

Unifying Building Instance Extraction and Recognition in UAV Images

Abstract
1. Introduction
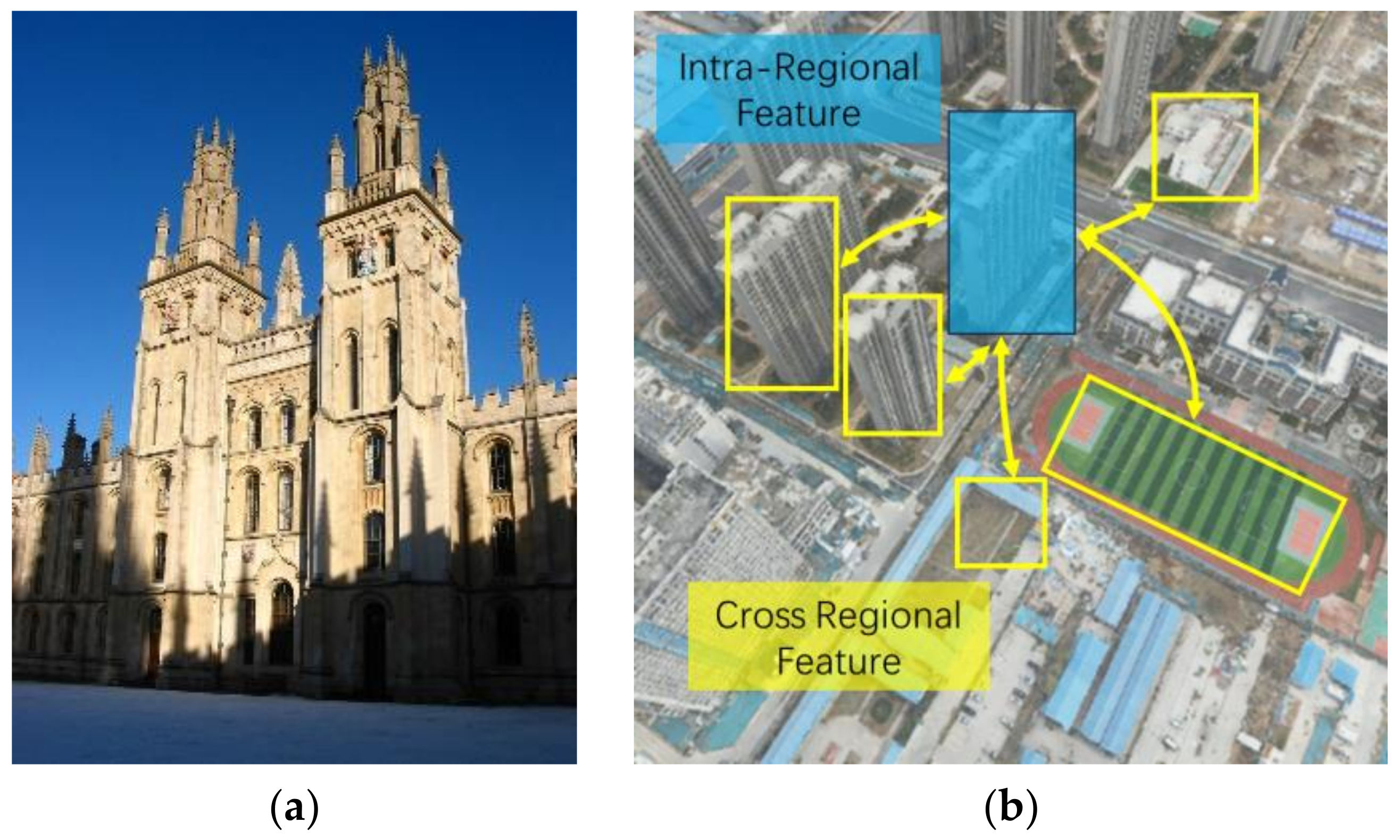
- We propose a novel BIR method (Cross-Mixer) based on the dual-branch structure, which can capture the global context while preserving spatial-detailed. The method achieves the state-of-the-art performance on the test benchmarks.
- We discovered the complementarity between BIE and BIR tasks. Integrating them into a unified model effectively can not only reduce computational redundancy but also improves performance in both tasks.
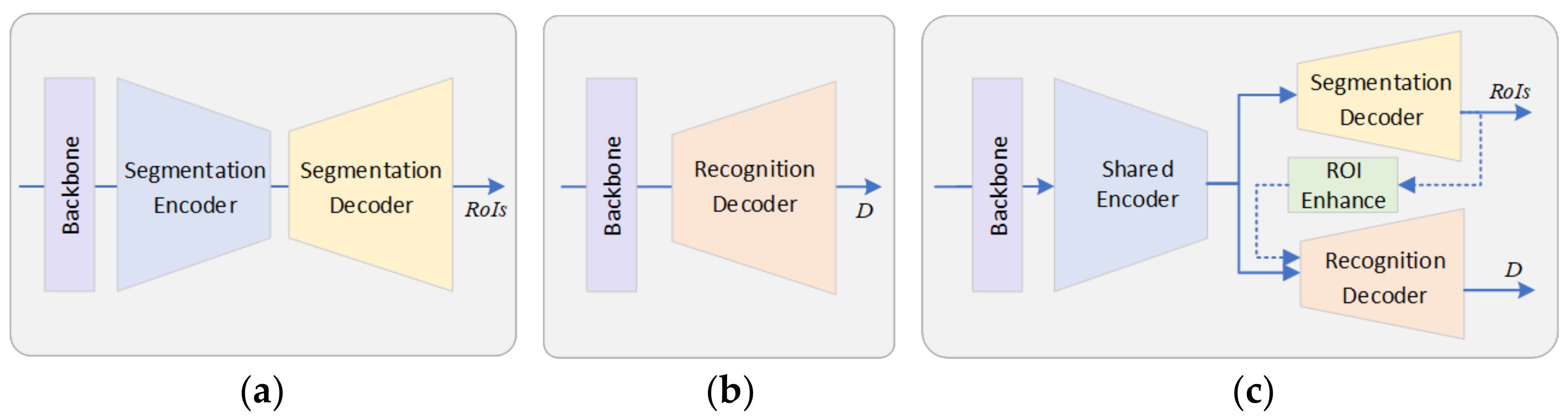
- We developed an end-to-end BEAR network (BEAR-Former). BIE and BIR are effectively integrated by designing a CGFM module and an RoI enhancement strategy.
- We developed an evaluation metric for the BEAR task. Additionally, we introduce a virtual matching-based building instance annotation generation method, which reduces the workload of training and evaluation data preparation.
2. Related Work
2.1. Building Instance Recognition
2.2. Building Instance Extraction
3. Materials and Methods
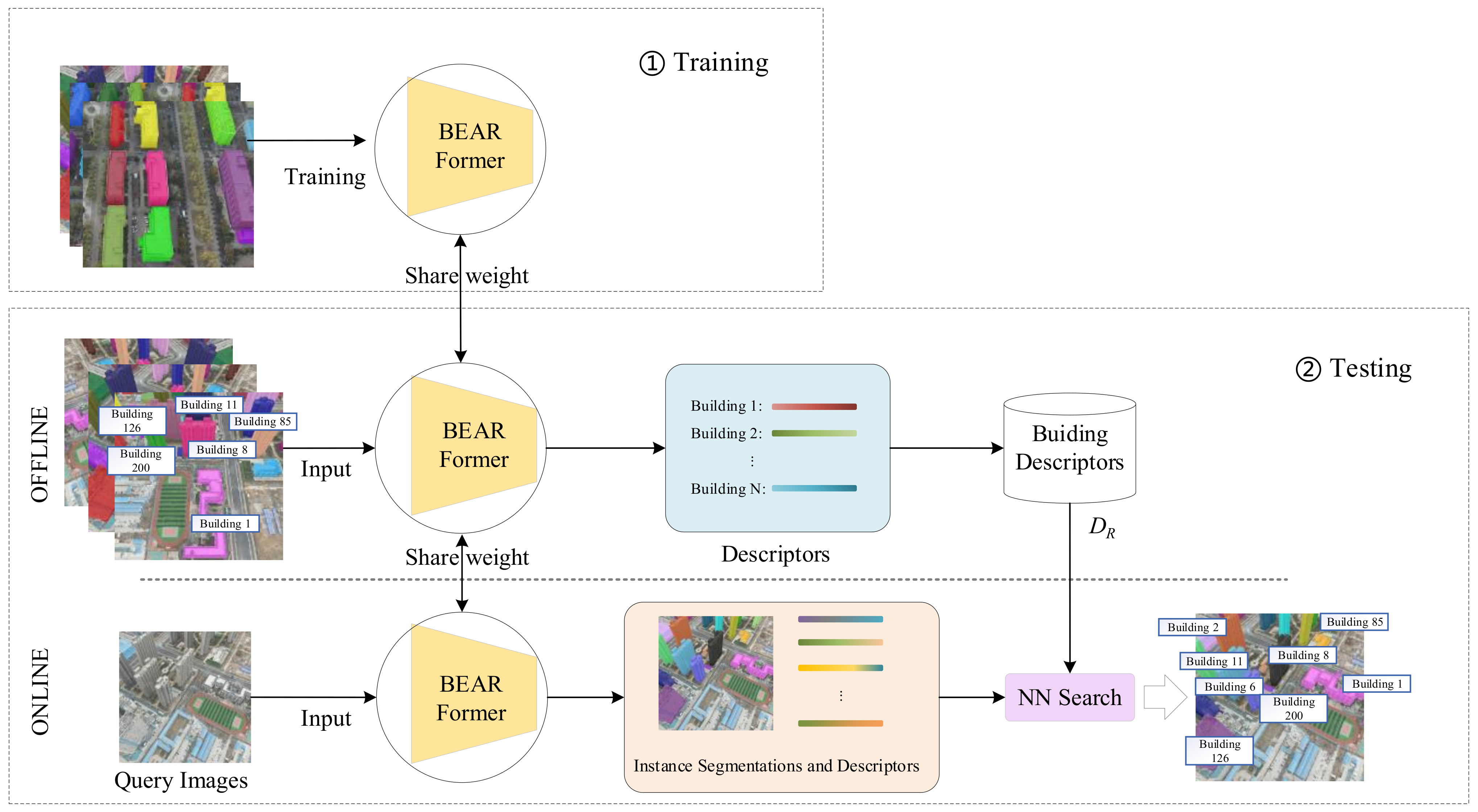
3.1. Problem Formulation
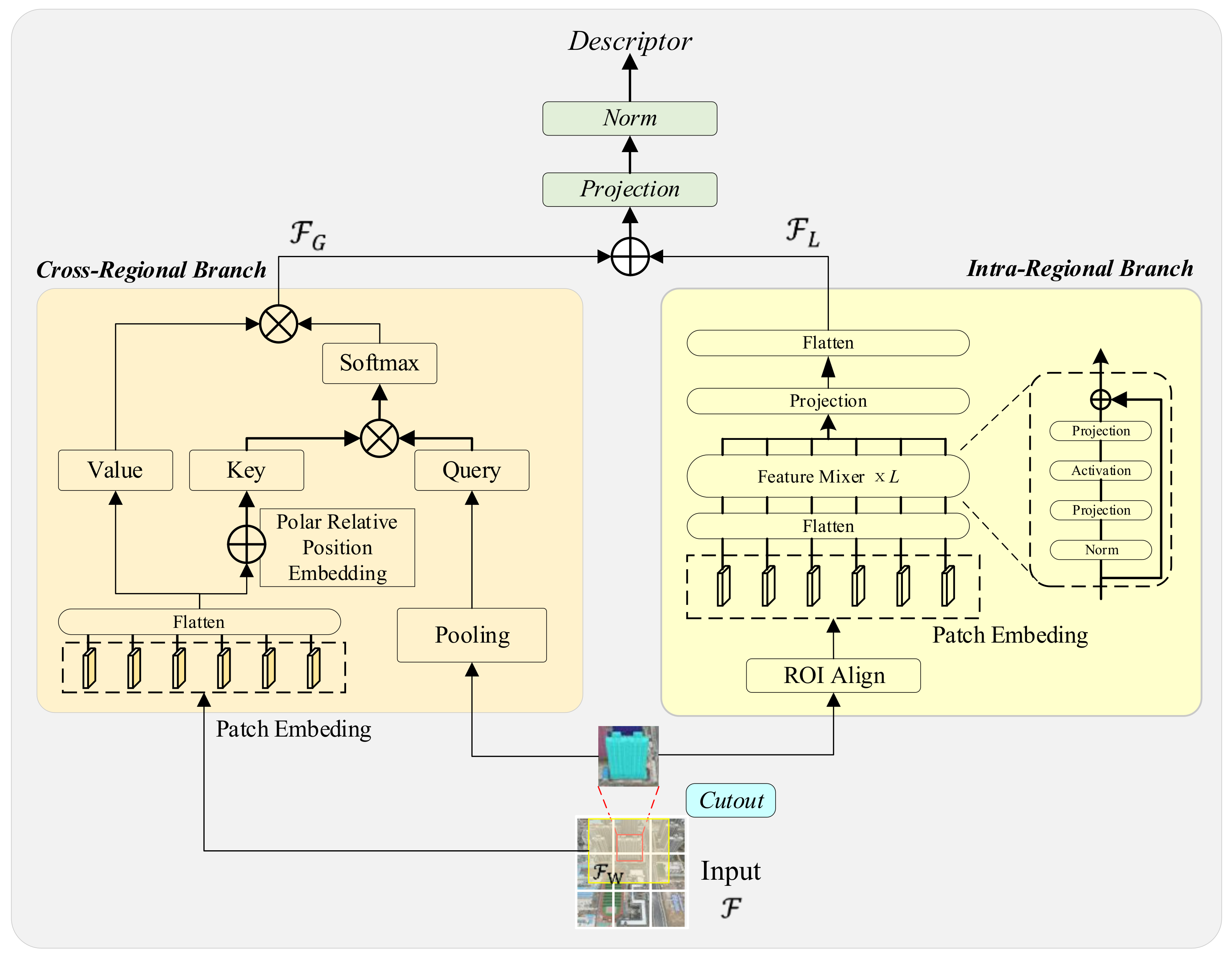
3.2. Recognition Decoder Based on Cross-Mixer
3.2.1. Cross-Regional Branch with Cross-Attention
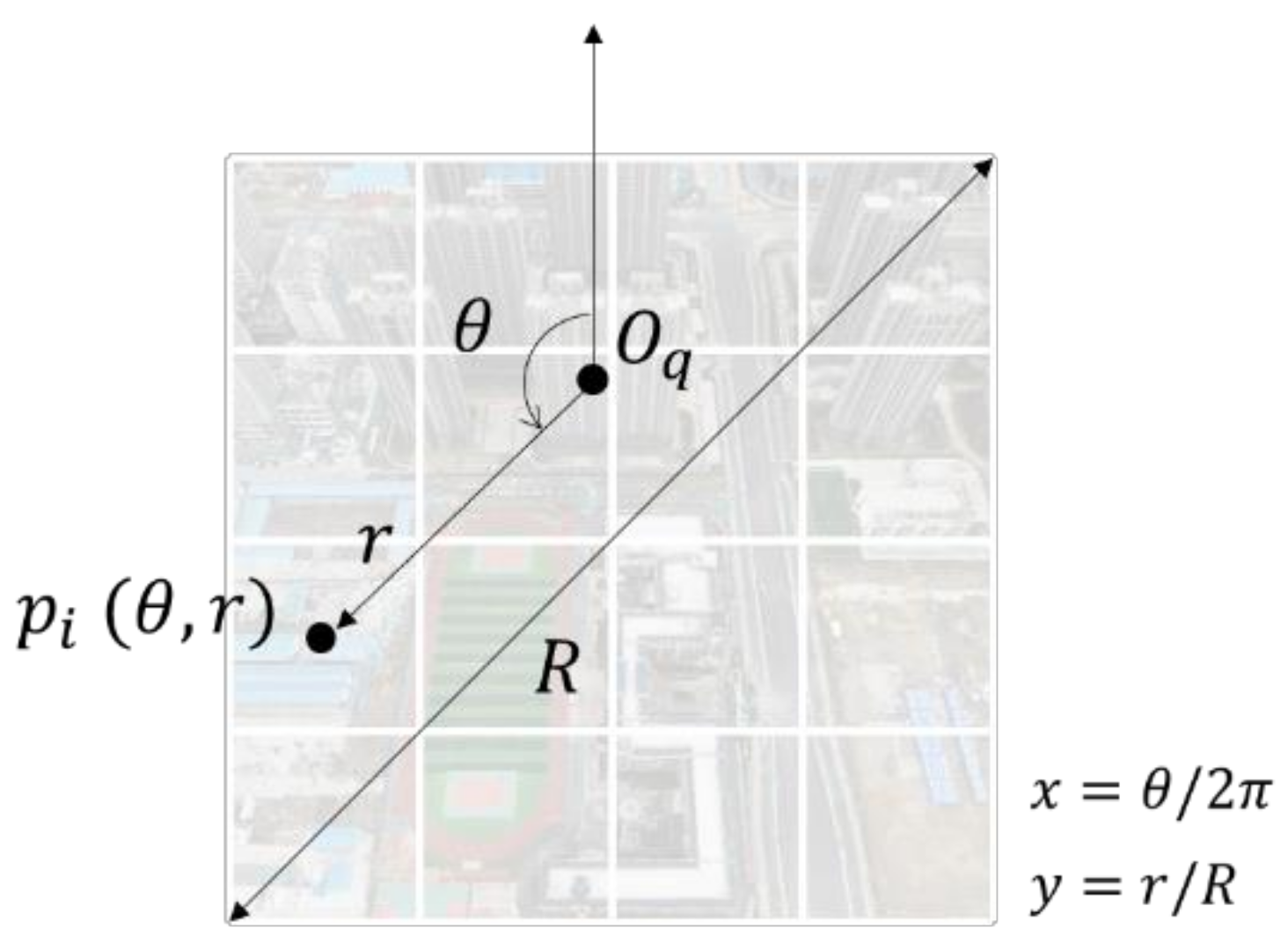
3.2.2. Polar Relative Position Embedding (PRPE)
3.2.3. Intra-Regional Branch with the Feature Mixer
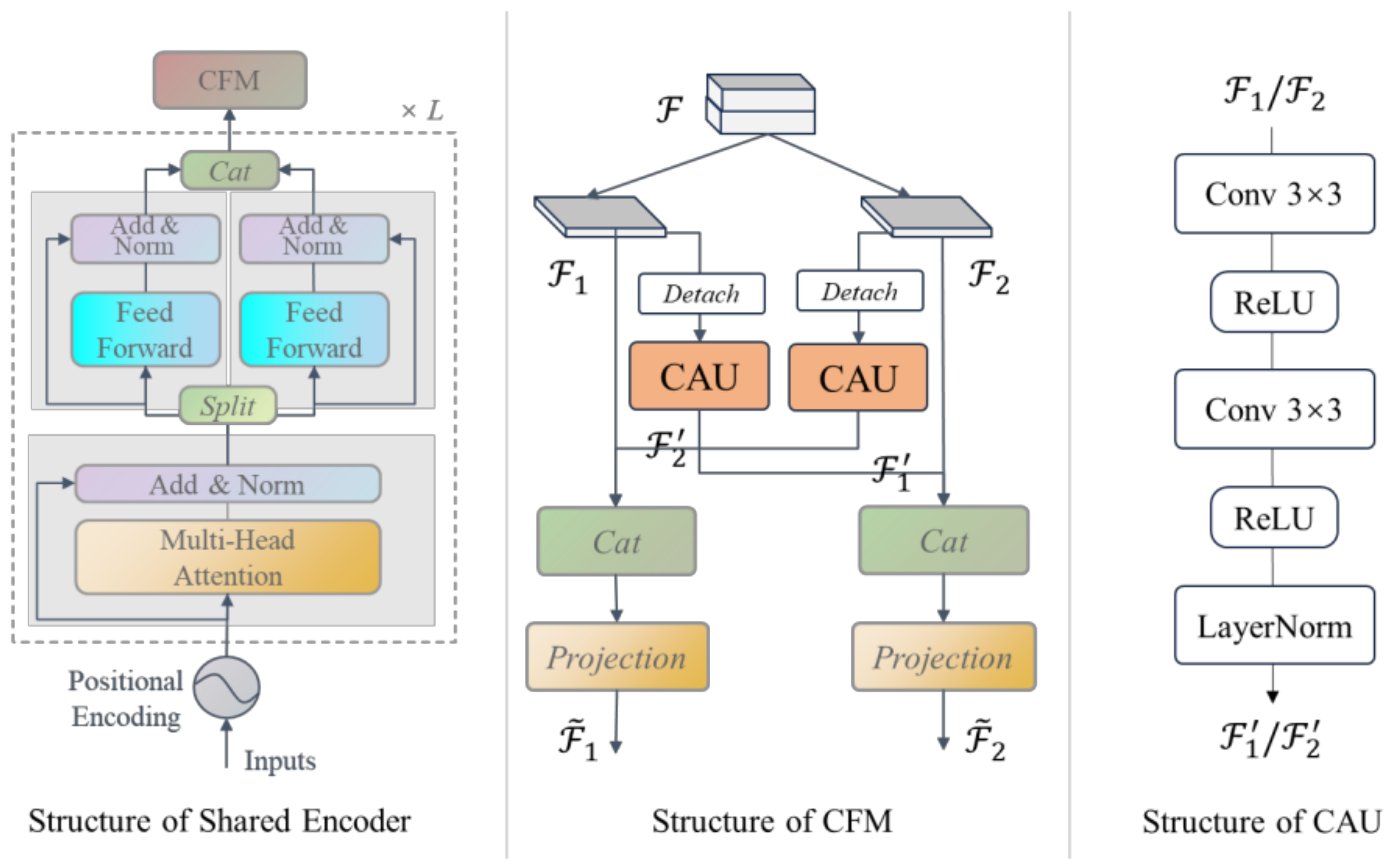
3.3. Shared Encoder Based on a CGFM
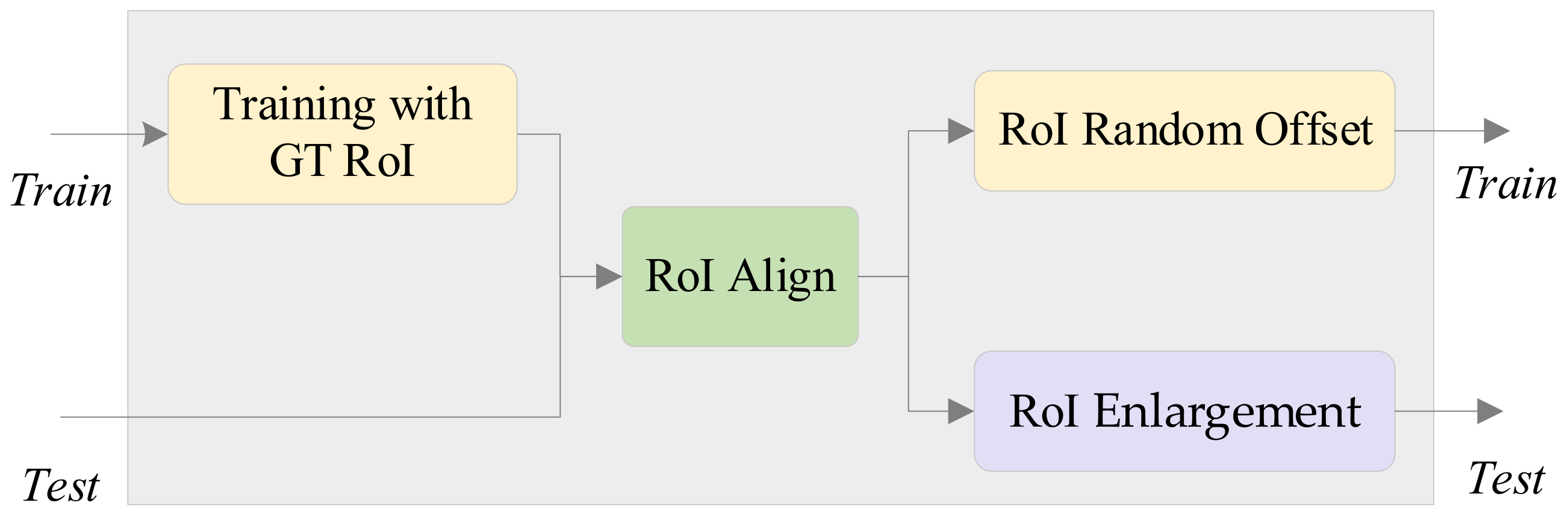
3.4. RoI Enhancement
3.5. Loss Function
4. Results and Discussion
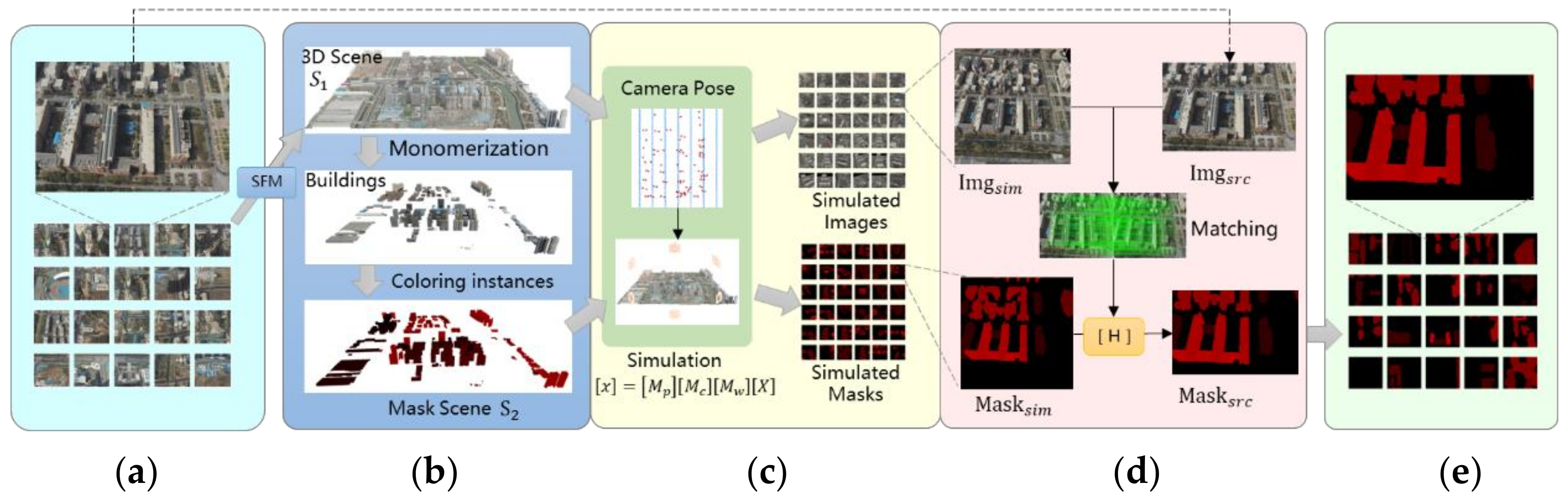
4.1. Building Instance Annotation Generation Based on Virtual Matching
4.2. Dataset Description
4.3. Evaluation Metrics
4.4. Implementation Settings
4.5. BEAR Experiment
4.6. BIR Experiment
4.7. Ablation Study
4.7.1. A CGFM
4.7.2. Effectiveness of the Cross-Regional Branch
4.7.3. Impact of PRPE
4.7.4. Importance of RoI Enhancement
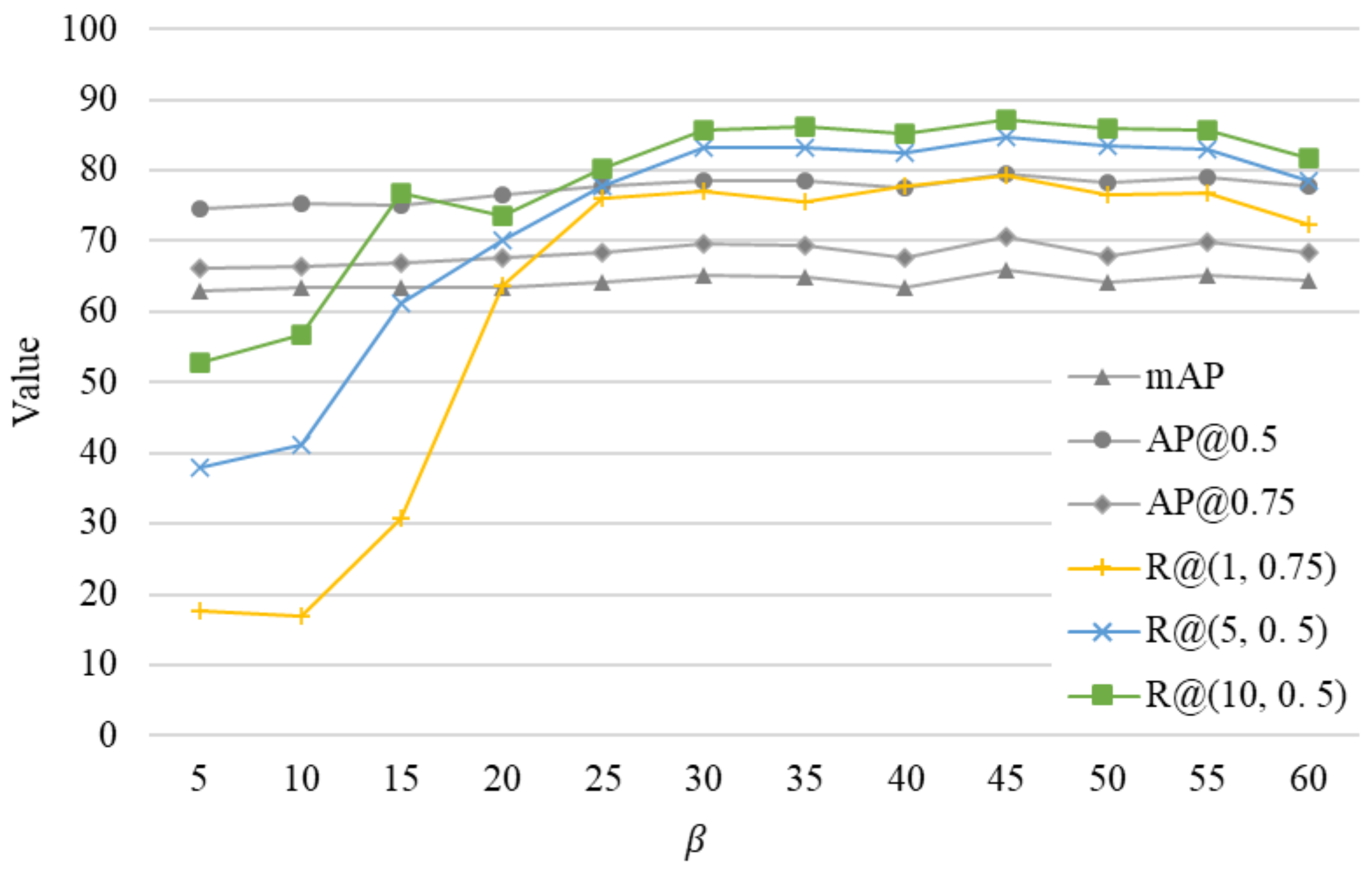
4.7.5. Optimization of the Loss Weight Parameter
4.7.6. Loss Function Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, Q.; Mou, L.; Sun, Y.; Hua, Y.; Shi, Y.; Zhu, X.X. A Review of Building Extraction from Remote Sensing Imagery: Geometrical Structures and Semantic Attributes. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4702315. [Google Scholar] [CrossRef]
- Wang, L.; Fang, S.; Meng, X.; Li, R. Building Extraction with Vision Transformer. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5625711. [Google Scholar] [CrossRef]
- Li, J.; Huang, X.; Tu, L.; Zhang, T.; Wang, L. A Review of Building Detection from Very High Resolution Optical Remote Sensing Images. GIScience Remote Sens. 2022, 59, 1199–1225. [Google Scholar] [CrossRef]
- Deng, R.; Guo, Z.; Chen, Q.; Sun, X.; Chen, Q.; Wang, H.; Liu, X. A Dual Spatial-Graph Refinement Network for Building Extraction from Aerial Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–20. [Google Scholar] [CrossRef]
- Chen, S.; Ogawa, Y.; Zhao, C.; Sekimoto, Y. Large-scale individual building extraction from open-source satellite imagery via super-resolution-based instance segmentation approach. ISPRS J. Photogramm. Remote Sens. 2023, 195, 129–152. [Google Scholar]
- Shao, Z.; Tang, P.; Wang, Z.; Saleem, N.; Yam, S.; Sommai, C. BRRNet: A fully convolutional neural network for automatic building extraction from high-resolution remote sensing images. Remote Sens. 2020, 12, 1050. [Google Scholar] [CrossRef]
- Shakeel, A.; Sultani, W.; Ali, M. Deep built-structure counting in satellite imagery using attention based re-weighting. ISPRS J. Photogramm. Remote Sens. 2019, 151, 313–321. [Google Scholar]
- Lyu, Y.; Vosselman, G.; Xia, G.-S.; Yilmaz, A.; Yang, M.Y. UAVid: A Semantic Segmentation Dataset for UAV Imagery. ISPRS J. Photogramm. Remote Sens. 2020, 165, 108–119. [Google Scholar] [CrossRef]
- Xu, L.; Li, Y.; Xu, J.; Guo, L. Gated Spatial Memory and Centroid-Aware Network for Building Instance Extraction. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4402214. [Google Scholar] [CrossRef]
- Li, J.; Huang, W.; Shao, L.; Allinson, N. Building Recognition in Urban Environments: A Survey of State-of-the-Art and Future Challenges. Inf. Sci. 2014, 277, 406–420. [Google Scholar] [CrossRef]
- Deng, J.; Guo, J.; Xue, N.; Zafeiriou, S. ArcFace: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Huang, B.; Lian, D.; Luo, W.; Gao, S. Look before you leap: Learning landmark features for one-stage visual grounding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 16888–16897. [Google Scholar]
- Xue, F.; Budvytis, I.; Reino, D.O.; Cipolla, R. Efficient large-scale localization by global instance recognition. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 17327–17336. [Google Scholar]
- Tian, Y.; Chen, C.; Shah, M. Cross-View Image Matching for Geo-Localization in Urban Environments. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1998–2006. [Google Scholar] [CrossRef]
- Brar, S.; Rabbat, R.; Raithatha, V.; Runcie, G.; Yu, A. Drones for Deliveries; Technical Report; Sutardja Center for Entrepreneurship & Technology, University of California: Berkeley, CA, USA, 2015; Volume 8, p. 2015. [Google Scholar]
- Ge, J.; Tang, H.; Yang, N.; Hu, Y. Rapid identification of damaged buildings using incremental learning with transferred data from historical natural disaster cases. ISPRS J. Photogramm. Remote Sens. 2023, 195, 105–128. [Google Scholar]
- Yi, S.; Liu, X.; Li, J.; Chen, L. UAVformer: A composite transformer network for urban scene segmentation of UAV images. Pattern Recognit. 2023, 133, 109019. [Google Scholar]
- Muhmad Kamarulzaman, A.M.; Wan Mohd Jaafar, W.S.; Mohd Said, M.N.; Saad, S.N.M.; Mohan, M. UAV implementations in urban planning and related sectors of rapidly developing nations: A review and future perspectives for Malaysia. Remote Sens. 2023, 15, 2845. [Google Scholar] [CrossRef]
- Liu, X.; Chen, Y.; Wang, C.; Tan, K.; Li, J. A lightweight building instance extraction method based on adaptive optimization of mask contour. Int. J. Appl. Earth Observ. Geoinf. 2023, 122, 103420. [Google Scholar]
- Zhang, X.; Wang, L.; Su, Y. Visual place recognition: A survey from deep learning perspective. Pattern Recognit. 2021, 113, 107760. [Google Scholar]
- Zheng, Z.; Wei, Y.; Yang, Y. University-1652: A multi-view multi-source benchmark for drone-based geo-localization. In Proceedings of the 28th ACM International Conference on Multimedia, MM ’20, Seattle, WA, USA, 12–16 October 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1395–1403. [Google Scholar]
- Peng, G.; Yue, Y.; Zhang, J.; Wu, Z.; Tang, X.; Wang, D. Semantic reinforced attention learning for visual place recognition. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 13415–13422. [Google Scholar]
- Sarlin, P.-E.; Cadena, C.; Siegwart, R.; Dymczyk, M. From coarse to fine: Robust hierarchical localization at large scale. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–17 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 12708–12717. [Google Scholar]
- Nie, J.; Feng, J.; Xue, D.; Pan, F.; Liu, W.; Hu, J.; Cheng, S. A training-free, lightweight global image descriptor for long-term visual place recognition toward autonomous vehicles. IEEE Trans. Intell. Transp. Syst. 2023, 25, 1291–1302. [Google Scholar]
- Zhuang, J.; Dai, M.; Chen, X.; Zheng, E. A faster and more effective cross-view matching method of UAV and satellite images for UAV geolocalization. Remote Sens. 2021, 13, 3979. [Google Scholar] [CrossRef]
- Thakur, N.; Nagrath, P.; Jain, R.; Saini, D.; Sharma, N.; Hemanth, D.J. Artificial intelligence techniques in smart cities surveillance using UAVs: A survey. In Machine Intelligence and Data Analytics for Sustainable Future Smart Cities; Ghosh, U., Maleh, Y., Alazab, M., Pathan, A.-S.K., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 329–353. [Google Scholar]
- Lowe, D.G. Distinctive image features from scaleinvariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Van Gool, L. SURF: Speeded up robust features. In Computer Vision—ECCV 2006, Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 404–417. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to sift or surf. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Bampis, L.; Gasteratos, A. Revisiting the bag-of-visual-words model: A hierarchical localization architecture for mobile systems. Rob. Auton. Syst. 2019, 113, 104–119. [Google Scholar]
- Arandjelovic, R.; Zisserman, A. All about VLAD. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1578–1585. [Google Scholar]
- Zheng, L.; Yang, Y.; Tian, Q. SIFT meets CNN: A decade survey of instance retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1224–1244. [Google Scholar]
- Arandjelovic, R.; Gronat, P.; Torii, A.; Pajdla, T.; Sivic, J. NetVLAD: CNN architecture for weakly supervised place recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 5297–5307. [Google Scholar]
- Kim, H.J.; Dunn, E.; Frahm, J.M. Learned contextual feature reweighting for image geolocalization. In Proceedings of the IEEE/CVF International Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3251–3260. [Google Scholar]
- Hausler, S.; Garg, S.; Xu, M.; Milford, M.; Fischer, T. Patch-NetVLAD: Multi-scale fusion of locally-global descriptors for place recognition. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 14136–14147. [Google Scholar]
- Radenovic, F.; Tolias, G.; Chum, O. Finetuning CNN image retrieval with no human annotation. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1655–1668. [Google Scholar] [PubMed]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.; et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 6881–6890. [Google Scholar]
- Wang, R.; Shen, Y.; Zuo, W.; Zhou, S.; Zheng, N. TransVPR: Transformer-based place recognition with multi-level attention aggregation. In Proceedings of the IEEE/CVF International Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 13648–13657. [Google Scholar]
- Keetha, N.; Mishra, A.; Karhade, J.; Jatavallabhula, K.M.; Scherer, S.; Krishna, M.; Garg, S. Anyloc: Towards universal visual place recognition. arXiv 2023, arXiv:2308.00688. [Google Scholar]
- Oquab, M.; Darcet, T.; Moutakanni, T.; Marc Szafraniec, H.; Khalidov, V.; Fernandez, P.; Haziza, D.; Massa, F.; El-Nouby, A.; Assran, M.; et al. Dinov2: Learning robust visual features without supervision. arXiv 2023, arXiv:2304.07193. [Google Scholar]
- Ali-Bey, A.; Chaib-Draa, B.; Giguere, P. MixVPR: Feature mixing for visual place recognition. In Proceedings of the 2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–7 January 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 2997–3006. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: High quality object detection and instance segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1483–1498. [Google Scholar]
- Zhang, G.; Lu, X.; Tan, J.; Li, J.; Zhang, Z.; Li, Q.; Hu, X. RefineMask: Towards high-quality instance segmentation with fine-grained features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2021), Virtual, 19–25 June 2021; pp. 6857–6865. [Google Scholar]
- Wang, W.; Shi, Y.; Zhang, J.; Hu, L.; Li, S.; He, D.; Liu, F. Traditional village building extraction based on improved mask R-CNN: A case study of beijing, China. Remote Sens. 2023, 15, 2616. [Google Scholar] [CrossRef]
- Wang, X.; Kong, T.; Shen, C.; Jiang, Y.; Li, L. SOLO: Segmenting objects by locations. In Proceedings of the Computer Vision–ECCV 2020, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 649–665. [Google Scholar]
- Wang, X.; Zhang, R.; Kong, T.; Li, L.; Shen, C. SOLOv2: Dynamic and fast instance segmentation. In Proceedings of the 34th International Conference on Neural Information Processing Systems (NeurIPS 2020), Vancouver, BC, Canada, 6–12 December 2020; pp. 17721–17732. [Google Scholar]
- Kirillov, A.; Levinkov, E.; Andres, B.; Savchynskyy, B.; Rother, C. InstanceCut: From edges to instances with MultiCut. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5008–5017. [Google Scholar]
- Wagner, F.H.; Dalagnol, R.; Tarabalka, Y.; Segantine, T.Y.F.; Thomé, R.; Hirye, M.C.M. U-Net-Id, an instance segmentation model for building extraction from satellite images—Case study in the Joanópolis City, Brazil. Remote Sens. 2020, 12, 1544. [Google Scholar] [CrossRef]
- Iglovikov, V.; Seferbekov, S.; Buslaev, A.; Shvets, A. TernausNetV2: Fully convolutional network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision, and Pattern Recognition (CVPR) Workshops, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Cheng, B.; Misra, I.; Schwing, A.G.; Kirillov, A.; Girdhar, R. Masked-attention mask transformer for universal image segmentation. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1280–1289. [Google Scholar]
- Fu, W.; Xie, K.; Fang, L. Complementarity-aware local-global feature fusion network for building extraction in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5617113. [Google Scholar]
- Chen, K.; Liu, C.; Chen, H.; Zhang, H.; Li, W.; Zou, Z.; Shi, Z. RSPrompter: Learning to prompt for remote sensing instance segmentation based on visual foundation model. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4701117. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.-Y.; et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 4015–4026. [Google Scholar]
- He, X.; Zhou, Y.; Zhou, Z.; Bai, S.; Bai, X. Triplet-Center Loss for Multi-View 3D Object Retrieval. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1945–1954. [Google Scholar] [CrossRef]
- Chen, M.; Hu, Q.; Yu, Z.; Thomas, H.; Feng, A.; Hou, Y.; McCullough, K.; Ren, F.; Soibelman, L. STPLS3D: A large-scale synthetic and real aerial photogrammetry 3D point cloud dataset. arXiv 2022, arXiv:2203.09065. [Google Scholar]
- Ji, S.; Wei, S.; Lu, M. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Trans. Geosci. Remote Sens. 2019, 57, 574–586. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.Y.; Girshick, R. Detectron2. 2019. Available online: https://github.com/facebookresearch/detectron2 (accessed on 16 September 2024).
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Ali-bey, A.; Chaib-draa, B.; Giguère, P. GSV-Cities: Toward appropriate supervised visual place recognition. Neurocomputing 2022, 513, 194–203. [Google Scholar]
- Cao, B.; Araujo, A.; Sim, J. Unifying deep local and global features for image search. In Proceedings of the 16th European Conference, Computer Vision–ECCV 2020, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 726–743. [Google Scholar]
- Wang, X.; Han, X.; Huang, W.; Dong, D.; Scott, M.R. Multi-similarity loss with general pair weighting for deep metric learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | R@(1, 0.75) | R@(5, 0.5) | R@(10, 0.5) | mAP | AP@0.5 | AP@0.75 |
|---|---|---|---|---|---|---|
| STPLS3D | 79.2 | 84.6 | 87.3 | 65.9 | 79.5 | 70.5 |
| UAV-Buildings (Scene 1) | 65.4 | 78.4 | 83.6 | 56.8 | 79.1 | 61.6 |
| UAV-Buildings (Scene 2) | 92.9 | 96.2 | 98.6 | 74.0 | 90.2 | 81.8 |
| Method | STPLS3D | UAV-Buildings (Scene 1) | UAV-Buildings (Scene 2) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |
| NetVLAD | 33.6 | 51.7 | 58.3 | 31.1 | 64.8 | 67.5 | 90.3 | 92.4 | 95.5 |
| GeM | 4.6 | 5.7 | 5.89 | 16.4 | 25.7 | 35.0 | 46.7 | 55.0 | 58.9 |
| CosPlace | 42.6 | 53.9 | 54.4 | 53.1 | 59.3 | 71.8 | 75.6 | 82.3 | 86.1 |
| ConvAP | 21.8 | 26.0 | 26.3 | 36.6 | 46.0 | 53.3 | 62.1 | 79.3 | 81.8 |
| DELG | 56.3 | 61.9 | 63.6 | 49.5 | 57.2 | 64.9 | 91.1 | 93.3 | 96.5 |
| Patch-NetVLAD | 35.5 | 53.3 | 60.1 | 48.1 | 58.3 | 70.5 | 90.1 | 93.3 | 94.5 |
| MixVPR | 57.2 | 61.7 | 62.8 | 49.8 | 59.7 | 65.5 | 88.3 | 91.2 | 96.0 |
| Cross-Mixer | 69.5 | 75.3 | 78.6 | 60.1 | 67.1 | 72.8 | 92.7 | 95.6 | 97.6 |
| Method | STPLS3D | UAV-Buildings Scene 1 | UAV-Buildings Scene 2 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |
| Baseline | 60.6 | 68.5 | 71.6 | 54.3 | 60.9 | 65.4 | 91.1 | 93.0 | 95.2 |
| With CGFM | 69.5 | 75.3 | 78.6 | 60.1 | 67.1 | 72.8 | 92.7 | 95.6 | 97.6 |
| Dataset | Method | mAP | AP@0.5 | AP@0.75 |
|---|---|---|---|---|
| WHU Buildings | BIE256 | 60.8 | 84.7 | 69.3 |
| BIE128 | 57.7 | 80.3 | 65.5 | |
| F256 | 57.7 | 80.9 | 65.9 | |
| CGFM | 60.3 | 82.8 | 68.7 | |
| STPLS3D | BIE256 | 64.4 | 76.1 | 67.4 |
| BIE256 | 61.3 | 73.2 | 64.6 | |
| F256 | 60.6 | 75.1 | 64.4 | |
| CGFM | 65.9 | 79.5 | 70.5 |
| Method | R@(1, 0.75) | R@(5, 0.5) | R@(10, 0.5) | mAP | AP@0.5 | AP@0.75 |
|---|---|---|---|---|---|---|
| Baseline | 77.5 | 83.2 | 86.1 | 65.1 | 79.3 | 70.8 |
| Ours | 79.2 | 84.6 | 87.3 | 65.9 | 79.5 | 70.5 |
| Methods | R@(1, 0.75) | R@(5, 0.5) | R@(10, 0.5) |
|---|---|---|---|
| Baseline | 70.7 | 75.8 | 78.1 |
| TGR | 76.6 | 82.1 | 84.1 |
| TGR + RRO | 78.0 | 83.0 | 86.2 |
| TGR + RRO + RE | 79.2 | 84.6 | 87.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, X.; Zhou, Y.; Lan, C.; Gan, W.; Shi, Q.; Zhou, H. Unifying Building Instance Extraction and Recognition in UAV Images. Remote Sens. 2024, 16, 3449. https://doi.org/10.3390/rs16183449
Hu X, Zhou Y, Lan C, Gan W, Shi Q, Zhou H. Unifying Building Instance Extraction and Recognition in UAV Images. Remote Sensing. 2024; 16(18):3449. https://doi.org/10.3390/rs16183449
Chicago/Turabian StyleHu, Xiaofei, Yang Zhou, Chaozhen Lan, Wenjian Gan, Qunshan Shi, and Hanqiang Zhou. 2024. "Unifying Building Instance Extraction and Recognition in UAV Images" Remote Sensing 16, no. 18: 3449. https://doi.org/10.3390/rs16183449
APA StyleHu, X., Zhou, Y., Lan, C., Gan, W., Shi, Q., & Zhou, H. (2024). Unifying Building Instance Extraction and Recognition in UAV Images. Remote Sensing, 16(18), 3449. https://doi.org/10.3390/rs16183449