


Artificial Intelligence-Based Underwater Acoustic Target Recognition: A Survey

Abstract
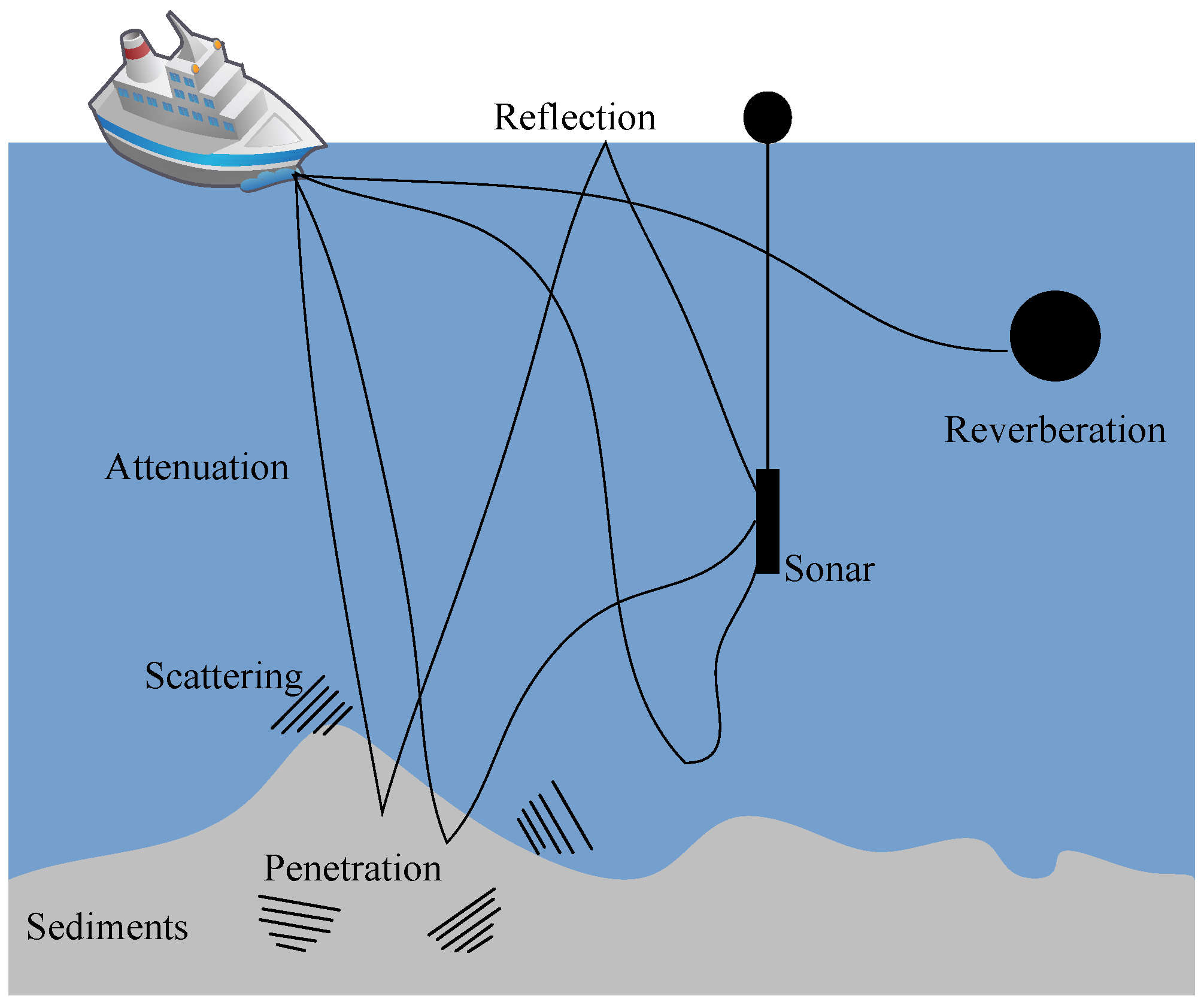
1. Introduction
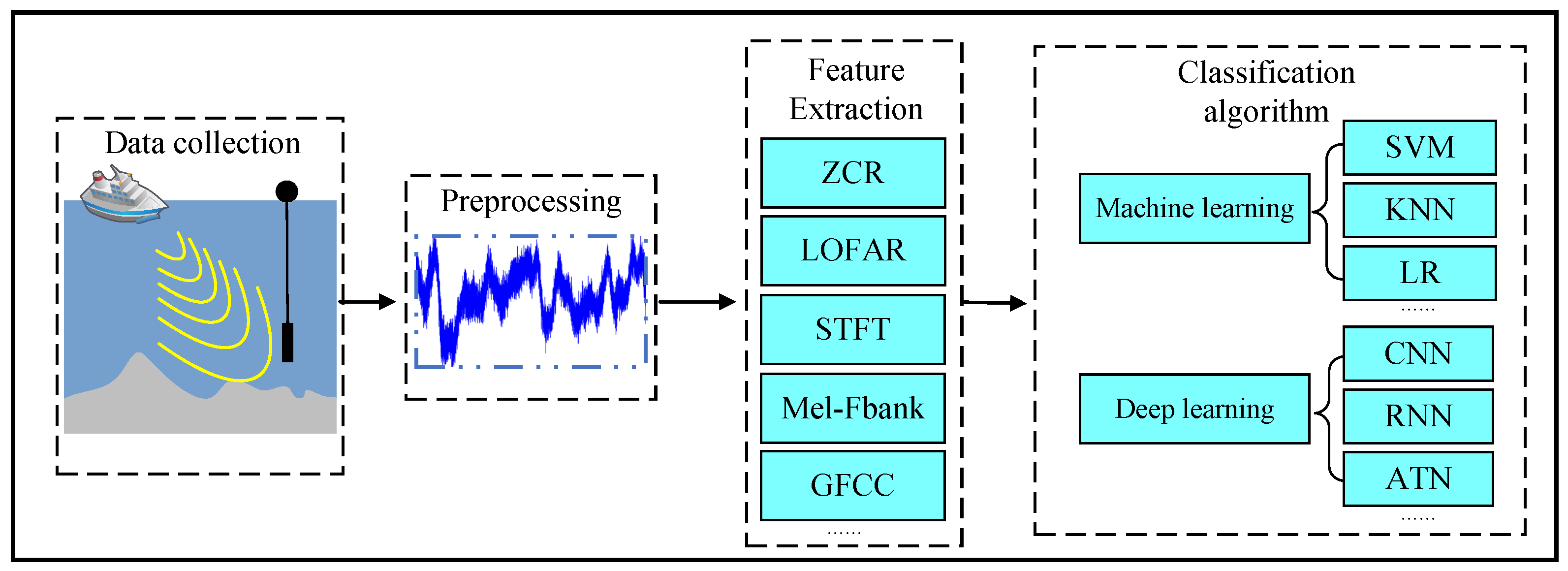
2. Feature Extraction Methods
2.1. Physical Significance Feature
2.1.1. LOFAR Physical Spectrum
2.1.2. DEMON Physical Spectrum
2.2. Joint Time–Frequency Feature
2.2.1. General Time–Frequency Feature
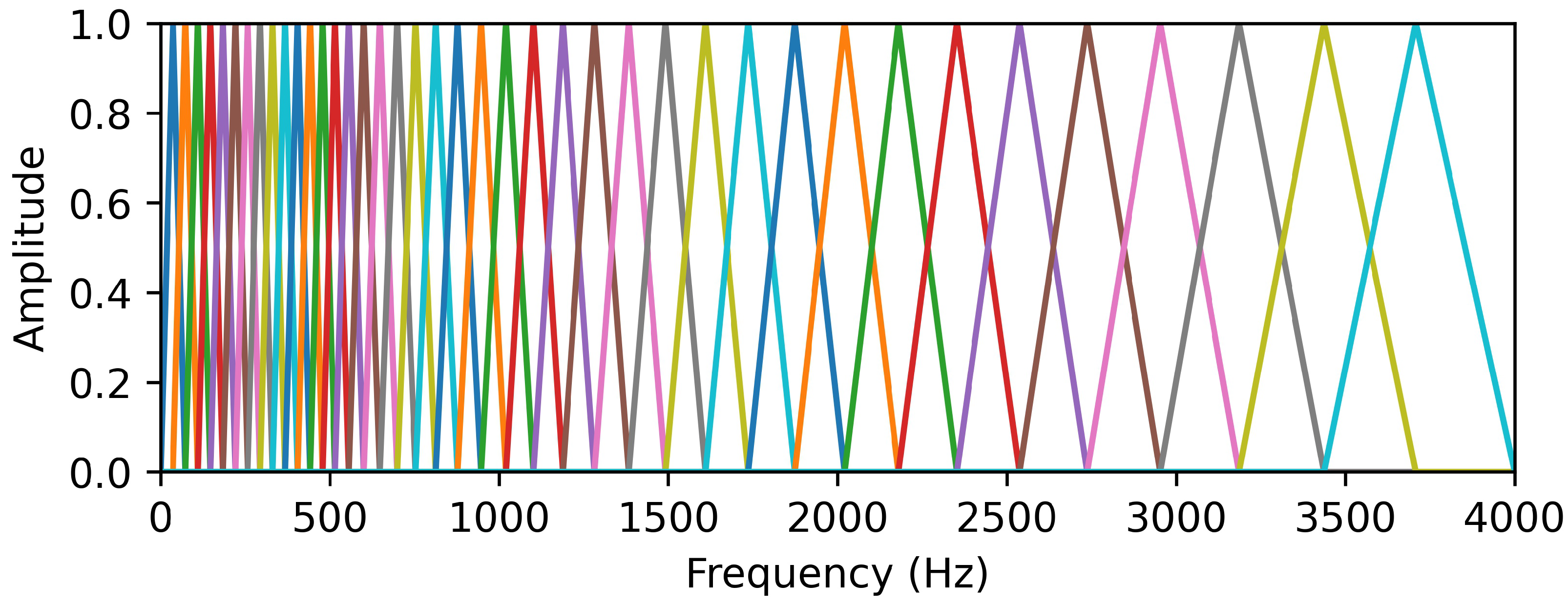
2.2.2. Auditory Perceptual Features
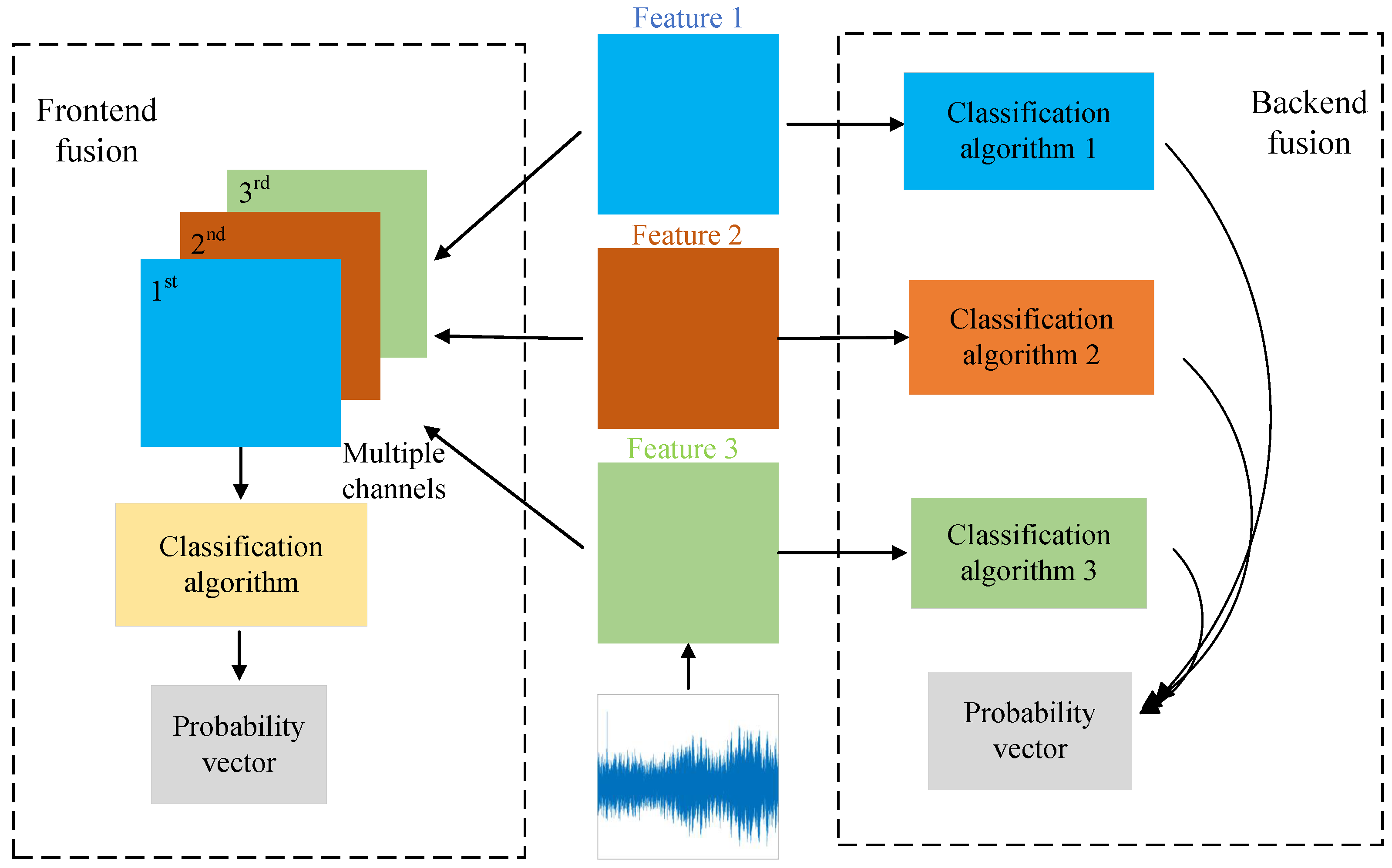
2.2.3. Multidimensional Fusion Features
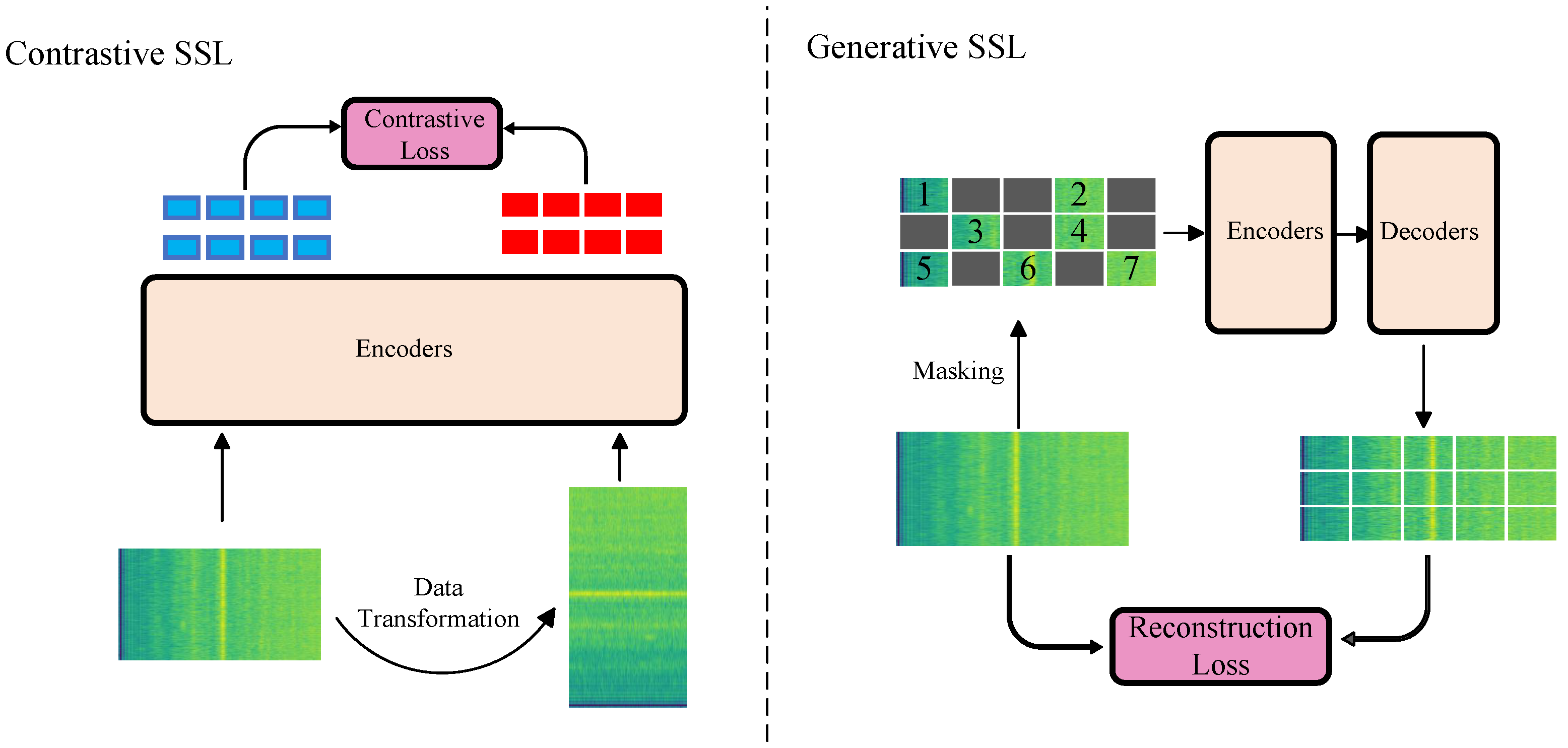
2.3. Autoencoding Feature
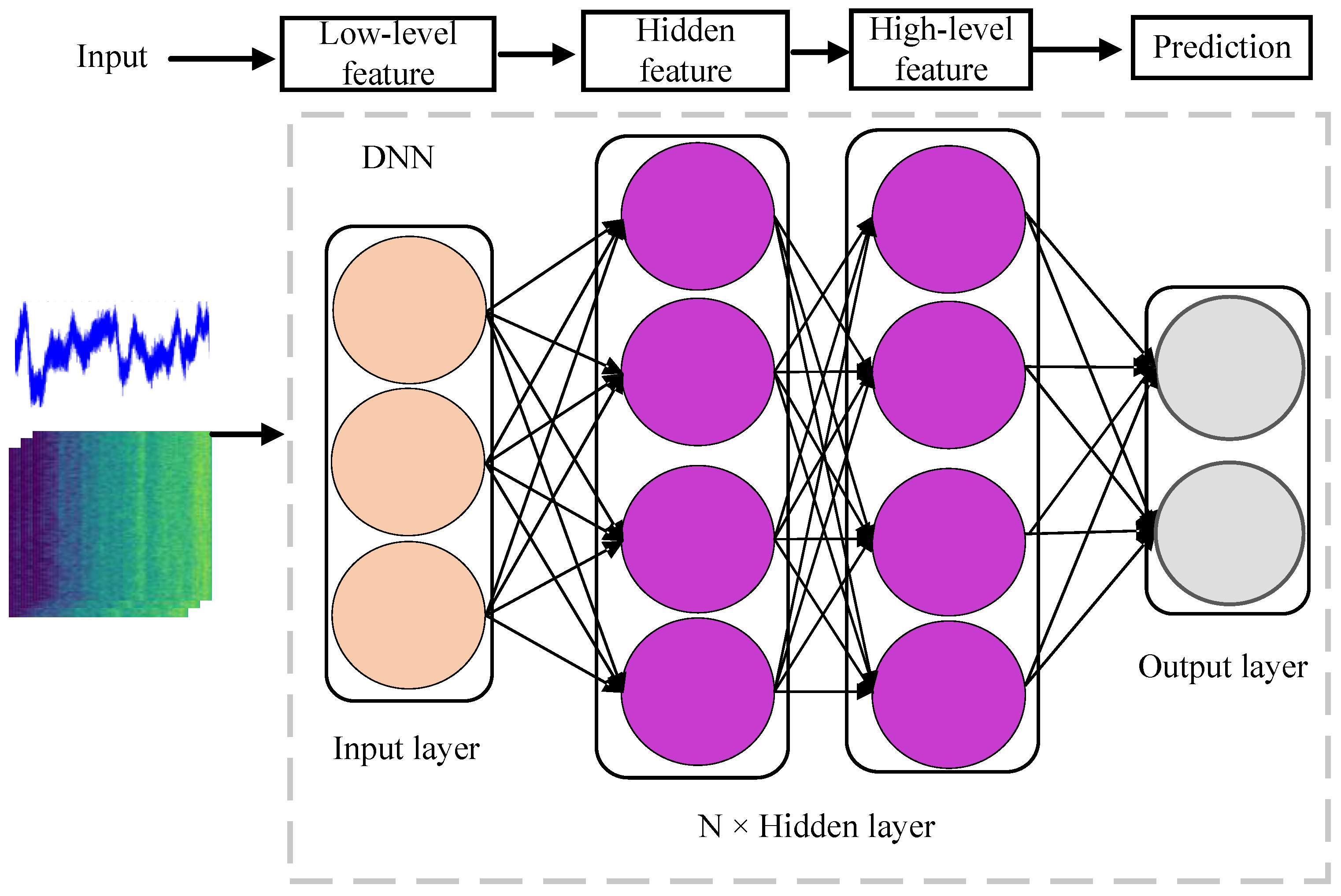
3. Machine Learning-Based Recognition Methods

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Feature | Method | Dataset | Result |
|---|---|---|---|---|
| Li et al. [82] | wavelet analysis | SVM | three-category dataset | 90.12% |
| Yang et al. [88] | feature selection | SVM | UCI sonar dataset [89] | 81% |
| Moura et al. [83] | LOFAR | SVM | four-category dataset | 76.73% |
| Sherin et al. [84] | MFCC | SVM | four-category dataset | 74.28% |
| Wang et al. [85] | STFT | SVM | four-category dataset | 88.64% (10 dB) |
| Yao et al. [86] | STFT | SVM | two-category dataset | 90% |
| Liu et al. [87] | multidimensional fusion feature | SVM | 4-category dataset | 97% |
| Choi et al. [90] | cross-spectral density matrix | SVM | simulation dataset | 97.98% |
| Wei et al. [91] | MFCC | SVM | five-category dataset | 93% |
| Chen et al. [92] | spectral ridge | SVM | four-category whale call dataset | 99.415% |
| Yaman et al. [93] | 512-dimensional feature vector | SVM | five-category propeller dataset | 99.8% |
| Saffari et al. [94] | FFT | KNN | ten-category ship simulation dataset | 98.26% |
| Li et al. [95] | complex multiscale diffuse entropy | KNN | four-category dataset | 96.25% |
| Alvaro et al. [81] | - | KNN | five-category dataset | 98.04% |
| Jin et al. [96] | eigenmode function | KNN | Shipsear dataset [1] | 95% |
| Mohammed et al. [97] | GFCC | HMM | ten-category dataset | 89% |
| You et al. [98] | GFCC | HMM | simulation dataset | 90% (8 dB) |
| Yang et al. [17] | mutual information | LR | UCI sonar dataset [89] | 94.7% |
| Seo et al. [99] | FFT | LR | simulation dataset | 77.43% |
| Yang et al. [100] | auditory cortical representation | LR | 3-category dataset | 100% |
| K et al. [101] | mutual information | decision tree | UCI sonar dataset [89] | 95% |
| Yaman et al. [93] | 512-dimensional feature vector | decision tree | five-category dataset | 99% |
| Yu et al. [102] | covariance matrix | decision tree | two-category dataset | 99.2% |
| Zhou et al. [103] | multicorrelation coefficient | random forest | South China Sea dataset | 93.83% |
| Choi et al. [90] | cross-spectral covariance matrix | random forest | two simulation datasets | 96.83% |
| Chen et al. [92] | spectral ridge | random forest | four-category whale call dataset | 99.69% |
| Wang et al. [104] | MFCC | GMM | four-category dataset | ARI 77.97 |
| Sabara et al. [105] | - | GMM | SUBECO dataset [105] | 74% |
| Yang et al. [106] | MFCC | GMM | five-category dataset | - |
| Yang et al. [106] | MFCC | fuzzy clustering | five-category dataset | - |
| Agersted et al. [107] | intensity spectrum | hierarchical clustering | Norwegian Institute of Marine Research | Best clusters = 7 |
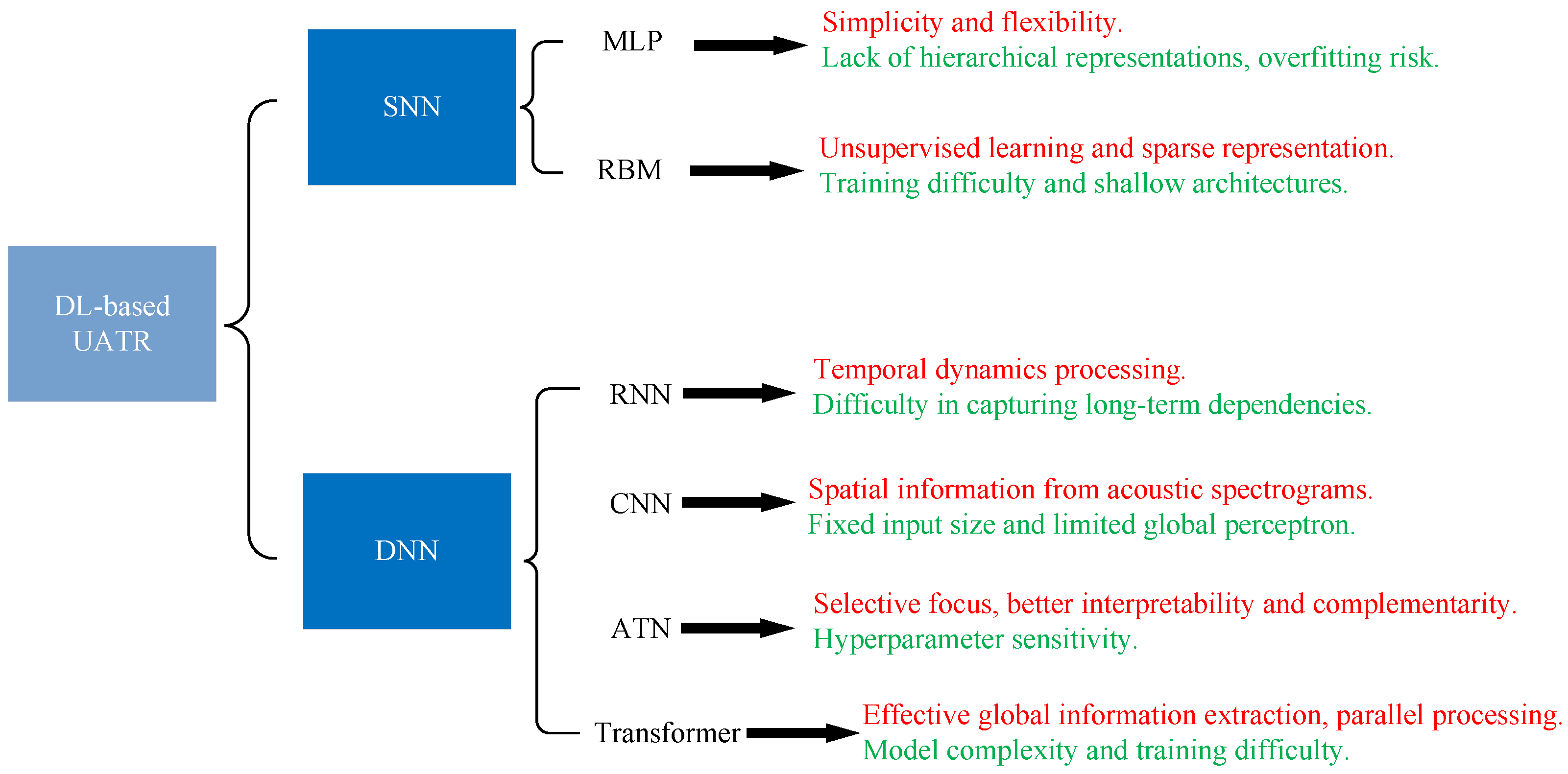
4. Deep Learning-Based Recognition Methods

4.1. RNN
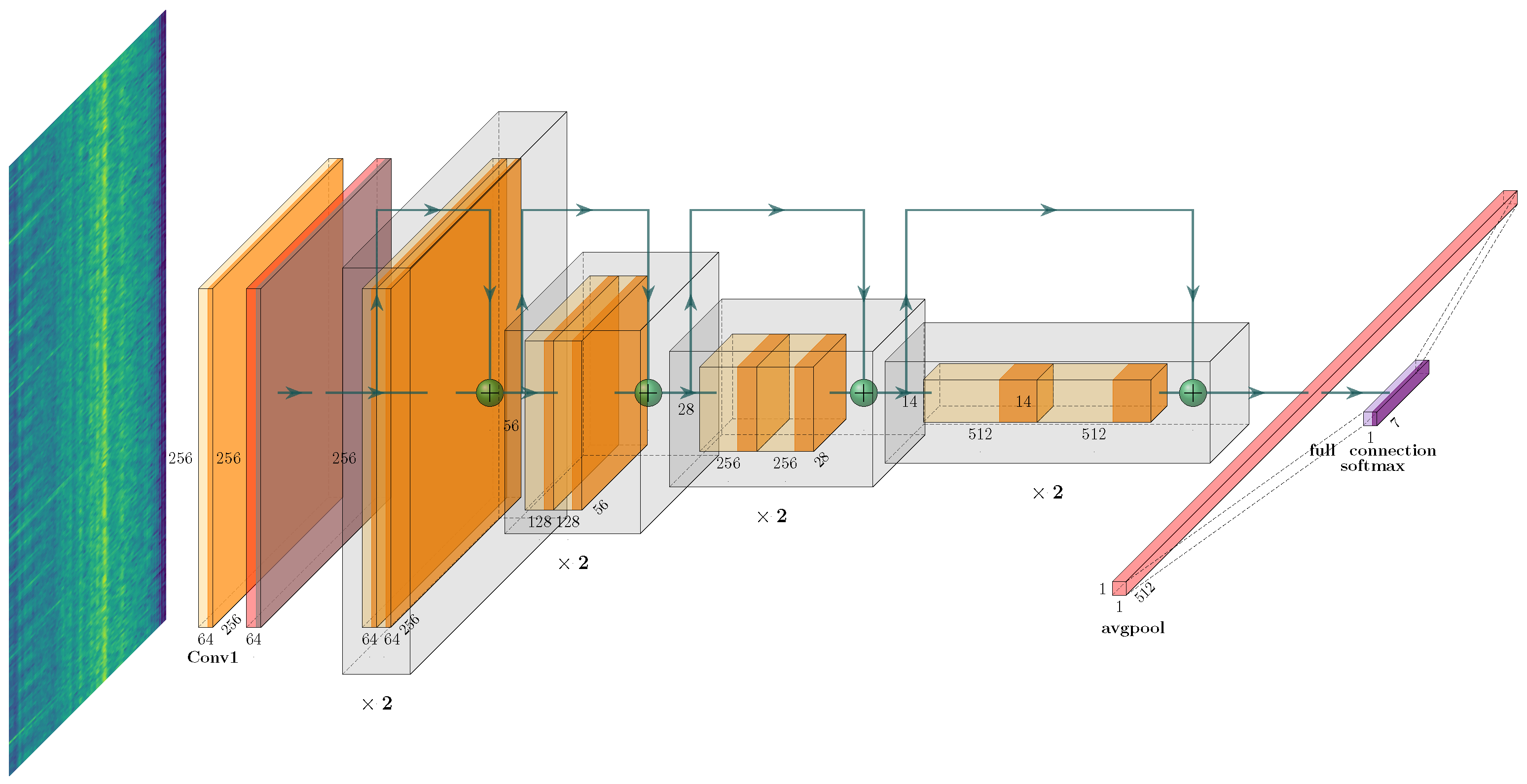
4.2. CNN
4.3. ATN
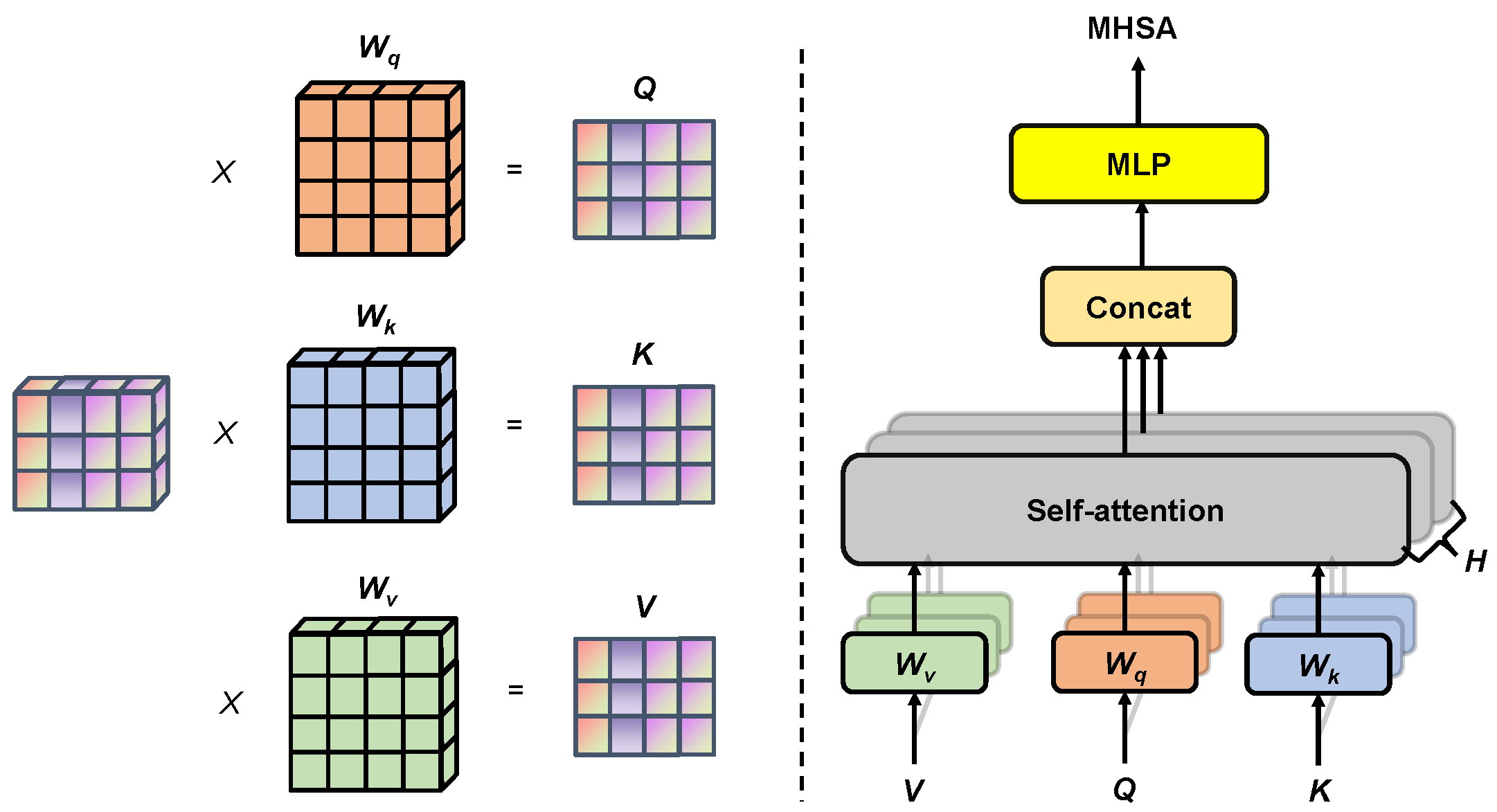
4.4. Transformer
5. Challenges and Future Prospects
5.1. Complex Recognition Condition Issue
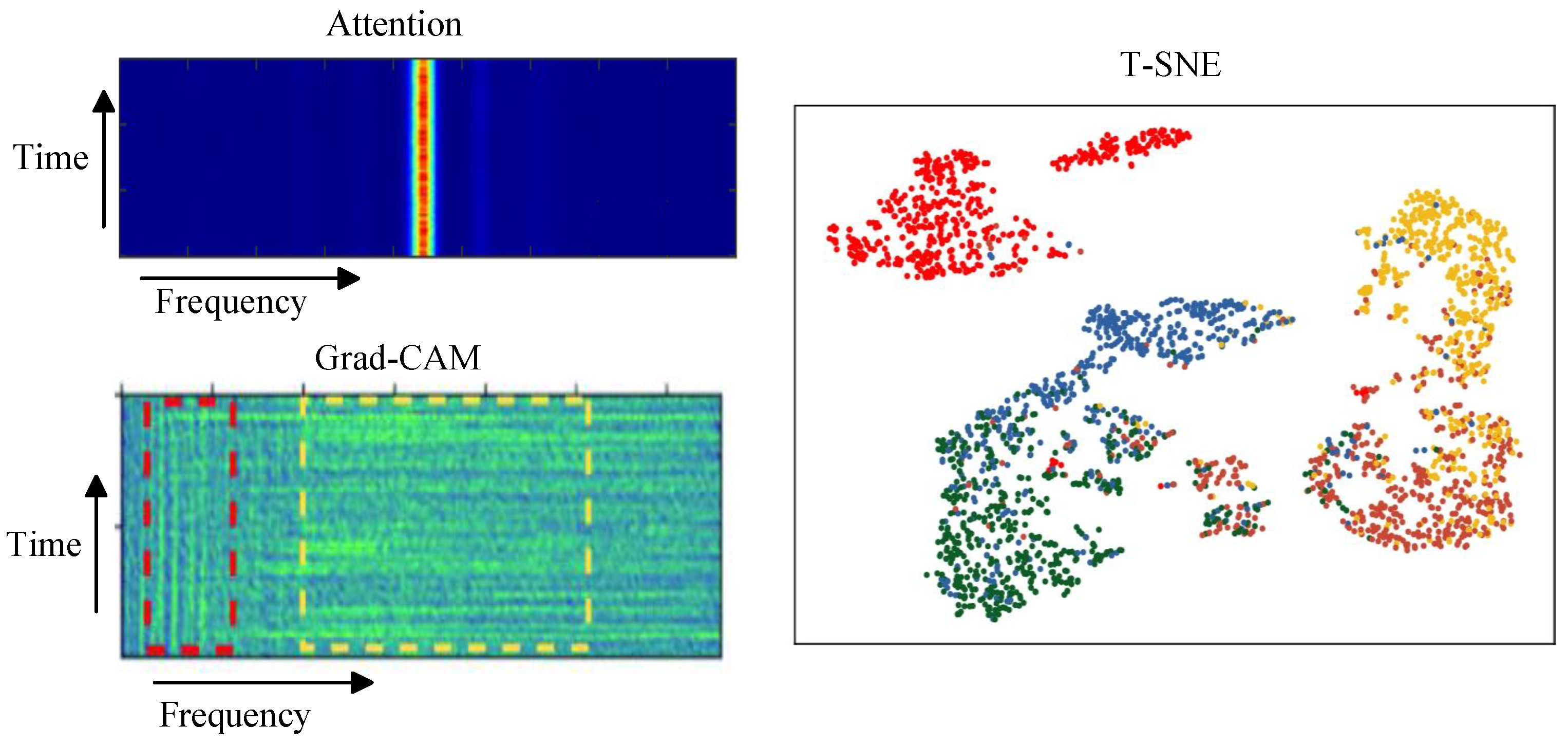
5.2. Interpretability Problem
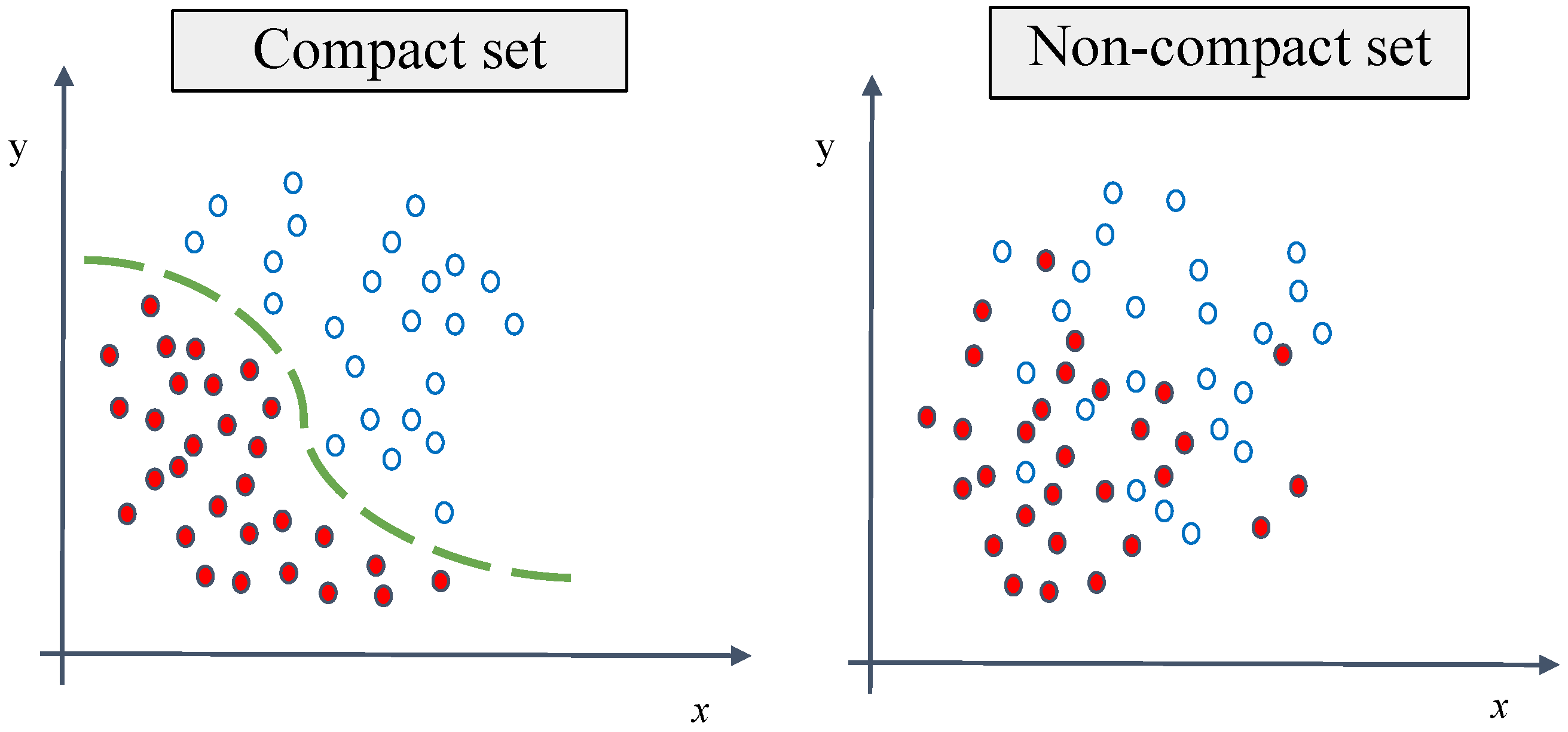
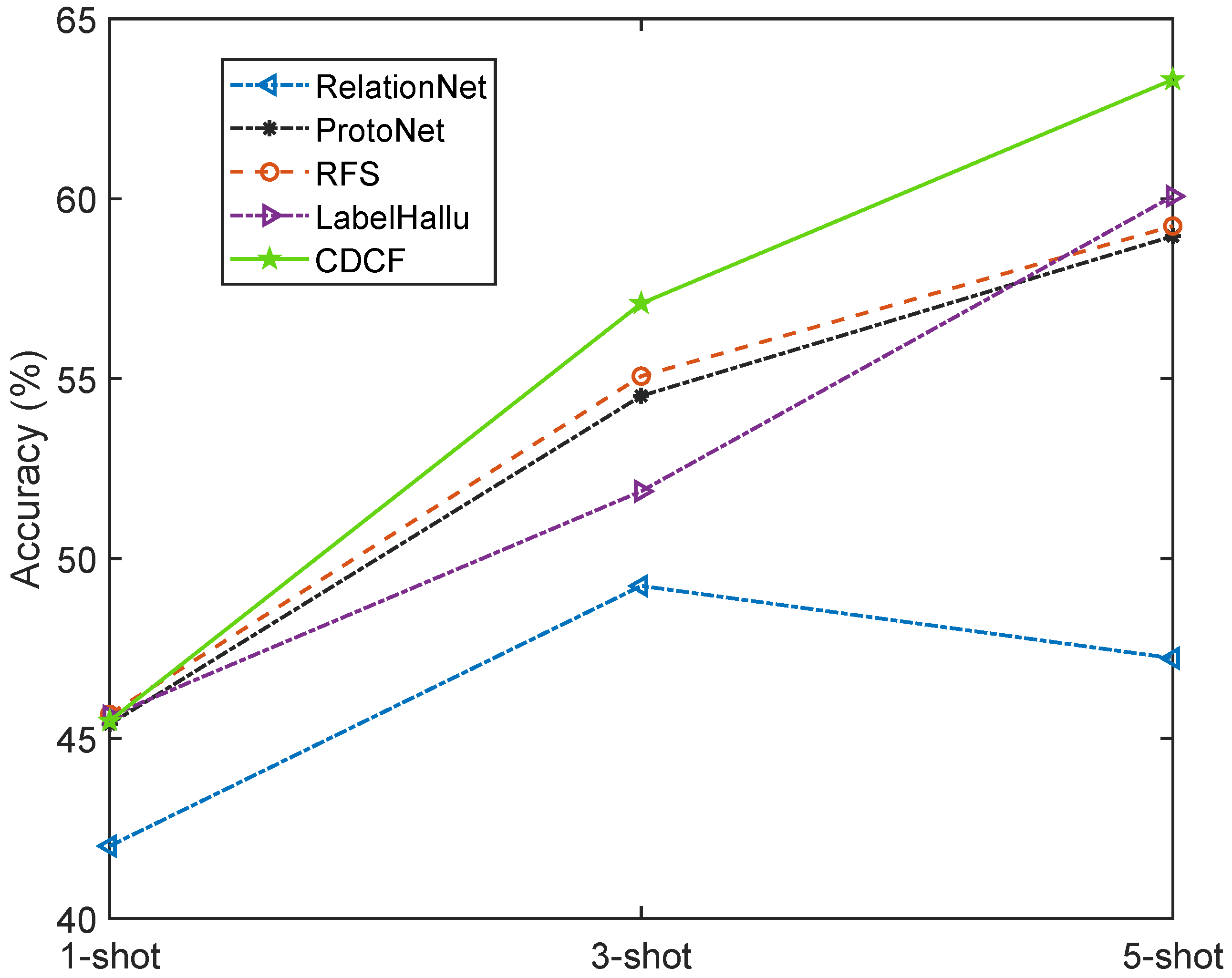
5.3. Generalization Issue
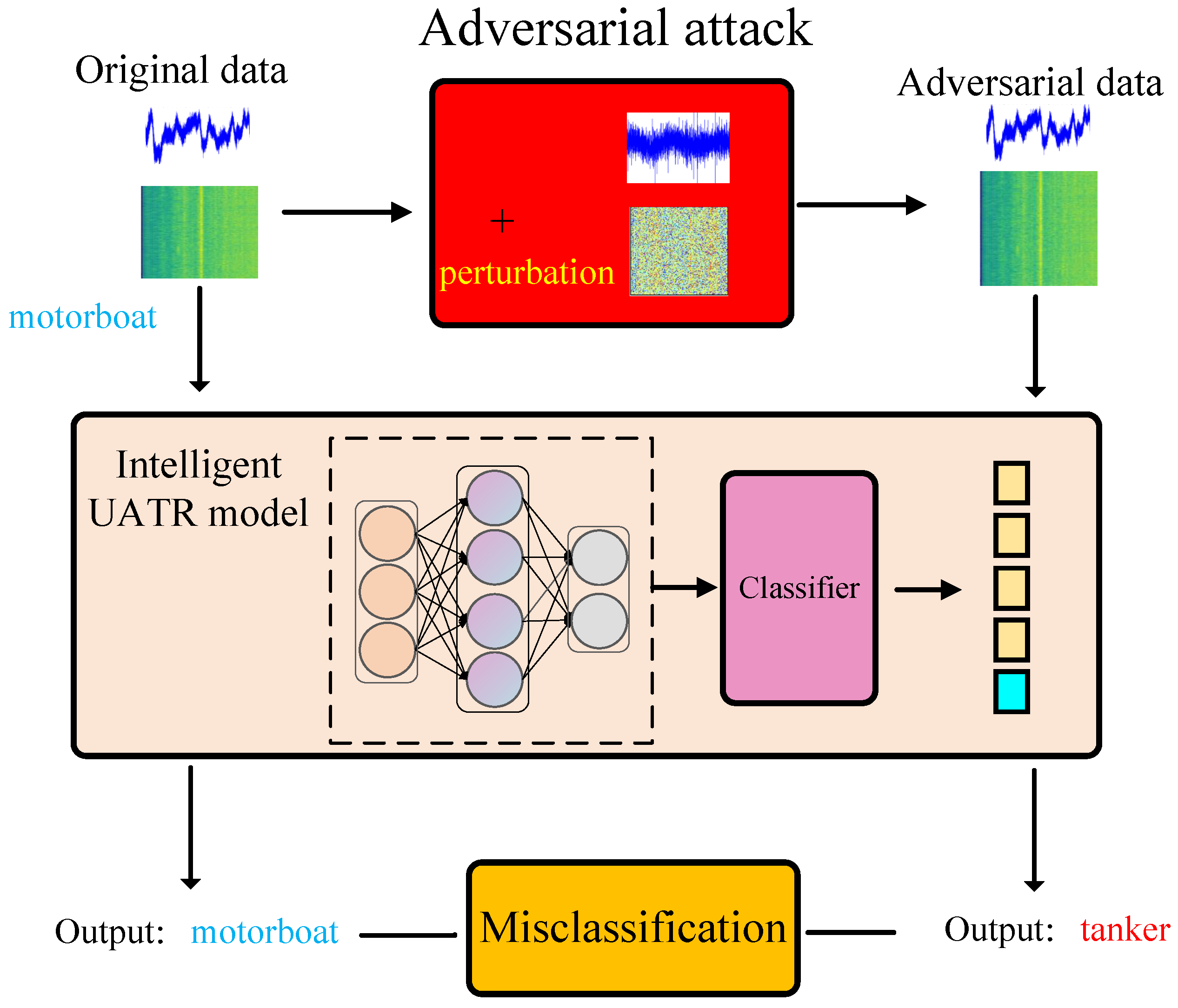
5.4. Adversarial Robustness Challenge
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Santos-Domínguez, D.; Torres-Guijarro, S.; Cardenal-López, A.; Pena-Gimenez, A. ShipsEar: An underwater vessel noise database. Appl. Acoust. 2016, 113, 64–69. [Google Scholar] [CrossRef]
- Irfan, M.; Jiangbin, Z.; Ali, S.; Iqbal, M.; Masood, Z.; Hamid, U. DeepShip: An underwater acoustic benchmark dataset and a separable convolution based autoencoder for classification. Expert Syst. Appl. 2021, 183, 115270. [Google Scholar] [CrossRef]
- Niu, H.; Li, X.; Zhang, Y.; Xu, J. Advances and applications of machine learning in underwater acoustics. Intell. Mar. Technol. Syst. 2023, 1, 8. [Google Scholar] [CrossRef]
- Zhang, X.; Yang, P.; Wang, Y.; Shen, W.; Yang, J.; Wang, J.; Ye, K.; Zhou, M.; Sun, H. A Novel Multireceiver SAS RD Processor. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–11. [Google Scholar] [CrossRef]
- Zhang, X.; Yang, P.; Wang, Y.; Shen, W.; Yang, J.; Ye, K.; Zhou, M.; Sun, H. LBF-Based CS Algorithm for Multireceiver SAS. IEEE Geosci. Remote Sens. Lett. 2024, 21, 1–5. [Google Scholar] [CrossRef]
- Zhang, H.; Shafiq, M.O. Survey of transformers and towards ensemble learning using transformers for natural language processing. J. Big Data 2024, 11, 25. [Google Scholar] [CrossRef]
- Zhang, X.; Yang, P.; Sun, H. Frequency-domain multireceiver synthetic aperture sonar imagery with Chebyshev polynomials. Electron. Lett. 2022, 58, 995–998. [Google Scholar] [CrossRef]
- Zhang, X.; Yang, P.; Feng, X.; Sun, H. Efficient imaging method for multireceiver SAS. IET Radar Sonar Navig. 2022, 16, 1470–1483. [Google Scholar] [CrossRef]
- Zhang, R.; He, C.; Jing, L.; Zhou, C.; Long, C.; Li, J. A Modulation Recognition System for Underwater Acoustic Communication Signals Based on Higher-Order Cumulants and Deep Learning. J. Mar. Sci. Eng. 2023, 11, 1632. [Google Scholar] [CrossRef]
- Jiang, Z.; Zhang, J.; Wang, T.; Wang, H. Modulation recognition of underwater acoustic communication signals based on neural architecture search. Appl. Acoust. 2024, 225, 110155. [Google Scholar] [CrossRef]
- Wu, J.; Chen, Y.; Jia, B.; Li, G.; Zhang, Y.; Yong, J. Optimal design of emission waveform for acoustic scattering test under multipath interference. In Proceedings of the 2020 5th International Conference on Communication, Image and Signal Processing (CCISP), Chengdu, China, 13–15 November 2020; pp. 102–106. [Google Scholar] [CrossRef]
- Sumithra, G.; Ajay, N.; Neeraja, N.; Adityaraj, K. Hybrid Acoustic System for Underwater Target Detection and Tracking. Int. J. Appl. Comput. Math. 2023, 9, 149. [Google Scholar] [CrossRef]
- Zhu, J.; Xie, Z.; Jiang, N.; Song, Y.; Han, S.; Liu, W.; Huang, X. Delay-Doppler Map Shaping through Oversampled Complementary Sets for High-Speed Target Detection. Remote Sens. 2024, 16, 2898. [Google Scholar] [CrossRef]
- Zhu, J.; Song, Y.; Jiang, N.; Xie, Z.; Fan, C.; Huang, X. Enhanced Doppler Resolution and Sidelobe Suppression Performance for Golay Complementary Waveforms. Remote Sens. 2023, 15, 2452. [Google Scholar] [CrossRef]
- Yoo, K.B.; Edelmann, G.F. Low complexity multipath and Doppler compensation for direct-sequence spread spectrum signals in underwater acoustic communication. Appl. Acoust. 2021, 180, 108094. [Google Scholar] [CrossRef]
- Klionskii, D.M.; Kaplun, D.I.; Voznesensky, A.S.; Romanov, S.A.; Levina, A.B.; Bogaevskiy, D.V.; Geppener, V.V.; Razmochaeva, N.V. Solution of the Problem of Classification of Hydroacoustic Signals Based on Harmonious Wavelets and Machine Learning. Pattern Recognit. Image Anal. 2020, 30, 480–488. [Google Scholar] [CrossRef]
- Quraishi, S.J.; Singh, M.; Prasad, S.K.; Arora, K.; Pathak, S.; Singh, A. A Machine Learning Approach to Rock and Mine Classification in Sonar Systems Using Logistic Regression. In Proceedings of the 2023 3rd International Conference on Technological Advancements in Computational Sciences (ICTACS), Tashkent, Uzbekistan, 1–3 November 2023; pp. 462–468. [Google Scholar] [CrossRef]
- Wang, P.; Peng, Y. Research on Feature Extraction and Recognition Method of Underwater Acoustic Target Based on Deep Convolutional Network. In Proceedings of the 2020 IEEE International Conference on Advances in Electrical Engineering and Computer Applications (AEECA), Dalian, China, 25–27 August 2020; pp. 863–868. [Google Scholar] [CrossRef]
- Doan, V.S.; Huynh-The, T.; Kim, D.S. Underwater Acoustic Target Classification Based on Dense Convolutional Neural Network. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Meng, Q.; Yang, S. A wave structure based method for recognition of marine acoustic target signals. J. Acoust. Soc. Am. 2015, 137, 2242. [Google Scholar] [CrossRef]
- Deng, J.; Yang, X.; Liu, L.; Shi, L.; Li, Y.; Yang, Y. Real-Time Underwater Acoustic Homing Weapon Target Recognition Based on a Stacking Technique of Ensemble Learning. J. Mar. Sci. Eng. 2023, 11, 2305. [Google Scholar] [CrossRef]
- Meng, Q.; Yang, S.; Piao, S. The classification of underwater acoustic target signals based on wave structure and support vector machine. J. Acoust. Soc. Am. 2014, 136, 2265. [Google Scholar] [CrossRef]
- Sun, Y.; Zhang, X. Analysis of Chaotic Characteristics of Ship Radiated Noise Signals with Different Data Lengths. In Proceedings of the OCEANS 2022, Chennai, VA, USA, 17–20 October 2022; pp. 1–7. [Google Scholar] [CrossRef]
- van Haarlem, M. LOFAR: The Low Frequency Array. Eas Publ. Ser. 2005, 15, 431–444. [Google Scholar] [CrossRef]
- Chung, K.W.; Sutin, A.; Sedunov, A.; Bruno, M.S. DEMON Acoustic Ship Signature Measurements in an Urban Harbor. Adv. Acoust. Vib. 2011, 2011, 952798. [Google Scholar] [CrossRef]
- Jin, G.; Liu, F.; Wu, H.; Song, Q. Deep learning-based framework for expansion, recognition and classification of underwater acoustic signal. J. Exp. Theor. Artif. Intell. 2019, 32, 205–218. [Google Scholar] [CrossRef]
- Chen, J.; Han, B.; Ma, X.; Zhang, J. Underwater Target Recognition Based on Multi-Decision LOFAR Spectrum Enhancement: A Deep-Learning Approach. Future Internet 2021, 13, 265. [Google Scholar] [CrossRef]
- Shi, Y.; Piao, S.; Guo, J. Line spectrum detection and motion parameters estimation for underwater moving target. J. Phys. Conf. Ser. 2024, 2718, 012090. [Google Scholar] [CrossRef]
- Pollara, A.; Sutin, A.; Salloum, H. Improvement of the Detection of Envelope Modulation on Noise (DEMON) and its application to small boats. In Proceedings of the OCEANS 2016 MTS/IEEE, Monterey, CA, USA, 19–23 September 2016; pp. 1–10. [Google Scholar] [CrossRef]
- Tong, W.; Wu, K.; Wang, H.; Cao, L.; Huang, B.; Wu, D.; Antoni, J. Adaptive Weighted Envelope Spectrum: A robust spectral quantity for passive acoustic detection of underwater propeller based on spectral coherence. Mech. Syst. Signal Process. 2024, 212, 111265. [Google Scholar] [CrossRef]
- Li, L.; Song, S.; Feng, X. Combined LOFAR and DEMON Spectrums for Simultaneous Underwater Acoustic Object Counting and F0 Estimation. J. Mar. Sci. Eng. 2022, 10, 1565. [Google Scholar] [CrossRef]
- Yan, J.; Sun, H.; Chen, H.; Junejo, N.U.R.; Cheng, E. Resonance-Based Time-Frequency Manifold for Feature Extraction of Ship-Radiated Noise. Sensors 2018, 18, 936. [Google Scholar] [CrossRef] [PubMed]
- Cao, X.; Togneri, R.; Zhang, X.; Yu, Y. Convolutional Neural Network with Second-Order Pooling for Underwater Target Classification. IEEE Sens. J. 2019, 19, 3058–3066. [Google Scholar] [CrossRef]
- Li, J.; Wang, B.; Cui, X.; Li, S.; Liu, J. Underwater Acoustic Target Recognition Based on Attention Residual Network. Entropy 2022, 24, 1657. [Google Scholar] [CrossRef]
- Gabor, D. Theory of communication. J. Inst. Electr. Eng. Part I Gen. 1946, 94, 58. [Google Scholar] [CrossRef]
- Ioup, J.W. Time-frequency analysis for acoustics education and for listening to whales in the Gulf of Mexico. J. Acoust. Soc. Am. 2013, 134, 4124. [Google Scholar] [CrossRef]
- Luo, X.; Zhang, M.; Liu, T.; Huang, M.; Xu, X. An Underwater Acoustic Target Recognition Method Based on Spectrograms with Different Resolutions. J. Mar. Sci. Eng. 2021, 9, 1246. [Google Scholar] [CrossRef]
- Zhang, Y.; Zeng, Q. MSLEFC: A low-frequency focused underwater acoustic signal classification and analysis system. Eng. Appl. Artif. Intell. 2023, 123, 106333. [Google Scholar] [CrossRef]
- Yang, M.; Li, X.; Yang, Y.; Meng, X. Characteristic analysis of underwater acoustic scattering echoes in the wavelet transform domain. J. Mar. Sci. Appl. 2017, 16, 93–101. [Google Scholar] [CrossRef]
- Jing, L.; Zheng, T.; He, C.; Yin, H. Iterative adaptive frequency-domain equalization based on sliding window strategy over time-varying underwater acoustic channels. JASA Express Lett. 2021, 1, 076002. [Google Scholar] [CrossRef] [PubMed]
- Morlet, J.; Arens, G.; Fourgeau, E.; Glard, D. Wave propagation and sampling theory—Part I: Complex signal and scattering in multilayered media. Geophysics 1982, 47, 203–221. [Google Scholar] [CrossRef]
- Xin-xin, L.; Shi-e, Y.; Ming, Y. Feature extraction from underwater signals using wavelet packet transform. In Proceedings of the 2008 International Conference on Neural Networks and Signal Processing, Nanjing, China, 7–11 June 2008; pp. 400–405. [Google Scholar] [CrossRef]
- Rademan, M.; Versfeld, D.; du Preez, J. Soft-output signal detection for cetacean vocalizations using spectral entropy, k-means clustering and the continuous wavelet transform. Ecol. Inform. 2023, 74, 101990. [Google Scholar] [CrossRef]
- Han, Z.; Zhang, X.; Yan, B.; Qiao, L.; Wang, Z. The time-frequency analysis of the acoustic signal produced in underwater discharges based on Variational Mode Decomposition and Hilbert–Huang Transform. Sci. Rep. 2023, 13, 22. [Google Scholar] [CrossRef]
- Choo, Y.S.; Byun, S.H.; Kim, S.M.; Lee, K. Target detection in pseudo Wigner-Ville distribution of underwater beamformed signals. J. Acoust. Soc. Am. 2019, 146, 2960. [Google Scholar] [CrossRef]
- Wu, Y.; Li, X.; Wang, Y. Extraction and classification of acoustic scattering from underwater target based on Wigner-Ville distribution. Appl. Acoust. 2018, 138, 52–59. [Google Scholar] [CrossRef]
- Wang, S.; Zeng, X. Robust underwater noise targets classification using auditory inspired time–frequency analysis. Appl. Acoust. 2014, 78, 68–76. [Google Scholar] [CrossRef]
- Domingos, L.C.F.; Santos, P.E.; Skelton, P.S.M.; Brinkworth, R.S.A.; Sammut, K. An Investigation of Preprocessing Filters and Deep Learning Methods for Vessel Type Classification with Underwater Acoustic Data. IEEE Access 2022, 10, 117582–117596. [Google Scholar] [CrossRef]
- Liu, Y.; Zhao, Y.; Gerstoft, P.; Zhou, F.; Qiao, G.; Yin, J. Deep transfer learning-based variable Doppler underwater acoustic communications. J. Acoust. Soc. Am. 2023, 154, 232–244. [Google Scholar] [CrossRef] [PubMed]
- Tang, N.; Zhou, F.; Wang, Y.; Zhang, H.; Lyu, T.; Wang, Z.; Chang, L. Differential treatment for time and frequency dimensions in mel-spectrograms: An efficient 3D Spectrogram network for underwater acoustic target classification. Ocean Eng. 2023, 287, 115863. [Google Scholar] [CrossRef]
- Abdul, Z.K.; Al-Talabani, A.K. Mel Frequency Cepstral Coefficient and its Applications: A Review. IEEE Access 2022, 10, 122136–122158. [Google Scholar] [CrossRef]
- Zhang, Y.; Xu, K.; Wan, J. Rubost Feature for Underwater Targets Recognition Using Power-Normalized Cepstral Coefficients. In Proceedings of the 2018 14th IEEE International Conference on Signal Processing (ICSP), Beijing, China, 12–16 August 2018; pp. 90–93. [Google Scholar] [CrossRef]
- Tong, Y.; Zhang, X.; Ge, Y. Classification and Recognition of Underwater Target Based on MFCC Feature Extraction. In Proceedings of the 2020 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), Macau, China, 21–24 August 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Ren, J.; Huang, Z.; Li, C.; Guo, X.; Xu, J. Feature Analysis of Passive Underwater Targets Recognition Based on Deep Neural Network. In Proceedings of the OCEANS 2019, Marseille, France, 17–20 June 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Hu, F.; Fan, J.; Kong, Y.; Zhang, L.; Guan, X.; Yu, Y. A Deep Learning Method for Ship-Radiated Noise Recognition Based on MFCC Feature. In Proceedings of the 2023 7th International Conference on Transportation Information and Safety (ICTIS), Xian, China, 4–6 August 2023; pp. 1328–1335. [Google Scholar] [CrossRef]
- Lian, Z.; Xu, K.; Wan, J.; Li, G. Underwater acoustic target classification based on modified GFCC features. In Proceedings of the 2017 IEEE 2nd Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 25–26 March 2017; pp. 258–262. [Google Scholar] [CrossRef]
- Cao, Y.; Yan, J.; Sun, K.; Luo, X. Hydroacoustic Target Detection Based on Improved GFCC and Lightweight Neural Network. In Proceedings of the 2023 42nd Chinese Control Conference (CCC), Tianjin, China, 24–26 July 2023; pp. 6239–6243. [Google Scholar] [CrossRef]
- Liu, G.K. Evaluating Gammatone Frequency Cepstral Coefficients with Neural Networks for Emotion Recognition from Speech. arXiv 2018, arXiv:1806.09010. [Google Scholar]
- Song, K.; Wang, N.; Zhang, Y. An Improved Deep Canonical Correlation Fusion Method for Underwater Multisource Data. IEEE Access 2020, 8, 146300–146307. [Google Scholar] [CrossRef]
- Hong, F.; Liu, C.; Guo, L.; Chen, F.; Feng, H. Underwater Acoustic Target Recognition with a Residual Network and the Optimized Feature Extraction Method. Appl. Sci. 2021, 11, 1442. [Google Scholar] [CrossRef]
- Chen, Z.; Tang, J.; Qiu, H.; Chen, M. MGFGNet: An automatic underwater acoustic target recognition method based on the multi-gradient flow global feature enhancement network. Front. Mar. Sci. 2023, 10, 1306229. [Google Scholar] [CrossRef]
- Tan, J.; Pan, X. Underwater acoustic target recognition based on convolutional neural network and multi-feature fusion. In Proceedings of the Third International Conference on Computer Vision and Pattern Analysis (ICCPA 2023), Hangzhou, China, 31 March–2 April 2023; Shen, L., Zhong, G., Eds.; International Society for Optics and Photonics, SPIE. Volume 12754, p. 1275432. [Google Scholar] [CrossRef]
- Liu, F.; Shen, T.; Luo, Z.; Zhao, D.; Guo, S. Underwater target recognition using convolutional recurrent neural networks with 3-D Mel-spectrogram and data augmentation. Appl. Acoust. 2021, 178, 107989. [Google Scholar] [CrossRef]
- Wu, J.; Li, P.; Wang, Y.; Lan, Q.; Xiao, W.; Wang, Z. VFR: The Underwater Acoustic Target Recognition Using Cross-Domain Pre-Training with FBank Fusion Features. J. Mar. Sci. Eng. 2023, 11, 263. [Google Scholar] [CrossRef]
- Yang, Y.; Lv, H.; Chen, N. A Survey on ensemble learning under the era of deep learning. Artif. Intell. Rev. 2023, 56, 5545–5589. [Google Scholar] [CrossRef]
- Zhang, Q.; Da, L.; Zhang, Y.; Hu, Y. Integrated neural networks based on feature fusion for underwater target recognition. Appl. Acoust. 2021, 182, 108261. [Google Scholar] [CrossRef]
- Luo, X.; Feng, Y. An Underwater Acoustic Target Recognition Method Based on Restricted Boltzmann Machine. Sensors 2020, 20, 5399. [Google Scholar] [CrossRef]
- Nie, L.; Zhang, Y.; Wang, H. Classification of underwater soundscapes using raw hydroacoustic signals. J. Acoust. Soc. Am. 2023, 154, A304. [Google Scholar] [CrossRef]
- Chen, Y.; Shang, J. Underwater Target Recognition Method Based on Convolution Autoencoder. In Proceedings of the 2019 IEEE International Conference on Signal, Information and Data Processing (ICSIDP), Chongqing, China, 11–13 December 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Khishe, M. DRW-AE: A Deep Recurrent-Wavelet Autoencoder for Underwater Target Recognition. IEEE J. Ocean. Eng. 2022, 47, 1083–1098. [Google Scholar] [CrossRef]
- Berahmand, K.; Daneshfar, F.; Salehi, E.S.; Li, Y.; Xu, Y. Autoencoders and their applications in machine learning: A survey. Artif. Intell. Rev. 2024, 57, 28. [Google Scholar] [CrossRef]
- Dong, Y.; Shen, X.; Wang, H. Bidirectional Denoising Autoencoders-Based Robust Representation Learning for Underwater Acoustic Target Signal Denoising. IEEE Trans. Instrum. Meas. 2022, 71, 1–8. [Google Scholar] [CrossRef]
- Li, J.; Yang, H.; Shen, S.; Xu, G. The Learned Multi-scale Deep Filters for Underwater Acoustic Target Modeling and Recognition. In Proceedings of the OCEANS 2019, Marseille, France, 17–20 June 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Luo, X.; Feng, Y.; Zhang, M. An Underwater Acoustic Target Recognition Method Based on Combined Feature with Automatic Coding and Reconstruction. IEEE Access 2021, 9, 63841–63854. [Google Scholar] [CrossRef]
- Sun, B.; Luo, X. Underwater acoustic target recognition based on automatic feature and contrastive coding. IET Radar Sonar Navig. 2023, 17, 1277–1285. [Google Scholar] [CrossRef]
- Wang, X.; Meng, J.; Liu, Y.; Zhan, G.; Tian, Z. Self-supervised acoustic representation learning via acoustic-embedding memory unit modified space autoencoder for underwater target recognition. J. Acoust. Soc. Am. 2022, 152, 2905–2915. [Google Scholar] [CrossRef] [PubMed]
- Gomez, B.; Kadri, U. Earthquake source characterization by machine learning algorithms applied to acoustic signals. Sci. Rep. 2021, 11, 23062. [Google Scholar] [CrossRef] [PubMed]
- Zelada Leon, A.; Huvenne, V.A.; Benoist, N.M.; Ferguson, M.; Bett, B.J.; Wynn, R.B. Assessing the Repeatability of Automated Seafloor Classification Algorithms, with Application in Marine Protected Area Monitoring. Remote Sens. 2020, 12, 1572. [Google Scholar] [CrossRef]
- Harakawa, R.; Ogawa, T.; Haseyama, M.; Akamatsu, T. Automatic detection of fish sounds based on multi-stage classification including logistic regression via adaptive feature weighting. J. Acoust. Soc. Am. 2018, 144, 2709–2718. [Google Scholar] [CrossRef]
- Xinhua, Z.; Zhenbo, L.; Chunyu, K. Underwater acoustic targets classification using support vector machine. In Proceedings of the International Conference on Neural Networks and Signal Processing, Nanjing, China, 14–17 December 2003; Volume 2, pp. 932–935. [Google Scholar] [CrossRef]
- Alvaro, A.; Schwock, F.; Ragland, J.; Abadi, S. Ship detection from passive underwater acoustic recordings using machine learning. J. Acoust. Soc. Am. 2021, 150, A124. [Google Scholar] [CrossRef]
- Li, H.; Cheng, Y.; Dai, W.; Li, Z. A method based on wavelet packets-fractal and SVM for underwater acoustic signals recognition. In Proceedings of the 2014 12th International Conference on Signal Processing (ICSP), HangZhou, China, 19–23 October 2014; pp. 2169–2173. [Google Scholar] [CrossRef]
- de Moura, N.N.; de Seixas, J.M. Novelty detection in passive SONAR systems using support vector machines. In Proceedings of the 2015 Latin America Congress on Computational Intelligence (LA-CCI), Curitiba, Brazil, 13–16 October 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Sherin, B.M.; Supriya, M.H. Selection and parameter optimization of SVM kernel function for underwater target classification. In Proceedings of the 2015 IEEE Underwater Technology (UT), Chennai, India, 23–25 February 2015; pp. 1–5. [Google Scholar] [CrossRef]
- Wang, B.; Wu, C.; Zhu, Y.; Zhang, M.; Li, H.; Zhang, W. Ship Radiated Noise Recognition Technology Based on ML-DS Decision Fusion. Comput. Intell. Neurosci. 2021, 2021, 8901565. [Google Scholar] [CrossRef]
- Yao, Q.; Jiang, J.; Chen, G.; Li, Z.; Yao, Z.; Lu, Y.; Hou, X.; Fu, X.; Duan, F. Recognition method for underwater imitation whistle communication signals by slope distribution. Appl. Acoust. 2023, 211, 109531. [Google Scholar] [CrossRef]
- Liu, F.; Li, G.; Yang, H. Application of multi-algorithm mixed feature extraction model in underwater acoustic signal. Ocean Eng. 2024, 296, 116959. [Google Scholar] [CrossRef]
- Yang, H.; Gan, A.; Chen, H.; Pan, Y.; Tang, J.; Li, J. Underwater acoustic target recognition using SVM ensemble via weighted sample and feature selection. In Proceedings of the 2016 13th International Bhurban Conference on Applied Sciences and Technology (IBCAST), Islamabad, Pakistan, 12–16 January 2016; pp. 522–527. [Google Scholar] [CrossRef]
- Fisher, R.A. Iris; UCI Machine Learning Repository: Espoo, Finland, 1988. [Google Scholar] [CrossRef]
- Choi, J.; Choo, Y.; Lee, K. Acoustic Classification of Surface and Underwater Vessels in the Ocean Using Supervised Machine Learning. Sensors 2019, 19, 3492. [Google Scholar] [CrossRef]
- Wei, M.; Chen, K.; Lin, Y.; Cheng, E. Recognition of behavior state of Penaeus vannamei based on passive acoustic technology. Front. Mar. Sci. 2022, 9, 973284. [Google Scholar] [CrossRef]
- Chen, H.; Sun, H.; Junejo, N.U.R.; Yang, G.; Qi, J. Whale Vocalization Classification Using Feature Extraction with Resonance Sparse Signal Decomposition and Ridge Extraction. IEEE Access 2019, 7, 136358–136368. [Google Scholar] [CrossRef]
- Yaman, O.; Tuncer, T.; Tasar, B. DES-Pat: A novel DES pattern-based propeller recognition method using underwater acoustical sounds. Appl. Acoust. 2021, 175, 107859. [Google Scholar] [CrossRef]
- Saffari, A.; Zahiri, S.H.; Khishe, M. Automatic recognition of sonar targets using feature selection in micro-Doppler signature. Def. Technol. 2023, 20, 58–71. [Google Scholar] [CrossRef]
- Li, Y.X.; Jiao, S.B.; Geng, B.; Zhang, Q.; Zhang, Y.M. A comparative study of four nonlinear dynamic methods and their applications in classification of ship-radiated noise. Def. Technol. 2022, 18, 183–193. [Google Scholar] [CrossRef]
- Jin, S.Y.; Su, Y.; Guo, C.J.; Fan, Y.X.; Tao, Z.Y. Offshore ship recognition based on center frequency projection of improved EMD and KNN algorithm. Mech. Syst. Signal Process. 2023, 189, 110076. [Google Scholar] [CrossRef]
- Mohammed, S.K.; Hariharan, S.M.; Kamal, S. A GTCC-Based Underwater HMM Target Classifier with Fading Channel Compensation. J. Sens. 2018, 2018, 6593037:1–6593037:14. [Google Scholar] [CrossRef]
- You, H.; Byun, S.H.; Choo, Y. Underwater Acoustic Signal Detection Using Calibrated Hidden Markov Model with Multiple Measurements. Sensors 2022, 22, 5088. [Google Scholar] [CrossRef]
- Seo, Y.; On, B.; Im, S.; Shim, T.; Seo, I. Underwater Cylindrical Object Detection Using the Spectral Features of Active Sonar Signals with Logistic Regression Models. Appl. Sci. 2018, 8, 116. [Google Scholar] [CrossRef]
- Yang, L.; Chen, K. Performance and strategy comparisons of human listeners and logistic regression in discriminating underwater targets. J. Acoust. Soc. Am. 2015, 138, 3138–3147. [Google Scholar] [CrossRef]
- K, S.; R, K.; Kumar, P.S.; V, R.; Lakshmi, G. Rock/Mine Classification Using Supervised Machine Learning Algorithms. In Proceedings of the 2023 International Conference on Intelligent and Innovative Technologies in Computing, Electrical and Electronics (IITCEE), Bengaluru, India, 27–28 January 2023; pp. 177–184. [Google Scholar] [CrossRef]
- Yu, Q.; Zhang, W.; Zhu, M.; Shi, J.; Liu, Y.; Liu, S. Surface and Underwater Acoustic Source Recognition Using Array Feature Extraction Based on Machine Learning. J. Phys. Conf. Ser. 2024, 2718, 012100. [Google Scholar] [CrossRef]
- Zhou, X.; Yang, K. A denoising representation framework for underwater acoustic signal recognition. J. Acoust. Soc. Am. 2020, 147, EL377–EL383. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Wang, L.; Zeng, X.; Zhao, L. An Improved Deep Clustering Model for Underwater Acoustical Targets. Neural Process. Lett. 2018, 48, 1633–1644. [Google Scholar] [CrossRef]
- Sabara, R.; Soares, C.; Zabel, F.; Oliveira, J.V.; Jesus, S.M. Automatic Acoustic Target Detection and Classification off the Coast of Portugal. In Proceedings of the Global Oceans 2020: Singapore—U.S. Gulf Coast, Biloxi, MS, USA, 5–30 October 2020; pp. 1–9. [Google Scholar] [CrossRef]
- Yang, K.; Zhou, X. Unsupervised Classification of Hydrophone Signals with an Improved Mel-Frequency Cepstral Coefficient Based on Measured Data Analysis. IEEE Access 2019, 7, 124937–124947. [Google Scholar] [CrossRef]
- Agersted, M.D.; Khodabandeloo, B.; Liu, Y.; Melle, W.; Klevjer, T.A. Application of an unsupervised clustering algorithm on in situ broadband acoustic data to identify different mesopelagic target types. Ices J. Mar. Sci. 2021, 78, 2907–2921. [Google Scholar] [CrossRef]
- Luo, X.; Chen, L.; Zhou, H.; Cao, H. A Survey of Underwater Acoustic Target Recognition Methods Based on Machine Learning. J. Mar. Sci. Eng. 2023, 11, 384. [Google Scholar] [CrossRef]
- Baran, R.H.; Coughlan, J.M. Neural network for passive acoustic discrimination between surface and submarine targets. In Proceedings of the Automatic Object Recognition, San Francisco, CA, USA, 1 August 1991; Sadjadi, F.A., Ed.; International Society for Optics and Photonics, SPIE. Volume 1471, pp. 164–176. [Google Scholar] [CrossRef]
- Khotanzad.; Lu.; Srinath. Target detection using a neural network based passive sonar system. In Proceedings of the International 1989 Joint Conference on Neural Networks, Washington, DC, USA, 18–22 June 1989; Volume 1, pp. 335–340. [Google Scholar] [CrossRef]
- Filho, W. Preprocessing passive sonar signals for neural classification. IET Radar Sonar Navig. 2011, 5, 605–612. [Google Scholar] [CrossRef]
- Yue, H.; Zhang, L.; Wang, D.; Wang, Y.; Lu, Z. The Classification of Underwater Acoustic Targets Based on Deep Learning Methods. In Proceedings of the 2017 2nd International Conference on Control, Automation and Artificial Intelligence (CAAI 2017), Sanya, China, 25–26 June 2017; pp. 526–529. [Google Scholar] [CrossRef]
- Zhao, J.; Wang, S.; Jia, X.; Gao, Y.; Zhu, W.; Ma, F.; Liu, Q. Underwater target perception algorithm based on pressure sequence generative adversarial network. Ocean Eng. 2023, 286, 115547. [Google Scholar] [CrossRef]
- Li, D.; Liu, F.; Shen, T.; Chen, L.; Zhao, D. Data augmentation method for underwater acoustic target recognition based on underwater acoustic channel modeling and transfer learning. Appl. Acoust. 2023, 208, 109344. [Google Scholar] [CrossRef]
- Yang, J.; Yan, S.; Zeng, D.; Tan, G. Self-supervised learning minimax entropy domain adaptation for the underwater target recognition. Appl. Acoust. 2024, 216, 109725. [Google Scholar] [CrossRef]
- Wang, X.; Wu, P.; Li, B.; Zhan, G.; Liu, J.; Liu, Z. A self-supervised dual-channel self-attention acoustic encoder for underwater acoustic target recognition. Ocean Eng. 2024, 299, 117305. [Google Scholar] [CrossRef]
- Xu, K.; Xu, Q.; You, K.; Zhu, B.; Feng, M.; Feng, D.; Liu, B. Self-supervised learning–based underwater acoustical signal classification via mask modeling. J. Acoust. Soc. Am. 2023, 154, 5–15. [Google Scholar] [CrossRef] [PubMed]
- You, K.; Xu, K.; Feng, M.; Zhu, B. Underwater acoustic classification using masked modeling-based swin transformer. J. Acoust. Soc. Am. 2022, 152, A296. [Google Scholar] [CrossRef]
- Zhou, A.; Li, X.; Zhang, W.; Zhao, C.; Ren, K.; Ma, Y.; Song, J. An attention-based multi-scale convolution network for intelligent underwater acoustic signal recognition. Ocean Eng. 2023, 287, 115784. [Google Scholar] [CrossRef]
- Schoene, A.M.; Turner, A.P.; De Mel, G.; Dethlefs, N. Hierarchical Multiscale Recurrent Neural Networks for Detecting Suicide Notes. IEEE Trans. Affect. Comput. 2023, 14, 153–164. [Google Scholar] [CrossRef]
- Bansal, A.; Garg, N.K. Robust technique for environmental sound classification using convolutional recurrent neural network. Multimed. Tools Appl. 2023, 83, 54755–54772. [Google Scholar] [CrossRef]
- Wang, Y.; Wu, H.; Zhang, J.; Gao, Z.; Wang, J.; Yu, P.S.; Long, M. PredRNN: A Recurrent Neural Network for Spatiotemporal Predictive Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 2208–2225. [Google Scholar] [CrossRef]
- Zhang, X.; Zhong, C.; Zhang, J.; Wang, T.; Ng, W.W. Robust recurrent neural networks for time series forecasting. Neurocomputing 2023, 526, 143–157. [Google Scholar] [CrossRef]
- Hewamalage, H.; Bergmeir, C.; Bandara, K. Recurrent Neural Networks for Time Series Forecasting: Current status and future directions. Int. J. Forecast. 2021, 37, 388–427. [Google Scholar] [CrossRef]
- Zhang, S.; Xing, S. Intelligent Recognition of Underwater Acoustic Target Noise by Multi-Feature Fusion. In Proceedings of the 2018 11th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 8–9 December 2018; Volume 1, pp. 212–215. [Google Scholar] [CrossRef]
- Zhang, S.; Wang, C.; Sun, Q. Underwater Target Noise Recognition and Classification Technology based on Multi-Classes Feature Fusion. JNWPU 2020, 38, 366–376. [Google Scholar] [CrossRef]
- Yu, X.; Li, L.; Yin, J.; Shao, M.; Han, X. Modulation Pattern Recognition of Non-cooperative Underwater Acoustic Communication Signals Based on LSTM Network. In Proceedings of the 2019 IEEE International Conference on Signal, Information and Data Processing (ICSIDP), Chongqing, China, 11–13 December 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Yang, H.; Xu, G.; Yi, S.; Li, Y. A New Cooperative Deep Learning Method for Underwater Acoustic Target Recognition. In Proceedings of the OCEANS 2019, Marseille, France, 17–20 June 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Cho, K.; van Merrienboer, B.; Gülçehre, Ç.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, EMNLP, Doha, Qatar, 25–29 October 2014; A meeting of SIGDAT, a Special Interest Group of the ACL. Moschitti, A., Pang, B., Daelemans, W., Eds.; ACL: Edinburgh, UK, 2014; pp. 1724–1734. [Google Scholar] [CrossRef]
- Qi, P.; Yin, G.; Zhang, L. Underwater acoustic target recognition using RCRNN and wavelet-auditory feature. Multimed. Tools Appl. 2023, 83, 47295–47317. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, H.; Xu, L.; Cao, C.; Gulliver, T.A. Adoption of hybrid time series neural network in the underwater acoustic signal modulation identification. J. Frankl. Inst. 2020, 357, 13906–13922. [Google Scholar] [CrossRef]
- Liu, Y.; Li, X.; Yang, L.; Bian, G.; Yu, H. A CNN-Transformer Hybrid Recognition Approach for sEMG-Based Dynamic Gesture Prediction. IEEE Trans. Instrum. Meas. 2023, 72, 1–16. [Google Scholar] [CrossRef]
- Kamal, S.; Satheesh Chandran, C.; Supriya, M. Passive sonar automated target classifier for shallow waters using end-to-end learnable deep convolutional LSTMs. Eng. Sci. Technol. Int. J. 2021, 24, 860–871. [Google Scholar] [CrossRef]
- Qi, P.; Sun, J.; Long, Y.; Zhang, L.; Tianye. Underwater Acoustic Target Recognition with Fusion Feature. In Neural Information Processing, Proceedings of the 28th International Conference, ICONIP 2021, Sanur, Bali, Indonesia, 8–12 December 2021; Proceedings, Part I 28; Mantoro, T., Lee, M., Ayu, M.A., Wong, K.W., Hidayanto, A.N., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 609–620. [Google Scholar]
- Ma, Q.; Jiang, L.; Yu, W. Lambertian-based adversarial attacks on deep-learning-based underwater side-scan sonar image classification. Pattern Recognit. 2023, 138, 109363. [Google Scholar] [CrossRef]
- Steiniger, Y.; Kraus, D.; Meisen, T. Survey on deep learning based computer vision for sonar imagery. Eng. Appl. Artif. Intell. 2022, 114, 105157. [Google Scholar] [CrossRef]
- Wang, Y.; Jin, Y.; Zhang, H.; Lu, Q.; Cao, C.; Sang, Z.; Sun, M. Underwater Communication Signal Recognition Using Sequence Convolutional Network. IEEE Access 2021, 9, 46886–46899. [Google Scholar] [CrossRef]
- Xiaoping, S.; Jinsheng, C.; Yuan, G. A New Deep Learning Method for Underwater Target Recognition Based on One-Dimensional Time-Domain Signals. In Proceedings of the 2021 OES China Ocean Acoustics (COA), Harbin, China, 14–17 July 2021; pp. 1048–1051. [Google Scholar] [CrossRef]
- Zhu, P.; Zhang, Y.; Huang, Y.; Zhao, C.; Zhao, K.; Zhou, F. Underwater acoustic target recognition based on spectrum component analysis of ship radiated noise. Appl. Acoust. 2023, 211, 109552. [Google Scholar] [CrossRef]
- Dong, Y.; Shen, X.; Jiang, Z.; Wang, H. Recognition of imbalanced underwater acoustic datasets with exponentially weighted cross-entropy loss. Appl. Acoust. 2021, 174, 107740. [Google Scholar] [CrossRef]
- Feng, S.; Zhu, X. A Transformer-Based Deep Learning Network for Underwater Acoustic Target Recognition. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef]
- Yao, Y.; Zeng, X.; Wang, H.; Liu, J. Research on Underwater Acoustic Target Recognition Method Based on DenseNet. In Proceedings of the 2022 3rd International Conference on Big Data, Artificial Intelligence and Internet of Things Engineering (ICBAIE), Xi’an, China, 15–17 July 2022; pp. 114–118. [Google Scholar] [CrossRef]
- Hong, F.; Liu, C.; Guo, L.; Chen, F.; Feng, H. Underwater Acoustic Target Recognition with ResNet18 on ShipsEar Dataset. In Proceedings of the 2021 IEEE 4th International Conference on Electronics Technology (ICET), Chengdu, China, 7–10 May 2021; pp. 1240–1244. [Google Scholar] [CrossRef]
- Sun, Q.; Wang, K. Underwater single-channel acoustic signal multitarget recognition using convolutional neural networks. J. Acoust. Soc. Am. 2022, 151, 2245–2254. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar] [CrossRef]
- Mehta, S.; Rastegari, M.; Shapiro, L.; Hajishirzi, H. ESPNetv2: A Light-Weight, Power Efficient, and General Purpose Convolutional Neural Network. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9182–9192. [Google Scholar] [CrossRef]
- Hu, G.; Wang, K.; Liu, L. Underwater Acoustic Target Recognition Based on Depthwise Separable Convolution Neural Networks. Sensors 2021, 21, 1429. [Google Scholar] [CrossRef] [PubMed]
- Miao, Y.; Zakharov, Y.V.; Sun, H.; Li, J.; Wang, J. Underwater Acoustic Signal Classification Based on Sparse Time–Frequency Representation and Deep Learning. IEEE J. Ocean. Eng. 2021, 46, 952–962. [Google Scholar] [CrossRef]
- Zheng, Y.; Gong, Q.; Zhang, S. Time-Frequency Feature-Based Underwater Target Detection with Deep Neural Network in Shallow Sea. J. Phys. Conf. Ser. 2021, 1756, 012006. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Cai, W.; Zhu, J.; Zhang, M.; Yang, Y. A Parallel Classification Model for Marine Mammal Sounds Based on Multi-Dimensional Feature Extraction and Data Augmentation. Sensors 2022, 22, 7443. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:abs/1704.04861. [Google Scholar]
- Yan, C.; Yu, Y.; Yan, S.; Yao, T.; Yang, C.; Liu, L.; Pan, G. Underwater target recognition using a lightweight asymmetric convolutional neural network. In Proceedings of the 17th International Conference on Underwater Networks & Systems, WUWNet ’23, Shenzhen, China, 24–26 November 2023; Association for Computing Machinery: New York, NY, USA, 2024. [Google Scholar] [CrossRef]
- Tian, G.; Haiyang, Y.; Haiyan, W.; Fan, W.; Xiao, C. CA_MobileNetV2 for Underwater Acoustic Target Recognition. In Proceedings of the 2023 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), Zhengzhou, China, 14–17 November 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Jiang, Z.; Zhao, C.; Wang, H. Classification of Underwater Target Based on S-ResNet and Modified DCGAN Models. Sensors 2022, 22, 2293. [Google Scholar] [CrossRef]
- Xiao, X.; Wang, W.; Ren, Q.; Gerstoft, P.; Ma, L. Underwater acoustic target recognition using attention-based deep neural network. JASA Express Lett. 2021, 1, 106001. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Zhu, X.; Cheng, D.; Zhang, Z.; Lin, S.; Dai, J. An Empirical Study of Spatial Attention Mechanisms in Deep Networks. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6687–6696. [Google Scholar] [CrossRef]
- Wang, B.; Zhang, W.; Zhu, Y.; Wu, C.; Zhang, S. An Underwater Acoustic Target Recognition Method Based on AMNet. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Zhu, M.; Zhang, X.; Jiang, Y.; Wang, K.; Su, B.; Wang, T. Hybrid Underwater Acoustic Signal Multi-Target Recognition Based on DenseNet-LSTM with Attention Mechanism. In Proceedings of the 2023 Chinese Intelligent Automation Conference, Nanjing, China, 2–5 October 2023; Deng, Z., Ed.; Springer Nature: Singapore, 2023; pp. 728–738. [Google Scholar]
- Seo, M.J.; Kembhavi, A.; Farhadi, A.; Hajishirzi, H. Bidirectional Attention Flow for Machine Comprehension. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Liu, C.; Hong, F.; Feng, H.; Hu, M. Underwater Acoustic Target Recognition Based on Dual Attention Networks and Multiresolution Convolutional Neural Networks. In Proceedings of the OCEANS 2021: San Diego—Porto, San Diego, CA, USA, 20–23 September 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All You Need. arXiv 2017, arXiv:1706.03762v7. [Google Scholar]
- Gong, Y.; Chung, Y.A.; Glass, J. AST: Audio Spectrogram Transformer. In Proceedings of the Proc. Interspeech 2021, Brno, Czechia, 30 August–3 September 2021; pp. 571–575. [Google Scholar] [CrossRef]
- Li, P.; Wu, J.; Wang, Y.; Lan, Q.; Xiao, W. STM: Spectrogram Transformer Model for Underwater Acoustic Target Recognition. J. Mar. Sci. Eng. 2022, 10, 1428. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar] [CrossRef]
- Wu, F.; Yao, H.; Wang, H. Recognizing the State of Motion by Ship-Radiated Noise Using Time-Frequency Swin-Transformer. IEEE J. Ocean. Eng. 2024, 49, 1–12. [Google Scholar] [CrossRef]
- Yao, H.; Gao, T.; Wang, Y.; Wang, H.; Chen, X. Mobile_ViT: Underwater Acoustic Target Recognition Method Based on Local–Global Feature Fusion. J. Mar. Sci. Eng. 2024, 12, 589. [Google Scholar] [CrossRef]
- Feng, S.; Zhu, X.; Ma, S. Masking Hierarchical Tokens for Underwater Acoustic Target Recognition with Self-Supervised Learning. IEEE/ACM Trans. Audio Speech Lang. Process. 2024, 32, 1365–1379. [Google Scholar] [CrossRef]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition. In Proceedings of the Interspeech 2019, 20th Annual Conference of the International Speech Communication Association, Graz, Austria, 15–19 September 2019; Kubin, G., Kacic, Z., Eds.; ISCA: Copenhagen, Denmark, 2019; pp. 2613–2617. [Google Scholar] [CrossRef]
- Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge Distillation: A Survey. Int. J. Comput. Vis. 2021, 129, 1789–1819. [Google Scholar] [CrossRef]
- Zhou, A.; Li, X.; Zhang, W.; Li, D.; Deng, K.; Ren, K.; Song, J. A Novel Cross-Attention Fusion-Based Joint Training Framework for Robust Underwater Acoustic Signal Recognition. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–16. [Google Scholar] [CrossRef]
- Li, J.; Yang, H. Deep learning method with auditory passive attention for underwater acoustic target recognition under the condition of ship interference. Ocean Eng. 2024, 302, 117674. [Google Scholar] [CrossRef]
- Song, Y.; Liu, F.; Shen, T. A novel noise reduction technique for underwater acoustic signals based on dual-path recurrent neural network. IET Commun. 2023, 17, 135–144. [Google Scholar] [CrossRef]
- Yang, H.; Li, L.; Li, G. A New Denoising Method for Underwater Acoustic Signal. IEEE Access 2020, 8, 201874–201888. [Google Scholar] [CrossRef]
- Yang, H.; Liu, M.; Zhang, S.; Zheng, R.; Dong, S. Few-shot Underwater Acoustic Target Recognition Based on Siamese Network. In Proceedings of the 2023 42nd Chinese Control Conference (CCC), Tianjin, China, 24–26 July 2023; pp. 8252–8257. [Google Scholar] [CrossRef]
- Cui, X.; He, Z.; Xue, Y.; Tang, K.; Zhu, P.; Han, J. Cross-Domain Contrastive Learning-Based Few-Shot Underwater Acoustic Target Recognition. J. Mar. Sci. Eng. 2024, 12, 264. [Google Scholar] [CrossRef]
- Tian, S.; Bai, D.; Zhou, J.; Fu, Y.; Chen, D. Few-shot learning for joint model in underwater acoustic target recognition. Sci. Rep. 2023, 13, 17502. [Google Scholar] [CrossRef]
- Zheng, S.; Mai, S.; Sun, Y.; Hu, H.; Yang, Y. Subgraph-Aware Few-Shot Inductive Link Prediction Via Meta-Learning. IEEE Trans. Knowl. Data Eng. 2023, 35, 6512–6517. [Google Scholar] [CrossRef]
- Ma, R.; Li, S.; Zhang, B.; Fang, L.; Li, Z. Flexible and Generalized Real Photograph Denoising Exploiting Dual Meta Attention. IEEE Trans. Cybern. 2023, 53, 6395–6407. [Google Scholar] [CrossRef] [PubMed]
- Liang, Y.; Li, S.; Yan, C.; Li, M.; Jiang, C. Explaining the black-box model: A survey of local interpretation methods for deep neural networks. Neurocomputing 2021, 419, 168–182. [Google Scholar] [CrossRef]
- Gao, Y.; Mosalam, K.M. Deep learning visual interpretation of structural damage images. J. Build. Eng. 2022, 60, 105144. [Google Scholar] [CrossRef]
- Agrawal, P.; Ganapathy, S. Interpretable Representation Learning for Speech and Audio Signals Based on Relevance Weighting. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 2823–2836. [Google Scholar] [CrossRef]
- Montavon, G.; Samek, W.; Müller, K.R. Methods for interpreting and understanding deep neural networks. Digit. Signal Process. 2018, 73, 1–15. [Google Scholar] [CrossRef]
- Xie, Y.; Ren, J.; Xu, J. Guiding the underwater acoustic target recognition with interpretable contrastive learning. In Proceedings of the OCEANS 2023, Limerick, Ireland, 5–8 June 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Chen, Y.; Du, S.; Quan, H. Feature Analysis and Optimization of Underwater Target Radiated Noise Based on t-SNE. In Proceedings of the 2018 10th International Conference on Wireless Communications and Signal Processing (WCSP), Hangzhou, China, 18–20 October 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Xu, Y.; Kong, X.; Cai, Z. Cross-validation strategy for performance evaluation of machine learning algorithms in underwater acoustic target recognition. Ocean Eng. 2024, 299, 117236. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Guo, J.; Tang, Y.; Wu, E. Vision GNN: An Image is Worth Graph of Nodes. In Proceedings of the 36th International Conference on Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; pp. 8291–8303. [Google Scholar]
- Xu, J.; Xie, Y.; Wang, W. Underwater acoustic target recognition based on smoothness-inducing regularization and spectrogram-based data augmentation. Ocean Eng. 2023, 281, 114926. [Google Scholar] [CrossRef]
- Li, D.; Liu, F.; Shen, T.; Chen, L.; Yang, X.; Zhao, D. Generalizable Underwater Acoustic Target Recognition Using Feature Extraction Module of Neural Network. Appl. Sci. 2022, 12, 10804. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Proceedings of the Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, Virtual Conference, 6–12 December 2020; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; [Google Scholar]
- Radford, A.; Kim, J.W.; Xu, T.; Brockman, G.; McLeavey, C.; Sutskever, I. Robust speech recognition via large-scale weak supervision. In Proceedings of the 40th International Conference on Machine Learning. JMLR.org, Honolulu, HI, USA, 23–29 July 2023. ICML’23. [Google Scholar]
- Bi, K.; Xie, L.; Zhang, H.; Chen, X.; Gu, X.; Tian, Q. Accurate medium-range global weather forecasting with 3D neural networks. Nature 2023, 619, 533–538. [Google Scholar] [CrossRef]
- Wang, X.; Wang, R.; Hu, N.; Wang, P.; Huo, P.; Wang, G.; Wang, H.; Wang, S.; Zhu, J.; Xu, J.; et al. XiHe: A Data-Driven Model for Global Ocean Eddy-Resolving Forecasting. arXiv 2024, arXiv:2402.02995. [Google Scholar]
- Sun, W.; Yan, R.; Jin, R.; Zhao, R.; Chen, Z. FedAlign: Federated Model Alignment via Data-Free Knowledge Distillation for Machine Fault Diagnosis. IEEE Trans. Instrum. Meas. 2024, 73, 1–12. [Google Scholar] [CrossRef]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Chen, W. LoRA: Low-Rank Adaptation of Large Language Models. arXiv 2021, arXiv:2106.09685. [Google Scholar]
- Dettmers, T.; Pagnoni, A.; Holtzman, A.; Zettlemoyer, L. QLoRA: Efficient Finetuning of Quantized LLMs. In Proceedings of the Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, 10–16 December 2023; Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S., Eds.; [Google Scholar]
- Lu, J.; Jin, F.; Zhang, J. Adapter Tuning with Task-Aware Attention Mechanism. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing ICASSP 2023, Rhodes Island, Greece, 4–10 June 2023; IEEE: New York, NY, USA, 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Liu, X.; Xie, L.; Wang, Y.; Zou, J.; Xiong, J.; Ying, Z.; Vasilakos, A.V. Privacy and security issues in deep learning: A survey. IEEE Access 2020, 9, 4566–4593. [Google Scholar] [CrossRef]
- Modas, A.; Sanchez-Matilla, R.; Frossard, P.; Cavallaro, A. Toward Robust Sensing for Autonomous Vehicles: An Adversarial Perspective. IEEE Signal Process. Mag. 2020, 37, 14–23. [Google Scholar] [CrossRef]
- Svenmarck, P.; Luotsinen, L.; Nilsson, M.; Schubert, J. Possibilities and challenges for artificial intelligence in military applications. In Proceedings of the NATO Big Data and Artificial Intelligence for Military Decision Making Specialists’ Meeting, Bordeaux, France, 30 May–1 June 2018; pp. 1–16. [Google Scholar]
- Feng, S.; Zhu, X.; Ma, S.; Lan, Q. Adversarial Attacks in Underwater Acoustic Target Recognition with Deep Learning Models. Remote Sens. 2023, 15, 5386. [Google Scholar] [CrossRef]
- Bai, T.; Luo, J.; Zhao, J.; Wen, B.; Wang, Q. Recent Advances in Adversarial Training for Adversarial Robustness. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21; International Joint Conferences on Artificial Intelligence Organization, Montreal, QC, Canada, 19–27 August 2021; pp. 4312–4321. [Google Scholar] [CrossRef]
- Aldahdooh, A.; Hamidouche, W.; Fezza, S.A.; Déforges, O. Adversarial example detection for DNN models: A review and experimental comparison. Artif. Intell. Rev. 2022, 55, 4403–4462. [Google Scholar] [CrossRef]
- Çatak, F.Ö.; Kuzlu, M.; Çatak, E.; Cali, U.; Guler, O. Defensive Distillation-Based Adversarial Attack Mitigation Method for Channel Estimation Using Deep Learning Models in Next-Generation Wireless Networks. IEEE Access 2022, 10, 98191–98203. [Google Scholar] [CrossRef]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, S.; Ma, S.; Zhu, X.; Yan, M. Artificial Intelligence-Based Underwater Acoustic Target Recognition: A Survey. Remote Sens. 2024, 16, 3333. https://doi.org/10.3390/rs16173333
Feng S, Ma S, Zhu X, Yan M. Artificial Intelligence-Based Underwater Acoustic Target Recognition: A Survey. Remote Sensing. 2024; 16(17):3333. https://doi.org/10.3390/rs16173333
Chicago/Turabian StyleFeng, Sheng, Shuqing Ma, Xiaoqian Zhu, and Ming Yan. 2024. "Artificial Intelligence-Based Underwater Acoustic Target Recognition: A Survey" Remote Sensing 16, no. 17: 3333. https://doi.org/10.3390/rs16173333
APA StyleFeng, S., Ma, S., Zhu, X., & Yan, M. (2024). Artificial Intelligence-Based Underwater Acoustic Target Recognition: A Survey. Remote Sensing, 16(17), 3333. https://doi.org/10.3390/rs16173333