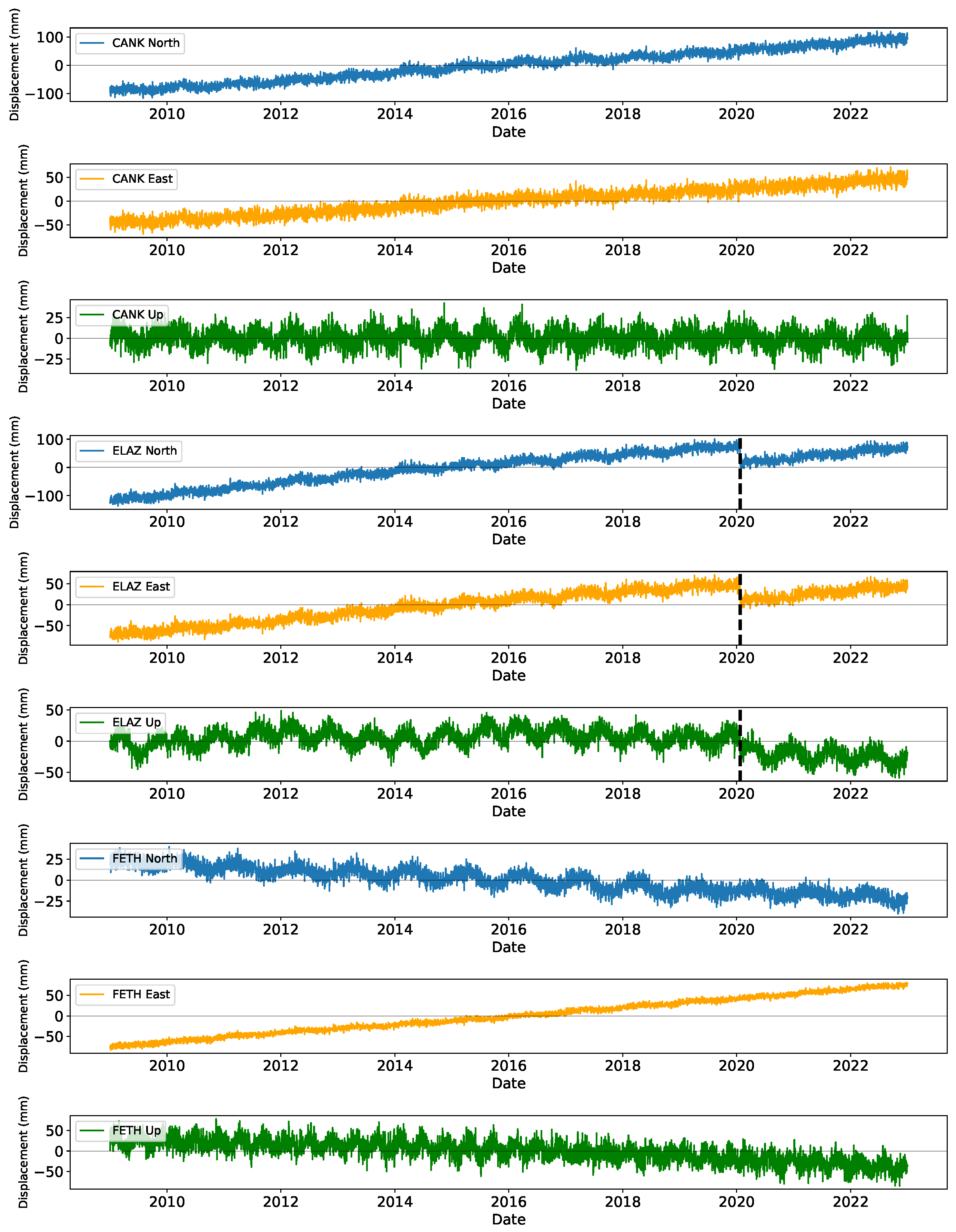
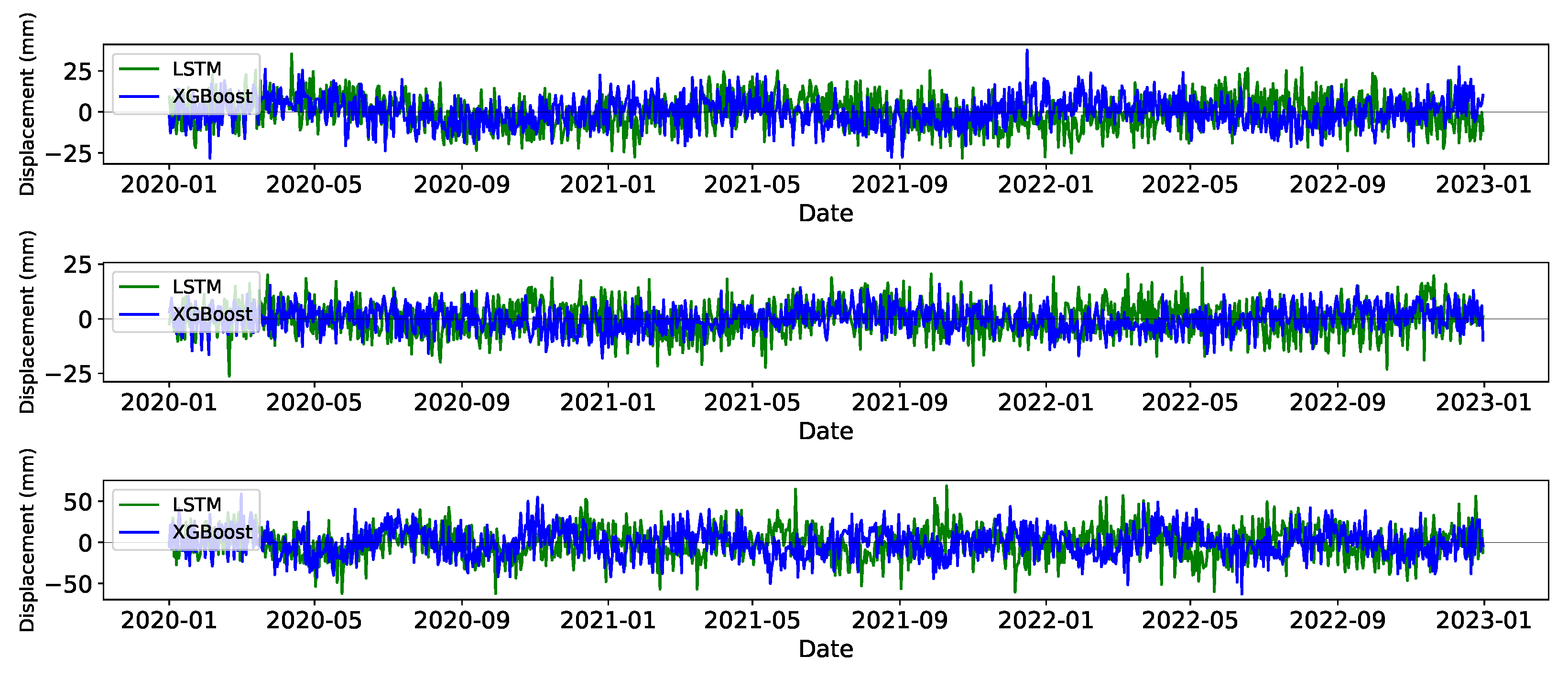
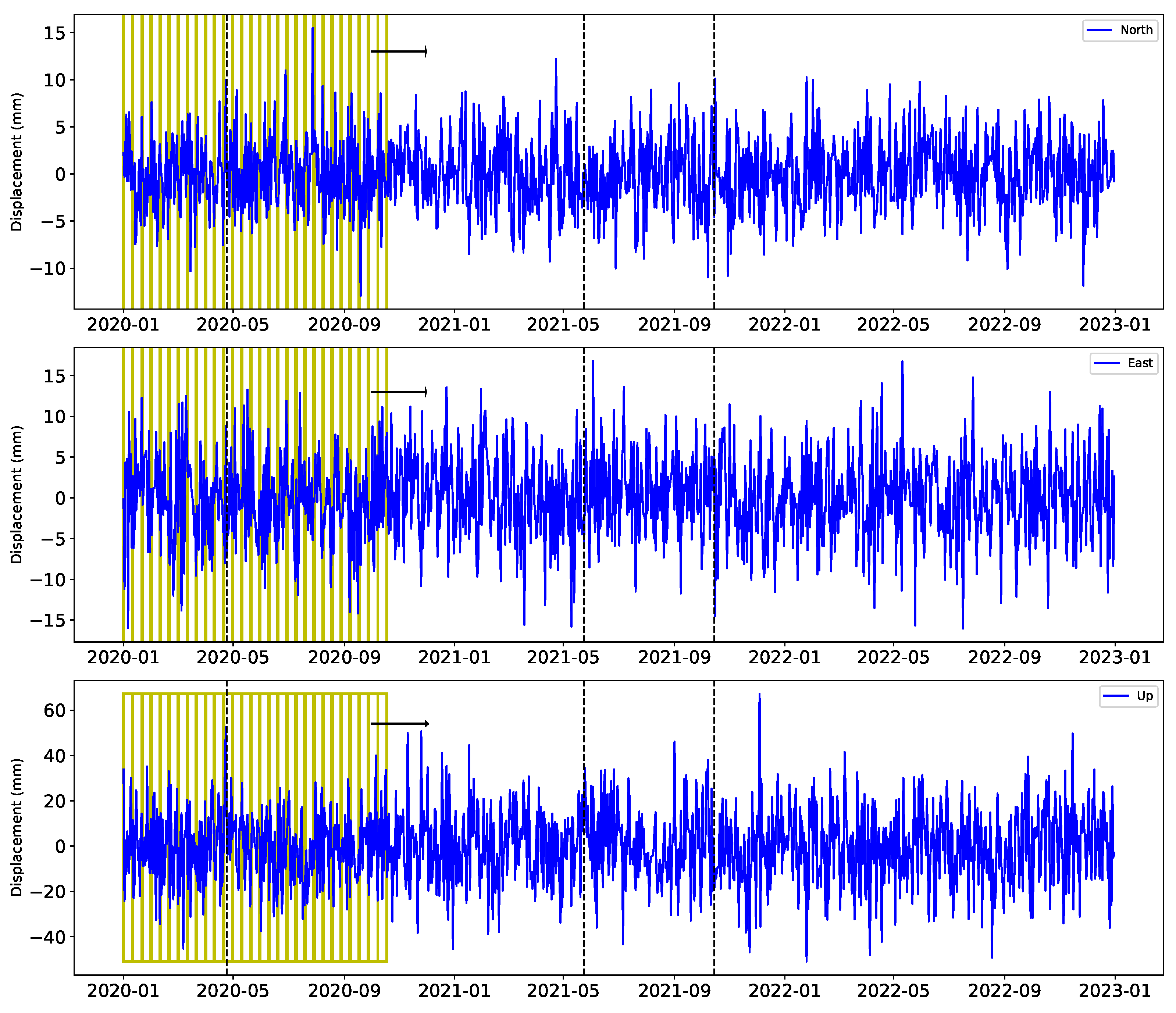
In this section, we present the results of applying XGBoost and LSTM algorithms to GNSS time series data from 15 continuous stations, covering the period from July 2009 to December 2022. The analysis includes data preprocessing to detect and analyze trends and seasonal variations at each station. We trained both XGBoost and LSTM models, extracting features and setting various hyperparameters. We then discuss the validation process and its key parameters to address the precision of each model. Additionally, we examine the evaluation metrics and the comparative performance of both models.
4.1. Preprocessing of the Time Series
The preprocessing of GNSS time series data is a critical step to enhance the accuracy and reliability of subsequent analysis. It allows us to isolate the tectonic signals of interest by removing extra patterns and trends that may obscure the underlying geophysical phenomena.
The first step in preprocessing the GNSS time series data is to remove linear trends and seasonal signals. Linear trends can result from various factors, including tectonic plate motions, which manifest as long-term linear displacements. Removing these trends allows us to focus on shorter-term variations and transient events. Seasonal variations, often annual or semi-annual, are common in GNSS time series data and can result from environmental factors such as temperature changes, snow load, and hydrological effects [
41]. To construct the models, we began by selecting relevant features from the GNSS time series data that could help in predicting the linear and seasonal components. These features included time indices and any additional external factors that might influence the data. The model was trained using a supervised learning approach and multi-class segmentation (see [
18,
19]), where the target variable was the GNSS positional data. By optimizing the parameters through cross-validation, we fine-tuned the model to accurately detect the linear trends and periodic signals. The fitted models were then used to predict all these components, which were subsequently subtracted from the original time series to obtain residuals.
Missing data is a common issue in GNSS time series analysis, which can arise due to various reasons such as equipment malfunctions, data transmission errors, or environmental obstructions. To maintain the integrity and continuity of the dataset, it is essential to address these gaps. In this study, we employed linear interpolation to fill the missing data points, which provides a simple yet effective method for estimating the missing values based on the available data. This approach helps maintain the temporal structure of the data while minimizing potential biases introduced by more complex imputation methods. After removing the linear and seasonal trends, the normalization of the time series data to have a mean of zero and a standard deviation of one was performed. This process ensures that the data are on a consistent scale, which is essential for the effective application of machine learning algorithms. Normalization helps to mitigate the effects of varying magnitudes in the data, allowing the algorithms to focus on the underlying patterns rather than the absolute values. Finally, once all these preprocessing stages were applied, we assumed that the residuals primarily contained the tectonic signals and other short-term variations of interest. The combined use of XGBoost and LSTM ensures a comprehensive approach to detrending and denoising the GNSS time series data, providing a cleaner dataset for subsequent analysis.
The training process involves preparing the data, initializing the models with optimal hyperparameters, and executing the training process to minimize the loss and maximize the accuracy. The GNSS time series data were split into three sets: training, validation, and testing. The training set comprises data from July 2009 to December 2018. The validation set covers data from January 2019 to December 2020, and the testing set includes data from January 2021 to December 2022. This split ensures that the models are trained on a substantial portion of the data while storing enough data for validation and testing.
Table 3 shows the hyperparameters and initial values for the training process.
The models were trained using the backpropagation algorithm to minimize the loss function. The training process was monitored using loss and accuracy metrics, with the XGBoost model showing a steady decrease in loss from 25% to 7% and accuracy improvement from 75% to 93%, while the LSTM model saw its loss reduced from 27% to 9% and accuracy increased from 70% to 90% over 50 epochs. The loss and accuracy curves for both models are plotted in
Figure 4. The XGBoost model achieved a training loss of 7%, while the LSTM model achieved a training loss of 9%. The training accuracy for the XGBoost model reached 93%, whereas the LSTM model attained a training accuracy of 90%.
Figure 5 illustrates the time series components utilized for training the XGBoost and LSTM models.
The validation process employed 15% of the data as the validation set. The models were assessed on this set to identify the optimal hyperparameters. For the XGBoost model, hyperparameter tuning was conducted using Grid Search, while for the LSTM model, Random Search was adopted as given in
Table 4. It seems that there are no strong differences in the results between the initial values of the training process and the tuned hyperparameters. The same values were obtained as best fitted for most of the hyperparameters.
Once the best model and hyperparameters were selected, the final evaluation was performed on the testing set to assess the models’ generalization abilities. The final testing phase utilized the remaining 15% of the data, spanning from January 2021 to December 2022. This evaluation aimed to test the model performances for the “new” data. Comparing the testing results with the validation results revealed consistent performance across both phases, indicating no significant overfitting or underfitting (
Figure 6).
The XGBoost model achieved a testing MAE of 1.8 mm and RMSE of 2.2 mm, which were closely aligned with the validation MAE of 1.7 mm and RMSE of 2.1 mm, demonstrating consistent predictive accuracy. This consistency implies the model’s robustness and reliability in predicting GNSS time series data for removing trend and seasonal signals. Similarly, the LSTM model’s testing metrics were in alignment with its validation metrics, although slightly lower than those of the XGBoost model.
The results, summarized in
Table 5, show that both models achieved
values of 0.84 for XGBoost and 0.81 for LSTM, indicating a strong ability to explain 84% and 81% of the variance in the data, respectively. The ability to accurately remove linear trends and seasonal variations from the GNSS time series data is crucial for isolating the tectonic signals of interest. Moreover, the evaluation metrics show the models’ capacity to handle complex, multi-dimensional classified time series data effectively. The consistent performance across training, validation, and testing phases can be interpreted as a contribution to more precisely detecting discontinuities. The model results also indicate the effectiveness of using machine learning techniques for preprocessing GNSS time series to monitor the general characteristic(s) of a long-term time series.
4.2. Residual Analysis
The residual analysis section aims to rigorously evaluate the performance of the XGBoost and LSTM models in detecting discontinuities within the GNSS time series data. After removing the linear trends and seasonal variations, we assume that the residuals primarily represent tectonic signals, including potential discontinuities caused by seismic events. In this study, we define a discontinuity as a sudden change in the GNSS time series exceeding a threshold value of 10 mm. We also investigate the impact of varying the threshold to 5 mm and 20 mm to investigate the robustness of the initial model. By comparing the model-detected discontinuities with an established earthquake catalog, we aim to validate the accuracy and reliability of our models. This analysis not only highlights the strengths and weaknesses of the XGBoost and LSTM models but also provides insights into the effectiveness of different threshold values in capturing significant seismic events.
Figure 7 shows the detrended residual time series for the ONIY station and the segmentation of the time series for the discontinuity analysis. Here, it is worthy noting that we mostly follow the aforementioned strategies and parameters for the residual analysis as well. The most important difference is implementing a displacement threshold for the feature classification.
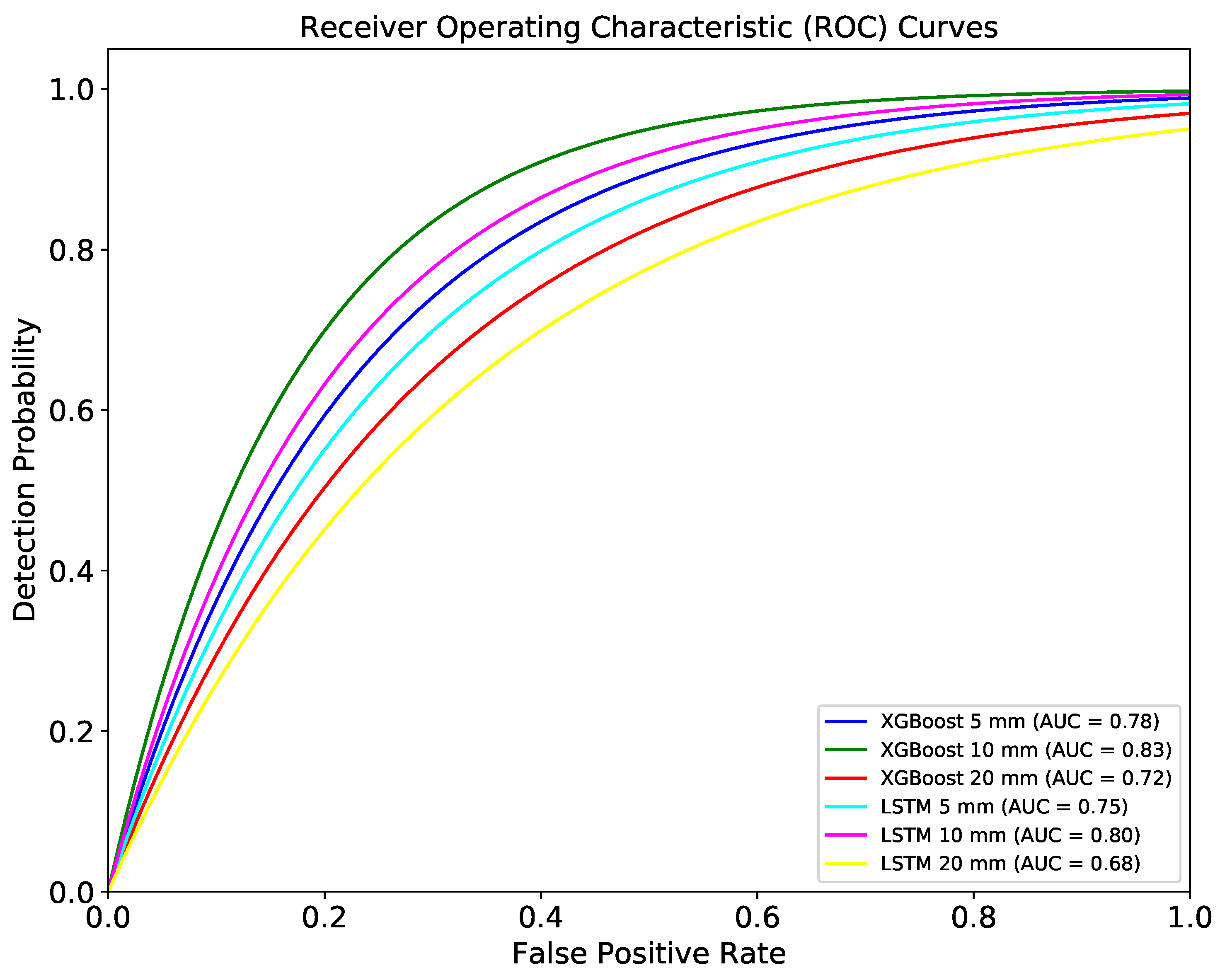
ROC and AUC are particularly valuable over the residual analysis because they allow us to assess how well the models can identify true discontinuities within the residuals of the GNSS time series. By comparing the ROC curves of both models, we can obtain further information into their relative performance and robustness under varying threshold conditions. Additionally, AUC provides a single scalar value that summarizes the models’ performance, making it easier to compare and interpret results. We calculate the ROC curves and AUC values for both models across different threshold values (5 mm, 10 mm, and 20 mm) to understand the impact of threshold selection on model performance. The ROC and AUC curves provide a detailed evaluation of the XGBoost and LSTM models’ performance in detecting discontinuities within the residuals of the GNSS time series. As shown in
Figure 8, the ROC curves for both models were plotted for three different threshold values as 5 mm, 10 mm, and 20 mm. The AUC values for each threshold provide a clear quantitative measure of the models’ ability to discriminate between true discontinuities and false detections. For the XGBoost model, the AUC values were 0.79, 0.83, and 0.76 for the 5 mm, 10 mm, and 20 mm thresholds, respectively. This indicates that the model performs exceptionally well in distinguishing discontinuities, with the highest discriminative power observed at the 10 mm threshold. The LSTM model, on the other hand, achieved AUC values of 0.74, 0.78, and 0.76 for the same thresholds.
The ROC curves highlight that both models maintain high true positive rates with relatively low false positive rates, particularly at the 10 mm threshold. However, the XGBoost model consistently outperforms the LSTM model, as evidenced by its higher AUC values. This suggests that XGBoost has a better capability of accurately detecting discontinuities within the residual data, making it a more reliable choice for this application.
The confusion matrix results for the training phase of the XGBoost and LSTM models reveal extra implications for their performance in detecting discontinuities within the GNSS time series data. For the XGBoost model, the confusion matrix indicates a 0.79 true positive rate (
TP+
TP′), a 0.16 false positive rate, and a 0.21 false negative rate. These results suggest that the model has a high true positive rate, indicating its capability of correctly identifying discontinuities. The relatively low number of false positives and false negatives further shows the model’s precision and recall, reinforcing its robustness in handling the training data. In contrast, the LSTM model’s confusion matrix shows 0.73 true positive, 0.09 false positive, and 0.27 false negative rates, as shown in
Figure 9. While the LSTM model also demonstrates a high true positive rate, it also exhibits a lower number of false positives compared to the XGBoost model. It might be interpreted that a lower false positive rate indicates the reliability of the LSTM model in terms of minimizing incorrect identifications of non-events as events.
Moreover, the XGBoost model achieves an MAE of 1.94 mm, RMSE of 2.38 mm, and R² of 0.77, indicating its higher predictive accuracy and degree of explained variance. The LSTM model, with an MAE of 2.16 mm, RMSE of 2.70 mm, and R² of 0.75, performs well but lags slightly behind the XGBoost model. The precision, recall, and F1 score results provide insightful comparisons between the models. XGBoost demonstrates a balanced performance with a solid trade-off between precision and recall, indicating its robustness in correctly identifying true events while maintaining a reasonable rate of false positives. In contrast, the LSTM model shows higher precision, suggesting it is better at minimizing false positives, thus ensuring that most of its positive predictions are accurate. However, LSTM’s lower recall values to a slight weakness in realizing all true events, which might lead to missing some actual events. Despite this, the F1 scores of both models are comparable, indicating that each offers valuable strengths depending on the specific requirements of minimizing false positives or maximizing the detection of true events.
Figure 10 illustrates the time series of BTMN station and actual and detected (both true and false) discontinuities. During the training phase of our analysis, both models were evaluated for their ability to accurately detect discontinuities in GNSS time series data from stations located within 100 km of actual seismic events. For this part of the study, we focused on 80 events to train the models. The True Positive (
TP) rates were particularly notable for the XGBoost model, indicating its capability of accurately identifying discontinuities. For instance, at station BTMN, XGBoost identified 8 out of the 10 events correctly, while the LSTM model identified 6. This higher
TP rate for XGBoost indicates its effectiveness in learning and predicting precise discontinuities during the training phase.
Conversely, the LSTM model exhibited a slight advantage in reducing FPs, highlighting its sensitivity in detecting subtle changes. At station CANK, LSTM showed one FP compared to three for XGBoost, demonstrating LSTM’s precision in distinguishing between true and false events. However, XGBoost maintained a lower FN rate overall, implying fewer incorrect predictions of discontinuities. XGBoost recorded two FN cases, whereas LSTM had three, suggesting that LSTM’s architecture is slightly more adept at capturing less obvious shifts.
When evaluating the True Positive Prime (TP′) values, which reflect detection within the same window but not on the exact date, both models performed sufficiently well. For example, XGBoost achieved nine TP′ cases, while LSTM recorded seven for the ELAZ station. This shows that both models can reliably identify shifts within a reasonable timeframe, though XGBoost exhibited slightly better accuracy.
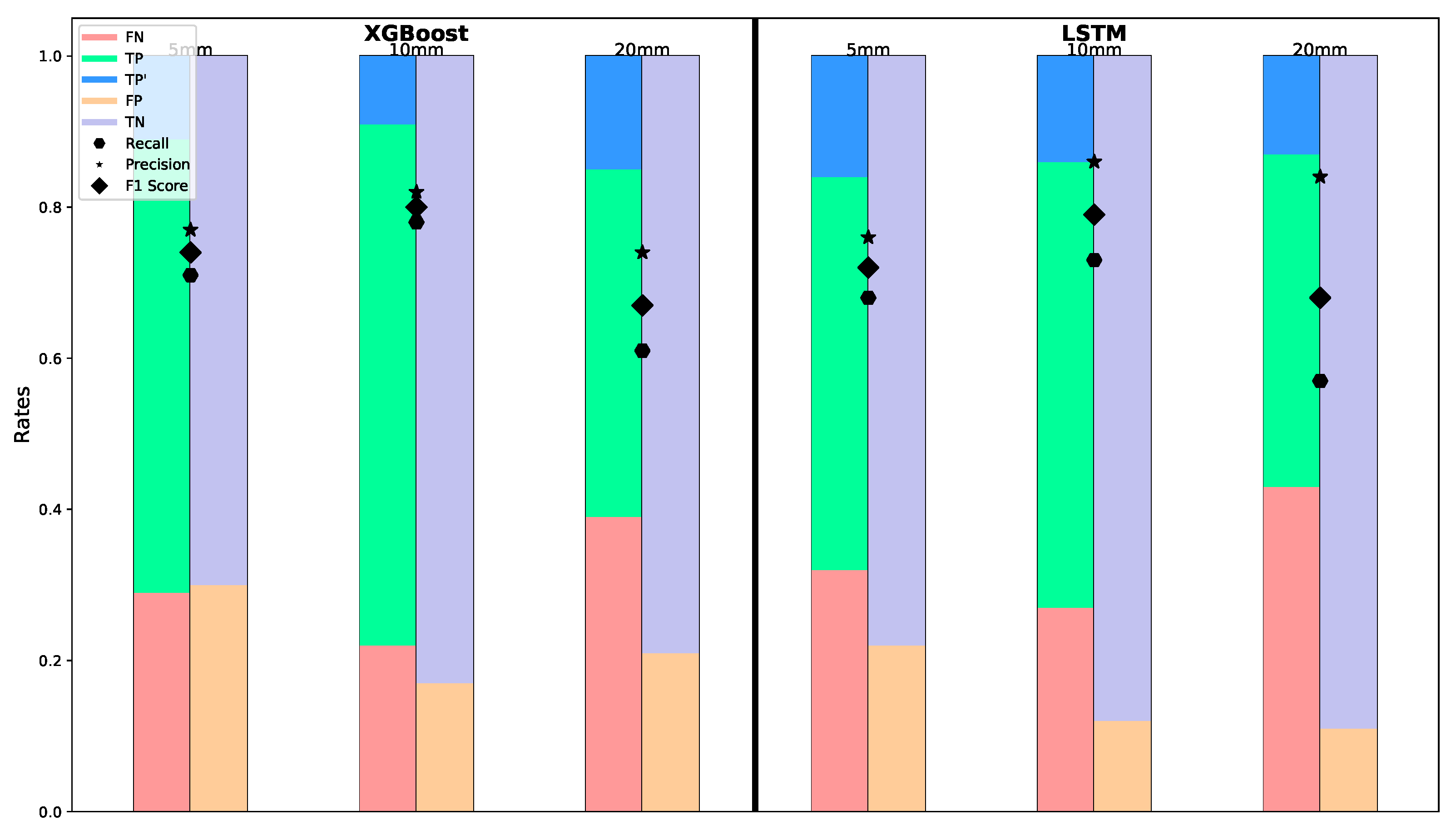
The confusion matrix results for the testing phase, on the other hand, have a very similar pattern with training data. It indicates both models are capable of learning sufficient information from their training process The similar rate with validation also implies the selection of hyperparameters. The precision of the XGBoost model in the testing phase stands at 0.82, recall at 0.78, and F1 score at 0.80, while the LSTM model has 0.86, 0.73 and 0.79, respectively (
Figure 11). The LSTM model scores reflect a balanced but slightly lower performance across these metrics compared to the XGBoost model.
The comparison of the evaluation metrics, with XGBoost achieving an overall precision of 82% and recall of 78%, and confusion matrix results indicates the model’s robustness and reliability in detecting discontinuities within the GNSS time series data. In our analysis, we evaluated the performance of XGBoost and LSTM models in detecting discontinuities within GNSS time series data across stations located within 100 km of actual seismic events. Based on the analysis of over 460 events that occurred within the relevant time frame and consistent with the GNSS time series in the zone of interest, both models demonstrated significant capabilities, each with distinct strengths. The True Positive (TP) rates were higher for the XGBoost model, indicating its ability to detect exact discontinuities accurately. For instance, the XGBoost model has a 0.9 TP for the MARD station which is one of the best scores among the stations.
However, the LSTM model showed better performance in terms of the False Positive (FP) rate, showing that it made fewer incorrect predictions of discontinuities when none existed. This suggests that LSTM is more precise in its predictions, reducing the likelihood of false alarms. For the station BEYS, LSTM had two FP cases compared to five for XGBoost, indicating that LSTM is more sensitive to discriminating oscillations with discontinuities. This sensitivity can be critical in ensuring that minor but significant shifts are not overlooked. The LSTM model’s ability to interpret minor discontinuities, reflected in its 86% precision rate, can be attributed to its recurrent neural network architecture, which effectively captures temporal dependencies and patterns over time. Additionally, the True Negative (TN) rates were fairly comparable between the two models, suggesting that both models are equally effective in correctly identifying periods of stability in the time series data. Furthermore, when considering True Positive Prime (TP′) values, both models showed considerable effectiveness. For instance, five TP′ cases were detected for both models at the RHIY station. This indicates that both models can identify shifts within reasonable proximity to the actual event date.
Our analysis reveals that the best-fitting models for both methods demonstrate a robust ability to detect seismic events (Mw ≥ 4.0). Particularly, these models achieve an impressive precision of approximately 85%. This high precision indicates the reliability of our models in identifying significant seismic events, thereby reducing the rate of false positives and enhancing the overall accuracy of our predictions. Notably, it is important to reiterate that we obtained this score by only taking into account the nearest station of an earthquake. On the other hand, both models successfully detected all discontinuities corresponding to seismic events larger than Mw 6.0 for all stations within the 100 km radius buffer zone. The consistent detection of these larger events highlights the models’ reliability particularly concerning larger events that can be evaluated as "hazards".





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}