1. Introduction
Hyperspectral-high spatial resolution (H
2) [
1] images have finer spectral and spatial information [
2] and can effectively distinguish spectrally similar objects by capturing subtle differences in continuous shape of the spectral features [
3], realizing landmark recognition at the image element level [
4]. H
2 images have been widely used in environmental monitoring, pollution monitoring, geologic exploration, agricultural evaluation, etc. [
5]. However, high dimensionality, a small number of labeled samples, spectral variability, and complex noise effects in H
2 data [
6] make it a great challenge to perform effective feature extraction, which leads to poor classification accuracy and low accuracy of feature recognition [
7].
Traditional machine learning methods have a strong dependence on a priori knowledge and specialized knowledge when extracting features of an HSI, which makes it hard to extract deep features from an HSI [
8]. Deep learning methods can better handle nonlinear data and outperform traditional machine learning-based feature extraction methods [
9]. Convolutional neural networks (CNNs) [
10] are good at extracting effective spectral spatial features from HSIs. Zhong et al. [
11] operated directly on an original HSI and designed an end-to-end spectral spatial residual network (SSRN) using spectral and spatial residual blocks. Roy et al. [
12] constructed a model called HybridSN by concatenating a 2D-CNN and a 3D-CNN to maximize accuracy. However, these methods also exhibit complex structures and high computational requirements [
13]. Recently, transformers [
14] have had good performance in processing HS data due to their self-self attention mechanism. Hong et al. [
15]. proposed a novel network called SpectralFormer, which learns local spectral features from multiple neighboring bands at each coding location. Nonetheless, the transformers-based networks, e.g., ViT [
16], inevitably experience a degradation in performance when processing HSI data [
17]. Johnson et al. [
18] proposed a neuro-fuzzy modeling method for constructing a fitness predictive model. Zhao et al. [
19] proposed a new shuffle Net-CA-SSD lightweight network. Li et al. [
20] proposed a variational autoencoder, GAN, for fault classification. Yu Li et al. [
21] proposed a distillation-constrained prototype representation network for image classification. Bhosle et al. [
22] proposed a deep learning CNN model for digit recognition. Sun et al. [
23] proposed a deep learning data generation method for predicting ice resistance. Wang et al. [
24] proposed a spatio-temporal deep learning model for predicting streamflow. Shao et al. [
25] proposed a task-supervised ANIL for fault classification. Dong et al. [
26] designed a hybrid model with a support vector machine and a gate recurrent unit. Dong et al. [
27] designed a region-based convolutional neural network for epigraphical images. Zhao et al. [
28] designed a interpretable dynamic inference system based on fuzzy broad learning. Yan et al. [
29] designed a lightweight framework using separable multiscale convolution and broadcast self-attention. Wang et al. [
30] designed a deep learning interpretable model with multi-source data fusion. Li et al. [
31] proposed an adaptive weighted ensemble clustering method. Li et al. [
32] proposed an automatic assessment method for depression symptoms. Li et al. [
33] proposed an optimization-based federated learning for non-IID data. Xu et al. [
34] proposed an ensemble clustering method based on structure information. Li et al. [
35] proposed a deep convolutional neural network for automatic diagnosis of depression.
Deep learning-based feature extraction methods for HSIs are widely used because they can better extract the deep features of the image. Traditional convolutional neural networks (CNNs) [
10] need to be trained with a massive number of labeled samples and have a high training time complexity. Graph Convolutional Neural Networks (GCNs) [
36] can handle arbitrary structural data, adaptively learn parameters according to specific feature types, and optimize these parameters, which improves a model’s recognition performance in different feature types compared to traditional CNNs [
37]. Hong et al. [
3] proposed a miniGCN to reduce computation cost and realize the complementary positive aspect between a CNN and a GCN in a small batch. However, pixel-based feature extraction methods generate high-dimensional feature vectors and extract a large amount of redundant information. Therefore, in order to extract features more efficiently, researchers have introduced superpixels for use instead of pixels. Sellars et al. proposed a semi-supervised method (SGL) [
38] that combines superpixels with graphical representations and pure-graph classifiers to greatly reduce the computational overhead. Sheng et al. [
39] designed a multi-scale dynamic graph-based network (MDGCN), exploiting the multi-scale information with dynamic transformation. To enhance the computational efficiency and speed up the training process, Li et al. [
40] designed a new symmetric graph metric learning (SGML) model by introducing a symmetry mechanism, which mitigates the spectral variability through symmetry mechanisms. Although the above methods utilize superpixels instead of pixels to reduce the computational complexity, these methods can only generate features at the superpixel level and fail to take into account subtle features within each superpixel during the spectral feature extraction process. Consequently, classification maps generated by GCNs are sensitive to over-smoothing and produce false boundaries between classes [
17]. To overcome this problem, Liu et al. [
41] proposed a heterogeneous deep network (CEGCN) that utilizes CNNs to complement the superpixel-level features of GCNs by generating local pixel-level features. Moreover, graph encoders and decoders are proposed to solve the incompatibility between CNNs and GCN data. Based on the above idea, the Multi-layer Superpixel Structured Graph U-Net (MSSG-UNet) [
42], which gradually extracts varied scale features from coarse to fine and performs feature fusion, was generated. Meanwhile, in order to better utilize neighboring nodes to prevent information loss, [
36] proposed the graph attention network (GAT), which uses k-nearest neighbors to find the adjacency matrix and compute the weights of different nodes. Dong et al. [
43] used weighted feature fusion of a CNN and a GAT. Ding et al. [
44] designed a fusion network (MFGCN) [
45] and a multi-scale receptive field graph attention neural network (MRGAT). The above improved GCNs and enabled a more comprehensive use of spatial and spectral features by reconfiguring the adjacency matrices; however, converting the connections of the nodes may present superfluous information and degrade the classification performance. Xue et al. designed a multihop GCN using different branches and different hopping graphs [
46], which aggregates multiscale contextual information by hopping. Zhou et al. proposed a fusion network with attention multi-hop graph and multi-scale convolutional (AMGCFN) [
47]. Xiao et al. [
48] proposed a privacy-preserving federated learning system in IIoT. Tao et al. [
49] proposed a memory-guided population stage-wise control spherical search algorithm. However, the above networks are complex in structure and inefficient in model training. Some new methods have been proposed in recent years [
50,
51,
52,
53,
54,
55,
56,
57,
58,
59], which can be used to optimize these models.
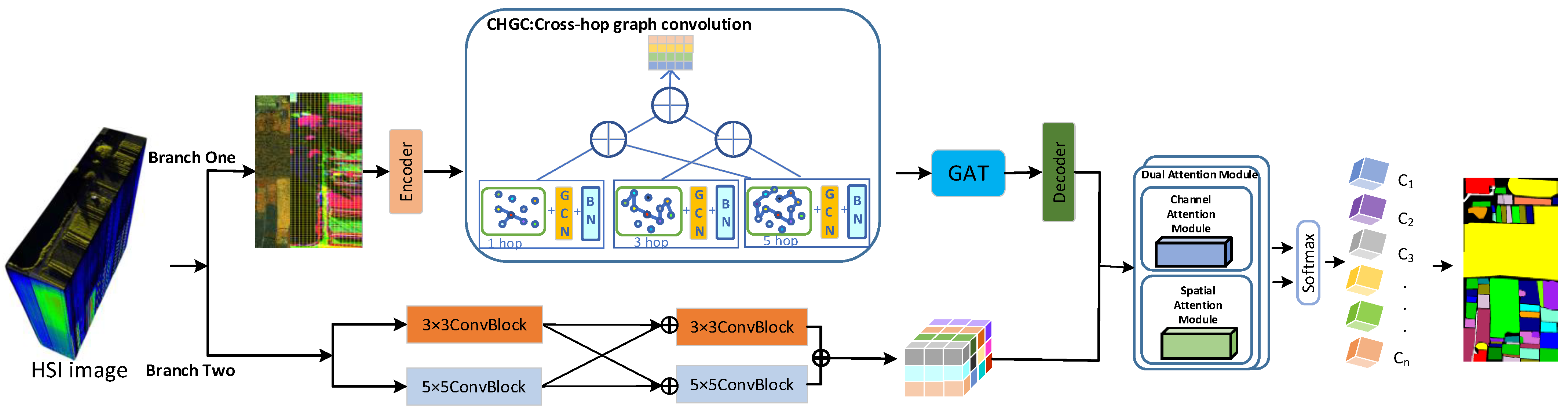
Aimed at solving the above problems in extracting and classifying features from HSIs, such as the inconsistency of superpixel segmentation processing for similar feature classification, the limitation of the traditional single-hop GCN for node characterization, and the loss of information in joint classification of the spatial spectrum, this paper proposes a cross-hop graph network model for H2 image classification (H2-CHGN). The model utilizes two branches consisting of a cross-hop graph attention network (CGAT) and a multiscale convolutional neural network (MCNN) to classify H2 images in parallel. Considering the computational complexity of graph construction, the GCN-based feature extraction first refines the graph nodes by means of superpixel segmentation, then constructs the graph convolution by using the cross-hop graph (replacing the ordinary neighbor-hopping operation with interval-hopping), which is combined with the multi-head GAT to jointly extract the superpixel features in order to obtain more representational global features. CNN-based feature extraction is performed in parallel to obtain multi-scale pixel-level features using improved CNNs. Finally, features from both branches are fused using a two-channel attention mechanism to gain more comprehensive and enriched feature representation. The contributions of this paper are outlined below:
- (1)
A two-branch neural network (CGAT and MCNN) was designed for feature extraction of H2 images separately, which aims at fully leveraging the collective characteristics of hyperspectral imagery, encompassing both the superpixel and pixel levels.
- (2)
A cross-hopping graph operation algorithm was proposed to perform graph convolution operations from near to far, which can better capture the local and global correlation features between spectral features. To better capture multi-scale node features, a pyramid feature extraction structure was used to comprehensively learn multilevel graph structure information.
- (3)
In order to improve the adaptivity of the multilayer graph, a multi-head graph attention mechanism was introduced to portray different aspects of similarity between nodes, thus providing richer feature information.
- (4)
So as to reduce the computational complexity, dual convolutional kernels were utilized in convolutional neural networks using different sizes of convolutional kernels at different layers to extract pixel-level multiscale features by means of cross connectivity. The features from the two branches were fused through the dual-channel attention mechanism, in order to gain a more comprehensive and accurate feature representation.
The subsequent content of this article is organized as follows. The introduction of the H
2-CHGN is in
Section 2. The experimental settings are depicted in
Section 3. In
Section 4, the extensive experiments and analyses are carried out. Finally, summaries are made in
Section 5.
2. Proposed H2-CHGN Framework
We denote the H2 image cube as , and ,, and represent the height, width, and number of spectral bands of the spatial dimension, respectively.
In the H
2-CHGN model, as shown
Figure 1, the CGAT branch first uses superpixel segmentation on the H
2 image to filter out the samples with high spatial correlation with samples to be classified. The data structure transformation is performed through the coder (decoder), which facilitates the operations in the graph space. The cross-hop operation is utilized in graph convolution to broaden the range of graph convolution. For increasing feature diversity, we use the pyramid feature extraction structure to comprehensively learn multilevel graph structure information. Then, the contextual information is captured by graph attention mechanism to obtain more representational global features. Meanwhile, for enriching local features, the MCNN branch extracts multi-scale pixel-level features by parallel cross connectivity with dual convolutional kernels (3 × 3 and 5 × 5). Finally, in order to make image elements more prominent, the features of varied scales are transferred into the dual-channel attention fusion module to obtain fused features, then final classification results are obtained through the
layer.
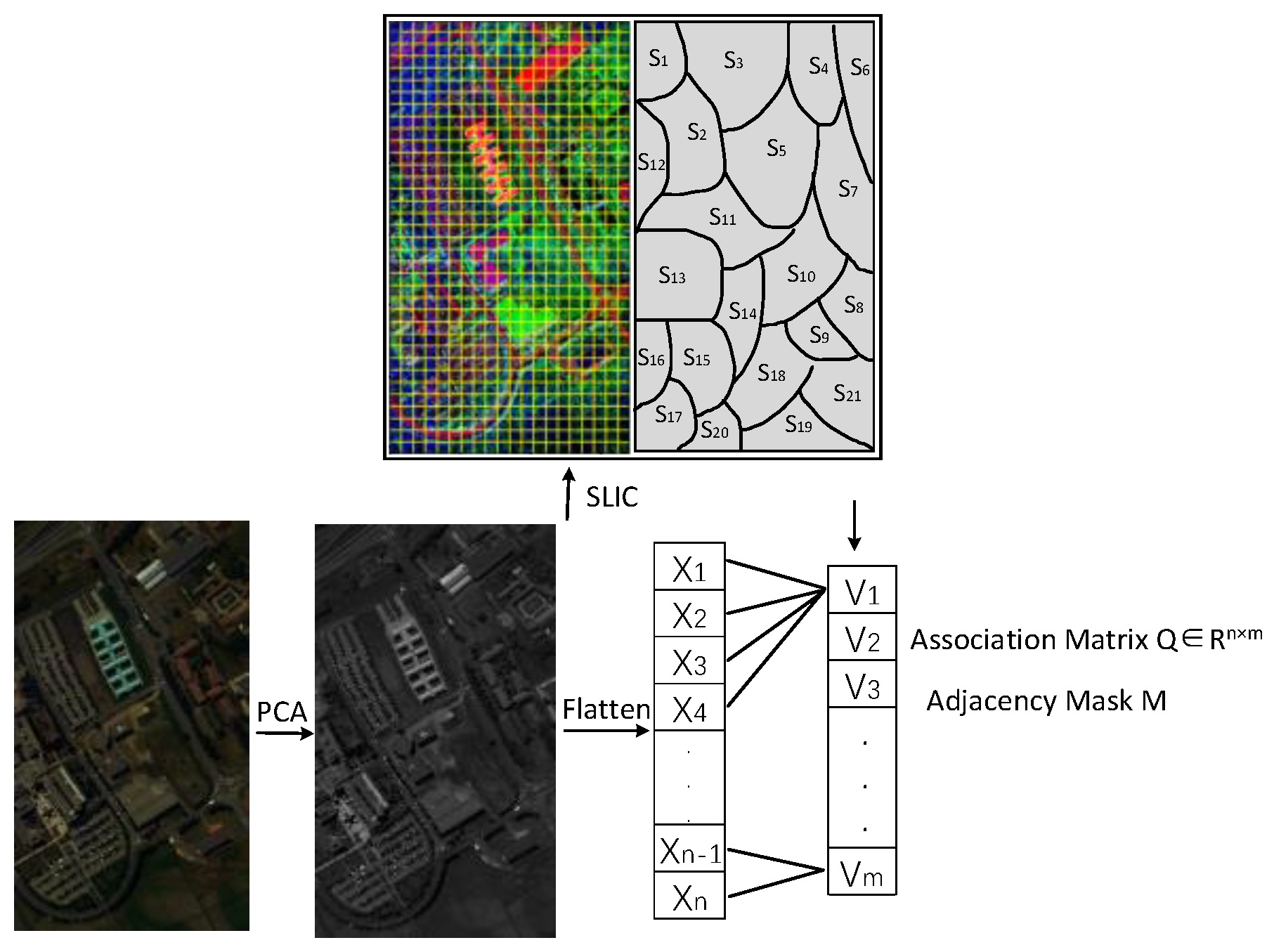
2.1. Graph Construction Process Based on Superpixel Segmentation
In order to apply graph neural networks to an HSI, we need to convert standard Euclidean data like H
2 images into graph data. However, if we directly consider the pixels in H
2 images as graph nodes, the resulting graph must be very large and the computational complexity will be extremely high. Thus, we first applied principal component analysis (PCA) on the original HSI to improve the efficiency of the graph construction process. It is followed by a simple linear iterative clustering (SLIC) method, which generated spatially neighboring and spectrally similar superpixels. The adjacency matrix input into the GCN afterwards is constructed by establishing the adjacency relationship between superpixels, as shown in
Figure 2.
Specifically, an H2 image is divided into superpixels by PCA-SLIC, wherein is the superpixel segmentation scale. Let denote the superpixels set, with as the superpixel, as the number of pixels in , and as the pixel in ( and ).
Since the subsequent output features of the GCN need to be merged with the CNN’s, in order to alleviate the data incompatibility between the two networks, we apply the graphical encoder and decoder proposed in [
41] to perform the data structure conversion. It is assumed that the association matrix of conversion is
and is denoted as follows [
41]:
where
denotes the expansion of original data into spatial dimensions and
denotes the value
at position
. Then the matrix of node v in graph
(
) can be expressed as follows [
41]:
where
is the result of column normalization and
represents the process that encodes the pixel map of the HSI into the graph node of G. The superpixel node features are then mapped back to pixel features using the
equation as follows [
41]:
2.2. Cross-Hop Graph Attention Convolution Module
It is feasible to obtain more node information by the way of stacking multiple convolutional layers in the GCN model; however, this operation will inevitably increase the computational complexity of the network. Merely using a shallow GCN lacks deeper feature information and causes poor classification accuracy. In contrast, the multi-hop graph [
46] has more flexibility and can fully utilize the multi-hop node information to broaden the acceptance domain and mine the potential relationship between hop nodes.
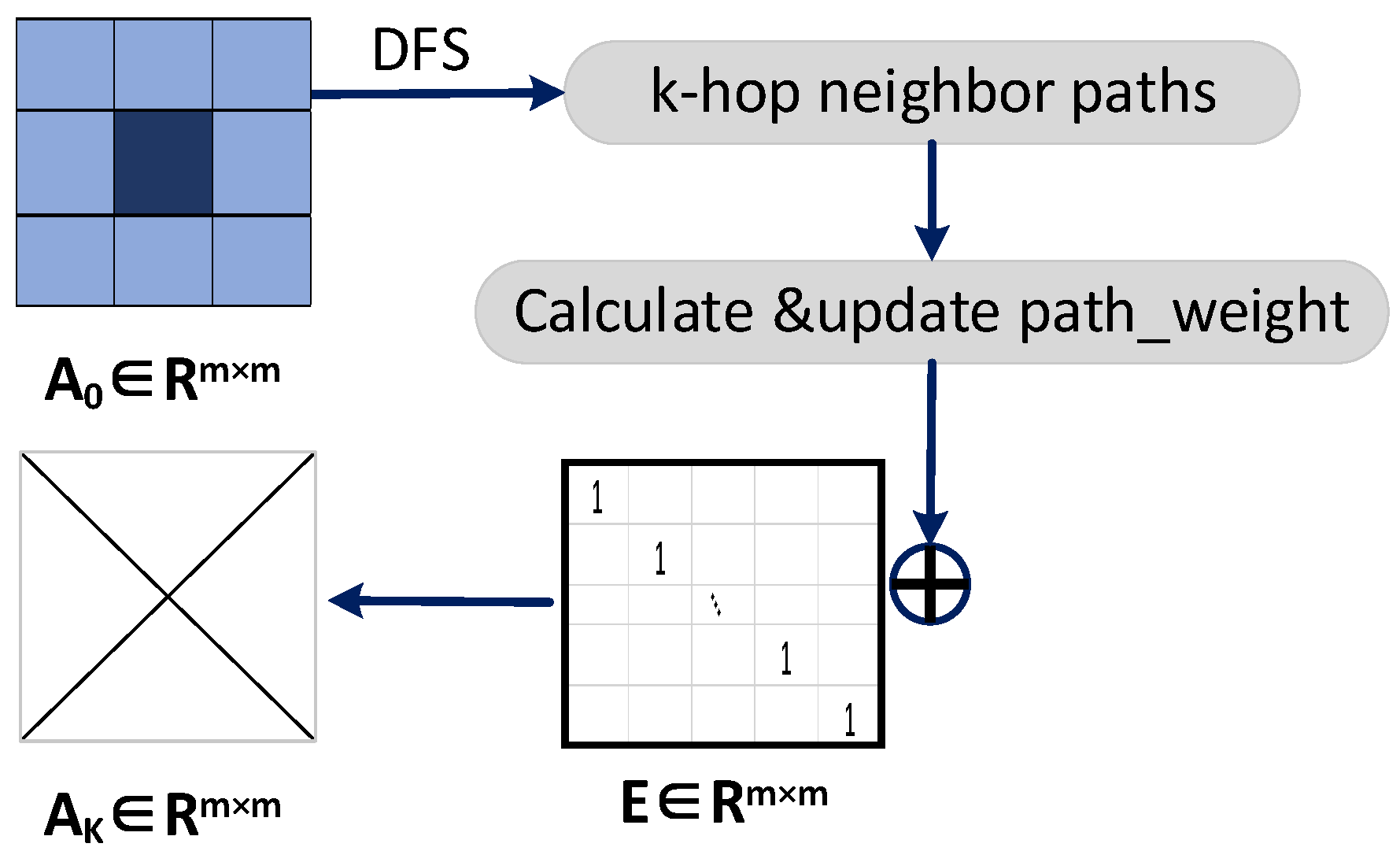
As shown in
Figure 3, the weight matrix
between the superpixel nodes is obtained by the superpixel segmentation algorithm for constructing the neighbor matrix of the multi-hop graph structure; the concrete steps are as follows:
Step 1. Assuming that the graph node is at located at the center, first obtain all the surrounding k-hop neighborhood paths by using a Depth-First Search (DFS) starting at .
Step 2. Calculate the path weights as:
where
,…,
represents the nodes in the path. (Note: For the case of having different paths, we select the maximum value of the corresponding path weight and the current weight.)
Step 3. Add the current weight matrix with the unit matrix to ensure that each node is connected to itself to obtain a new k-hop matrix (,,…,).
The k-hop neighbor matrix
is applied to find the graph convolution through the GCN and BN layers as follows:
where
denotes the output of k-hop neighbor matrix
through layer
,
is the degree matrix of
, and
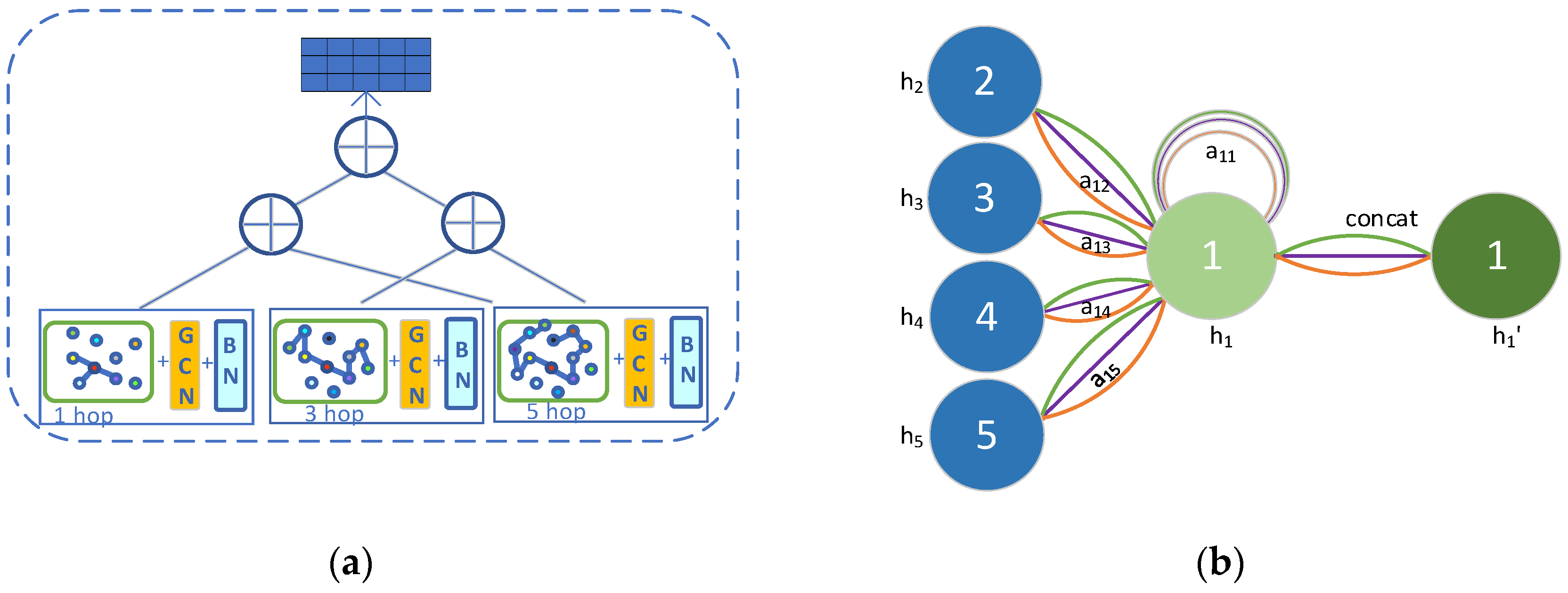
indicates weight matrix. The node features of different jumps can feed different visual field information, as in the structure of
Figure 4a, through the pyramid feature extraction structure to obtain the features of different depths and splice them to obtain the following:
To compute the hidden information of each node, as in
Figure 4b, a self-attention sharing mechanism
was applied to compute the attention coefficients between node
and node
:
. Here, the first-order attention mechanism is carried by merely computing the first-order neighbor nodes
of the node
, where
is a domain of
. Then, normalization by the
function is executed to make the coefficients more easily comparable across nodes:
Then, the corresponding features undergo a linear combination to calculate the node output features .
To obtain the node features stably, we apply multiple attention mechanisms to obtain multiple sets of new features, which are spliced in feature dimensions and placed into the final fully connected layer to obtain the final features as follows:
where
denotes the
group of attention coefficients;
is the number of heads, which means there are
groups of attention coefficients; and
denotes splicing operation of the total number of
groups in the feature dimensions.
denotes the weight matrix, where
indicates input feature dimensions and
denotes the output feature dimensions, which equal the number of classes of the hyperspectral images.
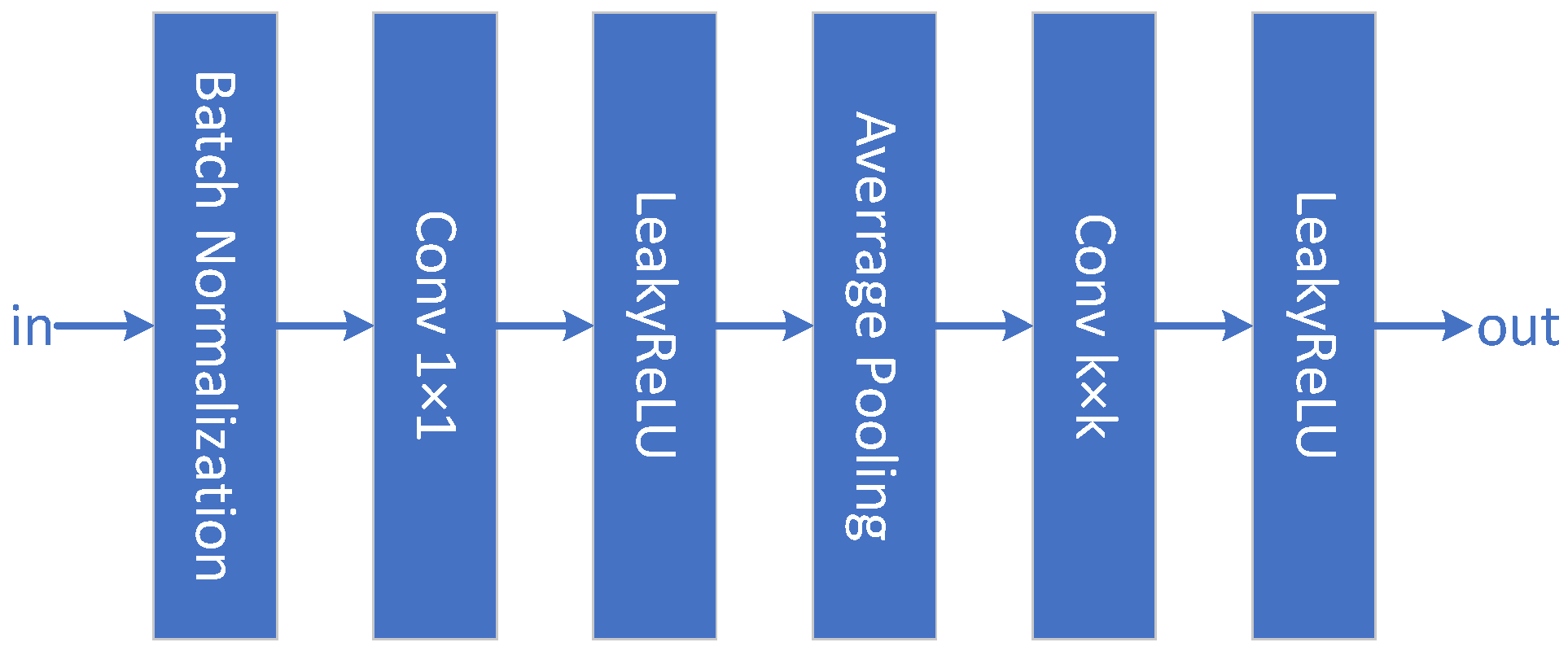
2.3. CNN-Based Multiscale Feature Extraction Module
Although traditional 2D-CNNs can extract context space features, considering the multi-parameters in the convolutional kernel and a limited number of training samples, we prevent overfitting and enhance training efficiency by applying batch normalization (BN) to each convolutional layer unit [
47], which is calculated as follows:
where
,
,
,
,
, and
denote the size of the convolution kernel and their corresponding indices;
indicates the output by the
convolutional layer at
; and
,
, and
denote the weight, bias term, and
activation function, respectively.
For broadening the sensory field of the network to obtain local features at varied scales, as shown in
Figure 5, features are extracted from different sized convolution kernels in parallel, and then the different scale information is integrated by cross-path fusion. Because of the high dimensionality of the HSI spectrum, a 1D convolution kernel is first used in the convolution module to remove redundant spectral information and reduce parameter usage. Then an average pooling layer is used between the different convolutional layers to reduce the feature space size and prevent overfitting, where the pooling window size, stride, and padding size are, respectively, set to 3 × 3, 1, and 1.
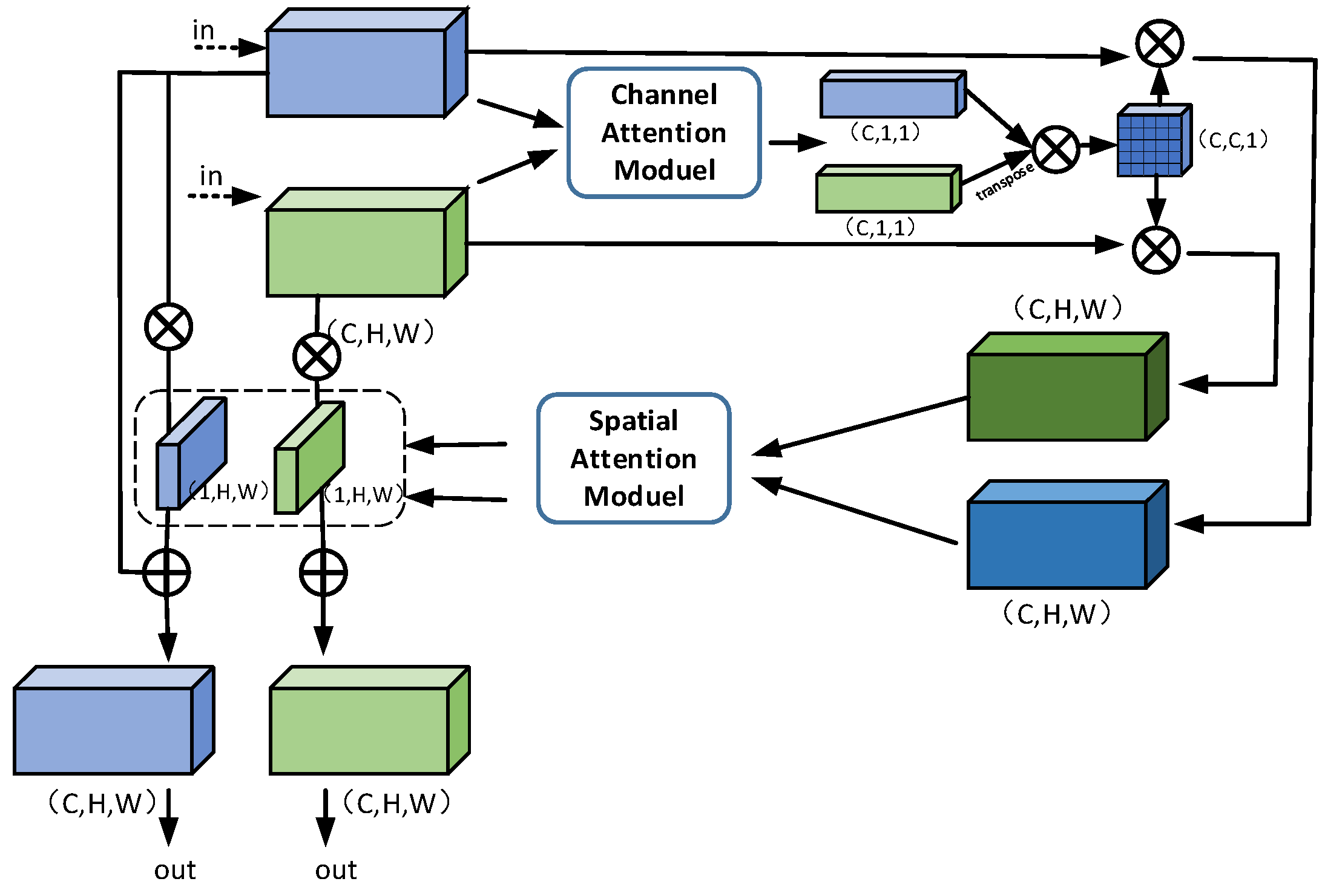
2.4. Dual-Channel Attention Fusion Module
To better employ the channel relationship between hyperspectral pixels, we utilize the Convolutional Block Attention Network [
60] (CBAM) module displayed in
Figure 6 to sequentially infer the attention mapping along channel and spatial dimensions independently, multiplying it by the input for adaptive feature refinement.
Suppose the input feature map is
; after the CBAM module there are channel and spatial attention maps
and
and their attention processes is expressed as follows:
Feature fusion inspired by [
47] utilizes the cross-attention fusion mechanism as shown in
Figure 7.
Specifically, the input is first aggregated by global and max pooling on the spatial information of the feature maps to generate two features:
and
. There is a shared network composed of a multilayer perceptron (MLP) and a hidden layer where the above-mentioned features are input to get a channel attention map
:
where
and
represent the shared weight parameters of the MLP,
is the reduction ratio in the hidden layer, and
and is the
function. From this, we can obtain mappings
and
, which correspond to the previous two branch features
and
, respectively, and multiply them to obtain
:
After the channel crossing module, the characteristics are obtained as follows:
Unlike the channel attention operation, we input two pooled features into the convolutional layer to generate the spatial attention mapping
[
47]
where
is a convolutional layer with kernel size
. Similarly obtain the spatial weight coefficients
and
, multiply them with the input features, and add the residuals to get the noted features, respectively:
Eventually, through the fully connected layer, the last features are obtained [
47] as follows:
where
and
are the weight and bias. The progress is summarized in Algorithm 1.
| Algorithm 1 Dual-Channel Attention Fusion Algorithm |
| Input:
|
| Step 1: Calculate and of separately by global pooling and max pooling. |
Step 2: Calculate channel weight coefficients for both branches as and according to Equation (12).
Step3: Calculate crossover coefficient by Equation (13).
Step 4: Use the channel crossover module to calculate and , respectively, according to Equations (14) and (15).
Step 5: Similar to steps 1–4 above, calculate the spatial weight coefficients and and the fusion features and by Equations (16)–(18).
Step 6: Calculate final fusion features according to Equation (19). |
| Output:
|
3. Experimental Details
To validate the effectiveness and generalization of the H
2-CHGN, we chose the following three datasets: a classical HSI dataset (Pavia University) and two H
2 image datasets (WHU-Hi-LongKou [
1] and WHU-Hi-HongHu [
61]). They are captured by different sensors for different types of scenes, providing richer samples. This diversity helps to improve the generalization ability of the model so that it performs well in different scenes.
Table 1 lists the detailed information about the datasets.
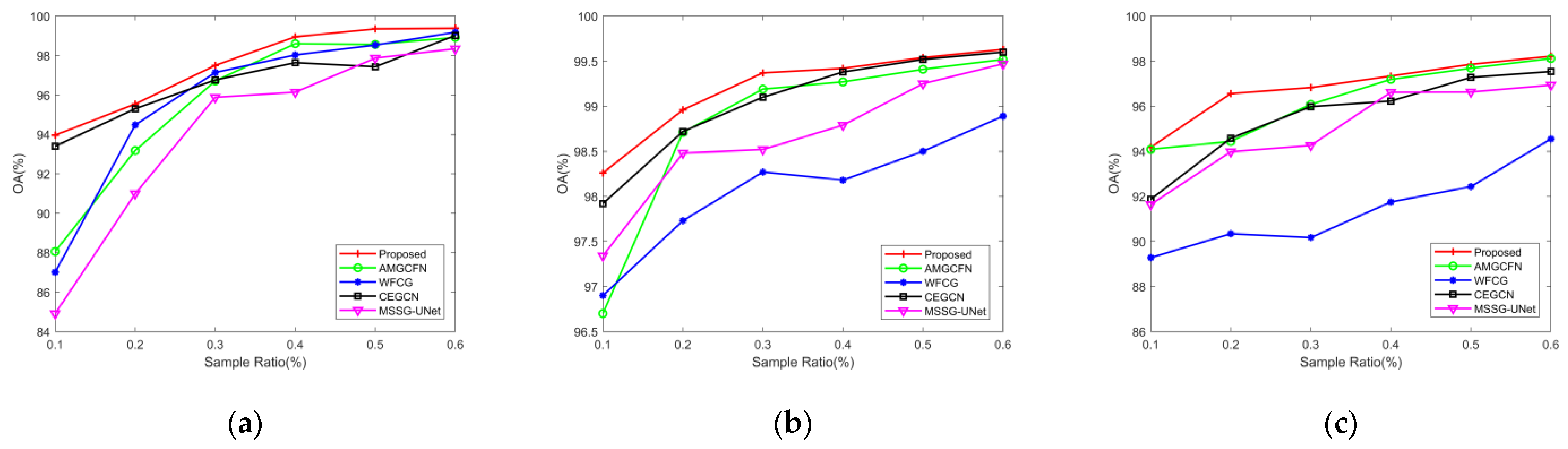
Table 2,
Table 3 and
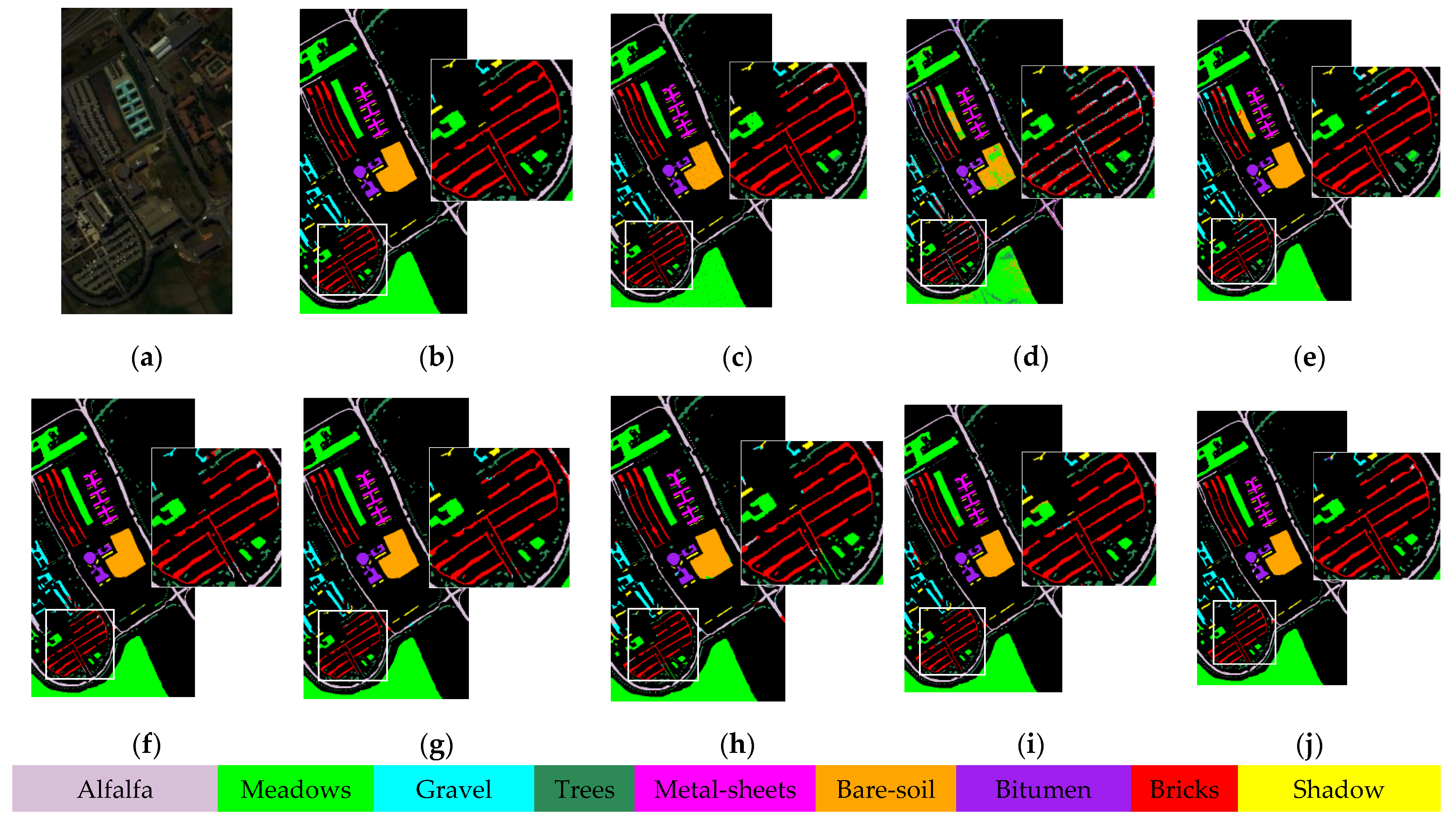
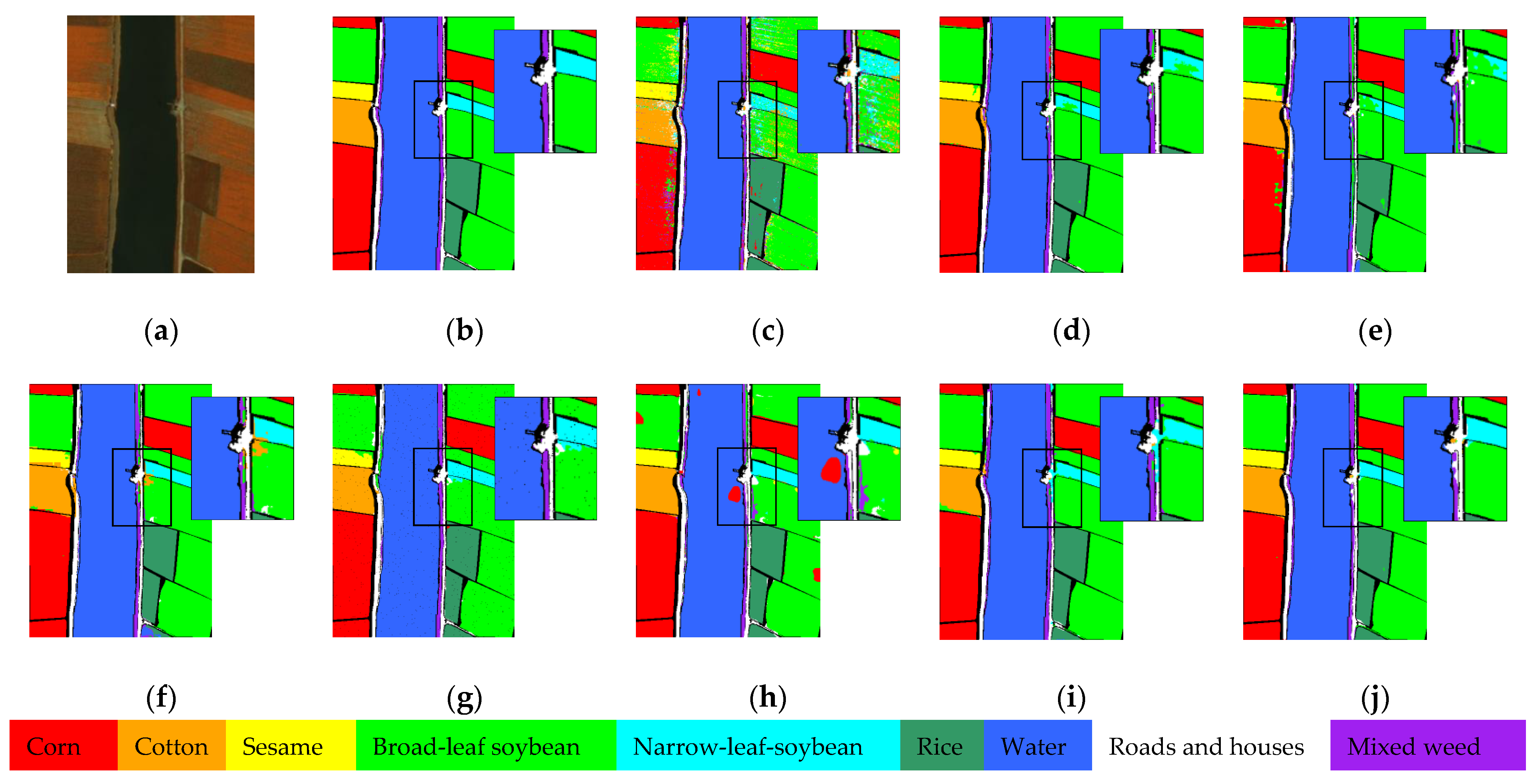
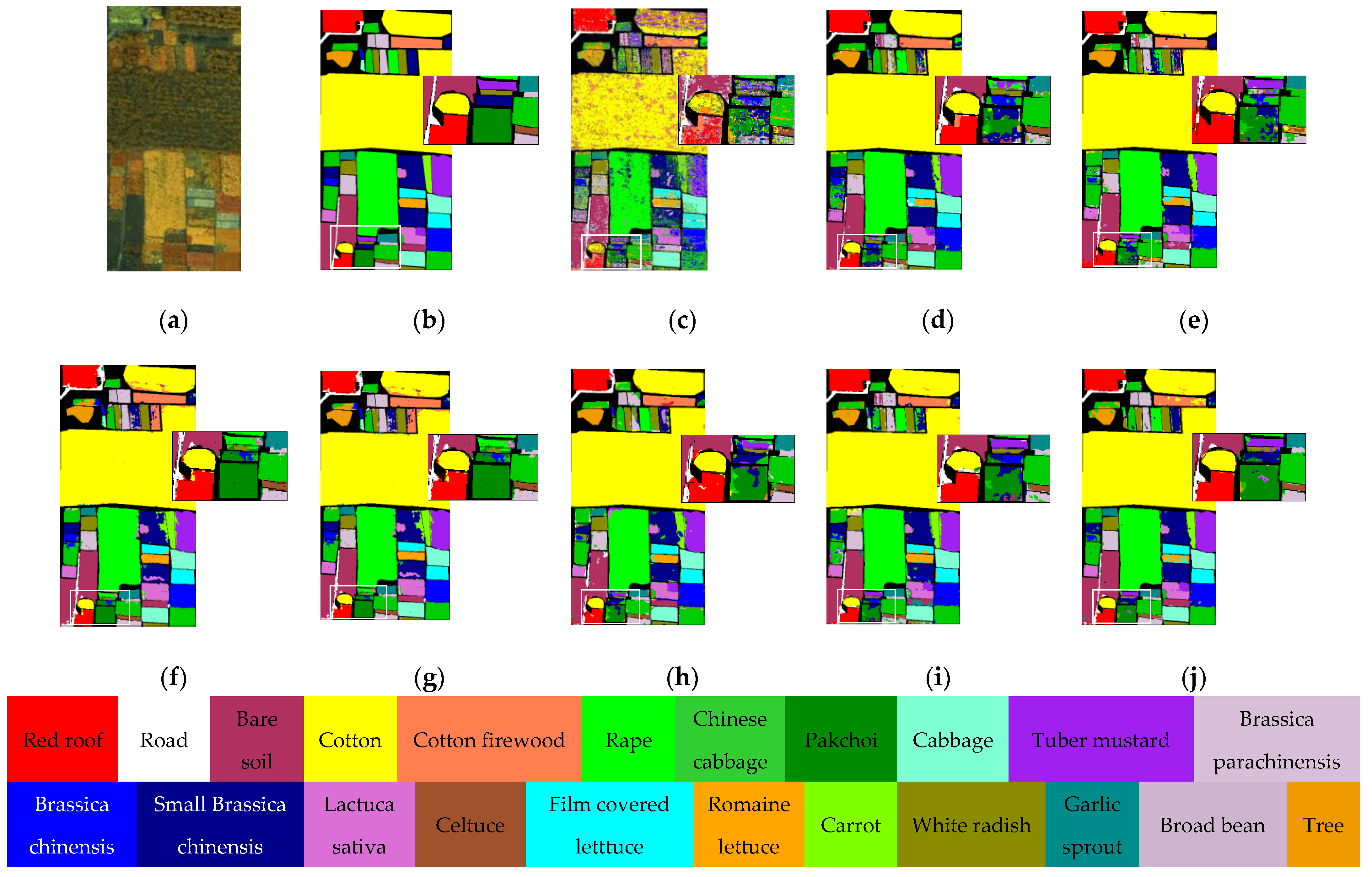
Table 4 list training and testing set divisions of the three datasets. The comparison methods are SVM (OA: PU = 79.54%, LK = 92.88%, and HH = 66.34%), CEGCN [
41] (OA: PU = 97.81%, LK = 98.72%, and HH = 94.01%), SGML (OA: PU = 94.30%, LK = 96.03%, and HH = 92.51%), WFCG (OA: PU = 97.53%, LK = 98.29%, and HH = 93.98%), MSSG-UNet (OA: PU = 98.52%, LK = 98.56%, and HH = 93.73%), MS-RPNet (OA: PU = 96.96%, LK = 97.17%, and HH = 93.56%), AMCGFN (OA: PU = 98.24%, LK = 98.44%, and HH = 94.44%) and H
2-CHGN (OA: PU = 99.24%, LK = 99.19%, and HH = 96.60%). To quantitatively and qualitatively assess the classification performance of the network [
62], three evaluation indices are used: overall accuracy (OA), average accuracy (AA), and kappa coefficient (Kappa). All experimental results are averaged over ten runs independently. The experiments were run via Python 3.7.16 with i5-8250U CPU and NVIDIA GeForce RTX 3090 GPU.
3.1. Parametric Setting
Table 5 shows the architecture of the H
2-CHGN where it is used for all activation functions. In addition, the network uses the Adam optimizer with a learning rate of 5 ×10
−4 to train. The remaining setup parameters include the superpixel segmentation scale and the number of attentional heads, and the iterations are explained in the following sections. We discuss and analyze these parameters through experiments, and the ultimate optimal parameter settings are shown in
Table 6.
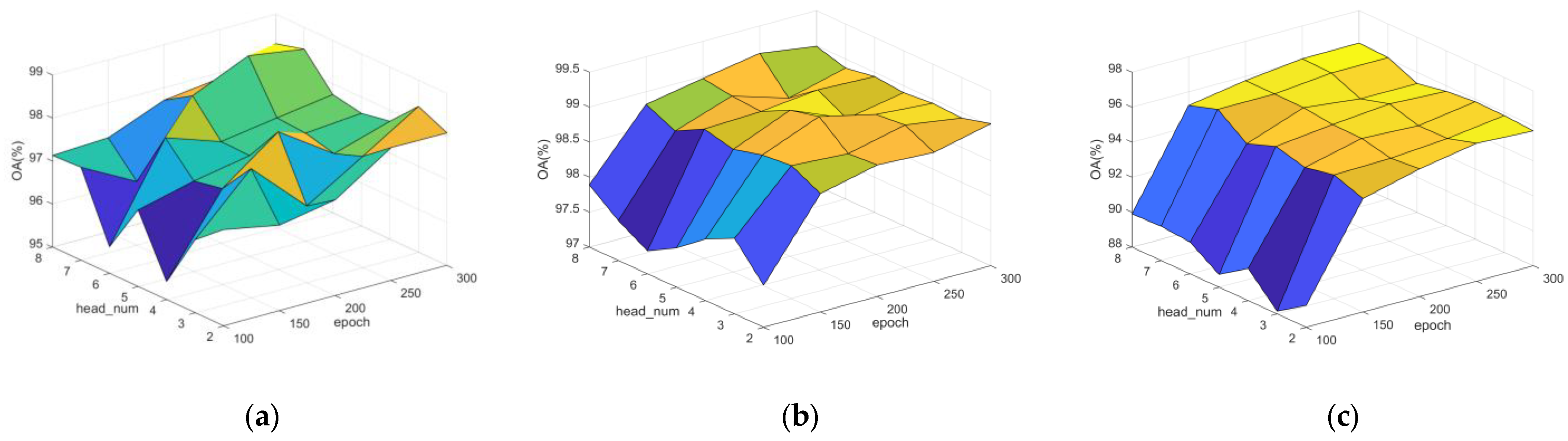
3.2. Analysis of Multi-Head Attention Mechanism in Graph Attention
By using multiple attention heads, a GAT is able to learn the attention weights between different nodes and combine them to obtain a more comprehensive and accurate image features. Notably, the number of heads controls different node relationships that the model is able to learn. Increasing attention heads allows the model to capture richer node relationships and improves the model’s representation, but at the same time this increases the computational complexity and memory overhead and is prone to overfitting. Therefore, as shown in
Figure 8, so as to weigh the balance between model performance and computational complexity, the number of heads is taken as 7, 6, and 5 for three datasets individually.
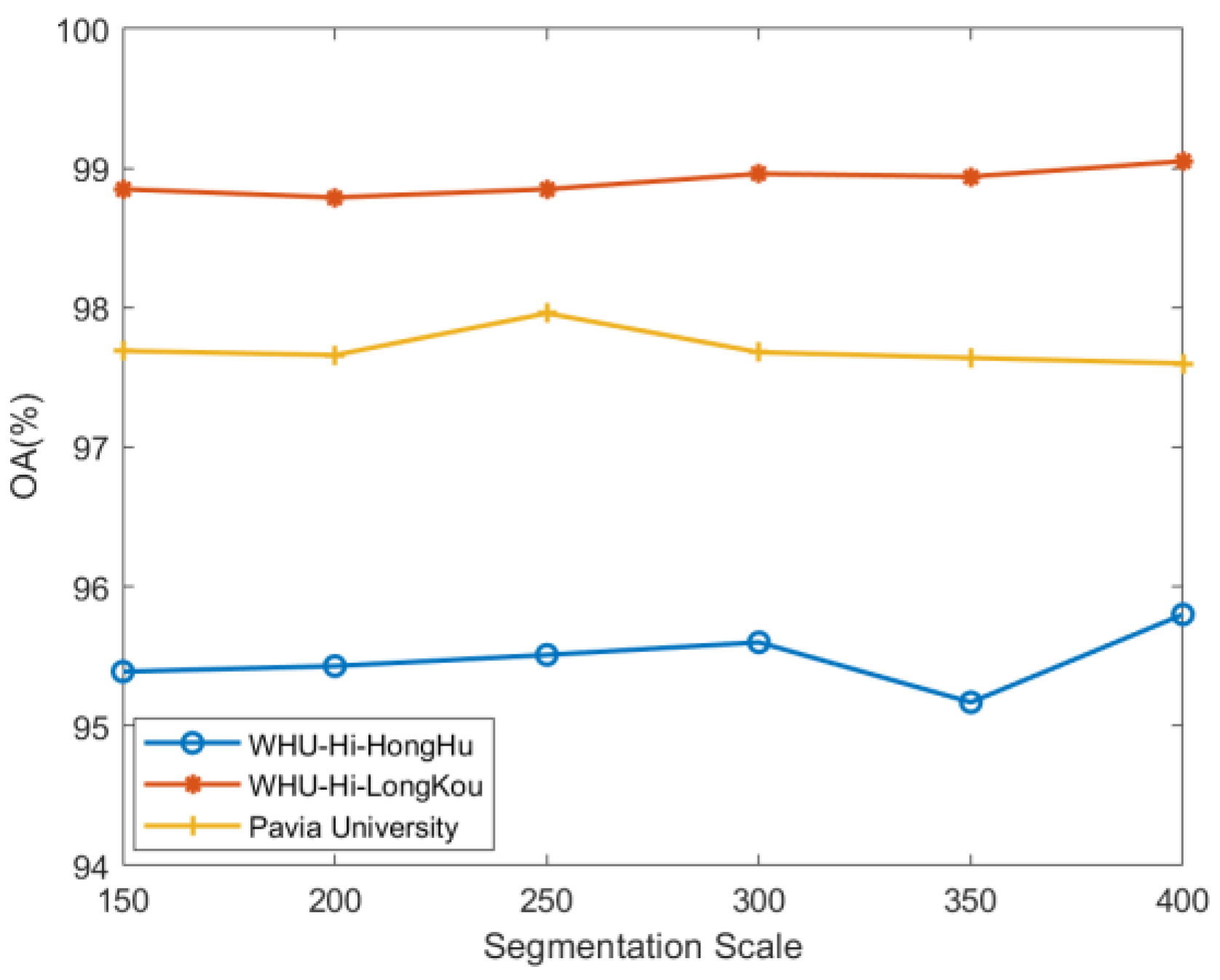
3.3. Impact of Superpixel Segmentation Scale
The size of the superpixel segmentation scale molds the size of the graph construction area. The larger the superpixel area, the more pixels are contained in the segmented superpixel area and the fewer the number graph nodes that have to be constructed. The experiments are set
’s as 150, 200, 250, 300, 350, 400. Regions with different numbers of superpixels are visualized in mean color as in
Figure 9, where the most representative features of each region can be seen more clearly. The larger the superpixel segmentation scale, the more superpixels in the segmented region, indicating a more detailed segmentation.
Figure 10 demonstrates that as the scale increases, the classification accuracy initially increases but eventually declines, with the WHU-Hi-HongHu dataset experiencing a more significant decrease compared to the other two datasets. This is attributed to its greater complexity, featuring 22 categories and a relatively denser distribution of features. When different varieties of the same crop type are planted in a region, finer segmentation can lead to a higher likelihood of misclassifying various pixel categories into a single node. Additionally, the overall accuracy improves again when the segmentation scale increases from 350 to 400, likely due to the enhanced category separability achieved through more detailed segmentation.
3.4. Cross-Hopping Connection Analysis
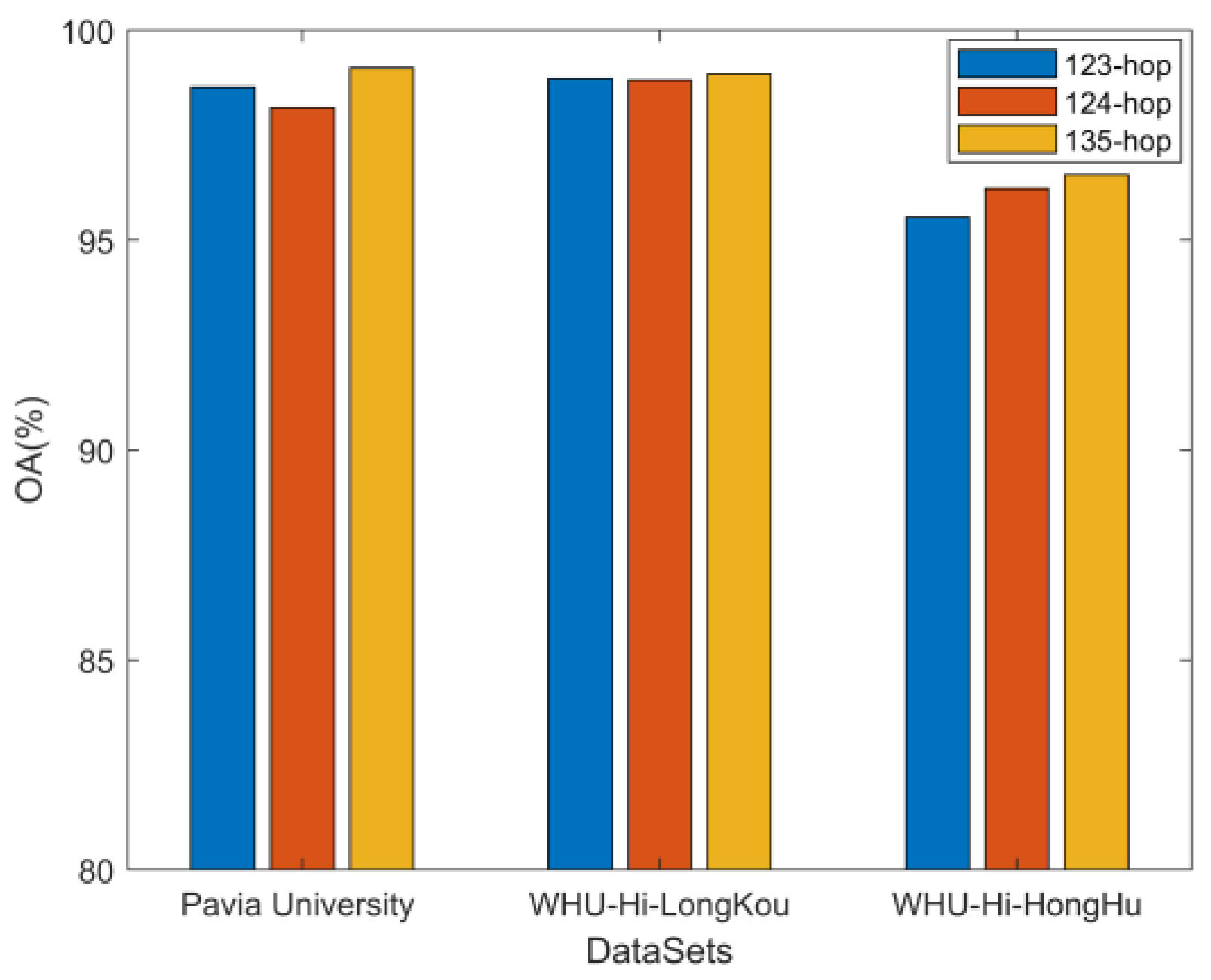
Because HSI contains feature distributions of varying shapes and sizes, the cross-hop mechanism plays a critical role in modeling complex spatial topologies. Precisely, the near-hop graph structure contains fewer nodes, which is good for modeling small feature distributions, but makes it hard to learn continuous smooth features on large one. In contrast to the neighbor-hopping graph structure, in which most of the graph nodes are duplicated, the cross-hopping graph can better model large feature distributions but fails to account for subtle differences. To affirm the competence of the cross-hop hopping operation, we repeated the experiment 10 times for three sets of experiments (123-hop for adjacent hops, 124-hop for cross-even hops, and 135-hop for cross-odd hops). As shown in
Figure 11, there is no significant effect for the simpler WHU-Hi-LongKou dataset. In contrast, for other two more complex datasets, the cross odd-hop 135-hop operation has a better performance. The reason can be inferred that the cross-hop mechanism enables a larger range of graph convolution operations, which can effectively extract a wider range of sample information and perform better.
5. Conclusions
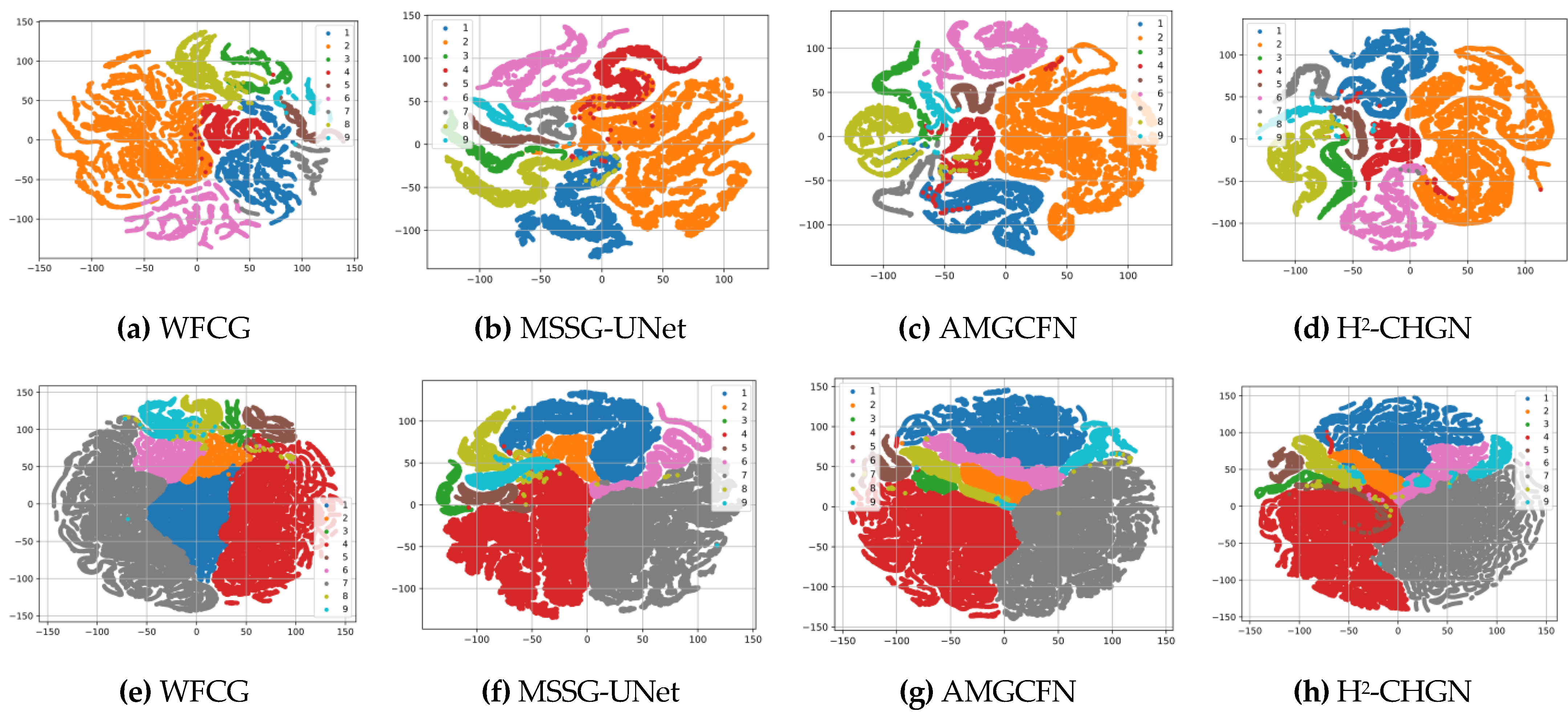
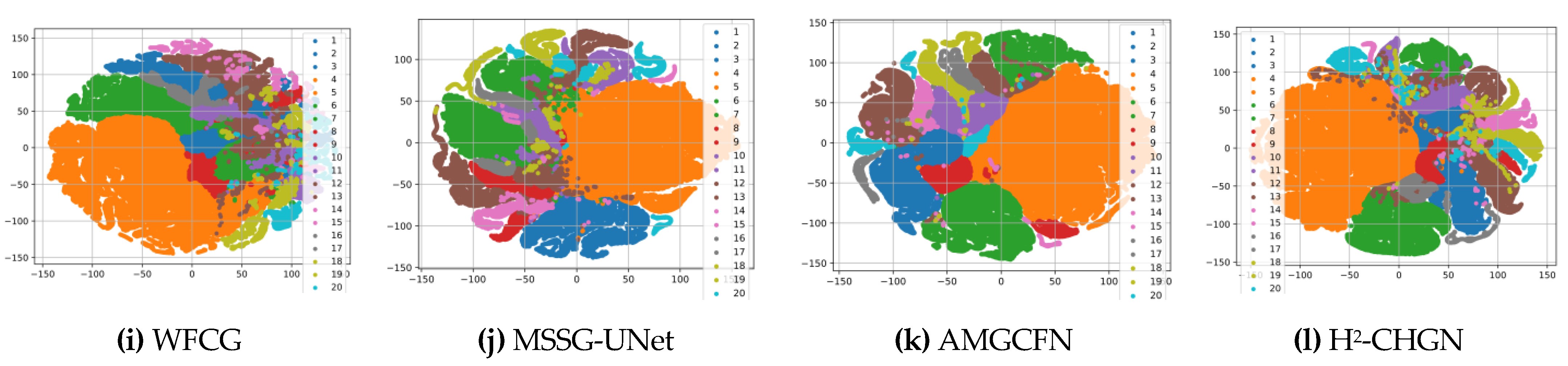
In this paper, a cross-hop graph network (H2-CHGN) model for H2 image classification is proposed to alleviate the spatial heterogeneity and spectral variability of an H2 image. It is also essentially a hybrid neural network based on a superpixel-based GCN and a pixel-based CNN to extract spatial and global spectral features. Among them, a cross-hop graph attention network (CGAT) branch widens the range of graph convolution and the pyramid feature extraction structure is utilized to fuse multilevel features. So as to better capture relationship between nodes and contextual information, the H2-CHGN also employs a graph attention mechanism that specializes in graph-structured data. Meanwhile, the multi-scale convolutional neural network (MCNN) employs dual convolutional kernels to extract features at different scales and obtains multi-scale localized features in pixel level by means of cross connectivity. Finally, the dual-channel attention fusion module is used to effectively integrate multi-scale information, while strengthening the key features and improving generalization capability. Experimental results verify the validity and generalization of the H2-CHGN. Specifically, the overall accuracy of the three datasets (Pavia University, WHU-Hi-LongKou, WHU-Hi-HongHu) is as high as 99.24%, 99.19%, 96.60% respectively.
Our study possesses certain limitations containing a large number of model parameters and high computational demands. First, we noticed that the H2-CHGN is the result of superpixel segmentation, cross-hop convolution, and the attention mechanism working together. Therefore, suitable parameter matching is essential. In addition, a GCN needs to construct the adjacency matrix on all data, while the H2-CHGN can reduce the computational cost by cross-hop graph convolution.
In the future, we will explore strategies to enhance the cross-hop graph by employing more advanced techniques, such as transformers. Additionally, we aim to develop lighter-weight networks to reduce complexity while preserving performance.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}