2.1.1. Semantic Map Generation
Before UAV formation path planning, the UVAs need to perceive the task environment through sensors, obtain maps of the task area, and gather information on targets and threats. Pixel-level semantic segmentation technology is a primary method of scene understanding. It labels all pixels in an image according to their respective categories using predefined identifiers or color signals, grouping pixels of the same type into color regions to distinguish targets [
26]. Each region contains semantic knowledge information such as buildings, cars, highways, and more. Semantic image segmentation technology has had significant impacts in fields such as medical image analysis, autonomous driving, and geographic information systems, making it a key issue in modern computer vision [
27].
This paper uses a UAV multi-scale feature extraction integrated semantic segmentation network model. This model utilizes skip connections to transmit information between encoding and decoding layers. In the encoding layers, continuous downsampling of features extracts semantic features of a reasonable scale for targets [
28]. On the other hand, the decoder gradually restores image clarity through a multi-scale feature extraction fusion module that performs continuous upsampling of features.
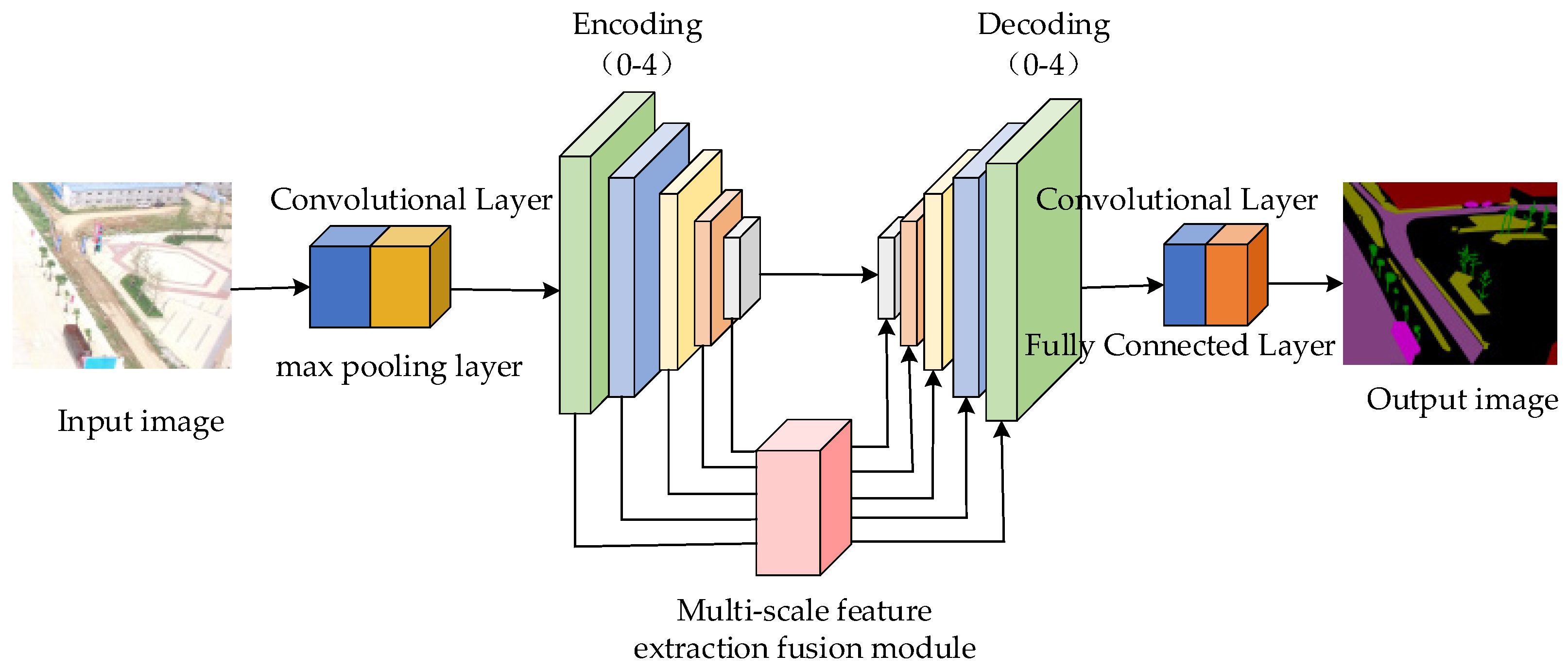
Figure 1 illustrates the semantic segmentation network model with multi-scale feature extraction fusion.
In this paper, the network model introduces a multi-scale feature extraction and fusion module, utilizing multi-scale spatial feature extraction and multi-scale channel feature extraction to synergistically optimize the extracted complementary information, thereby learning more detailed feature representations. Specifically, after the input image is processed by the max-pooling layer and convolutional layer; then, it enters the encoding layer, where the encoder downsamples the image features and outputs the feature results. Next, before each upsampling layer’s decoder, a multi-scale feature extraction and fusion module is added. This module sends the processed image feature values into the decoding layer, where the decoder performs continuous upsampling to restore the image resolution. During this process, the image data are normalized and processed by the ReLU activation function each time it passes through a convolutional layer. Each upsampling layer doubles the feature dimensions while reducing the number of channels to half of the original. Additionally, the fused features output by the multi-scale feature extraction and fusion module are integrated with the encoded results of the same feature dimensions through skip connections. The skip connections use element-wise summation to merge corresponding elements.
The multi-scale feature extraction and fusion module presented in this paper effectively integrates detail and semantic information by combining the multi-scale channel feature extraction module with the multi-scale spatial feature extraction module. This approach incorporates a substantial amount of contextual information during the convolution process, addressing the issue of poor segmentation performance in shallow algorithmic models. Consequently, it enhances the recovery of finer segmentation details for various targets. The specific network structure of the module is illustrated in
Figure 2.
The multi-scale feature extraction and fusion module is primarily divided into two components: the multi-scale channel feature extraction module and the multi-scale spatial feature extraction module. Here, represents the features from the i-th stage of the encoder, with the feature channels and dimensions being C and , respectively. The operator denotes element-wise multiplication, while denotes element-wise addition. serves as the input to the multi-scale feature extraction and fusion module. The first component is the multi-scale channel feature extraction module. Initially, global average pooling is used to extract the primary channel information from the input features. This information is then input into a sized convolution layer to compress the convolution parameters. The sigmoid activation function is applied to normalize the input values, resulting in the multi-scale channel feature mask . The processed result is then multiplied with the original feature values to obtain the calibrated feature map . The second component is the multi-scale spatial feature extraction module. This module derives spatial feature maps by leveraging spatial correlations among the input feature maps. Compared to multi-scale channel feature extraction, this component focuses more on the spatial information of the feature maps. The input feature map is sequentially processed through convolutional and activation layers, and the output from the sigmoid layer produces the activated multi-scale spatial feature mask . Combining this with the original feature values yields the spatially calibrated feature map , thus completing the spatial information calibration process.
To mitigate the influence of background information on the results and address the issue of insufficient global context due to the shallow nature of the algorithm and thereby enhancing the segmentation capability of the model, context information can be incorporated during the decoding process. This involves further refinement of the features at each stage of model processing. In the multi-scale channel feature extraction and multi-scale spatial feature extraction modules, the input is the original feature block
. The weighted feature maps
and
are balanced, and the feature weights are re-adjusted to obtain the corresponding weight maps
and
.
A higher weight ratio indicates greater importance. Therefore, in this study, the range of values for the elements in and is set from 0 to 1. When a value at a particular position approaches 1, the corresponding feature at that position increases. Conversely, when the value at a position approaches 0, the feature at that position remains close to the initial feature . Consequently, after processing through the fusion module, the multi-scale spatial features are adapted to the multi-scale channel features while preserving the information of the original features. This approach enhances network learning and improves feature representation.
Furthermore, the output feature
from the multi-scale feature extraction and fusion module can be obtained using the following algorithm:
Here, concat denotes the concatenation operation performed along the channel dimension, and represents a nonlinear transformation encompassing ReLU activation: a convolutional network with a stride of 1 and batch normalization. After this processing, the feature dimensions remain unchanged, while the total number of channels is reduced to half of the initial count.
Global features and detail features are effectively represented throughout the process. This not only significantly reduces the computational burden of the model, but also enhances the segmentation performance by connecting information across different layers, thereby achieving a richer global context with minimal computational cost. Additionally, incorporating initial feature maps from each stage further strengthens the global feature extraction capability. The multi-scale feature extraction and fusion module refines the output fused features, thereby enhancing the interaction between data. This, in turn, improves the analysis and prediction of features through the fusion of encoded stages, ultimately enhancing the segmentation characteristics.
The UAV aerial semantic map is obtained through the semantic segmentation network model mentioned in this section, as shown in
Figure 3.
2.1.2. Task Point Acquisition
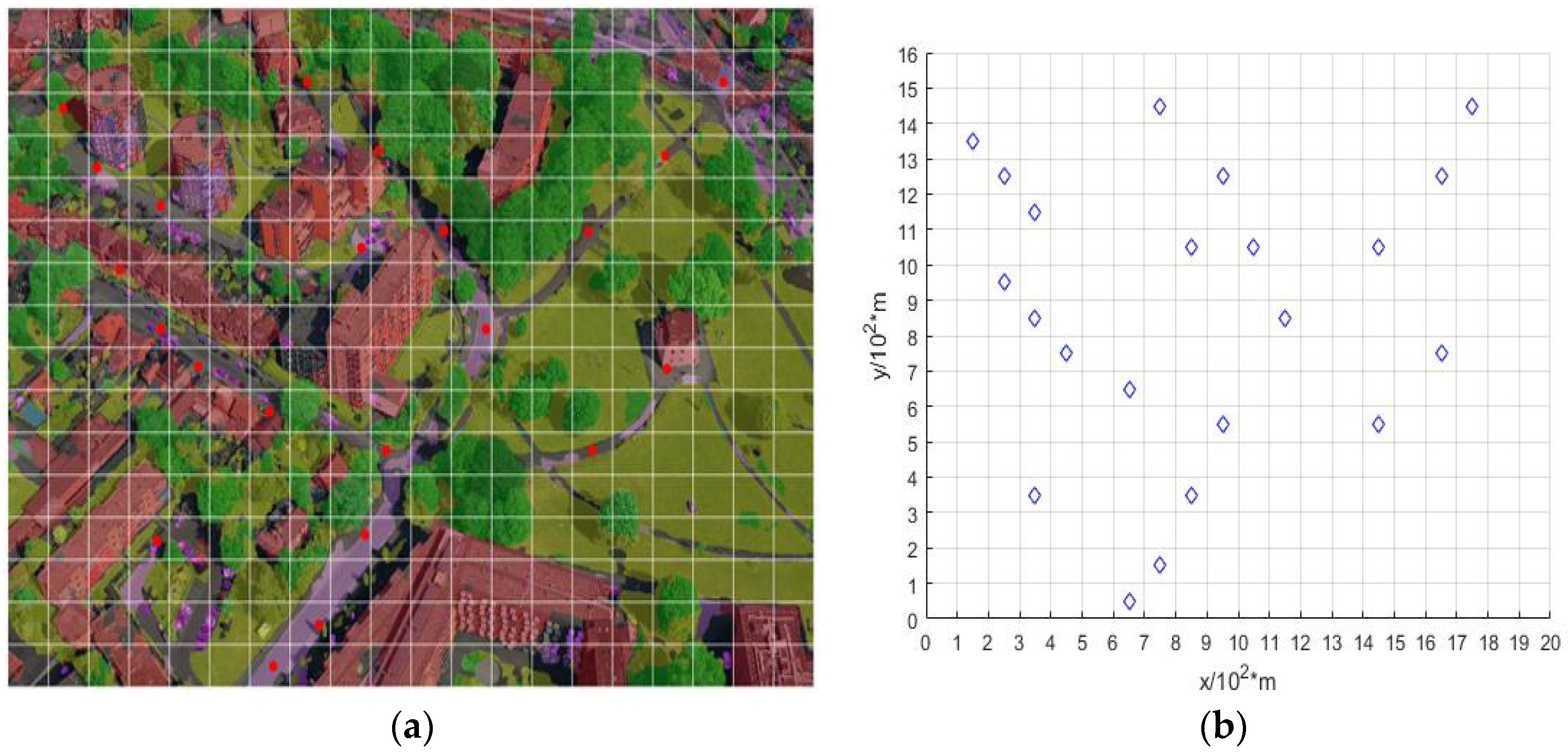
The UAV target reconnaissance mission area map is obtained through UAV aerial photography, as shown in
Figure 4a. Using the multi-scale feature extraction fusion UAV semantic segmentation method proposed in the previous section, the task map with semantic information is acquired, as shown in
Figure 4b.
How to extract sufficient and effective information from semantic segmentation results is the focus of this research. Assuming the UAV needs to search for vehicles, different probability values are assigned to different scenes in the semantic segmentation results based on the likelihood of vehicles appearing. For example, the probability of vehicles appearing on roads may be set to 0.8, while in vegetation areas it might be set to 0.3. Probability values in other locations are set according to the likelihood of vehicle presence. The final result is a UAV aerial semantic map that includes probability information for task points.
Based on the semantic map, regions requiring a focused search are identified, which may consist of multiple scattered areas. To efficiently search these areas, selective processing of search regions is conducted. Here, a sliding window approach is used to select essential points in the task area reconnaissance. The central point of high-probability areas serves as the center Oc, and essential points within the region are selected using a unit step length d, as shown in Equation (4).
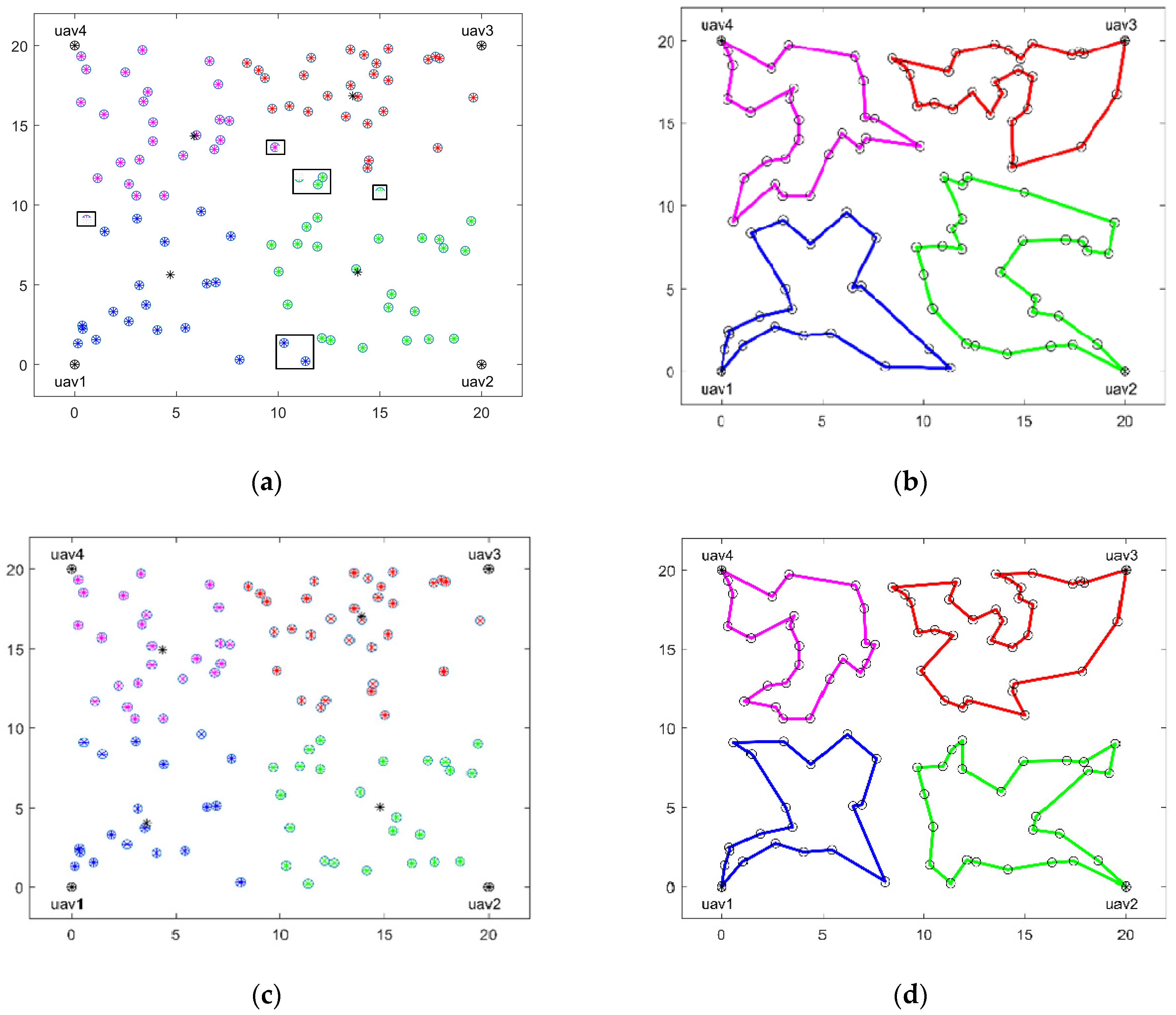
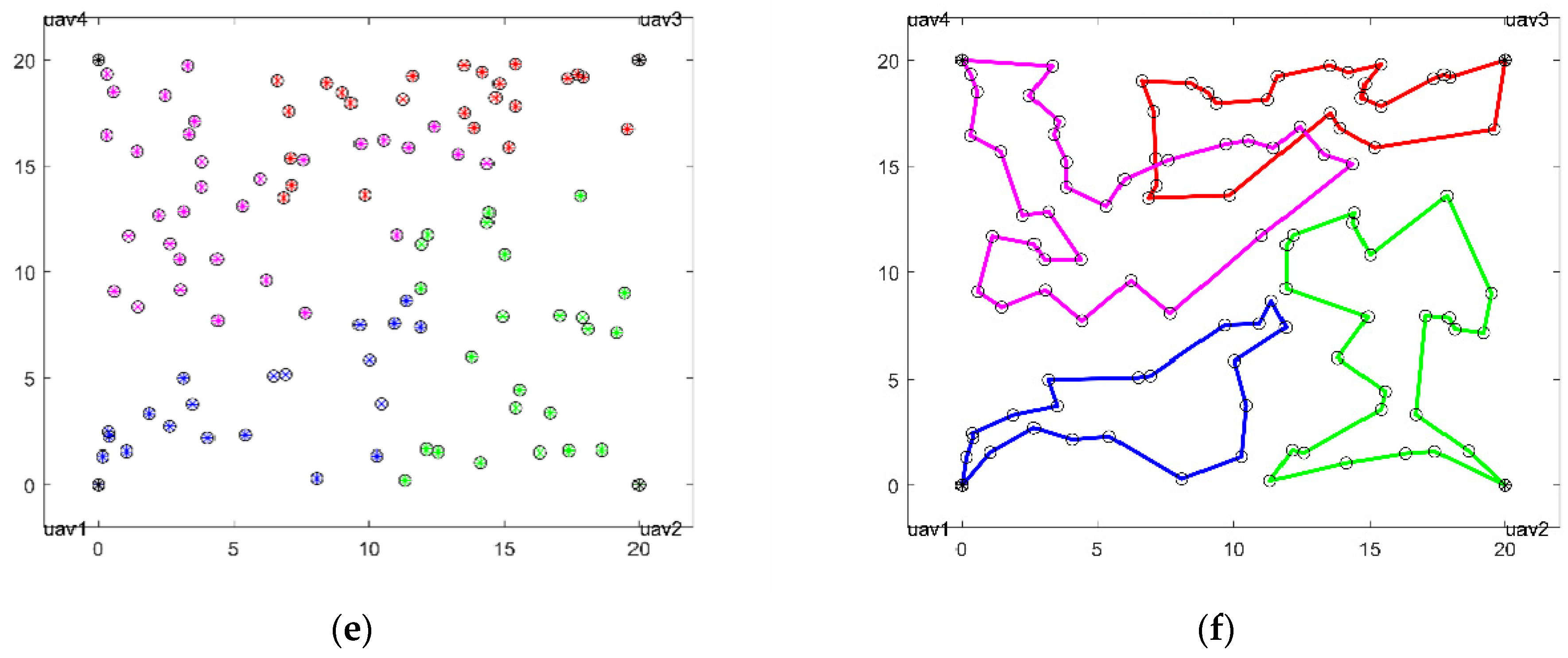
By traversing all search regions and focusing on scattered small areas, selecting the networks with the highest probability as necessary search points provides guidance for UAV target reconnaissance, as shown in
Figure 5.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}