1. Introduction
Optically complex coastal and inshore waters represent some of the most productive aquatic environments worldwide [
1] and contribute significantly to global biogeochemical cycles [
2], despite their relatively small area compared with the open oceans. Around 37% of the world’s population, circa 3 billion people, live within 100 km of the coast, relying on resources therefrom for human consumption, food production, industry including terrestrial and coastal fisheries or aquaculture, as well as nature and recreation services. Coastal systems are also one of the marine areas most highly impacted by human activities [
3,
4]; thus, there emerges a natural interest to monitor these regions, over large areas, under changing human demographic and climate conditions. This creates a strong motivation to provide operational monitoring over large coastal areas, but efforts to produce a seamless product from inland waters to the open ocean are hindered by algorithm limitations. Transitional waters (defined as estuaries, lagoons, deltas, and river mouths) introduce particular challenges for Earth Observation (EO)-based optical water quality indicator algorithm development. Water reflectance properties are influenced by coastal processes such as river inputs, sediment resuspension (due to forcing from wind or tidal movement), bottom reflectance, adjacency to land effects, and algal or cyanobacterial blooms. The optical complexity of inland waters exceeds that of open marine systems [
5] and it is reasonable to assume that transitional waters cover at least as much of the complexity represented within both these environments. Local and regional algorithm development can achieve higher performance for predicting water quality indicators as compared to global algorithms, such as suspended particulate matter (SPM) or chlorophyll-a (Chl-a), but it is difficult to determine the applicability of these algorithms for different areas and/or time periods [
6,
7]. Some have suggested that it is not feasible to develop a universal bio-optical parameter algorithm that performs optimally in phytoplankton, SPM, and colored dissolved organic matter (CDOM)-dominated waters [
8]. Using disparate regional algorithms for these transitional water systems can produce artifacts along mixing boundaries, which hinder intra-system comparison and pan-regional monitoring efforts. Further artifacts can be introduced from errors in atmospheric correction processing, which may be tuned differently for fresh- or saltwater systems. Optical water quality indicators, hereafter referred to simply as water quality (WQ), have largely been developed separately for freshwater, saltwater, or transitional waters systems. Identifying optically similar water types, with different associated optimal WQ algorithms, across these regions provides a pathway to address these difficulties.
A set of optical water types (OWT) can be regarded as a simplified representation of the spectral variability within the training data taken from a particular system. An OWT set can either be used in its own right to determine trends in the variation of the study system or provide a basis for WQ algorithm improvement. It is well-established to utilize water spectral typologies as a basis for the delineation of water parcels with distinct properties [
5,
7,
9,
10]. The creation of an OWT set can be broken into four steps: (i) the determination of a representative and balanced training dataset which sufficiently captures the space/time variability of the study system, (ii) focusing cluster formation through the normalization of the training data prior to clustering, (iii) the selection and application of a cluster formation optimization routine, and (iv) the membership assignment of novel data to those clusters. The question of sufficient representative training data can be challenging, often as a result of lacking a priori awareness of short-term or small-scale events within the study system. There are two general schools of thought regarding the appropriate source of training data for clustering, discussed in more detail in Methods
Section 2.4. Following training data selection, the normalization of training data impacts which spectral features the cluster formation process optimally separates. Mélin et al. [
6] discuss how integral normalization of the training data shifts the focus of the OWT cluster set distribution from the separation of particulate gradient concentrations (mainly impacting spectral amplitude) to absorption parameters (mainly impacting spectral shape). Eleveld et al. [
11] compared cluster set performance with and without integral normalization, concluding that very dark, high-CDOM-absorbing lakes were better represented with integral normalization while shallow high-reflecting lakes with high sediment load were better represented without.
OWT cluster sets can be determined using techniques including hard clustering k-means [
8,
12,
13,
14,
15] and the related ISODATA method [
6], soft clustering fuzzy c-means [
11,
16,
17] and the hierarchical Ward’s algorithm [
18,
19,
20], the Gordon model [
21], max-classification [
22], and self-organizing maps [
23]. Once clusters have been identified from a training dataset, novel data are assigned memberships to clusters based on a variety of metrics and sometimes irrespective of whether a fuzzy clustering scheme was used in the cluster formation optimization process. In the Ocean Colour-Climate Change Initiative (OC-CCI), overall error, bias, and relative error were reduced for open-ocean WQ products using a blended algorithm approach based on OWT fuzzy c-means classification [
7], which is now part of the operational OC-CCI Chl-a processing chain. Significant improvement in retrieval accuracy (25%) for inland Chl-a products was achieved using retuned algorithms with parameters optimized for each OWT [
5,
24], and is currently used in the operational Lakes-Climate Change Initiative (Lakes-CCI) processing chain. While there are an ever-increasing number of OWT cluster sets being published, relatively little comparison between sets has occurred to examine the similarity or dissimilarity of classes, for instance, as with a unique OWT class not captured within another set.
The CERTO (Copernicus Evolution—Research for harmonised and Transitional water Observation) project focused on closing remote sensing knowledge gaps in transitional waters and improving coastal water quality monitoring through the harmonization of EO-derived WQ products. In this study, we focus on the following hypotheses within the context of CERTO: (1) fuzzy clustering offers valuable site-specific insights into transitional water systems, (2) it is feasible to compare and merge cluster sets from various sites to generate a pan-regional representative cluster set, and (3) the methods employed in this study can feasibly be extrapolated to other less explored regions. A global OWT cluster set which retains sufficient regional specificity would offer an advancement in water quality data collection and interpretation across diverse aquatic environments, thus helping to remedy the monitoring gap of coastal and transitional marine systems.
2. Materials and Methods
2.1. Overview
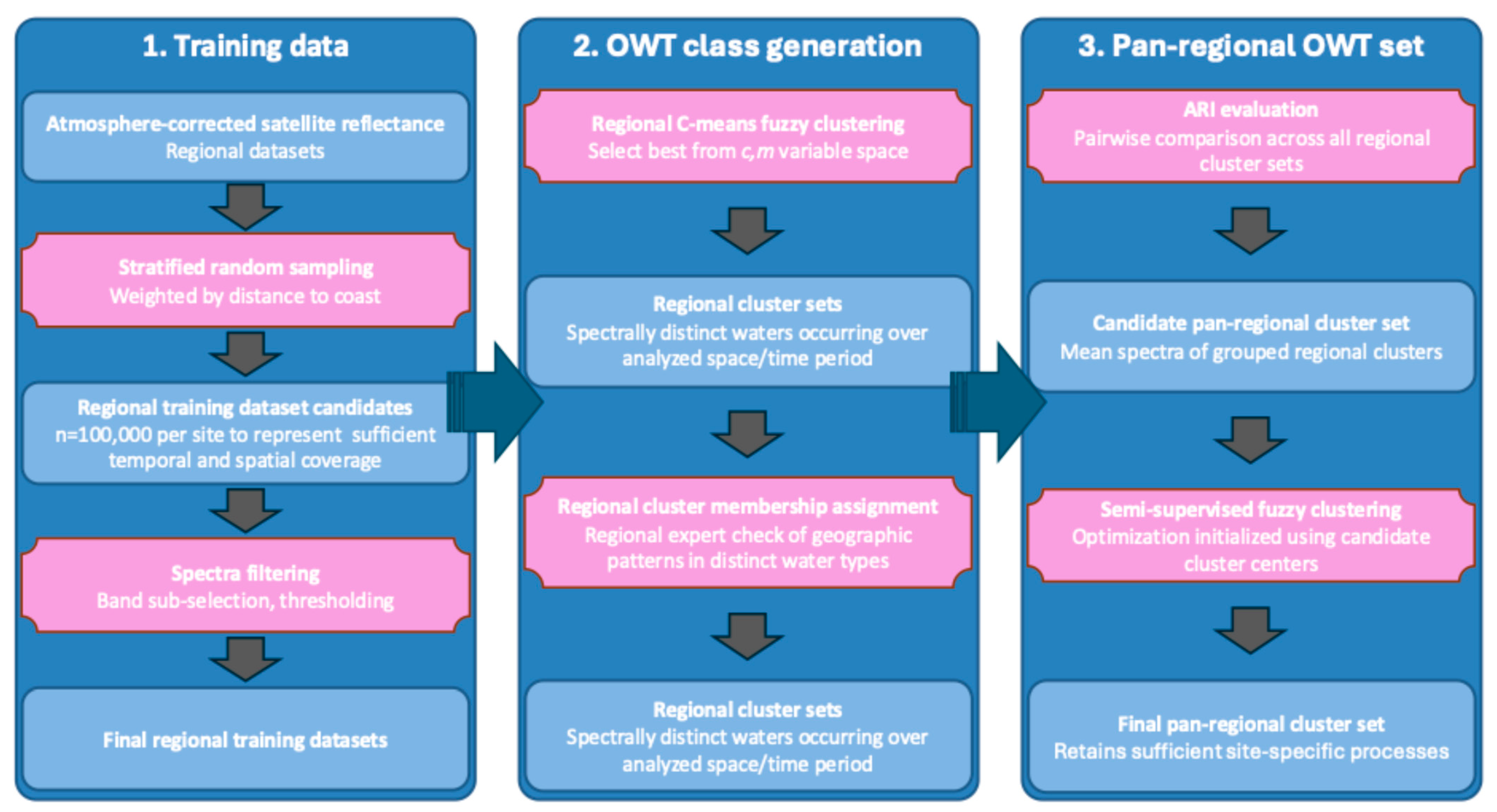
Figure 1 provides an overview of the methodological steps for regional and pan-regional OWT steps. In the first step, representative training data for each study site were compiled, taking into account sufficient temporal and spatial coverage to capture small-area and rare events in each region. In the second step, these training data were used to generate OWT classes, or clusters, with a fuzzy clustering method to represent spectrally distinct waters occurring over the analyzed space/time period for each site. Using the identified OWT classes, membership values were assigned to each cluster for all water pixels within a satellite image, highlighting through high membership values where geographically a particular spectrally distinct water type is dominant. Spatiotemporal patterns in OWT coverage were checked with regional site leads to determine if regional OWT clusters represented site-specific events or annual flux patterns. In a final step, regional clusters were compared pairwise to build a wider representative cluster set, which was then used as an input to a semi-supervised cluster optimization to produce a pan-regional cluster set able to sufficiently capture site-specific processes.
2.2. Study Areas
The six sites (
Figure 2) consisted of three delta/lagoon systems and three estuary systems. The former group includes the Curonian Lagoon stretching between Lithuania and Russia bordering the Baltic Sea, the Danube Razelm–Sinoe Lagoon System in Romania flowing into the Black Sea, and the Venice Lagoon located in Italy connected to the northwestern Adriatic Sea. The latter group comprises the Elbe Estuary in Germany flowing into the German Bight, the Tagus and Sado Estuaries located in Portugal, and the Tamar Estuary connected to Plymouth Sound in the UK.
For brevity, the Tagus and Sado Estuaries are used as the example system within the main text, while site overviews for the other areas are provided in the
Supplemental Material. The Tagus Estuary covers 34,000 hectares, representing the largest estuary system in Western Europe, located within the city limits of Lisbon, Portugal. The Tagus River originates in Spain and eventually merges with the Atlantic Ocean after flowing through Lisbon. It is a semi-diurnal mesotidal system with an average tidal range at the seaward side of 2.4 m [
25]. The estuary is characterized by a long deep inlet channel reaching depths of about 40 m and an inner bay with an average depth of 7 m. Tidal flats, occupying about 40% of the estuary’s total area [
26], provide important wintering habitat for many waterfowl species. South of the Tagus, the Sado Estuary represents the second largest estuary in Portugal (circa 23,100 hectares). This system also features a shallow basin (average depth of 10 m) with a maximum depth of 50 m in the inlet channel used for navigation. The well-mixed estuary is subject to semi-diurnal mesotidal tides, with amplitude varying between 1.3 m during neaps and 3.5 m during springs [
27]. Water circulation is mainly tidally driven given the low flow rate of the Sado river (0.7 m
3/s in summer to 60.0 m
3/s in winter) [
28].
2.3. Earth Observation Data
EO datasets included acquisitions by the Ocean and Land Colour Instrument (OLCI; Manufacturer: Thales Alenia Space, Cannes, France) onboard Sentinel-3 platforms (3A and 3B) and the MultiSpectral Instrument (MSI; Manufacturer: Airbus Defense and Space, Paris, France) onboard Sentinel-2 platforms (2A and 2B), both multi-satellite missions within the European Copernicus Programme. Sentinel-3A was launched in February 2016 and was joined by Sentinel-3B in April 2018. The OLCI sensor is an along-track (push broom) scanner providing 21 spectral bands from the optical to the near-infrared (400 nm to 1020 nm). Data have spatial resolution down to 300 m and are operationally managed by the European Organisation for the Exploitation of Meteorological Satellites (EUMETSAT). The Sentinel-3 constellation provides a revisit time of less than two days at the equator for OLCI data. Sentinel-2A was launched in June 2015, followed by Sentinel-2B in March 2017. The MSI sensor is also an along-track scanner, providing 13 spectral bands ranging from the optical to the short-wave infrared (490 nm to 1370 nm). Data are provided with spatial resolutions of 10, 20, and 60 m, dependent upon the band. High-resolution imagery from MSI is designed to complement SPOT-5 and Landsat-8/9 missions, with a core focus being land classification but, owing to key wavebands in the near and shortwave infrared, is also used for water remote sensing purposes, in particular smaller inland water bodies [
29,
30,
31]. The Sentinel-2 constellation provides a revisit time of 2–3 days at mid-latitudes. Data from both sensors were atmospherically corrected using the
Calimnos processing chain [
32]. The first half of the processing chain used Idepix (Identification of Pixel properties, in SNAP 8) masking to remove land, cloud, and spurious data points with high uncertainty [
33]. In the second half of the processing chain, Polymer v4.15 is implemented for atmospheric correction [
34,
35], selected for its relatively high performance with Sentinel products [
36,
37], optimized for inland water remote sensing [
33,
38].
2.4. Building Training Data
The appropriate sourcing of training data for clustering is an area of active discussion, which one can separate into two positions: (i) in situ hyperspectral data, and (ii) satellite reflectance data. In this study, we use satellite reflectance data alone for model training, given the following considerations. In situ hyperspectral data (i) will be least impacted by corrections for atmospheric effects and provide a basis through convolution plus inverse atmospheric correction modeling to translate developed hyperspectral cluster sets to the multispectral band set of a particular satellite sensor. Fuzzy clustering efforts in coastal and inland waters to date, such as those in [
5,
20,
39], used in situ hyperspectral data as training data. However, in situ data are often limited in their representation of the full variability over space and time of the entire study system [
10], and thus run the risk of being less representative of system variability compared to a multi-year satellite acquisition database. Furthermore, the applicability of use on novel satellite sensor data is highly dependent on atmospheric correction model performance. Using satellite reflectance data (ii) as the basis for cluster formation provides the second position. The quality of these reflectance data is tied to the sensor–atmospheric correction combination, but consistent errors will be accounted for in the cluster formation optimization step. Thus, the acquired cluster set should ideally be implemented on the same processed data as that on which the model has been trained. The capture of spatial and temporal variability in the training data, at least to the level possible with that particular sensor, is improved due to the comprehensive nature of satellite imagery coverage (e.g., a single image can cover the entire study system). The convolution of a satellite OWT set to another sensor may be possible, but results would be questionable. Where cluster sets have been generated and applied to multi-sensor records, such as within OC-CCI, the reflectance data are harmonized and homogenized across sensors before sampling and cluster creation, meaning that the data used for training remains consistently processed with the data to be classified. In this study, following (ii) as utilized in [
10], we created clusters for a particular sensor and atmospheric correction combination that were only used with data from that same sensor plus atmospheric correction processing.
To capture interannual variability for each study site, per site multi-year datasets (2016–2021) were subsampled both temporally and spatially to balance processing efficiency during model training against sufficient coverage to capture rare or relatively small-area events (such as a cyanobacteria bloom or a wind-induced sediment resuspension event). Building a robust, representative training dataset benefits from extensive, long-term knowledge of the study site, and thus continual communication with the CERTO regional site leads during training dataset creation was of central importance. Based on these criteria, target training data size was set to 100,000 sample points per region. Spatial sampling was designed with a stratified random approach, with sampling density increasing closer to the coastline and decreasing further from shore. Stratified random sampling was selected to ensure that spectral diversity across the study area had balanced representation (in both time and space), with weighting the sample frequency by distance from land aimed to equalize input from smaller coastal and inland waters with that from larger ocean areas.
Winter months with low incident light levels were excluded (solar noon elevation < 30° calculated using NOAA solcalc,
https://gml.noaa.gov/grad/solcalc/, accessed on 11 June 2024, overview in
Table 1). Bands from each sensor that were heavily affected by spurious atmospheric correction results were excluded, resulting in the following final band lists used in the cluster optimization: for OLCI, 400, 412, 443, 490, 510, 560, 620, 665, 674, 681, 709, 754, 779, 865, and 885 nm; for MSI, 443, 490, 560, 665, 705, 740, 783, and 865 nm. Furthermore, MSI data from the same relative orbit for each region were used to ensure that no part of the total study site was sampled more frequently than another.
2.5. Fuzzy Water Clustering: Scikit-Learn-Compatible Flexible Tool
To enable easy implementation of fuzzy c-means clustering and parameter optimization, we created the Fuzzy Water Clustering package in Python v3.9 (
https://github.com/CERTO-project/D4.3_Classification_toolbox, accessed on 11 June 2024). It is extensible, integrates with the scikit-learn v1.0 machine learning framework and is not necessarily specific to water related data. At its heart is the c-means model, a fuzzy c-means clustering routine that can be combined with scikit-learn transformers, such as Principal Component Analysis (PCA), to form new models. Parameters for these models can be optimized using cross-validation routines from scikit-learn and their performance evaluated against several scoring metrics (
Table 2). A wrapper is provided which changes the input and output of scikit-learn estimators from 2D arrays to xarray datasets, greatly improving processing efficiency. This is carried out under the assumption that each pixel is an independent measurement and each variable is a feature. In this manner, clustering models can be trained directly on opened netcdf datasets and the prediction of class membership can be performed at scale by using the dask.array package to address data on disk one chunk at a time.
2.6. Regional Cluster Set Formation
Training data were transformed prior to clustering. Spectral curve integral normalization is well accepted [
5,
20,
39], which allows cluster optimization to be focused on groups of spectral shape as opposed to amplitude. Using the integral of each sample introduces a problem of invertibility when implementing identified cluster centers to assign OWT memberships to new datasets in the original reflectance space. We thus elected a log transformation for each feature (i.e., satellite band) to retain invertibility and for consistency with earlier versions used in OC-CCI. Furthermore, a log transformation will retain normality of the log-normal distributed reflectance data while reducing amplitude differences. Some training data contained negative reflectance within particular bands, arising from the atmospheric correction step. In order to retain as much of this information as possible in the cluster formation step and allow the exploration of clustering as a tool to identify these problematic pixels, a small additive shift was implemented prior to log transformation, chosen to balance reducing data loss while keeping the shift as small as possible. A PCA was run on transformed data, with all components (equal to the number of input features from the training data) being used as input for the c-means clustering optimization. For c-means, two parameters must be set a priori to run the optimization: the number of clusters (
c) and degree of fuzziness (
m). We explored the expected parameter space for these two factors using a grid search routine as part of the Fuzzy Water Clustering package. C-means cluster optimization was carried out for all
c/
m parameter pair nodes using Euclidean distance, which in PCA transformed space is proportional to Mahalanobis distance [
46,
47]. The best performing
c/m parameter configuration was chosen based on selected scoring metrics (
Table 2), which provided the optimized cluster statistics (cluster centers, covariance matrix) for that configuration. To assess cluster membership performance across training data, non-constrained membership values are assigned using the squared Mahalanobis distance and an χ
2 distribution, following [
10,
48,
49]. For visualization, cluster geospatial performance in novel imagery was assessed from each region over the entire study period (2016–2021) together with regional teams using constrained Euclidean distance memberships (with 1.0 indicating perfect cluster membership).
2.7. Pan-Regional Cluster Set Formation
The initial testing of pan-regional clustering with the full training dataset from all six sites (n = 600,000) was unable to capture sufficient site-specific processes, thus regional cluster sets were used to build a better representative pan-regional cluster set. As stated above, some processes (such as cyanobacteria blooms or wind-induced sediment resuspension events) are very short-lived and can happen over relatively short timescales, posing challenges to building a balanced training dataset representative of the variability across all six study sites. Both parametric (Welch’s t-test; given reflectance data within a cluster should be log-normal distributed but still indicate variance heterogeneity) and non-parametric methods were explored; only the latter are presented here for brevity.
Regional clusters were compared pairwise between sets using the Adjusted Rand Index (ARI), the corrected-for-chance version of the Rand Index (
R), where:
with
a being the number of element pairs that are in the same cluster in both regional sets being compared,
b the number of element pairs that are in different clusters for both regional sets, and
c + d the same subset in one but not in the other regional set. The index
R can be understood as the ratio comparing the number of cluster pair assignment agreements (
a + b) to all pairwise comparisons (
a + b + c + d, or
, where
n is the total number of elements). ARI builds on this basis while accounting for different models from random clustering (which can differ in number of clusters or cluster size distribution), where
with
nij being the number of elements in common between cluster
i and cluster
j from each cluster set, respectively (i.e., the intersection of cluster
i and cluster
j),
ai the sum of elements in cluster set
i and
bj the sum of elements in cluster set
j.
To provide information on specific cluster pair similarity between regional sets, ARI was calculated based on one cluster within a set being successively retained and all other clusters within that same set being conglomerated to “other” (and the same being performed with the comparison cluster set). This results in all pairwise comparisons of clusters between the two sets being assigned an ARI score. ARI values can be negative up to one, with those closer to one indicating the cluster pair between regional sets being essentially the same. The grouping of similar regional clusters while retaining those regional clusters which prove unique across all regional cluster sets provided an estimated pan-regional cluster set, which was used for setting the parameter space and as the initialization configuration for a semi-supervised fuzzy clustering analysis combining training data across all six study sites.
4. Discussion
Regional fuzzy clustering was found to provide useful site-specific information for the transitional water systems considered. This was demonstrated through the ability to represent transition zones of freshwater mixing into saline coastal water with per-pixel maximum membership values in excess of 0.60 across all study sites. In particular, this held true for transitional water systems which have proven challenging for monitoring with satellite imagery due to artificial boundaries and artifacts introduced from varying optically active constituent concentrations (phytoplankton- vs SPM- vs CDOM-dominated waters) or differing atmospheric correction algorithm performances between clearer offshore waters and more turbid transition and inshore waters. Optimal cluster parameters for
c and
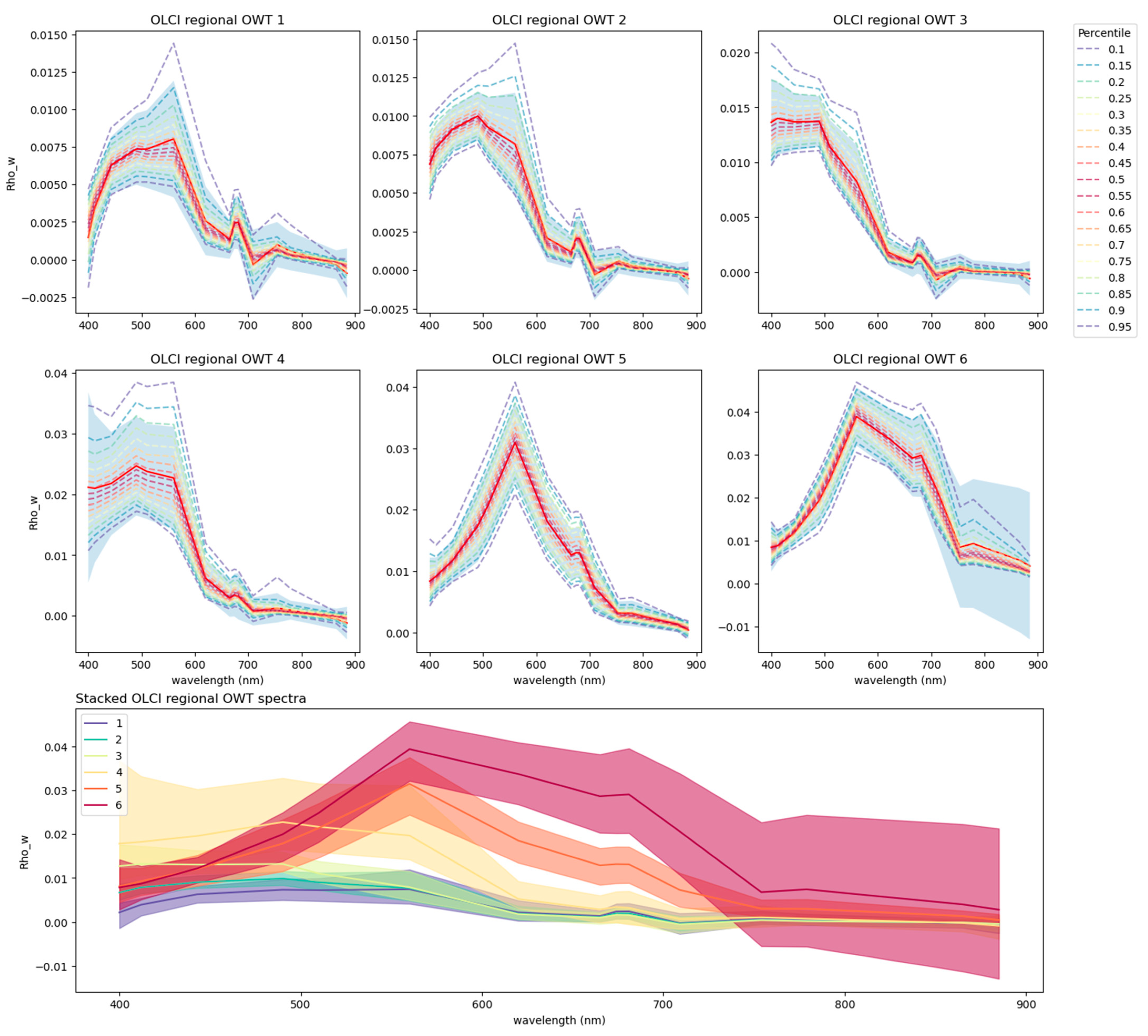
m were determined via a comprehensive grid search. A final regional cluster set was found to reduce multimodality contained within the regional training dataset, better fulfilling the expected log-normal distribution of reflectance from a cohesive single target within an OWT class. The spatial distribution of dominant OWT coverage across the study sites conformed with regional teams’ expert understandings of dynamics for their particular region. Seasonal patterns, due to forcing such as a variation in the river discharge rate, were evident in monthly composite images. It should be noted that despite best efforts, the training data are not free of atmospheric correction impacts from land-water mixed pixels, adjacency effects, and optically shallow waters, as can in part be evidenced by the negative reflectance values seen in
Figure 3,
Figure 6 and
Figure 9. A benefit of using an OWT set on novel data which was trained on data processed the same is that these impacts should inherently be part of the optimization procedure and thus have representation in the OWT classes obtained.
Comparison between regional cluster sets provided the basis for the creation of a pan-regional OWT set that retained site-specific cluster features while combining common OWT classes. Using the non-parametric ARI score, patterns in membership occurrence over both space and time are the basis for grouping similar regional OWT classes. Regional cluster groupings are further confirmed through visual inspection of the spectral curves. The grouped set is used in a semi-supervised cluster analysis to produce a pan-regional OWT set. The pan-regional cluster set has tight standard deviations around cluster center spectra for most classes. Geographic coverage by dominant membership from the pan-regional OWT set suggests that site-specific features highlighted in the regional analyses were retained, but often represented with finer definition (more classes covering spatial variability, as observed in
Figure 13). Viewing the spatial distribution with the dominant OWT from membership values is a useful tool for a simplified understanding of which areas are primarily represented by which OWT classes, but one should remember that this hides the “fuzzy” aspect of the c-mean cluster optimization algorithm. Two or more OWT classes from the pan-regional set could be sufficiently similar in spectral space such that a pixel has high memberships to those classes, with the dominant OWT only determined by minimal differences in membership. The comparison method can be used when analyzing new study sites in order to determine if unique OWT classes occur, and the pan-regional cluster set expanded to better encompass spectral variability from a wider assemblage of transitional water systems. ARI scoring is independent of the cluster method or data transformation implemented. So long as membership values can be calculated based on a common dataset, ARI scoring presents an ideal method for the comparison of OWT cluster sets from different studies.
The impact of increasing spectral resolution, using the Tagus regional clusters from MSI (
Figure 6) to OLCI (
Figure 3) as an example, suggests that while some optically active spectral features are lost with the lower spectral resolution of MSI, regional cluster sets from the two sensors are comparable. The more turbid OWT classes 5 and 6 from both sensors have their max peak in the 560 nm band, and OWT class 6 displays a convex curve between this max peak and the mid-700 nm bands for both OLCI and MSI. OWT classes 3 and 4 from both sensors have peaks at 490 nm, albeit for MSI OWT 4 this peak is secondary to one at 560 nm. Comparing the clearer offshore OWT classes 1 and 2, cluster numbering appears switched between the sensors, with OLCI OWT 2 having a small but relatively pronounced peak at 490 nm, matching the same feature in MSI OWT 1. The OLCI OWT classes display the Chl-a absorption feature between 650 and 700 nm, which is missing from the MSI OWT classes due to the lower spectral resolution of this sensor. A comparison of the geographic distribution between the regional OLCI (
Figure 5) and MSI (
Figure 7) OWT classes shows a similar partition of the Tagus Estuary, although it should be noted that the tidal condition between the Sentinel-2 overpass time and that of Sentinel-3 will be different. OWT classes 1 and 2 from both sensors represent the offshore waters, with a switch in predominant coverage by OLCI OWT 2 to MSI OWT 1 (matching the spectral comparison between the sensor regional OWT sets).
Coherent OWT class sets created from different sensors offer a method for inter-sensor harmonization of EO products. OLCI sensors provide medium-resolution (300 m) daily imagery with a high Signal-To-Noise Ratio (SNR), while MSI sensors provide high-resolution imagery (10–60 m) every 5–10 days with a lower SNR. Across the transitional water sites focused upon within CERTO, large systems such as the Tagus and Sado Estuaries can be well characterized spatially with medium-resolution OLCI data. But smaller systems, such as the Tamar Estuary, are too small in area for sufficient valid pixel coverage by OLCI for insightful characterization. Differences in the estimates of WQ parameters from disparate sensors are an issue, which inhibit the cohesive use of the full satellite imagery portfolio. Coherent sensor-specific OWT classes between MSI and OLCI could be used in a variety of ways, such as filling the temporal gaps between MSI acquisitions with coarser resolution OLCI imagery, or provide high-quality WQ estimates for MSI images based on the same OWT class estimates from OLCI imagery with a higher SNR, allowing for high spatial resolution estimates of WQ in smaller transitional water systems.
We used our determination of common OWT classes between different regional cluster sets to support the coordination of CERTO field campaigns between the respective sites. This use case allowed us to create a consistent dataset across all study sites, representing the full range of WQ conditions present within these regions. The use of harmonized OWT classes helps determine which water masses are well sampled and which should receive more focus in future sampling efforts. In general, OWT coverage maps provide useful information for sampling location planning within field campaigns in order to increase sampling within rarer OWT classes. Furthermore, it is possible to infer the WQ characterization of a specific OWT class at a site where no in situ sampling has occurred, if the equivalent OWT has been sampled and analyzed in other sites.
Future work should focus on making comparisons between pan-regional OWT sets and other widely implemented OWT classifications, such as that of OC-CCI and Lakes-CCI. Each of these cluster sets are based on different types of training data, with OC-CCI clustering based on multi-sensor global satellite reflectance and Lakes-CCI based on in situ hyperspectral data from LIMNADES. As discussed in
Section 2.4, each of these training data approaches provide various benefits and pitfalls, which need to be considered in the context of the intended application of the OWT classes. Wei et al. [
14] performed a pairwise comparison of clusters across seven cluster sets, all trained on different data types and normalization schemes, using minimum cosine distance that focuses on comparing cluster center spectral shape. Nearness in spectral space is a clear indicator of cluster center similarity but, given that one can use OWT class partitioning to decipher the optical complexity and unravel the optical diversity of natural waters globally [
50], a cluster comparison method that takes account of occurrence patterns in geographic and temporal space is just as important. A method such as the ARI comparison technique is well suited for the task of cluster set comparison given that the direct comparison of cluster center spectral curves may be difficult to impossible, depending on data formats. A cross-comparison would allow for determination if a particular OWT classification scheme had identified a unique water type that may have been missing.
5. Conclusions
Fuzzy c-means clustering is a classification tool well suited for transitional water systems through membership representation of mixing processes occurring within river mouths, estuaries, lagoons, and deltas that affect water-leaving reflectance. Cluster analysis at the regional level proved to be valuable to identify site-specific information from transitional water systems, and effectively captured transition zones where freshwater and coastal waters mix. The spatial distribution of dominant OWT coverage across the study sites accurately reflected the expected dynamics for each individual site. We presented a novel cluster set comparison method using ARI scoring over memberships to build a representative pan-regional cluster set that retained site-specific features. The pan-regional OWT set demonstrated here can be used as a basis for per-OWT class calibration of WQ algorithms, from which the optimum performing algorithm can be selected and membership values for those OWT classes used as a basis for a weighted blending of algorithms to produce a final WQ product. This method provides a first attempt to harmonize WQ data products across oceans (OC-CCI, C3S, NASA), regional seas (CMEMS), and inland waters (Lakes-CCI, CLMS). A harmonized EO monitoring system that represents well the continuum from inland aquatic systems to the open ocean would improve coastal water quality monitoring capabilities needed to address international water quality directives.


 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}