| SA-SatMVS | 1.704 | 84.02 | 96.77 |
| Methods | MAE (m)↓ | RMSE (m)↓ | <2.5 m (%)↑ | <7.5 m (%)↑ | Comp. (%)↑ |
|---|---|---|---|---|---|
| Adapted COLMAP | 2.227 | 5.291 | 73.35 | 96.00 | 79.10 |
| RED-Net | 2.171 | 4.514 | 74.13 | 95.91 | 81.82 |
| CasMVSNet | 2.031 | 4.351 | 77.39 | 96.53 | 82.33 |
| UCS-Net | 2.039 | 4.084 | 76.40 | 96.66 | 82.08 |
| SatMVS (RED-Net) | 1.945 | 4.070 | 77.93 | 96.59 | 82.29 |
| SatMVS (CasMVSNet) | 2.020 | 3.841 | 76.79 | 96.73 | 81.54 |
| SatMVS (UCS-Net) | 2.026 | 3.921 | 77.01 | 96.54 | 82.21 |
| SA-SatMVS | 1.879 | 3.785 | 79.02 | 96.62 | 82.37 |
| Modules | ||||||||
|---|---|---|---|---|---|---|---|---|
| Method | ASFE | UBHS | TPGF | MAE (m)↓ | RMSE (m)↓ | <2.5 m (%)↑ | <7.5 m (%)↑ | Comp. (%)↑ |
| -ASFE | ✓ | ✓ | 1.945 | 3.833 | 78.71 | 96.31 | 82.31 | |
| -UBHS | ✓ | ✓ | 1.968 | 3.841 | 78.47 | 96.45 | 82.29 | |
| -TPGF | ✓ | ✓ | 1.973 | 3.863 | 78.34 | 96.37 | 82.21 | |
| SA-SatMVS | ✓ | ✓ | ✓ | 1.879 | 3.785 | 79.02 | 96.62 | 82.37 |
| Methods | MAE (m) | <2.5 m (%) | <7.5 m (%) |
|---|---|---|---|
| SA-SatMVS (linear) | 1.786 | 83.59 | 96.61 |
| SA-SatMVS (softmax) | 1.704 | 84.02 | 96.77 |
| Methods | MAE (m)↓ | RMSE (m)↓ | <2.5 m (%)↑ | <7.5 m (%)↑ | Comp. (%)↑ |
|---|---|---|---|---|---|
| SA-SatMVS (linear) | 1.933 | 3.894 | 78.52 | 96.47 | 82.16 |
| SA-SatMVS (softmax) | 1.879 | 3.785 | 79.02 | 96.62 | 82.37 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Diao, W.; Zhang, S.; Wei, Z.; Liu, C. SA-SatMVS: Slope Feature-Aware and Across-Scale Information Integration for Large-Scale Earth Terrain Multi-View Stereo. Remote Sens. 2024, 16, 3474. https://doi.org/10.3390/rs16183474
Chen X, Diao W, Zhang S, Wei Z, Liu C. SA-SatMVS: Slope Feature-Aware and Across-Scale Information Integration for Large-Scale Earth Terrain Multi-View Stereo. Remote Sensing. 2024; 16(18):3474. https://doi.org/10.3390/rs16183474
Chicago/Turabian StyleChen, Xiangli, Wenhui Diao, Song Zhang, Zhiwei Wei, and Chunbo Liu. 2024. "SA-SatMVS: Slope Feature-Aware and Across-Scale Information Integration for Large-Scale Earth Terrain Multi-View Stereo" Remote Sensing 16, no. 18: 3474. https://doi.org/10.3390/rs16183474
APA StyleChen, X., Diao, W., Zhang, S., Wei, Z., & Liu, C. (2024). SA-SatMVS: Slope Feature-Aware and Across-Scale Information Integration for Large-Scale Earth Terrain Multi-View Stereo. Remote Sensing, 16(18), 3474. https://doi.org/10.3390/rs16183474