
LTSCD-YOLO: A Lightweight Algorithm for Detecting Typical Satellite Components Based on Improved YOLOv8

 , , ,
, , ,
Abstract

1. Introduction
- A typical satellite component dataset was established, consisting of 3800 labeled satellite images. This is known to be the largest dataset of typical satellite components. By incorporating data augmentation techniques, the number of images in the dataset was expanded to 16,400, offering substantial support for future research in related fields.
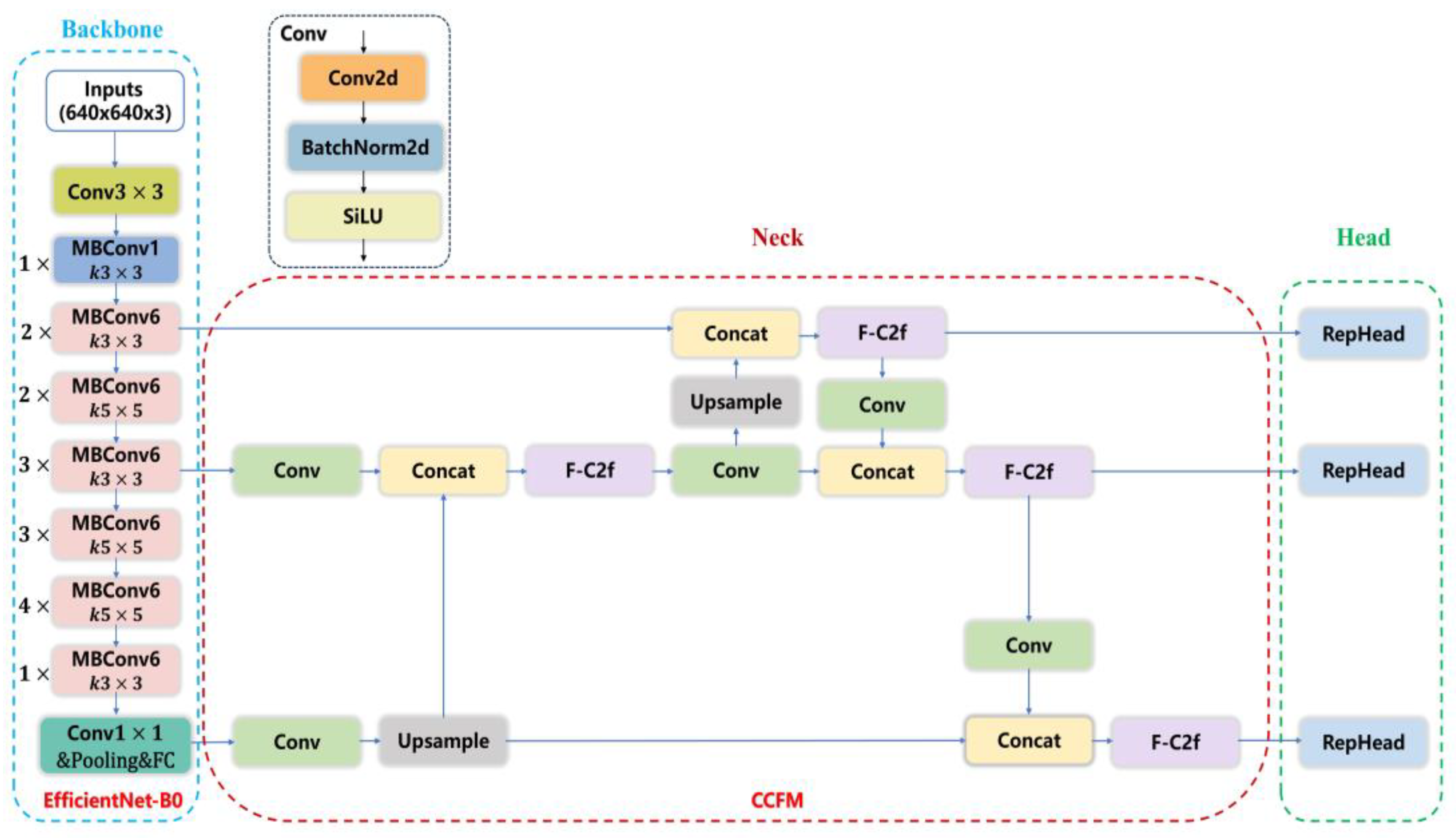
- To construct a lightweight detection model, this paper innovatively proposes the Faster-C2f (F-C2f) module and the RepHead detection head. The network structure is redesigned, utilizing the lightweight network EfficientNet-B0 as the Backbone of LTSCD-YOLO, and a lightweight Cross-Scale Feature Fusion Module was adopted in the Neck part. By fusing features of different resolutions across scales, the detection performance is enhanced.
- Focal-EIoU was adopted as the model’s loss function to obtain more accurate predicted bounding boxes, optimize the training process, and improve the model’s performance on typical satellite component detection tasks.
2. Methods
2.1. Lightweight Network Design
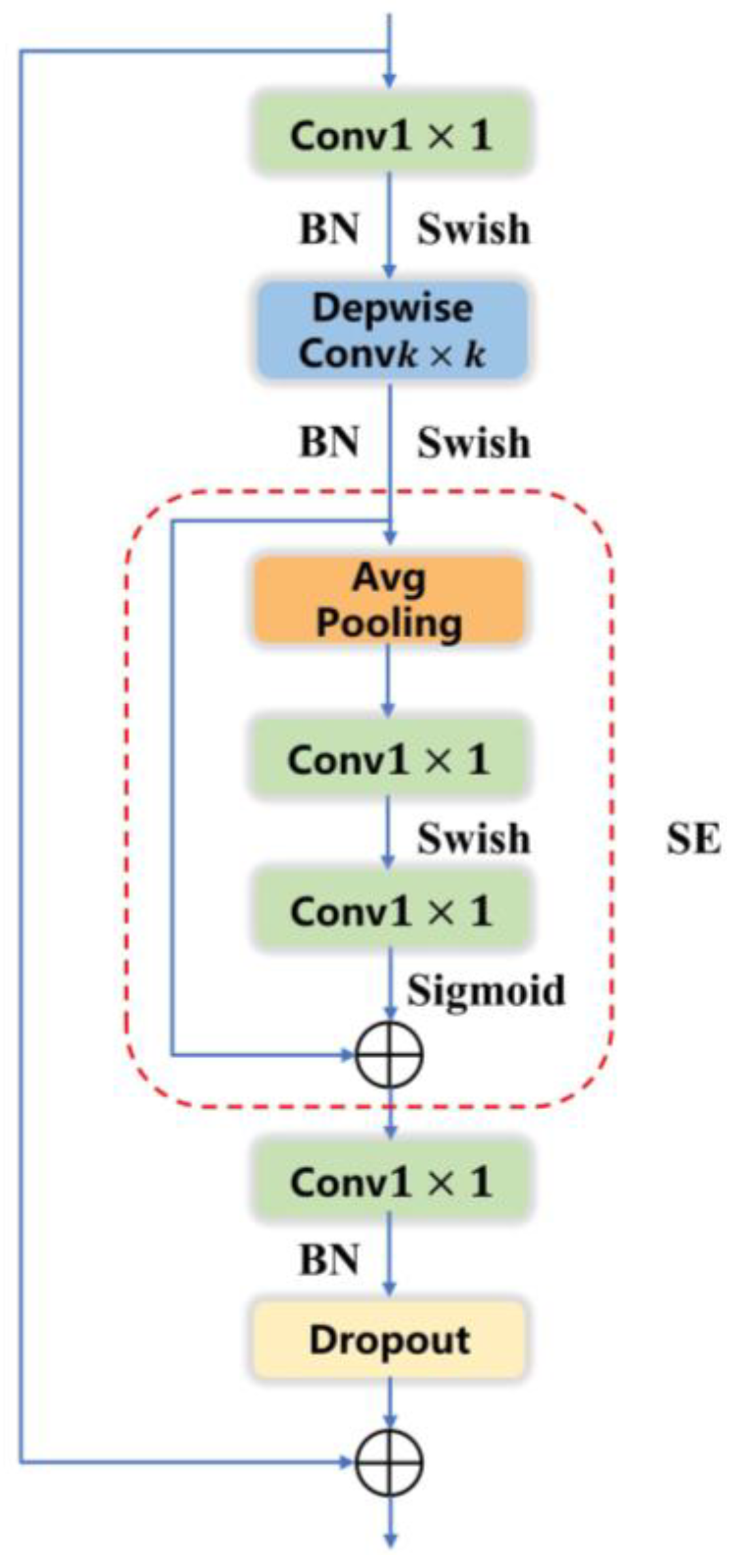
2.1.1. Backbone Network Improvement
2.1.2. Neck Network Improvement
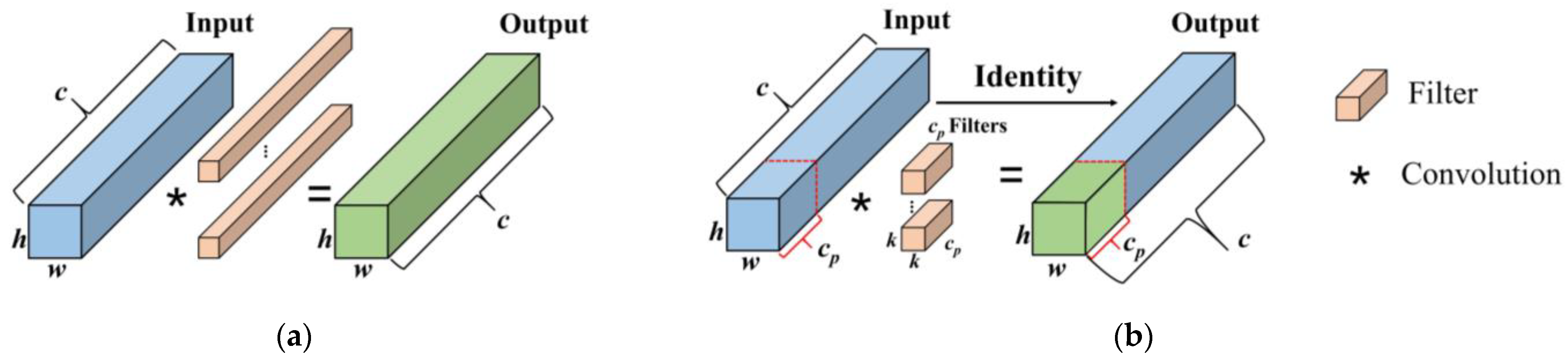
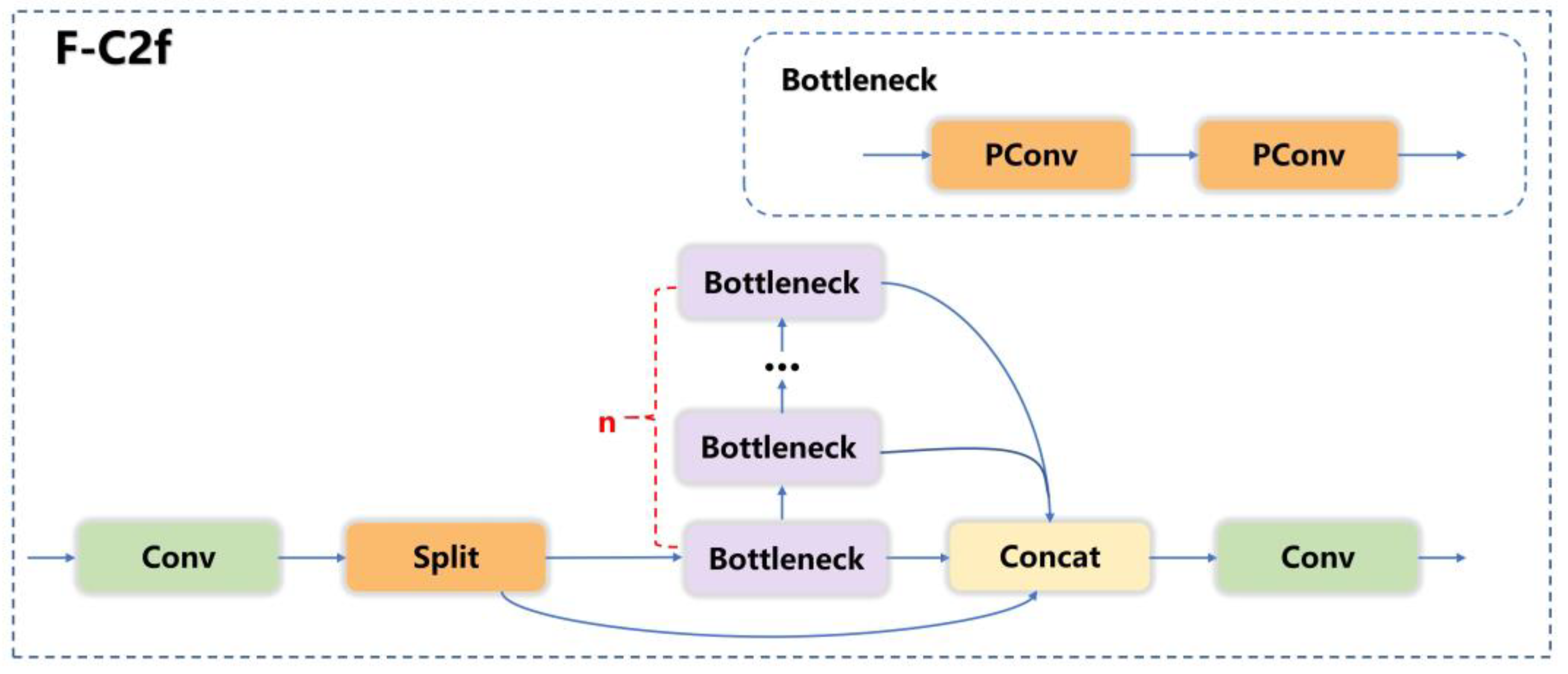
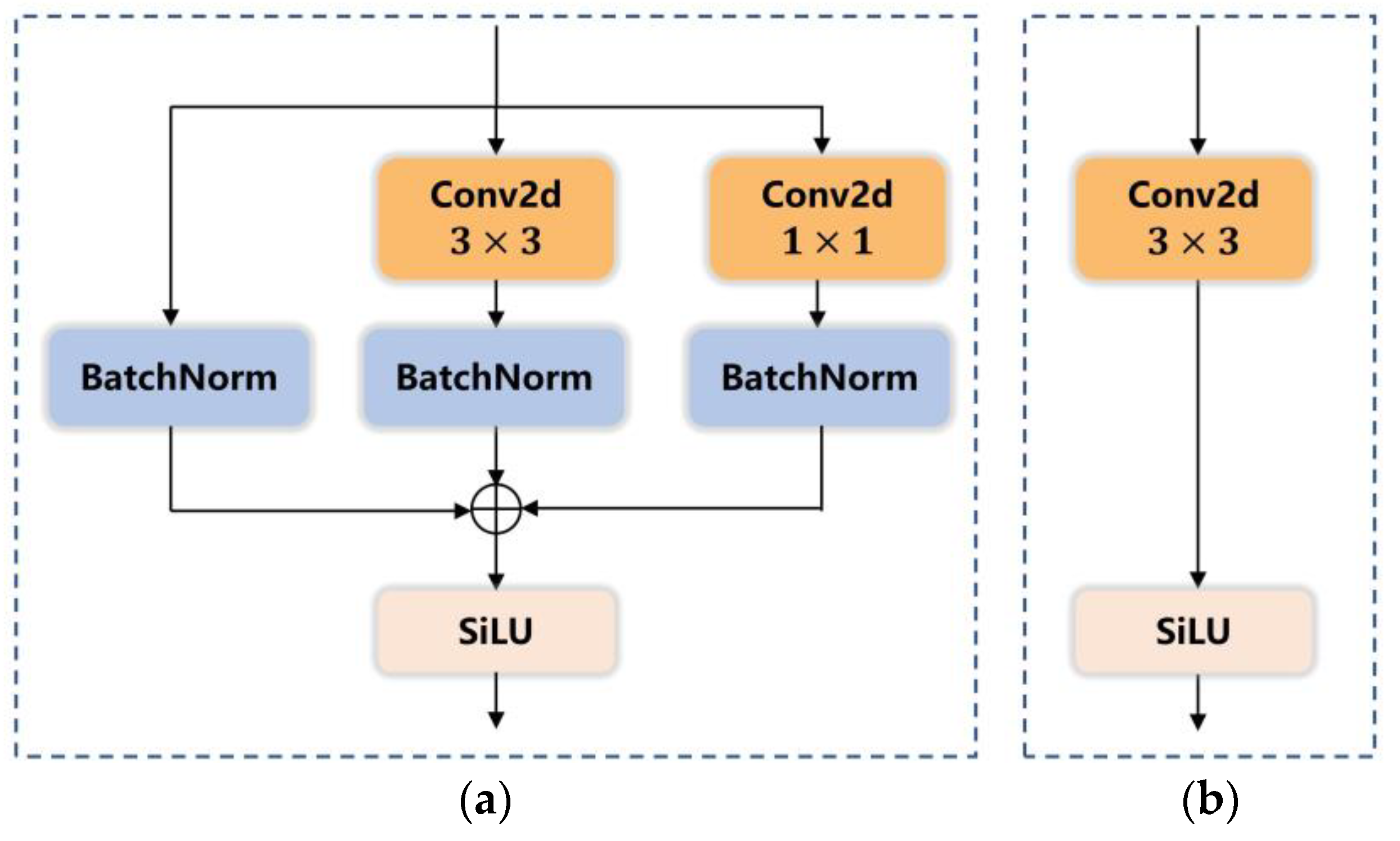
2.1.3. C2f Module Improvement
2.2. Optimize Loss Function
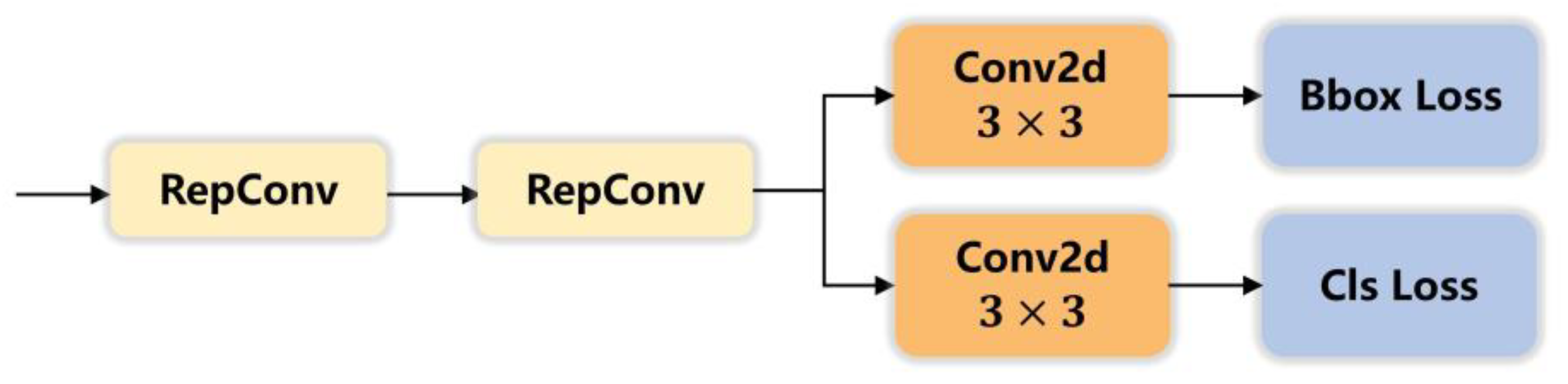
2.3. Detection Head Improvement
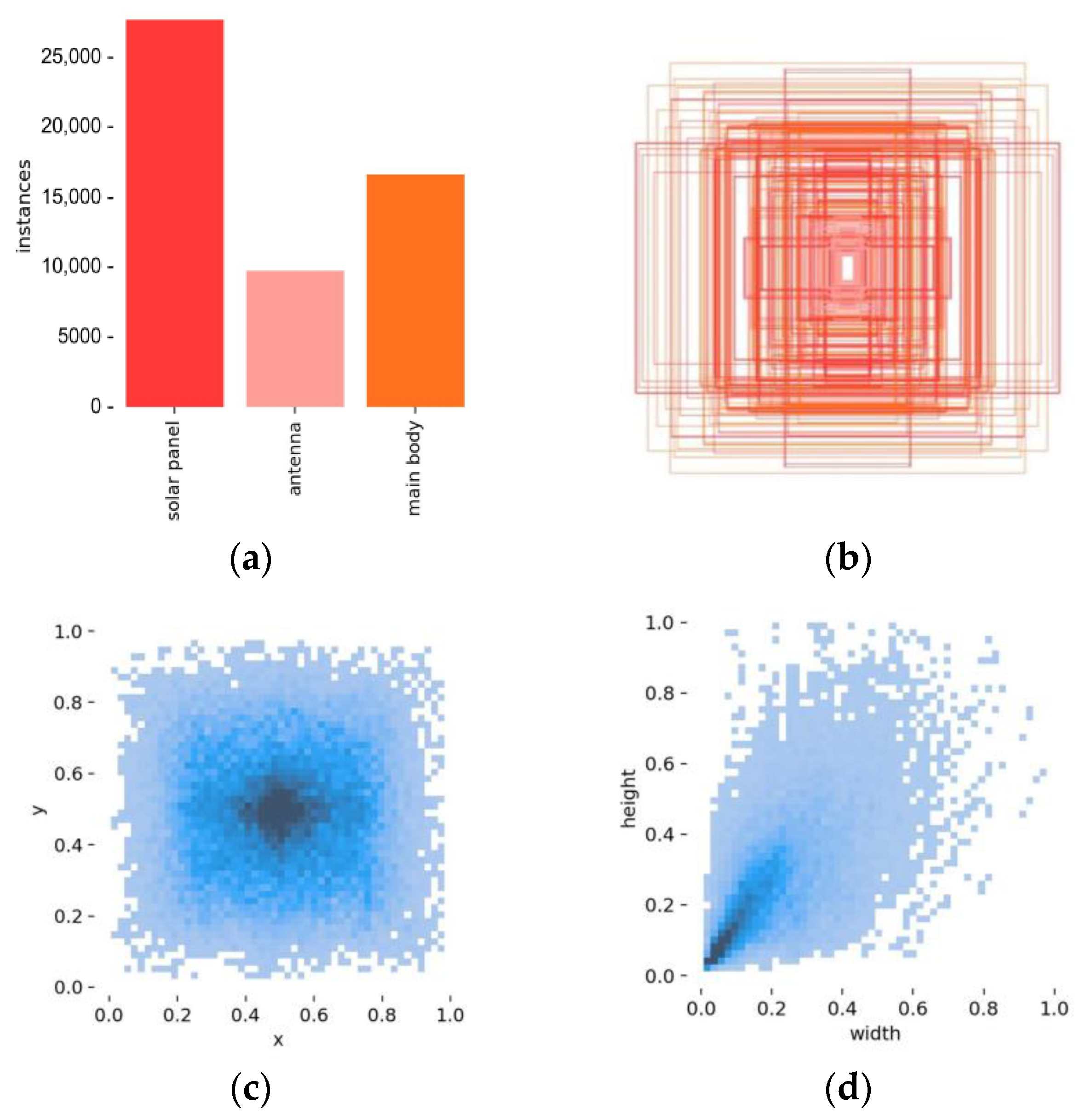
3. Construction of the Experimental Dataset
4. Experimental Detail
4.1. Experimental Environment
4.2. Experimental Evaluation Criteria
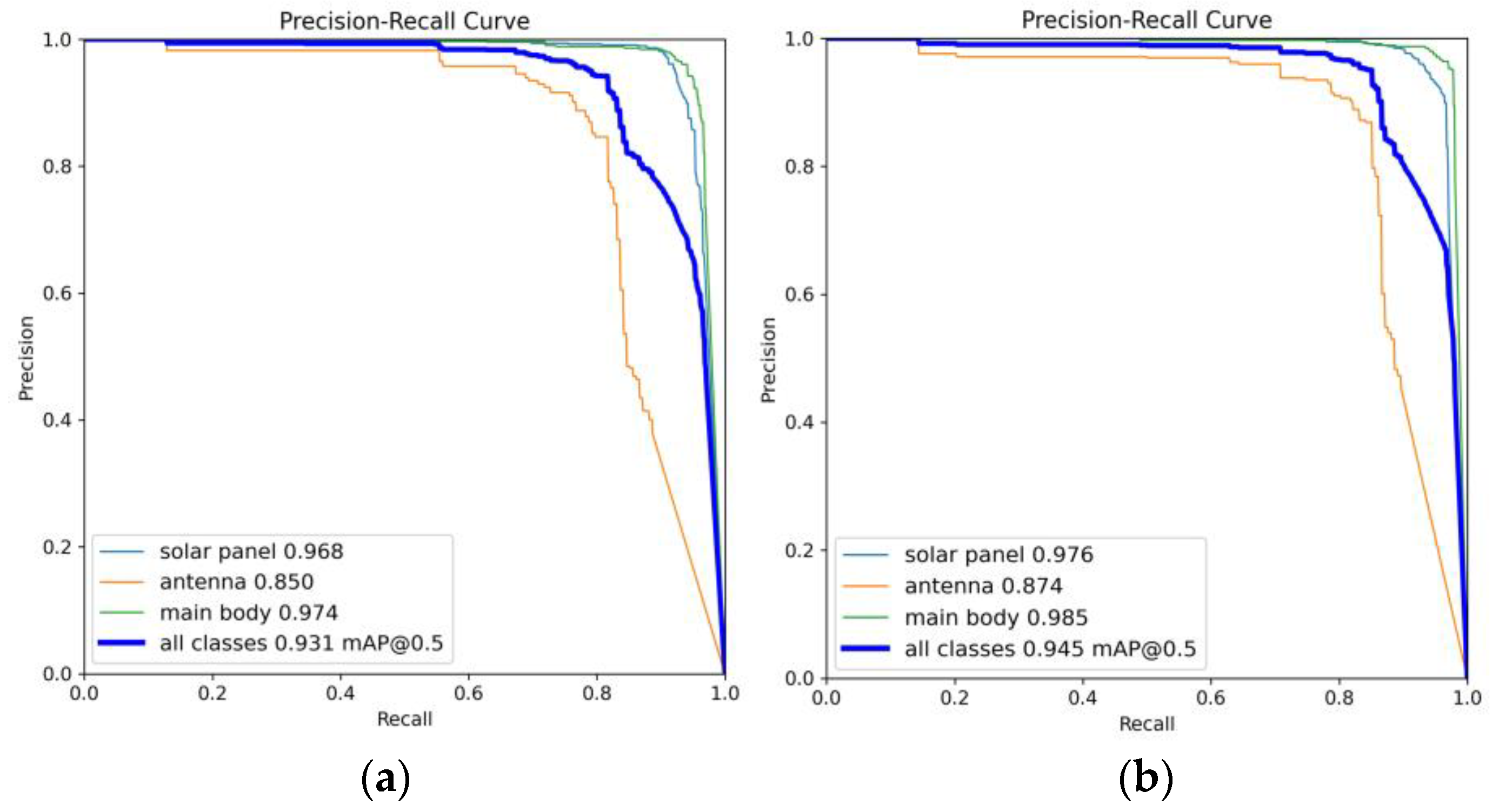
5. Results
5.1. Backbone Network Comparison Experiment
5.2. Ablation Experiment
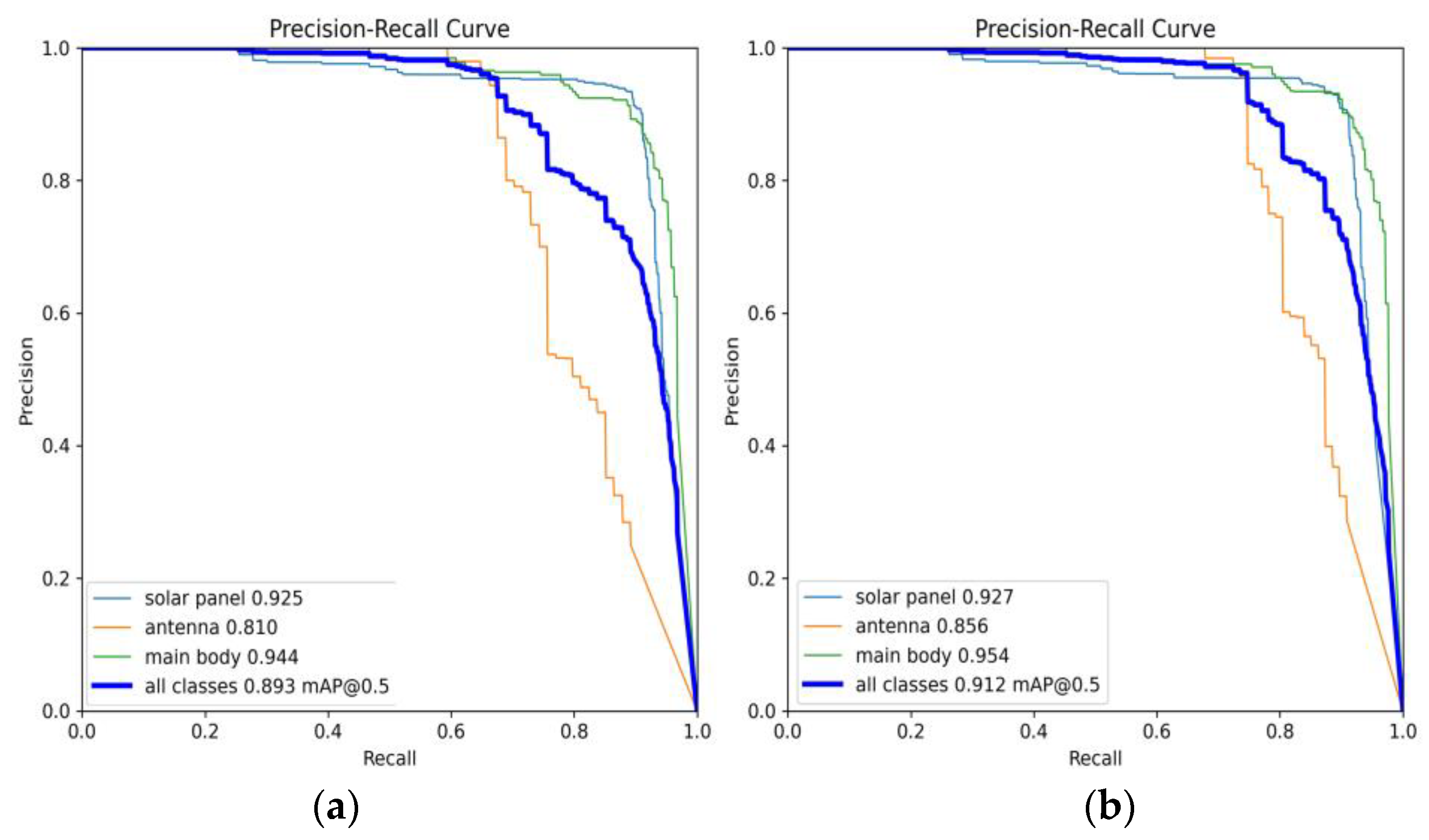
5.3. Comparative Experiment of Different Models
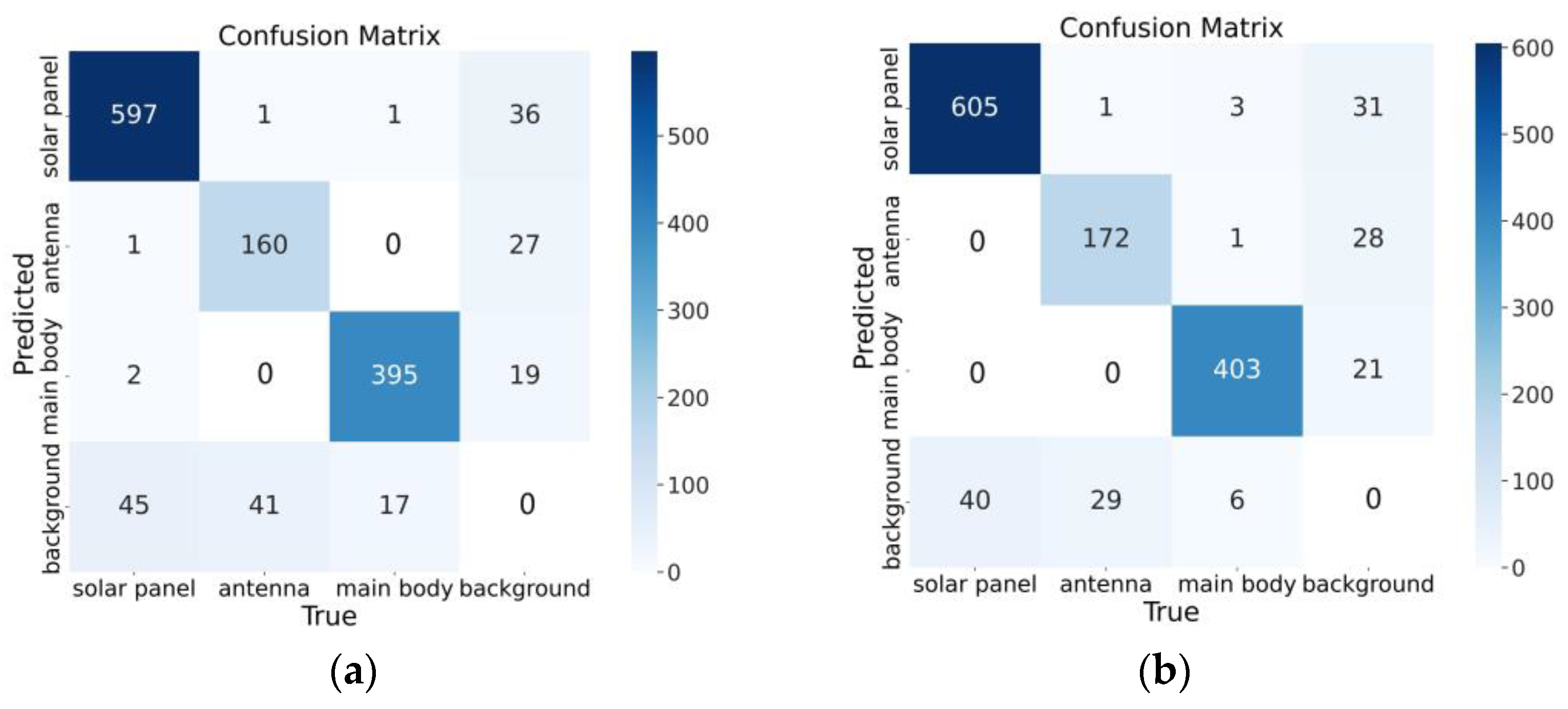
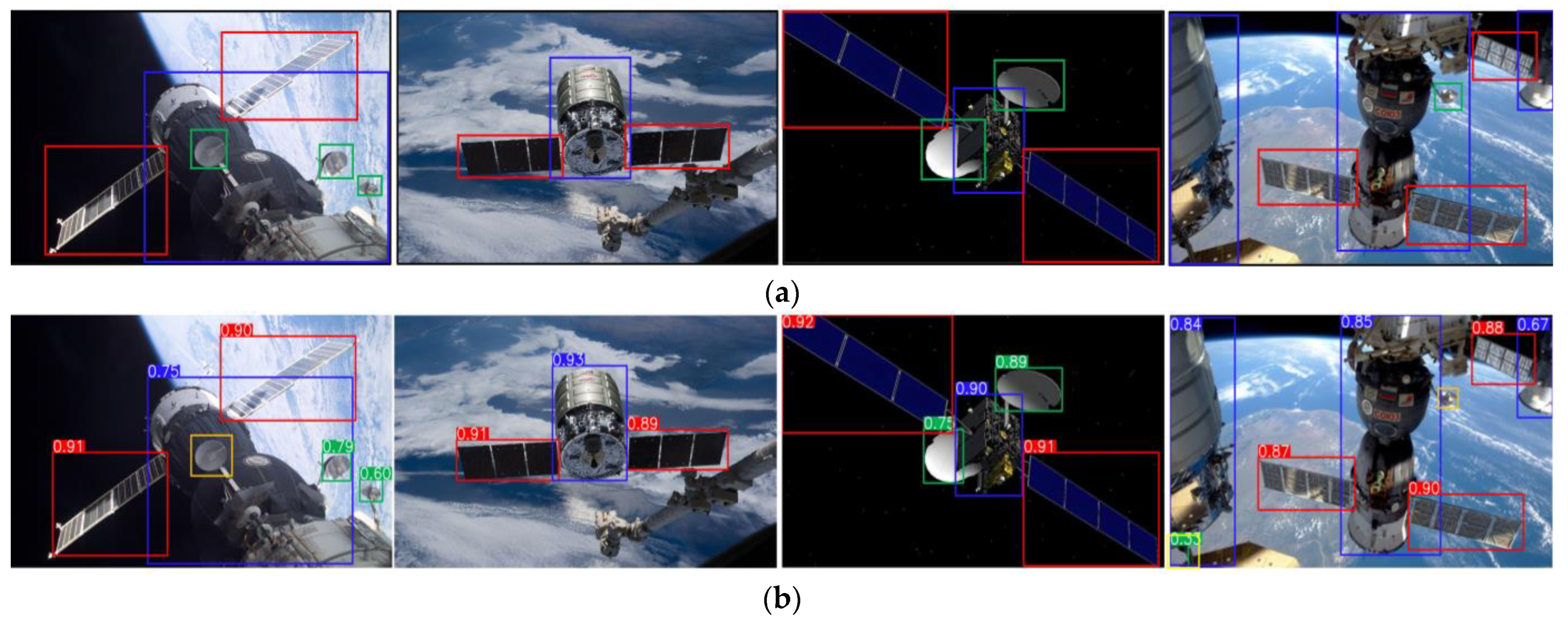
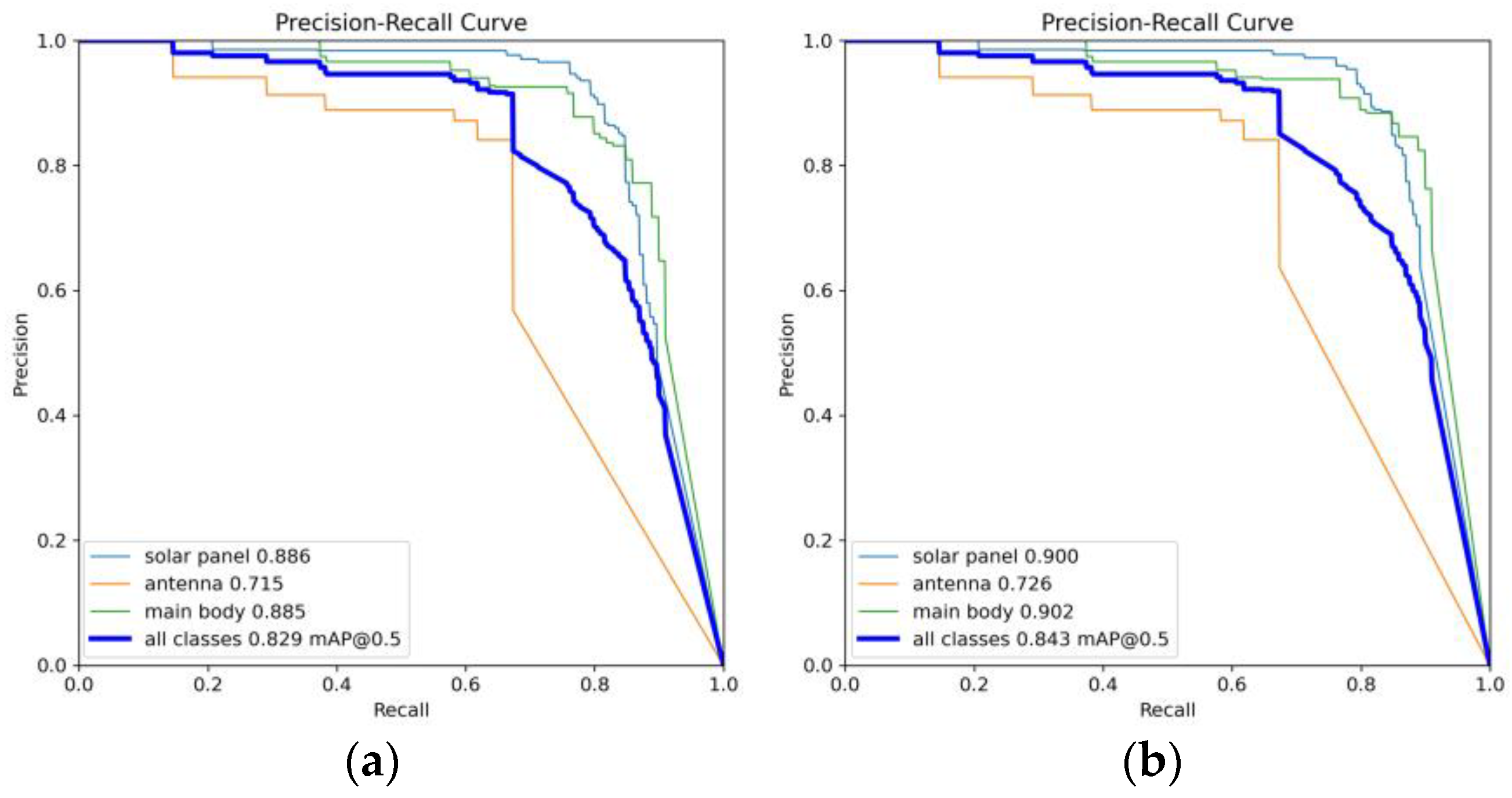
5.4. Visualization Experiments
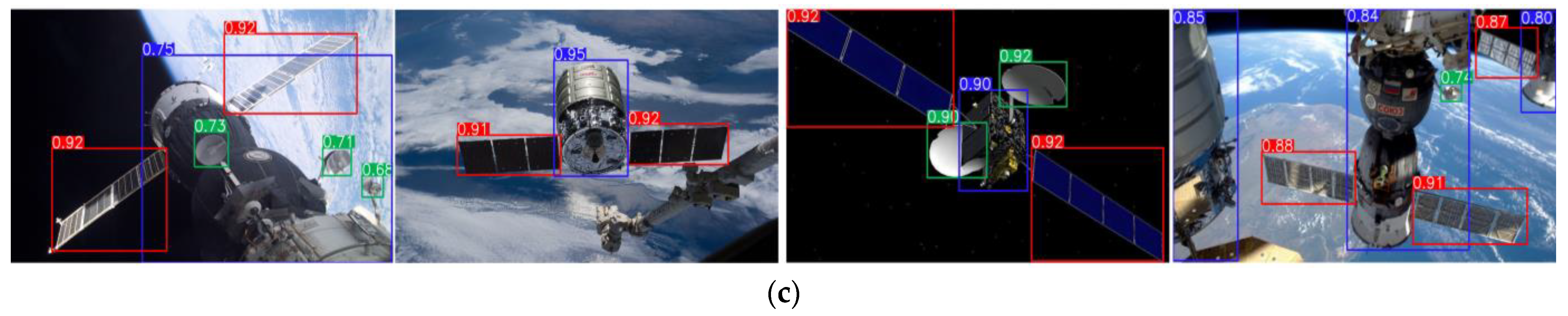
5.5. Generalization Experiment
5.6. Validation Experiment
6. Discussion
6.1. Memory Application Analysis of the LTSCD-YOLO Algorithm
6.2. Limitations and Future Work
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Satellite Database|Union of Concerned Scientists. Available online: https://www.ucsusa.org/resources/satellite-database (accessed on 26 June 2024).
- Zhang, H.; Zhang, C.; Jiang, Z.; Yao, Y.; Meng, G. Vision-Based Satellite Recognition and Pose Estimation Using Gaussian Process Regression. Int. J. Aerosp. Eng. 2019, 2019, 5921246. [Google Scholar] [CrossRef]
- Volpe, R.; Circi, C. Optical-Aided, Autonomous and Optimal Space Rendezvous with a Non-Cooperative Target. Acta Astronaut. 2019, 157, 528–540. [Google Scholar] [CrossRef]
- Liu, L.; Zhao, G.; Bo, Y. Point Cloud Based Relative Pose Estimation of a Satellite in Close Range. Sensors 2016, 16, 824. [Google Scholar] [CrossRef]
- Opromolla, R.; Fasano, G.; Rufino, G.; Grassi, M. A Review of Cooperative and Uncooperative Spacecraft Pose Determination Techniques for Close-Proximity Operations. Prog. Aerosp. Sci. 2017, 93, 53–72. [Google Scholar] [CrossRef]
- Cao, S.; Mu, J.; Wu, H.; Liang, Y.; Wang, G.; Wang, Z. Recognition and Instance Segmentation of Space Non-Cooperative Satellite Components Based on Deep Learning. In Proceedings of the 2021 China Automation Congress (CAC), Kunming, China, 22–24 October 2021; pp. 7734–7739. [Google Scholar]
- Leung, S.; Montenbruck, O. Real-Time Navigation of Formation-Flying Spacecraft Using Global-Positioning-System Measurements. J. Guid. Control Dyn. 2005, 28, 226–235. [Google Scholar] [CrossRef]
- Massimi, F.; Ferrara, P.; Petrucci, R.; Benedetto, F. Deep Learning-Based Space Debris Detection for Space Situational Awareness: A Feasibility Study Applied to the Radar Processing. IET Radar Sonar Navig. 2024, 18, 635–648. [Google Scholar] [CrossRef]
- Cai, J.; Huang, P.; Chen, L.; Zhang, B. A Fast Detection Method of Arbitrary Triangles for Tethered Space Robot. In Proceedings of the 2015 IEEE International Conference on Robotics and Biomimetics (ROBIO), Zhuhai, China, 6–9 December 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 120–125. [Google Scholar]
- Du, X.; Liang, B.; Xu, W.; Qiu, Y. Pose Measurement of Large Non-Cooperative Satellite Based on Collaborative Cameras. Acta Astronaut. 2011, 68, 2047–2065. [Google Scholar] [CrossRef]
- Peng, J.; Xu, W.; Yan, L.; Pan, E.; Liang, B.; Wu, A.-G. A Pose Measurement Method of a Space Noncooperative Target Based on Maximum Outer Contour Recognition. IEEE Trans. Aerosp. Electron. Syst. 2020, 56, 512–526. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G. YOLOv5 [EB/OL]. Available online: https://github.com/ultralytics/yolov5 (accessed on 14 April 2024).
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 July 2023; pp. 7464–7475. [Google Scholar]
- Jocher, G. YOLOv8 [EB/OL]. Available online: https://github.com/ultralytics/ultralytics (accessed on 14 April 2024).
- Wang, C.-Y.; Yeh, I.-H.; Liao, H.-Y.M. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-Time End-to-End Object Detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Cao, J.; Bao, W.; Shang, H.; Yuan, M.; Cheng, Q. GCL-YOLO: A GhostConv-Based Lightweight YOLO Network for UAV Small Object Detection. Remote Sens. 2023, 15, 4932. [Google Scholar] [CrossRef]
- Chen, G.; Cheng, R.; Lin, X.; Jiao, W.; Bai, D.; Lin, H. LMDFS: A Lightweight Model for Detecting Forest Fire Smoke in UAV Images Based on YOLOv7. Remote Sens. 2023, 15, 3790. [Google Scholar] [CrossRef]
- Liu, Y.; Ma, Y.; Chen, F.; Shang, E.; Yao, W.; Zhang, S.; Yang, J. YOLOv7oSAR: A Lightweight High-Precision Ship Detection Model for SAR Images Based on the YOLOv7 Algorithm. Remote Sens. 2024, 16, 913. [Google Scholar] [CrossRef]
- Zeng, H.; Xia, Y. Space Target Recognition Based on Deep Learning. In Proceedings of the 2017 20th International Conference on Information Fusion (Fusion), Xi’an, China, 10–13 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–5. [Google Scholar]
- Fomin, I.S.; Bakhshiev, A.V.; Gromoshinskii, D.A. Study of Using Deep Learning Nets for Mark Detection in Space Docking Control Images. Procedia Comput. Sci. 2017, 103, 59–66. [Google Scholar] [CrossRef]
- Wang, L.; Xiao, H.; Bai, C. Spatial Multi-Object Recognition Based on Deep Learning. In Proceedings of the 2019 IEEE International Conference on Unmanned Systems (ICUS), Beijing, China, 17–19 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 736–741. [Google Scholar]
- Chen, J.; Wei, L.; Zhao, G. An Improved Lightweight Model Based on Mask R-CNN for Satellite Component Recognition. In Proceedings of the 2020 2nd International Conference on Industrial Artificial Intelligence (IAI), Shenyang, China, 23–25 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Chen, Y.; Gao, J.; Zhang, K. R-CNN-Based Satellite Components Detection in Optical Images. Int. J. Aerosp. Eng. 2020, 2020, 8816187. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhong, R.; Cui, L. Intelligent Recognition of Spacecraft Components from Photorealistic Images Based on Unreal Engine 4. Adv. Space Res. 2023, 71, 3761–3774. [Google Scholar] [CrossRef]
- Cao, Y.; Cheng, X.; Mu, J.; Li, D.; Han, F. Detection Method Based on Image Enhancement and an Improved Faster R-CNN for Failed Satellite Components. IEEE Trans. Instrum. Meas. 2023, 72, 5005213. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. RepVGG: Making VGG-Style ConvNets Great Again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 13733–13742. [Google Scholar]
- Zhang, Y.-F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and Efficient IOU Loss for Accurate Bounding Box Regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. DETRs Beat YOLOs on Real-Time Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 16965–16974. [Google Scholar]
- Chen, J.; Kao, S.; He, H.; Zhuo, W.; Wen, S.; Lee, C.-H.; Chan, S.-H.G. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 12021–12031. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Dung, H.A.; Chen, B.; Chin, T.-J. A Spacecraft Dataset for Detection, Segmentation and Parts Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 2012–2019. [Google Scholar]
- Wang, A.; Chen, H.; Lin, Z.; Han, J.; Ding, G. RepViT: Revisiting Mobile CNN From ViT Perspective. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 15909–15920. [Google Scholar]
- Liu, X.; Peng, H.; Zheng, N.; Yang, Y.; Hu, H.; Yuan, Y. EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 14420–14430. [Google Scholar]
- Mehta, S.; Rastegari, M. MobileViT: Light-Weight, General-Purpose, and Mobile-Friendly Vision Transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar]
- Mehta, S.; Rastegari, M. Separable Self-Attention for Mobile Vision Transformers. arXiv 2022, arXiv:2206.02680. [Google Scholar]
- Howard, A.; Sandler, M.; Chen, B.; Wang, W.; Chen, L.-C.; Tan, M.; Chu, G.; Vasudevan, V.; Zhu, Y.; Pang, R.; et al. Searching for MobileNetV3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1314–1324. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Chen, H.; Wang, Y.; Guo, J.; Tao, D. Vanillanet: The Power of Minimalism in Deep Learning. arXiv 2023, arXiv:2305.12972. [Google Scholar]
- Tang, Y.; Han, K.; Guo, J.; Xu, C.; Xu, C.; Wang, Y. GhostNetv2: Enhance Cheap Operation with Long-Range Attention. Adv. Neural Inf. Process. Syst. 2022, 35, 9969–9982. [Google Scholar]
- CubeSat Launch Initiative—NASA. Available online: https://www.nasa.gov/kennedy/launch-services-program/cubesat-launch-initiative/ (accessed on 25 June 2024).
- Landsat 8|Landsat Science. Available online: https://landsat.gsfc.nasa.gov/satellites/landsat-8/ (accessed on 25 June 2024).
- Geostationary Operational Environmental Satellites—R Series|NOAA/NASA. Available online: https://www.goes-r.gov/ (accessed on 25 June 2024).
- Bedi, R. On-Board Mass Memory Requirements for the New Space Age [EB/OL]. Available online: https://www.ednasia.com/on-board-mass-memory-requirements-for-the-new-space-age/ (accessed on 19 August 2024).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Operator | Resolution | Channels | Layers |
|---|---|---|---|---|
| 1 | Conv | 32 | 1 | |
| 2 | MBConv1, k | 16 | 1 | |
| 3 | MBConv6, k | 24 | 2 | |
| 4 | MBConv6, k | 40 | 2 | |
| 5 | MBConv6, k | 80 | 3 | |
| 6 | MBConv6, k | 112 | 3 | |
| 7 | MBConv6, k | 192 | 4 | |
| 8 | MBConv6, k | 320 | 1 | |
| 9 | Conv & Pooling & FC | 1280 | 1 |
| Experimental Environment | Details |
|---|---|
| Operating system | Ubuntu18.04 |
| GPU | NVIDIA GeForce RTX 3090, 24 GB |
| CPU | Intel Xeon Gold 6248R |
| Memory | 125 G |
| Programming language | Python3.8.18 |
| Framework | PyTorch 1.11.0 + CUDA 11.3 + cuDNN 8.2.0 |
| IDE | PyCharm2022.3.3 |
| Backbone Network | P/% | R/% | mAP@0.50/% | Params/106 | GFLOPs/G | FPS/(frame·s−1) | |
|---|---|---|---|---|---|---|---|
| CSPDarknet (Baseline) | 92.9 | 88.2 | 93.1 | 11.14 | 28.8 | 98.04 | |
| RepViT-M0_9 [45] | 92.0 | 85.6 | 92.0 | 8.57 | 22.7 | 80.64 | |
| Vision | EfficientViT_M0 [46] | 91.0 | 83.6 | 90.0 | 8.38 | 20.4 | 56.75 |
| Transformers | EfficientViT_M1 [46] | 93.0 | 83.9 | 91.0 | 9.03 | 25.1 | 57.69 |
| MobileViTv1-XXS [47] | 92.4 | 86.3 | 92.2 | 7.64 | 20.9 | 76.92 | |
| MobileViTv2-XXS [48] | 92.9 | 86.7 | 92.6 | 7.71 | 22.4 | 81.56 | |
| Mobilenetv3_small [49] | 90.1 | 84.8 | 89.7 | 6.73 | 16.7 | 90.91 | |
| ShuffleNetv2 [50] | 91.4 | 83.5 | 89.3 | 5.94 | 16.0 | 105.65 | |
| ConvNets | VanillaNet-5 [51] | 91.4 | 80.6 | 88.5 | 6.36 | 18.3 | 117.65 |
| FasterNet [42] | 89.3 | 85.2 | 90.2 | 6.08 | 16.1 | 114.94 | |
| GhostNetV2 [52] | 92.9 | 86.0 | 92.0 | 8.24 | 19.1 | 75.56 | |
| ConvNets | Efficientnet_B0 | 93.5 | 87.5 | 92.8 | 6.53 | 17.3 | 96.15 |
| Group | A1 | A2 | A3 | A4 | A5 | mAP@0.50/% | Params/106 | GFLOPs/G | FPS/(frame·s−1) |
|---|---|---|---|---|---|---|---|---|---|
| 1 | — | — | — | — | — | 93.1 | 11.14 | 28.8 | 98.04 |
| 2 | √ | — | — | — | — | 92.8 | 6.53 | 17.3 | 96.15 |
| 3 | — | √ | — | — | — | 93.2 | 7.26 | 23.2 | 107.53 |
| 4 | — | — | √ | — | — | 93.8 | 7.59 | 19.7 | 104.17 |
| 5 | — | — | — | √ | — | 94.3 | 11.14 | 28.8 | 119.05 |
| 6 | — | — | — | — | √ | 93.5 | 15.82 | 32.9 | 98.75 |
| 7 | — | √ | — | — | √ | 93.7 | 7.05 | 21.9 | 103.09 |
| 8 | √ | √ | — | — | — | 93.0 | 2.90 | 12.3 | 103.74 |
| 9 | √ | √ | √ | — | — | 93.4 | 2.63 | 11.0 | 108.15 |
| 10 | √ | √ | √ | √ | — | 94.0 | 2.63 | 11.0 | 113.35 |
| 11 | √ | √ | √ | √ | √ | 94.5 | 2.40 | 9.8 | 115.35 |
| Model | P/% | R/% | mAP@0.50/% | Params/106 | GFLOPs/G | FPS/(frame·s−1) |
|---|---|---|---|---|---|---|
| YOLOv3-tiny | 88.7 | 83.3 | 88.7 | 12.13 | 18.9 | 143.85 |
| YOLOv4-CSP | 89.4 | 84.2 | 89.7 | 52.50 | 119.7 | 72.15 |
| YOLOv5s | 93.8 | 86.8 | 92.4 | 7.03 | 16.0 | 86.2 |
| YOLOv6n | 89.2 | 81.1 | 88.9 | 4.5 | 11.8 | 90.09 |
| YOLOv7-tiny | 94.2 | 85.8 | 92.0 | 6.02 | 13.2 | 85.29 |
| YOLOv7 | 94.6 | 89.4 | 93.8 | 36.49 | 103.2 | 74.86 |
| YOLOv8s | 92.9 | 88.2 | 93.1 | 11.14 | 28.8 | 98.04 |
| YOLOv8s-ghost | 93.6 | 87.0 | 91.9 | 5.92 | 16.1 | 90.91 |
| YOLOv9t | 92.1 | 88.4 | 92.9 | 2.62 | 10.7 | 50.36 |
| YOLOv9s | 95.0 | 89.9 | 94.3 | 9.60 | 38.7 | 41.67 |
| YOLOv10s | 93.4 | 87.9 | 93.3 | 8.04 | 24.5 | 97.59 |
| RT-DETR-ResNet50 | 92.4 | 87.2 | 92.3 | 42.0 | 130.5 | 22.69 |
| RT-DETR-ResNet101 | 93.0 | 88.3 | 93.2 | 61.76 | 191.4 | 16.89 |
| DETR-L | 92.3 | 87.2 | 92.2 | 32.8 | 108.0 | 25.35 |
| DETR-X | 92.4 | 89.2 | 93.5 | 67.3 | 232.3 | 15.68 |
| Ours | 95.7 | 88.2 | 94.5 | 2.40 | 9.8 | 115.35 |
| Model | Typical Satellite Components | P/% | R/% | Params/106 | GFLOPs/G | Number of Images |
|---|---|---|---|---|---|---|
| YOLOv8 (Baseline) | Solar panel | 95.8 | 91.9 | 11.14 | 28.8 | 360 |
| Antenna | 86.9 | 78.9 | ||||
| Main body | 96.0 | 93.7 | ||||
| LTSCD-YOLO (Ours) | Solar panel | 96.0 | 93.1 | 2.40 | 9.8 | 360 |
| Antenna | 88.8 | 83.2 | ||||
| Main body | 96.4 | 96.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, Z.; Zhang, W.; Li, J.; Liu, R.; Xu, Y.; Chen, S.; Fang, Z.; Zhao, F. LTSCD-YOLO: A Lightweight Algorithm for Detecting Typical Satellite Components Based on Improved YOLOv8. Remote Sens. 2024, 16, 3101. https://doi.org/10.3390/rs16163101
Tang Z, Zhang W, Li J, Liu R, Xu Y, Chen S, Fang Z, Zhao F. LTSCD-YOLO: A Lightweight Algorithm for Detecting Typical Satellite Components Based on Improved YOLOv8. Remote Sensing. 2024; 16(16):3101. https://doi.org/10.3390/rs16163101
Chicago/Turabian StyleTang, Zixuan, Wei Zhang, Junlin Li, Ran Liu, Yansong Xu, Siyu Chen, Zhiyue Fang, and Fuchenglong Zhao. 2024. "LTSCD-YOLO: A Lightweight Algorithm for Detecting Typical Satellite Components Based on Improved YOLOv8" Remote Sensing 16, no. 16: 3101. https://doi.org/10.3390/rs16163101
APA StyleTang, Z., Zhang, W., Li, J., Liu, R., Xu, Y., Chen, S., Fang, Z., & Zhao, F. (2024). LTSCD-YOLO: A Lightweight Algorithm for Detecting Typical Satellite Components Based on Improved YOLOv8. Remote Sensing, 16(16), 3101. https://doi.org/10.3390/rs16163101