

Refined Intelligent Landslide Identification Based on Multi-Source Information Fusion

 , ,
, ,
Abstract
1. Introduction
- (1)
- We constructed a sample library for landslide recognition in Ya’an City with multi-source features.
- (2)
- We analyzed the learning process of the deep learning model on multi-source feature samples using a heat map.
- (3)
- We constructed a Swin Transformer-based model based on landslide recognition and introduced a boundary loss function to address the problem of low recognition accuracy for a few target classes. We compared our model with classical networks, and it was observed that, after multi-source feature fusion, the model effectively solved the abovementioned problems and improved landslide recognition accuracies.
- (4)
- We explored a potential application of the Swin Transformer-based model in landslide detection. Based on the Bijie landslide dataset, the expressiveness of the Swin Transformer-based model based on the boundary constraint function and multi-source feature fusion was explored in order to validate its effectiveness and explore its generalization ability.
2. Materials
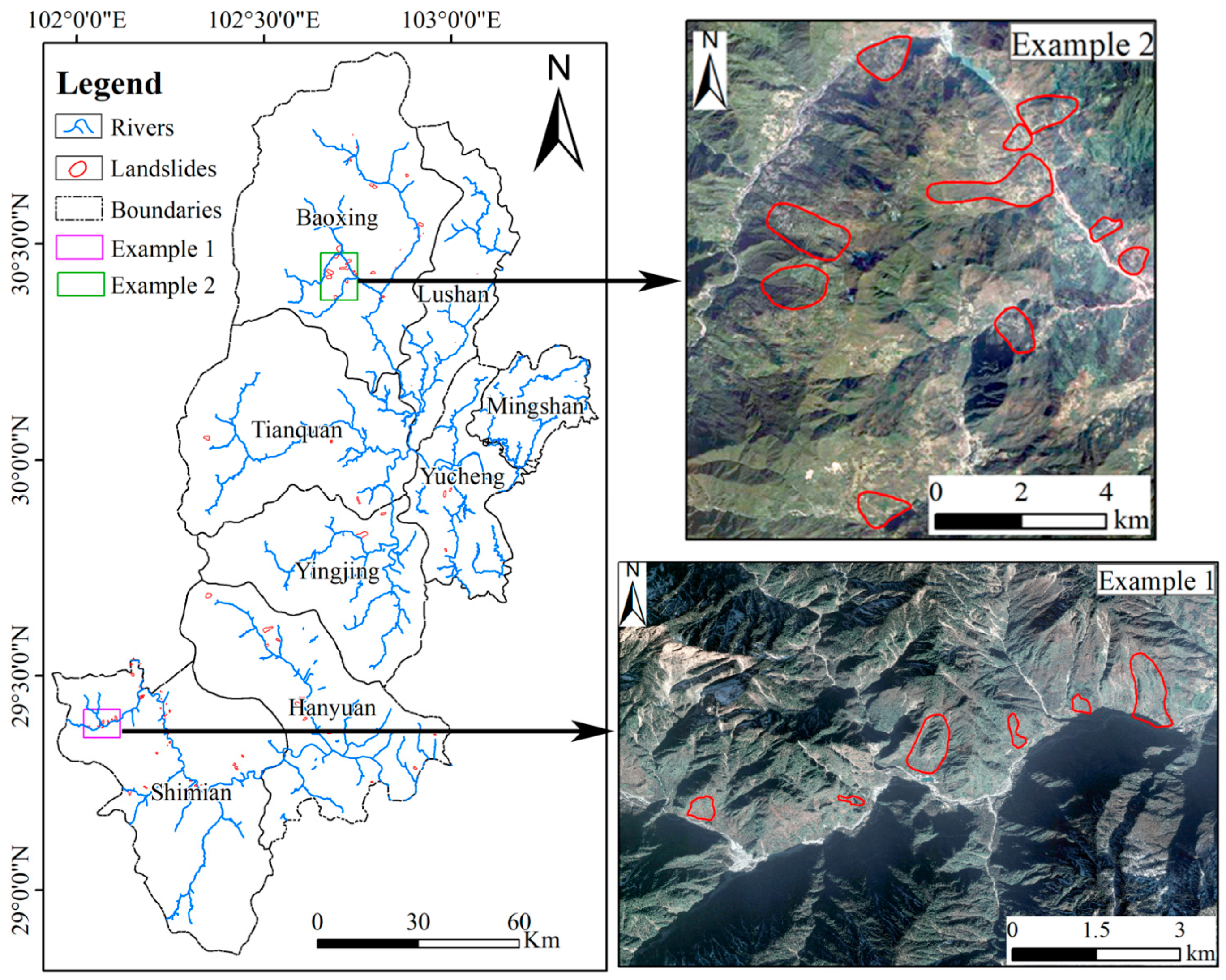
2.1. Study Area
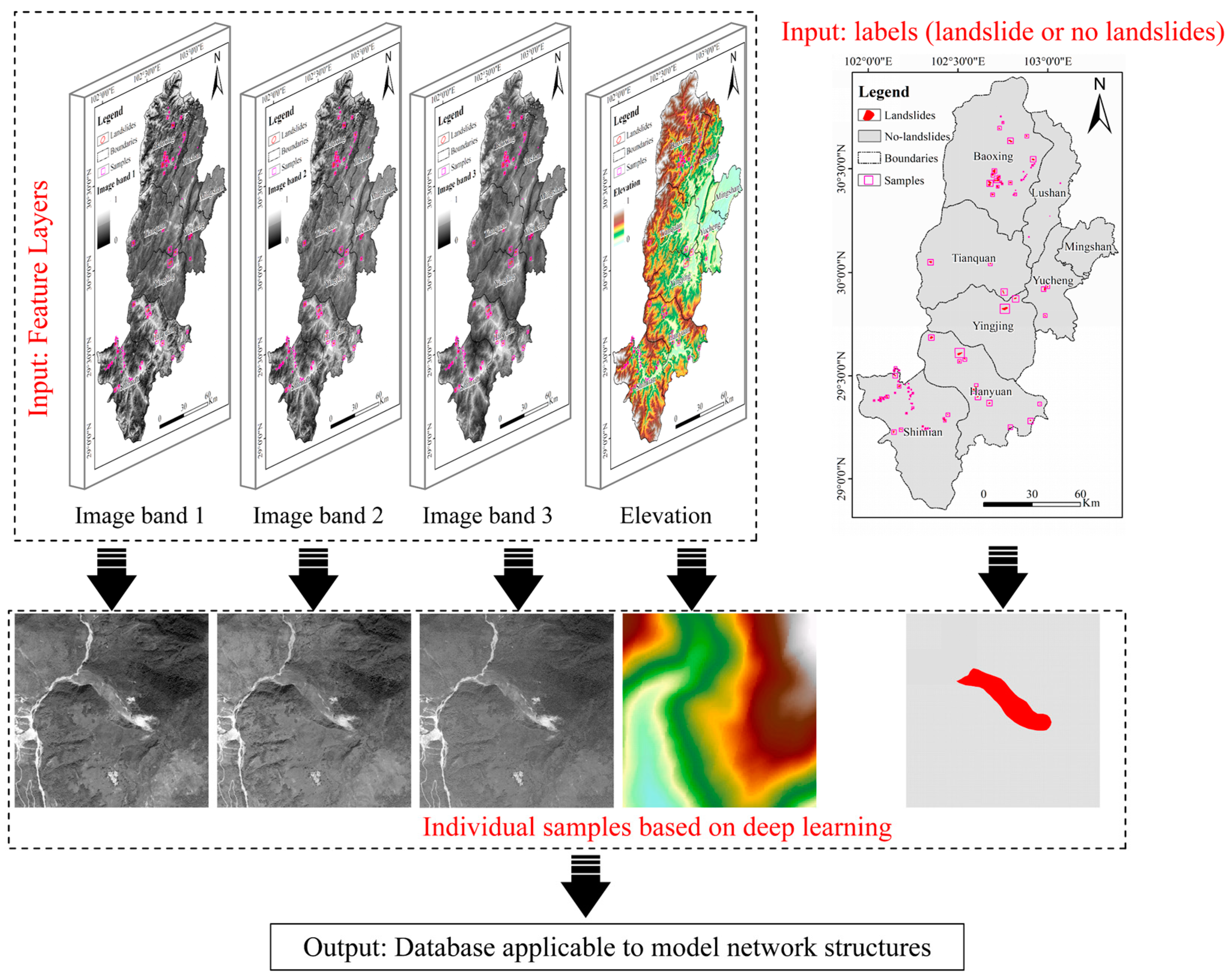
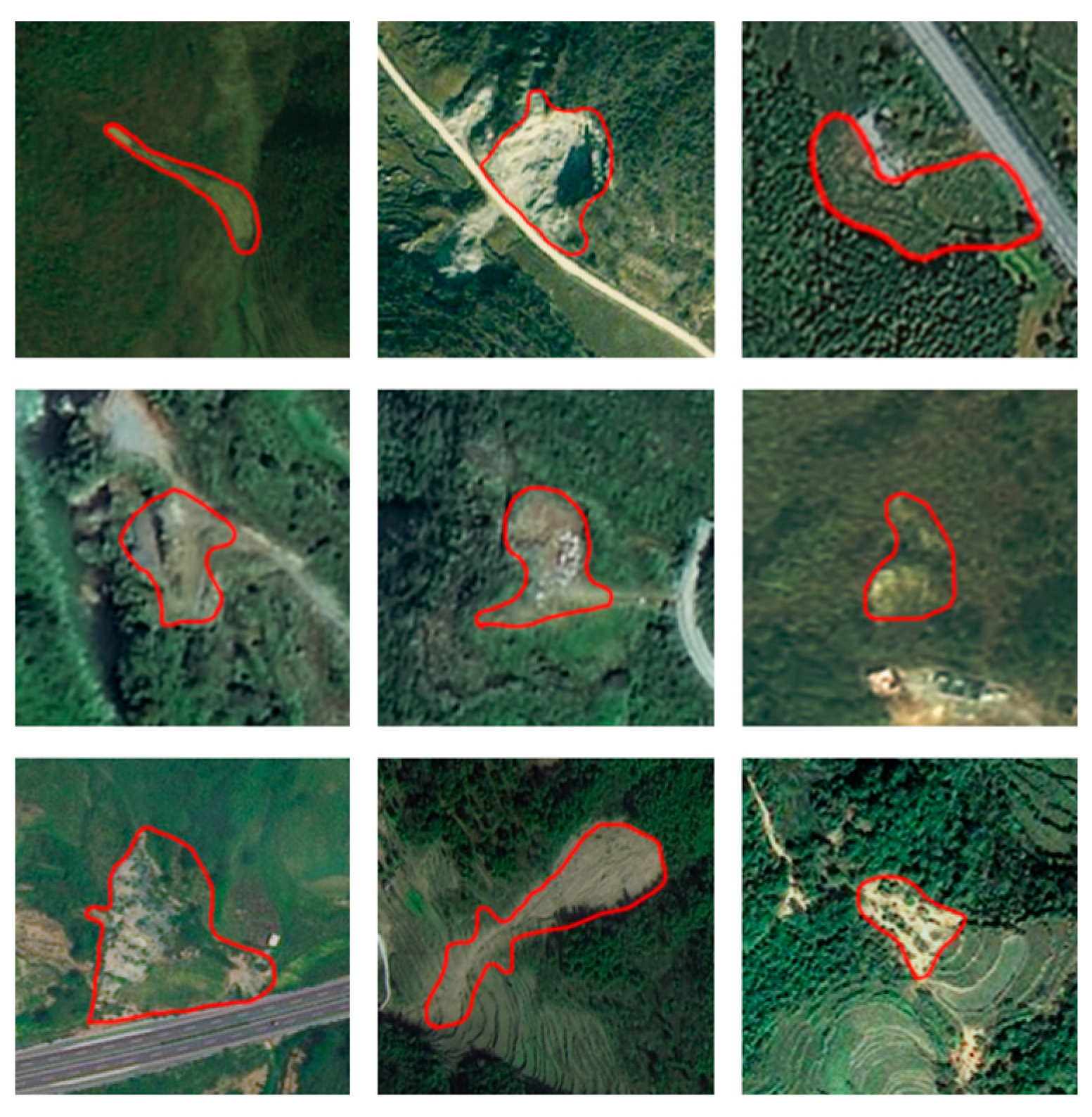
2.2. Landslide Identification Database
2.2.1. Visual Interpretation of Landslides
2.2.2. Database Production for Multi-Source Data
3. Methods
3.1. Swin Transformer
3.2. Loss Functions
3.2.1. Binary Cross-Entropy (BCE)
3.2.2. Boundary Loss Function
3.3. Precision Evaluation Indicator
3.4. Experimental Environment Settings
4. Experimental Analysis
4.1. Training Details
4.1.1. Model Training Strategies
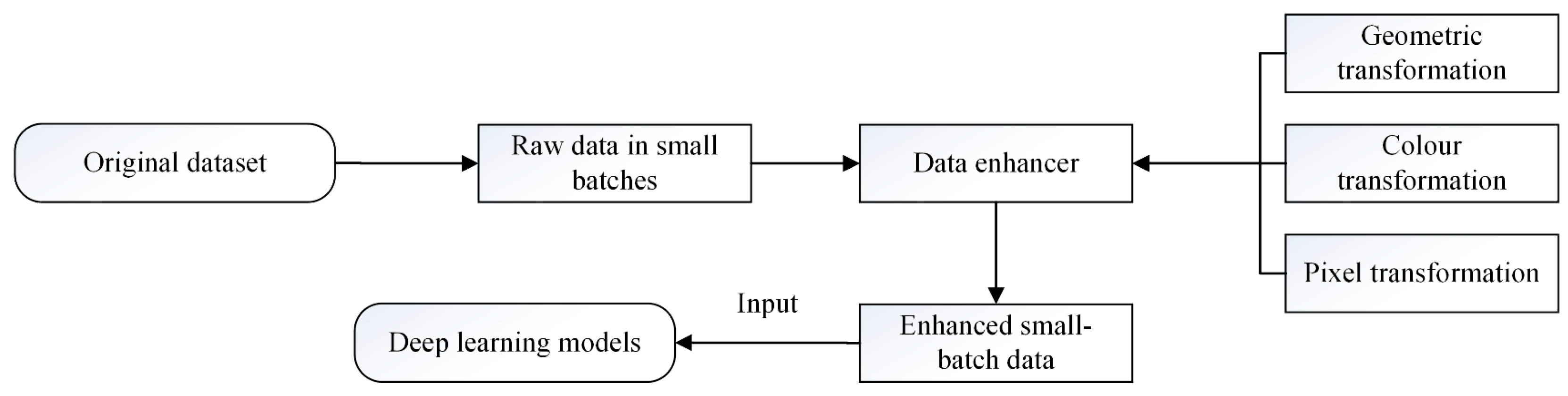
4.1.2. Online Data Enhancement
Geometric Shape Transformation
Image Color Transformation
4.2. Analysis of Experimental Results
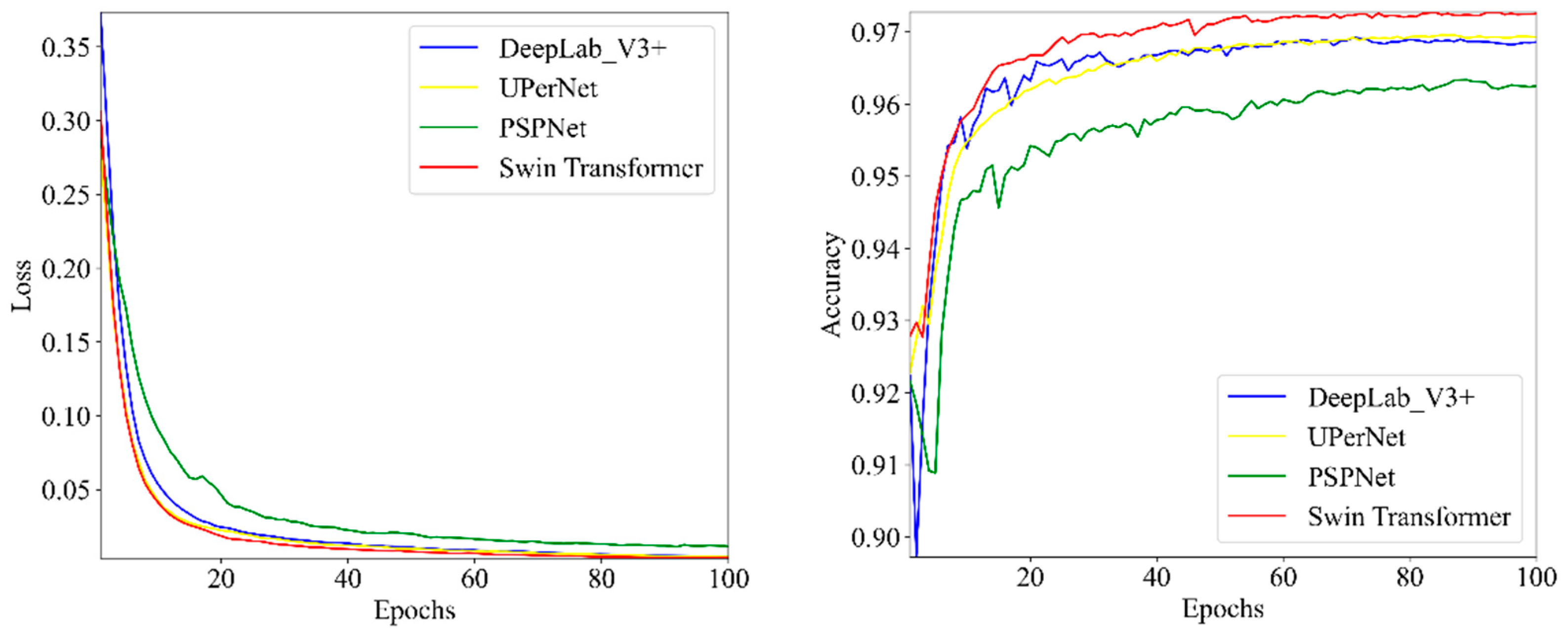
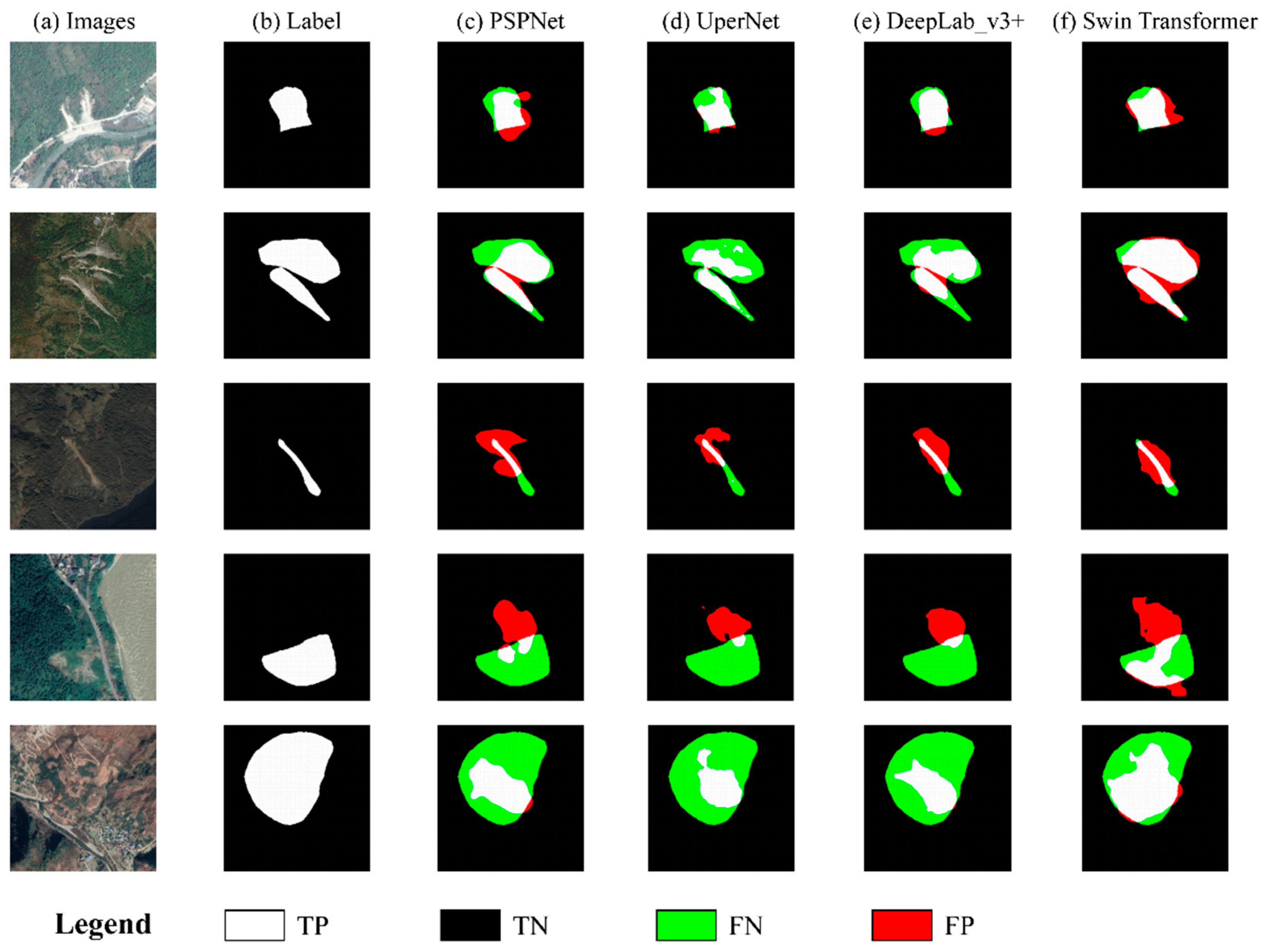
4.2.1. Comparison of Different Feature Extraction Networks
4.2.2. Network Comparison Experiments after Adding DEM Features
4.2.3. Optimization Experiments Using Boundary Loss Functions
5. Discussion
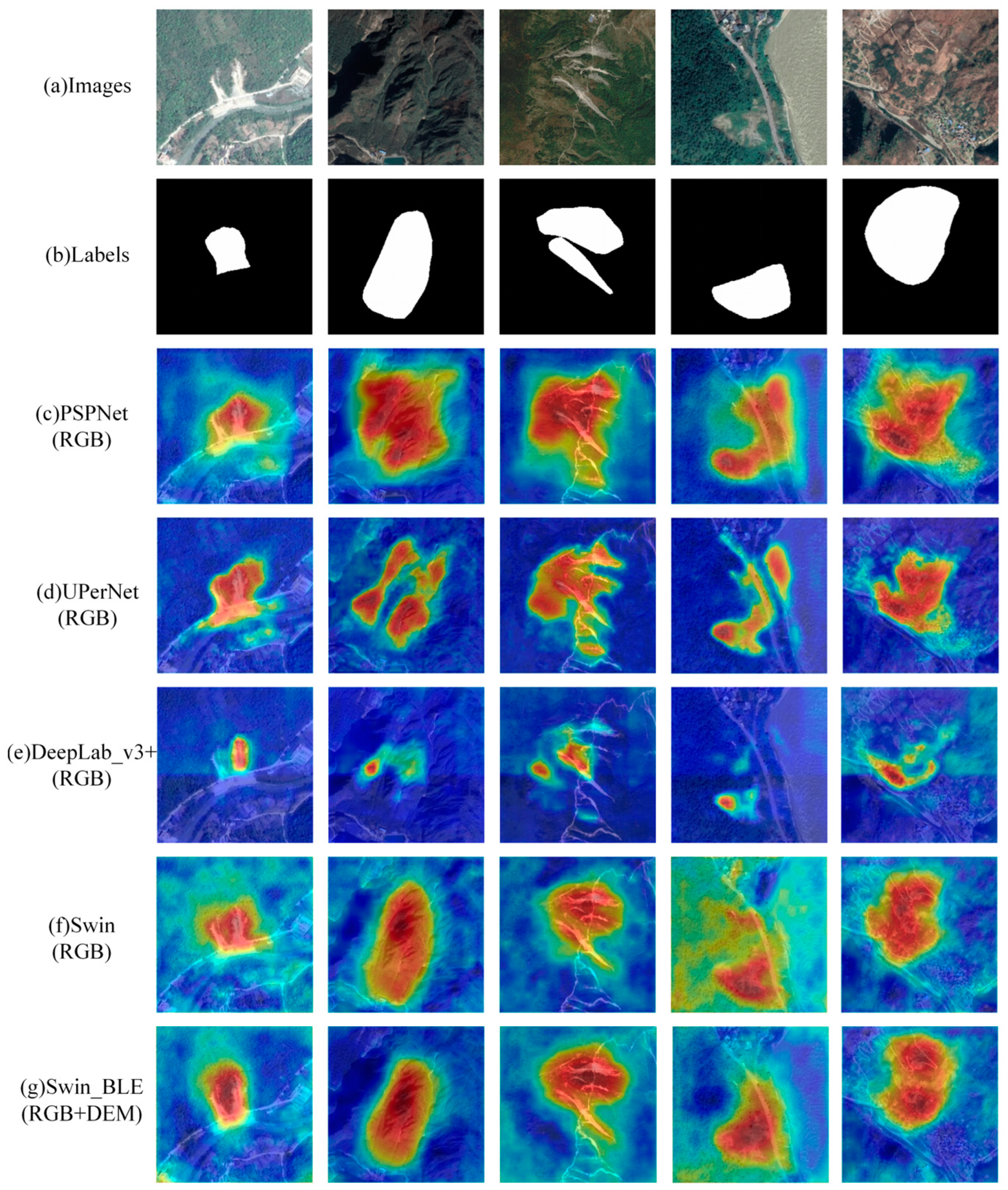
5.1. Interpretation of the Models’ Visualization Results
5.2. Model Resilience Analysis Based on a Publicly Available Landslide Dataset
5.3. Comparison of Model Recognition Performance for Different Datasets
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhao, Z.; Lan, H.; Li, L.; Strom, A. Landslide Spatial Prediction Using Cluster Analysis. Gondwana Res. 2024, 130, 291–307. [Google Scholar] [CrossRef]
- Chen, X.; Chen, W. GIS-Based Landslide Susceptibility Assessment Using Optimized Hybrid Machine Learning Methods. Catena 2021, 196, 104833. [Google Scholar] [CrossRef]
- Bui, D.T.; Tsangaratos, P.; Nguyen, V.-T.; Van Liem, N.; Trinh, P.T. Comparing the Prediction Performance of a Deep Learning Neural Network Model with Conventional Machine Learning Models in Landslide Susceptibility Assessment. Catena 2020, 188, 104426. [Google Scholar] [CrossRef]
- Yang, C.; Liu, L.-L.; Huang, F.; Huang, L.; Wang, X.-M. Machine Learning-Based Landslide Susceptibility Assessment with Optimized Ratio of Landslide to Non-Landslide Samples. Gondwana Res. 2023, 123, 198–216. [Google Scholar] [CrossRef]
- Cheng, G.; Wang, Z.; Huang, C.; Yang, Y.; Hu, J.; Yan, X.; Tan, Y.; Liao, L.; Zhou, X.; Li, Y.; et al. Advances in Deep Learning Recognition of Landslides Based on Remote Sensing Images. Remote Sens. 2024, 16, 1787. [Google Scholar] [CrossRef]
- Xu, Y.; Ouyang, C.; Xu, Q.; Wang, D.; Zhao, B.; Luo, Y. CAS Landslide Dataset: A Large-Scale and Multisensor Dataset for Deep Learning-Based Landslide Detection. Sci. Data 2024, 11, 12. [Google Scholar] [CrossRef]
- Ju, Y.; Xu, Q.; Jin, S.; Li, W.; Su, Y.; Dong, X.; Guo, Q. Loess Landslide Detection Using Object Detection Algorithms in Northwest China. Remote Sens. 2022, 14, 1182. [Google Scholar] [CrossRef]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep Learning in Remote Sensing Applications: A Meta-Analysis and Review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Semantic Segmentation of Earth Observation Data Using Multimodal and Multi-Scale Deep Networks. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 180–196. [Google Scholar]
- Tao, A.; Sapra, K.; Catanzaro, B. Hierarchical Multi-Scale Attention for Semantic Segmentation. arXiv 2020, arXiv:2005.10821. [Google Scholar]
- Hoyer, L.; Dai, D.; Van Gool, L. Daformer: Improving Network Architectures and Training Strategies for Domain-Adaptive Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9924–9935. [Google Scholar]
- He, H.; Cai, J.; Pan, Z.; Liu, J.; Zhang, J.; Tao, D.; Zhuang, B. Dynamic Focus-Aware Positional Queries for Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 11299–11308. [Google Scholar]
- Nguyen, T.; Nguyen, L.; Tran, P.; Nguyen, H. Improving Transformer-Based Neural Machine Translation with Prior Alignments. Complexity 2021, 2021, 5515407. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Pourghasemi, H.R.; Sadhasivam, N.; Amiri, M.; Eskandari, S.; Santosh, M. Landslide Susceptibility Assessment and Mapping Using State-of-the Art Machine Learning Techniques. Nat. Hazards 2021, 108, 1291–1316. [Google Scholar] [CrossRef]
- Lee, S.I.; Koo, K.; Lee, J.H.; Lee, G.; Jeong, S.; O, S.; Kim, H. Vision Transformer Models for Mobile/Edge Devices: A Survey. Multimed Syst. 2024, 30, 109. [Google Scholar] [CrossRef]
- Liu, Y.; Nand, P.; Hossain, M.A.; Nguyen, M.; Yan, W.Q. Sign Language Recognition from Digital Videos Using Feature Pyramid Network with Detection Transformer. Multimed. Tools Appl. 2023, 82, 21673–21685. [Google Scholar] [CrossRef]
- Dong, Z.; Wang, Q.; Zhu, P. Multi-Head Second-Order Pooling for Graph Transformer Networks. Pattern Recognit. Lett. 2023, 167, 53–59. [Google Scholar] [CrossRef]
- Nie, J.; Xie, J.; Sun, H. Remote Sensing Image Dehazing via a Local Context-Enriched Transformer. Remote Sens. 2024, 16, 1422. [Google Scholar] [CrossRef]
- Pacal, I.; Alaftekin, M.; Zengul, F.D. Enhancing Skin Cancer Diagnosis Using Swin Transformer with Hybrid Shifted Window-Based Multi-Head Self-Attention and SwiGLU-Based MLP. J. Imaging Inform. Med. 2024, 1–19. [Google Scholar] [CrossRef]
- Kim, H.; Yim, C. Swin Transformer Fusion Network for Image Quality Assessment. IEEE Access 2024, 12, 57741–57754. [Google Scholar] [CrossRef]
- Zhong, F.; He, K.; Ji, M.; Chen, J.; Gao, T.; Li, S.; Zhang, J.; Li, C. Optimizing Vitiligo Diagnosis with ResNet and Swin Transformer Deep Learning Models: A Study on Performance and Interpretability. Sci. Rep. 2024, 14, 9127. [Google Scholar] [CrossRef]
- Liu, E.; He, B.; Zhu, D.; Chen, Y.; Xu, Z. Tiny Polyp Detection from Endoscopic Video Frames Using Vision Transformers. Pattern Anal. Appl. 2024, 27, 38. [Google Scholar] [CrossRef]
- Ramkumar, K.; Medeiros, E.P.; Dong, A.; de Albuquerque, V.H.C.; Hassan, M.R.; Hassan, M.M. A Novel Deep Learning Framework Based Swin Transformer for Dermal Cancer Cell Classification. Eng. Appl. Artif. Intell. 2024, 133, 108097. [Google Scholar] [CrossRef]
- Pacal, I. A Novel Swin Transformer Approach Utilizing Residual Multi-Layer Perceptron for Diagnosing Brain Tumors in MRI Images. Int. J. Mach. Learn. Cybern. 2024, 15, 3579–3597. [Google Scholar] [CrossRef]
- Dai, Y.; Liu, F.; Chen, W.; Liu, Y.; Shi, L.; Liu, S.; Zhou, Y. Swin MAE: Masked Autoencoders for Small Datasets. Comput. Biol. Med. 2023, 161, 107037. [Google Scholar]
- Masood, A.; Naseem, U.; Kim, J. Multi-Level Swin Transformer Enabled Automatic Segmentation and Classification of Breast Metastases. In Proceedings of the 2023 45th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Sydney Australia, 24–27 July 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–4. [Google Scholar]
- Guo, Z.; He, Z.; Lyu, L.; Mao, A.; Huang, E.; Liu, K. Automatic Detection of Feral Pigeons in Urban Environments Using Deep Learning. Animals 2024, 14, 159. [Google Scholar] [CrossRef]
- Gao, L.; Zhang, J.; Yang, C.; Zhou, Y. Cas-VSwin Transformer: A Variant Swin Transformer for Surface-Defect Detection. Comput. Ind. 2022, 140, 103689. [Google Scholar] [CrossRef]
- Yuan, W.; Xu, W. Neighborloss: A Loss Function Considering Spatial Correlation for Semantic Segmentation of Remote Sensing Image. IEEE Access 2021, 9, 75641–75649. [Google Scholar] [CrossRef]
- Yeung, M.; Sala, E.; Schönlieb, C.-B.; Rundo, L. Unified Focal Loss: Generalising Dice and Cross Entropy-Based Losses to Handle Class Imbalanced Medical Image Segmentation. Comput. Med. Imaging Graph. 2022, 95, 102026. [Google Scholar] [CrossRef]
- Guo, Q.; Wang, C.; Xiao, D.; Huang, Q. A Novel Multi-Label Pest Image Classifier Using the Modified Swin Transformer and Soft Binary Cross Entropy Loss. Eng. Appl. Artif. Intell. 2023, 126, 107060. [Google Scholar] [CrossRef]
- Agarwal, N.; Balasubramanian, V.N.; Jawahar, C.V. Improving Multiclass Classification by Deep Networks Using DAGSVM and Triplet Loss. Pattern Recognit. Lett. 2018, 112, 184–190. [Google Scholar] [CrossRef]
- Xiang, S.; Liang, Q.; Hu, Y.; Tang, P.; Coppola, G.; Zhang, D.; Sun, W. AMC-Net: Asymmetric and Multi-Scale Convolutional Neural Network for Multi-Label HPA Classification. Comput. Methods Programs Biomed. 2019, 178, 275–287. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Qian, Z.; Tan, Y.; Xie, Y.; Li, M. Investigation of Pavement Crack Detection Based on Deep Learning Method Using Weakly Supervised Instance Segmentation Framework. Constr. Build. Mater. 2022, 358, 129117. [Google Scholar] [CrossRef]
- Zhang, M.; Wang, H.; Wang, L.; Saif, A.; Wassan, S. CIDN: A Context Interactive Deep Network with Edge-Aware for X-Ray Angiography Images Segmentation. Alex. Eng. J. 2024, 87, 201–212. [Google Scholar] [CrossRef]
- Pawara, P.; Okafor, E.; Groefsema, M.; He, S.; Schomaker, L.R.B.; Wiering, M.A. One-vs-One Classification for Deep Neural Networks. Pattern Recognit. 2020, 108, 107528. [Google Scholar] [CrossRef]
- Wang, P.; Chung, A.C.S. Relax and Focus on Brain Tumor Segmentation. Med. Image Anal. 2022, 75, 102259. [Google Scholar] [CrossRef]
- Wang, G.; Wang, F.; Zhou, H.; Lin, H. Fire in Focus: Advancing Wildfire Image Segmentation by Focusing on Fire Edges. Forests 2024, 15, 217. [Google Scholar] [CrossRef]
- Ma, J.; Liang, P.; Yu, W.; Chen, C.; Guo, X.; Wu, J.; Jiang, J. Infrared and Visible Image Fusion via Detail Preserving Adversarial Learning. Inf. Fusion 2020, 54, 85–98. [Google Scholar] [CrossRef]
- Zhai, J.; Mu, C.; Hou, Y.; Wang, J.; Wang, Y.; Chi, H. A Dual Attention Encoding Network Using Gradient Profile Loss for Oil Spill Detection Based on SAR Images. Entropy 2022, 24, 1453. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; He, Y.; Xu, Q.; Deng, J.; Li, W.; Wei, Y. Detection and Segmentation of Loess Landslides via Satellite Images: A Two-Phase Framework. Landslides 2022, 19, 673–686. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, H.; Yang, R.; Yao, G.; Xu, Q.; Zhang, X. A Novel Weakly Supervised Remote Sensing Landslide Semantic Segmentation Method: Combining CAM and CycleGAN Algorithms. Remote Sens. 2022, 14, 3650. [Google Scholar] [CrossRef]
- Feng, X.; Du, J.; Wu, M.; Chai, B.; Miao, F.; Wang, Y. Potential of Synthetic Images in Landslide Segmentation in Data-Poor Scenario: A Framework Combining GAN and Transformer Models. Landslides 2024, 21, 2211–2226. [Google Scholar] [CrossRef]
- Lan, H.; Liu, X.; Li, L.; Li, Q.; Tian, N.; Peng, J. Remote Sensing Precursors Analysis for Giant Landslides. Remote Sens. 2022, 14, 4399. [Google Scholar] [CrossRef]
- Grigoryan, A.M.; Agaian, S.S. Monotonic Sequences for Image Enhancement and Segmentation. Digit. Signal Process. 2015, 41, 70–89. [Google Scholar] [CrossRef]
- Liang, L.; Zhang, Z.-M. Structure-Aware Enhancement of Imaging Mass Spectrometry Data for Semantic Segmentation. Chemom. Intell. Lab. Syst. 2017, 171, 259–265. [Google Scholar] [CrossRef]
- Domokos, C.; Kato, Z. Parametric Estimation of Affine Deformations of Planar Shapes. Pattern Recognit. 2010, 43, 569–578. [Google Scholar] [CrossRef]
- Qin, Z.; Chen, Q.; Ding, Y.; Zhuang, T.; Qin, Z.; Choo, K.-K.R. Segmentation Mask and Feature Similarity Loss Guided GAN for Object-Oriented Image-to-Image Translation. Inf. Process. Manag. 2022, 59, 102926. [Google Scholar] [CrossRef]
- Schmitter, D.; Unser, M. Shape Projectors for Landmark-Based Spline Curves. IEEE Signal Process. Lett. 2017, 24, 1517–1521. [Google Scholar] [CrossRef]
- Mehrish, A.; Subramanyam, A.V.; Emmanuel, S. Sensor Pattern Noise Estimation Using Probabilistically Estimated RAW Values. IEEE Signal Process. Lett. 2016, 23, 693–697. [Google Scholar] [CrossRef]
- Yang, Y.; Mei, G. Deep Transfer Learning Approach for Identifying Slope Surface Cracks. Appl. Sci. 2021, 11, 11193. [Google Scholar] [CrossRef]
- Li, D.; Tang, X.; Tu, Z.; Fang, C.; Ju, Y. Automatic Detection of Forested Landslides: A Case Study in Jiuzhaigou County, China. Remote Sens. 2023, 15, 3850. [Google Scholar] [CrossRef]
- Ji, S.; Yu, D.; Shen, C.; Li, W.; Xu, Q. Landslide Detection from an Open Satellite Imagery and Digital Elevation Model Dataset Using Attention Boosted Convolutional Neural Networks. Landslides 2020, 17, 1337–1352. [Google Scholar] [CrossRef]
- Ma, Z.; Mei, G. Deep Learning for Geological Hazards Analysis: Data, Models, Applications, and Opportunities. Earth-Sci. Rev. 2021, 223, 103858. [Google Scholar] [CrossRef]
- Merghadi, A.; Yunus, A.P.; Dou, J.; Whiteley, J.; ThaiPham, B.; Bui, D.T.; Avtar, R.; Abderrahmane, B. Machine Learning Methods for Landslide Susceptibility Studies: A Comparative Overview of Algorithm Performance. Earth-Sci. Rev. 2020, 207, 103225. [Google Scholar] [CrossRef]
- Becek, K.; Ibrahim, K.; Bayik, C.; Abdikan, S.; Kutoglu, H.S.; Glabicki, D.; Blachowski, J. Identifying Land Subsidence Using Global Digital Elevation Models. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 8989–8998. [Google Scholar] [CrossRef]
- Zhong, C.; Liu, Y.; Gao, P.; Chen, W.; Li, H.; Hou, Y.; Nuremanguli, T.; Ma, H. Landslide Mapping with Remote Sensing: Challenges and Opportunities. Int. J. Remote Sens. 2020, 41, 1555–1581. [Google Scholar] [CrossRef]
- Lian, X.-G.; Li, Z.-J.; Yuan, H.-Y.; Liu, J.-B.; Zhang, Y.-J.; Liu, X.-Y.; Wu, Y.-R. Rapid Identification of Landslide, Collapse and Crack Based on Low-Altitude Remote Sensing Image of UAV. J. Mt. Sci. 2020, 17, 2915–2928. [Google Scholar] [CrossRef]
- Wasowski, J.; Bovenga, F. Investigating Landslides and Unstable Slopes with Satellite Multi Temporal Interferometry: Current Issues and Future Perspectives. Eng. Geol. 2014, 174, 103–138. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hardware and Software | Parameters |
|---|---|
| CPU | 13th Gen Intel(R) Core(TM) i7-13700KF |
| GPU | NVIDIA GeForce RTX 4090(NVIDIA Corporation, located in Santa Clara, CA, USA) |
| Operating Memory | 64 GB |
| Total Video Memory | 24 GB |
| Operating System | Windows 11 |
| Python | Python 3.7.16 |
| IDE | PyCharm 2023.1 (Professional Edition) PyCharm |
| CUDA | CUDA 11.1 |
| CUDNN | CUDNN 8.0.1 |
| Deep Learning Architecture | PyTorch 1.8.1 |
| Models | OA | F1-Score | IoU | PA | Recall |
|---|---|---|---|---|---|
| UPerNet | 0.942 | 0.611 | 0.439 | 0.769 | 0.506 |
| PSPNet | 0.938 | 0.594 | 0.423 | 0.663 | 0.539 |
| DeepLab_v3+ | 0.944 | 0.632 | 0.462 | 0.713 | 0.567 |
| Swin Transformer | 0.945 | 0.693 | 0.531 | 0.629 | 0.772 |
| Models | Input Samples | OA | F1-Score | IoU | PA | Recall |
|---|---|---|---|---|---|---|
| UPerNet | RGB | 0.942 | 0.611 | 0.439 | 0.769 | 0.506 |
| RGB+DEM | 0.949 | 0.674 | 0.509 | 0.733 | 0.624 | |
| PSPNet | RGB | 0.938 | 0.594 | 0.423 | 0.663 | 0.539 |
| RGB+DEM | 0.938 | 0.622 | 0.452 | 0.646 | 0.601 | |
| DeepLab_v3+ | RGB | 0.944 | 0.632 | 0.462 | 0.713 | 0.567 |
| RGB+DEM | 0.941 | 0.656 | 0.489 | 0.718 | 0.666 | |
| Swin Transformer | RGB | 0.945 | 0.693 | 0.531 | 0.629 | 0.772 |
| RGB+DEM | 0.957 | 0.747 | 0.596 | 0.755 | 0.739 |
| Input Samples | Models | OA | F1-Score | IoU | PA | Recall |
|---|---|---|---|---|---|---|
| RGB | Swin Transformer (BCE) | 0.945 | 0.693 | 0.531 | 0.629 | 0.772 |
| Swin Transformer (BCE+Boundary) | 0.951 | 0.698 | 0.536 | 0.711 | 0.684 | |
| RGB+DEM | Swin Transformer (BCE) | 0.957 | 0.747 | 0.596 | 0.755 | 0.739 |
| Swin Transformer (BCE+Boundary) | 0.959 | 0.756 | 0.608 | 0.753 | 0.761 |
| Models | Input Samples | OA | F1-Score | IoU | PA | Recall |
|---|---|---|---|---|---|---|
| UPerNet | RGB | 0.961 | 0.815 | 0.688 | 0.769 | 0.867 |
| RGB+DEM | 0.963 | 0.816 | 0.689 | 0.790 | 0.844 | |
| PSPNet | RGB | 0.958 | 0.792 | 0.655 | 0.780 | 0.804 |
| RGB+DEM | 0.962 | 0.817 | 0.691 | 0.779 | 0.859 | |
| DeepLab_v3+ | RGB | 0.966 | 0.823 | 0.700 | 0.846 | 0.802 |
| RGB+DEM | 0.966 | 0.831 | 0.710 | 0.824 | 0.837 | |
| Swin Transformer | RGB | 0.965 | 0.836 | 0.718 | 0.782 | 0.897 |
| RGB+DEM | 0.970 | 0.856 | 0.748 | 0.821 | 0.894 |
| Input Samples | Models | OA | F1-Score | IoU | PA | Recall |
|---|---|---|---|---|---|---|
| RGB | Swin Transformer (BCE) | 0.965 | 0.836 | 0.718 | 0.782 | 0.897 |
| Swin Transformer (BCE+Boundary) | 0.970 | 0.855 | 0.746 | 0.816 | 0.898 | |
| RGB+DEM | Swin Transformer (BCE) | 0.970 | 0.856 | 0.748 | 0.821 | 0.894 |
| Swin Transformer (BCE+Boundary) | 0.973 | 0.868 | 0.766 | 0.843 | 0.895 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Wang, D.; Liu, C.; Zhang, M.; Xu, L.; Sun, T.; Li, W.; Cheng, S.; Dong, J. Refined Intelligent Landslide Identification Based on Multi-Source Information Fusion. Remote Sens. 2024, 16, 3119. https://doi.org/10.3390/rs16173119
Wang X, Wang D, Liu C, Zhang M, Xu L, Sun T, Li W, Cheng S, Dong J. Refined Intelligent Landslide Identification Based on Multi-Source Information Fusion. Remote Sensing. 2024; 16(17):3119. https://doi.org/10.3390/rs16173119
Chicago/Turabian StyleWang, Xiao, Di Wang, Chenghao Liu, Mengmeng Zhang, Luting Xu, Tiegang Sun, Weile Li, Sizhi Cheng, and Jianhui Dong. 2024. "Refined Intelligent Landslide Identification Based on Multi-Source Information Fusion" Remote Sensing 16, no. 17: 3119. https://doi.org/10.3390/rs16173119
APA StyleWang, X., Wang, D., Liu, C., Zhang, M., Xu, L., Sun, T., Li, W., Cheng, S., & Dong, J. (2024). Refined Intelligent Landslide Identification Based on Multi-Source Information Fusion. Remote Sensing, 16(17), 3119. https://doi.org/10.3390/rs16173119