

MDFA-Net: Multi-Scale Differential Feature Self-Attention Network for Building Change Detection in Remote Sensing Images



Abstract

1. Introduction
2. Related Work
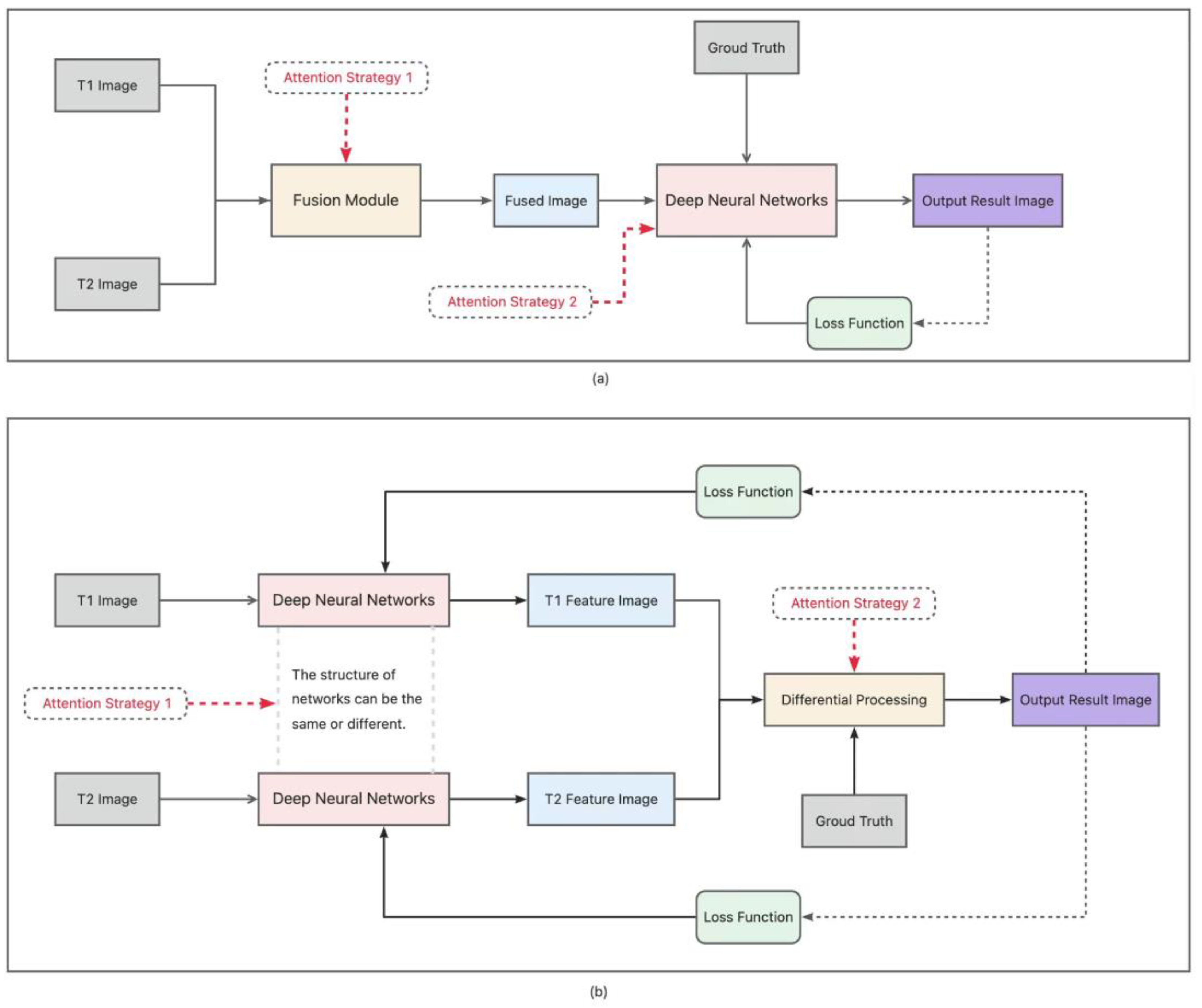
2.1. General DL Frameworks
2.2. Multi-Scale Bi-Temporal Feature Extraction
2.3. Attention Mechanisms
3. Methods
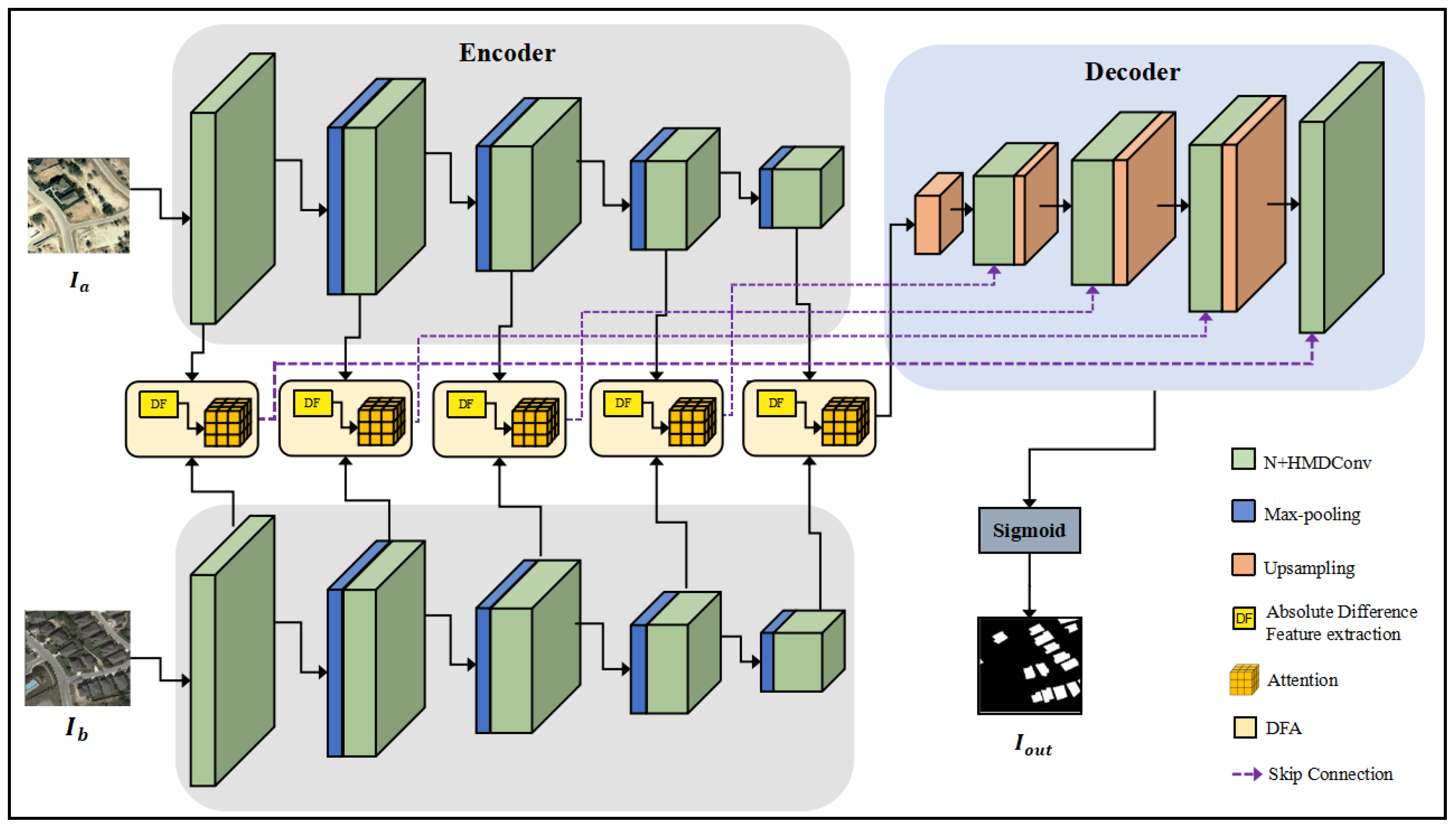
3.1. Overview
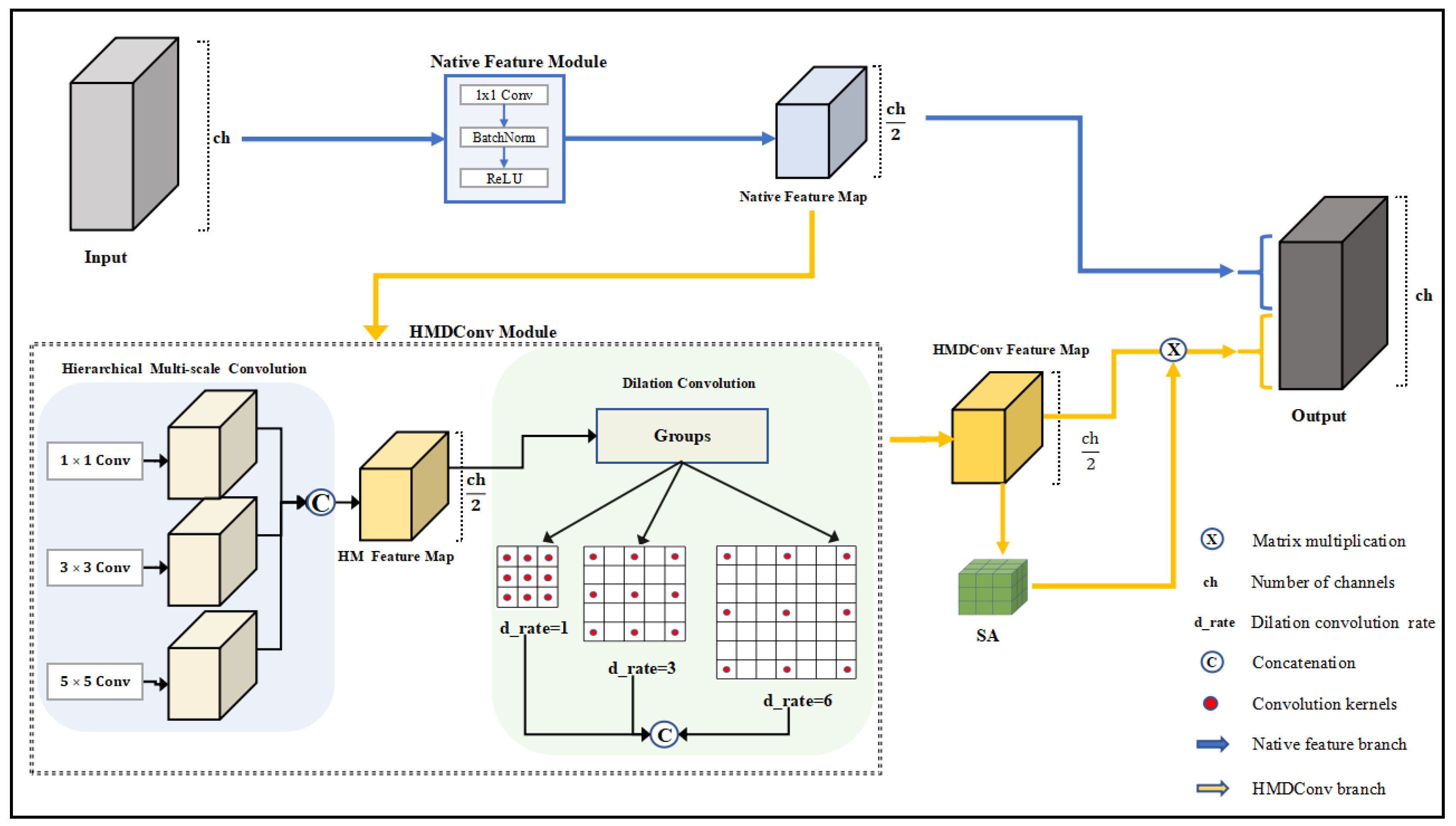
3.2. N + HMDConv Module
3.2.1. Native Feature Branch
3.2.2. HMDConv Branch
- (1)
- HM Convolution
- (2)
- Dilated Convolution (DConv)
- (3)
- Spatial Attention Module (SA)
3.3. DFA Module
3.3.1. Absolute Differential Feature Calculation
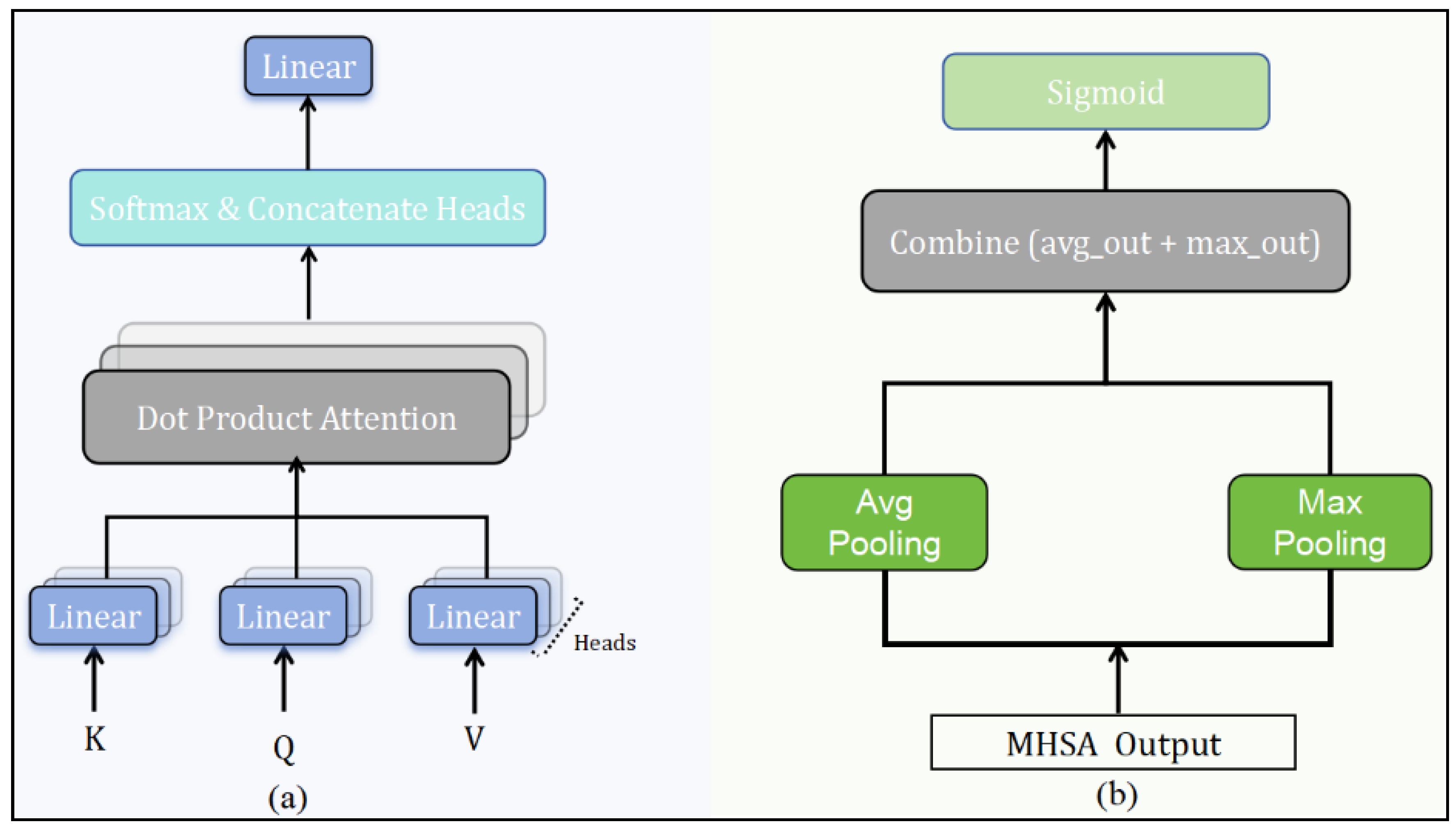
3.3.2. Multi-Head Self Attention
3.3.3. Channel Attention
3.3.4. Transformer Blocks
3.4. The Other Compositions of the MDFA-Net Architecture
3.4.1. Other Compositions of the Encoder
- (1)
- Multi-Stage Convolutional Layers
- (2)
- Activation Functions
- (3)
- Batch Normalization
- (4)
- Max Pooling
3.4.2. Other Compositions of the Decoder
- (1)
- Upsampling Layers
- (2)
- Feature Concatenation
- (3)
- Convolutional Refinement
- (4)
- Final Output Layer
3.5. Loss Function
4. Results
4.1. Experimental Setup
4.1.1. Datasets
4.1.2. Implementation Details
4.1.3. Evaluation Metrics
4.2. Comparative Studies of State-of-the-Art Methods
4.2.1. Overview of Baseline Models and State-of-the-Art Approaches
4.2.2. Accuracy Performance Comparison
- (1)
- Comparison on WHU-CD
- (2)
- Comparison on CDD
- (3)
- Comparison on LEVIR-CD
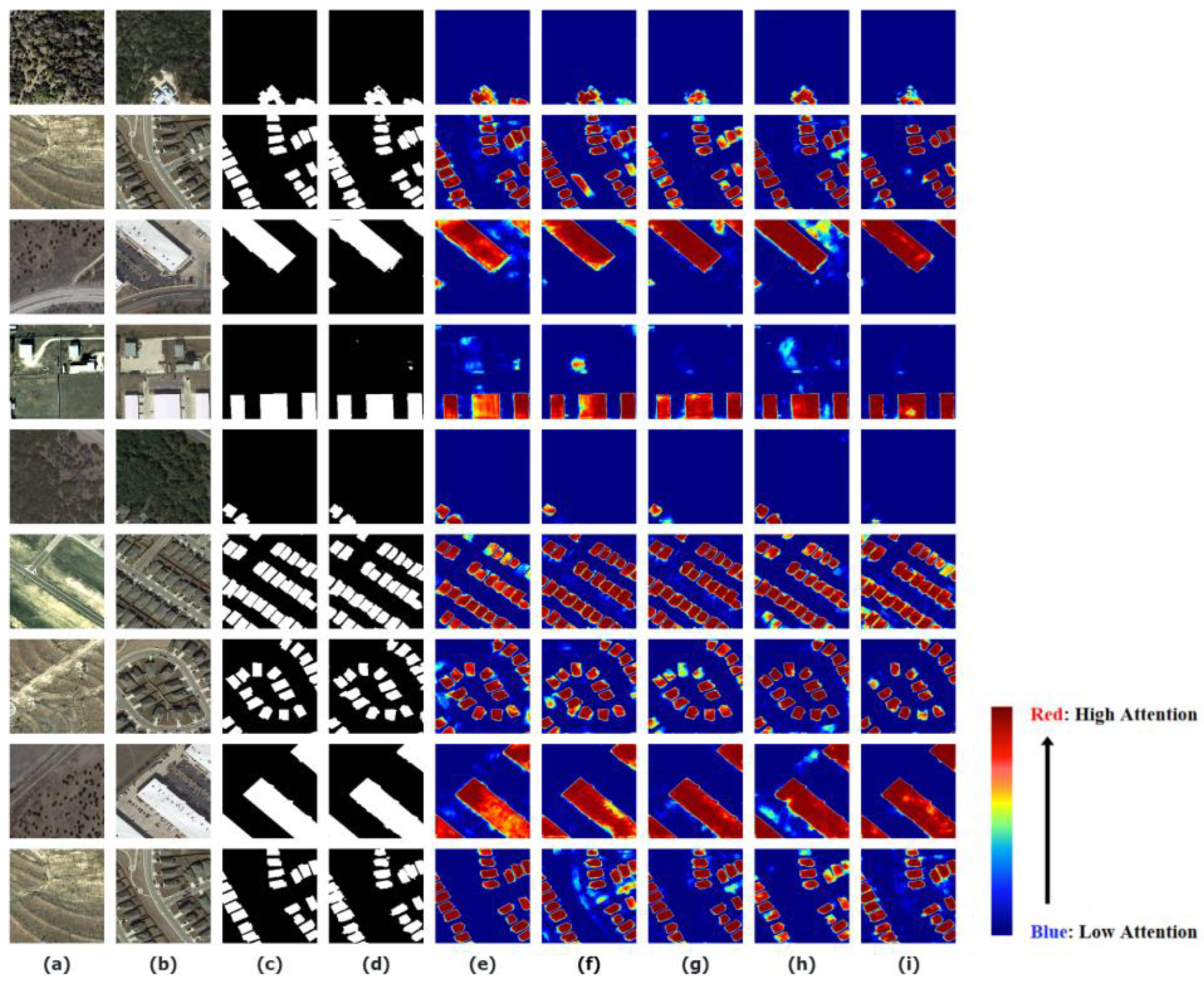
4.3. Comparative Analysis
5. Discussion
5.1. Advantages
5.2. Limitations and Further Directions
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Singh, A. Review article digital change detection techniques using remotely-sensed data. Int. J. Remote Sens. 1989, 10, 989–1003. [Google Scholar] [CrossRef]
- Smith, J.; Doe, J.; Brown, A. A comprehensive study on remote sensing techniques. IEEE Trans. Geosci. Remote Sens. 2024, 62, 123–132. [Google Scholar]
- Yuan, Z.; Mou, L.; Xiong, Z.; Zhu, X.X. Change detection meets visual question answering. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5630613. [Google Scholar] [CrossRef]
- Liu, Y.; Pang, C.; Zhan, Z.; Zhang, X.; Yang, X. Building change detection for remote sensing images using a dual-task constrained deep Siamese convolutional network model. IEEE Geosci. Remote Sens. Lett. 2020, 18, 811–815. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef]
- Liu, S.; Bruzzone, L.; Bovolo, F.; Zanetti, M.; Du, P. Sequential spectral change vector analysis for iteratively discovering and detecting multiple changes in hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4363–4378. [Google Scholar] [CrossRef]
- Jabari, S.; Rezaee, M.; Fathollahi, F.; Zhang, Y. Multispectral change detection using multivariate Kullback-Leibler distance. ISPRS J. Photogramm. Remote Sens. 2019, 147, 163–177. [Google Scholar] [CrossRef]
- Huang, L.; Zhang, G.; Li, Y. An object-based change detection approach by integrating intensity and texture differences. In Proceedings of the 2010 2nd International Asia Conference on Informatics in Control, Automation and Robotics (CAR 2010), Wuhan, China, 6–7 March 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 258–263. [Google Scholar]
- Gong, M.; Zhao, J.; Liu, J.; Miao, Q.; Jiao, L. Change detection in synthetic aperture radar images based on deep neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2015, 27, 125–138. [Google Scholar] [CrossRef]
- Wang, D.; Chen, X.; Jiang, M.; Du, S.; Xu, B.; Wang, J. ADS-Net: An attention-based deeply supervised network for remote sensing image change detection. Int. J. Appl. Earth Obs. Geoinf. 2021, 101, 102348. [Google Scholar]
- Shen, L.; Wang, Y.; Wu, Z. Multi-scale feature model for object detection. IEEE Trans. Image Process. 2020, 29, 4223–4235. [Google Scholar]
- Zhang, Y.; Li, J.; Song, Q. End-to-end superpixel-enhanced network for semantic segmentation. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 4567–4576. [Google Scholar]
- Zhang, C.; Yue, P.; Tapete, D.; Jiang, L.; Shangguan, B.; Huang, L.; Liu, G. A deeply supervised image fusion network for change detection in high resolution bi-temporal remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 166, 183–200. [Google Scholar] [CrossRef]
- Wahbi, M.; El Bakali, I.; Ez-zahouani, B.; Azmi, R.; Moujahid, A.; Zouiten, M.; Alaoui, O.Y.; Boulaassal, H.; Maatouk, M.; El Kharki, O. A deep learning classification approach using high spatial satellite images for detection of built-up areas in rural zones: Case study of Souss-Massa region, Morocco. Remote Sens. Appl. Soc. Environ. 2023, 29, 100898. [Google Scholar] [CrossRef]
- Yang, G.; Tang, H.; Ding, M.; Sebe, N.; Ricci, E. Transformer-based attention networks for continuous pixel-wise prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 16269–16279. [Google Scholar]
- Chen, H.; Qi, Z.; Shi, Z. Remote sensing image change detection with transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 15607514. [Google Scholar] [CrossRef]
- Cheng, G.; Huang, Y.; Li, X.; Lyu, S.; Xu, Z.; Zhao, H.; Zhao, Q.; Xiang, S. Change detection methods for remote sensing in the last decade: A comprehensive review. Remote Sens. 2024, 16, 2355. [Google Scholar] [CrossRef]
- Zang, J.; Lian, C.; Xu, B.; Zhang, Z.; Su, Y.; Xue, C. AmtNet: Attentional multi-scale temporal network for phonocardiogram signal classification. Biomed. Signal Process. Control 2023, 85, 104934. [Google Scholar] [CrossRef]
- Liu, W.; Lin, Y.; Liu, W.; Yu, Y.; Li, J. An attention-based multiscale transformer network for remote sensing image change detection. ISPRS J. Photogramm. Remote Sens. 2023, 202, 599–609. [Google Scholar] [CrossRef]
- Zheng, Z.; Ma, P.; Wu, Z. A context-structural feature decoupling change detection network for detecting earthquake-triggered damage. ISPRS Int. J. Appl. Earth Obs. Geoinf. 2024, 131, 103961. [Google Scholar] [CrossRef]
- Lei, T.; Geng, X.; Ning, H.; Lv, Z.; Gong, M.; Jin, Y.; Nandi, A.K. Ultralightweight spatial–spectral feature cooperation network for change detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4402114. [Google Scholar] [CrossRef]
- Lin, H.; Wang, X.; Li, M.; Huang, D.; Wu, R. A multi-task consistency enhancement network for semantic change detection in HR remote sensing images and application of non-agriculturalization. Remote Sens. 2023, 15, 5106. [Google Scholar] [CrossRef]
- Li, W.; Xue, L.; Wang, X.; Li, G. ConvTransNet: A CNN–transformer network for change detection with multiscale global–local representations. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5610315. [Google Scholar] [CrossRef]
- Daudt, R.C.; Le Saux, B.; Boulch, A. Fully convolutional Siamese networks for change detection. In Proceedings of the 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar]
- He, Y.; Zhang, H.; Ning, X.; Zhang, R.; Chang, D.; Hao, M. Spatial-Temporal Semantic Perception Network for Remote Sensing Image Semantic Change Detection. Remote Sens. 2023, 15, 4095. [Google Scholar] [CrossRef]
- Shen, Q.; Huang, J.; Wang, M.; Tao, S.; Yang, R.; Zhang, X. Semantic feature-constrained multitask siamese network for building change detection in high-spatial-resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2022, 189, 78–94. [Google Scholar] [CrossRef]
- Fang, S.; Li, K.; Shao, J.; Li, Z. SNUNet-CD: A densely connected Siamese network for change detection of VHR images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 8007805. [Google Scholar] [CrossRef]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. NAS-FPN: Learning scalable feature pyramid architecture for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–19 June 2019; pp. 7036–7045. [Google Scholar]
- Wang, Z.; Zhao, Y.; Chen, J. Multi-scale fast Fourier transform based attention network for remote-sensing image super-resolution. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 2728–2740. [Google Scholar] [CrossRef]
- Zhang, J.; Shao, Z.; Ding, Q.; Huang, X.; Wang, Y.; Zhou, X.; Li, D. AERNet: An attention-guided edge refinement network and a dataset for remote sensing building change detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5617116. [Google Scholar] [CrossRef]
- Zuo, Q.; Chen, S.; Wang, Z. R2AU-Net: Attention recurrent residual convolutional neural network for multimodal medical image segmentation. Secur. Commun. Netw. 2021, 2021, 6625688. [Google Scholar] [CrossRef]
- Li, Z.; Tang, C.; Liu, X.; Zhang, W.; Dou, J.; Wang, L.; Zomaya, A.Y. Lightweight remote sensing change detection with progressive feature aggregation and supervised attention. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5602812. [Google Scholar] [CrossRef]
- Zhao, Y.; Chen, P.; Chen, Z.; Bai, Y.; Zhao, Z.; Yang, X. A triple-stream network with cross-stage feature fusion for high-resolution image change detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5600417. [Google Scholar] [CrossRef]
- Li, L.; Liu, H.; Li, Q.; Tian, Z.; Li, Y.; Geng, W.; Wang, S. Near-infrared blood vessel image segmentation using background subtraction and improved mathematical morphology. Bioengineering 2023, 10, 726. [Google Scholar] [CrossRef] [PubMed]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV 2018), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Chen, P.; Zhang, B.; Hong, D.; Chen, Z.; Yang, X.; Li, B. FCCDN: Feature constraint network for VHR image change detection. ISPRS J. Photogramm. Remote Sens. 2022, 187, 101–119. [Google Scholar] [CrossRef]
- Jiang, H.; Hu, X.; Li, K.; Zhang, J.; Gong, J.; Zhang, M. PGA-SiamNet: Pyramid feature-based attention-guided Siamese network for remote sensing orthoimagery building change detection. Remote Sens. 2020, 12, 484. [Google Scholar] [CrossRef]
- Gong, M.; Jiang, F.; Qin, A.K.; Liu, T.; Zhan, T.; Lu, D.; Zheng, H.; Zhang, M. A Spectral and Spatial Attention Network for Change Detection in Hyperspectral Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5521614. [Google Scholar] [CrossRef]
- Zhang, J.; Wu, T.; Wang, Z.; Liang, J.; Liu, W. ChangeFormer: A Change Detection Framework Based on Transformer for Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar]
- Feng, Y.; Jiang, J.; Xu, H.; Zheng, J. Change Detection on Remote Sensing Images Using Dual-Branch Multilevel Intertemporal Network. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4401015. [Google Scholar] [CrossRef]
- Ma, H.; Zhao, L.; Li, B.; Niu, R.; Wang, Y. Change Detection Needs Neighborhood Interaction in Transformer. Remote Sens. 2023, 15, 5459. [Google Scholar] [CrossRef]
- Zhang, K.; Zhao, X.; Zhang, F.; Ding, L.; Sun, J.; Bruzzone, L. Relation changes matter: Cross-temporal difference transformer for change detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5611615. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, M.; Hao, Z.; Wang, Q.; Wang, Q.; Ye, Y. MSGFNet: Multi-Scale Gated Fusion Network for Remote Sensing Image Change Detection. Remote Sens. 2024, 16, 572. [Google Scholar] [CrossRef]
- Li, D.; Li, L.; Chen, Z.; Li, J. Shift-ConvNets: Small convolutional kernel with large kernel effects. arXiv 2024, arXiv:2401.12736. [Google Scholar]
- Fan, C.-L. Multiscale Feature Extraction by Using Convolutional Neural Network: Extraction of Objects from Multiresolution Images of Urban Areas. ISPRS Int. J. Geo-Inf. 2024, 13, 5. [Google Scholar] [CrossRef]
- Li, D.; Yao, A.; Chen, Q. PSConv: Squeezing Feature Pyramid into One Compact Poly-Scale Convolutional Layer. In Proceedings of the European Conference on Computer Vision (ECCV), Cham, Switzerland, 23–28 August 2020. [Google Scholar]
- Guo, Y.; Zhang, Y.; Chen, Z.; Wu, B. Attention Mechanisms for Change Detection in Remote Sensing: A Comprehensive Review. ISPRS J. Photogramm. Remote Sens. 2023, 194, 85–98. [Google Scholar]
- Ji, S.; Wei, S.; Lu, M. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Trans. Geosci. Remote Sens. 2019, 57, 574–586. [Google Scholar] [CrossRef]
- Lebedev, M.; Vizilter, Y.V.; Vygolov, O.; Knyaz, V.A.; Rubis, A.Y. Change detection in remote sensing images using conditional adversarial networks. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 42, 565–571. [Google Scholar] [CrossRef]
- Chen, H.; Shi, Z. A spatial-temporal attention-based method and a new dataset for remote sensing image change detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Codegoni, A.; Lombardi, G.; Ferrari, A. TINYCD: A (not so) deep learning model for change detection. Neural Comput. Appl. 2023, 35, 8471–8486. [Google Scholar] [CrossRef]
- Sayed, A.N.; Himeur, Y.; Bensaali, F. Deep and transfer learning for building occupancy detection: A review and comparative analysis. Eng. Appl. Artif. Intell. 2022, 115, 105254. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Space Resolution | Coverage | Training Dataset Size | Validation Dataset Size | Test Dataset Size | Changed Objects |
|---|---|---|---|---|---|---|
| WHU-CD | 0.2 m/pixel | Christchurch, New Zealand. | 5947 pairs | 743 pairs | 744 pairs | building |
| CDD-CD | 0.03~1 m/pixel | Multiple regions around the world | 10,000 pairs | 3000 pairs | 3000 pairs | building, road |
| LEVIR-CD | 0.5 m/pixel | Twenty cities in Texas, USA. | 7120 pairs | 1024 pairs | 2048 pairs | building |
| Network | F1 (%) | Pre (%) | Rec (%) | IoU (%) | OA (%) |
|---|---|---|---|---|---|
| FC-EF | 76.88 | 79.33 | 74.58 | 62.45 | 97.10 |
| FC-Siam-Diff | 86.31 | 89.61 | 83.22 | 75.91 | 95.90 |
| FC-Siam-Conc | 65.31 | 68.93 | 62.06 | 48.54 | 89.89 |
| STANet | 87.11 | 86.11 | 88.14 | 77.17 | 96.52 |
| Change Former | 90.25 | 91.23 | 85.46 | 84.98 | 98.17 |
| DSIFN | 88.52 | 85.89 | 91.31 | 79.40 | 98.49 |
| BIT | 85.71 | 82.04 | 89.74 | 74.96 | 98.00 |
| SNUNet | 87.76 | 87.84 | 87.68 | 78.19 | 98.16 |
| USSFC-Net | 92.68 | 93.37 | 94.04 | 86.37 | 99.25 |
| Our Model (MDFA-Net) | 93.81 | 92.79 | 94.84 | 88.34 | 99.36 |
| Network | F1 (%) | Pre (%) | Rec (%) | IoU (%) | OA (%) |
|---|---|---|---|---|---|
| FC-EF | 68.67 | 79.79 | 61.28 | 53.05 | 89.90 |
| FC-Siam-Diff | 72.67 | 74.83 | 70.64 | 57.08 | 92.17 |
| FC-Siam-Conc | 70.98 | 89.71 | 58.73 | 55.02 | 92.57 |
| STANet | 83.34 | 76.97 | 92.91 | 73.00 | 96.02 |
| Change Former | 92.47 | 94.69 | 90.86 | 88.97 | 97.98 |
| DSIFN | 93.39 | 92.33 | 94.48 | 87.60 | 98.11 |
| BIT | 93.54 | 92.79 | 94.56 | 87.94 | 98.56 |
| SNUNet | 92.31 | 93.41 | 91.24 | 85.73 | 98.38 |
| USSFC-Net | 94.26 | 93.05 | 95.50 | 89.14 | 98.51 |
| Our Model (MDFA-Net) | 95.32 | 95.23 | 95.42 | 91.06 | 98.85 |
| Network | F1 (%) | Pre (%) | Rec (%) | IoU (%) | OA (%) |
|---|---|---|---|---|---|
| FC-EF | 72.91 | 81.38 | 66.07 | 58.82 | 97.48 |
| FC-Siam-Diff | 86.84 | 89.45 | 84.66 | 76.83 | 98.01 |
| FC-Siam-Conc | 83.96 | 90.48 | 78.60 | 72.45 | 98.37 |
| STANet | 87.33 | 90.53 | 84.71 | 77.79 | 98.81 |
| Change Former | 90.50 | 90.83 | 90.18 | 82.66 | 99.00 |
| DSIFN | 87.58 | 87.30 | 88.27 | 77.82 | 99.01 |
| BIT | 90.11 | 91.67 | 87.38 | 80.67 | 98.97 |
| SNUNet | 89.71 | 90.62 | 89.47 | 81.77 | 98.96 |
| USSFC-Net | 91.04 | 89.70 | 92.42 | - | - |
| Our Model (MDFA-Net) | 91.21 | 91.04 | 91.39 | 84.10 | 99.07 |
| Network | F1 (%) | Pre (%) | Rec (%) | IoU (%) | OA (%) |
|---|---|---|---|---|---|
| Baseline | 88.46 | 86.29 | 90.75 | 79.32 | 98.85 |
| Baseline + HMDConv | 89.75 | 86.53 | 93.23 | 81.41 | 98.99 |
| Baseline + DFA | 90.45 | 90.57 | 90.34 | 82.57 | 99.03 |
| Baseline + HMDConv + DFA | 91.21 | 91.04 | 91.39 | 84.10 | 99.07 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Zou, S.; Zhao, T.; Su, X. MDFA-Net: Multi-Scale Differential Feature Self-Attention Network for Building Change Detection in Remote Sensing Images. Remote Sens. 2024, 16, 3466. https://doi.org/10.3390/rs16183466
Li Y, Zou S, Zhao T, Su X. MDFA-Net: Multi-Scale Differential Feature Self-Attention Network for Building Change Detection in Remote Sensing Images. Remote Sensing. 2024; 16(18):3466. https://doi.org/10.3390/rs16183466
Chicago/Turabian StyleLi, Yuanling, Shengyuan Zou, Tianzhong Zhao, and Xiaohui Su. 2024. "MDFA-Net: Multi-Scale Differential Feature Self-Attention Network for Building Change Detection in Remote Sensing Images" Remote Sensing 16, no. 18: 3466. https://doi.org/10.3390/rs16183466
APA StyleLi, Y., Zou, S., Zhao, T., & Su, X. (2024). MDFA-Net: Multi-Scale Differential Feature Self-Attention Network for Building Change Detection in Remote Sensing Images. Remote Sensing, 16(18), 3466. https://doi.org/10.3390/rs16183466